
Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning

Abstract
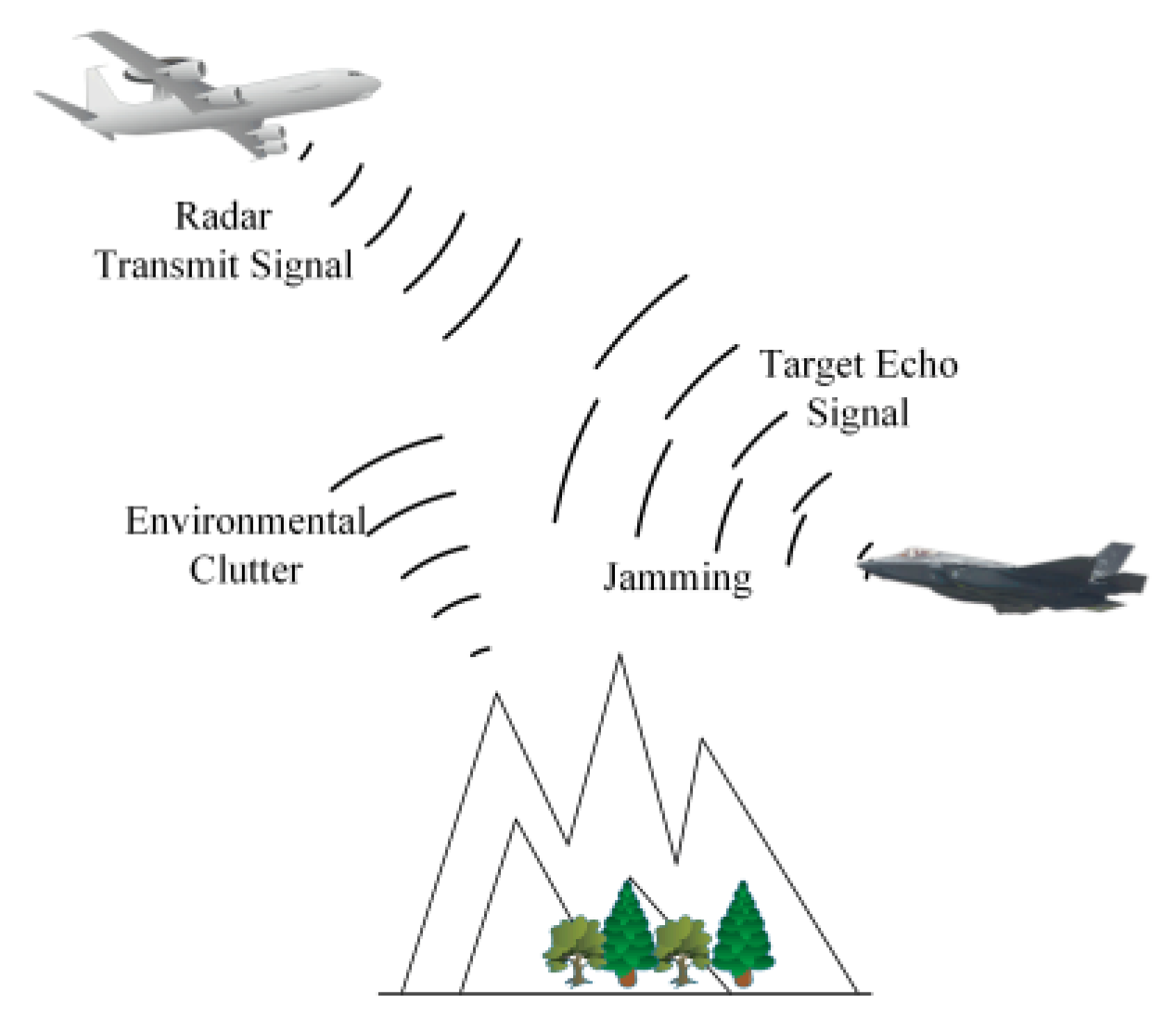
1. Introduction
1.1. Background and Motivation
1.2. Related Works
1.3. Main Contributions
- To address the problems of single and idealized airborne radar countermeasure scenario models, this paper investigates a Markov decision process (MDP)-based approach for modelling dynamic airborne radar countermeasure scenarios. The airborne radar electromagnetic environment under clutter and jamming conditions is investigated, and the dynamic countermeasure process between airborne radar and jamming is modelled using MDP. The MDP-based radar modelling approach allows for the analysis of the electromagnetic information present in realistic scenarios and the arbitrary design of countermeasure models containing a variety of influencing factors such as noise, clutter, the impulse response of the detected target, radar-transmitted signals and jamming signals. The method overcomes the limitations of traditional models and improves the flexibility, accuracy and predictability of the description of airborne radar operating scenarios, providing a viable way to realize the increasingly complex modelling of actual airborne radar operating scenarios.
- This paper proposes an intelligent waveform design method based on DRL to address the problem of anti-jamming of radar under clutter and jamming conditions. Radar-environment information interaction is determined by modelling the MDP for radar and jamming countermeasures. A radar frequency domain optimal anti-jamming waveform strategy generation method based on the D3QN algorithm is proposed. We build two deep neural networks to fit the state value function and action value function of the radar. The “overestimation” problem of the value function is solved using the fixed Q target method and the preferred experience replay method. To improve radar learning efficiency, prevent training overfitting, etc., the action value function network adopts a pairwise structure. Once the optimal frequency domain waveform strategy has been computationally selected, the ITM is used to generate the corresponding time domain signal with a constant envelope. The simulation results show that the radar transmit waveform designed by this method achieves intelligent anti-jamming of airborne radar while further improving the radar target detection probability compared to the conventional LFM signal, based on the radar waveform strategy generated by the strategy iterative method.
- Through extensive simulation experiments, the results show that the optimal waveform design method for airborne radar proposed in this paper significantly improves the anti-jamming performance and target detection performance of airborne radar, and outperforms traditional linear FM signals and previous research results based on reinforcement learning.
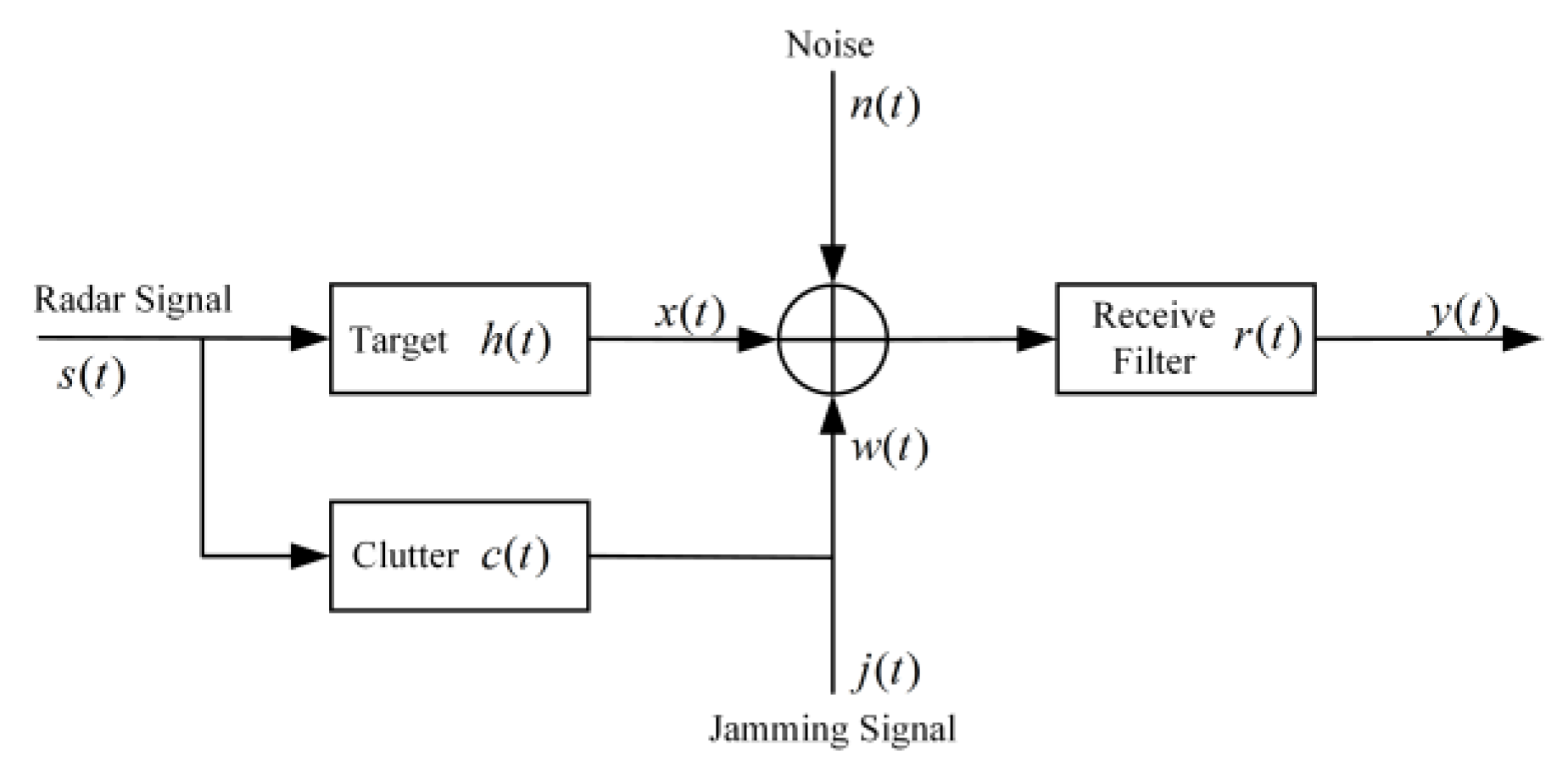
2. Airborne Radar Signal and MDP Model
2.1. Airborne Radar Signal Model
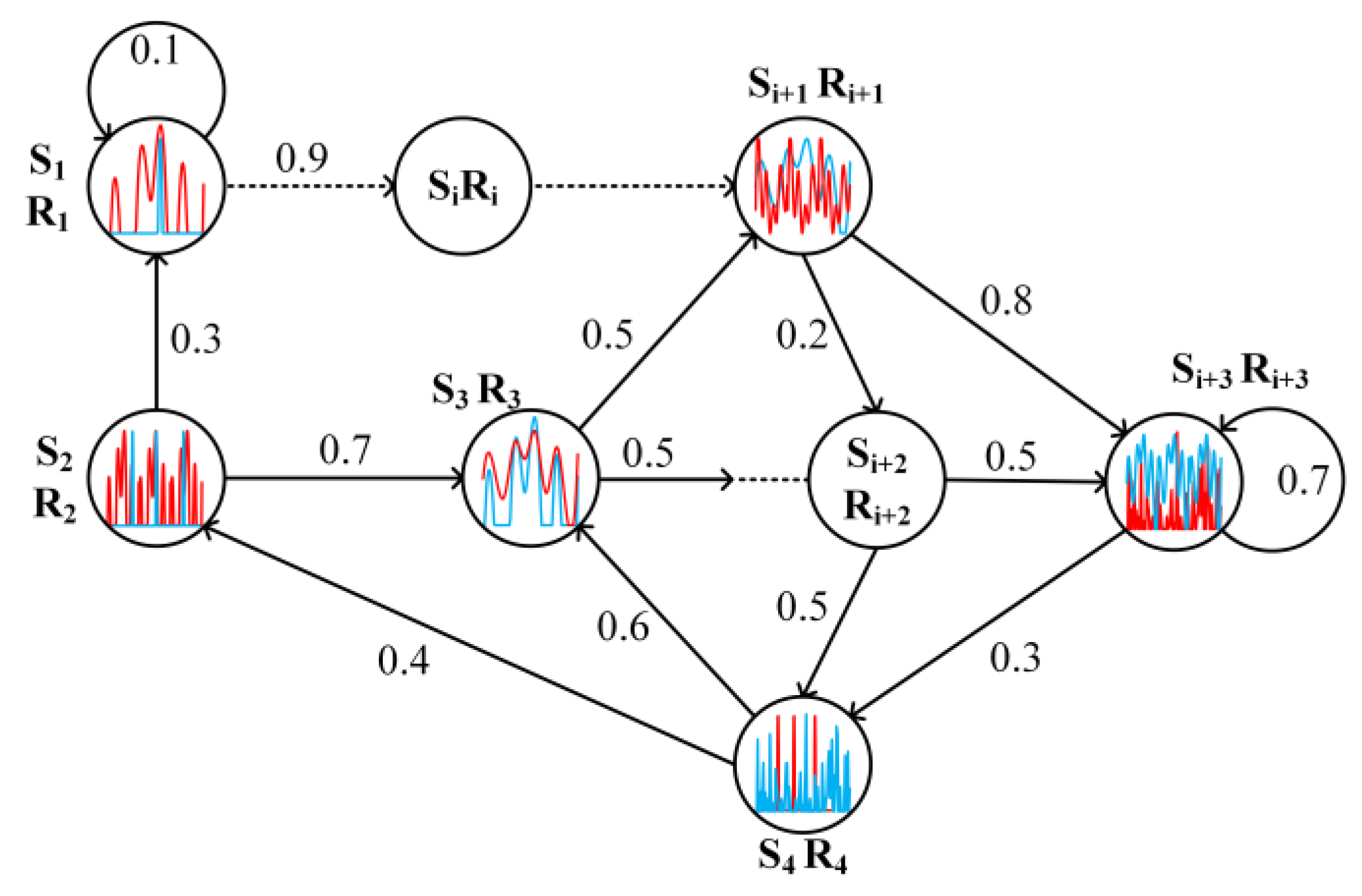
2.2. MDP Model
3. MDP-Based Radar Countermeasure Environment Modelling
3.1. Radar Action, Status and Reward Design
3.2. Confrontation Model Key Parameter Settings
4. D3QN-Based Strategy Generation for Optimal Radar Anti-Jamming
4.1. Fixed Q Targets
4.2. Prioritized Experience Replay
4.3. Value Function V and Dominance Function A
4.4. Design Flow of Optimal Anti-Jamming Strategy for Radar Based on the D3QN Algorithm
| Algorithm 1: Airborne radar anti-jamming strategy design algorithm based on D3QN. |
|
|
4.5. Performance Indicators
5. Simulation Results and Analysis
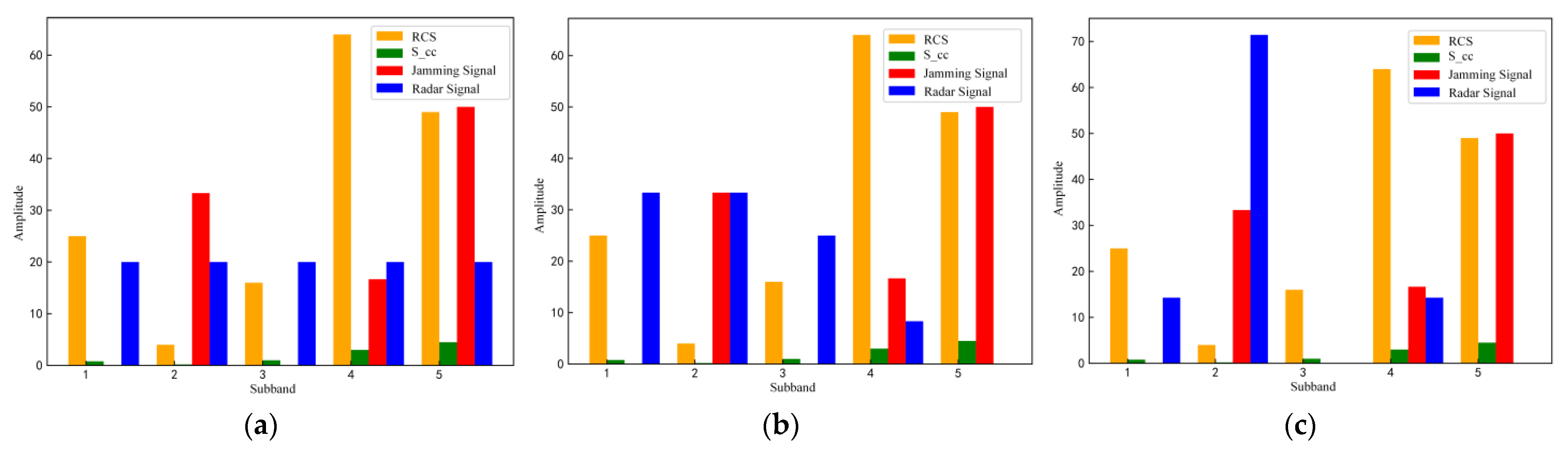
5.1. Radar and Jamming Game Strategy Generation
5.2. Performance Comparison
5.2.1. Performance Analysis When the Total Target Disturbance Power Pb Is a Constant Value
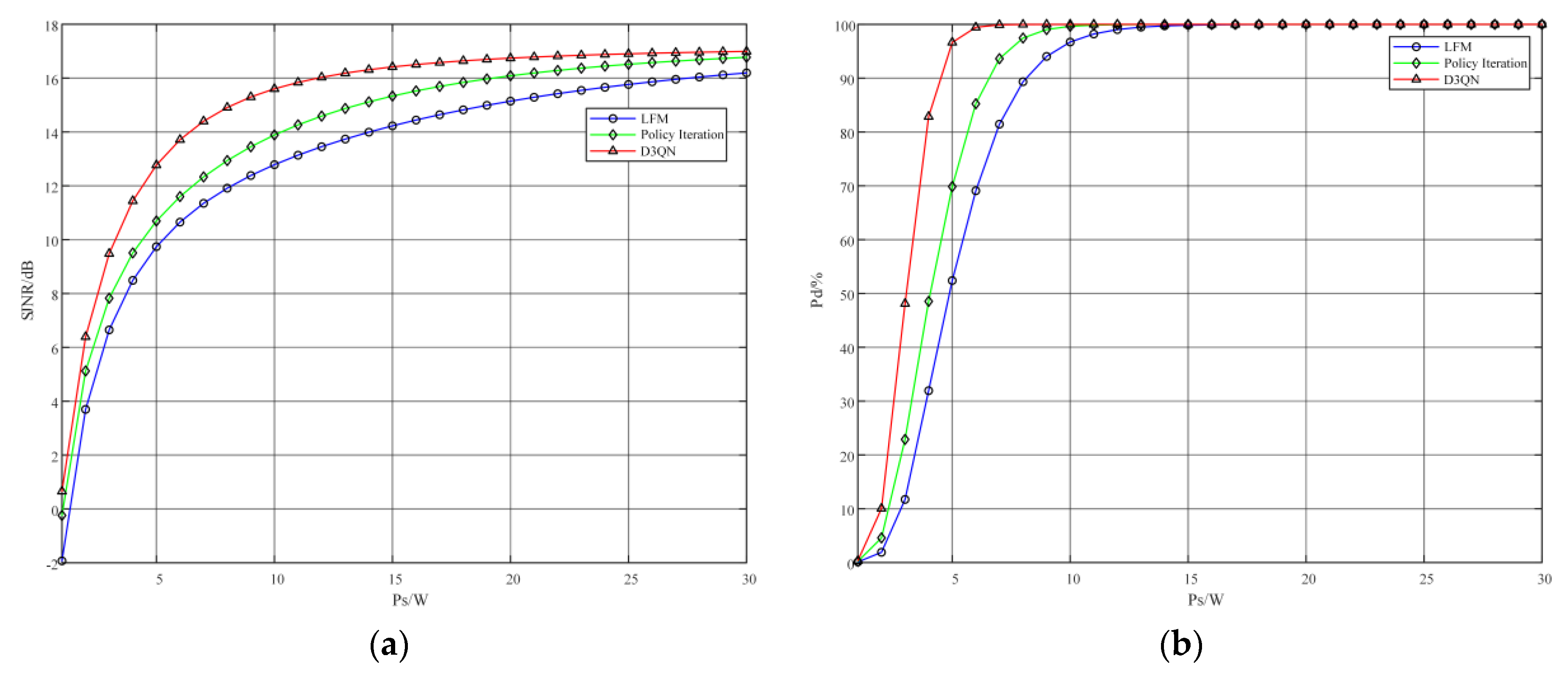
5.2.2. Performance Analysis When the Total Radar Signal Power Ps Is a Constant Value
5.2.3. Performance Analysis When the Total Radar Signal Power Ps Is a Constant Value
5.3. Time Domain Waveform Synthesis
6. Conclusions
6.1. Article Work Summary
- In response to the problems of single and idealized radar countermeasure scenario models in traditional anti-jamming technology research, we study a dynamic radar countermeasure scenario modelling method based on the Markov decision process. The MDP model overcomes the limitations of traditional models, improves the accuracy and predictability of the actual radar operating environment and provides a model basis for radar waveform design research. The MDP model overcomes the limitations of traditional models, improves the accuracy and prediction of the actual radar operating environment and lays the model foundation for post-radar waveform design research, further promoting the development and application of cognitive radar.
- To address the problem of dynamic countermeasures between airborne radar and jamming in complex environments, we propose a deep-reinforcement-learning-based anti-jamming waveform design method for airborne radar under clutter and jamming conditions from a waveform design perspective and build a dynamic countermeasure model for airborne radar and jamming in complex environments based on MDP. We construct two deep neural networks for training learning of the neural networks by iteratively computing the reward values to the adversarial data using different radar waveforms in different jamming states. We recommend a design technique for the optimal anti-jamming waveform strategy of airborne radar based on the D3QN algorithm and synthesize the optimal time domain transmitted signal by iterative transformation method. It has certain reference significance for the realization of radar intelligent confrontation technology in electronic warfare and has laid a theoretical foundation for the realization of cognitive radar.
6.2. Future Research Perspectives
- The waveform design problem for complex environments has focused on the waveform design problem for electromagnetic information environments containing clutter, noise and jamming, while the waveform design for the non-smooth and non-uniform actual combat environments faced by airborne radars has still not been considered. Therefore, subsequent work should fully investigate waveform design methods for airborne radars in various non-smooth, non-uniform electromagnetic environments, such as clutter and new types of jamming signals, and discuss the performance of waveform design technology methods in a variety of complex environments, which is of great significance for improving the anti-jamming performance of airborne radars in actual combat.
- In response to traditional anti-principal flap jamming techniques’ difficulty coping with diverse and dexterous new types of jamming, we investigate a deep-reinforcement-learning-based approach to airborne radar waveform design. When building a dynamic countermeasure model between radar and jamming based on a Markov decision process, a discrete signal form and a reward function design based on a single performance indicator of the SJNR are mainly used, without considering continuous state and action representations, and a reward function setting that combines multiple performance indicators. The future development trend of radar must be multi-functional and intelligent, and in the subsequent research, attempts should be made to establish a continuous state and action space, which is conducive to the application of airborne radar intelligent waveform design technology in practice; the use of multiple radar performance indicators to combine the design of reward functions is of great significance to the development of multi-functional radar waveform design.
- To address the difficulty of the practical application of theoretical waveform design methods, we focus on the design of frequency domain optimal anti-jamming waveform strategies based on artificial intelligence algorithms, using an iterative transformation method to synthesize the corresponding constant envelope time domain signal. However, only the real, imaginary, amplitude and phase information of the time domain signal is obtained, and no actual transmittable time domain waveform is found. Most of the current radar waveform design studies do not consider the actual emission of the designed waveform. On the one hand, this is because the modelling of the problem deviates significantly from the actual environment when considering waveform design methods, making it difficult to apply to real-world scenarios. On the other hand, the hardware is limited by the production process of electronic equipment, and current radar transmitters are not yet able to meet the demand for transmitting arbitrary waveforms. Therefore, to ensure that radar waveform design research results can be used in practical equipment and truly improve airborne radar performance, future radar waveform design research should be closely integrated with practical application scenarios and equipment, so as to lay a solid foundation for the successful implementation of airborne radar waveform design and the smooth development of new system radars.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DQN | deep Q network |
| DRL | deep reinforcement learning |
| D3QN | duelling double deep Q network |
| IFFT | inverse fast Fourier transform |
| ITM | iterative transform method |
| LFM | linear frequency modulation |
| MDP | Markov decision process |
| RL | reinforcement learning |
| SJNR | signal-to-jamming plus noise ratio |
| TD error | time difference error |
References
- Li, Z.; Tang, B.; Zhou, Q.; Shi, J.; Zhang, J. A review of research on the optimal design of new system airborne radar waveforms. Syst. Eng. Electron. Technol. 2022, 1–20. Available online: http://kns.cnki.net/kcms/detail/11.2422.TN.20220328.2210.037.html (accessed on 6 November 2022).
- Zhao, G. Principles of Radar Countermeasures, 2nd ed.; Xidian University Press: Xi’an, China, 2015. [Google Scholar]
- Skolnik, M. Translated by Nanjing Electronics Technology Research Institute. Radar Handbook; Electronic Industry Press: Beijing, China, 2010. [Google Scholar]
- Chen, X.; Xue, Y.; Zhang, L.; Huang, Y. Airborne Radar System and Information Processing; Electronic Industry Press: Beijing, China, 2021; pp. 333–347. [Google Scholar]
- Haykin, S. Cognitive radar networks. In Proceedings of the 2005 1st IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, Puerta Vallarta, Mexico, 13–15 December 2005; pp. 1–3. [Google Scholar]
- Yan, Y.; Chen, H.; Su, J. Overview of anti-jamming technology in the main lobe of radar. In Proceedings of the 2021 IEEE 4th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 19–21 November 2021; pp. 67–71. [Google Scholar]
- Fang, W.; Quan, Y.; Sha, M.; Liu, Z.; Gao, X.; Xing, M. Dense False Targets Jamming Suppression Algorithm Based on the Frequency Agility and Waveform Entropy. Syst. Eng. Electron. 2021, 43, 1506–1514. [Google Scholar]
- Quan, Y.; Fang, W.; Sha, M.; Chen, M.; Ruan, F.; Li, X.; Meng, F.; Wu, Y.; Xing, M. Status and Prospects of Frequency Agile Radar Waveform Countermeasure Technology. Syst. Eng. Electron. 2021, 43, 3126–3136. [Google Scholar]
- Yan, F.; Su, J.; Li, Y. Research and Test of Radar Low Intercept Waveform Anti-Main Lobe Jamming Technology. Fire Control. Radar Technol. 2021, 50, 31–35. [Google Scholar] [CrossRef]
- Wei, S.; Zhang, L.; Liu, H. Joint frequency and PRF agility waveform optimization for high-resolution ISAR imaging. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–23. [Google Scholar] [CrossRef]
- Ou, J.; Li, J.; Zhang, J.; Zhan, R. Frequency Agility Radar Signal Processing; Science Press: Beijing, China, 2020. [Google Scholar]
- Thornton, C.; Buehrer, R.M.; Martone, A. Constrained contextual andit learning for adaptive radar waveform selection. IEEE Trans. Aerosp. Electron. Syst. 2021. [Google Scholar]
- Cui, G.; De, M.; Farina, A.; Li, J. Radar Waveform Design Based on Optimization Theory; The Institution of Engineering and Technology: London, UK, 2020. [Google Scholar]
- Xia, D.; Zhang, K.; Ding, B.; Li, B. Anti-simultaneous jamming based on phase-coded waveform shortcuts and CFAR techniques. Syst. Eng. Electron. 2022, 44, 1210–1219. [Google Scholar]
- Hu, H.; Lui, R.; Zhang, J. An improved radar anti-jamming method. In Proceedings of the 2018 IEEE 3rd International Conference on Signal and Image Processing, Shenzhen, China, 13–15 July 2018; pp. 439–443. [Google Scholar]
- Wang, H.; Yang, X.; Li, Y. Radar anti-retransmitted jamming technology based on agility waveforms. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–6. [Google Scholar]
- Zhou, C.; Liu, F.; Liu, Q. An Adaptive Transmitting Scheme for Interrupted Sampling Repeater Jamming Suppression. Sensors 2017, 17, 2480. [Google Scholar] [CrossRef]
- Gong, X.; Meng, H.; Wei, Y.; Wang, X. Phase-Modulated Waveform Design for Extended Target Detection in the Presence of Clutter. Sensors 2011, 11, 7162–7177. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, Y. A cognitive-based approach to the design of anti-folding extended clutter waveforms. Syst. Eng. Electron. 2018, 40, 2216–2222. [Google Scholar]
- He, J.; Cheng, Z.; He, Z. Cognitive constant-mode waveform design method for resisting intermittent sampling and forwarding jamming. Syst. Eng. Electron. 2021, 43, 2448–2456. [Google Scholar]
- Hao, T.; Hu, S.; Gao, W.; Li, J.; Cao, X.; Wang, P. Detection-oriented low peak-to-average ratio robust waveform design for cognitive radar. Electron. Inf. Warf. Technol. 2022, 37, 70–75. [Google Scholar]
- Yu, R.; Yang, W.; Fu, Y.; Zhang, W. A Review of Cognitive Waveform Optimisation for Different Radar Tasks. Acta Electron. Sin. 2022, 50, 726–752. [Google Scholar]
- Wei, Y.; Meng, H.; Liu, Y.; Wang, X. Extended Target Recognition in Cognitive Radar Networks. Sensors 2010, 10, 10181–10197. [Google Scholar] [CrossRef]
- Ailiya; Wei, Y.; Yuan, Y. Reinforcement learning-based joint adaptive frequency hopping and pulse-width allocation for radar anti-jamming. In Proceedings of the 2020 IEEE Radar Conference, Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Liu, K.; Lu, X.; Xiao, L.; Xu, L. Learning based energy efficient radar power control against deceptive jamming. In Proceedings of the 2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Wang, H.; Wang, F. Application of a reinforcement learning algorithm in intelligent anti-jamming of radar. Mod. Radar 2020, 42, 40–44+48. [Google Scholar]
- Ahmed, A.; Ahmed, A.; Fortunati, S.; Sezgin, A.; Greco, M.; Gini, F. A reinforcement learning based approach for multitarget detection in massive MIMO radar. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 2622–2636. [Google Scholar] [CrossRef]
- Li, K.; Jiu, B.; Liu, H.; Liang, S. Reinforcement Learning based Anti-jamming Frequency Hopping Strategies Design for Cognitive Radar. In Proceedings of the 2018 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Qingdao, China, 14–16 September 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Li, K.; Jiu, B.; Liu, H. Deep Q-network based anti-jamming strategy design for frequency agile radar. In Proceedings of the 2019 International Radar Conference, Toulon, France, 30 September–4 October 2019; pp. 1–5. [Google Scholar]
- Li, K.; Jiu, B.; Wang, P.; Liu, H.; Shi, Y. Radar Active Antagonism through Deep Reinforcement Learning: A Way to Address The Challenge of Mainlobe Jamming. Signal Process. 2021, 186, 108130. [Google Scholar] [CrossRef]
- Ak, S.; Brüggenwirth, S. Avoiding Jammers: A Reinforcement Learning Approach. In Proceedings of the 2020 IEEE International Radar Conferenc (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 321–326. [Google Scholar] [CrossRef]
- Selvi, E.; Buehrer, R.; Martone, A.; Sherbondy, K. On The Use of Markov Decision Processes in Cognitive Radar: An Application to Target Tracking. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 537–542. [Google Scholar] [CrossRef]
- Kozy, M.; Yu, J.; Buehrer, R.; Martone, A.; Sherbondy, K. Applying Deep-Q Networks to Target Tracking to Improve Cognitive Radar. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shi, Y.; Jiu, B.; Yan, J.; Liu, H.; Li, K. Data-Driven Simultaneous Multibeam Power Allocation: When Multiple Targets Tracking Meets Deep Reinforcement Learning. IEEE Syst. J. 2020, 15, 1264–1274. [Google Scholar] [CrossRef]
- Hessel, M.; Modayil, J.; Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the 32rd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. Available online: https://arxiv.org/pdf/1312.5602.pdf (accessed on 6 November 2022).
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34rd International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017; pp. 449–458. Available online: https://arxiv.org/pdf/1707.06887.pdf (accessed on 6 November 2022).
- Hasselt, V.H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. The 30rd AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. Available online: https://arxiv.org/pdf/1509.06461v3.pdf (accessed on 6 November 2022).
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. Available online: https://arxiv.org/pdf/1511.05952.pdf (accessed on 6 November 2022).
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016; pp. 1995–2003. Available online: https://arxiv.org/pdf/1511.06581.pdf (accessed on 6 November 2022).
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O.; et al. Noisy Networks for Exploration. arXiv 2017, arXiv:1706.10295. Available online: https://arxiv.org/pdf/1706.10295.pdf (accessed on 6 November 2022).
- Zheng, Z.; Li, W.; Zou, K.; Li, Y. Anti-jamming Waveform Design of Ground-to-air Radar Based on Reinforcement Learning. Acta Armamentarii 2022, 1–9. Available online: http://kns.cnki.net/kcms/detail/11.2176.TJ.20220722.1003.002.html (accessed on 6 November 2022).
- Wang, H.; Li, W.; Wang, H.; Xu, J.; Zhao, J. Radar Waveform Strategy Based on Game Theory. Radio Eng. 2019, 28, 757–764. [Google Scholar] [CrossRef]
- Romero, R.; Bae, J.; Goodman, N. Theory and Application of SNR and Mutual Information Matched Illumination Waveforms. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 912–927. [Google Scholar] [CrossRef]
- Gagniuc, P. Markov Chains: From Theory to Implementation and Experimentation; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Steven, M.K. Fundamentals of Statistical Signal Processing: Estimation and Detection Theory; Electronic Industry Press: Beijing, China, 2014; pp. 425–445. [Google Scholar]
- Li, X.; Fan, M. Research Advance on Cognitive Radar and Its Key Technology. Acta Electron. Sin. 2012, 40, 1863–1870. Available online: https://www.ejournal.org.cn/EN/10.3969/j.issn.0372-2112.2012.09.025 (accessed on 6 November 2022).
- Jackson, L.; Kay, S.; Vankayalapati, N. Iterative Method for Nonlinear FM Synthesis of Radar Signals. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 910–917. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification by DRL Algorithm | DRL Algorithm | Brief Description | References |
|---|---|---|---|
| Value-based | Q learning (1992.05) | Q learning uses Q Table to store the value of each pair of state actions. When the state and action space are high-dimensional or continuous, it is not realistic to use Q Table. | Watkins et al. [36] |
| Deep Q Network (DQN,2013.12) | DQN can directly use raw high-dimensional sensor data for reinforcement learning, and training using stochastic gradient descent and the training process is more stable. | Mnih et al. [37] | |
| Distributional DQN (2015.08) | In DQN, the expected estimate of the state-action value Q of the network output ignores a lot of information. A deep reinforcement learning model modelled from a distributed perspective can obtain more useful information and obtain better and more stable results. | Bellemare et al. [38] | |
| Double DQN (2015.12) | In the original DQN, there will be a situation where the Q value is overestimated. To decouple the action selection and the value estimate, when calculating the actual value of Q in double DQN, the action selection is obtained by the evaluation network, while the value estimate is obtained by the target network. | Hasselt et al. [39] | |
| Prioritized Experience Replay (2016.02) | In the experience pool of traditional DQNs, the data selected for batch training are random, without taking into account the priority relationship of the samples. This method gives each sample a priority and samples according to the priority of the sample. | Schaul et al. [40] | |
| Duelling DQN (2016.04) | In the original DQN, the neural network directly outputs the Q value of each action, while the Q value of each action of the duelling DQN is determined by the state value V and the dominance function A, that is, Q = V + A. | Wang et al. [41] | |
| Noisy DQN (2017.06) | This method increases the exploration ability of the model by adding noise to the parameters. | Fortunato et al. [42] |
| Markov Decision Model | Parameter Settings |
|---|---|
| Number of signal sub-band divisions | |
| Number of sub-band energy divisions | |
| State space | |
| Action space | |
| Single state | |
| Single action | |
| 0.9 |
| A Certain Foreign Radar | Simulation Parameter Settings |
|---|---|
| Working band | X-band |
| Centre frequency | 9.5 GHz |
| Signal bandwidth | 100 MHz |
| Sub-band bandwidth | 20 MHz |
| Target aircraft speed | 250 m/s |
| Clutter | |
| Noise | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Li, W.; Zou, K. Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning. Sensors 2022, 22, 8689. https://doi.org/10.3390/s22228689
Zheng Z, Li W, Zou K. Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning. Sensors. 2022; 22(22):8689. https://doi.org/10.3390/s22228689
Chicago/Turabian StyleZheng, Zexin, Wei Li, and Kun Zou. 2022. "Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning" Sensors 22, no. 22: 8689. https://doi.org/10.3390/s22228689
APA StyleZheng, Z., Li, W., & Zou, K. (2022). Airborne Radar Anti-Jamming Waveform Design Based on Deep Reinforcement Learning. Sensors, 22(22), 8689. https://doi.org/10.3390/s22228689