
Autonomous Control of the Large-Angle Spacecraft Maneuvers in a Non-Cooperative Mission

Abstract
:1. Introduction
- The adaptive dual-channel feature extraction module and the convolutional attention mechanism are integrated into the attitude estimation of the non-cooperative target spacecraft so that the network has higher accuracy and Robustness, which indirectly improves the adaptability of autonomous control;
- The participation of the backstepping method enables the finite-time saturation controller to effectively solve the input saturation problem even in the presence of external disturbances.
2. Spacecraft Attitude Control Model
3. Design of a Limited Time Autonomous Controller for Large Attitude Maneuvers
3.1. Pose Estimation Network Design
3.2. Design of a Finite-Time Saturation Controller
- (1)
- V is a positive definite function.
- (2)
- There are positive real numbers, , and , and an open neighborhood containing the origin, where holds . Then the system is fast finite-time stable, and the convergence time satisfies . If , the system is globally fast and finite-time stable.
- (1)
- V is a positive definite function.
- (2)
- There exists a positive real numberand an open neighborhoodcontaining the origin, wheremakeshold. Then the system is stable in finite time; if, the system is stable in global finite time.
- (1)
- When , variables and converge in finite time, and when and satisfies , variables and converge in finite time.
- (2)
- The angular velocity error converges in a finite time.
4. Simulation Verification
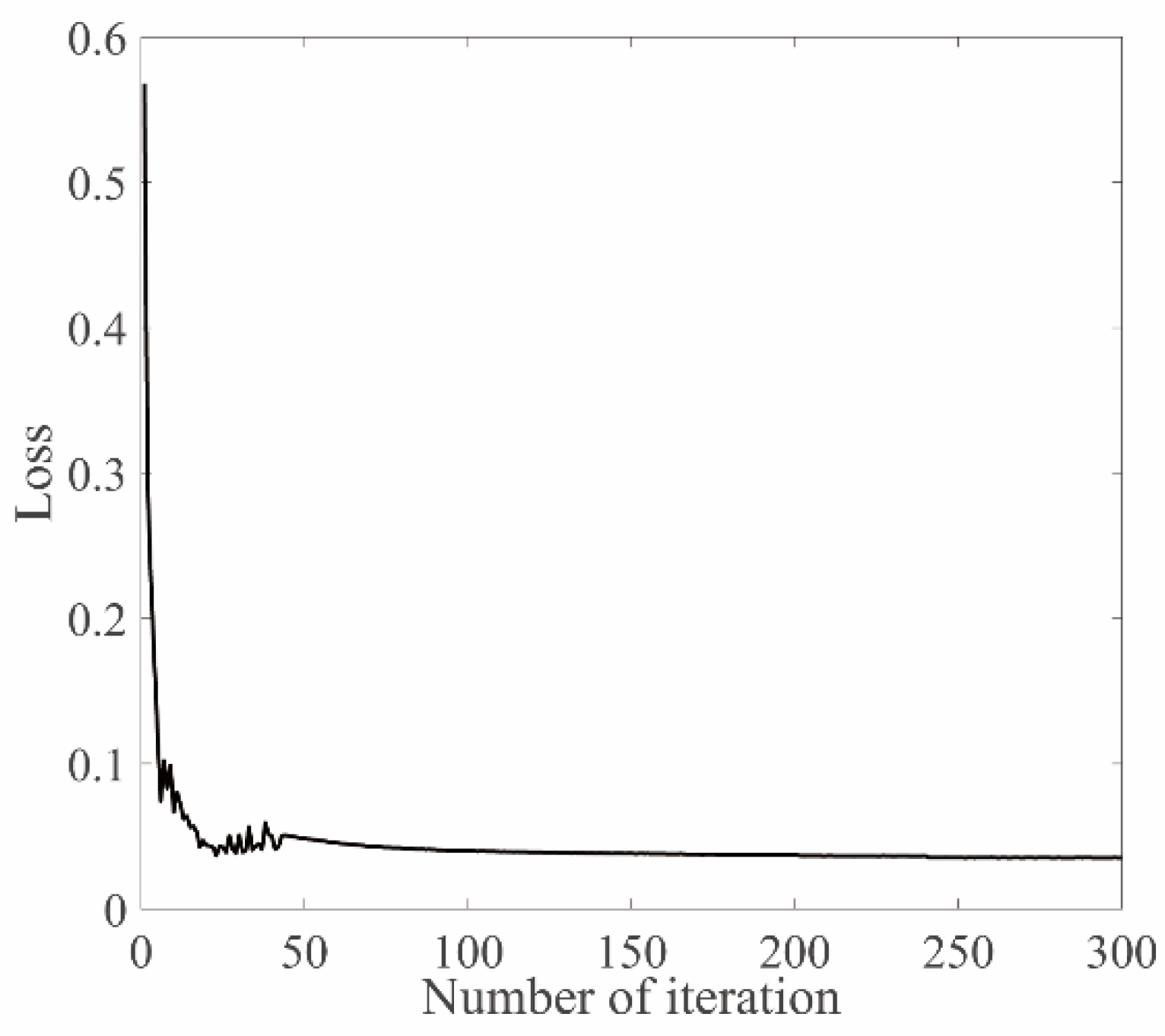
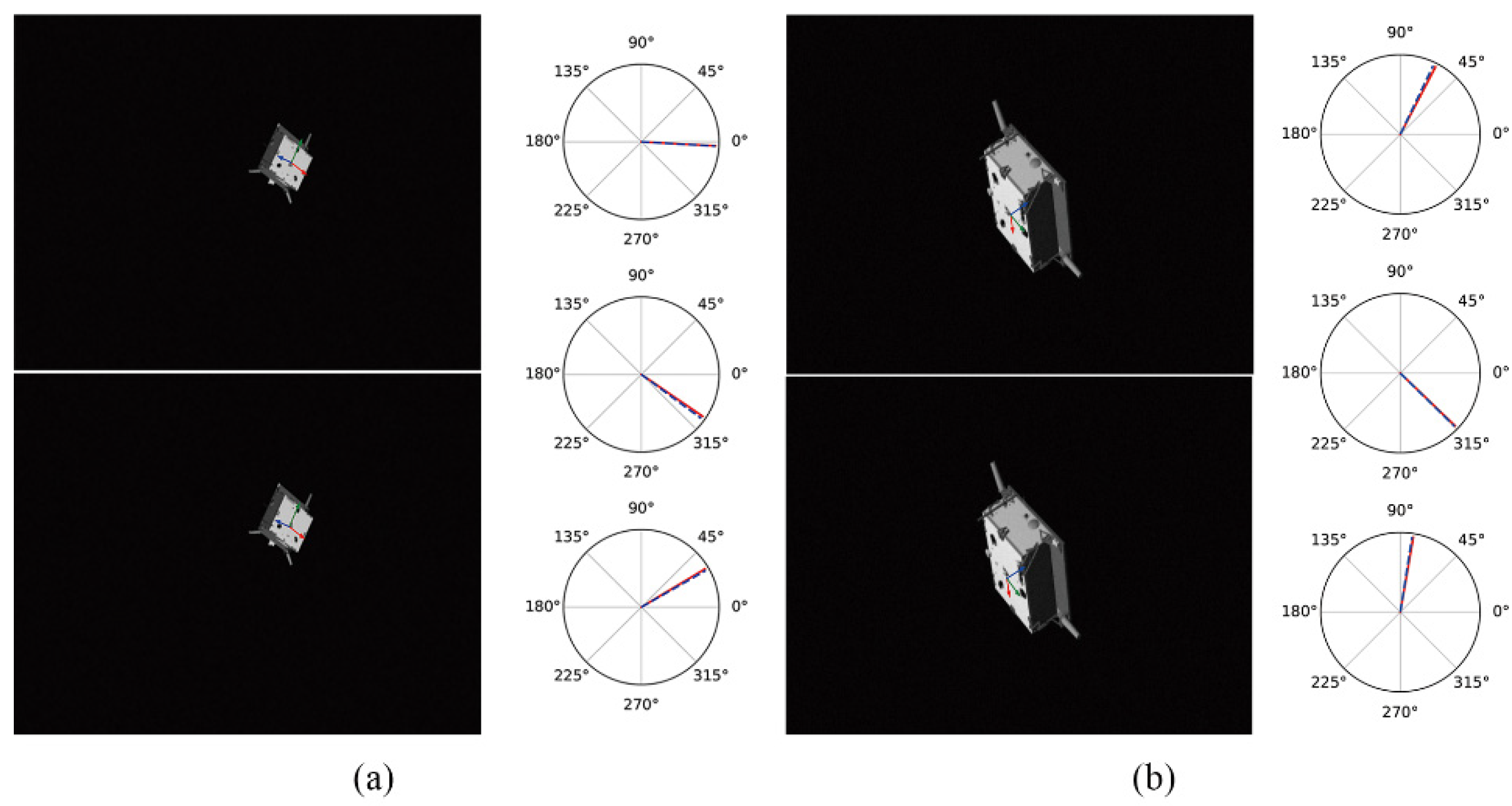
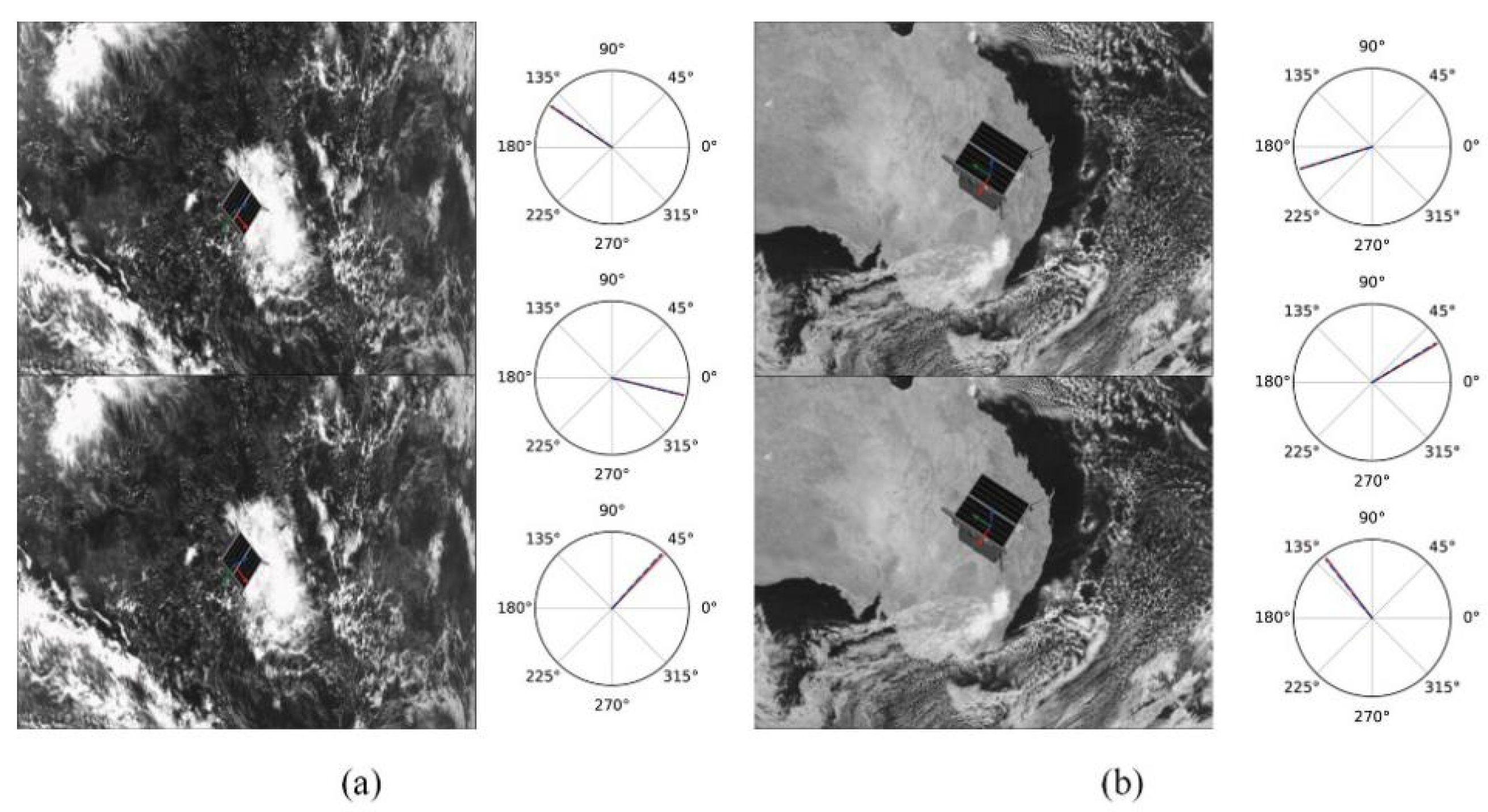
4.1. Pose Estimation
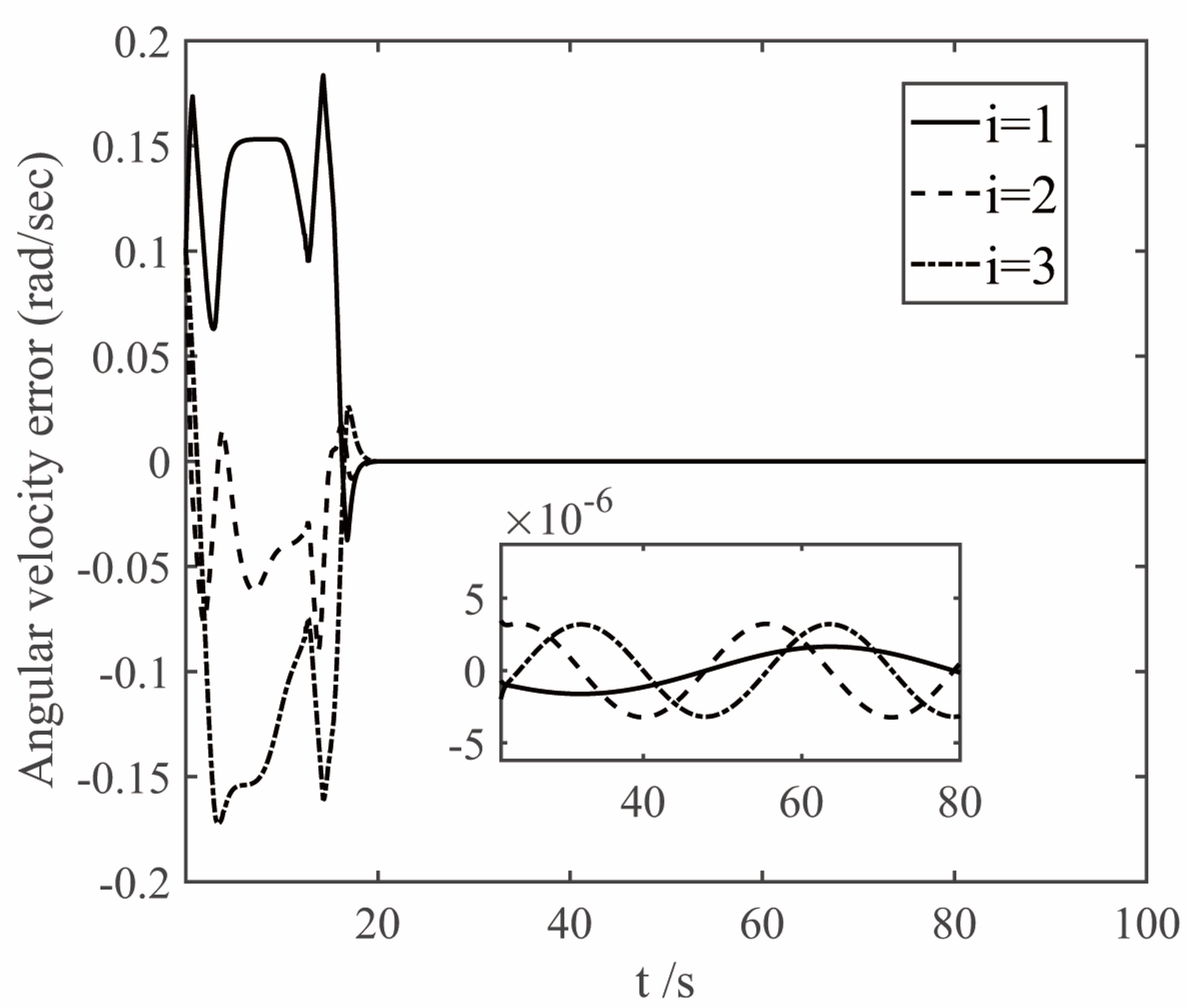
4.2. Attitude Tracking
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Du, H.; Yu, B.; Wei, J.; Zhang, J.; Wu, D.; Tao, W. Attitude trajectory planning and attitude control for quad-rotor aircraft based on finite-time control technique. Appl. Math. Comput. 2020, 386, 125493. [Google Scholar] [CrossRef]
- Huang, C.; Wang, Y.; Deng, L.W. Finite-Time Control for Spacecraft Attitude Large-Angle Maneuver. Chin. J. Aeronaut. 2020, 41, 1058–1066. [Google Scholar]
- Ma, Z.; Wang, Y.; Yang, Y.; Wang, Z.; Tang, L.; Ackland, S. Reinforcement learning-based satellite attitude stabilization method for non-cooperative target capturing. Sensors 2018, 18, 4331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, G.; Zhu, Z.H. Kinematics-based incremental visual servo for robotic capture of non-cooperative target. Robot. Auton. Syst. 2019, 112, 221–228. [Google Scholar] [CrossRef]
- Kisantal, M.; Sharma, S.; Park, T.H.; Izzo, D.; Märtens, M.; D’Amico, S. Satellite pose estimation challenge: Dataset, competition design, and results. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4083–4098. [Google Scholar] [CrossRef] [Green Version]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Silvestrini, S.; Lavagna, M. Deep Learning and Artificial Neural Networks for Spacecraft Dynamics, Navigation and Control. Drones 2022, 6, 270. [Google Scholar] [CrossRef]
- Hogan, M.; Rondao, D.; Aouf, N.; Dubois-Matra, O. Using Convolutional Neural Networks for Relative Pose Estimation of a Non-Cooperative Spacecraft with Thermal Infrared Imagery. arXiv 2021, arXiv:2105.13789. [Google Scholar]
- Park, T.H.; Sharma, S.; D’Amico, S. Towards robust learning-based pose estimation of noncooperative spacecraft. arXiv 2019, arXiv:1909.00392. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate O(n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Cao, J.; Parra, A.; Chin, T.-J. Satellite pose estimation with deep landmark regression and nonlinear pose refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Sharma, S.; Beierle, C.; D’Amico, S. Pose estimation for non-cooperative spacecraft rendezvous using convolutional neural networks. In Proceedings of the 2018 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–12. [Google Scholar]
- Cao, L.; Xiao, B.; Golestani, M. Robust fixed-time attitude stabilization control of flexible spacecraft with actuator uncertainty. Nonlinear Dyn. 2020, 100, 2505–2519. [Google Scholar] [CrossRef]
- Han, G.; Yuanqing, X.; Zhang, X.; Zhang, G. Distributed fixed-time attitude coordinated control for multiple spacecraft with actuator saturation. Chin. J. Aeronaut. 2022, 35, 292–302. [Google Scholar]
- Zhuang, M.; Tan, L.; Li, K.; Song, S. Fixed-time formation control for spacecraft with prescribed performance guarantee under input saturation. Aerosp. Sci. Technol. 2021, 119, 107176. [Google Scholar] [CrossRef]
- Yu, H.; Dai, K.; Li, H.; Zou, Y.; Ma, X.; Ma, S.; Zhang, H. Three-dimensional adaptive fixed-time cooperative guidance law with impact time and angle constraints. Aerosp. Sci. Technol. 2022, 123, 107450. [Google Scholar] [CrossRef]
- Zou, A.-M.; de Ruiter, A.H.; Kumar, K.D. Distributed finite-time velocity-free attitude coordination control for spacecraft formations. Automatica 2016, 67, 46–53. [Google Scholar] [CrossRef]
- Lu, K.; Xia, Y. Adaptive attitude tracking control for rigid spacecraft with finite-time convergence. Automatica 2013, 49, 3591–3599. [Google Scholar] [CrossRef]
- Ran, D.; Chen, X.; de Ruiter, A.; Xiao, B. Adaptive extended-state observer-based fault tolerant attitude control for spacecraft with reaction wheels. Acta Astronaut. 2018, 145, 501–514. [Google Scholar] [CrossRef]
- Jiang, B.; Li, C.; Ma, G. Finite-time output feedback attitude control for spacecraft using “Adding a power integrator” technique. Aerosp. Sci. Technol. 2017, 66, 342–354. [Google Scholar] [CrossRef]
- Wang, F.; Hou, M.; Cao, X.; Duan, G. Event-triggered backstepping control for attitude stabilization of spacecraft. J. Frankl. Inst. 2019, 356, 9474–9501. [Google Scholar] [CrossRef]
- Gui, H.; Jin, L.; Xu, S. Simple finite-time attitude stabilization laws for rigid spacecraft with bounded inputs. Aerosp. Sci. Technol. 2015, 42, 176–186. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, Q.; Wang, D. Bounded finite-time attitude tracking control for rigid spacecraft via output feedback. Aerosp. Sci. Technol. 2017, 64, 75–84. [Google Scholar] [CrossRef]
- Lu, P.; Gan, C.; Liu, X. Finite-time distributed cooperative attitude control for multiple spacecraft with actuator saturation. IET Control Theory Appl. 2014, 8, 2186–2198. [Google Scholar] [CrossRef]
- Xia, K.; Huo, W. Robust adaptive backstepping neural networks control for spacecraft rendezvous and docking with input saturation. ISA Trans. 2016, 62, 249–257. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Guo, J.-H.; Song, S.-M. Backstepping control for attitude tracking of the spacecraft under input saturation. Acta Astronaut. 2017, 138, 318–325. [Google Scholar] [CrossRef]
- Proença, P.F.; Gao, Y. Deep learning for spacecraft pose estimation from photorealistic rendering. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6007–6013. [Google Scholar]
- Du, H.; Li, S.; Qian, C. Finite-time attitude tracking control of spacecraft with application to attitude synchronization. IEEE Trans. Autom. Control 2011, 56, 2711–2717. [Google Scholar] [CrossRef]
- Yu, S.; Yu, X.; Shirinzadeh, B.; Man, Z. Continuous finite-time control for robotic manipulators with terminal sliding mode. Automatica 2005, 41, 1957–1964. [Google Scholar] [CrossRef]
- Huo, M.; Huo, X.; Karimi, H.R.; Ni, J. In Finite-time control for attitude tracking maneuver of rigid satellite. In Abstract and Applied Analysis; Hindawi: London, UK, 2014. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real Images | Simulated Images | |
|---|---|---|
| Training set | 5 | 12,000 |
| Test set | 300 | 2998 |
| Model | |||
|---|---|---|---|
| URSONet | 0.0604 | 0.1630 | 5.46 |
| URSONet-D | 0.0531 | 0.1561 | 5.35 |
| URSONet-D | 0.0462 | 0.1464 | 5.12 |
| URSONet-S | 0.0442 | 0.1448 | 5.13 |
| URSONet-C | 0.0424 | 0.1430 | 4.88 |
| URSONet-Improve | 0.0296 | 0.1328 | 4.74 |
| Top 10 average | 1.3848 | 0.1515 | 10.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Cao, T.; Huang, J. Autonomous Control of the Large-Angle Spacecraft Maneuvers in a Non-Cooperative Mission. Sensors 2022, 22, 8586. https://doi.org/10.3390/s22228586
Huang C, Cao T, Huang J. Autonomous Control of the Large-Angle Spacecraft Maneuvers in a Non-Cooperative Mission. Sensors. 2022; 22(22):8586. https://doi.org/10.3390/s22228586
Chicago/Turabian StyleHuang, Cheng, Tianzeng Cao, and Jinglin Huang. 2022. "Autonomous Control of the Large-Angle Spacecraft Maneuvers in a Non-Cooperative Mission" Sensors 22, no. 22: 8586. https://doi.org/10.3390/s22228586
APA StyleHuang, C., Cao, T., & Huang, J. (2022). Autonomous Control of the Large-Angle Spacecraft Maneuvers in a Non-Cooperative Mission. Sensors, 22(22), 8586. https://doi.org/10.3390/s22228586