1. Introduction
In this paper, an approach based on the time–chirp (
) transform used for the estimation and classification of signals with nonlinear frequency modulation (NLFM) has been presented. The chirp rate (
), also called the instantaneous frequency rate (IFR), is the signal phase acceleration and can be calculated as the time derivative of a frequency function. The analysis and processing of NLFM signals are exploited in a wide range of applications for example in Electronic Support Measures/Electronic Intelligence (ESM/ELINT), Electronic Warfare (EW), Electronic Reconnaissance (ER) systems, as well as in passive bistatic radar (PBR) [
1]. Modern electronic intelligence and electronic support are designed to automatically distinguish the modulation type of an intercepted radar signal, which can be utilized in early warning systems or give more information about hostile radars [
2,
3,
4,
5,
6,
7]. Passive bistatic radar uses emissions from communications, broadcast, or radionavigation transmitters instead of dedicated, cooperative radar transmitters. The transmitted waveforms are not explicitly designed for passive radar purposes. Therefore, knowledge about the received signal is crucial in the ability of waveform recognition and reconstruction. New sources of target illumination in passive radars are constantly being searched. Solutions with using the 5G cellular network as a source of illumination in a passive radar system have recently appeared [
8]. The NLFM waveform for synthetic aperture radar (SAR) applications is important for improving spaceborne SAR image quality and reducing system costs [
9,
10]. The NLFM waveform was also proposed for active sonars [
11].
The NLFM signal can be synthesized in different ways in order to obtain desired properties by shaping the power spectral density (PSD). Due to nonlinear frequency modulation, such signals can achieve the desired PSD and desired autocorrelation function with reduced sidelobes compared to LFM signals [
12,
13,
14]. In the case of narrowband signals, the Doppler offset may be miscalculated in the narrowband ambiguity function [
15,
16]. The potential advantage of NLFM is its Doppler shift tolerance. These properties make NLFM signals very attractive especially for radar applications. Generally, synthesis of signals with limitation of the required level of AC-sidelobes and desired power spectral density is a great challenge. These conditions require multi-objective optimization approach with strong constraints and high computational load and may result in inconsistent requirements [
11,
15,
17,
18,
19,
20]. Appropriate NLFM chirps achieving the desired shape of the power spectrum have been suggested as a solution to this problem. Signals for which parameterized nonlinear frequency modulations satisfy the desired spectral properties, achieving low level sidelobes, have been proposed by a lot of authors. Signal models presented by Collins and Atkins [
11], Pirce [
21] or Yue and Zhang [
22] are very popular and are also the subject of analysis in this paper.
A special class of NLFM signals, which enables the shaping of the PSD and obtains the desired AC function, is polynomial phased signals (PPS). This kind of nonlinear signal plays a significant role in modern radar systems, including SAR, ISAR and OTHR systems, as well as in sonars, biomedicine, machine engine testing, etc., especially in the ISAR, where due to target movement or extreme target maneuvers, the radar returns contain mainly PPS components, possibly with high-order phase terms [
23,
24]. The simplest type of a signal with a polynomial phase is a signal with linear frequency modulation. Unfortunately, the PSD of an LFM signal is approximately rectangular and after matched filtering (MF) the peak-to-sidelobe ratio (PSLR) is rather low, reaching about 13.3 [dB]. Therefore, NLFM signals are considered to be a good alternative to LFM signals.
Modern radar systems, especially surveillance systems, can emit a pulse train with inter-pulse and intra-pulse complex modulation, including both linear and nonlinear frequency modulation. If such radars operate in the dense, hostile electromagnetic environment, intercepted signals should be recognized or classified by means of spectrum-sensing systems such as ELINT, ER and EW. The main problem of recognition and estimation of intercepted signals is the determination of the modulation type and its parameters. If any information is not available, it is reasonable to assume a phase polynomial for such signals with a sufficiently high order of polynomial nonlinearity. Even parameterized nonlinearities, which usually have a complex analytical description, can be approximated by polynomial form with a sufficiently high order to obtain a simpler description for further analysis. In this paper, the polynomial approximation of the NLFM models has been evaluated for estimation and classification purposes. The set of selected coefficients of polynomial approximation is suggested as distinctive features allowing the identification of a type of unknown emission by means of classification. This approach requires a database containing a set of nonlinearity types. In this paper, the estimation of the PPS parameters as well as identification by classification of other type of nonlinearities are considered.
The general description of nonstationary signals embedded in noise can be presented as follows:
where
is the phase of the signal,
is the amplitude of the signal and
is white Gaussian noise.
There is an unambiguous relationship between frequency function
(the instantaneous frequency (IF)) and the instantaneous phase function
of a nonstationary signal
through the differentiation operation:
Knowledge of the IF function automatically determines the phase function and vice versa. It seems natural to use time–frequency (T-F) distributions for IF analysis and estimation of NLFM signals. However, the most known quadratic T-F distributions, such as the pseudo Wigner–Ville distribution and the Choi–Williams distribution, contain cross-term components, and the estimation of the instantaneous frequency modulation is performed with unacceptable accuracy. Therefore, they are practically useless [
2]. For analysis of the PPS, the high order ambiguity function (HAF) or the product HAF (PHAF) seems to be attractive. In these distributions, the phase-differentiation (PD) operation is repeated many times until a single complex sinusoidal signal is obtained [
25,
26]. The frequency of the obtained sinusoidal signal indicates the highest order PPS coefficient. Next, the original signal is dechirped with the use of this PPS coefficient. The remaining parameters are estimated by repeating the same procedure. Although these methods provide good accuracy, they suffer from high computational burden and error propagation during dechirping operations. Therefore, they seem to be useless for NLFM.
This paper deals with the effective estimation of the PPS of higher order. The proposed method is based on the concept of nonlinear sampling and the cubic phase function distribution (CPF) developed on the time–chirp (
) plane [
27]. The CPF distribution turned out to be effective in parameter estimation of the quadratic frequency modulation signals [
28]. In this paper, the CPF is proposed to extract distinctive features of parameterized nonlinearities approximated by a polynomial useful in classification. Nonlinearities within the paper are replaced by the polynomial form containing sufficient information to classify NLFM signals. Although the CPF was originally designed for the estimation of the third order PPS, in this paper, the CPF method is used for estimation of the sixth order PPS.
The classification of NLFM using the set of distinctive properties obtained from the CPF method on the (
) plane is presented in the next part of the paper. The classification process comprises three types of nonlinearities typical for radar applications. The classification of NLFM signals is not trivial, especially for signals with abrupt frequency changes, and requires advanced systems such as neural networks to achieve high classification efficiency [
29,
30,
31,
32]. Generally, due to the ability of self-learning and adaptability, neural networks can outperform other classification approaches. Two neural classifiers based on learning vector quantization (LVQ) and multilayer perceptron (MLP) networks have been used and compared. Other concepts of LFM and NLFM classification based on neural networks can be found in [
33,
34,
35]. The neural network classification, considered in this paper, also takes into account the classification between NLFM and LFM signals [
36].
The paper is organized as follows:
Section 2 presents selected NLFM signals used in radar and sonar and discusses the use of their polynomial approximations.
Section 3 discusses various methods of IF estimation and describes the proposed IF estimator based on the cubic phase function, while
Section 4 presents the results of simulation studies on the quality of the proposed IF estimator.
Section 5 proposes the use of the CPF-based estimator of phase polynomial coefficients in the classification of the NLFM signals and presents the results of simulation tests.
Section 6 presents the conclusions.
2. Nlfm Signals and Their Polynomial Approximations
In this section, some selected examples of nonlinear functions used for the generation of NLFM signals for radar and echolocation systems are presented. Then, using the Taylor expansion of these functions, some aspects related to the accuracy of the polynomial approximation are illustrated and discussed.
Currently, NLFM signals are mainly developed for use in radar and sonar technologies. To present the proposed estimation and classification methods, three representative NLFM functions have been selected and presented by Formulas (
3)–(
7). The functions and their parameters were designed by their authors to minimize the sidelobes of the autocorrelation function.
The NLFM signal developed by Collins and Atkins [
11] consists of a linear and nonlinear part. The nonlinearity impact is determined by two parameters
and
:
where
B is the signal bandwidth,
T is the time duration of the pulse, and
is the parameter that defines the weight between the linear and nonlinear part, while the parameter
affects the intensity of the nonlinear part.
Parameter values that minimize the sidelobes of the autocorrelation function are
and
[
11].
The NLFM signal proposed by Price [
21] also consists of a linear part represented by the
parameter and a nonlinear part controlled by
:
In the paper, the following form of Formula (
4), explicitly showing the signal bandwidth
B [
12], is used:
where the parameters:
and
, with values
and
minimizing sidelobes [
12], and the time interval
covering bandwidth
B.
The NLFM signal proposed by Yue and Zhang [
22] is given by the formula:
where the parameters
and
that minimize the sidelobes take values:
and
.
In the presented analyses, the
LFM signal is also used. It has the same bandwidth
B and the pulse duration
T as NLFM signals. The frequency of the
LFM signal is described by the following formula:
Nonlinear, continuous functions , , determined on the closed interval:, according to the Weierstrass approximation theorem, can be approximated with desired accuracy using polynomial functions of a sufficiently high order. The approximation error for a particular nonlinear function depends on the order of the polynomial.
The proposed estimation and classification method is based on simplified polynomial models of nonlinear functions that describe the frequency and phase of the NLFM signals. An important issue is the selection of the order of the approximating polynomial. In the paper, this issue is analyzed using the Taylor series approximation, which makes it possible to obtain an analytical description of the signal frequency and phase as a function of time.
Examples of the approximation of the nonlinear functions
,
,
are presented by (
8)–(
10). Polynomials of the fifth order were calculated using the Taylor expansion around the time point
t = 0:
where
,
and
are reminder terms.
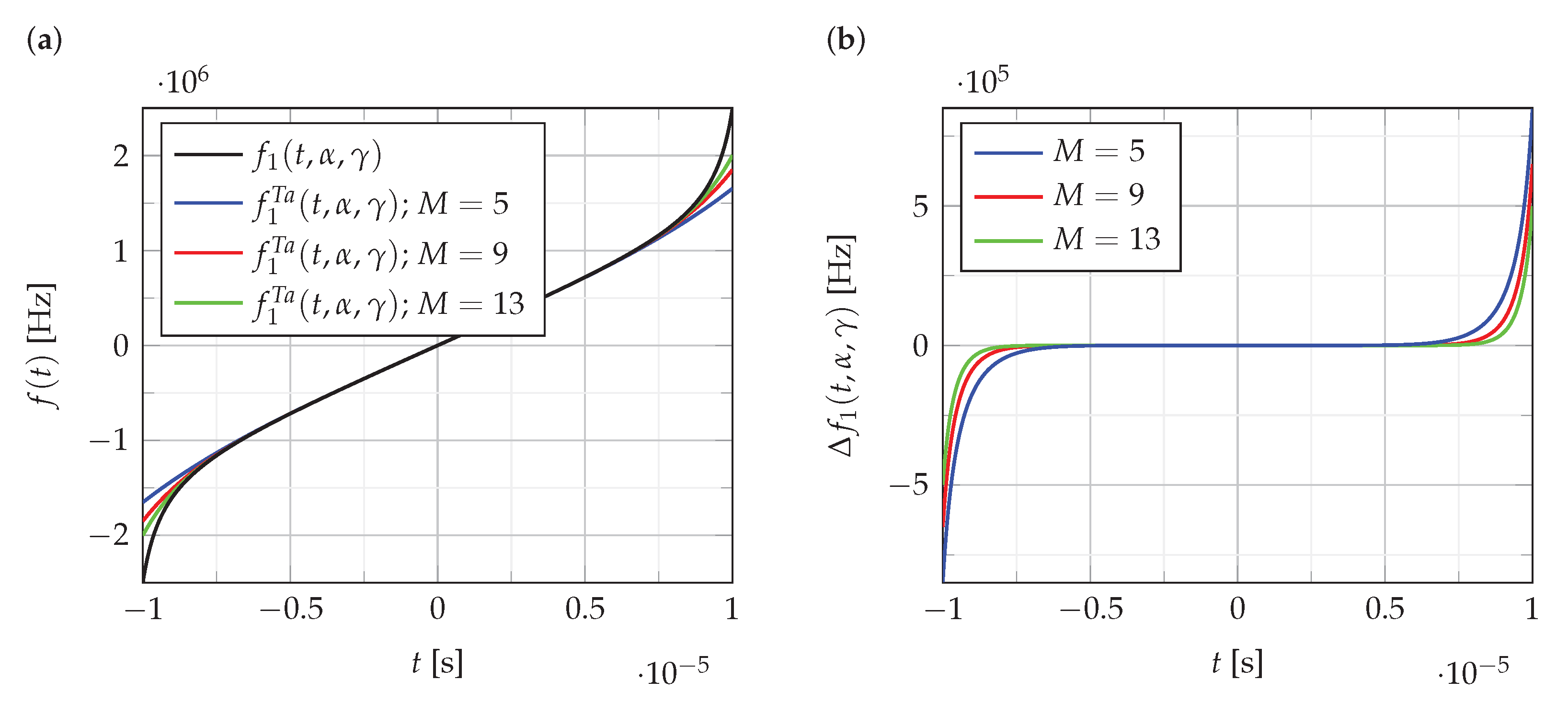
Figure 1 illustrates a change in the accuracy of
approximation depending on the polynomial order.
Figure 1a shows the function
and its polynomial approximations of order
.
Figure 1b shows the error
of these approximations.
As can be seen from the analysis of the results presented in
Figure 1, the error of polynomial approximation for the order
slowly decreases. Similar results are obtained for the approximation of the functions
and
.
Based on the relationship (
2), it is possible to calculate the analytical functions (
12)–(
15) that describe the instantaneous phase of the NLFM and LFM signals:
where
,
,
,
are initial phase values, while the time interval is is
.
The Taylor polynomial approximation is calculated around the time moment
nd phase value:
, as the phase function is symmetrical with respect to this point. Taylor approximations of the phase with polynomials of the sixth order are presented by (
16)–(
18).
where
,
,
are reminder terms.
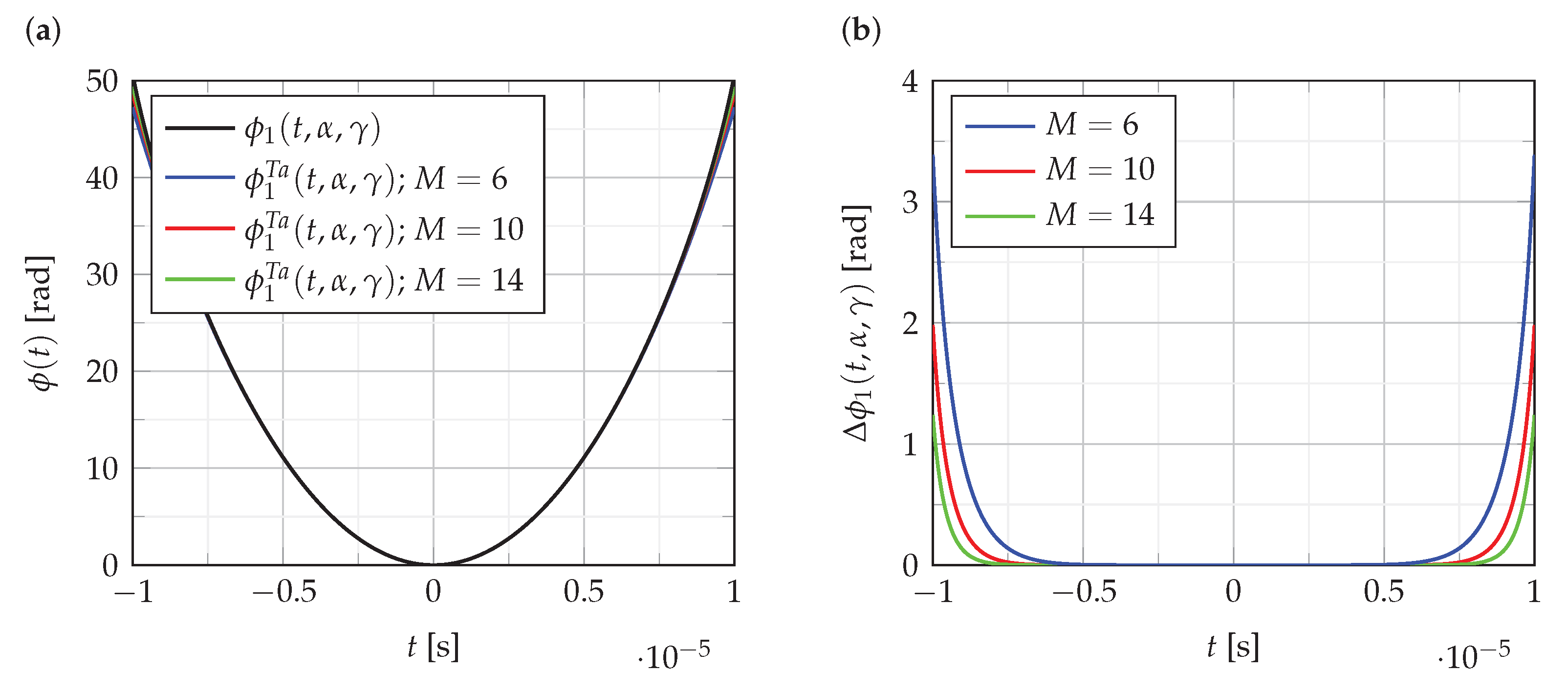
The influence of polynomial order on the accuracy of the polynomial approximation of the phase function
is presented in
Figure 2.
Figure 2a shows the function
, and its polynomial approximations of order
.
Figure 2b shows the error
of these approximations:
As can be seen from the analysis of the results presented in
Figure 2, the error of polynomial approximation of phase function is quite small compared to phase value. Similar results are obtained for the approximation of the functions
and
.
In the paper, the polynomial approximation of a phase function has been analyzed to classify NLFM signals. The nonlinear change in the frequency of analyzed signals is described by the odd function, which results in an odd order of approximating polynomial. Taking into account this feature and the relationship (
2), the polynomial approximation of the phase function is of an even order. In our case, after preliminary investigation, we decided that the order of the polynomial approximation of the phase function can be limited to
. The set of selected coefficients of the approximating polynomial is chosen as a set of distinctive features in the proposed method of classification of NLFM signals. The sixth order of the approximating polynomial seems sufficient to constitute a set of distinctive features. Although the selected order of the approximating polynomial does not guarantee a perfect polynomial fitting, especially on signal parts with abrupt nonlinear changes, it allows for effective classification with the low computational load.
3. The CPF-Based Estimator of the IFR
The recognition of signals with nonlinear frequency modulation is usually performed with the use of estimation of the instantaneous frequency of the signal. There are many methods for analyzing nonlinear frequency functions, including all distributions of the group belonging to the Cohen class. These are, among others, time–frequency distributions such as the Wigner–Ville distribution, the Choi–Wiliams distribution and the short-time Fourier transform (STFT). A large group of signals with a nonlinear frequency are PPS. Very good estimation results of the higher order PPS are obtained by the quasi-maximum likelihood (QML) method, which is an extended version of the STFT transformation [
37,
38,
39]. Estimation of the IF is performed by the STFT. Coefficients of the PPS are obtained from the IF estimates using the classical polynomial regression. The QML method requires an additional refining procedure to improve the quality of coarse estimates of polynomial coefficients. The refining process consists of four steps: dechirping the received signal using coarse initial estimates of the polynomial phase parameters provided by the STFT, filtering through an M-point moving average (MA) filter combined with an M-fold decimation, polynomial phase estimation of the obtained signal by phase unwrapping and least squares estimation. The final estimates are calculated as a combination of estimates obtained in step 3 with the initial coarse estimates [
40]. In the last step of the QML method, the optimal STFT window is searched by maximizing the quasi-ML function. Rather than directly searching through all parameters of phase polynomial, the maximum QML function is calculated for the estimates provided by STFT and polynomial regression. The QML is computationally exhaustive for higher order PPS because it requires multiple STFT calculations and multiple polynomial regression calculations, which are slow but precise processes. Therefore, it is desirable to search for a new transform with results comparable to the QML transform, but with less computational effort. A proposed alternative method of estimating the parameters of approximating polynomials is the CPF distribution defined for discrete signals.
Discrete signals of interest (i.e., PPS)
are characterized by a constant amplitude
and phase
and are defined as:
where the phase function
is described by the
order polynomial with coefficients
and
is Gaussian white noise with variance
. The discrete phase function is specified by the following formula:
The CPF is defined as follows:
where
is the frequency rate.
The discrete time
resulting from sampling with the period
and the discrete frequency rate
define a discrete grid on the time—frequency rate plane
. Therefore, the discrete results of the estimation of phase polynomial coefficients may differ from the continuous case if the discrete grid is sparse. The estimate of IFR [
28,
41] for each point in time is obtained as follows:
The CPF presented in the literature is mainly used to estimate the parameters of a signal phase polynomial up to the third order [
28,
41,
42]. However, according to the analysis presented in
Section 2, the proposed classification approach requires estimation of the coefficients of the sixth order phase polynomial. In this paper, the extension of the CPF to analysis of a sixth order polynomial is considered. The proposed approach assumes that only one run of the CPF-based method is used to estimate coefficients of the phase polynomial of the required order. Having had the set of estimated phase polynomial coefficients, the set of frequency polynomial coefficients can also be calculated according to the relationship (
2). The proposed method based on the CPF has a lower computational load than the QML and other commonly known methods dedicated to the analysis of signals in the frequency or time–frequency domains.
NLFM signals are most often defined by frequency functions, such as functions
,
and
given in
Section 2 described by (
3)–(
6). Generating signals by means of Equation (
1) requires the knowledge of the corresponding phase functions, which for the analyzed signals are represented by the functions
,
and
described by (
12)–(
14). The CPF algorithm, which processes the received noise-disturbed signal (
20), estimates the coefficients of the discrete phase polynomial model. In the proposed classification method, these coefficients of the phase polynomial are used as a set of distinctive features. Classification methods are described in more detail in
Section 5. Moreover, the estimation of the instantaneous frequency with the use of a discrete polynomial approximating the continuous frequency function is proposed. The coefficients of the approximating frequency polynomial are calculated from the coefficients of the phase polynomial obtained using CPF.
The proposed
order polynomial approximating frequency function
is of the form:
where
are the coefficients of the frequency polynomial.
The coefficients of the frequency polynomial (
24) can be obtained from phase polynomial coefficients using relationships (
2) and take the following value:
where the coefficients
of the phase polynomial are obtained by the CPF.
Modification of the kernel of the classical CPF distribution (
22) with the use of nonuniform sampling allows for higher order PPS decomposition. By sampling the signal at nonuniformly spaced time moments, the order of the PPS estimator can be lowered [
43]. The kernel of the original CPF distribution (
22) is as follows:
and the modified kernel takes the following form:
where
defines the nonlinear sampling [
44].
The proposed sampling allows the calculation of the CPF using the FFT method, which results in a significant reduction of the computational load.
If we consider the modified kernel for
n = 0 and the signal model (
2) processed by this kernel, a third order polynomial form is obtained with only even coefficients from the set of all coefficients of the sixth order phase polynomial, which is proposed as a polynomial approximation of considered nonlinearities:
where the parameter
controls the sampling process, and
,
,
are polynomial parameters related to phase polynomial coefficients from (
21).
The kernel
creates the signal with the polynomial phase of the 3rd order. Coefficients of such a polynomial can be efficiently computed using the CPF distribution (
22). Parameters
,
and
are related to
,
,
, respectively. Therefore, the estimation of the polynomial parameters can be performed directly by the CPF procedure:
It is natural to assume the parameter
, but parameter
should be chosen to obtain a statistically optimal estimate of parameters. It strongly depends on the properties of analyzed signals. The
and
allow for calculating
and
according to Equations (31) and (32) [
28]:
An estimate of
from (28) is obtained by dechirping and finding the Fourier transform peak and
can be calculated as follows:
The kernel (
28) is independent of the remaining parameters
,
,
of the phase polynomial. The accuracy of the estimation process depends on the SNR, and operations above a certain SNR threshold are performed with acceptable accuracy.
The estimated parameters
,
and
are used for the estimation of the nonlinear frequency function and the signal classification process. The proposed method including estimation and classification is summarized in the flow diagram presented in
Figure 3.
4. Frequency Estimation of NLFM Signals Based on CPF
Simulation investigations of the proposed algorithms were carried out for three waveforms NLFM and one LFM waveforms. The NLFM functions, marked as
,
and
, are presented in
Section 2 and are described by (
3)–(
6). Their specific parameters ensuring minimal sidelobes are presented there. The up-chirp LFM waveform
is described by Formula (
15). The following time and bandwidth parameters for all signals were assumed: pulse duration
s. (with time frame:
); sampling frequency
MHz; signal bandwidth
MHz. The signal noise was assumed to be complex Gaussian with variance depending on the SNR. To evaluate the proposed methods,
Monte Carlo simulations were carried out for each case.
For assumed sixth order phase polynomial and odd frequency functions, the estimation function takes the form:
where
,
and
are polynomial coefficients that can be calculated as follows:
where
,
and
are the coefficients of the polynomial approximating phase obtained from the CPF.
The quality of the estimation of the instantaneous frequency of the signal can be assessed by the root mean square error (RMSE) determined according to the relationship:
where
is the number of simulation runs.
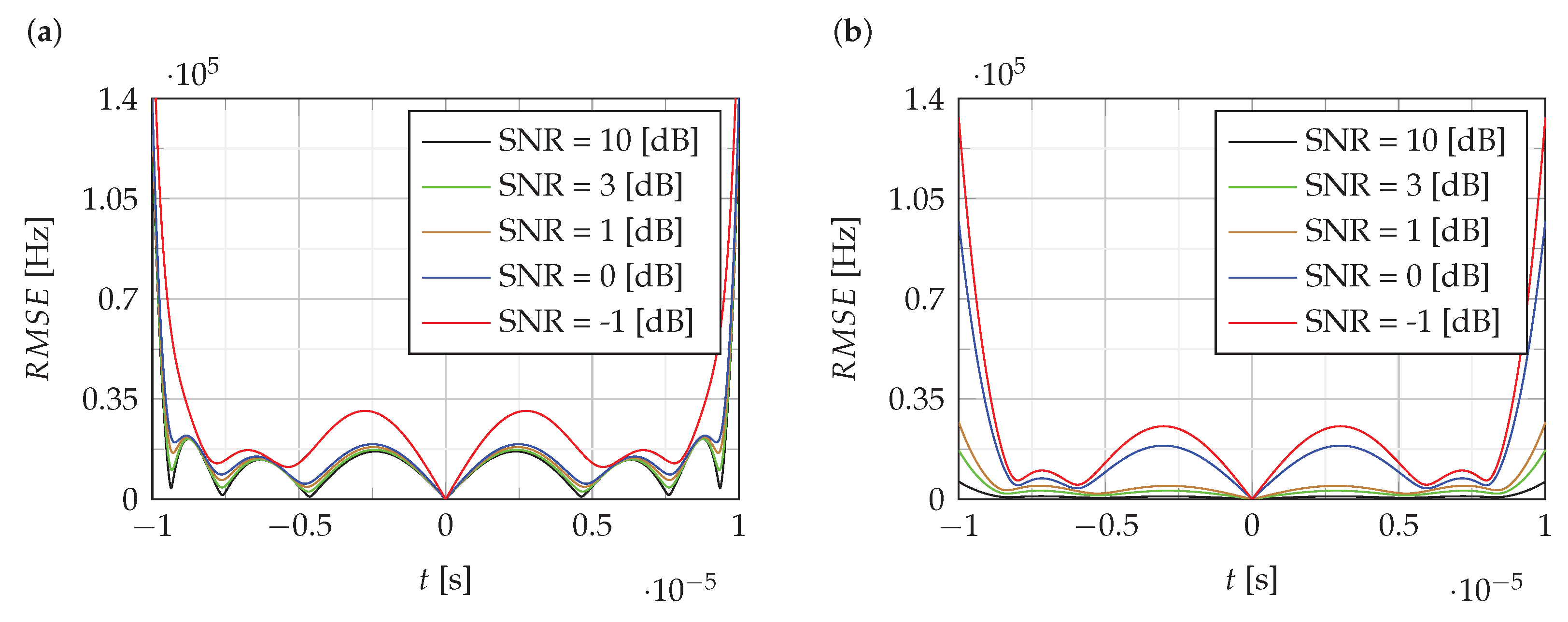
Figure 4 and
Figure 5 show the RMSE of the estimation of the instantaneous value of the frequency of NLFM signals obtained using the proposed CPF-based method. For comparison,
Figure 5b shows the RMSE for the LFM signal.
The analysis of RMSE presented in
Figure 4 and
Figure 5 shows that the estimation error level is mainly around 0.5% of the bandwidth B, except for the edges where it increases to 5%.
Then, the mean square error (MSE) dependence on the SNR was determined for the estimates of the individual NLFM and LFM signals. The MSE was defined as follows:
where
is the number of simulation runs, and Nsl is the number of signal samples (signal length).
The MSE defined in this way allows for determining the estimation error for the entire signal (the entire pulse) and enabling the comparison of the obtained results with the results presented in the publication [
2].
Figure 6 presents the MSE of estimation of the instantaneous frequency in various SNR conditions.
The analysis of the MSE of NLFM signals estimation presented in
Figure 6 shows that the estimation error level of the NLFM signal depends on its type. The error remains constant at
dB and increases slightly for
dB. However, in the case of
dB, the MSE increases significantly. On the other hand, the MSE for LFM is much lower than for NLFM, and the error decreases as the noise level decreases. Compared to other methods of estimation of the IF, the method based on CPF shows a similar estimation quality. For example, comparing the obtained results with those presented in [
2], it can be noticed that, for LFM, the MSE obtained using the CPF method for
dB is smaller than for the QML method, which, according to [
2], shows lower estimation errors than methods such as the backward finite difference (BFD) method, central finite difference (CFD) estimator, Kay estimator, estimators based on the Choi–Williams distribution (CWD) and pseudo-Wigner distribution (PWD). However, for a higher noise level, QML provides better results. In the case of the estimation of NLFM signals, the QML method comes up with a slightly lower MSE than the CPF method over the entire SNR range.
The complexity of the QML algorithm, in terms of the number of operations performed, depends on the assumed instantaneous frequency (IF) resolution in the procedure of searching the STFT maximum. Similarly, the complexity of the CPF algorithm strongly depends on the instantaneous frequency rate (IFR) resolution in the procedure of searching for the CPF maximum. These maximization operations are performed on two different planes i.e., time–frequency (T-F) and time–chirp rate (T-FR). This imposes different resolution requirements that must be applied when we calculate the maximum points for the STFT and the CPF in successive identical time moments. This affects the accuracy of the estimation, as well as the execution time of the algorithms. In the comparison, the experiments with the typical values of the procedure parameters in both algorithms showed the lower computational load for the CPF algorithm compared to the QML method several dozen times.
Despite the slightly lower quality of the estimation, considering the much lower computational load of the CPF method compared to the QML, it can be concluded that the CPF may be preferred in real-time applications.
5. Classification of Signals Based on Phase Polynomial Coefficiencies Obtained from CPF
The classification procedure presented in this paper concerns the problem of recognizing signal types with nonlinear frequency modulation. The main problem is to find a set of distinctive features that allow the received signals to be distinguished and classified into a class related to a specific emitter. Generally, three kinds of classification tasks are mainly used:
Binary classification—in this case, there are only two classes;
Multiclass classification—in this case, there are more than two classes, and the classifier can only report one of them as output;
Multilabel classification—in this case, the classifier is allowed to choose many answers. This type of classification can be simply considered as a combination of multiple independent binary classifiers.
The classification task considered in the paper can be associated with a multiclass classification, in which the class is defined by a specific type of nonlinearity of the frequency function. Therefore, it is the type of classification indicated in item 2 of the above three-point list.
Many different modifications of the multiclass classification method have been proposed in the literature [
45,
46,
47]. The proposed method uses multiclass classification with a vector of features. The classification between three types of NLFM signals and one LFM signal described in
Section 2 is considered. The feature vector is formed by aggregation of selected CPF coefficients describing the polynomial approximation of the considered phase functions.
The extracted features are processed by the classifier to select the most probable class. A supervised classification is considered, where the classes are known in advance and samples of the features describing each class are available. The feature vectors for individual nonlinearities can be treated as a pattern in the feature space. Therefore, classification carried out, especially by a neural network, is a problem of recognizing patterns [
33,
34]. In this paper, two types of neural network classifiers: learning vector quantization (LVQ) and multilayer perceptron (MLP) are considered. The LVQ neural network has been chosen because of its high ability to learn data classification, where similar input vectors are grouped into a region represented by the so-called coded vector (CV). LVQ can be applied directly to multiclass classification problems. LVQ is a supervised version of vector quantization. LVQ uses known target output classifications for each input pattern in supervised learning of the neural network. The input space of samples is covered by the “codebook vectors” (CVs) determined during the neural network learning stage. The LVQ neural network is built as a feedforward net with one hidden layer of neurons (the Kohonen layer), fully connected with the input layer and one output layer. During the training stage, the values of weights used to form the coded vectors are adjusted, according to the previously predefined input patterns. The distance
of an input vector signed
x to the weight vector
of each node in the Kohonen layer is computed. The node of a particular class, which has the smallest distance to the presented input vector (for example the Euclidean distance), is declared to be the winner:
The weights will be moved closer to that class, which is expected as the winning class. Otherwise, they will be moved away. The classification after learning is relied on finding a Voronoi cell, specified by the CV with the smallest distance to the input vector and assigning it to a particular class.
The designed LVQ classifier contains
competing neurons with the logistic sigmoid function as an activation function, where
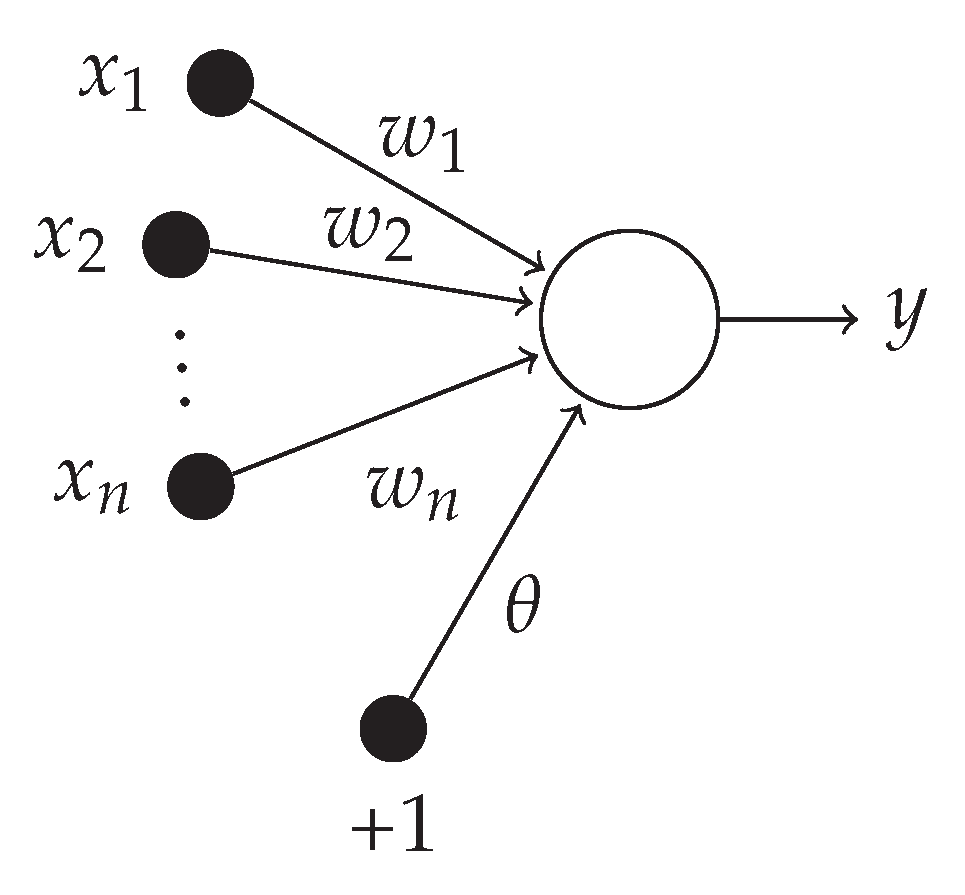
N is the number of classes. The MLP is a fundamental type of neural network architecture with the ability to learn nonlinear models. The multi-layer perceptron (MLP) is a type of artificial neural network organized in several layers in which the flow of information takes place from the input layer to the output layer; therefore, it is a feedforward network. Each layer is made up of a variable number of neurons, and the neurons of the last layer (called the “output”) are the outputs of the entire system. A network of such perceptrons is termed a neural network of perceptrons. A perceptron with only an input and output layer is called a simple perceptron. A single layer feed-forward network consists of one or more output neurons
o, each of which is connected with a weighting factor
to all of the inputs
i. The input of the neuron is the weighted sum of the inputs plus the bias term
. A example of a single layer network with
n inputs and one output is shown in
Figure 7.
The output of the network is formed by the activation of the output neuron, which is some function of inputs:
The training of a neural network is the procedure of setting its weights. If there is one hidden layer, this one is a two layer perceptron. The aim of the supervised MLP network training is to achieve an appropriately small mean square error obtained in the Levenberg–Marquardt backpropagation procedure by adjusting weights. The complexity of the neural network classifier strongly depends on a number of neurons, which require an adjustment of their weighs at the learning stage. Therefore, the neural architecture should be as simple as possible.
For the assumed classification task, a simple single hidden layer MLP classifier with the number of neurons equal to has been chosen.
Evaluation of the classification process requires appropriate quality criteria. The classification performance is usually visualized using the confusion matrix, which is a table summarizing true and false decisions. The matrix compares the actual types of objects with those predicted by the classifier. This issue can be easily presented on the example of binary classification. In this case, the
confusion matrix is formulated as shown in
Figure 8.
The abbreviations TP, TN, FP and FN shown in
Figure 8 denote:
true positives (TP): the actual value is positive and the prediction is also positive;
true negatives (TN): the actual value is negative and the prediction is also negative;
false positives (FP): the actual value is negative, but the prediction is positive (type I error);
false negatives (FN): the actual value is positive, but the prediction is negative (type II error).
It is difficult to compare the properties of different classifiers based on the confusion matrix alone. Therefore, a simpler description of the classification can be obtained using metrics calculated on the basis of data from the confusion matrix. Some common metrics [
48] can be calculated as follows:
Precision also known as positive predictive value (
PPV)
Sensitivity also known as recall, hit rate or true positive rate (
TPR)
The above metrics are defined similarly for multiclass classifiers. To evaluate the performance of the proposed multiclass model, the confusion matrix is used, where N is the number of classes that describe the NLFM or LFM signals. The quality of the selected classifiers can be assessed by comparing the metrics calculated from their confusion matrix.
The performance of the proposed method was evaluated with the use of the simulation experiment. The proposed CPF-based classification method was tested for three NLFM (
,
,
) and one LFM (
) signal. Their specific parameters are presented in
Section 2. The simulation parameters were assumed to be the same as in the case of simulation presented in
Section 4, namely: pulse duration
s.; sampling frequency
MHz; signal bandwidth
MHz and Gaussian noise with variance depending on SNR. Thus, having four signals to recognize, the problem of 4-class classification is studied. The feature vector used in the classification process was formed by the coefficients (
,
,
) of the polynomial which is an approximate signal phase. The coefficients are determined by the proposed CPF method.
Figure 9 shows an example of the realizations of the coefficients
,
and
obtained by CPF for four signal classes in the case of
dB,
dB,
dB and
dB. Each signal is marked with a different colour. The points in the figure represent the estimates of the coefficients
,
and
obtained in
realizations of individual signals.
The analysis of the spatial position of the coefficients
,
and
shown in
Figure 9 shows that, in the case of
dB and
dB, the constellations of points corresponding to individual signals are well separable, which should result in the effective operation of classification algorithms. In the case of
dB, a significant relocation of several points can be observed, which may cause deterioration of the separation and thus of the quality of the classification. For
dB, the spaces of the individual coefficients overlap, which may result in the incorrect classification.
The classification task was addressed using LVQ and MLP neural networks. The tests were carried out at different SNRs. In each case,
Monte Carlo simulations were carried out for each signal. The
realizations constituted a training set and the remaining
realizations were used to test the classifiers.
Figure 10 and
Figure 11 show the confusion matrices for MLP and LVQ classifiers obtained for
dB and
dB, respectively.
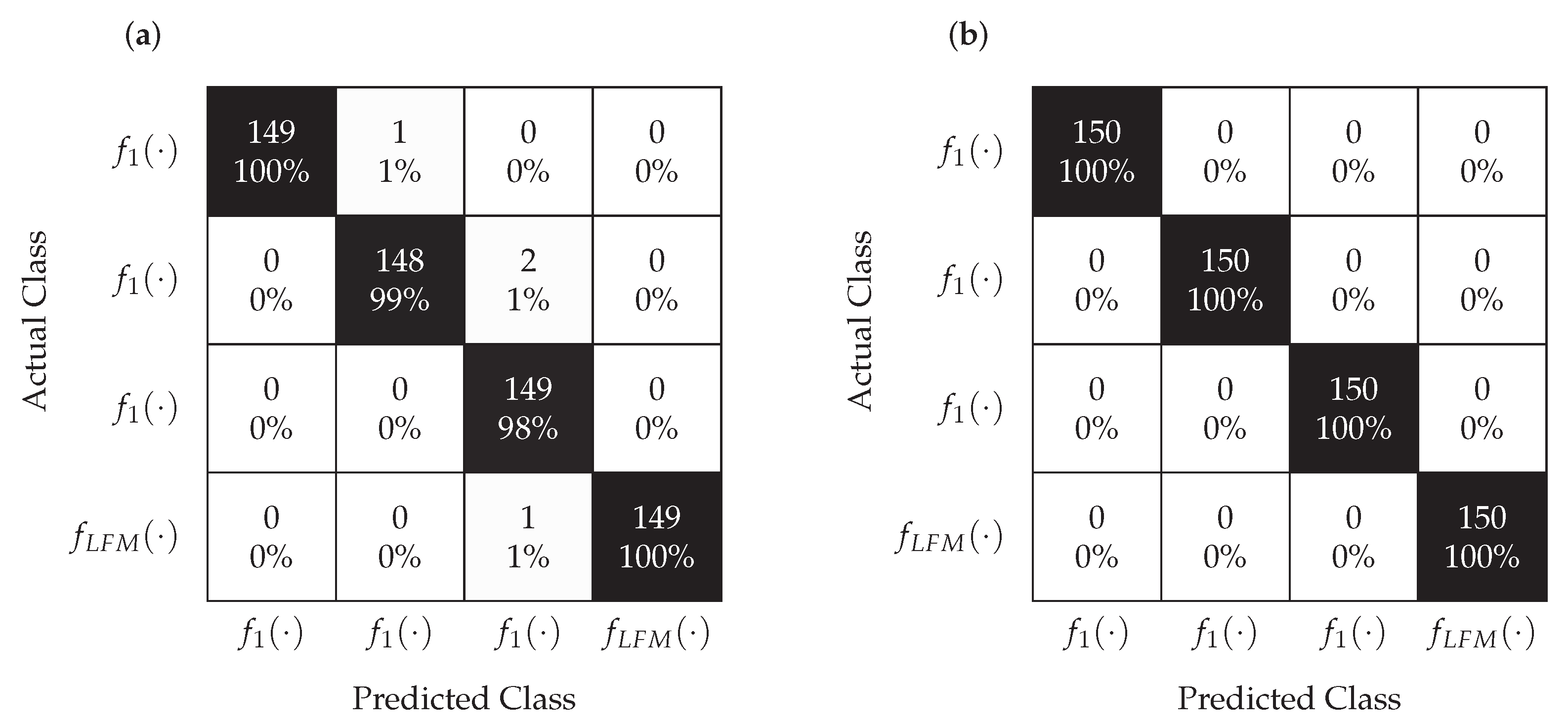
According to the analysis of the confusion matrix presented in
Figure 10, for
dB, the classification is correct in the case of the MLP classifier and slightly worse for the LVQ. This means that even the significant relocation of points corresponding to the individual signals, which is visible in
Figure 9, does not affect the proper classification performed by classifiers. However, as it results from the analysis of the confusion matrix shown in
Figure 11, in the case of
dB, the classification is not correct for both MLP and LVQ. This result corresponds to the results shown in
Figure 9, where for this SNR the constellations of points overlap.
The quality of the MLP and LVQ classifiers was also analyzed with the use of ACC metrics. The results for
dB
dB are shown in
Figure 12.
As can be seen in
Figure 12, both classifiers for
dB provide almost 100% correct identifications of signals. In the case of
dB, the classification accuracy slightly decreases, with MLP being a more effective classifier. For
below
dB, the classification quality for the MLP algorithm gradually decreases, while in the case of LVQ, the decisions are made completely randomly.
The ACC metrics assess the overall quality of classification without being able to evaluate the identification ability of each class. In this case, PPV and TPR metrics can be used. For multiclass classification, the PPV for each class is the ratio of a correctly predicted class to all predicted classes, while TPR is defined as the ratio of a correctly predicted class to all true class values.
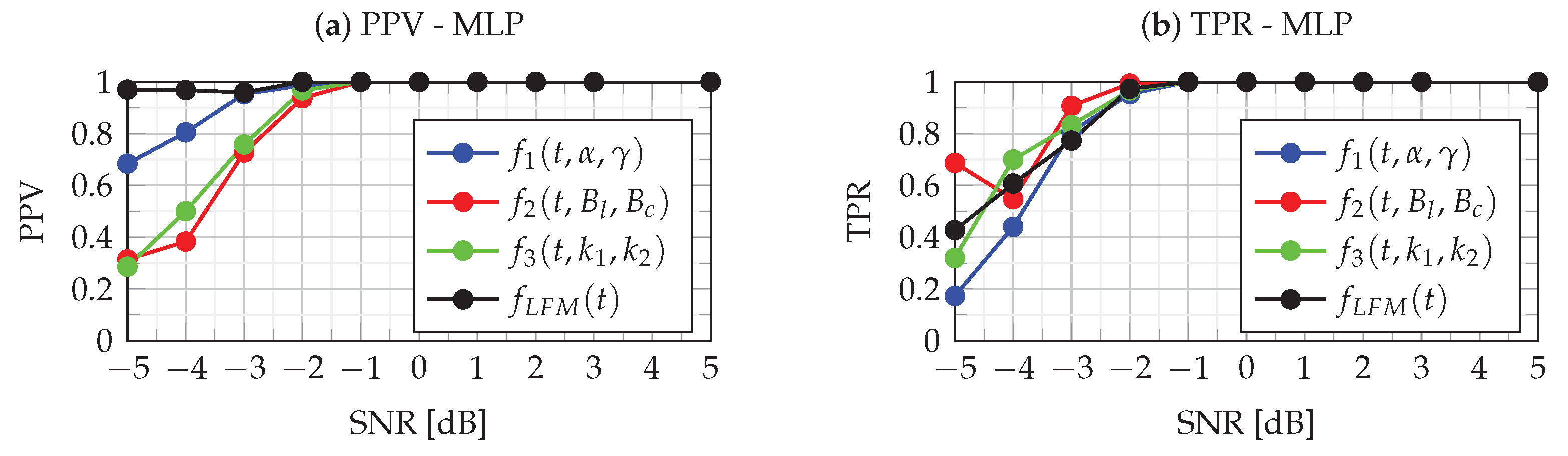
Figure 13 and
Figure 14 show the PPV and TPR metrics for four classes for MLP and LVQ classifiers. When analyzing the results of the PPV metrics, it should be kept in mind that, in case of the absence of recognition of a given class (both TP and FP), according to definition (
43), the PPV value is undefined, and therefore there are missing points in the figure.
The analysis of
Figure 13 and
Figure 14 allows for assessing the quality of the MLP and LVQ classifiers. The quality of the classifier is indicated by the combined analysis of PPV and TPR values. As can be seen in these figures, in the case of
dB, both PPV and TPR for all classes take values approximately equal to one, which means that errors of type I and type II are at a minimum level. This means that the identification of each class for
dB is very good for both MLP and LVQ classifiers. As can be seen in the figures, for the
dB, the classifiers’ performance breaks down. In this case, for the MLP classifier, the PPV and TPR metrics take values in the range of
while for LVQ slightly less, i.e.,
. This means a slight decrease in the quality of the classification, while the MLP classifier is slightly better. In the case of
dB, the quality of both classifiers is slightly degraded. In this case, as can be seen in
Figure 8 for the LVQ classifier, there is a significant dispersion of type I and type II errors, which means favoring certain classes. However, in the case of MLP (
Figure 14), type I and type II errors are at a similar level, and the predictions of classes are more uniform. The incorrect classification results from errors in the estimation of parameters
,
and
the determination of which depends on the accuracy of the IFR estimation (
23). Due to noise, the location of the maximum CPF obtained for IFR
0 for noiseless NLFM is shifted to a new random location:
It should be emphasized that, for
dB, which is important for practical applications, the classification is error-free for the analyzed classifiers. Classification errors appear for
dB. Due to the gradual shifting and overlapping of the
,
and
parameter space, visible in
Figure 9, classification becomes problematic. An additional source of error is the use of the polynomial approximation of the NLFM functions proposed for classification, as discussed in
Section 3.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













