

Deep Learning Based One-Class Detection System for Fake Faces Generated by GAN Network




Abstract
1. Introduction
1.1. Fake Image Generation Technology
1.2. Problem Statement and Motivation
1.3. Contributions and Paper Outline
- We adopt Gaussian blur, Gaussian noise, and Homomorphic filter enhancement methods as basic pseudo-image generation methods for data enhancement.
- An improved Multi-Channel Convolutional Neural Network is used as the main network to accept multiple preprocessed data individually, obtain feature maps, and extract attention maps.
- Data are augmented using weakly supervised learning methods to add attention cropping and dropping to the data.
- The main network is trained in two steps, employing (a) a binary classification loss function to ensure that known fake facial features generated by known GAN networks are filtered out and (b) a one-class classification loss function to deal with different GAN networks or unknown fake face generation methods.
- A comparison of our proposed method against four recent methods in cross-domain and source-domain along with a numerical and graphical demonstration of the experimental results.
2. Proposed Methods
2.1. General Definition and Technical Background
2.1.1. Weakly Supervised Learning
2.1.2. Bilinear Attention Pooling
2.1.3. Attention Regularization
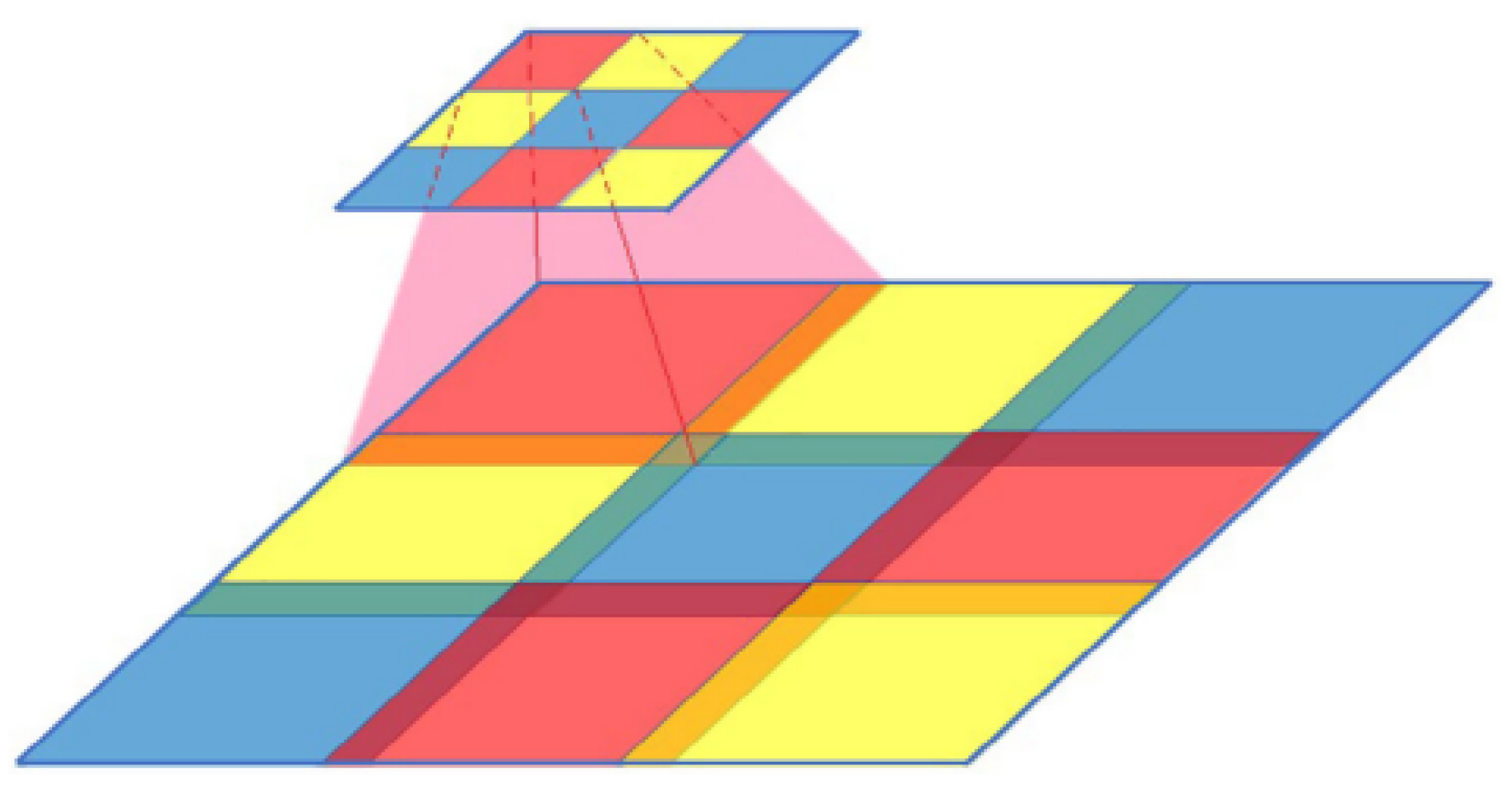
2.1.4. Coordinate Location of Essential Features Based on Feature Attention Map
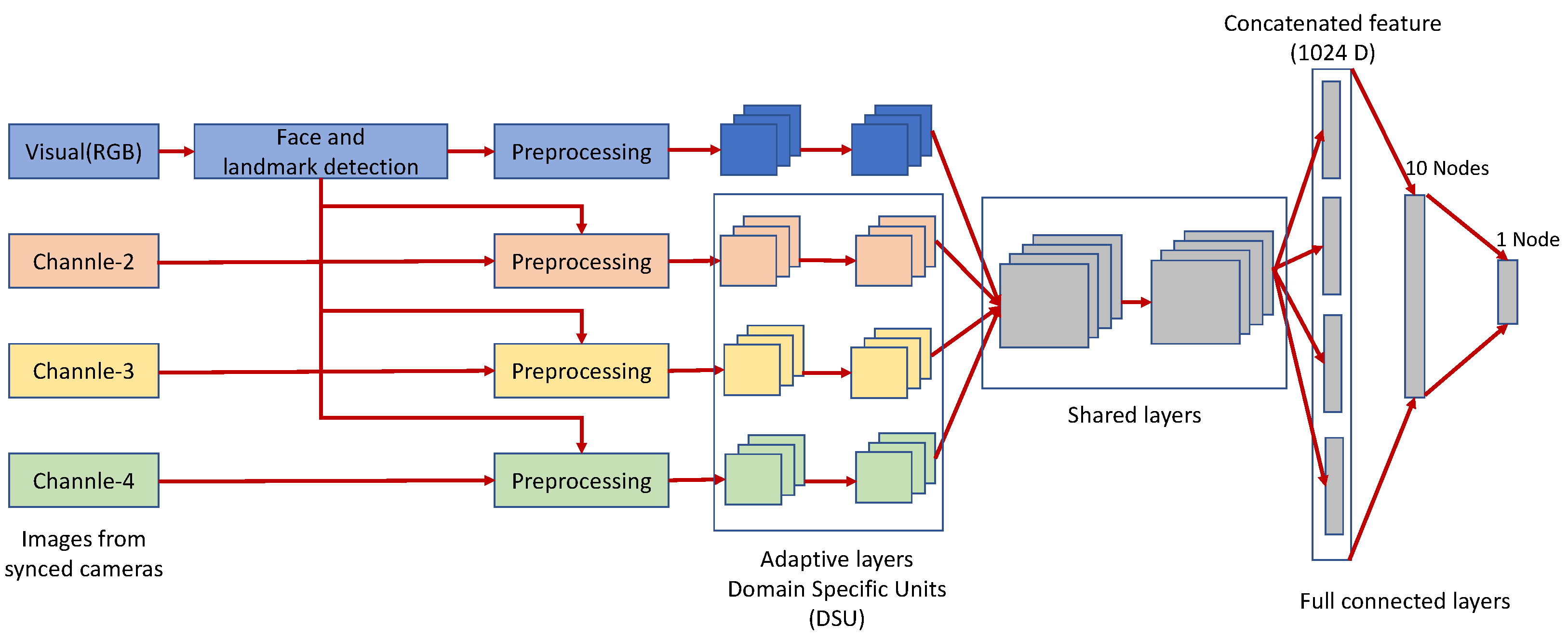
2.1.5. Multi-Channel Convolutional Neural Network
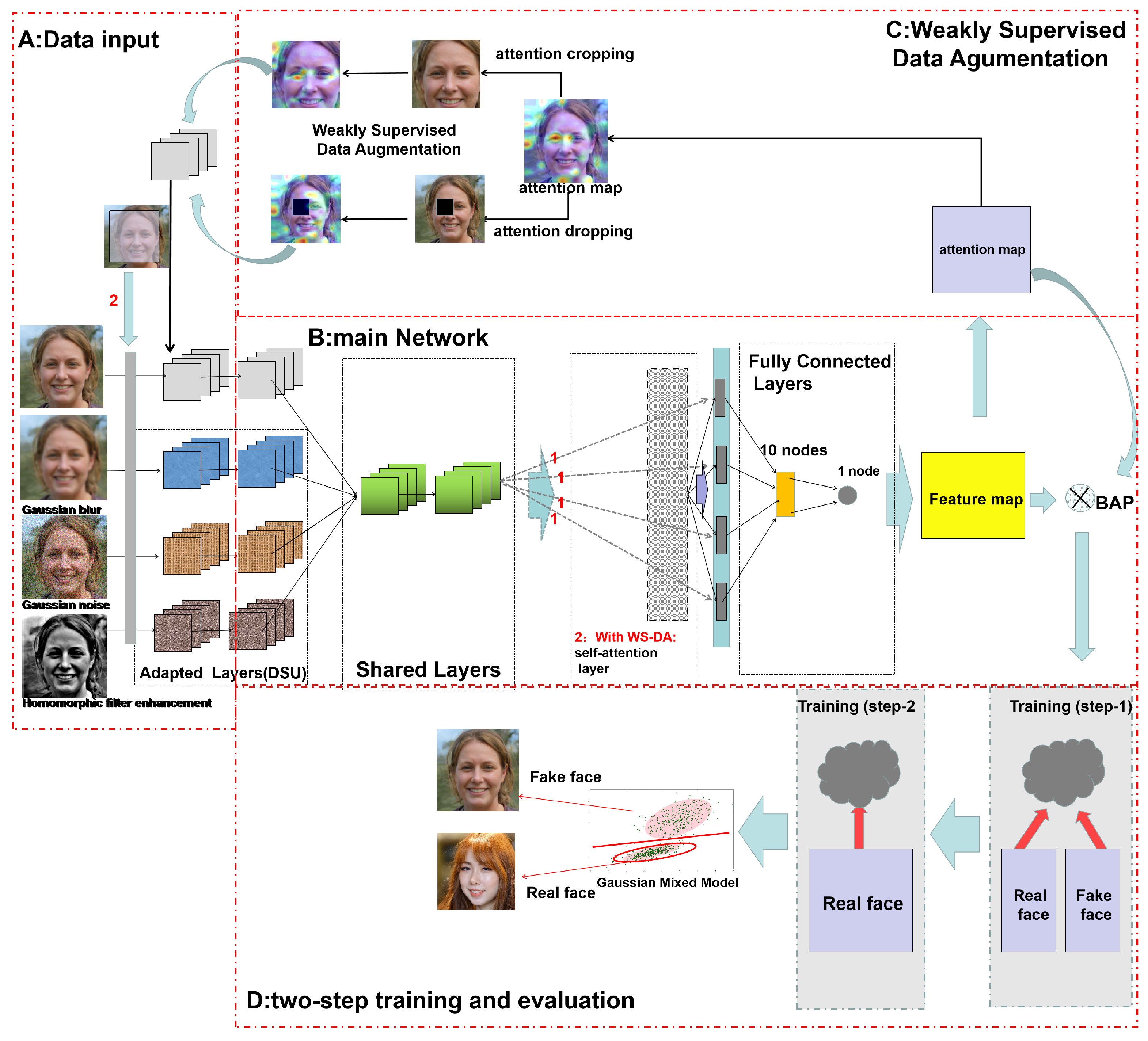
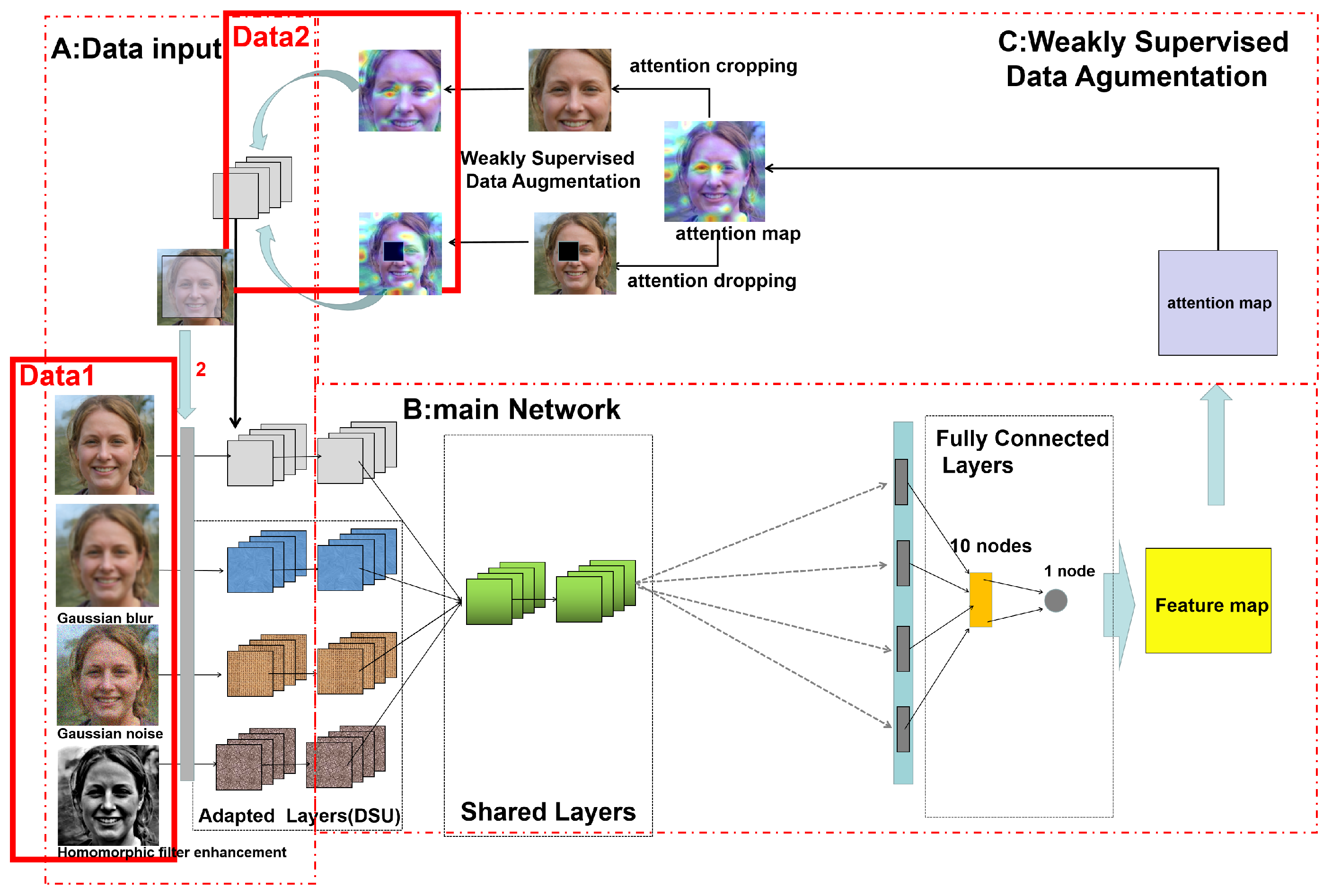
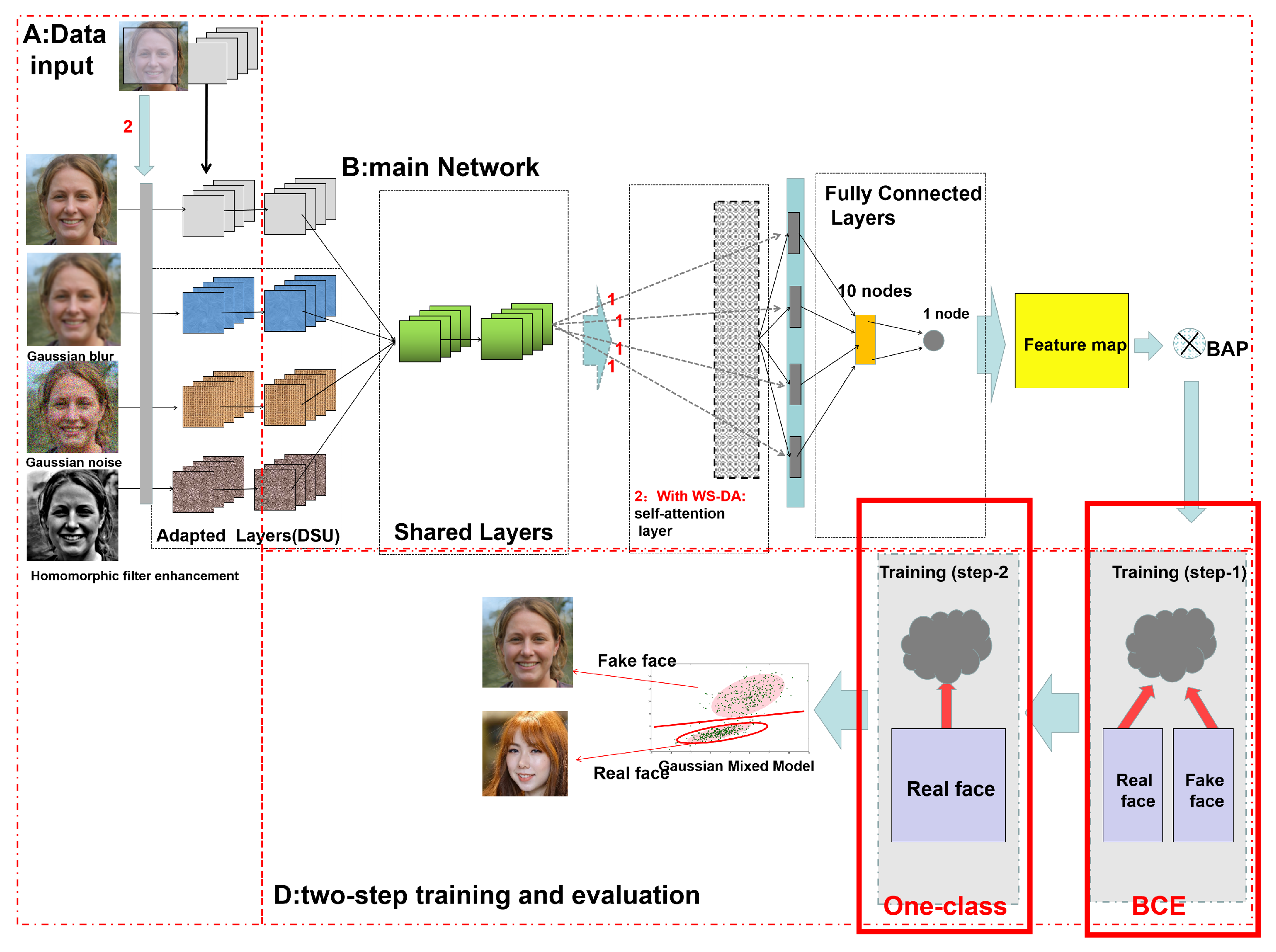
2.2. Architecture of the Proposed Network
2.3. Data Augmentation and Preprocessing
- Gaussian blur
- Gaussian noise
- Motion blur
- Homomorphic filter enhancement
- Fourier transform (magnitude spectrum)
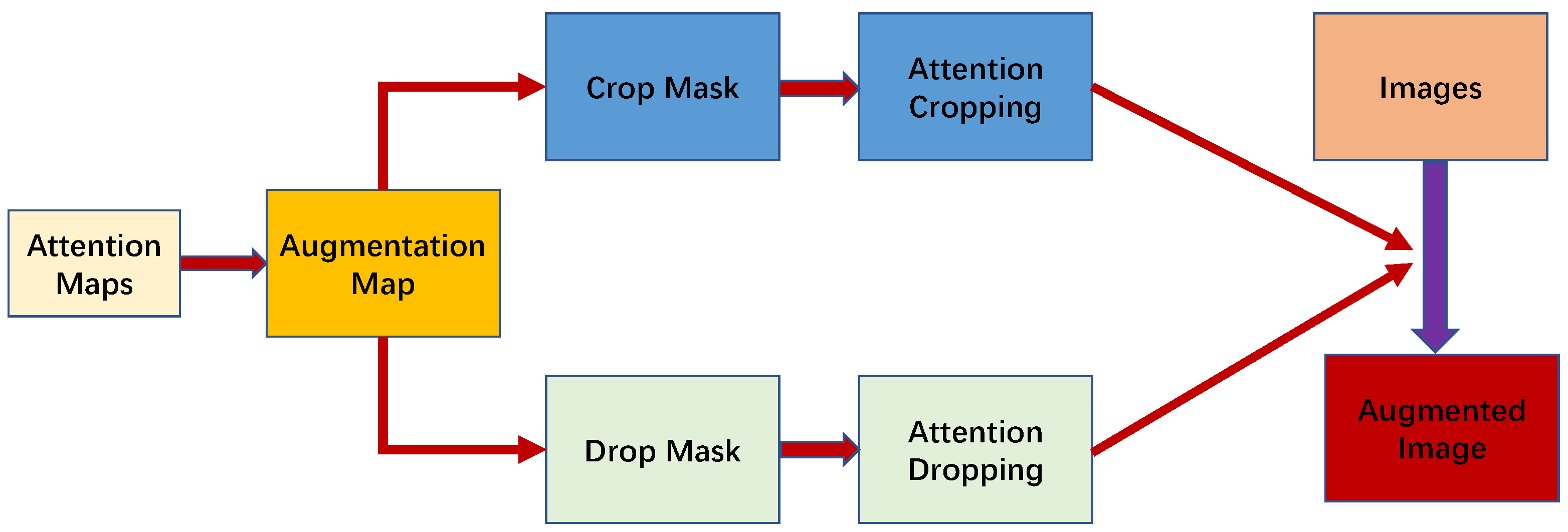
2.3.1. Data Augmentation Based on Weakly Supervised Learning
2.3.2. Removing Low-Impact Influence Part
2.4. The Process of Training
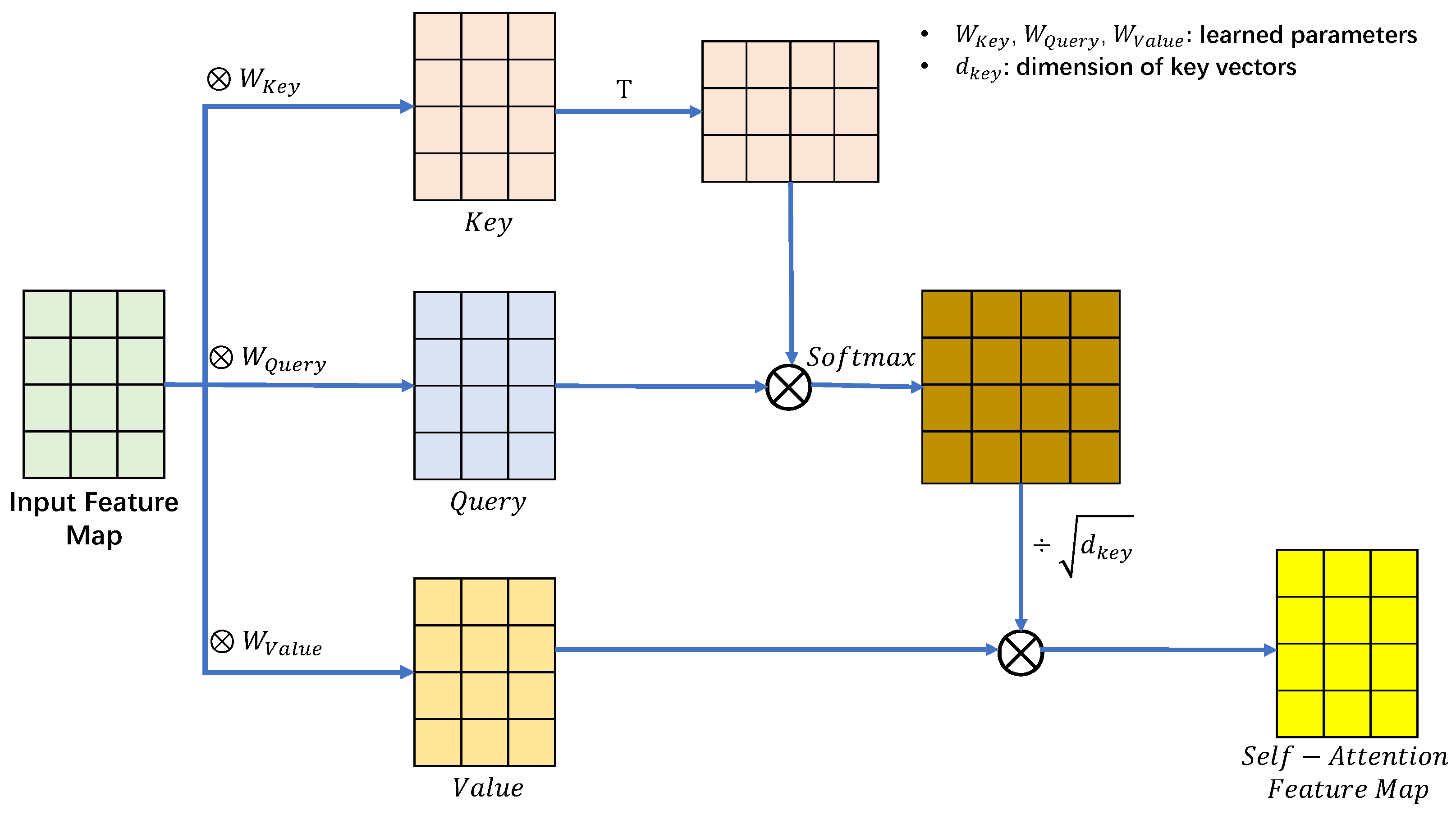
2.4.1. Self-Attention Layer
2.4.2. Two-Step Training of One-Class Classification
2.5. Final Model–Gaussian Mixture Model
3. Datasets, Experiments, and Results
3.1. Dataset
3.2. Environment Settings
3.3. Experiments and Results
3.3.1. Experiment 1: Scrutinizing Performance of the Source Domain
3.3.2. Experiment 2: Scrutinizing Cross-Domain Performance
3.4. Findings
4. Conclusions and Future Work
4.1. Conclusions
- (1)
- Method and main process of the model
- (2)
- Experiments and evaluation
4.2. Future Work
- (1)
- Considerations focusing on one certain facial feature
- (2)
- GANs considering different principles
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mo, H.; Chen, B.; Luo, W. Fake faces identification via convolutional neural network. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 43–47. [Google Scholar]
- Cozzolino, D.; Thies, J.; Rössler, A.; Riess, C.; Nießner, M.; Verdoliva, L. Forensictransfer: Weakly-supervised domain adaptation for forgery detection. arXiv 2018, arXiv:1812.02510. [Google Scholar]
- Quan, W.; Wang, K.; Yan, D.M.; Zhang, X. Distinguishing between natural and computer-generated images using convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2772–2787. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Daras, G.; Odena, A.; Zhang, H.; Dimakis, A.G. Your local GAN: Designing two dimensional local attention mechanisms for generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13 June 2020; pp. 14531–14539. [Google Scholar]
- Gao, H.; Pei, J.; Huang, H. Progan: Network embedding via proximity generative adversarial network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1308–1316. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karnewar, A.; Wang, O. MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7796–7805. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Neethirajan, S. Is Seeing Still Believing? Leveraging Deepfake Technology for Livestock Farming. Front. Vet. Sci. 2021, 8, 740253. [Google Scholar] [CrossRef] [PubMed]
- Greengard, S. Will deepfakes do deep damage? Commun. ACM 2019, 63, 17–19. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Marra, F.; Saltori, C.; Boato, G.; Verdoliva, L. Incremental learning for the detection and classification of gan-generated images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), San Jose, CA, USA, 28–30 March 2019; pp. 1–6. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Park, S.; Kwak, N. Analysis on the dropout effect in convolutional neural networks. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 189–204. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Singh, K.K.; Lee, Y.J. Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3544–3553. [Google Scholar]
- Hu, T.; Qi, H.; Huang, Q.; Lu, Y. See better before looking closer: Weakly supervised data augmentation network for fine-grained visual classification. arXiv 2019, arXiv:1901.09891. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- George, A.; Mostaani, Z.; Geissenbuhler, D.; Nikisins, O.; Anjos, A.; Marcel, S. Biometric face presentation attack detection with multi-channel convolutional neural network. IEEE Trans. Inf. Forensics Secur. 2019, 15, 42–55. [Google Scholar] [CrossRef]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A light cnn for deep face representation with noisy labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef]
- George, A.; Marcel, S. Learning one class representations for face presentation attack detection using multi-channel convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2020, 16, 361–375. [Google Scholar] [CrossRef]
- Goodfellow, I.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1319–1327. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. Gan-generated image detection with self-attention mechanism against gan generator defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel transposed convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1218–1227. [Google Scholar] [CrossRef]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and checkerboard artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5999–6009. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Yu, G.; Sapiro, G.; Mallat, S. Solving inverse problems with piecewise linear estimators: From Gaussian mixture models to structured sparsity. IEEE Trans. Image Process. 2011, 21, 2481–2499. [Google Scholar]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Razavi, A.; Van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; 2019; 32. [Google Scholar]
- Dutta, V.; Zielinska, T. Prognosing human activity using actions forecast and structured database. IEEE Access 2020, 8, 6098–6116. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combination | ProGAN | StyleGAN2 |
|---|---|---|
| 1 + 2 + 3 | 98.3% | 82.4% |
| 1 + 2 + 4 | 98.5% | 83.7% |
| 1 + 2 + 5 | 98.3% | 82.1% |
| 1 + 3 + 4 | 98.9% | 85.1% |
| 1 + 3 + 5 | 98.3% | 80.9% |
| 1 + 4 + 5 | 98.2% | 83.4% |
| 2 + 3 + 4 | 98.4% | 84.1% |
| 2 + 3 + 5 | 95.1% | 81.9% |
| 2 + 4 + 5 | 98.3% | 82.4% |
| 3 + 4 + 5 | 98.5% | 82.1% |
| Method | FFHQ | ProGAN | |
|---|---|---|---|
| Ours | Accuracy | 0.994 | 0.989 |
| Precision | 0.990 | ||
| Recall | 0.994 | ||
| F1-Score | 0.992 | ||
| CNN+Self-attention (2020) | Accuracy | 0.991 | 0.974 |
| Precision | 0.984 | ||
| Recall | 0.991 | ||
| F1-Score | 0.987 | ||
| Pupil regular recognition+Boundary IoU score (2022) | Accuracy | 0.995 | 0.988 |
| Precision | 0.988 | ||
| Recall | 0.995 | ||
| F1-Score | 0.992 | ||
| Dual-color spaces+improved Xception model (2021) | Accuracy | 0.994 | 0.981 |
| Precision | 0.981 | ||
| Recall | 0.994 | ||
| F1-Score | 0.988 | ||
| MaskCNN+RAN (2022) | Accuracy | 0.989 | 0.975 |
| Precision | 0.975 | ||
| Recall | 0.989 | ||
| F1-Score | 0.982 | ||
| Method | StyleGAN | StyleGAN2 | BigGAN | |
|---|---|---|---|---|
| Ours | Accuracy | 0.872 | 0.851 | 0.827 |
| Precision | 0.886 | 0.870 | 0.852 | |
| Recall | 0.994 | 0.994 | 0.994 | |
| F1-Score | 0.937 | 0.928 | 0.917 | |
| CNN+Self-attention (2020) | Accuracy | 0.514 | 0.497 | 0.551 |
| Precision | 0.671 | 0.663 | 0.688 | |
| Recall | 0.991 | 0.991 | 0.991 | |
| F1-Score | 0.800 | 0.795 | 0.812 | |
| Pupil regular recognition+ Boundary IoU score (2022) | Accuracy | 0.861 | 0.754 | 0.817 |
| Precision | 0.878 | 0.802 | 0.845 | |
| Recall | 0.995 | 0.995 | 0.995 | |
| F1-Score | 0.933 | 0.888 | 0.914 | |
| Dual-color spaces+improved Xception model (2021) | Accuracy | 0.769 | 0.728 | 0.657 |
| Precision | 0.811 | 0.785 | 0.743 | |
| Recall | 0.994 | 0.994 | 0.994 | |
| F1-Score | 0.893 | 0.877 | 0.851 | |
| MaskCNN+RAN (2022) | Accuracy | 0.507 | 0.501 | 0.751 |
| Precision | 0.667 | 0.665 | 0.799 | |
| Recall | 0.989 | 0.989 | 0.989 | |
| F1-Score | 0.797 | 0.795 | 0.884 |
| Method | DCGAN | DeepFake | VQ-VAE2.0 | |
|---|---|---|---|---|
| Ours | Accuracy | 0.931 | 0.897 | 0.809 |
| Precision | 0.935 | 0.906 | 0.839 | |
| Recall | 0.994 | 0.994 | 0.994 | |
| F1-Score | 0.964 | 0.948 | 0.910 | |
| CNN+Self-attention (2020) | Accuracy | 0.412 | 0.532 | 0.461 |
| Precision | 0.628 | 0.679 | 0.648 | |
| Recall | 0.991 | 0.991 | 0.991 | |
| F1-Score | 0.769 | 0.806 | 0.783 | |
| Pupil regular recognition+ Boundary IoU score (2022) | Accuracy | 0.921 | 0.874 | 0.722 |
| Precision | 0.926 | 0.888 | 0.782 | |
| Recall | 0.995 | 0.995 | 0.995 | |
| F1-Score | 0.959 | 0.938 | 0.875 | |
| Dual-color spaces+improved Xception model (2021) | Accuracy | 0.834 | 0.787 | 0.614 |
| Precision | 0.859 | 0.824 | 0.720 | |
| Recall | 0.994 | 0.994 | 0.994 | |
| F1-Score | 0.920 | 0.901 | 0.835 | |
| MaskCNN+RAN (2022) | Accuracy | 0.745 | 0.671 | 0.719 |
| Precision | 0.795 | 0.750 | 0.779 | |
| Recall | 0.989 | 0.989 | 0.989 | |
| F1-Score | 0.881 | 0.853 | 0.871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Dutta, V.; He, X.; Matsumaru, T. Deep Learning Based One-Class Detection System for Fake Faces Generated by GAN Network. Sensors 2022, 22, 7767. https://doi.org/10.3390/s22207767
Li S, Dutta V, He X, Matsumaru T. Deep Learning Based One-Class Detection System for Fake Faces Generated by GAN Network. Sensors. 2022; 22(20):7767. https://doi.org/10.3390/s22207767
Chicago/Turabian StyleLi, Shengyin, Vibekananda Dutta, Xin He, and Takafumi Matsumaru. 2022. "Deep Learning Based One-Class Detection System for Fake Faces Generated by GAN Network" Sensors 22, no. 20: 7767. https://doi.org/10.3390/s22207767
APA StyleLi, S., Dutta, V., He, X., & Matsumaru, T. (2022). Deep Learning Based One-Class Detection System for Fake Faces Generated by GAN Network. Sensors, 22(20), 7767. https://doi.org/10.3390/s22207767