1. Introduction
The development of 3D scanning sensor technology, such as light detection and ranging (LiDAR), has gifted us with point cloud data with accurate coordinates together with other attributes [
1], which enables it to play an increasingly important role in many fields such as road extraction [
2], agriculture supervision [
3], manufacturing monitoring [
4], and terrain sensing [
5]. However, the high-volume data that contain billions of points may cause great burdens in terms of data processing with regard to computing cost and storage space [
6]. For this reason, it is necessary to simplify point clouds in order to alleviate the pressure [
7]. This paper is intended to propose a solution to the simplification of point clouds obtained by scanning 3D models and field areas.
Numerous algorithms have been proposed for point cloud simplification. Depending on whether the point cloud is reconstructed, there are two types: mesh-based algorithms and point-based algorithms [
8]. Usually, mesh-based algorithms require too many computing resources. Consequently, more attention has been paid to point-based simplification algorithms. In terms of the data attributes used for simplification, there are three categories: geometric features, spatial division, and extra features [
9]. The extra feature algorithms do not yield enough information, and thus the first two kinds have been more broadly researched.
Simplification algorithms based on geometric features require the preservation of the global shape, the sharp areas, and some transition areas [
10]. This can be achieved through evaluating the importance of each point via commonly defined feature indexes: curvature, density, distance, slope, and normal [
6]. Moreover, some new feature indexes have been proposed in recent years. Direct Hausdorff distance is a measure that indicates how far two subsets of a metric space are from each other. Li et al. [
11] used this measure to simplify point clouds. Markovic et al. [
12] proposed a sensitive feature based on insensitive support vector regression.
Spatial division simplification algorithms commonly divide point cloud space into several sub-sets based on grid, octree, kd-tree, or other principles, or gather similar points into sub-clusters by k-means, the density-based spatial clustering of applications with noise (DBSCAN), etc. Some new point cloud division methods have also been devised. For example, Shoaib et al. [
13] applied a fractal sense to a kind of 2D bubble point cloud division method. This kind of spatial division is able to relieve computational and memory stress and support a multi-scale operation.
It is reasonable to combine the above two categories: selecting feature points according to one or more geometric features and then resampling the points via spatial division. Additionally, some researchers have utilized more than one feature. Wang et al. [
14] defined a comprehensive feature index including the average distance, normal, and curvature to distinguish feature points. After that, the non-feature points are simplified by uniform spherical sampling. Zhu et al. [
15] set the importance level for point clouds by principal component analysis (PCA) and resampled them using different grid sizes. Zhang et al. [
9] defined four kinds of entropy including scale-keeping, profile-keeping, and curve-keeping simplification to quantify the geometric features and then simplified the data under the consideration of neighborhoods. Ji et al. [
16] calculated four feature indexes to extract feature points by describing the importance of points based on a space bounding box and then used octree to simplify the non-feature points. However, these methods either do not apply enough indexes to reveal the inner characteristics or do not consider the weight of multiple indexes. Furthermore, they do not take the relative position relationship between non-feature points and feature points into account. Some algorithms that extract the surface attributes of point clouds demand too much computation.
Thus, it can be concluded that some of the drawbacks of the existing point-based algorithms are: nonuniform simplification, the deficient reflection of point cloud characteristics by feature indexes, undiscussed weight distribution between feature indexes, and high computation cost. To deal with these problems, we propose a new algorithm named the multi-index weighting simplification algorithm (MIWSA). The MIWSA gives the following solutions to these problems:
- (1)
Regarding the nonuniform simplification of point clouds, the MIWSA uses a bounding box and kd-trees to organize the points, which can precisely identify the relationship of the local points.
- (2)
In order to achieve the deficient reflection of point cloud characteristics, the MIWSA applies five existing or newly created feature indexes to extract the characteristics of point clouds. More indexes enable the MIWSA to deal with different types of point clouds and to discover more inner information.
- (3)
To solve the weight distribution problem, we use the improved analytic hierarchy process (AHP) and the criteria importance through intercriteria correlation (CRITIC) to reveal the relative importance of each index. These two weighting methods work based on data traits and human experience, respectively, which guarantees a more credible weight distribution scheme.
- (4)
In order to reduce the computational complexity, the MIWSA makes some adjustments to the formulas. Moreover, the bounding box and kd-trees can also help improve its efficiency.
We remarkably promote point simplification effects in terms of both precision and efficiency with these improvements.
The rest of the paper is structured as follows.
Section 2 looks at the research related to the MIWSA, including the point cloud organization method, the analysis of several point cloud features, and the AHP and CRITIC methods. After that, the procedures and key steps of MIWSA are elaborated in
Section 3.
Section 4 describes an experiment using several types of datasets and compares the results of different algorithms. Conclusions are drawn in
Section 5.
3. The Methodology
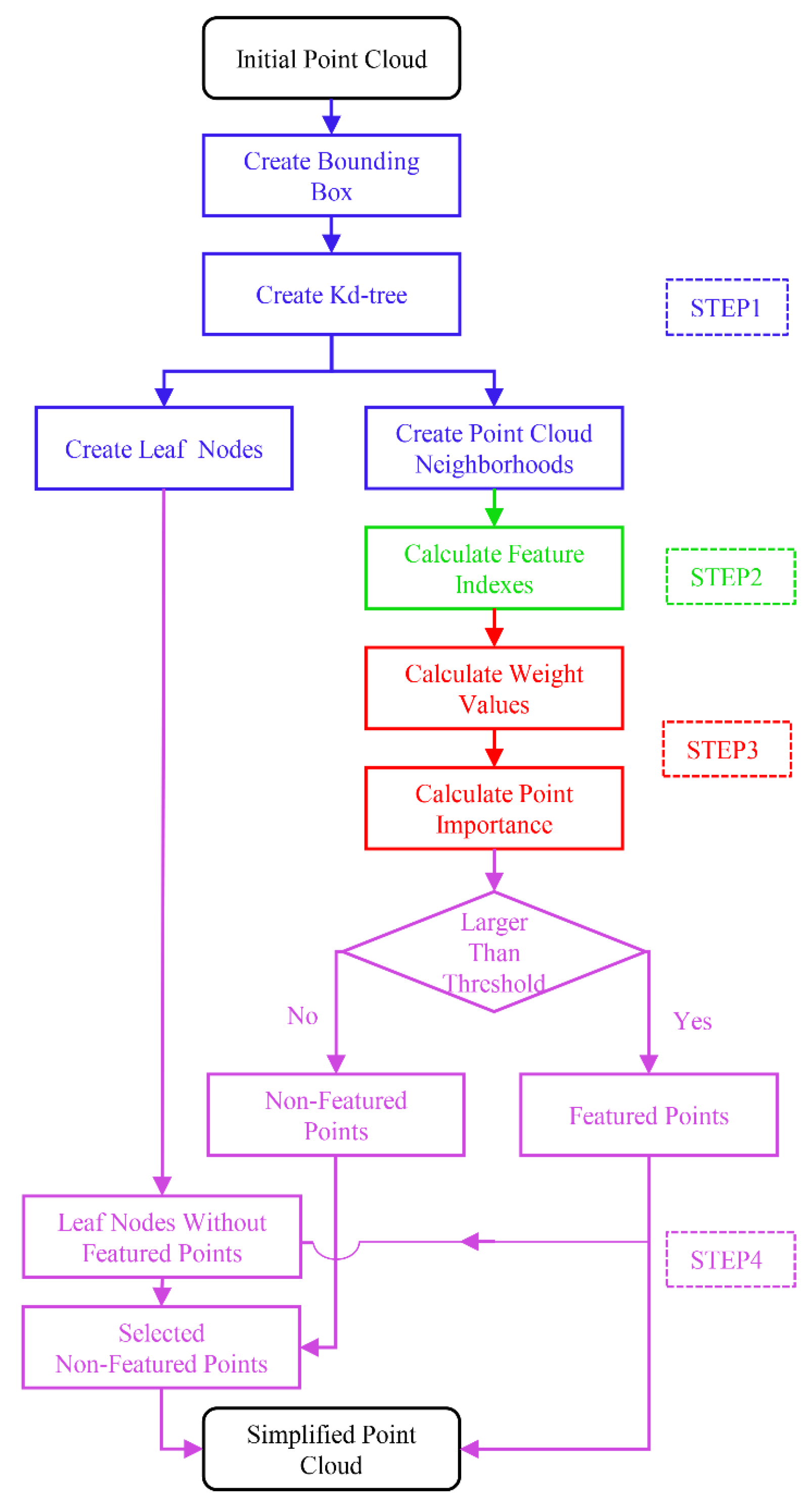
The process of the MIWSA is shown in
Figure 1. It contains four steps: point cloud space division and organization, point cloud feature calculation, feature index weighting, and final simplified point selection. The main computer code is contained in
Code S1.
3.1. Point Cloud Space Division and Organization
Although a kd-tree can increase the efficiency, it takes up memory space. The index pointer data, for abundant points, increase the depth of a kd-tree. This leads to high search computation complexity [
38]. Thus, the organization that combines a bounding box and a kd-tree is constructed, from which the neighborhood and leaf nodes are determined.
First, a space bounding box is established for the whole point cloud. The pre-set number should be around the number of neighborhood points in the following operation.
Second, the local kd-tree is constructed. Each kd-tree is constructed in a total of 27 3 3 3 cubes. The neighborhood points of each point are found in the kd-tree constructed in the cube where the point is and the surrounding 26 cubes. The size of the kd-tree leaf node has an influence on the subsequent simplified points selection.
After the disposition, the point number for each kd-tree is
, reducing the depth of the kd-tree effectively. After that, according to Equations (6)–(8), the computation complexity of creating a kd-tree for all points, neighborhood depth-first search, and worst backtracking can be expressed, respectively, as:
Because
tends to be much larger than 27, it is obvious that the complexity is cut down due to the reduction in tree depth, especially for the backtracking computation. In addition, memory space is saved. As for the accuracy, the MIWSA ensures exactness by searching neighborhood points in the surrounding cubes. Former methods tend to contain errors when dealing with points in the marginal region of the first-level division space [
39].
3.2. Point Cloud Feature Extraction
Five feature indexes are used in the paper, among which the existing calculation formulas are used for the edge and density feature index without change, while the curvature and terrain complexity feature indexes have some modifications in their computation. Moreover, a new feature index is defined to describe the relative point location feature.
3.2.1. Curvature Feature Index
To reduce the calculation process, the MISWA improves the PCA method to estimate the point cloud sharp feature. It was proposed by Hoppe [
40] to estimate the normal vector of scattered point clouds using the PCA method.
A covariance matrix is constructed based on local neighborhood data points. Let the coordinate of a point in the neighborhood of point
be
while its neighborhood gravity center is
, then the covariance matrix can be expressed as:
The covariance matrix
is obviously a symmetric and positive semidefinite matrix, which reflects the geometric information of the local neighborhood surface. The Jacobian method is used to solve the covariance matrix and obtain its eigenvalues
,
, and
, corresponding to eigenvectors
,
, and
, respectively. We can use these values to estimate the curvature of the surface. If one eigenvalue
is smaller than the other two, its corresponding eigenvector can be recognized as the normal vector
. The greater the included angles between the normal vectors of one point and its neighborhood point, the larger the curvature value of this point. Thus, the mean included angles of the eigenvectors are used as the curvature feature index:
where
and
are the normal vectors for points
and
, respectively. The number 1.1 is added to avoid negative values, which may affect subsequent calculations. This formula requires no calculation of included angle, which reduces the computational amount, and can ensure the linear relationship between the calculated result and the included angle of the normal vectors.
3.2.2. Density Feature Index
From the mean distance between point
and its neighborhood points [
28], the density feature index is calculated as:
3.2.3. Edge Feature Index
The edge feature index is written as the distance between each point and its neighborhood center of gravity [
41] as:
where
is the number of neighborhood points and
and
are the coordinate vectors of points
and
, respectively.
3.2.4. Terrain Feature Index
For terrain point clouds, an index describing the terrain complexity is necessary to evaluate the point importance. This paper uses an index developed from the method of Xu et al. [
42]. It is given by:
where
is the height of point
,
is the average height of neighbor points of point
, and
is the average of all the points. The index reveals the local area undulating characteristics.
3.2.5. 3D Feature Index
The above feature indexes mostly analyze the surface features of point clouds, but the obtained 2.5-dimensional (namely, 2.5D) [
43] features are not enough when scanning targets with high vertical complexity such as 3D models, dense buildings, or lush jungles. Hence, a new index is designed for this. As shown in
Figure 2, the index calculates the average value of the included angle between vectors from point
to points
,
, …,
in its neighborhood so as to judge the particularity of a point in space. The smaller the average value of the included angles, the more special the point is. Conversely, the larger the angle, the more the point can be represented by the surrounding points.
The index is written by:
where
is the set of all the vectors from point
to its neighborhood points and
and
are a pair of different vectors in
. The number 1.1 has the same function as in Equation (22).
3.3. Feature Indexes Weighting
Afterwards, the weights of the indexes are calculated by the AHP method and the CRITIC method. Based on Equations (10) and (13), the weights are integrated as:
where
is the final weights of indexes
,
,
,
, and
for each point, respectively. Then, the importance quantification result of point
is:
3.4. Final Simplified Points Selection
The simplified points are selected according to whether they are classified as feature or non-feature points.
First, feature points and non-feature points are determined by sorting the values of all points. Points with larger values are feature points and are saved as simplified points, and those with smaller values are non-feature ones. Second, according to the kd-tree constructed in the previous process, it is judged whether there are feature points in each leaf node. If not, we select the non-feature point that is closest to the center of gravity of the node to join the simplified points. Finally, a simplified point cloud is obtained.
4. Experiment and Discussion
This article focuses on 3D models and field area point clouds. Thus, two experiments were designed to verify the effects of the MIWSA for the two kinds of point clouds. Each experiment utilized two sets of data. We compared the proposed algorithm with the following existing algorithms: the random algorithm [
44], the normal algorithm [
27], the voxel algorithm [
45], the k-means clustering algorithm [
23], and the curvature algorithm [
30].
In the experiment involving 3D model point clouds, the effects were checked by qualitatively comparing what the results look like after point cloud simplification. Then, we encapsulated the surfaces and quantitatively compared the surface areas and patch numbers of results from different algorithms. Comprehensive evaluations of these algorithms were acquired.
In the field area point cloud experiments, we compared the proposed MIWSA with the five abovementioned algorithms. The simplified results were compared in a preliminary analysis. After that, we created the digital elevation models (DEM) by fitting the original and simplified point clouds. These DEMs were used to accurately evaluate the simplification property of the algorithms.
4.1. 3D Model Point Cloud Simplification Test
The dragon dataset (
Data S1) and buddha dataset (
Data S2) released by Stanford University were used for the 3D model point cloud simplification test.
After calculating the feature indexes, the scale values for these indexes in the AHP method are determined. We describe the results as follows. The bending characteristics of the 3D model surface tend to be the most important, so the curvature ranks first. At the same time, we found that the stereoscopic attributes of points are prominent, and the points are distributed on the surface of the model object. Consequently, the angle and edge feature indexes follow. The density feature is not important by comparison. Overall, the descending order of characteristic parameters according to importance is: the density index, the edge index, the angle index, and the curvature index. The scale values between the indexes are shown in
Table 2. Each scale value means the corresponding feature index’s multiple over its left one. The farther to the left, the larger the index value.
4.1.1. Point Clouds Simplification Results
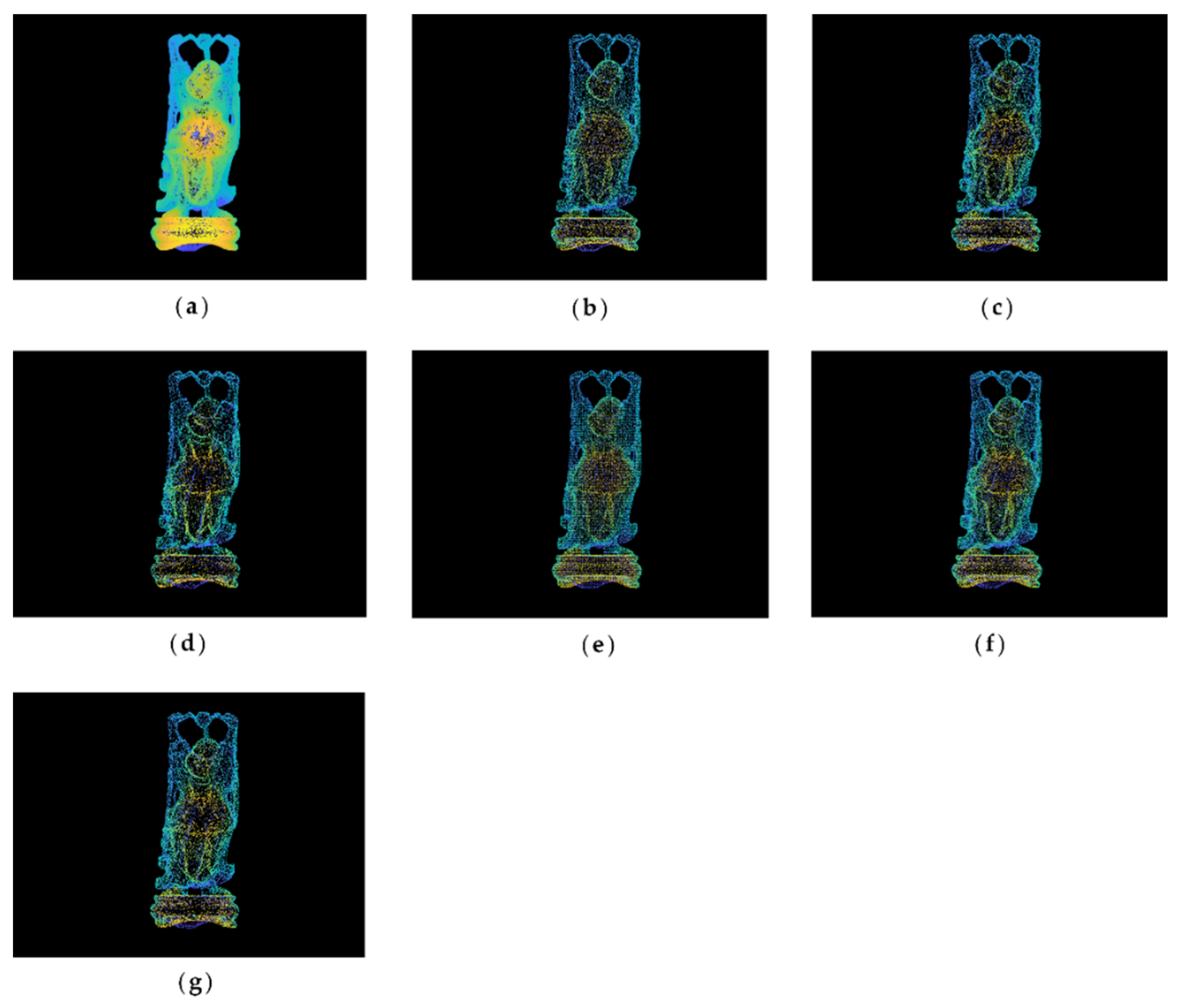
The original point cloud and simplified results of the buddha dataset at a simplification rate of 65% are shown in
Figure 3. It can be seen from
Figure 3a that the buddha has wrinkles on its hemline, which are the sharp feature areas. After simplification, the result of the MIWSA has the best balance between keeping the feature areas prominent and maintaining the integrity of the whole point cloud. In contrast, the normal algorithm and curvature algorithm preserved too many points in feature areas and led to some hollow areas. Meanwhile, the voxel algorithm did not perform well when retaining the feature areas despite avoiding empty areas. For the random algorithm, it also led to some cavities due to its uniform selection in some sparse areas of the point cloud. The k-means algorithm result appears more appropriate, but it still has weaknesses in some convex areas.
Figure 4 shows the original and simplified point clouds at a 65% simplification rate of the dragon dataset. It is clear that there is winding in all parts of the dragon, especially on its back and claws. Compared with other algorithms, the MIWSA can maintain the uniformity of the overall point cloud, and at the same time, it has a better extraction effect on areas with more complex model changes and obvious characteristics. In contrast, the random algorithm was greatly affected by the density of the point cloud, and there are too many reserved points in some areas. The voxel algorithm is insufficient for feature extraction. There are some holes in the results of the curvature and normal algorithms, and their effect is not as good as that of the MIWSA algorithm.
4.1.2. Model Encapsulation Results
To compare the point cloud simplification results more clearly, the point clouds were surface encapsulated, and the results for the buddha dataset and dragon datasets are shown in
Figure 5 and
Figure 6, respectively. The blue areas in the figures are the surface of the encapsulated model, and the yellow ones are the hollow parts.
It can be seen that for the buddha dataset, the encapsulated surface of the MIWSA has fewer hollows than the other methods, and the representation is more refined at the bending sleeves and skirts. For the dragon dataset, although the surface corresponding to the MIWSA has a certain degree of distortion and deviation in the head and the back of the neck of the dragon, there are basically no cavity areas and few abnormal model surface areas.
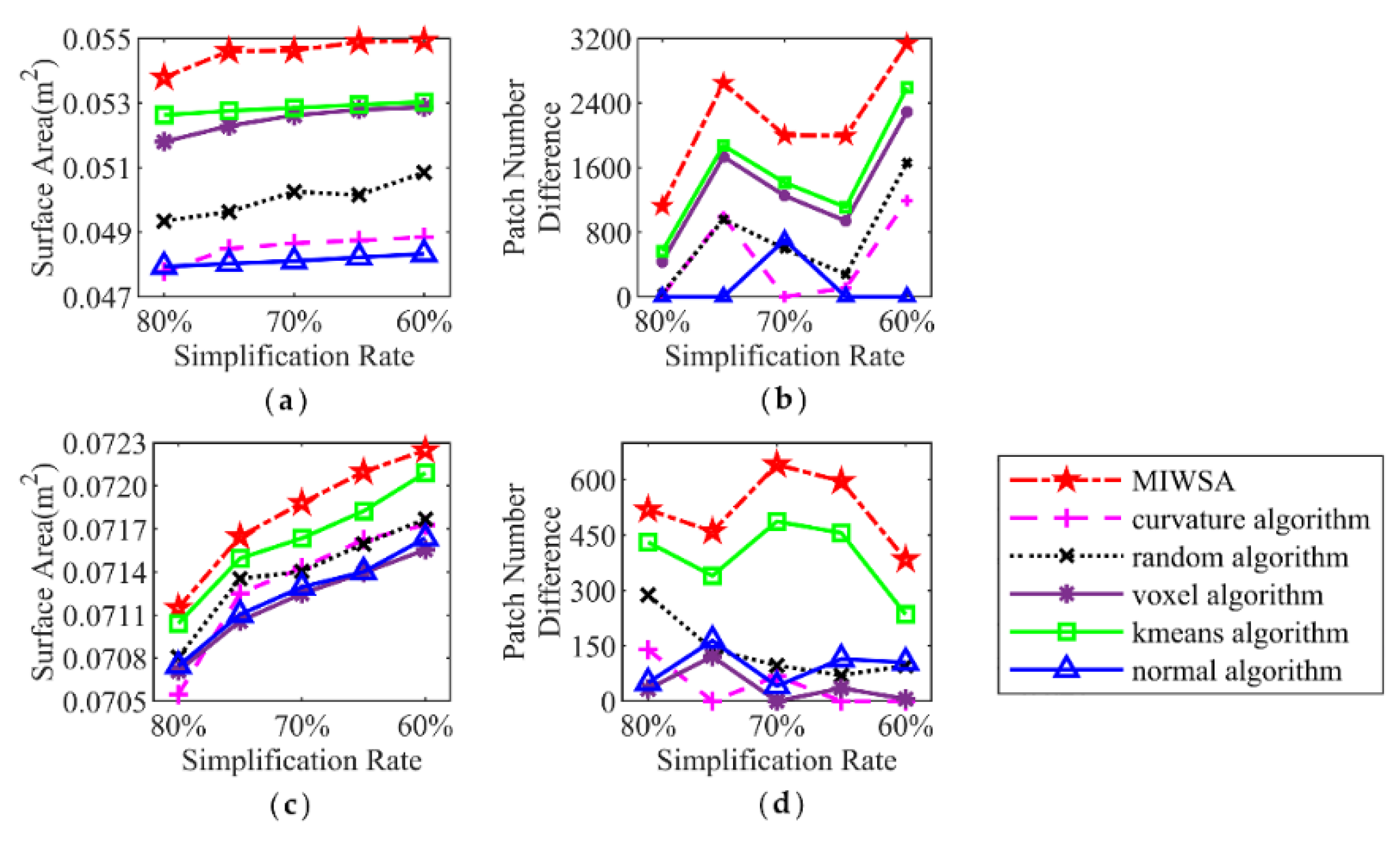
Aiming at quantitatively analyzing the accuracy of the model, the surface areas of the model surfaces encapsulated from the simplified point clouds are calculated. The larger the area, the more microscopical the representation of the encapsulated surface. Therefore, the accuracy of the simplified point clouds can be measured.
The comparisons of the surface areas corresponding to the algorithms under different simplification rates are shown in
Figure 7a,c. It can be seen that with a reduction in the simplification rate of point clouds, the surface area increases. For the buddha dataset, the surface area corresponding to the result of the MIWSA is 5% to 15% larger than those of the other algorithms. For the dragon dataset, the comparative advantage is not that large, but the value of the MIWSA still occupies first place, which is 0.0002–0.0004 m
2 larger when compared with the other algorithms.
Similar to the surface area, the patch number of the 3D model can also be used to quantitatively indicate the simplification accuracy of point clouds. The larger the patch numbers, the more precise the simplified results. The patch numbers for the point clouds of the two datasets are shown in
Figure 7b,d. In order to clearly express the large values, they are processed by subtracting the minimum value from all the values for each simplification rate.
Figure 7b shows the patch numbers of the buddha dataset. It can be seen that the patch number of the MIWSA is always the largest. The lead number above the second largest value ranges from 400 to 1200. As for the dragon dataset, the lead is around 150.
Combined with both the processed point clouds and encapsulated surfaces, it can be concluded that the MIWSA has higher accuracy than the other algorithms for 3D model point clouds. It is able to describe the simplified point clouds in more detail by keeping or abandoning the points using a more appropriate strategy.
4.1.3. Simplification Efficiency
In order to compare the algorithms’ efficiency, we carried out point cloud simplification experiments on the same platform. The type of CPU was Ryzen 4800H (manufactured by Lenovo in China) and the memory was 16 GB. The running time for each algorithm for these point cloud datasets can be seen in
Table 3.
It is obvious that the MIWSA has an edge over the normal, k-means, and curvature algorithms in terms of calculating time, which is about 60%, 80%, and 3% of these three algorithms, respectively. Though the random and voxel algorithms can simplify points more quickly, these two can hardly take the points’ geometric and spatial features into account, making their simplification performance terrible.
4.2. Field Area Point Cloud Simplification Test
To test the simplification ability of MIWSA for field area point clouds, datasets Samp52 (
Data S3) and Samp53 (
Data S4) released by the International Society for Photogrammetry and Remote Sensing were used.
The order of indexes and their scale values in AHP were determined according to the following analysis. In the field areas in Samp52 and Samp53, the undulating characteristic of the terrain is the key factor for the simplification of point clouds. Thus, the terrain feature index is the most important. For the local parts not covered by vegetation, it is necessary to collect bending information about the object surface, making the angle feature index the second most important. Meanwhile, for wood-covering areas with hierarchical features, it is necessary to extract the feature points inside the cluster point cloud, which means the curvature feature index ranks next. Additionally, the edge and density feature indexes are both not influential in these kinds of point clouds. In general, the terrain complexity index, the angle index, and the curvature index are ranked in the top three. Meanwhile, the density index and the edge index are the last two. The index values and scale values are shown in
Table 4.
4.2.1. Point Cloud Simplification Results
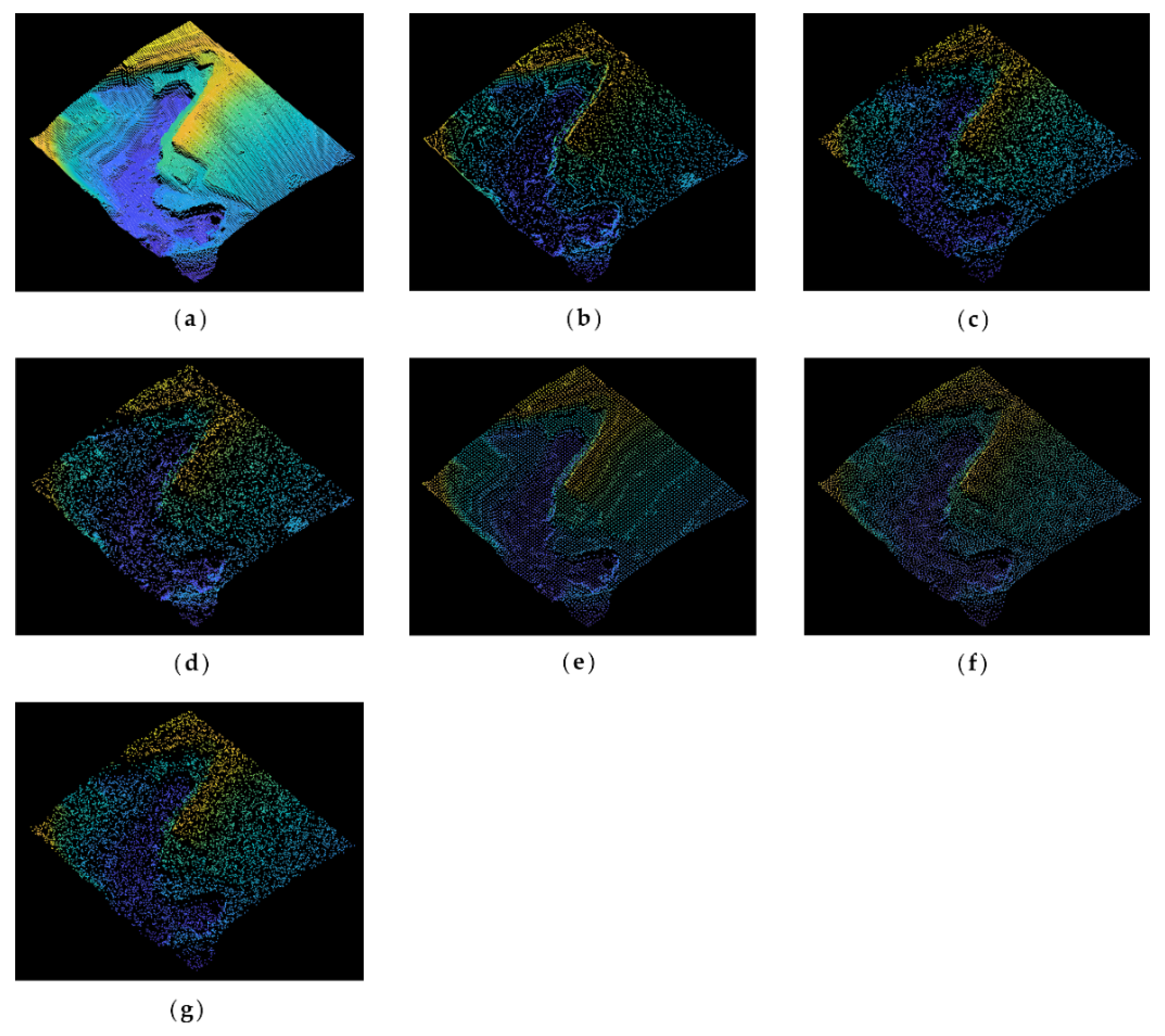
Figure 8 illustrates the original and simplified point clouds at an 80% simplification rate. As is shown in
Figure 8a, the original point cloud of Samp52 mainly includes gentle slopes, cliffs, rivers, and trees. It can be seen from
Figure 8b that the MISWA result reserves more points in the cliffs, trees, and other bump regions, while points in flat areas and slopes are reduced greatly. In contrast, the results of the other algorithms have shortcomings either when extracting features or retaining the overall shape. This reveals that the MISWA has the character of choosing relatively important points and abandoning points that can be replaced by other points without significantly affecting the accuracy.
The original point cloud of Samp53 is shown in
Figure 9a, in which cliffs and stepped terrain features can be seen. In addition, there are some wavy parts distributed on the plain. The simplification rate is 80%. The normal algorithm and curvature algorithm choose the points with local special characteristics. However, these characteristics are not suitable for geography point clouds, making these simplified points imprecise. The voxel algorithm and k-means algorithm results retain the overall shape of the point cloud, but they do not emphasize the key features. In comparison, the MIWSA not only extracts the feature points in areas with changing topography but also keeps the dataset integrated.
4.2.2. DEM Construction Results
In order to evaluate the accuracy of the simplification results for field area datasets more intuitively, a method based on geographical analysis is proposed in this subsection.
One of the uses of terrain point clouds is to construct digital elevation models (DEMs) with which this paper evaluates the algorithm accuracy. Grid DEMs are generated by fitting the original and the simplified point clouds. Then, the elevation values of the corresponding position grids in the two models are made different to indicate the simplification error reflected in each grid. By analyzing the overall spatial distribution and statistical characteristics of the errors, the point cloud simplification results can be evaluated.
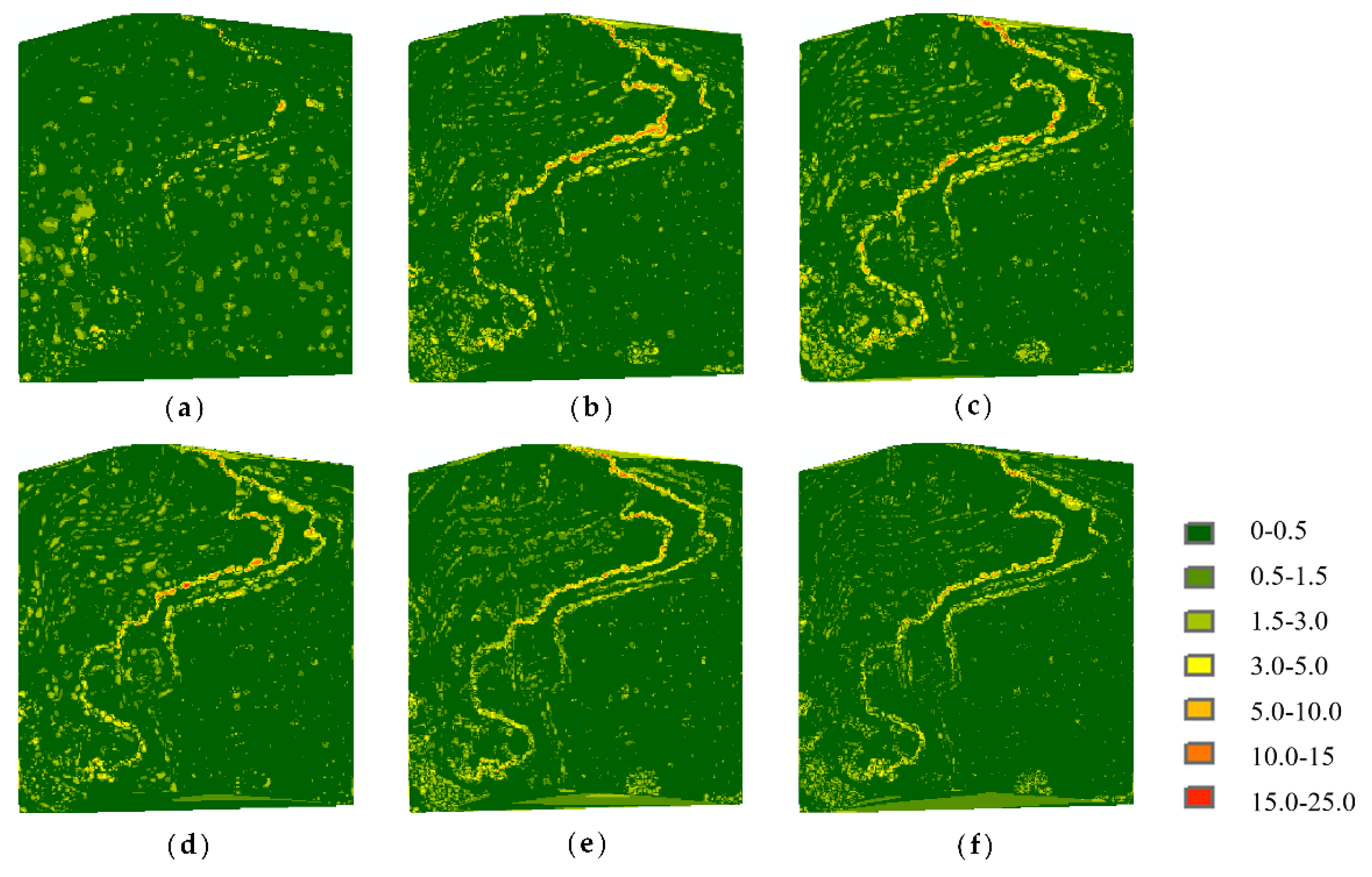
Figure 10 shows the elevation difference distributions of Samp52 at a simplification rate of 80%. The errors are more remarkable along the river for all results, among which the MIWSA keeps both the extreme values and overall values to the minimum.
As for Samp53,
Figure 11 shows the elevation difference distributions. It can be seen that although the MIWSA leads to more errors in the plain to some extent, there are significantly fewer errors in the steep terrain areas than there are when using the other algorithms. This reflects that the MIWSA properly adjusts the strategy of retention and abandonment for points to raise the point cloud simplification accuracy in general.
In order to assess the precision of the simplified results quantitatively, we calculated two indicators, namely the mean value
and root mean square value
of the different values in the grids.
and
are given by:
where
is the number of grids and
is the elevation difference in each grid.
Figure 12 illustrates the results at simplification rates from 80% to 50% at 5% intervals.
Figure 12a,b corresponds to Samp52, and
Figure 12c,d corresponds to Samp53.
For Samp52, the MIWSA has the smallest indicator values other than at a rate of 80%. With a reduction in the simplification rate, the advantage of the MIWSA becomes greater. Overall, the indicator values of the MIWSA are 0–80% smaller than those of other algorithms. Among the other algorithms, the k-means algorithm is the best, while the random algorithm performs the worst.
For Samp53, the MIWSA has the best effects at all the simplification rates. Its smallest value difference with other algorithms is around 0.01 m, while its greatest difference is 0.1 m. In addition, the value of the MIWSA is 2–15% smaller. As the simplification rate declines, the advantage of the proposed algorithm also becomes prominent.
Generally, the MIWSA has good adaptation for field area point clouds. Compared with the existing algorithms, it is able to better maintain the features and the overall shape. By quantitative assessment, the results of the MIWSA algorithm are less different from the original point cloud, and the error distribution is more uniform. The MIWSA is able to maintain a small numerical error value and a narrow distribution range.
4.2.3. Simplification Efficiency
As in the 3D model point cloud simplification experiment, the algorithms’ efficiency is compared. The running time can be seen in
Table 5.
As shown in
Table 5, the MIWSA running times are about 30% and 50% shorter than the normal algorithm. The k-means algorithm is much slower. The curvature algorithm’s performance is close to that of the MIWSA. The random and voxel algorithms are comparatively quicker due to their simple principle.
5. Conclusions
To solve the issues of computation cost and storage space occupation caused by large point clouds collected during 3D scanning, this paper proposes a novel point cloud simplification algorithm, MIWSA, based on point features and spatial relationships. First, the point cloud is organized via a bounding box and a kd-tree for subsequent neighborhood searching and point division. Second, five feature indexes are calculated to reveal the characteristics from different perspectives: point cloud shape, density, object edge information, terrain information contained, and inner relationship. Third, the AHP and CRITIC methods are utilized to give the weights of the feature indexes, and a comprehensive index is thus attained. Fourth, each point is classified as a feature point or non-feature point according to the comprehensive index value. The former are saved into final simplified points, and the latter are determined to be saved or abandoned according to their location relationship with the feature points. Overall, the MIWSA is able to extract multifaceted points by considering both the geometric attributes and the spatial relative position.
In order to verify the effectiveness of the MIWSA, experiments using 3D model point clouds and field area point clouds are carried out. Compared with five existing algorithms, the MIWSA has superior simplification effects in both quantitative and qualitative terms. For 3D model point clouds, the MIWSA is able to maintain the details and contour of the object well and retains the largest surface area and the greatest patch number. For field area point clouds, the MIWSA algorithm can reduce the number of errors and keep the error distribution more uniform. By adjusting the scale order and values according to the point cloud scenes, the proposed algorithm can flexibly simplify different point clouds. In terms of efficiency, the MIWSA operates more quickly than the normal, curvature, and k-means algorithms and more slowly than the random and voxel algorithms. When comprehensively considering the effect, adaptation, and efficiency, the MIWSA is better than the other algorithms.
The MIWSA should be tested on more point cloud datasets. Meanwhile, the AHP weighting method relies on subjective analysis. Thus, it requires the acquisition of a detailed summary of weight distributions for different types of point clouds.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}