

Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection

 , ,
, ,  , and
, and
Abstract
1. Introduction
- We propose a method by applying the non-local network to fuse two-frame point clouds. This method does not need external-information-based registration and can handle stationary and moving objects.
- To solve the problem that non-local-based fusion modes consume massive computing resources, we propose a non-local network with an index table, which only calculates similarities among non-empty units.
- We apply the triple attention mechanism to suppress the background noise and enhance the key information. It plays a role in improving the performance of the non-local fusion module.
2. Related Work
2.1. Single-Frame-Based Lidar Object Detection
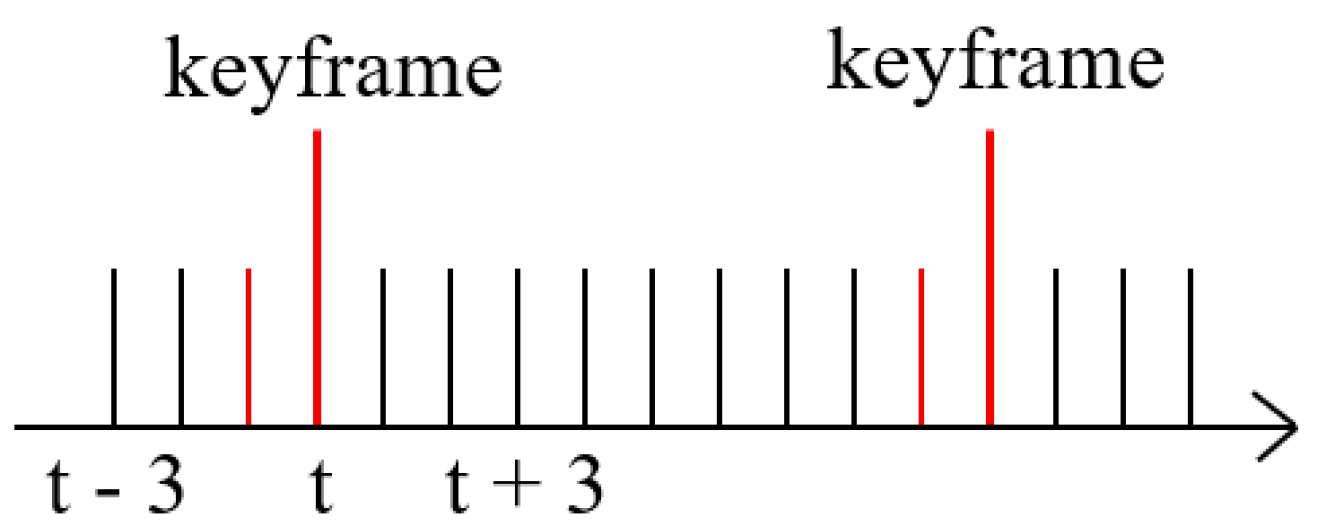
2.2. Multi-Frame-Based Lidar Object Detection
2.3. Attention Mechanism
3. Methods
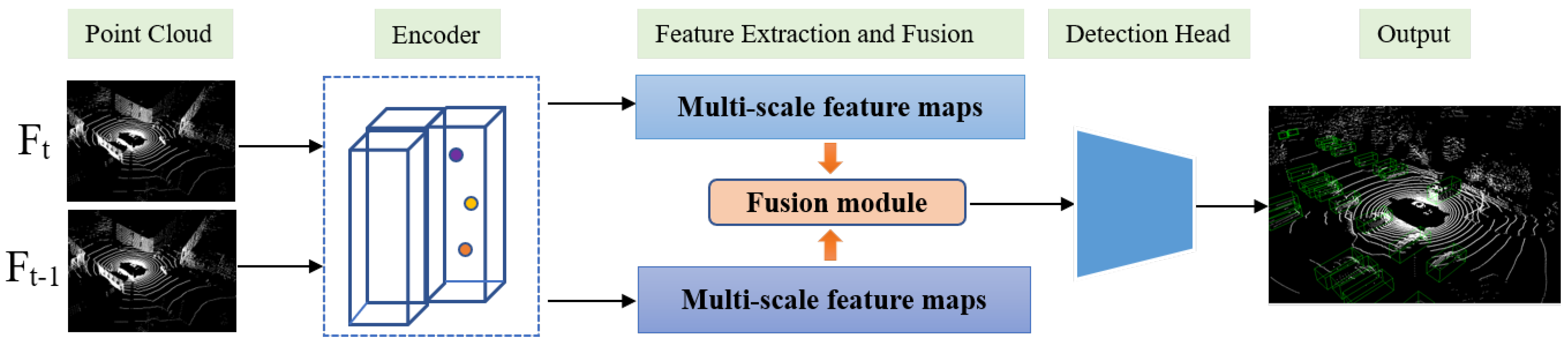
3.1. Overview
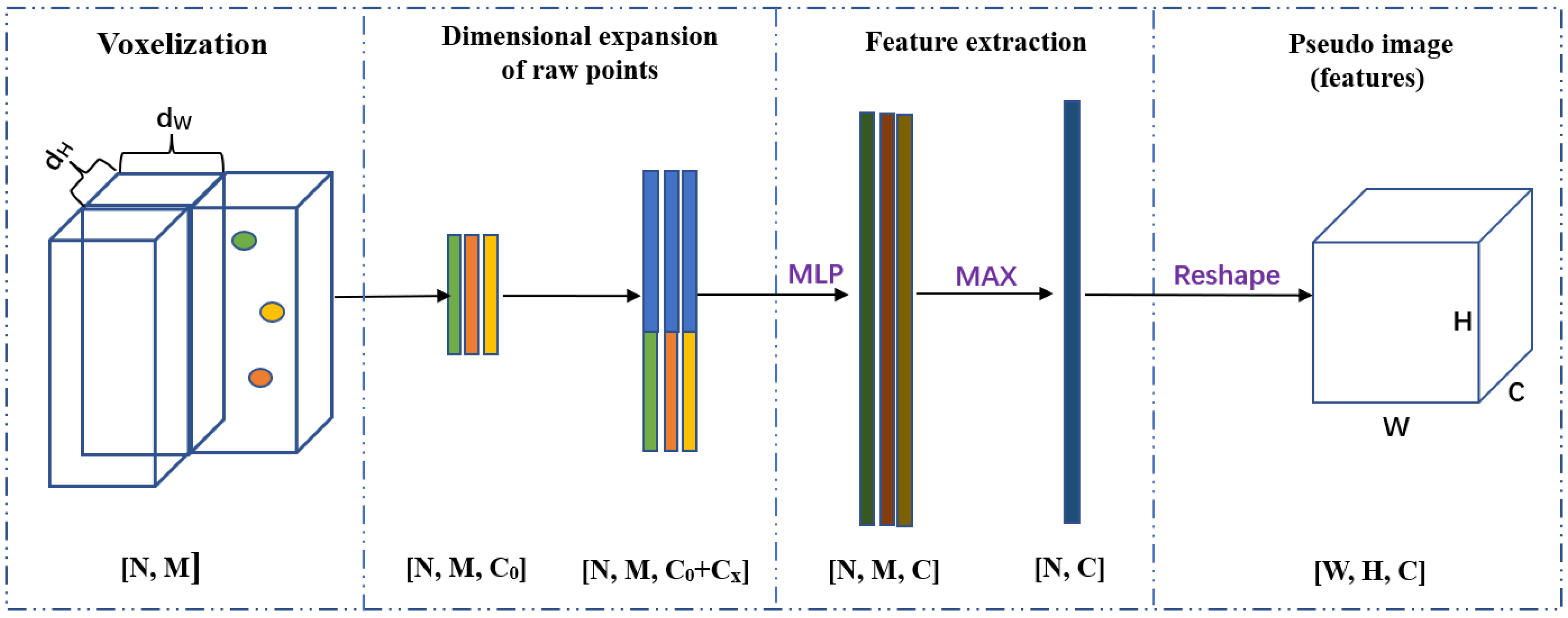
3.2. Grid-Based Point Cloud Encoder
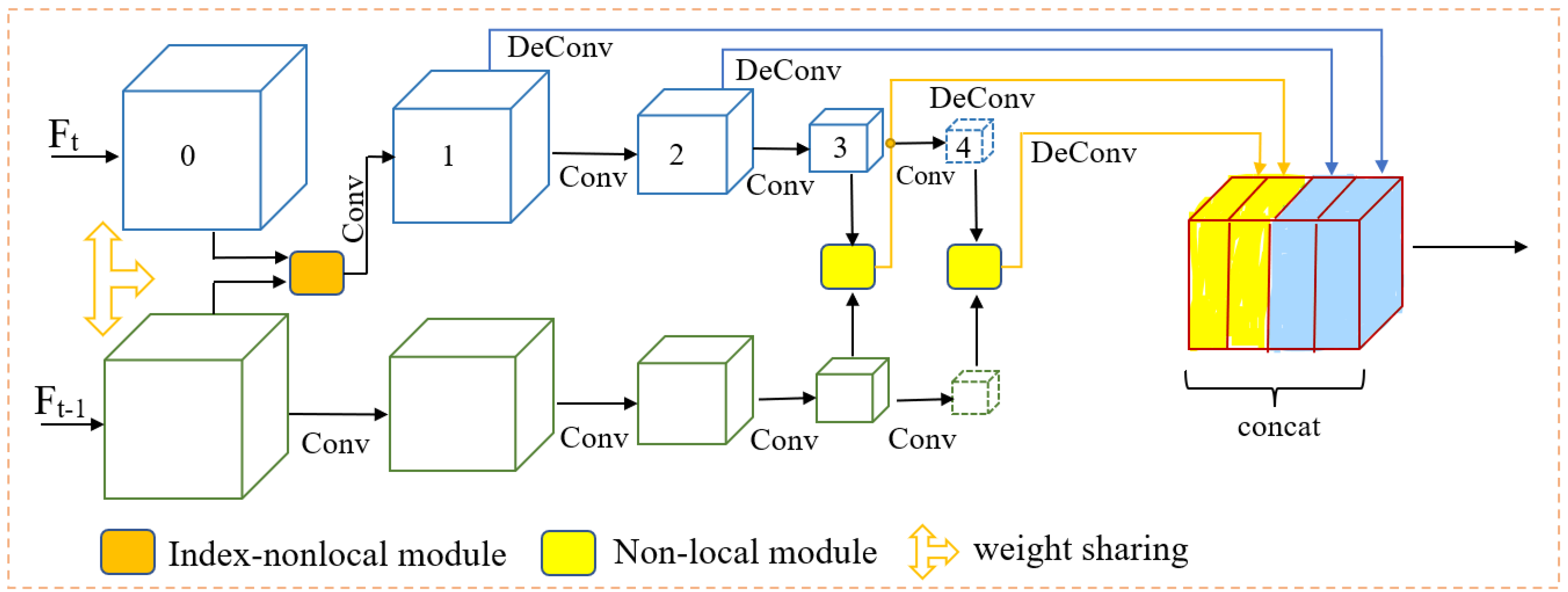
3.3. Feature Fusion
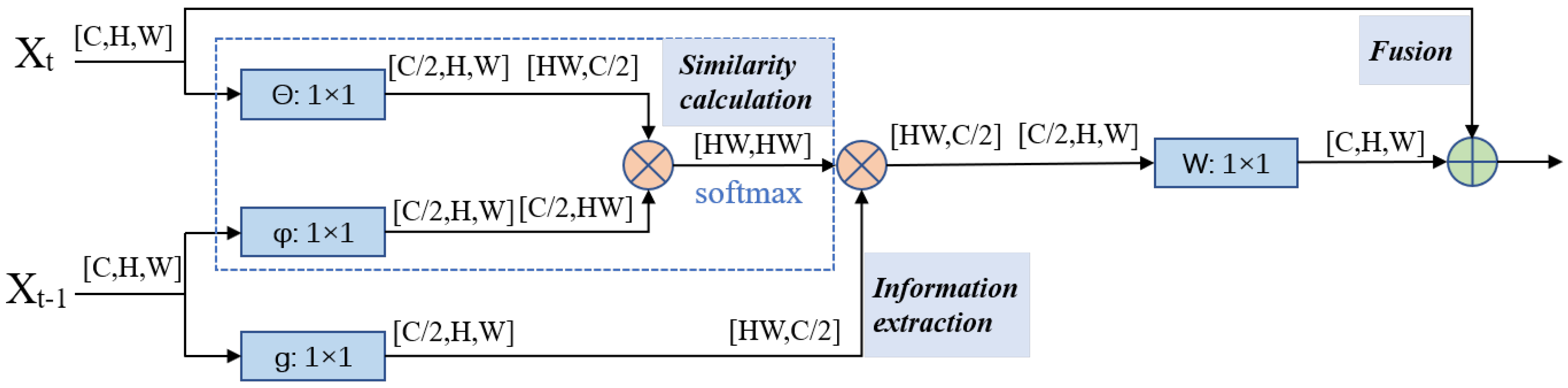
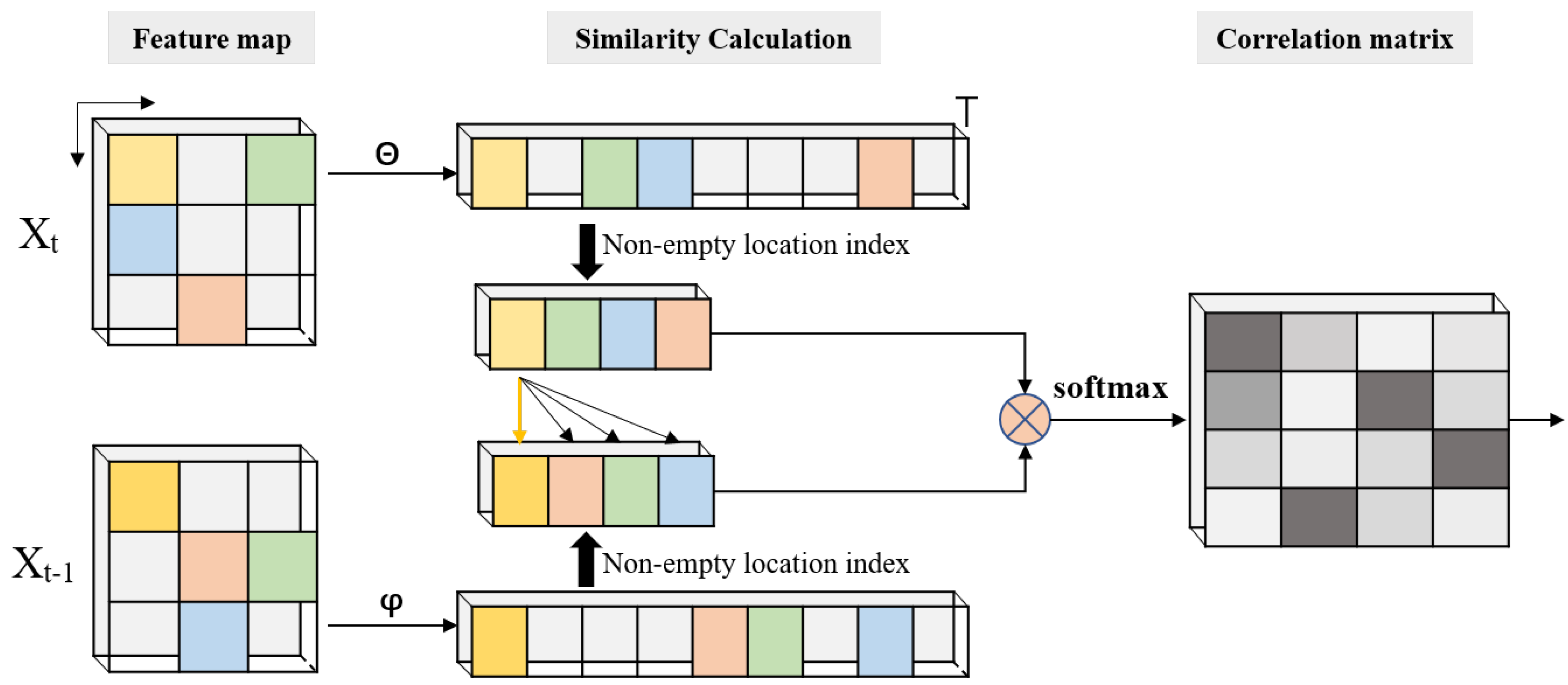
3.4. Index-Nonlocal Module
3.4.1. Analysis of Non-local Calculation
3.4.2. Simplify Non-local Modules with an Index Table
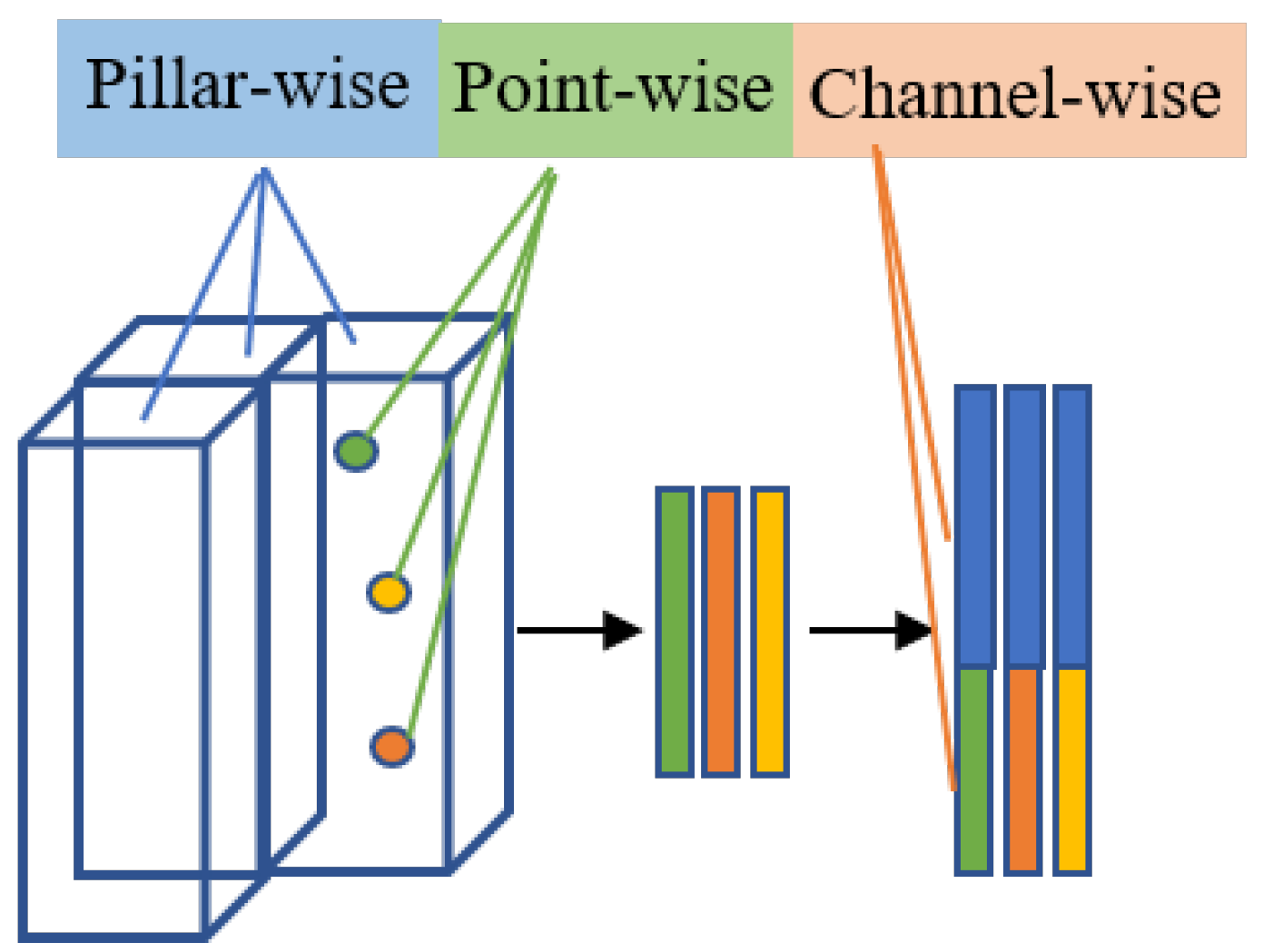
3.5. Point Cloud Triple Attention Mechanism
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Results
4.3.1. Quantitative Analysis
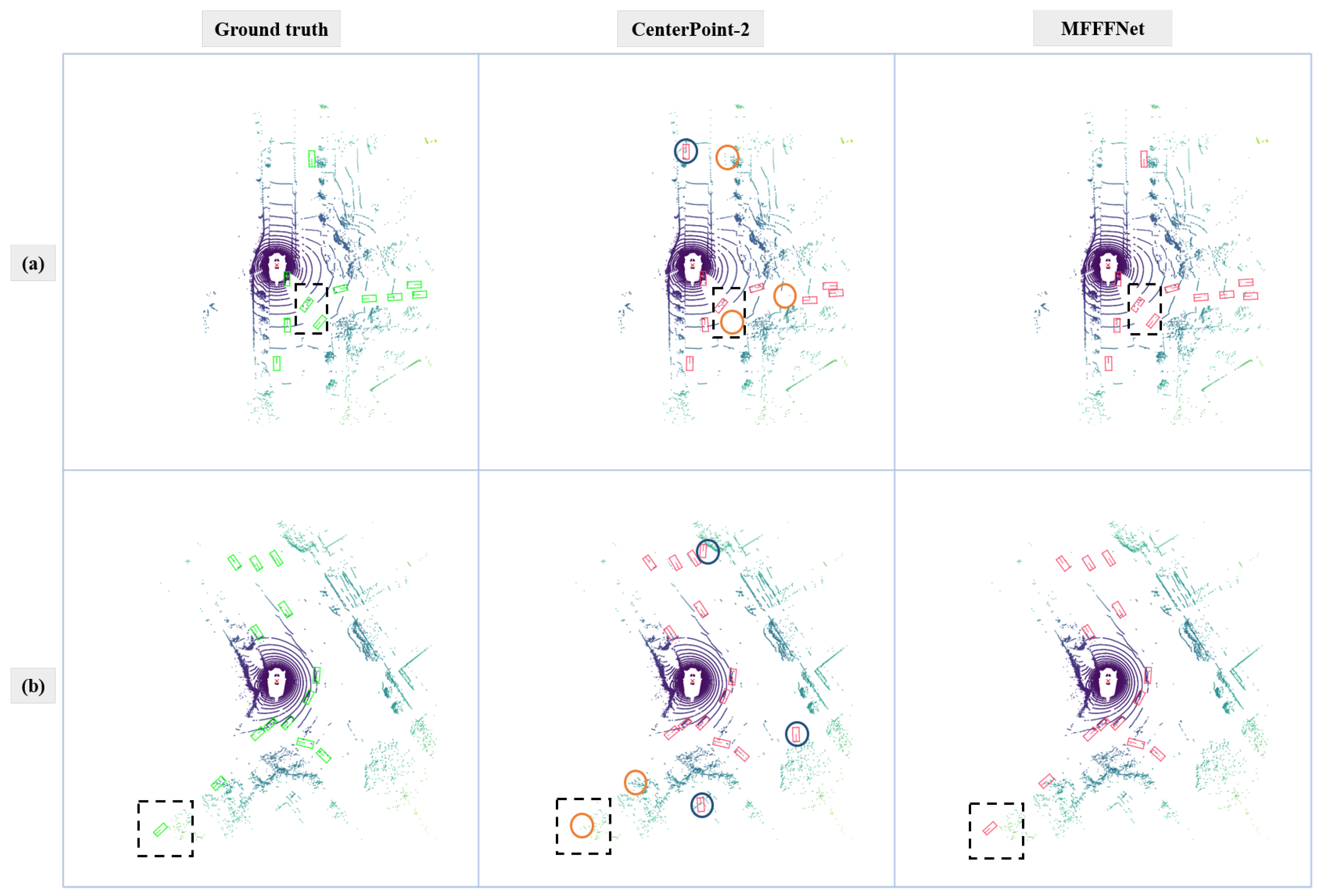
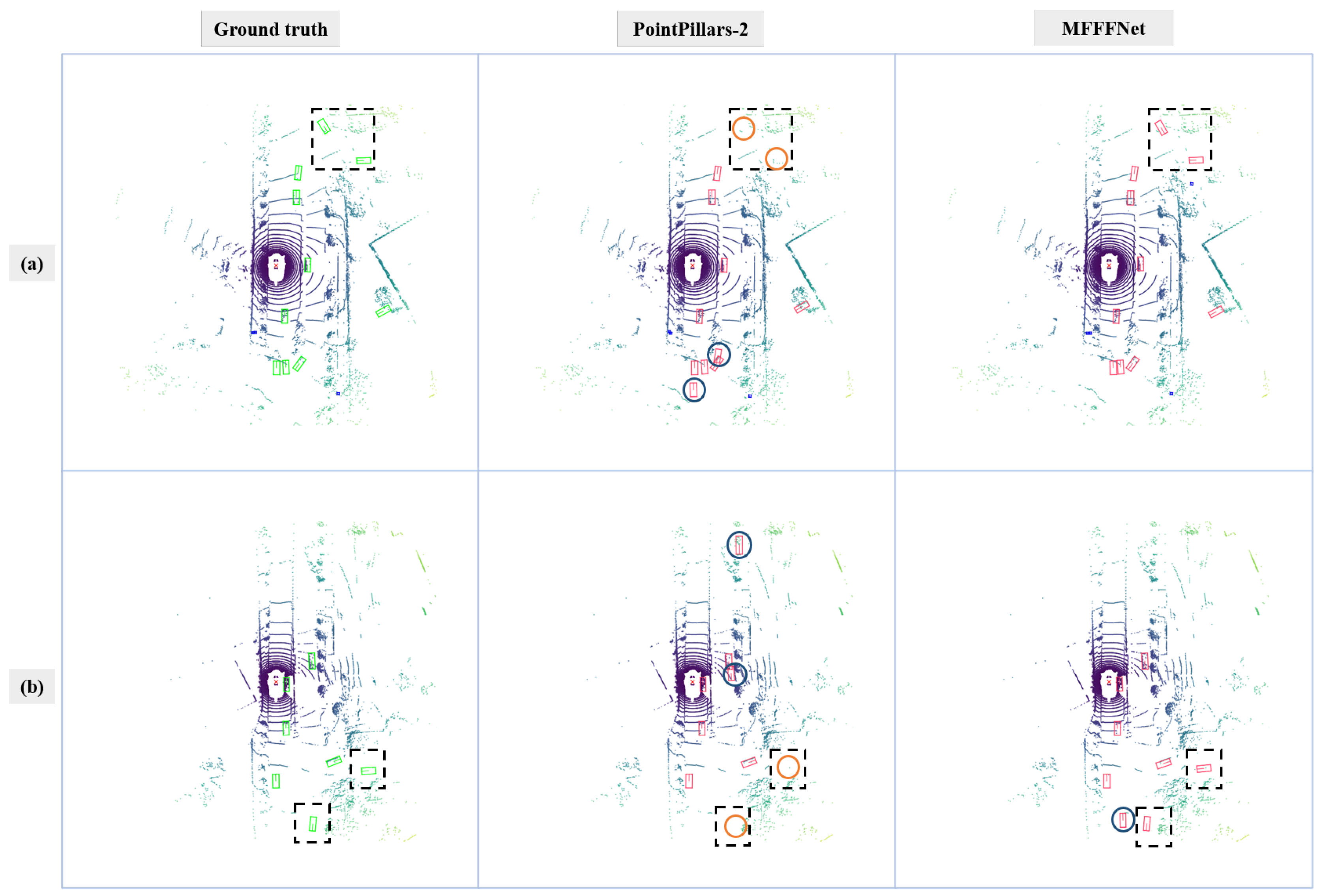
4.3.2. Qualitative Analysis
4.3.3. Ablation Studies


5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Huang, R.; Zhang, W.; Kundu, A.; Pantofaru, C.; Ross, D.A.; Funkhouser, T.; Fathi, A. An lstm approach to temporal 3d object detection in lidar point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 266–282. [Google Scholar]
- El Sallab, A.; Sobh, I.; Zidan, M.; Zahran, M.; Abdelkarim, S. YOLO4D: A Spatio-temporal Approach for Real-time Multi-object Detection and Classification from LiDAR Point Clouds. In Proceedings of the Neural Information Processing Systems (NIPS), Machine Learning in Inteligent Transportation MLITS Workshop, Montreal, QC, Canada, 5–10 December 2018. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3569–3577. [Google Scholar]
- Qi, C.R.; Zhou, Y.; Najibi, M.; Sun, P.; Vo, K.; Deng, B.; Anguelov, D. Offboard 3d object detection from point cloud sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6134–6144. [Google Scholar]
- Sun, J.; Xie, Y.; Zhang, S.; Chen, L.; Zhang, G.; Bao, H.; Zhou, X. You Don’t Only Look Once: Constructing Spatial-Temporal Memory for Integrated 3D Object Detection and Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3185–3194. [Google Scholar]
- Yin, J.; Shen, J.; Guan, C.; Zhou, D.; Yang, R. Lidar-based online 3d video object detection with graph-based message passing and spatiotemporal transformer attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11495–11504. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhang, Y.; Ye, Y.; Xiang, Z.; Gu, J. SDP-Net: Scene Flow Based Real-Time Object Detection and Prediction from Sequential 3D Point Clouds. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3d object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11677–11684. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.; Li, M. MonoPair: Monocular 3D Object Detection Using Pairwise Spatial Relationships. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12090–12099. [Google Scholar]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6850–6859. [Google Scholar]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8437–8445. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. DSGN: Deep Stereo Geometry Network for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12533–12542. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Hu, P.; Ziglar, J.; Held, D.; Ramanan, D. What you see is what you get: Exploiting visibility for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11001–11009. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 720–736. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4604–4612. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Zhai, Z.; Wang, Q.; Pan, Z.; Hu, W.; Hu, Y. 3D Object Detection Based on Feature Fusion of Point Cloud Sequences. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 17–20 July 2022. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International conference on machine learning. PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving Deeper into Convolutional Networks for Learning Video Representations. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Huang, L.; Yuan, Y.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Interlaced sparse self-attention for semantic segmentation. arXiv 2019, arXiv:1907.12273. [Google Scholar]
- Zhang, L.; Xu, D.; Arnab, A.; Torr, P.H. Dynamic graph message passing networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3726–3735. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-Excitation Networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2017; Volume 42, pp. 2011–2023. [Google Scholar]
- Team, O.D. OpenPCDet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. 2020. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 10 November 2021).
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv Preprint 2019, arXiv:1908.09492. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Antequera, M.L.; Kontschieder, P. Disentangling monocular 3d object detection: From single to multi-class recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2020; Volume 44, pp. 1219–1231. [Google Scholar]
- Ye, Y.; Chen, H.; Zhang, C.; Hao, X.; Zhang, Z. Sarpnet: Shape attention regional proposal network for lidar-based 3d object detection. Neurocomputing 2020, 379, 53–63. [Google Scholar] [CrossRef]
- Qin, P.; Zhang, C.; Dang, M. GVnet: Gaussian model with voxel-based 3D detection network for autonomous driving. Neural Comput. Appl. 2022, 34, 6637–6645. [Google Scholar] [CrossRef]
- Wang, J.; Lan, S.; Gao, M.; Davis, L.S. Infofocus: 3d object detection for autonomous driving with dynamic information modeling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 405–420. [Google Scholar]
- Barrera, A.; Beltrán, J.; Guindel, C.; Iglesias, J.A.; García, F. BirdNet+: Two-Stage 3D Object Detection in LiDAR Through a Sparsity-Invariant Bird’s Eye View. IEEE Access 2021, 9, 160299–160316. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Du, L.; Ye, X.; Tan, X.; Johns, E.; Chen, B.; Ding, E.; Xue, X.; Feng, J. Ago-net: Association-guided 3d point cloud object detection network. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Zhu, X.; Ma, Y.; Wang, T.; Xu, Y.; Shi, J.; Lin, D. Ssn: Shape signature networks for multi-class object detection from point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 581–597. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Fusion Mode | Registration | mAP |
|---|---|---|---|---|
| PointPillars-1 | 1-frame | / | / | 32.7 |
| PointPillars-2 | 2-frames | concatenate | Yes | 34.7 |
| Method | Input | Fusion Mode | Registration | mAP |
|---|---|---|---|---|
| PointPillars-2 | 2-frames | concatenate | Yes | 34.7 |
| PointPillars-2 | 2-frames | concatenate | No | 32.6 |
| Method | Input | Fusion mode | mAP | Car | Ped | Bus | Barrier | TC | Truck | Motor | Trailer | Bicycle | CV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointPillars-2 | 2 | concatenate | 34.7 | 72.0 | 56.5 | 56.0 | 37.3 | 33.8 | 34.9 | 21.1 | 28.2 | 1.4 | 5.7 |
| MFFFNet-PP | 2 | Non-local-based | 38.6 | 73.6 | 60.9 | 60.4 | 44.1 | 39.0 | 36.2 | 24.2 | 33.4 | 1.8 | 12.5 |
| improvement | / | / | +3.9 | +1.6 | +4.4 | +4.4 | +6.8 | +5.2 | +1.3 | +3.1 | +5.2 | +0.4 | +6.8 |
| CenterPoint-2 | 2 | concatenate | 42.5 | 78.8 | 70.5 | 59.4 | 52.3 | 46.1 | 45.1 | 33.3 | 27.3 | 7.0 | 5.6 |
| MFFFNet-CP | 2 | Non-local-based | 46.6 | 79.7 | 74.1 | 64.9 | 56.5 | 51.6 | 46.8 | 36.5 | 32.5 | 14.1 | 8.9 |
| improvement | / | / | +4.1 | +0.9 | +3.6 | +5.5 | +4.2 | +5.5 | +1.7 | +3.2 | +5.2 | +7.1 | +3.3 |
| Method | Input | Fusion mode | mAP | Car | Ped | Bus | Barrier | TC | Truck | Motor | Trailer | Bicycle | CV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAIR [43] | 10 | concatenate | 30.4 | 47.8 | 37.0 | 18.8 | 51.1 | 48.7 | 22.0 | 29.0 | 17.6 | 24.5 | 7.4 |
| SARPNet [44] | 10 | concatenate | 32.4 | 59.9 | 69.4 | 19.4 | 38.3 | 44.6 | 18.7 | 29.8 | 18.0 | 14.2 | 11.6 |
| WYSWYG [24] | 10 | concatenate | 35.4 | 80.0 | 66.9 | 54.1 | 34.5 | 27.9 | 35.8 | 18.5 | 28.5 | 0.0 | 7.5 |
| GVNet [45] | 10 | concatenate | 35.4 | 76.2 | 59.2 | 42.3 | 32.0 | / | 29.7 | 20.7 | 22.1 | 0.8 | / |
| InfoFocus [46] | 10 | concatenate | 36.4 | 77.6 | 61.7 | 50.5 | 43.4 | 33.4 | 35.4 | 25.2 | 25.6 | 2.5 | 8.3 |
| BirdNet+ [47] | 10 | concatenate | 36.5 | 67.3 | 48.6 | 48.4 | 51.5 | 18.9 | 44.4 | 31.4 | 32.3 | 10.0 | 12.4 |
| 3DSSD [48] | 10 | concatenate | 42.7 | 81.2 | 70.2 | 61.4 | 47.9 | 31.1 | 47.2 | 36.0 | 30.5 | 8.6 | 12.6 |
| AGO-Net [49] | 10 | concatenate | 45.1 | 81.5 | 72.2 | 62.2 | 51.2 | 48.1 | 50.1 | 32.5 | 34.0 | 5.9 | 13.3 |
| SSN [50] | 10 | concatenate | 46.3 | 80.7 | 72.3 | 39.9 | 56.3 | 54.2 | 37.5 | 43.7 | 43.9 | 20.1 | 14.6 |
| 3D-VID [8] | 10 × 3 | ConvGRU | 45.4 | 79.7 | 76.5 | 47.1 | 48.8 | 58.8 | 33.6 | 40.7 | 43.0 | 7.9 | 18.1 |
| MFFFNet-CP | 2 | Non-local-based | 46.6 | 79.7 | 74.1 | 64.9 | 56.5 | 51.6 | 46.8 | 36.5 | 32.5 | 14.1 | 8.9 |
| Method | Input | Fusion Mode | mAP | Improvement |
|---|---|---|---|---|
| PointPillars-2 | 2 | concatenate | 34.7 | / |
| PP + Non-local | 2 | Non -local -based | 36.6 | +1.9 |
| PP + Non-local + TANet | 2 | Non -local -based | 37.5 | +0.9 |
| PP + Non-local + TANet + Index-nonlocal | 2 | Non -local -based | 38.6 | +1.1 |
| CenterPoint-2 | 2 | concatenate | 42.5 | / |
| CP + Non-local | 2 | Non -local -based | 43.9 | +1.4 |
| CP + Non-local + TANet | 2 | Non -local -based | 44.7 | +0.8 |
| CP + Non-local + TANet + Index-nonlocal | 2 | Non -local -based | 46.6 | +1.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, Z.; Wang, Q.; Pan, Z.; Gao, Z.; Hu, W. Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection. Sensors 2022, 22, 7473. https://doi.org/10.3390/s22197473
Zhai Z, Wang Q, Pan Z, Gao Z, Hu W. Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection. Sensors. 2022; 22(19):7473. https://doi.org/10.3390/s22197473
Chicago/Turabian StyleZhai, Zhenyu, Qiantong Wang, Zongxu Pan, Zhentong Gao, and Wenlong Hu. 2022. "Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection" Sensors 22, no. 19: 7473. https://doi.org/10.3390/s22197473
APA StyleZhai, Z., Wang, Q., Pan, Z., Gao, Z., & Hu, W. (2022). Muti-Frame Point Cloud Feature Fusion Based on Attention Mechanisms for 3D Object Detection. Sensors, 22(19), 7473. https://doi.org/10.3390/s22197473