
An Integrated Framework for Multi-State Driver Monitoring Using Heterogeneous Loss and Attention-Based Feature Decoupling



Abstract
:1. Introduction
- The different modules should be independent of each other so the functions are convenient to use;
- The framework should be easy to maintain and update based on the development of deep learning technology;
- The framework should provide various configuration models to coordinate computing power and accuracy;
- The included functional modules should achieve state-of-the-art performance.
2. Related Work
2.1. Visual Sensor-Based Head Pose Estimation
2.2. Visual Sensor-Based 3D Gaze Estimation
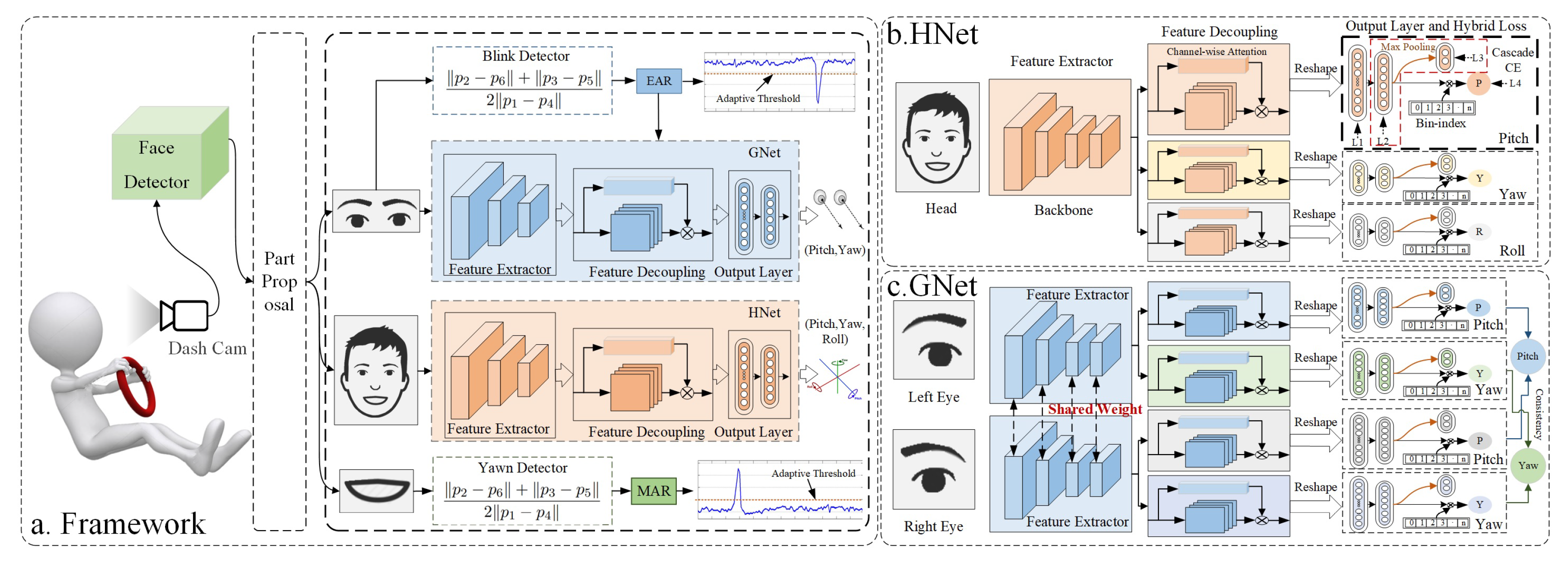
3. Methodology
3.1. Attention-Based Feature Decoupling
3.2. Heterogeneous Loss with Cascade Cross-Entropy
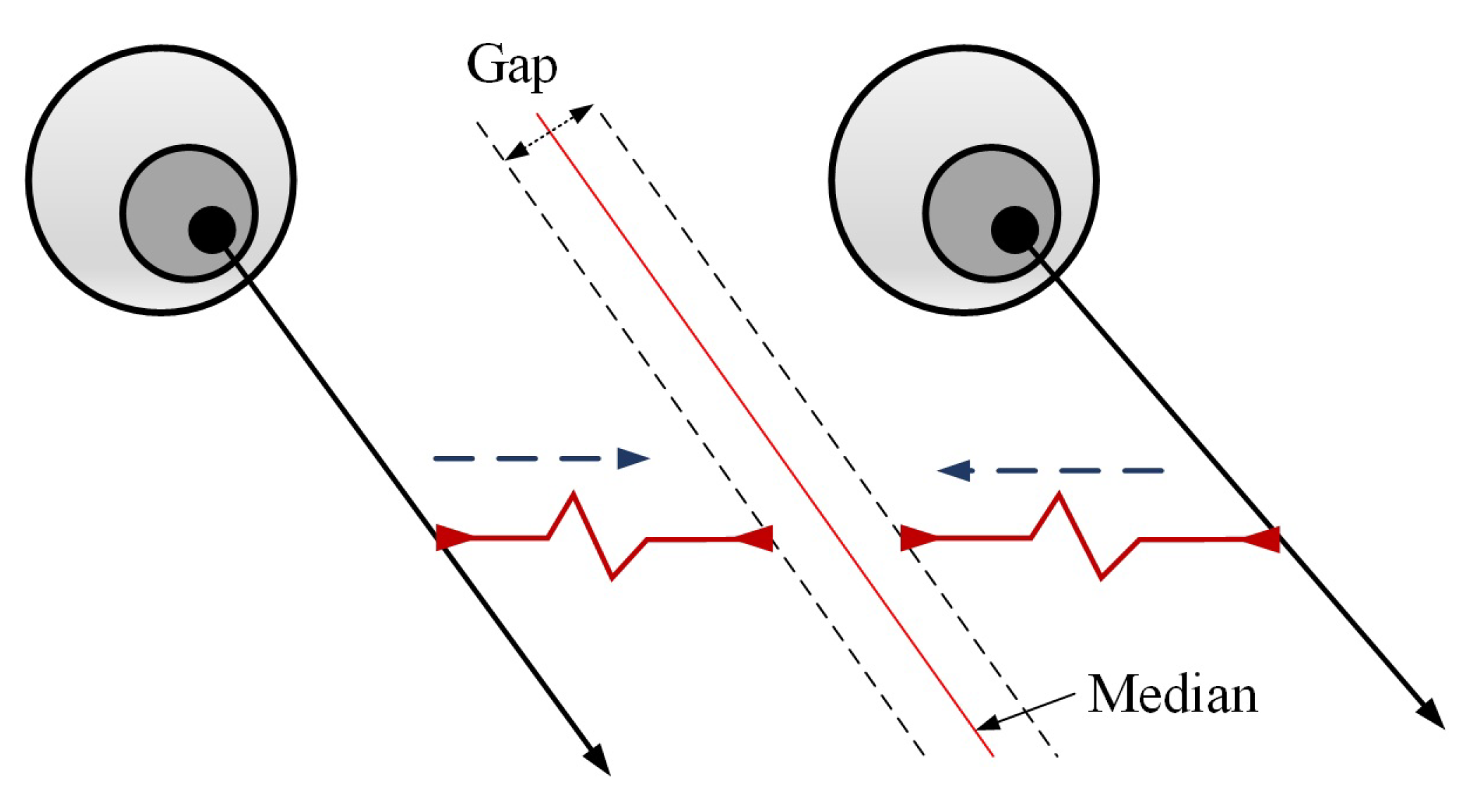
3.3. Eye Consistency Principle
3.4. Blinking and Yawning Detection Using Aspect Ratios
4. Experiments
4.1. Datasets
4.2. Experimental Protocol
- Two fully connected layers were used to estimate the features that were extracted from the backbone feature extractor and the number of hidden layers was 512;
- Only and were used to train the model without feature decoupling. One baseline principle was used for GE, which was similar to the first baseline principle for HPE, but both the left and right eyes were used as the input.
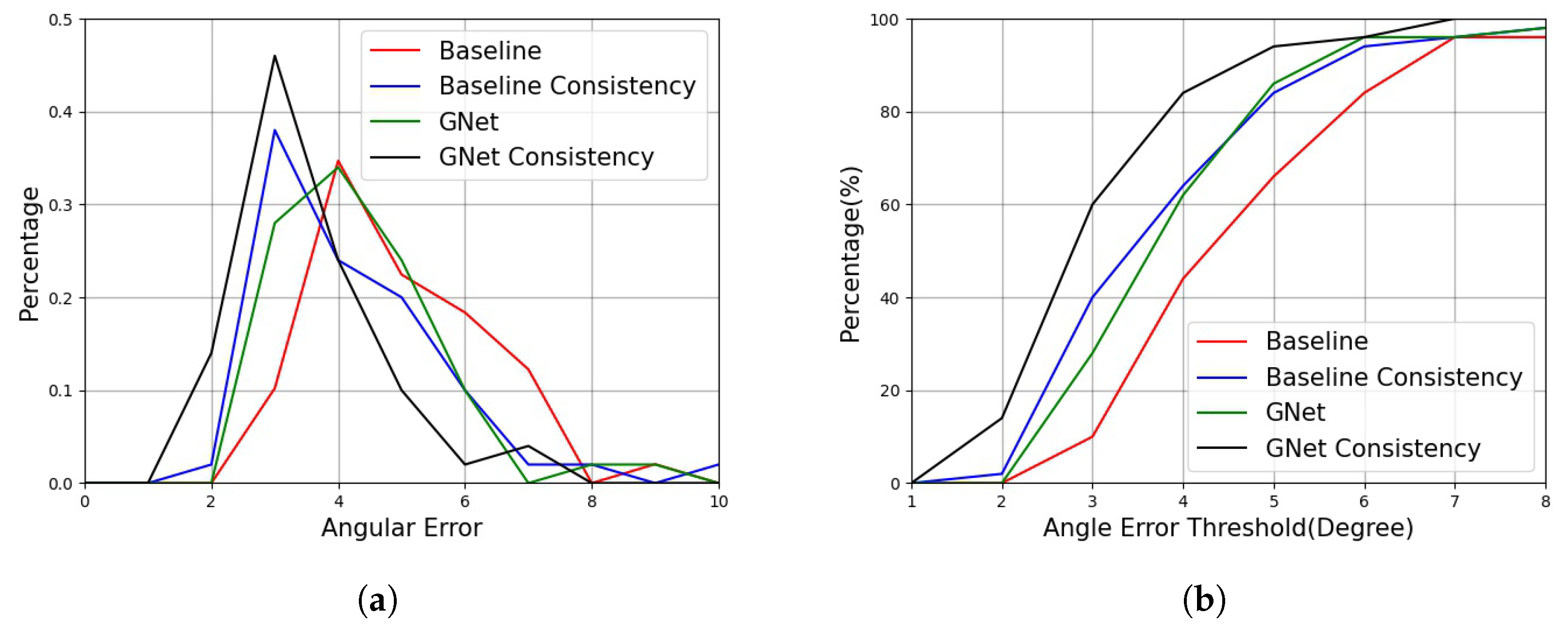
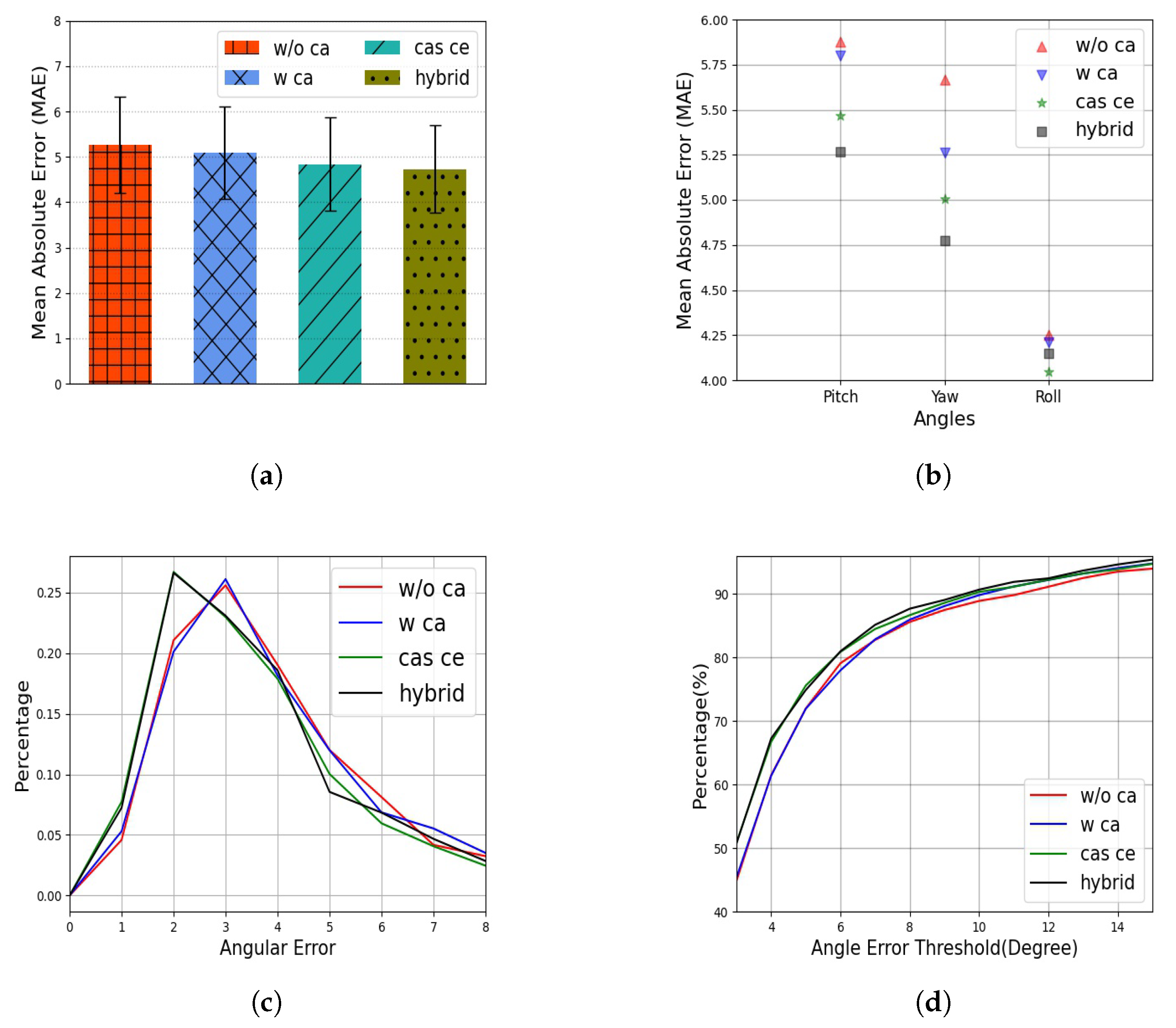
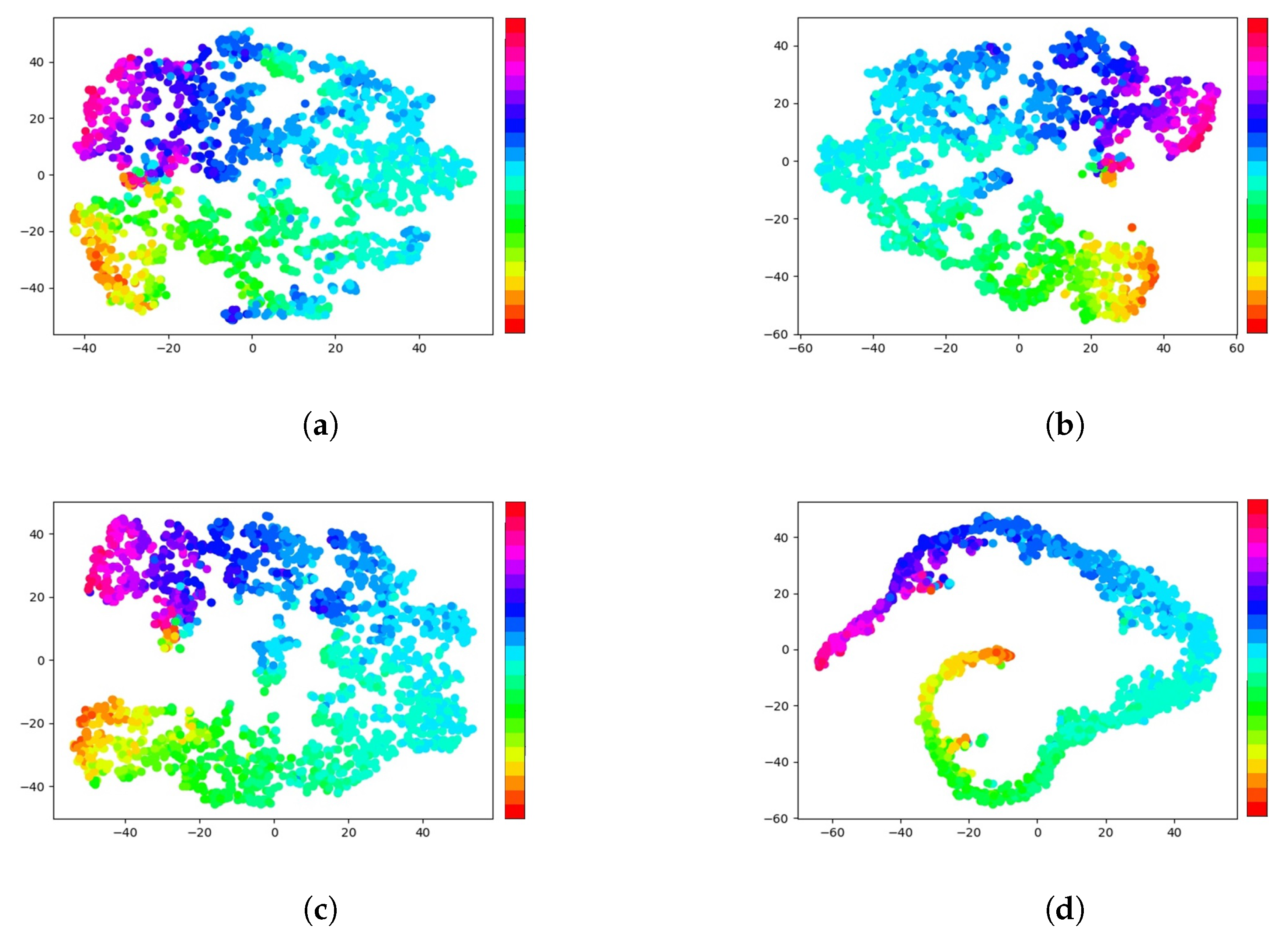
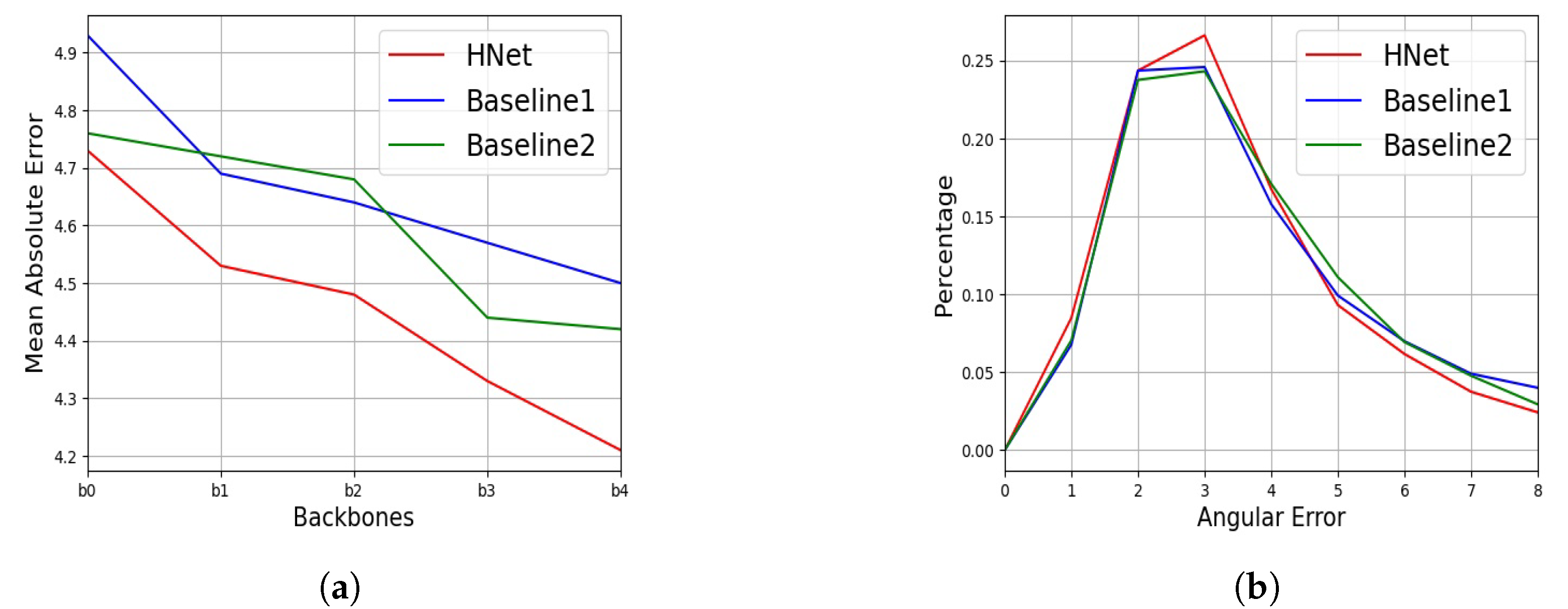
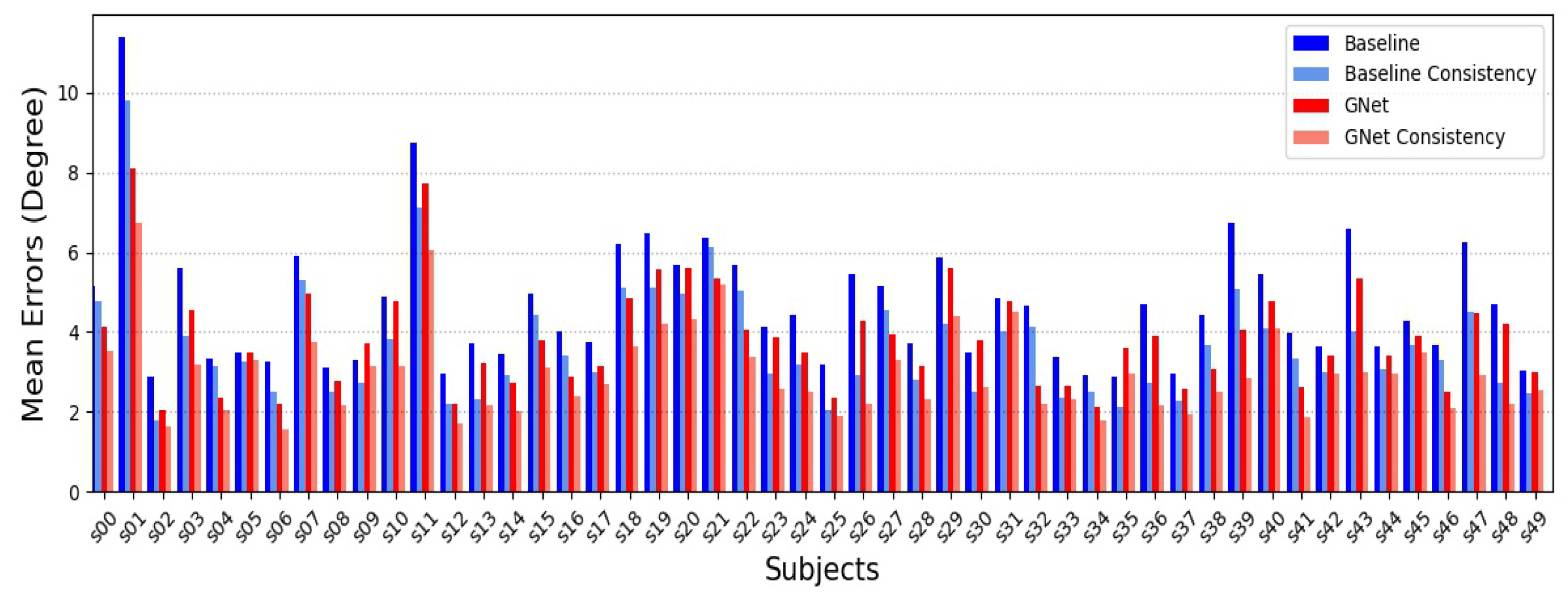
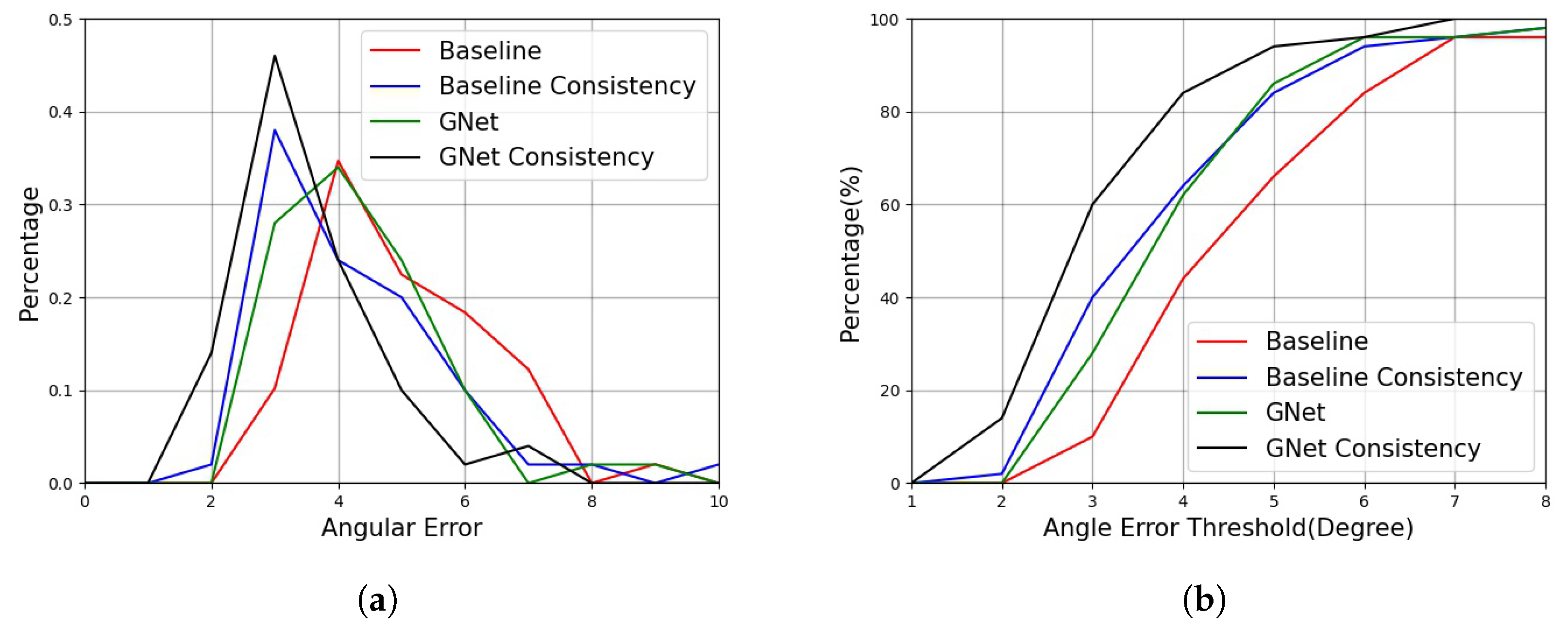
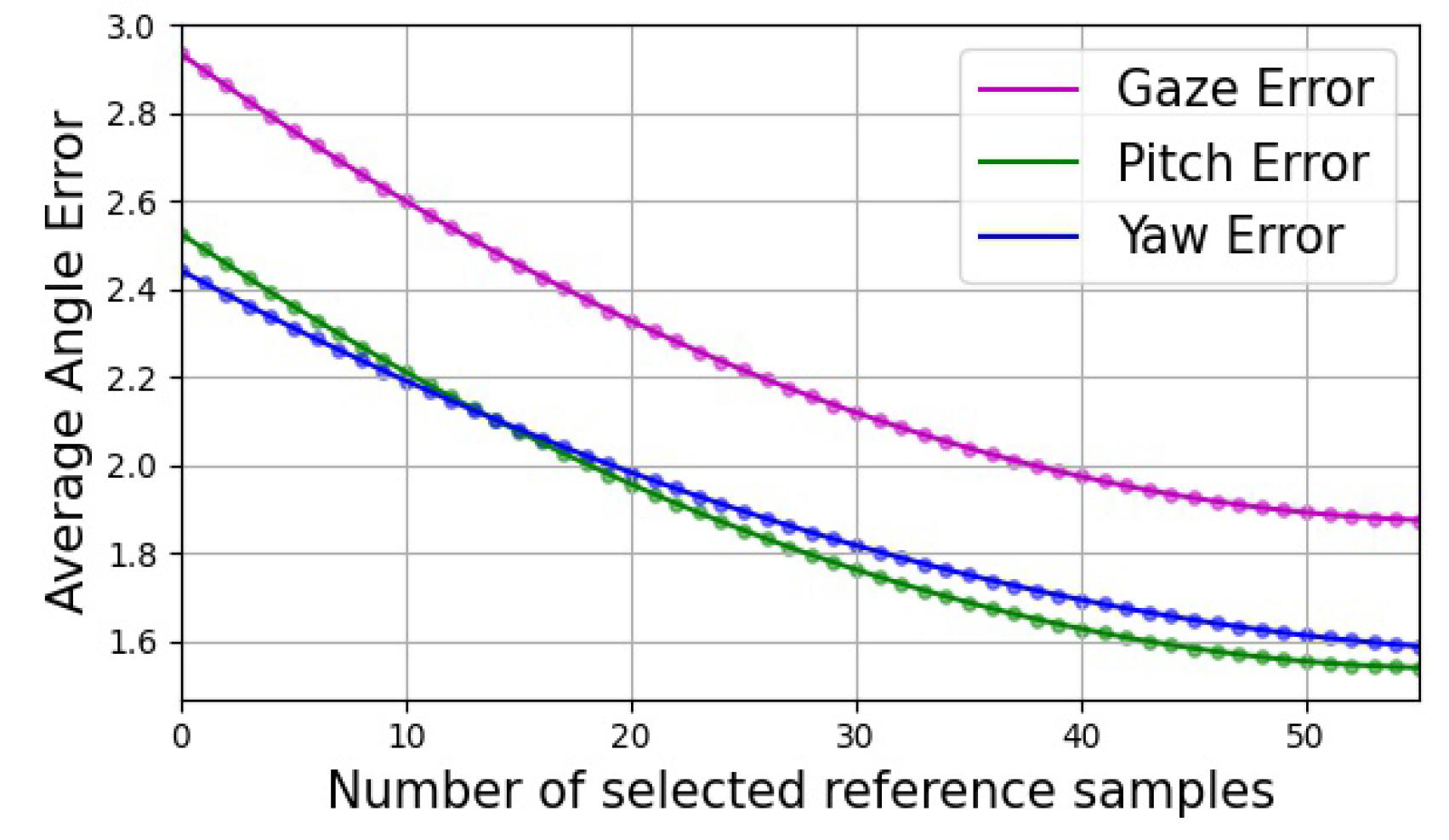
4.3. Experimental Results
4.4. Comparison to State-of-the-Art Methods
4.4.1. Head Pose Estimation
4.4.2. Gaze Estimation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, D.; Wang, X.; Li, L.; Lv, C.; Na, X.; Xing, Y.; Li, X.; Li, Y.; Chen, Y.; Wang, F.Y. Future Directions of Intelligent Vehicles: Potentials, Possibilities, and Perspectives. IEEE Trans. Intell. Veh. 2022, 7, 7–10. [Google Scholar] [CrossRef]
- Li, P.; Nguyen, A.T.; Du, H.; Wang, Y.; Zhang, H. Polytopic LPV approaches for intelligent automotive systems: State of the art and future challenges. Mech. Syst. Signal Process. 2021, 161, 107931. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Z.; Huang, W.; Lv, C. Prioritized Experience-Based Reinforcement Learning With Human Guidance for Autonomous Driving. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Huang, H.; Zhang, J.; Hang, P.; Hu, Z.; Lv, C. Human-Machine Cooperative Trajectory Planning and Tracking for Safe Automated Driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12050–12063. [Google Scholar] [CrossRef]
- Hu, Z.; Lou, S.; Xing, Y.; Wang, X.; Cao, D.; Lv, C. Review and Perspectives on Driver Digital Twin and Its Enabling Technologies for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2022. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Sentouh, C.; Popieul, J.C. Driver-Automation Cooperative Approach for Shared Steering Control Under Multiple System Constraints: Design and Experiments. IEEE Trans. Ind. Electron. 2017, 64, 3819–3830. [Google Scholar] [CrossRef]
- Li, W.; Yao, N.; Shi, Y.; Nie, W.; Zhang, Y.; Li, X.; Liang, J.; Chen, F.; Gao, Z. Personality openness predicts driver trust in automated driving. Automot. Innov. 2020, 3, 3–13. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Xing, Y.; Huang, C.; Hu, Z. Human-Like Decision Making for Autonomous Driving: A Noncooperative Game Theoretic Approach. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2076–2087. [Google Scholar] [CrossRef]
- Clark, J.R.; Stanton, N.A.; Revell, K. Automated vehicle handover interface design: Focus groups with learner, intermediate and advanced drivers. Automot. Innov. 2020, 3, 14–29. [Google Scholar] [CrossRef]
- Sentouh, C.; Nguyen, A.T.; Benloucif, M.A.; Popieul, J.C. Driver-automation cooperation oriented approach for shared control of lane keeping assist systems. IEEE Trans. Control. Syst. Technol. 2018, 27, 1962–1978. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Z.; Hu, Z.; Lv, C. Toward human-in-the-loop AI: Enhancing deep reinforcement learning via real-time human guidance for autonomous driving. Engineering 2022. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Y.; Li, Q.; Lv, C. Human–Machine Telecollaboration Accelerates the Safe Deployment of Large-Scale Autonomous Robots During the COVID-19 Pandemic. Front. Robot. AI 2022, 104. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Hang, P.; Hu, Z.; Lv, C. Collision-Probability-Aware Human-Machine Cooperative Planning for Safe Automated Driving. IEEE Trans. Veh. Technol. 2021, 70, 9752–9763. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Rath, J.J.; Lv, C.; Guerra, T.M.; Lauber, J. Human-machine shared driving control for semi-autonomous vehicles using level of cooperativeness. Sensors 2021, 21, 4647. [Google Scholar] [CrossRef] [PubMed]
- Terken, J.; Pfleging, B. Toward shared control between automated vehicles and users. Automot. Innov. 2020, 3, 53–61. [Google Scholar] [CrossRef]
- Hu, Z.; Lv, C.; Hang, P.; Huang, C.; Xing, Y. Data-Driven Estimation of Driver Attention Using Calibration-Free Eye Gaze and Scene Features. IEEE Trans. Ind. Electron. 2022, 69, 1800–1808. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Huang, C.; Cai, J.; Hu, Z.; Xing, Y. An Integrated Framework of Decision Making and Motion Planning for Autonomous Vehicles Considering Social Behaviors. IEEE Trans. Veh. Technol. 2020, 69, 14458–14469. [Google Scholar] [CrossRef]
- Xing, Y.; Golodetz, S.; Everitt, A.; Markham, A.; Trigoni, N. Multiscale Human Activity Recognition and Anticipation Network. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Allison, C.K.; Stanton, N.A. Constraining design: Applying the insights of cognitive work analysis to the design of novel in-car interfaces to support eco-driving. Automot. Innov. 2020, 3, 30–41. [Google Scholar] [CrossRef]
- Hu, Z.; Xing, Y.; Gu, W.; Cao, D.; Lv, C. Driver Anomaly Quantification for Intelligent Vehicles: A Contrastive Learning Approach with Representation Clustering. IEEE Trans. Intell. Veh. 2022. [Google Scholar] [CrossRef]
- Quante, L.; Zhang, M.; Preuk, K.; Schießl, C. Human Performance in Critical Scenarios as a Benchmark for Highly Automated Vehicles. Automot. Innov. 2021, 4, 274–283. [Google Scholar] [CrossRef]
- Albiero, V.; Chen, X.; Yin, X.; Pang, G.; Hassner, T. img2pose: Face alignment and detection via 6dof, face pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 7617–7627. [Google Scholar]
- Hu, Z.; Xing, Y.; Lv, C.; Hang, P.; Liu, J. Deep convolutional neural network-based Bernoulli heatmap for head pose estimation. Neurocomputing 2021, 436, 198–209. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, Y.; Xing, Y.; Zhao, Y.; Cao, D.; Lv, C. Toward Human-Centered Automated Driving: A Novel Spatiotemporal Vision Transformer-Enabled Head Tracker. IEEE Veh. Technol. Mag. 2022. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Duan, J.; Hu, C.; Zhan, X.; Zhou, H.; Liao, G.; Shi, T. MS-SSPCANet: A powerful deep learning framework for tool wear prediction. Robot. Comput.-Integr. Manuf. 2022, 78, 102391. [Google Scholar] [CrossRef]
- Valle, R.; Buenaposada, J.M.; Baumela, L. Multi-task head pose estimation in-the-wild. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2874–2881. [Google Scholar] [CrossRef]
- Ruiz, N.; Chong, E.; Rehg, J.M. Fine-grained head pose estimation without keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2074–2083. [Google Scholar]
- Zhou, Y.; Gregson, J. WHENet: Real-time Fine-Grained Estimation for Wide Range Head Pose. arXiv 2020, arXiv:2005.10353. [Google Scholar]
- Yang, T.Y.; Chen, Y.T.; Lin, Y.Y.; Chuang, Y.Y. Fsa-net: Learning fine-grained structure aggregation for head pose estimation from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 1087–1096. [Google Scholar]
- Zhang, H.; Wang, M.; Liu, Y.; Yuan, Y. FDN: Feature decoupling network for head pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12789–12796. [Google Scholar]
- Guo, T.; Zhang, H.; Yoo, B.; Liu, Y.; Kwak, Y.; Han, J.J. Order Regularization on Ordinal Loss for Head Pose, Age and Gaze Estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 1496–1504. [Google Scholar]
- Hsu, H.W.; Wu, T.Y.; Wan, S.; Wong, W.H.; Lee, C.Y. Quatnet: Quaternion-based head pose estimation with multiregression loss. IEEE Trans. Multimed. 2018, 21, 1035–1046. [Google Scholar] [CrossRef]
- Cao, Z.; Chu, Z.; Liu, D.; Chen, Y. A vector-based representation to enhance head pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 1188–1197. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 162–175. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cheng, Y.; Zhang, X.; Lu, F.; Sato, Y. Gaze estimation by exploring two-eye asymmetry. IEEE Trans. Image Process. 2020, 29, 5259–5272. [Google Scholar] [CrossRef]
- Lindén, E.; Sjostrand, J.; Proutiere, A. Learning to personalize in appearance-based gaze tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Liu, G.; Yu, Y.; Mora, K.A.F.; Odobez, J.M. A differential approach for gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1092–1099. [Google Scholar] [CrossRef]
- Dubey, N.; Ghosh, S.; Dhall, A. Unsupervised learning of eye gaze representation from the web. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Cech, J.; Soukupova, T. Real-time eye blink detection using facial landmarks. In Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Fanelli, G.; Gall, J.; Van Gool, L. Real time head pose estimation with random regression forests. In Proceedings of the CVPR 2011, Washington, DC, USA, 20–25 June 2011; pp. 617–624. [Google Scholar]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Learning-by-synthesis for appearance-based 3d gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1821–1828. [Google Scholar]
- Zhang, Y.; Fu, K.; Wang, J.; Cheng, P. Learning from discrete Gaussian label distribution and spatial channel-aware residual attention for head pose estimation. Neurocomputing 2020, 407, 259–269. [Google Scholar] [CrossRef]
- Biswas, P. Appearance-Based Gaze Estimation Using Attention and Difference Mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 3143–3152. [Google Scholar]
- Yu, Y.; Liu, G.; Odobez, J.M. Deep multitask gaze estimation with a constrained landmark-gaze model. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, Y.; Chen, B.; Qu, D. LNSMM: Eye Gaze Estimation With Local Network Share Multiview Multitask. arXiv 2021, arXiv:2101.07116. [Google Scholar]
- Chen, Z.; Shi, B.E. Geddnet: A network for gaze estimation with dilation and decomposition. arXiv 2020, arXiv:2001.09284. [Google Scholar]
- Cheng, Y.; Bao, Y.; Lu, F. Puregaze: Purifying gaze feature for generalizable gaze estimation. arXiv 2021, arXiv:2103.13173. [Google Scholar] [CrossRef]
- Wang, K.; Zhao, R.; Su, H.; Ji, Q. Generalizing eye tracking with bayesian adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 11907–11916. [Google Scholar]
- Gu, S.; Wang, L.; He, L.; He, X.; Wang, J. Gaze estimation via a differential eyes’ appearances network with a reference grid. Engineering 2021, 7, 777–786. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AFLW2000 | BIWI | ||||||
|---|---|---|---|---|---|---|---|---|
| Pitch | Yaw | Roll | Mean | Pitch | Yaw | Roll | Mean | |
| KEPLER [29] | - | - | - | - | 17.2 | 8.08 | 16.1 | 13.8 |
| Dlib(68) [30] | 13.6 | 23.1 | 10.5 | 15.8 | 13.8 | 16.8 | 6.19 | 12.2 |
| FAN(12) [29] | 7.48 | 8.53 | 7.63 | 7.88 | - | - | - | - |
| 3DDFA [43] | 8.53 | 5.40 | 8.25 | 7.39 | 12.3 | 36.2 | 8.78 | 19.1 |
| HPE-40 [46] | 6.18 | 4.87 | 4.80 | 5.28 | 5.18 | 4.57 | 3.12 | 4.29 |
| HopeNet [28] | 6.55 | 6.47 | 5.43 | 6.15 | 6.60 | 4.81 | 3.26 | 4.89 |
| Shao [29] | 6.37 | 5.07 | 4.99 | 5.48 | 7.25 | 4.59 | 6.15 | 6.00 |
| SSR-Net [30] | 7.09 | 5.14 | 5.89 | 6.01 | 6.31 | 4.49 | 3.61 | 4.65 |
| FSA-Net [30] | 6.08 | 4.50 | 4.64 | 5.07 | 4.96 | 4.27 | 2.76 | 4.00 |
| QuatNet [33] | 5.61 | 3.97 | 3.92 | 4.50 | 5.49 | 4.01 | 2.93 | 4.14 |
| FDN [31] | 5.61 | 3.97 | 3.88 | 4.42 | 4.70 | 4.52 | 2.56 | 3.93 |
| WHENet-V [29] | 5.75 | 4.44 | 4.31 | 4.83 | 4.10 | 3.60 | 2.73 | 3.48 |
| TriNet [34] | 5.76 | 4.19 | 4.04 | 4.66 | 4.75 | 3.04 | 4.11 | 3.97 |
| Ordinal [32] | - | - | - | - | 4.36 | 3.68 | 3.02 | 3.69 |
| DGDL [46] | 5.35 | 3.77 | 4.06 | 4.39 | 4.46 | 3.63 | 3.08 | 3.72 |
| MNN [27] † | 4.69 | 3.34 | 3.48 | 3.83 | 4.61 | 3.98 | 2.39 | 3.66 |
| img2pose [22] ‡ | 5.03 | 3.42 | 3.27 | 3.91 | 3.54 | 4.56 | 3.24 | 3.78 |
| HNet-b0 | 5.24 | 4.47 | 4.05 | 4.58 | 4.74 | 3.56 | 3.22 | 3.84 |
| HNet-b1 | 5.17 | 4.41 | 3.68 | 4.42 | 4.43 | 3.20 | 3.20 | 3.61 |
| HNet-b2 | 5.03 | 4.28 | 3.71 | 4.34 | 4.79 | 3.12 | 2.95 | 3.62 |
| HNet-b3 | 5.04 | 3.98 | 3.55 | 4.19 | 3.86 | 3.30 | 3.12 | 3.42 |
| HNet-b4 | 4.70 | 4.07 | 3.20 | 3.99 | 4.35 | 3.46 | 3.30 | 3.70 |
| Method | Input | MPIIGaze | UT-Multiview | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Face | Head | Center | Right | Avg | Center | Right | Avg | ||
| nRef | iTracker [47] | - | 5.6 | 5.6 | 5.6 | - | - | - | |
| GazeNet [36] | - | ✓ | 5.5 | 5.5 | 5.5 | 4.4 | 4.4 | 4.4 | |
| Dilated-Net [47] | ✓ | - | 5.2 | 5.2 | 5.2 | - | - | - | |
| CrtCLGM [48] | ✓ | - | - | - | - | 5.7 | 5.7 | 5.7 | |
| MeNet [47] | ✓ | - | 4.9 | 4.9 | 4.9 | 5.5 | 5.5 | 5.5 | |
| RT-GENE [47] | ✓ | - | 4.8 | 4.8 | 4.8 | 5.1 | 5.1 | 5.1 | |
| LNSMM [49] | - | - | 4.8 | 4.8 | 4.8 | 4.8 | 4.8 | 4.8 | |
| U-Train [40] | - | - | - | - | - | 5.5 | 5.5 | 5.5 | |
| GEDDne [50] | ✓ | - | 4.5 | 4.5 | 4.5 | - | - | - | |
| PureGaze [51] | ✓ | - | 4.5 | 4.5 | 4.5 | - | - | - | |
| BAL-Net [52] | - | - | 4.3 | 4.3 | 4.3 | 5.4 | 5.4 | 5.4 | |
| FAR-Net [37] | ✓ | - | 4.3 | 4.3 | 4.3 | - | - | - | |
| I2D-Net [47] | ✓ | - | 4.3 | 4.3 | 4.3 | - | - | - | |
| AGENet [47] | ✓ | - | 4.1 | 4.1 | 4.1 | - | - | - | |
| CA-Net [51] | ✓ | ✓ | 4.1 | 4.1 | 4.1 | - | - | - | |
| GNet-b0 | - | - | 3.83 | 4.01 | 3.92 | 2.97 | 2.98 | 2.98 | |
| Ref | DEANet [53] | - | ✓ | 4.38 | 4.38 | 4.38 | 3.56 | 3.56 | 3.56 |
| Diff-NN [39] | - | - | 4.69 | 4.62 | 4.64 | 4.17 | 4.08 | 4.13 | |
| Diff-VGG [39] | - | - | 3.88 | 3.73 | 3.80 | 3.88 | 3.68 | 3.78 | |
| GNet-b0(5) | - | - | 3.13 | 3.28 | 3.21 | 2.74 | 2.75 | 2.75 | |
| GNet-b0(10) | - | - | 3.19 | 3.17 | 3.18 | 2.60 | 2.59 | 2.60 | |
| GNet-b0(20) | - | - | 2.98 | 3.04 | 3.01 | 2.33 | 2.33 | 2.33 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Zhang, Y.; Xing, Y.; Li, Q.; Lv, C. An Integrated Framework for Multi-State Driver Monitoring Using Heterogeneous Loss and Attention-Based Feature Decoupling. Sensors 2022, 22, 7415. https://doi.org/10.3390/s22197415
Hu Z, Zhang Y, Xing Y, Li Q, Lv C. An Integrated Framework for Multi-State Driver Monitoring Using Heterogeneous Loss and Attention-Based Feature Decoupling. Sensors. 2022; 22(19):7415. https://doi.org/10.3390/s22197415
Chicago/Turabian StyleHu, Zhongxu, Yiran Zhang, Yang Xing, Qinghua Li, and Chen Lv. 2022. "An Integrated Framework for Multi-State Driver Monitoring Using Heterogeneous Loss and Attention-Based Feature Decoupling" Sensors 22, no. 19: 7415. https://doi.org/10.3390/s22197415
APA StyleHu, Z., Zhang, Y., Xing, Y., Li, Q., & Lv, C. (2022). An Integrated Framework for Multi-State Driver Monitoring Using Heterogeneous Loss and Attention-Based Feature Decoupling. Sensors, 22(19), 7415. https://doi.org/10.3390/s22197415