
Cross-World Covert Channel on ARM Trustzone through PMU



Abstract
1. Introduction
- This is the first covert channel built and trained through PMU readings from the user space. The PMU-based exfiltration encoding programs can model PMU footprint created through secure world execution in the normal world execution.
- This study presents three attack models with different levels of synchronization. The covert channel can achieve as high as 99.29% accuracy in inferring exfiltrated tokens from the secure world to the normal world.
- This study evaluates the covert channel bandwidth of the previous PMU cache events-based inference versus our covert channel-based on finer-grained microarchitecture level PMU events. Without the most time-consuming cache encoding and decoding process, our covert channel achieves 100 times higher throughput. Previous research explicitly generates L1/L2 cache level events to encode the leaked information into PMU event counters. The cache events takes 100 s of clock cycles. We instead use microarchitecture pipeline level events to encode the leaked information. These events take 10 s of clock cycles leading to a significant advantage in the covert channel bandwidth.
- This study shows that the existing covert channel mitigation techniques focused on cache side-channel attack do not mitigate our PMU-based covert channel. We do not need cache level event capture for our covert channel.
1.1. Background
1.1.1. TrustZone Hardware Architecture: Processors
1.1.2. TrustZone Software Architecture: Secure Subsystem
1.1.3. TrustZone Cryptographic Operations
1.1.4. The Vulnerability of TrustZone
1.2. Related Work
2. Materials and Methods
2.1. Adversary Model
2.2. Experimental Setup
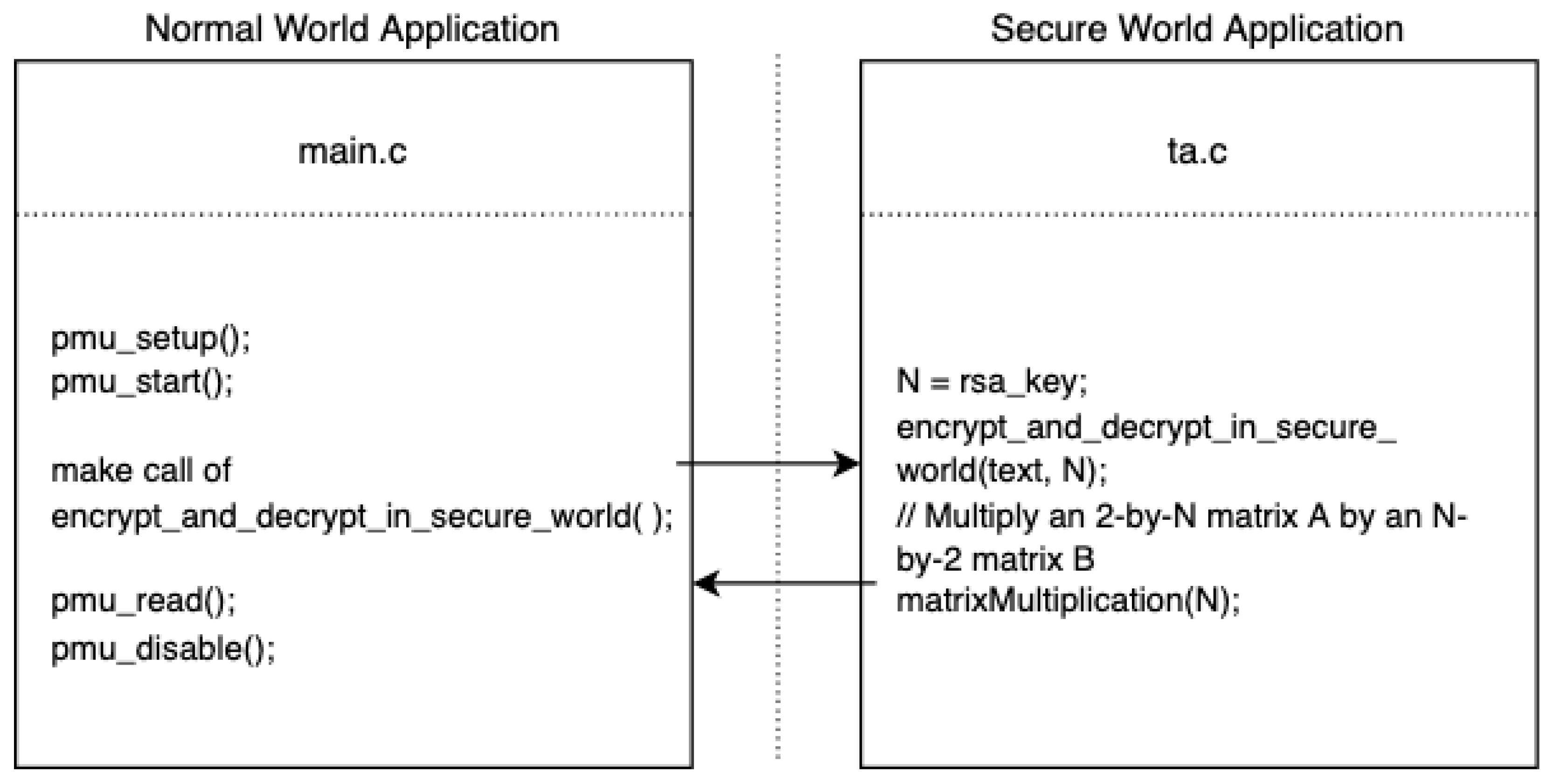
2.2.1. Synchronous Access Attack Model
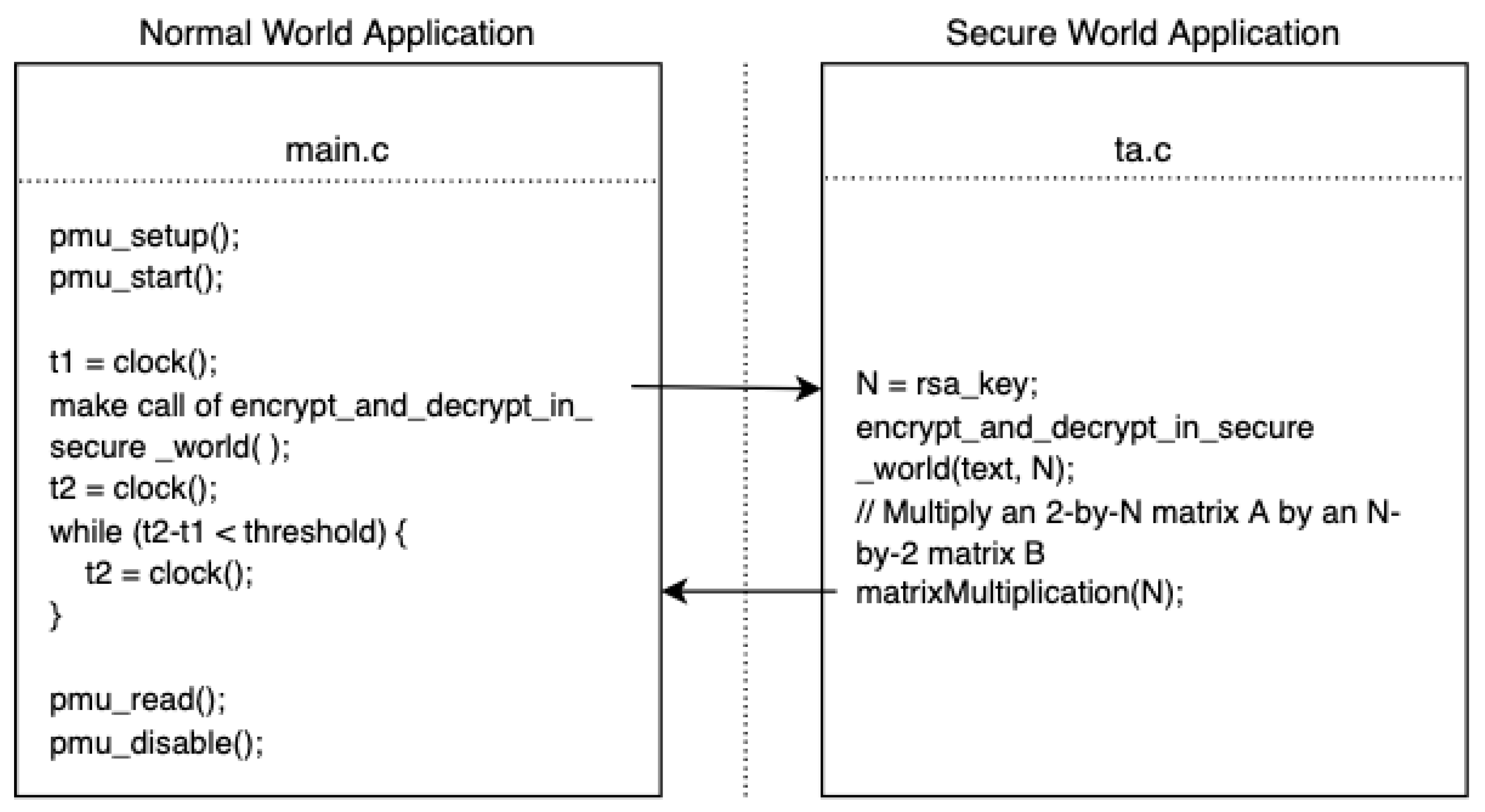
2.2.2. Semi-Asynchronous Access Attack Model
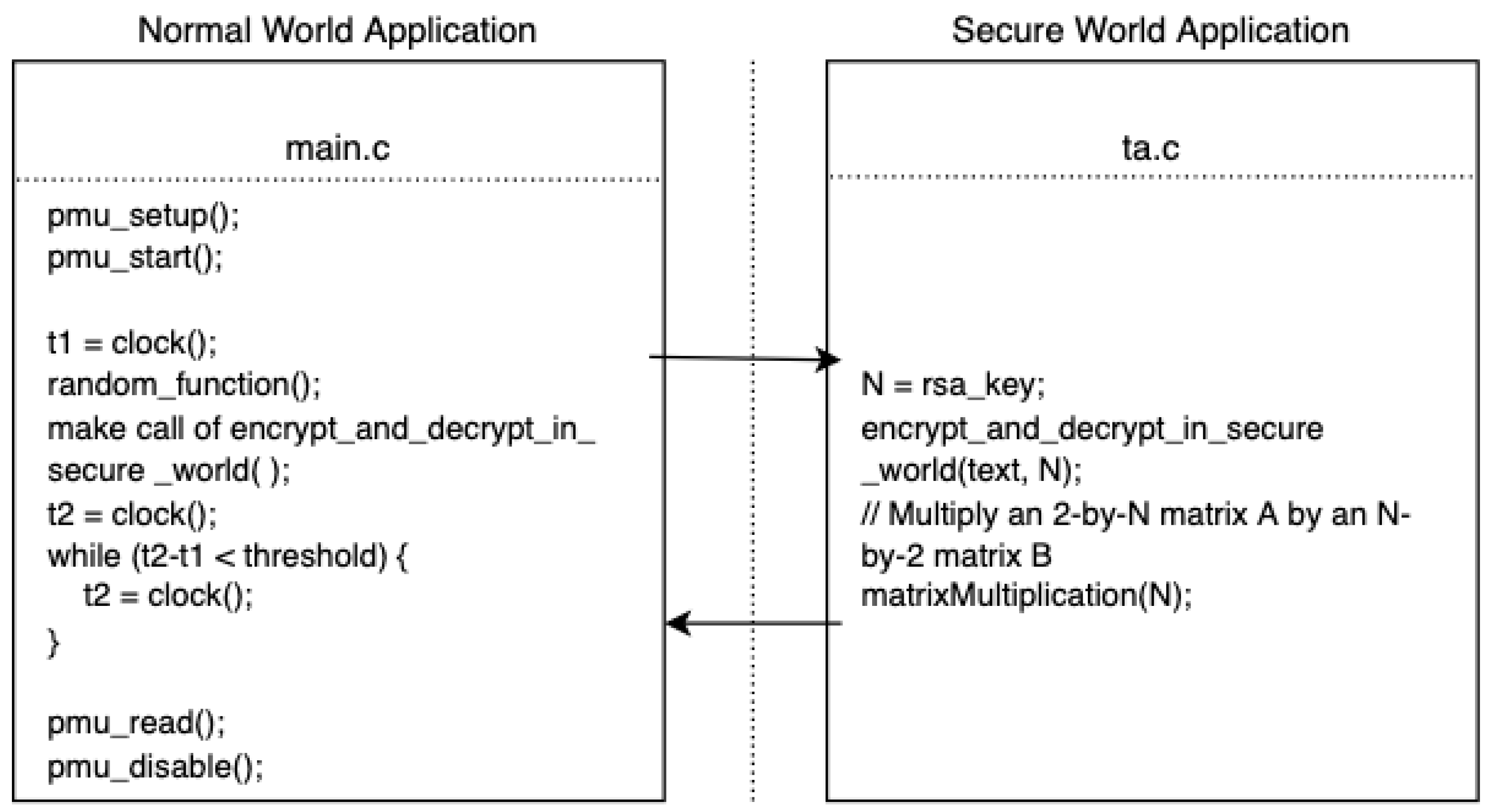
2.2.3. Asynchronous Access Attack Model
3. Results
- PERF_COUNT_SW_CPU_CLOCK,
- PERF_COUNT_HW_CACHE_L1I,
- PERF_COUNT_HW_BRANCH_MISSES,
- PERF_COUNT_HW_CPU_CYCLES,
- PERF_COUNT_HW_BUS_CYCLES,
- PERF_COUNT_HW_CACHE_RESULT_MISS.
4. Discussion
4.1. Machine Learning Models
4.1.1. Linear Regression
4.1.2. Support Vector Machine (SVM)
4.1.3. Principal Component Analysis (PCA)
4.2. Limitations & Mitigation Strategies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Evtyushkin, D.; Ponomarev, D.; Abu-Ghazaleh, N. Understanding and mitigating covert channels through branch predictors. ACM Trans. Archit. Code Optim. (TACO) 2016, 13, 1–23. [Google Scholar] [CrossRef]
- Carrara, B.; Adams, C. Out-of-band covert channels—A survey. ACM Comput. Surv. (CSUR) 2016, 49, 1–36. [Google Scholar] [CrossRef]
- Leignac, P.; Potin, O.; Rigaud, J.B.; Dutertre, J.M.; Pontie, S. Comparison of side-channel leakage on Rich and Trusted Execution Environments. In Proceedings of the Sixth Workshop on Cryptography and Security in Computing Systems, Valencia, Spain, 21 January 2019; pp. 19–22. [Google Scholar]
- Koutroumpouchos, N.; Ntantogian, C.; Xenakis, C. Building trust for smart connected devices: The challenges and pitfalls of TrustZone. Sensors 2021, 21, 520. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Venkataramani, G. Cc-hunter: Uncovering covert timing channels on shared processor hardware. In Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 216–228. [Google Scholar]
- Han, Y.; Kim, J. A novel covert channel attack using memory encryption engine cache. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Evtyushkin, D.; Riley, R.; Abu-Ghazaleh, N.C.; ECE; Ponomarev, D. Branchscope: A new side-channel attack on directional branch predictor. ACM SIGPLAN Notices 2018, 53, 693–707. [Google Scholar] [CrossRef]
- Masti, R.J.; Rai, D.; Ranganathan, A.; Müller, C.; Thiele, L.; Capkun, S. Thermal covert channels on multi-core platforms. In Proceedings of the 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, USA, 12–14 August 2015; pp. 865–880. [Google Scholar]
- Van Bulck, J.; Minkin, M.; Weisse, O.; Genkin, D.; Kasikci, B.; Piessens, F.; Silberstein, M.; Wenisch, T.F.; Yarom, Y.; Strackx, R. Foreshadow: Extracting the Keys to the Intel {SGX} Kingdom with Transient {Out-of-Order} Execution. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 14–17 August 2018; pp. 991–1008. [Google Scholar]
- Szefer, J. Survey of microarchitectural side and covert channels, attacks, and defenses. J. Hardw. Syst. Secur. 2019, 3, 219–234. [Google Scholar] [CrossRef]
- Bukasa, S.K.; Lashermes, R.; Bouder, H.L.; Lanet, J.L.; Legay, A. How TrustZone could be bypassed: Side-channel attacks on a modern system-on-chip. In Proceedings of the IFIP International Conference on Information Security Theory and Practice, Heraklion, Greece, 28–29 September 2017; pp. 93–109. [Google Scholar]
- Shakevsky, A.; Ronen, E.; Wool, A. Trust Dies in Darkness: Shedding Light on Samsung’s TrustZone Keymaster Design. IACR Cryptol. ePrint Arch. 2022, 2022, 208. [Google Scholar]
- Mobile Now Exceeds PC: The Biggest Shift Since the Internet Began. Available online: https://searchenginewatch.com/2014/07/08/mobile-now-exceeds-pc-the-biggest-shift-since-the-internet-began.html (accessed on 24 September 2022).
- Lipp, M.; Gruss, D.; Spreitzer, R.; Maurice, C.; Mangard, S. Armageddon: Cache attacks on mobile devices. In Proceedings of the 25th {USENIX} Security Symposium ({USENIX} Security 16), Austin, TX, USA, 10–12 August 2016; pp. 549–564. [Google Scholar]
- Liu, N.; Yu, M.; Zang, W.; Sandhu, R.S. Cost and Effectiveness of TrustZone Defense and Side-Channel Attack on ARM Platform. J. Wirel. Mob. Networks Ubiquitous Comput. Dependable Appl. 2020, 11, 1–15. [Google Scholar]
- Lapid, B.; Wool, A. Cache-attacks on the ARM TrustZone implementations of AES-256 and AES-256-GCM via GPU-based analysis. In Proceedings of the International Conference on Selected Areas in Cryptography, Calgary, AB, Canada, 15–17 August 2018; pp. 235–256. [Google Scholar]
- Zhang, N.; Sun, K.; Shands, D.; Lou, W.; Hou, Y.T. Truspy: Cache side-channel information leakage from the secure world on arm devices. Cryptol. ePrint Arch. 2016. Available online: https://eprint.iacr.org/2016/980 (accessed on 20 June 2022).
- Kou, Z.; He, W.; Sinha, S.; Zhang, W. Load-Step: A Precise TrustZone Execution Control Framework for Exploring New Side-channel Attacks Like Flush+ Evict. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 979–984. [Google Scholar]
- Ahn, N.Y.; Lee, D.H. Countermeasure against side-channel attack in shared memory of trustzone. arXiv 2017, arXiv:1705.08279. [Google Scholar]
- Zhang, N.; Sun, K.; Shands, D.; Lou, W.; Hou, Y.T. Trusense: Information leakage from trustzone. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1097–1105. [Google Scholar]
- Cho, H.; Zhang, P.; Kim, D.; Park, J.; Lee, C.H.; Zhao, Z.; Doupé, A.; Ahn, G.J. Prime+ count: Novel cross-world covert channels on arm trustzone. In Proceedings of the Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 441–452.
- Wang, H.; Sayadi, H.; Mohsenin, T.; Zhao, L.; Sasan, A.; Rafatirad, S.; Homayoun, H. Mitigating cache-based side-channel attacks through randomization: A comprehensive system and architecture level analysis. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1414–1419. [Google Scholar]
- Cerdeira, D.; Santos, N.; Fonseca, P.; Pinto, S. Sok: Understanding the prevailing security vulnerabilities in trustzone-assisted tee systems. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18-21 May 2020; pp. 1416–1432. [Google Scholar]
- Sadique, U.M.; James, D. A novel approach to prevent cache-based side-channel attack in the cloud. Procedia Technol. 2016, 25, 232–239. [Google Scholar] [CrossRef]
- Braun, B.A.; Jana, S.; Boneh, D. Robust and efficient elimination of cache and timing side channels. arXiv 2015, arXiv:1506.00189. [Google Scholar]
- Saileshwar, G.; Fletcher, C.W.; Qureshi, M. Streamline: A fast, flushless cache covert-channel attack by enabling asynchronous collusion. In Proceedings of the Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Virtual, 19–23 April 2021; pp. 1077–1090.
- Koutroumpouchos, N. A Security Evaluation of TrustZone Based Trusted Execution Environments. Master’s Thesis, University of Piraeus, Piraeus, Greece, 2019. [Google Scholar]
- Winter, J. Trusted computing building blocks for embedded linux-based ARM trustzone platforms. In Proceedings of the Proceedings of the 3rd ACM Workshop on Scalable Trusted Computing, Alexandria, Egypt, 31 October 2008; pp. 21–30.
- Sabt, M.; Achemlal, M.; Bouabdallah, A. Trusted execution environment: What it is, and what it is not. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 1, pp. 57–64. [Google Scholar]
- Jang, J.S.; Kong, S.; Kim, M.; Kim, D.; Kang, B.B. SeCReT: Secure Channel between Rich Execution Environment and Trusted Execution Environment. In Proceedings of the NDSS, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Oleksenko, O.; Trach, B.; Krahn, R.; Silberstein, M.; Fetzer, C. Varys: Protecting {SGX} Enclaves from Practical {Side-Channel} Attacks. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 227–240. [Google Scholar]
- Steffan, A.; Running a language interpreter inside the ARM TrustZone: An exploration of dynamic code execution in trusted execution environments. Department of Informatics. Available online: https://adriansteffan.com/pdf/bthesis.pdf (accessed on 11 October 2021).
- Gao, T.; Olofsson, S.; Lu, S. Minimum-volume-regularized weighted symmetric nonnegative matrix factorization for clustering. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 247–251. [Google Scholar]
- Gao, T.; Chu, C. Did: Distributed incremental block coordinate descent for nonnegative matrix factorization. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range | Linear Regression | SVM | PCA + SVM |
|---|---|---|---|
| 94.30% | 95.14% | 95.14% | |
| 84.96% | 88.07% | 88.07% | |
| 83.91% | 85.53% | 85.53% |
| Bits | Test Acc. | BW Max | BW Min | BW Ave. |
|---|---|---|---|---|
| Synchronous attack model | ||||
| 7 | 98.53% | 8.199 | 4.613 | 6.649 |
| 8 | 99.18% | 9.339 | 4.696 | 7.238 |
| 9 | 99.04% | 9.295 | 3.960 | 7.235 |
| 10 | 99.29% | 11.701 | 3.535 | 6.556 |
| Semi-Synchronous attack model | ||||
| 7 | 94.52% | 8.140 | 5.037 | 6.603 |
| Bits | Range | Test Acc. | BW Max | BW Min | BW Ave. |
|---|---|---|---|---|---|
| 7 | [0, 5] | 95.14% | 8.204 | 4.617 | 6.593 |
| 7 | [0, 10] | 84.96% | 8.186 | 4.592 | 6.494 |
| 7 | [0, 50] | 83.91% | 8.212 | 4.193 | 6.619 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Tyagi, A. Cross-World Covert Channel on ARM Trustzone through PMU. Sensors 2022, 22, 7354. https://doi.org/10.3390/s22197354
Li X, Tyagi A. Cross-World Covert Channel on ARM Trustzone through PMU. Sensors. 2022; 22(19):7354. https://doi.org/10.3390/s22197354
Chicago/Turabian StyleLi, Xinyao, and Akhilesh Tyagi. 2022. "Cross-World Covert Channel on ARM Trustzone through PMU" Sensors 22, no. 19: 7354. https://doi.org/10.3390/s22197354
APA StyleLi, X., & Tyagi, A. (2022). Cross-World Covert Channel on ARM Trustzone through PMU. Sensors, 22(19), 7354. https://doi.org/10.3390/s22197354