
Cooperative Downloading for LEO Satellite Networks: A DRL-Based Approach



Abstract
:1. Introduction
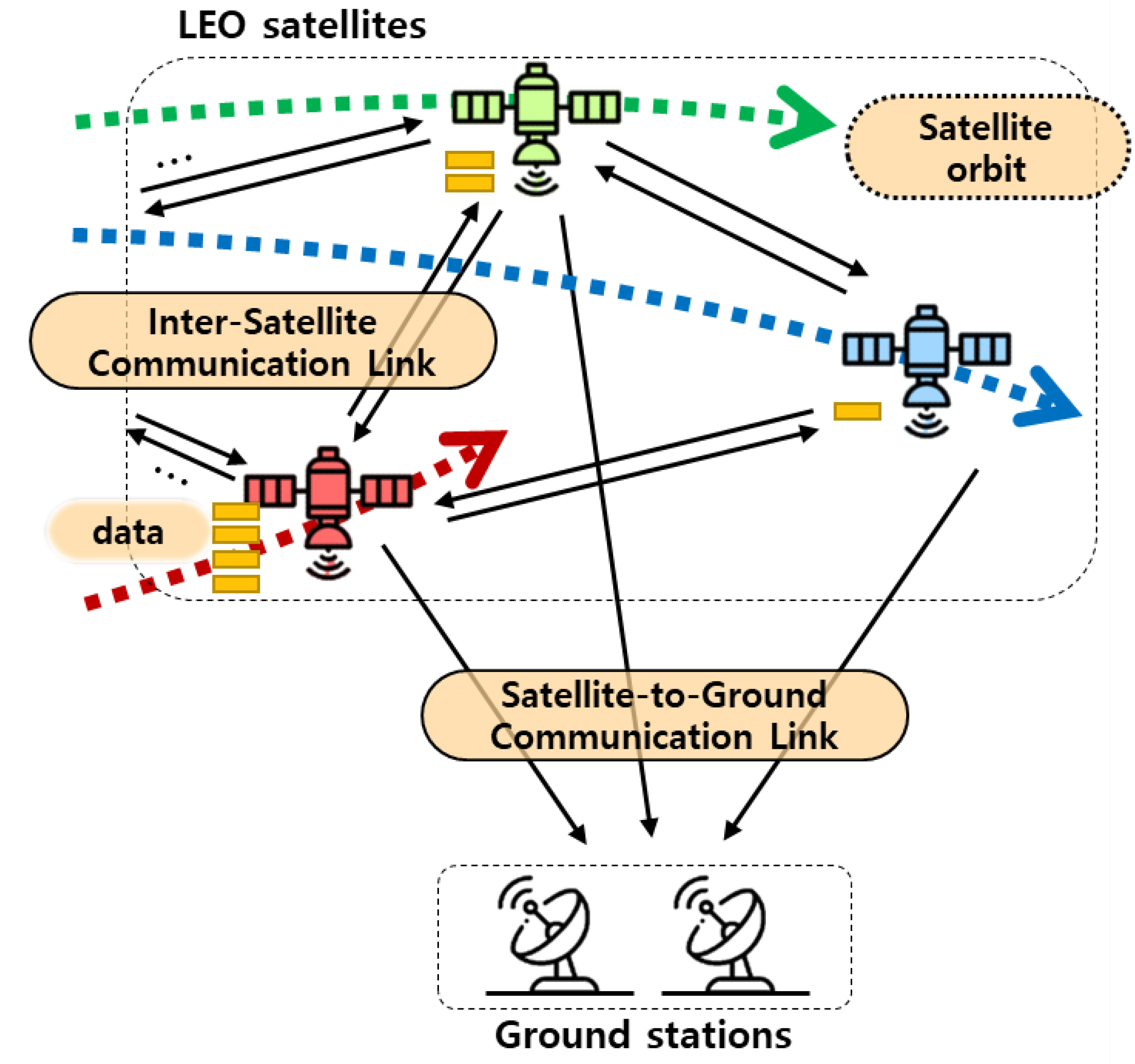
2. System Model
3. Deep-Reinforcement-Learning-Based Cooperative Downloading Scheme
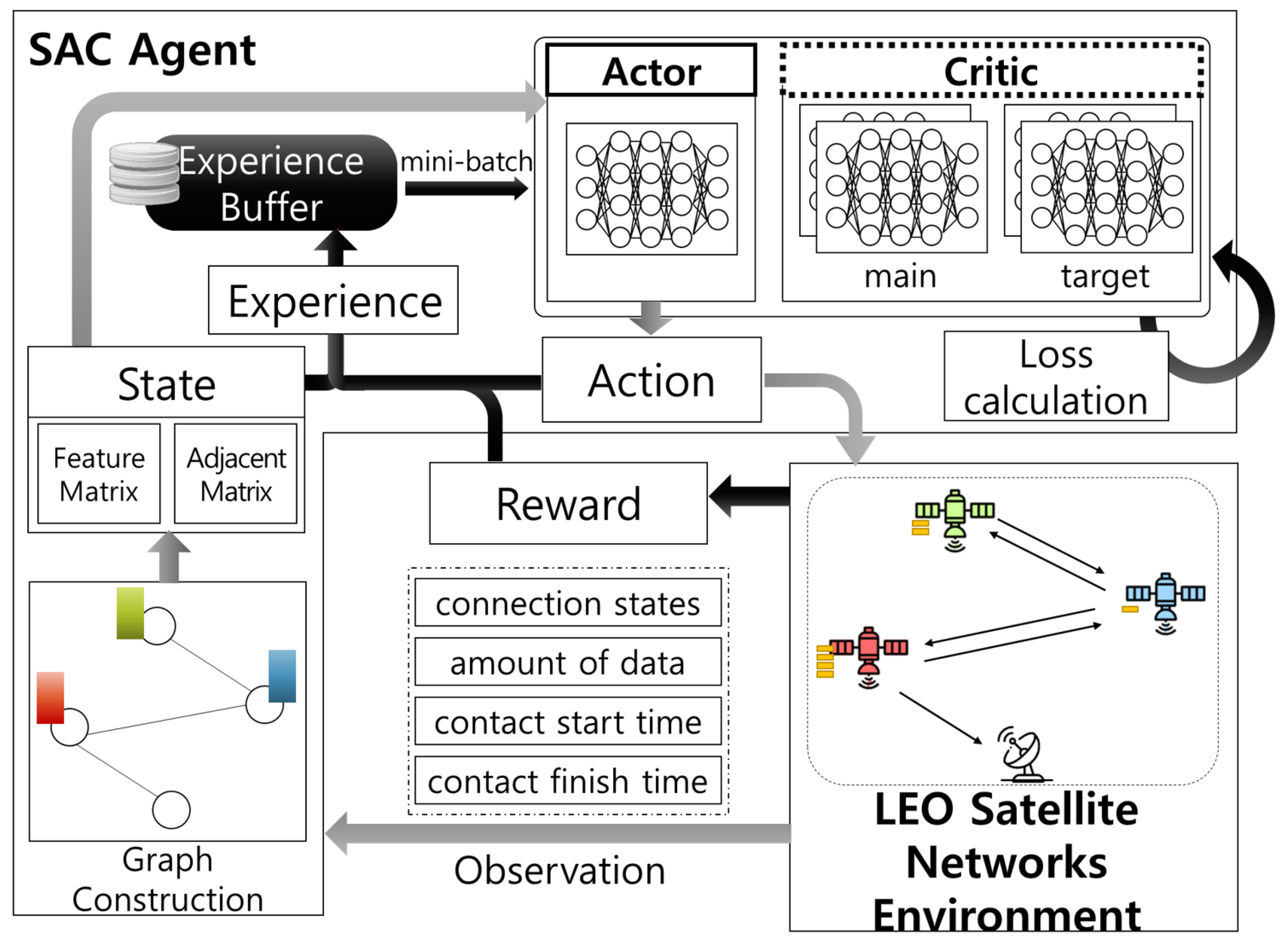
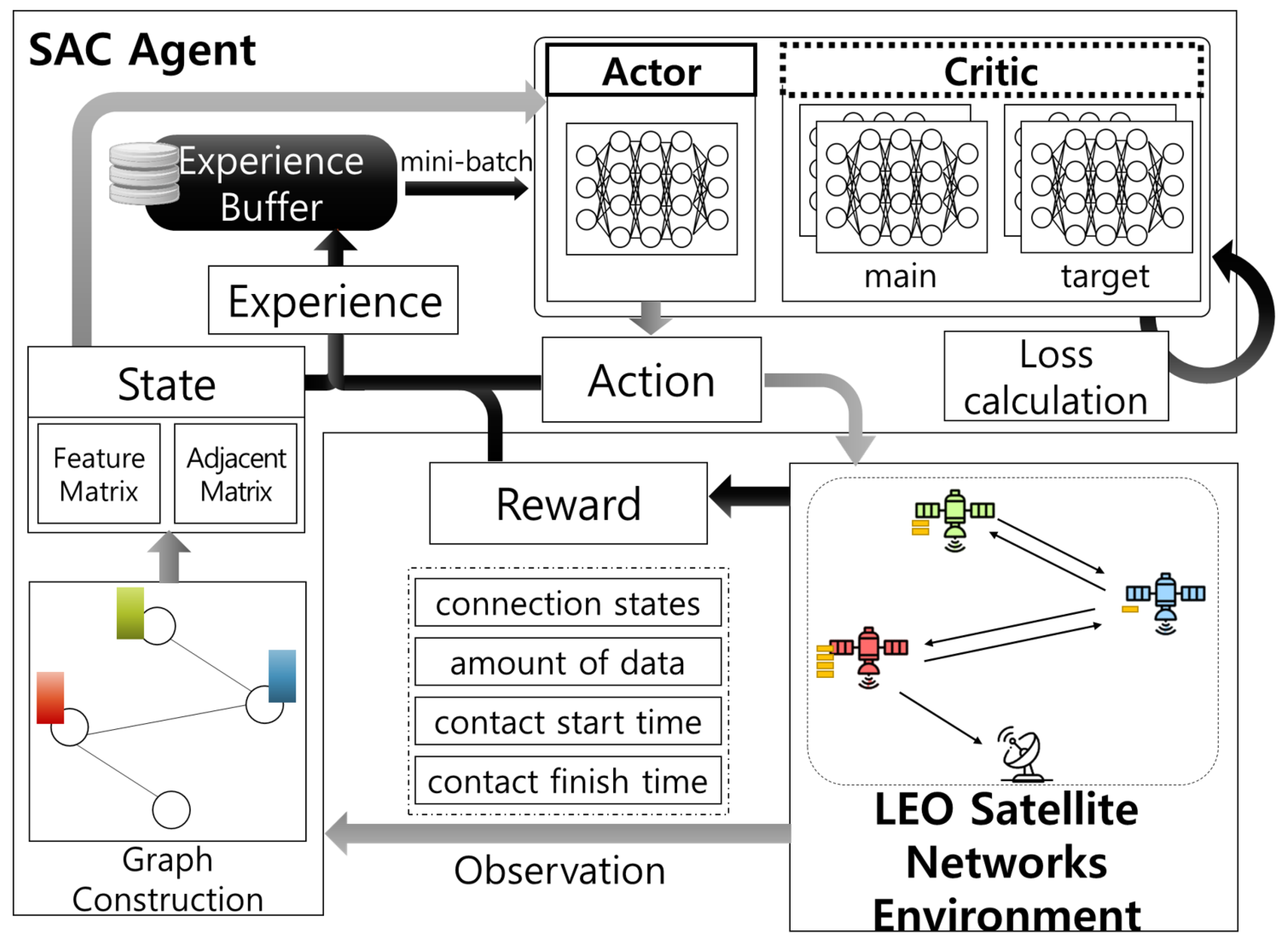
3.1. Overview
3.2. MDP Formulation
3.2.1. State
3.2.2. Action
3.2.3. Reward
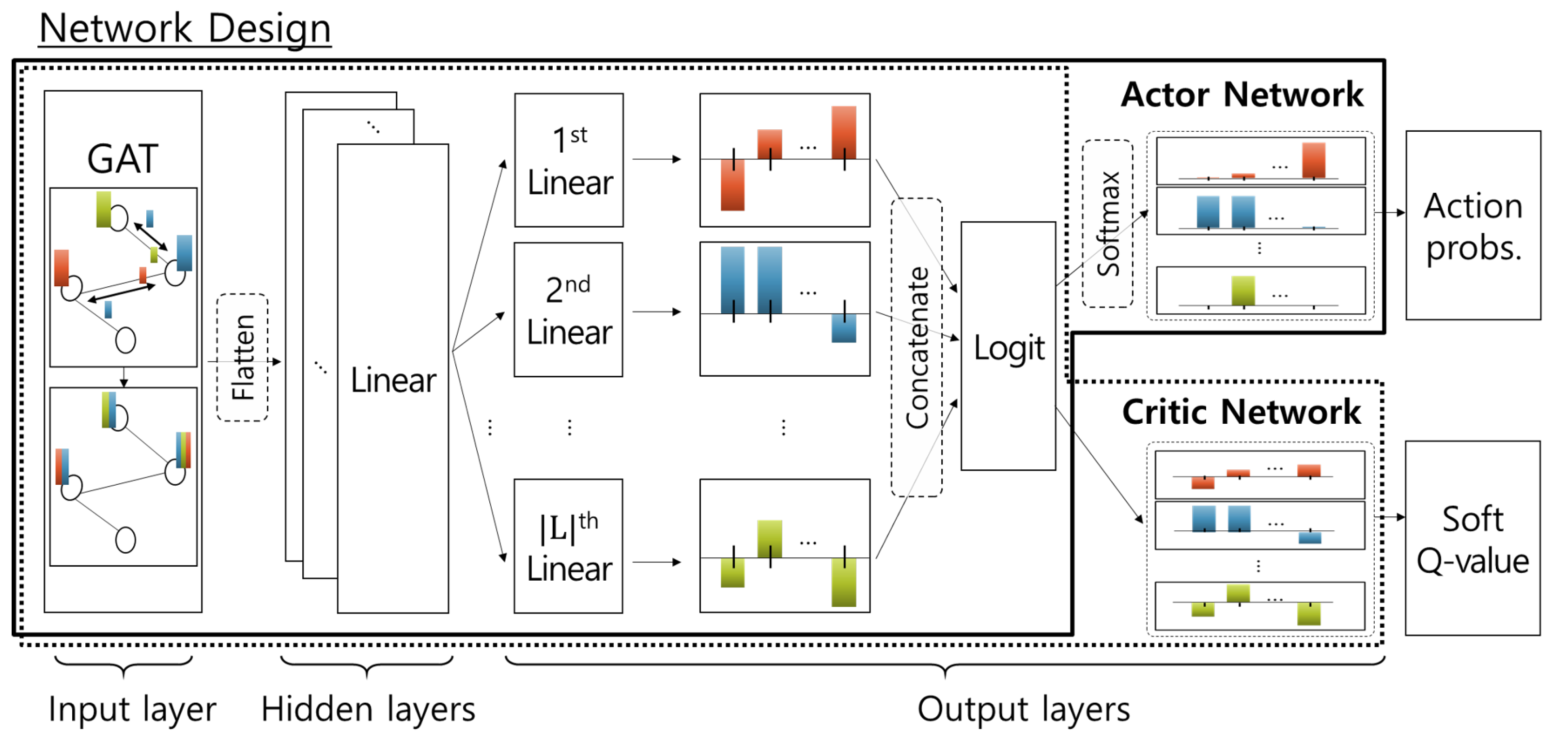
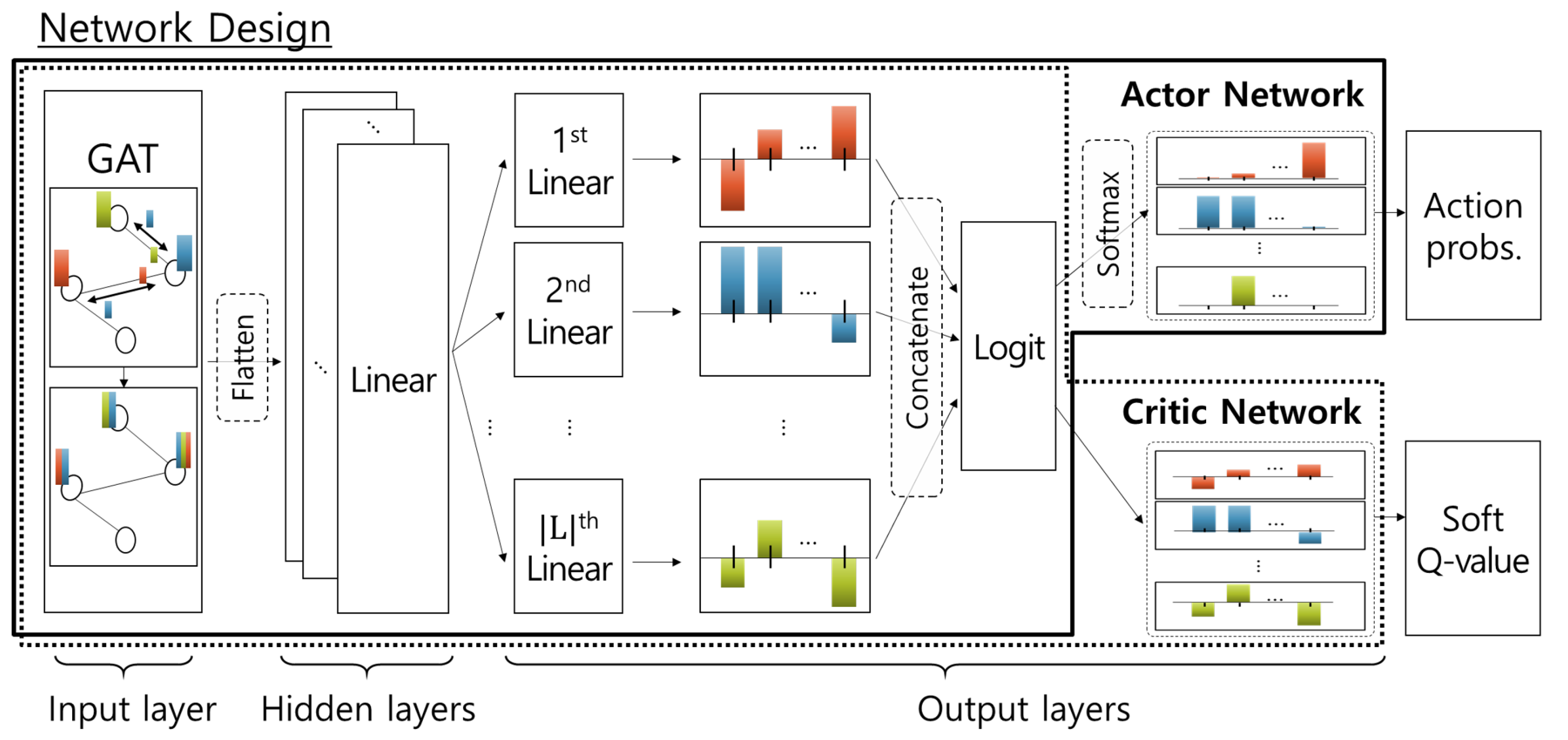
3.3. Discretized SAC-Based Learning Algorithm
| Algorithm 1 Discretized soft-actor-critic algorithm. |
|
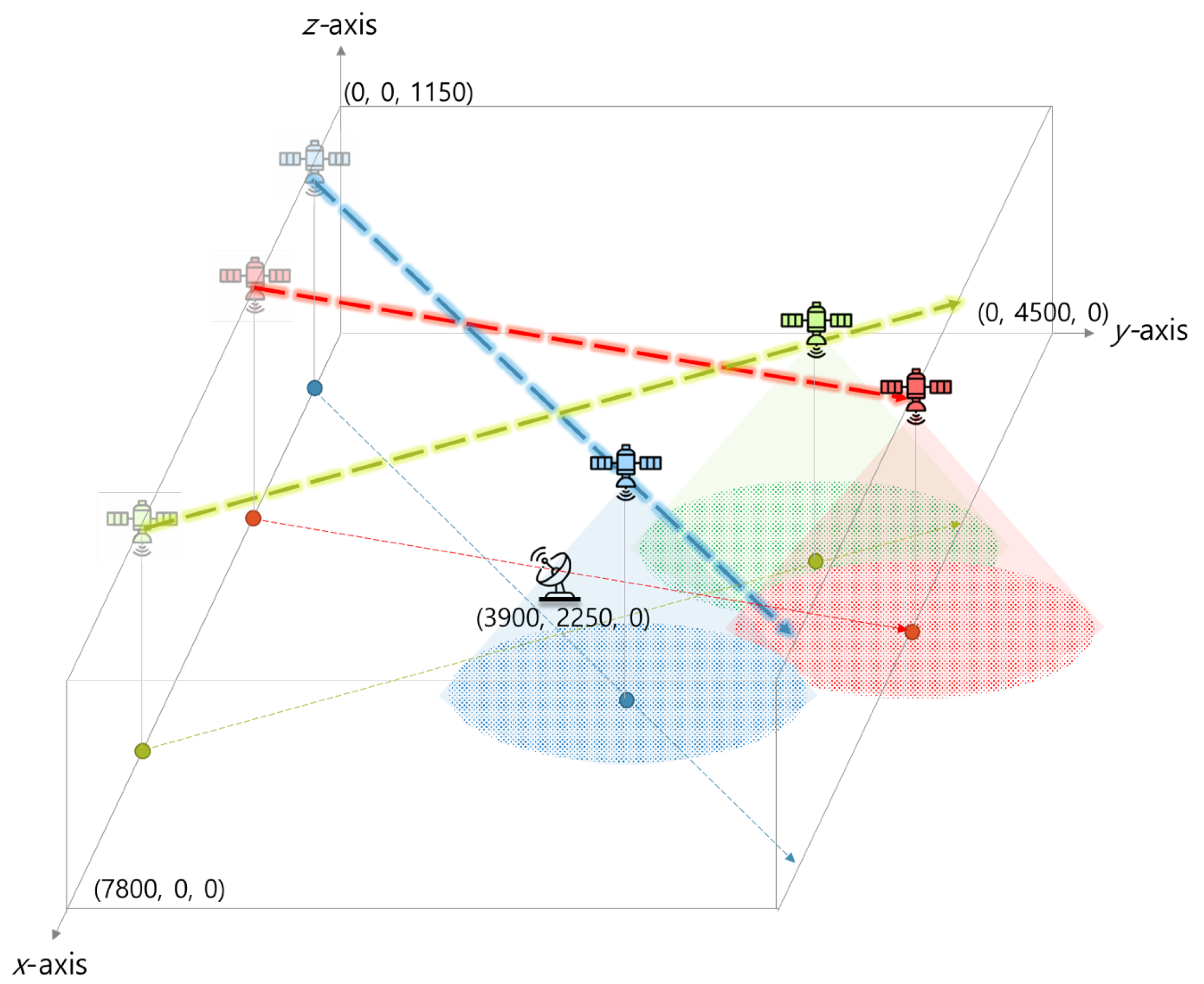
4. Performance Evaluation
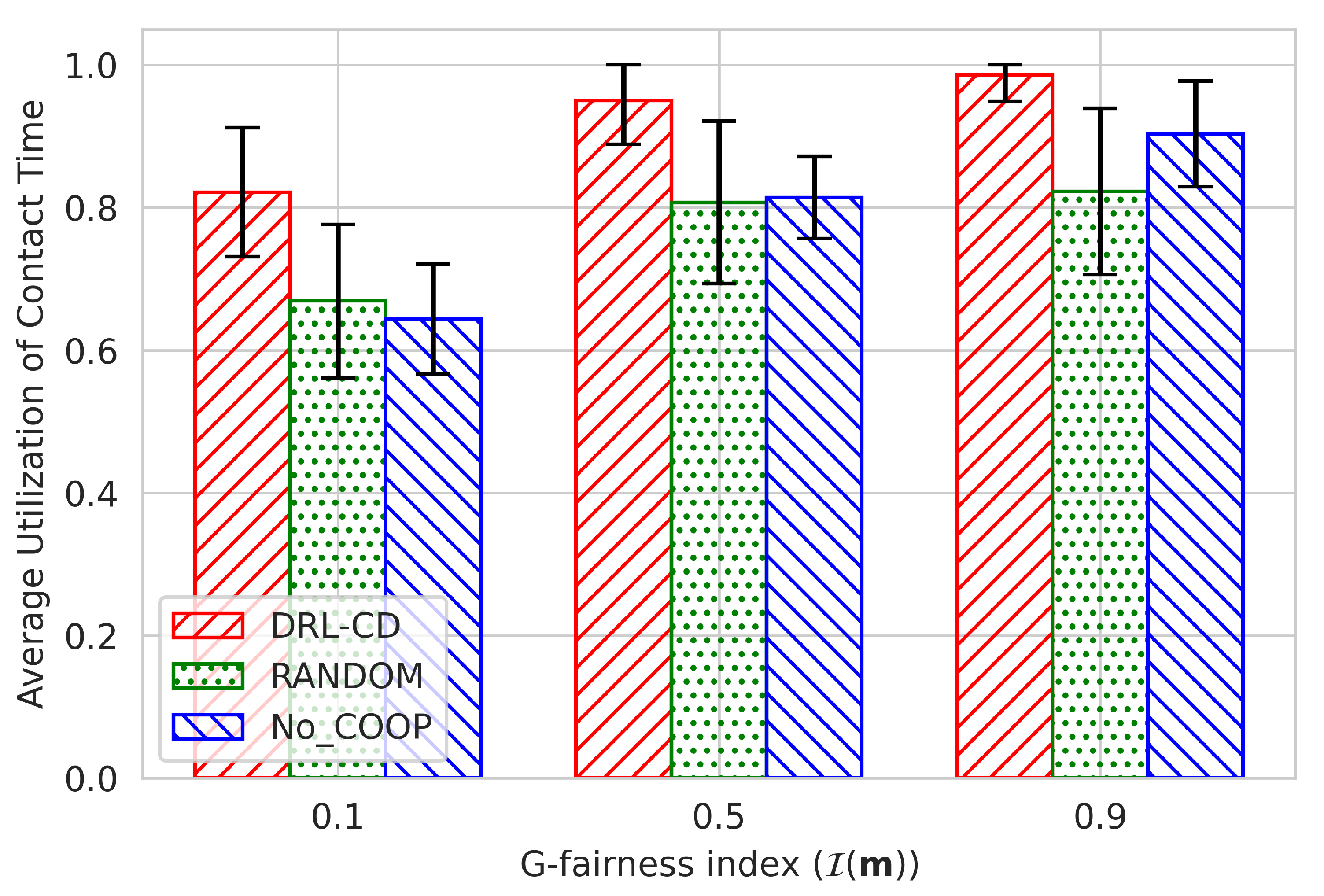
4.1. Effect of Initial Data Distribution
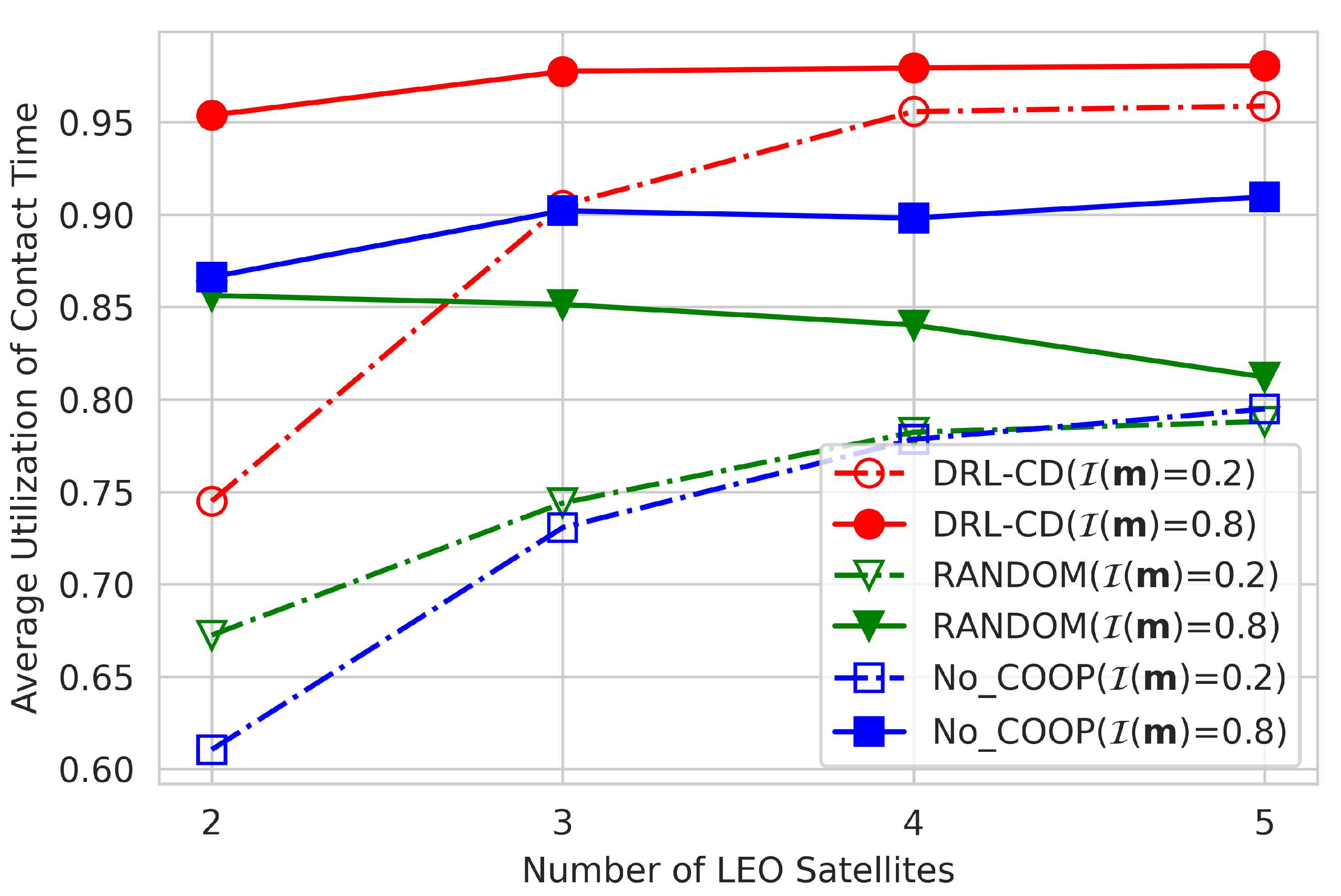
4.2. Effect of Number of Satellites
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yao, X.; Han, J.; Cheng, G.; Qian, X.; Guo, L. Semantic Annotation of High-Resolution Satellite Images via Weakly Supervised Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3660–3671. [Google Scholar] [CrossRef]
- Christos, S.C.; Christos, G. Data-centric operations in oil & gas industry by the use of 5G mobile networks and industrial Internet of Things (IIoT). In Proceedings of the 13th International Conference Digital Telecommunications (ICDT), Athens, Greece, 1–5 April 2018. [Google Scholar]
- Xu, B.; Li, X.; Ma, Y.; Xin, X.; Kadoch, M. Dual Stream Transmission and Downlink Power Control for Multiple LEO Satellites-Assisted IoT Networks. Sensors 2022, 22, 6050. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.J.; Yousaf, A.; Javed, N.; Nadeem, S.; Khurshid, K. Automatic Target Detection in Satellite Images using Deep Learning. J. Space Technol. 2017, 7, 44–49. [Google Scholar]
- Portillo, I.; Cameron, B.G.; Crawley, E.F. A technical comparison of three low earth orbit satellite constellation systems to provide global broadband. Acta Astronaut. 2019, 159, 123–135. [Google Scholar] [CrossRef]
- Zhu, X.; Jiang, C. Integrated Satellite-Terrestrial Networks Toward 6G: Architectures, Applications, and Challenges. IEEE Internet Things J. 2022, 9, 437–461. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. Satellite Edge Computing for the Internet of Things in Aerospace. Sensors 2019, 19, 4375. [Google Scholar] [CrossRef] [PubMed]
- Pfandzelter, T.; Hasenburg, J.; Bermbach, D. Towards a Computing Platform for the LEO Edge. In Proceedings of the 4th International Workshop on Edge Systems, Analytics and Networking (EdgeSys), New York, NY, USA, 26 April 2021. [Google Scholar]
- Li, C.; Zhang, Y.; Xie, R.; Hao, X.; Huang, T. Integrating Edge Computing into Low Earth Orbit Satellite Networks: Architecture and Prototype. IEEE Access 2021, 9, 39126–39137. [Google Scholar] [CrossRef]
- Fang, X.; Feng, W.; Wei, T.; Chen, Y.; Ge, N.; Wang, C.-X. 5G Embraces Satellites for 6G Ubiquitous IoT: Basic Models for Integrated Satellite Terrestrial Networks. IEEE Internet Things J. 2021, 8, 14399–14417. [Google Scholar] [CrossRef]
- Consultative Committee for Space Data Systems (CCSDS). Image Data Compression CCSDS 122.0-B-2; Blue Book; CCSDS Secretariat, National Aeronautics and Space Administration: Washington, DC, USA, 2017.
- Oliveira, V.; Chabert, M.; Oberlin, T.; Poulliat, C.; Bruno, M.; Latry, C.; Carlavan, M.; Henrot, S.; Falzon, F.; Camarero, R. Satellite Image Compression and Denoising With Neural Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Dong, H.; Hua, C.; Liu, L.; Xu, W. Towards Integrated Terrestrial-Satellite Network via Intelligent Reflecting Surface. In Proceedings of the IEEE International Conference on Communications (ICC), Montreal, QC, Canada, 1–6 June 2021. [Google Scholar]
- Khan, W.U.; Ali, Z.; Lagunas, E.; Chatzinotas, S.; Ottersten, B. Rate Splitting Multiple Access for Cognitive Radio GEO-LEO Co-Existing Satellite Networks. arXiv 2022, arXiv:2208.02924v1. [Google Scholar]
- Khan, W.U.; Ali, Z.; Lagunas, E.; Mahmood, A.; Asif, M.; Ihsan, A.; Chatzinotas, S.; Ottersten, B.; Dobre, O.A. Rate Splitting Multiple Access for Next Generation Cognitive Radio Enabled LEO Satellite Networks. arXiv 2022, arXiv:2208.03705v1. [Google Scholar]
- Khan, W.U.; Lagunas, E.; Ali, Z.; Javed, M.A.; Ahmed, M.; Chatzinotas, S.; Ottersten, B.; Popovski, P. Opportunities for Physical Layer Security in UAV Communication Enhanced with Intelligent Reflective Surfaces. arXiv 2022, arXiv:2203.16907v1. [Google Scholar]
- Khan, W.U.; Lagunas, E.; Mahmood, A.; Chatzinotas, S.; Ottersten, B. When RIS Meets GEO Satellite Communications: A New Sustainable Optimization Framework in 6G. arXiv 2022, arXiv:2202.00497v2. [Google Scholar]
- Tekbıyık, K.; Kurt, G.K.; Ekti, A.R.; Yanikomeroglu, H. Reconfigurable Intelligent Surfaces Empowered THz Communication in LEO Satellite Networks. arXiv 2022, arXiv:2007.04281v4. [Google Scholar]
- Castaing, J. Scheduling Downloads for Multi-Satellite, Multi-Ground Station Missions. In Proceedings of the Small Satellite Conference, Logan, UT, USA, 2–7 August 2014. [Google Scholar]
- Wang, Y.; Sheng, M.; Zhuang, W.; Zhang, S.; Zhang, N.; Liu, R.; Li, J. Multi-Resource Coordinate Scheduling for Earth Observation in Space Information Networks. IEEE J. Selected Areas Commun. 2018, 36, 268–279. [Google Scholar] [CrossRef]
- He, L.; Liang, B.; Li, J.; Sheng, M. Joint Observation and Transmission Scheduling in Agile Satellite Networks. IEEE Trans. Mob. Comput. 2021. [Google Scholar] [CrossRef]
- Jia, X.; Lv, T.; He, F.; Huang, H. Collaborative Data Downloading by Using Inter-Satellite Links in LEO Satellite Networks. IEEE Trans. Wirel. Commun. 2017, 16, 1523–1532. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, W. Energy-Efficient Collaborative Data Downloading by Using Inter-Satellite Offloading. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- He, L.; Guo, K.; Gan, H.; Wang, L. Collaborative Data Offloading for Earth Observation Satellite Networks. IEEE Commun. Lett. 2022, 26, 1116–1120. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Liu, J.; Ahmed, M.; Mirza, M.A.; Khan, W.U.; Xu, D.; Li, J.; Aziz, A.; Han, Z. RL/DRL Meets Vehicular Task Offloading Using Edge and Vehicular Cloudlet: A Survey. IEEE Internet Things J. 2022, 9, 8315–8338. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone Deep Reinforcement Learning: A Review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Wang, J.; Mu, W.; Liu, Y.; Guo, L.; Zhang, S.; Gui, G. Deep Reinforcement Learning-based Satellite Handover Scheme for Satellite Communications. In Proceedings of the 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), Changsha, China, 1–6 October 2021. [Google Scholar]
- Tang, S.; Pan, Z.; Hu, G.; Wu, Y.; Li, Y. Deep Reinforcement Learning-Based Resource Allocation for Satellite Internet of Things with Diverse QoS Guarantee. Sensors 2022, 22, 2979. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Yang, Y.; Yin, L.; He, D.; Yan, Q. Deep Reinforcement Learning Based Power Allocation for Rate-Splitting Multiple Access in 6G LEO Satellite Communication System. IEEE Commun. Lett. 2022. [Google Scholar] [CrossRef]
- Yoo, S.; Lee, W. Federated Reinforcement Learning Based AANs with LEO Satellites and UAVs. Sensors 2021, 21, 8111. [Google Scholar] [CrossRef]
- Data Centers in Orbit? Space-Based Edge Computing Gets a Boost. Available online: https://datacenterfrontier.com/data-centers-in-orbit-space-based-edge-computing-gets-a-boost/ (accessed on 13 July 2022).
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903v3. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2019, arXiv:1812.05905v2. [Google Scholar]
- Christodoulou, P. Soft Actor-Critic for Discrete Action Settings. arXiv 2019, arXiv:1910.07207v2. [Google Scholar]
- SpaceX FCC Filing. SpaceX V-BAND NON-GEOSTATIONARY SATELLITE SYSTEM. 2017. Available online: https://fcc.report/IBFS/SAT-LOA-20170301-00027/1190019.pdf (accessed on 13 July 2022).
- Chen, Q.; Yang, L.; Liu, X.; Cheng, B.; Guo, J.; Li, X. Modeling and Analysis of Inter-Satellite Link in LEO Satellite Networks. In Proceedings of the 2021 13th International Conference on Communication Software and Networks (ICCSN), Chongqing, China, 4–7 June 2021. [Google Scholar]
- Mehta, R. Recursive quadratic programming for constrained nonlinear optimization of session throughput in multiple-flow network topologies. Eng. Rep. 2020, 2, 1–14. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Neurons of each hidden layer | 512 |
| Neurons of each output layer | number of satellites + number of GSs |
| Batch size | 128 |
| Replay buffer size | 1,000,000 |
| Learning rate | 3 × 10 |
| Discount rate | 0.99 |
| Optimizer | Adam |
| Target entropy | |
| Weight for offloading () | −0.3 |
| Soft update cycle (B) | 2 |
| Coefficient for soft update () | 5 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Pack, S. Cooperative Downloading for LEO Satellite Networks: A DRL-Based Approach. Sensors 2022, 22, 6853. https://doi.org/10.3390/s22186853
Choi H, Pack S. Cooperative Downloading for LEO Satellite Networks: A DRL-Based Approach. Sensors. 2022; 22(18):6853. https://doi.org/10.3390/s22186853
Chicago/Turabian StyleChoi, Hongrok, and Sangheon Pack. 2022. "Cooperative Downloading for LEO Satellite Networks: A DRL-Based Approach" Sensors 22, no. 18: 6853. https://doi.org/10.3390/s22186853
APA StyleChoi, H., & Pack, S. (2022). Cooperative Downloading for LEO Satellite Networks: A DRL-Based Approach. Sensors, 22(18), 6853. https://doi.org/10.3390/s22186853