
A Deep Sequence Learning Framework for Action Recognition in Small-Scale Depth Video Dataset



Abstract
:1. Introduction
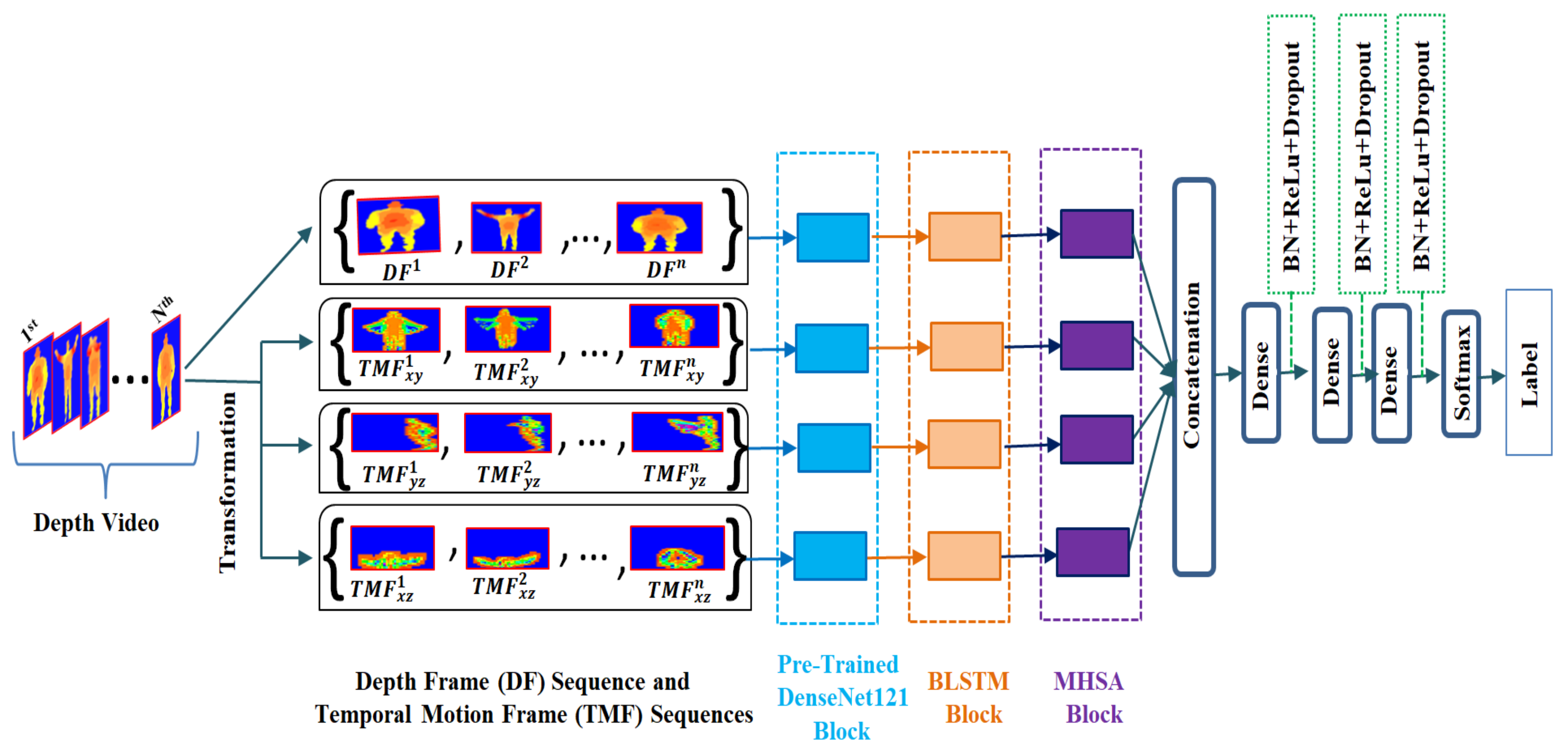
- Learned patterns extraction using deep models with a small-scale dataset is very challenging. To address this issue, we employed a unified framework of BLSTM and MHSA to achieve better sequence-based action recognition in depth videos.
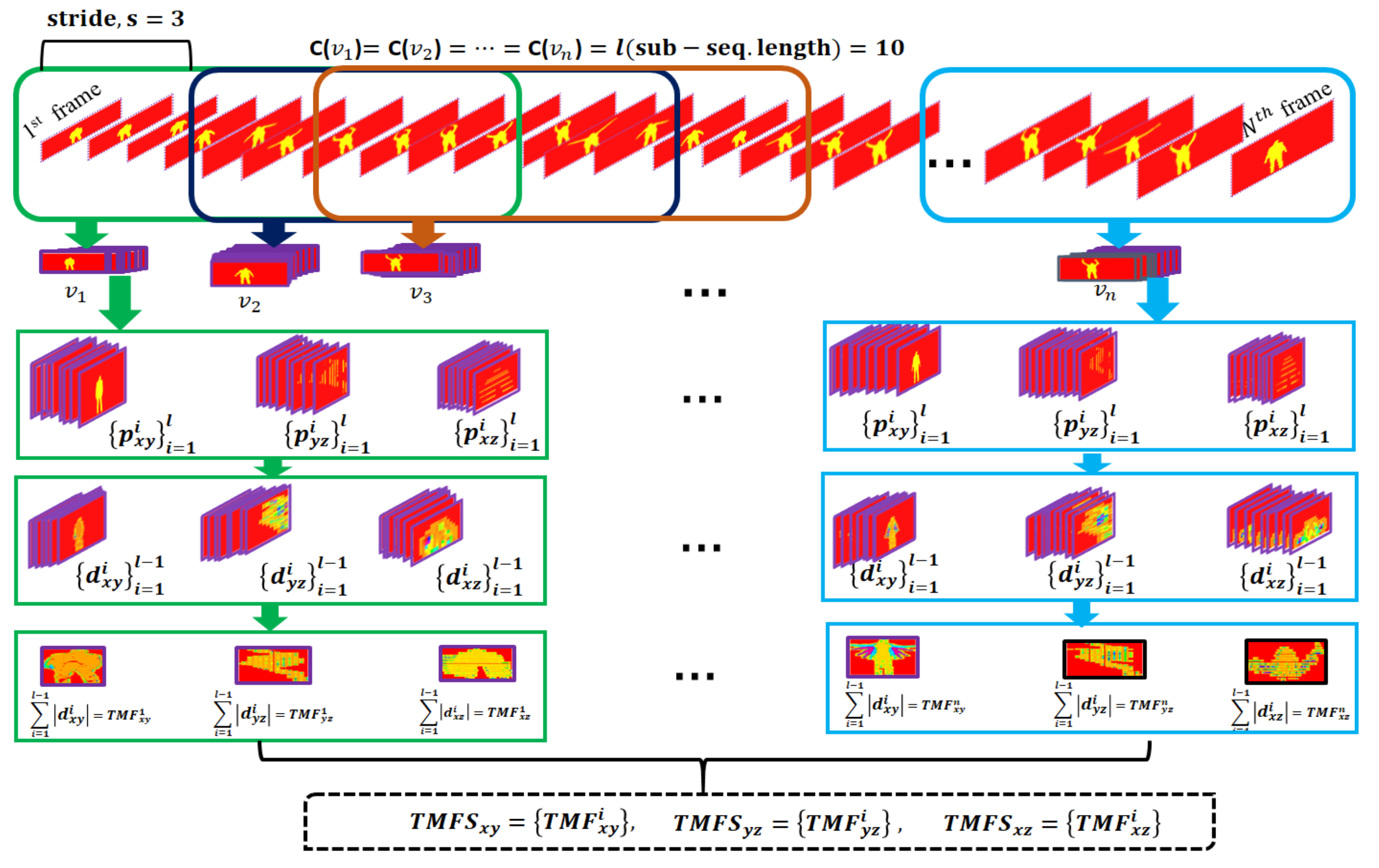
- We propose a single depth video representation through four data streams to boost the depth action representation. The four data streams have a single depth frame sequence and three temporal motion frame sequences. The depth frame sequence is the original input sequence, and the other three sequences are derived from the original one. The other three motion sequences preserve the spatiotemporal motion cues of the front, side, and top flank performers.
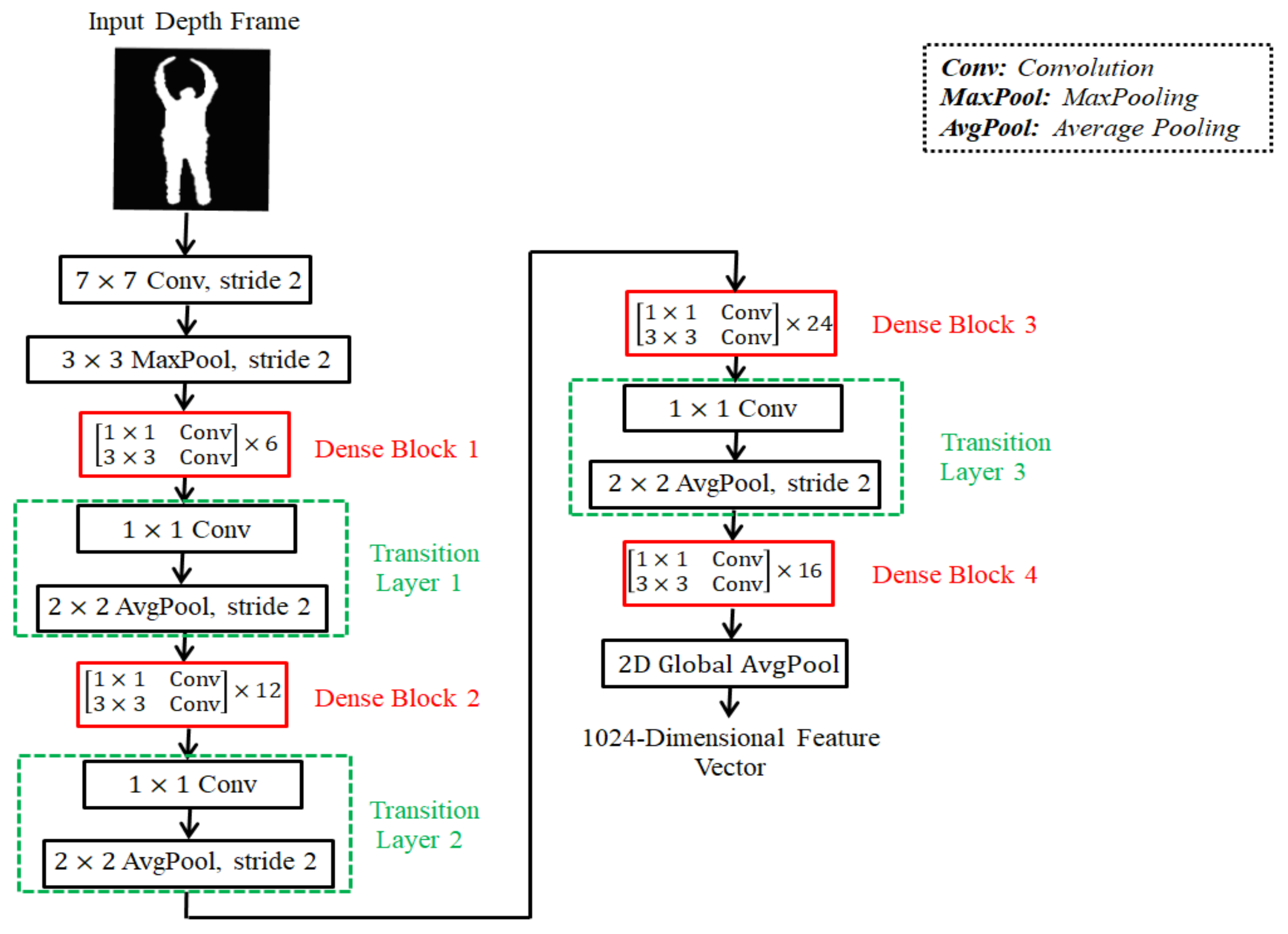
- Frame level features extraction is an essential step for sequence-based decisions for action recogntion. We employ a pre-trained 2D CNN model with a transfer learning strategy for robust depth features representations.
- The sequence classification model is developed with the one-to-one integration of BLSTM and MHSA layers. A set of optimal parameters for the BLSTM-MHSA combination is determined, providing the key support for the performance improvement of the proposed method.
- BLSTM-MHSA correlation features are encoded with fully connected layers with a features dropout strategy to achieve model generalization for the unseen test set.
- An ablation study is also provided for different 2D CNN models and the number of data streams for robust action classification.
- The proposed method is assessed in terms of two public datasets, MSRAction3D [82] and DHA [83], and our results are compared with other state-of-the-art methods. In summary, our method exhibits superiority over the recent (published on 20 April 2022) state-of-the-art 3D CNN-based recognition method [29] by 1.9% for MSRAction3D and by 2.3% for DHA. In contrast to the 3D CNN model, our approach involves fewer video frames in each sequence and fewer trainable parameters.
2. Proposed System
2.1. Four-Stream Action Representation
2.2. Extraction of Action Features
2.3. Organization of Feature Vectors and Their Correlation Modeling
2.4. Weight Assignment to Prominent Feature Vectors
2.5. Action Class Assignment
3. Experiment and Results
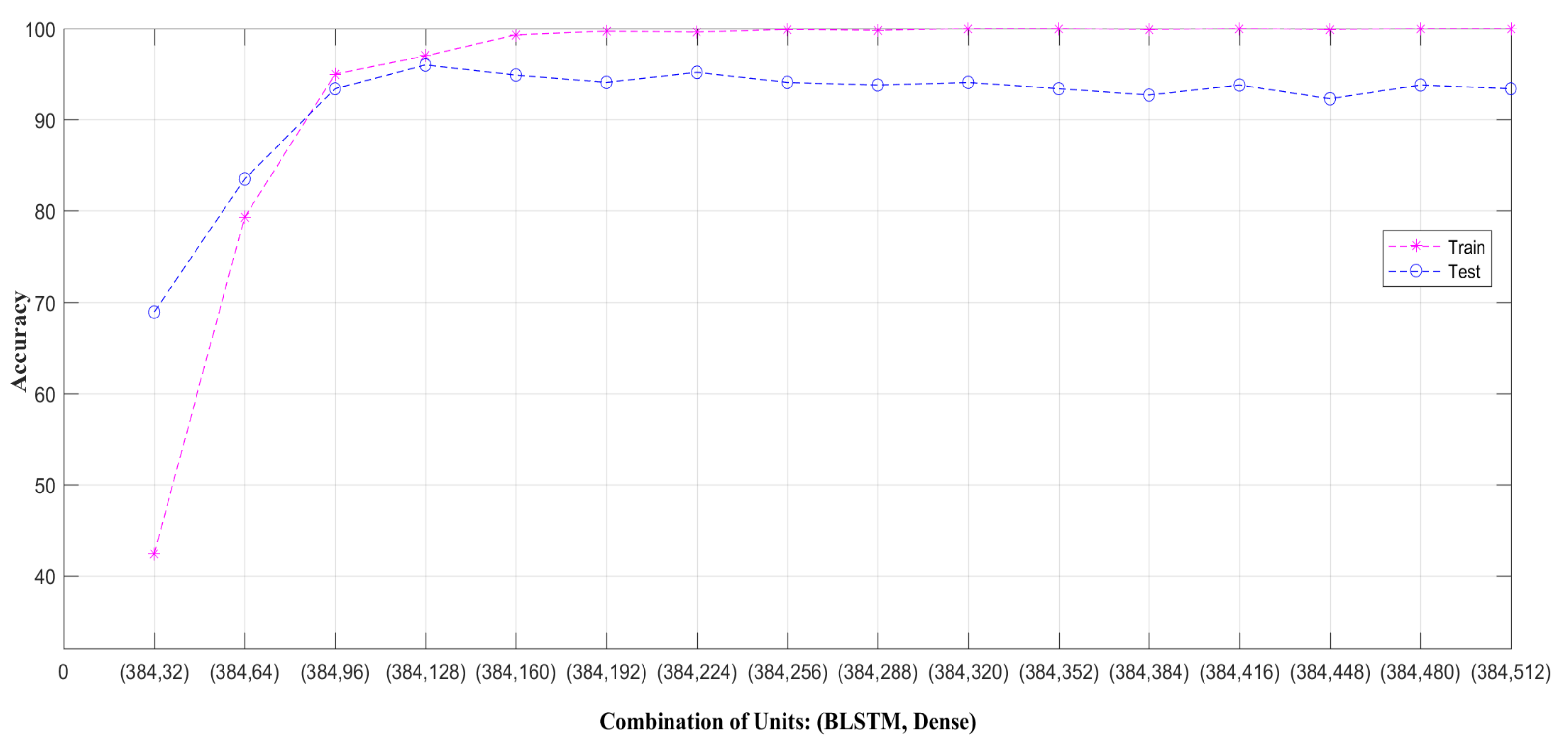
3.1. Optimization of Hyper-Parameters
3.2. Evaluation on MSRAction3D Dataset
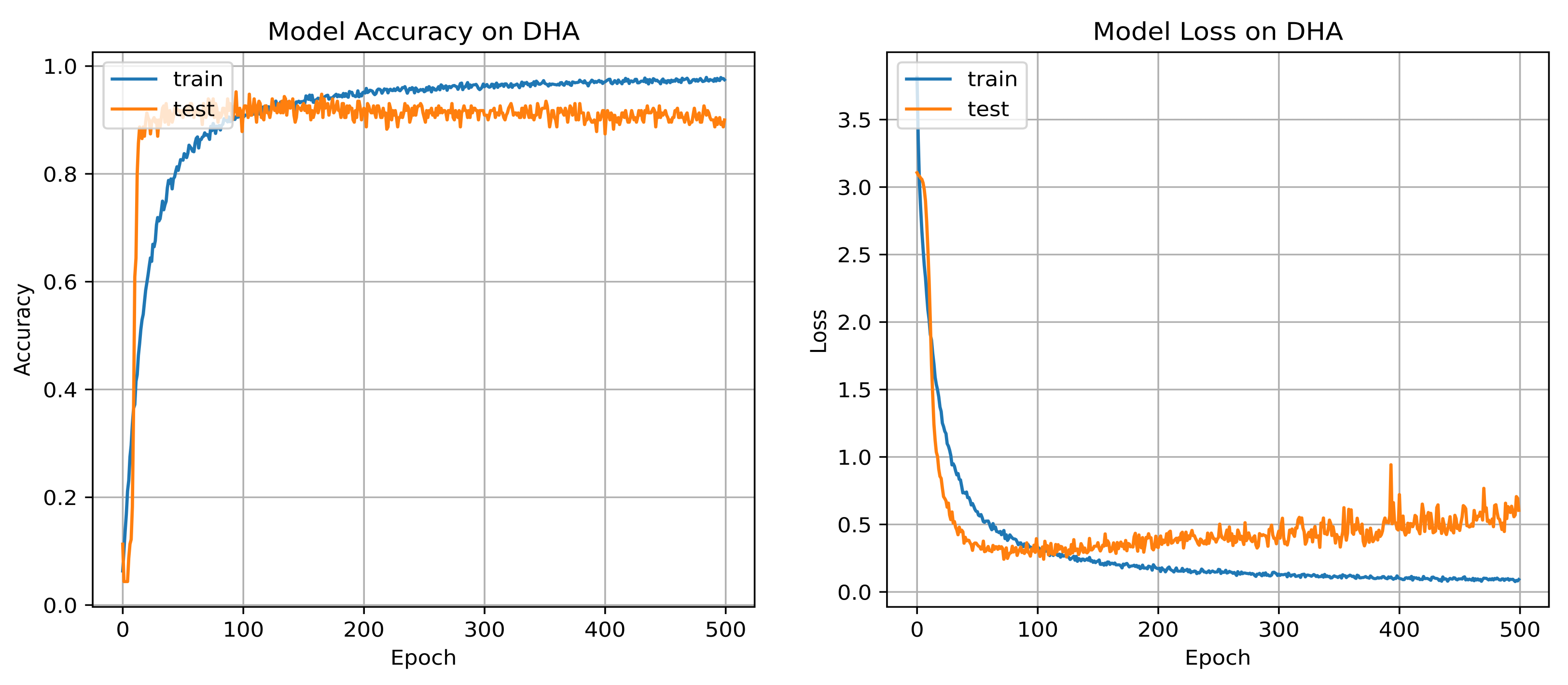
3.3. Evaluation on DHA Dataset
3.4. Ablation Study
3.4.1. Data Stream
3.4.2. Architecture
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shaikh, M.B.; Chai, D. Rgb-d data-based action recognition: A review. Sensors 2021, 21, 4246. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Ma, N.; Wang, P.; Li, J.; Wang, P.; Pang, G.; Shi, X. Survey of pedestrian action recognition techniques for autonomous driving. Tsinghua Sci. Technol. 2020, 25, 458–470. [Google Scholar] [CrossRef]
- Dawar, N.; Kehtarnavaz, N. Continuous detection and recognition of actions of interest among actions of non-interest using a depth camera. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4227–4231. [Google Scholar]
- Zhu, H.; Vial, R.; Lu, S. Tornado: A spatio-temporal convolutional regression network for video action proposal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5813–5821. [Google Scholar]
- Chaaraoui, A.A.; Padilla-López, J.R.; Ferrández-Pastor, F.J.; Nieto-Hidalgo, M.; Flórez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef]
- Wei, H.; Laszewski, M.; Kehtarnavaz, N. Deep learning-based person detection and classification for far field video surveillance. In Proceedings of the 2018 IEEE 13th Dallas Circuits and Systems Conference (DCAS), Dallas, TX, USA, 12 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; IEEE: Piscataway, NJ, USA, 2015; pp. 65–72. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Liu, J.; Shah, M. Learning human actions via information maximization. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Wu, H.; Ma, X.; Li, Y. Hierarchical dynamic depth projected difference images–based action recognition in videos with convolutional neural networks. Int. J. Adv. Robot. Syst. 2019, 16, 1729881418825093. [Google Scholar] [CrossRef]
- Shen, X.; Ding, Y. Human skeleton representation for 3D action recognition based on complex network coding and LSTM. J. Vis. Commun. Image Represent. 2022, 82, 103386. [Google Scholar] [CrossRef]
- Tasnim, N.; Islam, M.K.; Baek, J.H. Deep learning based human activity recognition using spatio-temporal image formation of skeleton joints. Appl. Sci. 2021, 11, 2675. [Google Scholar] [CrossRef]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 253–256. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 579–583. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27, pp. 568–576. Available online: https://proceedings.neurips.cc/paper/2014/file/00ec53c4682d36f5c4359f4ae7bd7ba1-Paper.pdf (accessed on 20 June 2022).
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 807–811. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio–temporal image representation of 3D skeletal movements for view-invariant action recognition with deep convolutional neural networks. Sensors 2019, 19, 1932. [Google Scholar] [CrossRef]
- Tasnim, N.; Islam, M.; Baek, J.H. Deep learning-based action recognition using 3D skeleton joints information. Inventions 2020, 5, 49. [Google Scholar] [CrossRef]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Spatio-temporal attention-based LSTM networks for 3D action recognition and detection. IEEE Trans. Image Process. 2018, 27, 3459–3471. [Google Scholar] [CrossRef] [PubMed]
- Verma, P.; Sah, A.; Srivastava, R. Deep learning-based multi-modal approach using RGB and skeleton sequences for human activity recognition. Multimed. Syst. 2020, 26, 671–685. [Google Scholar] [CrossRef]
- Dhiman, C.; Vishwakarma, D.K. View-invariant deep architecture for human action recognition using two-stream motion and shape temporal dynamics. IEEE Trans. Image Process. 2020, 29, 3835–3844. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. HybridNet: Integrating GCN and CNN for skeleton-based action recognition. Appl. Intell. 2022, 1–12. [Google Scholar] [CrossRef]
- Yang, G.; Zou, W.x. Deep learning network model based on fusion of spatiotemporal features for action recognition. Multimed. Tools Appl. 2022, 81, 9875–9896. [Google Scholar] [CrossRef]
- Tasnim, N.; Baek, J.H. Deep Learning-Based Human Action Recognition with Key-Frames Sampling Using Ranking Methods. Appl. Sci. 2022, 12, 4165. [Google Scholar] [CrossRef]
- Sanchez-Caballero, A.; de López-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Casillas-Perez, D.; Sarker, M.I. 3DFCNN: Real-time action recognition using 3d deep neural networks with raw depth information. Multimed. Tools Appl. 2022, 81, 24119–24143. [Google Scholar] [CrossRef]
- Trelinski, J.; Kwolek, B. Embedded Features for 1D CNN-based Action Recognition on Depth Maps. In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Online, 8–10 February 2021; pp. 536–543. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Tang, C.; Ogunbona, P.O. Depth pooling based large-scale 3-d action recognition with convolutional neural networks. IEEE Trans. Multimed. 2018, 20, 1051–1061. [Google Scholar] [CrossRef]
- Chen, J.; Xiao, Y.; Cao, Z.; Fang, Z. Action recognition in depth video from RGB perspective: A knowledge transfer manner. In MIPPR 2017: Pattern Recognition and Computer Vision; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10609, p. 1060916. [Google Scholar]
- Imran, J.; Kumar, P. Human action recognition using RGB-D sensor and deep convolutional neural networks. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 144–148. [Google Scholar]
- Treliński, J.; Kwolek, B. Ensemble of Multi-channel CNNs for Multi-class Time-Series Classification. Depth-Based Human Activity Recognition. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 23–26 March 2020; Springer: Cham, Switzerland, 2020; pp. 455–466. [Google Scholar]
- Trelinski, J.; Kwolek, B. CNN-based and DTW features for human activity recognition on depth maps. Neural Comput. Appl. 2021, 33, 14551–14563. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P.O. Action recognition from depth maps using deep convolutional neural networks. IEEE Trans. Hum.-Mach. Syst. 2015, 46, 498–509. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 July 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Wu, H.; Ma, X.; Li, Y. Spatiotemporal multimodal learning with 3D CNNs for video action recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1250–1261. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Huang, L.; Zhang, Q.; Zhu, S.; Ma, Y. CrossFuNet: RGB and Depth Cross-Fusion Network for Hand Pose Estimation. Sensors 2021, 21, 6095. [Google Scholar] [CrossRef] [PubMed]
- Verma, K.K.; Singh, B.M. Deep Multi-Model Fusion for Human Activity Recognition Using Evolutionary Algorithms. Int. J. Interact. Multimed. Artif. Intell. 2021, 7, 44–58. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 9 October–2 November 2012; ACM: New York, NY, USA, 2012; pp. 1057–1060. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Yang, X.; Tian, Y. Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 804–811. [Google Scholar]
- Chen, C.; Liu, M.; Zhang, B.; Han, J.; Jiang, J.; Liu, H. 3D Action Recognition Using Multi-Temporal Depth Motion Maps and Fisher Vector. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; pp. 3331–3337. [Google Scholar]
- Asadi-Aghbolaghi, M.; Kasaei, S. Supervised spatio-temporal kernel descriptor for human action recognition from RGB-depth videos. Multimed. Tools Appl. 2018, 77, 14115–14135. [Google Scholar] [CrossRef]
- Miao, J.; Jia, X.; Mathew, R.; Xu, X.; Taubman, D.; Qing, C. Efficient action recognition from compressed depth maps. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 16–20. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. DMMs-based multiple features fusion for human action recognition. Int. J. Multimed. Data Eng. Manag. (IJMDEM) 2015, 6, 23–39. [Google Scholar] [CrossRef]
- Chen, C.; Hou, Z.; Zhang, B.; Jiang, J.; Yang, Y. Gradient local auto-correlations and extreme learning machine for depth-based activity recognition. In International Symposium on Visual Computing; Springer: Cham, Switzerland, 2015; pp. 613–623. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1092–1099. [Google Scholar]
- Youssef, C. Spatiotemporal representation of 3d skeleton joints-based action recognition using modified spherical harmonics. Pattern Recognit. Lett. 2016, 83, 32–41. [Google Scholar]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action recognition using 3D histograms of texture and a multi-class boosting classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Hou, Z.; Jiang, J.; Liu, M.; Yang, Y. Action recognition from depth sequences using weighted fusion of 2D and 3D auto-correlation of gradients features. Multimed. Tools Appl. 2017, 76, 4651–4669. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Kasaei, S.; Escalera, S. Dynamic 3D hand gesture recognition by learning weighted depth motion maps. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1729–1740. [Google Scholar] [CrossRef]
- Shekar, B.; Rathnakara Shetty, P.; Sharmila Kumari, M.; Mestetsky, L. Action recognition using undecimated dual tree complex wavelet transform from depth motion maps/depth sequences. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W12, 203–209. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Tian, L.; Liu, M.; Tang, H. Sdm-bsm: A fusing depth scheme for human action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Québec, QC, Canada, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4674–4678. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C.; Najafian, M. Energy-based global ternary image for action recognition using sole depth sequences. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 47–55. [Google Scholar]
- Wang, L.; Ding, Z.; Tao, Z.; Liu, Y.; Fu, Y. Generative multi-view human action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6212–6221. [Google Scholar]
- Al-Obaidi, S.; Abhayaratne, C. Privacy protected recognition of activities of daily living in video. In Proceedings of the 3rd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2019), London, UK, 25 March 2019. [Google Scholar]
- Liu, Y.; Wang, L.; Bai, Y.; Qin, C.; Ding, Z.; Fu, Y. Generative View-Correlation Adaptation for Semi-supervised Multi-view Learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 318–334. [Google Scholar]
- Bai, Y.; Tao, Z.; Wang, L.; Li, S.; Yin, Y.; Fu, Y. Collaborative Attention Mechanism for Multi-View Action Recognition. arXiv 2020, arXiv:2009.06599. [Google Scholar]
- Wang, L.; Huynh, D.Q.; Koniusz, P. A comparative review of recent kinect-based action recognition algorithms. IEEE Trans. Image Process. 2019, 29, 15–28. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Yang, R. DMM-pyramid based deep architectures for action recognition with depth cameras. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Springer: Cham, Switzerland, 2014; pp. 37–49. [Google Scholar]
- Xiao, Y.; Chen, J.; Wang, Y.; Cao, Z.; Zhou, J.T.; Bai, X. Action recognition for depth video using multi-view dynamic images. Inf. Sci. 2019, 480, 287–304. [Google Scholar] [CrossRef]
- Keceli, A.S.; Kaya, A.; Can, A.B. Combining 2D and 3D deep models for action recognition with depth information. Signal Image Video Process. 2018, 12, 1197–1205. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the myopia of inductive learning algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, Z.; Lin, F.; Leung, H.; Li, Q. Action recognition from depth sequence using depth motion maps-based local ternary patterns and CNN. Multimed. Tools Appl. 2019, 78, 19587–19601. [Google Scholar] [CrossRef]
- Wu, H.; Ma, X.; Li, Y. Convolutional networks with channel and STIPs attention model for action recognition in videos. IEEE Trans. Multimed. 2020, 22, 2293–2306. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based deep convolutional neural network for action recognition with depth sequences. Image Vis. Comput. 2016, 55, 93–100. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.; Yang, Y.; Ndzi, D. Deep learning of fuzzy weighted multi-resolution depth motion maps with spatial feature fusion for action recognition. J. Imaging 2019, 5, 82. [Google Scholar] [CrossRef]
- Singh, R.; Khurana, R.; Kushwaha, A.K.S.; Srivastava, R. Combining CNN streams of dynamic image and depth data for action recognition. Multimed. Syst. 2020, 26, 313–322. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 585–590. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Kot, A.C.; Wang, G. Skeleton-based action recognition using spatio-temporal lstm network with trust gates. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 3007–3021. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Liu, X.; Xiao, J. On geometric features for skeleton-based action recognition using multilayer lstm networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 148–157. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1227–1236. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 9–14. [Google Scholar]
- Lin, Y.C.; Hu, M.C.; Cheng, W.H.; Hsieh, Y.H.; Chen, H.M. Human action recognition and retrieval using sole depth information. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1053–1056. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Accuracy (%) |
|---|---|
| Decision-level-Fusion (MV) [49] | 91.9 |
| DMM-GLAC-FF [50] | 89.38 |
| DMM-GLAC-DF [50] | 92.31 |
| DMM-LBP-FF [51] | 91.9 |
| DMM-LBP-DF [51] | 93.0 |
| MTDMM [46] | 95.97 |
| CDF [48] | 80.8 |
| Skeleton-MSH [52] | 90.98 |
| 3D HoT_S [53] | 91.9 |
| 3D HoT_M [53] | 88.3 |
| SSTKDes [47] | 95.60 |
| Depth-STACOG [54] | 75.82 |
| DMM-GLAC [54] | 89.38 |
| WDMM [55] | 90.0 |
| DMM-UDTCWT [56] | 92.67 |
| 3D CNN+DMM-Pyramid [64] | 86.08 |
| CNN [70] | 84.07 |
| 2D CNN+DMM-Pyramid [64] | 91.21 |
| Depth+1D CNN [31] | 90.18 |
| Multi-channel-CNN-Ensemble+Bag [35] | 94.55 |
| 1D CNN+DTW [36] | 95.6 |
| 3D CNN+DHI+Relieff+SVM [66] | 92.8 |
| Depth+3D CNN [29] | 94.1 |
| (DFS+TMFS)+DenseNet121+MHSA+BLSTM | 78 |
| (DFS+TMFS)+DenseNet121+BLSTM+MHSA (Ours) | 96 |
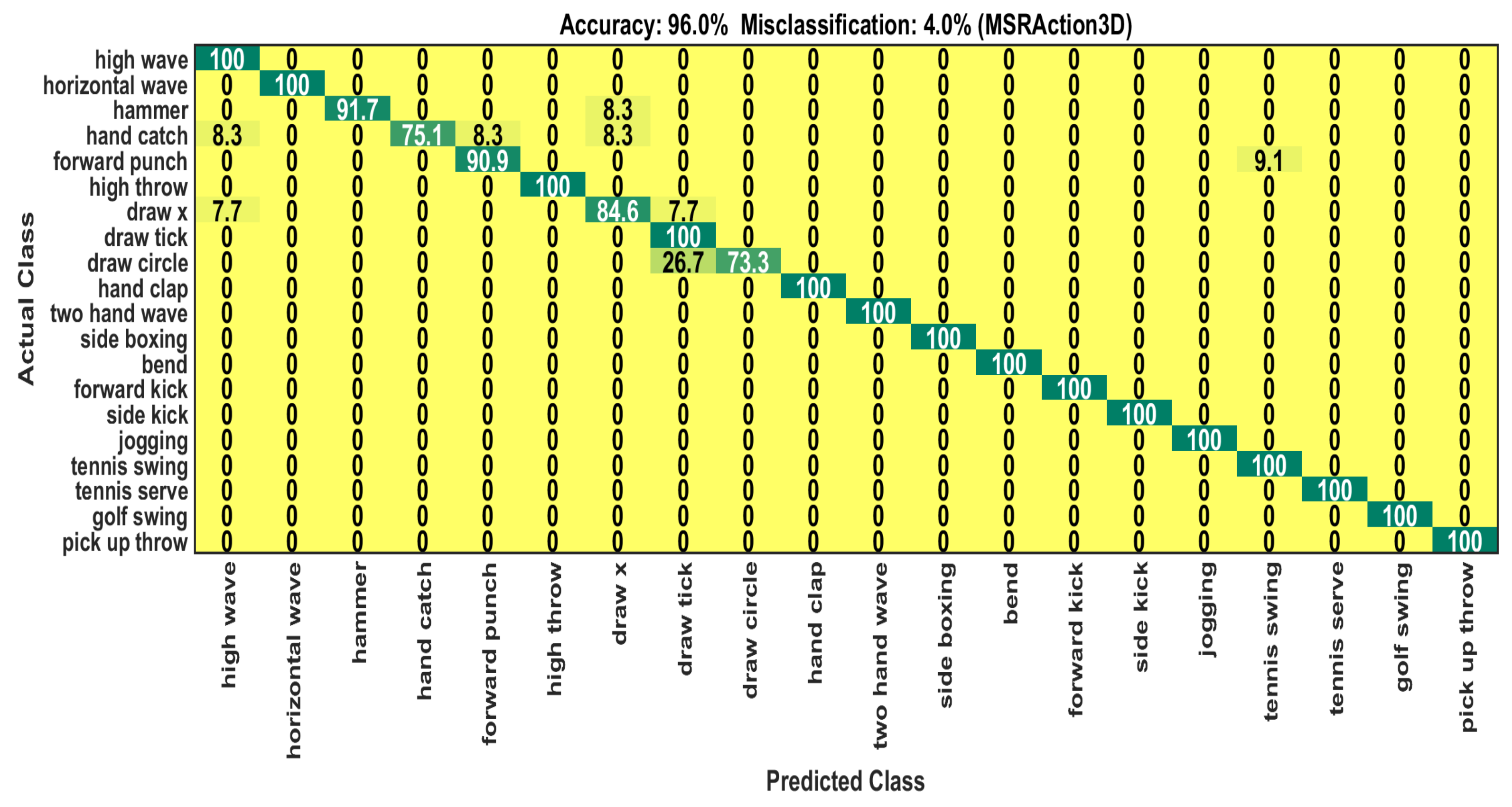
| Class | Precision | Recall | F1-Score | Accuracy (%) | Confusion (%) |
|---|---|---|---|---|---|
| High wave | 86.0 | 100 | 92.0 | 100 | No |
| Horizontal wave | 100 | 100 | 100 | 100 | No |
| Hammer | 100 | 92.0 | 96.0 | 91.7 | Draw x (8.3) |
| Hand catch | 100 | 75.0 | 86.0 | 75.1 | High wave (8.3), Forward punch (8.3), Draw x (8.3) |
| Forward punch | 91.0 | 91.0 | 91.0 | 90.9 | Tennis swing (9.1) |
| High throw | 100 | 100 | 100 | 100 | No |
| Draw x | 85.0 | 85.0 | 85.0 | 84.6 | High wave (7.7), Draw tick (7.7) |
| Draw tick | 75.0 | 100 | 86.0 | 100 | No |
| Draw circle | 100 | 73.0 | 85.0 | 73.3 | Draw tick (26.7) |
| Hand clap | 100 | 100 | 100 | 100 | No |
| Two hand wave | 100 | 100 | 100 | 100 | No |
| Side boxing | 100 | 100 | 100 | 100 | No |
| Bend | 100 | 100 | 100 | 100 | No |
| Forward kick | 100 | 100 | 100 | 100 | No |
| Side kick | 100 | 100 | 100 | 100 | No |
| Jogging | 100 | 100 | 100 | 100 | No |
| Tennis swing | 94.0 | 100 | 97.0 | 100 | No |
| Tennis serve | 100 | 100 | 100 | 100 | No |
| Golf swing | 100 | 100 | 100 | 100 | No |
| Pick up and throw | 100 | 100 | 100 | 100 | No |
| Approach | Accuracy (%) |
|---|---|
| SDM-BSM [57] | 89.50 |
| GTI-BoVW [58] | 91.92 |
| Depth WDMM [55] | 81.05 |
| RGB-VCDN [59] | 84.32 |
| VCDN [59] | 88.72 |
| Binary Silhouette [60] | 91.97 |
| DMM-UDTCWT [56] | 94.2 |
| Stridden DMM-UDTCWT [56] | 94.6 |
| VCA [61] | 89.31 |
| CAM [62] | 87.24 |
| Depth+3D CNN [29] | 92.9 |
| (DFS+TMFS)+DenseNet121+MHSA+BLSTM | 90.9 |
| (DFS+TMFS)+DenseNet121+BLSTM+MHSA (Ours) | 95.2 |
| Class | Precision | Recall | F1-Score | Accuracy (%) | Confusion (%) |
|---|---|---|---|---|---|
| Bend | 91.0 | 100 | 95.0 | 100 | No |
| Jack | 100 | 100 | 100 | 100 | No |
| Jump | 83.0 | 100 | 91.0 | 100 | No |
| Pjump | 100 | 100 | 100 | 100 | No |
| Run | 100 | 100 | 100 | 100 | No |
| Side | 100 | 100 | 100 | 100 | No |
| Skip | 100 | 80.0 | 89.0 | 80.0 | Jump (20.0) |
| Walk | 100 | 100 | 100 | 100 | No |
| One-hand-wave | 100 | 100 | 100 | 100 | No |
| Two-hand-wave | 100 | 100 | 100 | 100 | No |
| Front-clap | 100 | 100 | 100 | 100 | No |
| Arm-swing | 100 | 100 | 100 | 100 | No |
| Leg-kick | 91.0 | 100 | 95.0 | 100 | No |
| Rod-swing | 80.0 | 80.0 | 80.0 | 80.0 | Golf-swing (20.0) |
| Side-box | 100 | 90.0 | 95.0 | 90.0 | Rod-swing (10.0) |
| Side-clap | 100 | 100 | 100 | 100 | No |
| Arm-curl | 100 | 100 | 100 | 100 | No |
| Leg-curl | 100 | 90.0 | 95.0 | 90.0 | Bend (10.0) |
| Golf-swing | 70.0 | 70.0 | 70.0 | 70.0 | Rod-swing (10.0), Pitch (20.0) |
| Front-box | 100 | 100 | 100 | 100 | No |
| Tai-chi | 100 | 100 | 100 | 100 | No |
| Pitch | 82.0 | 90.0 | 86.0 | 90.0 | Golf-swing (10.0) |
| Kick | 100 | 90.0 | 95.0 | 90.0 | Leg-kick (10.0) |
| Approach | MSRAction3D Test Set | DHA Test Set |
|---|---|---|
| Single-stream: DFS+DenseNet121+BLSTM+MHSA | 64.8 | 82.2 |
| Three-stream: TMFS+DenseNet121+BLSTM+MHSA | 93.7 | 93.4 |
| Four-stream: (DFS+TMFS)+DenseNet121+BLSTM+MHSA | 96 | 95.2 |
| Approach | MSRAction3D Test Set | DHA Test Set |
|---|---|---|
| (DFS+TMFS)+ResNet101V2+BLSTM+MHSA | 89.3 | 91.3 |
| (DFS+TMFS)+DenseNet169+BLSTM+MHSA | 93.4 | 93.9 |
| (DFS+TMFS)+DenseNet121+BLSTM+MHSA | 96 | 95.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulbul, M.F.; Ullah, A.; Ali, H.; Kim, D. A Deep Sequence Learning Framework for Action Recognition in Small-Scale Depth Video Dataset. Sensors 2022, 22, 6841. https://doi.org/10.3390/s22186841
Bulbul MF, Ullah A, Ali H, Kim D. A Deep Sequence Learning Framework for Action Recognition in Small-Scale Depth Video Dataset. Sensors. 2022; 22(18):6841. https://doi.org/10.3390/s22186841
Chicago/Turabian StyleBulbul, Mohammad Farhad, Amin Ullah, Hazrat Ali, and Daijin Kim. 2022. "A Deep Sequence Learning Framework for Action Recognition in Small-Scale Depth Video Dataset" Sensors 22, no. 18: 6841. https://doi.org/10.3390/s22186841
APA StyleBulbul, M. F., Ullah, A., Ali, H., & Kim, D. (2022). A Deep Sequence Learning Framework for Action Recognition in Small-Scale Depth Video Dataset. Sensors, 22(18), 6841. https://doi.org/10.3390/s22186841