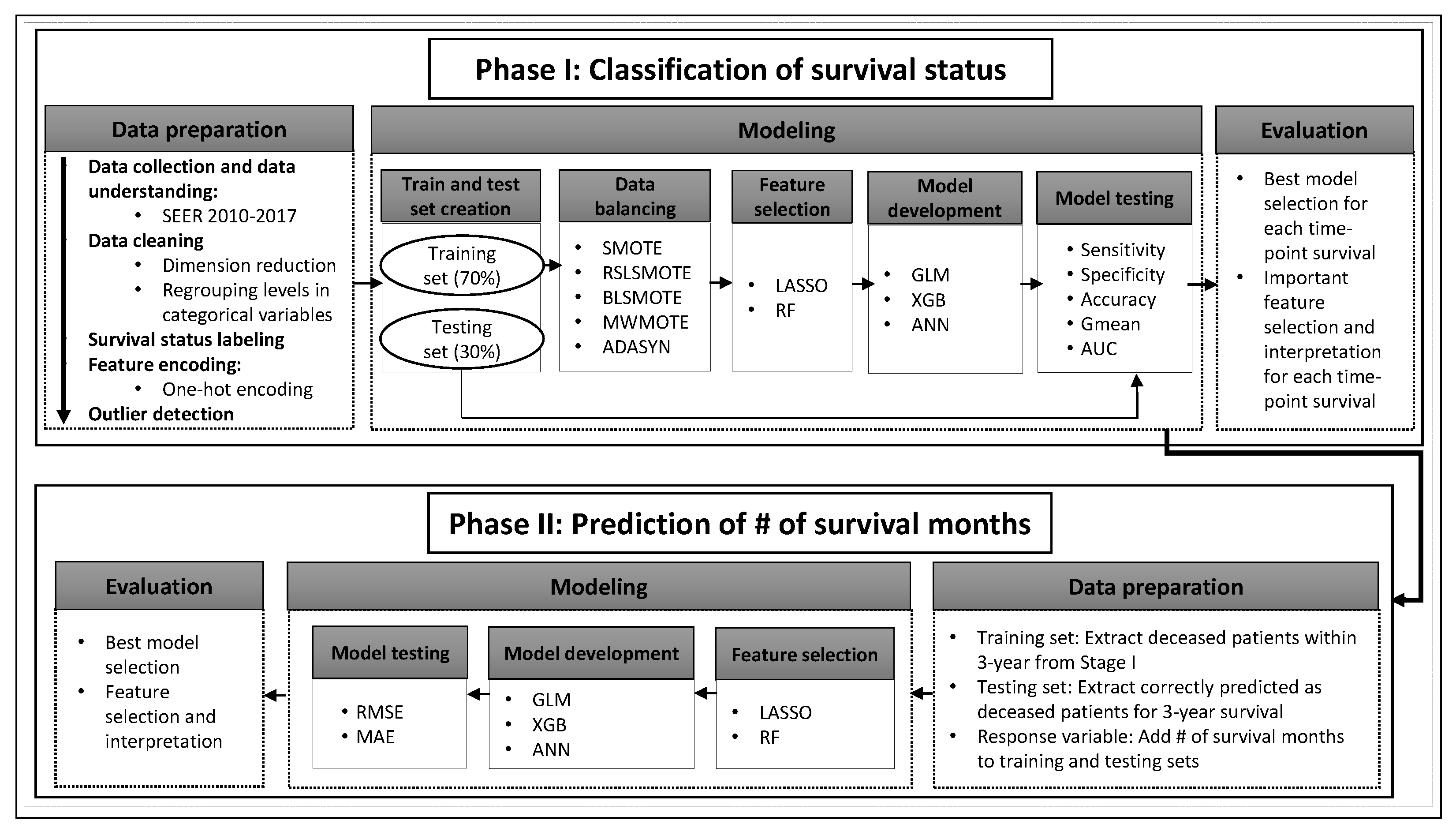
In this section, we present the prediction results for phases I and II. For phase I, due to the computational cost of XGB and ANN models, we prune the total number of model combinations, which take into account two feature selection methods and five resampling approaches. Firstly, we develop all model combinations for 1-year survival prediction and identify the best feature selection method and data balancing technique for GLM, XGB and ANN models (
Table 4). These initial model benchmarks are based on 1-year survival data, which contain the largest number of observations compared to other time-points, with the exception of six-month survival. In addition to having a substantial sample size (high reliability), 1-year survival is one of the most commonly reported time-points in the literature [
7,
15,
17]. We use these benchmark results to delimit the best feature selection and data balancing methods. Next, we combine the top feature selection and data balancing techniques found in
Table 4 with GLM, XGB, and ANN for 0.5-, 1.5-, 2-, 2.5-, and 3-year survival prediction (
Table 5).
3.1. Phase I: Classification
Table 4 presents the classification results for 1-year survival prediction. Firstly, LASSO feature selection performs marginally better than RF feature selection across all models and all data balancing techniques using G-mean as a criterion. The G-mean values range between 0.847–0.870 and 0.846–0.858 for all models using LASSO and RF feature selection, respectively. Note that LASSO is computationally efficient compared to RF feature selection. Second, the use of ADASYN for data balancing provides equal or higher G-mean values (0.855–0.870) across all models compared to the remaining four data balancing techniques. Models utilizing balancing techniques such as SMOTE and MWMOTE are among the top performing models just below the ADASYN method. The best-performing GLM, XGB, and ANN models based on the G-mean metric (marked in bold in
Table 4) are used in 0.5-, 1.5-, 2-, 2.5-, and 3-year survival predictions.
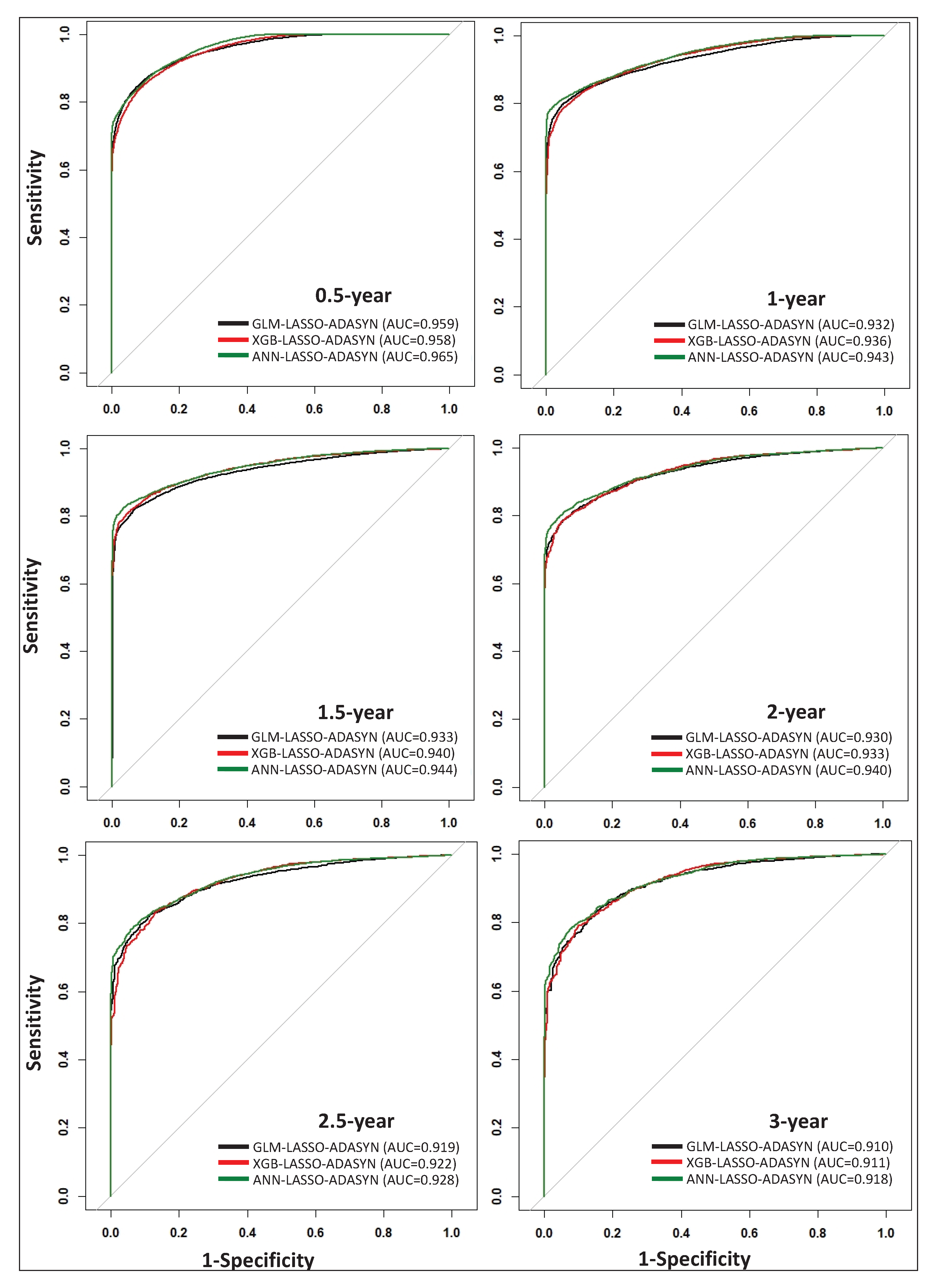
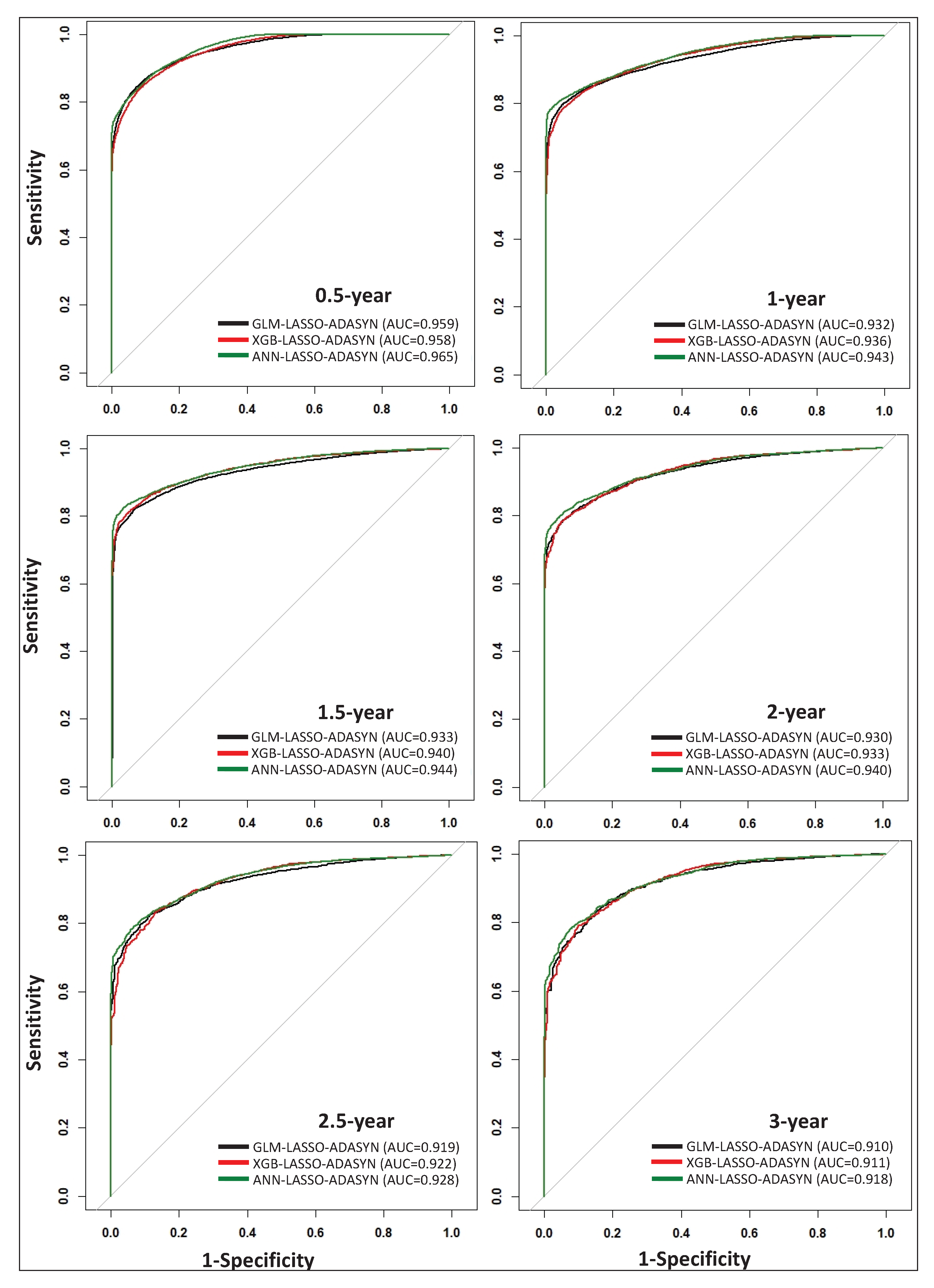
Table 5 presents the classification results for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year survival predictions using GLM, XGB, and ANN, along with LASSO feature selection and the ADASYN data balancing technique. The highest-performing models for each of the six time-points are marked in bold using the G-mean value as a criterion. Based on
Table 5, GLM is the top model for 0.5-year survival prediction, with a G-mean value of 0.887, while ANN is the top-performing model for 1-, 1.5-, 2-, 2.5-, and 3-year survival prediction. Although ANN models exhibit higher performance compared to GLM and XGB for 1-, 1.5-, 2-, 2.5-, and 3-year survival prediction, the G-mean values for GLM and XGB are nearly on par with those offered by ANN models. Additionally, ROC curves for all models listed in
Table 5 are plotted in
Figure 2, which visually demonstrates the comparable performance of each technique. By incorporating a thorough data scheme within our model framework, we demonstrate that simple models such as GLM can perform comparably to more complex models such as XGB and ANN.
3.2. Important Features for Survival Prediction
We use the GLM–LASSO–ADASYN models to extract the topmost significant survival predictors for all time-points (see
supplementary materials https://github.com/zahrame/LungCancerPrediction for a list of GLM equations). Besides their interpretability, GLM models provide relatively high classification results (see
Table 5) at low computational cost. We define the odds ratio (OR
in which
p is the probability of survival) and calculate the relative change in OR (
OR) to quantify the impact of each important feature based on its respective GLM coefficient:
By defining the difference between the odds (
) of an individual feature increasing by one unit (
) and exponentiating both sides of the equation, we can decouple each feature’s effect on the odds of survival (confined within the logarithmic function of Equation (
7)). By subtracting one from the results, we obtain the effective change in the odds ratio (Equation (
8)) by an individual feature [
23].
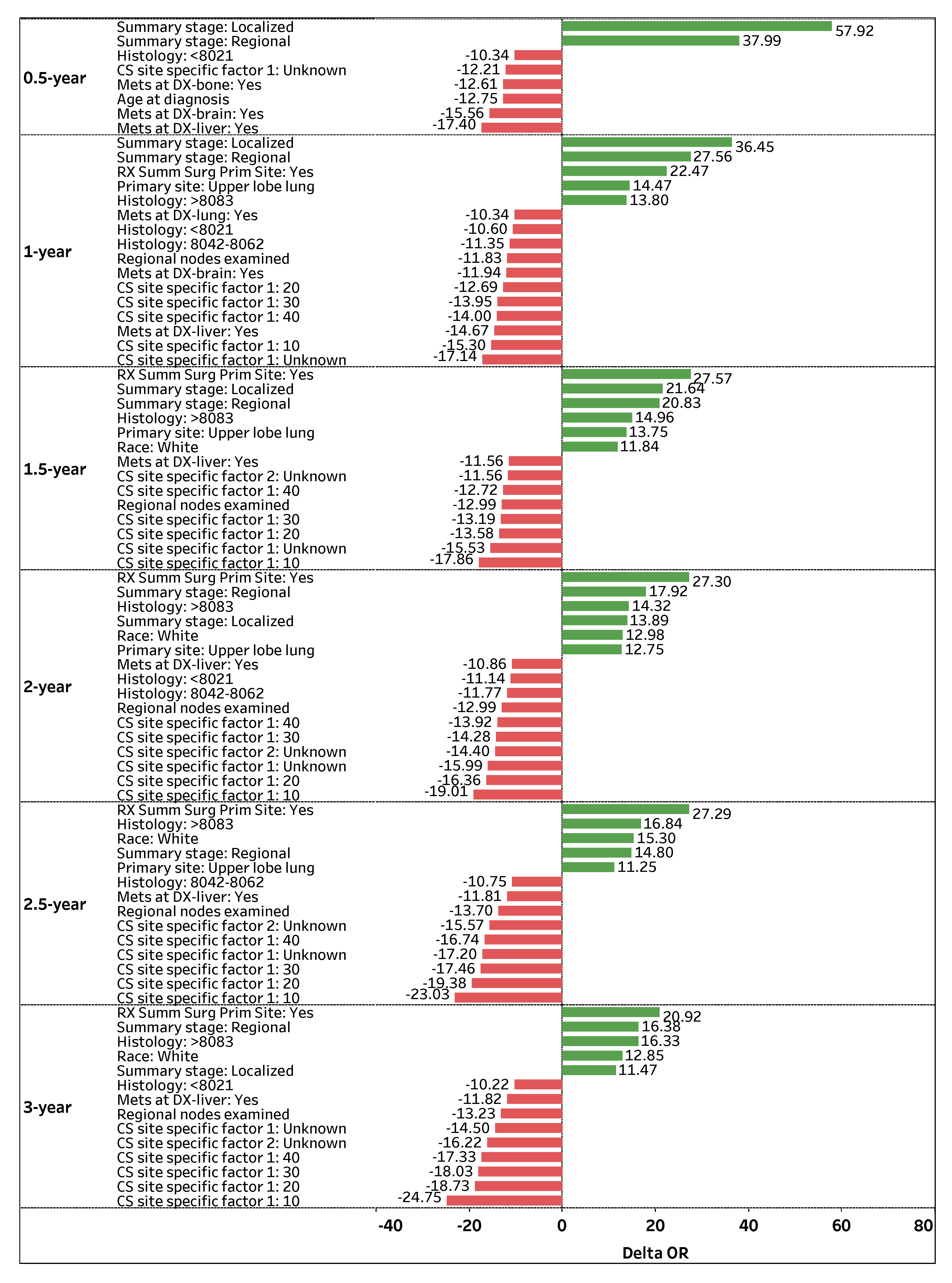
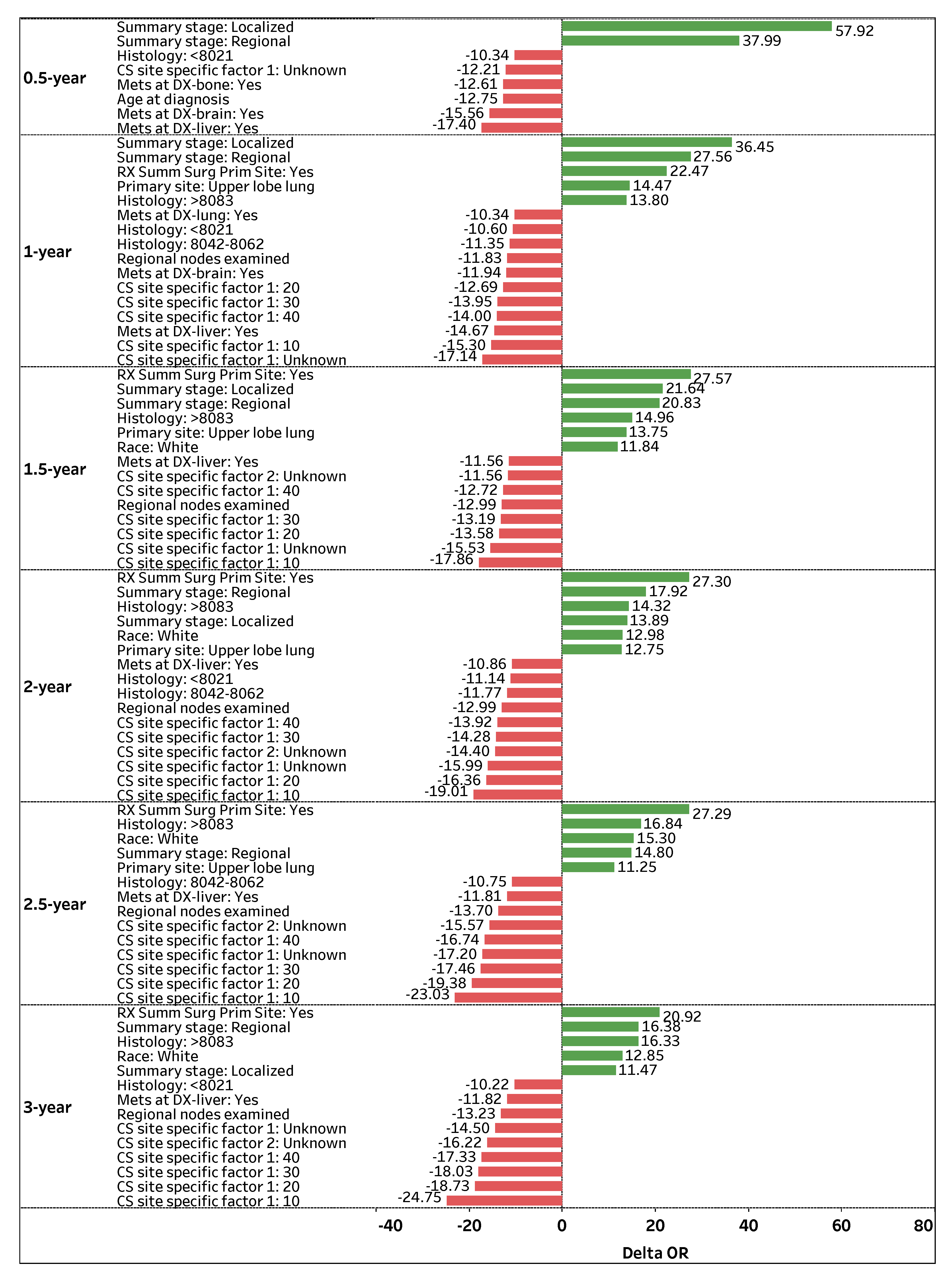
Figure 3 visualizes the top-contributing features with
OR values greater than
for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year survival predictions. The green positive (red negative) bars correspond to an increase (decrease) in the odds of survival.
Summary stage: Regional is a highly significant and consistent feature that positively impacts (OR > 0) a patient’s odds of survival across all time-points. If the spread of lung cancer (Summary stage) in a patient is categorized as Regional, the odds of survival are 37.99%, 27.56%, 21.64%, 17.92%, 14.80%, and 16.38% higher on average (holding other features constant) for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points, respectively. Similarly, Summary stage: Localized is a significant feature that positively affects a patient’s survival status, particularly for early time-points. If the spread of lung cancer is categorized as Localized, the odds of survival are 57.92%, 36.45%, 21.64%, 13.89%, and 11.47% higher on average (holding other features constant) for 0.5-, 1-, 1.5-, 2-, and 3-year time-points, respectively.
Another prominent feature that positively contributes to patient survival is
RX Summ Surg Prim Site: Yes, a feature that documents if a surgery procedure is performed on the primary cancer site.
Figure 3 shows that if surgery is performed on a primary site, a patient’s odds of survival are 22.47%, 27.57%, 27.30%, 27.29%, and 20.92% higher on average (holding other features constant) for 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points, respectively. Regarding primary cancer sites,
Primary site: Upper lobe lung is attributed to higher odds of survival for several time-points. If the primary cancer site of a patient is
Upper lobe lung, the patient’s odds of survival are 14.47%, 13.75%, 12.75%, and 11.25% higher on average (holding other features constant) for 1-, 1.5-, 2-, and 2.5-year survival time-points, respectively.
In contrast, CS site specific factor 1: Unknown is one of the most significant and consistent features that negatively impacts (OR < 0) a patient’s odds of survival across all time-points. If the existence of separate tumor nodules (CS site specific factor 1) cannot be assessed in a patient’s ipsilateral lung, the odds of survival are 12.21%, 17.14%, 15.53%, 15.99%, 17.20%, and 14.5% lower on average (holding other features constant) for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points, respectively. Note that the presence of separate tumor nodules in the ipsilateral lung (CS site specific factor 1: 10, 20, 30, and 40) is highly significant, which negatively impacts (OR < 0) a patient’s survival status for 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points.
Mets at DX-liver: Yes is another significant and consistent feature that negatively affects a patient’s odds of survival. If a patient experiences a distant metastatic involvement of the liver, the odds of survival are 17.40%, 14.67%, 11.56%, 10.86%, 11.81%, and 11.82% lower on average (holding other features constant) for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points, respectively. Moreover, Regional nodes examined is a vital feature that negatively affects a patient’s odds of survival. If the number of removed and examined regional lymph nodes for a patient increases by one node, the patient’s odds of survival are 11.83%, 12.99%, 12.99%, 13.7%, and 13.23% lower (holding other features constant) for 1-, 1.5-, 2-, 2.5-, and 3-year survival time-points, respectively.
3.3. Phase II: Regression
Table 6 presents the number of survival months prediction results for deceased patients within 3 years, where the best models are marked in bold. Similar to phase I, LASSO outperforms RF feature selection with marginally smaller values of RMSE and MAE for each model methodology. The GLM and XGB models offer similar survival month prediction performance with an MAE ∼ 5.6 months. Even though ANN is a more complex model compared to GLM and XGB, the MAE values for ANN using LASSO and RF feature selection are ∼6.7 and ∼7.1 months, respectively. These findings illustrate that although ANN outperforms GLM and XGB in classification problems (phase I), ANN is not guaranteed to outperform the simpler models in regression problems (phase II).
Similar to phase I, we use the GLM–LASSO model to extract significant features and their coefficients (see
supplementary https://github.com/zahrame/LungCancerPrediction for a list of GLM equations).
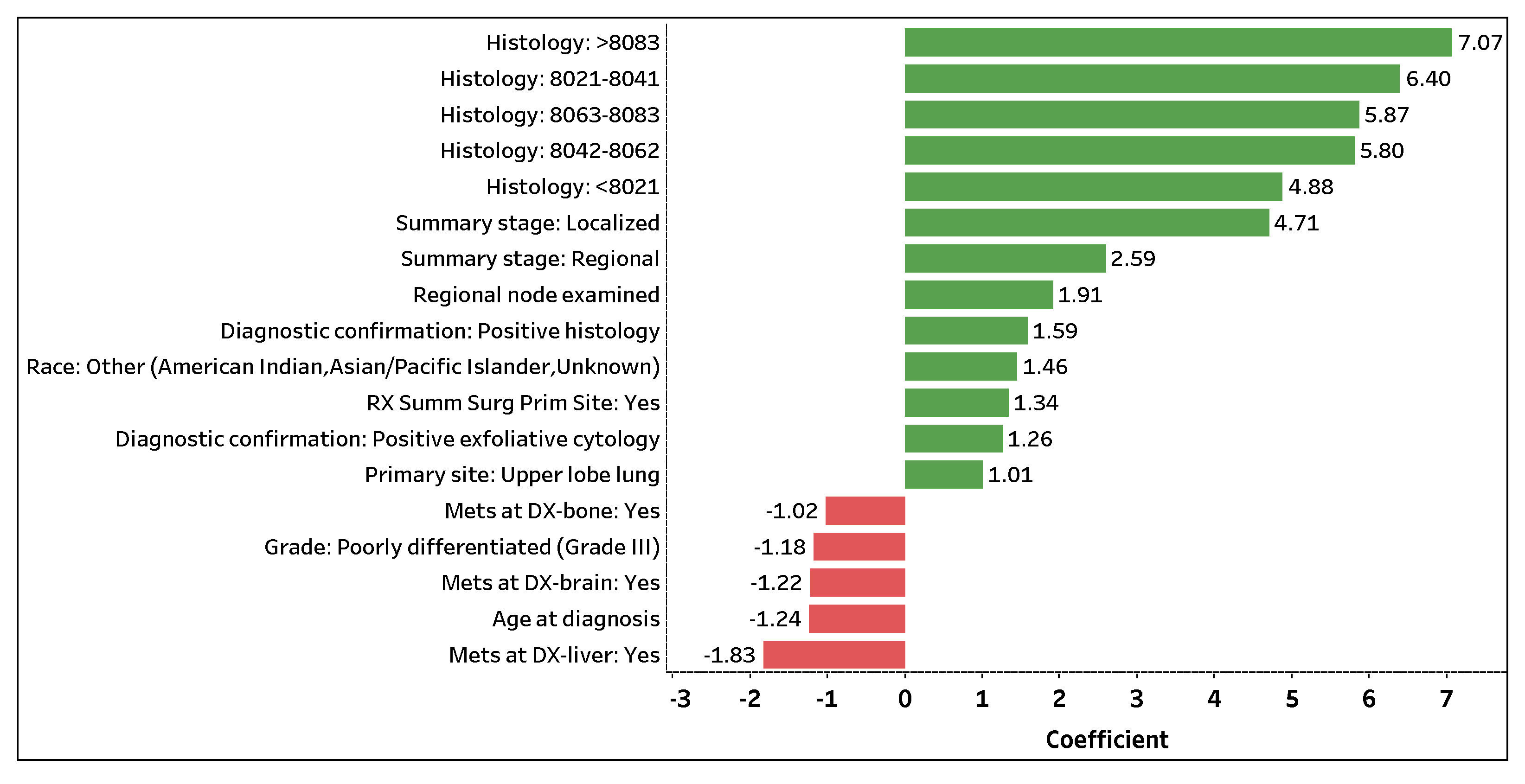
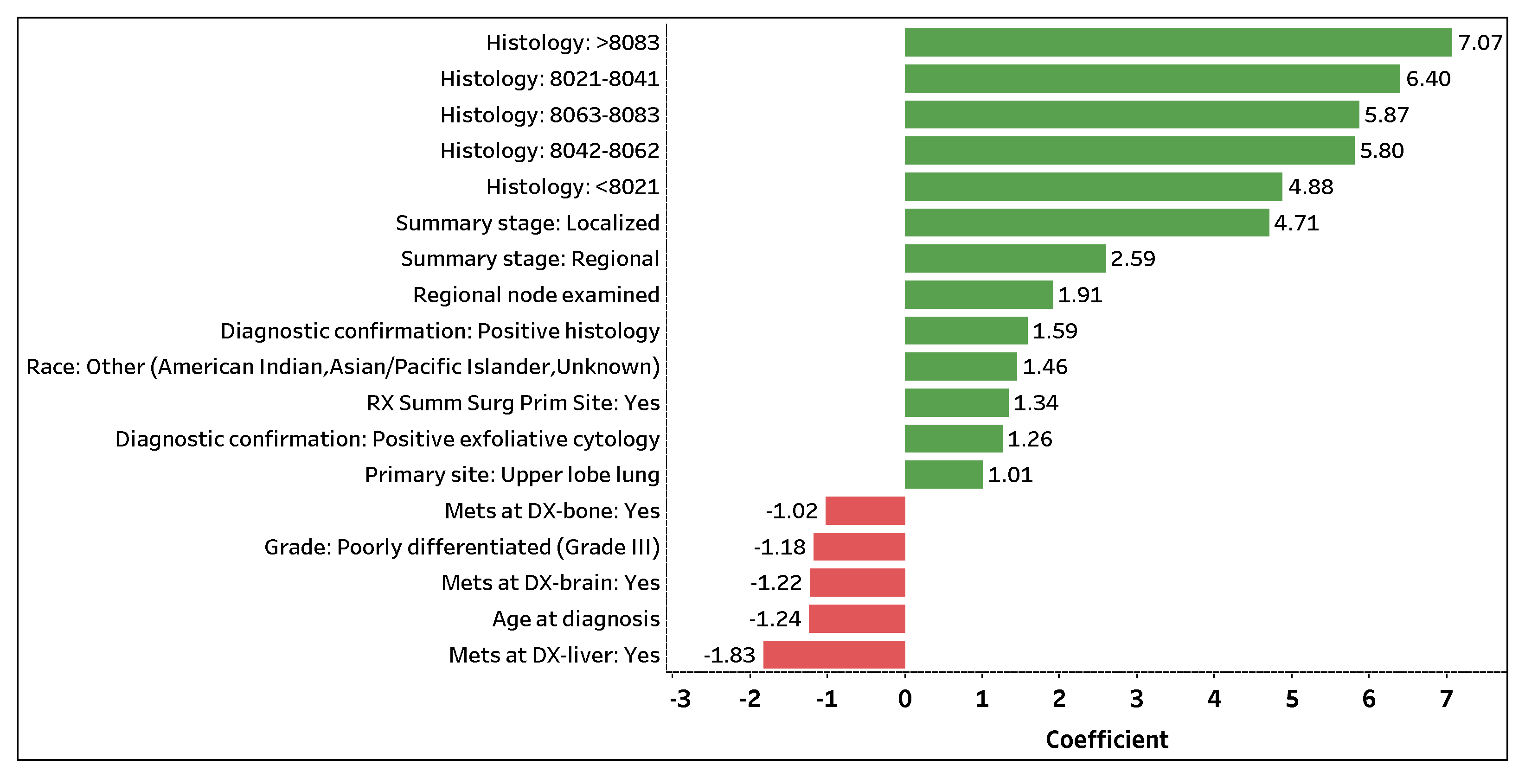
Figure 4 visualizes the top 18 contributing features with coefficient values greater than
that predict the number of survival months. The 13 (5) features with positive green (negative red) bars are attributed to an increase (decrease) in the number of survival months.
Histology: >8083 is the topmost significant feature that positively impacts the number of survival months. If a patient (predicted to perish) is assigned a histology code greater than 8083, the patient is expected to survive 7.07 months longer on average (holding other features constant). Note that a patient (predicted to perish) assigned a histology code, regardless of carcinoma group type, is expected to live several months longer on average compared to a patient who was not or could not be assigned a code (holding other features constant).
Summary stage: Localized and Summary stage: Regional are the next important features that positively contribute to the number of survival months. If the spread of lung cancer in a patient (predicted to perish) is localized or regional, the patient is expected to survive 4.71 or 2.59 months longer on average (holding other features constant), respectively. Additionally, Regional nodes examined and RX Summ Surg Prime Site: Yes are significant features in predicting the number of survival months of a lung cancer patient. If a patient (predicted to perish) has an additional lymph node removed and examined or has surgery performed on a primary cancer site, the patient is expected to live 1.91 or 1.34 months longer on average (holding other features constant). Note that a higher number of examined regional lymph nodes implies a decrease in a patient’s odds of survival (phase I); yet, with the removal and examination of additional lymph nodes, the survival length of a patient expected to perish may be prolonged (holding other features constant).
Contrarily, Mets at DX-liver: Yes is the top significant feature that negatively affects the number of survival months. If distant liver metastases have formed in a patient (predicted to perish), the patient is expected to live 1.83 months less on average (holding other features constant). Moreover, if distant brain (Mets at DX-brain: Yes) or bone (Mets at DX-bone: Yes) metastases have formed in a patient (predicted to perish), the patient is expected to live 1.22 or 1.02 months less on average (holding other features constant), respectively. For every additional year in age (Age at diagnosis), a patient (predicted to perish) is expected to live 1.24 months less on average (holding other features constant). Lastly, if a patient (predicted to perish) is diagnosed with Grade III lung cancer (Grade: Poorly differentiated (Grade III)), the patient is expected to live 1.18 months less on average (holding other features constant). Similar to phase I, the use of one-hot encoding enables us to not only extract significant categorical levels but to interpret the individual levels.
3.4. Recent Literature Comparison
In spite of the fact that a proper one-to-one comparison between our research and prior lung cancer data mining studies is not possible due to variations in dataset time ranges, feature availability, data collection criteria, data preprocessing techniques, modeling approaches, and prediction time-points, we highlight some similarities and differences to provide a synopsis. In a recent study, Doppalapudi et al. [
13] yielded AUC values as high as 0.83, 0.86, and 0.92 for 0.5-, 0.5–2-, and >2-year survival prediction, respectively, based on 2004–2016 SEER data using CNN. Our data and approach yield AUC values as high as 0.97, 0.94, 0.94, 0.94, 0.93, and 0.92 for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year time-points, respectively (
Figure 2). Similar to our study, Doppalapudi et al. found that
Histology,
Age at diagnosis,
Summary stage, and
Primary site are important lung cancer survival predictors. Unlike our results, Doppalapudi et al. found that
Registry information,
Sex,
Number of radiation rounds, and two discontinued variables (
Number of lymph nodes and
Derived AJCC TNM) in the SEER dataset are important features. Although this study reports the relative importance of various contributing features in survival prediction, the effect of each feature is not quantified.
In another recent study, Wang et al. [
7] achieved accuracies (AUC was not reported) of 0.93, 0.78, and 0.72 for 1-, 3-, and 5-year survival prediction, respectively, based on 2010–2015 SEER data using XGB and LR. Our study yields accuracies as high as 0.89, 0.86, 0.87, 0.86, 0.85, and 0.84 for 0.5-, 1-, 1.5-, 2-, 2.5-, and 3-year time-points, respectively. The important predictors
Surgery,
Grade,
Histology,
Age at diagnosis, and
Race found by Wang et al. are consistent with our results; however,
Laterality,
Sex,
Marital status, and
Derived AJCC TNM (a discontinued variable in SEER data) are not. In addition, Jonson et al. [
14] yielded an AUC value of 0.94 for 5-year survival prediction based on 1975–2015 SEER data using RF and AdaBoost models. Although Jonson et al. explored intermediate-term survival, they found that
Age at diagnosis,
Histology,
Surgery on primary site, and
Summary stage are important features for survival prediction, similarly found in our study for short-term survival. Jonson et al. also found that
Sequence Number (used as one of our criteria for data collection) and two discontinued variables (
Number of lymph nodes and
Extent of disease) are important predictors, which differ from our study. Again, the impact of each feature on lung cancer survival is not quantified in the latter two studies.








{kind=link}
{kind=link}
{kind=link}
{kind=link}