
A Human Visual System Inspired No-Reference Image Quality Assessment Method Based on Local Feature Descriptors


Abstract
:1. Introduction
1.1. Contributions
1.2. Structure of the Paper
2. Related Work
3. Materials and Methods
3.1. Materials
3.1.1. Applied IQA Benchmark Databases
3.1.2. Evaluation Protocol and Metrics
3.2. Proposed Method
3.3. Bilaplacian Feature Maps
3.4. High-Boost Feature Maps
3.5. Derivative Feature Maps
3.6. Feature Extraction
3.7. Perceptual Quality Estimation
4. Experimental Results
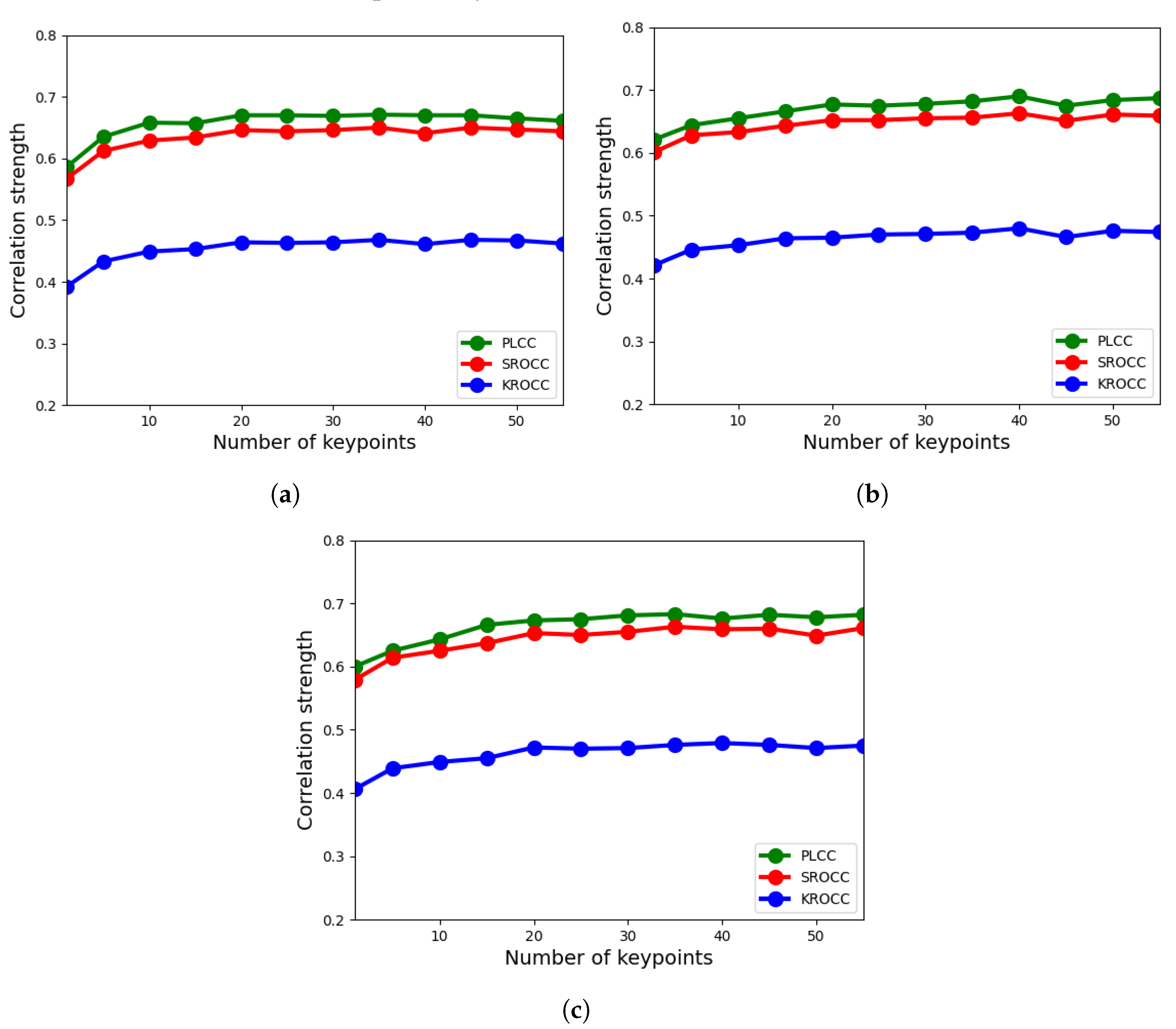
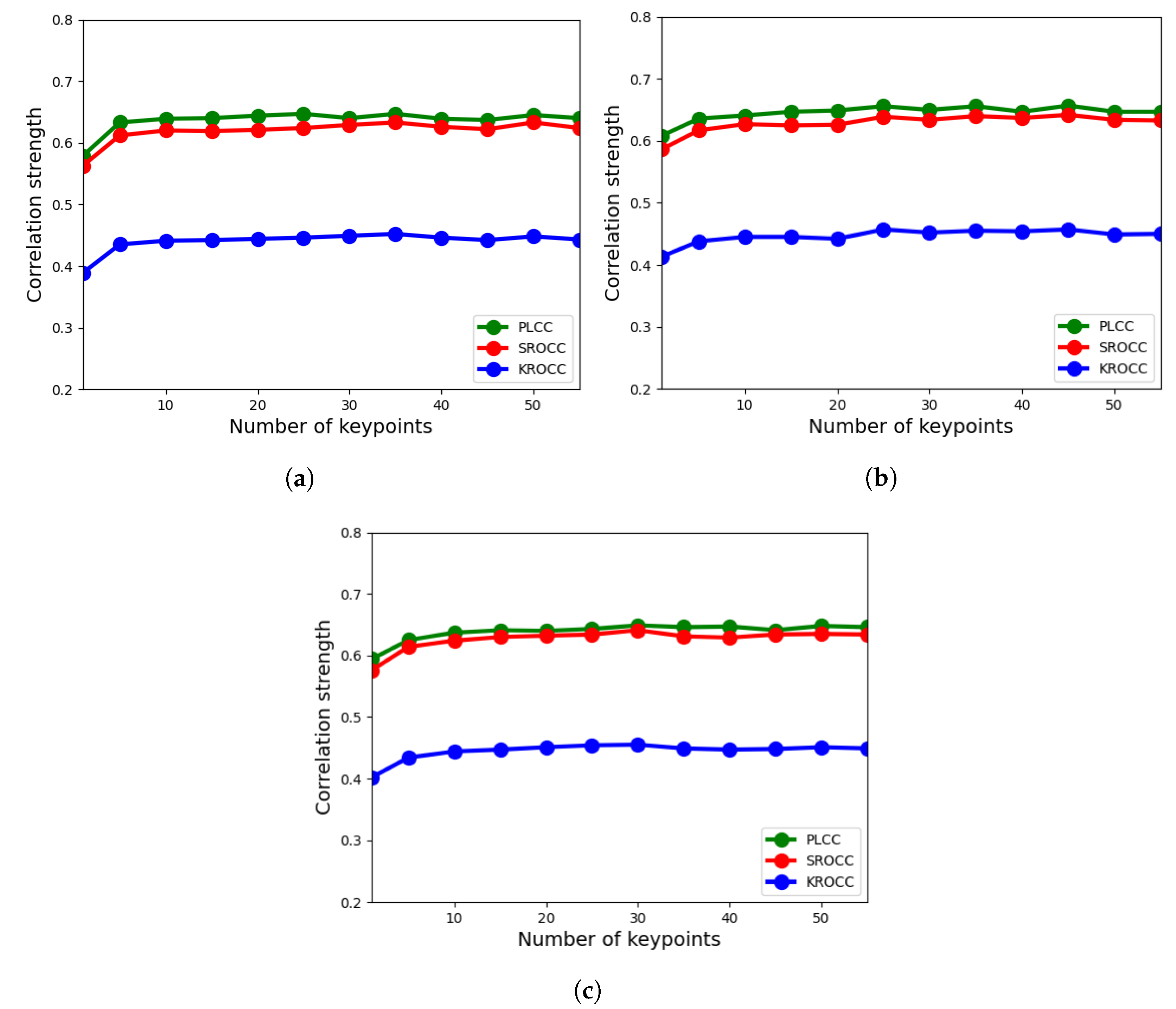
4.1. Ablation Study
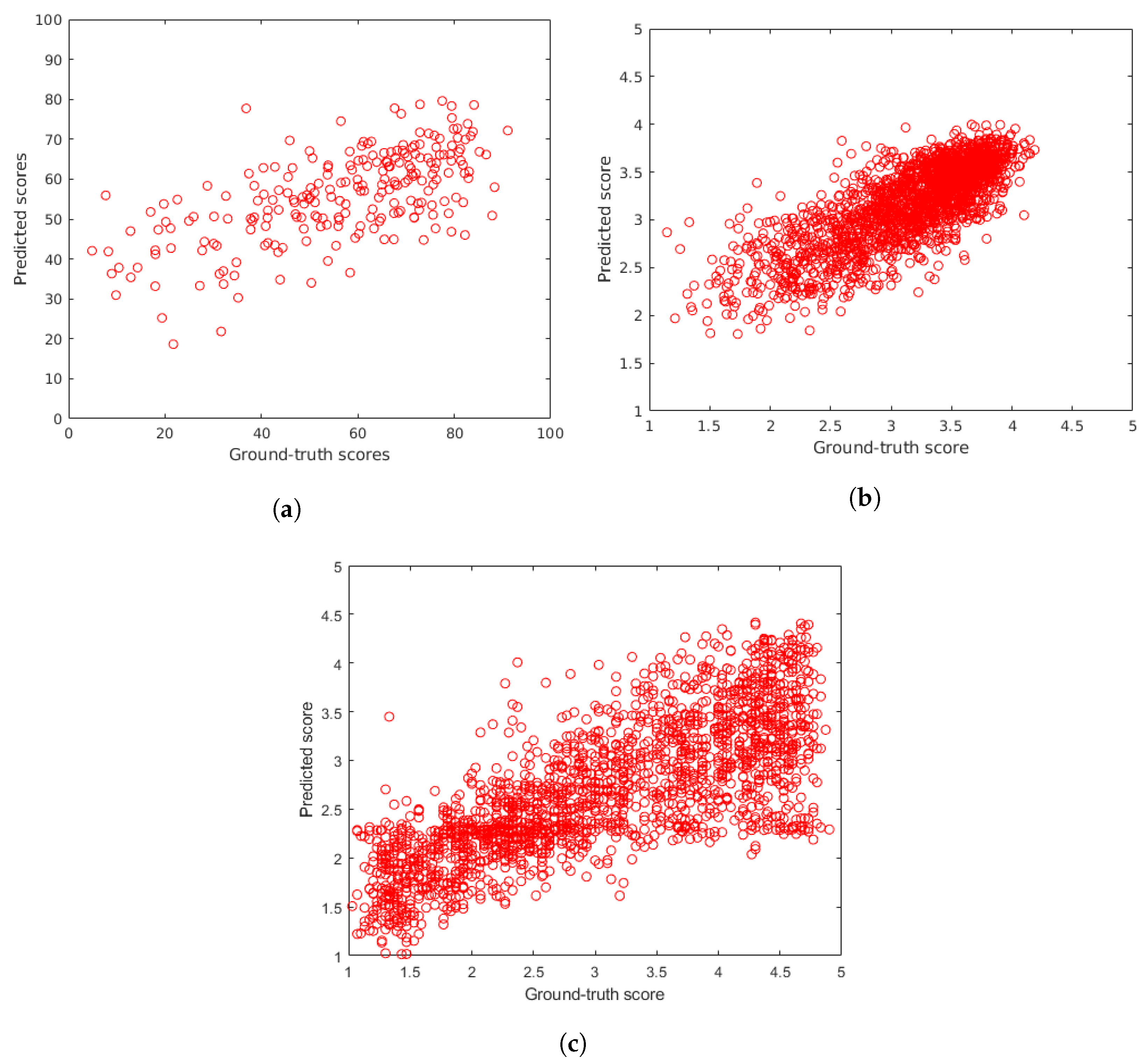
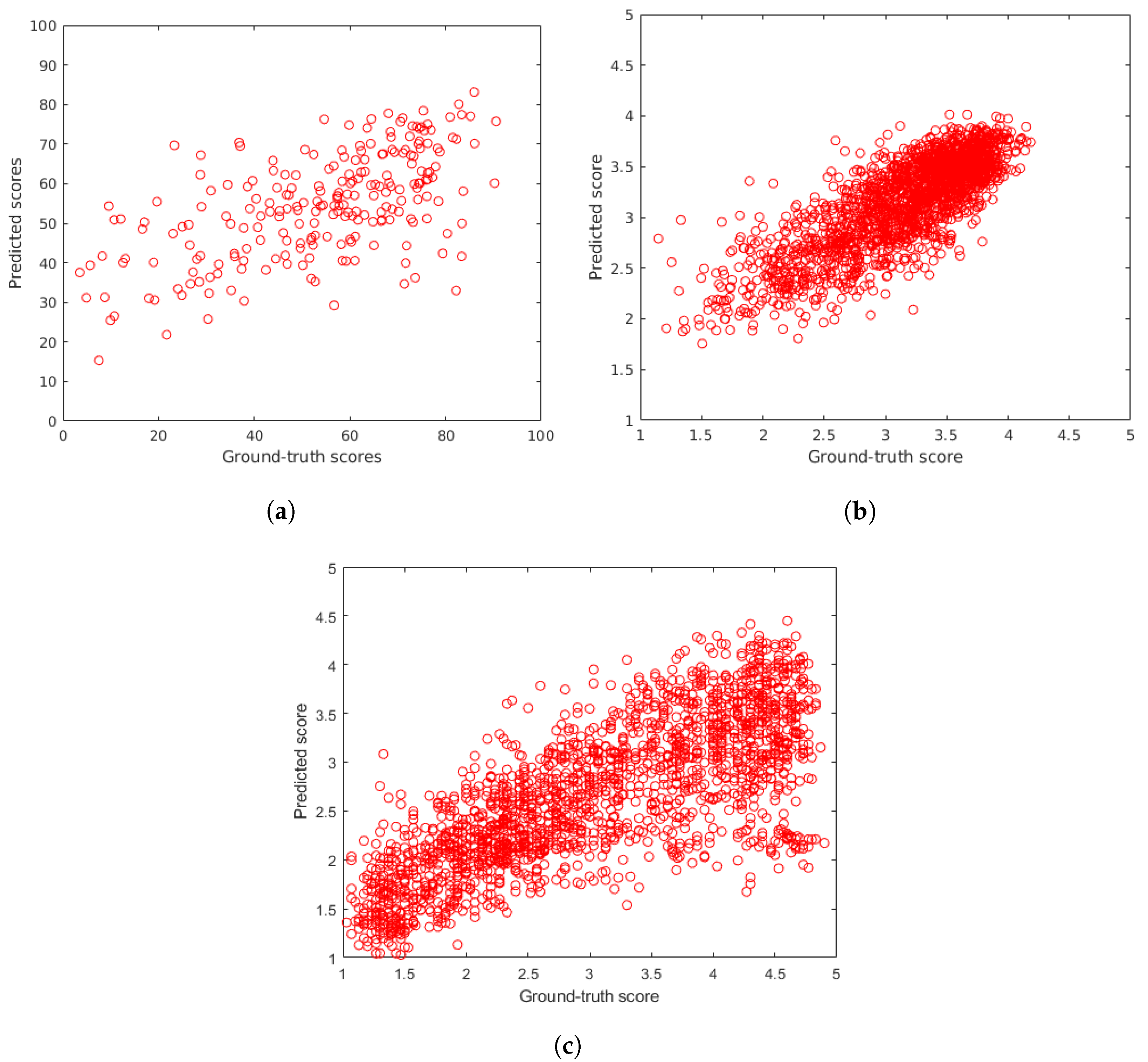
4.2. Comparison to the State-of-the-Art
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BRIEF | binary robust independent elementary features |
| BRISK | binary robust invariant scalable keypoints |
| CNN | convolutional neural network |
| DCT | discrete cosine transform |
| FAST | features from accelerated segment test |
| FR | full-reference |
| GPR | Gaussian process regressor |
| GPU | graphical processing unit |
| HVS | human visual system |
| IQA | image quality assessment |
| KADID | Konstanz artificially distorted image quality database |
| KROCC | Kendall rank order correlation coefficient |
| LIVE | laboratory for image and video engineering |
| NR | no-reference |
| NSS | natural scene statistics |
| ORB | oriented FAST and rotated BRIEF |
| PLCC | Pearson linear correlation coefficient |
| RR | reduced-reference |
| SPAQ | smartphone photography attribute and quality |
| SROCC | Spearman rank order correlation coefficient |
| SURF | speeded up robust features |
| SVR | support vector regressor |
| TID | Tampere image database |
References
- Williams, M.B.; Krupinski, E.A.; Strauss, K.J.; Breeden, W.K., III; Rzeszotarski, M.S.; Applegate, K.; Wyatt, M.; Bjork, S.; Seibert, J.A. Digital radiography image quality: Image acquisition. J. Am. Coll. Radiol. 2007, 4, 371–388. [Google Scholar] [CrossRef] [PubMed]
- Ma, K.; Yeganeh, H.; Zeng, K.; Wang, Z. High dynamic range image compression by optimizing tone mapped image quality index. IEEE Trans. Image Process. 2015, 24, 3086–3097. [Google Scholar]
- Flohr, T.; Stierstorfer, K.; Ulzheimer, S.; Bruder, H.; Primak, A.; McCollough, C. Image reconstruction and image quality evaluation for a 64-slice CT scanner with-flying focal spot. Med. Phys. 2005, 32, 2536–2547. [Google Scholar] [CrossRef]
- Rahman, Z.; Jobson, D.J.; Woodell, G.A.; Hines, G.D. Image enhancement, image quality, and noise. In Proceedings of the Photonic Devices and Algorithms for Computing VII, San Diego, CA, USA, 31 July 2005; SPIE: Bellingham, WA, USA, 2005; Volume 5907, pp. 164–178. [Google Scholar]
- Wang, Z. Applications of objective image quality assessment methods [applications corner]. IEEE Signal Process. Mag. 2011, 28, 137–142. [Google Scholar] [CrossRef]
- Woodard, J.P.; Carley-Spencer, M.P. No-reference image quality metrics for structural MRI. Neuroinformatics 2006, 4, 243–262. [Google Scholar] [CrossRef]
- Hung, S.C.; Wu, H.C.; Tseng, M.H. Integrating Image Quality Enhancement Methods and Deep Learning Techniques for Remote Sensing Scene Classification. Appl. Sci. 2021, 11, 11659. [Google Scholar] [CrossRef]
- Lee, C.; Woo, S.; Baek, S.; Han, J.; Chae, J.; Rim, J. Comparison of objective quality models for adaptive bit-streaming services. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Torr, P.H.; Zissermann, A. Performance characterization of fundamental matrix estimation under image degradation. Mach. Vis. Appl. 1997, 9, 321–333. [Google Scholar] [CrossRef]
- Chubarau, A.; Akhavan, T.; Yoo, H.; Mantiuk, R.K.; Clark, J. Perceptual image quality assessment for various viewing conditions and display systems. Electron. Imaging 2020, 2020, 67-1–67-9. [Google Scholar] [CrossRef]
- Zhai, G.; Min, X. Perceptual image quality assessment: A survey. Sci. China Inf. Sci. 2020, 63, 211301. [Google Scholar] [CrossRef]
- Shao, F.; Tian, W.; Lin, W.; Jiang, G.; Dai, Q. Toward a blind deep quality evaluator for stereoscopic images based on monocular and binocular interactions. IEEE Trans. Image Process. 2016, 25, 2059–2074. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Freitas, P.G.; Da Eira, L.P.; Santos, S.S.; de Farias, M.C.Q. On the Application LBP Texture Descriptors and Its Variants for No-Reference Image Quality Assessment. J. Imaging 2018, 4, 114. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Lin, W.; Shi, G. Image quality assessment with degradation on spatial structure. IEEE Signal Process. Lett. 2014, 21, 437–440. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Quality Assessment of Authentically Distorted Images Based on Local and Global Features. J. Imaging 2022, 8, 173. [Google Scholar] [CrossRef] [PubMed]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Computer Vision—ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 214–227. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Liu, G.H.; Li, Z.Y.; Zhang, L.; Xu, Y. Image retrieval based on micro-structure descriptor. Pattern Recognit. 2011, 44, 2123–2133. [Google Scholar] [CrossRef]
- Manjunath, B.S.; Ma, W.Y. Texture features for browsing and retrieval of image data. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 837–842. [Google Scholar] [CrossRef]
- Ghadiyaram, D.; Bovik, A.C. Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans. Image Process. 2015, 25, 372–387. [Google Scholar] [CrossRef]
- Lin, H.; Hosu, V.; Saupe, D. KonIQ-10K: Towards an ecologically valid and large-scale IQA database. arXiv 2018, arXiv:1803.08489. [Google Scholar]
- Fang, Y.; Zhu, H.; Zeng, Y.; Ma, K.; Wang, Z. Perceptual quality assessment of smartphone photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3677–3686. [Google Scholar]
- Ponomarenko, N.; Jin, L.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Astola, J.; Vozel, B.; Chehdi, K.; Carli, M.; Battisti, F.; et al. Image database TID2013: Peculiarities, results and perspectives. Signal Process. Image Commun. 2015, 30, 57–77. [Google Scholar] [CrossRef]
- Lin, H.; Hosu, V.; Saupe, D. KADID-10k: A large-scale artificially distorted IQA database. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–3. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bovik, A.C. A feature-enriched completely blind image quality evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT statistics-based blind image quality index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef]
- Priya, K.M.; Channappayya, S.S. A novel sparsity-inspired blind image quality assessment algorithm. In Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Atlanta, GA, USA, 3–5 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 984–988. [Google Scholar]
- Leonardi, M.; Napoletano, P.; Schettini, R.; Rozza, A. No Reference, Opinion Unaware Image Quality Assessment by Anomaly Detection. Sensors 2021, 21, 994. [Google Scholar] [CrossRef] [PubMed]
- Mishkin, D.; Sergievskiy, N.; Matas, J. Systematic evaluation of convolution neural network advances on the imagenet. Comput. Vis. Image Underst. 2017, 161, 11–19. [Google Scholar] [CrossRef]
- Reinagel, P.; Zador, A.M. Natural scene statistics at the centre of gaze. Netw. Comput. Neural Syst. 1999, 10, 341. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C.; Cormack, L. No-reference quality assessment using natural scene statistics: JPEG2000. IEEE Trans. Image Process. 2005, 14, 1918–1927. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [PubMed]
- Liu, L.; Dong, H.; Huang, H.; Bovik, A.C. No-reference image quality assessment in curvelet domain. Signal Process. Image Commun. 2014, 29, 494–505. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef]
- Jenadeleh, M.; Moghaddam, M.E. BIQWS: Efficient Wakeby modeling of natural scene statistics for blind image quality assessment. Multimed. Tools Appl. 2017, 76, 13859–13880. [Google Scholar] [CrossRef]
- Simoncelli, E.P.; Freeman, W.T.; Adelson, E.H.; Heeger, D.J. Shiftable multiscale transforms. IEEE Trans. Inf. Theory 1992, 38, 587–607. [Google Scholar] [CrossRef] [Green Version]
- Bagade, J.V.; Singh, K.; Dandawate, Y.H. No reference image quality assessment with shape adaptive discrete wavelet features using neuro-wavelet model. Multimed. Tools Appl. 2022, 81, 31145–31160. [Google Scholar] [CrossRef]
- Jenadeleh, M.; Masaeli, M.M.; Moghaddam, M.E. Blind image quality assessment based on aesthetic and statistical quality-aware features. J. Electron. Imaging 2017, 26, 043018. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- El-Nouby, A.; Neverova, N.; Laptev, I.; Jégou, H. Training vision transformers for image retrieval. arXiv 2021, arXiv:2102.05644. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5187–5196. [Google Scholar]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Conference on cOmputer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar]
- Kim, J.; Lee, S. Fully deep blind image quality predictor. IEEE J. Sel. Top. Signal Process. 2016, 11, 206–220. [Google Scholar] [CrossRef]
- Bare, B.; Li, K.; Yan, B. An accurate deep convolutional neural networks model for no-reference image quality assessment. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1356–1361. [Google Scholar]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Conde, M.V.; Burchi, M.; Timofte, R. Conformer and Blind Noisy Students for Improved Image Quality Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 940–950. [Google Scholar]
- Ayyoubzadeh, S.M.; Royat, A. (ASNA) An Attention-based Siamese-Difference Neural Network with Surrogate Ranking Loss function for Perceptual Image Quality Assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 388–397. [Google Scholar]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. MUSIQ: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5148–5157. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30., 1–11. [Google Scholar]
- Zhu, H.; Zhou, Y.; Shao, Z.; Du, W.L.; Zhao, J.; Yao, R. ARET-IQA: An Aspect-Ratio-Embedded Transformer for Image Quality Assessment. Electronics 2022, 11, 2132. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sun, S.; Yu, T.; Xu, J.; Zhou, W.; Chen, Z. GraphIQA: Learning distortion graph representations for blind image quality assessment. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, W.; Li, X.; Xu, J.; Chen, Z. LIQA: Lifelong blind image quality assessment. IEEE Trans. Multimed. 2022, 1–16. [Google Scholar] [CrossRef]
- Jenadeleh, M. Blind Image and Video Quality Assessment. Ph.D. Thesis; University of Konstanz: Konstanz, Germany, 2018. [Google Scholar]
- Xu, L.; Lin, W.; Kuo, C.C.J. Visual Quality Assessment by Machine Learning; Springer: Singapore, 2015. [Google Scholar]
- Zhou, W.; Chen, Z.; Li, W. Dual-stream interactive networks for no-reference stereoscopic image quality assessment. IEEE Trans. Image Process. 2019, 28, 3946–3958. [Google Scholar] [CrossRef]
- Cui, Y.; Yu, M.; Jiang, Z.; Peng, Z.; Chen, F. Blind light field image quality assessment by analyzing angular-spatial characteristics. Digit. Signal Process. 2021, 117, 103138. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, J.; Jiang, Q.; Chen, Z. No-reference quality assessment for 360-degree images by analysis of multifrequency information and local-global naturalness. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1778–1791. [Google Scholar] [CrossRef]
- Ribeiro, F.; Florencio, D.; Nascimento, V. Crowdsourcing subjective image quality evaluation. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3097–3100. [Google Scholar]
- Xu, Q.; Huang, Q.; Yao, Y. Online crowdsourcing subjective image quality assessment. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 359–368. [Google Scholar]
- Hosu, V.; Lin, H.; Saupe, D. Expertise screening in crowdsourcing image quality. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 28 May–1 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C.; De Veciana, G. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans. Image Process. 2005, 14, 2117–2128. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Lin, W.; Xue, P. Just-noticeable difference estimation with pixels in images. J. Vis. Commun. Image Represent. 2008, 19, 30–41. [Google Scholar] [CrossRef]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Li, Q.; Lin, W.; Fang, Y. No-reference quality assessment for multiply-distorted images in gradient domain. IEEE Signal Process. Lett. 2016, 23, 541–545. [Google Scholar] [CrossRef]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind image quality assessment by relative gradient statistics and adaboosting neural network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Poynton, C.A. A Technical Introduction to Digital Video; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1996. [Google Scholar]
- Gerhard, H.E.; Wichmann, F.A.; Bethge, M. How sensitive is the human visual system to the local statistics of natural images? PLoS Comput. Biol. 2013, 9, e1002873. [Google Scholar] [CrossRef]
- Marr, D.; Hildreth, E. Theory of edge detection. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1980, 207, 187–217. [Google Scholar]
- Ghosh, K.; Sarkar, S.; Bhaumik, K. A possible mechanism of zero-crossing detection using the concept of the extended classical receptive field of retinal ganglion cells. Biol. Cybern. 2005, 93, 1–5. [Google Scholar] [CrossRef]
- Ghosh, K.; Sarkar, S.; Bhaumik, K. Understanding image structure from a new multi-scale representation of higher order derivative filters. Image Vis. Comput. 2007, 25, 1228–1238. [Google Scholar] [CrossRef]
- Patil, S.B.; Patil, B. Automatic Detection of Microaneurysms in Retinal Fundus Images using Modified High Boost Filtering, Line Detectors and OC-SVM. In Proceedings of the 2020 International Conference on Industry 4.0 Technology (I4Tech), Pune, India, 13–15 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 148–153. [Google Scholar]
- Li, Q.; Lin, W.; Fang, Y. No-reference image quality assessment based on high order derivatives. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Huang, D.; Zhu, C.; Wang, Y.; Chen, L. HSOG: A novel local image descriptor based on histograms of the second-order gradients. IEEE Trans. Image Process. 2014, 23, 4680–4695. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1–2, pp. 1508–1515. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, September 1988; The British Machine Vision Association and Society for Pattern Recognition: Durham, UK, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Shi, J.; Tomasi. Good features to track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 593–600. [Google Scholar]
- Moorthy, A.; Bovik, A. A modular framework for constructing blind universal quality indices. IEEE Signal Process. Lett. 2009, 17, 7. [Google Scholar]
- Min, X.; Zhai, G.; Gu, K.; Liu, Y.; Yang, X. Blind image quality estimation via distortion aggravation. IEEE Trans. Broadcast. 2018, 64, 508–517. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Q.; Lin, M.; Yang, G.; He, C. No-reference color image quality assessment: From entropy to perceptual quality. EURASIP J. Image Video Process. 2019, 2019, 77. [Google Scholar] [CrossRef]
- Ou, F.Z.; Wang, Y.G.; Zhu, G. A novel blind image quality assessment method based on refined natural scene statistics. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1004–1008. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Making image quality assessment robust. In Proceedings of the 2012 Conference Record of the Forty Sixth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 4–7 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1718–1722. [Google Scholar]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Zhang, Z.; Dai, G.; Liang, X.; Yu, S.; Li, L.; Xie, Y. Can signal-to-noise ratio perform as a baseline indicator for medical image quality assessment. IEEE Access 2018, 6, 11534–11543. [Google Scholar] [CrossRef]
- Merdjanovska, E.; Rashkovska, A. Cross-Database Generalization of Deep Learning Models for Arrhythmia Classification. In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 346–351. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | CLIVE [21] | KonIQ-10k [22] | SPAQ [23] | TID2013 [24] | KADID-10k [25] |
|---|---|---|---|---|---|
| #Distorted images | 1162 | 10,073 | 11,125 | 3000 | 10,125 |
| #Reference images | - | - | - | 25 | 81 |
| #Distortion types | - | - | - | 24 | 25 |
| #Distortion levels | - | - | - | 5 | 5 |
| Resolution | ∼ | ||||
| #Subjects | 8100 | 1467 | 600 | 971 | 2209 |
| #Annotations | 1400 | 1,200,000 | 186,400 | 27,000 | 303,750 |
| Scale of quality scores | 0–100 | 1–5 | 0–100 | 0–9 | 1–5 |
| Subjective methodology | crowdsourcing | crowdsourcing | laboratory | laboratory | crowdsourcing |
| Year | 2017 | 2018 | 2020 | 2013 | 2019 |
| CLIVE [21] | KonIQ-10k [22] | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BIQI [85] | 0.519 | 0.488 | 0.329 | 0.688 | 0.662 | 0.471 |
| BLIINDS-II [35] | 0.473 | 0.442 | 0.291 | 0.574 | 0.575 | 0.414 |
| BMPRI [86] | 0.541 | 0.487 | 0.333 | 0.637 | 0.619 | 0.421 |
| BRISQUE [36] | 0.524 | 0.497 | 0.345 | 0.707 | 0.677 | 0.494 |
| CurveletQA [37] | 0.636 | 0.621 | 0.421 | 0.730 | 0.718 | 0.495 |
| DIIVINE [38] | 0.617 | 0.580 | 0.405 | 0.709 | 0.693 | 0.471 |
| ENIQA [87] | 0.596 | 0.564 | 0.376 | 0.761 | 0.745 | 0.544 |
| GRAD-LOG-CP [69] | 0.607 | 0.604 | 0.383 | 0.705 | 0.696 | 0.501 |
| GWH-GLBP [70] | 0.584 | 0.559 | 0.395 | 0.723 | 0.698 | 0.507 |
| IL-NIQE [27] | 0.487 | 0.415 | 0.280 | 0.463 | 0.447 | 0.306 |
| NBIQA [88] | 0.629 | 0.604 | 0.427 | 0.771 | 0.749 | 0.515 |
| NIQE [26] | 0.328 | 0.299 | 0.200 | 0.319 | 0.400 | 0.272 |
| OG-IQA [71] | 0.545 | 0.505 | 0.364 | 0.652 | 0.635 | 0.447 |
| PIQE [89] | 0.172 | 0.108 | 0.081 | 0.208 | 0.246 | 0.172 |
| Robust BRISQUE [90] | 0.522 | 0.484 | 0.330 | 0.718 | 0.668 | 0.477 |
| SSEQ [91] | 0.487 | 0.436 | 0.309 | 0.589 | 0.572 | 0.423 |
| LFD-IQA-SVR | 0.669 | 0.647 | 0.464 | 0.786 | 0.769 | 0.569 |
| LFD-IQA-GPR | 0.696 | 0.667 | 0.480 | 0.801 | 0.775 | 0.577 |
| Method | PLCC | SROCC | KROCC |
|---|---|---|---|
| BIQI [85] | 0.783 | 0.776 | 0.566 |
| BLIINDS-II [35] | 0.676 | 0.675 | 0.486 |
| BMPRI [86] | 0.739 | 0.734 | 0.506 |
| BRISQUE [36] | 0.726 | 0.720 | 0.518 |
| CurveletQA [37] | 0.793 | 0.774 | 0.503 |
| DIIVINE [38] | 0.774 | 0.756 | 0.514 |
| ENIQA [87] | 0.813 | 0.804 | 0.603 |
| GRAD-LOG-CP [69] | 0.786 | 0.782 | 0.572 |
| GWH-GLBP [70] | 0.801 | 0.796 | 0.542 |
| IL-NIQE [27] | 0.374 | 0.348 | 0.297 |
| NBIQA [88] | 0.802 | 0.793 | 0.539 |
| NIQE [26] | 0.264 | 0.310 | 0.206 |
| OG-IQA [71] | 0.726 | 0.724 | 0.594 |
| PIQE [89] | 0.211 | 0.156 | 0.091 |
| Robust BRISQUE [90] | 0.735 | 0.731 | 0.524 |
| SSEQ [91] | 0.745 | 0.742 | 0.549 |
| LFD-IQA-SVR | 0.852 | 0.847 | 0.627 |
| LFD-IQA-GPR | 0.869 | 0.864 | 0.664 |
| TID2013 [24] | KADID-10k [25] | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BIQI [85] | 0.468 | 0.296 | 0.207 | 0.302 | 0.294 | 0.206 |
| BLIINDS-II [35] | 0.521 | 0.490 | 0.342 | 0.553 | 0.534 | 0.379 |
| BMPRI [86] | 0.692 | 0.583 | 0.422 | 0.555 | 0.534 | 0.382 |
| BRISQUE [36] | 0.565 | 0.411 | 0.289 | 0.426 | 0.398 | 0.276 |
| CurveletQA [37] | 0.560 | 0.471 | 0.337 | 0.471 | 0.442 | 0.316 |
| DIIVINE [38] | 0.521 | 0.487 | 0.340 | 0.429 | 0.436 | 0.307 |
| ENIQA [87] | 0.596 | 0.545 | 0.385 | 0.637 | 0.641 | 0.466 |
| GRAD-LOG-CP [69] | 0.662 | 0.627 | 0.454 | 0.590 | 0.570 | 0.415 |
| GWH-GLBP [70] | 0.315 | 0.357 | 0.245 | 0.302 | 0.285 | 0.196 |
| IL-NIQE [27] | 0.516 | 0.456 | 0.317 | 0.588 | 0.630 | 0.453 |
| NBIQA [88] | 0.695 | 0.628 | 0.459 | 0.646 | 0.615 | 0.446 |
| NIQE [26] | 0.263 | 0.277 | 0.184 | 0.302 | 0.338 | 0.228 |
| OG-IQA [71] | 0.564 | 0.452 | 0.321 | 0.527 | 0.447 | 0.314 |
| PIQE [89] | 0.491 | 0.364 | 0.255 | 0.289 | 0.237 | 0.201 |
| Robust BRISQUE [90] | 0.487 | 0.315 | 0.218 | 0.375 | 0.301 | 0.209 |
| SSEQ [91] | 0.615 | 0.520 | 0.373 | 0.454 | 0.434 | 0.304 |
| LFD-IQA-SVR | 0.637 | 0.645 | 0.470 | 0.845 | 0.838 | 0.640 |
| LFD-IQA-GPR | 0.705 | 0.669 | 0.492 | 0.857 | 0.848 | 0.654 |
| Direct Average | Weighted Average | |||||
|---|---|---|---|---|---|---|
| Method | PLCC | SROCC | KROCC | PLCC | SROCC | KROCC |
| BIQI [85] | 0.552 | 0.503 | 0.356 | 0.584 | 0.556 | 0.398 |
| BLIINDS-II [35] | 0.559 | 0.543 | 0.382 | 0.592 | 0.583 | 0.416 |
| BMPRI [86] | 0.633 | 0.591 | 0.413 | 0.647 | 0.623 | 0.434 |
| BRISQUE [36] | 0.590 | 0.541 | 0.384 | 0.615 | 0.582 | 0.417 |
| CurveletQA [37] | 0.638 | 0.605 | 0.414 | 0.658 | 0.633 | 0.431 |
| DIIVINE [38] | 0.610 | 0.590 | 0.407 | 0.631 | 0.618 | 0.424 |
| ENIQA [87] | 0.681 | 0.660 | 0.475 | 0.723 | 0.711 | 0.521 |
| GRAD-LOG-CP [69] | 0.670 | 0.656 | 0.465 | 0.691 | 0.678 | 0.491 |
| GWH-GLBP [70] | 0.545 | 0.539 | 0.377 | 0.588 | 0.578 | 0.403 |
| IL-NIQE [27] | 0.486 | 0.459 | 0.331 | 0.476 | 0.468 | 0.345 |
| NBIQA [88] | 0.709 | 0.678 | 0.477 | 0.734 | 0.710 | 0.495 |
| NIQE [26] | 0.295 | 0.325 | 0.218 | 0.292 | 0.340 | 0.229 |
| OG-IQA [71] | 0.603 | 0.553 | 0.408 | 0.629 | 0.590 | 0.442 |
| PIQE [89] | 0.274 | 0.222 | 0.160 | 0.255 | 0.221 | 0.159 |
| Robust BRISQUE [90] | 0.567 | 0.500 | 0.352 | 0.600 | 0.547 | 0.389 |
| SSEQ [91] | 0.578 | 0.541 | 0.392 | 0.598 | 0.577 | 0.421 |
| LFD-IQA-SVR | 0.758 | 0.749 | 0.554 | 0.807 | 0.799 | 0.596 |
| LFD-IQA-GPR | 0.786 | 0.765 | 0.573 | 0.827 | 0.811 | 0.616 |
| Method | CLIVE [21] | KonIQ-10k [22] | SPAQ [23] | TID2013 [24] | KADID-10k [25] |
|---|---|---|---|---|---|
| BIQI [85] | 1 | 1 | 1 | 1 | 1 |
| BLIINDS-II [35] | 1 | 1 | 1 | 1 | 1 |
| BMPRI [86] | 1 | 1 | 1 | 1 | 1 |
| BRISQUE [36] | 1 | 1 | 1 | 1 | 1 |
| CurveletQA [37] | 1 | 1 | 1 | 1 | 1 |
| DIIVINE [38] | 1 | 1 | 1 | 1 | 1 |
| ENIQA [87] | 1 | 1 | 1 | 1 | 1 |
| GRAD-LOG-CP [69] | 1 | 1 | 1 | 1 | 1 |
| GWH-GLBP [70] | 1 | 1 | 1 | 1 | 1 |
| NBIQA [88] | 1 | 1 | 1 | 1 | 1 |
| OG-IQA [71] | 1 | 1 | 1 | 1 | 1 |
| Robust BRISQUE [90] | 1 | 1 | 1 | 1 | 1 |
| SSEQ [91] | 1 | 1 | 1 | 1 | 1 |
| Method | CLIVE [21] | KonIQ-10k [22] | SPAQ [23] | TID2013 [24] | KADID-10k [25] |
|---|---|---|---|---|---|
| BIQI [85] | 1 | 1 | 1 | 1 | 1 |
| BLIINDS-II [35] | 1 | 1 | 1 | 1 | 1 |
| BMPRI [86] | 1 | 1 | 1 | 1 | 1 |
| BRISQUE [36] | 1 | 1 | 1 | 1 | 1 |
| CurveletQA [37] | 1 | 1 | 1 | 1 | 1 |
| DIIVINE [38] | 1 | 1 | 1 | 1 | 1 |
| ENIQA [87] | 1 | 1 | 1 | 1 | 1 |
| GRAD-LOG-CP [69] | 1 | 1 | 1 | 1 | 1 |
| GWH-GLBP [70] | 1 | 1 | 1 | 1 | 1 |
| NBIQA [88] | 1 | 1 | 1 | 1 | 1 |
| OG-IQA [71] | 1 | 1 | 1 | 1 | 1 |
| Robust BRISQUE [90] | 1 | 1 | 1 | 1 | 1 |
| SSEQ [91] | 1 | 1 | 1 | 1 | 1 |
| Method | PLCC | SROCC | KROCC |
|---|---|---|---|
| BIQI [85] | 0.477 | 0.424 | 0.289 |
| BLIINDS-II [35] | 0.107 | 0.090 | 0.063 |
| BMPRI [86] | 0.453 | 0.389 | 0.298 |
| BRISQUE [36] | 0.509 | 0.460 | 0.310 |
| CurveletQA [37] | 0.496 | 0.505 | 0.347 |
| DIIVINE [38] | 0.479 | 0.434 | 0.299 |
| ENIQA [87] | 0.428 | 0.386 | 0.272 |
| GRAD-LOG-CP [69] | 0.427 | 0.384 | 0.261 |
| GWH-GLBP [70] | 0.480 | 0.479 | 0.328 |
| NBIQA [88] | 0.503 | 0.509 | 0.284 |
| OG-IQA [71] | 0.442 | 0.427 | 0.289 |
| Robust BRISQUE [90] | 0.516 | 0.481 | 0.327 |
| SSEQ [91] | 0.270 | 0.256 | 0.170 |
| LFD-IQA-SVR | 0.567 | 0.561 | 0.390 |
| LFD-IQA-GPR | 0.603 | 0.585 | 0.409 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varga, D. A Human Visual System Inspired No-Reference Image Quality Assessment Method Based on Local Feature Descriptors. Sensors 2022, 22, 6775. https://doi.org/10.3390/s22186775
Varga D. A Human Visual System Inspired No-Reference Image Quality Assessment Method Based on Local Feature Descriptors. Sensors. 2022; 22(18):6775. https://doi.org/10.3390/s22186775
Chicago/Turabian StyleVarga, Domonkos. 2022. "A Human Visual System Inspired No-Reference Image Quality Assessment Method Based on Local Feature Descriptors" Sensors 22, no. 18: 6775. https://doi.org/10.3390/s22186775
APA StyleVarga, D. (2022). A Human Visual System Inspired No-Reference Image Quality Assessment Method Based on Local Feature Descriptors. Sensors, 22(18), 6775. https://doi.org/10.3390/s22186775