1. Introduction
In the modern battlefield, when the missile executes the interception mission, the fuel consumption, rapid attitude maneuver, and other uncertain factors may lead to the nonlinear dynamic characteristics of the system. Moreover, external disturbances, which may cause the system to lose control, are important factors in practice applications. Furthermore, the missile intercepts maneuvering targets with a fixed terminal time, which is a more effective attack. Therefore, it is of great significance to study the finite-time robust differential game law in nonlinear circumstances with external disturbance.
Traditional interception guidance strategies include proportional navigation guidance (PNG) [
1] and augmented proportional navigation guidance (APNG) [
2,
3]. In these works, the interception problem was simplified into a two-dimensional plane and the target aircrafts were assumed to be non-maneuvering targets. With the development of the modern control theory, optimal guidance laws (OGLs), sliding mode control (SMC) guidance laws, and linear quadratic differential game (LQDG) guidance laws are investigated to solve the missile interception problem. In [
4], first-order interceptor dynamics were taken into account, and an optimal guidance law (OGL) was proposed to control the impact time and impact angle. In [
5], a combination of a line-of-sight (LOS) rate shaping technique and a second-order SMC was proposed. However, the target position was assumed to be known in advance. In [
6], three-party pursuit and evasion guidance strategies were derived from a linear dynamic system, analytical solutions were derived via the Game Algebraic Riccati equation (GARE) and LQDG guidance laws were proposed. However, it is almost impossible, or even impossible, to acquire the analytic solution, due to the inherent nonlinearity. To circumvent the inherent nonlinearity of the system, in [
7], an SDRE guidance law was proposed by solving the nonlinear Hamilton–Jacobi–Isaacs (HJI) equation. However, the external disturbance was neglected and it was difficult for the analytical solution to find its Nash equilibrium. Recently, an artificial neural network [
8] has been applied to solve the nonlinear HJI equation for an unknown system. However, the finite-horizon optimal guidance law still remains an unsolved problem.
To solve the GARE, adaptive dynamic programming (ADP) techniques serve as powerful tools to solve the optimal control problems. In [
9], a novel online mode-free reinforcement learning algorithm was proposed to solve the multiplayer non-zero-sum games, and the algebraic Riccati equation (ARE) was solved by an iterative algorithm. However, external disturbances were not considered. Unfortunately, in practice applications, external disturbances always exist. In [
10], the author proposed a data-driven value iteration (VI) algorithm to handle the adaptive CT linear optimal output regulation. The optimal feedback control gain was learned by an online value iteration algorithm. However, the iterative algorithm requires a significant number of iterations within a fixed sampling interval to guarantee the stability of the system. In the above references, no matter what the mode-free integral RL algorithm or the data-driven value iteration algorithm, all the proposed methods were based on a solvable ARE. However, in most practice applications, external disturbances and parameter uncertainties always exist, which the ARE cannot obtain, in addition to the optimal controller.
For other contemporary approaches related to ADP, one can refer to refs. [
11,
12]. However, these are not applicable to practice applications with unknown or inaccurate system dynamics. The neuro-dynamic programming (NDP) technique is a typical method used to solve the nonlinear Hamilton–Jacobi–Isaacs (HJI) equation. In [
13], the policy or value iteration-based NDP scheme was proposed to obtain the finite-horizon
-optimal control for the discrete-time nonlinear system by using offline neural network (NN) training. In [
14], an online algorithm based on policy iteration was proposed to attain the synchronous optimal policy with infinite horizon time for nonlinear systems with known dynamics. However, inadequate iterations within a sampling interval may lead to instability. To avoid this problem, in [
15], a time-based NDP method was studied, and iteration-based optimal solutions were replaced by using the previous history of system states and cost function approximations. However, this NDP scheme was not suitable for finite-time nonlinear control; furthermore, external disturbances were not considered and only infinite-time optimal control was studied. In [
16], an online concurrent learning NDP algorithm was presented to solve the two-player zero-sum game of nonlinear CT systems with unknown system dynamics and three NN approximators were tuned to learn about the value function corresponding to the optimal control strategies. However, two or more NNs led to an increase in computational complexity.
Although the above research has solved the HJB problem to a certain extent, unfortunately, there are few kinds of literature involved in the missile–target interception problem. In [
17], a novel sliding mode adaptive neural network guidance law was proposed to intercept highly maneuvering targets. Aimed at the external disturbance caused by the target maneuvering, the RBF neural network was adopted to eliminate estimation errors without prior information about the target. Similarly, in [
18], an adaptive NN-based scheme with an estimation cost function was proposed for solving the interception problem of the spacecraft with limited communication and external disturbances, but it did consider the target maneuverability. However, in these studies, only the missile interception strategy is considered, and the target control strategy is ignored.
In this paper, the nonlinear system of missile–target engagement with external disturbances is considered, and a time-varying cost function is designed for satisfying the terminal interception time. The uncertain nonlinear two-player zero-sum game is developed via the HJI equation based on differential game theory. The main contributions of this paper include two aspects. First, for solving the external disturbances problem, unlike the work [
14], an extended robust interception guidance strategy for the missile to intercept the maneuvering target within a fixed final time is proposed. Second, two novel NNs are designed, one online NN identifier is designed to approximate the unknown nonlinear system, and the other critic NN is developed to approximate the cost function without policy or value iterations, while online learning is adopted. Finally, the nonlinear finite-time robust differential game guidance law is proposed.
The advantages of the proposed method of this paper are listed as follows:
- (1)
The nonlinear guidance law for missile–target engagement within a fixed interception time is studied by using the differential game theory based on neuro-dynamic programming (NDP). More importantly, a time-varying cost function is reconstructed by a critic NDP with two additional terms added to ensure the stability of the nonlinear system and to meet the fixed interception time, which implies that the missile can intercept the target at different terminal times.
- (2)
In practical applications, there are always external disturbances, and a robust interception guidance law is proposed to deal with this problem. Furthermore, inspired by the work [
19], our proposed method extends the controller by considering the target.
- (3)
Unlike the discrete system, our proposed method is the CT. Moreover, compared with the existing work [
15,
16], a clear advantage of our method is that a simpler critic NN structure is designed; thus, the computational burden is alleviated.
The remainder of this paper is organized as follows. The statement of the normal guidance problem is presented in part II. The robust control strategy of the nonlinear system with external disturbances is developed in part III. In part IV, an online NN identifier and a novel NDP-based approximator are presented. The stability of the nonlinear system is proved in part V. The nonlinear model of the missile–target engagement is established and numerical experiments are carried out to evaluate the performance of the proposed robust differential game guidance strategy in part VI. Part VII presents some conclusions.
2. Problem Formulation
In this paper, the two players are the missile and the target, which are described in detail in part VI. For the finite-time nonlinear two-player zero-sum differential game, the object of the missile input
is to minimize the cost function, while the target input
is to maximize the cost function in a specified time. The continuous-time (CT) uncertain nonlinear two-player zero-sum differential game is now presented as
where
,
, and
represent the system state vector, the control input of the missile and the target, respectively.
denotes the internal system dynamics,
are the control coefficient matrices, with
are locally Lipschitz, respectively.
represent external disturbances, which are both bounded by known functions
and
, i.e.,
and
. Furthermore, we assume that
and
, with
and
are symmetric positive definite matrices, respectively.
The nominal system (without external disturbances) of the system (1) can be described as
We assume that is Lipschitz continuous on a set and the system (2) is controllable.
Considering external disturbances in the nonlinear system (1), for the nominal system (2), the finite-time two-player zero-sum differential game cost function is defined as
where
, with
;
is a semi-positive function. The terminal cost, external disturbances, control efforts of the missile and the target, the system state, and fixed terminal time are chosen as the performance evaluation indicators.
reflects the terminal cost between the missile with the target. The term
reflects external disturbances and the system state simultaneously, which is positively defined. Moreover,
represents the influence of the target disturbance.
reflects the missile control effort.
reflects the target control effort. All parameters
,
and
are positively defined. The goal of this paper is to find the saddle point of the cost function (3).
Remark 1. First, unlike the infinite-time scenario, the terminal costis a time-varying function.is needed to guarantee the finite-time scenario. Second, external disturbances are considered in the cost function via adopting a positive constantand the robust control problem can be addressed by designing the finite-time guidance strategy of the nominal system (2).
Assuming that
, an infinitesimal equivalent to (3) can be derived as
when
, the terminal cost function can be expressed as
The Hamiltonian function of the nonlinear system (2) can be defined as
where
and
. It can be clearly observed that the Hamiltonian function includes a time-dependent term
.
In the Nash equilibrium theory, the saddle point with respect to the optimal control pair
can be obtained by
If one recalls the classical optimal game theory, both optimal controllers can be solved by using stationary conditions
and
, which yields
where
is the optimal two-player zero-sum game cost function, which is the saddle point of the cost function, such that
By substituting optimal strategy (8) into Equation (4), the Hamilton–Jacobi–Isaacs (HJI) equation reduces to
Remark 2. For the linear system case, the HJB equation can be easily solved by the Riccati equation [
19]
. However, it is difficult or even impossible to attain the mathematical solution of the HJI Equation (10), when system dynamics exist in nonlinear terms. Moreover, the fixed final time is provided in this nonlinear system for solving the inadequate iterations problem, a novel time-based online optimal guidance law design is proposed and the system dynamics are demonstrated. 3. The Nonlinear Finite-Time Robust Differential Game Guidance Law
In this part, the nonlinear finite-time robust differential game guidance law is presented. First, for coping with the robust stabilization problem of the system (1) with external disturbances, a robust controller is designed. Then, the finite-time NDP-based optimal guidance strategy is designed.
3.1. Robust Controller Design of Uncertain Nonlinear Differentia Games
By extending the work [
20], two feedback gains
are added to the optimal feedback control (8) of the system (2) for the missile and the target, respectively. The robust optimal feedback control yields as follows:
Here, some lemmas are presented for indicating that the robust optimal control has an infinite gain margin.
Lemma 1. For the nominal system (2), the optimal control strategy given by (11) can ensure that the closed-loop system is asymptotically stable forand.
Proof of Lemma 1. The optimal cost function
is selected as the Lyapunov function. In light of (3), it is easily found that
is positive definite. By combining (10) and (11), the derivative of the
along the trajectory of the closed-loop system yields
Hence, whenever , and . □
Theorem 1. For the system (1), there exists two positive gains,and, with, such that for anyand, the robust control (11) ensures that the closed-loop system (1) is asymptotically stable.
Proof of Theorem 1. The optimal cost function
is selected as the Lyapunov function, and the derivative of the
along the trajectory of the closed-loop system can be obtained as
Based on (12), (13) can be rewritten as
If
; thus, (14) can be rewritten as
where
.
According to the Lyapunov function, the determinant represents the and implies that the closed-loop system is asymptotically stable. Thus, it can be concluded that and can ensure the positive definiteness of . When and , the closed-loop system is asymptotically stable. □
3.2. Finite-Time NDP-Based Optimal Guidance Strategy
First, a novel online NN identifier is proposed to approximate the unknown system dynamics. Next, a critical NDP-based approximator is utilized to estimate the cost function within a fixed final time and an online adaptive weight tuning law is proposed with additional terms to guarantee the stability of the nonlinear system. Finally, combining the identified system and estimated cost function, the finite-horizon optimal differential guidance strategy is derived.
3.2.1. NN Identifier
System dynamics are necessary for developing guidance laws of the nonlinear two-player zero-sum differential games. However, system dynamics may be unknown in practice applications. To overcome this problem, a novel online NN identifier is designed. Based on the NN universal function approximation property, the nonlinear system can be represented as
where
, and
are ideal weight matrices.
, and
denote NN activation function vectors,
N is the number of hidden layer neurons, and
and
represent NN approximation errors.
Then, the nominal system (2) can be represented by using (16) as
Because the ideal NN weights are typically unknown, we define the state estimator as follows:
where
represents the estimate of the
.
denotes the state estimation error.
is a design parameter, which can guarantee the stability of the NN identifier.
From (17) and (18), the derivative of the state estimation error yields
Inspired by [
9], in order to make the approximated NN identifier weight matrix close to its ideal value, the online tuning law is given by
where
is the learning rate of the critical NN.
Next, by defining
, the identifier weight estimation error yields the following equation by using (20):
Theorem 2. For the NN identifier (18), let the initial ideal critic NN weightreside in a compact set by selecting the proposed NN weight tuning law provided (20). There exists a positive tuning parameter (). Then, the identification (19) and the weight estimation errorsare uniformly ultimately bounded (UUB) with a fixed terminal time.
Proof of Theorem 2. Let the Lyapunov function candidate be as follows:
Then,
where
, the eigenvalue
K and
are the design parameters that guarantee the stability of the system. Therefore, when
and
, the following inequalities hold
It can be observed from (24) that bound can be decreased by increasing the eigenvalue K. Therefore, is quantified by selecting the minimum eigenvalue . According to (19) and the relationship between and , the smaller will enforce the to converge into a small bound. Therefore, we have and it can be concluded that and are UUB.
This completes the proof. □
3.2.2. NDP-Based Guidance Strategy
In order to confront the nonlinear HJI function, according to the universal approximation property of the neural network, the optimal cost function can be reconstructed by a critic NDP on a compact set as
where
the ideal weight matrix.
denotes NN activation function vectors,
N is the number of hidden layer neurons, and
represents the NN approximation error.
Thus, the terminal cost function can be expressed as
Remark 3. The critic NN activation functionand its gradientare upper bounded, i.e.,and, withandpositive constants. The critic NN weight W is upper bounded, i.e.,, withbeing a positive constant. The critic NN approximation errorand its gradientare upper bounded, i.e.,and, withandpositive constants. Obviously, the activation function is a time-varying function, which can maintain the fixed final time.
Next, the partial derivation of
with respect to
x and
t can be obtained, respectively.
where
,
,
, and
.
Therefore, by substituting (27) into (8), we then obtain the differential game guidance strategy as
By substituting (28) into (10), the HJI function can be rewritten as
where
and
Because ideal NN weights are typically unknown, we define the estimated cost function
as follows
The estimated terminal cost function is
where
denotes the estimate of the
and
is the activation function with the estimated terminal state
.
Next, the partial derivation of the estimated cost function
with respect to
x and
t can be obtained, respectively.
where
and
.
Then, by applying (33) to (8), the estimated differential game guidance strategy can be rewritten as
By applying (34) to (10), the estimated HJB function yields
In order to obtain the optimal differential game guidance strategy, we define the estimated terminal cost error as
where
.
Moreover, in order to guarantee the estimated NN weight
, which is approximated to the ideal NN weight
, and after combining the time-varying nature of the cost function and the estimated terminal cost error, the total NN approximation error is defined as
By using the gradient descent algorithm, a novel simplified weight tuning law is proposed with additional terms to ensure the stability of the nonlinear system (1), as follows:
where
,
Remark 4. It is important to mention that the first term in (38) is used to minimize the squared residual error. The second term is used to minimize the terminal cost estimation error. The last term is used to guarantee that the system states remain bounded.
4. Stability Analysis
In order to prove the stability of the weight tuning law and the nonlinear system by choosing the optimal strategy, and without loss of generality, the weight estimation error of the critic NN is defined as
; then, we have
. Therefore, the approximated HJI is
Assumption 1. For the nonlinear system (1) with the cost function (2) and the optimal guidance law (34), let the value functionbe the Lyapunov function and continuously differentiable, when Exists and it is clear that the inequation holds Theorem 3. For the nonlinear system (1) with the ideal HJI Equation (9), let the updated law for the NN-based identifier and NDP-based cost function approximator be provided by (20) and (38), respectively and the estimated optimal guidance laws are given in (34). The existence of the positive constants,,andmean that the identification error, weight estimation error and the controller are UUB.
Proof of Theorem 3. Select the Lyapunov candidate function as
where
,
,
,
.
It can be observed that .
First, the derivation of
with respect to time is given by
where
,
and
,
satisfies
.
The derivation of
is governed by
where
and
.
and
is the minimum and the maximum eigenvalue of the matrix
.
. and are the upper bounds of the optimal guidance strategy and .
Therefore, when the following conditions hold, the first derivation of
is less than zero.
This completes the proof. □
Remark 5. The eigenvalue K,,, , andare the tuning parameters for guaranteeing the lower bound of ,, and, which can quantify the bound of the system. In additions, from the proof, we can observe that the estimated optimal guidance laws given in (34) can ensure the system is UUB. Thus, by combining the robust optimal feedback control (11), the complete nonlinear finite-time robust differential game guidance law is provided.
5. Application
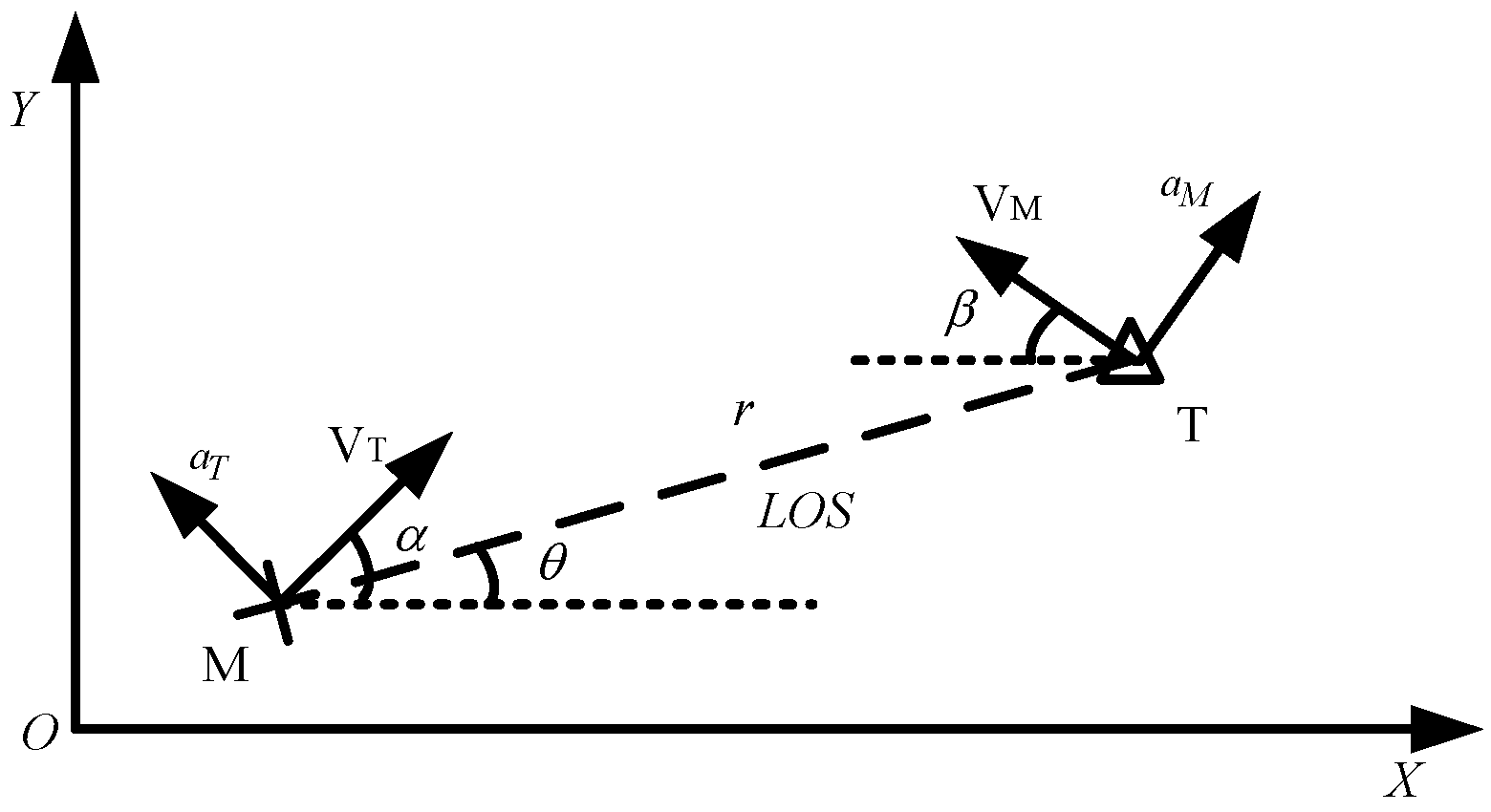
A missile–target engagement scenario is considered in this section. The engagement geometry of the missile–target is shown in
Figure 1, where the
X-Y plane represents the Cartesian reference frame. The variables
denote the speed and the normal acceleration of the missile and the target, respectively.
α and
β denote the flight angles of the missile and the target, respectively. The variables
r and
θ represent the missile–target distance and the line of sight (
LOS) angle, and
LOS angular rate is
donated by
.
and
are the control vectors perpendicular to the velocity of the missile, and the target.
The engagement occurs in the terminal guidance phase and all the participators are assumed to neglect the effect of gravity and have constant velocity. The nonlinear kinematics of the missile and the target, in a polar coordinate system, is given by
where
represents the closing velocity.
The first-order dynamics of the missile are considered, and the motions of the missile are as follows:
where
is the position of the missile along with the Cartesian reference frame.
is the lateral acceleration of the missile and
is a time constant.
Similarly, the motion equations of the target are as follows:
where
is the position of the target along with the Cartesian reference frame.
is the lateral acceleration of the target and
is a time constant.
To obtain the capture zone, the guidance principle is adopted as follows.
Definition 2. Zero effort miss distance (ZEMD) is the closest distance between the missile and the target at an instant, while the missile and the target do not impose any control and the agents continue to perform their scheduled maneuver strategy from the current time to the endgame. The ZEMD is computed as In this scenario, the missile applies its optimal strategy (34) to minimize the ZEMD, while the target applies its optimal strategy (34) to maximize the ZEMD. In addition, from (57), we can observe that if
tends to be zero, the ZEMD also tends to be zero. Meanwhile, the closing
is also less than zero. Therefore, to ensure that the missile successfully intercepts the target, the following two conditions hold, which will be verified in simulations:
Based on the two conditions mentioned above, by choosing the
as the system state, differentiating the Equation (48) with respect to time, the nonlinear system can be given by
Remark 6. From (59), it can be observed that whenis close to 0, the nonlinear termstend to be infinite. It will mean that the system is broken and the proposed differential game guidance laws do not work. Thus, a minimized ZEMD () should be designed, which means that when the displacement between the missile and the target is less or equal to the, the missile completes the interception mission. Moreover, in the practice application, the missile has an actual killing radius; thus, this design is reasonable.
Remark 7. From (59), it also can be found that whenand, no matter what the proposed guidance laws change, the nonlinear system is an unstable equilibrium. Therefore, the domain where the differential game-based guidance laws are applicable is given by 6. Simulation Results
In this section, some experiments are designed to verify the proposed finite-time robust differential game guidance strategy. To further explain the performance of the proposed differential game guidance strategy based on NDP, some simulation experiments are designed and analyzed. The initial engagement occurs in the terminal guidance phase. The speeds of the missile and the target are VM = 700 m/s, and VT = 400 m/s, respectively. The initial position of the target is at (0 m, 0 m), and the position of the missile is (2500 m, 0 m). The initial flight path angles of the missile and the target are and , respectively. The time constants are , respectively. The weight parameters , are set. , where .
Furthermore, the initial parameters of the critic NN are selected inside
randomly and the critic NN identifier activation function is designed as
, which refers to [
18,
21]. In addition, polynomial basis functions can better approximate the nonlinear system. The initial parameters of the critic NN are
and the critic NN vector activation function for estimating the cost function is designed as
The learning rates are , respectively. The experiment environments are performed on a PC platform with i7-9750H CPU, using Matlab 2020b.
6.1. Effect of the Proposed Finite-Time Differential Game Guidance Strategy without Unknown Uncertainties
In this case, the performance of the proposed finite-time differential game guidance strategy is verified without unknown uncertainties and the missile and the target choose the optimal guidance strategy (34). More importantly, the
ZEMD and the lateral acceleration of the agents are the performance evaluation indicators and we have rewritten the physical meaning. The performance of the
ZEMD tends to be zero, indicating that the missile intercepts the target successfully. The performance of the lateral accelerations of the agents is limited in the range ±100 g and stable change indicates that the agents can be reasonably controlled. The simulation results for this engagement scenario are shown in
Figure 2,
Figure 3 and
Figure 4.
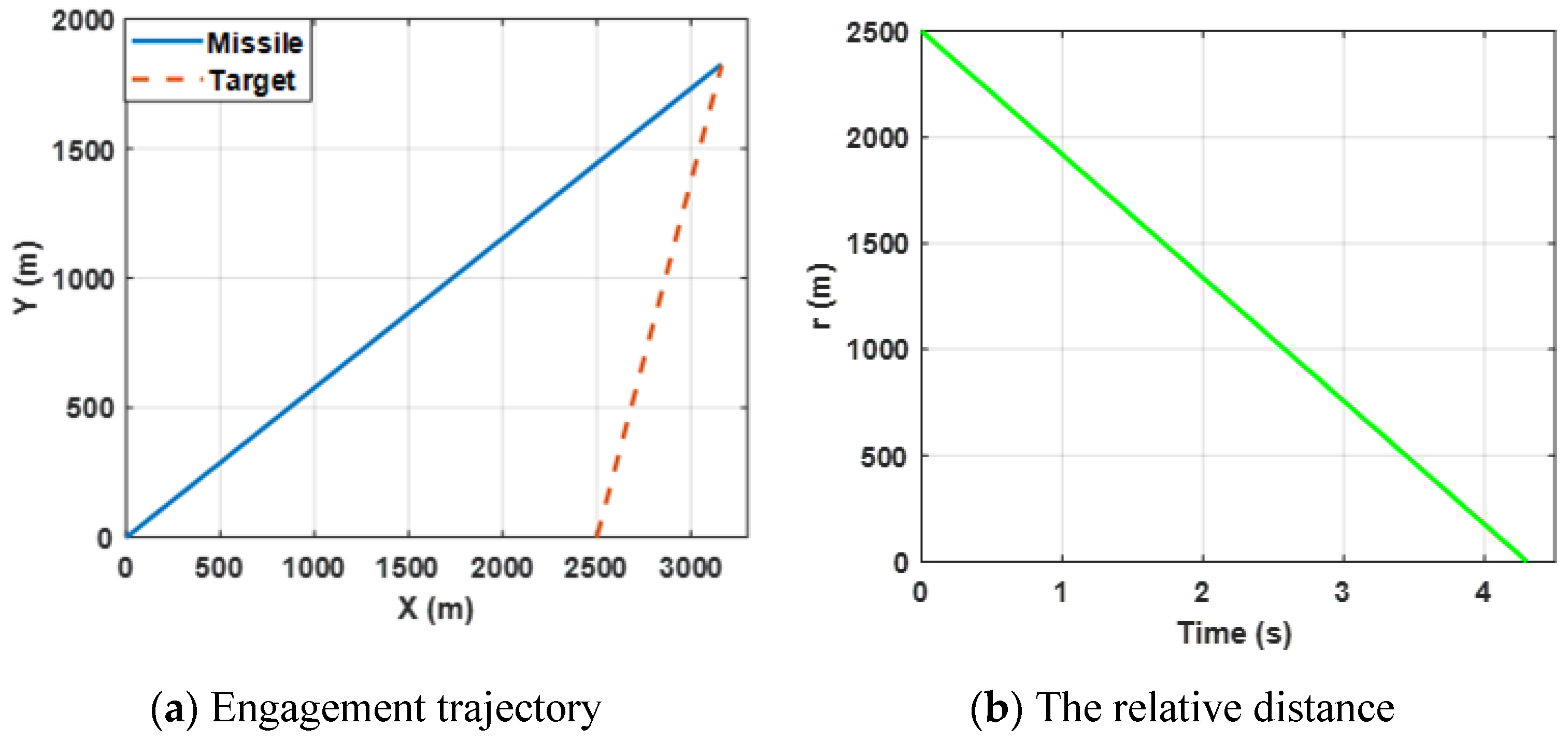
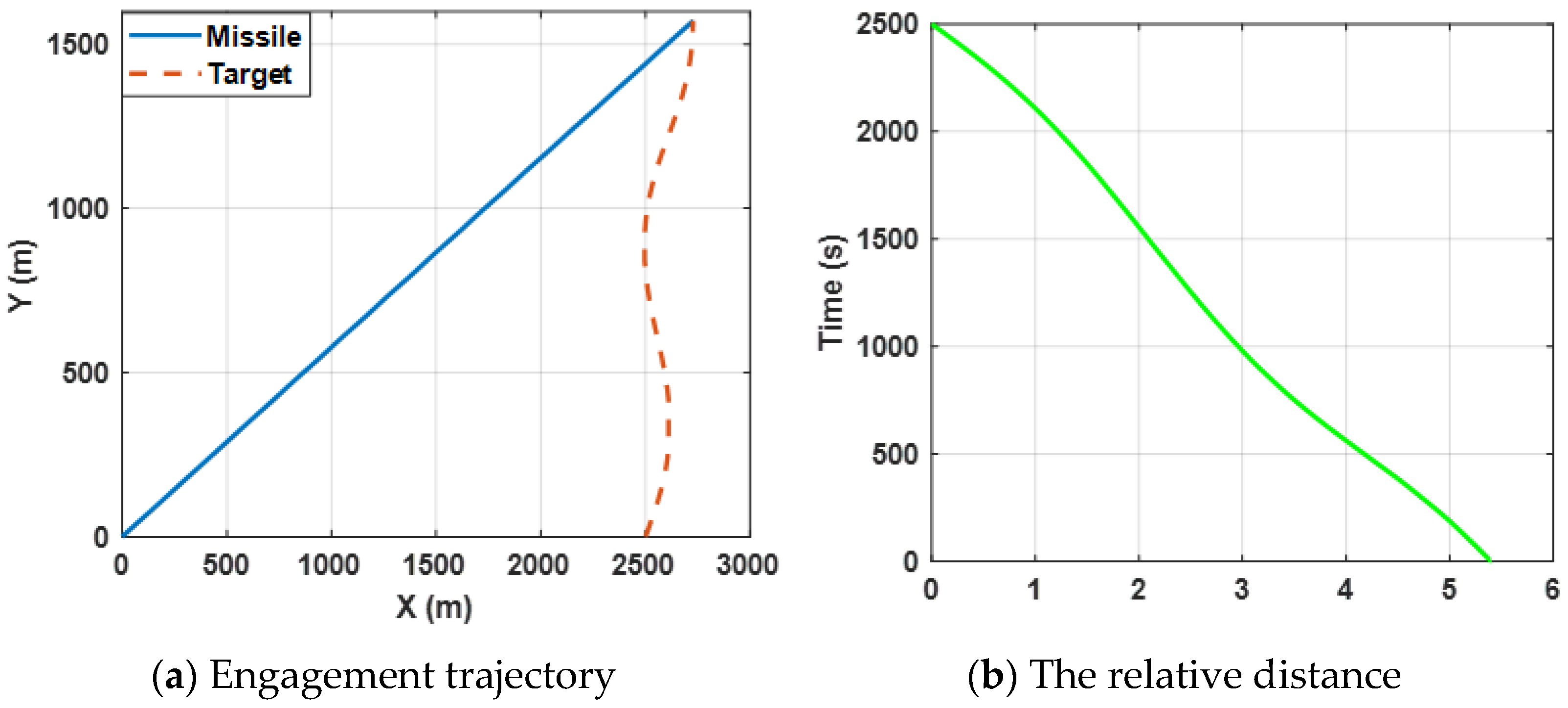
Figure 2a shows the trajectories of the missile and the target by selecting the proposed finite-time differential game guidance strategy (34).
Figure 3b presents the change in the relative distance between the missile and the target and it can be observed that the
ZEMD is less than 0.5 m. By bombining (a) and (b), the results reveal that the missile intercepts the target successfully.
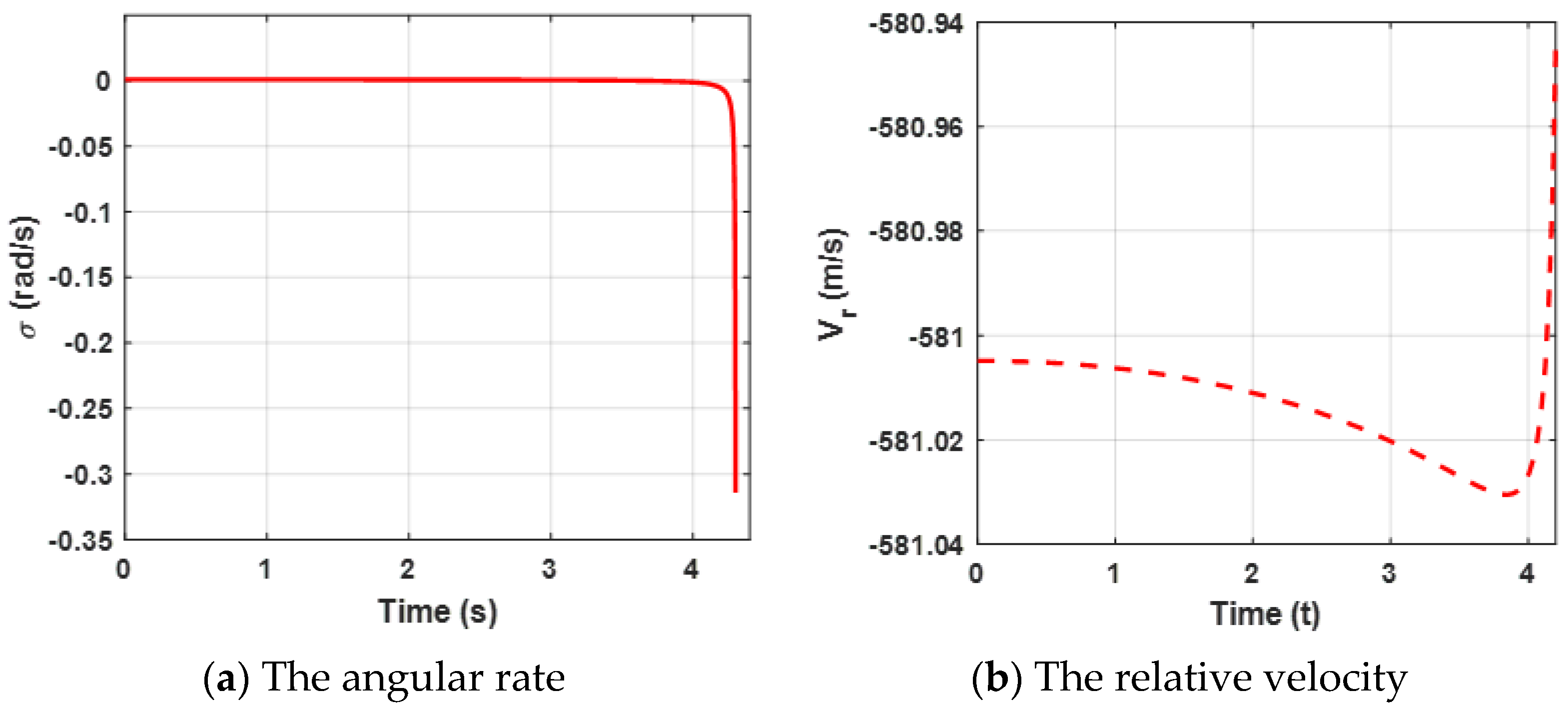
Both the angular rate and the relative velocity are presented in
Figure 3. From
Figure 3a, it can be observed that the state variable (the angular rate) bound is zero at about 4.5 s, which leads the ZEMD to be zero according to the Equation (57) and
Figure 2b.
tends to be zero, which can ensure that the missile intercepts the target. Furthermore, the negative
guarantees the relative distance between the missile and the target tends to be zero in
Figure 3b. Moreover, sharp changes between
and
are reasonable due to the system characteristics. Furthermore, it also verifies Definition 2, which mentioned that
.
Figure 4 presents lateral acceleration curves of the target and the missile. It can be observed that both lateral accelerations are maintained within a reasonable range, which can ensure that the missile intercepts the target. However, due to the system characteristics, the lateral accelerations decrease sharply at the end of the engagement.
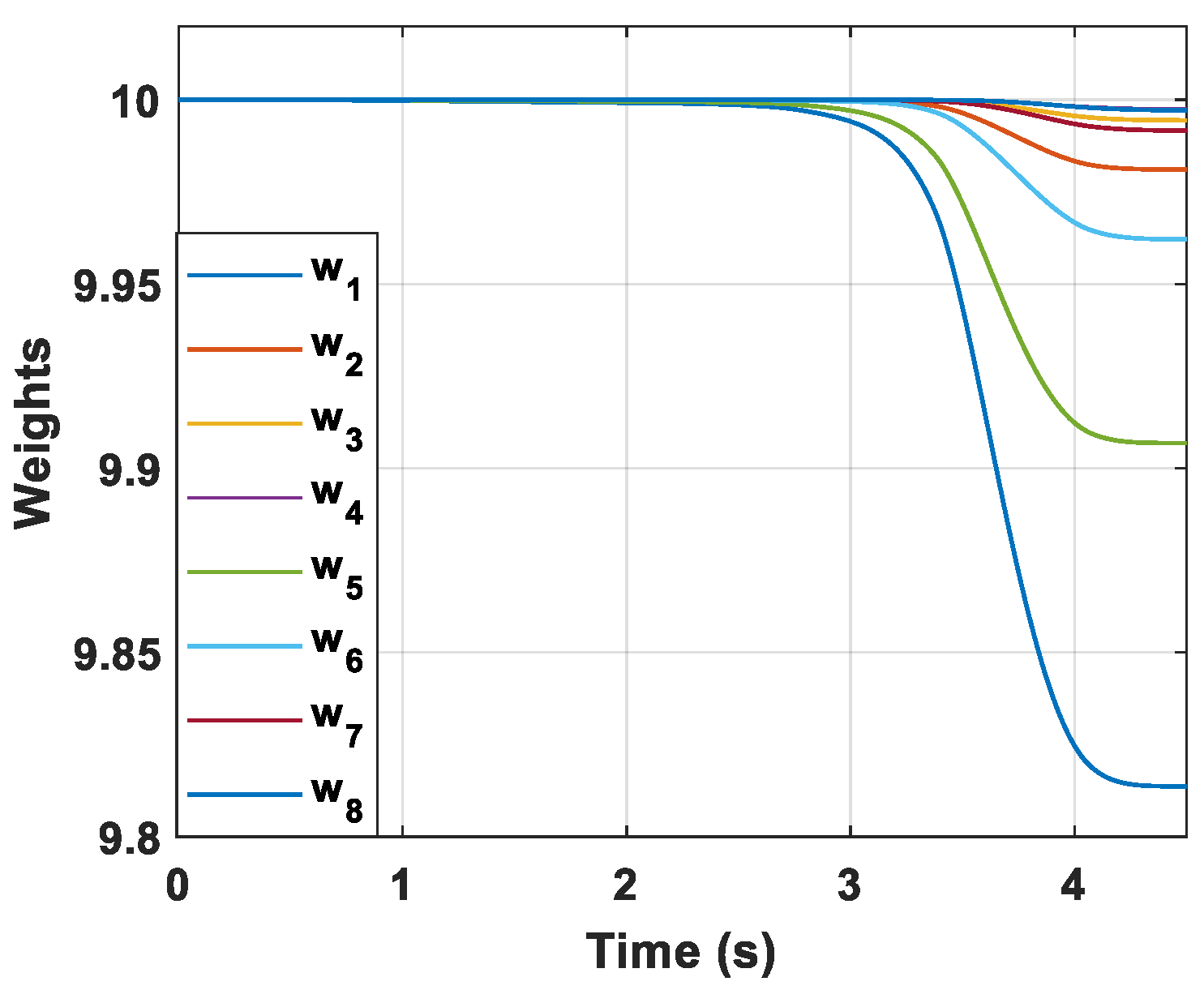
The convergence curves of critic NN weights are presented in
Figure 5 and it can be observed that the critic NN weights finally converge to stable coefficients. The result reveal that critic NN weights can guarantee the stability of the closed-loop nonlinear system.
6.2. Engagement without Unknown Uncertainties for a Maneuvering Target
To further verify the effectiveness of the proposed guidance strategy dealing with the target executing other forms of target maneuvers, the following experiment is presented. In this experiment, the target is expected to perform a sin-wave maneuver with a magnitude of 10 g and the missile still selects the guidance law (34). The simulation results for this engagement scenario are shown in
Figure 6,
Figure 7 and
Figure 8.
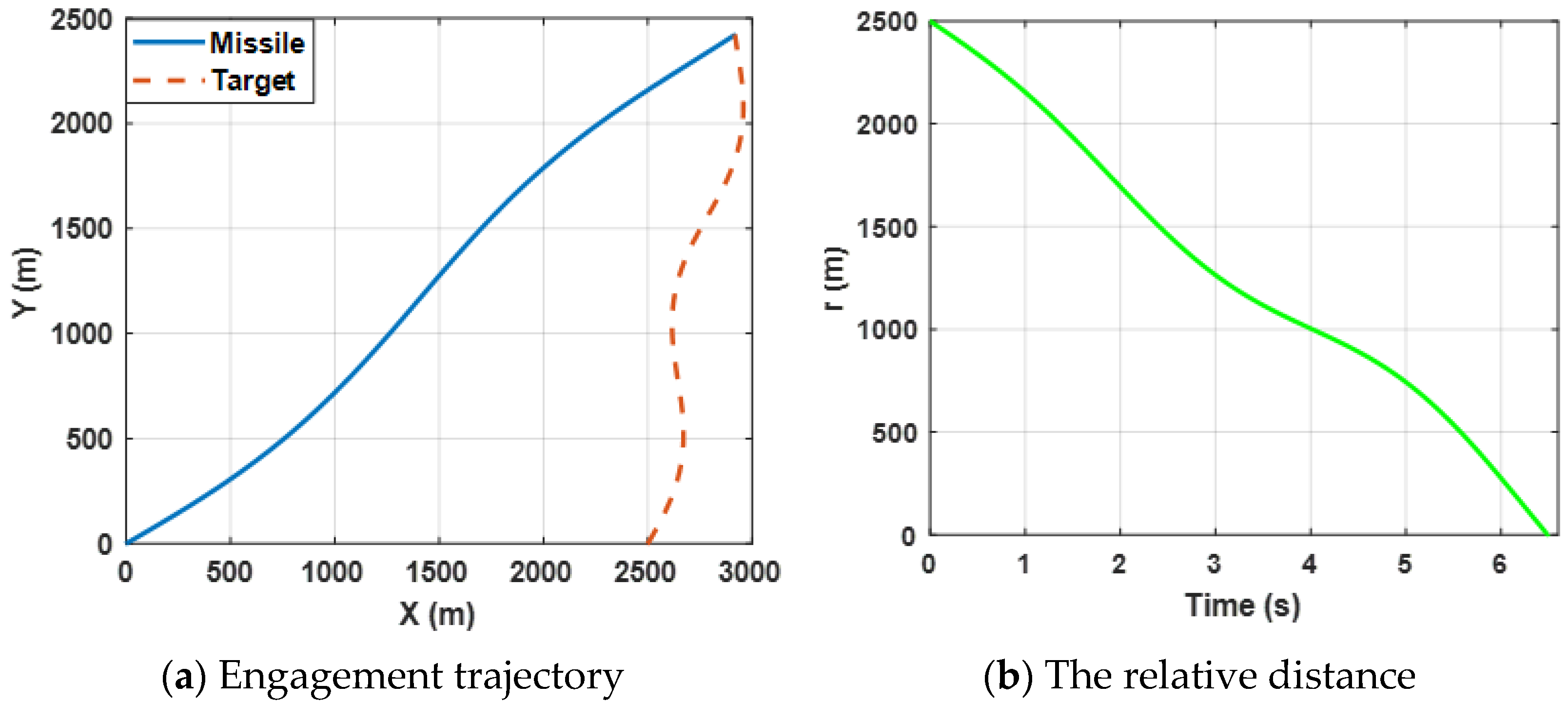
Figure 6a shows the engagement trajectories of the missile confronting the target, which is expected to perform a sin-wave maneuver by selecting the proposed guidance law (34).
Figure 6b presents the change in the relative distance between the missile and the target and it can be observed that the final ZEMD is less than 0.5 m. The results reveal that the missile intercepts the maneuvering target successfully.
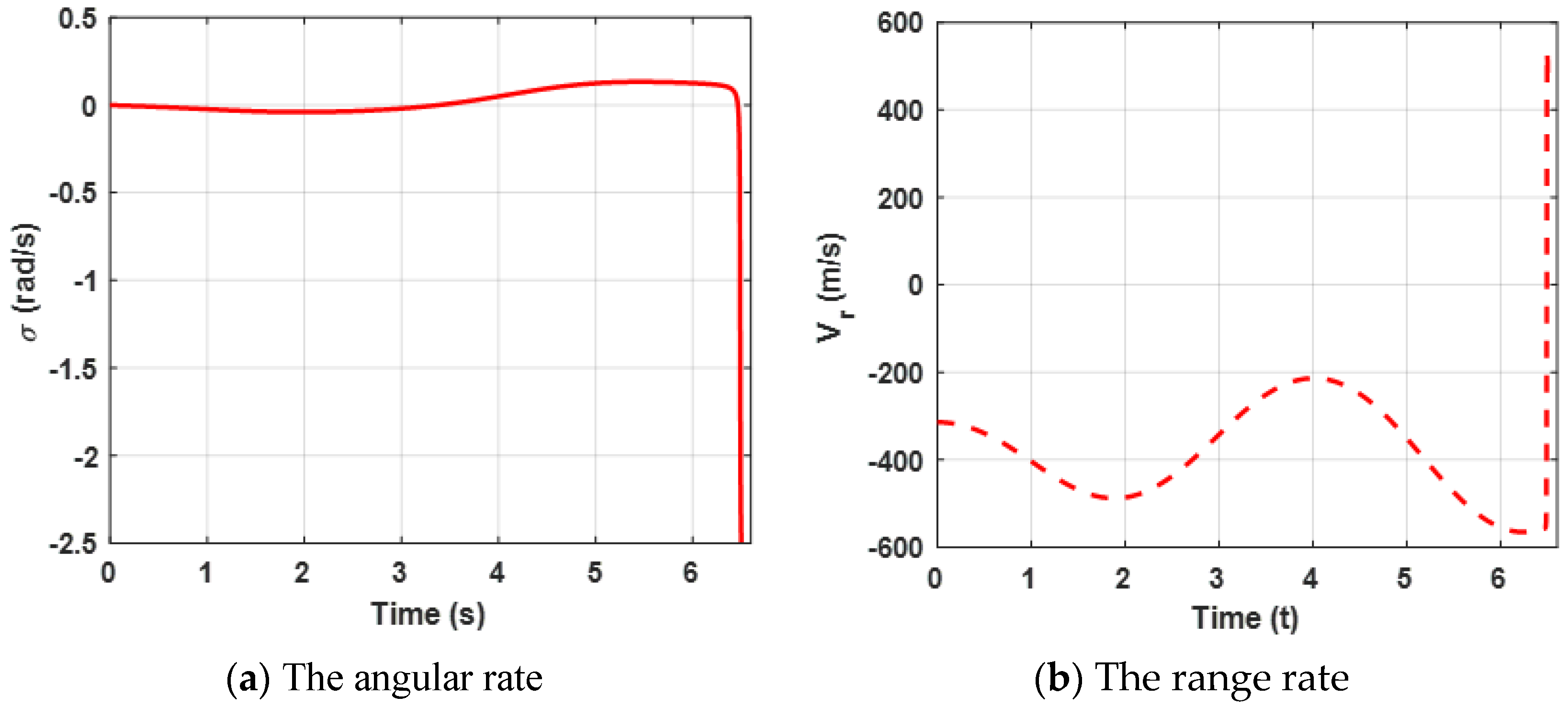
Curves of the angular rate and the range rate are presented in
Figure 7. The results reveal the same conclusion as case 1.
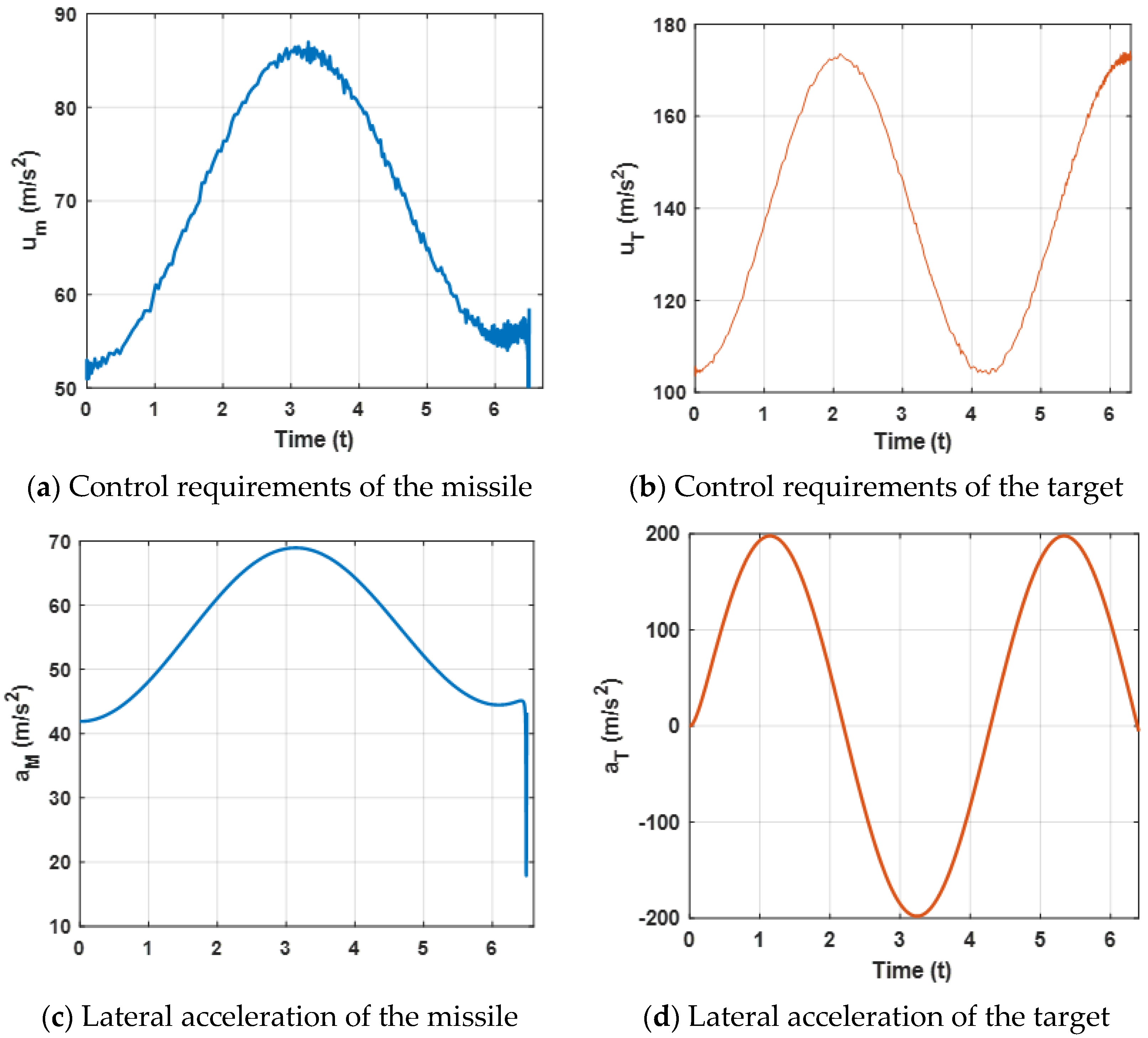
Figure 8 presents the lateral acceleration curves of the target and the missile. It can be observed that both lateral accelerations are maintained within a reasonable range, which can ensure that the missile intercepts the target. Furthermore, compared with
Figure 4a, due to the maneuvering target, higher acceleration demands of the missile are needed.
6.3. Engagement with Unknown Uncertainties for a Maneuvering Target
To further verify how the proposed finite-time robust guidance strategy deals with unknown uncertainties, the following experiment is presented. In this experiment, the missile selects the robust differential game guidance law (11), and the target is expected to perform a sin-wave maneuver with a magnitude of 10 g. Furthermore, external disturbances, with a uniform distribution between −0.2 and 0.2, are considered in both input vectors. The simulation results for this engagement scenario are shown in
Figure 9,
Figure 10 and
Figure 11.
Figure 9a shows the trajectories of the missile confronting the target, which is expected to perform a sin-ware maneuver by selecting the proposed guidance law.
Figure 9b presents the change in the relative distance between the missile and the target and it can be observed that the miss distance is less than 0.5 m. By combining (a) and (b), the results reveal that the missile intercepts the maneuvering target successfully.
Curves of the angular rate and the range rate are presented in
Figure 10. The results reveal the same conclusion as case 1.
Figure 11 presents the acceleration demands and the control requirements of the target and the missile. It can be observed that the lateral accelerations are maintained within a reasonable range, which can that ensure the missile intercepts the target. Furthermore, when the missile experiences external disturbances, the proposed robust differential game guidance strategy can successfully intercept maneuvering targets with external disturbances.
6.4. Effect of the Proposed Robust Optimal Differential Game Guidance Strategy with Other Methods
To confirm the advantage of the proposed robust optimal differential game guidance law, we offer a comparative experiment. In this experiment, the target selects the proposed robust optimal differential game guidance strategy (11), while the missile chooses the proposed differential game guidance strategy (11), i.e., the OGL in [
4], and the conventional differential game guidance law (CDGGL) in [
18], respectively. To further illustrate the advantages of the proposed differential game guidance strategy, the control effort
J is defined as
The comparison results for this engagement scenario are shown in
Figure 12.
The engagement trajectories and the control effort of the missile are presented in
Figure 12a. It can be observed that the OGL, the CDGGL, and the proposed robust optimal differential game guidance strategy both can successfully intercept the target, with a miss distance equal to 0.985, 1.218, and 0.0024 m, respectively. Furthermore, the curves of the missile control effort are presented in
Figure 12b. It can be shown that the minimal control effort is our proposed robust optimal differential game guidance strategy, the second control effort is the CDGGL in [
18], and the maximum control effort is the OGL in [
4]. All control efforts are limited to the setting range (100 g). More importantly, it also can be observed that before the missile intercepts the target, the control effect we proposed is always at its minimum at different times. For example, when
t = 4.8 s, the control effort of our method is minimal. Thus, the missile uses our method to intercept the target, which saves more energy. Furthermore, the OGL in [
4] is larger than the proposed robust optimal differential game guidance strategy, which means that the missile may not successfully intercept the target when using the OGL in some acceleration-limited scenes. In general, our proposed guidance law is superior to the OGL in [
4] and the CDGGL in [
18]. To further illustrate the superiority of the proposed robust optimal differential game guidance strategy, the energy consumption and the simulation time are compared in 100 average experiments. The comparison results are shown in
Table 1.
From
Table 1, it is easily found that less control effort is needed in our proposed method compared with the OGL in [
4] and the CDGGL in [
18], which implies that our proposed guidance law can reduce unnecessary energy consumption. The missile can intercept the target with minimal control. Moreover, the computation time of our proposed method is shorter compared with the OGL in [
4] and the CDGGL in [
18], which means that our proposed method can make the confrontation strategy in the shortest time. In general, our proposed guidance law can intercept targets with minimal control effort and a fast response.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}