


Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry

 , , ,
, , , 
Abstract
:1. Introduction
2. Research Methodology
2.1. Research Questions (RQs)
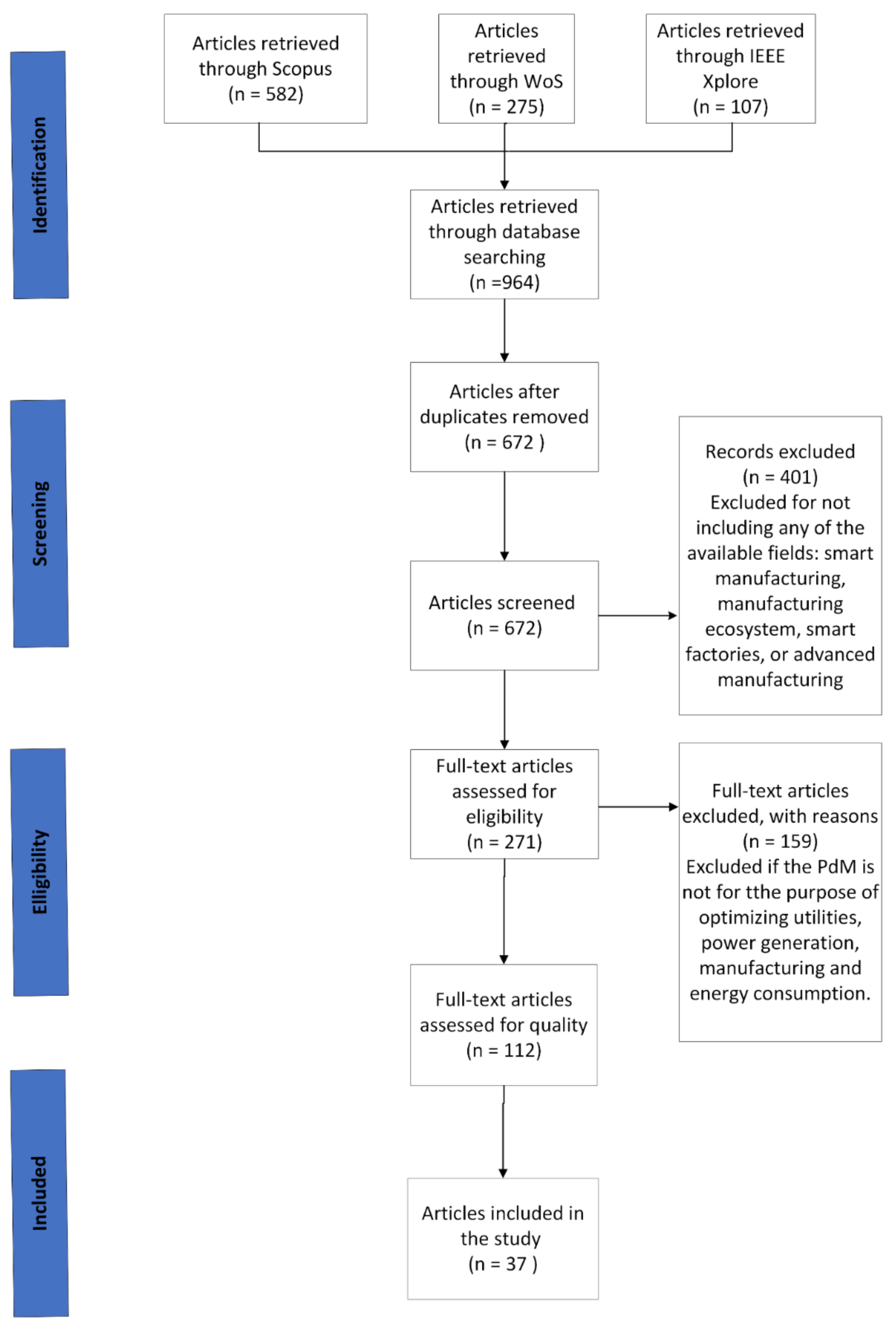
2.2. Search Strategy
2.3. Inclusion Criteria
2.4. Assessing Study Relevance
- Novelty: Is the proposed concept truly original, or is it just an improved version of an existing concept?
- Content and Analysis: Was the information presented technically sound and supported by ideas and data that had comparative advantages over state-of-the-art methods?
- Results: When compared to the benchmark data set, was the result presented clearly?
2.5. Data Extraction
2.6. Data Synthesis
3. Results
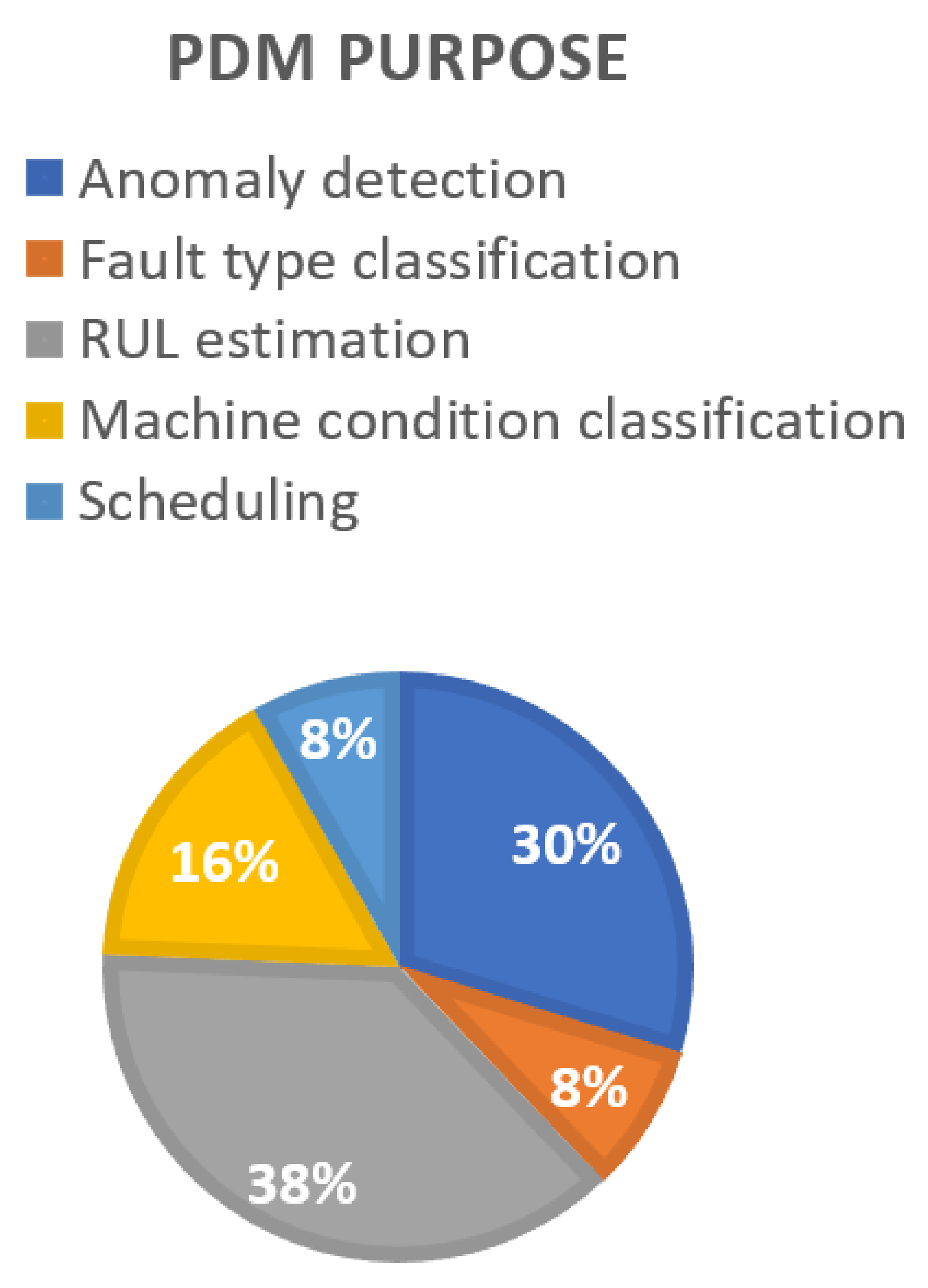
3.1. Techniques or Algorithms Required for PdM of Different Utilities
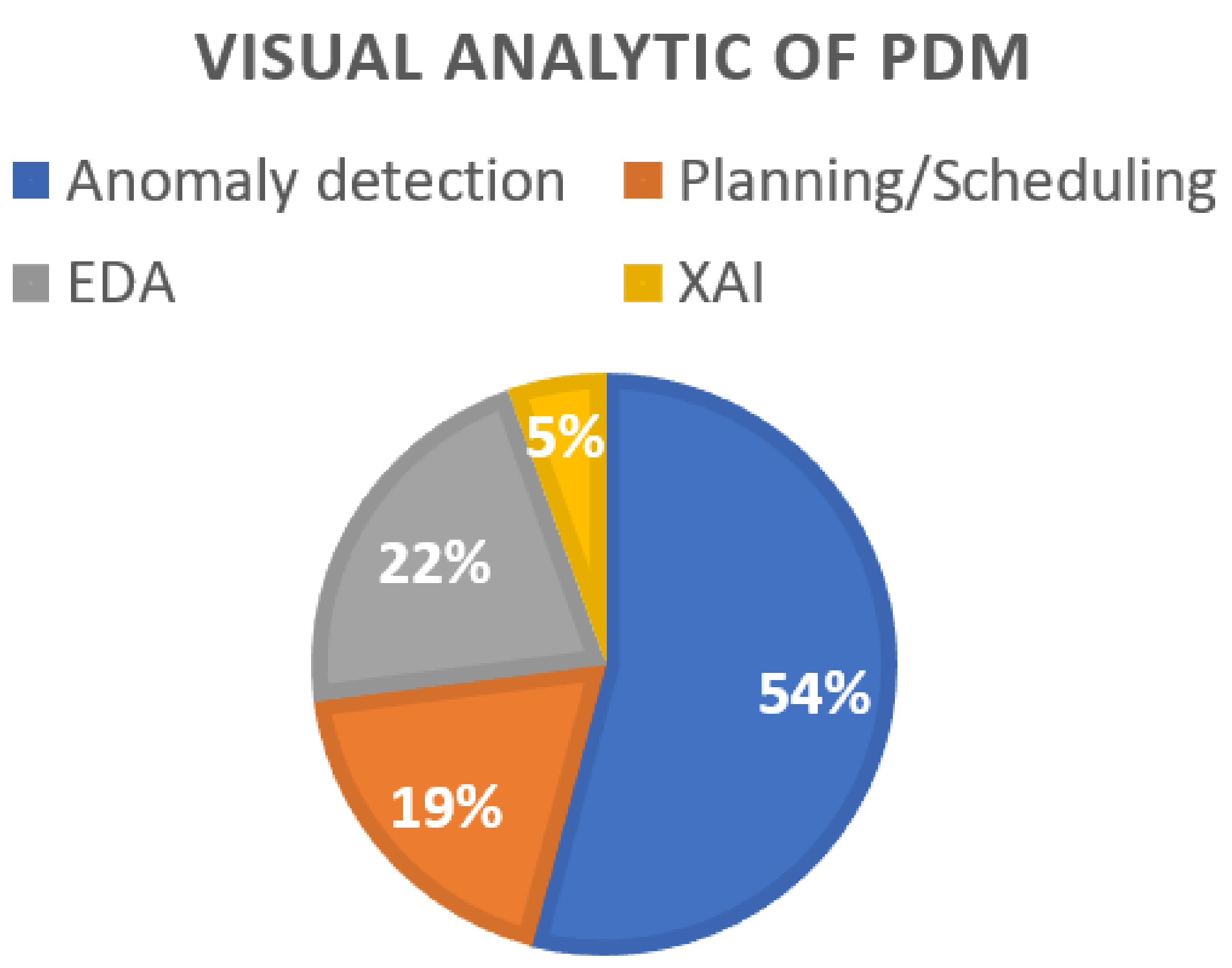
3.2. Visual Analytic of PdM
- 1.
- Anomaly detection. Wenjin Yu et al. [14] used fault detection in PdM where a four-layer architecture was presented, consisting of big data intake, management, analytic, and visualization levels, with functionalities ranging from Internet-of-Things (IoT) data acquisition to real-time system condition monitoring. The importance of visual analytics was highlighted here as it extended until the monitoring stage, where the engineer was responsible for monitoring the condition of the compressor even if an anomaly was detected. A 5-minute deterministic mechanism was implemented to set the timestamp from ‘0′ to ‘1′ if more than 15 anomalies out of 300 observations were detected in every 5-minute window. The involvement of an engineer could reduce the possibility of false alarms.
- 2.
- Planning/scheduling. From the planning and scheduling perspective, machine learning (ML) with real-time data acquisition can effectively forecast the causes of manufacturing disruptions, which allows the personnel to respond to the changes on the shop floor in a more timely and cost-effective manner. Eman Azab et al. [34] included the PdM timeslot predicted by the optimal machine learning model in the production schedule, which was then visualized in Gantt chart format. Simon Zhai et al. [49] involved maintenance personnel only once to select relevant operational parameters for PdM. Then, K-means clustering was adopted to group the operational conditions. The clusters served as the response variables for training a Health Indicator model. The output of this model would be integrated into scheduling algorithms which are not elaborated on in this study.
- 3.
- EDA. PdM promotes the use of machine learning technologies to track asset health and schedule repairs accordingly. Informative features are required to train an effective machine learning model. Hence, thorough EDA is normally performed before the modeling process. This is because effective predictive modeling necessitates a number of stages, but the interpretability of the results may become harder to grasp and less generalizable in the latter stages. Different models have respective metrics to present the feature importance. For example, the metric used to show the feature importance of logistic regression is the coefficients found for each input variable [57], while the decision tree looks for the decrease in node impurity weighted by the probability of reaching that node [58]. In contrast, EDA could be the gold standard methodology to analyze a dataset due to its generalizability, such as correlation scores or pair-plot [59].
- 4.
- XAI. Steenwinckel et al. [22] integrated data-driven techniques with knowledge-driven techniques in PdM, allowing it to complement the weaknesses of one with the strengths of another and, therefore, improve the interpretability of an ML model with optimized performance. Although the PdM’s purpose of this study was not in the manufacturing industry, it was included in the SLR due to its significant results in showing the importance of incorporating context-aware alerts to the operating personnel. The authors proposed to fuse domain knowledge in every phase of methodology in their study. In the first phase, i.e., the EDA stage, the outputs of the data- and knowledge-driven techniques were merged into a semantic database so that the detected anomalies were accompanied by reasons for why they happened. In the second phase, a dashboard visualization was created to let users provide feedback on the anomalies by indicating their accuracy or relabeling them based on an expert’s knowledge. The third phase is the optimization stage, where anomalies were detected by using all the background knowledge, context information, anomalies, causes, and feedback maintained in the semantic database. Even at this stage, the visualization enables a continuous feedback loop between the detected events and their cause based on the semantic database.
4. Discussion
- 1.
- The PdM approach lacks the ability to generalize. This is because the degradation processes vary widely across industries, facilities, and machines. Furthermore, the PdM approaches are designed and customized to specific problems based on the data collected from the sensors to assess the asset’s health condition. Hence, different machines in the same manufacturing factory may require an individual PdM approach to achieve effective results.
- 2.
- To achieve generalizability, PdM approaches collect temperature, vibration, power consumption, and noise from different machines. However, PdM approaches are dependent on the type of degradation. It would require different measures to detect partial breakage or deterioration of a component or the asset’s operating condition in which some measures may be less informative than others.
- 3.
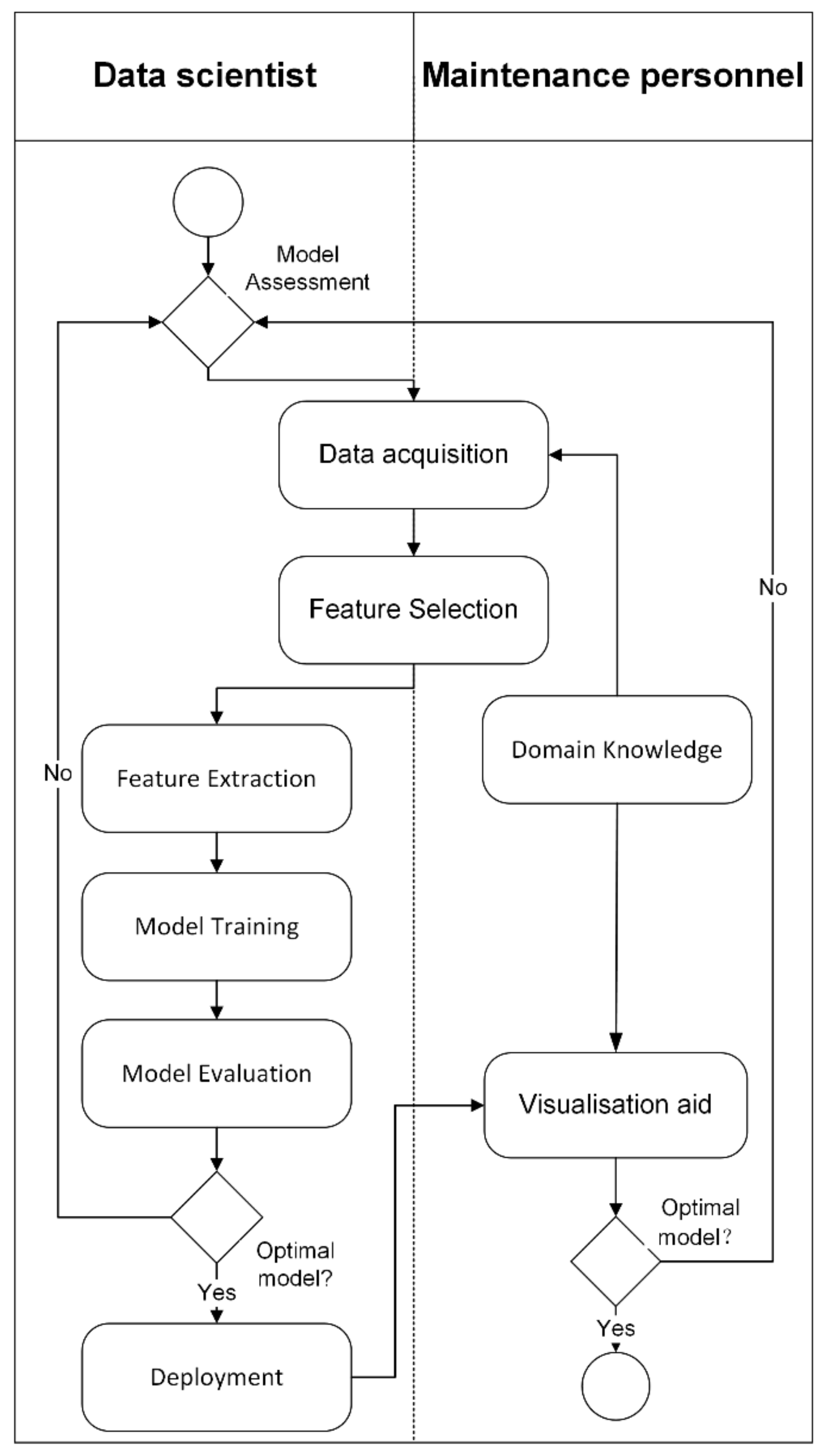
- To ensure that each measure is properly treated, the PdM approaches engage both data scientists and maintenance personnel in the framework to perform manual feature engineering. Another significant aspect of manual feature engineering is the high management cost because this process may be repeated during the architecture training and evaluation to achieve better performance. As a result, most of the studies involved the maintenance personnel until the EDA stage only. Some of the studies [44,45,46,47,48,49,50,51,52] adopted a more automatic feature engineering process, such as CNN.
- 4.
- The deep learning approach, such as CNN, was often used to achieve higher performance for PdM. Nevertheless, this black-box approach only allows the prominent display of input and output parameters while hiding the intrinsic relationships between them. By using this approach, the features are obtained as a non-linear combination of the inputs, making it difficult to grasp the contribution of the inputs to the classification output and, hence, the model’s logic. In real-world applications, such as industrial manufacturing processes, it is preferable to prevent such a lack of transparency. This is because PdM applications may involve important decision-making that requires the practitioner’s feedback. It can only be more reliable to have some justifications behind the individual prediction made by an AI algorithm, particularly in an automated setting.
- 1.
- Anomaly detection. Undoubtedly, machine learning models are booming in PdM applications. They have shown promising results in anomaly detection, where they could predict machine failures or RUL via measurement from sensors, unknown or abnormal patterns, and events. The drawback is that small, inconsistent anomalies may occur that do not reflect the real condition of the machine [14]. Visual analytics allows domain experts to point out redundant anomaly detection, thereby improving the performance of PdM.
- 2.
- Planning/scheduling. After PdM is employed, the health indicators or degradation indicators could help maintenance personnel better plan the maintenance operation. By optimizing the maintenance schedule, unnecessary maintenance and high prevention costs can be avoided [60].
- 3.
- EDA. To gain a better insight into the data acquired, an unsupervised clustering technique (i.e., K-means) was often implemented at the EDA stage to discover if the resulting clustering labels matched the order of the actual health stage labels. Scatter plots are then presented as a group of points where those that follow the same general pattern are visualized as the same cluster and vice-versa for those that have different patterns.
- 4.
- XAI. Visual analytics was used as an aid to realizing XAI. The outcome provided by the machine learning models could be justified by interpretable XAI techniques such as Shapley values [61]. The Shapley values are able to demonstrate which features are significant for the machine learning model or even relate the decision it made to the specific parts of the input. What is interesting in this SLR is the low adoption of such techniques in PdM despite its high interpretability.
4.1. What Knowledge Gaps Exist in the PdM Field, and What Obstacles Must Be Overcome in PdM Research before Visual Analytics Can Fully Complement Data-Driven Techniques?
- 1.
- Due to the different nature of machines, a custom Data Acquisition (DAQ) device can be embedded into the machines to realize a framework that can process the data via the Digital Twin of the equipment for the calculation of the RUL of critical components.
- 2.
- To leverage the benefits of data-driven techniques, knowledge-driven techniques of maintenance personnel have to be included in the framework of PdM in the manufacturing industry. Visual analytics should not be only at the EDA stage but also at the PdM final stage, where the maintenance personnel could provide feedback to improve the operational efficiency of machines.
- 3.
- The Augmented Reality (AR) module can be implemented for PdM. An AR module can be installed to make the process of monitoring industrial equipment easier. This module can be implemented as a multi-platform application from which clients can view critical information about their equipment and interact with it quickly and intuitively by using cutting-edge digital technology, whether remotely or on-site.
- 4.
- Using the sensor data to train a health model for each component can result in a more interpretable health indicator for PdM and help locate possible failure reasons, such as components with low health indicator values. This is because aggregating component-specific sensor data may prevent the sensor data of two independent, unrelated components from contradicting the overall health indicator trend and canceling each other out. Consequently, the individual health indicator is projected to perform better in terms of evaluation metrics.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Yang, F.; Gu, S. Industry 4.0, a Revolution That Requires Technology and National Strategies. Complex Intell. Syst. 2021, 7, 1311–1325. [Google Scholar] [CrossRef]
- Walther, J.; Weigold, M. A Systematic Review on Predicting and Forecasting the Electrical Energy Consumption in the Manufacturing Industry. Energies 2021, 14, 968. [Google Scholar] [CrossRef]
- Himeur, Y.; Ghanem, K.; Alsalemi, A.; Bensaali, F.; Amira, A. Artificial Intelligence Based Anomaly Detection of Energy Consumption in Buildings: A Review, Current Trends and New Perspectives. Appl. Energy 2021, 287, 116601. [Google Scholar] [CrossRef]
- Wang, A.; Lam, J.C.K.; Song, S.; Li, V.O.K.; Guo, P. Can Smart Energy Information Interventions Help Householders Save Electricity? A SVR Machine Learning Approach. Environ. Sci. Policy 2020, 112, 381–393. [Google Scholar] [CrossRef]
- Luo, X.J.; Oyedele, L.O.; Ajayi, A.O.; Akinade, O.O. Comparative Study of Machine Learning-Based Multi-Objective Prediction Framework for Multiple Building Energy Loads. Sustain. Cities Soc. 2020, 61, 102283. [Google Scholar] [CrossRef]
- Kammerer, K.; Hoppenstedt, B.; Pryss, R.; Stökler, S.; Allgaier, J.; Reichert, M. Anomaly Detections for Manufacturing Systems Based on Sensor Data—Insights into Two Challenging Real-World Production Settings. Sensors 2019, 19, 5370. [Google Scholar] [CrossRef] [PubMed]
- Tanuska, P.; Spendla, L.; Kebisek, M.; Duris, R.; Stremy, M. Smart Anomaly Detection and Prediction for Assembly Process Maintenance in Compliance with Industry 4.0. Sensors 2021, 21, 2376. [Google Scholar] [CrossRef] [PubMed]
- Dybkowski, M.; Klimkowski, K. Artificial Neural Network Application for Current Sensors Fault Detection in the Vector Controlled Induction Motor Drive. Sensors 2019, 19, 571. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, Z.; Karlsson, M.; Gong, S. Anomaly Detection Based on Machine Learning in IoT-Based Vertical Plant Wall for Indoor Climate Control. Build. Environ. 2020, 183, 107212. [Google Scholar] [CrossRef]
- Romeo, L.; Loncarski, J.; Paolanti, M.; Bocchini, G.; Mancini, A.; Frontoni, E. Machine Learning-Based Design Support System for the Prediction of Heterogeneous Machine Parameters in Industry 4.0. Expert Syst. Appl. 2020, 140, 112869. [Google Scholar] [CrossRef]
- Nielsen, M.; Brewer, R.S.; Grønbæk, K. Supporting Interactive Visual Analytics of Energy Behavior in Buildings through Affine Visualizations. In Proceedings of the 28th Australian Conference on Computer-Human Interaction, Launceston, Tasmania, Australia, 29 November–2 December 2016; pp. 238–246. [Google Scholar] [CrossRef]
- Al-Kababji, A.; Alsalemi, A.; Himeur, Y.; Bensaali, F.; Amira, A.; Fernandez, R.; Fetais, N. Energy Data Visualizations on Smartphones for Triggering Behavioral Change: Novel Vs. Conventional. In Proceedings of the 2020 2nd Global Power, Energy and Communication Conference (GPECOM), Izmir, Turkey, 20–23 October 2020; pp. 312–317. [Google Scholar] [CrossRef]
- Alfeo, A.L.; Cimino, M.G.C.A.; Vaglini, G. Degradation Stage Classification via Interpretable Feature Learning. J. Manuf. Syst. 2022, 62, 972–983. [Google Scholar] [CrossRef]
- Yu, W.; Dillon, T.; Mostafa, F.; Rahayu, W.; Liu, Y. A Global Manufacturing Big Data Ecosystem for Fault Detection in Predictive Maintenance. IEEE Trans. Ind. Inform. 2020, 16, 183–192. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An Experimental Platform for Bearings Accelerated Degradation Tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, Denver, CO, USA, 18–21 June 2012; IEEE Catalog Number: CPF12PHM-CDR. pp. 1–8. [Google Scholar]
- Mustakerov, I.; Borissova, D. An Intelligent Approach to Optimal Predictive Maintenance Strategy Defining. In Proceedings of the 2013 IEEE INISTA, Albena, Bulgaria, 19–21 June 2013; pp. 1–5. [Google Scholar]
- Campbell, H.F.; Brown, R.P.C. A Multiple Account Framework for Cost–Benefit Analysis. Eval. Program Plann. 2005, 28, 23–32. [Google Scholar] [CrossRef]
- Xiao, Y.; Watson, M. Guidance on Conducting a Systematic Literature Review. J. Plan. Educ. Res. 2017, 39, 93–112. [Google Scholar] [CrossRef]
- Kumar, A.; Garg, G. Systematic Literature Review on Context-Based Sentiment Analysis in Social Multimedia. Multimed. Tools Appl. 2019, 79, 15349–15380. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. BMJ 2009, 339, 332–336. [Google Scholar] [CrossRef]
- Brito, L.C.; Susto, G.A.; Brito, J.N.; Duarte, M.A. V Fault Detection of Bearing: An Unsupervised Machine Learning Approach Exploiting Feature Extraction and Dimensionality Reduction. Informatics 2021, 8, 85. [Google Scholar] [CrossRef]
- Steenwinckel, B.; De Paepe, D.; Hautte, S.V.; Heyvaert, P.; Bentefrit, M.; Moens, P.; Dimou, A.; Van Den Bossche, B.; De Turck, F.; Van Hoecke, S.; et al. FLAGS: A Methodology for Adaptive Anomaly Detection and Root Cause Analysis on Sensor Data Streams by Fusing Expert Knowledge with Machine Learning. Futur. Gener. Comput. Syst. Int. J. Escience 2021, 116, 30–48. [Google Scholar] [CrossRef]
- Orru, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability 2020, 12, 4776. [Google Scholar] [CrossRef]
- Scalabrini Sampaio, G.; Vallim Filho, A.R.A.; Santos da Silva, L.; Augusto da Silva, L. Prediction of Motor Failure Time Using An Artificial Neural Network. Sensors 2019, 19, 4342. [Google Scholar] [CrossRef]
- Ayvaz, S.; Alpay, K. Predictive Maintenance System for Production Lines in Manufacturing: A Machine Learning Approach Using IoT Data in Real-Time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Kang, Z.Q.; Catal, C.; Tekinerdogan, B. Remaining Useful Life (RUL) Prediction of Equipment in Production Lines Using Artificial Neural Networks. Sensors 2021, 21, 932. [Google Scholar] [CrossRef]
- Javier Maseda, F.; López, I.; Martija, I.; Alkorta, P.; Garrido, A.J.; Garrido, I. Sensors Data Analysis in Supervisory Control and Data Acquisition (Scada) Systems to Foresee Failures with an Undetermined Origin. Sensors 2021, 21, 2762. [Google Scholar] [CrossRef]
- Calabrese, M.; Cimmino, M.; Fiume, F.; Manfrin, M.; Romeo, L.; Ceccacci, S.; Paolanti, M.; Toscano, G.; Ciandrini, G.; Carrotta, A.; et al. SOPHIA: An Event-Based IoT and Machine Learning Architecture for Predictive Maintenance in Industry 4.0. Information 2020, 11, 202. [Google Scholar] [CrossRef]
- Venegas, P.; Ivorra, E.; Ortega, M.; de Ocariz, I.S. Towards the Automation of Infrared Thermography Inspections for Industrial Maintenance Applications. Sensors 2022, 22, 613. [Google Scholar] [CrossRef]
- Razgon, M.; Mousavi, A. Relaxed Rule-Based Learning for Automated Predictive Maintenance: Proof of Concept. Algorithms 2020, 13, 219. [Google Scholar] [CrossRef]
- Zhou, K.B.; Zhang, J.Y.; Shan, Y.H.; Ge, M.F.; Ge, Z.Y.; Cao, G.N. A Hybrid Multi-Objective Optimization Model for Vibration Tendency Prediction of Hydropower Generators. Sensors 2019, 19, 2055. [Google Scholar] [CrossRef]
- Fernandes, M.; Canito, A.; Bolon-Canedo, V.; Conceicao, L.; Praca, I.; Marreiros, G. Data Analysis and Feature Selection for Predictive Maintenance: A Case-Study in the Metallurgic Industry. Int. J. Inf. Manag. 2019, 46, 252–262. [Google Scholar] [CrossRef]
- Redondo, R.; Herrero, A.; Corchado, E.; Sedano, J. A Decision-Making Tool Based on Exploratory Visualization for the Automotive Industry. Appl. Sci. 2020, 10, 4355. [Google Scholar] [CrossRef]
- Azab, E.; Nafea, M.; Shihata, L.A.; Mashaly, M. A Machine-Learning-Assisted Simulation Approach for Incorporating Predictive Maintenance in Dynamic Flow-Shop Scheduling. Appl. Sci. 2021, 11, 11725. [Google Scholar] [CrossRef]
- Chuang, S.Y.; Sahoo, N.; Lin, H.W.; Chang, Y.H. Predictive Maintenance with Sensor Data Analytics on a Raspberry Pi-Based Experimental Platform. Sensors 2019, 19, 3884. [Google Scholar] [CrossRef] [PubMed]
- Hermansa, M.; Kozielski, M.; Michalak, M.; Szczyrba, K.; Wrobel, L.; Sikora, M. Sensor-Based Predictive Maintenance with Reduction of False Alarms-A Case Study in Heavy Industry. Sensors 2022, 22, 226. [Google Scholar] [CrossRef] [PubMed]
- Avendano, D.N.; Vandermoortele, N.; Soete, C.; Moens, P.; Ompusunggu, A.P.; Deschrijver, D.; Van Hoecke, S. A Semi-Supervised Approach with Monotonic Constraints for Improved Remaining Useful Life Estimation. Sensors 2022, 22, 1590. [Google Scholar] [CrossRef]
- Serradilla, O.; Zugasti, E.; de Okariz, J.R.; Rodriguez, J.; Zurutuza, U. Adaptable and Explainable Predictive Maintenance: Semi-Supervised Deep Learning for Anomaly Detection and Diagnosis in Press Machine Data. Appl. Sci. 2021, 11, 7376. [Google Scholar] [CrossRef]
- Trinh, H.C.; Kwon, Y.K. An Empirical Investigation on a Multiple Filters-Based Approach for Remaining Useful Life Prediction. Machines 2018, 6, 35. [Google Scholar] [CrossRef]
- Swana, E.; Doorsamy, W. An Unsupervised Learning Approach to Condition Assessment on a Wound-Rotor Induction Generator. Energies 2021, 14, 602. [Google Scholar] [CrossRef]
- Jakubowski, J.; Stanisz, P.; Bobek, S.; Nalepa, G.J. Anomaly Detection in Asset Degradation Process Using Variational Autoencoder and Explanations. Sensors 2022, 22, 291. [Google Scholar] [CrossRef]
- Aqueveque, P.; Radrigan, L.; Pastene, F.; Morales, A.S.; Guerra, E. Data-Driven Condition Monitoring of Mining Mobile Machinery in Non-Stationary Operations Using Wireless Accelerometer Sensor Modules. IEEE Access 2021, 9, 17365–17381. [Google Scholar] [CrossRef]
- Aqueveque, P.; Radrigan, L.; Morales, A.S.; Willenbrinck, E. Development of a Cyber-Physical System to Monitor Early Failures Detection in Vibrating Screens. IEEE Access 2021, 9, 145866–145885. [Google Scholar] [CrossRef]
- Liu, C.; Tang, D.; Zhu, H.; Nie, Q. A Novel Predictive Maintenance Method Based on Deep Adversarial Learning in the Intelligent Manufacturing System. IEEE Access 2021, 9, 49557–49575. [Google Scholar] [CrossRef]
- Kiangala, K.S.; Wang, Z. An Effective Predictive Maintenance Framework for Conveyor Motors Using Dual Time-Series Imaging and Convolutional Neural Network in an Industry 4.0 Environment. IEEE Access 2020, 8, 121033–121049. [Google Scholar] [CrossRef]
- Mazaev, T.; Crevecoeur, G.; Van Hoecke, S. Bayesian Convolutional Neural Networks for Remaining Useful Life Prognostics of Solenoid Valves with Uncertainty Estimations. IEEE Trans. Ind. Inform. 2021, 17, 8418–8428. [Google Scholar] [CrossRef]
- Kamat, P.V.; Sugandhi, R.; Kumar, S. Deep Learning-Based Anomaly-Onset Aware Remaining Useful Life Estimation of Bearings. PEERJ Comput. Sci. 2021, 7, e795. [Google Scholar] [CrossRef]
- Ullah, Z.; Lodhi, B.A.; Hur, J. Detection and Identification of Demagnetization and Bearing Faults in PMSM Using Transfer Learning-Based VGG. Energies 2020, 13, 3834. [Google Scholar] [CrossRef]
- Zhai, S.; Gehring, B.; Reinhart, G. Enabling Predictive Maintenance Integrated Production Scheduling by Operation-Specific Health Prognostics with Generative Deep Learning. J. Manuf. Syst. 2021, 61, 830–855. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Wang, S.X.; Sun, X.F.; Di Cairano-Gilfedder, C.; Titmus, S.; Syntetos, A.A. Predictive Maintenance Using Cox Proportional Hazard Deep Learning. Adv. Eng. Inform. 2020, 44, 101054. [Google Scholar] [CrossRef]
- Zschech, P.; Heinrich, K.; Bink, R.; Neufeld, J.S. Prognostic Model Development with Missing Labels: A Condition-Based Maintenance Approach Using Machine Learning. Bus. Inf. Syst. Eng. 2019, 61, 327–343. [Google Scholar] [CrossRef]
- Resende, C.; Folgado, D.; Oliveira, J.; Franco, B.; Moreira, W.; Oliveira, A.; Cavaleiro, A.; Carvalho, R. TIP4.0: Industrial Internet of Things Platform for Predictive Maintenance. Sensors 2021, 21, 4676. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, J.; Wei, B.; Chen, W.; Xu, S. Investigating the Construction, Training, and Verification Methods of k-Means Clustering Fault Recognition Model for Rotating Machinery. IEEE Access 2020, 8, 196515–196528. [Google Scholar] [CrossRef]
- Giordano, D.; Mellia, M.; Cerquitelli, T. K-MDTSC: K-Multi-Dimensional Time-Series Clustering Algorithm. Electronics 2021, 10, 1166. [Google Scholar] [CrossRef]
- Wu, Z.Y.; Luo, H.; Yang, Y.N.; Lv, P.; Zhu, X.N.; Ji, Y.; Wu, B.A. K-PdM: KPI-Oriented Machinery Deterioration Estimation Framework for Predictive Maintenance Using Cluster-Based Hidden Markov Model. IEEE Access 2018, 6, 41676–41687. [Google Scholar] [CrossRef]
- Bekar, E.T.; Nyqvist, P.; Skoogh, A. An Intelligent Approach for Data Pre-Processing and Analysis in Predictive Maintenance with an Industrial Case Study. Adv. Mech. Eng. 2020, 12, 1687814020919207. [Google Scholar] [CrossRef]
- Cheng, Q.; Varshney, P.K.; Arora, M.K. Logistic Regression for Feature Selection and Soft Classification of Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2006, 3, 491–494. [Google Scholar] [CrossRef]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding Variable Importances in Forests of Randomized Trees. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 431–439. [Google Scholar]
- Komorowski, M.; Marshall, D.C.; Salciccioli, J.D.; Crutain, Y. Exploratory Data Analysis. In Secondary Analysis of Electronic Health Records; Data, M.I.T.C., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 185–203. ISBN 978-3-319-43742-2. [Google Scholar]
- Wan, J.; Tang, S.; Li, D.; Wang, S.; Liu, C.; Abbas, H.; Vasilakos, A. V A Manufacturing Big Data Solution for Active Preventive Maintenance. IEEE Trans. Ind. Inform. 2017, 13, 2039–2047. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Friedman, J.H. Exploratory Projection Pursuit. J. Am. Stat. Assoc. 1987, 82, 249–266. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quality Level | Number of Studies | Percentage (%) |
|---|---|---|
| Good (7 < score <= 10) | 7 | 6.25 |
| Average (5 <= score <= 7) | 30 | 26.79 |
| Poor (score < 5) | 75 | 66.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Chaw, J.K.; Goh, K.M.; Ting, T.T.; Sahrani, S.; Ahmad, M.N.; Abdul Kadir, R.; Ang, M.C. Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry. Sensors 2022, 22, 6321. https://doi.org/10.3390/s22176321
Cheng X, Chaw JK, Goh KM, Ting TT, Sahrani S, Ahmad MN, Abdul Kadir R, Ang MC. Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry. Sensors. 2022; 22(17):6321. https://doi.org/10.3390/s22176321
Chicago/Turabian StyleCheng, Xiang, Jun Kit Chaw, Kam Meng Goh, Tin Tin Ting, Shafrida Sahrani, Mohammad Nazir Ahmad, Rabiah Abdul Kadir, and Mei Choo Ang. 2022. "Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry" Sensors 22, no. 17: 6321. https://doi.org/10.3390/s22176321
APA StyleCheng, X., Chaw, J. K., Goh, K. M., Ting, T. T., Sahrani, S., Ahmad, M. N., Abdul Kadir, R., & Ang, M. C. (2022). Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry. Sensors, 22(17), 6321. https://doi.org/10.3390/s22176321