
Efficient Massive Computing for Deformable Volume Data Using Revised Parallel Resampling


Abstract
:1. Introduction
- We propose an efficient volume deformation computing for massive data;
- User latency was improved through a high-speed deformable object creation algorithm;
- We present a more reliable barycentric interpolation method suitable for GPUs.
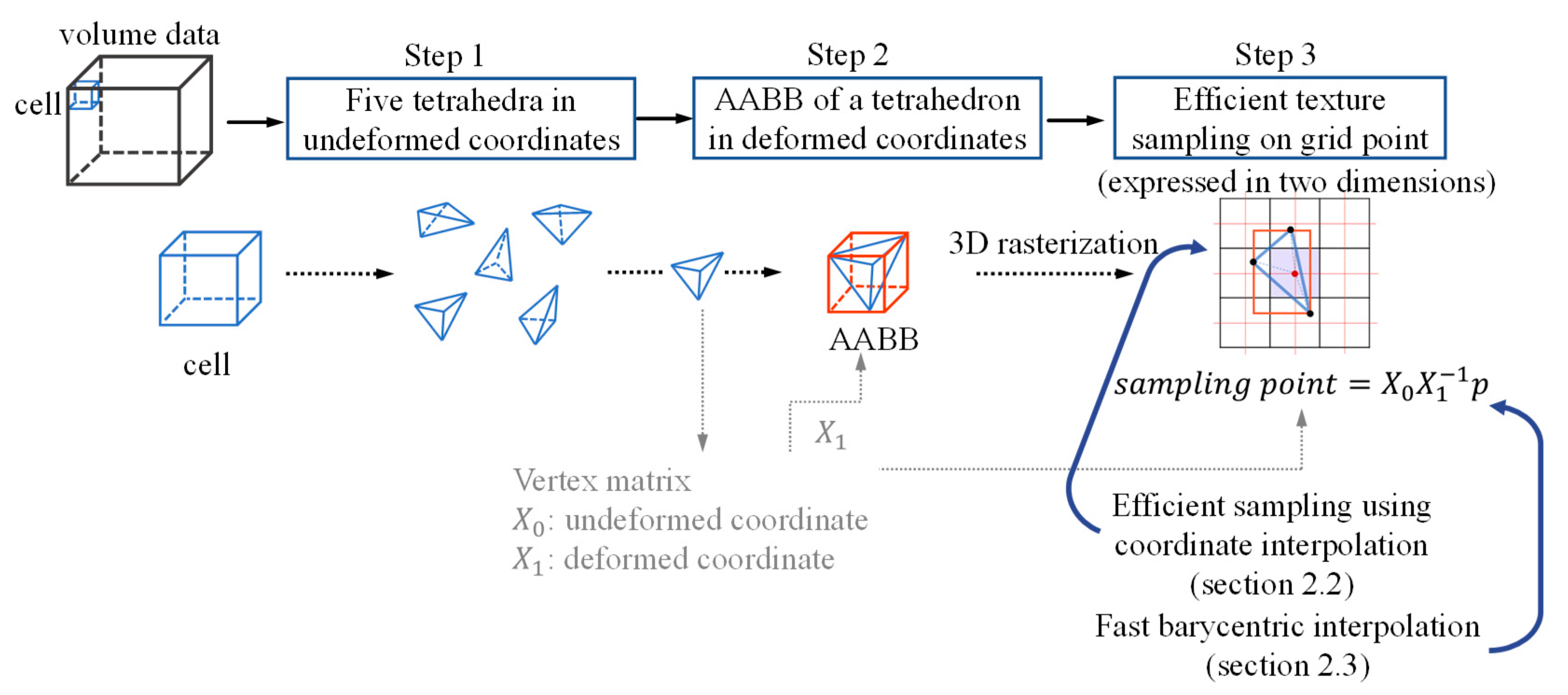
Overall Flow of Our System
2. Materials and Methods
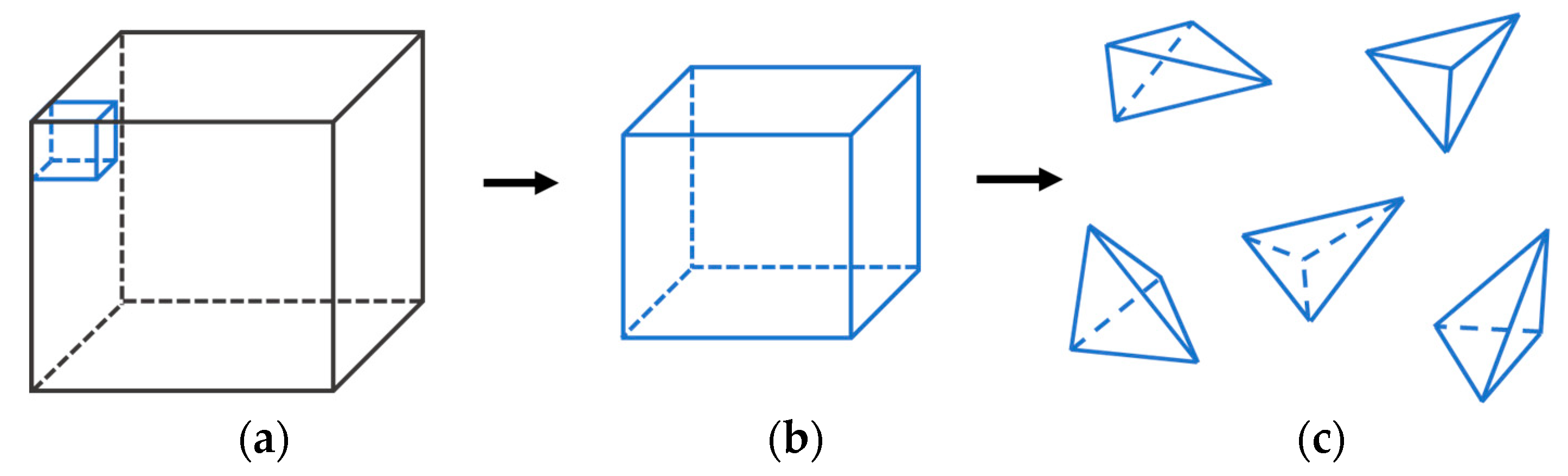
2.1. Related Work—Parallel Resampling
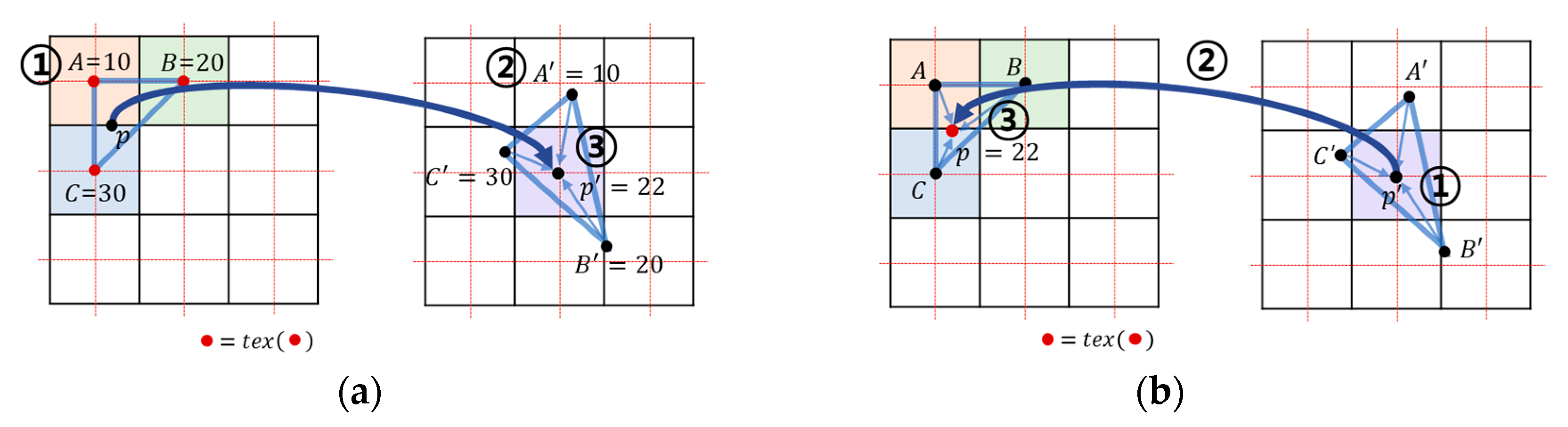
2.2. Efficient Sampling Using Coordinate Interpolation
| Algorithm 1 Parallel Resampling of Aguilera’s Method [16] |
| 1: struct vertex 2: float x,y,z; 3: short value; /* value has already been resampled */ 4: procedure SampleTetrahedron (vertex A, B, C, D, Tex3D outGrid) 5: aabb boundingBox = outGrid.computeAABB(A, B, C, D); 6: foreach (voxel in boundingBox) 7: float4 baryCoords = computeBaryCoords (voxel.center, A, B, C, D); 8: if (centerLiesInsideTetrahedron (baryCoords)) 9: short newValue = interpolateValue (baryCoords, A, B, C, D); 10: setValue (voxel, newValue); 11: end if 12: end foreach 13: end procedure |
| Algorithm 2 Parallel Resampling of Proposed Method |
| 1: struct vertex 2: float x,y,z; 3: float tx,tx,tz; /* original position */ 4: procedure SampleTetrahedron (Mat4 , vertex A, B, C, D, Tex3D outGrid, Tex3D inVolume) 5: aabb boundingBox = outGrid.computeAABB(A, B, C, D); 6: foreach (voxel in boundingBox) 7: float4 baryCoords = computeBaryCoords (voxel.center, A, B, C, D); /* in Equation (3) */ 8: if (centerLiesInsideTetrahedron(baryCoords)) 9: float4 inpos = * baryCoords; 10: float4 newValue = tex3D (inVolume, inpos.xyz); 11: setValue (voxel, newValue); 12: end if 13: end foreach 14: end procedure |
2.3. Efficient Barycentric Interpolation for a Massive Number of Tetrahedra
2.3.1. Barycentric Interpolation and Inverse Matrix
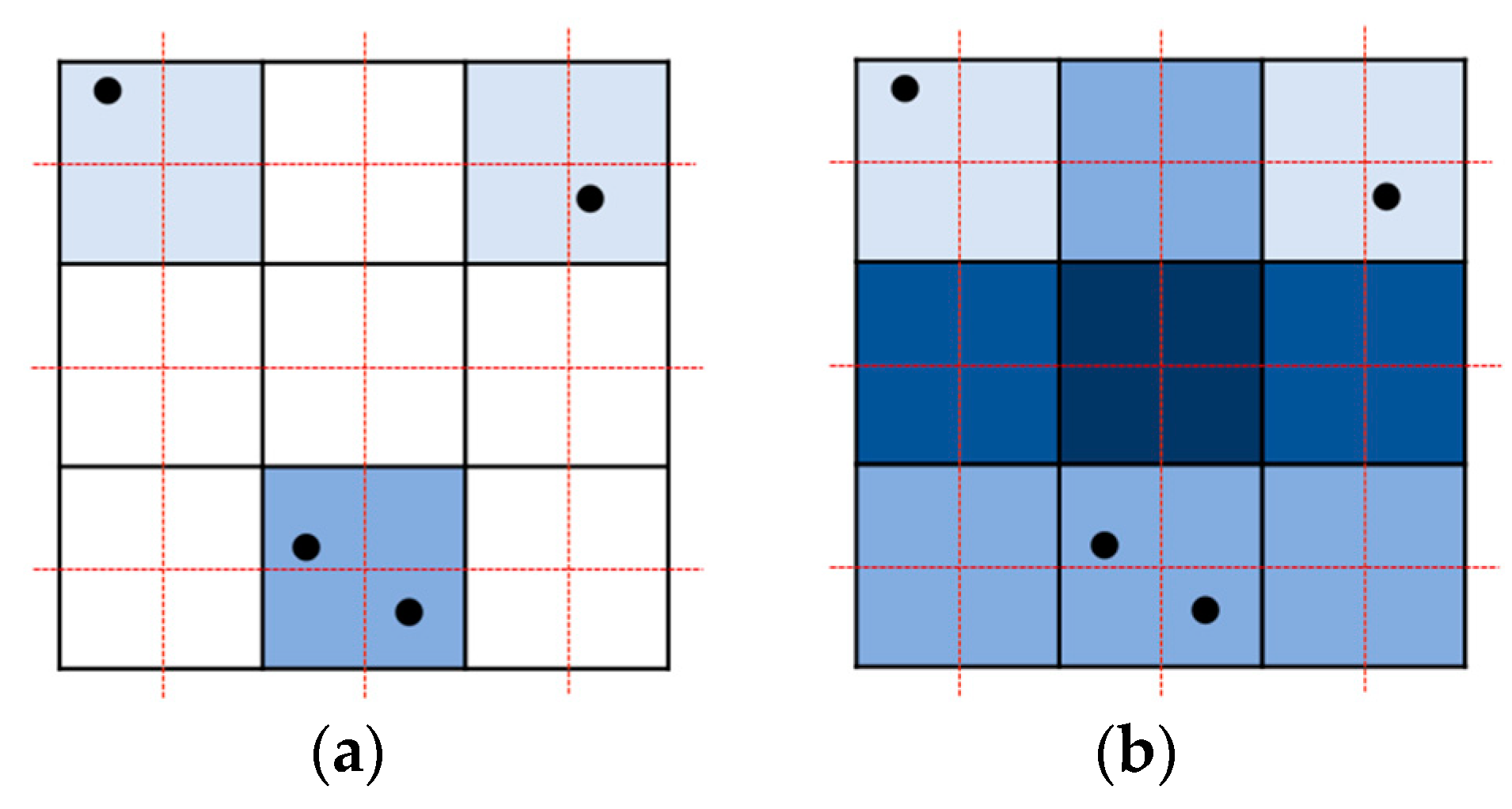
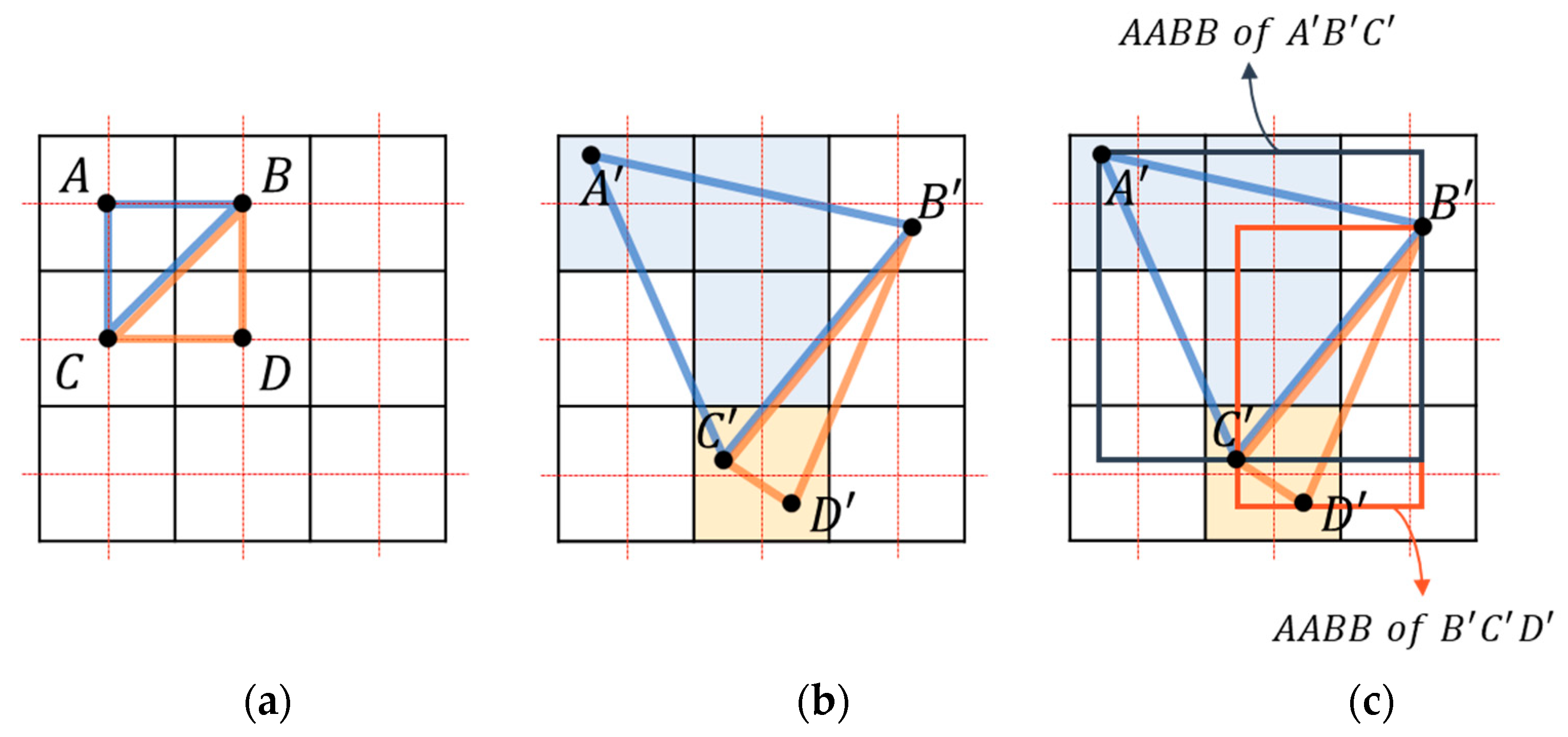
2.3.2. Calculation of the Barycentric Coordinates Using the Reference Point
3. Results
3.1. Experimental Setup
3.2. Efficient Barycentric Interpolation
3.3. Efficient Sampling Using Coordinate Interpolation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| template <typename T> /* T can be float or double */ T Determinant ( ) { T n11 = 255.9, n12 = 256.7, n13 = 256.7, n14 = 255.9; T n21 = 256.7, n22 = 255.9, n23 = 256.7, n24 = 255.9; T n31 = 133.1, n32 = 133.4, n33 = 132.3, n34 = 132.3; T n41 = 1, n42 = 1, n43 = 1, n44 = 1; T t11 = n23*n34*n42 − n24*n33*n42 + n24*n32*n43 − n22*n34*n43 − n23*n32*n44 + n22*n33*n44; T t12 = n14*n33*n42 − n13*n34*n42 − n14*n32*n43 + n12*n34*n43 + n13*n32*n44 − n12*n33*n44; T t13 = n13*n24*n42 − n14*n23*n42 + n14*n22*n43 − n12*n24*n43 − n13*n22*n44 + n12*n23*n44; T t14 = n14*n23*n32 − n13*n24*n32 − n14*n22*n33 + n12*n24*n33 + n13*n22*n34 − n12*n23*n34; T det = n11*t11 + n21*t12 + n31*t13 + n41*t14; return det; } |
References
- Nienhuys, H.W.; Frank van der Stappen, A. A surgery simulation supporting cuts and finite element deformation. In Proceedings of the Fourth International Conference on Medical Image Computing & Computer-Assisted Intervention, Utrecht, The Netherlands, 14–17 October 2001; pp. 145–152. [Google Scholar]
- Heng, P.A.; Cheng, C.Y.; Wong, T.T.; Xu, Y.; Chui, Y.P.; Chan, K.M.; Tso, S.K. A virtual-reality training system for knee arthroscopic surgery. IEEE Trans. Inf. Technol. Biomed. 2004, 8, 217–227. [Google Scholar] [CrossRef] [PubMed]
- Si, W.; Lu, J.; Liao, X.; Wang, Q. Towards interactive progressive cutting of deformable bodies via phyxel-associated surface mesh approach for virtual surgery. IEEE Access 2018, 6, 32286–32299. [Google Scholar] [CrossRef]
- Gibson, S.F. 3D Chainmail: A Fast Algorithm for Deforming Volumetric Objects. In Proceedings of the ACM Siggraph Symp Interact 3D Graph Games 1997, Providence, RI, USA, 27–30 April 1997; p. 149-ff. [Google Scholar]
- Liu, T.; Bargteil, A.W.; O’Brien, J.F.; Kavan, L. Fast simulation of mass-spring systems. ACM Trans. Graph (TOG) 2013, 32, 1–7. [Google Scholar] [CrossRef]
- Berndt, I.; Torchelsen, R.; Maciel, A. Efficient surgical cutting with position-based dynamics. IEEE Comput. Graph. Appl. 2017, 37, 24–31. [Google Scholar] [CrossRef] [PubMed]
- Rößler, F.; Wolff, T.; Ertl, T. Direct GPU-based Volume Deformation. In Proceedings of the CURAC, Leipzig, Germany, 24–26 September 2008; pp. 65–68. [Google Scholar]
- Kwon, K.; Chae, S.; Shin, B.S. Anti-aliasing on deformed area using adaptive super sampling during volume ray-casting. Biomed. Eng. Lett. 2011, 1, 168. [Google Scholar] [CrossRef]
- Rezk-Salama, C.; Scheuering, M.; Soza, G.; Greiner, G. Fast volumetric deformation on general purpose hardware. In Proceedings of the ACM SIGGRAPH/EUROGRAPHICS Workshop on Graphics Hardware, Los Angeles, CA, USA, 12–13 August 2001; pp. 17–24. [Google Scholar]
- Correa, C.D.; Silver, D.; Chen, M. Discontinuous displacement mapping for volume graphics. In Proceedings of the VG@ SIGGRAPH, Boston, MA, USA, 30–31 July 2006; pp. 9–16. [Google Scholar]
- Herrera, I.; Buchart, C.; Aguinaga, I.; Borro, D. Study of a ray casting technique for the visualization of deformable volumes. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1555–1565. [Google Scholar] [CrossRef] [PubMed]
- Schulze, F.; Bühler, K.; Hadwiger, M. Interactive deformation and visualization of large volume datasets. In Proceedings of the GRAPP (AS/IE), Barcelona, Spain, 8–11 March 2007; pp. 39–46. [Google Scholar]
- Murray, L.M.; Lee, A.; Jacob, P.E. Parallel resampling in the particle filter. J. Comput. Graph. Stat. 2016, 25, 789–805. [Google Scholar]
- Nicely, M.A.; Wells, B.E. Improved parallel resampling methods for particle filtering. IEEE Access 2019, 7, 47593–47604. [Google Scholar]
- Gascon, J.; Espadero, J.M.; Perez, A.G.; Torres, R.; Otaduy, M.A. Fast deformation of volume data using tetrahedral mesh rasterization. In Proceedings of the 12th Computer Animation, Anaheim, CA, USA, 19–21 July 2013; pp. 181–185. [Google Scholar]
- Aguilera, A.R.; Salas, A.L.; Perandrés, D.M.; Otaduy, M.A. A parallel resampling method for interactive deformation of volumetric models. Comput. Graphs 2015, 53, 147–155. [Google Scholar]
- Torres, R.; Rodríguez, A.; Otaduy, M. Hands-On Deformation of Volumetric Anatomical Images on a Touch screen. Appl. Sci. 2021, 11, 9502. [Google Scholar] [CrossRef]
- Chen, J.; Tai, K.W.; Chen, W.C.; Ouhyoung, M. Robust Voxelization and Visualization by Improved Tetrahedral Mesh Generation. arXiv 2021, arXiv:2106.01326. [Google Scholar]
- Teschner, M.; Heidelberger, B.; Müller, M.; Pomerantes, D.; Gross, M.H. Optimized spatial hashing for collision detection of deformable objects. Proc. Int. Fall Workshop Vis. Model Vis. 2003, 3, 47–54. [Google Scholar]
- Levoy, M. Display of surfaces from volume data. IEEE Comput. Graph. Appl. 1988, 8, 29–37. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Ha, T.; Kye, H. Real-Time Computed Tomography Volume Visualization with Ambient Occlusion of Hand-Drawn Transfer Function Using Local Vicinity Statistic. Healthc. Inform. Res. 2019, 25, 297–304. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size | Capacity | |
|---|---|---|
| Abdomen | 512 × 512 × 300 | 150 MB |
| Lung | 512 × 512 × 316 | 158 MB |
| Colon | 512 × 512 × 141 | 70.5 MB |
| Leg | 512 × 512 × 600 | 300 MB |
| Desktop | Notebook | |||||||
|---|---|---|---|---|---|---|---|---|
| Transform | No. Optimizations (a) | 3D Double (b) [19] | Our 3D Float (c) | (a)/(c) | No. Optimizations (a) | 3D Double (b) [19] | Our 3D Float (c) | (a)/(c) |
| Wave | 348.14 | 150.55 | 22.55 | 15.43x | 892.85 | 360.26 | 60.40 | 14.78x |
| Twist | 376.11 | 166.57 | 26.56 | 14.16x | 989.42 | 415.30 | 98.55 | 10.03x |
| Bubble | 385.36 | 168.49 | 17.44 | 22.09x | 940.06 | 402.53 | 58.39 | 16.09x |
| Desktop | Notebook | |||||
|---|---|---|---|---|---|---|
| Transform | Aguilera’s Method [16] (a) | Proposed Method (b) | (a)/(b) | Aguilera’s Method [16] (a) | Proposed Method (b) | (a)/(b) |
| Wave | 22.55 | 19.75 | 1.14x | 60.40 | 51.27 | 1.17x |
| Twist | 26.56 | 23.82 | 1.11x | 98.55 | 90.78 | 1.09x |
| Bubble | 17.44 | 14.08 | 1.23x | 58.39 | 47.18 | 1.23x |
| Data | Aguilera’s Method [16] | Proposed Method |
|---|---|---|
| Abdomen (300) | 60.40 | 51.27 |
| Lung (316) | 63.53 | 54.87 |
| Colon (141) | 29.37 | 24.46 |
| Legs (600) | 149.37 | 127.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Kye, H. Efficient Massive Computing for Deformable Volume Data Using Revised Parallel Resampling. Sensors 2022, 22, 6276. https://doi.org/10.3390/s22166276
Park C, Kye H. Efficient Massive Computing for Deformable Volume Data Using Revised Parallel Resampling. Sensors. 2022; 22(16):6276. https://doi.org/10.3390/s22166276
Chicago/Turabian StylePark, Chailim, and Heewon Kye. 2022. "Efficient Massive Computing for Deformable Volume Data Using Revised Parallel Resampling" Sensors 22, no. 16: 6276. https://doi.org/10.3390/s22166276
APA StylePark, C., & Kye, H. (2022). Efficient Massive Computing for Deformable Volume Data Using Revised Parallel Resampling. Sensors, 22(16), 6276. https://doi.org/10.3390/s22166276