1. Introduction
Visibility is a complex phenomenon that is affected by emissions, air pollutants, and other factors, including sunlight, humidity, temperature, and time. As a human-perceived concept, it is usually referred to as the distance of ‘an object being just visible’. The World Meteorological Organization (WMO) defines it as the longest distance at which a black object of suitable dimensions, located on or near the ground, can be seen and readily identified when observed against the horizon [
1].
Fog, a very common atmospheric phenomenon with horizontal visibility of less than 1000 m, influences human society in many ways [
2]. Usually, atmospheric visibility is measured by two major approaches: optical sensor-based and visual performance-based approaches. The former measures every possible atmospheric parameter, such as light scatter, air light, and light absorption, to derive visibility from a small part of the atmosphere, so the accuracy is limited. The latter relies on professional meteorologists. Due to high costs and complexity, the sensor-based meters installed by weather stations are not geographically extensive. As for visual observations by humans, they may be subjective, and they are easily affected by experience and the observation environment.
Fortunately, many video-surveillance cameras are widely deployed in public and private places. Estimating atmospheric visibility from a surveillance image has great value in meteorology, public transportation, and many other fields and has caught many researchers’ attention [
3]. Some previous image-based methods require the detection of a specified target or the use of auxiliary equipment [
4]. Since the additional information or extra device is not equipped in normal vision systems, the applications of these algorithms are limited. Therefore, single-image-based visibility estimation has been developed in recent years [
5].
Some simple image features, including the brightness, contrast between a target and background [
6,
7], and gray-scale level [
8], are already used to estimate visibility. However, these basic image features are sensitive to illumination variations. Fourier transform-combined Sobel operations [
9] are adopted to extract global features of the image to overcome illumination variations. Koschmieder’s law-based methods have been investigated extensively to estimate visibility, which describes the relation between transmission and atmospheric light and how haze or fog impacts the observed image [
9,
10,
11,
12]. However, these techniques need prior knowledge or manual settings [
13] to estimate the atmospheric light and transmission map, and thus face many challenges, such as light sources and absorption affecting the accuracy of the visibility estimation. In addition, Koschmieder’s law-based methods always build a model by assuming that the atmosphere is uniform, which is rare in real-world situations. Therefore, a learning-based approach that can be generally applied or adapted to different scenes is needed.
Inspired by the successful application of convolutional neural networks (CNN) in many computer vision tasks, researchers have turned their attention to learning-based approaches to visibility problems. Based on annotated image data, a CNN model was trained to obtain the final classification of visibility [
14]. However, it is still a very challenging problem to specify the absolute visibility from a single image accurately, even for human beings. Conversely, humans can easily specify relative relations between two images with different visibility levels. Therefore, a relative CNN-RNN was proposed to find the relative features from paired images [
15], which first proved the effectiveness of relative relations in visibility estimation.
Currently, there are two challenges to overcome for deep learning-based methods. One of them is that the available high-quality datasets are insufficient. Deep learning is a data-driven approach, and its performance heavily depends on the dataset size and annotation quality. However, only two synthetic image-classification datasets, Foggy ROad Sign Images (FROSI) [
16] and Extended Foggy Road Image Database (ExFRIDA) [
17], have been released recently. A large-scale dataset of annotated images collected from real scenes is still unavailable. Another challenge is that estimating the visibility level from the image is difficult when only using an ordinary classification model. Because of the ordinal information hidden in the data, visibility estimation is an intermediate task between regression and classification. Generally, visibility estimation can be viewed as a typical regression problem with many continuous labels, and the ordinal information of visibility among all images is more valuable for model training. In real scenes, the continuous visibility value for surveillance images is very difficult to acquire. However, the level labels for visibility contain intrinsic ordinal information. If the ordinal information among all images can be used to aid visibility estimation, the model performance is improved.
In this paper, we address these two challenges by collecting a large-scale dataset named Foggy Highway Visibility Images (FHVI) from real surveillance scenes and proposing VISOR-NET, a novel end-to-end pipeline, which is different from the existing deep learning-based classification or regression methods. Extensive experiments show that VISOR-NET can achieve better performance than the current state-of-the-art models in all visibility datasets.
The main contributions of this paper are summarized as follows:
- (1)
A novel end-to-end pipeline VISOR-NET is proposed for visibility estimation with ordinal relative learning, which combines ordinal regression with the relative features of images to map relative visibility values. Compared to the existing algorithms, the proposed method can achieve better performance with fewer image data in a short training time.
- (2)
A large-scale dataset, FHVI, taken from real surveillance data is collected. The visibility label of each image is annotated and manually checked by meteorological staff with reference to a professional visibility meter. This dataset will benefit further visibility estimation research.
- (3)
After adding a small number of continuous labels to training images as anchors, the relative values of VISOR-NET can be mapped to the real visibility. Regression experimental results demonstrate that the proposed VISOR-NET can obtain a satisfactory global regression function for visibility estimation under discrete class labels.
2. Related Work
Visibility estimation techniques can be divided into two broad categories: data-driven and statistical methods. Considering that our main concern is data-driven methods, we give a brief introduction to them here. Other related techniques, including ordinal regression and relative learning, are also discussed here.
2.1. Data-Driven Methods
As early as the 1990s, a simple feed-forward neural network [
4] was proposed to improve short-range visibility forecasts. A similar study was also conducted to map the nonlinear relation between visibility and multiple metrological features [
18]. However, these studies only use metrological data because extensive image datasets for visibility estimation were unavailable at that time. Recently, Chaabani et al. used an artificial neural network (ANN) [
19] to estimate the visibility distance under foggy weather conditions from camera images.
However, such a simple ANN-based model cannot handle complicated real-world situations. Therefore, deep learning-based methods have been proposed. Li et al. first employed a CNN [
20] to estimate the visibility distance from webcam images and a pre-trained AlexNet [
21] was used to extract the features for classification. Giyenko also built a shallow CNN (SCNN) [
22] containing three convolutional layers to conduct visibility detection on camera images. Akmaljon Palvanov et al. proposed an improved VISibility CNN-based network (VisNet) [
23], where a fast Fourier transform (FFT) algorithm and a high-pass filter were used to filter the original image into two images of the same size, and these images combined with the original image were input in an integrated CNN to obtain the final visibility classification. In essence, VisNet is a data augmentation method. In contrast to other methods, You et al. [
15] proposed a relative CNN-RNN to estimate the relative atmospheric visibility from outdoor images, where the CNN-RNN network was used to extract the relative features and the final classification task was conducted with a support vector machine (SVM). However, this method is not end-to-end and does not take full advantage of the potential capacity because it still ignores the ordinal information of images.
2.2. Ordinal Regression
Ordinal regression is a technique for predicting the ordinal relationship from a set of independent features, and it is widely used in age estimation [
14], face recognition [
24], and monocular depth estimation [
25]. Such as sensory grading of symptoms (no pain/slight pain/relatively pain/severe pain), age grading (1–18/…/60–100 years old), etc. There is a relative ranking among different values in the range of variables, but the differences between grades are not equal. For example, the age difference between young people and children is not necessarily equal to the age difference between the old and the middle age. Generally, there are two main types of approaches to solving ordinal problems. One is converting the ordinal regression problem to a
binary classification problem, and the k-th classifier is trained to predict the probability of
for the labeled instance
. Frank et al. [
26] and Li et al. [
27] put this idea into practice using several decision trees or a REDuction SVM (RED-SVM). The other approach can be informally described as transforming the ordinal regression to a regular regression problem, where the ordinal information of classes can be preserved. It is also named a threshold approach in [
28], and its goal is to learn the latent function and the boundaries of the intervals between ranks. Kramer et al. [
29] investigated a regression-tree learner by mapping the ordinal scale to real numeric values. The original SVM [
30], kernel-discriminant analysis (KDA) [
31], and learning-vector quantization (LVQ) [
32] were extended by a rank constraint to be suited for ordinal regression.
Recently, deep convolutional neural networks have been applied to this problem. Niu et al. [
14] transformed the ordinal problem into a series of binary classification problems using a Multiple Output CNN (MOCNN) for age estimation. Fu et al. [
25] introduced a spacing increasing discretization (SID) strategy to discretize depth and transform depth estimation into an ordinal regression problem, which achieved a much higher accuracy and faster convergence. Liu et al. [
33] introduced the idea of large-margin deep neural networks and proposed a Convolutional Neural Network with Pairwise regularization for Ordinal Regression (CNNPOR). It is a weighted combination of the softmax logistic regression loss and the pairwise constraint from adjacent ranks. The former is used to distinguish different categories of examples and the latter maps the instances to a line with a large margin, which sets the minimum distance between the examples of adjacent rank as 1.
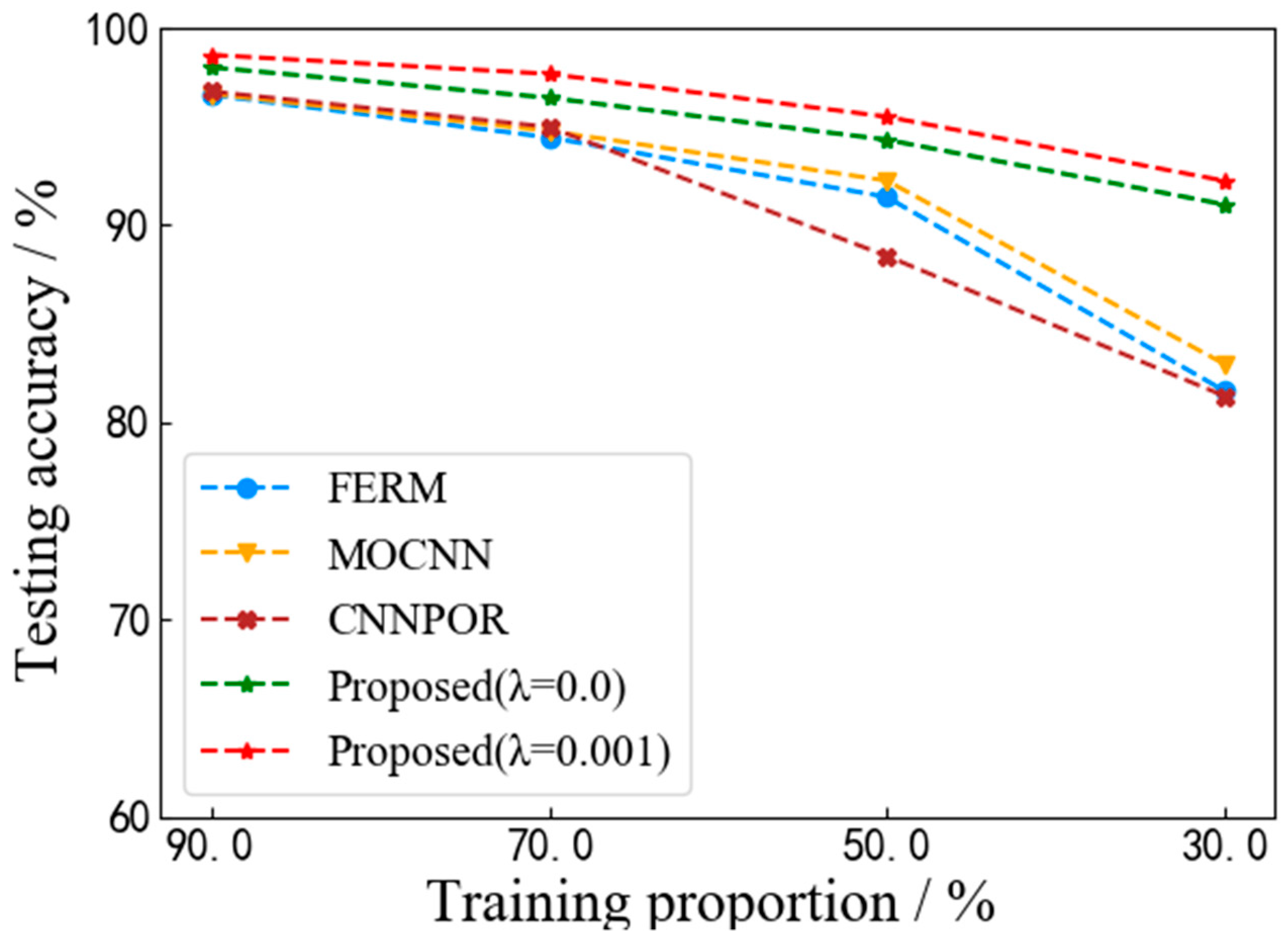
The first type, similar to a MOCNN, can be seen as an enhanced classification method combined with additional ordinal information by which a linear projection cannot be obtained. The main drawback of the second type (e.g., a CNNPOR) is that it cannot build a satisfying global function since the pairwise constraint from adjacent ranks is limited. In contrast to these two approaches, the proposed VISOR-NET learns a line by fully using the ordinal constraint from the dataset without a large margin setting.
2.3. Relative Attributes Learning
First, download relative attributes learning is an approach that finds a ranking function for each attribute using relative similarity constrains such as pairs of examples. Parikh and Grauman [
34] proposed a method to compare the strength of a certain attribute between data and employed SVM to learn the ranking functions and predict the relative relationships for novel images. The Ranking SVM [
35] has been extended to learn relative parts using local parts features that are shared across different categories. Li et al. [
36] converted the decision tree into a relative tree and created a relative forest algorithm for nonlinear ranking function learning.
As traditional machine learning algorithms use handcrafted visual features to learn a ranking function, deep learning is also employed in relative attribute learning. The deep relative attributes (DRA) method [
37] can learn the visual features and ranking function jointly using an end-to-end framework. The deep relative distance learning (DRDL) method [
38] projects raw vehicle images into metric space and measures the similarity of two arbitrary vehicles using the relative Euclidean distance. Compared with traditional relative attribute learning methods, deep learning-based methods have significantly improved the accuracy of many research fields.
Intuitively, the visibility of images can also be considered a relative attribute. When fog is thicker, the visibility attribute is lower. Compared with the threshold approaches in ordinal regression, relative learning focuses on the intensity of some attributes between examples and does not need a pre-defined margin between ranks. Therefore, a linear projection obtained in this way is more natural. In general, relative learning does not consider global ordinal information from the whole dataset and the comparison between examples is random. Therefore, the training process is not stable or efficient.
3. The Proposed Method
VISOR-NET is a novel ordinal regression method. In this paper, we encode the ordinal information into a series of paired images with relative order in each image batch. The proposed VISOR-NET learns a global rank function to quantify all the ordinal relative relations of images.
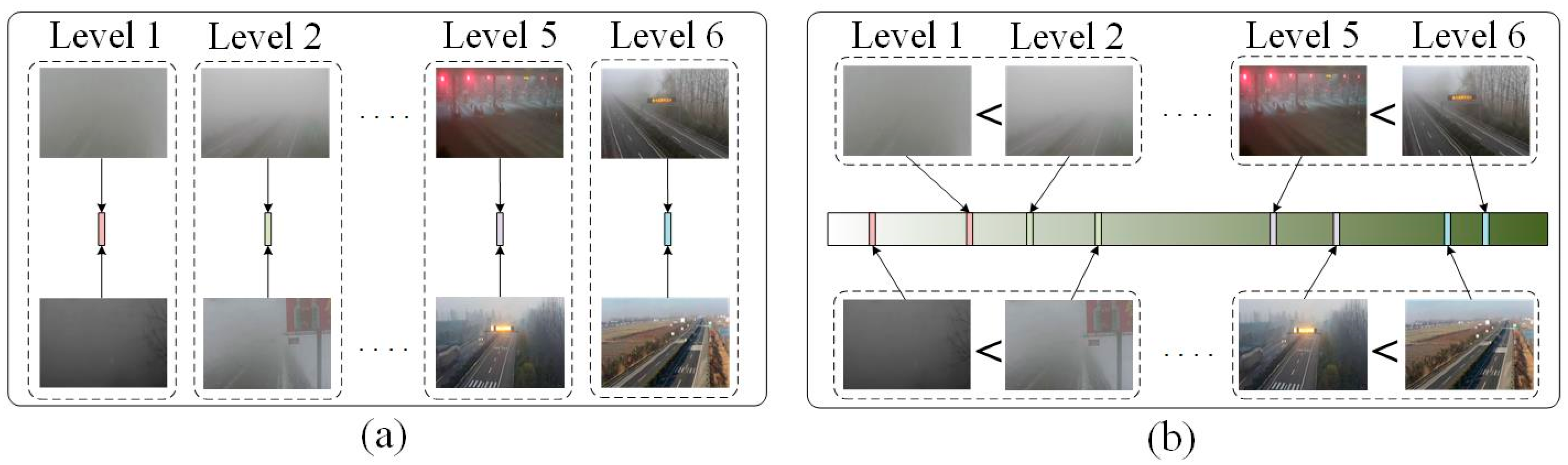
Figure 1 shows a demonstration diagram of the ordinary classification (a) and the proposed ordinal relative estimation (b). In contrast to classification methods that map the image features directly to the category labels, VISOR-NET learns an estimation function
for every image based on the intrinsic constraint of ordinal relative relations and encourages the keeping of both inter-class and intra-class differences. Even in the same category label, the fog concentration of different foggy images is still different. Therefore, our proposed method is to predict the continuous fog level of foggy images by ordinal relative learning. In contrast to the regression method, our estimation process does not require the use of continuous labels.
3.1. Model Architecture
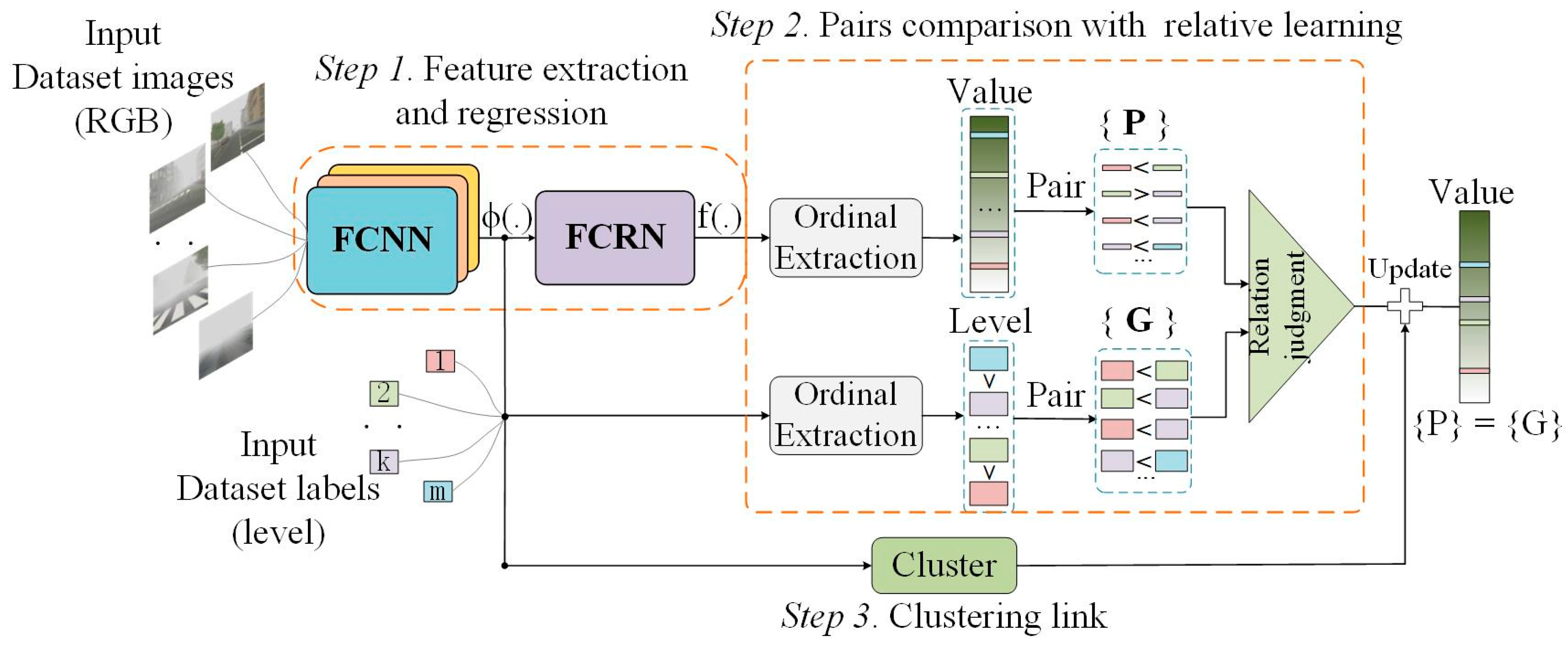
The proposed VISOR-NET consists of three components, and the whole pipeline is shown in
Figure 2. The first component is the feature extraction and regression module (FERM). In this step, a foggy convolutional neural network (FCNN) and a fully connected regression network (FCRN) are used as a feature extractor
and an estimation function
, respectively. The second component is a pairs comparison with relative learning, where the ordinal relationships within one batch are encoded into thousands of paired relative ordering sets
to constrain the relative learning and make the estimation outputs consistent with the original ordinal. The P and G in
Figure 2 mean predictions and ground truth, respectively. And the relation judgment means that the ordinal relationship between the predictions and the ordinal relationship between the ground truth should be consistent. Specifically, it refers to the logistic-like loss between paired images in
Section 3.3. The third component is an optional clustering link, where a lightweight clustering loss is added to assist convergence, which constrains the distribution range of values to facilitate the classification task.
It must be pointed out here that the outputs of the VISOR-NET are continuous values. In visibility datasets where only level labels are provided, we use the K-nearest neighbor algorithm (KNN) with majority voting to predict the final visibility level.
3.2. Feature Extraction Regression Module (FERM)
The Feature Extraction Regression Module (FERM) is composed of a foggy convolutional neural network (FCCN) and a fully connected regression network (FCRN). On the whole, FERM is an improvement of VGG16 [
39] for the visibility estimation task. First, FCNN is a feature extractor, and in this network, original image is first transformed into a 224 × 224 × 3 feature map by a padding layer, a convolution layer and a pooling layer to retain the local texture information of the fog image. As shown in
Figure 3, the 2-nd-14th convolutional layers of the network adopt the same parameters as the first 13 convolutional layers of VGG16. After the 3rd, 5th, 8th, 11th, and 14th convolutional layers, a maximum pooling layer is added for down-sampling. In order to speed up training and prevent over-fitting, batch normalization (BN) [
40] is conducted between each convolution layer and activation function, which can also prevent the proposed VISOR-NET from being sensitive to the initialization condition. Second, FCRN is a regressor consisting of four fully connected layers containing 4096, 4096, 1000 and 1 node in turn. In FCRN, dropout operation is added after the 1st–3rd fully connected layers to avoid over-fitting, and the coefficient is set to 0.1 uniformly. FCRN achieves regression prediction of fog level by returning a continuous value at the end.
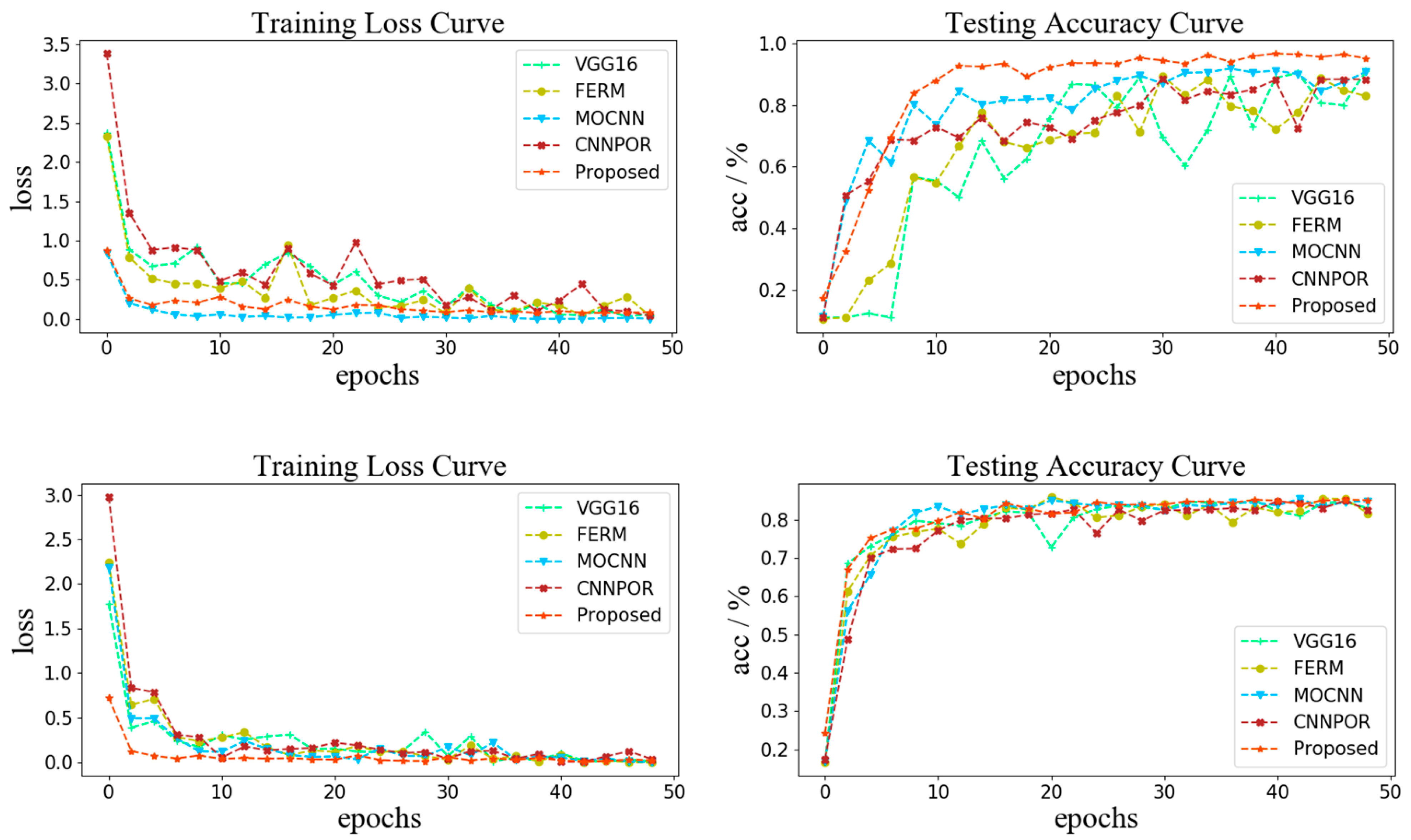
The number of parameters in VGG16 and the FERM are approximately equal, but more image texture features can be selectively retained by our FERM. In
Section 4.4, it is shown that the FERM is more suitable for visibility estimation from foggy images and achieves better performance that existing multi-classification algorithms [
21].
3.3. Pairs Comparison with Relative Learning
Suppose there are levels denoted by . A set of labeled instances in level can be denoted by . is the visibility attributes of image extracted by the FCNN, and is the relative value of mapped by the FCRN. To simplify the discussion below, let us replace with to represent a labeled instance in level .
According to the ordinal relationship, inter-class level labels
satisfy the equation:
. Although the real visibility
is unknown, the ordinal relationship of the relative value
should also be consistent with the equation above, which can be formulated as:
Via Equation (1), the proposed VISOR-NET adopts
tuple ordinal relations. The original relations are converted into a series of pairs:
This transformation can maintain the ordinal information between images. More importantly, it turns ordinal regression into relative learning, which can simplify the cost function and the learning process of the network. Considering a training batch
with corresponding label batch
,
paired images can be obtained in every iteration. Because the intra-class relationship is unknown, all pairs with known ordinal relationships in one batch compose the paired training set
. An ordinal matrix
is defined to indicate the ordinal relative relationship of
.
Let
measure the relation between the output values
of paired images
:
where
is the visibility difference in pairs, and
is obtained by normalizing
with a sigmoid function. If
,
tends to 1; if
,
is close to 0. By using the sigmoid function,
is not sensitive when
exceeds the range of [−5, 5], which allows for a greater value of
for larger level differences in pairs. This means that the relative estimation of paired images is able to be extended to the entire dataset.
The logistic-like loss is adopted as the objective function:
where
n is the number of paired images in sunset
.
3.4. Clustering Link
The network learns a regression function
within one batch by reducing
to 0. When
tends to 1, according to (4),
tends to be larger and the difference value of pairs will increase gradually. However, too dispersed a value distribution is not conducive to prediction. Therefore, we add an optional clustering loss in (6) to limit the output range of the estimation value indirectly and make the inter-class distinction more obvious by reducing the intra-class distance:
where
is the central point of level
and should be updated during forward calculation in each iteration.
is the number of images in level
of each batch. The composite loss function of the proposed VISOR-NET is defined in (7), where
is a hyper parameter to balance
and
.
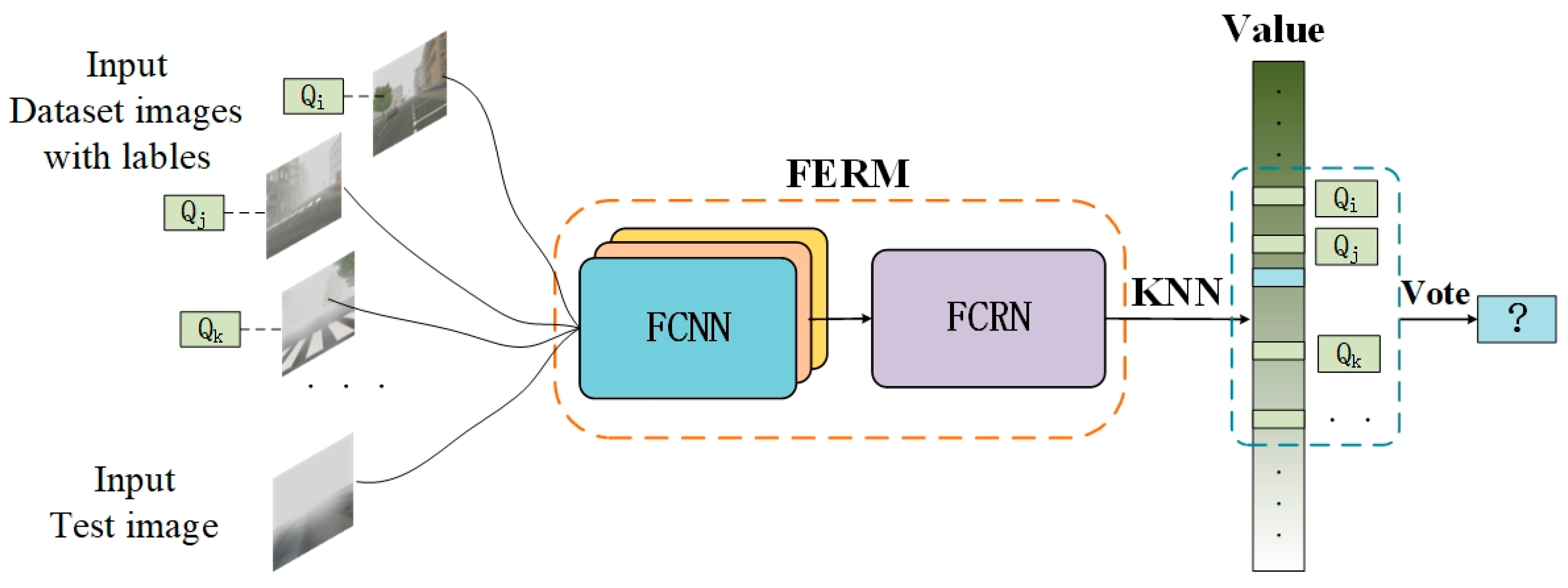
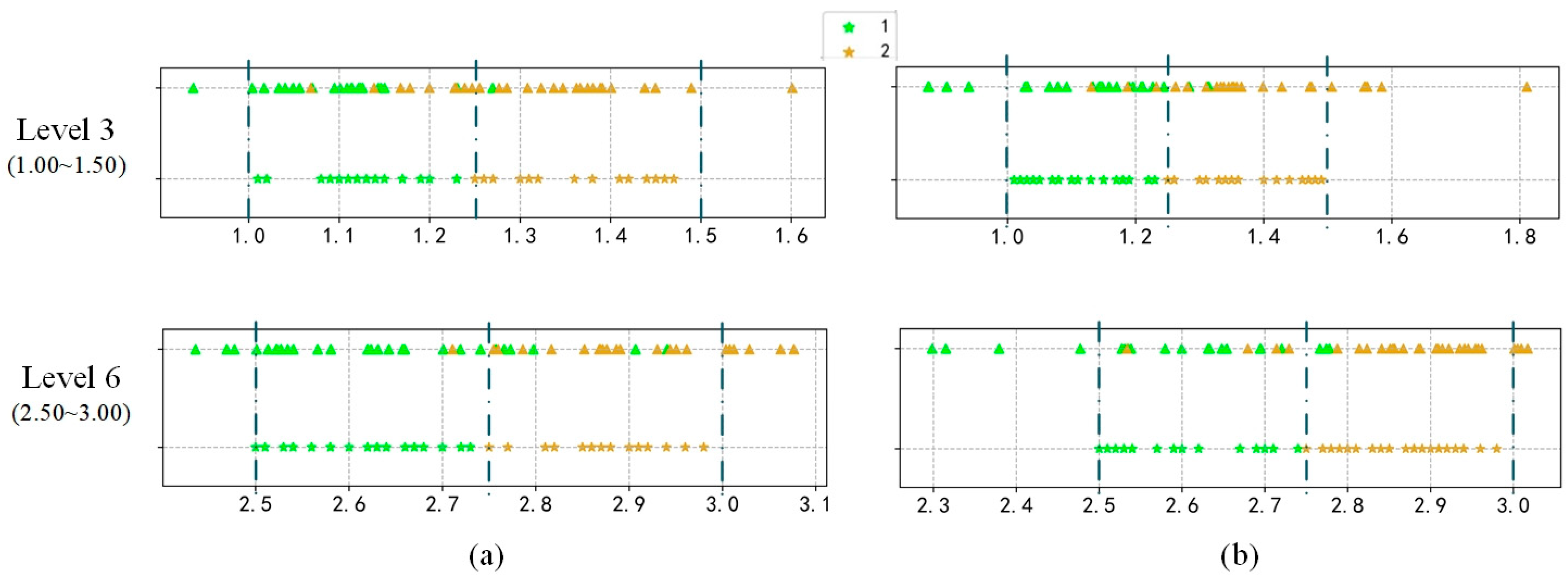
3.5. Predicting Image Visibility Level
Generally, in order to obtain classification results from a regression model, a series of thresholds—
—needs to be set up in advance. The final classification result
is determined by the location of the value
. Since the VISOR-NET pairs each image batch and cannot traverse all millions of pairs in the training dataset, there are still some instances in which the location is close to the boundary or even ventures into other categories. It is thus difficult to determine all the thresholds between the categories in our model. To solve this problem, we adopt the K-nearest neighbor (KNN) algorithm with majority voting to determine the final visibility level, which can help to avoid threshold tuning and to classify the hard samples more effectively. The demonstration diagram is shown in
Figure 4.
Firstly, we create a query library
by training set
. Then, in the prediction stage, we use the K nearest examples
. The prediction result
is determined by the majority voting of
in
:
3.6. Mapping a Relative Value to a Real Visibility
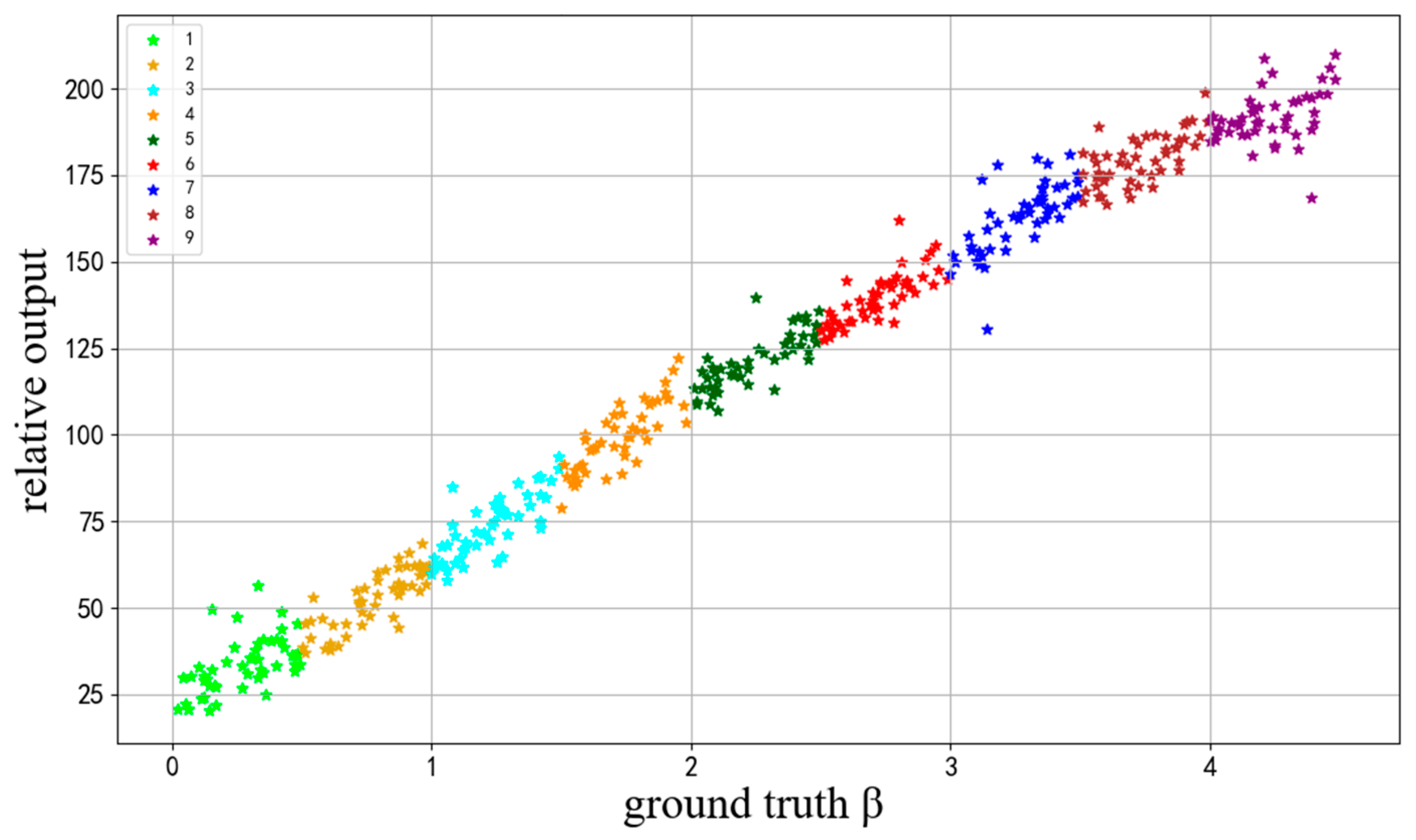
After the model is trained, we can obtain the relative visibility values of every image. However, it is difficult to evaluate the regression performance qualitatively using the relative output
of VISOR-NET. Therefore, we use some extra continuous labels as anchors to obtain a mapping function
. The relative values can be converted to absolute visibility values called Proposed (map). Because a real foggy image dataset with continuous visibility annotation is difficult to obtain, an INDF dataset with a continuous atmospheric extinction coefficient
is built based on atmospheric scattering model theory [
41], which is a further development of Koschmieder’s law and explains the visibility principle of foggy images. The proposed method only uses discrete-level labeled data of the INDF dataset for training and obtains relative output
. In order to compare the results of the proposed method and the regular regression method. After training, an extra 10% of continuous labels from training sets are selected as anchors. With a four-layer (32, 64, 32, 1) full connection network as a mapping function
, the absolute prediction values
of the remaining images are obtained from relative values
. Specifically, the full connection network uses
as input, uses the corresponding real atmospheric extinction coefficient β as the true value, and uses the MES loss function, and finally linearly maps
to
. Finally, we evaluate the regression effect of VISOR-NET using the absolute visibility prediction value. Specific experiments see
Section 4.4.2.
5. Conclusions
This paper proposed VISOR-NET, a novel end-to-end pipeline that uses the ordinal information and relative relation of the images to guide visibility estimation. To the best our knowledge, it is the first time an ordinal regression model has been used to estimate visibility under discrete-level labels. Since there is no visibility dataset of real images that is publicly available, we collected a large-scale dataset, FHVI, taken from real surveillance scenes. To evaluate the VISOR-NET algorithm’s performance, we compared VISOR-NET with other state-of-the-art deep learning-based methods by carrying out experiments with three datasets (FROSI, ExFRIDA, and FHVI). The extensive experimental results demonstrate that the proposed VISOR-NET algorithm is more effective than others, and the convergence analysis also shows that VISOR-NET is more stable and requires fewer examples during the training stage. Moreover, we synthesized an INDF image dataset with continuous labels to analyze the global estimation effectiveness of the relative output, which indicated that VISOR-NET has the potential ability to map real visibility values using only a few anchor images. Moreover, the proposed solution is applicable to the existence of ordinal relationships between different classes, which can make full use of the ordinal information in the data to achieve more accurate feature extraction and estimation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}