1. Introduction
Human Activity Recognition (HAR) has been considered as an indispensable technology in many Human-Computer Interaction (HCI) applications, such as smart homes, health-care services, security surveillance, entertainment, etc [
1,
2]. Both the device-based and device-free sensing approaches attract widespread attention [
3,
4,
5,
6]. Owing to their superiority involving sensing accuracy and robustness, sensor-based [
7,
8] and camera-based [
9,
10] HAR methods have been widely used in various fields. However, these techniques experience varied limitations in some applications. Specifically, sensor-based methods require the users to equip themselves with additional devices, which is inconvenient. Although the camera-based technique is successfully applied to various scenarios, it is restricted to well-lit conditions and fails to work in a non-line-of-sight (NLOS) scene. More critically, it raises privacy concerns.
Recently, device-free sensing technology based on wireless signals has been widely studied owing to its capacity to overcome the above defects effectively [
11,
12]. Since only radio frequency (RF) signals are utilized, it naturally has the strengths of working in darkness and NLOS circumstances and protecting users’ privacy in the meantime. Compared with the other wireless signals, such as Frequency Modulated Continuous Wave (FMCW) [
13,
14], millimeter-wave (MMW) [
15,
16], and Ultra-Wide Band (UWB) [
17,
18], Wi-Fi has an overwhelming advantage due to its ubiquity in daily life. Leveraging commercial off-the-shelf (COTS) devices, Wi-Fi-based human activity recognition obviates the need for additional specialized hardware. Consequently, study of the Wi-Fi-based HAR technique has proliferated rapidly over the past decade [
19,
20,
21,
22].
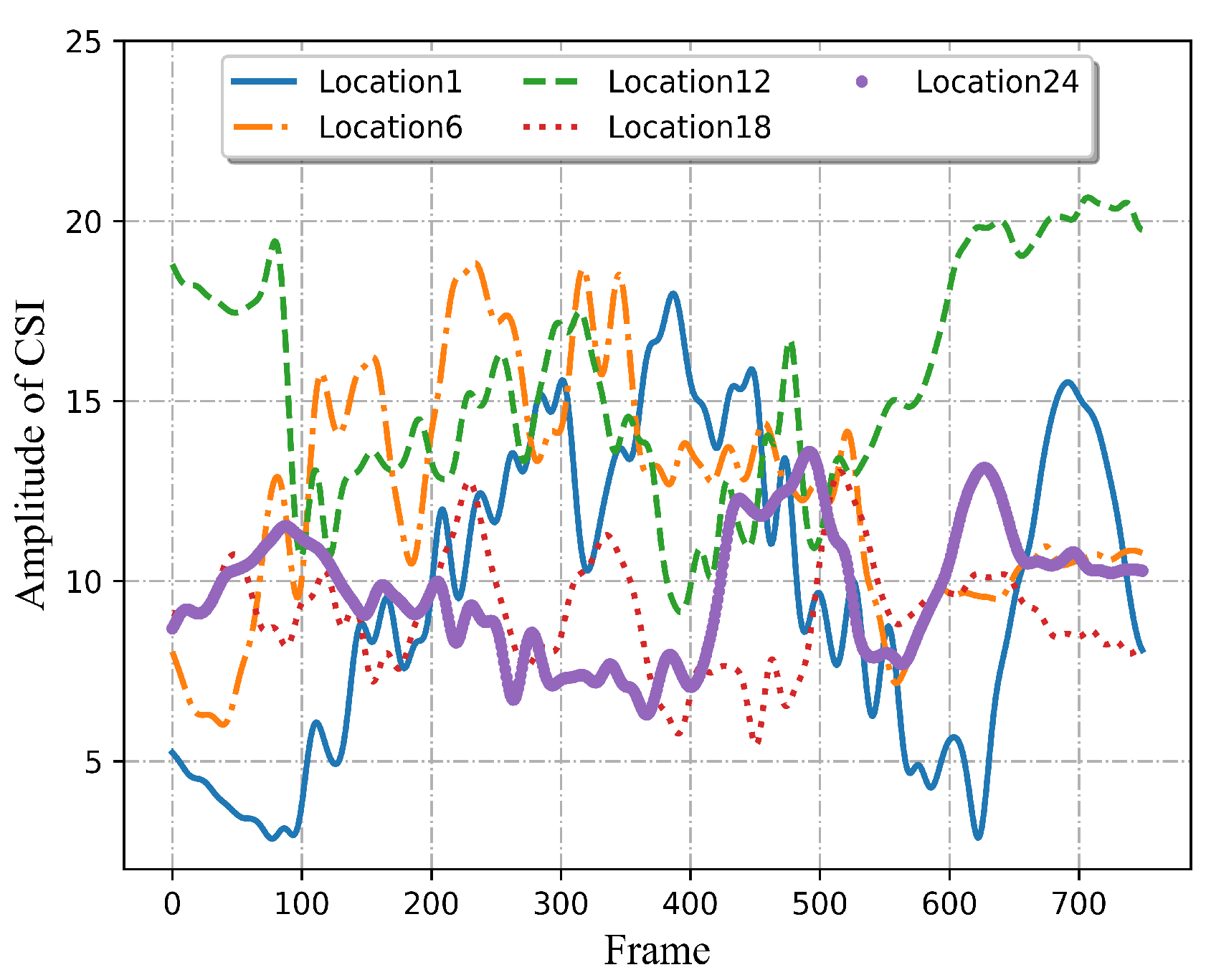
Although Wi-Fi-based HAR approaches have made significant achievements at a fixed location, it is still challenging in multi-location sensing. When it comes to intelligent control in smart homes, it will be seriously inconvenient for users if they can only control the smart devices at a specified location in a room. Moreover, a target that can be detected at one position but fails to be identified at other positions is not desired. Therefore, multi-location sensing is one of the most essential capabilities for the HAR system. According to the principle of RF signal propagation, when encountering an obstacle, the signal will be reflected, refracted, and scattered, leading to the superposition of multipath [
23,
24]. Therefore, both the activity and its location affect signal transmission to a certain extent. Consequently, even for the same human activity, different locations would result in signals having different patterns, which will lead to a serious decline in multi-location sensing accuracy. Furthermore, owing to the rapid development of the deep learning technique, the performance of human activity recognition has been effectively improved [
25]. However, these methods usually rely on abundant labeled or unlabeled samples, which have never been easily accessible for labor-intensive and time-consuming. In addition, it is quite difficult to obtain large amounts of data for all locations. Therefore, a multi-location human activity recognition method using small-scale data needs to be explored.
Literature [
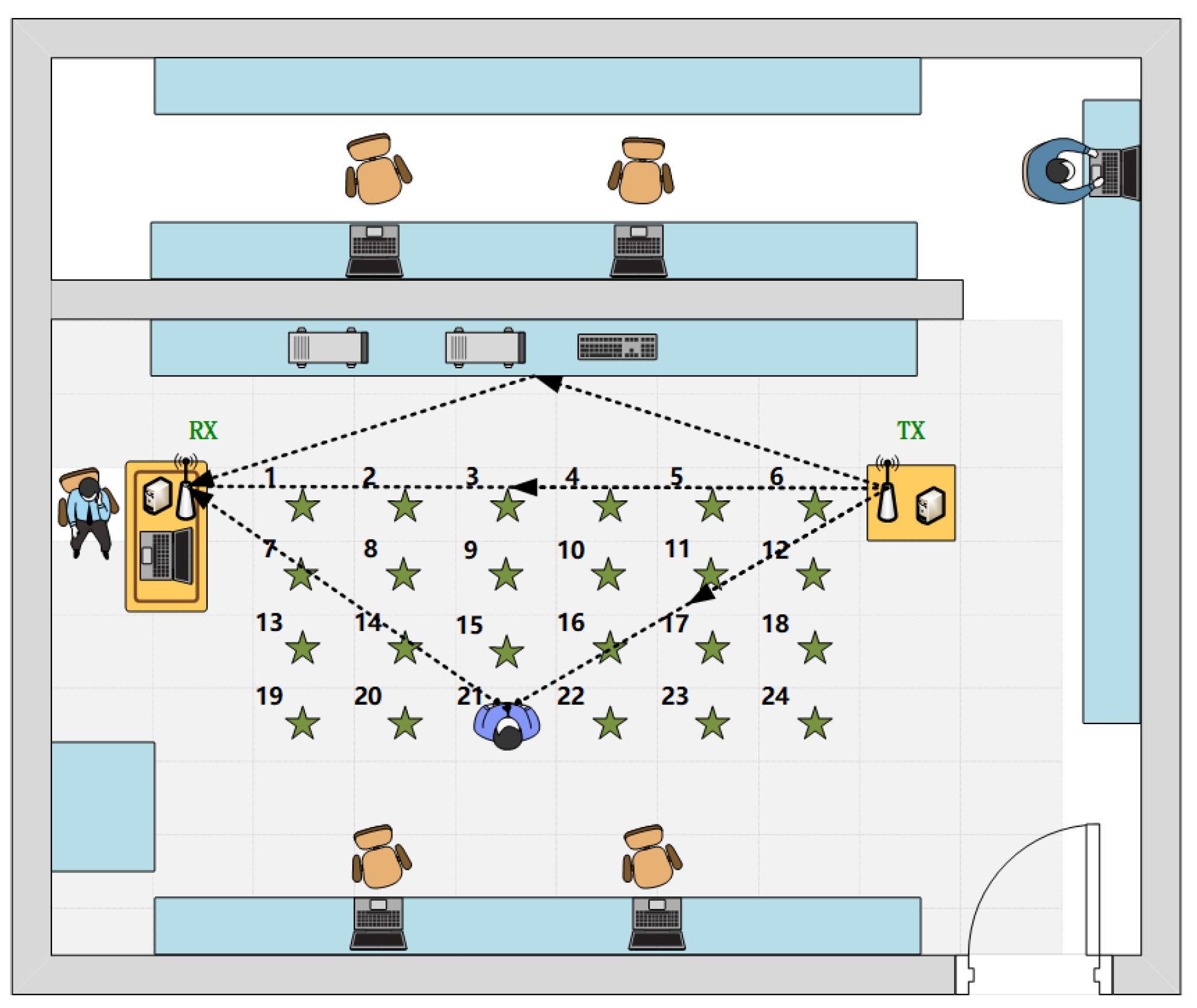
26] is the state-of-the-art multi-location human activity recognition method. An activity decomposition network (ActNet) is proposed to decompose the training samples into activity features and location features. In addition, data from different locations are assembled for training to mitigate the data limitation issue. The performance is evaluated at 24 sampling locations in the perceptual range. Using only 10 training samples for each position can achieve promising recognition accuracy.
Existing Wi-Fi-based sensing approaches for human activity recognition are mostly dependent on the amplitude of Channel State Information (CSI) because phase information contains certain errors caused by the hardware and software of the transceiver, including Sampling Time Offsets (STO) and Carrier Frequency Offsets (CFO) [
27,
28]. The proposed phase offsets removal method and phase difference make it possible to utilize phase information in Wi-Fi-based sensing [
29,
30]. However, it inevitably loses some useful information. Despite both amplitude and phase providing a wealth of activity-related information, only very few studies have used them simultaneously. In multi-location HAR, although the same activity conducted in different locations will lead to different signal delays at the receiver, the time delay generated by the same action may change with a certain rule, which is unrelated to the locations and will be reflected in the phase information. Therefore, leveraging the amplitude and phase information of CSI effectively at the same time can extract the feature representation that is more related to the activity. Furthermore, since more abundant features can be obtained, the sample size can be reduced to some extent. Although deep learning-based HAR methods emerge due to the key merit of automatically learning representative features, the amplitude and phase information are usually applied as the input of the neural network separately.
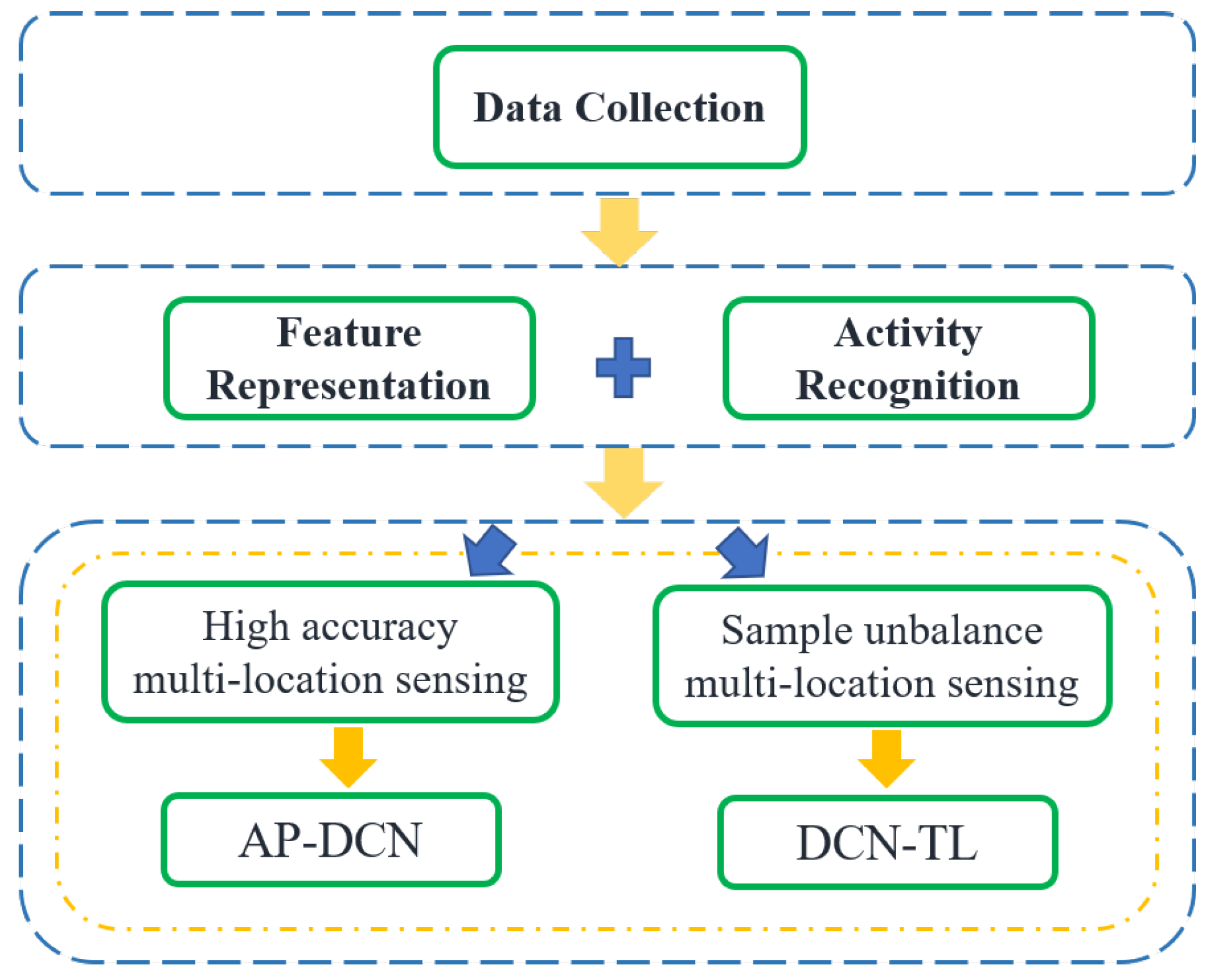
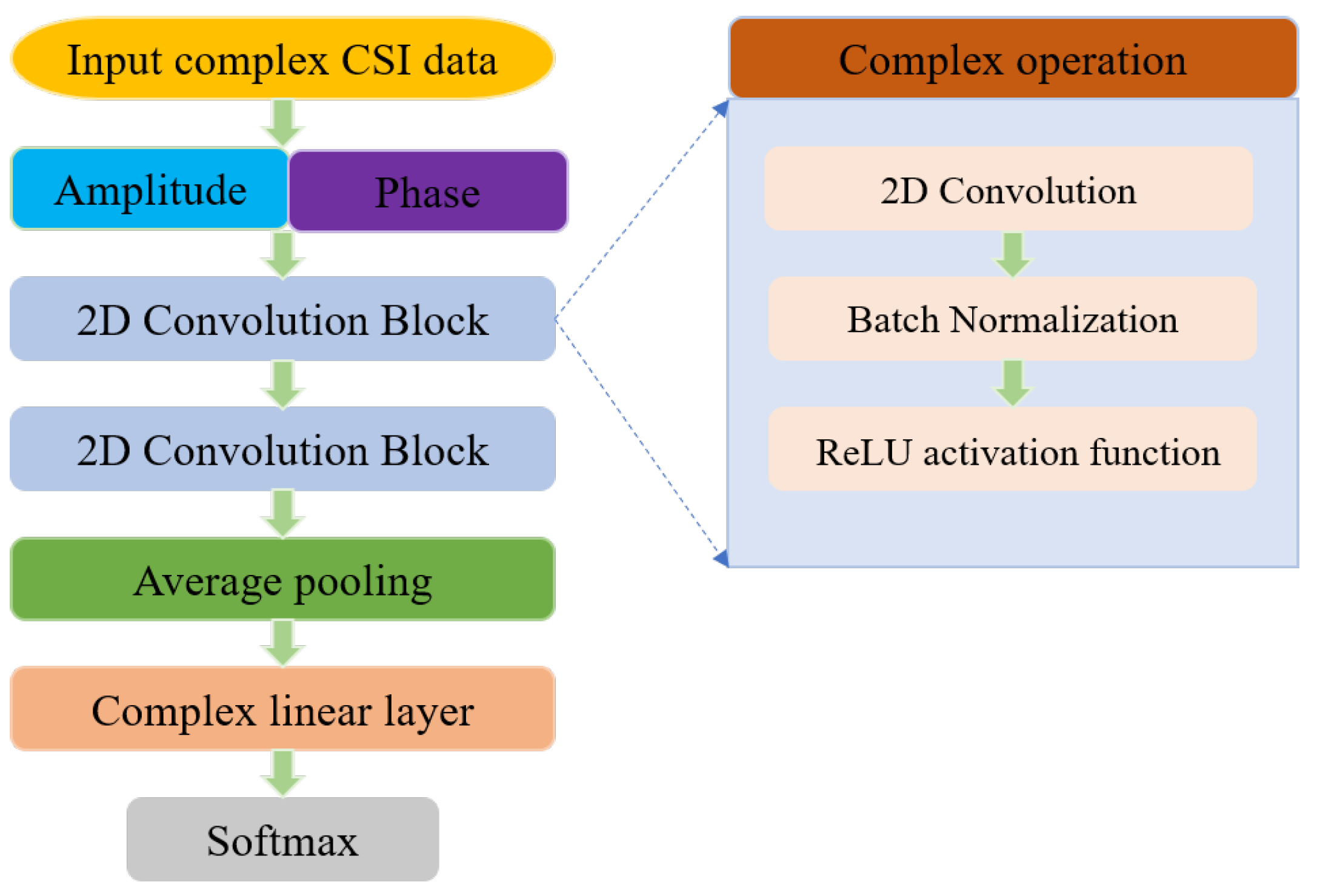
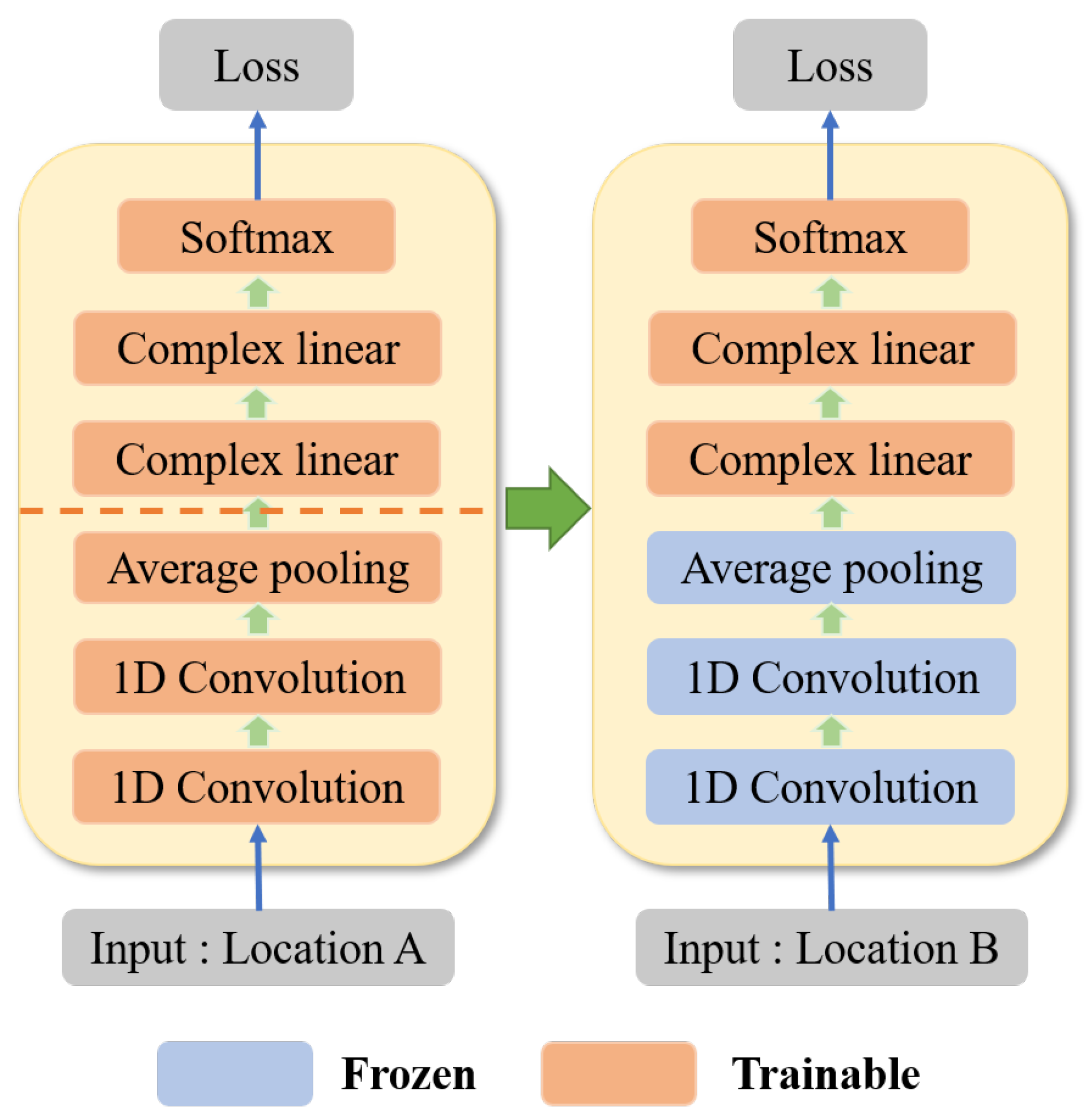
In this paper, inspired by the Deep Complex Network (DCN) [
31,
32] which is designed to extract meaningful information from the real and imaginary parts of complex numbers, we propose a multi-location human activity recognition system based on the Deep Complex Network. Firstly, we propose a multi-location human activity identification method based on Amplitude and Phase enhanced Deep Complex Network (AP-DCN), which can make efficient use of amplitude and phase information. Specifically, complex Convolutional Neural Network (CNN), complex Batch Normalization (BN), and the complex ReLU activation function are used for feature extraction. Softmax is used for activity classification. Under the condition of limited data samples, high accuracy multi-location human activity recognition is realized. Moreover, considering the imbalanced number of samples in different positions and the more restricted number of training samples in some positions, the transfer learning method is used to realize the sharing of human activity characteristics in distinct locations. A novel human activity sensing method based on Deep Complex Network-Transfer Learning (DCN-TL) is proposed. The model is trained with sufficient activity samples from source domain locations to learn the common features of the source domain and target domain, as well as the specific characteristics of the source domain. Then, the model is fine-tuned with a small number of samples from target domain locations to learn the specific characteristics of the target domain. Thereby, in the case of unbalanced samples at different locations, multi-location human activity recognition can be achieved.
The main contributions of this paper can be summarized as follows:
First, the effects of amplitude and phase information on Wi-Fi-based human activity recognition are analyzed. In order to make full use of the information in CSI, the AP-DCN-based recognition method is designed to improve the recognition accuracy of multi-location sensing.
Second, in order to alleviate the problem of unbalanced samples at different locations, the DCN-TL-based human activity recognition method is proposed to reduce the dependence of the perception method on the number of activity samples at a specific location.
Third, comprehensive experiments are conducted to evaluate the performance of the proposed AP-DCN-based and DCN-TL-based multi-location sensing methods. Experimental results demonstrate that the proposed approach can achieve satisfactory multi-location human activity recognition accuracy with very few samples.
The remainder of this article is organized as follows. In
Section 2, the preliminaries of Wi-Fi sensing are introduced. In
Section 3 provides an overview of the proposed system and a detailed description of the AP-DCN-based and DCN-TL-based multi-location human activity recognition methods. In
Section 4, the experiment setup and performance evaluation are elaborated. Our conclusions are presented in
Section 5.
5. Discussion
In the evaluation for this paper, 24 positions with an interval of 0.6m are sampled in a typical indoor area. When the range of sensing area is fixed, increasing the number of sampling locations will improve the perception effect. If the sensing area continues to expand, such as in a larger room, the perception effect will be decreased to some extent. When the sensing target is far away from the transmitter and receiver, the influence on signal transmission will be weakened. Theoretically speaking, the sensing performance decreases with the increase of the distance between the sensing target and the sensing device. For the number of activities, there may be more activities in practice scenarios. As for the experimental settings in most literature, five to eight activities are usually recognized in a typical smart home control scenario. If the number of activities continues to increase, the recognition accuracy will decrease to a certain extent, because some actions may have similar features and be easily confused. This is still a challenging issue for Wi-Fi-based human activity recognition, which will be further explored in future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}