1. Introduction
In recent years, with the development of modern digital society, new services and applications such as smart cities, smart houses, digital Internet of Everything, and wired/wireless distributed sensing systems have been constantly emerging, putting forward significantly higher requirements for communication capability [
1].
Surprisingly, ambient backscatter communication (AmBC) has been one of the most promising paradigms for the modern communication technologies [
2]. Particularly, the reciprocal communication among energy-free equipment is achieved with backscattering radio frequency (RF) signals [
3,
4]. Different from the traditional backscatter systems [
5], the requirements for a part of dedicated infrastructures are weakened with the appearance and growth of AmBC. Furthermore, the exploration of the scarce and expensive wireless spectrum is improved by the available AmBC signals. Particularly, AmBC signal detection is a fundamental and difficult problem to be solved.
So far, there has been some research focused on AmBC signal detection that can be roughly divided into three categories: the physical methods [
6], the statistical methods [
7], and the learning methods [
8]. However, there are several common thorny problems on most of the approaches above: (1) the obtained parameters are incomplete; (2) the direct link interference is serious; (3) the hide intrinsic representations and characteristics are difficult to extract. These issues above make it difficult for the most existing AmBC signal detection methods to be applied well in practice. Therefore, efficient and practical AmBC signal detection methods are urgently needed in both the theoretical and industrial fields.
It is worth noting that deep learning, especially deep reinforcement learning (DRL), has been widely used in wireless communications [
9,
10,
11]. Learning rules are ingeniously developed, and intrinsic features are learned autonomously from the environment by DRL, which is difficult to obtain by traditional methods in wireless communication systems. It has been proven that DRL may be an effective way to perform the design, operation, and optimization of the reconfigurable intelligent surface (RIS)-based wireless communication systems.
Therefore, in this paper, the RIS-assisted multi-antenna AmBC signal detection is investigated, and an efficient signal detection method is proposed based on DRL and RIS. Specifically, the contributions of this work can be summarized as follows:
- (1)
An RIS-assisted multi-antenna AmBC signal model is developed, which can achieve information transmission and energy collection cooperatively.
- (2)
A twin delayed deep deterministic (TD3) AmBC signal detection method is developed based on deep reinforcement learning and reconfigurable intelligent surface.
- (3)
Extensive quantitative and qualitative experiments are performed, showing that the presented method is more compelling than the state-of-the-art comparison approaches.
This paper is organized as follows. The related studies are given in
Section 2. The AmBC system model and the problem formulation are shown in
Section 3. The proposed solutions are described in
Section 4. The experimental results, comparisons, and analysis are presented in
Section 5. The conclusions are offered in
Section 6.
2. Related Works
Hu et al. [
12] proposed a signal detection method for a backscatter communication system in a supervised learning manner, where the label signal of AmBC is detected by transforming the detection problem into a classification problem. Particularly, support vector machine and random forest are used to decode label symbols. Simultaneously, efficient features are extracted to minimize the bit error rate of the AmBC system. Experimental results show that with different extended gains, the proposed detector has a lower bit error rate and higher data rate than the traditional minimum mean squared error (MMSE) detectors at low signal-to-noise ratio.
Wang et al. [
13] proposed an AmBC signal detection system in the binary phase shift keying (BPSK) modulation based on machine learning. Particularly, BPSK-based backscattering signal encoded by Hadamard code can be decoded with this method. Firstly, the direct path signal is eliminated, the residual signal is associated with the rough environment signal estimation to extract the tag signal’s learnable features. Then, the
k-nearest neighbor classification algorithm is used to recover the tag signal. The recovered signal is decoded by Hadamard to obtain the original information bits. Finally, the effectiveness of the method is verified by experimental simulation.
In reference [
14], the AmBC signal detection problem is transformed into a clustering problem, and two kinds of known labels are transmitted from the tags as prior knowledge to assist cluster initialization and signal detection. By directly using the received signals, two clustering-based detection methods are developed, i.e., one is the clustering of labeled signals (CLS), and the other one is the clustering of labeled and unlabeled signals (CLUS). Both two methods are developed based on the proposed modulation constrained Gaussian mixture model (GMM). Compared with the optimal detection method with perfect correlation channel state information, the proposed method has only a small gap.
An AmBC signal detection method is constructed in reference [
15] in an unsupervised learning manner. The characteristics of the received signals are directly utilized, which are clustered with an unsupervised learning means. In addition, the tag bits are transmitted for cluster bit mapping to assist signal detection without the estimation of channel coefficients and noise power. For the spread spectrum gain
N > 1 and
N = 1, two detection methods are proposed, in which the features follow different mixed distributions. The detection threshold is derived with the learned parameters to optimize the detection performance. Finally, a large number of simulation results are given to verify the performance of the proposed scheme.
In reference [
16], the tag signal detection problem for AmBC systems were studied by adopting the deep transfer learning (DTL) technology. Firstly, a universal DTL-based tag signal detection framework is designed, which uses a deep neural network (DNN) to implicitly extract the features of communication channels and directly recover the tag symbols. Based on the established pre-trained DNN and a few pilots, a DTL-based likelihood ratio test (DTL-LRT) was obtained through transfer learning. Moreover, exploiting the advantages of the convolutional neural networks’ powerful capability in exploring features of data in a matrix form, a covariance matrix-aware neural network (CMNet) for the sample covariance matrix is designed, and a CMNet-based detection algorithm is proposed. Finally, the simulation shows that the proposed CMNet method can achieve a close-to-optimal performance without explicitly obtaining the channel state information.
There are some differences between our proposed method and [
12,
13,
14,
15,
16]; the main differences are as follows.
First, supervised learning is used in references [
12,
13,
14,
16], manual intervention is required during learning, and the operation is complex and time-consuming. While in the proposed method, the unsupervised learning manner is applied, which does not need manual intervention, and the parameter learning is performed according to the data and model structure; thus, it is easy to operate. Moreover, the proposed method does not require a large number of manual annotation data in advance, so complex environments can be actively explored and better solutions can be obtained.
Second, for [
12], it is difficult to deal with missing data and the multi-classification problem, which can be handled well through deep reinforcement learning in our proposed method. Moreover, the relationships between data are easy to be ignored in [
12]. While for the proposed method, the explicit data, implicit data, and the relationship between data can be explored. For [
13], an appropriate proximity measure
K and data preprocessing are required; otherwise, wrong predictions can be achieved by
k-nearest neighbor. While this problem does not exist in our proposed method, which is simple, convenient, and flexible. For [
14], before signal detection using the CLS and CLUS clustering methods, the signal needs to be preprocessed with the modulation-constrained GGM, which is inflexible and has difficulty dealing with the situations different from agglomerative hierarchical clustering. While in the proposed method, pre-modulation is not needed, and both the same and different agglomerative hierarchical distributions can be processed. For [
15], unsupervised learning is used, which also does not need to label the data, but RIS is not used to improve the channel. The difference of signal characteristics when sending 0 and 1 tags is relatively small, which influences the improvement of detection effect. For [
16], an AmBC signal detection method is proposed based on a deep transfer learning framework and convolutional neural network, so the requirement of channel state information computation is eliminated. The problem of insufficient annotation data is solved. However, a large amount of pre-training, fine-tuning, and maul intervention are required, which is relatively complex and not flexible enough. While in our proposed method, pre-training, fine-tuning, and maul intervention are not needed.
Moreover, compared with references [
12,
13,
14,
15,
16], RIS and multi-antenna are introduced into AMBC signal detection in our proposed method; furthermore, the signal detection problem is converted into the optimization problem of the RIS phase shift matrix and receiving antenna combination coefficient, and then deep reinforcement learning without data labels is presented to effectively solve the optimization problem, which improves the signal detection performance of AmBC system.
3. System Model and Problem Formulation
3.1. Scenario Definition
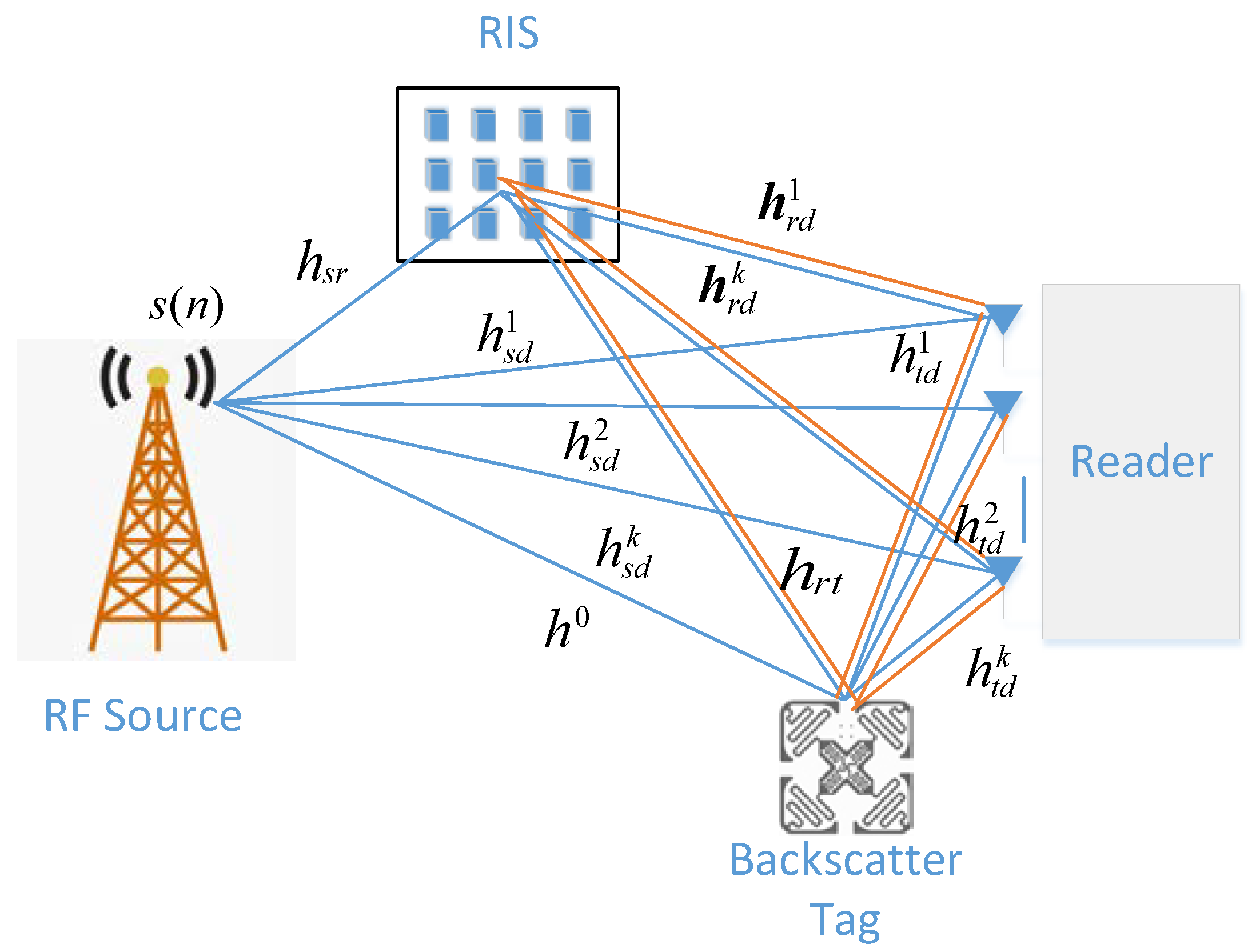
As shown in
Figure 1, a downlink AmBC system assisted by RIS is described, which consists of an ambient radio-frequency (RF) source with single antenna, a reader equipped with
antennas, a tag equipped with single antenna, and a RIS with
reflectors [
17]. The RF signal to the backscatter tag is offered by the ambient RF source, while its own information is transmitted. The backscatter tag’s information is modulated by on-off modulation to the ambient RF signal. A large number of reflective elements and passive beamforming are used to enhance the tag-to-reader wireless transmission link, while counteracting the direct link from ambient RF sources to the reader at the RIS. Multiple antennas are utilized at the reader to linearly combine the received signals to enhance the signal’s reception ability.
In this section, the flat-fading channel is assumed. The channel from the ambient RF source to the tag, from the RF source to the antenna of reader, from the RF source to the reflector of the RIS, from the backscatter tag to the antenna of the reader, from the tag to the reflector of RIS, and from the reflector of RIS to the antenna of the reader, is denoted by , , , , , and , respectively. Assume that all the channels follow the independent and identically distributed circularly symmetric complex Gaussian (CSCG) random variables with a mean value of zero and a variance of . Assume also that the channel state information (CSI) at the reader is not known, which is consistent with the actual situation. In practice, due to the complexity of the device, the channel often cannot be observed by the reader.
3.2. Problem Description
According to the above scenario, the equivalent complex baseband signal sent by the ambient RF source is denoted as
. The signals reach the tag by the reflected RF source-RIS-tag path and the direct RF source-tag path, which is denoted by the symbol
, and can be obtained by the following formula:
where
denotes the phase shift matrix of the RIS, and
for
is the phase shift induced by the
n-th reflect element. The tag can be switched between reflection and non-reflection by adjusting the impedance, so that two kinds of information “0” and “1” can be carried, which is also called on-off modulation. The tag is a passive device that cannot achieve the complete reflection due to the material limitations, and hence there will be a certain attenuation during reflection. Therefore, after being modulated by backscatter, the transmitted signal of the tag can be expressed as
where
represents a plural number indicating the attenuation of the tag,
denotes a 1-bit effective information that the tag needs to send to the reader. The tag information’s symbol rate is often lower than that of the ambient RF source, due to the limitations in tag equipment and energy consumption. Therefore, assume that
L RF sources symbols are spanned in 1 backscattered tag symbol. Thus,
L satisfies the following relationship as:
where
and
are the duration of the RF source and tag symbol, respectively.
3.3. Multi-Antenna Receiver Design
In general, the AmBC receiver owes larger physical size and more power and thus can support multiple antennas receiving together and more complex receiving algorithms than the AmBC tag [
18]. In addition, due to the insurmountable BER floor problem in a single antenna, while the spatial diversity can be used with multiple antennas to effectively improve the system’s transmission performance, the multiple antennas at the backscatter receiver are exploited for joint reception.
Signals from the RF source and the tag are received at the reader. There are two components in the signal from the RF source, i.e., one is the direct RF source-receiver link, and the other one is the reflected RF source-RIS-receiver link. Furthermore, there are also two components in the signal from the tag; i.e., one is the direct tag-receiver link, and the other one is the reflected tag-RIS-receiver link. Thus, for the
k-th receiver antenna, the received signal
can be expressed as:
where
,
, and
denotes the equivalent noise at the receiver. The received signal at all
K receiver antennas is expressed as
. Separating the two cases of
and
, the received signal
can be written as:
Taking Equations (1) and (2) into Equation (7), the following equation can be achieved:
where
Finally, the received signals on the multiple antennas are combined by a linear combiner at the receiver. The combine coefficient is represented by the vector , generally, without loss of generality. Therefore, the received signal after the combiner can be expressed as .
3.4. Energy Detection
After the combiner, energy detection is then used to recover the signal transmitted from the backscatter tag. According to the proposed RIS AmBC system model, both
and
follow the circularly symmetric complex Gaussian (CSCG) distribution, and the received signal
and the combined signal
also follow CSCG distribution, which can be express as:
where
According to [
17], the energy detector is the optimal detector to estimate the information of
:
where
. As shown in Equation (12), when
, the mean of
is
, and the variance of
is
. When
, the mean of
is
, and the variance of
is
. In the case of very large
N, applying the central limit law, the BER for backscatter tag signal detection can be obtained when
as follows:
where
.
3.5. Problem Formulation
Assume that
denotes the maximum energy difference of the received symbols,
, and
is brought into Equation (13). Thus the two cases of Equation (13) can be combined as:
As shown in Equation (14), the BER of the AmBC system decreases monotonically with increasing. This is consistent with the real situation. As increases, the gap between and becomes greater. Thus, the parts of the received signals’ conditional probability distributions under and are greater. So, the area of overlap between the two probability distribution curves is smaller, which means that the BER is smaller.
In this section, our goal is to maximize the maximum energy ratio
by jointly optimizing the active beamforming vector at the reader and the passive phase shift of the RIS, subjected to the RIS phase constraint, as well as the energy limitation of the beamforming vector. Mathematically, this problem can be formulated as follows:
Since the objective function and constraints are non-convex, P1 is a non-convex optimization problem. Generally, the alternating optimization (AO) method is used to solve the fixed weighting coefficient problem, but there is relatively high complexity. Furthermore, for the problem P1, it is difficult for AO to handle the weighting coefficient’s dynamic change. In this article, a DRL framework is proposed to solve the problem P1 effectively.
5. Numerical Results and Analysis
In this section, extensive quantitative and qualitative experiments, analysis, and discussion are performed to demonstrate the effectiveness of the proposed TD3 signal detection method for RIS-based multi-antenna AmBC.
5.1. Experimental Implementations
The related critical simulation parameters are set as follows: (1) all the RIS channels undergo Rician fading with Rician factor 3; (2) all other channels experience Rayleigh fading; (3) the path loss exponent is 2.5 for all the channels; (4) the ambient signal frequency is 2.4 GHz with transmit power 20 dBm; (5) the initial phase shift of the RIS and the initial received combined vector are set randomly and then are optimized gradually with TD3; (6) the critic and actor networks are fully connected deep neural networks (DNNs), which have one input layer, one output layer and two hidden layers; (7) the size of the actor and critic nets are (2
K, 2
N + 2
K, 4
N + 4
K, 2
N + 2
K) and (2
N + 4
K, 4
N + 8
K, 2
N + 4
K, 1), respectively. The DNN parameters are shown in
Table 1.
The simulated performance is achieved by performing the average of 5000 independent channels. All the training is executed by Windows 10 and CPU with 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80 GHz.
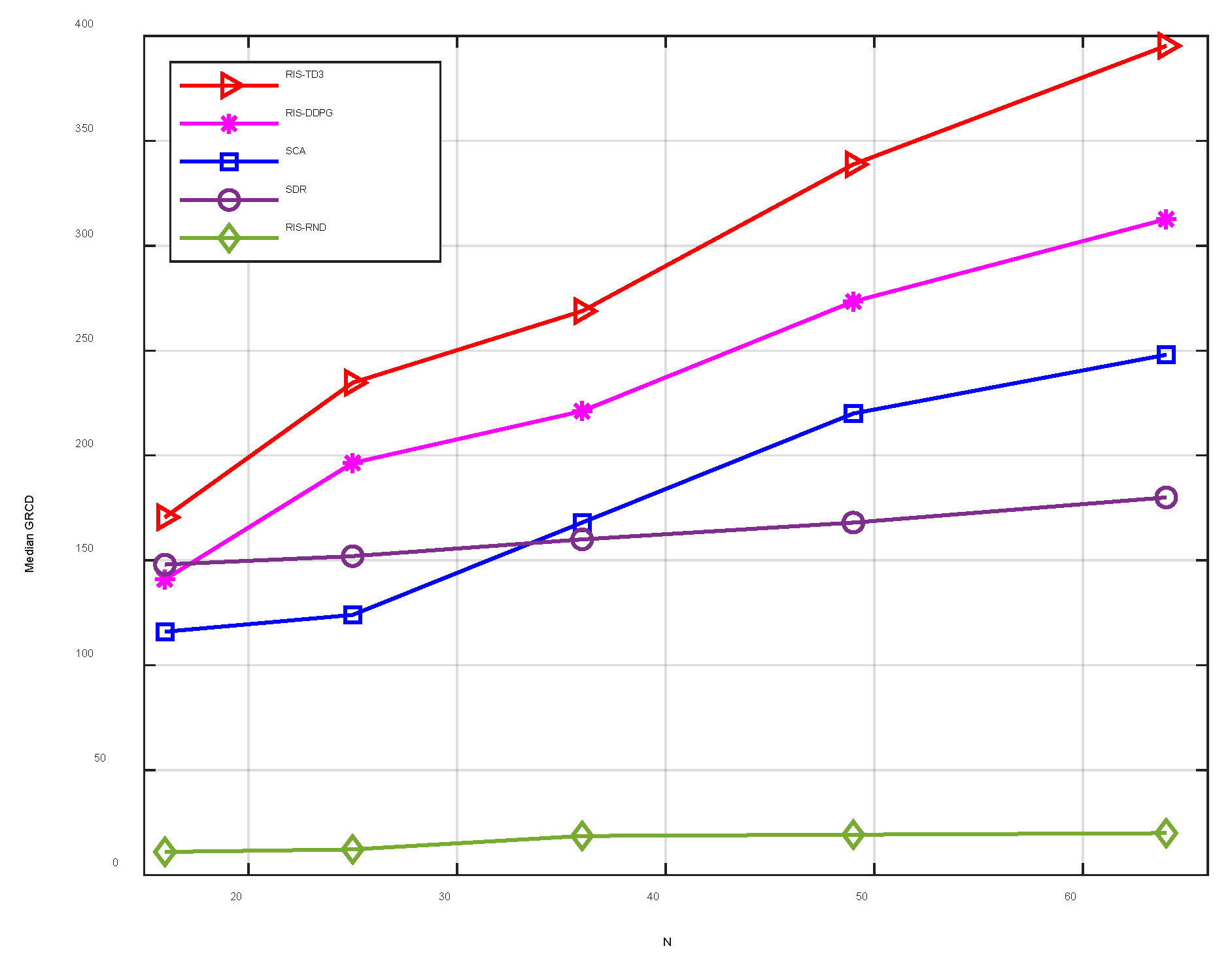
5.2. The Effect of the Number of Reflectors
In this section, the proposed TD3-based RIS-assisted multi-antenna AmBC signal detection method (denoted as RIS-TD3) is simulated to evaluate the effect of the receiving antennas number and the RIS reflective elements on the maximum energy ratio. The comparison benchmark algorithms include: (1) the RIS-assisted DDPG method, denoted as RIS-DDPG; (2) the RIS-assisted conventional method to optimize the phase shifts at the RIS, where the successive convex appropriation (SCA) method is used [
26] denoted as SCA; (3) the semi-define relaxation (SDR) method that is compared [
27] denoted as SDR; (4) the random RIS phase shift and receiver combiner coefficients, denoted as RIS-RND. The ambient RF source’s transmit power and the ambient noise variance are set as 20 and −95 dBm, respectively. The simulation results are illustrated in
Figure 3.
Figure 3 shows the median GRCD versus the number of antennas at the reader with different algorithms. It is observed from
Figure 3 that the proposed RIS-TD3 algorithm significantly outperforms the DDPG and the conventional methods. Particularly, with the increased antenna number, the three algorithms’ system performance can be enhanced, while the benefit of the proposed TD3 algorithm is the most important. This is because both the phase shift of RIS and the beamforming at the receiver are optimized by TD3, hence achieving the overall optimization, which obtains better median GRCD.
5.3. The Effect of Communication Distance on System Performance
This subsection presents a simulation of the convergence performance of the RIS-TD3 algorithm. The simulation conditions are as follows: the number of RIS reflection units is set to 49, the hidden layer dimensions of the Actor and Critic networks are set to 256, the number of exploration episode is 50, the agent-begins-to-learn episode is 100, and the total training episode is set to 200. We observe the cumulative reward of the episode obtained by the algorithm in each training episode, denoted as all_episode_reward, and apply a sliding average to it. Moreover, it is compared with the random RIS phase shift method, denoted as all_episode_reward_rnd. The simulation results are shown in
Figure 4.
From
Figure 4, it can be seen that the algorithm is in the random exploration and data accumulation phase before it starts learning (the first 100 rounds), and the accumulated episode reward obtained at this time is small and comparable to the average of the accumulated episode reward of the random RIS phase shift, which is within 200; when the algorithm starts to learn, the episode gain is able to increase rapidly, rising to a higher level of about 560 within about 25 episodes, and after that until the end of learning phase, the accumulated episode reward fluctuates in a smaller range, with the total gain above 500, which is much higher than that of the random RIS phase shifts. This demonstrates that the algorithm is able to be converged quickly and the rewards after convergence are greater, resulting in better convergence performance.
5.4. Computation Complexity Analysis
This subsection provides a time-consuming simulation for the complexity of the proposed algorithm. The benchmark algorithm used the RIS-DDPG algorithm, the SCA algorithm, and the SDR algorithm in the same way as in
Section 5.2. The simulation condition is
N = 36, the number of iterations for the SCA algorithm is 100, the iteration termination condition for the SDR algorithm is an error of less than 0.1, and the other simulation conditions are the same as in
Section 5.2. Since both RIS-TD3 and RIS-DDPG can be learned offline and run online, we take the simulation time spent per episode in the testing phase after training as the algorithm consumption time. We recorded the time consumed by each algorithm for 10 simulations and averaged them to obtain the algorithm time-consuming simulation results shown in
Table 2.
As can be seen from
Table 2, the simulation time consumed by the RIS-TD3 algorithm proposed in the paper for one episode (200 steps) is comparable to that of the RIS-DDPG algorithm, with an increase of only 0.03 s. This is due to the fact that the proposed algorithm uses six DNNs while the RIS-DDPG algorithm only uses four DNNs. However, combining the results of 5.2, the RIS-TD3 algorithm obtains a median GRCD gain of 50 at
N = 36 compared with that of RIS-DDPG, so the algorithm achieves a significant performance gain with a small time cost. Furthermore, the time consummation of the traditional SCA algorithm is 1.3 times longer than that of the proposed algorithm for only 100 iterations, but the average GRCD obtained is lower than that of the proposed RIS-TD3 algorithm. Finally, the traditional SDR algorithm needs the longest simulation time and has the lowest median GRCD performance. This indicates that the complexity of the proposed algorithm is significantly lower than that of the conventional algorithm.
5.5. Convergence Analysis
In this section, the hyperparameters’ effect on the RIS-TD3 intelligent signal detection algorithm’s performance is investigated. In the RIS-TD3, the main hyperparameters are as follows: the hidden layer size, exploration step size, discount rate, and learning rate. The effect of these hyperparameters on the RIS-TD3 algorithm’s performance is simulated. The other parameters and their corresponding values are as follows: the number of reflection units at RIS is 36, the length of batch learning data is 512, the discount rate is 0.99, the learning rate is 15 × 10−5, the hidden layer is 128, and the exploration step is 5000. The exploration noise gradually decreases when the empirical data are greater than two times the exploration step, with a decrease factor of 0.9999 until it decreases to 0.1.
- (1)
The hidden layer size:
As shown in
Figure 5, as the hidden layer gradually increases from 32 to 64, the maximum cumulative reward value of rounds of the RIS-TD3 algorithm keeps increasing, and the average energy ratio of normalized rounds increases to over 1000. However, when the hidden layer is further increased to 128 or 196, RIS-TD3′s performance gradually decreases. This is because as the hidden layer increases, the DNN network is larger, and its learning and training complexity increase significantly, making it difficult to perform the training in the limited number of rounds. This suggests that the choice of hidden layers is a compromise between the system performance and algorithm complexity.
- (2)
The exploration step:
As illustrated in
Figure 6, when the exploration step length is 4000, RIS-TD3 owes its first peak at around 80 rounds. As the iterations increase, RIS-TD3 owes its maximum peak at around 270 rounds, with a maximum peak of 131,703.35; when the exploration step length is 5000, RIS-TD3 has its maximum peak at around 90 rounds, with a maximum peak of 1,270,947.24. The optimal value can be achieved by RIS-TD3 quickly; when the exploration step length increases to 10,000, RIS-TD3 shows the first peak at 200 rounds and the maximum peak at 260 rounds, with a maximum peak of 463,016.65. According to the simulation results, it shows that as the exploration step length increases and more rounds are used, the later the DNN network starts learning, and the later the peak appears; however, with more exploration data as the initial sample for network learning, the faster the learning, and the higher the maximum peak can be achieved. When the exploration step is too large, the proposed RIS-TD3 algorithm cannot find the maximum value in the limited number of the iteration rounds, and the efficiency of the algorithm decreases.
- (3)
The discount rate:
Figure 7 illustrates that when the discount rate is 0.95, RIS-TD3 owes the maximum value of 265,010.03 at round 140; when the discount rate increases to 0.99, the algorithm has the maximum value at round 90, and the maximum value reaches 1,270,947.24. This shows that the acquisition of the optimal value can be influenced significantly by the discount rate. The larger the discount rate is, the larger the reward of the algorithm can be achieved.
- (4)
The learning rate:
As shown in
Figure 8, when the learning rate is 3 × 10
−5, RIS-TD3 peaks at round 140 with a peak value of 3174.04; when the learning rate is 15 × 10
−5, the algorithm peaks at round 90 with a peak pick higher than that of the former. This indicates that the learning rate has significant influence on the optimal value, and when the learning rate is small, the proposed algorithm obtains a smaller optimal value.
6. Conclusions
In this paper, an RIS-assisted multi-antenna AmBC system model is investigated, and an efficient RIS-assisted AmBC signal detection method based on deep reinforcement learning, named RIS-TD3, is developed. Particularly, an RIS-assisted multi-antenna AmBC signal model is presented, which enables the information transmission and energy collection simultaneously. Furthermore, a Twin Delayed Deep Deterministic (TD3) signal detection method is built for the AmBC system. Compared with several state-of-the-art comparison methods, the presented RIS-TD3 method achieves better performance. Because of the powerful ability of deep reinforcement learning, more essential recessive features are well explored.
There are some important advantages about RIS-TD3: (1) RIS-TD3 has good stability by delay updating and smooth regularization of the target policy network, so as to obtain the optimal solution of the nonconvex optimization problem, lower bit error rate is obtained. (2) The effect of a hyperparameter on the performance of the algorithm is explored, and the hyperparameter is chosen appropriately to further improve detection performance. (3) RIS-TD3 does not need to estimate channel information in advance. (4) RIS-TD3 has lower bit error rate and more stable convergence performance than the reference method under the condition of lack of channel information. (5) The problems of incomplete parameter acquisition and serious direct link interference in traditional AmBC signal detection methods are avoided.
To further improve the signal detection performance, we will consider introducing hierarchical deep multi-task joint learning to learn more discriminative features efficiently. For model speed acceleration, a series of ingenious model compression technologies will be tried to combine into the deep reinforcement learning framework. Moreover, the effects of delicate adaptive self-training and practical unsupervised training schemes will be explored.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}