
Speaker Adaptation on Articulation and Acoustics for Articulation-to-Speech Synthesis


Abstract
:1. Introduction
- Speaker-dependent ATS (SD-ATS) is where training and testing data are from the same speakers;
- Speaker-independent ATS (SI-ATS) is where training and testing data are from different speakers;
- Speaker-adaptive ATS (SA-ATS) is where training data are from other speakers and the target speaker.
2. Related Works
3. Dataset
4. Methods
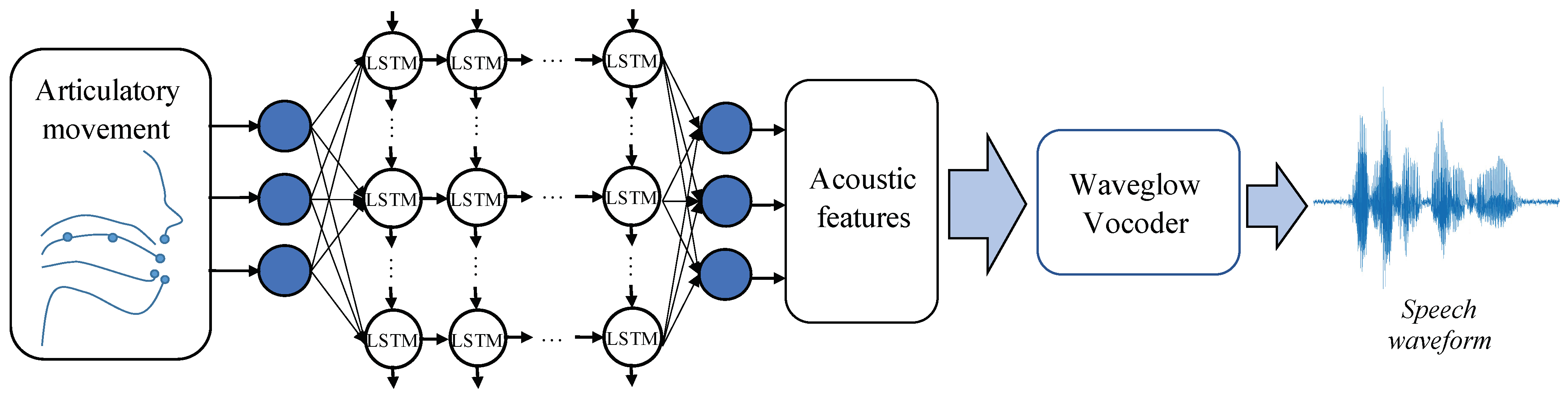
4.1. Articulation-to-Speech Synthesis
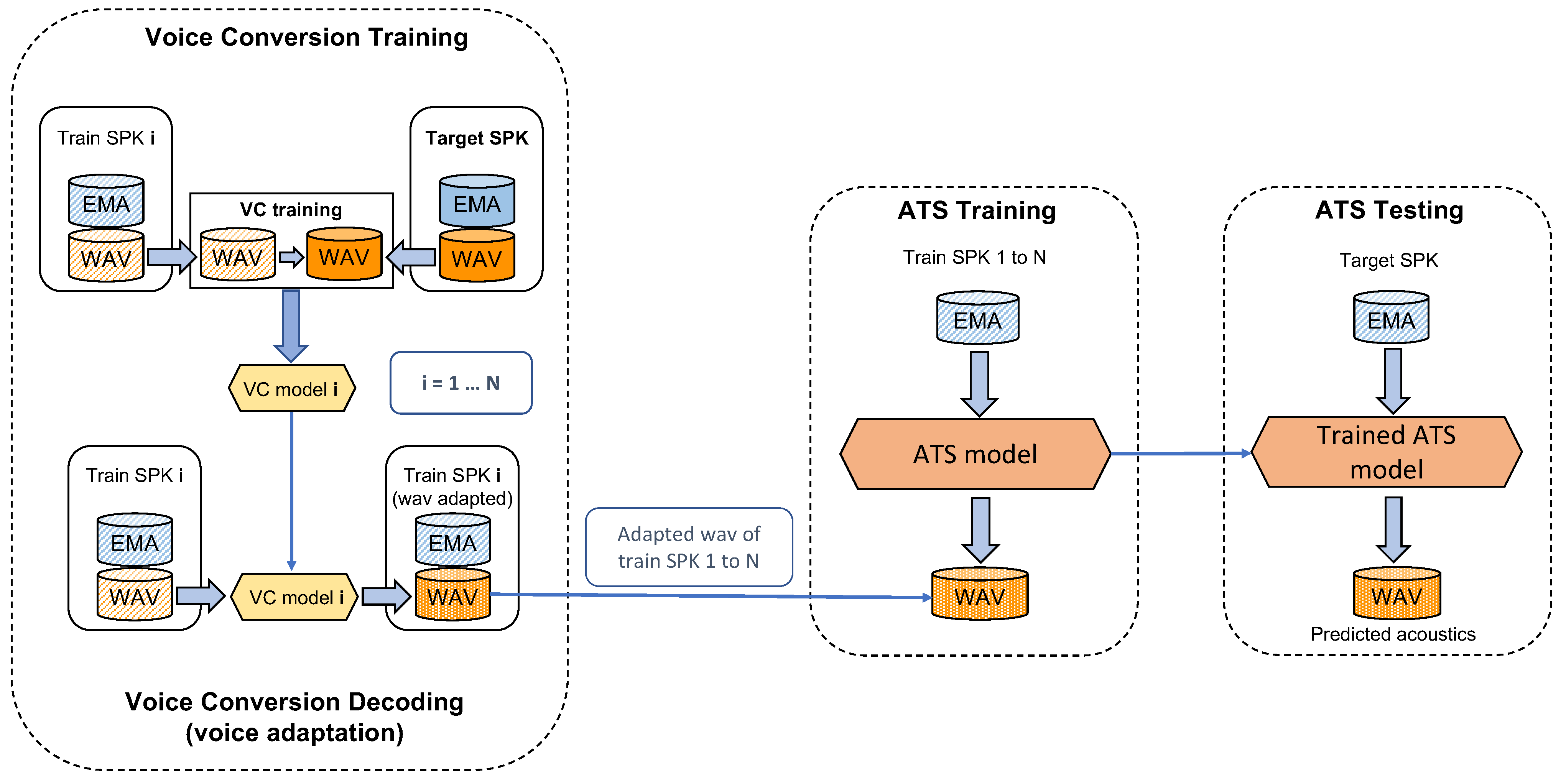
4.2. Acoustic Adaptation Using Voice Conversion
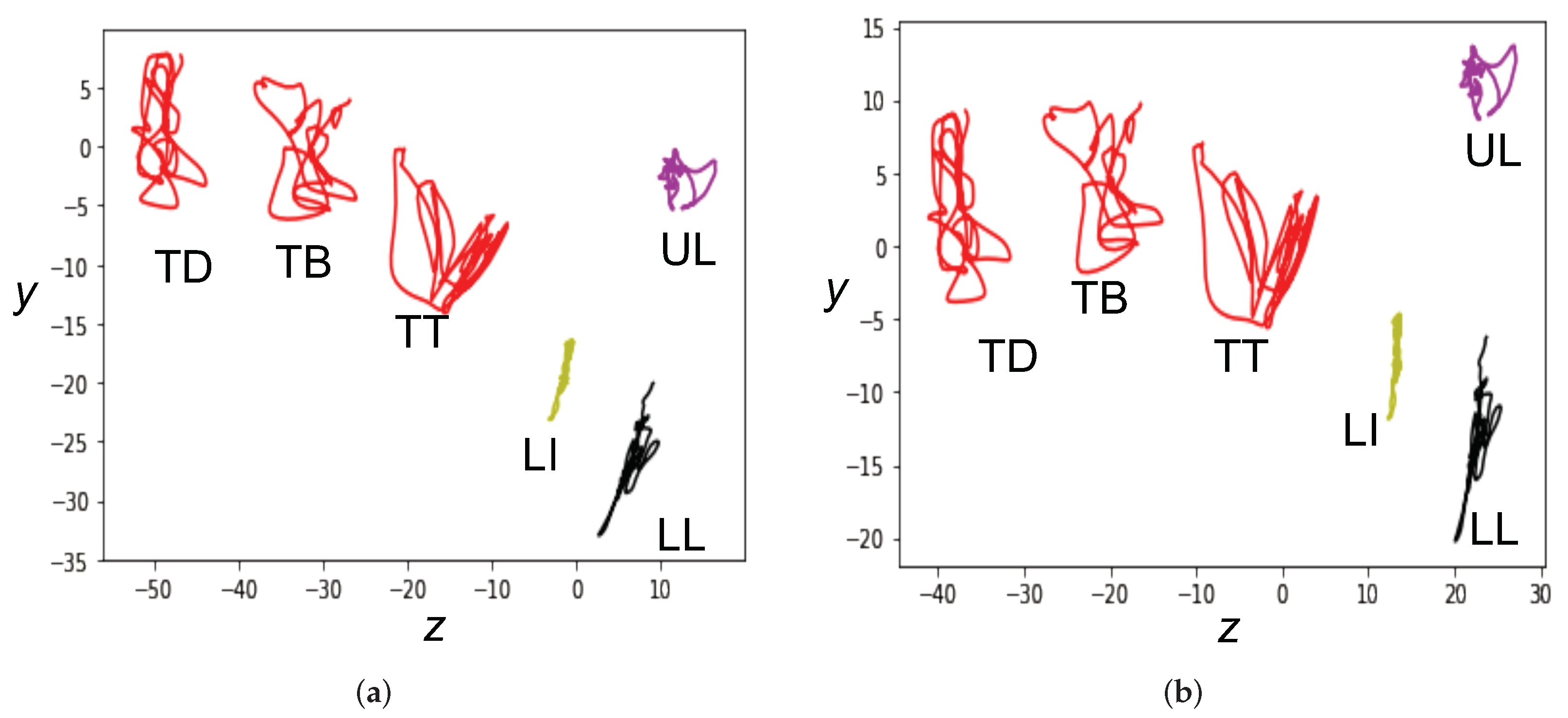
4.3. Articulation Adaptation Using Procrustes Matching
5. Experimental Setup
5.1. Speaker-Dependent (Target) and Speaker-Independent (Baseline) ATS
5.2. Acoustic Adaptation for SI-ATS Using Voice Conversion
5.3. Speaker Adaptive ATS including Training Data from Target Speakers
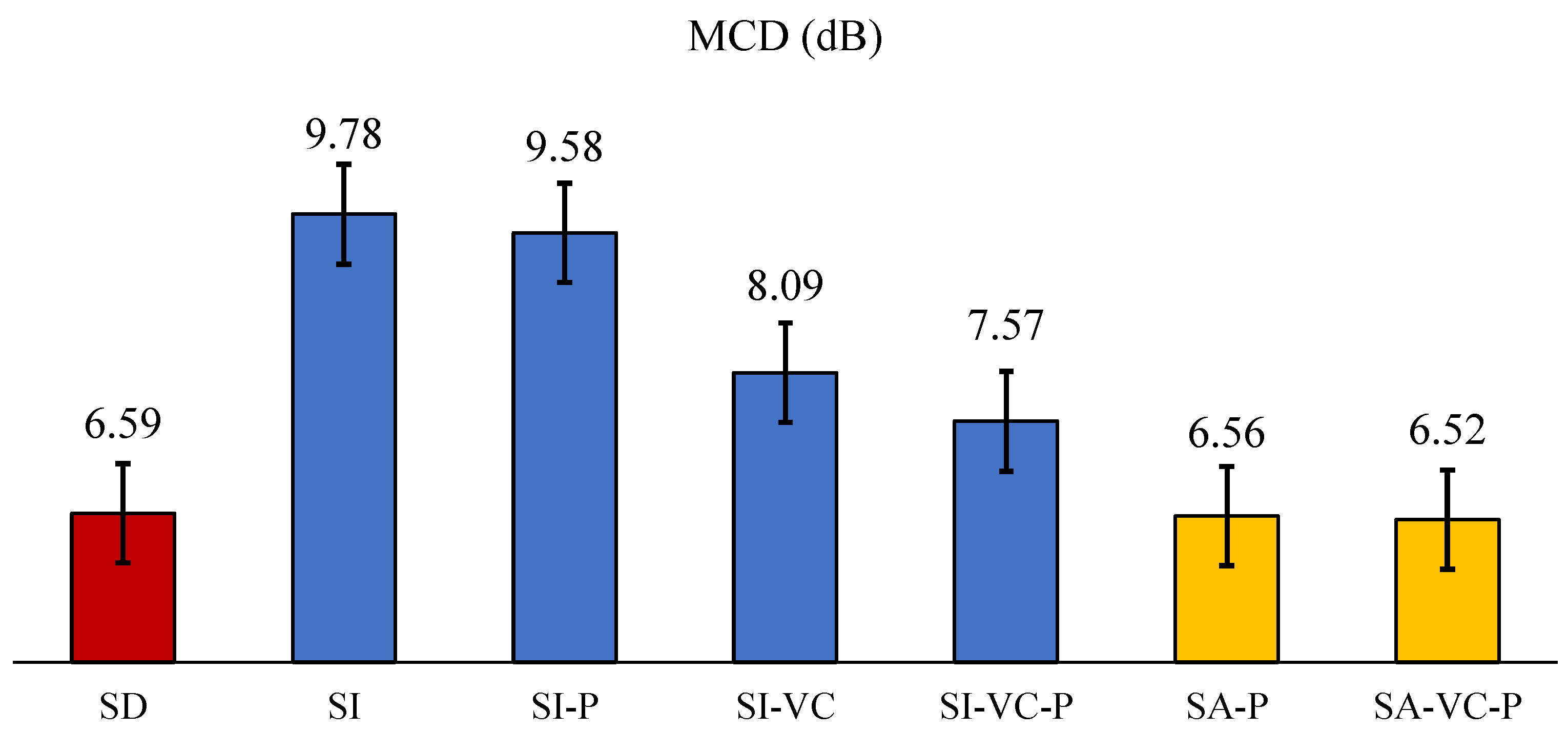
6. Results
7. Discussion
7.1. Acoustic and Articulation Adaptation Performances
7.2. Performance Variation across Speakers
7.3. Observations from the Synthetic Speech Samples
7.4. Relationship between VC and ATS Performances
7.5. Feasibility of Articulation Conversion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Braz, D.S.A.; Ribas, M.M.; Dedivitis, R.A.; Nishimoto, I.N.; Barros, A.P.B. Quality of life and depression in patients undergoing total and partial laryngectomy. Clinics 2005, 60, 135–142. [Google Scholar] [CrossRef] [PubMed]
- Nijdam, H.; Annyas, A.; Schutte, H.; Leever, H. A New Prosthesis for Voice Rehabilitation after Laryngectomy. Arch. Oto-Rhino-Laryngol. 1982, 237, 27–33. [Google Scholar] [CrossRef]
- Singer, M.I.; Blom, E.D. An Endoscopic Technique for Restoration of Voice after Laryngectomy. Ann. Otol. Rhinol. Laryngol. 1980, 89, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Ng, M.L. Electrolarynx in Voice Rehabilitation. Auris Nasus Larynx 2007, 34, 327–332. [Google Scholar] [CrossRef] [PubMed]
- Kaye, R.; Tang, C.G.; Sinclair, C.F. The Electrolarynx: Voice Restoration after Total Laryngectomy. Med. Devices 2017, 10, 133–140. [Google Scholar] [CrossRef]
- Eadie, T.L.; Otero, D.; Cox, S.; Johnson, J.; Baylor, C.R.; Yorkston, K.M.; Doyle, P.C. The Relationship between Communicative Participation and Postlaryngectomy Speech Outcomes. Head Neck 2016, 38, E1955–E1961. [Google Scholar] [CrossRef]
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent Speech Interfaces. Speech Commun. 2010, 52, 270–287. [Google Scholar] [CrossRef]
- Schultz, T.; Wand, M.; Hueber, T.; Krusienski, D.J.; Herff, C.; Brumberg, J.S. Biosignal-based Spoken Communication: A Survey. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2257–2271. [Google Scholar] [CrossRef]
- Gonzalez-Lopez, J.A.; Gomez-Alanis, A.; Martín-Doñas, J.M.; Pérez-Córdoba, J.L.; Gomez, A.M. Silent Speech Interfaces for Speech Restoration: A Review. IEEE Access 2020, 8, 177995–178021. [Google Scholar] [CrossRef]
- Cao, B.; Sebkhi, N.; Bhavsar, A.; Inan, O.T.; Samlan, R.; Mau, T.; Wang, J. Investigating Speech Reconstruction for Laryngectomees for Silent Speech Interfaces. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; pp. 651–655. [Google Scholar]
- Kim, M.; Cao, B.; Mau, T.; Wang, J. Speaker-Independent Silent Speech Recognition from Flesh-Point Articulatory Movements Using an LSTM Neural Network. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2017, 25, 2323–2336. [Google Scholar] [CrossRef] [PubMed]
- Zen, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7962–7966. [Google Scholar]
- Huang, X.; Lee, K.F. On speaker-independent, speaker-dependent, and speaker-adaptive speech recognition. IEEE Trans. Speech Audio Process. 1993, 1, 150–157. [Google Scholar] [CrossRef]
- Schönle, P.W.; Gräbe, K.; Wenig, P.; Höhne, J.; Schrader, J.; Conrad, B. Electromagnetic articulography: Use of alternating magnetic fields for tracking movements of multiple points inside and outside the vocal tract. Brain Lang. 1987, 31, 26–35. [Google Scholar] [CrossRef]
- Cao, B.; Kim, M.; Wang, J.R.; Van Santen, J.; Mau, T.; Wang, J. Articulation-to-Speech Synthesis Using Articulatory Flesh Point Sensors’ Orientation Information. In Proceedings of the Interspeech 2018, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; pp. 3152–3156. [Google Scholar]
- Gonzalez, J.A.; Cheah, L.A.; Bai, J.; Ell, S.R.; Gilbert, J.M.; Moore, R.K.; Green, P.D. Analysis of Phonetic Similarity in a Silent Speech Interface Based on Permanent Magnetic Articulography. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Diener, L.; Bredehoeft, S.; Schultz, T. A Comparison of EMG-to-Speech Conversion for Isolated and Continuous Speech. In Proceedings of the 13th ITG Symposium on Speech Communication, Oldenburg, Germany, 10–12 October 2018; pp. 66–70. [Google Scholar]
- Csapó, T.G.; Grósz, T.; Gosztolya, G.; Tóth, L.; Markó, A. DNN-Based Ultrasound-to-Speech Conversion for a Silent Speech Interface. In Proceedings of the Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3672–3676. [Google Scholar]
- Yamagishi, J.; Nose, T.; Zen, H.; Ling, Z.H.; Toda, T.; Tokuda, K.; King, S.; Renals, S. Robust speaker-adaptive HMM-based text-to-speech synthesis. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1208–1230. [Google Scholar] [CrossRef]
- Shandiz, A.H.; Tóth, L.; Gosztolya, G.; Markó, A.; Csapó, T.G. Neural Speaker Embeddings for Ultrasound-Based Silent Speech Interfaces. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; pp. 1932–1936. [Google Scholar] [CrossRef]
- Ribeiro, M.S.; Sanger, J.; Zhang, J.X.; Eshky, A.; Wrench, A.; Richmond, K.; Renals, S. TaL: A synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 1109–1116. [Google Scholar]
- Liu, F.H.; Stern, R.M.; Huang, X.; Acero, A. Efficient cepstral normalization for robust speech recognition. In Proceedings of the workshop on Human Language Technology, Plainsboro, NJ, USA, 21–24 March 1993; pp. 69–74. [Google Scholar]
- Eide, E.; Gish, H. A parametric approach to vocal tract length normalization. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 7–10 May 1996; Volume 1, pp. 346–348. [Google Scholar]
- Toda, T.; Black, A.W.; Tokuda, K. Voice Conversion Based on Maximum-Likelihood Estimation of Spectral Parameter Trajectory. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 2222–2235. [Google Scholar] [CrossRef]
- Tiede, M.; Espy-Wilson, C.Y.; Goldenberg, D.; Mitra, V.; Nam, H.; Sivaraman, G. Quantifying kinematic aspects of reduction in a contrasting rate production task. J. Acoust. Soc. Am. 2017, 141, 3580. [Google Scholar] [CrossRef]
- Gower, J.C. Generalized Procrustes Analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Dryden, I.L.; Mardia, K.V. Statistical Shape Analysis; Wiley: Chichester, UK, 1998. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3617–3621. [Google Scholar]
- Wang, J.; Hahm, S. Speaker-Independent Silent Speech Recognition with Across-speaker Articulatory Normalization and Speaker Adaptive Training. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Gonzalez, J.A.; Cheah, L.A.; Gomez, A.M.; Green, P.D.; Gilbert, J.M.; Ell, S.R.; Moore, R.K.; Holdsworth, E. Direct Speech Reconstruction from Articulatory Sensor Data by Machine Learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2362–2374. [Google Scholar] [CrossRef]
- Kim, M.; Sebkhi, N.; Cao, B.; Ghovanloo, M.; Wang, J. Preliminary Test of a Wireless Magnetic Tongue Tracking System for Silent Speech Interface. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar]
- Sebkhi, N.; Desai, D.; Islam, M.; Lu, J.; Wilson, K.; Ghovanloo, M. Multimodal Speech Capture System for Speech Rehabilitation and Learning. IEEE Trans. Biomed. Eng. 2017, 64, 2639–2649. [Google Scholar]
- Hueber, T.; Benaroya, E.L.; Chollet, G.; Denby, B.; Dreyfus, G.; Stone, M. Development of a silent speech interface driven by ultrasound and optical images of the tongue and lips. Speech Commun. 2010, 52, 288–300. [Google Scholar] [CrossRef]
- Csapó, T.G.; Zainkó, C.; Tóth, L.; Gosztolya, G.; Markó, A. Ultrasound-Based Articulatory-to-Acoustic Mapping with WaveGlow Speech Synthesis. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; pp. 2727–2731. [Google Scholar]
- Diener, L.; Felsch, G.; Angrick, M.; Schultz, T. Session-Independent Array-based EMG-to-Speech Conversion Using Convolutional Neural Networks. In Proceedings of the 13th ITG Symposium on Speech Communication, Oldenburg, Germany, 10–12 October 2018; pp. 276–280. [Google Scholar]
- Nakajima, Y.; Kashioka, H.; Shikano, K.; Campbell, N. Non-Audible Murmur Recognition Input Interface Using Stethoscopic Microphone Attached to the Skin. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP’03, Hong Kong, 6–10 April 2003; Volume 5, p. V-708. [Google Scholar]
- Toth, A.R.; Kalgaonkar, K.; Raj, B.; Ezzat, T. Synthesizing speech from Doppler signals. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4638–4641. [Google Scholar]
- Lee, K.S. Silent speech interface using ultrasonic Doppler sonar. IEICE Trans. Inf. Syst. 2020, 103, 1875–1887. [Google Scholar] [CrossRef]
- Kapur, A.; Kapur, S.; Maes, P. Alterego: A personalized wearable silent speech interface. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 43–53. [Google Scholar]
- Ferreira, D.; Silva, S.; Curado, F.; Teixeira, A. Exploring Silent Speech Interfaces Based on Frequency-Modulated Continuous-Wave Radar. Sensors 2022, 22, 649. [Google Scholar] [CrossRef] [PubMed]
- Sebkhi, N.; Bhavsar, A.; Anderson, D.V.; Wang, J.; Inan, O.T. Inertial Measurements for Tongue Motion Tracking Based on Magnetic Localization With Orientation Compensation. IEEE Sens. J. 2020, 21, 7964–7971. [Google Scholar] [CrossRef] [PubMed]
- Katsurada, K.; Richmond, K. Speaker-Independent Mel-cepstrum Estimation from Articulator Movements Using D-vector Input. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; pp. 3176–3180. [Google Scholar]
- Electrical, I.; Engineers, E. IEEE recommended practice for speech quality measurements. IEEE Trans. Audio Electroacoust. 1969, 17, 225–246. [Google Scholar]
- Richmond, K.; Hoole, P.; King, S. Announcing the electromagnetic articulography (day 1) subset of the mngu0 articulatory corpus. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011; pp. 1505–1508. [Google Scholar]
- Ji, A.; Berry, J.J.; Johnson, M.T. The Electromagnetic Articulography Mandarin Accented English (EMA-MAE) corpus of acoustic and 3D articulatory kinematic data. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7719–7723. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; pp. 10215–10224. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Arfib, D.; Keiler, F.; Zölzer, U.; Verfaille, V. Source-filter processing. DAFX–Digital Audio Eff. 2002, 9, 299–372. [Google Scholar]
- Black, A.W.; Zen, H.; Tokuda, K. Statistical parametric speech synthesis. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-1229–IV-1232. [Google Scholar]
- Imai, S.; Sumita, K.; Furuichi, C. Mel log spectrum approximation (MLSA) filter for speech synthesis. Electron. Commun. Jpn. (Part I Commun.) 1983, 66, 10–18. [Google Scholar] [CrossRef]
- Kawahara, H. STRAIGHT, exploitation of the other aspect of VOCODER: Perceptually isomorphic decomposition of speech sounds. Acoust. Sci. Technol. 2006, 27, 349–353. [Google Scholar] [CrossRef]
- Morise, M.; Yokomori, F.; Ozawa, K. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Kubichek, R. Mel-Cepstral Distance Measure for Objective Speech Quality Assessment. In Proceedings of the IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, BC, Canada, 19–21 May 1993; Volume 1, pp. 125–128. [Google Scholar]
- Battenberg, E.; Mariooryad, S.; Stanton, D.; Skerry-Ryan, R.; Shannon, M.; Kao, D.; Bagby, T. Effective use of variational embedding capacity in expressive end-to-end speech synthesis. arXiv 2019, arXiv:1906.03402. [Google Scholar]
- Mohammadi, S.H.; Kain, A. An Overview of Voice Conversion Systems. Speech Commun. 2017, 88, 65–82. [Google Scholar] [CrossRef]
- Müller, M. Dynamic time warping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Hahm, S.; Daragh, H.; Wang, J. Recognizing Dysarthric Speech due to Amyotrophic Lateral Sclerosis with Across-Speaker Articulatory Normalization. In Proceedings of the ACL/ISCA Workshop on Speech and Language Processing for Assistive Technologies, Dresden, Germany, 11 September 2015; pp. 47–54. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Cao, B. Demo of Speaker Adaptation of Articulation-to-Speech Synthesis. 2022. Available online: https://beimingcao.github.io/SI_ATS_demo/ (accessed on 30 June 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker | Phrase Num. | Duration (min) |
|---|---|---|
| F01 | 1738 | 61.75 |
| F02 | 1560 | 60.58 |
| F03 | 1617 | 58.63 |
| F04 | 1618 | 59.71 |
| M01 | 1553 | 55.67 |
| M02 | 1554 | 57.47 |
| M03 | 1610 | 60.31 |
| M04 | 1620 | 59.65 |
| Sum. | 12,870 | 472.82 |
| Ave. | 1609 | 59.22 |
| Acoustic Feature | |
| Mel-spectrogram | 80-dim. vectors |
| Sampling rate | 22,050 Hz |
| Windows length | 1024 |
| Step size | 256 |
| Articulatory Feature | 54-dim. vectors |
| Articulatory movement (6 sensors) | (18-dim. vectors) + + (54-dim.) |
| SD-ATS LSTM Topology | |
| Input | 54-dim. articulatory |
| Output. | 80-dim. acoustic feature |
| No. of LSTM nodes each hidden layer | 256 |
| Depth | 3-depth layers |
| Batch size | 1 sentence (one whole sentence per batch) |
| Max Epochs | 50 |
| Learning rate | 0.0003 |
| Optimizer | Adam |
| SI-ATS LSTM Topology | |
| Input | 54-dim. articulatory |
| Output. | 80-dim. acoustic feature |
| No. of LSTM nodes each hidden layer | 256 |
| Depth | 3-depth layers |
| Batch size | 1 sentence (one whole sentence per batch) |
| Max Epochs | 30 |
| Learning rate | 0.00001 |
| Optimizer | Adam |
| VC BLSTM Topology | |
| Input | 80-dim. acoustic feature |
| Output. | 80-dim. acoustic feature |
| No. of LSTM nodes each hidden layer | 128 |
| Depth | 3-depth layers |
| Batch size | 1 sentence (one whole sentence per batch) |
| Max Epochs | 30 |
| Learning rate | 0.00005 |
| Optimizer | Adam |
| Toolkit | Pytorch |
| SD | SI | SI-P | SI-VC | SI-VC-P | SA-P | SA-VC-P | |
|---|---|---|---|---|---|---|---|
| Train: | Tar SPK | Src SPK | Src SPK (P) | VC-Src SPK | VC-Src SPK (P) | Src + Tar SPK (P) | Tar + VC-Src SPK (P) |
| Test: | Tar SPK | Tar SPK | Tar SPK (P) | Tar SPK | Tar SPK (P) | Tar SPK (P) | Tar SPK (P) |
| F01 | 4.98 | 7.80 | 7.48 | 6.63 | 5.79 | 5.26 | 5.08 |
| F02 | 5.47 | 8.41 | 8.21 | 6.82 | 6.45 | 5.51 | 5.23 |
| F03 | 6.02 | 9.04 | 8.66 | 8.03 | 6.99 | 6.11 | 6.20 |
| F04 | 5.99 | 8.37 | 8.35 | 7.87 | 7.19 | 6.14 | 6.33 |
| M01 | 8.96 | 10.41 | 10.44 | 9.45 | 9.33 | 8.22 | 8.23 |
| M02 | 7.54 | 10.66 | 10.05 | 9.25 | 8.85 | 7.29 | 7.21 |
| M03 | 6.59 | 8.18 | 8.37 | 7.95 | 7.55 | 6.87 | 6.85 |
| M04 | 7.14 | 8.83 | 8.69 | 8.71 | 8.38 | 7.11 | 7.03 |
| Mean | 6.59 | 8.96 | 8.78 | 8.09 | 7.57 | 6.56 | 6.52 |
| STD | 1.27 | 1.04 | 0.98 | 1.03 | 1.21 | 0.99 | 1.05 |
| Target | F01 | F02 | F03 | F04 | M01 | M02 | M03 | M04 | |
|---|---|---|---|---|---|---|---|---|---|
| Source | |||||||||
| F01 | 6.32 | 7.23 | 6.71 | 7.08 | 6.86 | 7.91 | 8.69 | ||
| F02 | 9.26 | 6.75 | 7.60 | 7.66 | 7.55 | 8.46 | 9.15 | ||
| F03 | 7.43 | 7.01 | 7.02 | 6.85 | 7.04 | 7.83 | 8.77 | ||
| F04 | 7.15 | 6.24 | 7.45 | 7.24 | 7.66 | 8.02 | 9.25 | ||
| M01 | 6.64 | 6.40 | 6.32 | 7.38 | 7.03 | 7.68 | 8.52 | ||
| M02 | 6.47 | 6.64 | 6.50 | 7.56 | 6.78 | 7.77 | 8.70 | ||
| M03 | 6.97 | 6.63 | 6.65 | 7.51 | 6.70 | 7.05 | 8.50 | ||
| M04 | 7.01 | 6.32 | 7.05 | 7.42 | 7.96 | 7.17 | 7.71 | ||
| Average | 7.30 | 6.51 | 6.85 | 7.31 | 7.18 | 7.19 | 7.91 | 8.80 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, B.; Wisler, A.; Wang, J. Speaker Adaptation on Articulation and Acoustics for Articulation-to-Speech Synthesis. Sensors 2022, 22, 6056. https://doi.org/10.3390/s22166056
Cao B, Wisler A, Wang J. Speaker Adaptation on Articulation and Acoustics for Articulation-to-Speech Synthesis. Sensors. 2022; 22(16):6056. https://doi.org/10.3390/s22166056
Chicago/Turabian StyleCao, Beiming, Alan Wisler, and Jun Wang. 2022. "Speaker Adaptation on Articulation and Acoustics for Articulation-to-Speech Synthesis" Sensors 22, no. 16: 6056. https://doi.org/10.3390/s22166056
APA StyleCao, B., Wisler, A., & Wang, J. (2022). Speaker Adaptation on Articulation and Acoustics for Articulation-to-Speech Synthesis. Sensors, 22(16), 6056. https://doi.org/10.3390/s22166056