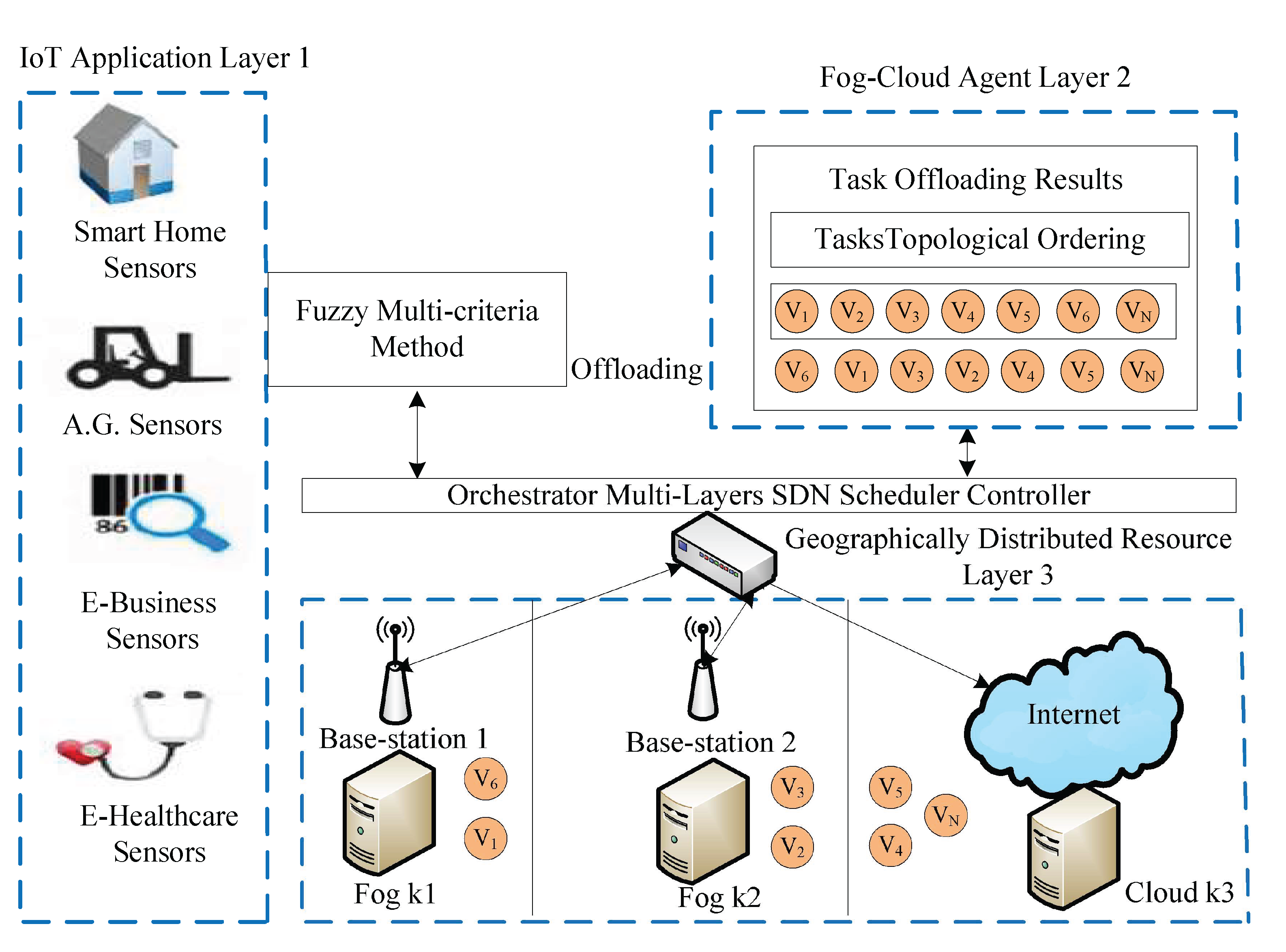
The study considered offloading and scheduling problems as a joint optimization and formulated a combinatorial integer linear programming (CILP). The objective function is an integer value, where all constraints are integer numbers and are denoted as a convex set. For a feasible solution, it is necessary to satisfy all conditions of the problem during the entire process in the system. The CILP is an NP-hard problem when it processes heterogeneous machines in the distributed fog cloud network. In joint optimization, offloading decides whether to offload or not based on certain values to obtain the minimum network delay and computation delay of applications. Moreover, scheduling will handle resource allocation mechanisms of tasks under deadline and failure constraints. Keep the balance between the total delay of
and deadline and constraints, and the joint optimization will achieve the overall objective of the study. Furthermore, the CILP problem will be divided into more sub-problems, such as offloading, sequencing, and scheduling. To solve the CILP problem, the study proposes the JTOS algorithmic framework, which consists of different components for processing user requests. JTOS framework initially takes the input of all tasks of applications. The study suggests that an Algorithm 1 is the main algorithmic framework that consists of different methods in the sequences. For instance, the FMCM method is the framework method that makes the offloading decision based on the following parameters (e.g., network delay, computation delay, required computing instructions (ms) data size, and total delay). The Fuzzy indexes and weight ratios consist of different attributes, including execution time, communication time, resource availability, and deadline. The pairwise comparisons of giving elements are produced based on the normalized comparison scale on nine levels as illustrated in
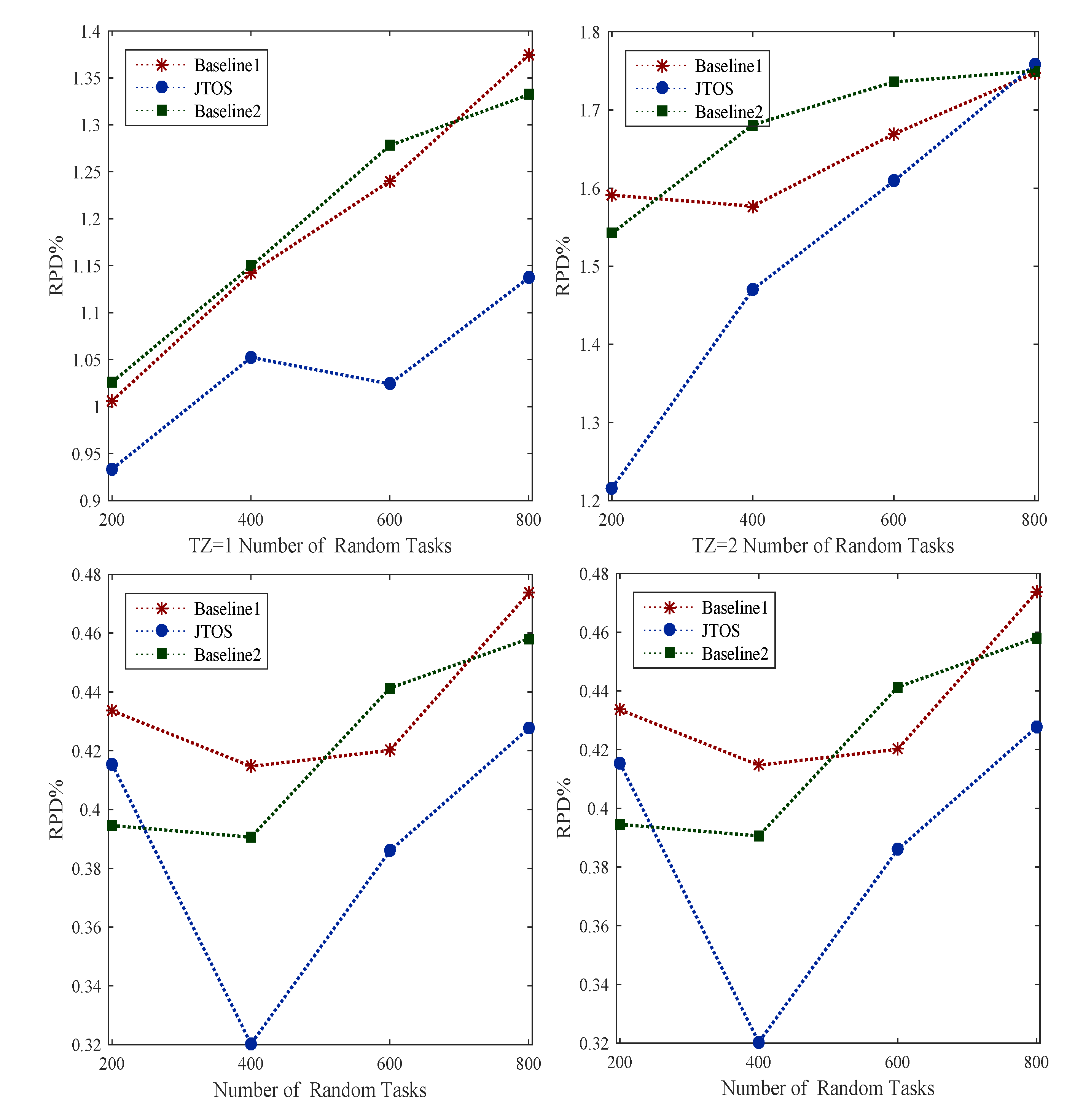
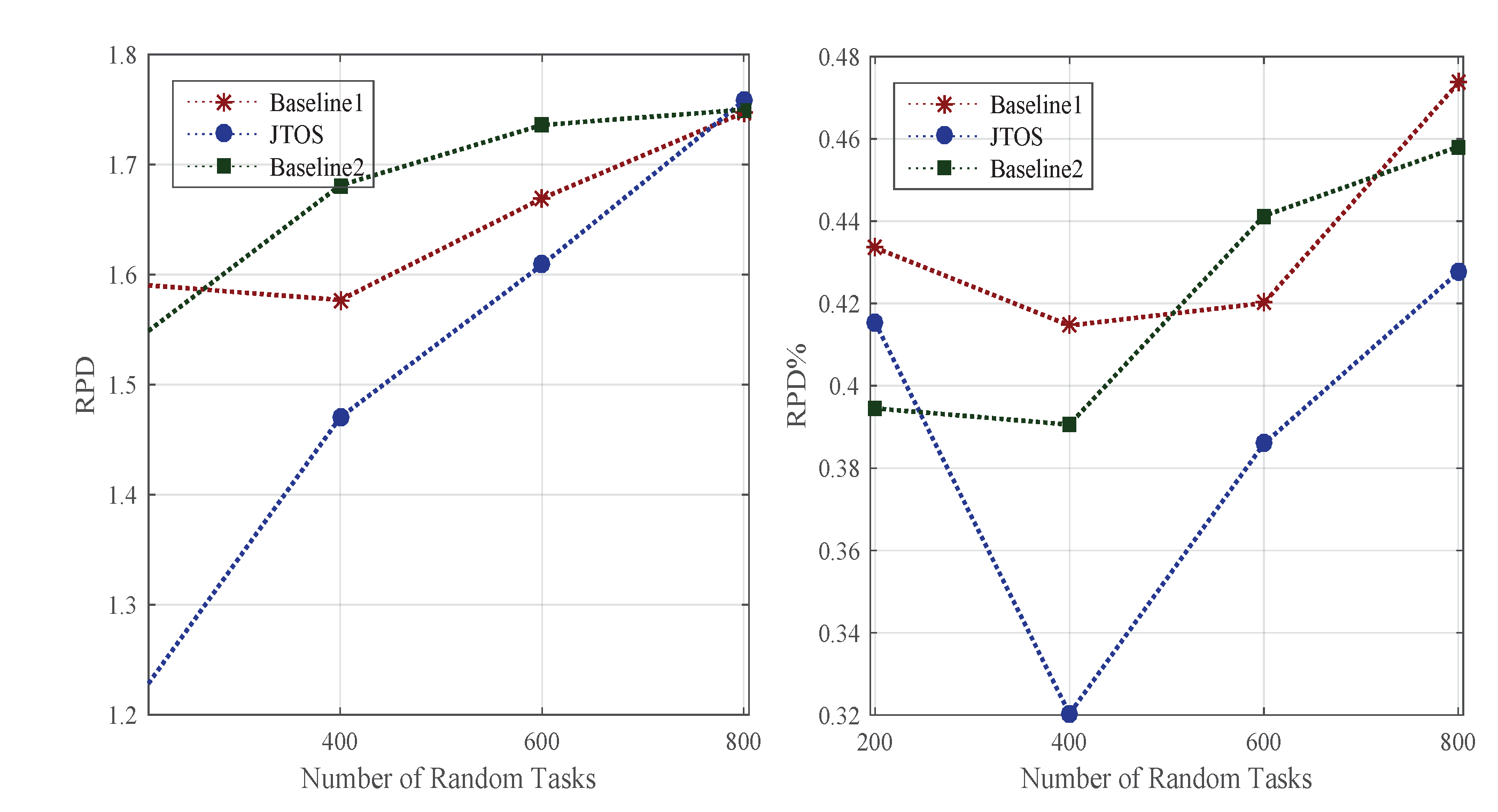
Table 3. Task offloading results are a result of tasks, as shown in
Table 4. Each task has different requirements, such as a small workload, a small deadline, and being delay-sensitive and delay-tolerant. Therefore, all listed tasks are furthermore sorted into the proposed topological ordering of their needs. Based on topological ordering, machine learning-based search finds the optimal computing node for each task. Based on topological sorting, all tasks are scheduled onto search nodes based on their objective function. However, initial scheduling incurs the failure of tasks it will handle in two ways. Firstly, the transient failure tasks will recover under their deadlines and comprehensively failed tasks will re-offload from scratch to the system. The work discusses all components in the corresponding subsections.
| Algorithm 1: JTOS Framework |
![Sensors 22 05937 i001]() |
4.1. Fuzzy Multi-Criteria Method (Fmcm)
The offloading is the sub-problem of the CILP type problem, which makes the decision when and where to offload tasks in such a way that total
is minimized for all applications. The offloading problem only ensures that it delays optimal offloading from users to computing nodes without considering deadlines and failure situations of tasks. In this study, offloading is a multi-criteria decision problem, where decision parameters have some weights to make the offloading for tasks. The fuzzy logic algorithm accommodates solving an enigma input. This study presented the FMCM offloading method for the applications, where the FMCM method evaluates the rank of each criterion according to criterion, i.e.,
based on Equation (
15). The goal is to sort and determine all ranks based on their given requirements. Furthermore, the FMCM method normalized aggregated fuzzy importance weight for each criterion based on Equation (
16). After that, the technique normalized the matrix for all applications
for each measure based on Equation (
17). Similarly, the FMCM method normalized stored weights based on Equation (
18). FMCM constructs the weighted normalized fuzzy decision matrix of application and makes decisions in the fifth and sixth. The seventh FMCM determines the fuzzy positive and negative ideal solution based on Equations (19) and (20). In the final step, FMCM determines the fuzzy closeness computing node for each task and ranks the alternatives according to their closeness based on Equation (
21). To solve the multi-criteria offloading decision, we propose the FMCM. The FMCM determines a decision based on the given weights to the criteria of the task during offloading matrix, i.e.,
, where each attribute includes relative weight for their importance, i.e.,
. We formulate the task offloading problem as a multi-criteria decision-making (MCDP) problem [
27]. The existing decision methods [
26] are not suitable for our task offloading where elements are dynamically changed. However, all decision methods are efficient and effective when the environment is stable with the perfective of all elements. We propose a lightweight and multi-criteria task offloading decision method, which tackles all elements dynamically based on their current values. Furthermore, we apply similar elements pairwise comparison to the analytic hierarchy process (AHP) method [
29] to obtain pairwise values. We show the pairwise value in the matrix
G.
Equation (
16) describes three alternative computing nodes, i.e.,
) and four attributes
. It determines the
resource matching calculation during the offloading decision. The attributes are execution time, communication time, resource availability, and deadline. The pairwise comparisons of giving elements are produced based on the normalized comparison scale on nine levels employed in matrix
G to compute the weight of the attributes by obtaining an eigenvector
, which is also associated to the prime eigenvalue
. As usual, the outcome of the pairwise comparison reliability index
is determined in the following way:
Equation (
18) shows the reliability indexes of elements, where
is the reliability index ration of
, whereas successive relative weights are produced by
, the possibility of multi-criteria derive via
. Where
x is a integer value, which is equal to 1 when it has ideal fuzzy weight. Because
k is a fascinating alternative (
) with
N number of tasks, it further normalizes in the following way:
Equation (
20) determines the selection of the best resources among all existing resources, as
x is any real number of
R which explores the choices that may be criteria and alternative. Where
is the
th decision maker whose task has the highest rank on the computing node. Due to the dynamic environment, tasks and resource offloading have many FMCM choices, i.e.,
.
Equation (
21) stored the related weight of each element (which is fixed in advance), where
is a weight which is already initialized above. The affirmative best solution and the aversive solutions for each decision maker can be determined
from the weight matrix.
where
is a positive solution of the decision maker for application objective, where
is aversive (negative) solution to the objective. It is natural to consider the real time information related to the available wireless network via the network profiler; the FMCM uses the Euclidean distance matrix among all possible alternatives and it can be calculated in this way:
Equation (
24) determines the best choice: which solution is best for each task before offloading. Because
and
show the best and worst solution for each alternative, the task offloading algorithm chooses the highest rank solution
solution from all alternatives, as follows:
Equation (
26) finds the highest rank of each node for every task during the offloading decision.
Algorithm 2 processes the offloading mechanism for all applications onto different heterogeneous computing nodes. In step 2–4, Algorithm 2 constructs the fuzzy weight tasks and resource matrix of each application based on Equation (
15). The reliability index is measured based on Equation (
16). In step 6–8, the algorithm normalized the tasks index based on Equation (
17). In step 9–14, Algorithm 2 constructs the decision matrix based on Equation (
18) and generates the position solution and negative solution based on Equation (
19). The algorithm determines each task’s best choice and worst choice for computing based on Equation (
20). In the end, the optimal and ideal rank of each task onto optimal computing are constructed based on Equation (
21). The output of Algorithm 2, i.e.,
is shown in
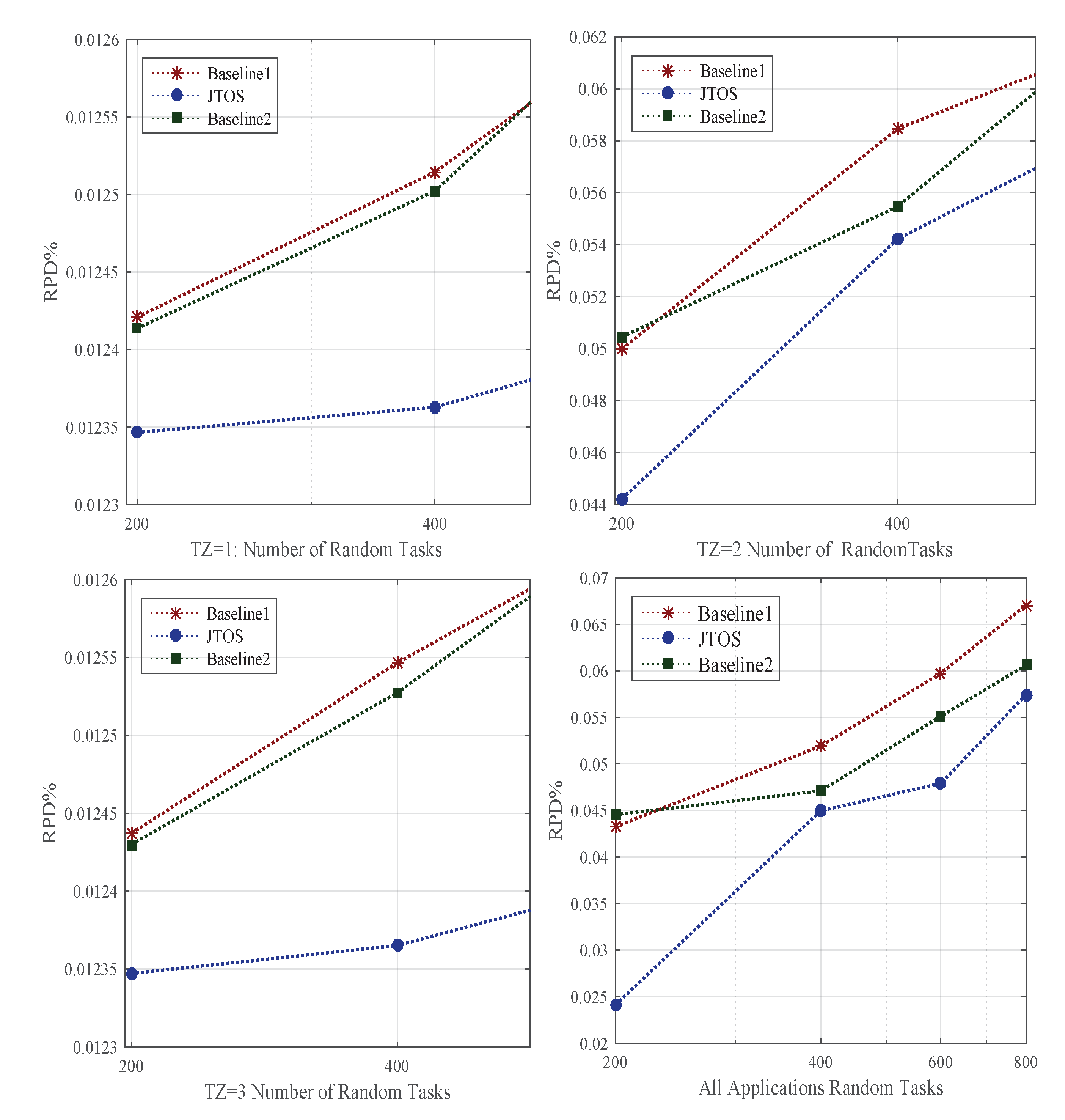
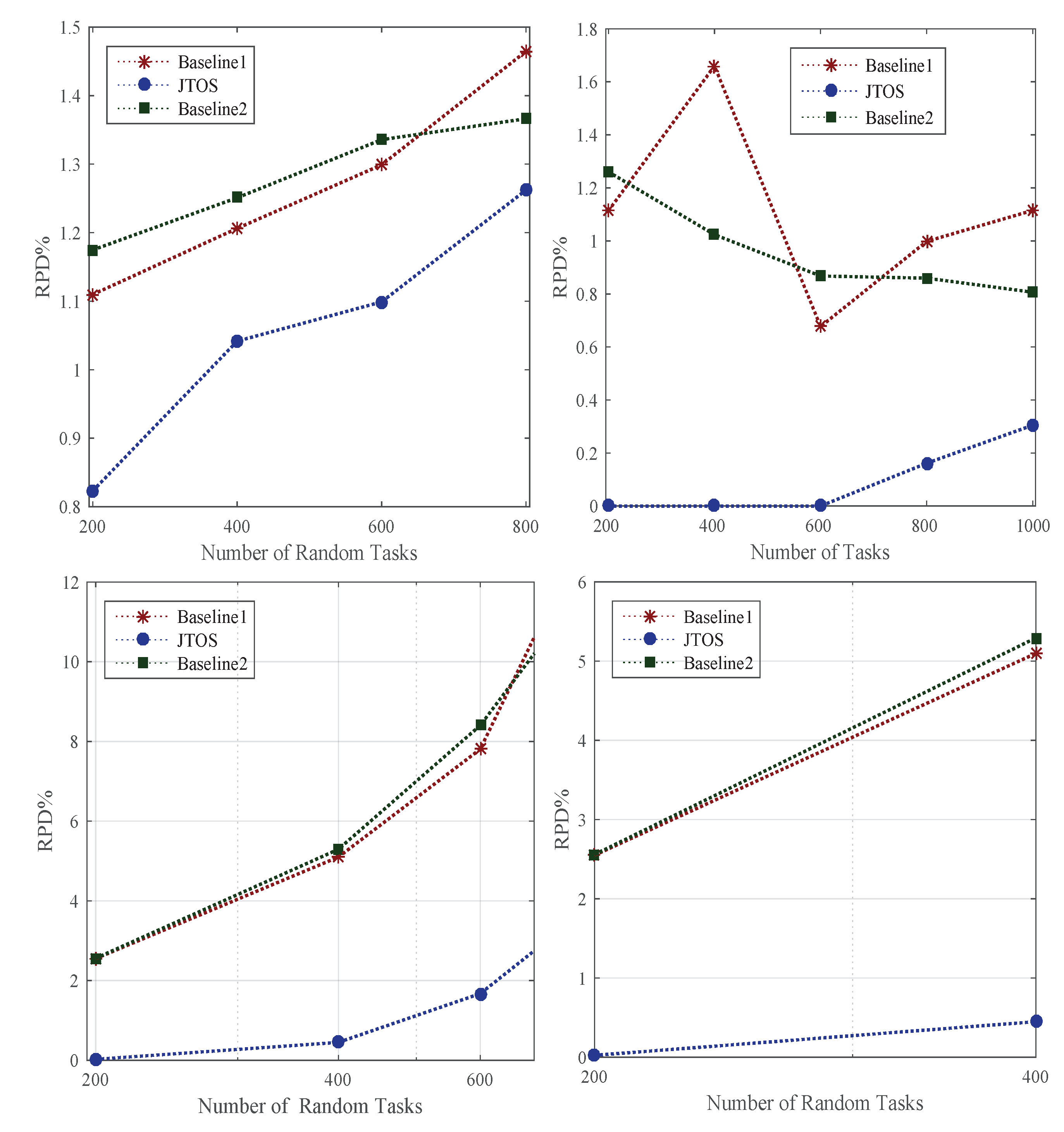
Table 4. The offloading results of four applications, such as E-Healthcare, E-Transport, Self-Autonomous (e.g., Augmented Reality), and smart home are analyzed by FMCM with different steps.
Table 4 shows that, in the result list, i.e.,
, each task has different
on different computing nodes. Therefore, these results will be passed to the system for further execution under deadlines and failure constraints.
| Algorithm 2: Task Offloading Phase |
![Sensors 22 05937 i002]() |
4.5. Transient Failure Aware Method
To understand the failure-aware mechanism, the study discusses a case study of the real-world practice of IoT applications. There are two types of failure in distributed computing that are often considered: communication node failure and computing node failure. However, this study considers the transient failure of computing nodes in a dynamic environment.
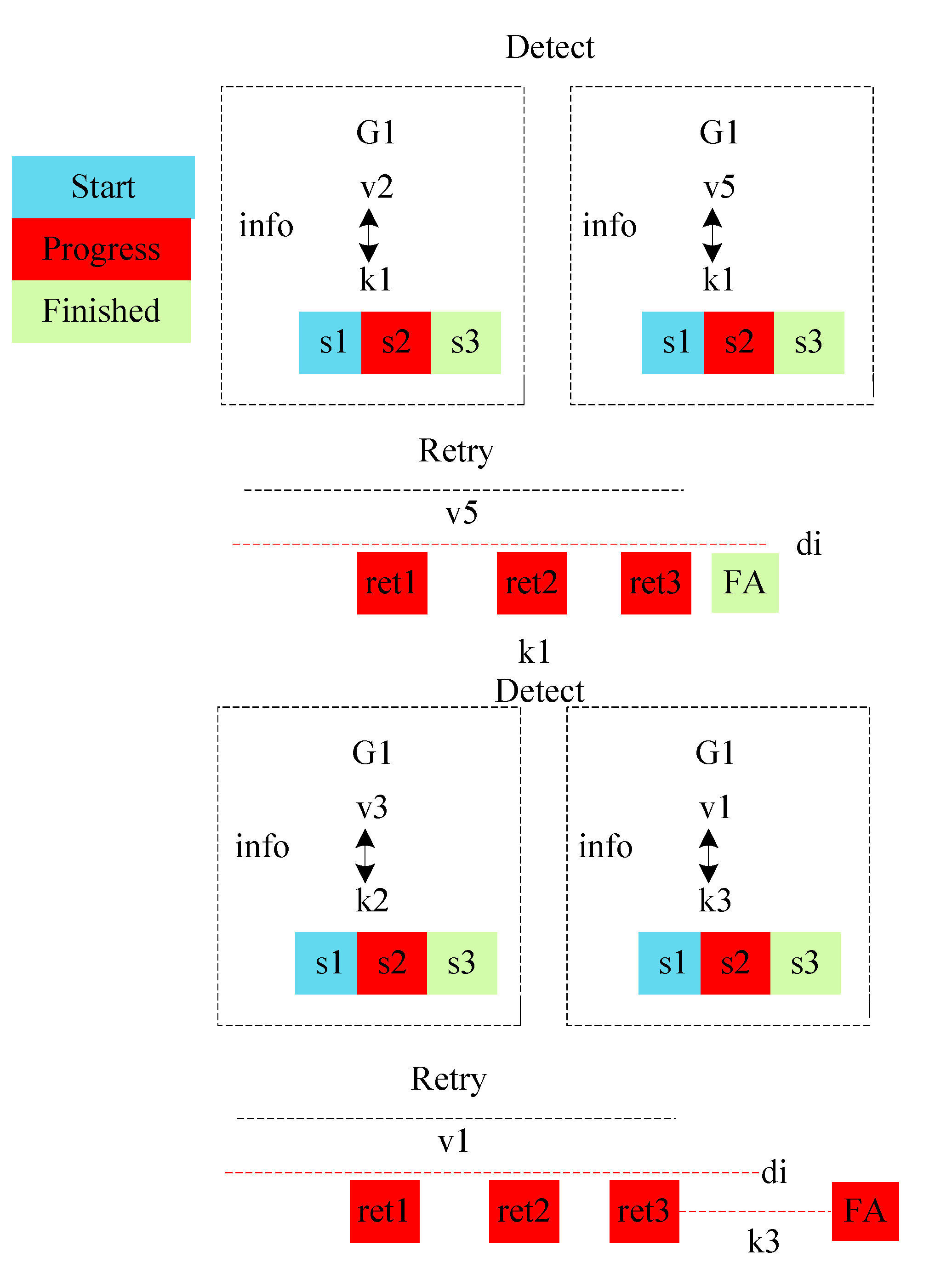
Figure 2 illustrates the execution process of application
with its tasks on different computing devices. The information is the history of a task from beginning to end. Each task has three statuses:
shows that a task has started its execution on a particular node.
illustrates that a task is still in the process of execution on any node, whereas
ensures the execution of a task is finished successfully. The tasks
and
of application
are scheduled on
. Let us assume that a task
failed at the computing node
. The detection strategy saves information on the failure of a task from the point of failure and sends it to the retry strategy. At the same time, the retry strategy tries to recover
status with two possible iterations left, i.e., three before the deadline, as shown in
Figure 2. The task
recovered with three retried operations on computing node
and final failure aware (FA) policy return success status to the system. In another case, a task
on computing node
failed, and the retry strategy tried possible iterations. However, a task failure exceeds its deadline limit, and then the FA will mark it as a failure. The
will reschedule from the scheduler from the start for execution.
Algorithm 5 handles the transient failure aware process of all applications robustly without violating their performances during execution.
The transient failure steps of Algorithm 5 are explained as below.
Initially, the failure list of all tasks saved those tasks which have failure status during scheduling.
The retry variable and max-iteration (max-ite) has a limited three attempts to recover the transient failure aware process of tasks.
The detection will return the information of tasks when they are failed on different computing nodes.
The retry strategy will retry tasks from their point of failure with three iterations. The retry duration is only 30 s, and the gap between the first iteration and the second iteration is about 15 s.
In the end, if the tasks are retried under their deadlines, then FA returns finished status. Otherwise, it will inform the scheduler of the tasks to be scheduled again from scratch.
4.6. Time Complexity of Jtos
A study mentioned above shows that the JTOS framework consists of different components, such as offloading, sequencing, searching, and scheduling. Therefore, the time complexity of JTOS is determined by various elements. The time complexity of offloading is divided into three phases: parameters, normalization, and weighting, and it is equal to
. In comparison, the time complexity of the positive ideal solution and negative ideal solution becomes n. The ranking of each task becomes
n. Therefore, the total complexity of the offloading algorithm is equal to
. The task sequence is divided into two ordered, such as
and deadline, and the time complexity becomes
. The
ordering becomes
n and it is the same for the deadline, which becomes
n. Therefore, the total time complexity is equal to
. The searching for an optimal solution for each task to the resource is equal to
.
n is several tasks, and
m matches each resource’s iteration during searching. Furthermore, all tasks are scheduled in
n order to the optimal solution. The total time complexity of searching and scheduling becomes
. The final time complexity transient failure algorithm is divided into three parts: detection, retry, and failure aware event. The detection strategy finds the failure of tasks when they have failed status in
n time, and the same for the retry method, i.e.,
n. The failure awareness is the decision scheme for all tasks, and then it is equal to
n. Therefore, the total time complexity of transient failure is equal to
.
| Algorithm 5: Transient Failure Aware Schemes |
![Sensors 22 05937 i005]() |


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}