
Fast and Robust Visual Tracking with Few-Iteration Meta-Learning



Abstract
:1. Introduction
- (1)
- We proposed a novel classification and regression model initialization procedure during offline training of single object tracking networks, which is based on an optimization meta-learning approach;
- (2)
- We considered that the features required for the classification and regression tasks of single visual object tracking are not identical, so two branches are used to obtain the final results;
- (3)
- We innovatively applied a new optimization-based meta-learning method in the field of single visual object tracking;
- (4)
- We proposed a novel template online update mechanism to the Siamese object tracking network to improve the accuracy of a tracker.
2. Related Work
2.1. Deep Neural Network-Based Tracking Algorithms
2.2. Meta-Learning for Visual Tracking
2.3. Online Model Update
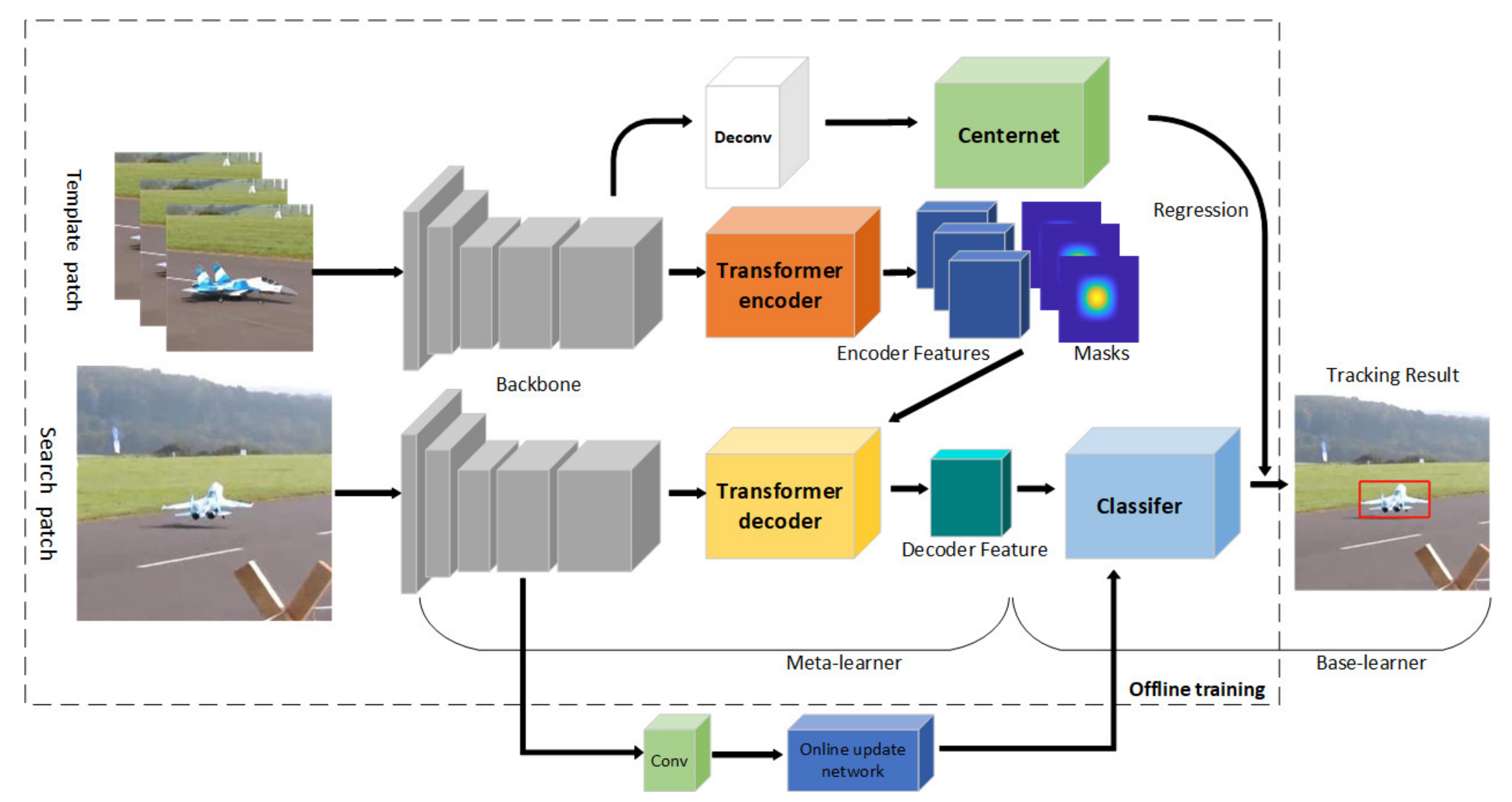
3. Proposed Method
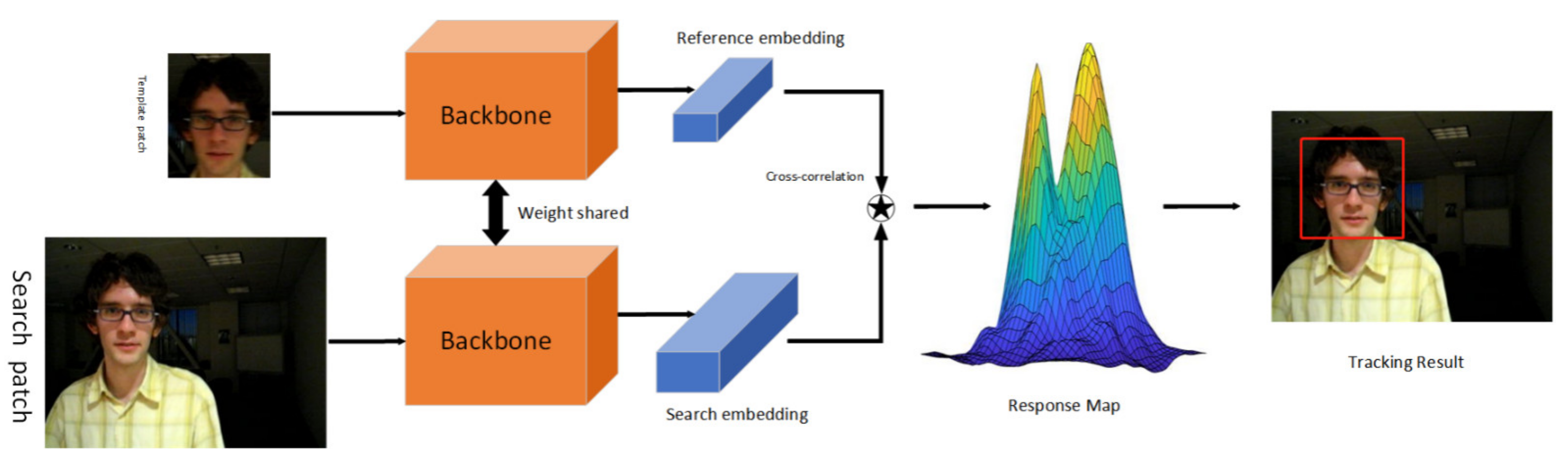
3.1. Background
3.2. Meta-Learner with Feature Extractor
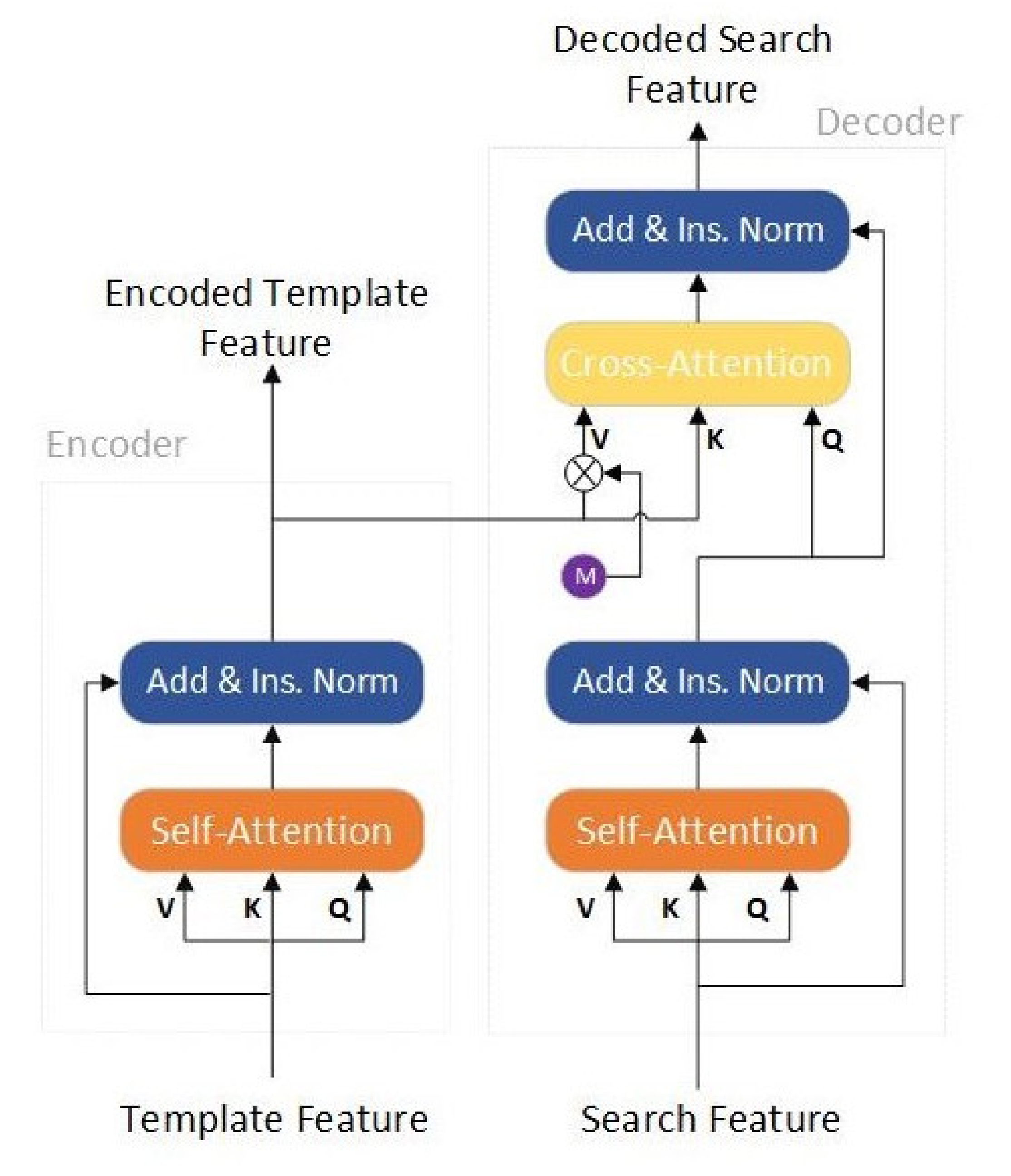
3.3. Base-Learner with Classification and Regression
3.4. Offline Training
3.5. Online Tracking
4. Experimental Result
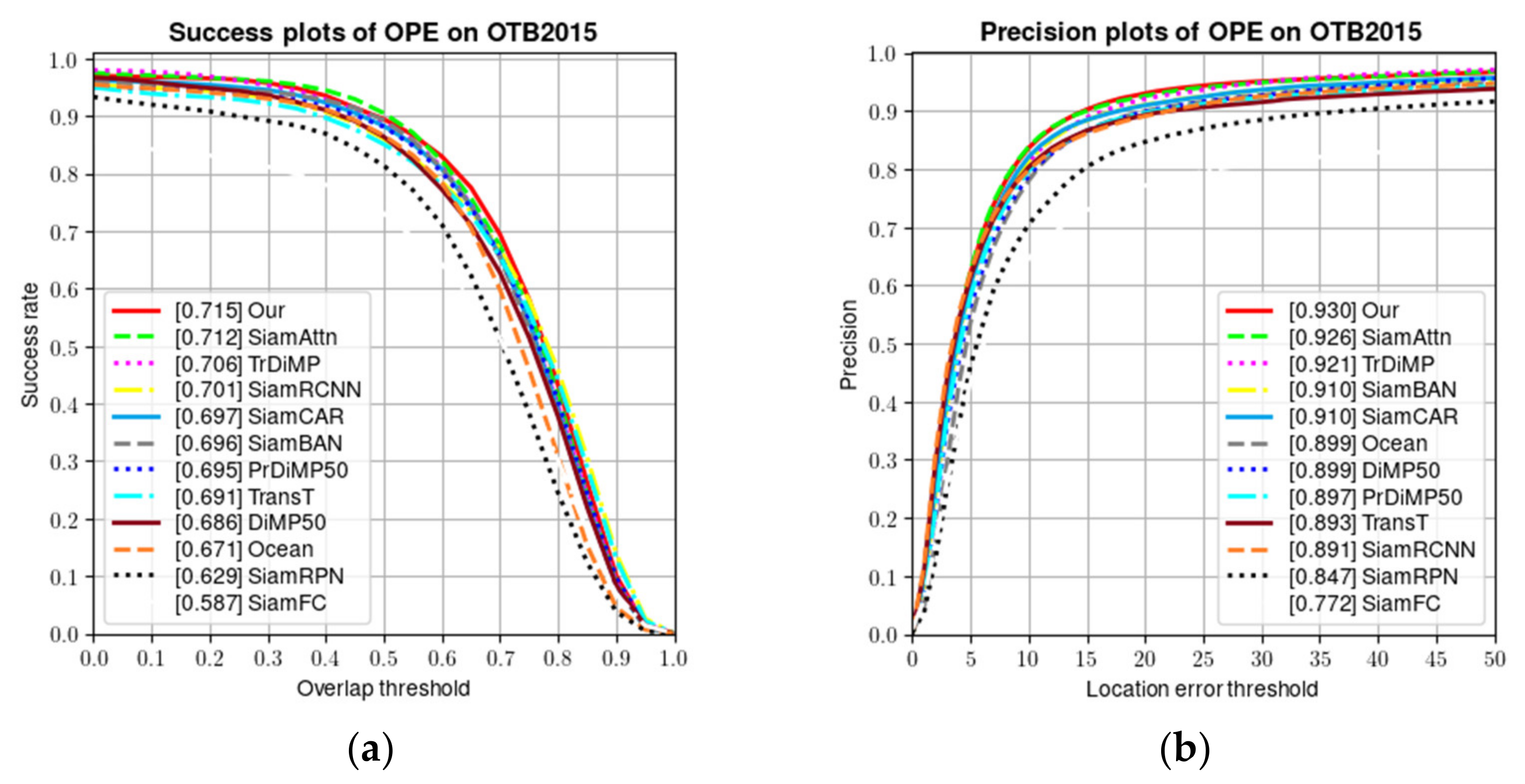
4.1. OTB2015
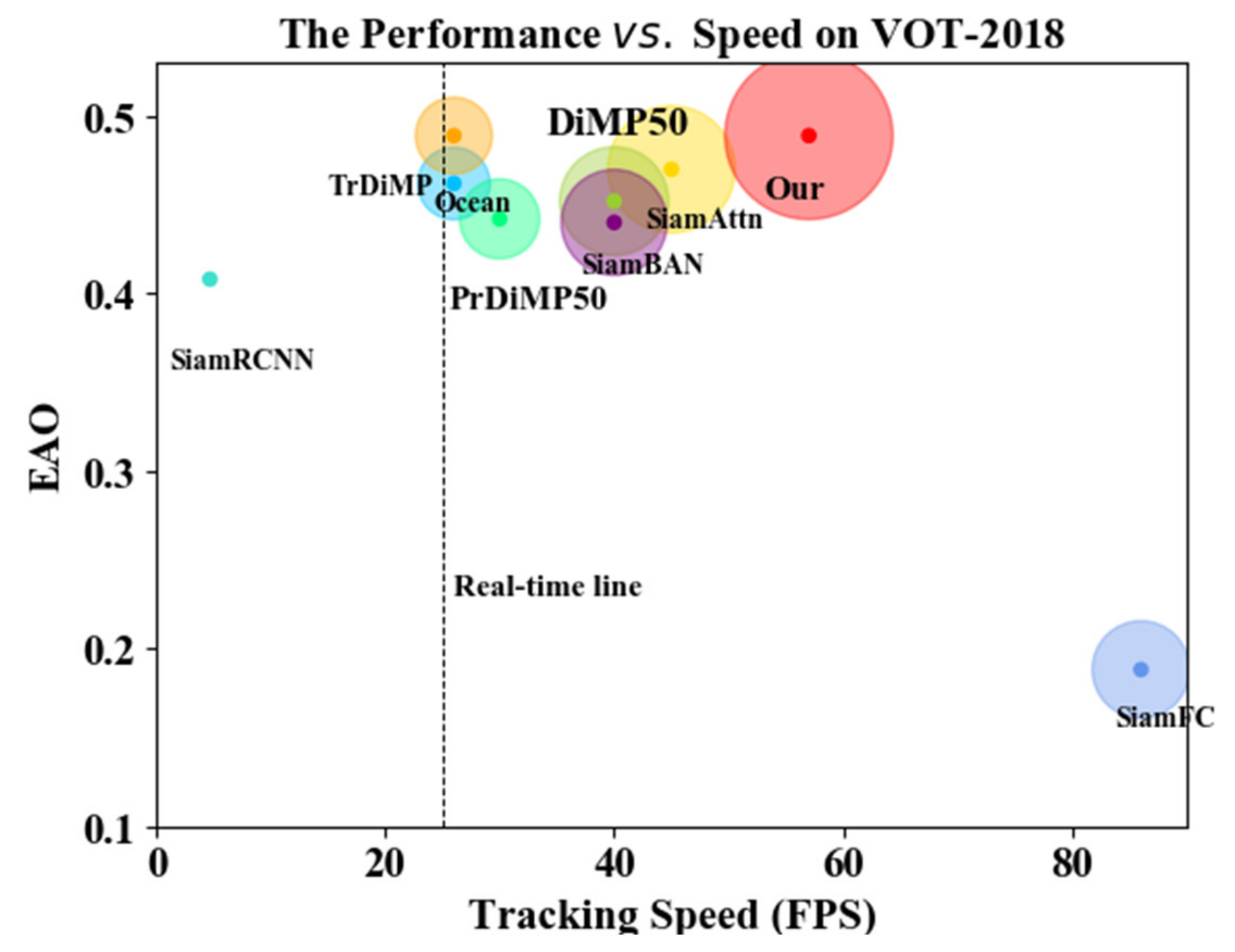
4.2. VOT2018
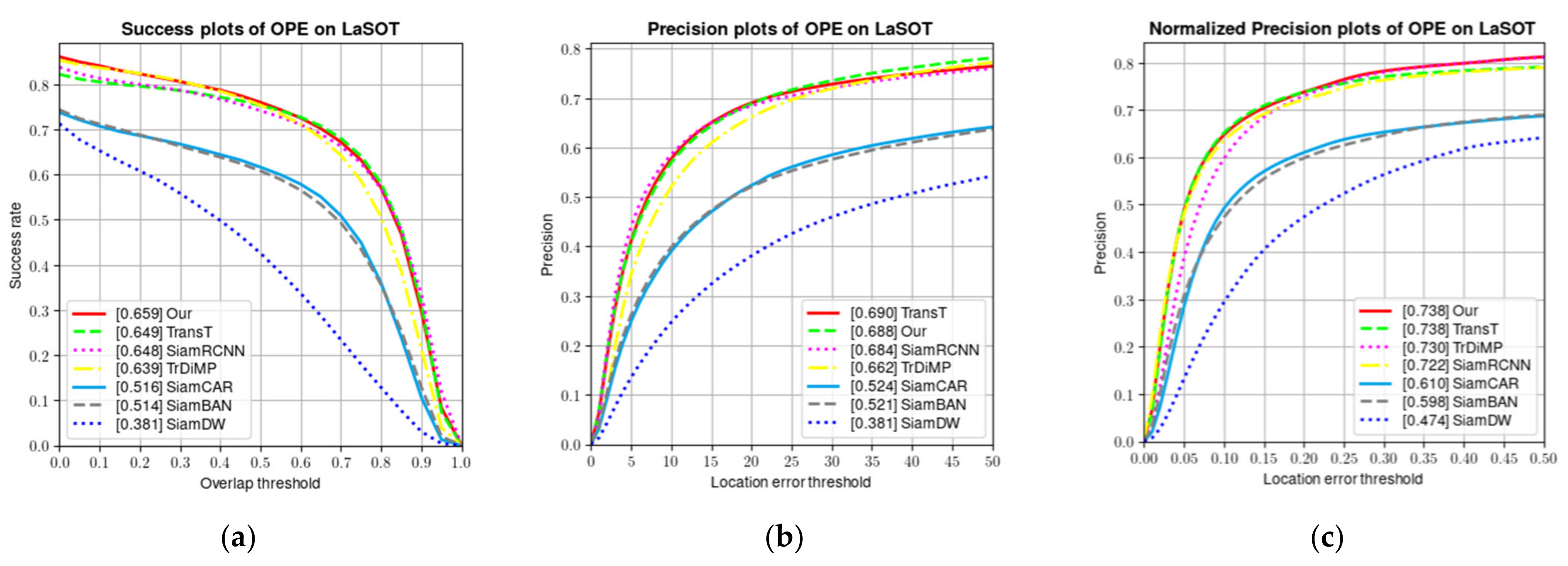
4.3. LaSOT
4.4. GOT-10k
4.5. Running Speed Comparison Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, C.; Qi, D.; Dou, S.G.; Tu, Y.P.; Sun, T.L.; Bai, S.; Jiang, X.Y.; Bai, X.; Miao, D.Q. Key Technologies of Intelligent Video Surveillance: A Review of Pedestrian Re-identification Research. Sci. Sin. Inf. 2021, 51, 1979–2015. [Google Scholar] [CrossRef]
- Pan, Z.; Liu, S.; Sangaiah, A.K.; Muhammad, K. Visual attention feature (VAF): A novel strategy for visual tracking based on cloud platform in intelligent surveillance systems. J. Parallel Distrib. Comput. 2018, 120, 182–194. [Google Scholar] [CrossRef]
- Tian, W.; Lauer, M. Tracking objects with severe occlusion by adaptive part filter modeling in traffic scenes and beyond. IEEE Intell. Transp. Syst. Mag. 2018, 10, 60–73. [Google Scholar] [CrossRef]
- Xin, X. Research on Target Tracking Methods of Contrast-Enhanced Ultrasound Lesion Area. Master’s Thesis, Southwest Jiaotong University, Chengdu, China, 16 September 2018. [Google Scholar]
- Zhou, Z.; Cao, B. Application of image processing technology in military field. Appl. Electron. Tech. 2021, 47, 26–29. [Google Scholar]
- Xi, L.; Hu, W.; Shen, C.; Zhang, Z.; Hengel, A. A survey of appearance models in visual object tracking. ACM Trans. Intell. Syst. Technol. 2013, 4, 58. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 19–25 June 2021. [Google Scholar]
- Tripathi, A.S.; Danelljan, M.; Van Gool, L.; Timofte, R. Fast Few-Shot Classification by Few-Iteration Meta-Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv, 2020; arXiv:2004.05439. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Cehovin, Z.L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15 June 2019. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fiaz, M.; Mahmood, A.; Javed, S.; Jung, S.K. Handcrafted and deep trackers: Recent visual object tracking approaches and trends. Comput. Surv. 2019, 52, 43. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Proceedings of the Computer Vision—ECCV 2012, 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition-CVPR 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bhat, G.; Johnander, J.; Danelljan, M.; Khan, F.S.; Felsberg, M. Unveiling the power of deep tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–3 November 2019. [Google Scholar]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic Regression for Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision Workshops (ECCVW), Amsterdam, The Netherlands, 8–10, 15–16 October 2016. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware anchor-free tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, KY, USA, 23–28 August 2020. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Lu, H. Transformer Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 19–25 June 2021. [Google Scholar]
- Vilalta, R.; Drissi, Y. A Perspective View and Survey of Meta-Learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Park, E.; Berg, A.C. Meta-tracker: Fast and Robust Online Adaptation for Visual Object Trackers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Song, Y.; Ma, C.; Gong, L.; Zhang, J.; Lau, R.W.; Yang, M.H. Crest: Convolutional residual learning for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HL, USA, 21–16 July 2017. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Wang, G.; Luo, C.; Sun, X.; Xiong, Z.; Zeng, W. Tracking by Instance Detection: A Meta-Learning Approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Gao, J.; Zhang, T.; Xu, C. Graph Convolutional Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. GradNet: Gradient-Guided Network for Visual Object Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Choi, J.; Kwon, J.; Lee, K.M. Deep meta-learning for real-time target-aware visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Tian, Q. Centernet: Object detection with keypoint triplets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhou, X.Y.; Koltun, V.; Philipp, K. Tracking Objects as Points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.; Leibe, B. Siam R-CNN: Visual Tracking by Re-Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M.R. Deformable siamese attention networks for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Accuracy | Robustness | EAO |
|---|---|---|---|
| SiamFC | 0.503 | 0.585 | 0.188 |
| SiamRPN | 0.490 | 0.464 | 0.244 |
| SiamR-CNN | 0.609 | 0.220 | 0.408 |
| SiamAttn | 0.630 | 0.160 | 0.470 |
| SiamBAN | 0.597 | 0.178 | 0.452 |
| Ocean | 0.592 | 0.117 | 0.489 |
| DiMP50 | 0.597 | 0.153 | 0.440 |
| PrDiMP50 | 0.618 | 0.165 | 0.442 |
| TrDiMP | 0.600 | 0.141 | 0.462 |
| Our | 0.625 | 0.119 | 0.489 |
| Tracker | AO | ||
|---|---|---|---|
| SiamFC | 0.392 | 0.426 | 0.135 |
| SiamRPN | 0.481 | 0.581 | 0.270 |
| SiamR-CNN | 0.649 | 0.728 | 0.597 |
| Ocean | 0.611 | 0.721 | - |
| DiMP50 | 0.611 | 0.717 | 0.492 |
| PrDiMP50 | 0.634 | 0.738 | 0.543 |
| TrDiMP | 0.671 | 0.777 | 0.583 |
| Our | 0.667 | 0.725 | 0.599 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhang, X.; Xu, L.; Zhang, W. Fast and Robust Visual Tracking with Few-Iteration Meta-Learning. Sensors 2022, 22, 5826. https://doi.org/10.3390/s22155826
Li Z, Zhang X, Xu L, Zhang W. Fast and Robust Visual Tracking with Few-Iteration Meta-Learning. Sensors. 2022; 22(15):5826. https://doi.org/10.3390/s22155826
Chicago/Turabian StyleLi, Zhenxin, Xuande Zhang, Long Xu, and Weiqiang Zhang. 2022. "Fast and Robust Visual Tracking with Few-Iteration Meta-Learning" Sensors 22, no. 15: 5826. https://doi.org/10.3390/s22155826
APA StyleLi, Z., Zhang, X., Xu, L., & Zhang, W. (2022). Fast and Robust Visual Tracking with Few-Iteration Meta-Learning. Sensors, 22(15), 5826. https://doi.org/10.3390/s22155826