
Distributed Visual Crowdsensing Framework for Area Coverage in Resource Constrained Environments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Proposing a distributed VCS framework for full-view area coverage in resource-constrained environments. In the proposed approach, the target area is divided into virtual sub-regions, each of which is represented by a set of boundary points of interest (BoI). An appropriate pattern of BoIs that can be used to investigate the full-view area coverage is found. The area is full-view covered if each BoI has full-view coverage in all k-view directions around the full scope. To the best of our knowledge, this is the first distributed framework in VCS to investigate full-view area coverage by utilizing a set of BoIs rather than the target region’s continuous domain or using dense grid methods. Because there are infinite points inside the target area, mobile devices have limited processing ability and energy to investigate the area coverage utilizing the continuous domain of the target region. The BoI scheme is proposed to investigate the full-view area coverage for applications with limited resources for this aim.
- Developing a clustering scheme to represent the geometric coverage conditions of each photo in VCS, based on the full-view area coverage conditions used in traditional camera sensor networks (CSN). Although there are data redundancy removal algorithms for full-view area coverage in CSN [15,16], these approaches are ineffective for VCS since users take different images from different positions each time. For instance, the authors in [15] proposed an approach that considers fixed locations of sensors and thus performs data redundancy elimination based on predefined locations.
- Developing adaptive photo redundancy elimination procedures based on the coverage of each photo in the target area. This allows the distributed VCS system to select the minimum number of photos with maximum area coverage. As a result, each sensor node can filter redundant photos without requiring high computational capabilities or a global understanding of all photos from all sensor nodes inside the target area. The proposed procedures prevent sending repeated photos across sensor nodes, which saves bandwidth and energy.
2. Related Works
3. Methodology
- A boundary points of interest model to generate the appropriate pattern for full-view area coverage.
- A classification method to represent the k-view geometric area coverage conditions. This subsystem collects and classifies photos with the same k-view geometric area coverage features with the application of the BoIs model in a distributed and adaptive manner.
- A set of procedures to eliminate redundancy among photos with identical geometric conditions for VCS. This includes the management of the sensor node storage to prevent storing redundant photos and how each sensor node stores photos with maximum added values so that photos with higher coverage overlap are skipped.
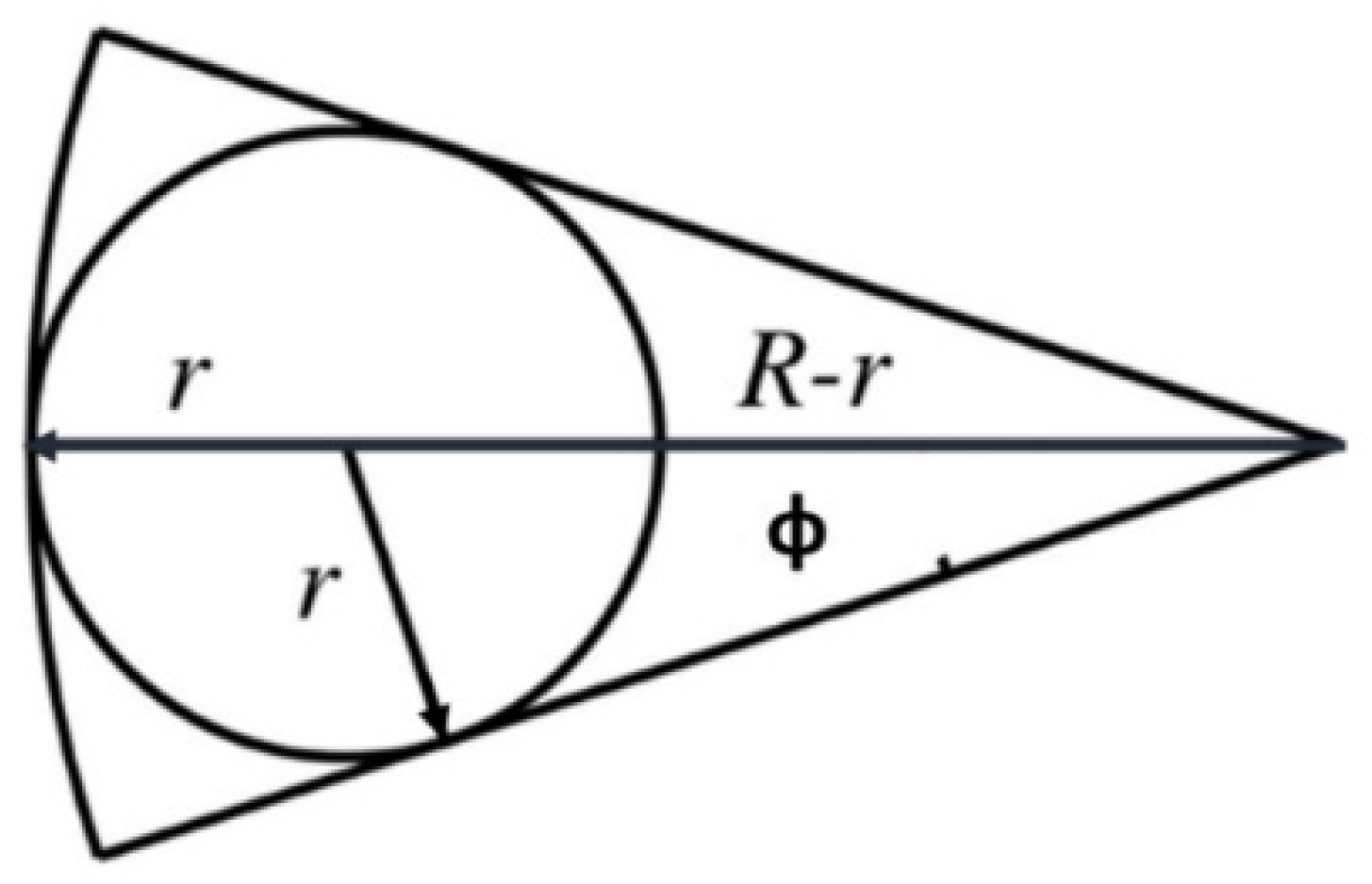
3.1. Proposed Model for Boundary Points of Interest
| Algorithm 1: BoIs generation |
| 1: Determine the length of the target area |
| 2: Determine the width of the target area |
| 3: Determine the radius of maximum coverage disk (r) |
| 4: Sub-region area = (2r × 2r)/2 |
| 5: Number of sub-regions = Target area/Sub-region area |
| 6: S: Total Number of sub-regions |
| 7: B: Number of BoIs for each sub-region |
| 8: Px(s): location-x center of sub-region (s) |
| 9: Py(s): location-y center of sub-region (s) |
| 10: for s = 1:S do |
| 11: for b = 1:B do |
| 12: BoIx(s, b) = Px(s) + r × cos((b − 1) × (360/B)) |
| 13: BoIy(s, b) = Py(s) + r × sin((b − 1) × (360/B)) |
| 14: end for |
| 15: end for |
- The points within each sub-region are covered by the same set of photos.
- The photos covering the same sub-region can be ordered in a clockwise or anti-clockwise direction depending on their positions with respect to the sub-region.
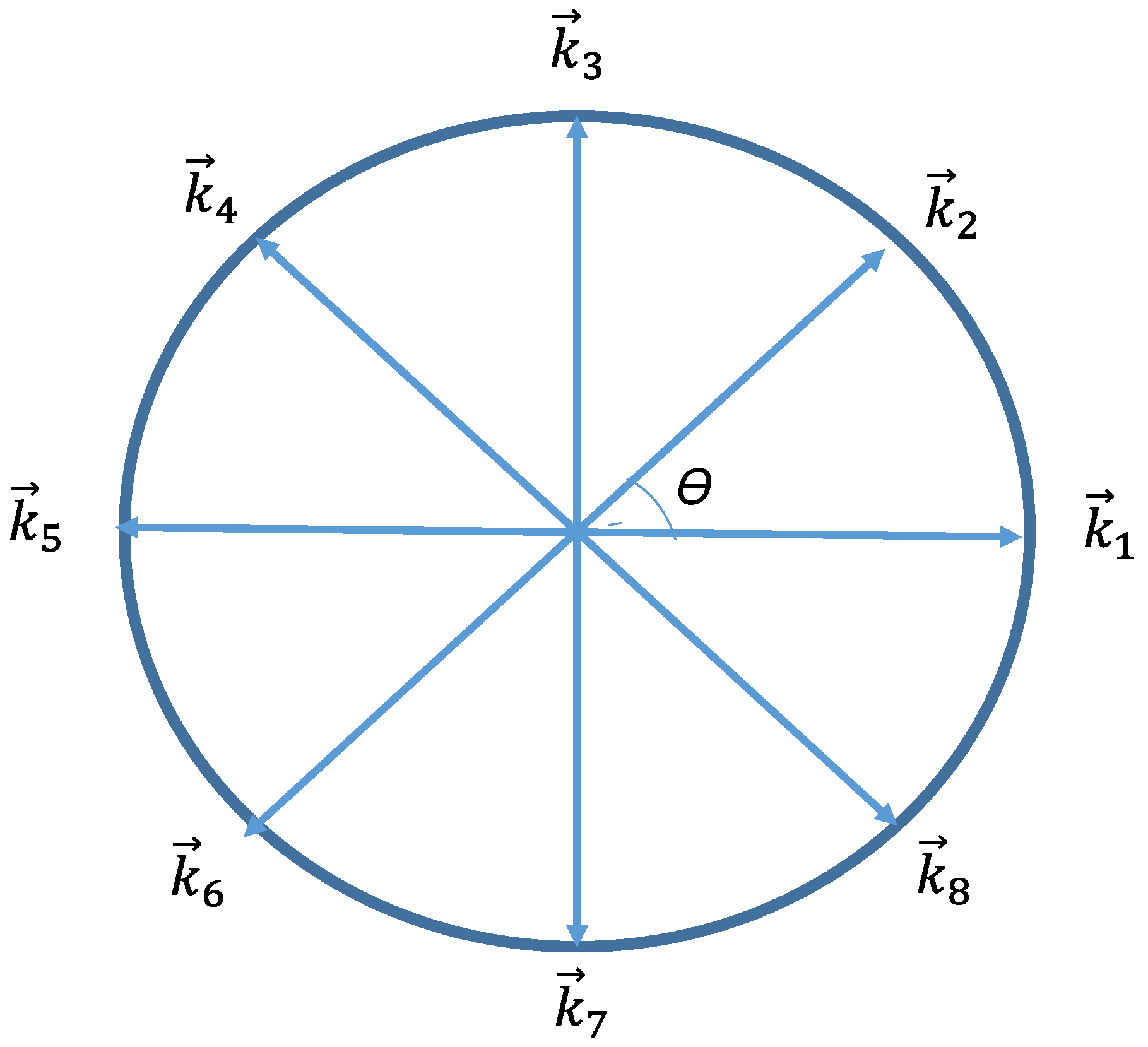
- The rotation angle between any two neighboring sensors within the same set and any point within the sub-region is either within the safe or unsafe region.
- The rotation angle between and is smaller than or equal to θ.
- The rotation angle between and is smaller than or equal to θ.
3.2. Proposed Photo Clustering and Selection Scheme
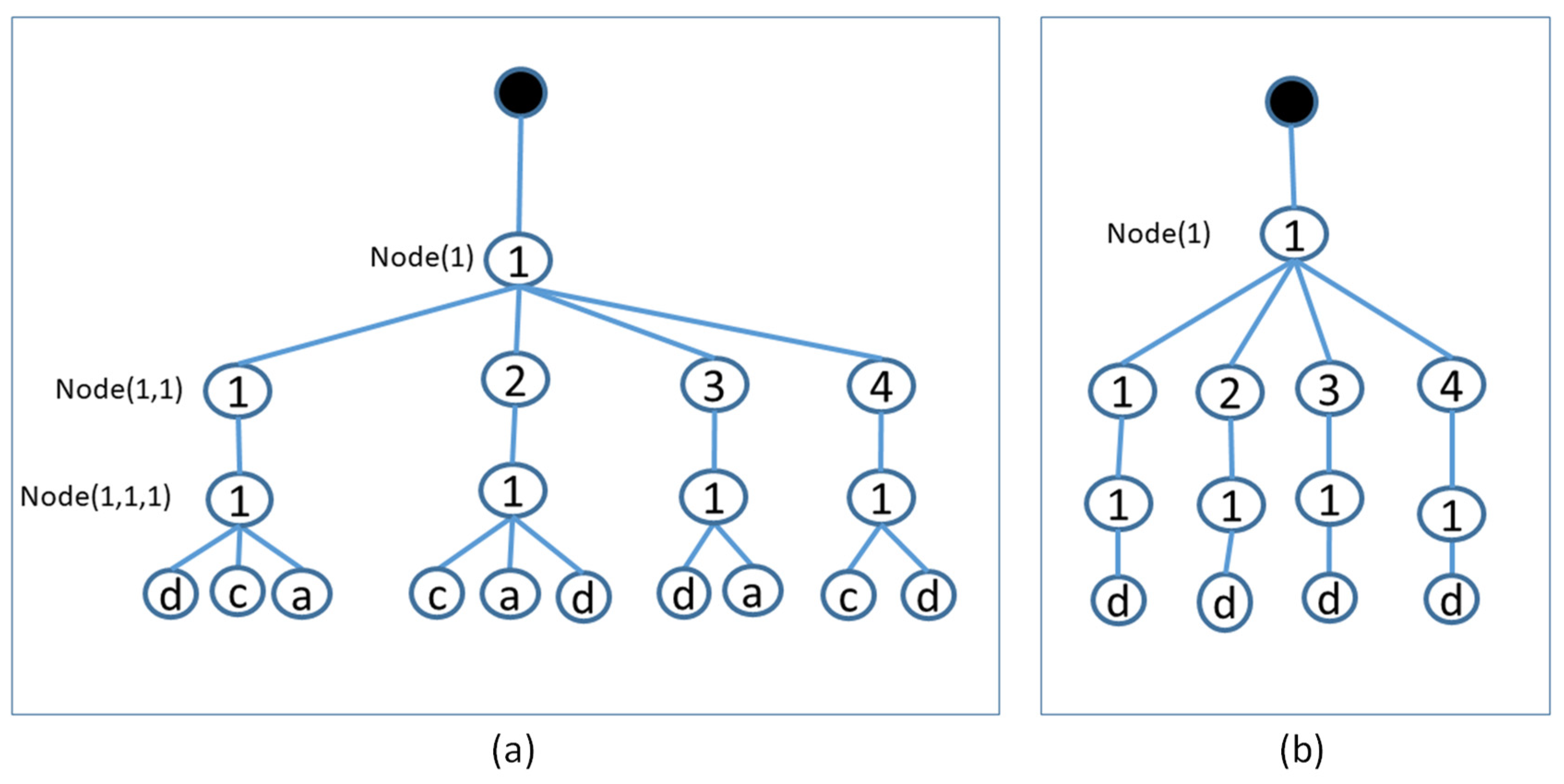
- The first layer comprises the ID of the sub-regions. The partitioning process is simplified by using photos belonging to the same sub-region ID.
- The second layer comprises all BoIs of each sub-region.
- The third layer comprises the ID of each covered sector for each covered BoI within each sub-region. This layer determines if all sectors around each BoI within the same sub-region are fully covered by the same set of photos.
- The fourth layer comprises the ID of each photo of all covered sub-regions, BoIs, and sectors. Each photo has a unique ID in terms of location, FoV, shooting angle, and sensing range.
| Algorithm 2 Initial K-CoverPicTree generation |
| 1: Input S: number of virtual sub-regions |
| 2: Input B: number of BoIs for each sub-region |
| 3: Input K: number of sectors for each BoI |
| 4: for s = 1:S do |
| 5: Node(s) = s; |
| 6: for b = 1:B do |
| 7: Node(s, b) = b; |
| 8: for k = 1:K do |
| 9: Node(s, b, k) = k; |
| 10: end for |
| 11: end for |
| 12: end for |
3.3. Data Redundancy Elimination
3.3.1. Local Data Management
- Local K-CoverPicTree: The initial local K-CoverPicTree is produced with the application of Algorithm 2. This tree is used in the classification and clustering of the existing set of photos within the local storage of each sensor.
- Local Boolean K-CoverPicTree: Prior to the addition of photos to the local K-CoverPicTree, the added value of each photo is examined by each sensor with the application of the local Boolean K-CoverPicTree. Within this tree, the index of each node comprises the sub-region ID, BoI ID, and sector ID.
| Algorithm 3 Counting the added value of a photo |
| 1: Extract the metadata of the photo |
| 2: Extract the sequence of coverage features values (s, b, k) of the photo |
| 3: Added value = 0; |
| 4: for each coverage sequence (s, b, k) in the local Boolean K-CoverPicTree do |
| 5: if Bool_Node(s, b, k) = 0 then |
| 6: Added value = Added value + 1 |
| 7: end if |
| 8: end for |
- A newly produced photo with ID = a (photo a) has the following coverage values sequence: (s = 1, b = 1, k = 1), (s = 1, b = 2, k = 1), and (s = 1, b = 3, k = 1). In this regard, utilizing Algorithm 3, the added value of photo a is 4. As the added value of the photo is higher than 0, the photo is appended to the local K-CoverPicTree. This is followed by the update of the value of the local Boolean K-CoverPicTree nodes (1, 1, 1), (1, 2, 1), and (1, 3, 1) to 1.
- A newly produced photo with ID = b (photo b) has the following coverage values sequence: (s = 1, b = 1, k = 1), (s =1, b = 2, k = 1), and (s =1, b = 3, k = 1). Utilizing Algorithm 3, the added value becomes 0. In the next step, the sensor searches in its local K-CoverPicTree to ascertain whether there exists a photo sharing a similar sequence of coverage features. As photo b covers a similar sequence of coverage features (s, b, k) as photo a, it is regarded as redundant.
- A newly produced photo with ID = c (photo c) has the following coverage sequence: (s = 1, b = 4, k = 1), (s = 1, b = 1, k = 1), and (s = 1, b = 2, k = 1). Utilizing Algorithm 3, the added value is 1. Photo c is appended to the local K-CoverPicTree, and following the new addition, the local Boolean K-CoverPicTree node (1, 4, 1) is revised as 1.
- A newly produced photo with ID = d (photo d) has the following sequence of coverage features: (s = 1, b = 1, k = 1), (s = 1, b = 2, k = 1), (s = 1, b = 3, k = 1) and (s =1, b = 4, k = 1). For photo d, the added value is 0. However, a photo with similar sequence of coverage features does not exist, and thus, photo d is appended to the local K-CoverPicTree.
| Algorithm 4 Removing redundant photos |
| 1: Input: Local K-CoverPicTree |
| 2: for s = 1:S do |
| 3: Find all photos that cover sub-region s (Photos(s)) |
| 4: for k = 1:K do |
| 5: for b = 1:B do |
| 6: Find photos that cover (s, b) from the same sector view (Photos(s, b, k)) |
| 7: end for |
| 8: Find photos that cover all BoIs of sub-region s from sector k (Photos(s, 1:B, k) = Photos(s, k)) |
| 9: end for |
| 10: if (size of Photos(s, k) > 0) do |
| 11: Redundant Photos = Photos(s, b, k) − Photos(s, k) |
| 12: Remove each redundant photo from the corresponding parent Node(s, b, k) in Local K-CoverPicTree |
| 13: end if |
| 14: end for |
| Algorithm 5 Calculating the utility of the photos |
| 1: Input: Local K-CoverPicTree |
| 2: Total utility = 0 |
| 3: Call Algorithm 4 |
| 4: for s = 1:S do |
| 5: for k = 1:K do |
| 6: if ((size of Photos(s, k) > 0)) then |
| 7: Total utility = Total utility + Area of sub-region × θ |
| 8: end if |
| 9: end for |
| 10: end for |
- In accordance with Algorithm 3, using the Boolean K-CoverPicTree, the added value of each photo is computed.
- The photo with the highest added value is appended to the local K-CoverPicTree. Then, the Boolean K-CoverPicTree is revised based on the new inclusion as updates to the values of s, b, and k of the photos from values 0 to 1 in the Boolean K-CoverPicTree.
- In the situation where the highest added value is zero, the next step is to look for photos with a similar sequence of coverage values. Alternatively, the subset of the coverage values of other available photos within the local K-CoverPicTree can be searched. In this regard, if photos with a similar sequence of coverage values or the subset of the coverage values cannot be found, the photo should be appended to the local K-CoverPicTree.
- Then, utilizing Algorithm 3, the added value of the remaining photos in the device storage is calculated again. The previous steps are repeated until the set of photos is empty.
- Utilizing Algorithm 4, redundant photos are removed.
3.3.2. Communication between Two Nodes
- Sensor nodes a and b share the initial local K-CoverPicTree with each other without photos transmission.
- Each sensor node then searches for Photo IDs that share similar sub-regions IDs between its local K-CoverPicTree and the local K-CoverPicTree of the other sensor nodes. In this regard, the sensor node processes only the photos with common sub-region IDs between the two sensors. In other words, within the target area, only certain photos from certain sub-region IDs are processed, resulting in the reduction of the overhead of transmission of photos associated with all sub-regions within the network. Each sensor node finds the common sub-regions (S-common) between its local K-CoverPicTree and local K-CoverPicTree of other sensor nodes.
- Sensor node a applies Algorithm 6 to merge its local K-CoverPicTree with the local K-CoverPicTree of sensor node b according to the shared sub-regions (S-common). As shown in lines 5–7, all branches of common sensor nodes in the local K-CoverPicTree of sensor node b are merged by sensor node a to its local K-CoverPicTree, resulting in a new tree called New Combined Tree(a). As shown in line 9, sensor node a identifies the newly added photos through the identification of the difference between the New Combined Tree(a) and its local K-CoverPicTree. Sensor node a then requests the required photos from sensor node b and updates its local K-CoverPicTree as shown in line 10.
- Sensor node b applies similar steps to Algorithm 6 to merge its local K-CoverPicTree with the local K-CoverPicTree of sensor node a according to the shared sub-regions (S-common). Sensor node b merges all branches of common sensor nodes of the local K-CoverPicTree of sensor node a to its local K-CoverPicTree, resulting in the New Combined Tree(b). The newly appended photos are computed by sensor node b through the difference identification between the New Combined Tree(b) and its local K-CoverPicTree. Sensor node b then requests the required photos from sensor node a and updates its local K-CoverPicTree.
- Finally, sensor nodes a and b update their local Boolean K-CoverPicTree, after adding the requested photos from each other.
| Algorithm 6 Merging local K-CoverPicTrees on sensor a |
| 1: Tree(a) = Local K-CoverPicTree of sensor a |
| 2: Tree(b) = Local K-CoverPicTree of sensor b |
| 3: New Combined Tree(a) = [] |
| 4: New Combined Tree(a) = Tree(a) |
| 5: for S’ = 1:size(S-common) do |
| 6: Merge all child nodes of common Node(S’) of Tree(b) into the common Node(S’) of the New Combined Tree(a) |
| 7: end for |
| 8: Call Algorithm 4 to remove redundant photos in the New Combined Tree(a) |
| 9: Requested Photos from sensor b = Photos IDs that generated from subtracting Tree(a) from New Combined Tree(a) |
| 10: Local K-CoverPicTree of sensor a = New Combined Tree(a). |
4. Performance Evaluation
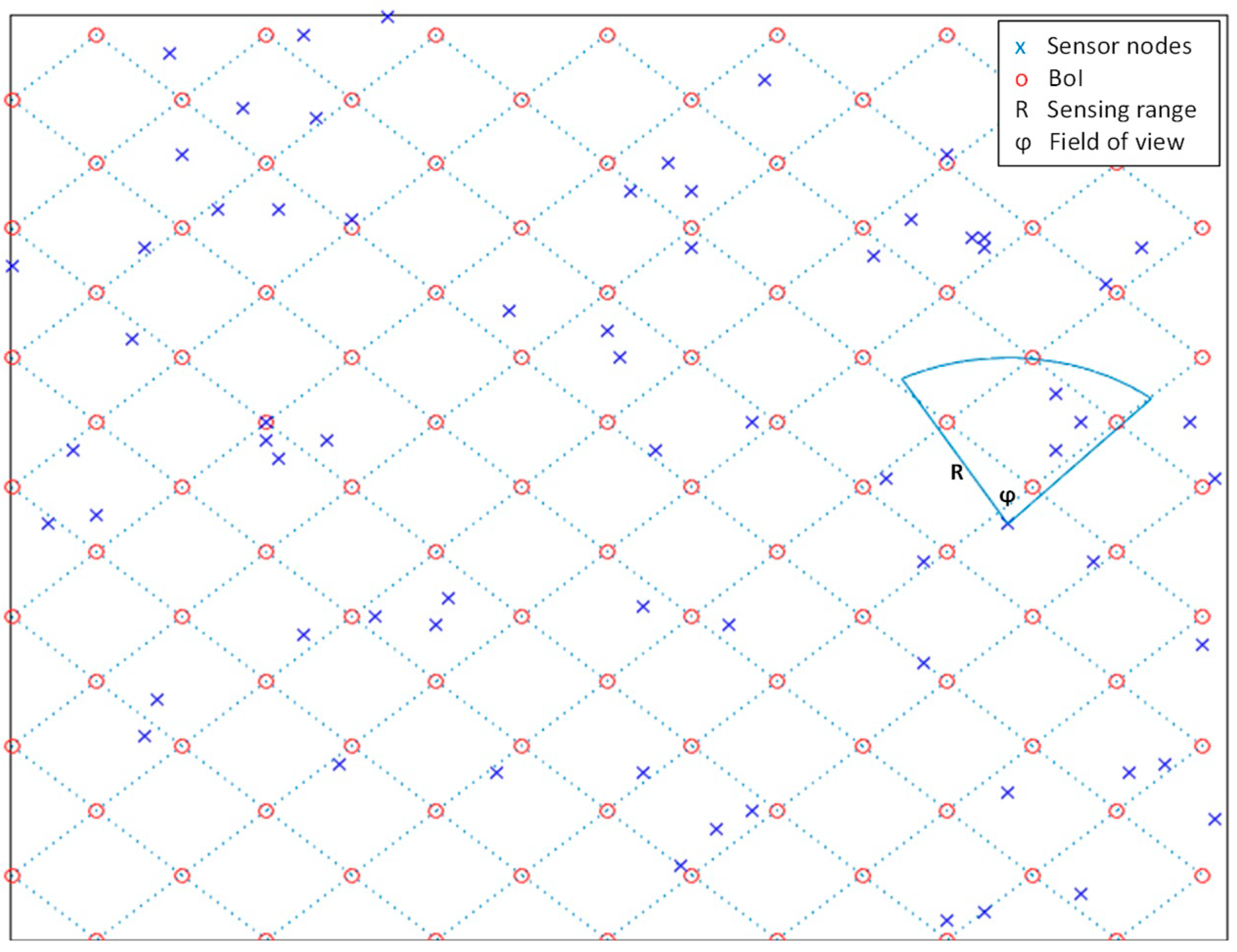
4.1. System Model and Experiment Setup
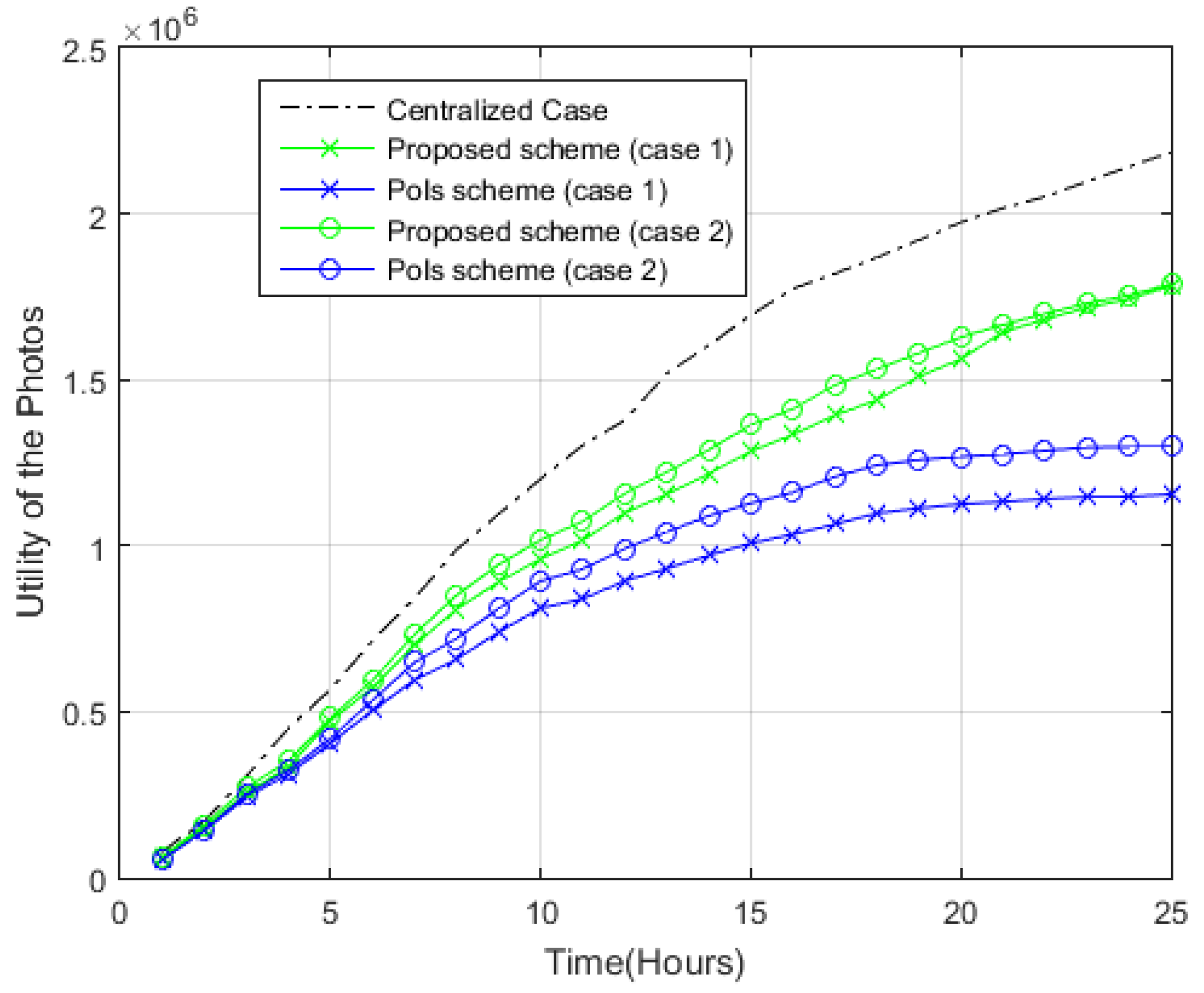
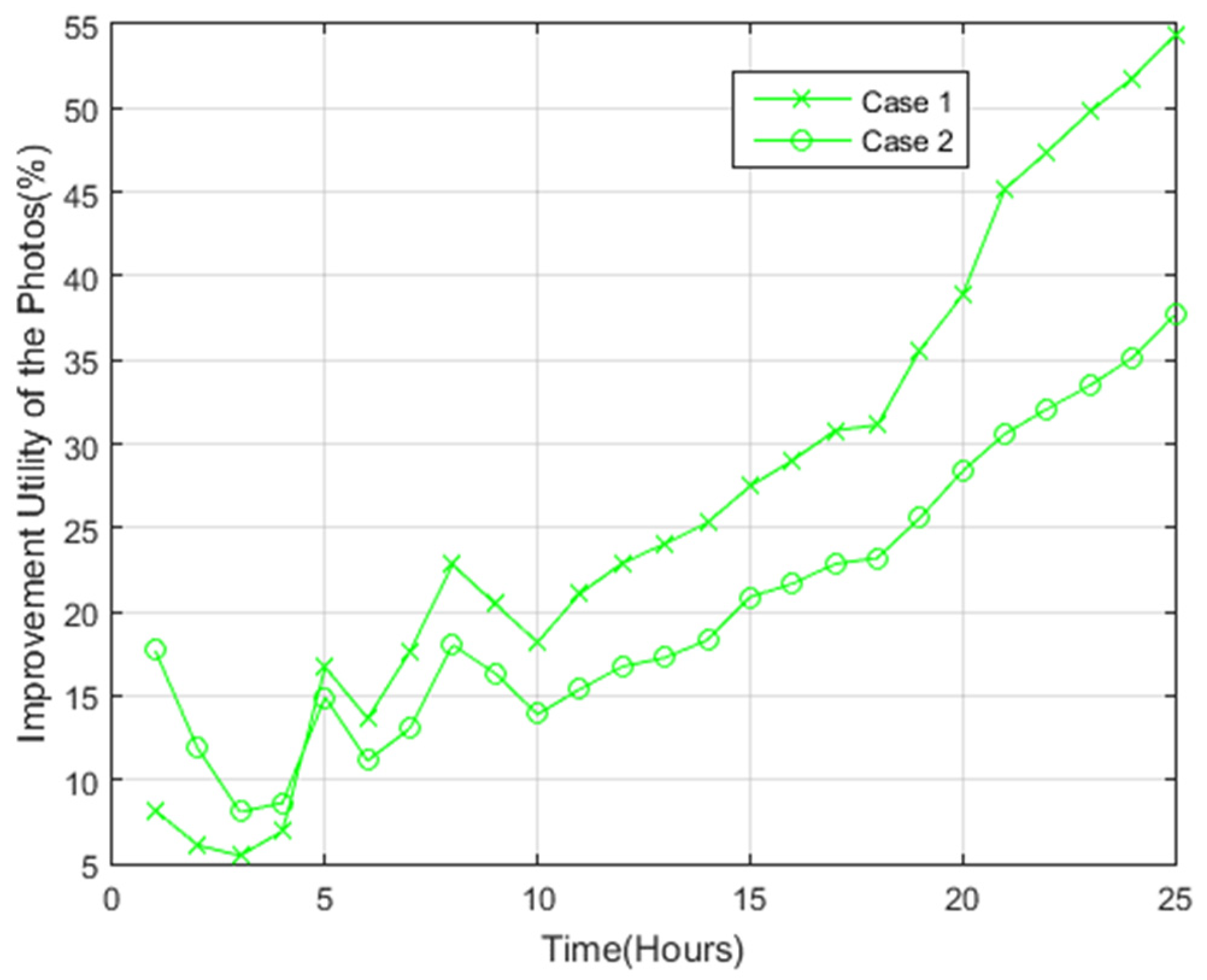
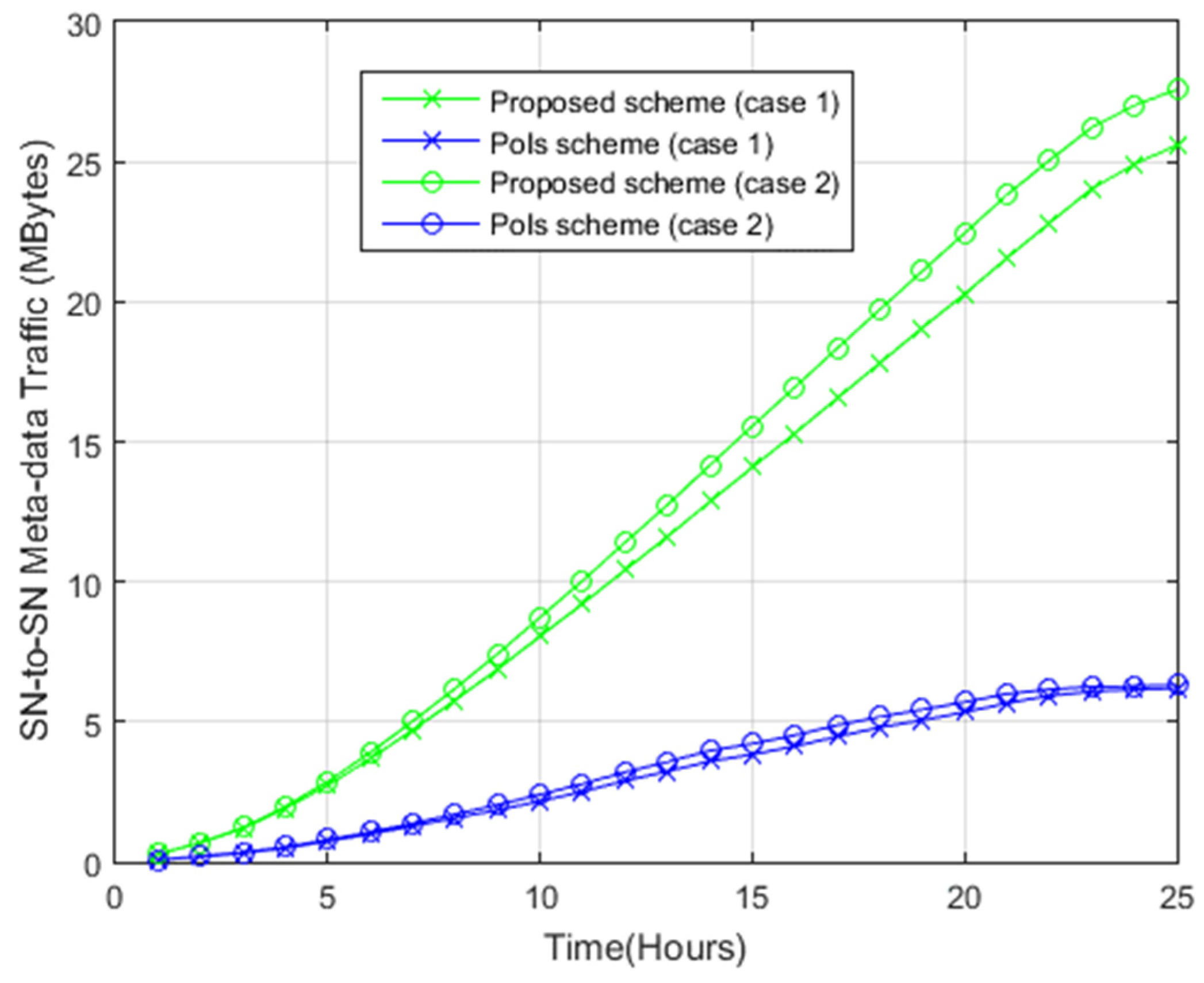
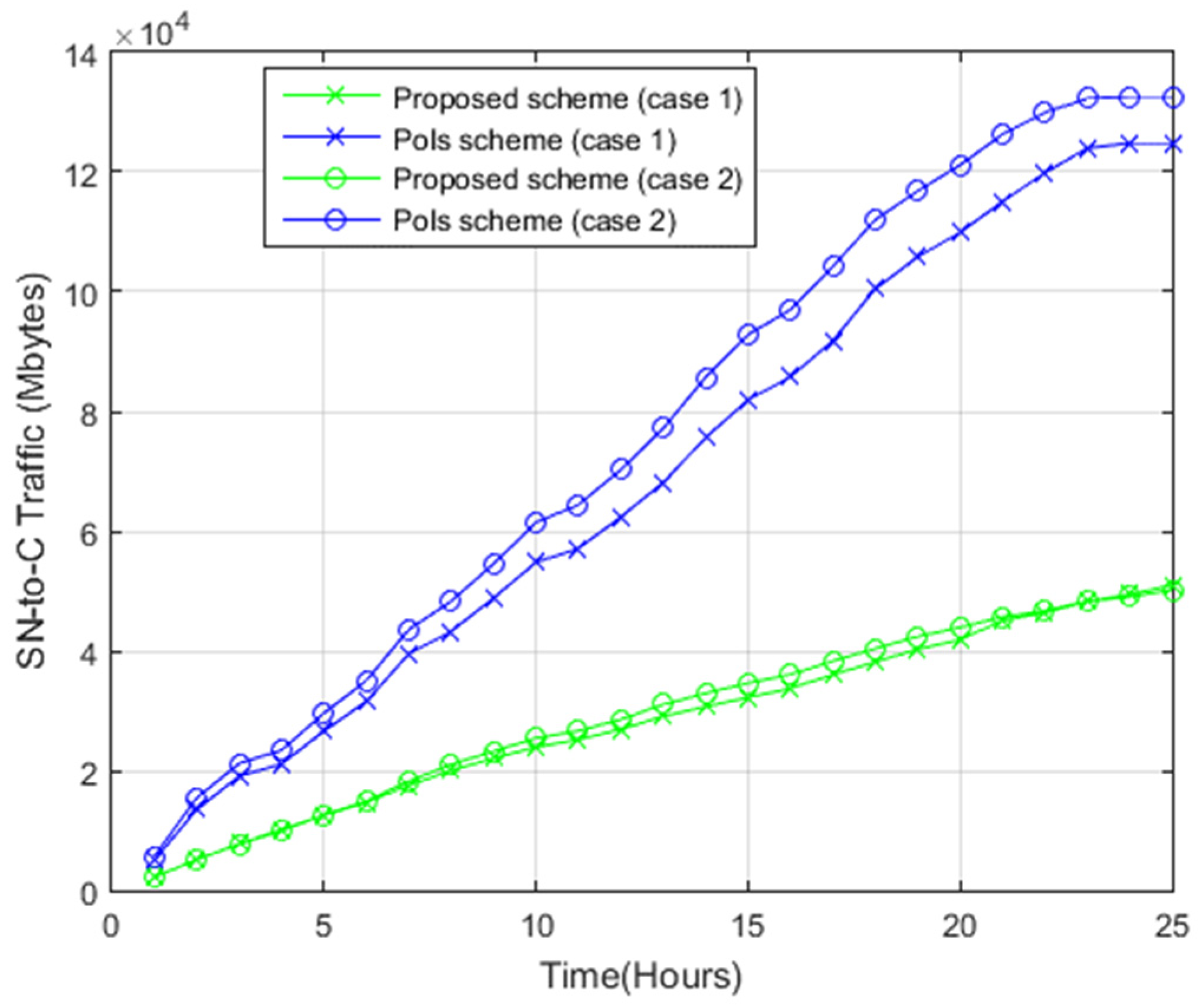
- Case 1: The coverage disk radius, r, is 5 m, while the sub-regions have an area of 50 m2 each. Considering a target area of 100 m × 100 m, the number of sub-regions is thus 200, resulting from (100 × 100)/50. Meanwhile, the number of BoIs is 800, resulting from 200 × 4. Nonetheless, owing to redundancy between adjacent sub-region BoIs, the actual number of points is 220.
- Case 2: The coverage disk radius, r, is 4 m, while the sub-regions have an area of 32 m2 each, resulting in 288 generated sub-regions. There are 1152 BoIs (288 × 4), but owing to redundancy between adjacent sub-region BoIs, there are 312 points.
4.2. Simulation Results
4.2.1. Utility of the Photos
4.2.2. Sensor Node-to-Sensor Node Photos Exchange
4.2.3. Sensor Node-to-Sensor Node Metadata Exchange
4.2.4. Sensor Node-to-Command Center Photos Transfer
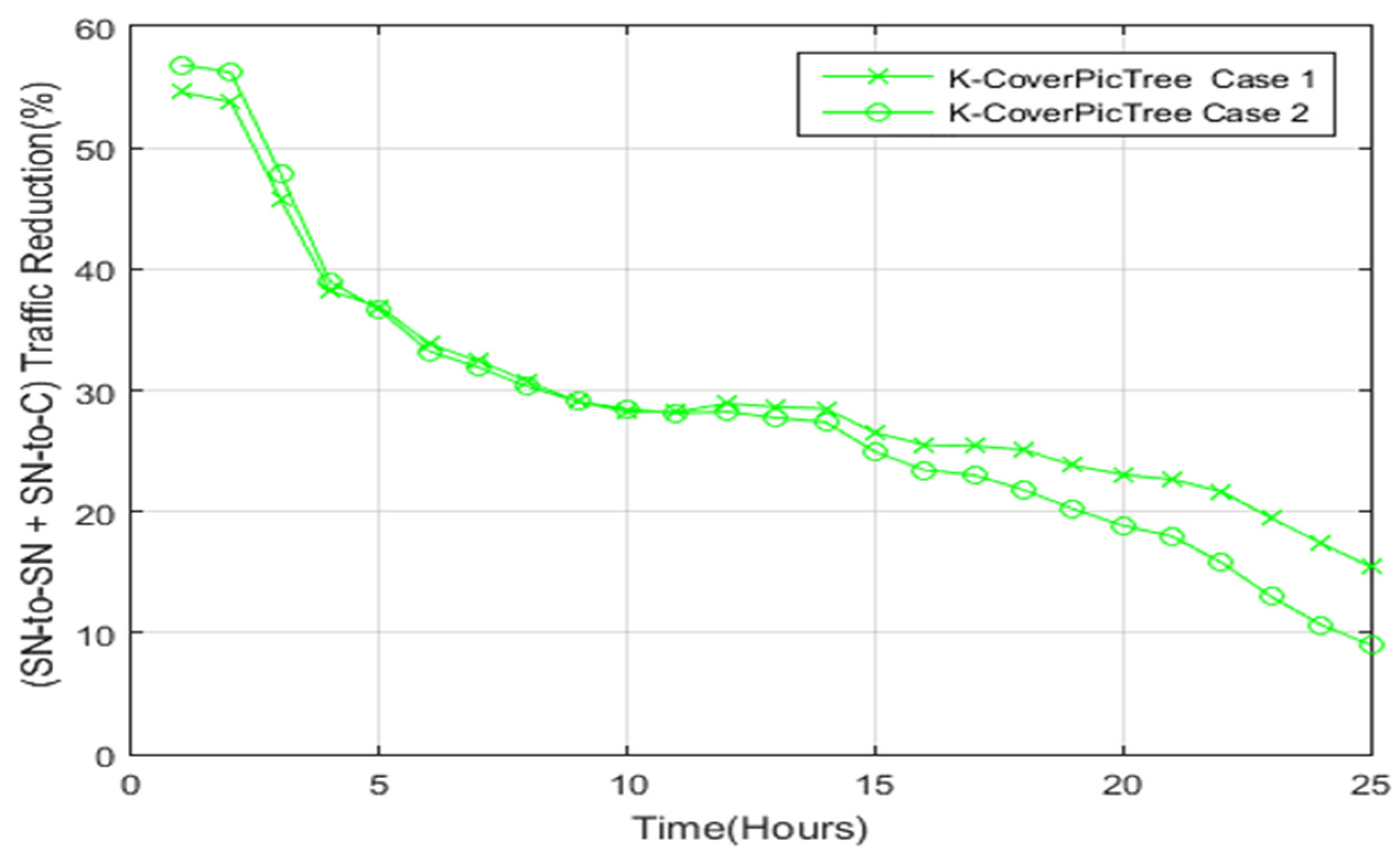
4.2.5. Total Data Transfer
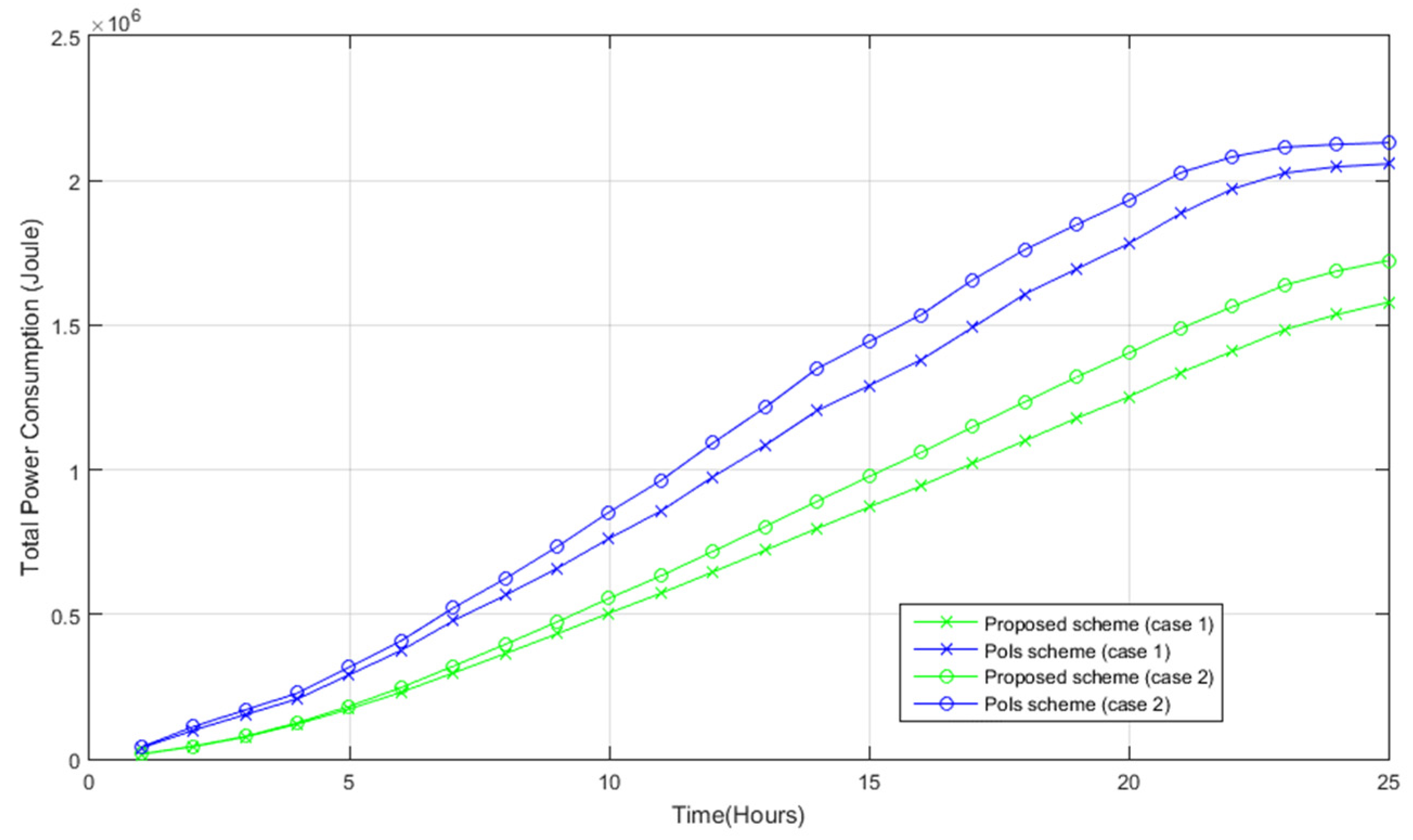
4.2.6. Power Consumption
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, B.; Han, Q.; Chen, H.; Shangguan, L.; Zhou, Z.; Yu, Z. The emergence of visual crowdsensing: Challenges and opportunities. IEEE Commun. Surv. Tutor. 2017, 19, 2526–2543. [Google Scholar] [CrossRef]
- Zhu, C.; Chiang, Y.H.; Xiao, Y.; Ji, Y. Flexsensing: A QoI and latency-aware task allocation scheme for vehicle-based visual crowdsourcing via deep Q-Network. IEEE Internet Things J. 2020, 8, 7625–7637. [Google Scholar] [CrossRef]
- Chen, H.; Cao, Y.; Guo, B.; Yu, Z. LuckyPhoto: Multi-facet photographing with mobile crowdsensing. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 29–32. [Google Scholar]
- Wu, Y.; Wang, Y.; Hu, W.; Cao, G. SmartPhoto: A resource-aware crowd-sourcing approach for image sensing with smartphones. IEEE Trans. Mob. Comput. 2016, 15, 1249–1263. [Google Scholar] [CrossRef]
- Guo, B.; Chen, H.; Yu, Z.; Xie, X.; Zhang, D. Picpick: A generic data selection framework for mobile crowd photography. Pers. Ubiquitous Comput. 2016, 20, 325–335. [Google Scholar] [CrossRef]
- Guo, B.; Chen, H.; Yu, Z.; Xie, X.; Huangfu, S.; Zhang, D. Fliermeet: A mobile crowdsensing system for cross-space public information reposting, tagging, and sharing. IEEE Trans. Mobile Comput. 2015, 14, 2020–2033. [Google Scholar] [CrossRef]
- Chen, H.; Guo, B.; Yu, Z.; Han, Q. CrowdTracking: Real-time vehicle tracking through mobile crowdsensing. IEEE Internet Things J. 2019, 6, 7570–7583. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M.; Kumar, M. 2D object recognition: A comparative analysis of SIFT, SURF and ORB feature descriptors. Multimed. Tools Appl. 2021, 80, 18839–18857. [Google Scholar] [CrossRef]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Yan, T.; Kumar, V.; Ganesan, D. Crowdsearch: Exploiting crowds for accurate real-time image search on mobile phones. In Proceedings of the ACM MobiSys, San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Wu, Y.; Wang, Y.; Hu, W.; Zhang, X.; Cao, G. Resource-aware photo crowdsourcing through disruption tolerant networks. In Proceedings of the 36th International Conference on Distributed Computing Systems (ICDCS), IEEE, Nara, Japan, 26–30 June 2016; pp. 374–383. [Google Scholar]
- Chen, H.; Guo, B.; Yu, Z. Coopersense: A cooperative and selective picture forwarding framework based on tree fusion. Int. J. Distrib. Sens. Netw. 2016, 12, 6968014. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Yi, W.; Cao, G. Photo crowdsourcing for area coverage in resource constrained environments. In Proceedings of the INFOCOM 2017-IEEE Conference on Computer Communications, IEEE, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Ma, H.; Zhao, D.; Yuan, P. Opportunities in mobile crowd sensing. IEEE Commun. Mag. 2014, 52, 29–35. [Google Scholar] [CrossRef]
- He, S.; Shin, D.H.; Zhang, J.; Chen, J.; Sun, Y. Full-view area coverage in camera sensor networks: Dimension reduction and near-optimal solutions. IEEE Trans. Veh. Technol. 2015, 65, 7448–7461. [Google Scholar] [CrossRef]
- Wu, P.F.; Xiao, F.; Sha, C.; Huang, H.P.; Wang, R.C.; Xiong, N.X. Node scheduling strategies for achieving full-view area coverage in camera sensor networks. Sensors 2017, 17, 1303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Capponi, A.; Fiandrino, C.; Kantarci, B.; Foschini, L.; Kliazovich, D.; Bouvry, P. A survey on mobile crowdsensing systems: Challenges, solutions, and opportunities. IEEE Commun. Surv. Tutor. 2019, 21, 2419–2465. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Guo, B.; Yu, Z.; Chen, L. CrowdPic: A multi-coverage picture collection framework for mobile crowd photographing. In Proceedings of the 2015 IEEE 12th International Conference on Ubiquitous Intelligence and Computing and 2015 IEEE 12th International Conference on Advanced and Trusted Computing, and 2015 IEEE 15th International Conference on Scalable Computing and Communications, Beijing, China, 10–14 August 2015; Volume 20, pp. 68–76. [Google Scholar]
- Yu, S.; Chen, X.; Wang, S.; Pu, L.; Wu, D. An edge computing-based photo crowdsourcing framework for real-time 3d reconstruction. IEEE Trans. Mob. Comput. 2020, 21, 421–432. [Google Scholar] [CrossRef]
- Loor, F.; Manriquez, M.; Gil-Costa, V.; Marin, M. Feasibility of P2P-STB based crowdsourcing to speed-up photo classification for natural disasters. Clust. Comput. 2022, 25, 279–302. [Google Scholar] [CrossRef]
- Datta, S.; Madria, S. Efficient photo crowdsourcing in delay-tolerant networks with evolving PoIs. In Proceedings of the IEEE International Conference on Mobile Data Management, Hong Kong, China, 10–13 June 2019; pp. 150–159. [Google Scholar]
- Datta, S.; Madria, S. Efficient photo crowdsourcing with evolving PoIs under delay-tolerant network environment. Pervasive Mob. Comput. 2020, 67, 101187. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, X.; Gan, X. Critical sensing range for mobile heterogeneous camera sensor networks. In Proceedings of the 33rd Annual IEEE International Conference on Computer Communications (INFOCOM’14), Toronto, ON, Canada, 27 April–2 May 2014; pp. 970–978. [Google Scholar]
- Lindgren, A.; Doria, A.; Schelen, O. Probabilistic routing in intermittently connected networks. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2003, 7, 19–20. [Google Scholar] [CrossRef]
- Leguay, J.; Lindgren, A.; Scott, J.; Friedman, T.; Crowcroft, J. Opportunistic content distribution in an urban setting. In Proceedings of the ACM SIGCOMM Workshop on Challenged Networks, Pisa, Italy, 11–15 September 2006. [Google Scholar]
- Rabiner Heinzelman, W.; Chandrakasan, A.; Balakrishnan, H. Energy efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000. 10p. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mowafi, M.; Awad, F.; Al-Quran, F. Distributed Visual Crowdsensing Framework for Area Coverage in Resource Constrained Environments. Sensors 2022, 22, 5467. https://doi.org/10.3390/s22155467
Mowafi M, Awad F, Al-Quran F. Distributed Visual Crowdsensing Framework for Area Coverage in Resource Constrained Environments. Sensors. 2022; 22(15):5467. https://doi.org/10.3390/s22155467
Chicago/Turabian StyleMowafi, Moad, Fahed Awad, and Fida’a Al-Quran. 2022. "Distributed Visual Crowdsensing Framework for Area Coverage in Resource Constrained Environments" Sensors 22, no. 15: 5467. https://doi.org/10.3390/s22155467
APA StyleMowafi, M., Awad, F., & Al-Quran, F. (2022). Distributed Visual Crowdsensing Framework for Area Coverage in Resource Constrained Environments. Sensors, 22(15), 5467. https://doi.org/10.3390/s22155467