1. Introduction
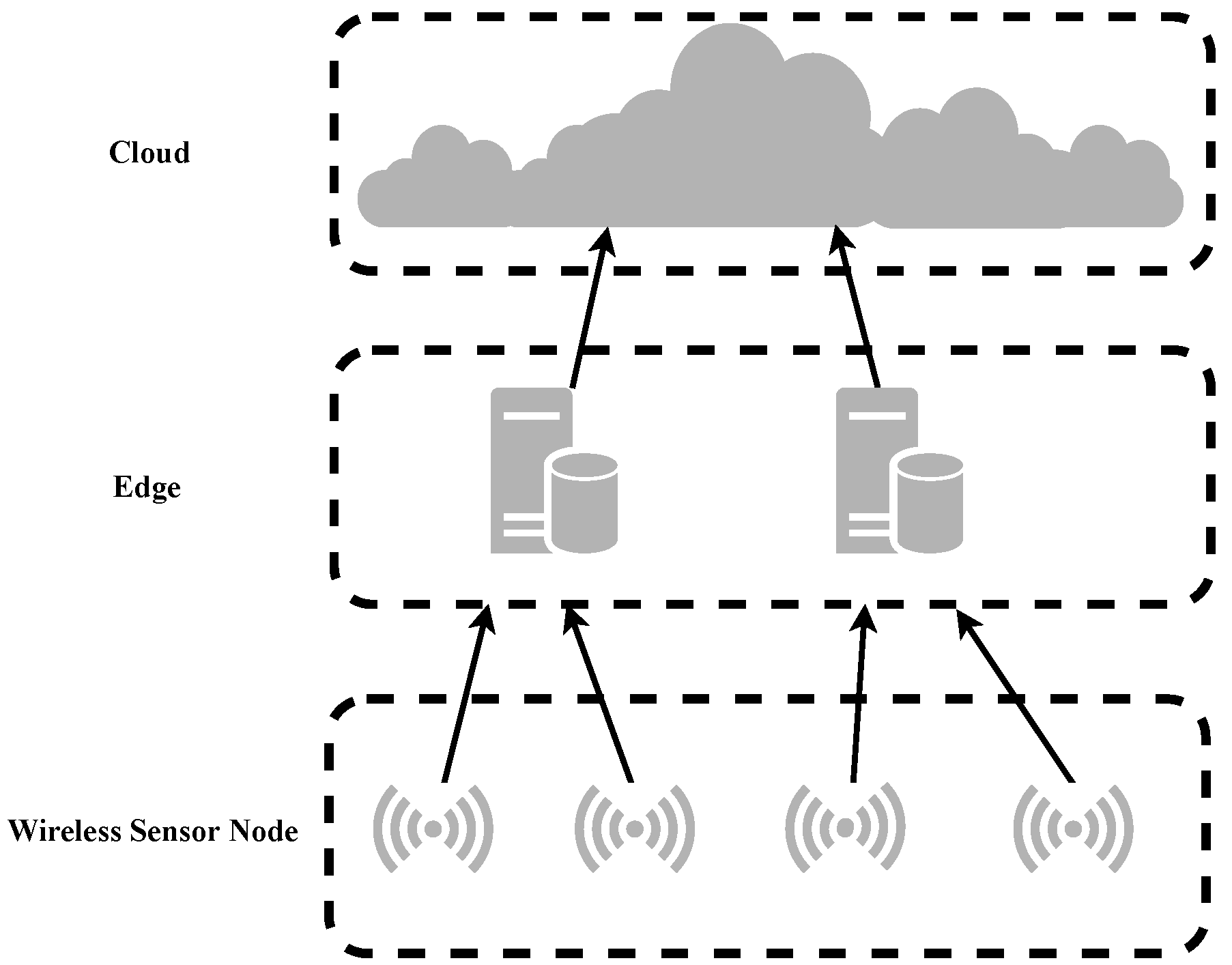
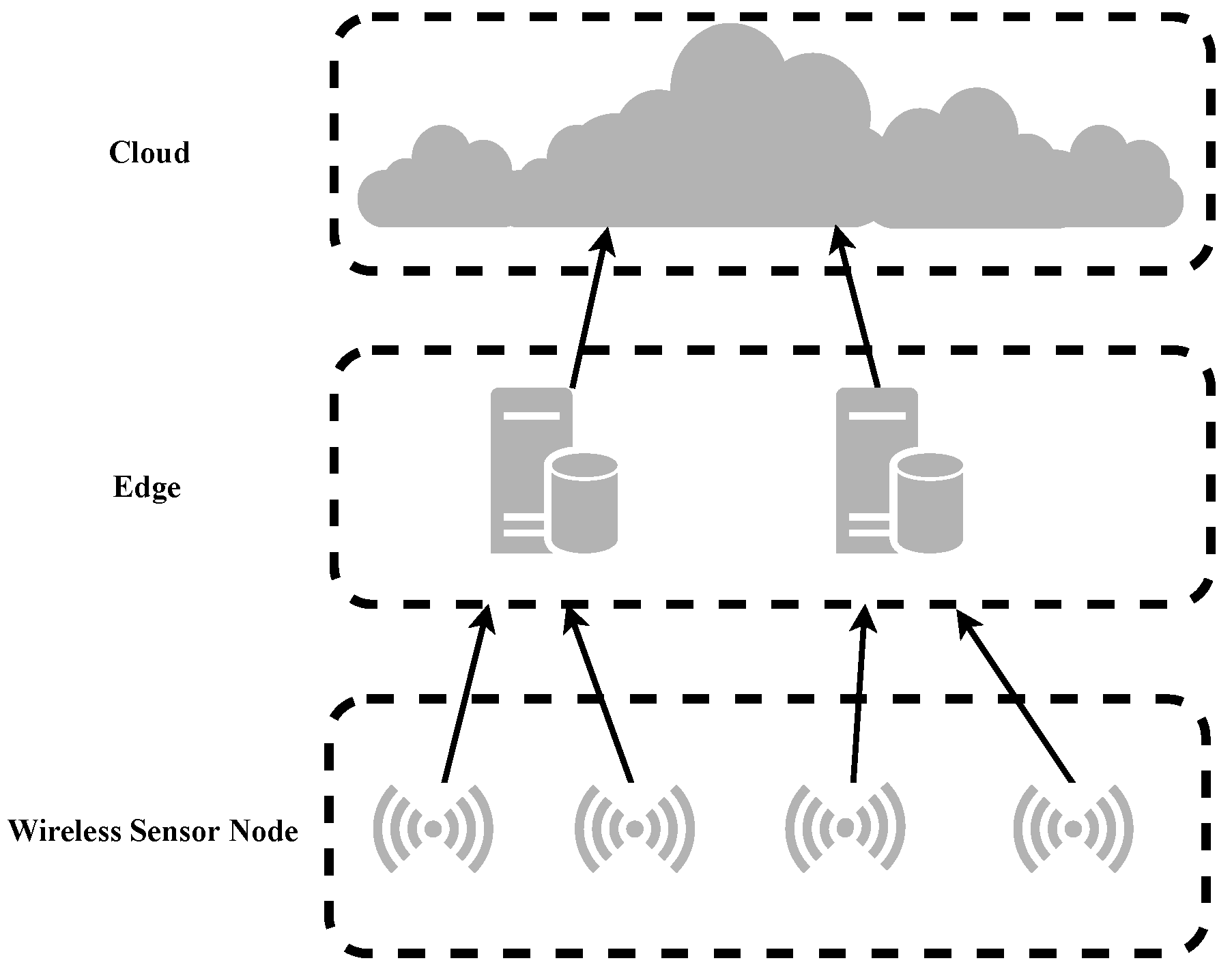
As devices become more and more interconnected, sensor nodes will collect massive amounts of data, which not only have a lot of redundancy but also occupy massive communication bandwidth resources during the transmission process. Compressing data in advance on the edge server close to the data source can not only improve the efficiency of data transmission but also enable more flexible data processing in the cloud service center [
1].
Deep learning has achieved good results in the field of data compression. Especially in the case of large amounts of data, it is better than traditional machine learning methods. Previous literature has described the shortcomings of machine learning in the field of neural network data compression [
2]. In one such example, recurrent neural networks were used for data compression [
3]. Although the compression rate was improved and the compression time was reduced, the quality of data recovery was reduced. Jalilian et al. [
4] thoroughly studied the compression performance of deep convolutional neural networks (CNN) in iris image compression for the first time and proved that this technology is superior to all other related compression technologies. The Convolutional Auto-Encoder Network (CAEN) is a kind of deep neural network that learns without supervision and encodes data effectively. Liu et al. [
5] proposed a simple and efficient CAEN structure for data compression in wireless sensor networks (WSN). In Lee et al. [
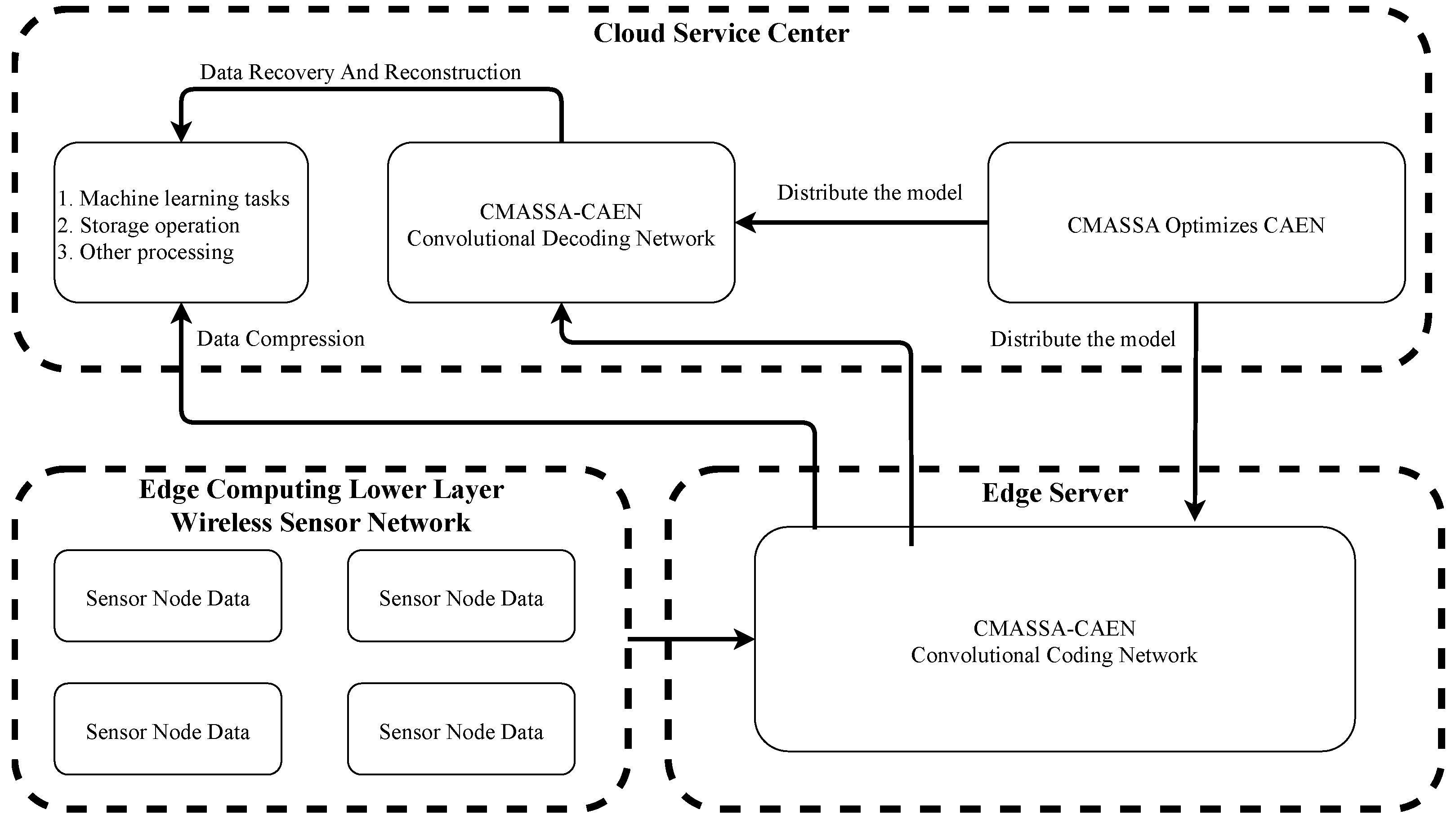
6], a CAEN compression model based on frequency selection was proposed, which improved reconstruction quality while maintaining the compression ratio (CR). In an edge server, CAEN is used to encode and compress the data and send it to the cloud service center, which can be directly used for machine learning tasks, or the convolution decoder of CAEN is used to reconstruct the data in the cloud service center [
7].
The hyperparameters of the network have a great impact on the quality of the final model. The setting of traditional hyperparameters usually requires a lot of manpower to tune, and it is difficult to find the optimal solution. In recent years, many researchers have been looking for suitable methods to construct optimal network hyperparameters to improve model performance. Ezzat et al. [
8], using a gravitational search algorithm to determine the optimal hyperparameters of the DenseNet121 architecture, achieved high accuracy in diagnosing COVID-19 from chest X-ray images. Roselyn et al. [
9] used particle swarm optimization (PSO) to optimize feature selection to improve the classification performance of the classifier. Liu et al. [
10] proposed a learning algorithm based on an evolutionary membrane algorithm to optimize the neural structure and network parameters of a liquid state machine (LSM). Guo et al. [
11] proposed a distributed particle swarm optimization (DPSO) method for optimizing hyperparameters to find high-performance convolutional neural networks but only compared this with a particle swarm algorithm, not with other algorithms. Tuba et al. [
12] used the bare-bones fireworks algorithm to optimize the hyperparameters of the convolutional neural network and achieved good classification results in multiple network structures, proving the feasibility of the evolutionary algorithm to optimize a deep neural network, but the characteristics of the datasets used are obvious, and the practical application is not fully considered.
The Sparrow Search Algorithm (SSA) [
13] is a swarm intelligence optimization algorithm proposed in recent years which has been widely used in many fields. Compared with traditional algorithms, the sparrow algorithm is simple in principle, easy to implement, and has strong optimization ability. However, the sparrow algorithm still has some limitations in aspects such as population initialization and location update strategy, resulting in the inconsistency of global search ability and local optimization ability and a weak ability to jump out of local optima. Wu et al. [
14] proposed an improved Sparrow Search Algorithm (ISSA) to optimize some parameters in a Fast Random Configuration Network (FSCN) to make it have better classification performance. Liu et al. [
15] proposed an improved SSA called CASSA to solve the UAV route planning problem. Nguyen et al. [
16] proposed a new and improved enhanced SSA (ESSA) for optimal operation planning of power microgrids. Although these improved methods have improved the performance of the SSA to a certain extent, further research is needed to enhance the global and local search capabilities of the algorithm, improve the algorithm convergence speed, and help the algorithm escape from local optima.
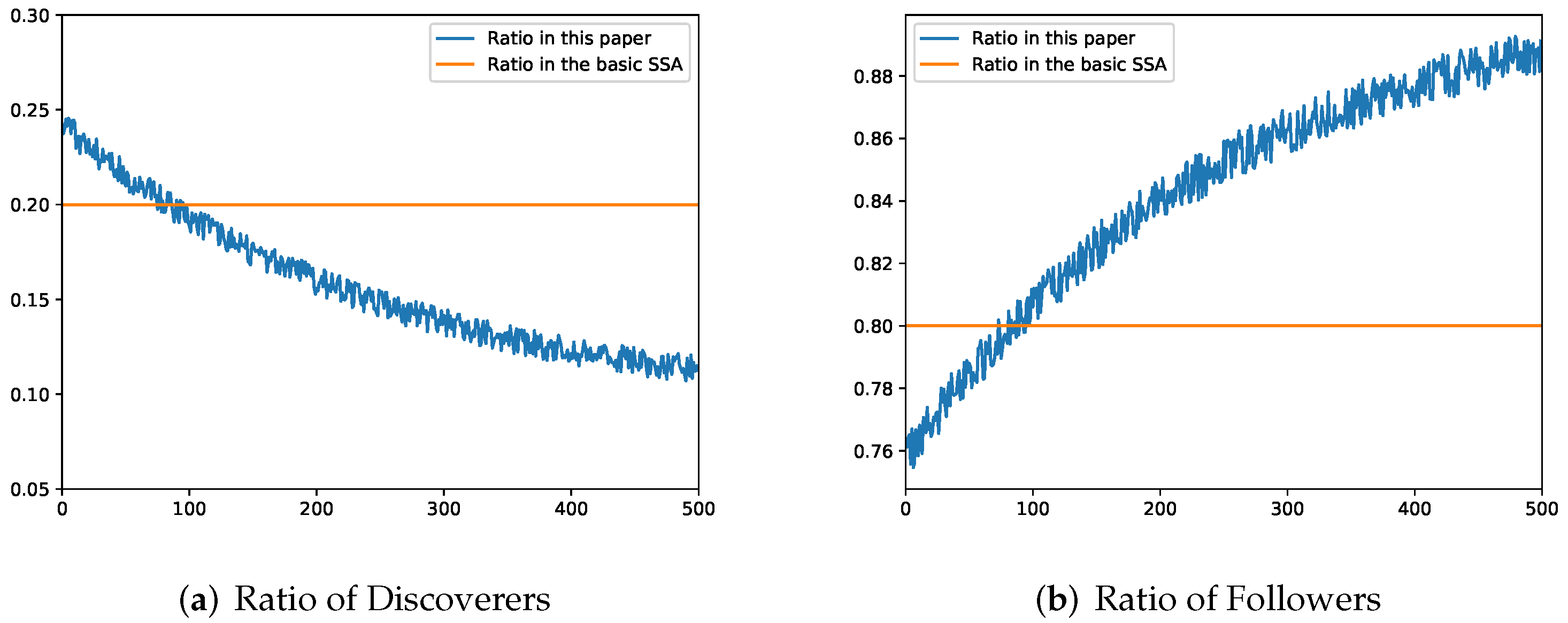
Based on the above research, this paper proposes a chaotic mutation adaptive sparrow search algorithm (CMASSA), which uses the improved Circle Map to initialize the individual sparrow population to enhance the diversity of the population. Sine and cosine operators are introduced into the alerters equation to improve searchability. In the sparrow search algorithm, the ratio of discoverers and followers is generally fixed, which leads to the inconsistency between global search ability and local optimization ability. An adaptive population adjustment strategy is proposed to balance the global search ability and local optimization ability of CMASSA; In the field of compression, a new fitness function is proposed by combining the CMASSA with CAEN, and the hyperparameters are encoded with real numbers. Finally, the optimal CAEN structure is obtained under the premise of ensuring a certain data compression ratio.
The contributions of this paper are:
- 1.
A chaotic mutation adaptive sparrow search algorithm (CMASSA) is proposed.
- 2.
A new fitness function is proposed to apply CMASSA to CAEN data compression under edge computing architecture.
- 3.
The simulation results show that the CMASSA outperforms other algorithms of the same type when optimizing 10 benchmark functions. In the data compression problem, the performance of CMASSA on MWD far outperforms other optimization algorithms.
The rest of the paper is structured as follows.
Section 2 summarizes related techniques.
Section 3 describes the relevant details of CMASSA.
Section 4 presents the specific details of CMASSA optimizing CAEN in the context of edge computing.
Section 5 discusses the experimental results.
Section 6 concludes this paper.
6. Conclusions
This paper proposes a novel chaotic mutation adaptive sparrow search algorithm (CMASSA), which is an excellent improvement on the sparrow search algorithm (SSA). The paper applies CMASSA to data compression. The idea is to build a new fitness function, and use the CMASSA to optimize the CAEN network hyperparameters in the cloud service center. The optimal network model obtained by training is sent to the edge server to compress the edge data. First, aiming at the problem of insufficient population diversity in the later stage of SSA, an improved Circle Map is introduced to enhance the diversity of the initial population; secondly, the sine and cosine mutation operator is introduced into the sparrow alerters equation to enhance the local development ability. To avoid falling into a local optimum early, an adaptive population adjustment strategy is proposed to adjust the ratio of discoverers and followers to balance the global search ability and local optimization ability of the sparrow search algorithm. Finally, the test results on multiple benchmark functions are excellent. Through comparative experiments, it is demonstrated that the data compressed by CMASSA-CAEN, with the compression ratio as high as 1/32, the accuracy of the classification task is significantly stronger than other optimization algorithms of the same type, and when the data is restored and reconstructed, the data reconstruction degree is as high as 99.41%, far exceeding other algorithms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}