
InjectMeAI—Software Module of an Autonomous Injection Humanoid




Abstract
:1. Introduction
- Obtain a 3D orientation of the human relative to the robot.
- Identify human pose from 2D image.
- Move the robot next to the seated patient.
- Find injection position on bare shoulder.
- Raise the hand of the robot to the required height.
2. Review of Related Work
2.1. Robots in Healthcare Assistance

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2.2. Two-Dimensional Human Pose Estimation
2.3. Deductions
2.3.1. Hardware
2.3.2. Accuracy
2.3.3. Adaptability
2.3.4. Speed
3. Design and Development
3.1. Bare Shoulder Verification
- The patient wears a short sleeve shirt that does not cover the whole upper arm but ends above the elbow.
- The patient does not wear a tattoo of the same color as the shirt and skin.
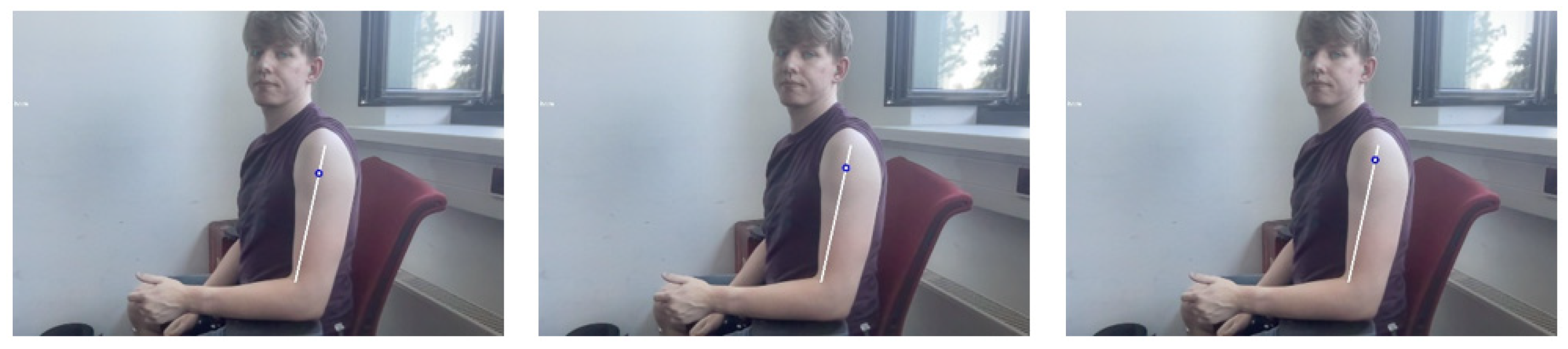
3.2. Injection Point Estimation
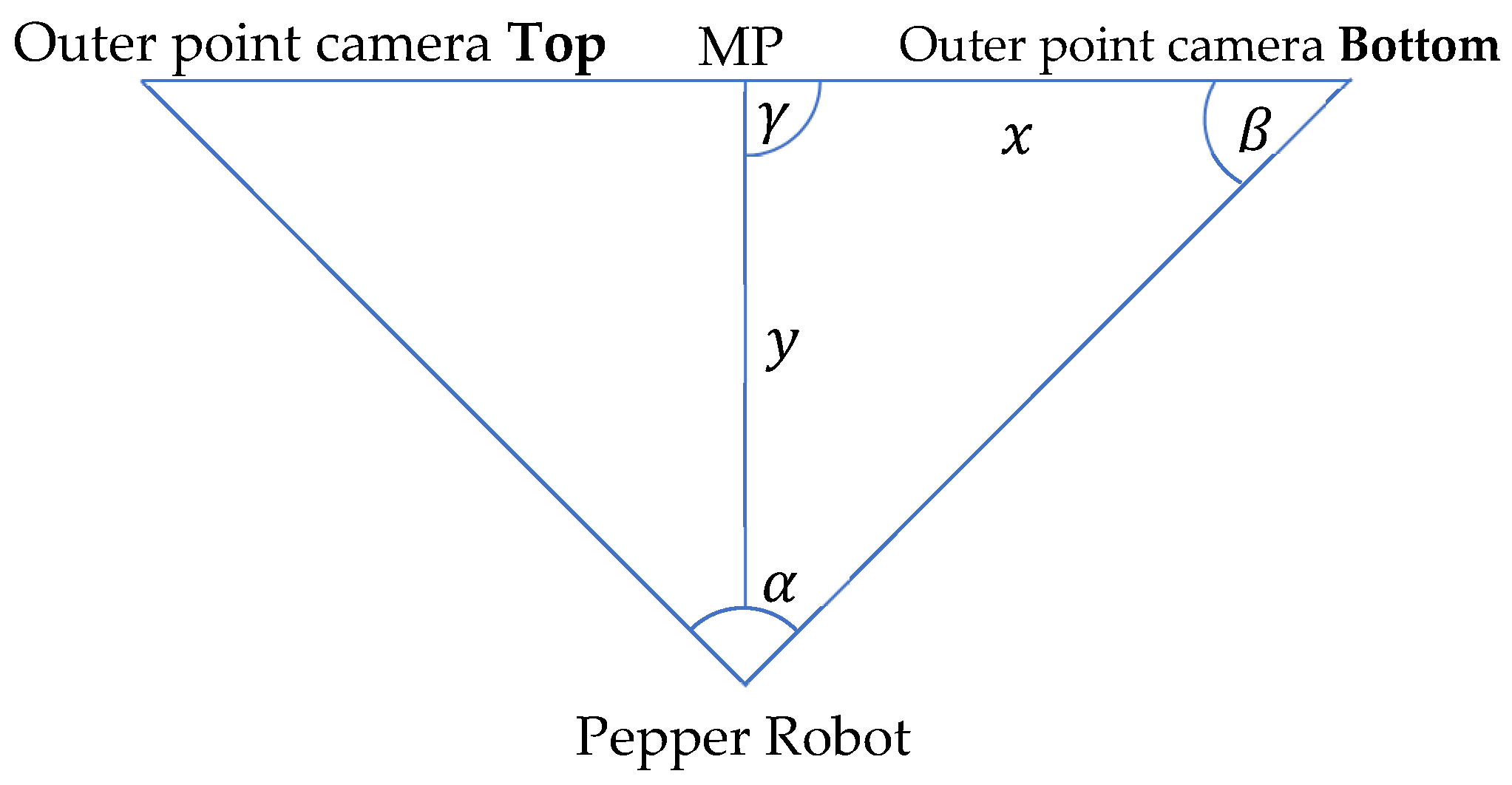
3.3. Hand to Injection Point Mapping
- The distance from robot to patient is predetermined.
- The robot has a direct line view of the patient.
- The injection point is below the head of the patient.
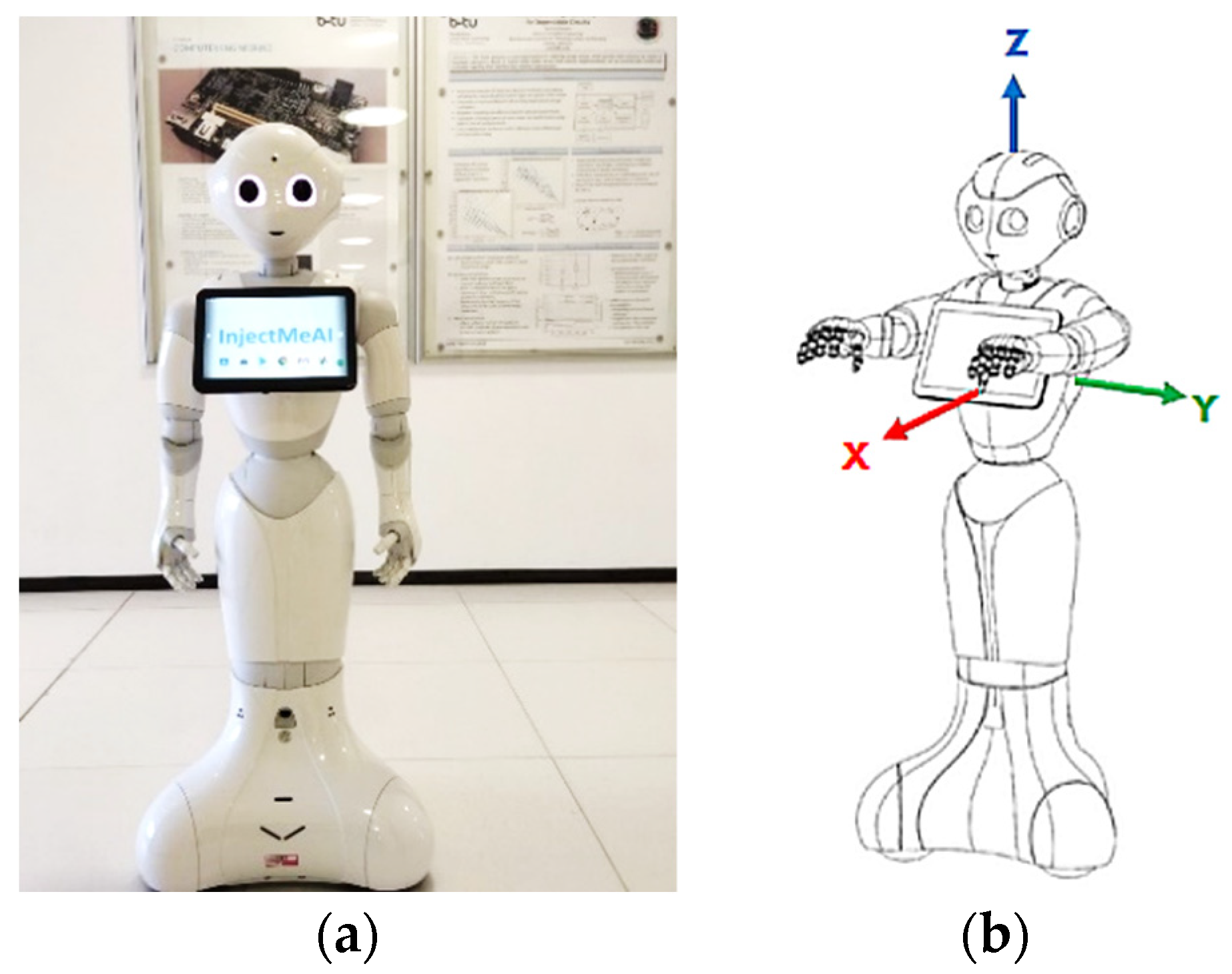
3.4. Joint Angle Estimation
4. Implementation and Evaluation
4.1. Implementation Concept
4.2. Closest Human (Patient) Detection
4.3. Pose Classification
4.4. Training Data
4.5. Bare Shoulder Classification and Injection Point Spotting
4.6. Joint Movement Actualization
4.7. Python Wrapper
4.8. Autonomous Behavior
4.9. Findings and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahmood, S.; Ampadu, K.O.; Antonopoulos, K.; Panagiotou, C.; Mendez, S.A.P.; Podlubne, A.; Antonopoulos, C.; Keramidas, G.; Hübner, M.; Goehringer, D.; et al. Prospects of robots in assisted living environment. Electronics 2021, 10, 2062. [Google Scholar] [CrossRef]
- Deruelle, T.; Engeli, I. The COVID-19 crisis and the rise of the european centre for disease prevention and control (ECDC). West Eur. Politics 2021, 44, 1–25. [Google Scholar] [CrossRef]
- SERVICE ROBOTS Record: Sales Worldwide Up 32%-International Federation of Robotics (ifr.org). Available online: https://ifr.org/ifr-press-releases/news/service-robot-record-sales-up-32 (accessed on 1 June 2021).
- Aymerich-Franch, L.; Ferrer, I. The implementation of social robots during the COVID-19 pandemic. arXiv 2020, arXiv:2007.03941. [Google Scholar]
- Wiederhold, B.K. The ascent of social robots. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 289–290. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Ma, Y.; Mushtaq, A.; Rajper, A.M.A.; Shehab, M.; Heybourne, A.; Song, W.; Ren, H.; Tse, Z.T.H. Applications of robotics, AI, and digital technologies during COVID-19: A review. Disaster Med. Public Health Prep. 2021, 1–11. [Google Scholar] [CrossRef]
- McHugh, M.D.; Aiken, L.H.; Sloane, D.M.; Windsor, C.; Douglas, C.; Yates, P. Effects of nurse-to-patient ratio legislation on nurse staffing and patient mortality, readmissions, and length of stay: A prospective study in a panel of hospitals. Lancet 2021, 397, 1905–1913. [Google Scholar] [CrossRef]
- Iris Völlnagel (SWR). “Pflegekräfte Hadern Mit Ihrem Job,“ April 2021. Available online: https://www.tagesschau.de/wirtschaft/pflege-arbeitsplatz-kuendigungen-101.html (accessed on 15 June 2021).
- Moustaka, E.; Constantinidis, T.C. Sources and effects of work-related stress in nursing. Health Sci. J. 2010, 4, 210. [Google Scholar]
- Chang, W.L.; Sabanovic, S. Interaction expands function: Social shaping of the therapeutic robot PARO in a nursing home. In Proceedings of the 2015 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Portland, OR, USA, 2–5 March 2015; pp. 343–350. [Google Scholar]
- Calo, C.J.; Hunt-Bull, N.; Lewis, L.; Metzler, T. Ethical implications of using the paro robot, with a focus on dementia patient care. In Proceedings of the Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]
- Huisman, C.; Kort, H. Two-year use of care robot Zora in Dutch nursing homes: An evaluation study. Healthcare 2019, 7, 31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mackenzie, D. Ultraviolet light fights new virus. Engineering 2020, 6, 851. [Google Scholar] [CrossRef] [PubMed]
- Balter, M.L.; Leipheimer, J.M.; Chen, A.I.; Shrirao, A.; Maguire, T.J.; Yarmush, M.L. Automated end-to-end blood testing at the point-of-care: Integration of robotic phlebotomy with downstream sample processing. Technology 2018, 6, 59–66. [Google Scholar] [CrossRef] [PubMed]
- Moss, M.; Good, V.S.; Gozal, D.; Kleinpell, R.; Sessler, C.N. An official critical care societies collaborative statement: Burnout syndrome in critical care health care professionals: A call for action. Am. J. Crit. Care 2016, 25, 368–376. [Google Scholar] [CrossRef] [PubMed]
- Da Vinci Education. Available online: https://www.intuitive.com/en-us/products-and-services/da-vinci/education (accessed on 27 July 2021).
- Ho, C.; Tsakonas, E.; Tran, K.; Cimon, K.; Severn, M.; Mierzwinski-Urban, M.; Corcos, J.; Pautler, S. Robot-Assisted Surgery Compared with Open Surgery and Laparoscopic Surgery: Clinical Effectiveness and Economic Analyses. 2011. Available online: https://europepmc.org/article/med/24175355 (accessed on 9 June 2022).
- Palep, J.H. Robotic assisted minimally invasive surgery. J. Minimal Access Surg. 2009, 5, 1. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Wu, W.; Yang, T.; Zhu, S.; Chen, C.; Liu, R.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. arXiv 2020, arXiv:2012.13392. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. BlazePose: On-device real-time body pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bulat, A.; Kossaifi, J.; Tzimiropoulos, G.; Pantic, M. Toward fast and accurate human pose estimation via soft-gated skip connections. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 8–15. [Google Scholar]
- Softbank. Pepper–Documentation–Aldebaran 2.5.11.14a. Available online: http://doc.aldebaran.com/2-5/home_pepper.html (accessed on 5 May 2021).
- Reed, R.G.; Cox, M.A.; Wrigley, T.; Mellado, B. A CPU benchmarking characterization of ARM based processors. Comput. Res. Model. 2015, 7, 581–586. [Google Scholar] [CrossRef] [Green Version]
- DGroos; Ramampiaro, H.; Ihlen, E.A. EfficientPose: Scalable single-person pose estimation. Appl. Intell. 2021, 51, 2518–2533. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Google. Mediapipe. Available online: https://github.com/google/mediapipe (accessed on 27 July 2021).
- SalinasJJ. BBpose. Available online: https://github.com/salinasJJ/BBpose (accessed on 27 July 2021).
- Elizabeth, H.W. The right site for IM injections. Am. J. Nurs. 1996, 96, 53. [Google Scholar]
- Doyle, G.R.; McCutcheon, J.A. Intramuscular Injections. In Clinical Procedures for Safer Patient Care, Chapter 7, Parental Medication Administration; BCCampus: Victoria, BC, Canada, 2015. [Google Scholar]
- DIN 33402-2:2005-12, Ergonomie–Körpermasße des Menschen ß Teil 2Ö Werte. Available online: https://doi.org/10.31030/9655264 (accessed on 10 June 2021).
- Softbank Robotics, QiSDK Tutorials. Available online: https://github.com/aldebaran/qisdk-tutorials (accessed on 5 August 2021).
- Softbank Robotics, Pepper QiSDK Design. Available online: https://developer.softbankrobotics.com/pepper-qisdk/design (accessed on 5 August 2021).
- Softbank Robotics Labs, Pepper Mask Detection. Available online: https://github.com/softbankrobotics-labs/pepper-mask-detection (accessed on 7 August 2021).
- Softbank Robotics, Pepper QiSDK Design. Available online: https://developer.softbankrobotics.com/pepper-qisdk/principles/mastering-focus-robot-lifecycle (accessed on 7 August 2021).
- Runblocking Documentation. Available online: https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html (accessed on 10 August 2021).
- Kroeger, E.; Humbert, R. Pepperextras, Softbank Robotics Labs. Available online: https://github.com/softbankroboitcs-labs/pepper-extras (accessed on 10 August 2021).
- Boulay, B. Human Posture Dataset. Available online: http://bbpostures.free.fr/Human%20Posture%20Datasets2.htm (accessed on 1 August 2021).
- Google, Pose Classification. Available online: https://mediapipe.page.link/pose_classification_extended (accessed on 1 August 2021).
- Softbank, GoTo, API Level 1. Available online: https://developer.softbankrobotics.com/pepper-isdk/api/motion/reference/goto (accessed on 10 August 2021).
- Softbank, Comparison of Pepper’s OS Versions. Available online: https://developer.softbankrobotics.com/blog/comparison-peppers-os-versions (accessed on 15 July 2021).
- Softbank, Pepper SDK for Android. Available online: https://developer.softbankrobotics.com/pepper-qisdk (accessed on 15 July 2021).
- Jeroen Van Erp, sshj. Available online: https://github.com/hierynomus/sshj (accessed on 20 August 2021).
- Dominic, D. Get Pepper’s IP Running QiSDK from Android APP on Pepper, NAOqi 2.9. Available online: https://stackoverflow.com/a/63806715 (accessed on 13 August 2021).
- McGlaun, S. Autonomous Robot Performs Its First Intramuscular Injection without Needles. Available online: https://www.slashgear.com/autonomous-robot-performs-its-first-intramuscular-injection-without-needles-08698592 (accessed on 11 July 2022).









| Pose Estimation Algorithm | Single Instance Run (s) |
|---|---|
| BlazePose | 0.0086 |
| Soft gated skip connections | 12.375 |
| OpenPose | 200.45 |
| RElbowYaw (o) | RElbowRoll min (o) | RElbowRoll Max (o) |
|---|---|---|
| −119.5 | 0.5 | 83.0 |
| −99.5 | 0.5 | 89.5 |
| 0 | 0.5 | 89.5 |
| 60.0 | 0.5 | 78.0 |
| 119.5 | 0.5 | 78.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ampadu, K.O.; Rokohl, F.; Mahmood, S.; Reichenbach, M.; Huebner, M. InjectMeAI—Software Module of an Autonomous Injection Humanoid. Sensors 2022, 22, 5315. https://doi.org/10.3390/s22145315
Ampadu KO, Rokohl F, Mahmood S, Reichenbach M, Huebner M. InjectMeAI—Software Module of an Autonomous Injection Humanoid. Sensors. 2022; 22(14):5315. https://doi.org/10.3390/s22145315
Chicago/Turabian StyleAmpadu, Kwame Owusu, Florian Rokohl, Safdar Mahmood, Marc Reichenbach, and Michael Huebner. 2022. "InjectMeAI—Software Module of an Autonomous Injection Humanoid" Sensors 22, no. 14: 5315. https://doi.org/10.3390/s22145315
APA StyleAmpadu, K. O., Rokohl, F., Mahmood, S., Reichenbach, M., & Huebner, M. (2022). InjectMeAI—Software Module of an Autonomous Injection Humanoid. Sensors, 22(14), 5315. https://doi.org/10.3390/s22145315