
Improved Dual Attention for Anchor-Free Object Detection

Abstract
:1. Introduction
- We introduce the adaptive weight assignment based on dual attention mechanism into anchor-free object detector. It can obtain the adaptive distribution of classification confidence scores automatically.
- We improve the dual attention mechanism designed for other tasks and apply it to object detection. The improved dual attention mechanism can prevent the confusion between spatial and channel attention, and is both efficient and effective.
- The experimental results on public MS-COCO dataset demonstrate that the proposed algorithm can achieve the state-of-the-art performance comparing with other anchor-free object detectors.
2. Related Work
3. The Proposed Approach
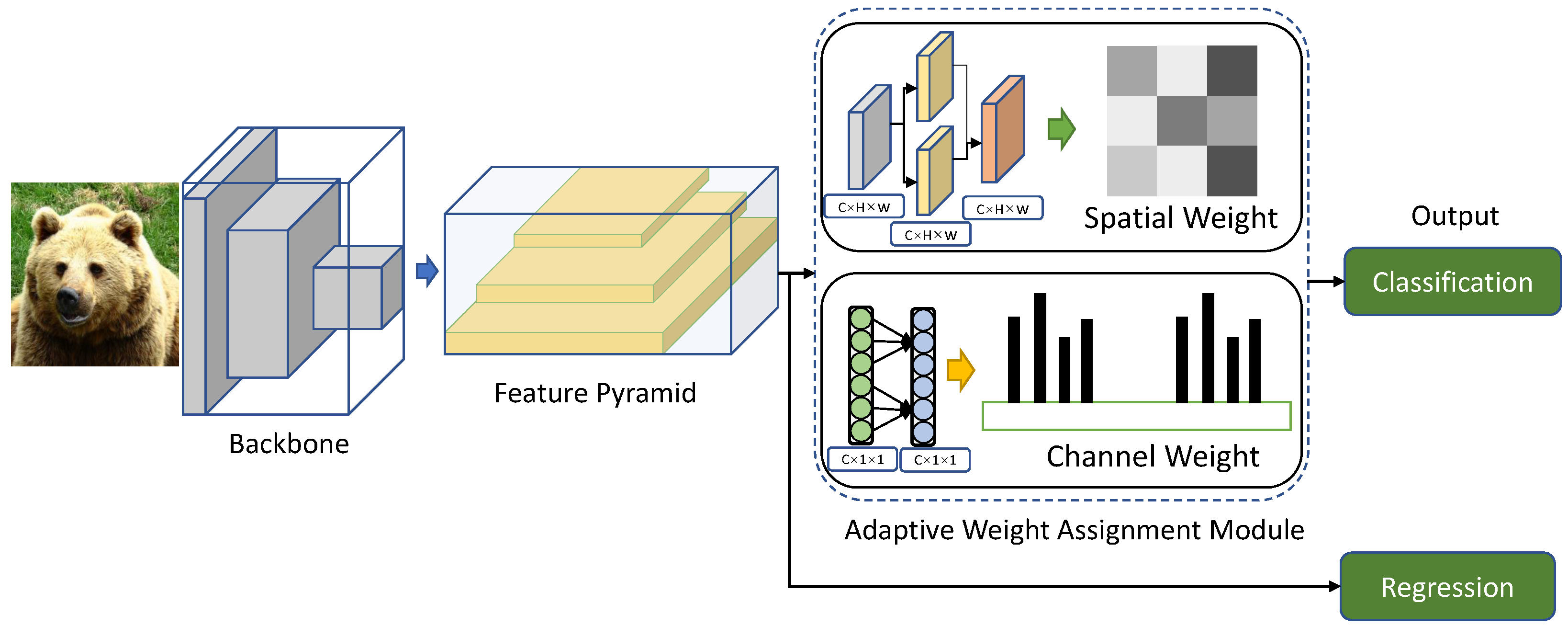
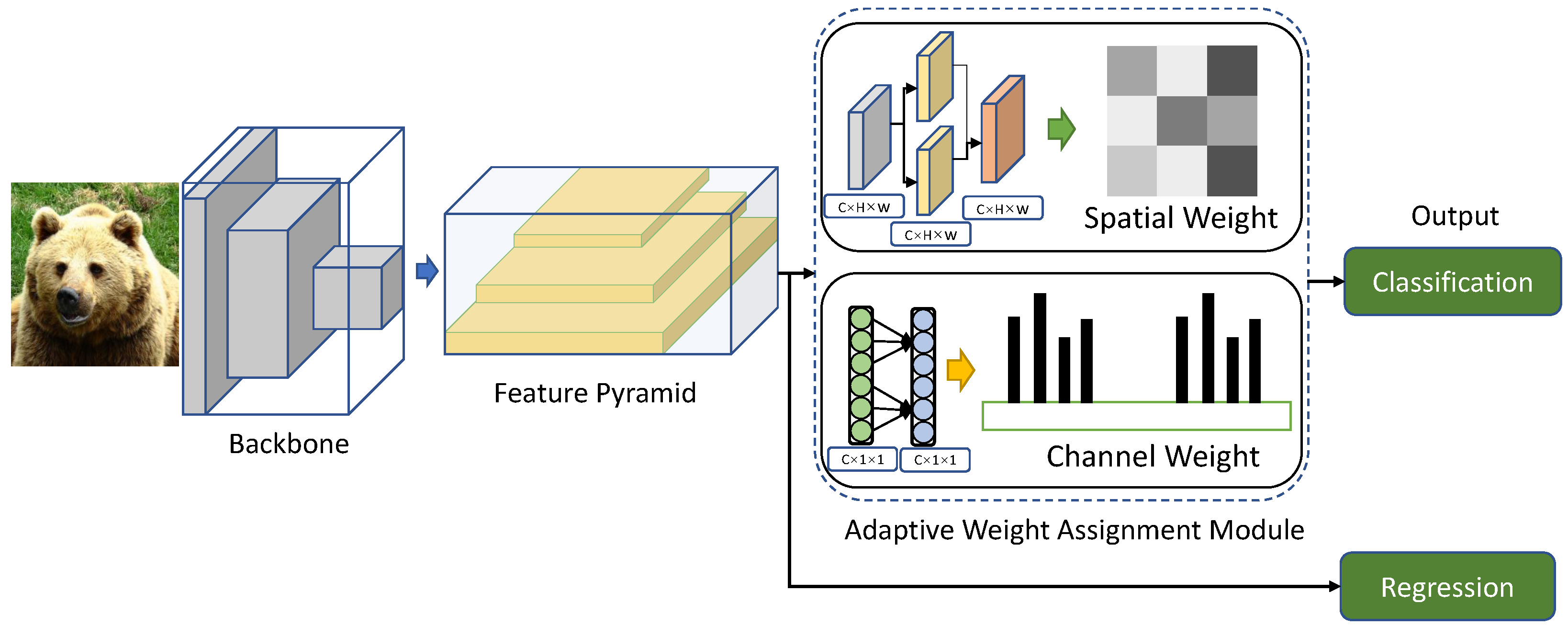
3.1. Overview
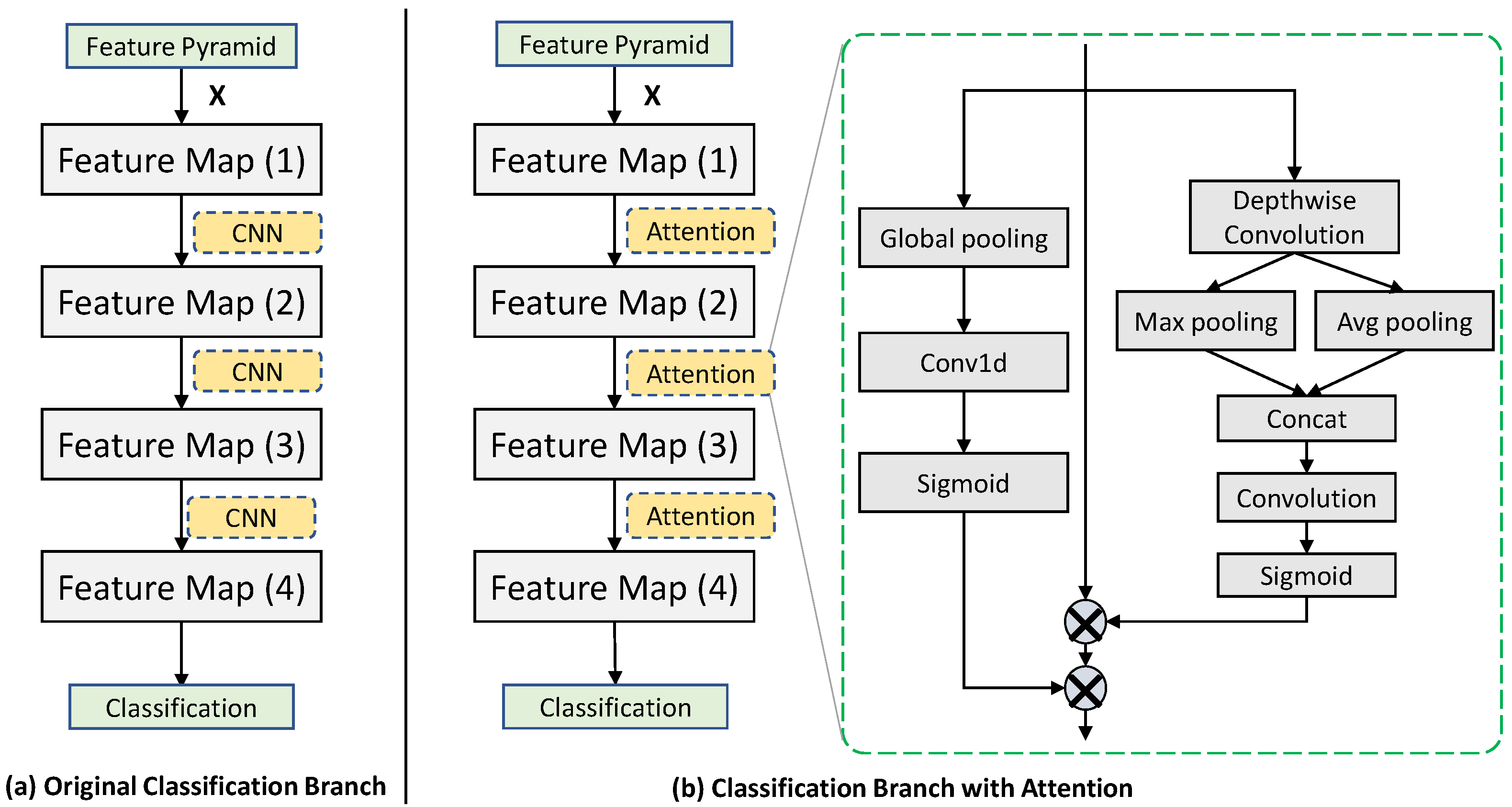
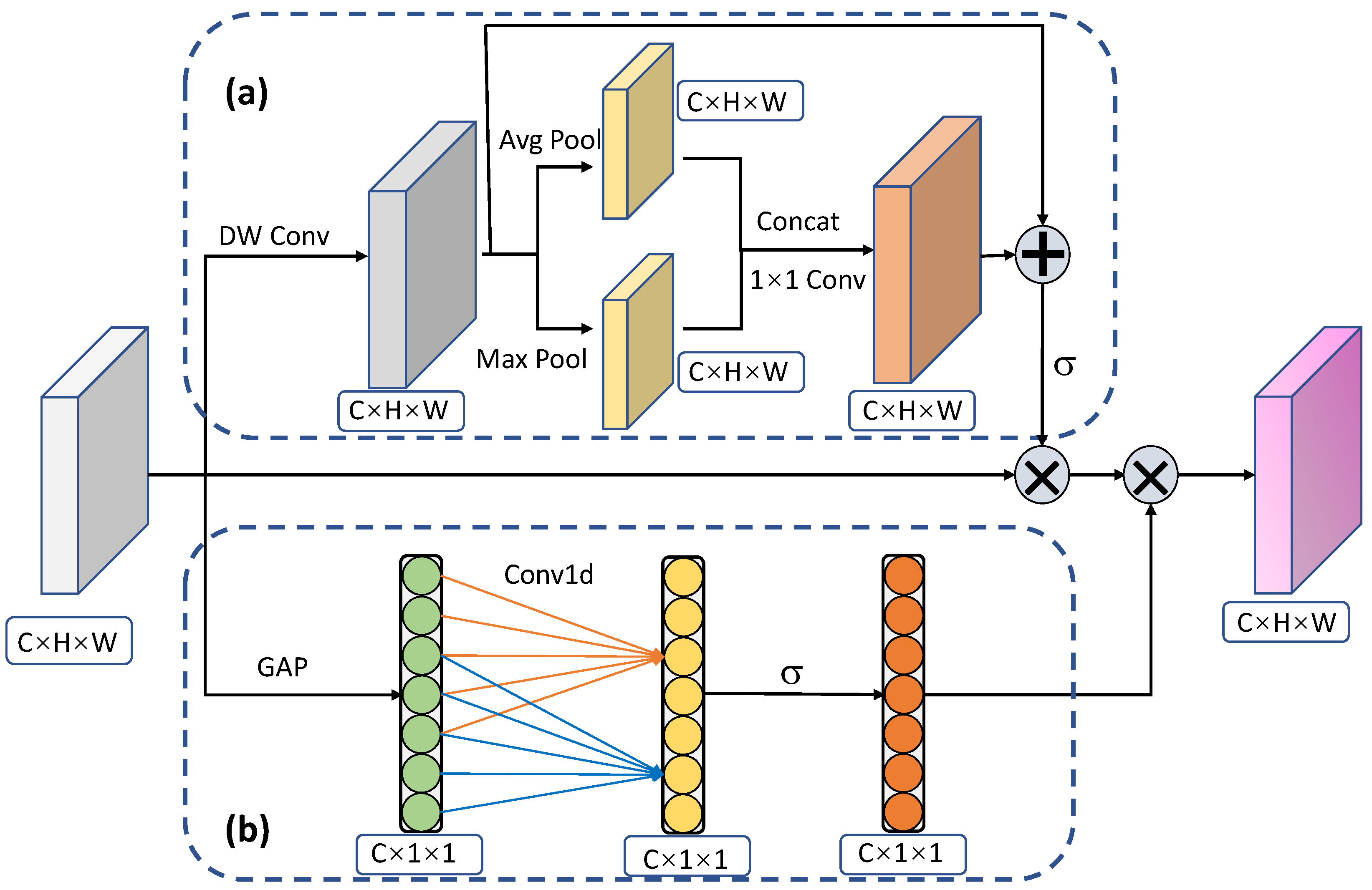
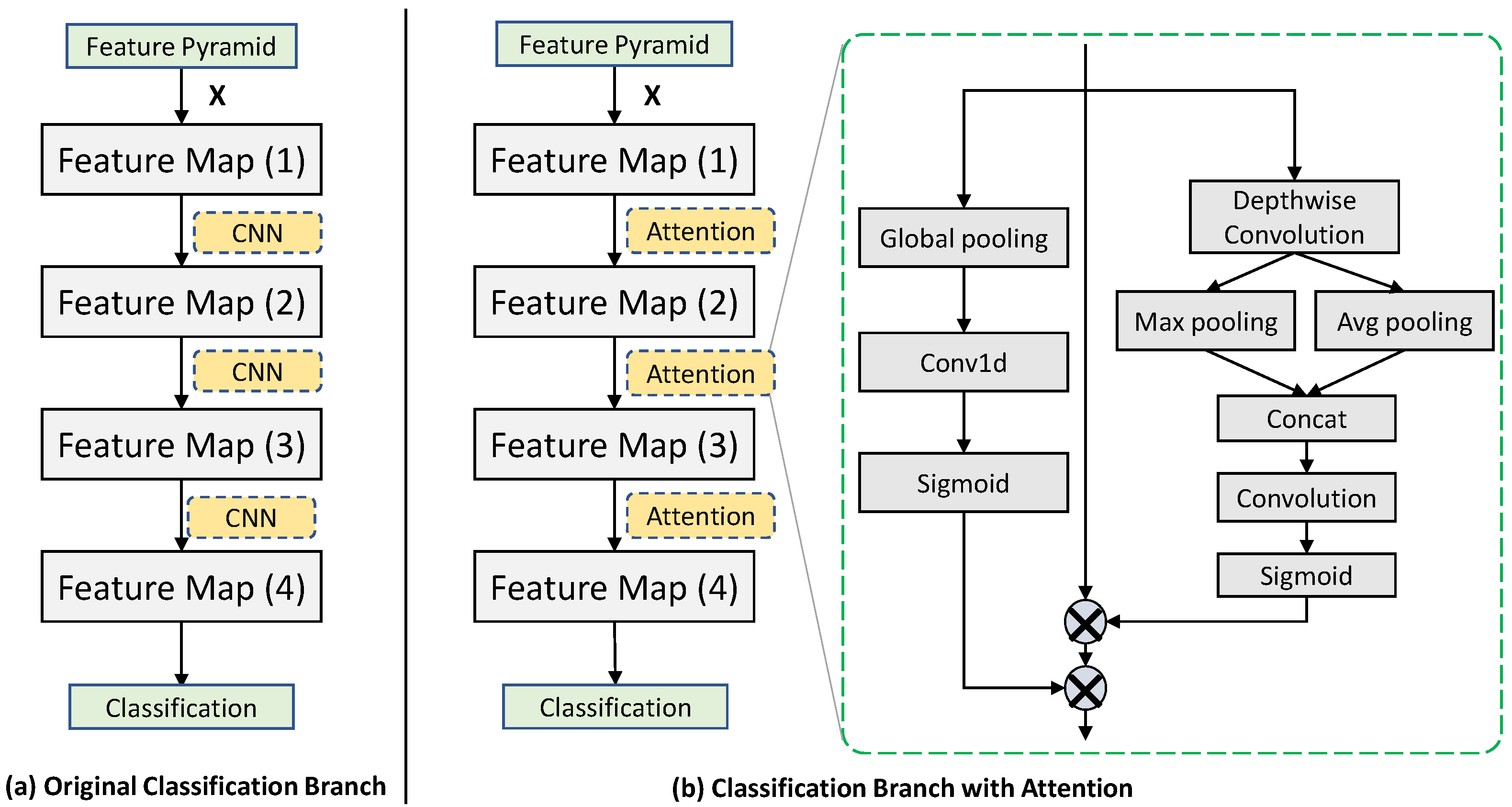
3.2. Adaptive Weight Assignment Based on Dual Attention
3.3. Loss
4. Experiment
4.1. Implementation Details
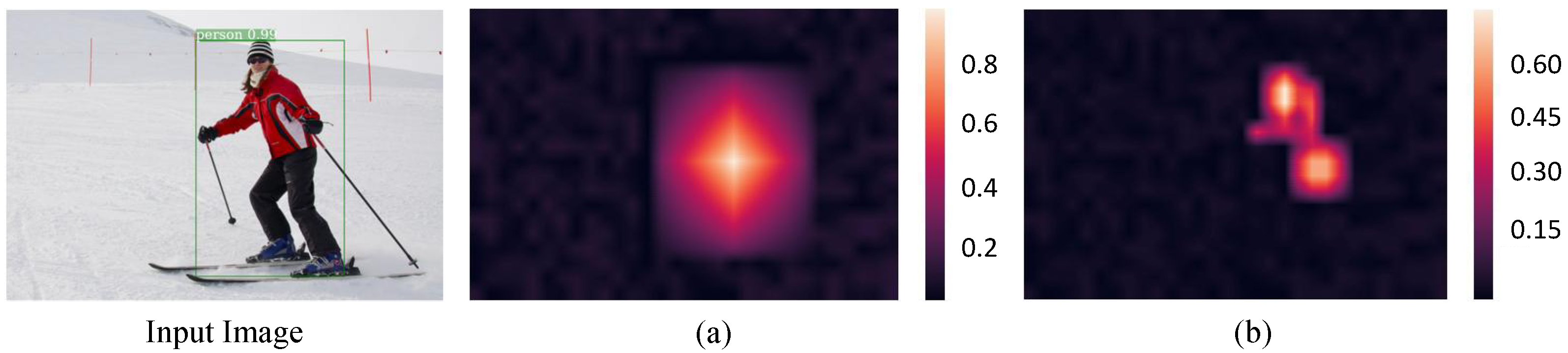
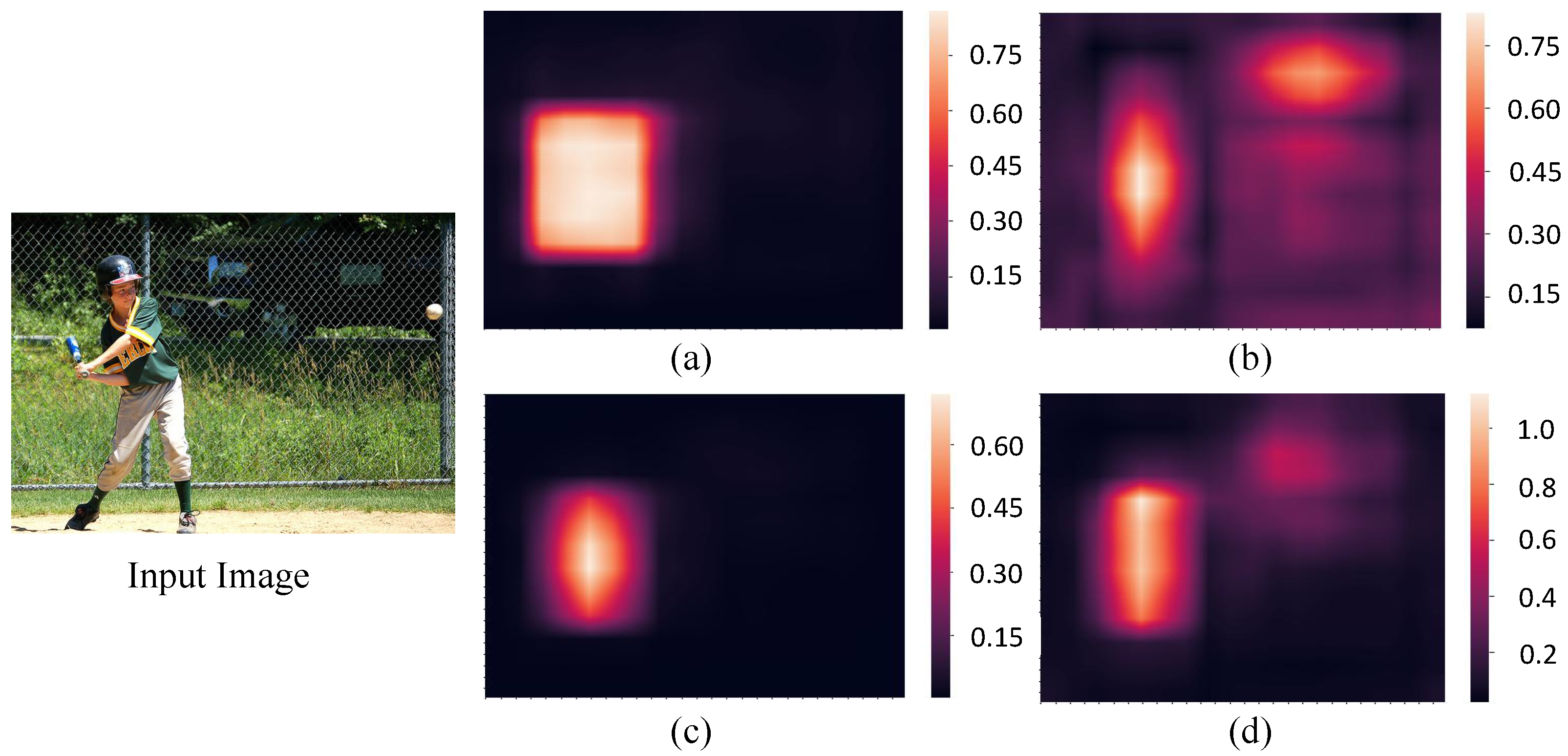
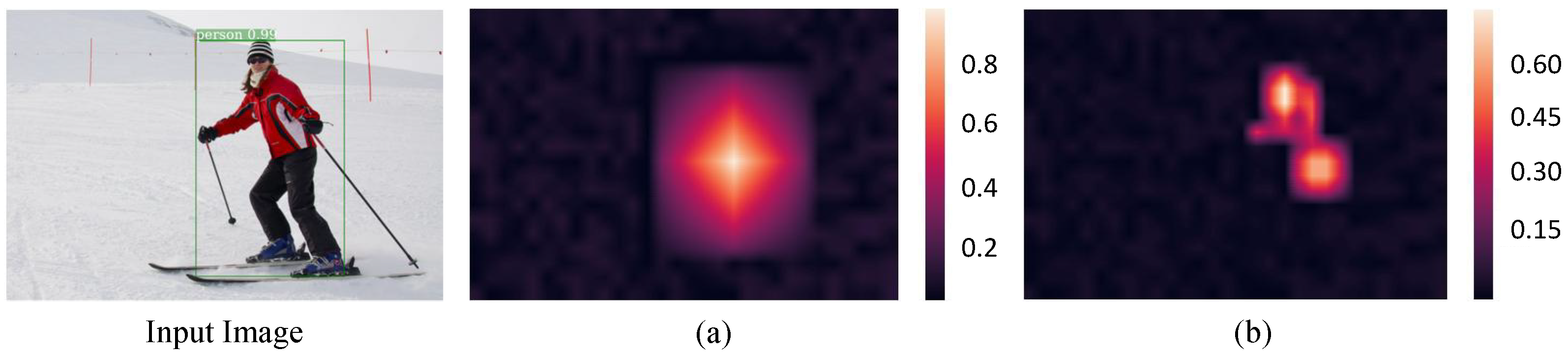
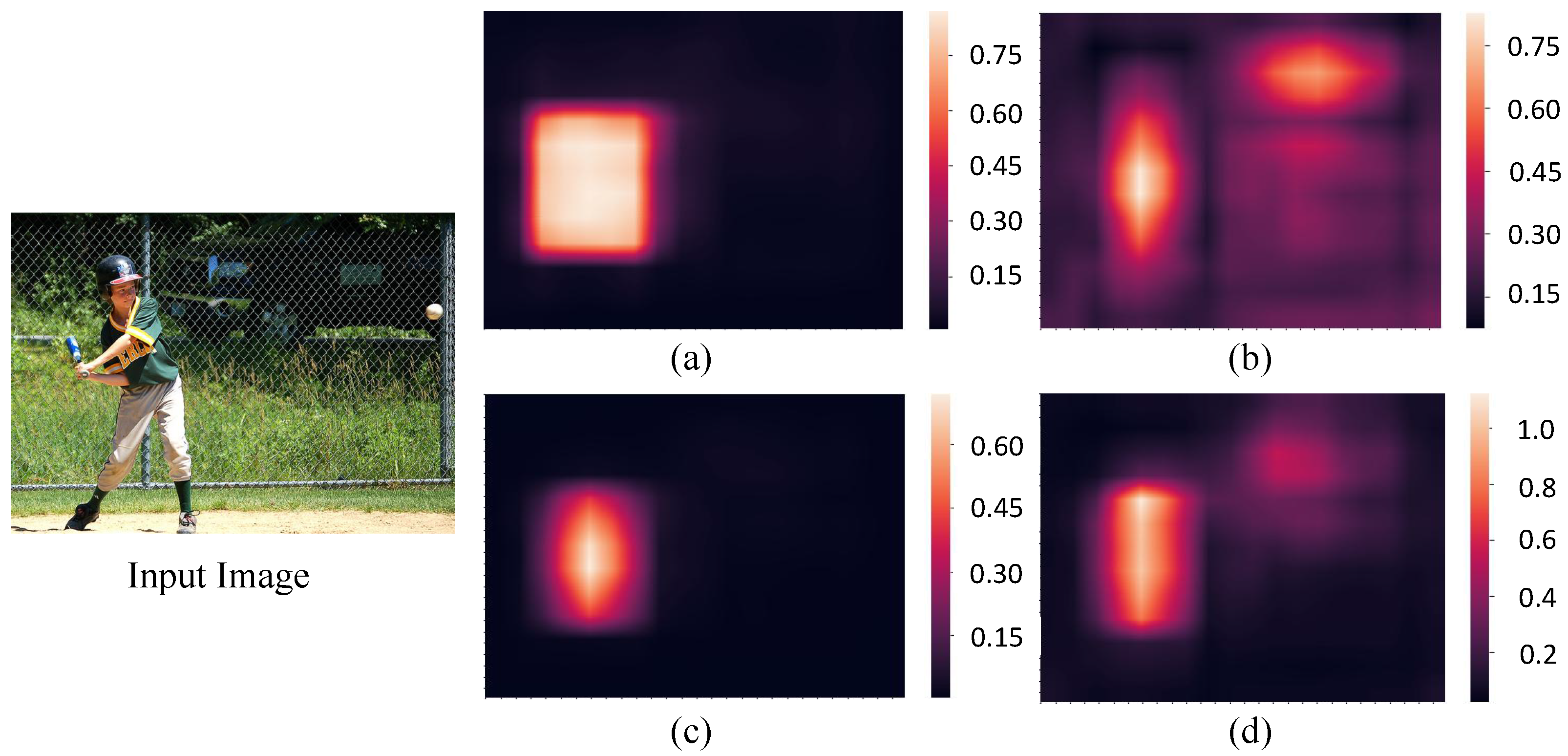
4.2. Visualized Analysis
4.3. Experimental Results
4.3.1. Effectiveness of Improved Dual Attention
4.3.2. Ablation Study
4.3.3. Comparison with the State of the Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.; Pal, D.K.; Savvides, M. Ring loss: Convex feature normalization for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5089–5097. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- Tufail, A.B.; Ullah, I.; Khan, R.; Ali, L.; Yousaf, A.; Rehman, A.U.; Alhakami, W.; Hamam, H.; Cheikhrouhou, O.; Ma, Y.K. Recognition of ziziphus lotus through aerial imaging and deep transfer learning approach. Mob. Inf. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Ahmad, I.; Ullah, I.; Khan, W.U.; Rehman, A.U.; Adrees, M.S.; Saleem, M.Q.; Cheikhrouhou, O.; Hamam, H.; Shafiq, M. Efficient algorithms for e-healthcare to solve multiobject fuse detection problem. J. Healthc. Eng. 2021, 1–16. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single shot multiBox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krähenbühl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point set representation for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 9657–9666. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Chen, R.; Liu, Y.; Zhang, M.; Liu, S.; Yu, B.; Tai, Y.W. Dive deeper into box for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 412–428. [Google Scholar]
- Samet, N.; Hicsonmez, S.; Akbas, E. Reducing label noise in anchor-free object detection. In Proceedings of the British Machine Vision Conference, Manchester, UK, 7–11 September 2020. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency channel attention networks. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Yuan, J.; Wei, J.; Wattanachote, K.; Zeng, K.; Luo, X.; Xu, Q.; Gong, Y. Attention-Based bi-directional refinement network for salient object detection. Appl. Intell. 2022, 1–13. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, S.; Chen, H. Attention-based fusion factor in FPN for object detection. Appl. Intell. 2022, 1–10. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Tang, H.; Bai, S.; Sebe, N. Dual attention GANs for semantic image synthesis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1994–2002. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Hosang, J.H.; Benenson, R.; Schiele, B. Learning non-maximum suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4507–4515. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014; pp. 740–755. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient keypoint based object detection. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Rashwan, A.; Kalra, A.; Poupart, P. Matrix Nets: A new deep architecture for object detection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. DenseBox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T.S. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized intersection over union: A Metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–29 June 2019; pp. 510–519. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tang, Z.; Yang, J.; Pei, Z.; Song, X. Coordinate-based anchor-free module for object detection. Appl. Intell. 2021, 51, 9066–9080. [Google Scholar] [CrossRef]
- Neubeck, A.; Gool, L.V. Efficient non-maximum suppression. In Proceedings of the International Conference on Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2006; pp. 850–855. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 29–25 June 2021; pp. 13029–13038. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2018 2020; pp. 10781–10790. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: Design Backbone for Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 334–350. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin1, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4470–4478. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS – Improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Chen, Z.; Huang, S.; Tao, D. Context refinement for object detection. In Proceedings of the European Conference Computer Vision, Munich, Germany, 8–14 September 2018; pp. 71–86. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.S.; Xiong, J.; Huang, T.S. Revisiting RCNN: On awakening the classification power of faster RCNN. In Proceedings of the European Conference Computer Vision, Munich, Germany, 8–14 September 2018; pp. 453–468. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection SNIP. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 6054–6063. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7363–7372. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. FoveaBox: Beyond anchor-based object detector. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, F.; Shen, Z.; Savvides, M. Soft anchor-point object detection. In Proceedings of the European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 91–107. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Framework | Backbone | AP |
|---|---|---|---|
| standard convolution | Serial | ResNet-50 | 45.0 |
| depthwise convolution | Serial | ResNet-50 | 46.7 |
| standard convolution | Parallel | ResNet-50 | 45.2 |
| depthwise convolution | Parallel | ResNet-50 | 47.1 |
| standard convolution | Serial | ResNet-101 | 49.0 |
| depthwise convolution | Serial | ResNet-101 | 52.2 |
| standard convolution | Parallel | ResNet-101 | 49.3 |
| depthwise convolution | Parallel | ResNet-101 | 52.7 |
| Method | Backbone | AP | FPS |
|---|---|---|---|
| fully connected layer | ResNet-50 | 42.7 | 9.8 |
| 1D convolution | ResNet-50 | 47.1 | 13.3 |
| AP | ||
|---|---|---|
| 1.0 | 1.0 | 47.1 |
| 1.0 | 2.0 | 43.6 |
| 2.0 | 2.0 | 43.5 |
| Channel Weight | Spatial Weight | Framework | AP |
|---|---|---|---|
| Serial | 33.1 | ||
| ✓ | Serial | 41.3 | |
| ✓ | ✓ | Serial | 46.9 |
| Parallel | 33.5 | ||
| ✓ | Parallel | 41.9 | |
| ✓ | ✓ | Parallel | 47.1 |
| Method | Backbone | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|
| Anchor-based detectors: | |||||||
| Faster R-CNN [8] | R-101 | 36.2 | 59.1 | 39.0 | 18.2 | 39.0 | 48.2 |
| DetNet [48] | D-59 | 40.3 | 62.1 | 43.8 | 23.6 | 42.6 | 50.0 |
| Soft-NMS [54] | R-101 | 40.8 | 62.4 | 44.9 | 23.0 | 43.4 | 53.2 |
| C-Mask R-CNN [55] | R-101 | 42.0 | 62.9 | 46.4 | 23.4 | 44.7 | 53.8 |
| Cascade R-CNN [29] | R-101 | 42.8 | 62.1 | 46.3 | 23.7 | 45.5 | 55.2 |
| Libra R-CNN [56] | X-101-64×4d | 43.0 | 64.0 | 47.0 | 25.3 | 45.6 | 54.6 |
| Revisting R-CNN [57] | R-101+R-152 | 43.1 | 66.1 | 47.3 | 25.8 | 45.9 | 55.3 |
| SNIP [58] | DPN-98 | 45.7 | 67.3 | 51.1 | 29.3 | 48.8 | 57.1 |
| TridentNet [59] | R-101-DCN | 46.8 | 67.6 | 51.5 | 28.0 | 51.2 | 60.5 |
| RefineDet512 [60] | R-101 | 36.4 | 57.5 | 39.5 | 16.6 | 39.9 | 51.4 |
| RetinaNet [30] | R-101 | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| YOLOv4 [7] | CSPDarkNet-53 | 43.5 | 65.7 | 47.3 | 26.7 | 46.7 | 53.3 |
| YOLOv4-P7 [46] | CSP-P7 | 55.5 | 73.4 | 60.8 | 38.4 | 59.4 | 67.7 |
| EfficientDet-D7 [47] | E-B6 | 53.7 | 72.4 | 58.4 | 35.8 | 57.0 | 66.3 |
| Anchor-free detectors: | |||||||
| ExtremeNet [10] | H-104 | 40.2 | 55.5 | 43.2 | 20.4 | 43.2 | 53.1 |
| CornerNet [14] | H-104 | 40.5 | 56.5 | 43.1 | 19.4 | 42.7 | 53.9 |
| CenterNet-HG [12] | H-104 | 42.1 | 61.1 | 45.9 | 24.1 | 45.5 | 52.8 |
| Grid R-CNN [61] | X-101 | 43.2 | 63.0 | 46.6 | 25.1 | 46.5 | 55.2 |
| CornerNet-Lite [31] | H-54 | 43.2 | - | - | 24.4 | 44.6 | 57.3 |
| CenterNet [15] | H-104 | 44.9 | 62.4 | 48.1 | 25.6 | 47.4 | 57.4 |
| RepPoints [11] | R-101-DCN | 45.0 | 66.1 | 49.0 | 26.6 | 48.6 | 57.5 |
| FoveaBox [62] | X-101 | 42.1 | 61.9 | 45.2 | 24.9 | 46.8 | 55.6 |
| FSAF [36] | X-101-64×4d | 42.9 | 63.8 | 46.3 | 26.6 | 46.2 | 52.7 |
| FCOS [13] w/imprv | X-101-64×4d | 44.7 | 64.1 | 48.4 | 27.6 | 47.5 | 55.6 |
| SAPD [63] | R-101-DCN | 46.0 | 65.9 | 49.6 | 26.3 | 49.2 | 59.6 |
| ATSS [64] | X-101-DCN | 47.7 | 66.5 | 51.9 | 29.7 | 50.8 | 59.7 |
| Ours | R-50 | 47.1 | 65.7 | 51.1 | 28.2 | 50.0 | 58.7 |
| Ours | R-101 | 52.7 | 71.1 | 56.9 | 35.0 | 56.0 | 66.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Y.; Zhao, B.; Zhao, K.; Wu, L.; Wang, X. Improved Dual Attention for Anchor-Free Object Detection. Sensors 2022, 22, 4971. https://doi.org/10.3390/s22134971
Xiang Y, Zhao B, Zhao K, Wu L, Wang X. Improved Dual Attention for Anchor-Free Object Detection. Sensors. 2022; 22(13):4971. https://doi.org/10.3390/s22134971
Chicago/Turabian StyleXiang, Ye, Boxuan Zhao, Kuan Zhao, Lifang Wu, and Xiangdong Wang. 2022. "Improved Dual Attention for Anchor-Free Object Detection" Sensors 22, no. 13: 4971. https://doi.org/10.3390/s22134971
APA StyleXiang, Y., Zhao, B., Zhao, K., Wu, L., & Wang, X. (2022). Improved Dual Attention for Anchor-Free Object Detection. Sensors, 22(13), 4971. https://doi.org/10.3390/s22134971