
A Machine-Learning-Based Analysis of the Relationships between Loneliness Metrics and Mobility Patterns for Elderly

 , , ,
, , ,  ,
,  and
and 
Abstract
:1. Introduction and Motivation
2. Research Questions
- RQ1
- What kind of mobility patterns or features can be extracted from indoor and outdoor sensors in a manner relevant to loneliness and social isolation studies?
- RQ2
- How much are these mobility patterns correlated with loneliness metrics such as the UCLA and Lubben scores?
- RQ3
- How well can we classify the user by using machine-learning algorithms with a user’s indoor, outdoor, and combined indoor-outdoor mobility patterns and which of this data types gives the highest classification accuracy?
- RQ4
- To what extent can one predict the indoor mobility patterns of a user by training the machine-learning algorithm on the outdoor mobility patterns of the same user and vice versa (i.e., predicting/classifying outdoor from indoor data)?
3. Description of Data Collection
3.1. User Demographics
3.2. Pre-Study Survey
3.3. Post-Study Survey
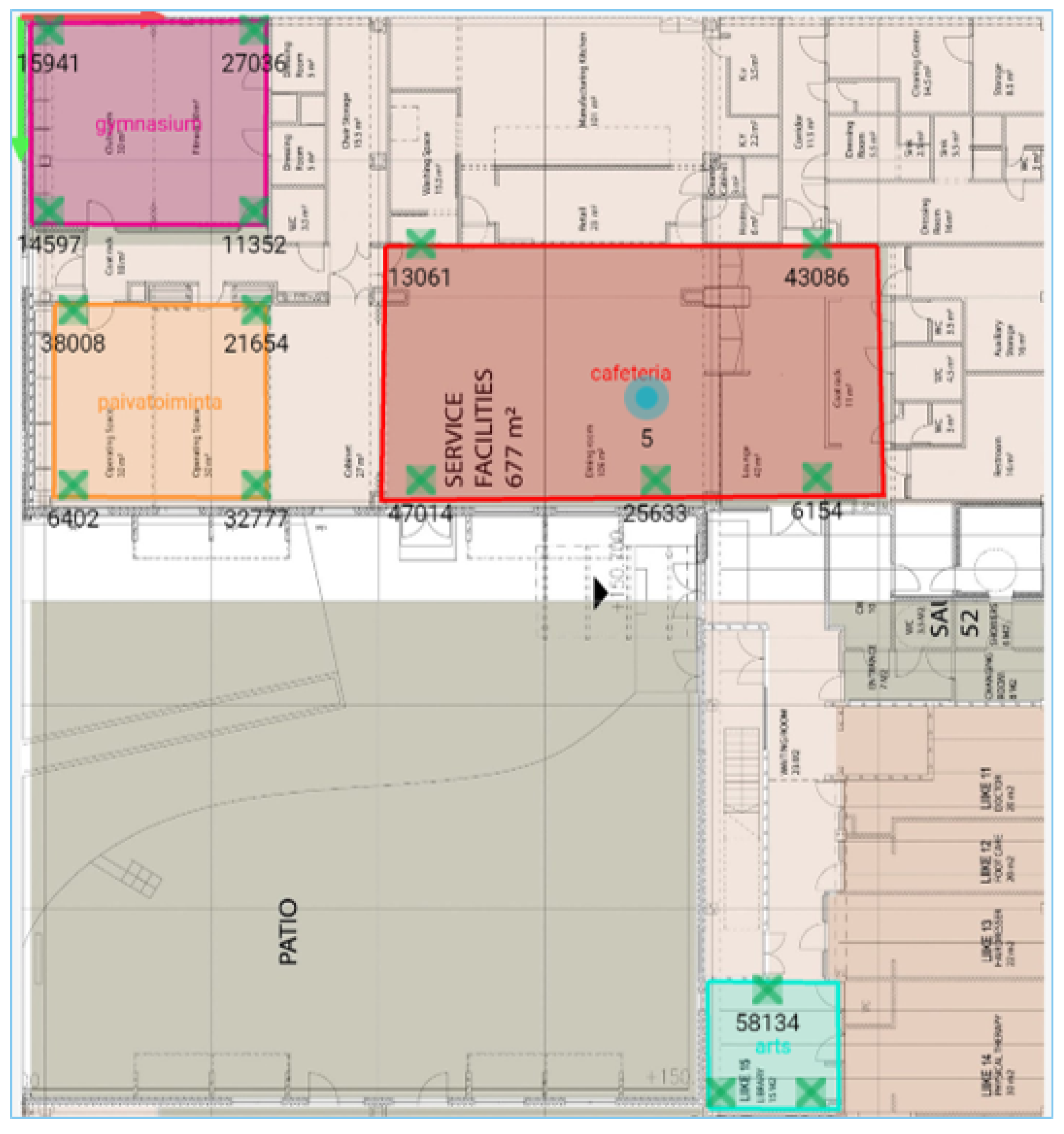
3.4. Indoor Data Collection
3.5. Outdoor Data Collection

4. Machine-Learning-Based Methodology and Analysis
4.1. Data Pre-Processing
- Converting date and time information into “YYYY-MM-DD HH:MM:SS” format.
- Extracting relevant attributes from the sensor data. This includes eliminating the metadata from the raw sensor data such as error information, version information, message identifier (ID) etc.
4.2. Exploratory Data Analysis
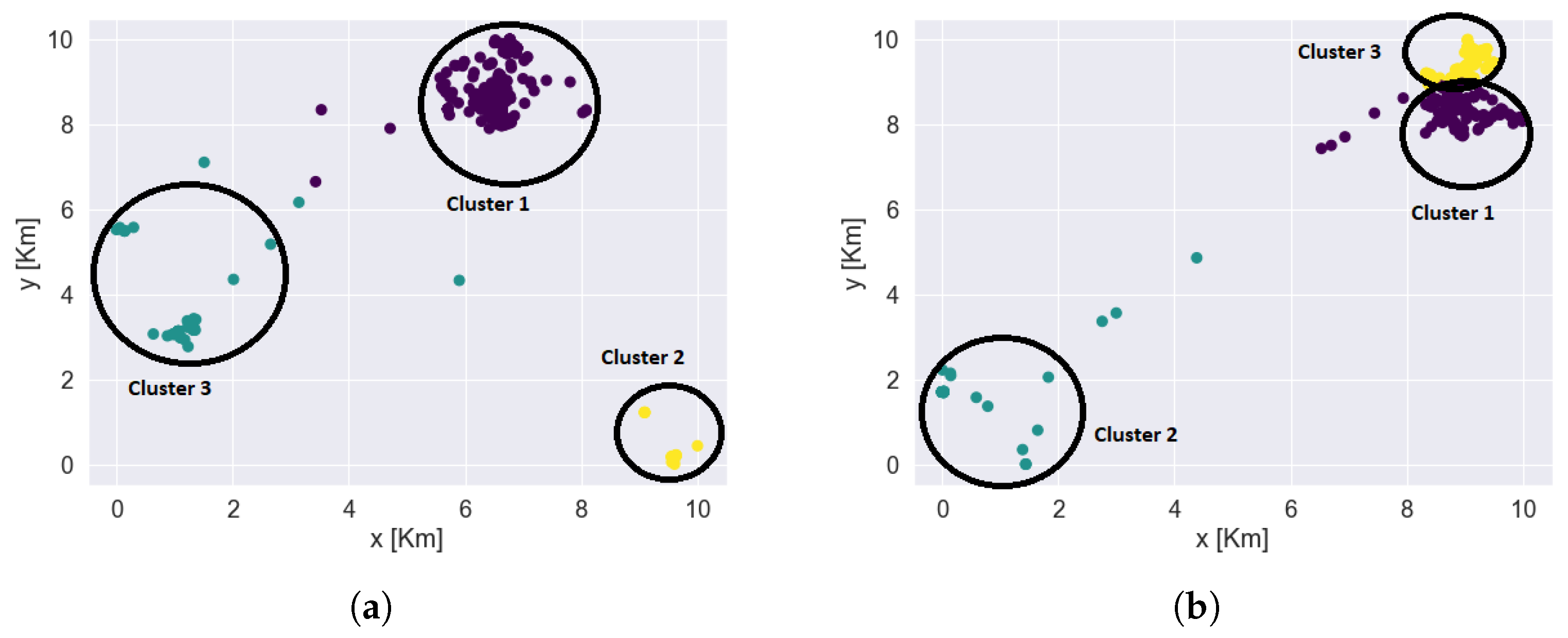
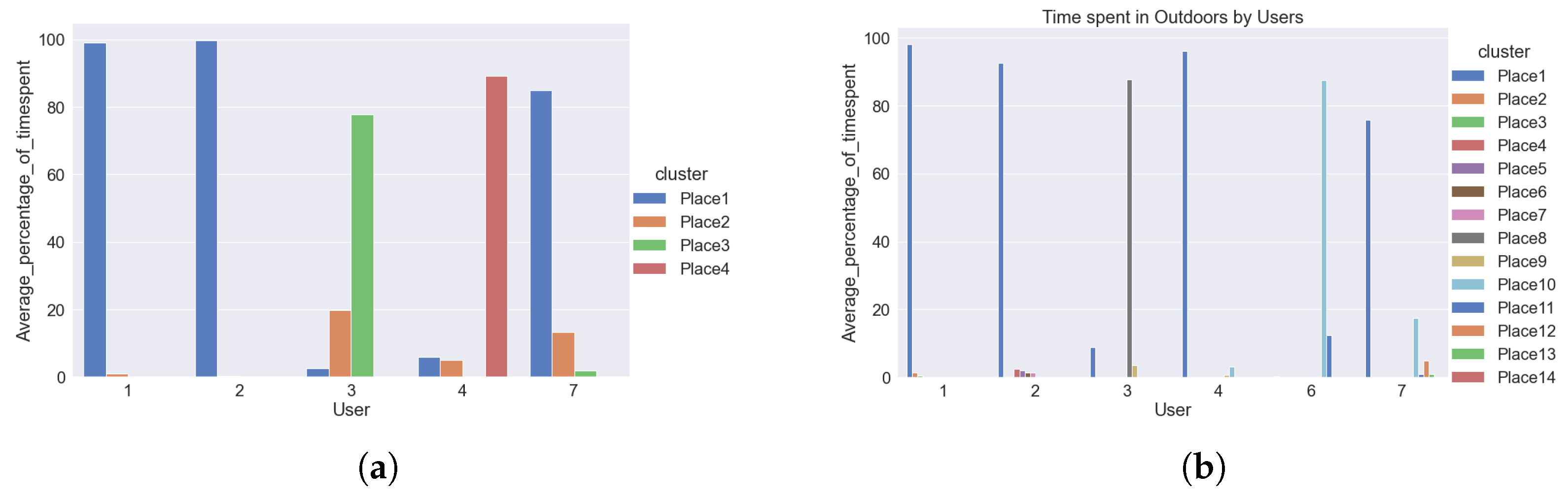
- Identifying clusters or frequently visited placesFor indoor data, the clusters or frequently visited places indoor were recorded by the sensors. For outdoor data, the clusters or frequently visited hotspot information were not recorded by the sensors. Outdoor sensors recorded only the information about the latitude and longitude of a person. We utilized this information to identify ourselves the clusters or frequently visited places outdoors. We used k-means clustering algorithms to identify each user’s frequently visited areas. These clusters or frequently visited places were recognized better after plotting the data on the maps. Figure 10 shows the outdoor clusters or frequently visited places identified for two users. Each color represents the different clusters. The black circles denote the cluster boundaries. A user can have several clusters; in the examples shown in Figure 10, both users have had three main clusters. The underlying map (also used in our analysis) is not shown here in order to preserve the users’ privacy.Based on the information obtained from the mobility patters, we performed exploratory data analysis to explore the behavioural context of the users. We summarized the information obtained from this analysis in the form of bar plots. The bar plot represented in Figure 11 tell about percentage of time spent by users in indoor and outdoor clusters.
- Average percentage of time spent by users in indoor and outdoor clustersTo obtain the average percentage of time spent by users, we used the cluster information and the days and times the user visited those clusters. For analyzing and visual representation of the average time spent by the users, indoor data were available from five users whereas outdoor data were obtained from six users. Users IDs are from 1 to 7, with some users missing, as initially 7 participants were enrolled to the trial, but one participant was retrieved before the process started, and a second participant was retrieved (due to health reasons) after the outdoor data was collected, but before the collection of the indoor data. So, for indoor data from user 1, 2, 3, 4, 7 were used and outdoor data from user 1, 2, 3, 4, 6, 7 were used. The average percentage of time spent by users in different places indoors and outdoors is represented by bar plot as shown in Figure 10.For indoor clusters, all five users—whose indoor data were being collected—visited up to four places frequently, marked by Place1, Place2, Place3, Place4 (not necessarily the same places for all users, therefore Place1 of user1 may be at a different location from Place2 of user2). They visited these places on certain days. The bar plot in Figure 11 shows that user1 and user2 visited only two places and spent most of the time almost to at one place on all the days. However, user3, user4, and user7 visited multiple places and spent significant amount of time in more than two places. For example, user3 spent about of her time at one place, around at a second place, and about at a third place indoors. Similarly, user4 and user7 are also spending time in different places. User4 seems to spend more than of time at one place but she is also interested in visiting other places, while user4 is spending around to at other places as well. Similar behaviour is observed in the mobility patterns of user7 as well. On one hand, it can be observed that user1 and user2 have less mobility indoors than the other three users, and, therefore, less physical activity. On other hand user3, user4 and user7 have better mobility as compared to the other two users and therefore better activity indoors.From the outdoor data and the computed clusters, we observed that all the users have been visiting to multiple places as per their interest and so overall, there are quite many clusters identified outdoors. Some of these clusters are common between the users. The bar plot in Figure 10 for time spent in outdoor clusters shows that user1, user2 have been spending most of the time, about to at one place on most of the days. They have been visiting to other places but not more than . For user1, user2, percentage of time spent in other places is quite less. So, these users might have less social engagement outdoors. Similar behaviour is observed for user4 as well. User4 is also spending most of the time, around in one cluster and not more than in other clusters. However, if we observe outdoor behaviour of user3, user6, user7 then it is slightly different from the behaviour of user1, user2, user4. Although, user3 is spending around in one cluster but user3 is also visiting and spending to of time in other cluster as well. User6 and user7 have also been visiting to multiple clusters and spending significant time in different clusters. This shows that there is a chance of user3, user6, user7 having better social engagement and mobility outdoors.We also compared information obtained from the indoor and outdoor mobility patterns with the Lubben score of the users. Lubben score obtained from 6-item social network scale tells about the social engagement of the user. The higher the score, the better the social engagement of the participant is. We observed that user1 and user2, who have less mobility indoors and outdoors than the other three users, also have lower Lubben scores. User3, who has better mobility patterns indoors and outdoors than user1 and user2, has good Lubben score. However, user4, who has better indoor mobility than user1 and user2, but lower outdoor mobility, has intermediate Lubben score values. We also observed that for user6 and user7, who have better indoor and outdoor mobility that user1 and user2, have very low Lubben score values. From the above information, it can be inferred that the mobility patterns can be associated to some extent with the social engagement of the person and hence the feeling of loneliness. Also, the average time spent in multiple places indoors and outdoors can also be used as one of the important characteristic to understand the mobility of users and this can help to understand the user’s behaviour such as social engagement, feeling of loneliness, etc. For a better understanding of the findings from the exploratory data analysis we have performed the classification task on the users’ mobility pattern using machine learning algorithms, the results of which are presented in Section 5.
4.3. Feature Extraction and Feature Selection
- Indoor data feature extraction and selectionThe raw data collected from the indoor sensors consist of attributes containing information about the timestamp, user ID, user’s positional coordinates, three axis accelerometer data, cluster ID, cluster name, emotional state of person, additional metadata related to error information, latency, communication success rate, etc. After initial pre-processing on the various attributes, raw data containing accelerometer values, user’s positional coordinates, cluster information, and emotional state were considered further for feature extraction. User’s position coordinates were used to calculate the distance and the speed of the user. Raw accelerometer values in three axis were transformed to extract the statistical features from them.We used a windowing technique with a window size of 10 s and we applied feature-extraction methods on that window size. Various statistical features such as mean, median, standard deviation, kurtosis, skewness, number of peaks, energy of signal, signals magnitude area, and average resultant acceleration were extracted from the three axis accelerometer data. The average value for these transformed statistical features were taken over the considered window period. Features such as traveled distance and speed, calculated from the position coordinates were also averaged over the window period. For categorical variables such as cluster ID and emotional state of person, the most frequent value in that window period was taken. This transformed feature vector consisting of statistical feature, average distance, average speed, cluster information from all windows was formed by appending the different individual features. This transformed dataset (or feature vector) was given as input to the machine learning algorithms for further analysis.
- Outdoor data feature extraction and selectionThe raw data collected from outdoor sensor consist of attributes containing information about the message header, UTC (Coordinated Universal Time) time, status tag to indicate if the data is valid or not, speed over ground in knots, latitude and longitude information, course over ground, north/south indicator, east/west indicator. In outdoor data, the information about the frequently visited places or cluster was not automatically recorded by the sensors, unlike in the indoor measurements. As mentioned in previous subsection, we extracted the cluster information from the latitude and longitude attributes using k-means clustering algorithm. To extract the features such as distance and the estimated speed, latitude and longitude information was converted into Cartesian coordinate system. The x, y, z coordinate information were further used to calculate the distance and the speed of the user.For outdoor data, a smaller window size was taken to obtain the transformed dataset since the time difference between the two consecutive values was 10 min. We used a similar methodology as used for indoor data in order to obtain the complete feature vector. Here, we used the window size of 40 min. However, due to the difference of 10 min. between consecutive values a particular window consisted of 4 values. We calculated the average distance, average estimated speed, speed (converted from knots to meter/second) and average course over a window period. For a categorical attribute such as the cluster ID, we used the most frequent value in the window. The values from multiple windows were appended and the transformed outdoor dataset (or complete feature vector) was further given as input to the machine-learning algorithm.
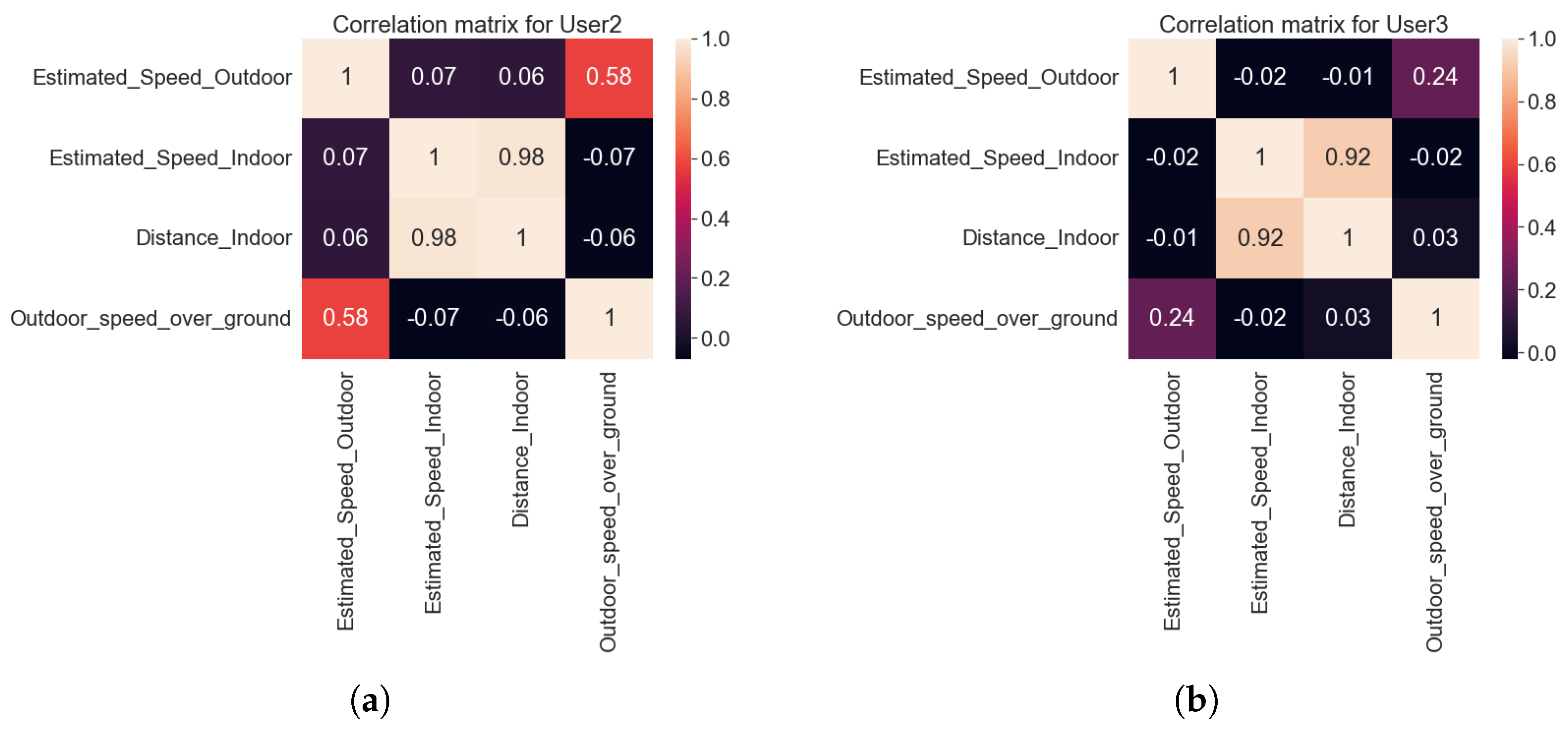
- Indoor and outdoor feature fusionFeature fusion combines the features obtained from the different sources into a single feature set. To obtain the loneliness prediction accuracy for the combined indoor and outdoor mobility patterns, we applied a feature level fusion. The main challenge for indoor and outdoor feature level fusion was to take the features from the same user on same days. Only the features common to both the indoor and outdoor data were selected. The selected features were: the estimated speed, distance, and indoor cluster ID from the indoor data and the estimated speed, speed over ground, distance, and the outdoor cluster ID from the outdoor data. For selecting the relevant features, we calculated the correlation matrix.It was observed from the correlation matrix of all users that the indoor distance and indoor estimated speed were highly correlated. Estimated speed and speed over grounds from outdoor data were also correlated. Similar behaviour is shown from the example correlation matrix for two users, in Figure 12, where the indoor distance and estimated speed indoors are highly correlated with a correlation value of more than . Also outdoor speed over ground and outdoor estimated speed were also positively correlated.The combined dataset from the indoor and outdoor data was given as input to the machine-learning analysis and we found that the best performance was achieved with the indoor distance used as a feature extracted from indoors and with the speed over ground used as a feature extracted from outdoors.
4.4. Machine Learning Based Analysis
- Classification of users (user1 to user4 and user6 to user7) based on their mobility patterns and other extracted features.
- Classification of users into three labeled classes, having high risk of loneliness, medium risk of loneliness, and low risk of loneliness with labels assigned based on the UCLA score of the user as mentioned in Table 5.
- Classification of users into three labeled classes, having high risk of loneliness, medium risk of loneliness, and low risk of loneliness with labels assigned based on the Lubben score of the user as mentioned in Table 5.
- How well the algorithm is able to identify the users based on the selected features from sensor data?
- How well the algorithm is able to classify the users into three defined loneliness levels (using the UCLA and Lubben loneliness metrics)?
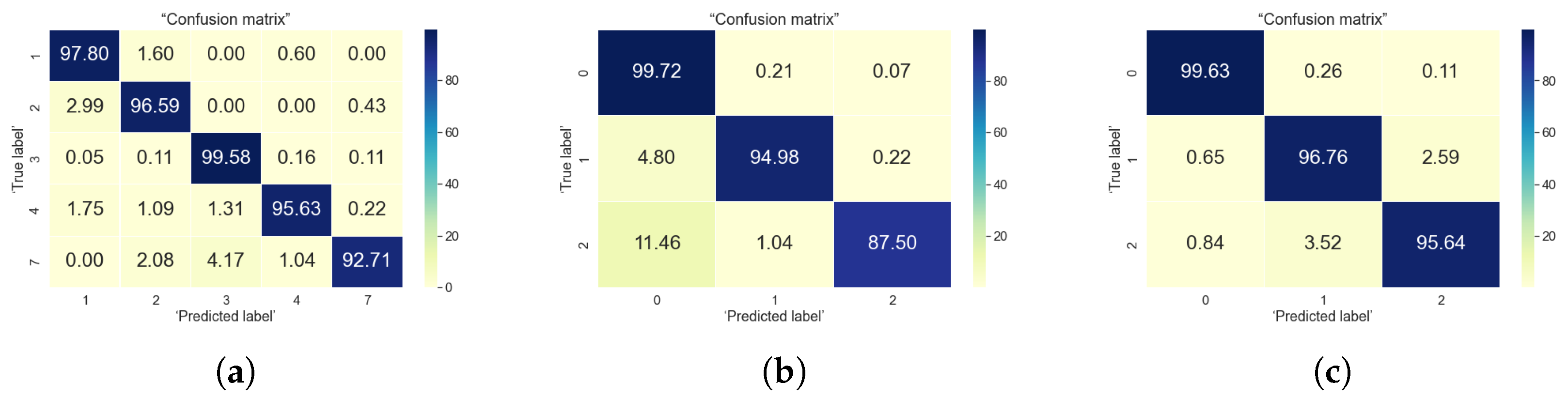
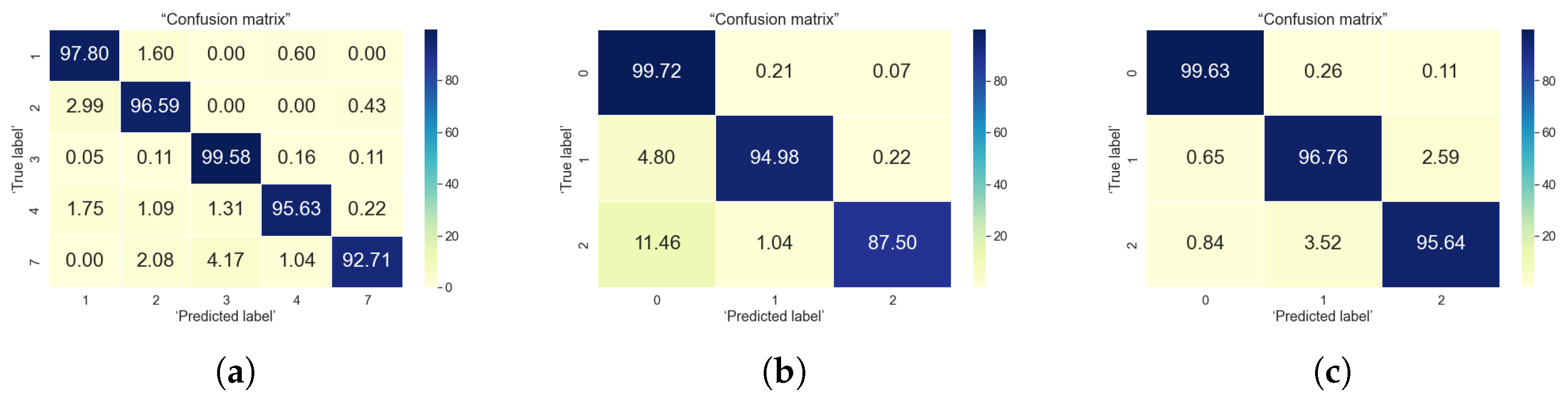
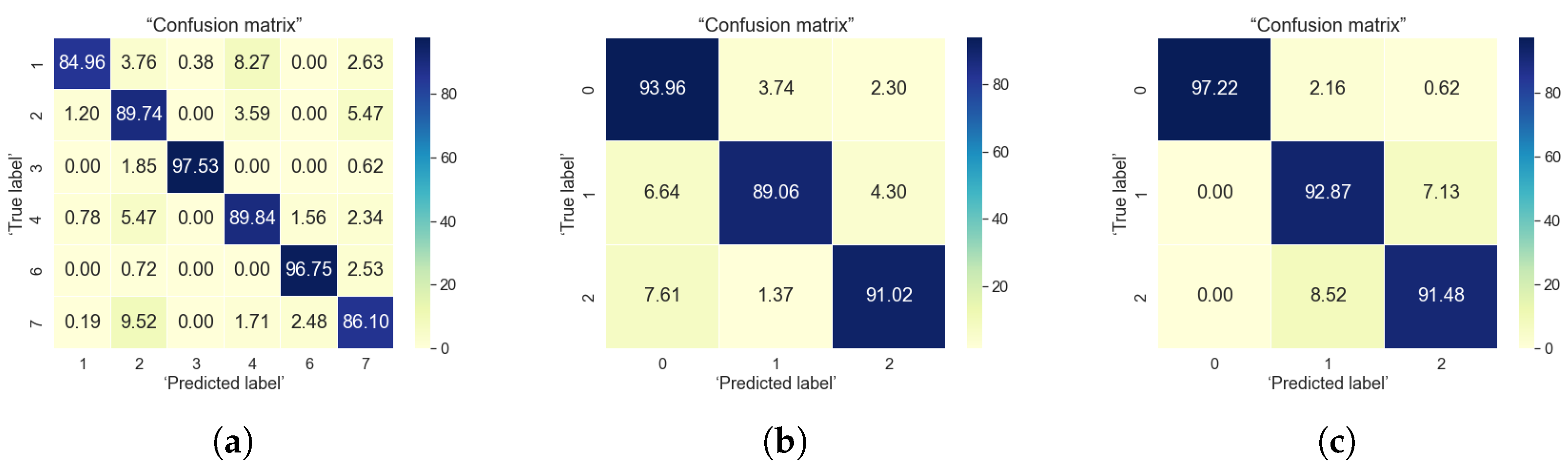
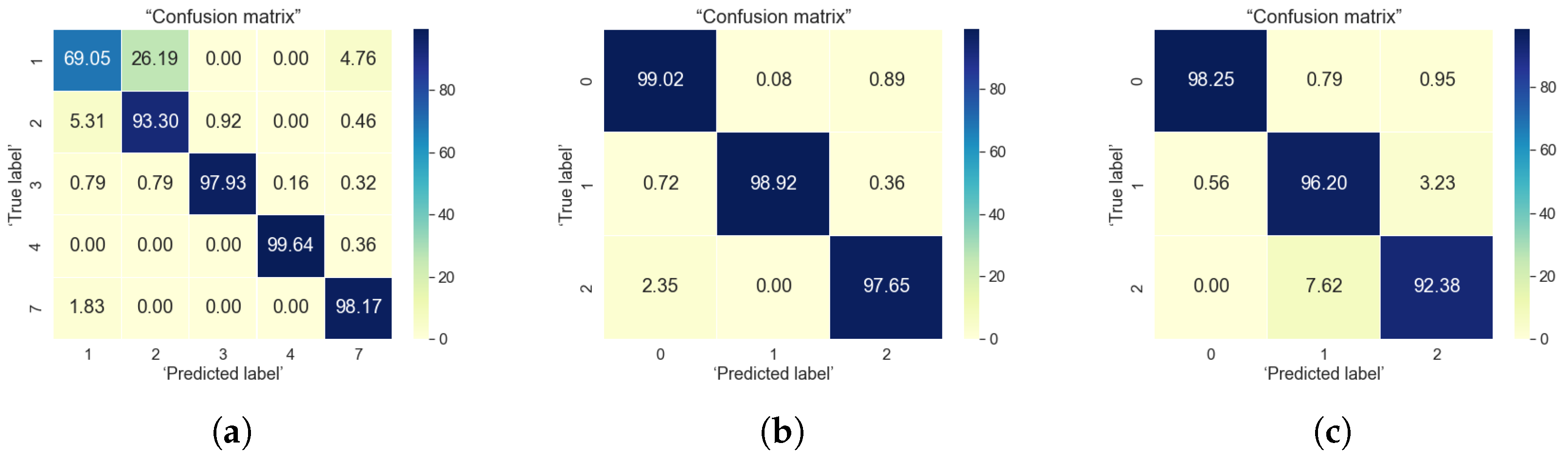
5. Classification Results
5.1. Indoor Data Analysis
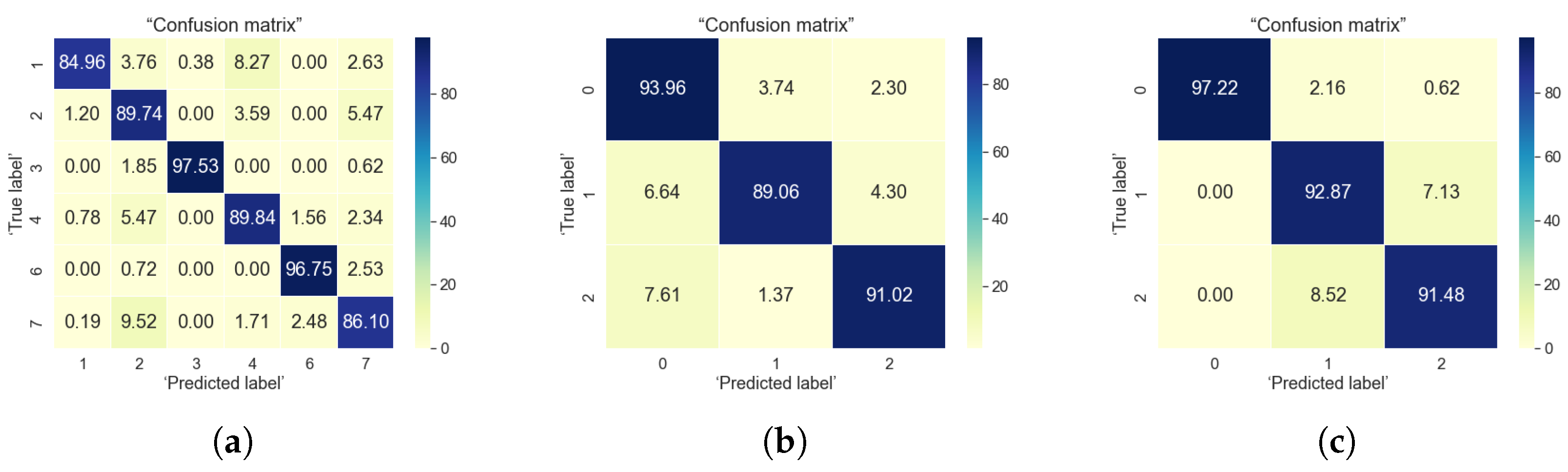
5.2. Outdoor Data Analysis
5.3. Indoor-to-Outdoor Correlations
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. AISOLA Technical Study—Post-Study Survey
- Device Related:
- The satisfaction level of the instructions provided for using the devices:
- a.
- Low
- b.
- Medium
- c.
- High
- d.
- Other (Please Explain):
- The devices were difficult to manage/maintain:
- a.
- Yes
- b.
- No
- c.
- Sometimes
- d.
- Other (Please Explain):
- The devices were easy to carry around while doing my everyday tasks.
- a.
- Low
- b.
- Medium
- c.
- High
- d.
- Other (Please Explain):
- I was aware of the different requirements and functionalities of the indoor and outdoor devices
- a.
- Yes, the instructions were clear
- b.
- Some, the instructions were not clear enough
- c.
- No, the instructions were not clear at all
- d.
- Other (Please Explain):
- I was able to get help regarding the devices at any point.
- a.
- Yes, the personnel were easy to contact and were in touch with us regularly
- b.
- Some, the personnel were somewhat easy to contact
- c.
- No, I did not get the help that I required
- d.
- Other (Please Explain):
- Explain briefly if you changed the states in the indoor device at any point in the study. If yes or no, please briefly explain your reason why.
- a.
- Yes
- b.
- No
- c.
- Sometimes
- d.
- Other (Please Explain):
- Physical and Emotional State:
- During the period of study my emotional state was:
- a.
- Very Poor
- b.
- Poor
- c.
- Neutral
- d.
- Good
- e.
- Excellent
- f.
- Other (Please Explain):
- During the period of study my social situation and human interactions were:
- a.
- Very Poor
- b.
- Poor
- c.
- Neutral
- d.
- Good
- e.
- Excellent
- f.
- Other (Please Explain):
- I was getting good exercise and was physically active during the study:
- a.
- Yes, A lot of exercise and physical activity
- b.
- Yes, Some exercise and physical activity
- c.
- Neutral
- d.
- No, Lesser exercise and physical activity than usual
- e.
- No, very little exercise and physical activity
- My sleeping habits during the study were:
- a.
- Regular and Healthy
- b.
- Poor quality of sleep, low duration
- c.
- Longer duration of sleep
- My quality of sleep:
- a.
- Very Poor
- b.
- Poor
- c.
- Neutral
- d.
- Good
- e.
- Excellent
- f.
- Other (Please Explain):
- My emotional state when I am in public or travelling from place to place during the study.
- a.
- Very Poor
- b.
- Poor
- c.
- Neutral
- d.
- Good
- e.
- Excellent
- f.
- Other (Please Explain):
- My physical health during the study was:
- a.
- Very Poor
- b.
- Poor
- c.
- Neutral
- d.
- Good
- e.
- Excellent
- f.
- Other (Please Explain):
- Physical ailments which led to difficulties in participating for the study:
- a.
- Yes (Please Explain):
- b.
- No
- General:
- My age:
- My hobbies:
- General feedback to the researchers/management regarding the study—Areas to improve:
References
- Yang, H.; Bath, P.A. Predicting loneliness in older age using two measures of loneliness. Int. J. Comput. Appl. 2020, 42, 602–615. [Google Scholar] [CrossRef] [Green Version]
- Awadalla, M.; Kausar, F.; Ahshan, R. Developing an IoT Platform for the Elderly Health Care. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 410–417. [Google Scholar] [CrossRef]
- Site, A.; Lohan, E.S.; Jolanki, O.; Valkama, O.; Hernandez, R.R.; Latikka, R.; Alekseeva, D.; Vasudevan, S.; Afolaranmi, S.; Ometov, A.; et al. Managing Perceived Loneliness and Social-Isolation Levels for Older Adults: A Survey with Focus on Wearables-Based Solutions. Sensors 2022, 22, 1108. [Google Scholar] [CrossRef] [PubMed]
- Latikka, R.; Rubio-Hernandez, R.; Lohan, E.; Rantala, J.; Nieto-Fernandez, F.; Laitinen, A.; Oksanen, A. Older Adults’ Loneliness, Social Isolation and Physical ICT in the Era of Ambient Assisted Living: A Systematic Literature Review. J. Med Internet Res. 2021, 23, e28022. [Google Scholar] [CrossRef] [PubMed]
- Site, A.; Nurmi, J.; Lohan, E.S. Systematic Review on Machine-Learning Algorithms Used in Wearable-Based eHealth Data Analysis. IEEE Access 2021, 9, 112221–112235. [Google Scholar] [CrossRef]
- Jeewandara, J.; Karunaratne, L.; Sanju, K. An Efficient Machine Learning Based Elderly Monitoring System. In Proceedings of the 2021 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Mauritius, Mauritius, 7–8 October 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Bergefurt, L.; Kemperman, A.; van den Berg, P.; Borgers, A.; van der Waerden, P.; Oosterhuis, G.; Hommel, M. Loneliness and Life Satisfaction Explained by Public-Space Use and Mobility Patterns. Int. J. Environ. Res. Public Health 2019, 16, 4282. [Google Scholar] [CrossRef] [Green Version]
- Shvedko, A.V.; Thompson, J.L.; Greig, C.A.; Whittaker, A.C. Physical Activity Intervention for Loneliness (PAIL) in community-dwelling older adults: A randomised feasibility study. Pilot Feasibility Stud. 2020, 6, 73. [Google Scholar] [CrossRef] [PubMed]
- AISOLA (Implementation of Contextual Complexity in AI-Based Assessment Systems of Older People’s Social Isolation). Available online: https://projects.tuni.fi/aisola/ (accessed on 14 June 2022).
- Lubben, J.; Blozik, E.; Gillmann, G.; Iliffe, S.; von Renteln Kruse, W.; Beck, J.C.; Stuck, A.E. Performance of an abbreviated version of the Lubben Social Network Scale among three European community-dwelling older adult populations. Gerontologist 2006, 46, 503–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russell, D.; Peplau, L.A.; Cutrona, C.E. The revised UCLA Loneliness Scale: Concurrent and discriminant validity evidence. J. Personal. Soc. Psychol. 1980, 39, 472. [Google Scholar] [CrossRef]
- Hughes, M.E.; Waite, L.J.; Hawkley, L.C.; Cacioppo, J.T. A short scale for measuring loneliness in large surveys: Results from two population-based studies. Res. Aging 2004, 26, 655–672. [Google Scholar] [CrossRef] [PubMed]
- Dabove, P.; Di Pietra, V.; Piras, M.; Jabbar, A.A.; Kazim, S.A. Indoor positioning using Ultra-wide band (UWB) technologies: Positioning accuracies and sensors’ performances. In Proceedings of the 2018 IEEE/ION Position, Location and Navigation Symposium (PLANS), Monterey, CA, USA, 23–26 April 2018; pp. 175–184. [Google Scholar] [CrossRef]
- Plachta, K. Autonomous tracking controller for photovoltaic systems using global positioning system. In Proceedings of the 2018 IEEE International Conference on Environment and Electrical Engineering and 2018 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Palermo, Italy, 12–15 June 2018; pp. 1–5. [Google Scholar]
- Toledo-Perez, D.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A study of computing zero crossing methods and an improved proposal for EMG signals. IEEE Access 2020, 8, 8783–8790. [Google Scholar] [CrossRef]
- Gallegos-Duarte, M.; Mendiola-Santibañez, J.D.; Ibrahimi, D.; Paredes-Orta, C.; Rodríguez-Reséndiz, J.; González-Gutiérrez, C.A. A novel method for measuring subtle alterations in pupil size in children with congenital strabismus. IEEE Access 2020, 8, 125331–125344. [Google Scholar] [CrossRef]
- Seguara, L.; Zamora-Antuñano, M.; Resendiz, J.; Paredes-García, W.; Altamirano-Corro, J.; Cruz-Pérez, M. Teaching challenges in COVID-19 scenery: Teams platform-based student satisfaction approach. Sustainability 2020, 12, 7514. [Google Scholar] [CrossRef]
- Barreda Luna, A.A.; Kuri, G.H.; Rodríguez-Reséndiz, J.; Zamora Antuñano, M.A.; Altamirano Corro, J.A.; Paredes-Garcia, W.J. Public space accessibility and machine learning tools for street vending spatial categorization. J. Maps 2022, 1–10. [Google Scholar] [CrossRef]
- Tobore, I.; Kandwal, A.; Li, J.; Yan, Y.; Omisore, O.M.; Enitan, E.; Sinan, L.; Yuhang, L.; Wang, L.; Nie, Z. Towards adequate prediction of prediabetes using spatiotemporal ECG and EEG feature analysis and weight-based multi-model approach. Knowl.-Based Syst. 2020, 209, 106464. [Google Scholar] [CrossRef]
- Gokul, H.; Suresh, P.; Hari Vignesh, B.; Pravin Kumaar, R.; Vijayaraghavan, V. Gait Recovery System for Parkinson’s Disease using Machine Learning on Embedded Platforms. In Proceedings of the 2020 IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24 August–20 September 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Yue, Z.; Jinjing, Z. Atrial Fibrillation Detection Based on EEMD and XGBoost. J. Phys. Conf. Ser. 2019, 1229, 012074. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Data | Sensors | Methodology | Findings | Results |
|---|---|---|---|---|---|
| [1] | ELSA dataset (The English Longitudinal Study of Ageing) | - | Machine learning analysis (XGBoost, LightGBM) | Predicting loneliness | AUC (Area under curve) 0.84–0.88 |
| [2] | Health parameters | Fitbit watch | mobility patterns, Machine learning analysis | IOT platform for elderly monitoring | - |
| [6] | Health parameters | Accelerometer, ECG | Machine learning analysis (Naive Bayes) | Human activity recognition | Accuracy 0.92 (Fall detection), 0.99 (Resting), 0.99 (Walking) |
| [7] | Questionnaire on demographics, mobility patterns, use of public spaces, neighbourhood | - | Path analysis | Identifying loneliness using public space use and mobility patterns | - |
| [8] | Demographic, physical activity, health parameters | - | ANOVA, chi-square test | Physical activity intervention in loneliness | - |
| Current study | Sensor based mobility patterns | Pozyx, Pico minifinder | Machine learning analysis (XGBoost, Random forest, Support vector machine) | Identifying risk of loneliness using mobility patterns | Accuracy 0.90–0.98 |
| Name | Data Type | Description |
|---|---|---|
| tagID | String | Tag which is captured |
| timestamp | Number | time of data capture (epoch time) |
| success | Boolean | indicating whether the position could be measured or not |
| data.coordinates | Array | The 3D location of the tag within the monitored region (local coordinates) |
| data.tagData.blinkIndex | Number | Index identifying the signal that the tag sent out. |
| data.tagData.accelerometer | Array | An array of acceleration measurements along X, Y and Z axes. |
| data.tagData.status | Number | The programmed state of the tag changeable with the interactive push button. |
| data.anchorData | Array | An array of the anchors which participated in detecting the tag location, and the RSS of the UWB packet at each anchor’s antenna. |
| data.zones | Array | Array containing the zone id and the zone name where the tag is present. |
| Colour Indicators | Device Status |
|---|---|
| Green | Online state (location data is being transmitted) |
| Orange | Passive state (location data was sent over 10 min ago) |
| Red | Passive state (location data was sent over 1 h ago) |
| White | Offline state |
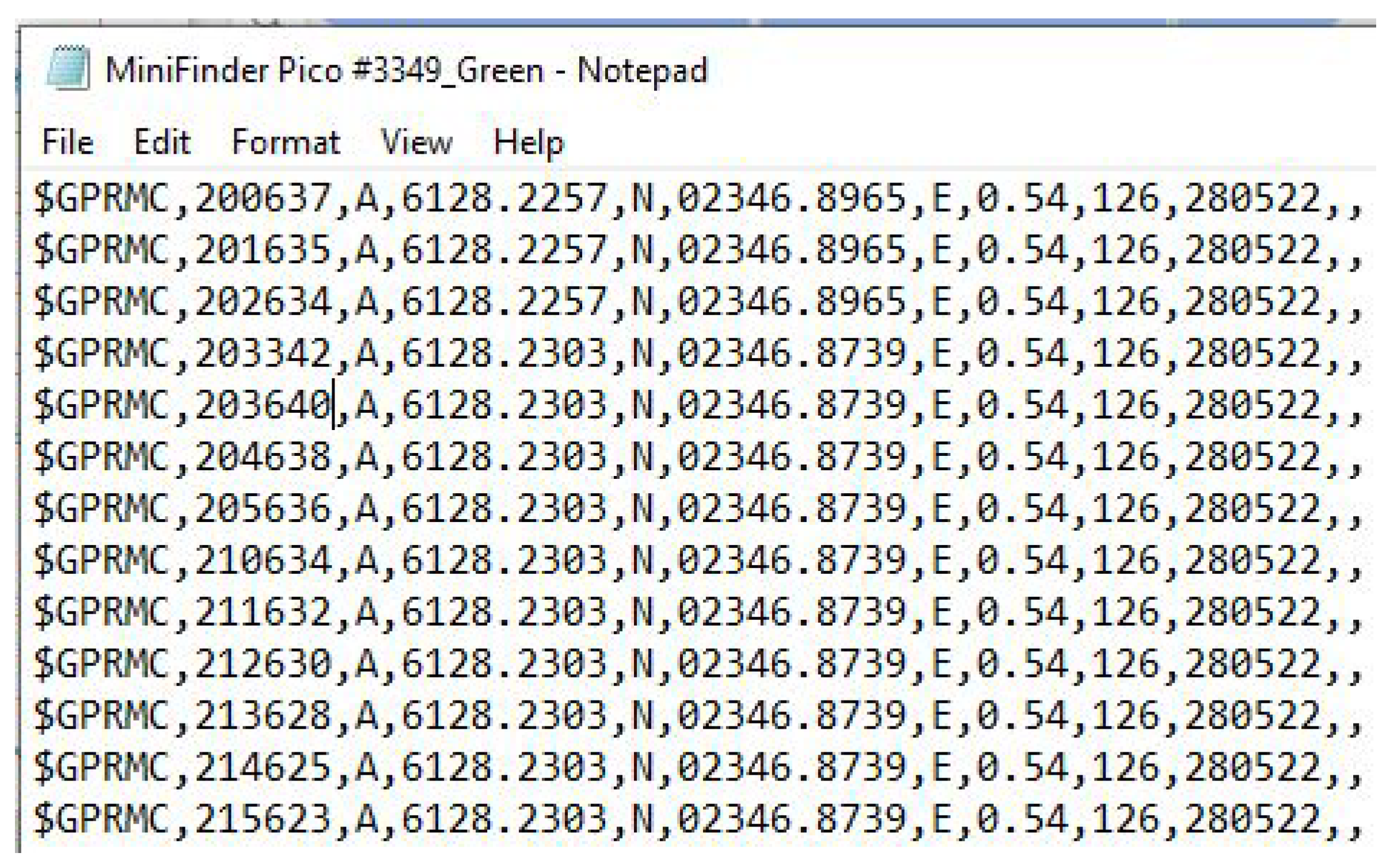
| Name | Data Type | Description |
|---|---|---|
| 200637 | Number | Time Stamp |
| A | String | Validity—A-OK, V-invalid. |
| 6128.2257 | Number | Current Latitude |
| N | String | North/South |
| 02346.8965 | Number | Current Longitude |
| E | String | East/West |
| 0.54 | Number | Speed in knots |
| 126 | Number | True course |
| 280522 | Number | Date Stamp |
| Name | Loneliness Labels |
|---|---|
| Low level of loneliness | 0 |
| Medium level of loneliness | 1 |
| High level of loneliness | 2 |
| Indoor Data Results | Outdoor Data Results | Combined Data Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Algorithm | User Classification | UCLA Based Classification | Lubben Based Classification | User Classification | UCLA Based Classification | Lubben Based Classification | User Classification | UCLA Based Classification | Lubben Based Classification |
| Support vector machines | |||||||||
| Random forest | |||||||||
| XGBoost | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Site, A.; Vasudevan, S.; Afolaranmi, S.O.; Lastra, J.L.M.; Nurmi, J.; Lohan, E.S. A Machine-Learning-Based Analysis of the Relationships between Loneliness Metrics and Mobility Patterns for Elderly. Sensors 2022, 22, 4946. https://doi.org/10.3390/s22134946
Site A, Vasudevan S, Afolaranmi SO, Lastra JLM, Nurmi J, Lohan ES. A Machine-Learning-Based Analysis of the Relationships between Loneliness Metrics and Mobility Patterns for Elderly. Sensors. 2022; 22(13):4946. https://doi.org/10.3390/s22134946
Chicago/Turabian StyleSite, Aditi, Saigopal Vasudevan, Samuel Olaiya Afolaranmi, Jose L. Martinez Lastra, Jari Nurmi, and Elena Simona Lohan. 2022. "A Machine-Learning-Based Analysis of the Relationships between Loneliness Metrics and Mobility Patterns for Elderly" Sensors 22, no. 13: 4946. https://doi.org/10.3390/s22134946
APA StyleSite, A., Vasudevan, S., Afolaranmi, S. O., Lastra, J. L. M., Nurmi, J., & Lohan, E. S. (2022). A Machine-Learning-Based Analysis of the Relationships between Loneliness Metrics and Mobility Patterns for Elderly. Sensors, 22(13), 4946. https://doi.org/10.3390/s22134946