
Deep Learning-Based Vehicle Classification for Low Quality Images

 , , , and
, , , and 
Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- (a)
- A new dataset containing tiny and low quality vehicle images collected by a standard security camera, which is installed distant from the ROI, is created (imperfections on the camera and its installation are introduced together as per typical ITS application).
- (b)
- A novel CNN model is developed for the classification of low quality vehicle images, and its accuracy is compared with well-known CNN models.
- (c)
- The proposed model is shown to achieve an acceptable accuracy with its lightweight solution even if a small dataset containing low resolution surveillance images is used.
2. Models for Classifying Low Quality Vehicle Images
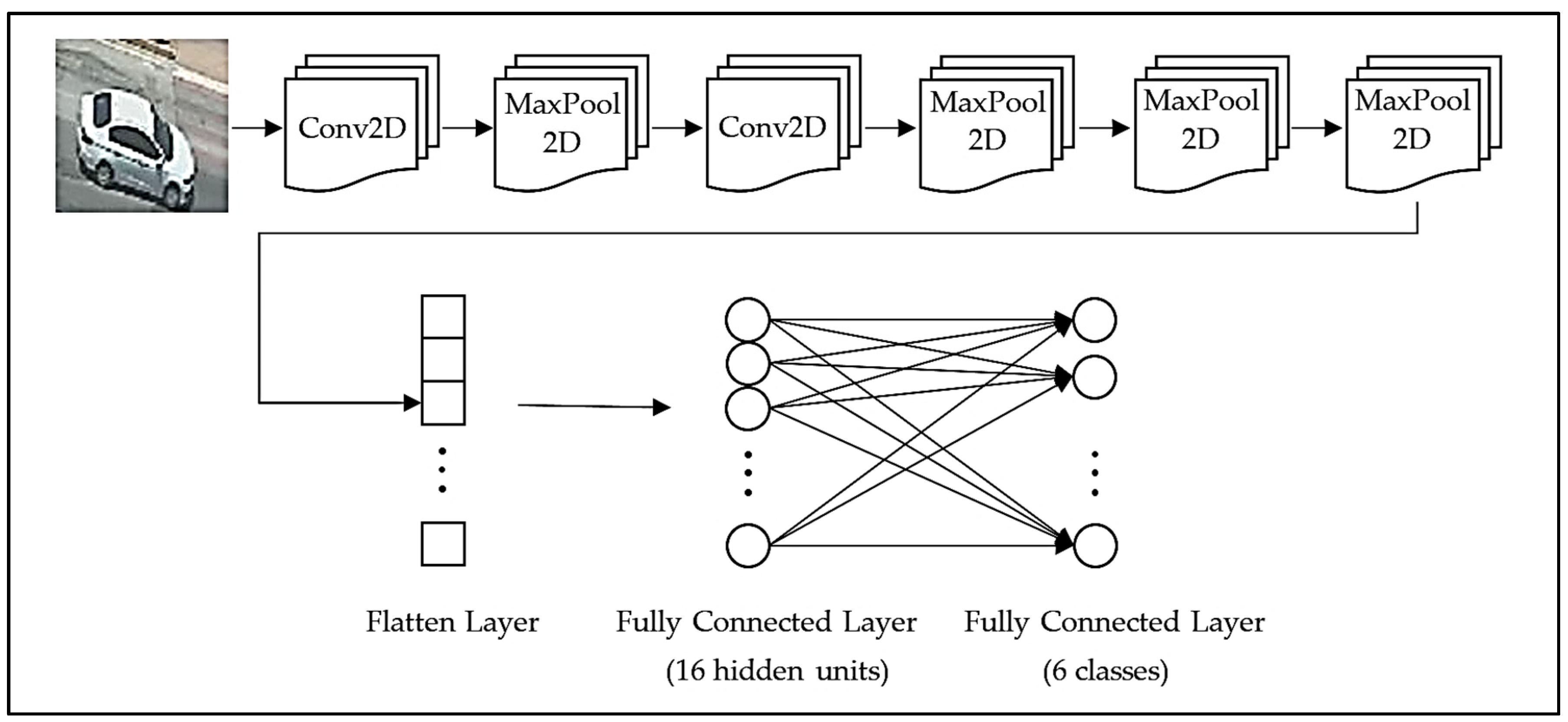
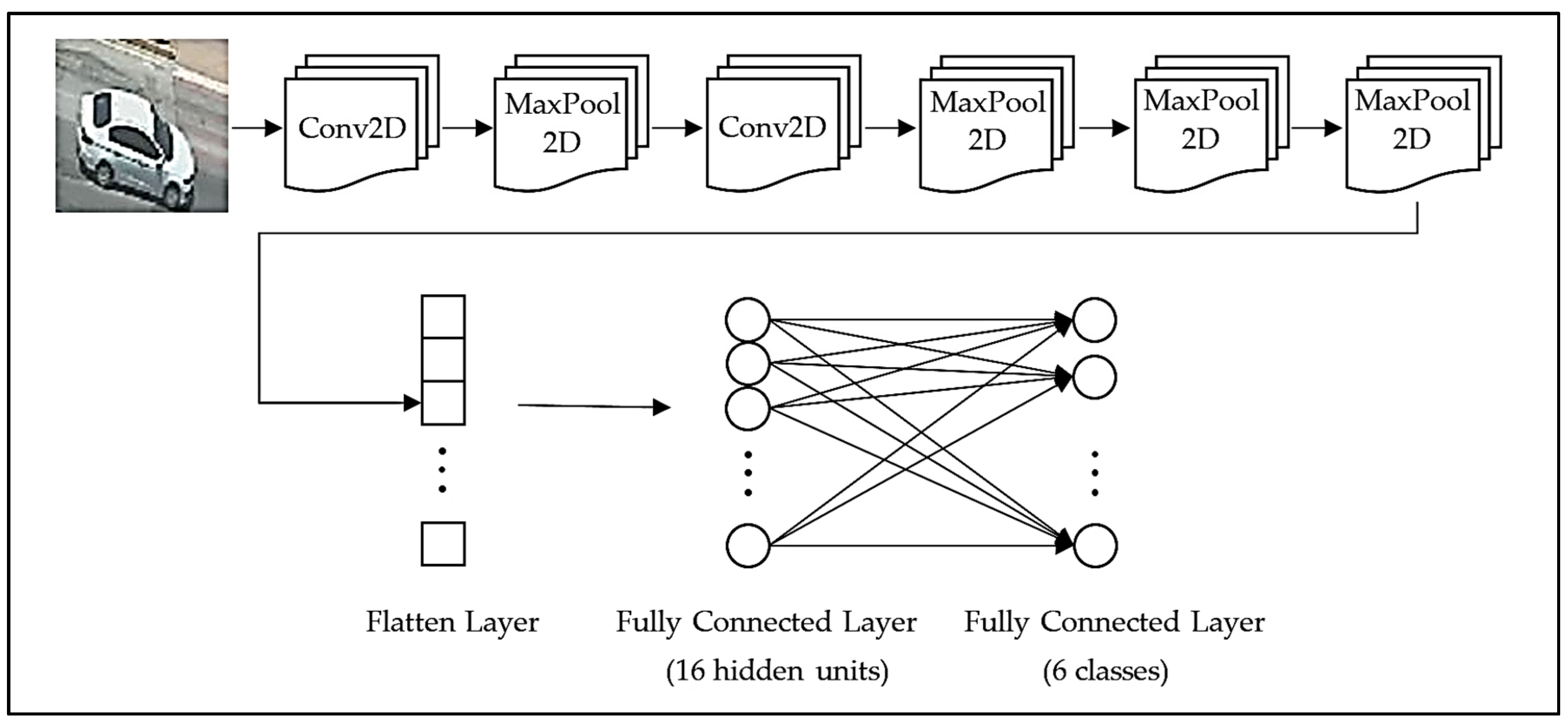
2.1. The Proposed Model
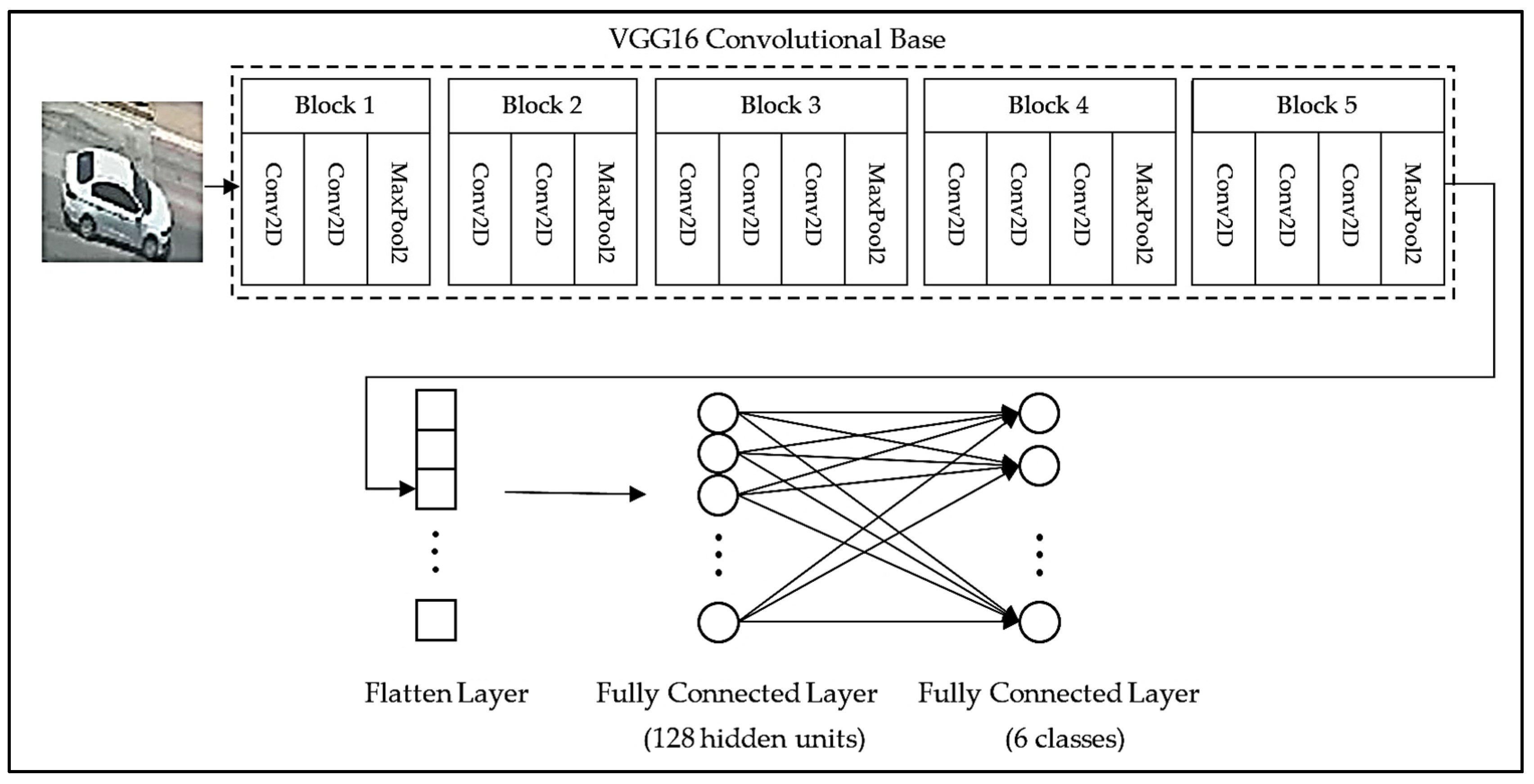
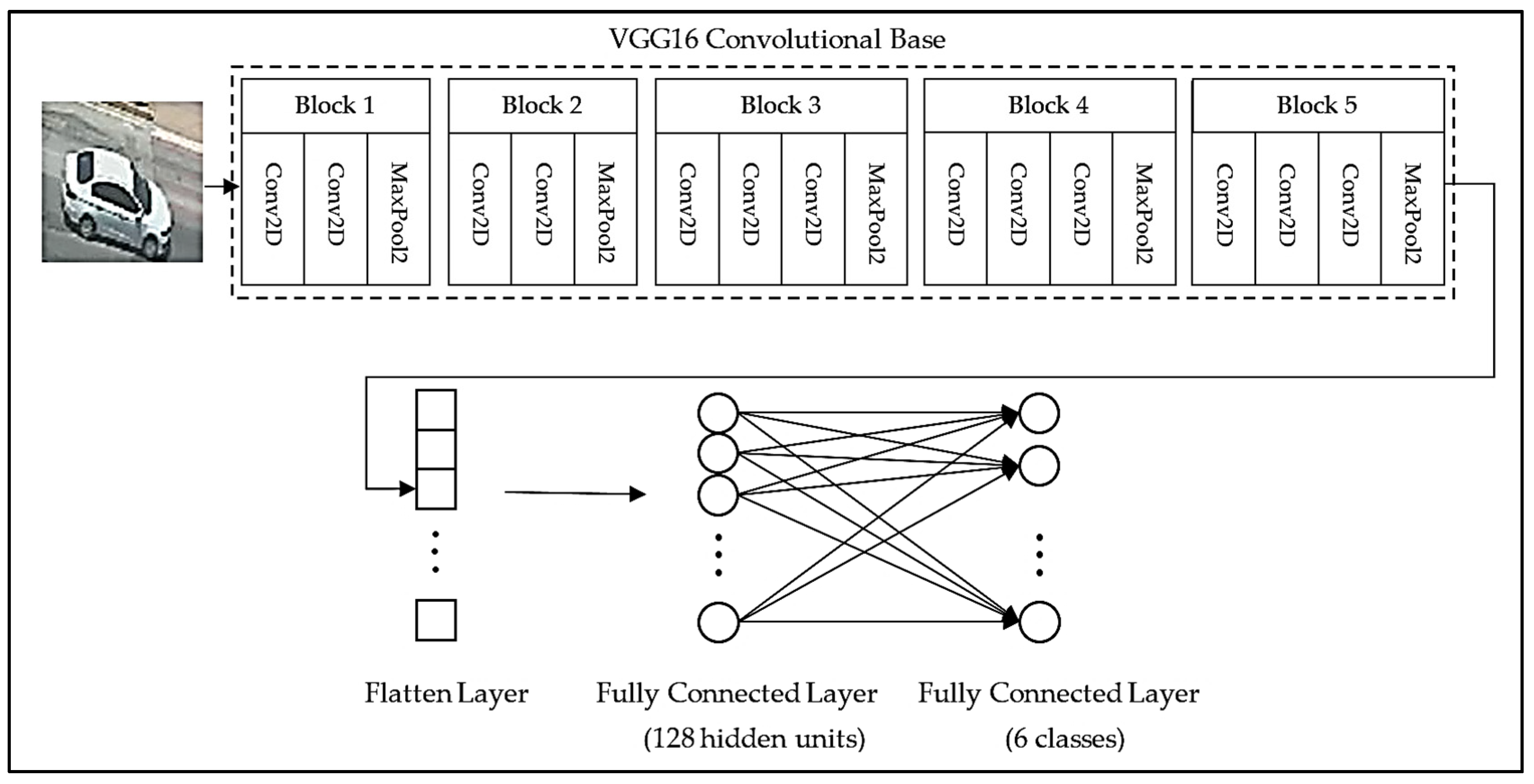
2.2. VGG16 Pre-Trained Model
2.3. VGG16 Fine-Tuning Pre-Trained Model
3. Experiments
3.1. Dataset and Preprocessing
3.2. Parameters and Training Details
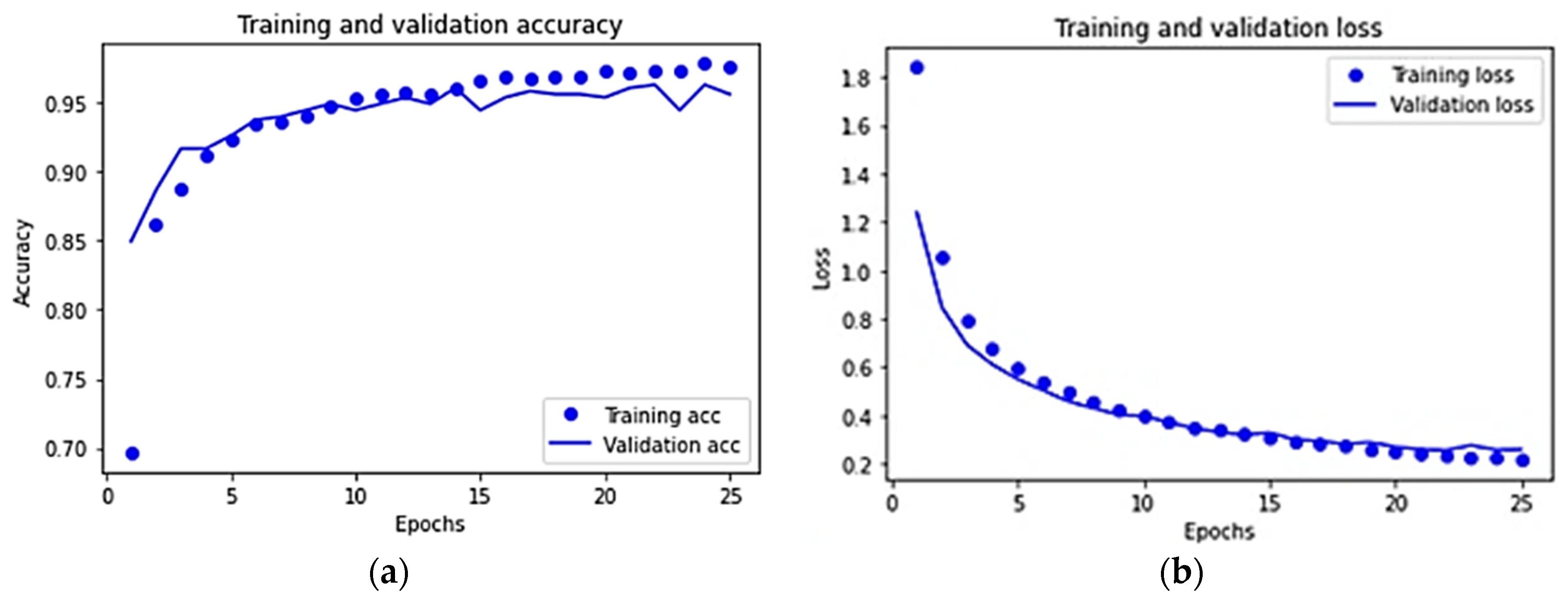
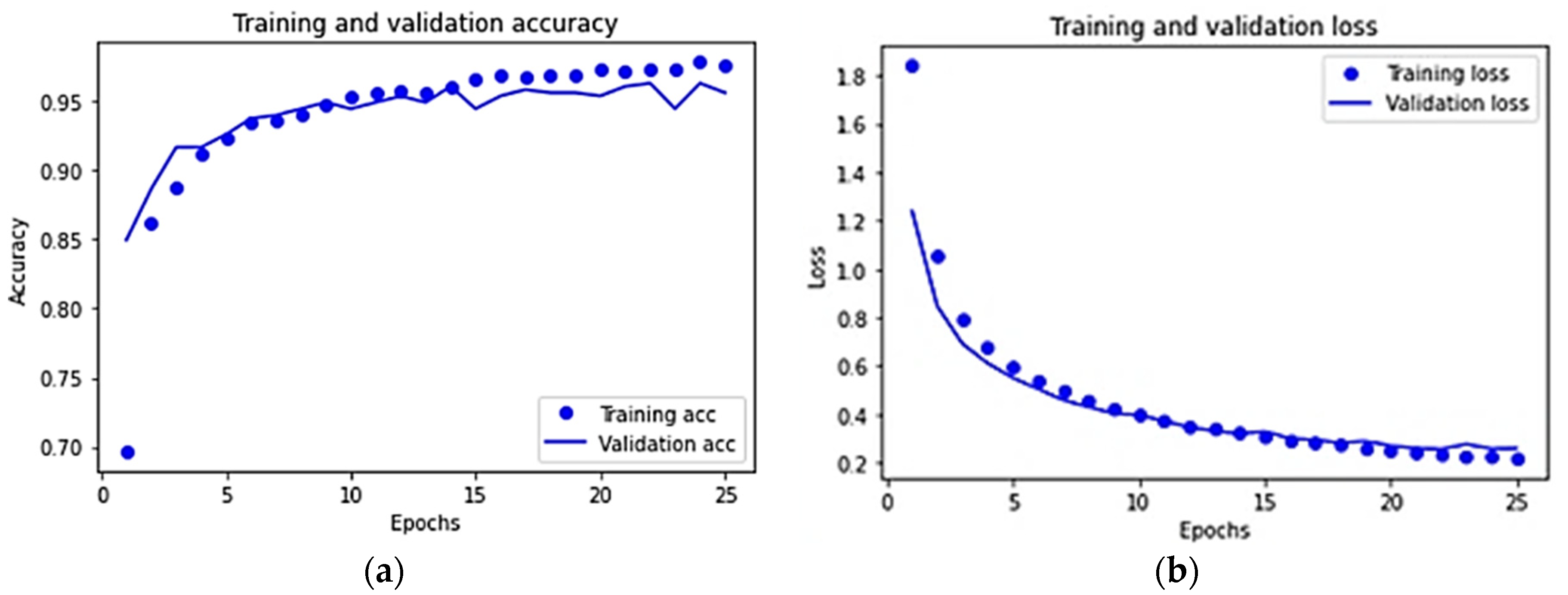
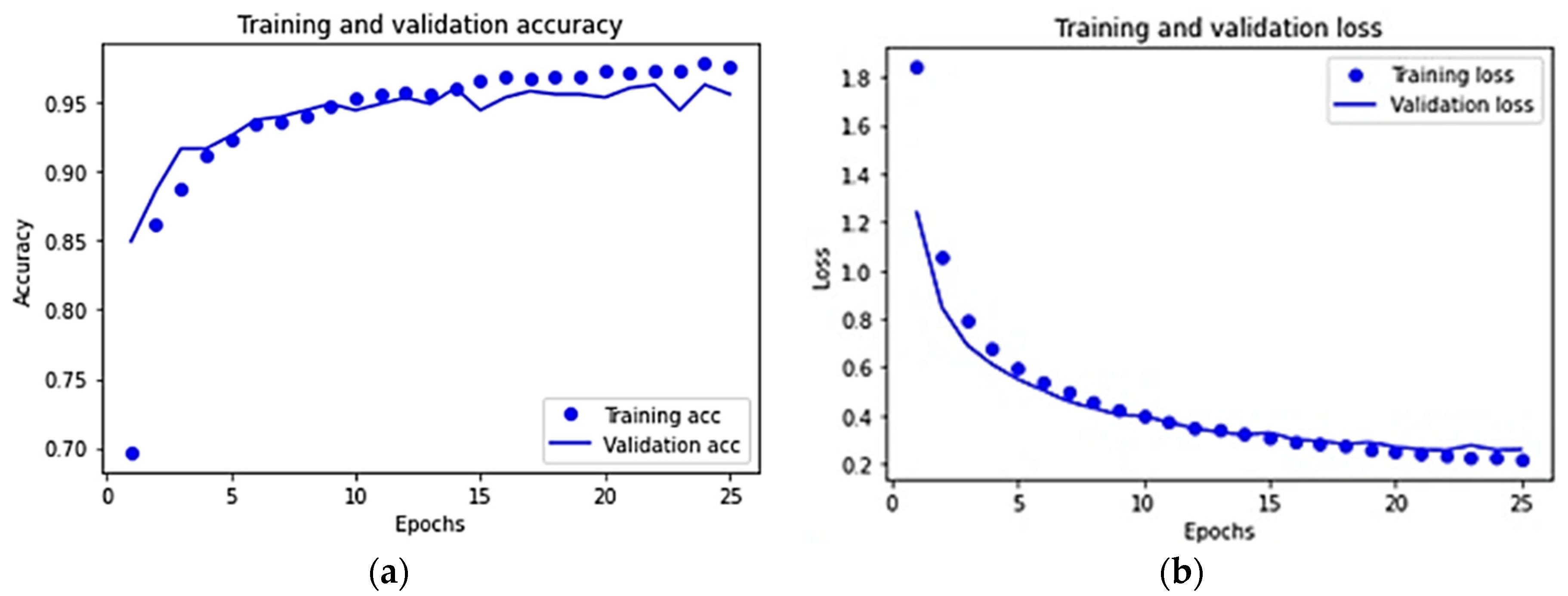
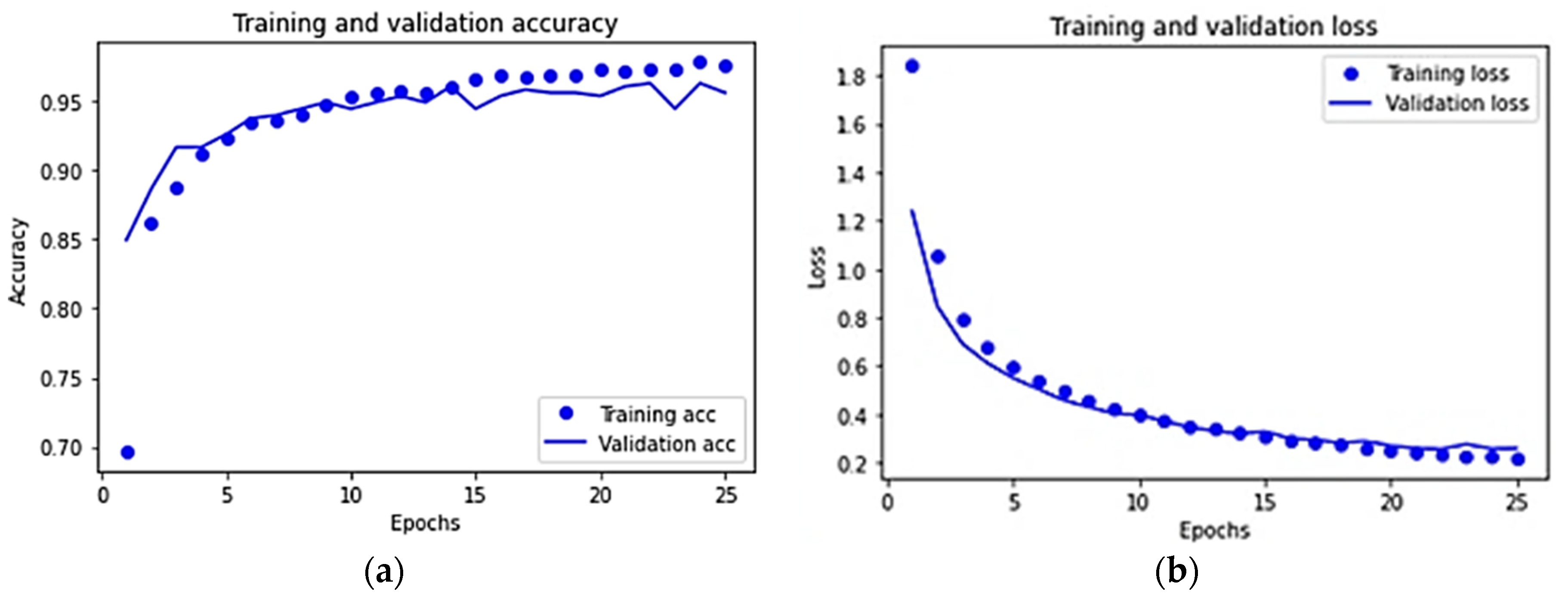
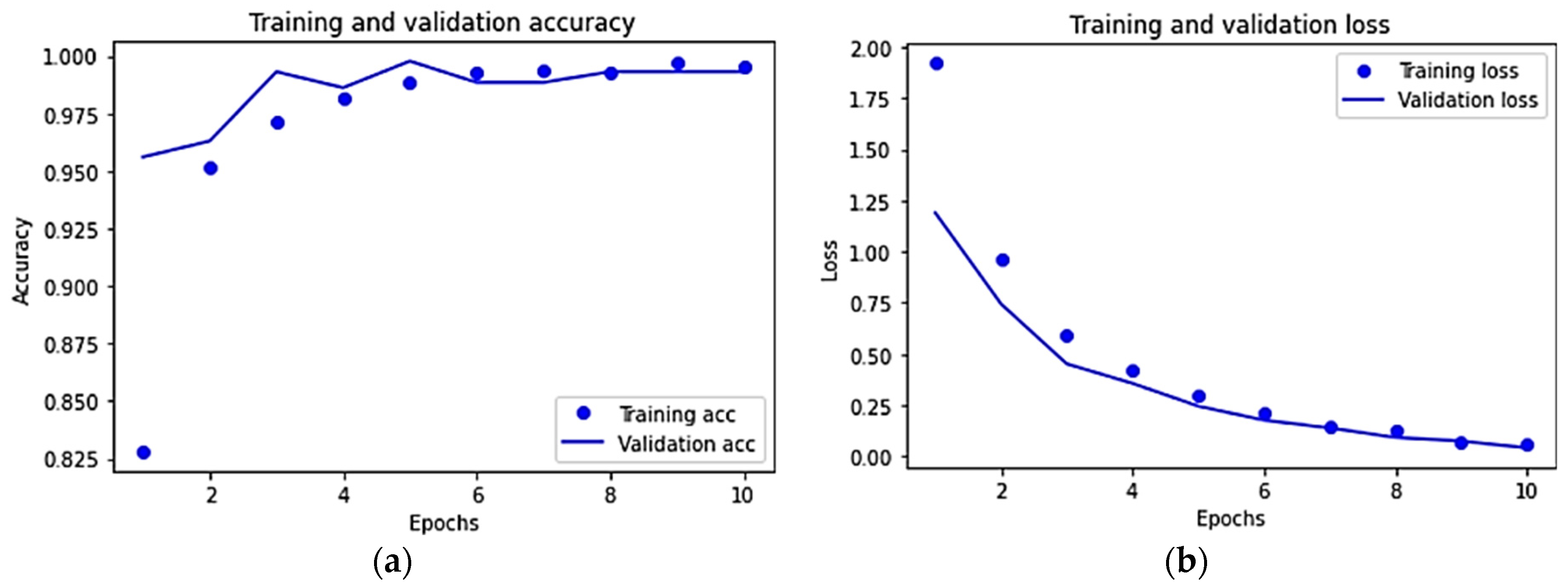
3.3. Results
4. Further Discussions and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gholamhosseinian, A.; Seitz, J. Vehicle Classification in Intelligent Transport Systems: An Overview, Methods and Software Perspective. IEEE Open J. Intell. Transp. Syst. 2021, 2, 173–194. [Google Scholar] [CrossRef]
- Shokravi, H.; Shokravi, H.; Bakhary, N.; Heidarrezaei, M.; Rahimian Koloor, S.S.; Petrů, M. A Review on Vehicle Classification and Potential Use of Smart Vehicle-Assisted Techniques. Sensors 2020, 20, 3274. [Google Scholar] [CrossRef]
- Won, M. Intelligent Traffic Monitoring Systems for Vehicle Classification: A Survey. IEEE Access 2020, 8, 73340–73358. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y. Vehicle Detection and Classification for Low-Speed Congested Traffic with Anisotropic Magnetoresistive Sensor. IEEE Sens. J. 2015, 15, 1132–1138. [Google Scholar] [CrossRef]
- Li, W.; Liu, Z.; Hui, Y.; Yang, L.; Chen, R.; Xiao, X. Vehicle Classification and Speed Estimation Based on a Single Magnetic Sensor. IEEE Access 2020, 8, 126814–126824. [Google Scholar] [CrossRef]
- Taghvaeeyan, S.; Rajamani, R. Portable Roadside Sensors for Vehicle Counting, Classification, and Speed Measurement. IEEE Trans. Intell. Transp. Syst. 2014, 15, 73–83. [Google Scholar] [CrossRef]
- Kaewkamnerd, S.; Pongthornseri, R.; Chinrungrueng, J.; Silawan, T. Automatic Vehicle Classification Using Wireless Magnetic Sensor. In Proceedings of the 2009 IEEE International Workshop on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Rende, Italy, 21–23 September 2009; pp. 420–424. [Google Scholar]
- Urazghildiiev, I.; Ragnarsson, R.; Ridderstrom, P.; Rydberg, A.; Ojefors, E.; Wallin, K.; Enochsson, P.; Ericson, M.; Lofqvist, G. Vehicle Classification Based on the Radar Measurement of Height Profiles. IEEE Trans. Intell. Transp. Syst. 2007, 8, 245–253. [Google Scholar] [CrossRef] [Green Version]
- Gupte, S.; Masoud, O.; Martin, R.F.K.; Papanikolopoulos, N.P. Detection and Classification of Vehicles. IEEE Trans. Intell. Transp. Syst. 2002, 3, 37–47. [Google Scholar] [CrossRef] [Green Version]
- De Matos, F.M.S.; de Souza, R.M.C.R. Hierarchical Classification of Vehicle Images Using Nn with Conditional Adaptive Distance. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 745–752. [Google Scholar]
- Ng, L.T.; Suandi, S.A.; Teoh, S.S. Vehicle Classification Using Visual Background Extractor and Multi-Class Support Vector Machines. In Proceedings of the the 8th International Conference on Robotic, Vision, Signal Processing & Power Applications, Penang, Malaysia, 10–12 November 2013; Springer: Berlin/Heidelberg, Germany, 2014; pp. 221–227. [Google Scholar]
- Chen, Y.; Qin, G. Video-Based Vehicle Detection and Classification in Challenging Scenarios. Int. J. Smart Sens. Intell. Syst. 2014, 7, 1077–1094. [Google Scholar] [CrossRef] [Green Version]
- Wen, X.; Shao, L.; Xue, Y.; Fang, W. A Rapid Learning Algorithm for Vehicle Classification. Inf. Sci. 2015, 295, 395–406. [Google Scholar] [CrossRef]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Cao, J.; Wang, W.; Wang, X.; Li, C.; Tang, J. End-to-End View-Aware Vehicle Classification via Progressive CNN Learning. In Proceedings of the CCF Chinese Conference on Computer Vision, Tianjin, China, 11–14 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 729–737. [Google Scholar]
- Hicham, B.; Ahmed, A.; Mohammed, M. Vehicle Type Classification Using Convolutional Neural Network. In Proceedings of the 2018 IEEE 5th International Congress on Information Science and Technology (CiSt), Marrakech, Morocco, 21–27 October 2018; pp. 313–316. [Google Scholar]
- Jo, S.Y.; Ahn, N.; Lee, Y.; Kang, S.-J. Transfer Learning-Based Vehicle Classification. In Proceedings of the 2018 International SoC Design Conference (ISOCC), Daegu, Korea, 12–15 November 2018; pp. 127–128. [Google Scholar]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Vision-Based Occlusion Handling and Vehicle Classification for Traffic Surveillance Systems. IEEE Intell. Transp. Syst. Mag. 2018, 10, 80–92. [Google Scholar] [CrossRef]
- Cai, J.; Deng, J.; Khokhar, M.S.; Aftab, M.U. Vehicle Classification Based on Deep Convolutional Neural Networks Model for Traffic Surveillance Systems. In Proceedings of the 2018 15th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 14–16 December 2018; pp. 224–227. [Google Scholar]
- Maungmai, W.; Nuthong, C. Vehicle Classification with Deep Learning. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–5 February 2019; pp. 294–298. [Google Scholar]
- Wang, X.; Zhang, W.; Wu, X.; Xiao, L.; Qian, Y.; Fang, Z. Real-Time Vehicle Type Classification with Deep Convolutional Neural Networks. J. Real-Time Image Process. 2019, 16, 5–14. [Google Scholar] [CrossRef]
- Mittal, U.; Potnuru, R.; Chawla, P. Vehicle Detection and Classification Using Improved Faster Region Based Convolution Neural Network. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 511–514. [Google Scholar]
- Chauhan, M.S.; Singh, A.; Khemka, M.; Prateek, A.; Sen, R. Embedded CNN Based Vehicle Classification and Counting in Non-Laned Road Traffic. In Proceedings of the 10th International Conference on Information and Communication Technologies and Development, Ahmedabad, India, 4–7 January 2019; pp. 1–11. [Google Scholar]
- Hedeya, M.A.; Eid, A.H.; Abdel-Kader, R.F. A Super-Learner Ensemble of Deep Networks for Vehicle-Type Classification. IEEE Access 2020, 8, 98266–98280. [Google Scholar] [CrossRef]
- Yang, Y. Realization of Vehicle Classification System Based on Deep Learning. In Proceedings of the 2020 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 28–30 July 2020; pp. 308–311. [Google Scholar]
- Bautista, C.M.; Dy, C.A.; Mañalac, M.I.; Orbe, R.A.; Cordel, M. Convolutional Neural Network for Vehicle Detection in Low Resolution Traffic Videos. In Proceedings of the 2016 IEEE Region 10 Symposium (TENSYMP), Bali, Indonesia, 9–11 May 2016; pp. 277–281. [Google Scholar]
- Tsai, C.-C.; Tseng, C.-K.; Tang, H.-C.; Guo, J.-I. Vehicle Detection and Classification Based on Deep Neural Network for Intelligent Transportation Applications. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1605–1608. [Google Scholar]
- Wang, X.; Chen, X.; Wang, Y. Small Vehicle Classification in the Wild Using Generative Adversarial Network. Neural Comput. Appl. 2021, 33, 5369–5379. [Google Scholar] [CrossRef]
- Tas, S.; Sari, O.; Dalveren, Y.; Pazar, S.; Kara, A.; Derawi, M. A Dataset Containing Tiny and Low Quality Images for Vehicle Classification. Zenodo 2022. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Véstias, M.P. A Survey of Convolutional Neural Networks on Edge with Reconfigurable Computing. Algorithms 2019, 12, 154. [Google Scholar] [CrossRef] [Green Version]
- Kim, P. MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Apress: New York, NY, USA, 2017; ISBN 9781484228449. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Washington, DC, USA, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A Large-Scale Car Dataset for Fine-Grained Categorization and Verification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar]
- Huilgol, P. Top 4 Pre-Trained Models for Image Classification—With Python Code; Analytics Vidhya: Gurgaon, India, 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | Intel Core i7-7500U @3.5 GHz |
| GPU | NVIDIA GeForce 920M |
| Memory (RAM) | 8 GB |
| Operating System | Windows 10 (64 bits) |
| CNN Models | Accuracy (%) | Loss (%) | # Layers | # Parameters | Training Time (Minutes) |
|---|---|---|---|---|---|
| Proposed Model | 92.9 | 30.3 | 9 | ~17 k | ~6 |
| VGG16 Pre-trained Model | 96 | 24.7 | 21 | ~15.3 M | ~28 |
| VGG16 Fine-tuning Pre-trained Model | 99.2 | 7.7 | 21 | ~15.3 M | ~15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tas, S.; Sari, O.; Dalveren, Y.; Pazar, S.; Kara, A.; Derawi, M. Deep Learning-Based Vehicle Classification for Low Quality Images. Sensors 2022, 22, 4740. https://doi.org/10.3390/s22134740
Tas S, Sari O, Dalveren Y, Pazar S, Kara A, Derawi M. Deep Learning-Based Vehicle Classification for Low Quality Images. Sensors. 2022; 22(13):4740. https://doi.org/10.3390/s22134740
Chicago/Turabian StyleTas, Sumeyra, Ozgen Sari, Yaser Dalveren, Senol Pazar, Ali Kara, and Mohammad Derawi. 2022. "Deep Learning-Based Vehicle Classification for Low Quality Images" Sensors 22, no. 13: 4740. https://doi.org/10.3390/s22134740
APA StyleTas, S., Sari, O., Dalveren, Y., Pazar, S., Kara, A., & Derawi, M. (2022). Deep Learning-Based Vehicle Classification for Low Quality Images. Sensors, 22(13), 4740. https://doi.org/10.3390/s22134740