
Method for Continuous Integration and Deployment Using a Pipeline Generator for Agile Software Projects




Abstract
:1. Introduction
2. Literature Review
2.1. Related Work
2.1.1. Argo CD
2.1.2. FluxCD
2.2. Core Concepts
2.2.1. Continuous Integration (CI)
2.2.2. Continuous Delivery (CD)
2.2.3. Continuous Deployment (CDT)
2.2.4. CI/CD Pipeline
2.2.5. CI/CD Tools
Version Control and Repository
Build Tools
Automation Tests
Deployment Tools
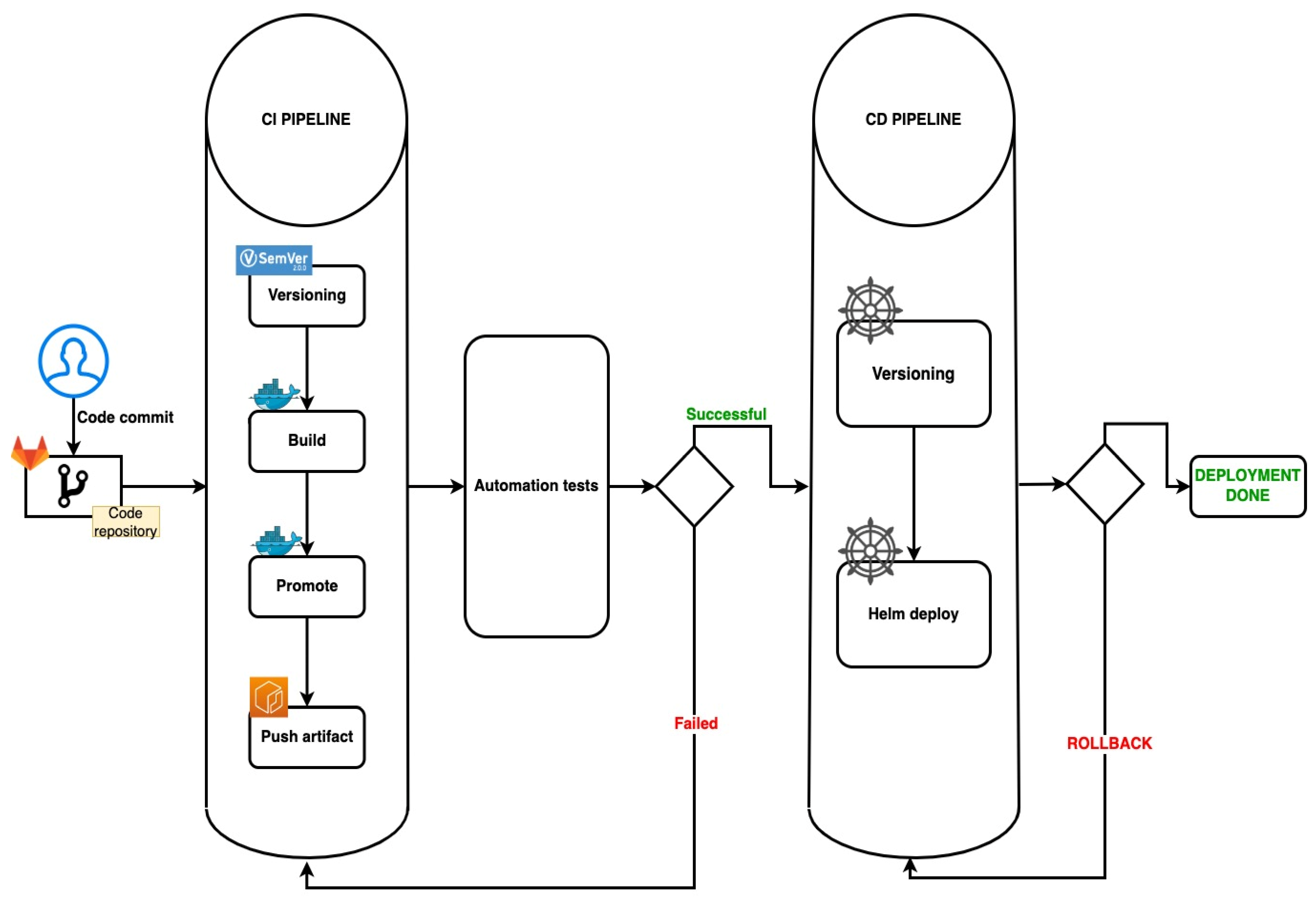
3. Proposed Solution Architecture
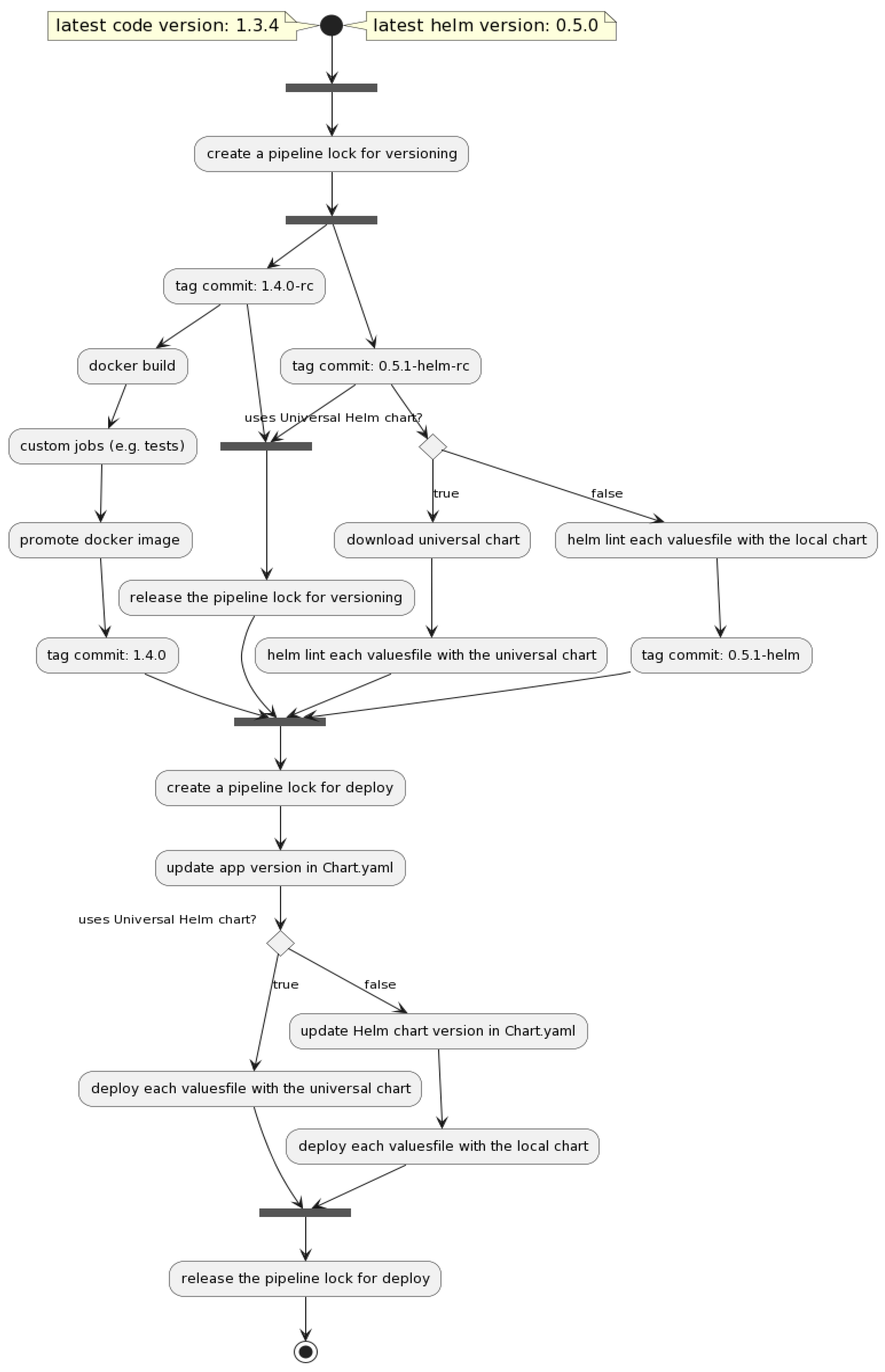
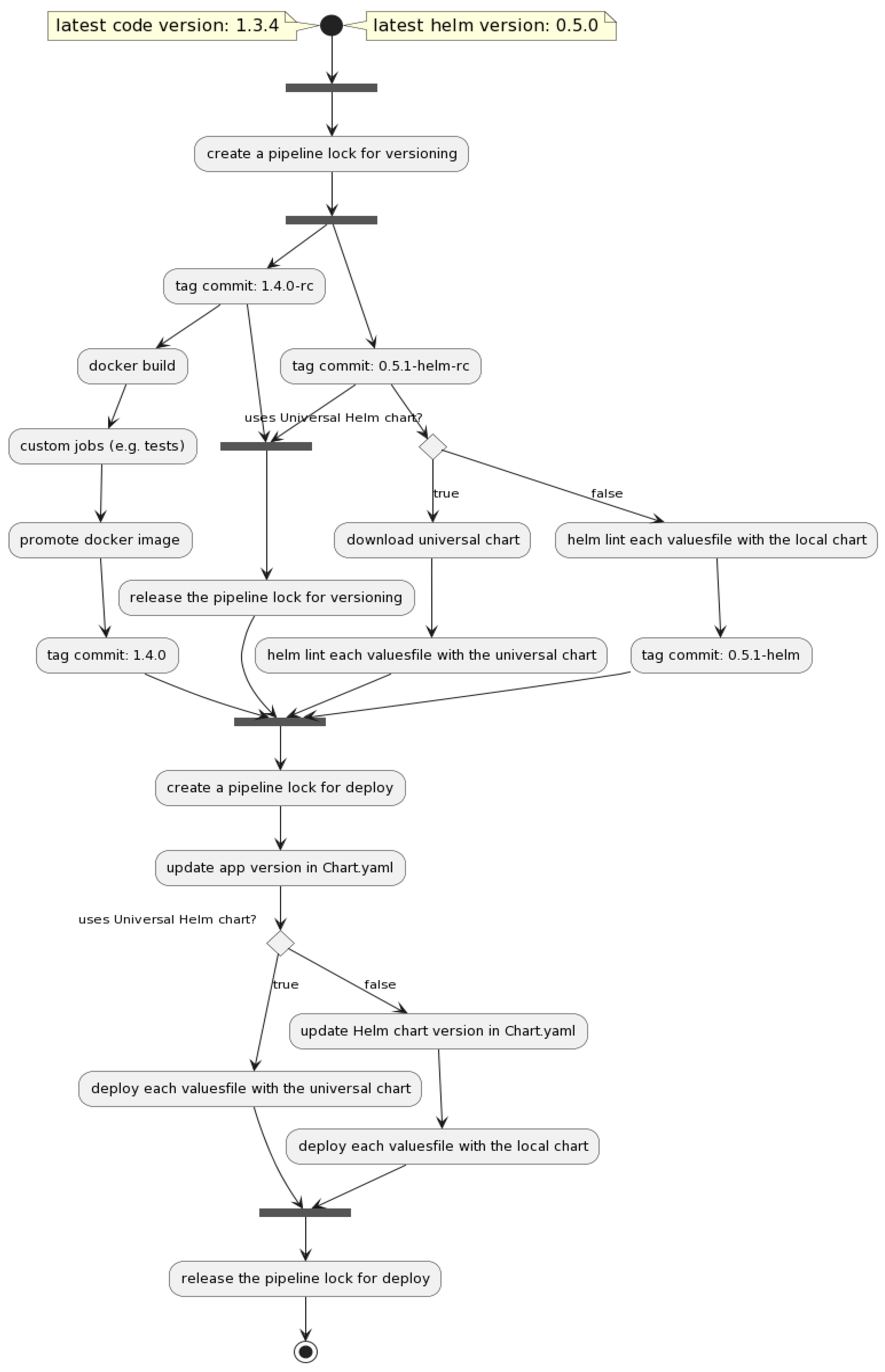
3.1. Pipeline Generator
- the pipeline configuration files (i.e., .gitlab-ci.yml and the files from the .ci/ folder) are regenerated with the latest stable templates;
- if there are changes, the pipeline configuration files are pushed back to the remote HEAD, and the current pipeline is forced to terminate.
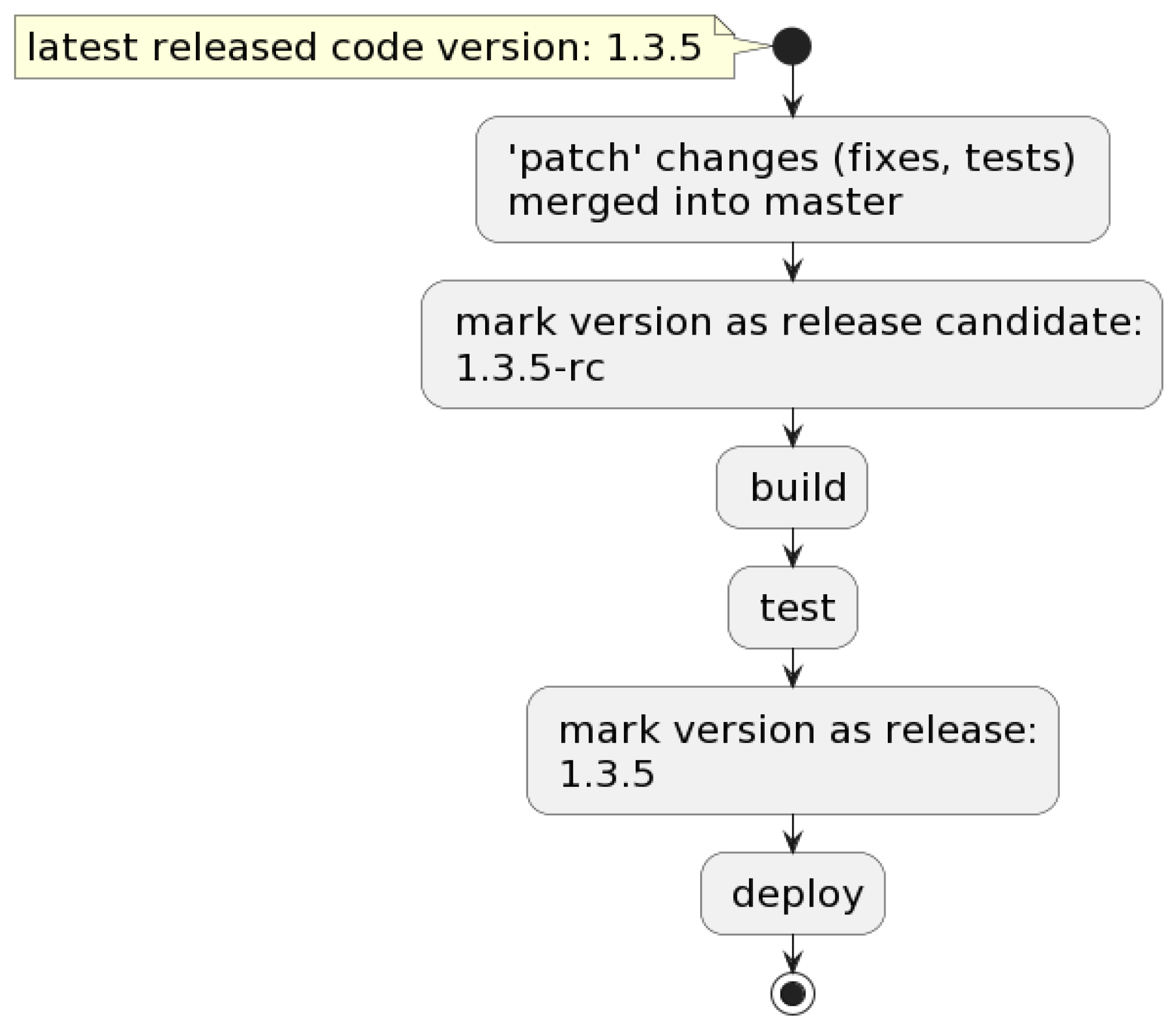
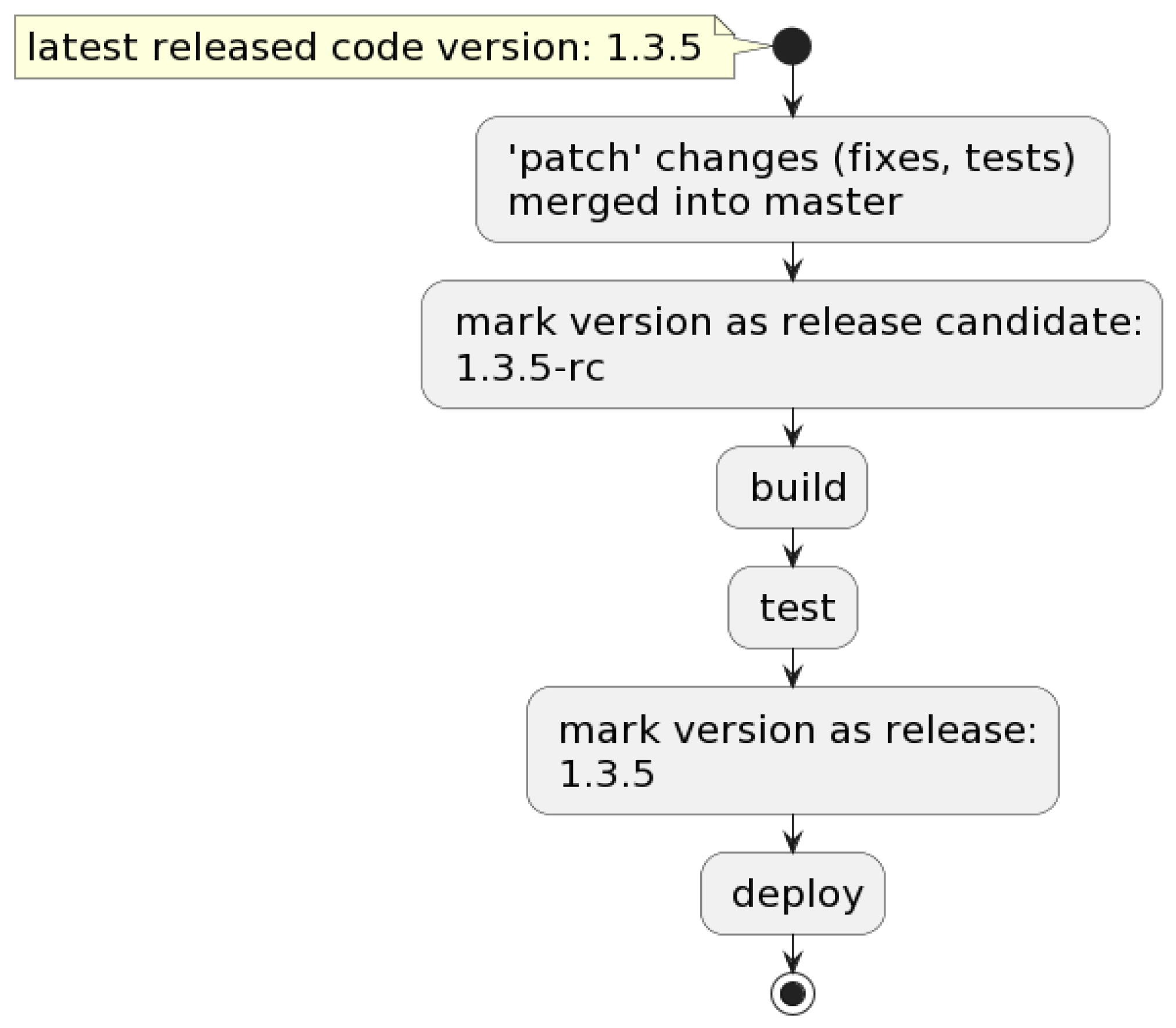
3.2. Versioning
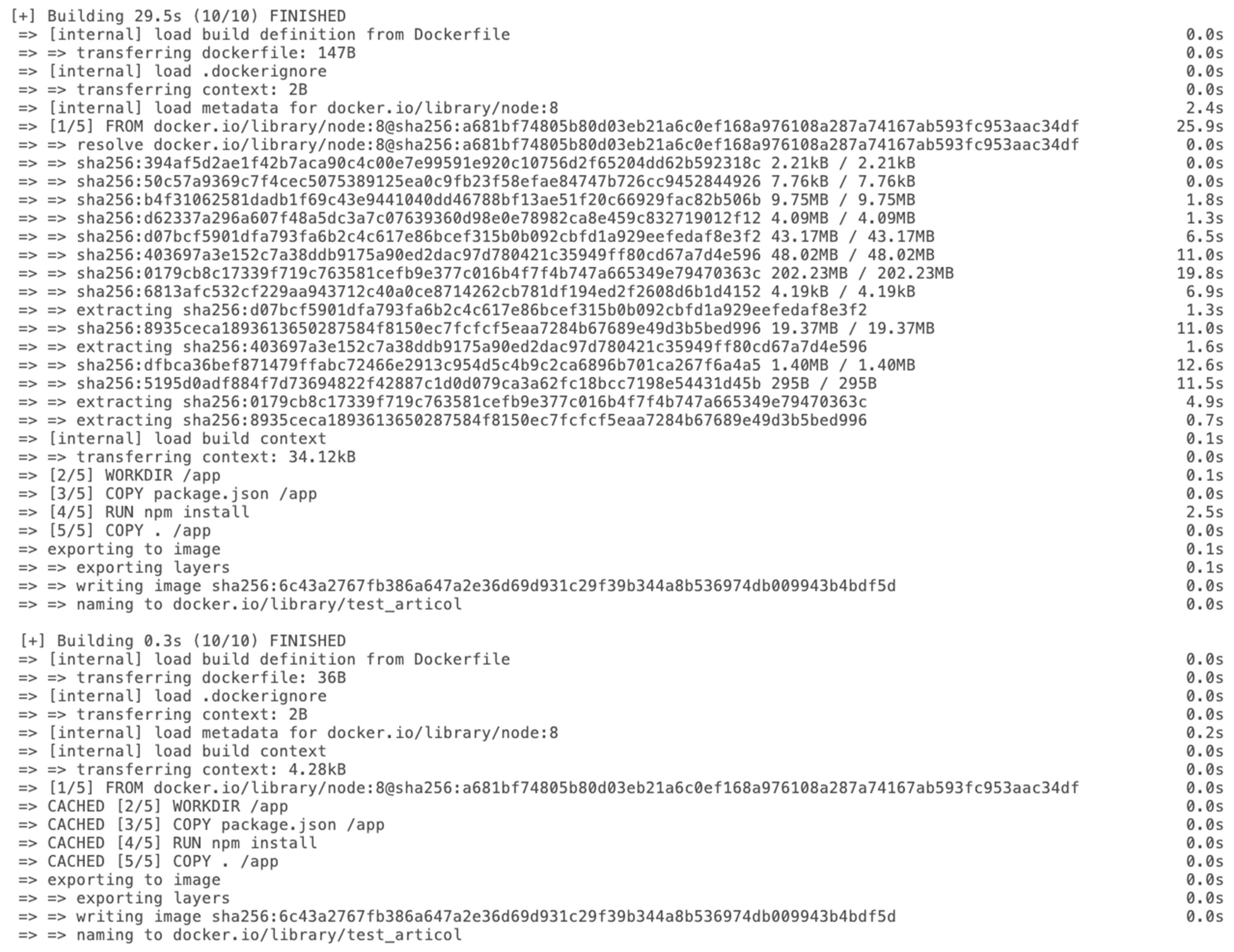
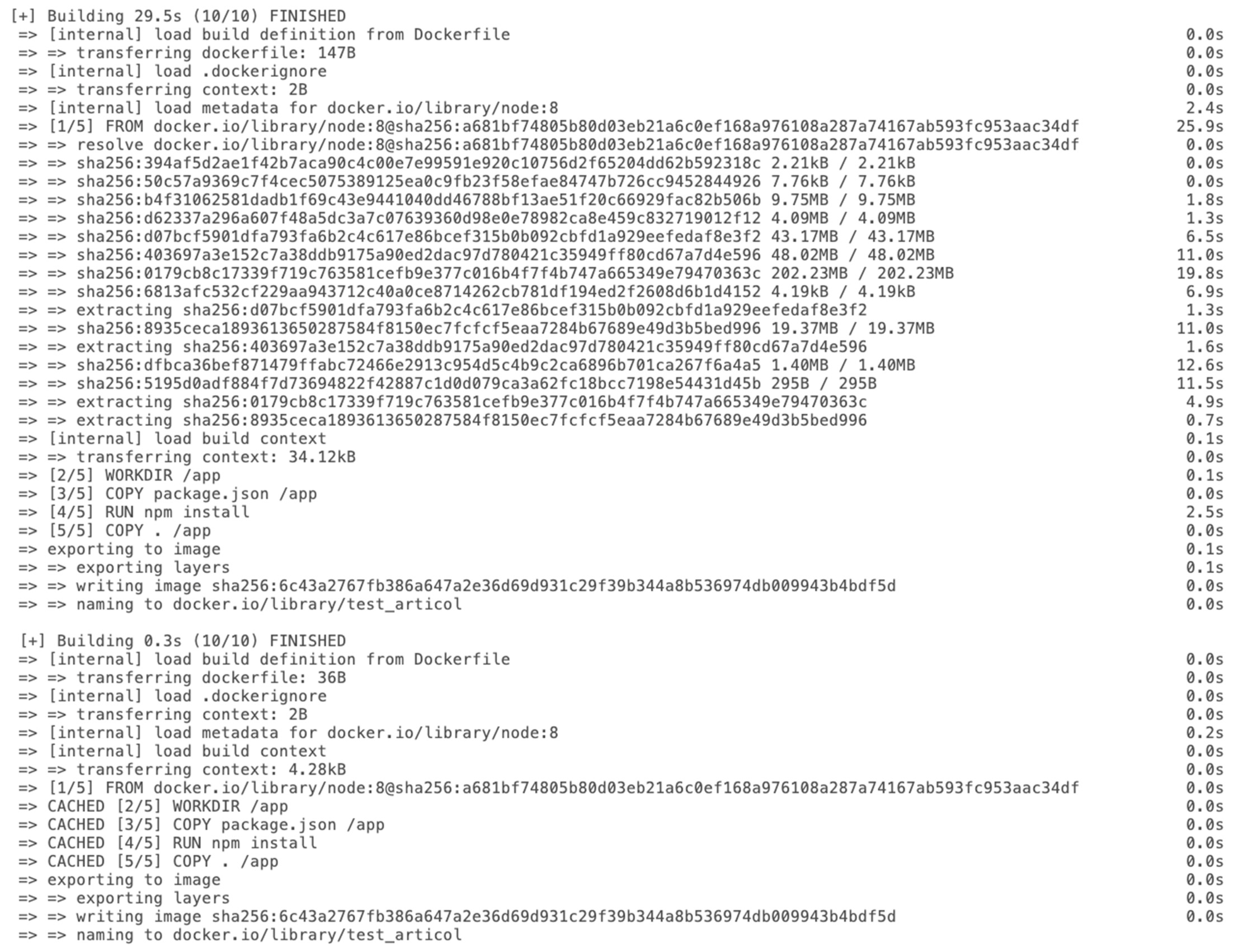
3.3. Build
3.4. Deploy
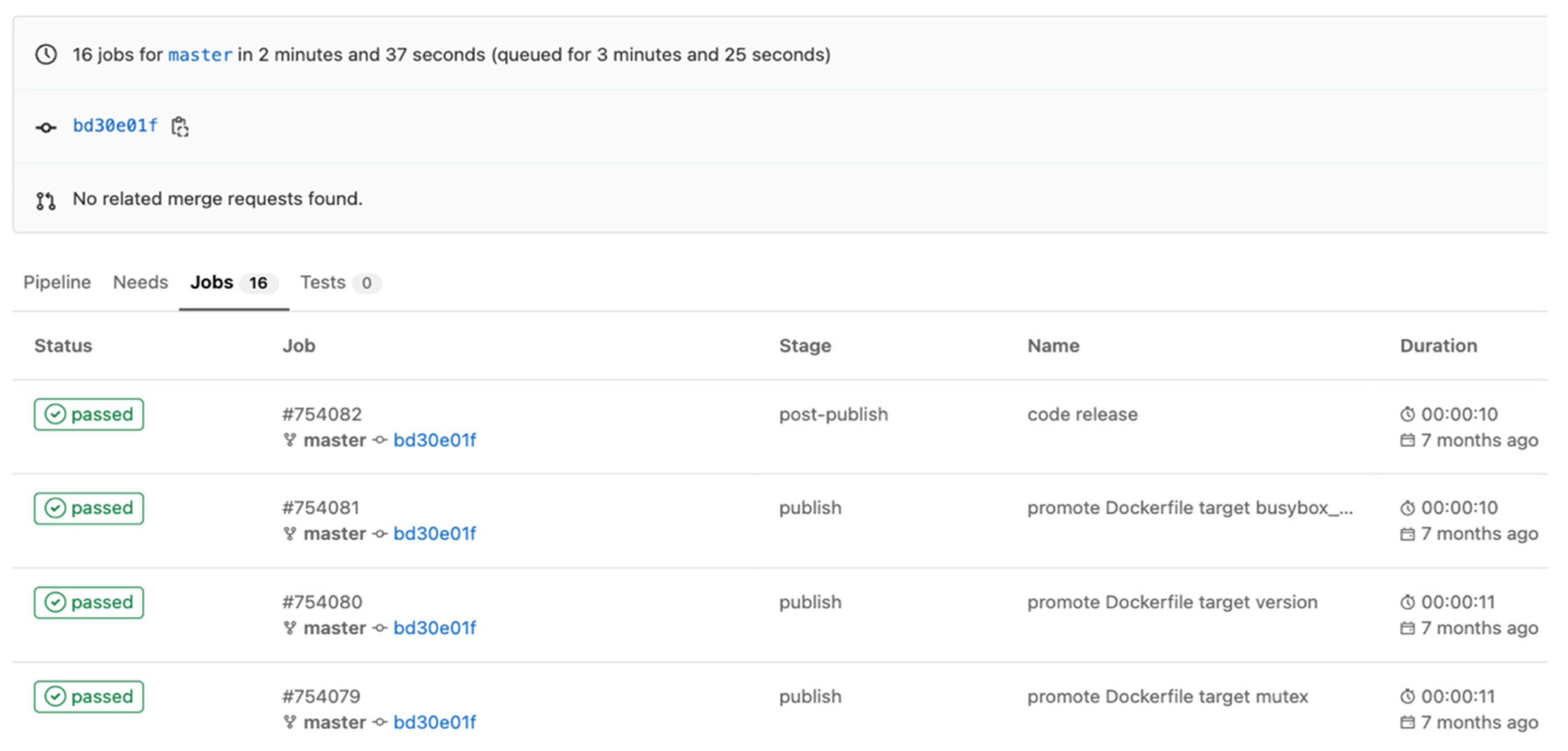
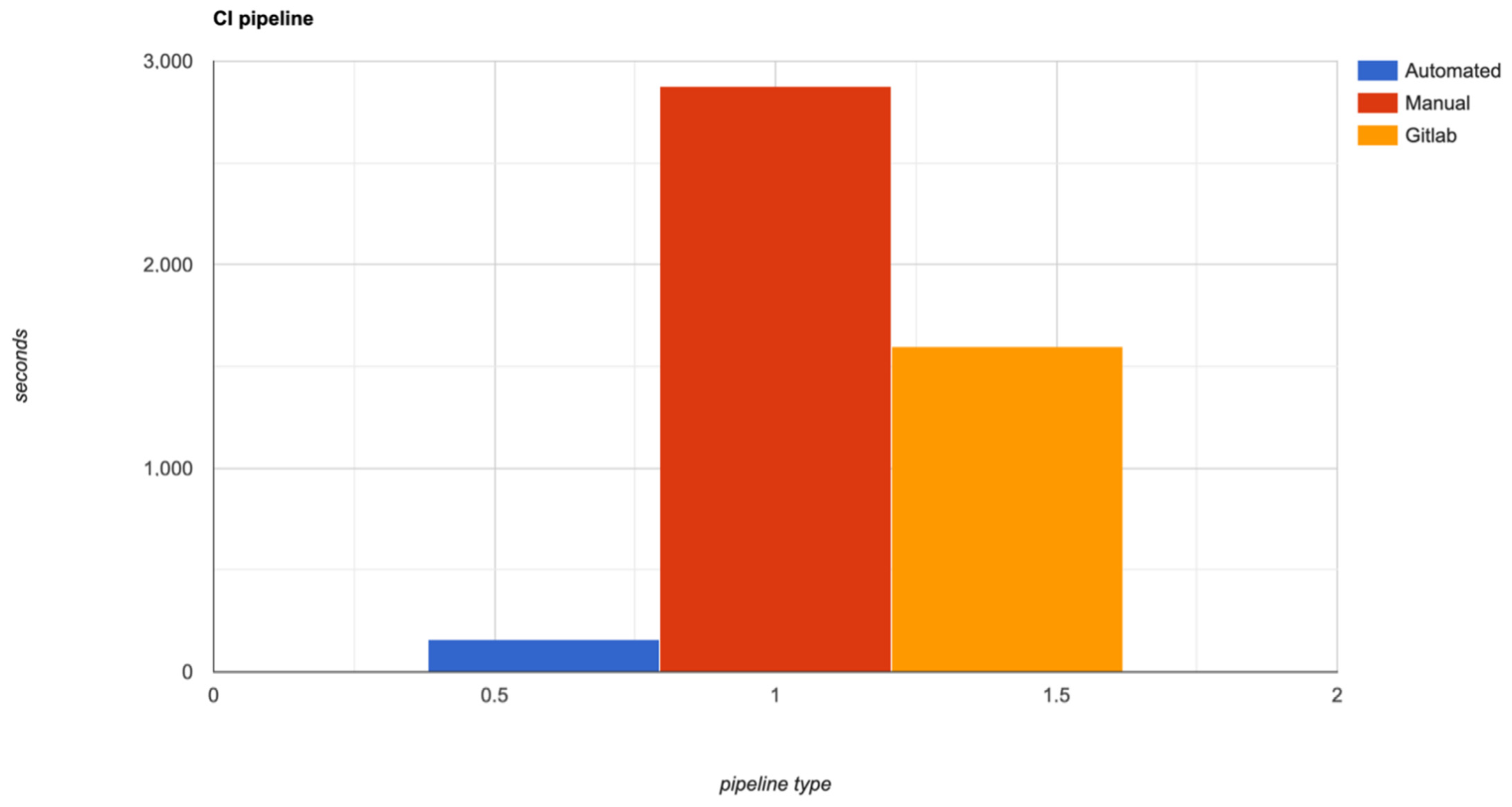
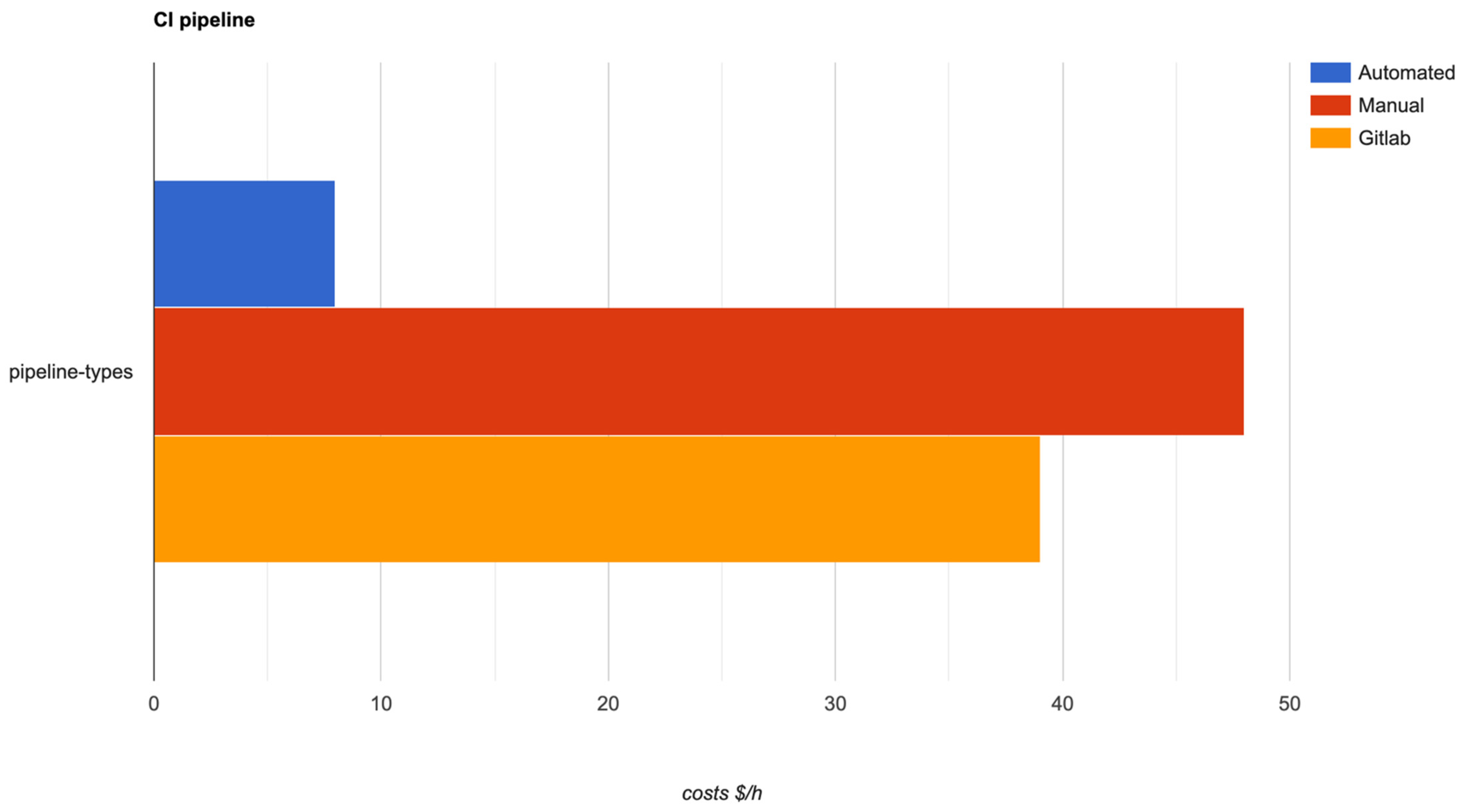
4. Application Effect Analysis and Experimental Results
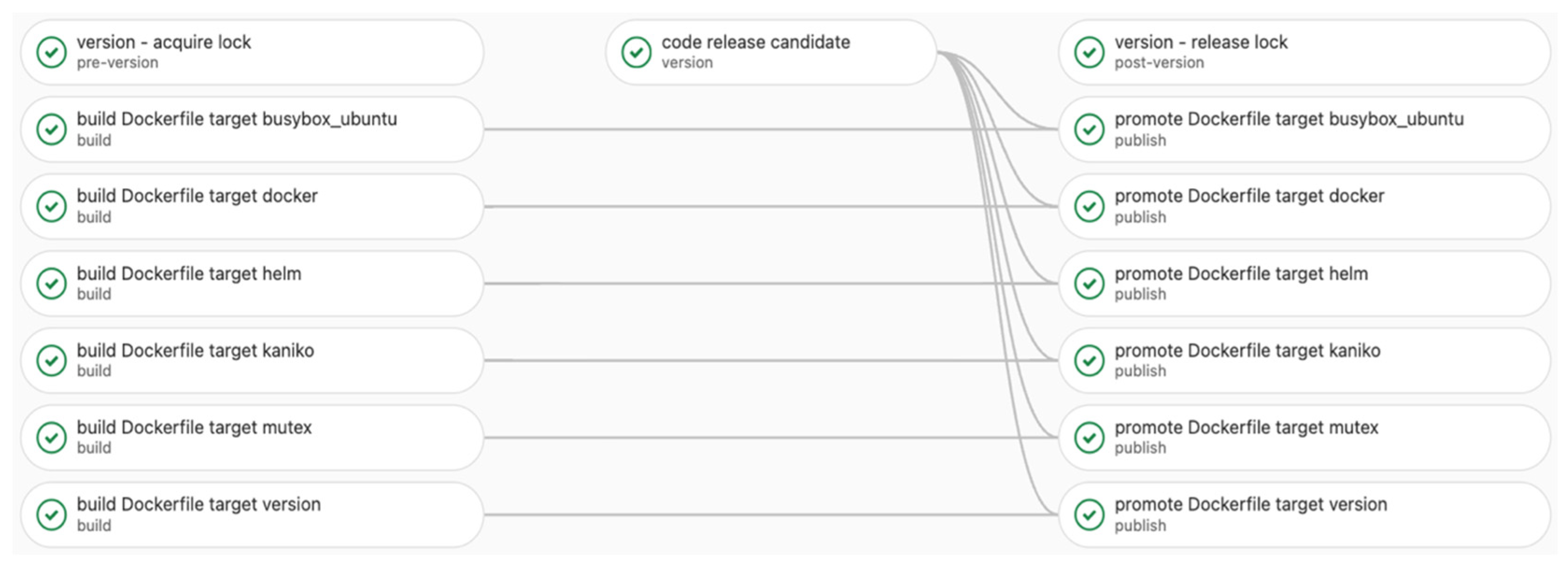
4.1. Application Effect Analysis
4.2. Experimental Results
5. Conclusions
Discussion, Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Fogelstrom, N.D.; Gorschek, T.; Svahnberg, M.; Olsson, P. The impact of agile principles on market-driven software product development. J. Softw. Maint. Evol. Res. Pract. 2010, 22, 53–80. [Google Scholar] [CrossRef]
- Weaveworks. Building Continuous Delivery Pipelines. Available online: https://www.weave.works/assets/images/blta8084030436bce24/CICD_eBook_Web.pdf (accessed on 10 January 2022).
- Moreira, M. The Agile Enterprise: Building and Running Agile Organizations, 1st ed.; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Singh, S.; Sharma, R.M. Handbook of Research on the IoT, Cloud Computing, and Wireless Network Optimization (Advances in Wireless Technologies and Telecommunication), 1st ed.; IGI Global Hershey: Pennsylvania, PA, USA, 2019. [Google Scholar]
- Losana, P.; Castro, J.W.; Ferre, X.; Villalba-Mora, E.; Acuña, S.T. A Systematic Mapping Study on Integration Proposals of the Personas Technique in Agile Methodologies. Sensors 2021, 21, 6298. [Google Scholar] [CrossRef] [PubMed]
- Fitzgerald, B.; Stol, K.-J. Continuous Software Engineering: A Roadmap and Agenda. J. Syst. Softw. 2017, 123, 176–189. [Google Scholar] [CrossRef]
- Awscloud. A Roadmap to Continuous Delivery Pipeline Maturity. Available online: https://pages.awscloud.com/rs/112-TZM-766/images/A-Roadmap-to-Continuous-Delivery-Pipeline-Maturity-dev-whitepaper.pdf (accessed on 14 January 2022).
- Arachchi, S.A.I.B.S.; Perera, I. Continuous Integration and Continuous Delivery Pipeline Automation for Agile Software Project Management. In Proceedings of the 2018 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 30 May–1 June 2018. [Google Scholar]
- Ramadoni; Utami, E.; Fatta, H.A. Analysis on the Use of Declarative and Pull-based Deployment Models on GitOps Using Argo CD. In Proceedings of the 2021 4th International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 30–31 August 2021. [Google Scholar]
- Beetz, F.; Harrer, S. GitOps: The Evolution of DevOps? IEEE Softw. 2021. [Google Scholar] [CrossRef]
- Leite, L.; Rocha, C.; Kon, F.; Milojicic, D.; Meirelles, P. A survey of DevOps concepts and challenges. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Shahin, M.; Babar, M.A.; Zhu, L. Continuous Integration Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices. IEEE Access 2017, 5, 3909–3943. [Google Scholar] [CrossRef]
- Flux. Flux Documentation. Available online: https://fluxcd.io/docs/ (accessed on 8 May 2021).
- Yiran, W.; Tongyang, Z.; Yidong, G. Design and Implementation of Continuous Integration scheme Based on Jenkins and Ansible. In Proceedings of the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–28 May 2018. [Google Scholar]
- Dusica, M.; Arnaud, G.; Marius, L. A Learning Algorithm for Optimizing Continuous Integration Development and Testing Practice. Softw. Pract. Exp. 2019, 49, 192–213. [Google Scholar]
- Zeller, M. Towards Continuous Safety Assessment in Context of DevOps. Comput. Saf. Reliab. Secur. 2021, 12853, 145–157. [Google Scholar]
- Maryam, S.; Javdani, G.T.; Rasool, S. Quality Aspects of Continuous Delivery in Practice. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 210–212. [Google Scholar]
- Górski, T. Continuous Delivery of Blockchain Distributed Applications. Sensors 2022, 22, 128. [Google Scholar] [CrossRef]
- Haibin, D.; Jun, C.; Kai, L. Design and Implementation of DevOps System Based on Docker. Command Inf. Syst. Technol. 2017, 8, 87–92. [Google Scholar]
- Liu, D.; Zhao, L. The Research and Implementation of Cloud Computing Platform Based on Docker. In Proceedings of the 11th International Computer Conference on Wavelet Actiev Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 19–21 December 2014. [Google Scholar]
- Xia, C.; Zhang, Y.; Wang, L.; Coleman, S.; Liu, Y. Microservice-based cloud robotics system for intelligent space. Robot. Auton. Syst. 2018, 110, 139–150. [Google Scholar] [CrossRef]
- Górski, T. Towards Continuous Deployment for Blockchain. Appl. Sci. 2021, 11, 11745. [Google Scholar] [CrossRef]
- Chacon, S.; Straub, B. Pro Git, 2nd ed.; Apress: Berkeley, CA, USA, 2014. [Google Scholar]
- Zolkifli, N.N.; Ngah, A.; Deraman, A. Version Control System: A Review. Procedia Comput. Sci. 2018, 135, 408–415. [Google Scholar] [CrossRef]
- Burns, B.; Grant, B.; Oppenheimer, D.; Brewer, E.; Wilkes, J. Borg, omega and kubernetes. Commun. ACM 2016, 14, 70–93. [Google Scholar]
- Gitlab Inc. Build with Kaniko. Available online: https://docs.gitlab.com/ee/ci/docker/using_kaniko.html (accessed on 12 March 2022).
- Jamal, M.; Joel, C. A Kubernetes CI/CD Pipeline with Asylo as a Trusted Execution Environment Abstraction Framework. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021. [Google Scholar]
- Reis, D.; Piedade, B.; Correia, F.F.; Dias, J.P.; Aguiar, A. Developing Docker and Docker-Compose Specifications: A Developers’ Survey. IEEE Access 2022, 10, 2318–2329. [Google Scholar] [CrossRef]
- Bhimani, J.; Yang, Z.; Mi, N.; Yang, J.; Xu, Q.; Awasthi, M.; Pandurangan, R.; Balakrishnan, V. Docker Container Scheduler for I/O Intensive Applications Running on NVMe SSDs. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 313–326. [Google Scholar] [CrossRef]
- Packard, M.; Stubbs, J.; Drake, J.; Garcia, C. Real-World, Self-Hosted Kubernetes Experience. In Proceedings of the Practice and Experience in Advanced Research Computing (PEARC 2021), Boston, MA, USA, 18–22 July 2021. [Google Scholar]
- Karamitsos, I.; Albarhami, S.; Apostolopoulos, C. Applying DevOps Practices of Continuous Automation for Machine Learning. Information 2020, 11, 363. [Google Scholar] [CrossRef]
- Zhou, Y.; Ou, Z.; Li, J. Automated Deployment of Continuous Integration Based on Jenkins. Comput. Digit. Eng. 2016, 44, 267–270. [Google Scholar]
- Buchanan, S.; Rangama, J.; Bellavance, N. Helm Charts for Azure Kubernetes Service. In Introducing Azure Kubernetes Service; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Fedak, V. What is Helm and Why You Should Love It? 2018. Available online: https://hackernoon.com/what-is-helm-and-why-you-should-love-it-74bf3d0aafc (accessed on 14 March 2022).
- Savor, T.; Douglas, M.; Gentili, M.; Williams, L.; Beck, K.; Stumm, M. Continuous Deployment at Facebook and Oanda. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), Austin, TX, USA, 14–22 May 2016. [Google Scholar]
- Humble, J.; Farley, D. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 2010. [Google Scholar]
- Chen, L. Continuous Delivery: Huge Benefits. but Challanges Too. IEEE Softw. 2015, 32, 50–54. [Google Scholar] [CrossRef]
- Pulkkinen, V. Continuous Deployment of Software: Proceedings of the the seminar No. 58312107; Cloud-Based Software Engineering: Helsinki, Finland, 2013. [Google Scholar]
- Shahin, M.; Zahedi, M.; Babar, M.A.; Zhu, L. An empirical study of architecting for continuous delivery and deployment. Empir. Softw. Eng. 2019, 24, 1061–1108. [Google Scholar] [CrossRef] [Green Version]
- Rahman, A.A.U.; Helms, E.; Williams, L.; Parnin, C. Synthesizing continuous deployment practices used in software development. In Proceedings of the Agile Conference, National Harbor, MD, USA, 3–7 August 2015. [Google Scholar]
- Andrawos, M.; Helmich, M. Cloud Native Programming with Golang: Develop Microservice-Based High Performance Web Apps for the Cloud with Go; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Whitney, J.; Gifford, C.; Pantoja, M. Distributed execution of communicating sequential process-style concurrency: Golang case study. J. Supercomput. 2019, 75, 1396–1409. [Google Scholar] [CrossRef]
- Yasir, R.M.; Asad, M.; Galib, A.H.; Ganguly, K.K.; Siddik, M.S. GodExpo: An Automated God Structure Detection Tool for Golang. In Proceedings of the 2019 IEEE/ACM 3rd International Workshop on Refactoring (IWoR), Montreal, QC, Canada, 28 May 2019; pp. 47–50. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nr.crt. | Step | Observation |
|---|---|---|
| 1 | (Re)generate pipeline |
|
| 2 | Create Amazon (AMW) Elastic Container Repository (ECR) | |
| 3 | Versioning with annotated git tags |
|
| 4 | Containerization with Docker |
|
| 5 | Deployment with Helm |
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Donca, I.-C.; Stan, O.P.; Misaros, M.; Gota, D.; Miclea, L. Method for Continuous Integration and Deployment Using a Pipeline Generator for Agile Software Projects. Sensors 2022, 22, 4637. https://doi.org/10.3390/s22124637
Donca I-C, Stan OP, Misaros M, Gota D, Miclea L. Method for Continuous Integration and Deployment Using a Pipeline Generator for Agile Software Projects. Sensors. 2022; 22(12):4637. https://doi.org/10.3390/s22124637
Chicago/Turabian StyleDonca, Ionut-Catalin, Ovidiu Petru Stan, Marius Misaros, Dan Gota, and Liviu Miclea. 2022. "Method for Continuous Integration and Deployment Using a Pipeline Generator for Agile Software Projects" Sensors 22, no. 12: 4637. https://doi.org/10.3390/s22124637
APA StyleDonca, I.-C., Stan, O. P., Misaros, M., Gota, D., & Miclea, L. (2022). Method for Continuous Integration and Deployment Using a Pipeline Generator for Agile Software Projects. Sensors, 22(12), 4637. https://doi.org/10.3390/s22124637