
Open Source Assessment of Deep Learning Visual Object Detection


Abstract
:1. Introduction
2. Related Work
2.1. Datasets
- ImageNet [12]: ImageNet is the largest public collection of images, containing 14,197,122 samples, where 1,034,908 images have been annotated with bounding boxes, ideal for training and evaluating object detection models.
- Pascal VOC [13]: Pascal VOC’s 2012 release contains 11,530 images in training and validation datasets, spanning 20 classes. It encloses a total of 27,450 bounding box annotated objects.
- Spinello dataset [15]: Spinello is a dataset consisting of 3000+ RGB-D images captured using a Microsoft Kinect containing people. It focuses on person detection and tracking in 3D space.
- Princeton RGB dataset [14]: This dataset contains 100 RGB-D videos of high diversity focused on the design and comparison of tracking algorithms. It is similar to Spinello and also uses a depth sensor to capture images.
- Common Objects in Context (COCO) [11]: COCO is designed for both object detection and segmentation. It contains around 330,000 images of which 200,000 are labeled, containing 1.5 million object instances in total.
- Open Images Dataset [16]: Open Images Dataset V6 is the largest existing dataset with object location annotations, containing 1.6 M images with 16 M bounding boxes for 600 object classes.
2.2. Frameworks
2.3. Performance Metrics
- Average Precision (AP): Fraction of the total amount of correct predictions. Ranges from 0 to 1.
- Average Recall (AR): Fraction of the total amount of predictions that are detected. Ranges from 0 to 1.
- Mean Average Precision (mAP) and mean Average Recall (mAR): We usually consider a range from 0.5 to 0.95 for Intersection over Union (IoU). The IoU metric compares the ground truth bounding box with the detected ground truth and retrieves a value between 0 and 1, indicating how close the detected bounding box is to the ground truth. The higher the value of IoU, the closer to the ground truth bounding box. In the present work, mAP and mAR with IoU values from 0.5 to 0.95 is calculated (IoU = 0.5:0.95) for the dataset classes.
- Mean inference time: Average time spent generating predictions. In milliseconds, the importance of these metrics depends on the scenario where the model is applied. This metric could be relevant in environments that imply generating fast and precise answers.
2.4. Network Models
2.4.1. Faster Regional-CNN
- Anchor generation: Anchors are regions that may contain an object. So, anchor generation must be as thorough as possible because if a particular region is mixed then there is no way that it would be detected in the succeeding layers. These anchors are later refined using a bounding box regressor to reduce the localization error to better localize objects. Anchor Generation uses sophisticated algorithms to cover the whole image, such as selective search, which is later fed into the Region Proposal Network (RPN).
- Region Proposal Network: The job of this component of the network is to generate regions with a high probability of containing objects. It takes anchors as input and produces highly probable regions. Again, if a region containing an object is not proposed then there is no way that the component would detect it in the following layers. Moreover, the number of regions should be as low as possible to reduce detection time and as thorough as possible to reduce false negatives.
- Classifier and bounding box regressor: The final component of the network classifies proposals from RPN into an object class or background (i.e., negative or no object present). Classification occurs first and then its results are better localized to reduce the localization error or to accurately place the bounding box on the classified object. This component regresses four parameters, namely x, y, w, and h, where x and y are the top-left coordinates and w and h are the width and height of the bounding box.
2.4.2. Single Shot MultiBox Detector
2.4.3. You Only Look Once (YOLO)
3. Detection Metrics Tool Kit
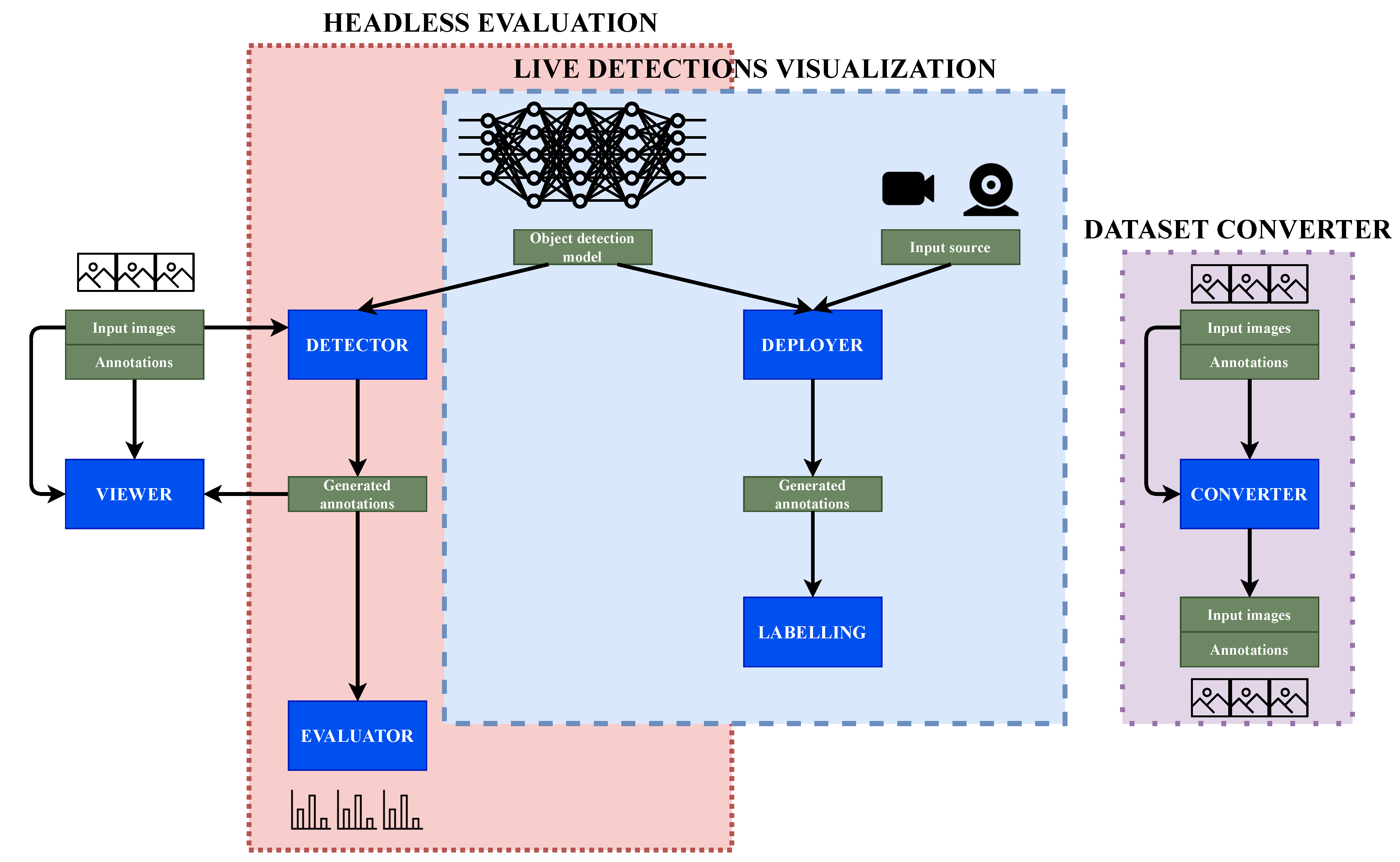
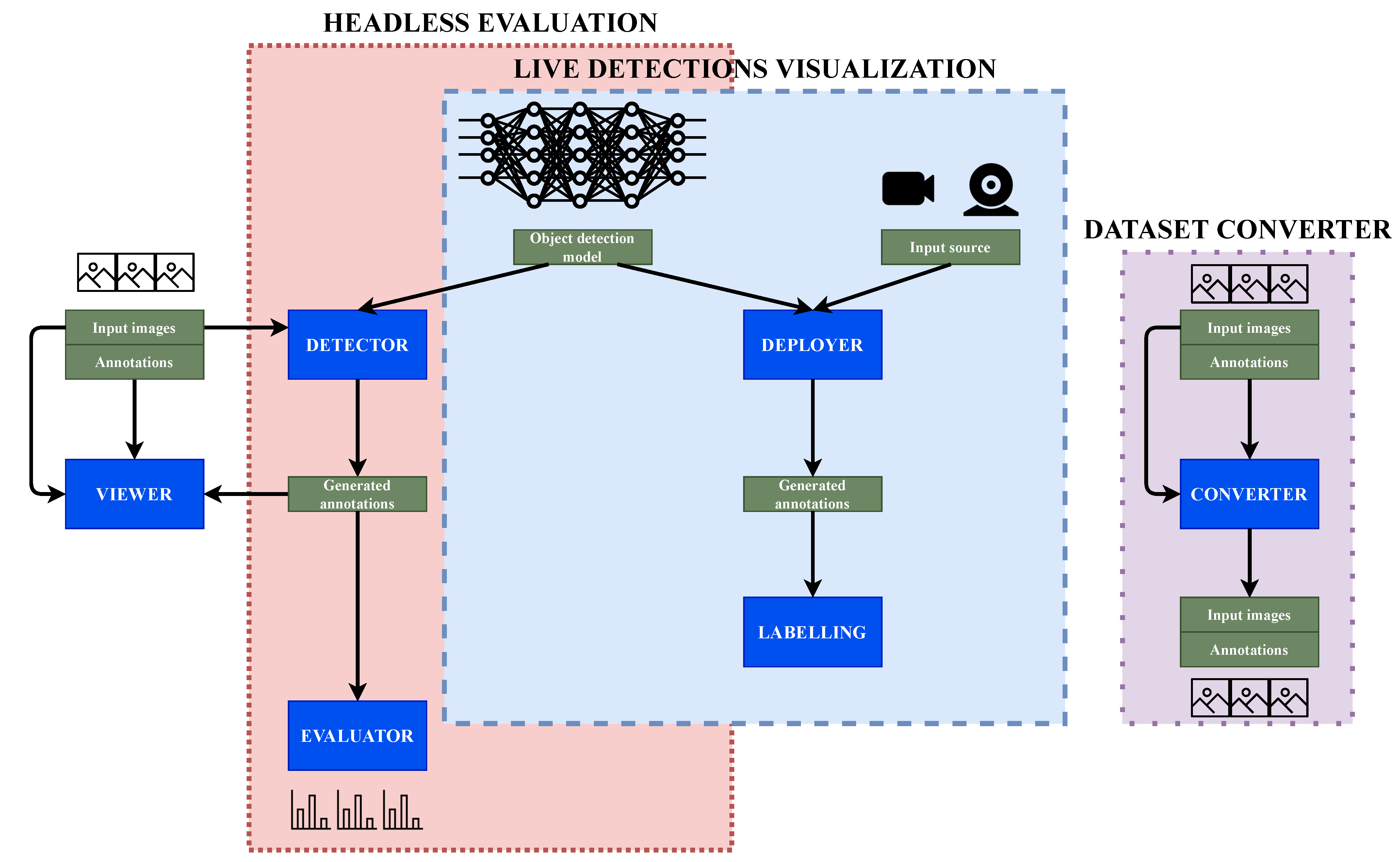
3.1. Global Architecture and Workflows
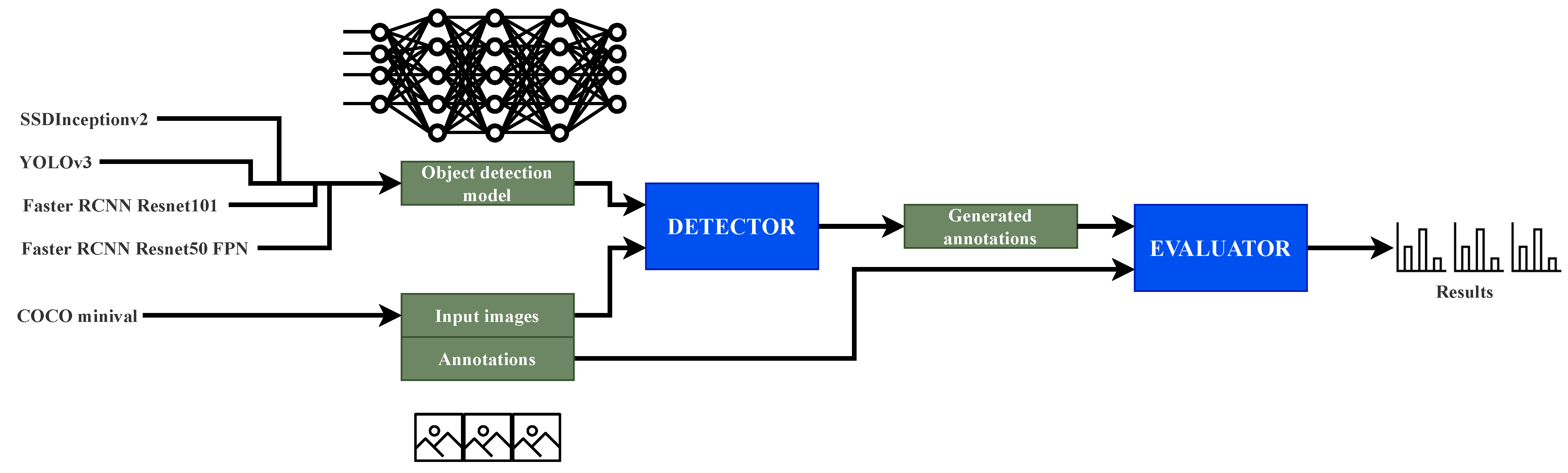
3.2. Headless Evaluation
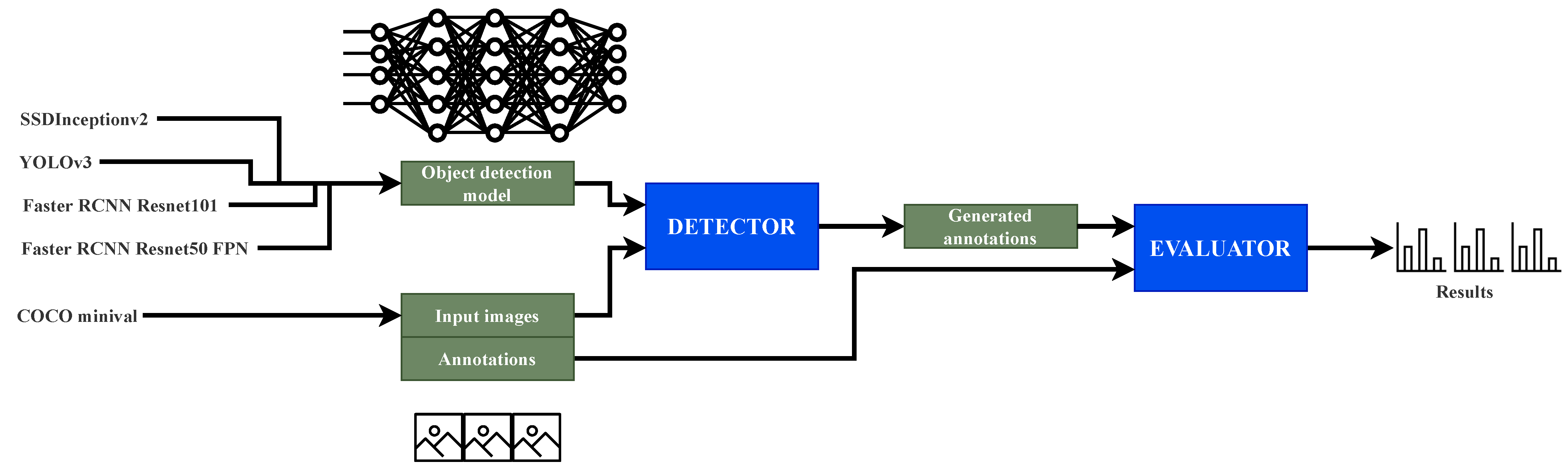
3.2.1. Detection Generation
3.2.2. Evaluation of Detections with Objective Metrics
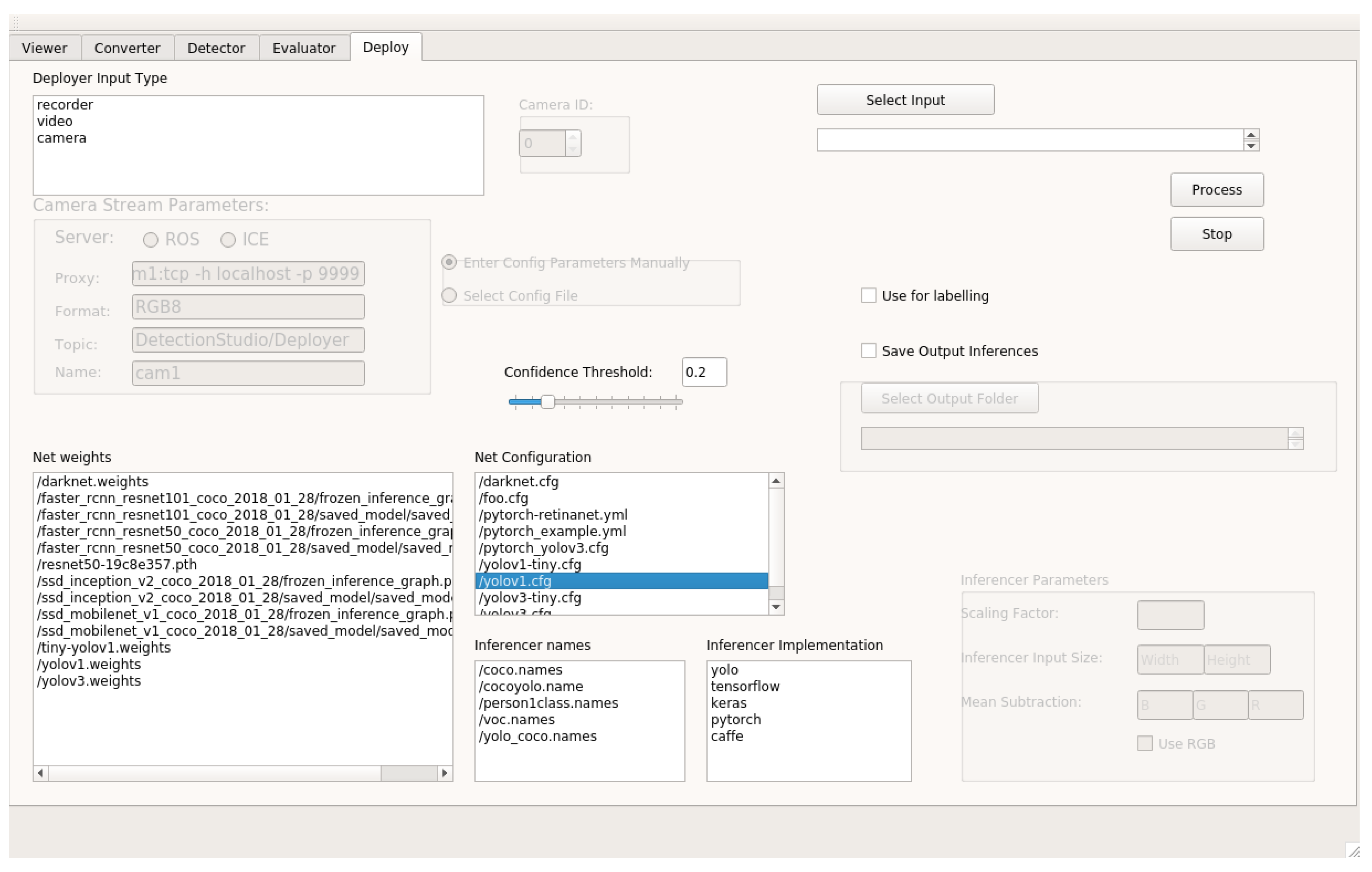
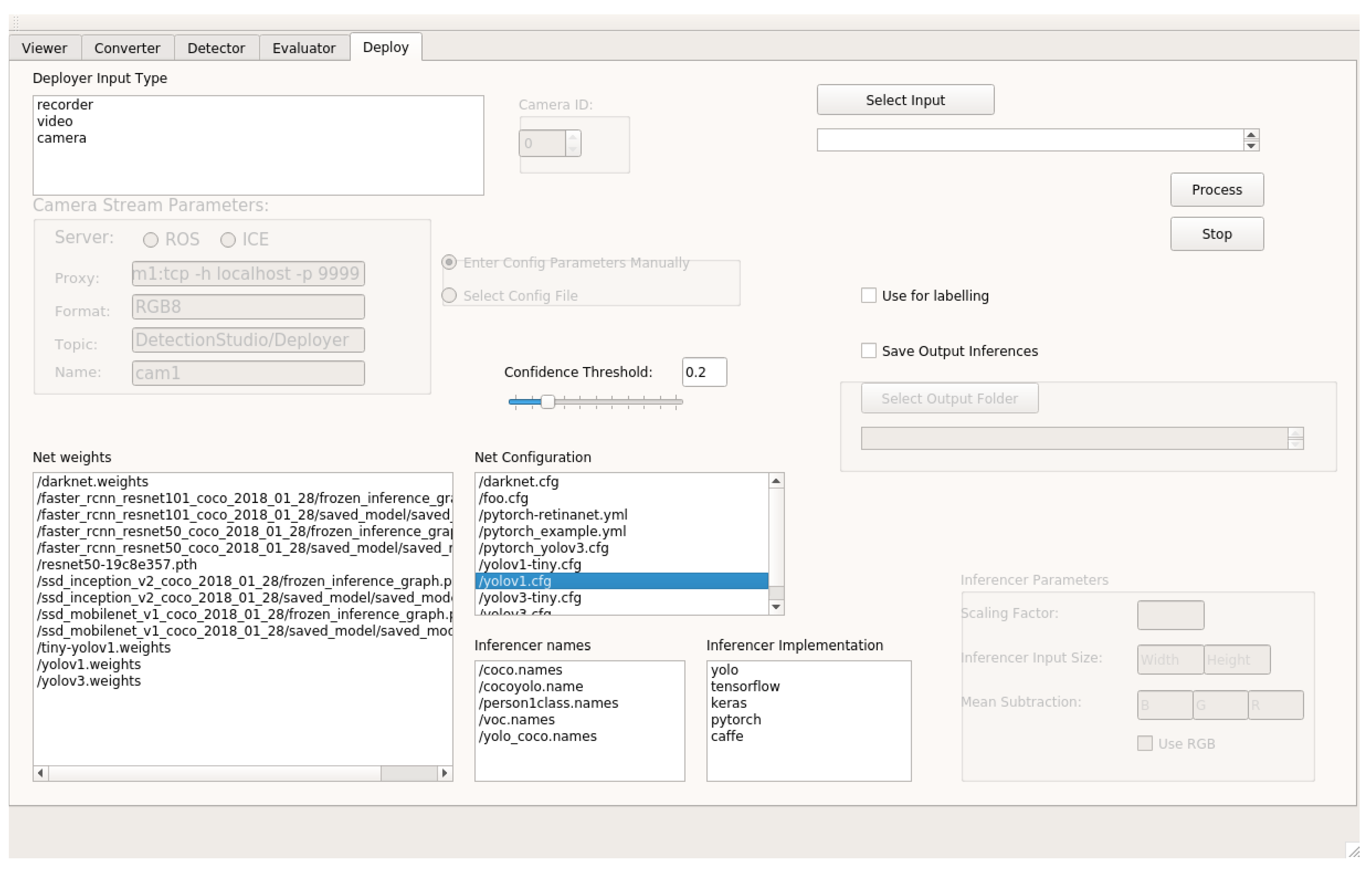
3.3. Live Detection Visualization
Labels Correction on Demand
- The first feature is the possibility of adjusting the bounding boxes generated. The user can adjust the size and position of a certain detection bounding box stopping the video when the error is found and then adjusting the distribution of the box to the object.
- The second feature is changing the class name for every detected object. This means that a user can select a detected bounding box in the video image and change the class name in real-time to one of the class names provided or to a completely different one, also having the chance of adjusting the probability of the selection.
- The third feature is related to the previous ones and is adding new detections. The user can draw a new bounding box in a stopped frame and then give this a class name and probability.
3.4. Dataset Converter
4. Experimental Results and Discussion
4.1. Comparison of State-of-the-Art Detection Networks
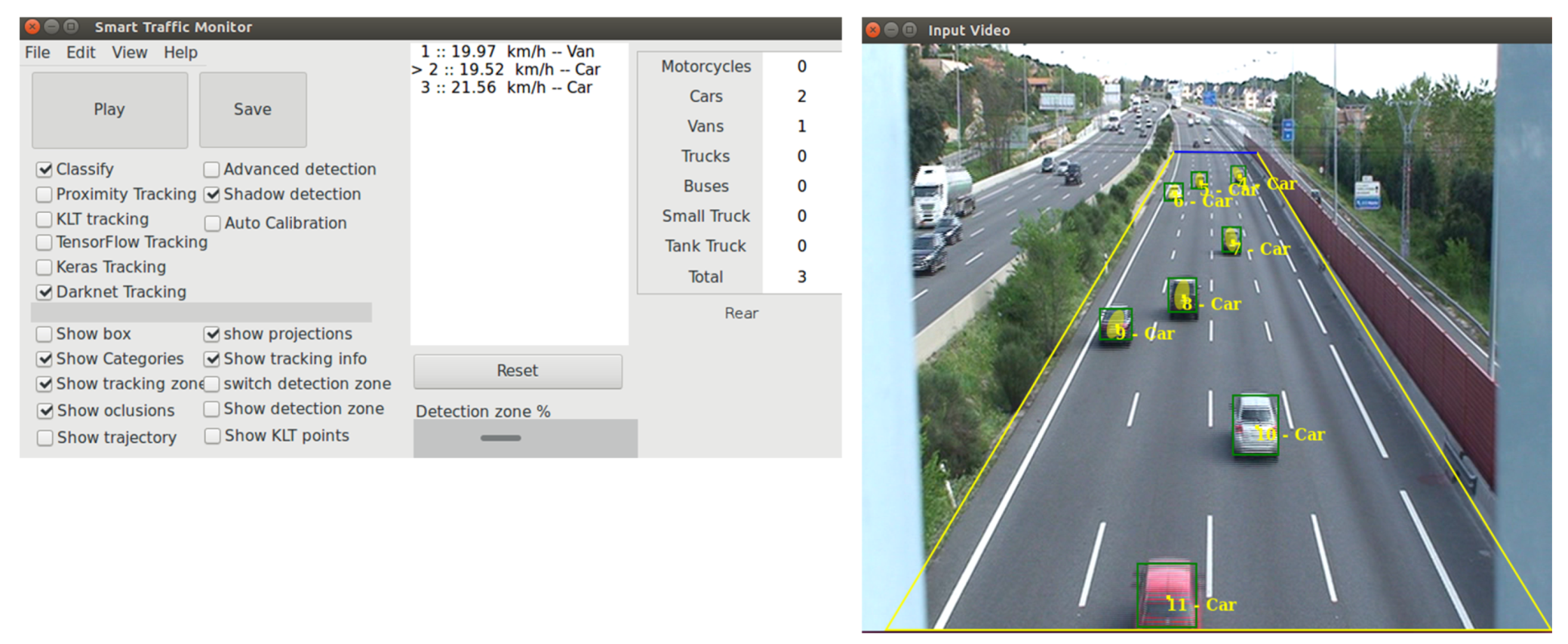
4.2. Usage on a Deep Learning Real Research Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. arXiv 2018, arXiv:1809.02165. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; du Terrail, J.O.; Jurie, F. Recent Advances in Object Detection in the Age of Deep Convolutional Neural Networks. arXiv 2018, arXiv:1809.03193. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. arXiv 2018, arXiv:1807.05511. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. arXiv 2019, arXiv:1908.03673. [Google Scholar] [CrossRef] [Green Version]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A Survey of Modern Deep Learning based Object Detection Models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015; pp. 2722–2730. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Nevatia, R. A multi-scale cascade fully convolutional network face detector. In Proceedings of the International Conference on Pattern Recognition (ICPR), Cancún, Mexico, 4–8 December 2016; pp. 633–638. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Wen, L.; Zhang, L.; Du, D.; Wang, W. Rethinking object detection in retail stores. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Song, S.; Xiao, J. Tracking Revisited Using RGBD Camera: Unified Benchmark and Baselines. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 2–8 December 2013; pp. 233–240. [Google Scholar]
- Spinello, L.; Arras, K.O. People detection in RGB-D data. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3838–3843. [Google Scholar] [CrossRef] [Green Version]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Ferrari, V. The Open Images Dataset V4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Arcos-García, Á.; Álvarez García, J.A.; Soria-Morillo, L.M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Jeune, P.L.; Mokraoui, A. A Unified Framework for Attention-Based Few-Shot Object Detection. arXiv 2022, arXiv:2201.02052. [Google Scholar]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote. Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar] [CrossRef]
- Weng, G.; Dong, B.; Lei, Y. A level set method based on additive bias correction for image segmentation. Expert Syst. Appl. 2021, 185, 115633. [Google Scholar] [CrossRef]
- Ge, P.; Chen, Y.; Wang, G.; Weng, G. A hybrid active contour model based on pre-fitting energy and adaptive functions for fast image segmentation. Pattern Recognit. Lett. 2022, 158, 71–79. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: https://pjreddie.com/darknet/ (accessed on 27 April 2022).
- Chollet, F.; Scott Zhu, Q.; Rahman, F.; Lee, T.; de Marmiesse, G.; Zabluda, O.; Jin, H.; Watson, M.; Chao, R.; Pumperla, M. Keras. 2015. Available online: https://keras.io (accessed on 27 April 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8026–8037. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 214–230. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Shatnawi, A.; Al-Bdour, G.; Al-Qurran, R.; Al-Ayyoub, M. A comparative study of open source deep learning frameworks. In Proceedings of the Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 72–77. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012.; Kwon, Y.; TaoXie; Fang, J.; imyhxy; Michael, K.; et al. ultralytics/yolov5: V6.1—TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference; Zenodo: Meyrin, Switzerland, 2022. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2017, arXiv:1612.08242. [Google Scholar]
- Tensorflow Detection Model Zoo. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md (accessed on 27 April 2022).
- Pytorch Torchvision Models. Available online: https://pytorch.org/vision/stable/models.html (accessed on 27 April 2022).
- Fernández, J.; Cañas, J.M.; Fernández, V.; Paniego, S. Robust Real-Time Traffic Surveillance with Deep Learning. Comput. Intell. Neurosci. 2021, 2021, 4632353. [Google Scholar] [CrossRef]
- SSD: Single-Shot MultiBox Detector Keras implementation. Available online: https://github.com/pierluigiferrari/ssd_keras (accessed on 27 April 2022).
- SSD Mobilenet V2 COCO Config. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/samples/configs/ssd_mobilenet_v2_coco.config (accessed on 27 April 2022).
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Kachach, R.; Cañas, J.M. Hybrid three-dimensional and support vector machine approach for automatic vehicle tracking and classification using a single camera. J. Electron. Imaging 2016, 25, 033021. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Framework | Published mAP | mAP Using Detection Metrics | Published mAR | mAR Using Detection Metrics | Published Mean Inference Time | Mean Inference Time Using Detection Metrics |
|---|---|---|---|---|---|---|---|
| SSD Inceptionv2 | TensorFlow-Keras | 0.24 | 0.27 | x | 0.31 | 42 | 44 |
| YOLOv3 | Darknet | 0.55 (IoU = 0.5) | 0.47 (IoU = 0.5) | x | 0.5 (IoU = 0.5) | 29 | 31 |
| Faster RCNN Resnet101 | TensorFlow-Keras | 0.32 | 0.37 | x | 0.43 | 106 | 122 |
| Faster RCNN Resnet50 FPN | PyTorch | 0.35 | 0.37 | x | 0.46 | 59 | 102 |
| Network | Framework | Transfer Learning | mAP | mAR | Mean Inference Time (ms) |
|---|---|---|---|---|---|
| SSD VGG-16 | Keras | Yes, retrained | 0.7478 | 0.7831 | 13 |
| SSD MobileNet v2 | TensorFlow | Yes, retrained | 0.5484 | 0.6136 | 10 |
| YOLOv3 | Darknet | No, pretrained | 0.4577 | 0.5843 | 34 |
| YOLOv3 | Darknet | Yes, retrained | 0.8926 | 0.9009 | 15 |
| YOLOv4 | Darknet | No, pretrained | 0.4799 | 0.5879 | 24 |
| YOLOv4 | Darknet | Yes, retrained | 0.9056 | 0.9670 | 13 |
| Dataset Image Type | Good Conditions | Bad Weather | Poor Quality | |||
|---|---|---|---|---|---|---|
| System Type | mAP | mAR | mAP | mAR | mAP | mAR |
| Traffic-Monitor | 0.4374 | 0.5940 | 0.2407 | 0.3162 | 0.4479 | 0.6303 |
| Smart-Traffic-Sensor YOLOv3 | 0.8926 | 0.9009 | 0.9899 | 0.9926 | 0.9439 | 0.9444 |
| Smart-Traffic-Sensor YOLOv4 | 0.9056 | 0.9670 | 0.9904 | 0.9949 | 0.9902 | 0.9911 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paniego, S.; Sharma, V.; Cañas, J.M. Open Source Assessment of Deep Learning Visual Object Detection. Sensors 2022, 22, 4575. https://doi.org/10.3390/s22124575
Paniego S, Sharma V, Cañas JM. Open Source Assessment of Deep Learning Visual Object Detection. Sensors. 2022; 22(12):4575. https://doi.org/10.3390/s22124575
Chicago/Turabian StylePaniego, Sergio, Vinay Sharma, and José María Cañas. 2022. "Open Source Assessment of Deep Learning Visual Object Detection" Sensors 22, no. 12: 4575. https://doi.org/10.3390/s22124575
APA StylePaniego, S., Sharma, V., & Cañas, J. M. (2022). Open Source Assessment of Deep Learning Visual Object Detection. Sensors, 22(12), 4575. https://doi.org/10.3390/s22124575