
Backhand-Approach-Based American Sign Language Words Recognition Using Spatial-Temporal Body Parts and Hand Relationship Patterns


Abstract
:1. Introduction
- (a)
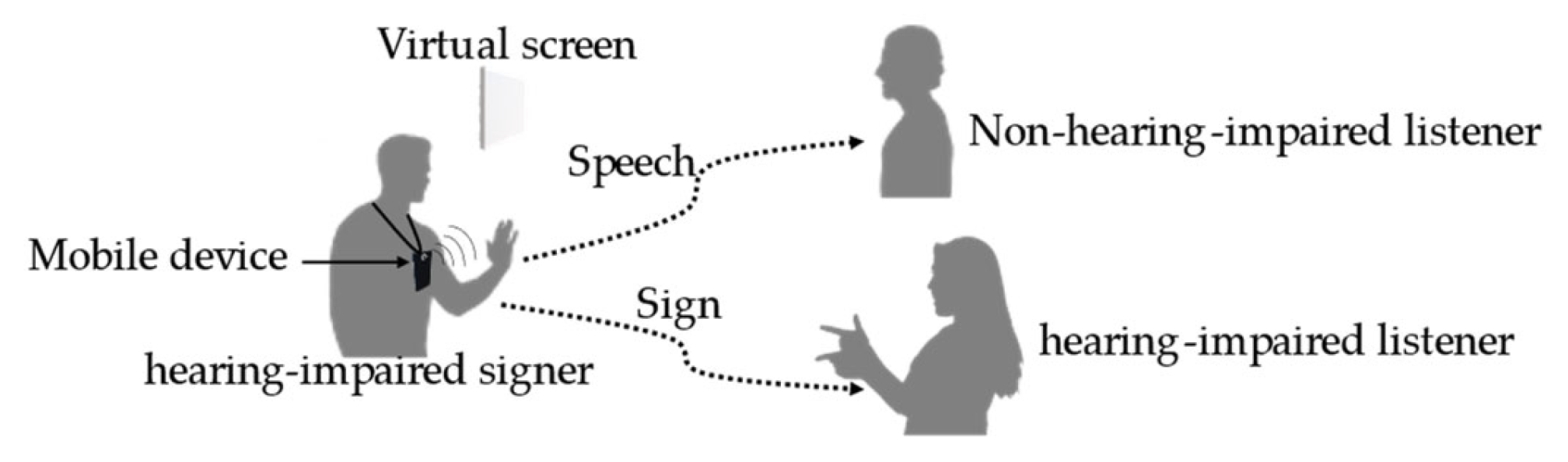
- We propose a method for a portable sign language recognition system based on a backhand approach to allow mobility by attaching a 3D small depth sensor to the chest area to detect the skeletons of hands.
- (b)
- The proposed method includes a new feature-based recognition approach in terms of the relationship between the hands and key points of the essential body to identify sign words with a similar shape, rotation, and movement, but with different meanings.
- (c)
- The developed system can be used with both single and double hands.
2. Related Works
3. Problem Analysis
4. System Overview
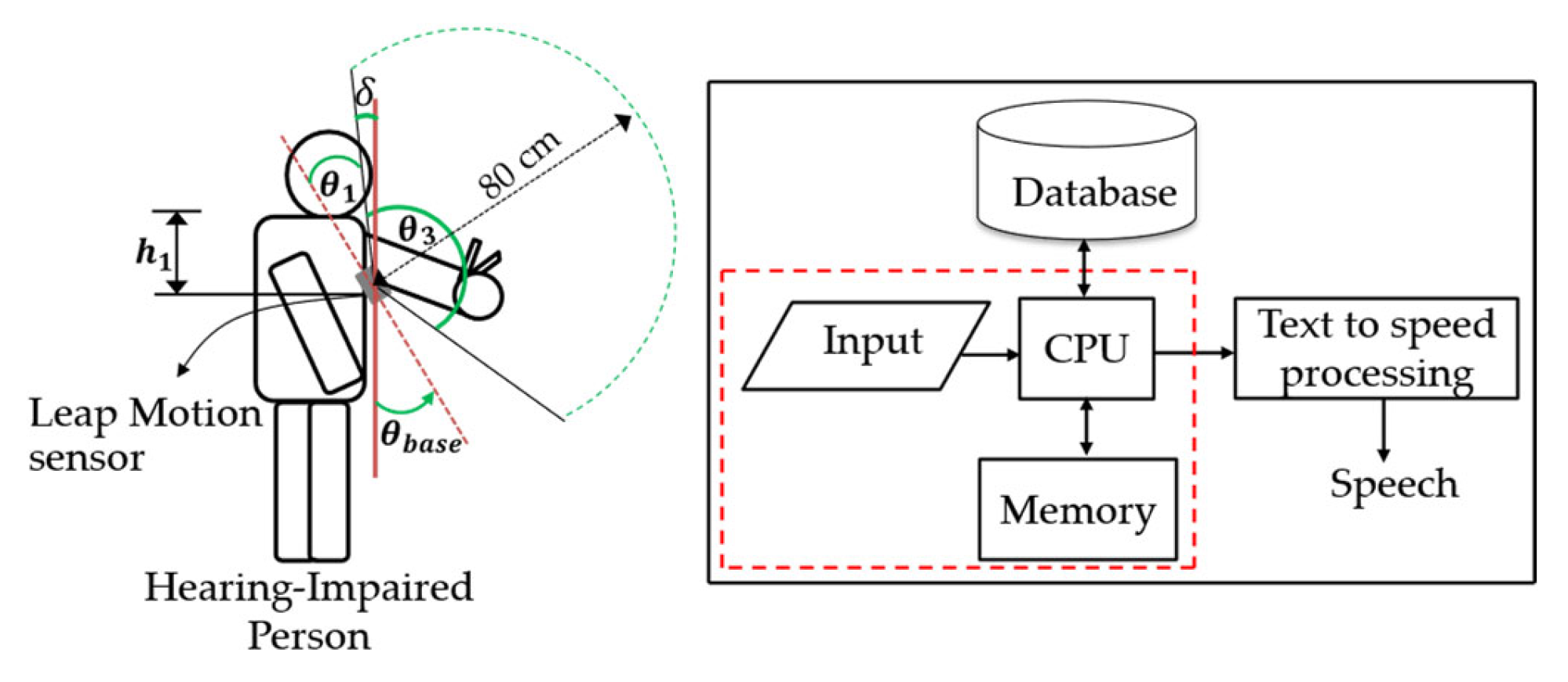
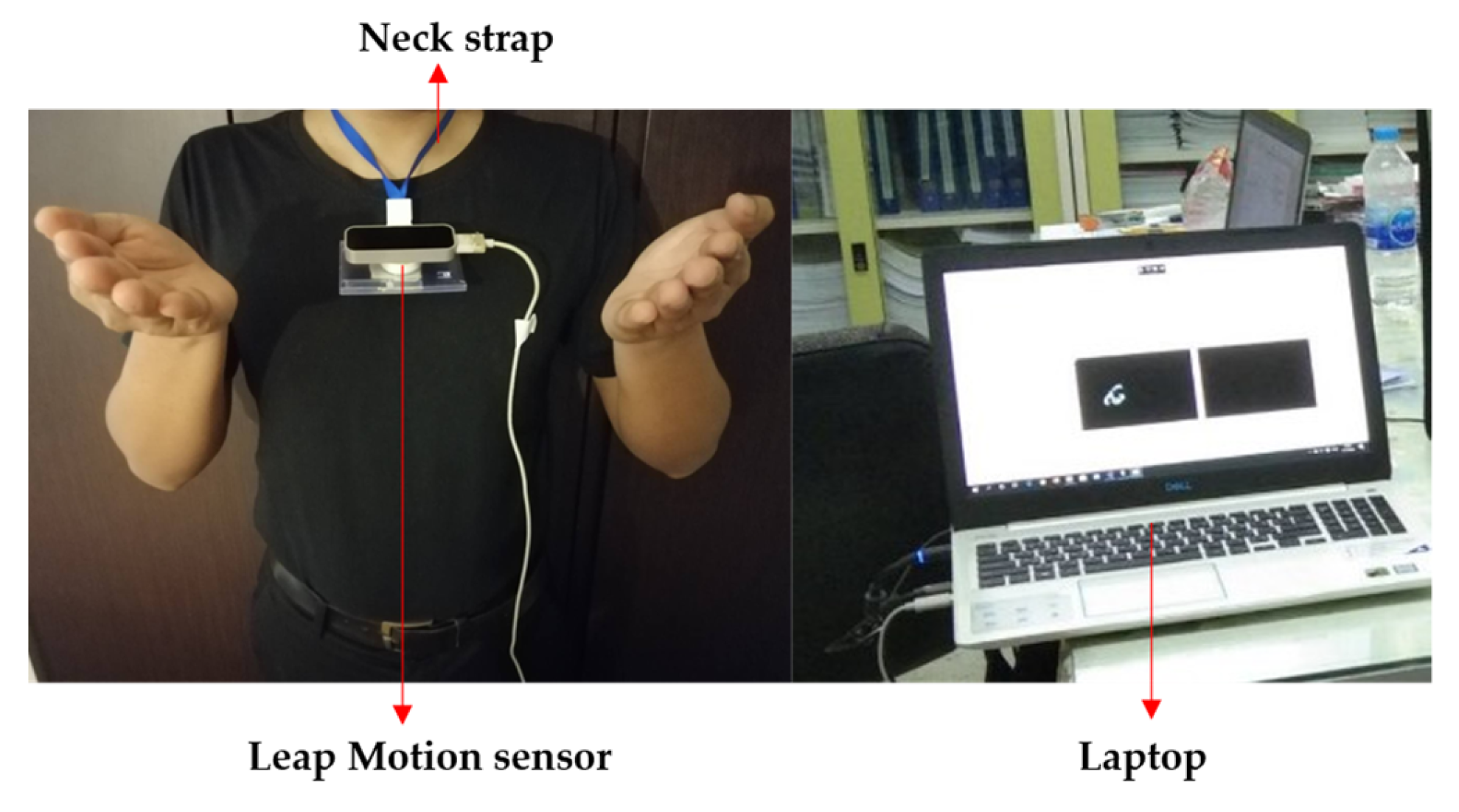
4.1. Hardware Unit
4.2. Software Unit
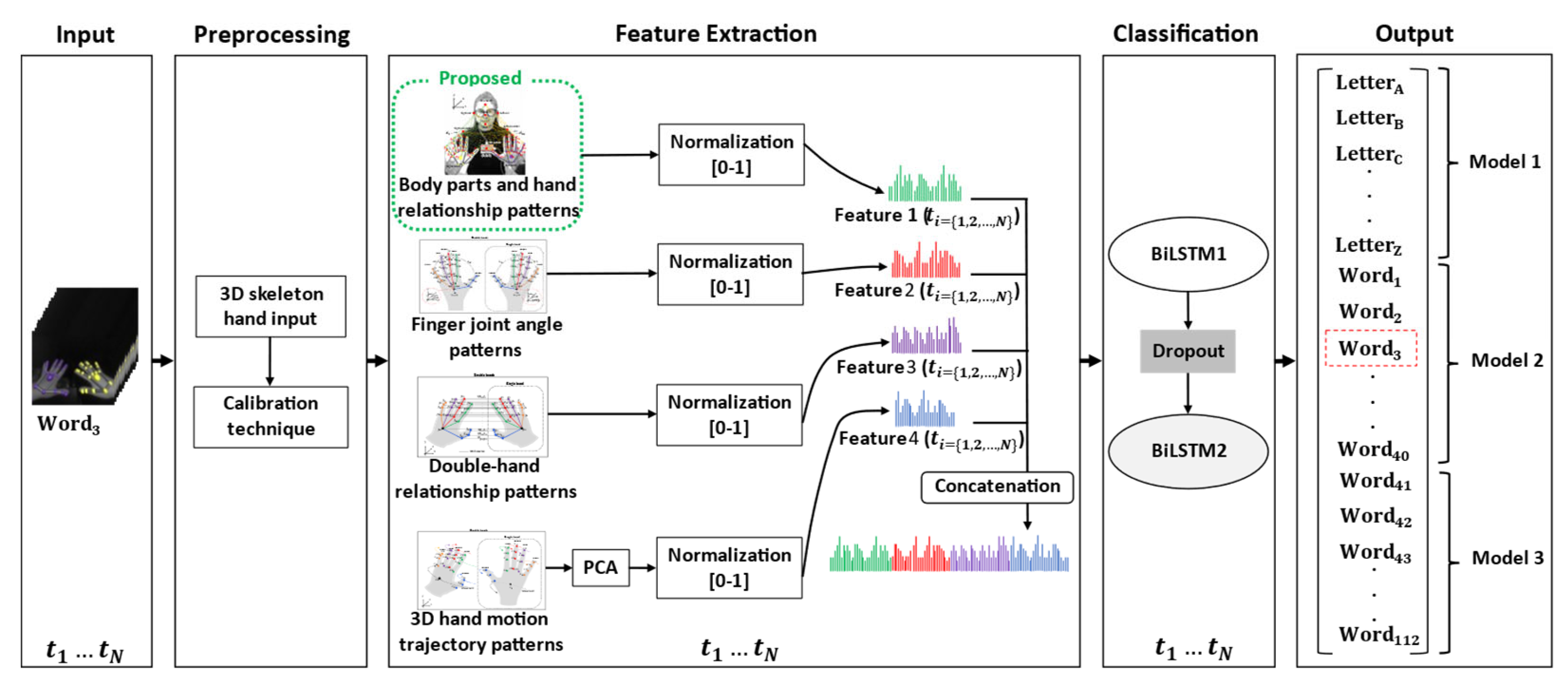
5. Proposed Method
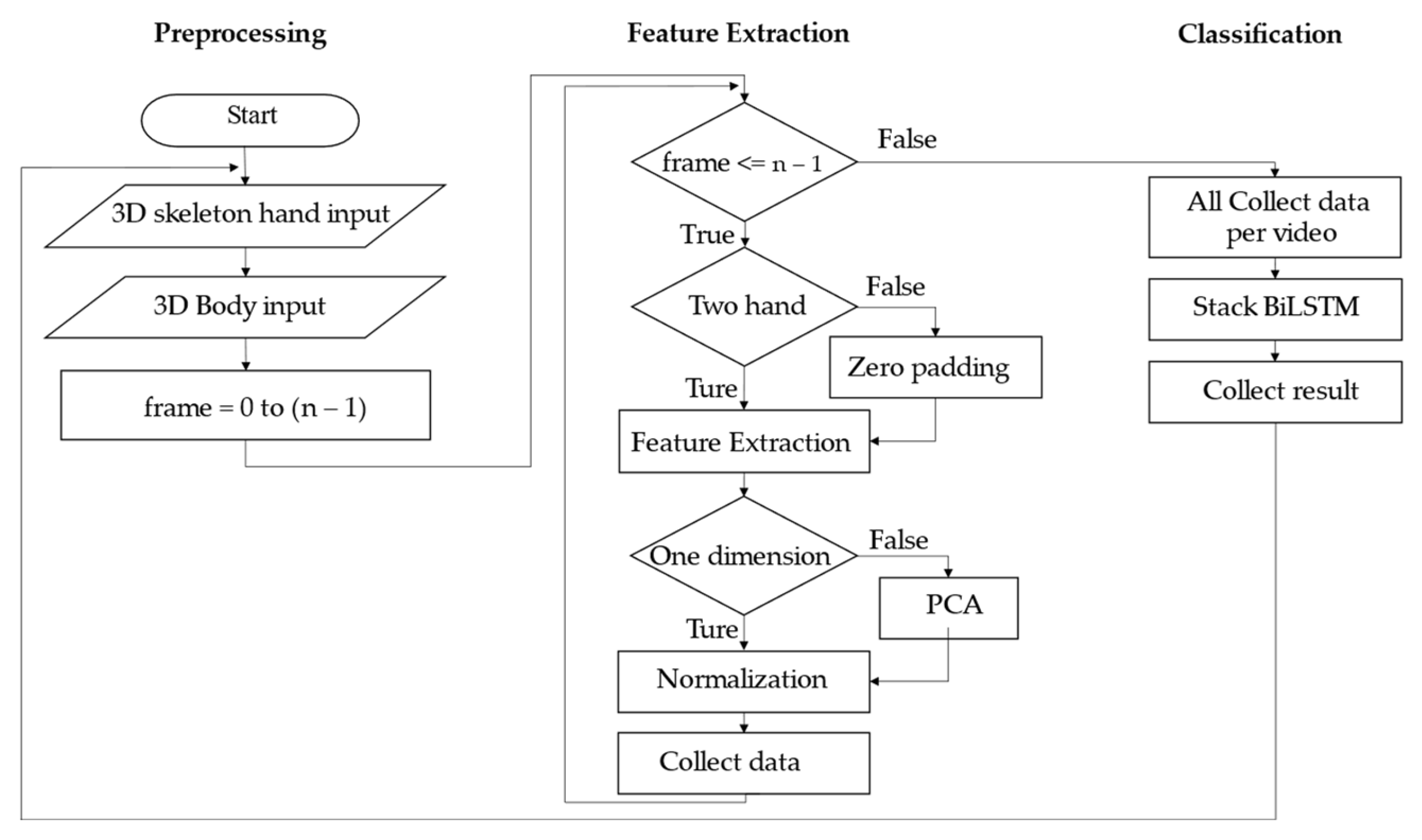
5.1. Preprocessing Technique
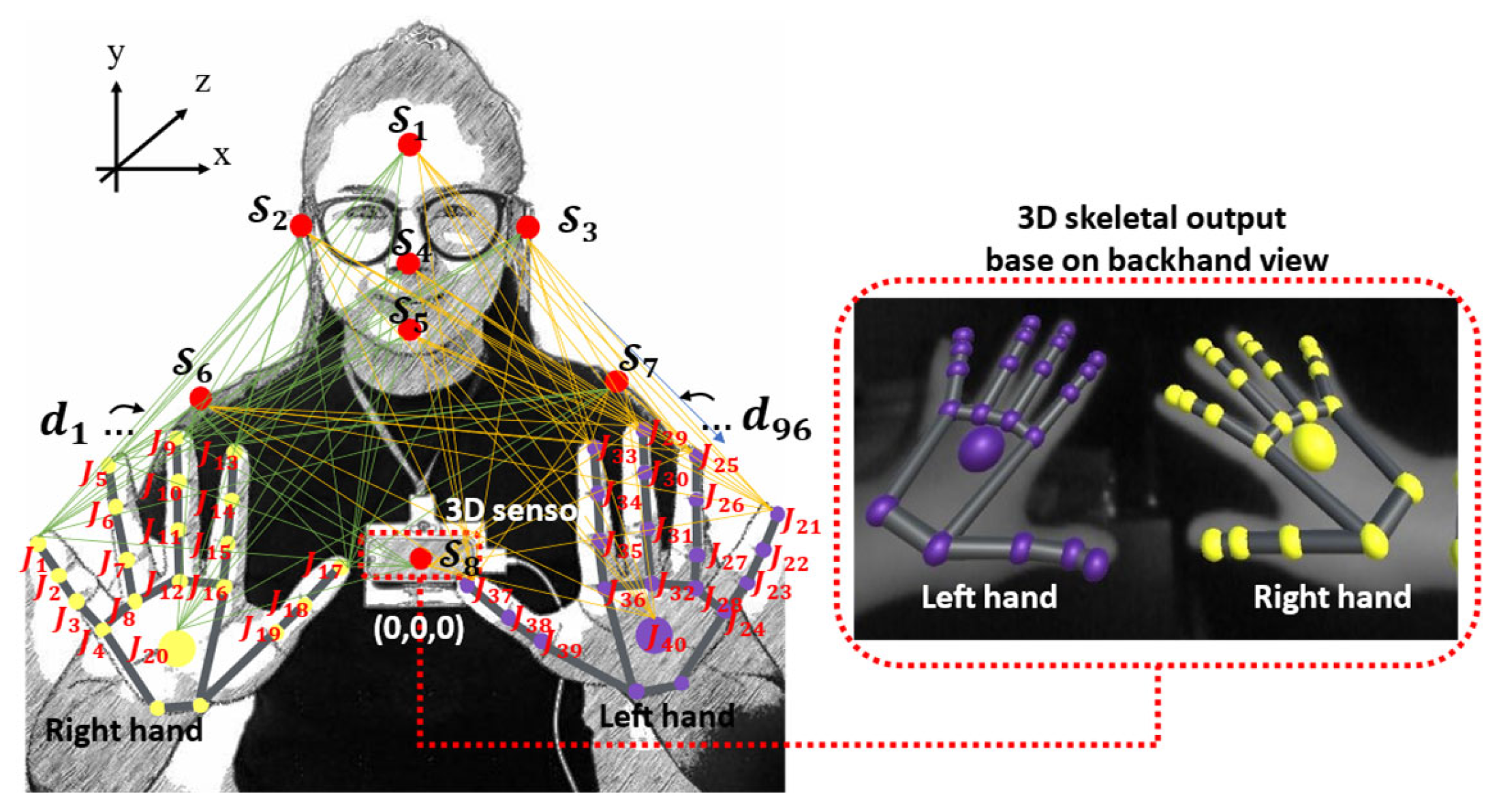
5.1.1. 3D Skeleton Joint Data
5.1.2. Calibration Technique
5.2. Feature Extraction
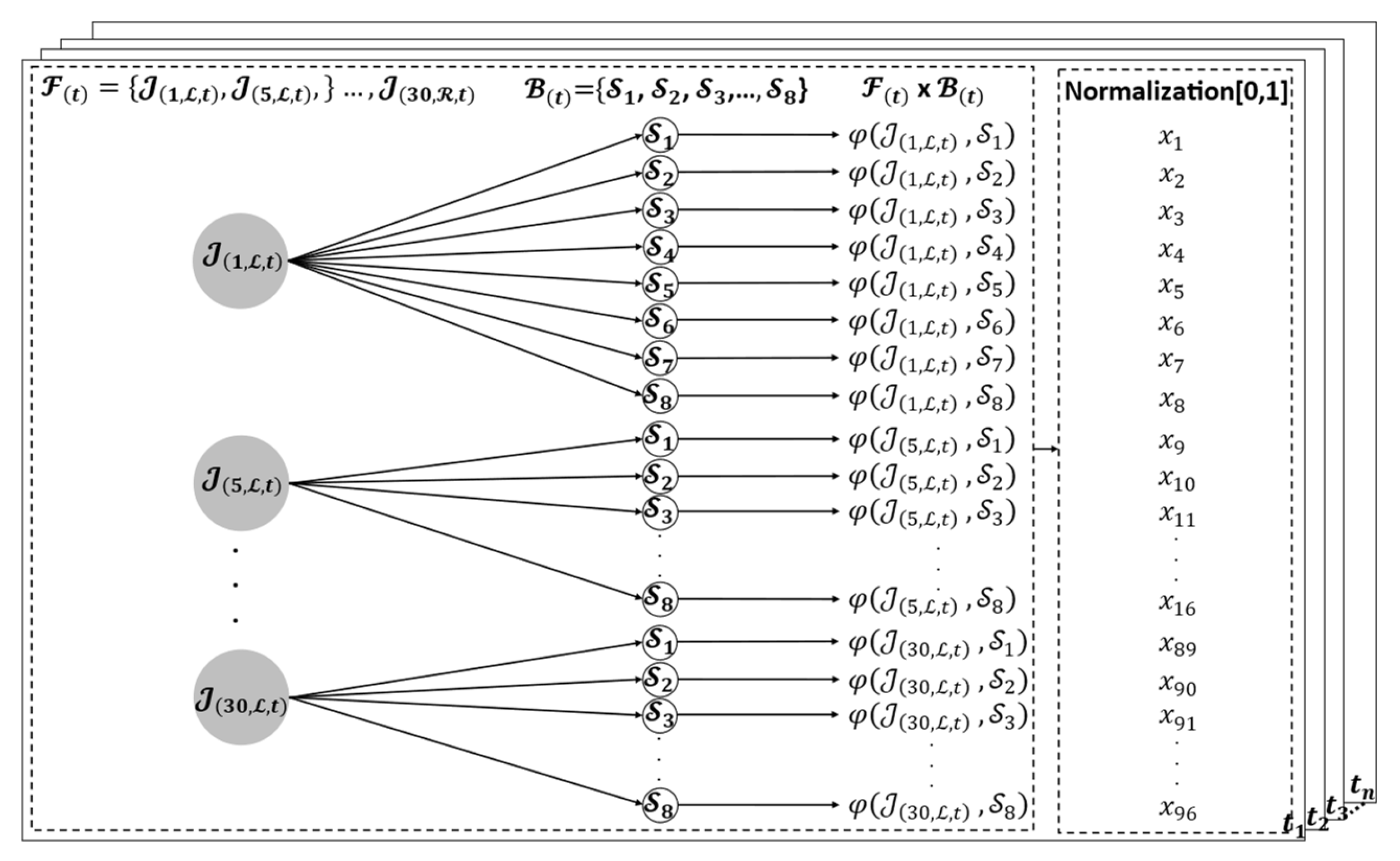
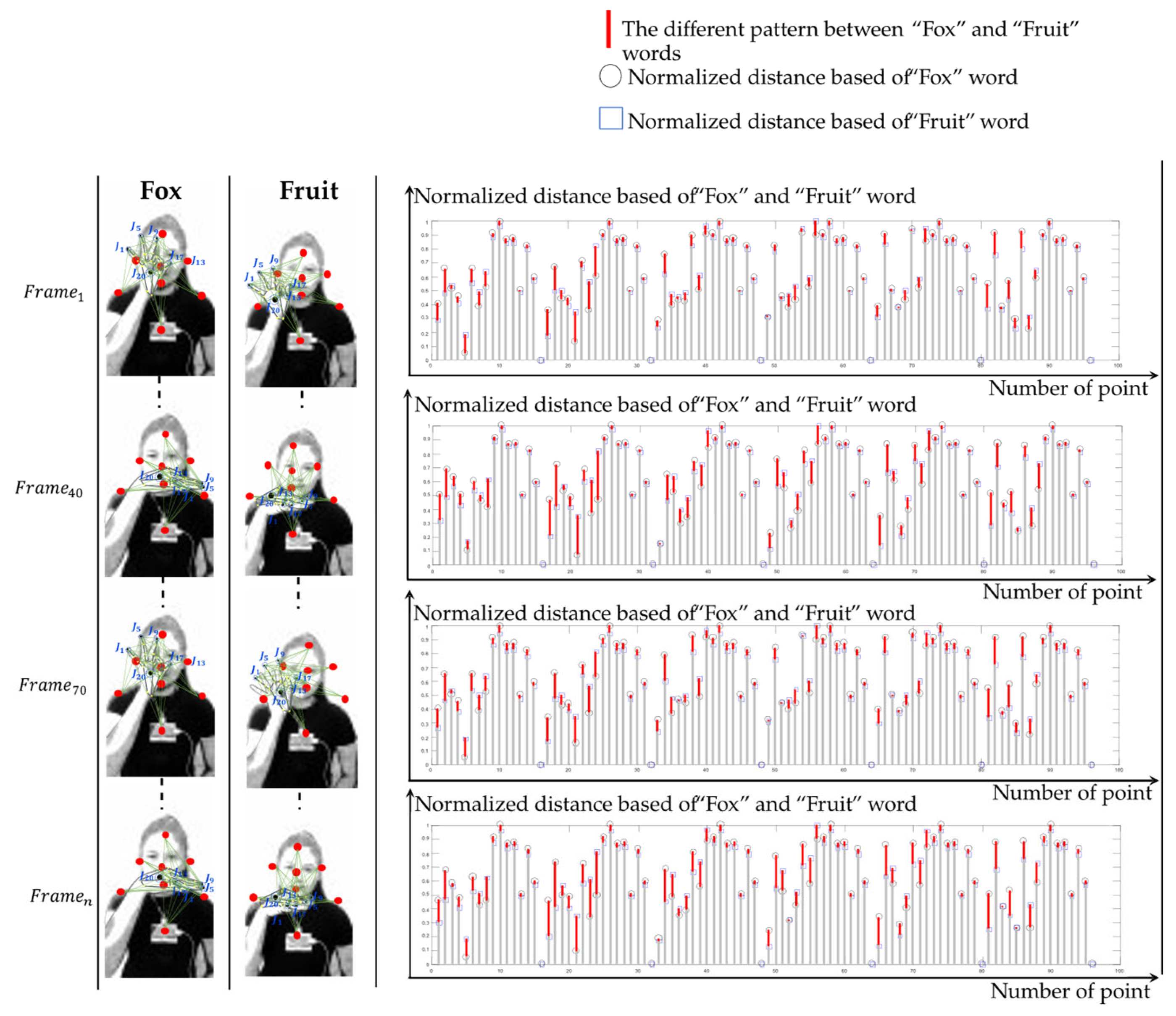
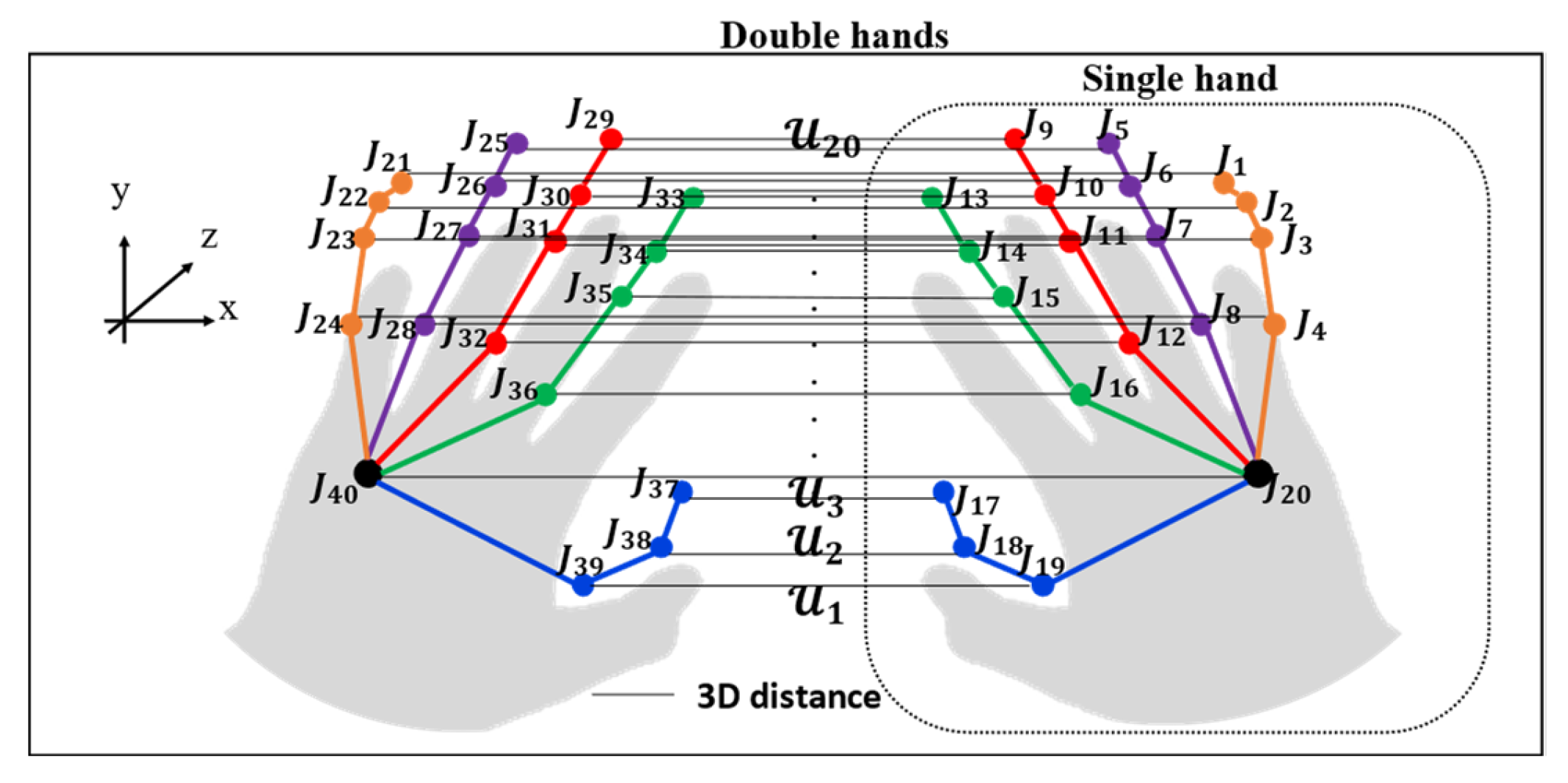
5.2.1. Spatial–Temporal Body Parts and Hand Relationship Patterns
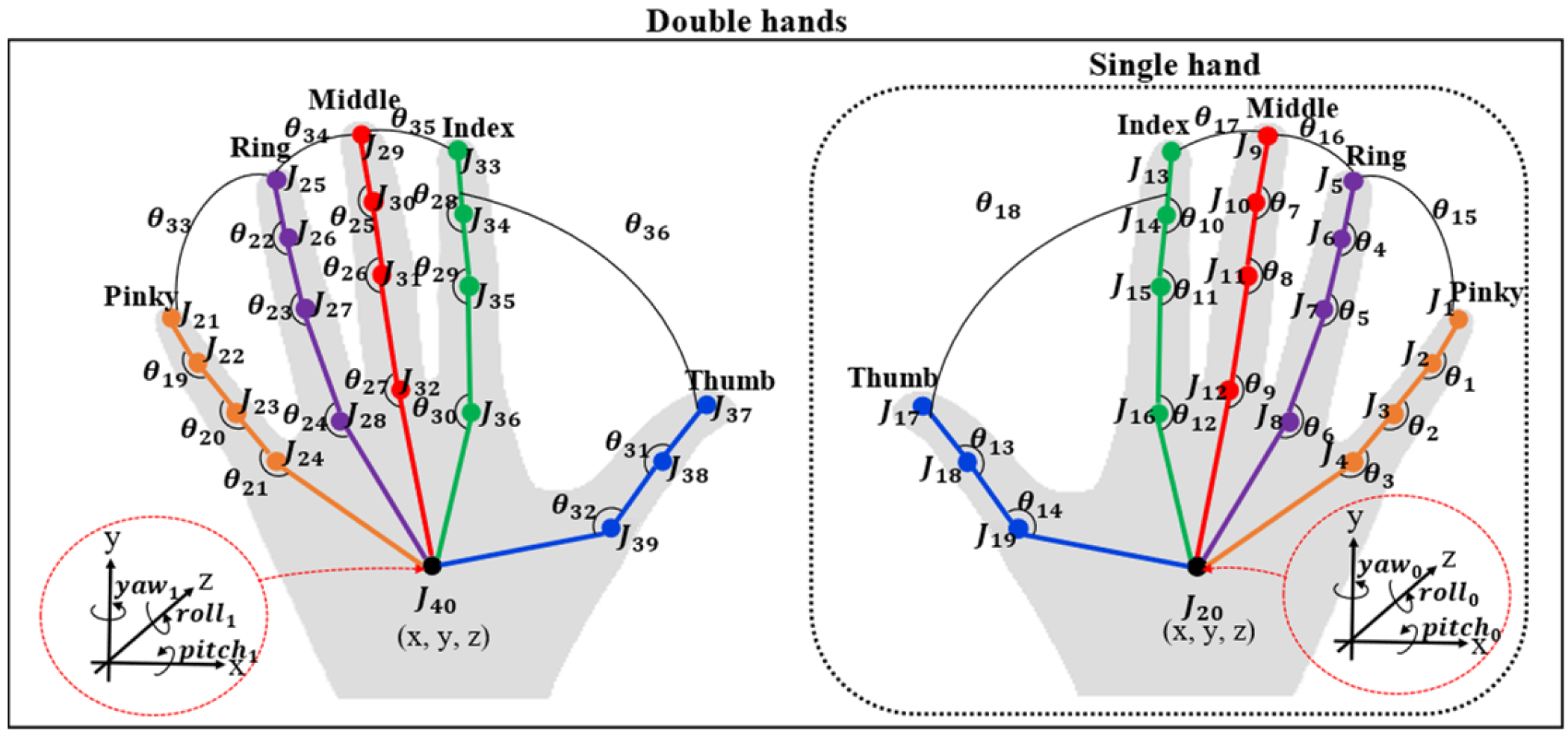
5.2.2. Spatial–Temporal Finger Joint Angle Patterns
5.2.3. Spatial–Temporal Double-Hand Relationship Patterns
5.2.4. Spatial–Temporal 3D Hand Motion Trajectory Patterns
5.3. Classification
6. Experiments and Results
6.1. Experiments
6.1.1. Dataset
6.1.2. Configuration Parameter
6.1.3. Evaluation of the Classification Model
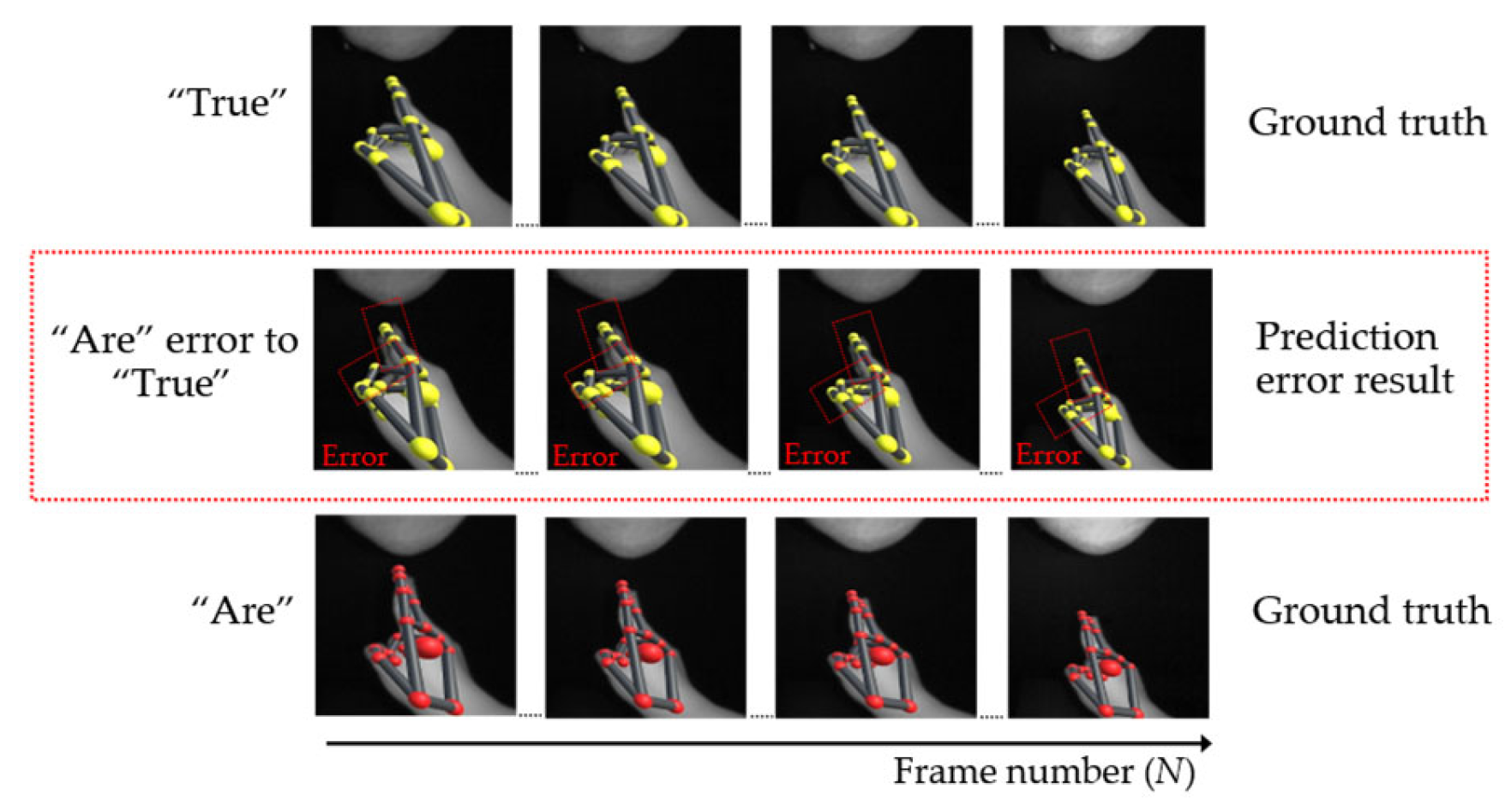
6.2. Results
Ablation Test
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Deafness and Hearing Loss. Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 9 January 2022).
- Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition using Spatio-Temporal Prosodic and Angle Features: A sequential learning approach. IEEE Access 2022, 10, 15911–15923. [Google Scholar] [CrossRef]
- Chophuk, P.; Chamnongthai, K. Backhand-view-based continuous-signed-letter recognition using a rewound video sequence and the previous signed-letter information. IEEE Access 2021, 9, 40187–40197. [Google Scholar] [CrossRef]
- In Medical Situations, Poor Communication Often Leads to Disaster. Deaf Services Unlimited. Available online: https://deafservicesunlimited.com/2016/05/in-medical-situations-poor-communication-often-leads-to-disaster/ (accessed on 11 January 2022).
- Garberoglio, C.L.; Palmer, J.L.; Cawthon, S.W.; Sales, A. Deaf People and Employment in the United States: 2019; National Deaf Center: Austin, TX, USA, 2019. [Google Scholar]
- Fang, B.; Co, J.; Zhang, M. DeepASL: Enabling Ubiquitous and Non-Intrusive Word and Sentence-Level Sign Language Translation. In Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, Shenzhen, China, 4–7 November 2018. [Google Scholar]
- Ma, Y.; Zhou, G.; Wang, S.; Zhao, H.; Jung, W. SignFi: Sign language recognition using WiFi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–21. [Google Scholar] [CrossRef]
- He, J.; Zhang, C.; He, X.L.; Dong, R.H. Visual Recognition of traffic police gestures with convolutional pose machine and handcrafted features. Neurocomputing 2020, 390, 248–259. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Chen, H.; Jiang, D.; Oveneke, M.C.; Sahli, H. Bipolar disorder recognition with histogram features of arousal and body gestures. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Korea, 22 October 2018; pp. 15–21. [Google Scholar]
- Chen, H.; Liu, X.; Li, X.; Shi, H.; Zhao, G. Analyze spontaneous gestures for emotional stress state recognition: A micro-gesture dataset and analysis with deep learning. In Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Pattanaworapan, K.; Chamnongthai, K.; Guo, J.-M. Signer independence finger alphabet recognition using discrete wavelet transform and area level run lengths. J. Vis. Commun. Image Represent. 2016, 38, 658–677. [Google Scholar] [CrossRef]
- Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition of Skeletal Videos Using Processed Video Driven Multi-Stacked Deep LSTM. Sensors 2022, 22, 1406. [Google Scholar] [CrossRef]
- Tennant, R.A.; Gluszak, M.; Brown, M.G. The American Sign Language Handshape Dictionary; Gallaudet University Press: Washington, DC, USA, 1998. [Google Scholar]
- Starner, T.; Pentland, A. Real-time American Sign Language recognition from video using hidden Markov models. In Proceedings of the International Symposium on Computer Vision (ISCV 1995), Coral Gables, FL, USA, 21–23 November 1995; pp. 265–270. [Google Scholar]
- Lee, B.G.; Chong, T.W.; Chung, W.Y. Sensor fusion of motion-based sign language interpretation with deep learning. Sensors 2020, 20, 6256. [Google Scholar] [CrossRef]
- Li, W.; Luo, Z.; Xi, X. Movement Trajectory Recognition of Sign Language Based on Optimized Dynamic Time Warping. Electronics 2020, 9, 1400. [Google Scholar] [CrossRef]
- Gurbuz, S.Z.; Rahman, M.M.; Kurtoglu, E.; Malaia, E.; Gurbuz, A.C.; Griffin, D.J.; Crawford, C. Multi-frequency rf sensor fusion for word-level fluent asl recognition. IEEE Sens. J. 2021, 12, 11373–11381. [Google Scholar] [CrossRef]
- Dong, W.; Yang, L.; Gravina, R.; Fortino, G. Soft wrist-worn multi-functional sensor array for real-time hand gesture recognition. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Lee, S.; Jo, D.; Kim, K.B.; Jang, J.; Park, W. Wearable sign language translation system using strain sensors. Sens. Actuator A Phys. 2021, 331, 113010. [Google Scholar] [CrossRef]
- Zaccagnino, R.; Capo, C.; Guarino, A.; Lettieri, N.; Malandrino, D. Techno-regulation and intelligent safeguards. Multimed. Tools Appl. 2021, 80, 15803–15824. [Google Scholar] [CrossRef]
- Abid, M.; Petriu, E.; Amjadian, E. Dynamic sign language recognition for smart home interactive application using stochastic linear formal grammar. IEEE Trans. Instrum. Meas. 2015, 64, 596–605. [Google Scholar] [CrossRef]
- Ranga, V.; Yadav, N.; Garg, P. American sign language fingerspelling using hybrid discrete wavelet transform-gabor filter and convolutional neural network. J. Eng. Sci. Technol. 2018, 13, 2655–2669. [Google Scholar]
- Miguel, R.A.; Susana, O.-C.; Jorge, R.; Federico, S.-I. American sign language alphabet recognition using a neuromorphic sensor and an artificial neural network. Sensors 2017, 17, 2176. [Google Scholar]
- Liwicki, S.; Everingham, M. Automatic recognition of fingerspelled words in British Sign Language. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Aldelfy, H.A.; Al-Mufraji, M.H.; Saeed, T.R. An Efficient Feature Extraction of Isolated Word for Dynamic Sign Language Classification. In Proceedings of the 2018 Third Scientific Conference of Electrical Engineering (IEEE), Baghdad, Iraq, 19–20 December 2018; pp. 305–309. [Google Scholar]
- Mohammed, A.A.Q.; Lv, J.; Islam, M. A deep learning-based End-to-End composite system for hand detection and gesture recognition. Sensors 2019, 19, 5282. [Google Scholar] [CrossRef] [Green Version]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, J.P.; Prakash, A.J.; Pławiak, P.; Samantray, S. Real-Time Hand Gesture Recognition Using Fine-Tuned Convolutional Neural Network. Sensors 2022, 22, 706. [Google Scholar] [CrossRef]
- Podder, K.K.; Chowdhury, M.E.; Tahir, A.M.; Mahbub, Z.B.; Khandakar, A.; Hossain, M.S.; Kadir, M.A. Bangla Sign Language (BdSL) Alphabets and Numerals Classification Using a Deep Learning Model. Sensors 2022, 22, 574. [Google Scholar] [CrossRef]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Maruyama, M.; Ghose, S.; Inoue, K.; Roy, P.P.; Iwamura, M.; Yoshioka, M. Word-level sign language recognition with multi-stream neural networks focusing on local regions. arXiv 2021, arXiv:2106.15989. [Google Scholar]
- Aly, S.; Aly, W. DeepArSLR: A Novel Signer-Independent Deep Learning Framework for Isolated Arabic Sign Language Gestures Recognition. IEEE Access 2020, 8, 83199–83212. [Google Scholar] [CrossRef]
- Liao, Y.Q.; Xiong, P.W.; Min, W.D.; Min, W.Q.; Lu, J.H. Dynamic sign language recognition based on video sequence with BLSTM-3D residual networks. IEEE Access 2019, 7, 38044–38054. [Google Scholar] [CrossRef]
- Al-Hammadi, M.; Muhammad, G.; Abdul, W.; Alsulaiman, M.; Bencherif, M.A.; Alrayes, T.S.; Mekhtiche, M.A. Deep learningbased approach for sign language gesture recognition with efficient hand gesture representation. IEEE Access 2020, 8, 192527–192542. [Google Scholar] [CrossRef]
- Murhij, Y.; Serebrenny, V. Hand gestures recognition model for Augmented reality robotic applications. In Proceedings of the 15th International Conference on Electromechanics and Robotics “Zavalishin’s Readings”, Ufa, Russia, 15–18 April 2020; Springer: Singapore, 2021; pp. 187–196. [Google Scholar]
- Lee, C.K.; Ng, K.K.; Chen, C.H.; Lau, H.C.; Chung, S.; Tsoi, T. American sign language recognition and training method with recurrent neural network. Expert Syst. Appl. 2021, 167, 114403. [Google Scholar] [CrossRef]
- Chong, T.-W.; Lee, B.-G. American Sign Language Recognition Using Leap Motion Controller with Machine Learning Approach. Sensors 2018, 18, 3554. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of american sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef] [Green Version]
- Ameur, S.; Khalifa, A.B.; Bouhlel, M.S. A novel hybrid bidirectional unidirectional LSTM network for dynamic hand gesture recognition with leap motion. Entertain. Comput. 2020, 35, 100373. [Google Scholar] [CrossRef]
- Naglot, D.; Kulkarni, M. Real time sign language recognition using the leap motion controller. In Proceedings of the 2016 IEEE International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; Volume 3, pp. 1–5. [Google Scholar]
- Shin, J.; Matsuoka, A.; Hasan, M.; Mehedi, A.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef]
- Khelil, B.; Amiri, H.; Chen, T.; Kammüller, F.; Nemli, I.; Probst, C.W. Hand Gesture Recognition Using Leap Motion Controller for Recognition of Arabic Sign Language. In Proceedings of the 3rd International Conference on Automation, Control, Engineering and Computer Science ACECS, Hammamet, Tunisia, 22 March 2016; Volume 16, pp. 233–238. [Google Scholar]
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting recurrent neural networks and leap motion controller for the recognition of sign language and semaphoric hand gestures. IEEE Trans. Multimed. 2018, 21, 234–245. [Google Scholar] [CrossRef] [Green Version]
- Katoch, S.; Singh, V.; Tiwary, U.S. Indian Sign Language recognition system using SURF with SVM and CNN. Array 2022, 14, 100141. [Google Scholar] [CrossRef]
- Bird, J.J.; Ekárt, A.; Faria, D.R. British sign language recognition via late fusion of computer vision and leap motion with transfer learning to american sign language. Sensors 2020, 20, 5151. [Google Scholar] [CrossRef]
- Smedt, Q.D.; Wannous, H.; Vandeborre, J.-P. Heterogeneous Hand Gesture Recognition Using 3D Dynamic Skeletal Data. Comput. Vis. Image Underst. 2019, 181, 60–72. [Google Scholar] [CrossRef] [Green Version]
- Mapari, R.B.; Kharat, G. Analysis of multiple sign language recognition using leap motion sensor. Int. J. Res. Advent Technol. 2017. [Google Scholar]
- Kumar, P.; Gauba, H.; Roy, P.P.; Dogra, D.P. A multimodal framework for sensor based sign language recognition. Neurocomputing 2017, 259, 21–38. [Google Scholar] [CrossRef]
- Jamaludin, N.A.N.; Fang, O.H. Dynamic Hand Gesture to Text using Leap Motion. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 199–204. [Google Scholar] [CrossRef] [Green Version]
- Moreira, L.L.; de Brito, M.M.; Kobiyama, M. Effects of different normalization, aggregation, and classification methods on the construction of flood vulnerability indexes. Water 2021, 13, 98. [Google Scholar] [CrossRef]
- Guzsvinecz, T.; Szucs, V.; Sik-Lanyi, C. Suitability of the Kinect Sensor and Leap Motion Controller—A Literature Review. Sensors 2019, 19, 1072. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Lin, P.; Nie, X. Research of stock price prediction based on PCA-LSTM model. IOP Conf. Ser. Mater. Sci. Eng. 2020, 790, 012109. [Google Scholar] [CrossRef]
- Kanai, S.; Fujiwara, Y.; Iwamura, S. Preventing gradient explosions in gated recurrent units. In Advances in Neural Information Processing Systems, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Huang, R.; Wei, C.; Wang, B.; Yang, J.; Xu, X.; Wu, S.; Huang, S. Well performance prediction based on Long Short-Term Memory (LSTM) neural network. J. Pet. Sci. Eng. 2022, 208, 109686. [Google Scholar] [CrossRef]
- Song, W.; Gao, C.; Zhao, Y.; Zhao, Y. A Time Series Data Filling Method Based on LSTM—Taking the Stem Moisture as an Example. Sensors 2020, 20, 5045. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhou, Q.; Wu, H. NLP at IEST 2018: BiLSTM-attention and LSTM-attention via soft voting in emotion classification. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 189–194. [Google Scholar]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.W. Fake news stance detection using deep learning architecture (cnn-lstm). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Kayhan, O.; Samur, E. A Wearable Haptic Guidance System Based on Skin Stretch around the Waist for Visually-Impaired Runners. In Proceedings of the IEEE Haptics Symposium (HAPTICS), IEEE, Santa Barbara, CA, USA, 21–24 March 2022; pp. 1–6. [Google Scholar]
- Ibrahim, N.B.; Zayed, H.H.; Selim, M.M. Advances, challenges and opportunities in continuous sign language recognition. J. Eng. Appl. Sci. 2020, 15, 1205. [Google Scholar] [CrossRef] [Green Version]
- Bhuiyan, M.H.; Fard, M.; Robinson, S.R. Effects of whole-body vibration on driver drowsiness: A review. J. Saf. Res. 2022, 81, 175–189. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Methodology | Acquisition Mode | Results (%) | Forehand/ Backhand | Limitation |
|---|---|---|---|---|---|
| 1. 2D approach | |||||
| [22] | 24 ASL letters + DWT Gabor filter + KNN | Image | 96.70 | Forehand | Fails to track SRM sign group |
| [23] | 24 ASL letters + Contour-based + ANN | Image | 79.58 | Forehand | Fails to track SRM sign group |
| [24] | 100 ASL words + HOG + HMM | Video | 98.90 | Forehand | Fails to track SRM sign group |
| [26] | 27 hand gestures + Lightweight CNN model | Image | 97.25 | Forehand | Fails to track SRM sign group |
| [27] | 20 ASL words + CNN model + SVM | Video | 97.28 | Forehand | Fails to track SRM sign group |
| [28] | 36 ASL letters + CNN model | Image | 90.26 | Forehand | Fails to track SRM sign group |
| 2. 3D approach | |||||
| 2.1 Single-hand model | |||||
| [36] | 26 ASL letters + 30 feature-based + LSTM | Video | 91.82 | Forehand | Fails to track SRM sign group |
| [37] | 26ASL letters + Position-based + DNN | Video | 93.81 | Forehand | Fails to track SRM sign group |
| [38] | 26 ASL letters + 56 feature-based + HMM | Video | 86.10 | Forehand | Fails to track SRM sign group |
| [39] | 12 ASL words + Position-based + D-LSTM | Video | 90.00 | Forehand | Fails to track SRM sign group |
| [40] | 26 ASL letters + Distance-based + ANN | Video | 96.15 | Forehand | Fails to track SRM sign group |
| [41] | 26 ASL letters + Distance-based + GBM | Image | 87.60 | Forehand | Fails to track SRM sign group |
| [3] | 26 ASL letters + Trajectory-based + LSTM | Video | 96.07 | Backhand | Fails to track SRM sign group |
| 2.2 Double-hand model | |||||
| [12] | 40 words + Motion and angle-based + BiLSTM | Video | 97.98 | Backhand | Fails to track SRM sign group |
| 3. Multi-single- and double-hand models | |||||
| [43] | 30 words + Angle-based + LSTM | Video | 96.00 | Forehand | Fails to track SRM sign group |
| [45] | 18 words + CNN model | Video | 82.55 | Forehand | Fails to track SRM sign group |
| [46] | 49 words + Hand skeletal + FV + SVM | Video | 86.86 | Forehand | Fails to track SRM sign group |
| [48] | 50 words + Position-based + BiLSTM-NN | Video | 94.55 | Forehand | Fails to track SRM sign group |
| [6] | 56 words + Trajectory-based + HB-RNN | Video | 94.50 | Backhand | Fails to track SRM sign group |
| [2] | 57 words + Angle-based + FFV-BiLSTM | Video | 98.60 | Backhand | Fails to track SRM sign group |
| Datasets | No. of Participants | Frequency (Times/Word) | No. of Samples |
|---|---|---|---|
| 36 single-hand ASL words (Created by author) | 10 | 10 | 3600 |
| 36 double-hand ASL words (Created by author) | 10 | 10 | 3600 |
| 26 signed letters (A–Z letters) by [3] | 10 | 20 | 5200 |
| 40 double-hand ASL words by [12] | 10 | 10 | 4000 |
| Total samples | 16,400 | ||
| Systems | Specification |
|---|---|
| Computer system | Dell G3 Gaming w56691425TH |
| CPU: Intel Core i7-8750H | |
| GPU: NVidia GeForce GTX 1050Ti | |
| Memory Size: 8 GB DDR4 | |
| Leap Motion sensor | Video: 120 frames per second |
| Infrared camera: 2 cameras | |
| Pixel: 640 × 240 | |
| Interaction zone: 80 cm | |
| FOV: 150 × 120 degrees | |
| Accuracy: 0.01 mm |
| Layer | Parameter Options | Value |
|---|---|---|
| Input layer | Sequence length | Longest |
| Batch size | 27 | |
| Learning rate | 0.0001 | |
| Input per sequence | 170 | |
| Feature vector | 1 dimension | |
| Hidden layer | BiLSTM layer | Longest |
| Hidden node | (2/3) × (input size per series) [3] | |
| Activation function | SoftMax | |
| Dropout layer | Dropout | 0.2 |
| Output layer | LSTM model | Many to one |
| Output class | Model 1 = 26 classes Model 2 = 40 classes Model 3 = 72 classes |
| Reference | Accuracy (%) | Error (%) | Precision (%) | Recall (%) | F1-Score (%) | SD (%) |
|---|---|---|---|---|---|---|
| [37] | 93.81 | 6.19 | - | - | - | - |
| [3] | 96.07 | 3.93 | - | - | - | - |
| Proposed method | 97.34 | 2.66 | 97.39 | 97.34 | 97.36 | 0.26 |
| Reference | Accuracy (%) | Error (%) | Precision (%) | Recall (%) | F1-Score (%) | SD (%) |
|---|---|---|---|---|---|---|
| [12] | 97.98 | 2.02 | 96.76 | 97.49 | 96.97 | - |
| Proposed method | 98.52 | 1.48 | 98.56 | 98.52 | 98.54 | 0.22 |
| Method | Accuracy (%) | Error (%) | Precision (%) | Recall (%) | F1-Score (%) | SD (%) |
|---|---|---|---|---|---|---|
| Proposed method | 96.99 | 3.01 | 97.01 | 96.99 | 97.00 | 1.01 |
| Feature Extraction | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | SD (%) |
|---|---|---|---|---|---|
| 92.38 | 92.67 | 92.38 | 92.52 | 0.51 | |
| 96.41 | 96.48 | 96.41 | 96.44 | 0.29 | |
| 97.34 | 97.39 | 97.34 | 97.36 | 0.26 |
| Feature Extraction | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | SD (%) |
|---|---|---|---|---|---|
| 86.95 | 88.95 | 86.95 | 87.94 | 0.60 | |
| 95.51 | 95.88 | 95.51 | 95.69 | 0.34 | |
| 98.52 | 98.56 | 98.52 | 98.54 | 0.22 |
| Single Hand Approach | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| G. | Words | Acc. (%) | Error (%) | SD (%) | G. | Words | Acc. (%) | Error (%) | SD (%) |
| 1 | Mouse | 96.20 | Lonely (2.2), Nephew (1.6) | 1.17 | 10 | Respect | 96.40 | Are (2.6), Nephew (1) | 1.20 |
| Lonely | 96.60 | Mouse (2.2), Niece (1.2) | 1.20 | Are | 97.00 | Respect (1), True (1), Mouse (1) | 0.89 | ||
| 2 | Grandfather | 95.60 | Grandmother (4), spit (0.3), vehicle (0.1) | 1.36 | 11 | Endorse | 97.20 | Latin (1.8), Am (1) | 0.40 |
| Grandmother | 97.20 | Grandfather (2), spit (0.8) | 0.75 | Latin | 96.20 | Endorse (2.8), Nephew (1) | 1.83 | ||
| 3 | Tend | 96.20 | Delicious (3.2), Vehicle (0.4), Spit (0.2) | 1.94 | 12 | Shave | 97.40 | Yesterday (1.6), Fruit (0.6), Earing (0.4) | 0.80 |
| Delicious | 96.60 | Tend (2.8), Spit (0.4), Vehicle (0.2) | 1.36 | Yesterday | 96.60 | Shave (2.8), Onion (0.6) | 0.80 | ||
| 4 | Hear | 97.60 | Whisper (1.8), Earring (0.3), Hair (0.3) | 0.49 | 13 | Apple | 96.40 | Onion (2.4), Niece (0.6), Eagle (0.6) | 1.20 |
| Whisper | 96.20 | Hear (2.4), Fox (0.6), Grandmother (0.4), Fruit (0.4) | 2.04 | Onion | 97.60 | Apple (2.2), Yesterday (0.2) | 0.49 | ||
| 5 | Better | 97.00 | Forget (2.2), Saturdays (0.8) | 1.09 | 14 | Deny | 97.40 | Drop (2.2), Spit (0.4) | 0.80 |
| Forget | 96.20 | Better (2.8), Nephew (1) | 2.64 | Drop | 98.00 | Deny (1.2), Vehicle (0.8) | 0.89 | ||
| 6 | Fox | 96.60 | Fruit (2.4), Earring (0.4), Hair (0.3), Whisper (0.3) | 0.80 | 15 | Niece | 96.00 | Nephew (2.4), Lonely (1.6) | 2.45 |
| Fruit | 97.40 | Fox (1.6), Whisper (1) | 0.49 | Nephew | 97.60 | Niece (1.2), Mouse (1), Respect (0.2) | 1.20 | ||
| 7 | Past | 96.80 | Know (2.2), Onion (0.6), Apple (0.4) | 0.98 | 16 | Eagle | 96.80 | Egypt (2), Onion (0.9), Apple (0.3) | 0.98 |
| Know | 98.00 | Past (2) | 0.63 | Egypt | 97.20 | Eagle (1.6), Hair (0.7), Latin (0.5) | 0.40 | ||
| 8 | Spit | 95.60 | Grandmother (3.4), Vehicle (1) | 1.62 | 17 | Am | 98.00 | True (1), Latin (1) | 0.63 |
| Vehicle | 95.80 | Spit (4.2) | 1.60 | True | 98.20 | Am (1.2), Spit (0.6) | 0.75 | ||
| 9 | Earring | 96.20 | Hair (2), Fox (1.4), Hear (0.4) | 0.97 | 18 | Saturdays | 97.00 | South (2.4), Lonely (0.6) | 1.26 |
| Hair | 96.80 | Earring (1.8), Fox (1), Hear (0.4) | 0.75 | South | 96.60 | Saturdays (2.8), Am (0.2), Lonely (0.2), True (0.2) | 1.36 | ||
| Double Hands Approach | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| G. | Words | Acc. (%) | Error (%) | SD (%) | G. | Words | Acc. (%) | Error (%) | SD (%) |
| 1 | Holiday | 98.20 | Retired (1), Fire (0.5), Embarrass (0.3) | 0.74 | 10 | Until | 96.80 | To (2.2), Keep (0.6), Pure (0.4) | 1.47 |
| Retired | 97.00 | Holiday (2), Fire (1) | 1.09 | To | 97.60 | Until (1.4), Pure (0.5), Keep (0.5) | 1.36 | ||
| 2 | Bath | 96.40 | Drum (3.2), Act (0.4) | 0.49 | 11 | Embarrass | 97.80 | Fire (1.2), Holiday (1) | 0.98 |
| Drum | 96.40 | Bath (2.6), Act (0.6), Science (0.4) | 0.80 | Fire | 95.60 | Embarrass (2.4), Introduce (1.2), Convince (0.8) | 0.80 | ||
| 3 | Act | 96.60 | Science (2.4), Drum (0.7), Bath (0.3) | 1.49 | 12 | Cool | 96.20 | Fear (2.8), Shock (0.7), Sweat (0.3) | 1.33 |
| Science | 98.60 | Act (1.4). | 0.80 | Fear | 97.00 | Cool (2), Street (1) | 1.09 | ||
| 4 | Carve | 98.40 | Page (1), Bath (0.6) | 0.49 | 13 | Father | 96.60 | Mother (2.6), Check (0.4), Fire (0.4) | 0.80 |
| Page | 97.00 | Carve (2), Bath (1) | 0.63 | Mother | 97.20 | Father (1.8), Check (0.7), Fire (0.3) | 0.40 | ||
| 5 | Major | 97.00 | Street (2), Convince (1) | 1.67 | 14 | Check | 97.20 | Pay (2.2), Convince (0.6) | 1.17 |
| Street | 95.80 | Major (2.6), Convince (1), Fear (0.6) | 1.72 | Pay | 97.60 | Check (1.4), Clean (0.5), Laid off (0.5) | 1.20 | ||
| 6 | Convince | 96.20 | Introduce (2.4), Major (0.5), Pay (0.5), Fire (0.4) | 1.47 | 15 | Apply | 97.80 | Plug (2), Keep (0.1), Pure (0.1) | 0.98 |
| Introduce | 96.80 | Convince (3), Fire (0.2) | 0.75 | Plug | 98.20 | Apply (1.4), Keep (0.4) | 0.40 | ||
| 7 | Clean | 97.00 | Laid off (2.4), Pay (0.6) | 0.74 | 16 | Shock | 98.00 | Sweat (1), Fear (0.5), Cool (0.5) | 0.63 |
| Laid off | 98.20 | Clean (1.2), Pay (0.4), Page (0.2) | 0.40 | Sweat | 97.00 | Shock (1.8), Cool (0.7), Fear (0.5) | 0.33 | ||
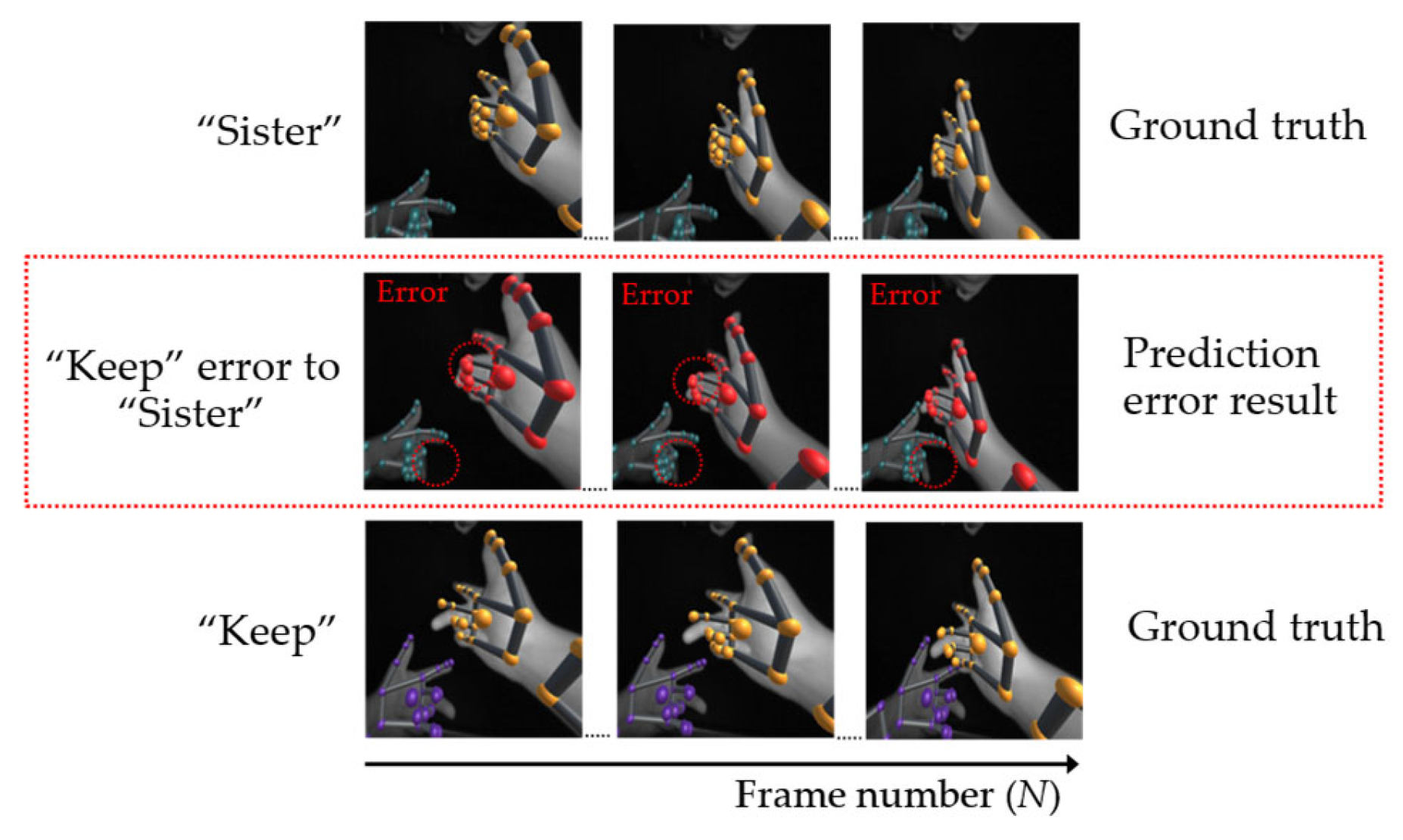
| 8 | Brother | 98.60 | Sister (1), Check (0.2), Keep (0.2) | 0.49 | 17 | Society | 96.20 | Team (2.8), Drum (1) | 0.75 |
| Sister | 98.00 | Brother (1.4), Keep (0.4), Pure (0.2) | 0.63 | Team | 97.20 | Society (1.8), Science (1) | 0.98 | ||
| 9 | Awake | 96.20 | Surprise (2.8), Embarrass (1) | 0.40 | 18 | Keep | 96.80 | Sister (2), Pure (1), Brother (0.2) | 1.17 |
| Surprise | 96.80 | Awake (2.2), Embarrass (1) | 0.40 | Pure | 97.20 | Keep (2.4), Sister (0.2), Brother (0.2) | 1.17 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chophuk, P.; Chamnongthai, K.; Chinnasarn, K. Backhand-Approach-Based American Sign Language Words Recognition Using Spatial-Temporal Body Parts and Hand Relationship Patterns. Sensors 2022, 22, 4554. https://doi.org/10.3390/s22124554
Chophuk P, Chamnongthai K, Chinnasarn K. Backhand-Approach-Based American Sign Language Words Recognition Using Spatial-Temporal Body Parts and Hand Relationship Patterns. Sensors. 2022; 22(12):4554. https://doi.org/10.3390/s22124554
Chicago/Turabian StyleChophuk, Ponlawat, Kosin Chamnongthai, and Krisana Chinnasarn. 2022. "Backhand-Approach-Based American Sign Language Words Recognition Using Spatial-Temporal Body Parts and Hand Relationship Patterns" Sensors 22, no. 12: 4554. https://doi.org/10.3390/s22124554
APA StyleChophuk, P., Chamnongthai, K., & Chinnasarn, K. (2022). Backhand-Approach-Based American Sign Language Words Recognition Using Spatial-Temporal Body Parts and Hand Relationship Patterns. Sensors, 22(12), 4554. https://doi.org/10.3390/s22124554