
A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- This review paper considers different techniques ranging across machine learning, deep learning, natural language processing (NLP), latent Dirichlet allocation (LDA), and others in detecting events from social media data. This is the first study to have incorporated such massive techniques in this field.
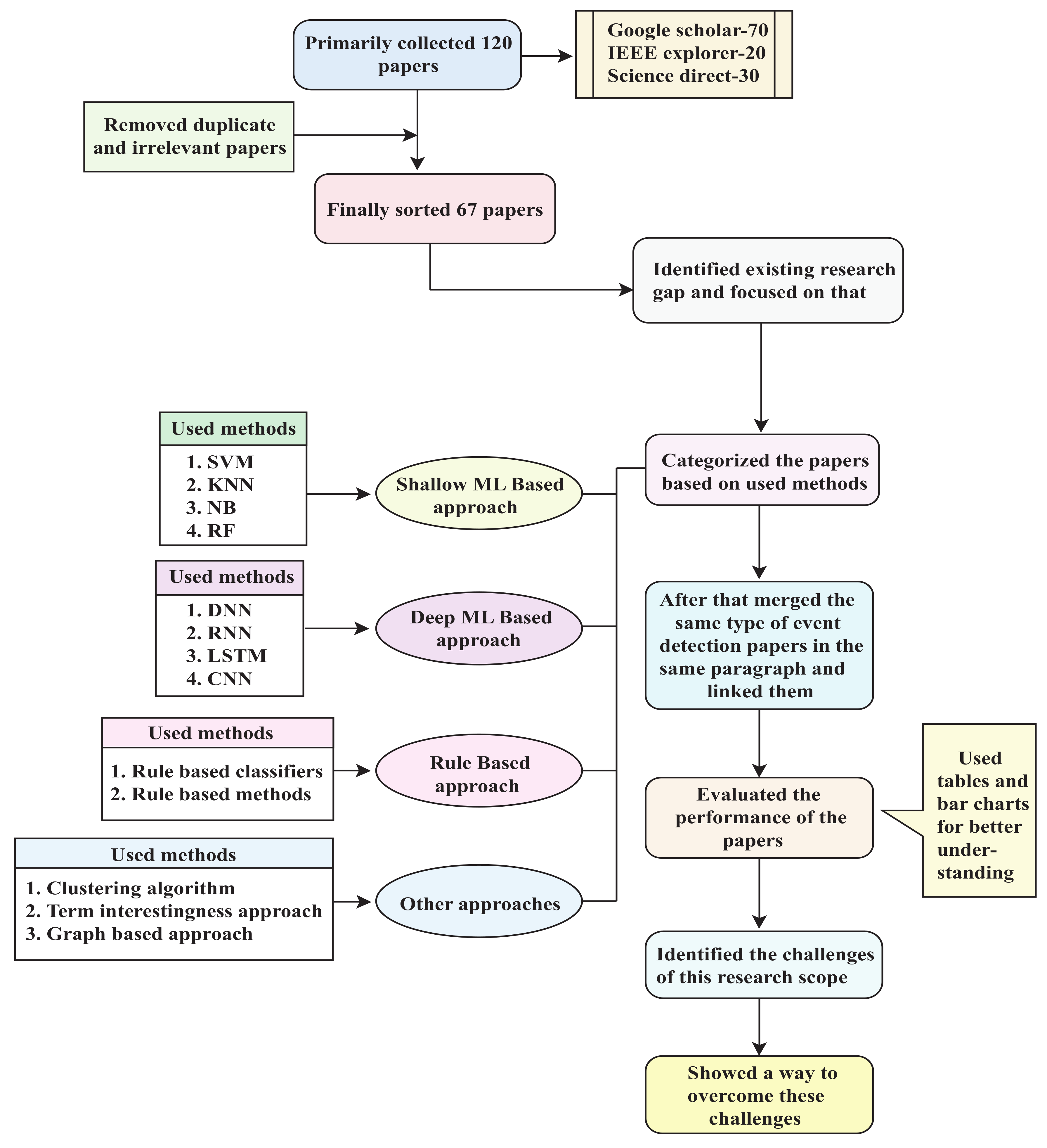
- A total of 67 research articles from the last decade from different renowned databases were studied.
- Detailed descriptions of the methodologies are provided.
- This study provides information about the datasets used by the respective authors. It also shows their duration of data collection, relative size, data collection area, and, most importantly, what different methods they used for their data collection.
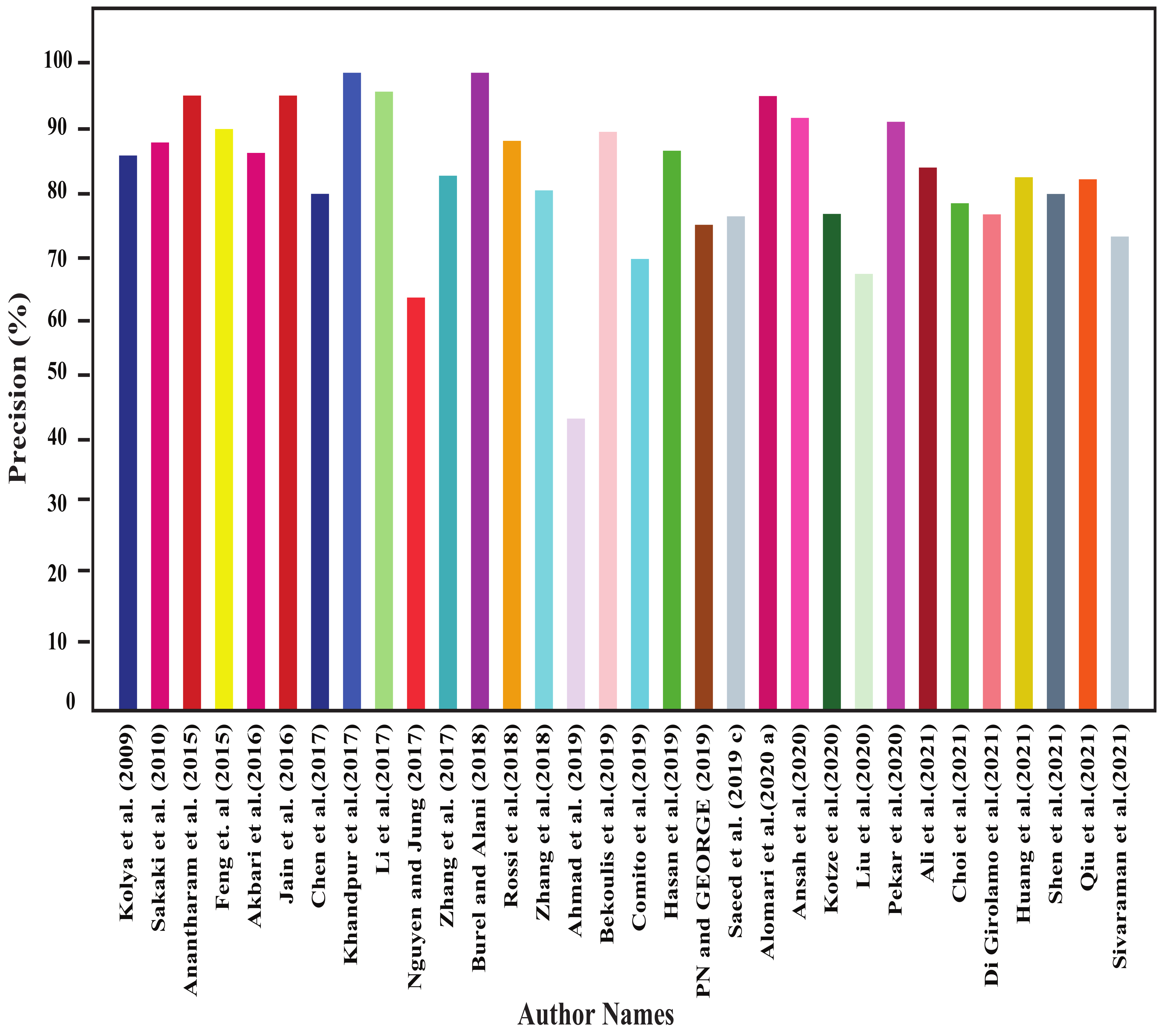
- Different methods’ performance comparison is also provided in this study, which helps understand the actual performance among the research works.
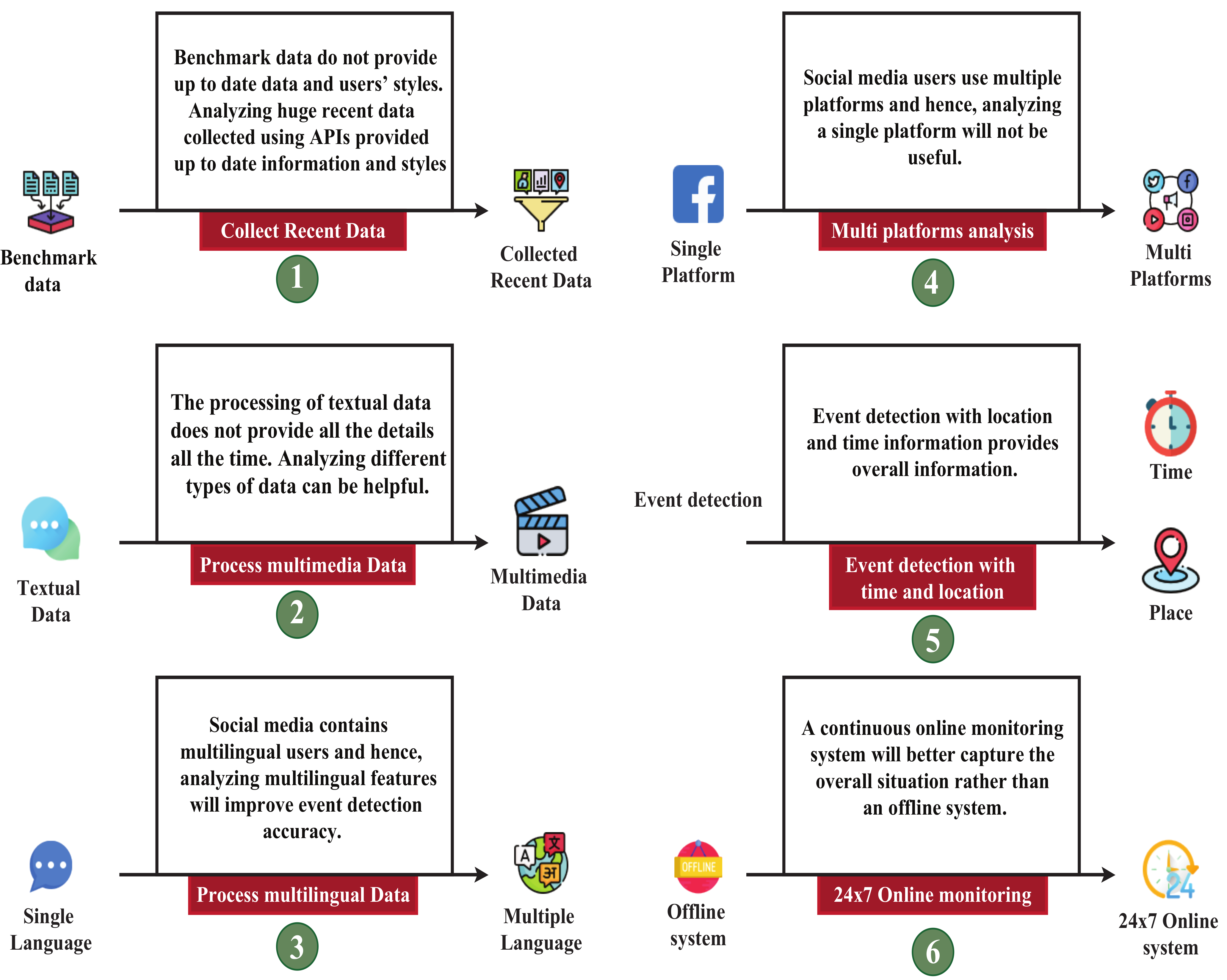
- We identify current research gaps in this field, and at the end of this paper, we also provide directions for future works in overcoming the mentioned gaps.
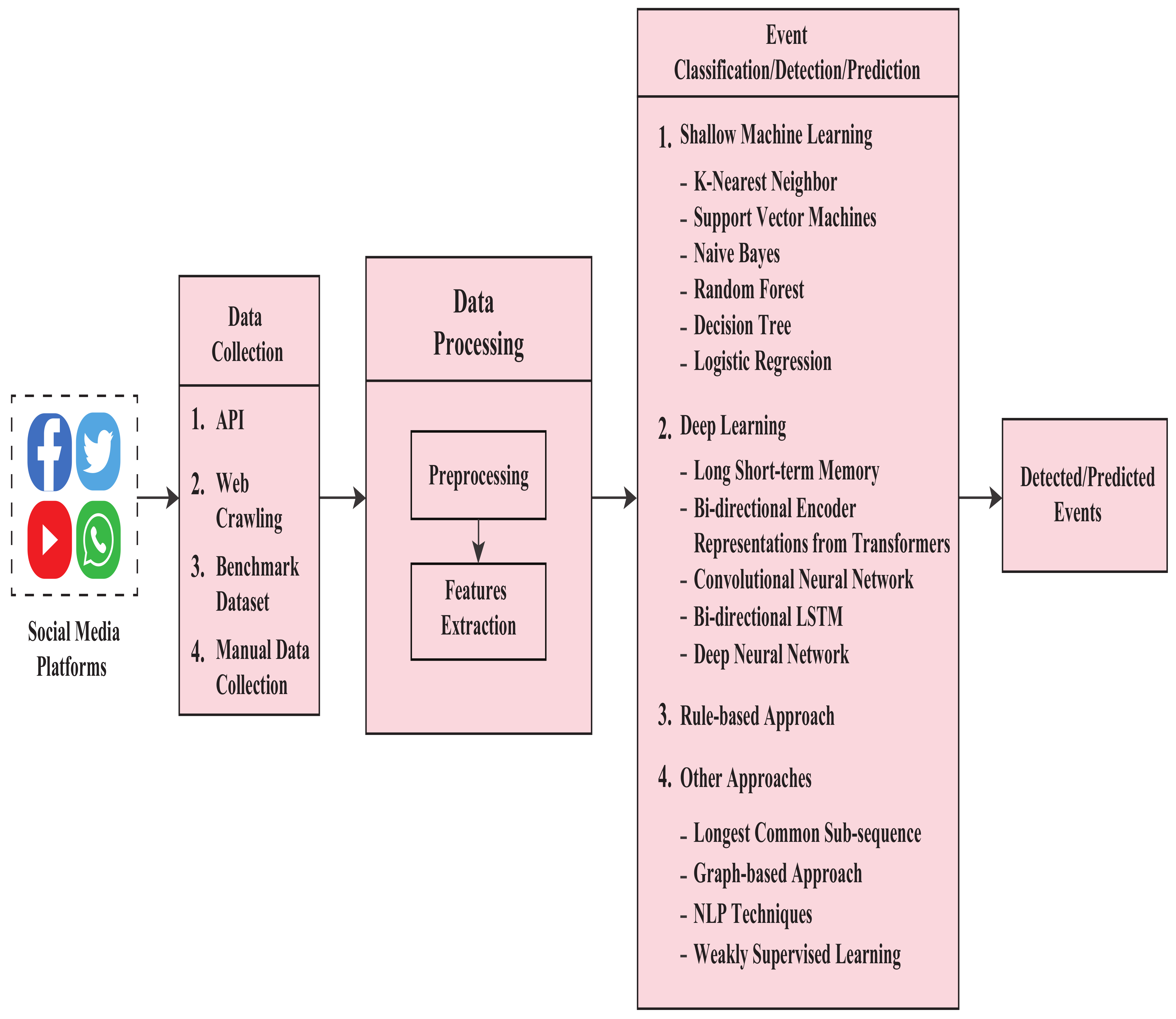
2. Research Procedure
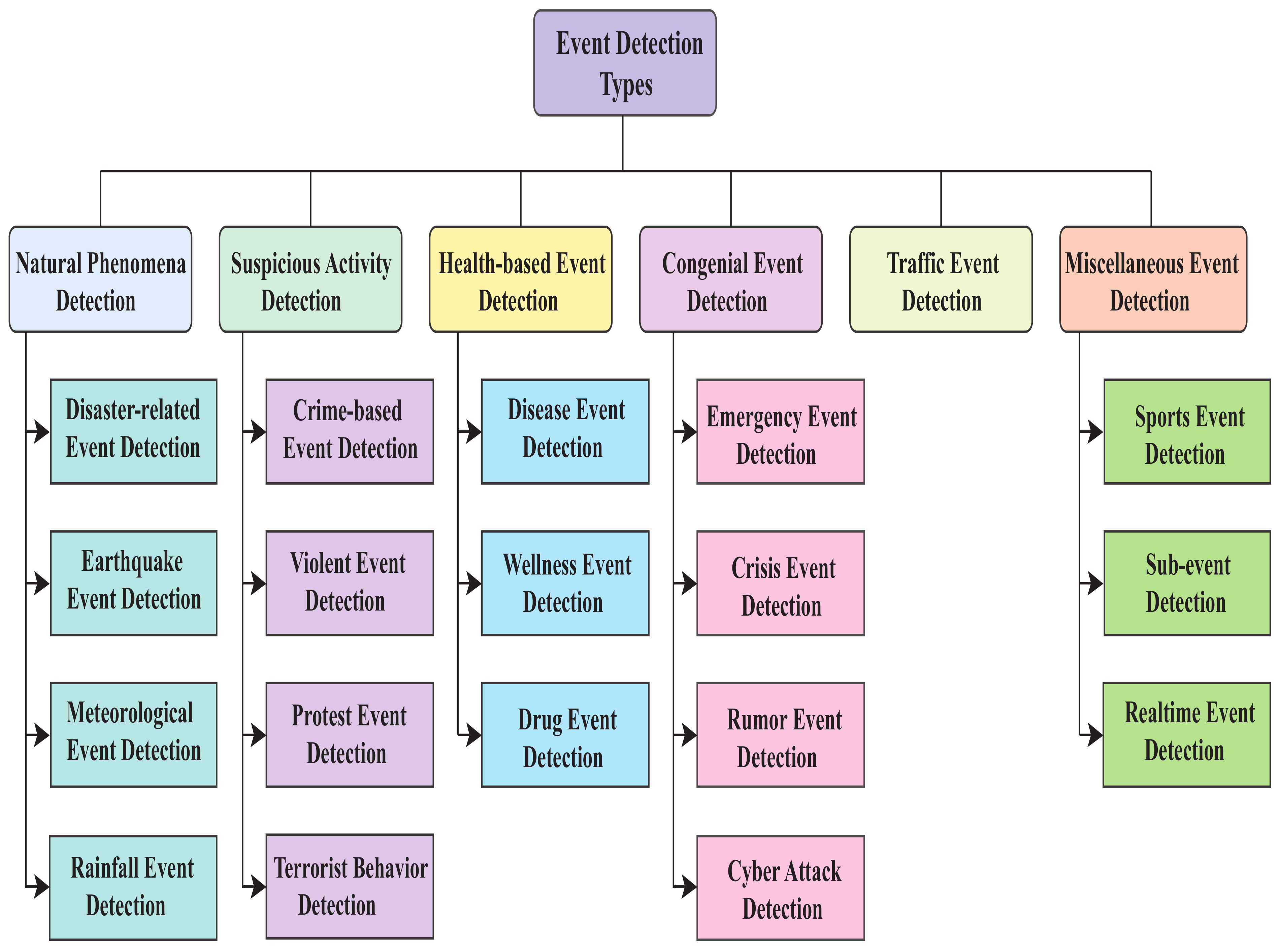
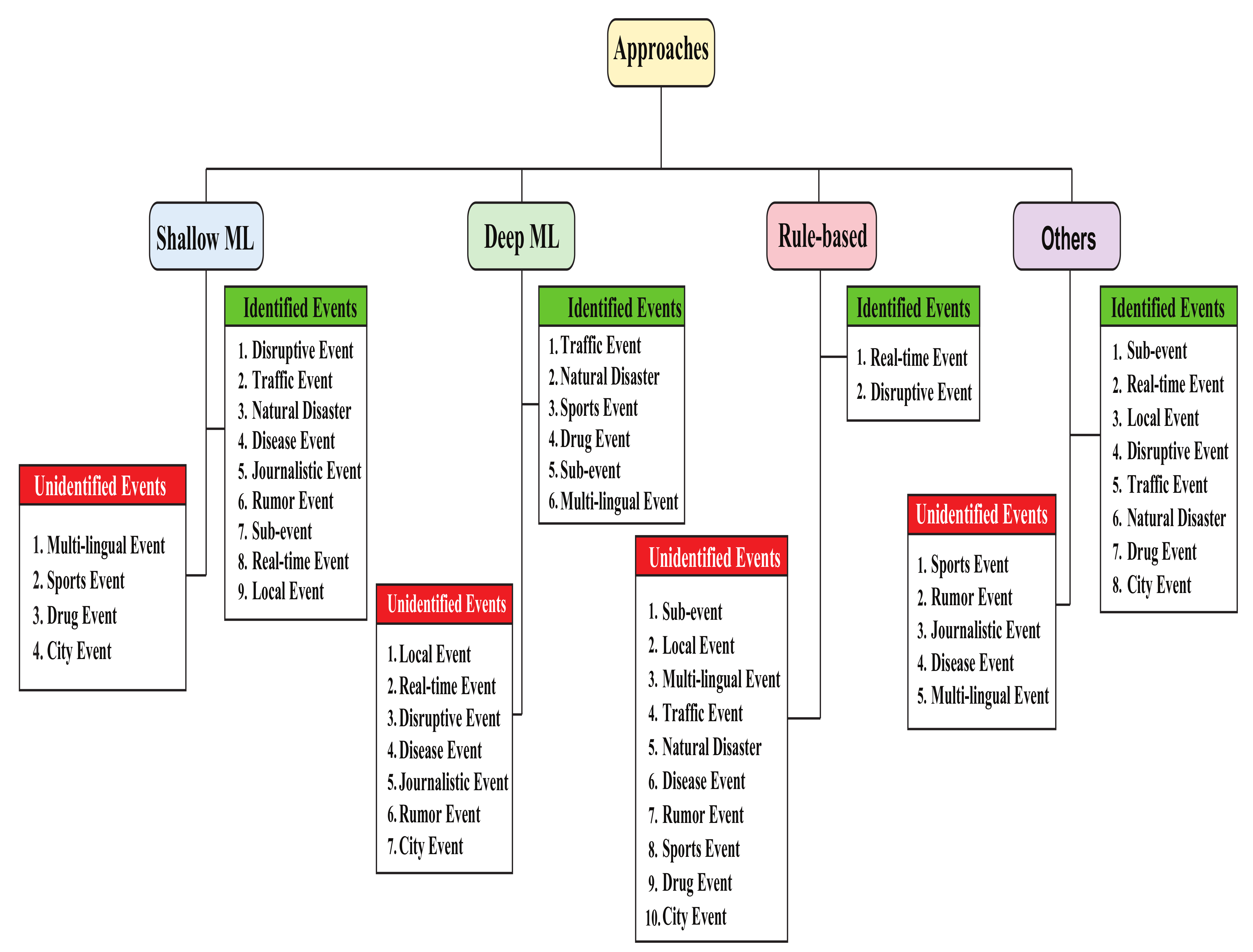
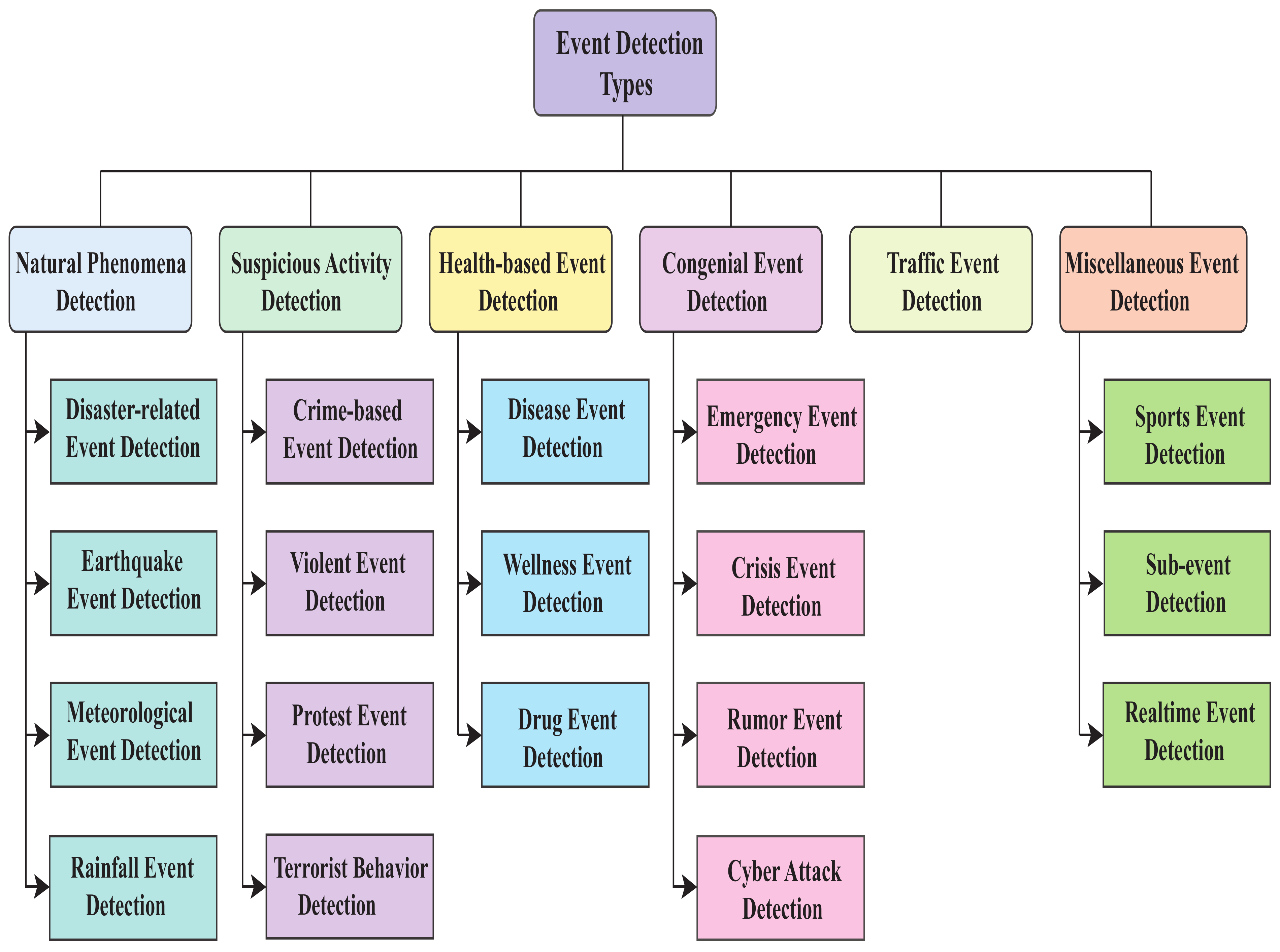
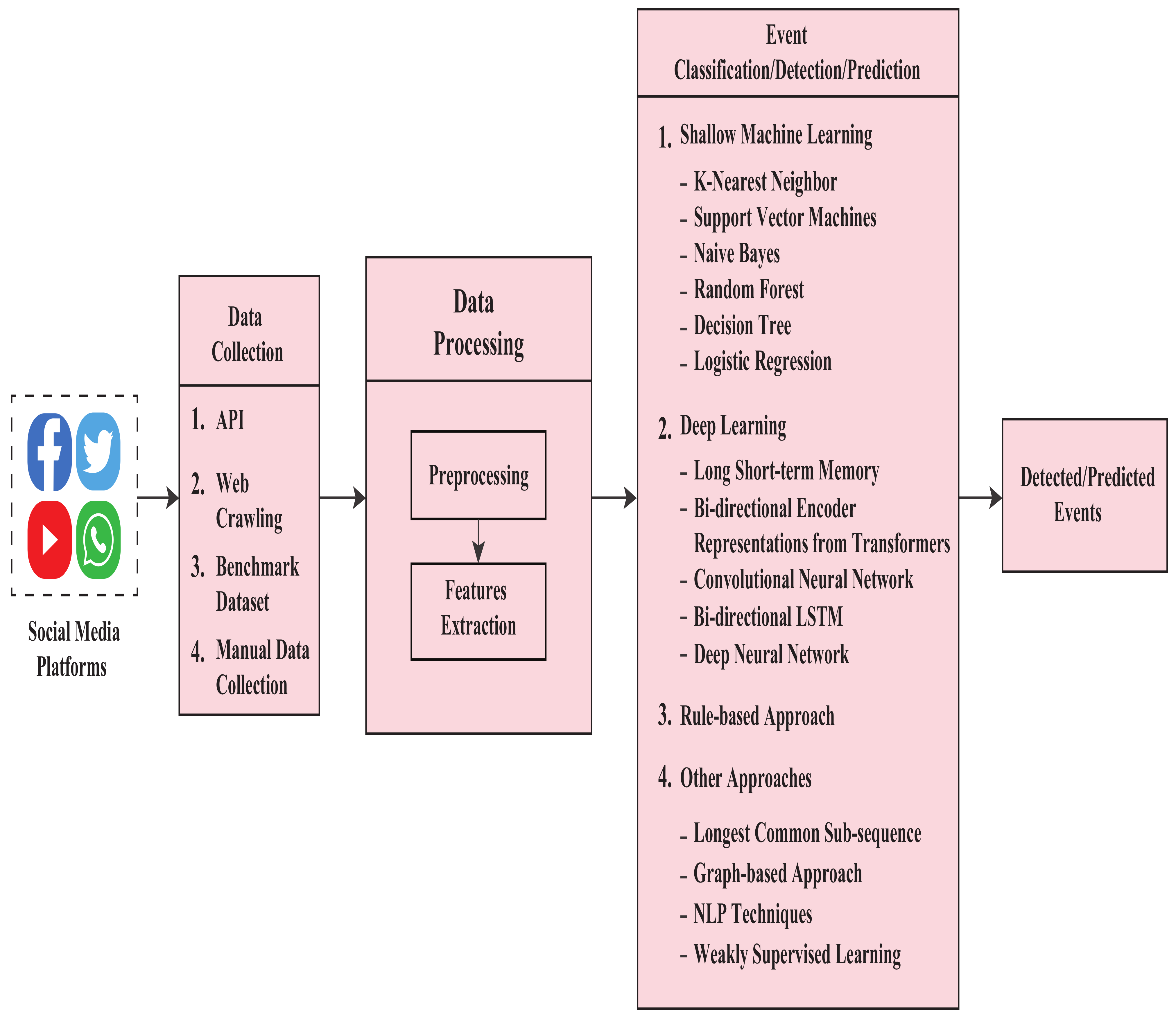
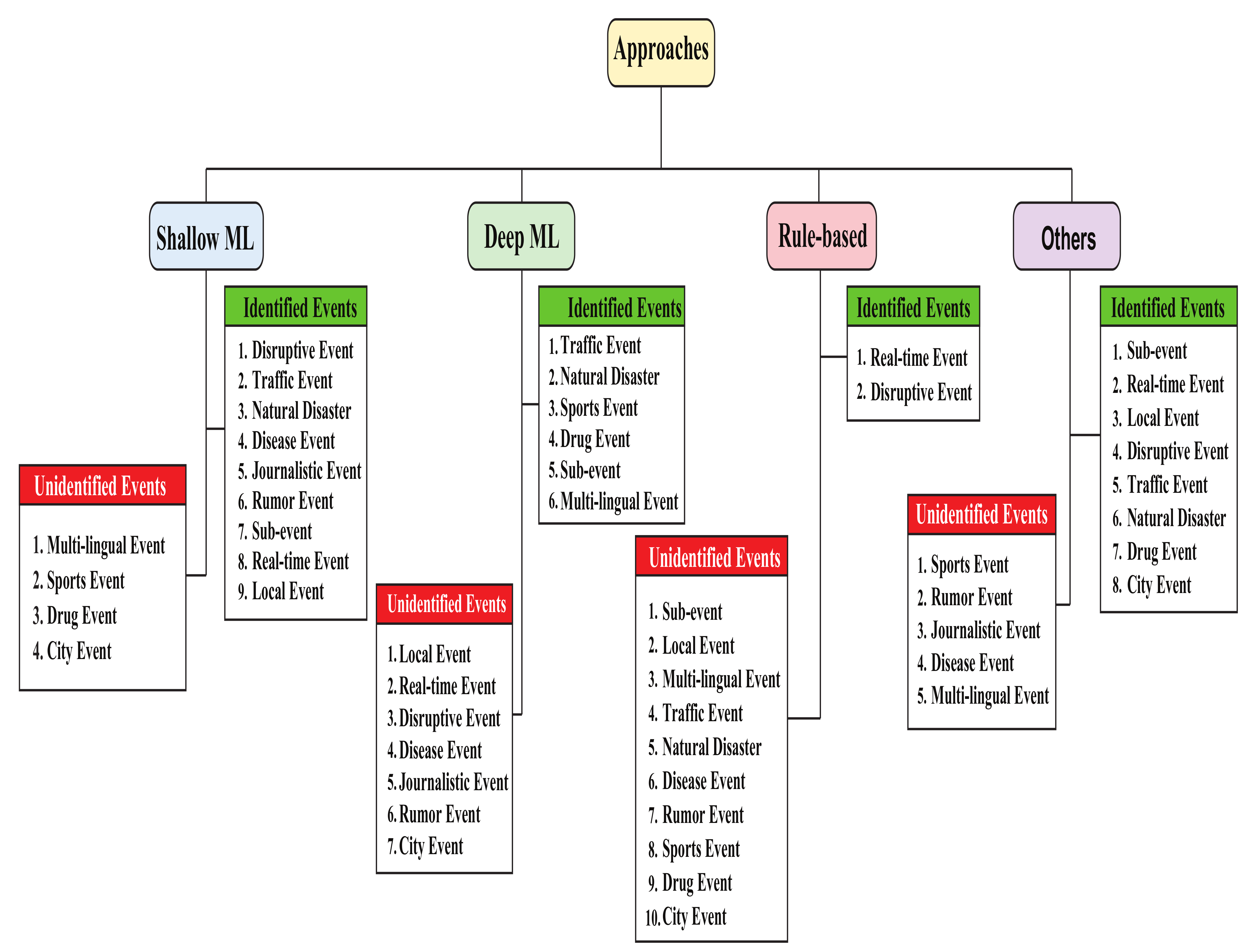
3. Approaches for Event Detection
3.1. Shallow-ML-Based Approaches
3.2. Deep-Machine-Learning-Based Approaches
3.3. Rule-Based Approaches
3.4. Other Approaches

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Selected Features | Used Languages | Evaluation Metrics |
|---|---|---|---|
| [82] | × | Arabic, Saudi dialect | |
| [83] | Semantic features such as proximity expression, lemmatization, exclusion | × | Precision, recall, F1 |
| [89] | × | English | Correlation |
| [90] | Annotated tweets with event terms and location (for CRF model creating) | English | Precision |
| [93] | × | English | Events detected fraction, clustering quality, merged event fraction, duplicate event fraction |
| [97] | × | English | Recall and precision |
| [106] | × | English tweet | Precision, recall, F1-score |
| [107] | NGrams, named entities, Gazetteer, and modality | × | Precision, recall, F1-score |
4. Results
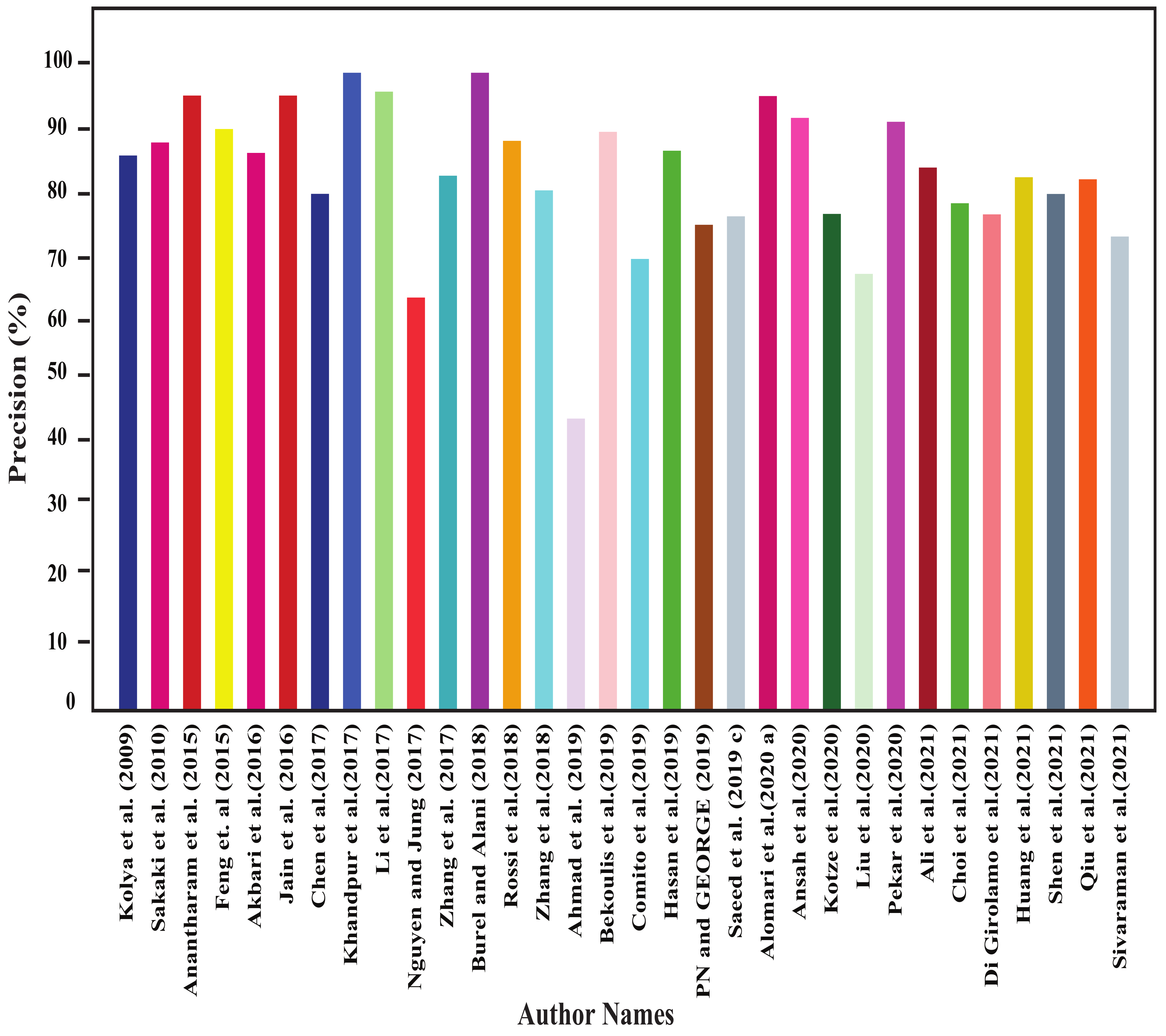
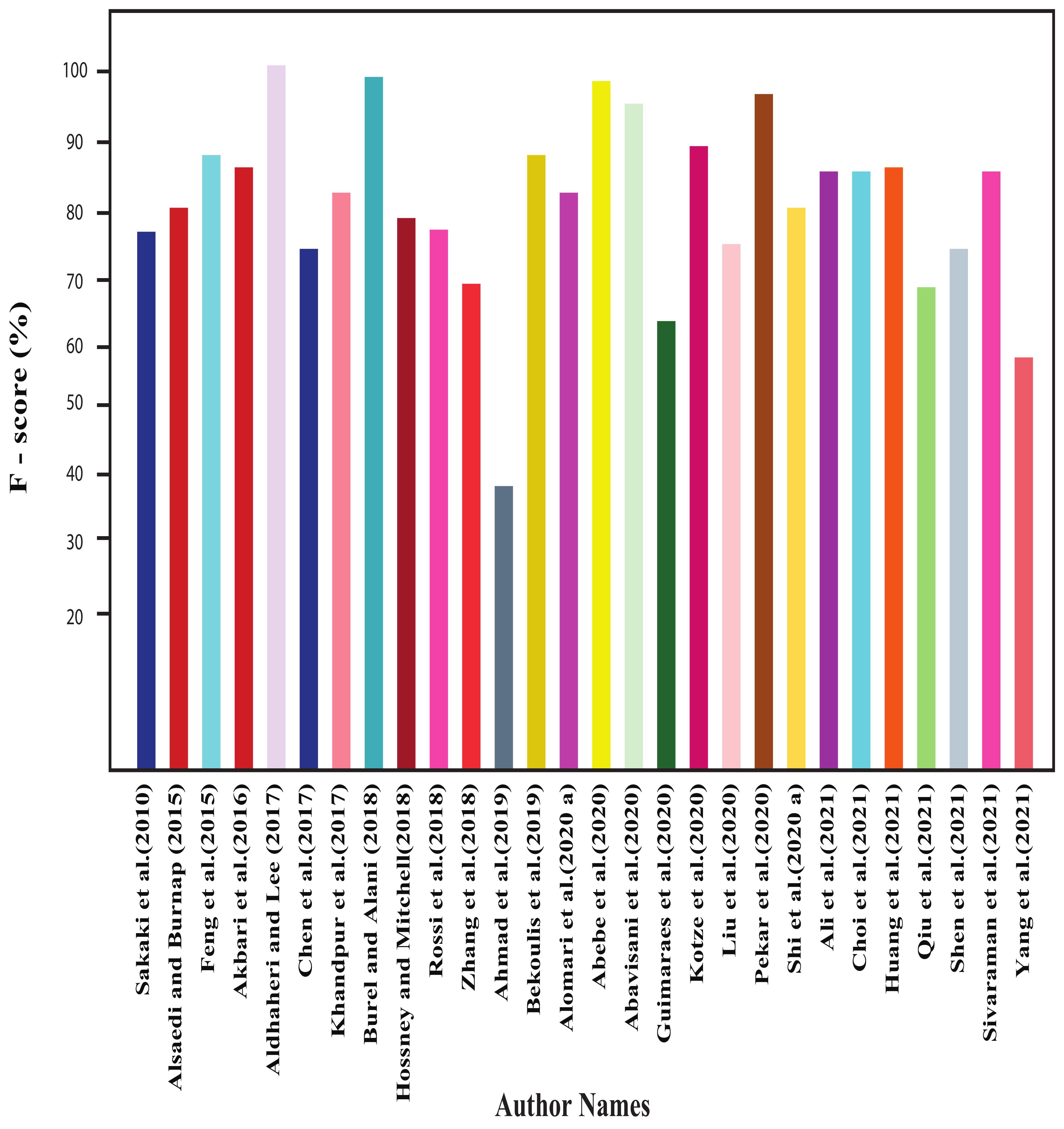
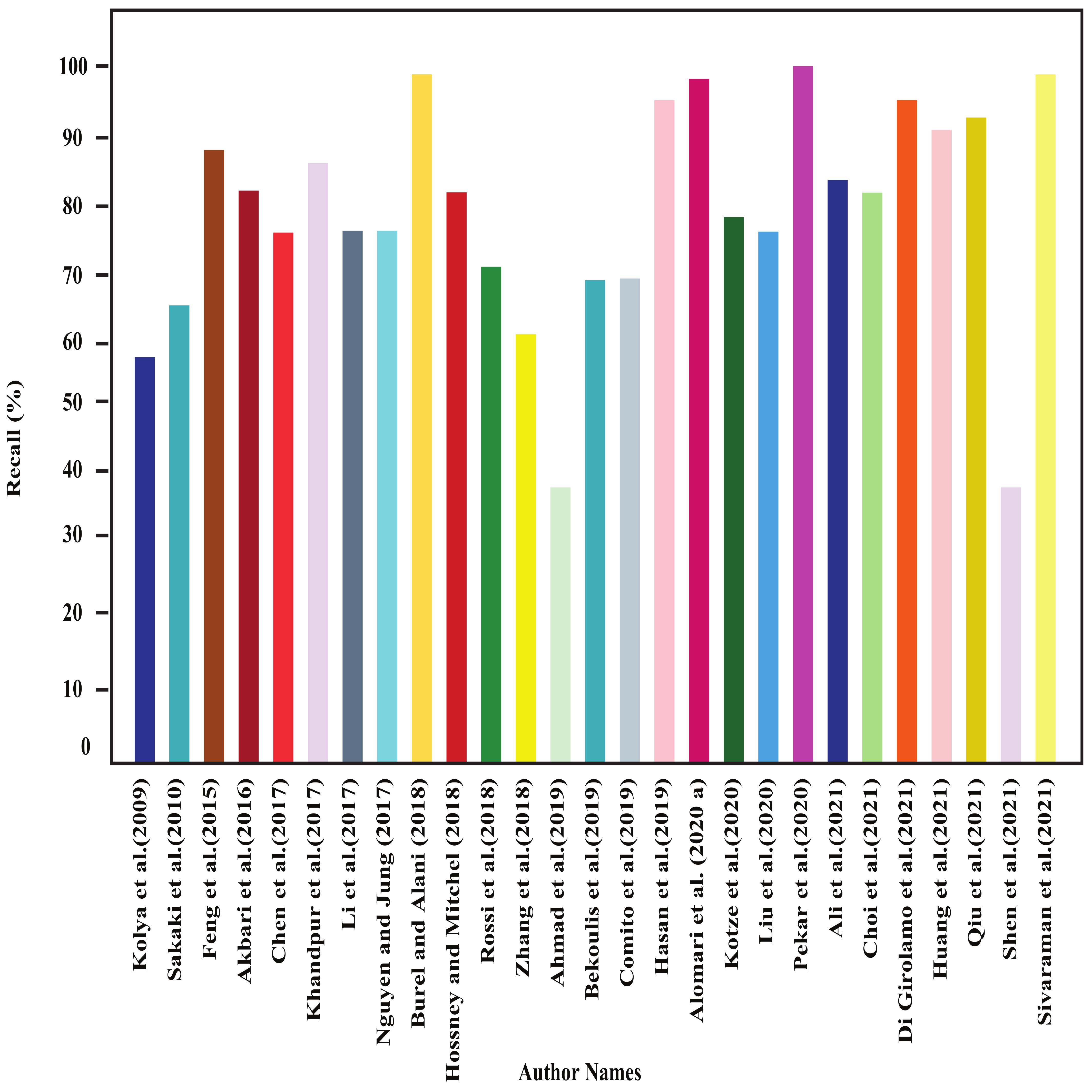
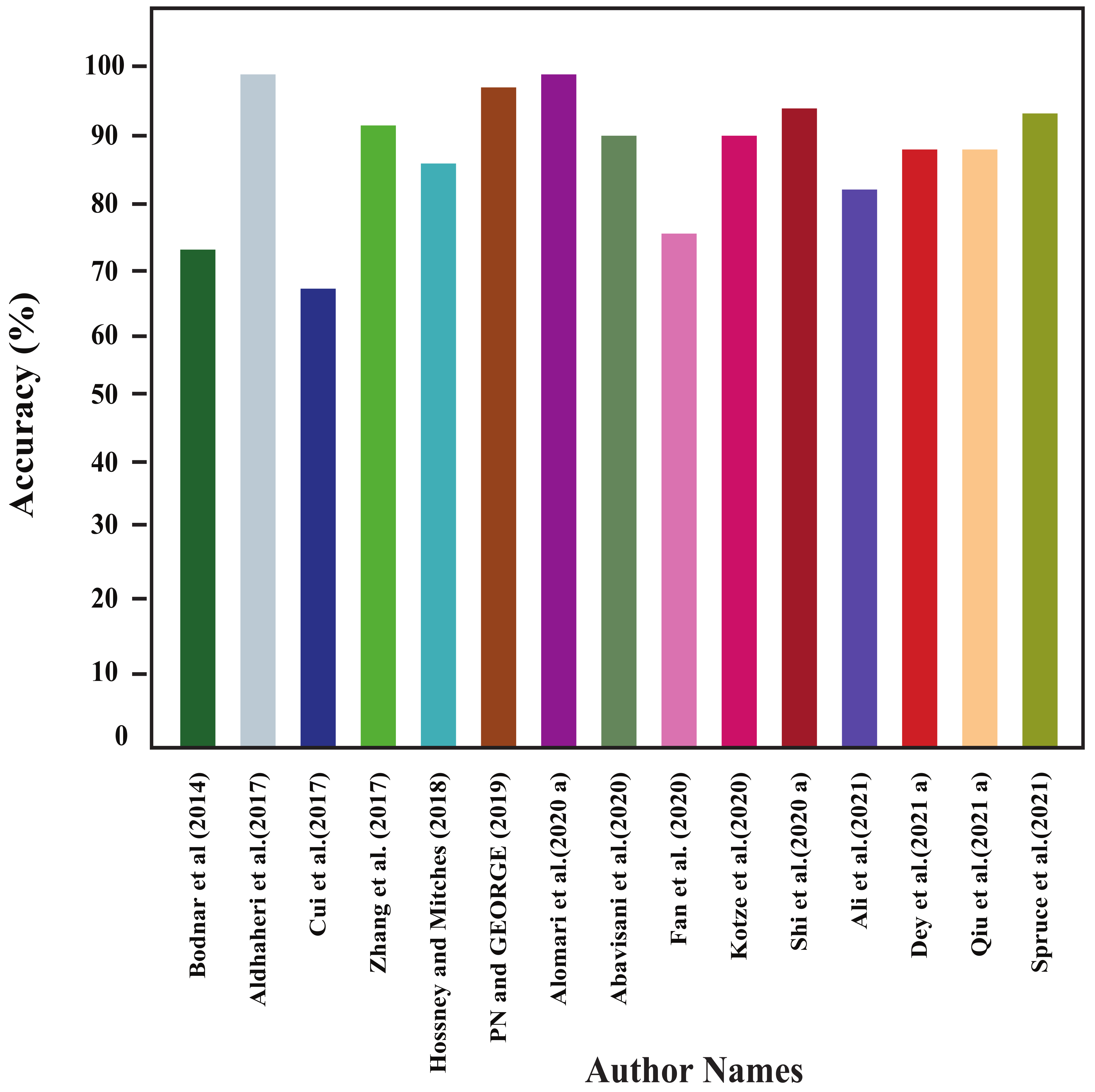
4.1. Results of Shallow-Machine-Learning-Based Approaches
4.2. Results of Deep-Machine-Learning-Based Approaches
4.3. Results of Rule-Based Approaches
4.4. Results of Other Approaches
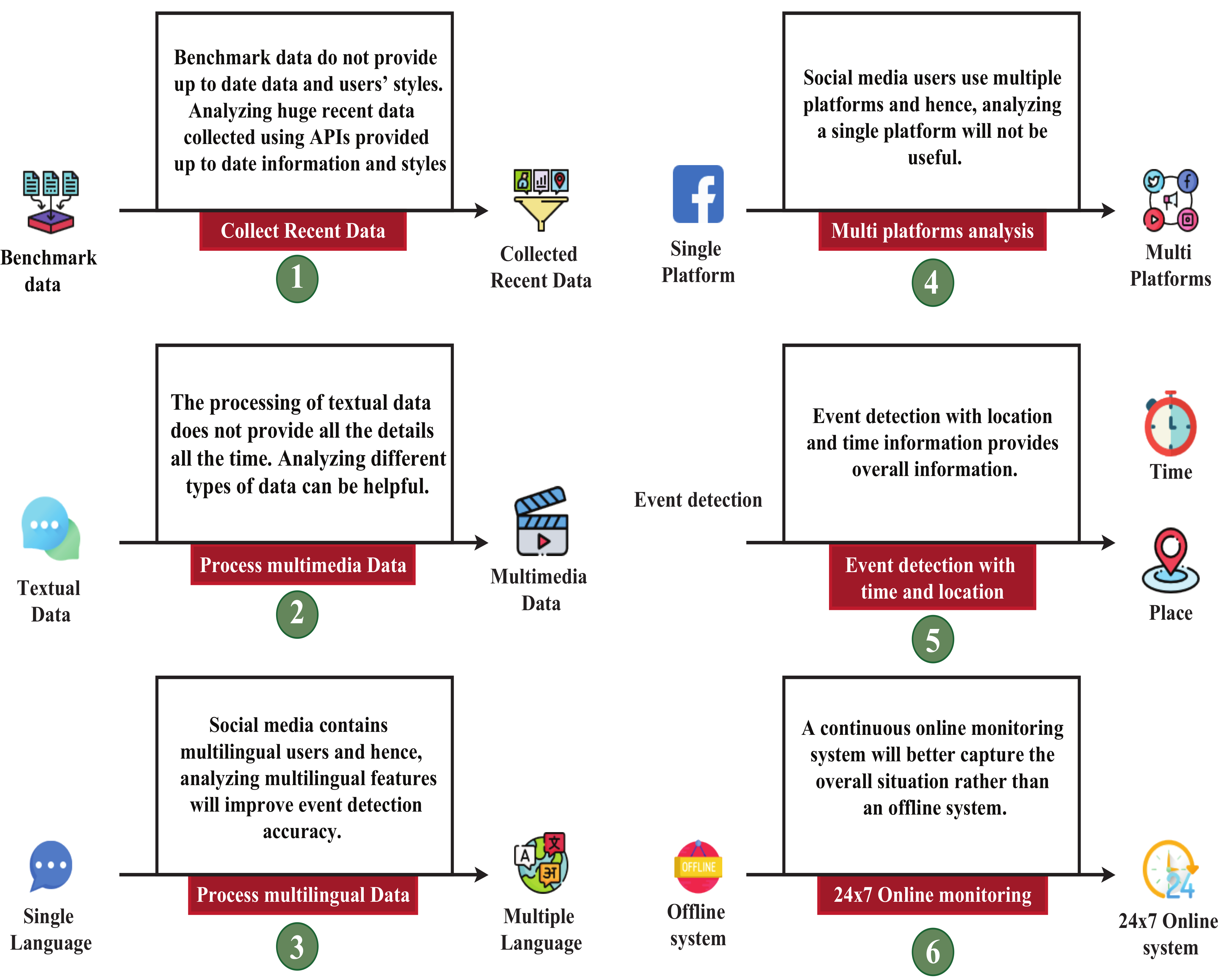
5. Discussion
6. Conclusions
- In the data collection phase, we noted their used datasets, collection process, and the regions from where they collected those data. Different researchers used different languages (e.g., English, Bengali, Banglish, Japanese, Hindi, Urdu, etc.) to detect events.
- In the preprocessing steps, data have been cleaned for processing. Various features have been collected and later sent for classification step in the processing phase.
- In the classification step, the articles discuss events such as disaster, traffic, disease, celebrating, protesting, religious, and many others. Their models include RF, DT, NBC, KNN, LR, LDA, SVM, LSH, BERT, LSTM, CRF, CNN, DNN, etc.
- The key performance metrics were precision, recall, accuracy, F-score, specificity, sensitivity, TP, TN, FP, FN, ROC, AUC, confusion matrix, etc.
- We found that different models perform well for different event detection. For example, for detecting a protest, NBC model performs best; for detecting disaster, bi-LSTM and CNN models perform best; for detecting disease and earthquake, SVM model works well; for detecting sports, LSH model performs better; for detecting violent events, LR model performs best.
Author Contributions
Funding
Conflicts of Interest
References
- DataReportal. Available online: Https://datareportal.com/social-media-users (accessed on 28 August 2021).
- Firstpost. Available online: Https://www.firstpost.com/world/students-end-protests-on-road-safety-in-bangladesh-after-nine-days-education-ministry-to-hold-meet-tomorrow-4913421.html (accessed on 2 September 2021).
- Dey, N.; Mredula, M.S.; Sakib, M.N.; Islam, M.N.; Rahman, M.S. A Machine Learning Approach to Predict Events by Analyzing Bengali Facebook Posts. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering, Johor Bahru, Malaysia, 21–22 October 2021; pp. 133–143. [Google Scholar]
- Cui, W.; Wang, P.; Du, Y.; Chen, X.; Guo, D.; Li, J.; Zhou, Y. An algorithm for event detection based on social media data. Neurocomputing 2017, 254, 53–58. [Google Scholar] [CrossRef]
- Joshi, A.; Sparks, R.; McHugh, J.; Karimi, S.; Paris, C.; MacIntyre, C.R. Harnessing tweets for early detection of an acute disease event. Epidemiology 2020, 31, 90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kannan, J.; Shanavas, A.M.; Swaminathan, S. Sportsbuzzer: Detecting events at real time in Twitter using incremental clustering. Trans. Mach. Learn. Artif. Intell. 2018, 6, 1. [Google Scholar]
- Kumar, A.; Sangwan, S.R. Rumor detection using machine learning techniques on social media. In Proceedings of the International Conference on Innovative Computing and Communications, Ostrava, Czech Republic, 21–22 March 2019; pp. 213–221. [Google Scholar]
- Fathima, P.N.; George, A. Event Detection and Text Summary by disaster warning. Int. Res. J. Eng. Technol. 2019, 6, 2510–2513. [Google Scholar]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Practical extraction of disaster-relevant information from social media. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1021–1024. [Google Scholar]
- Arachie, C.; Gaur, M.; Anzaroot, S.; Groves, W.; Zhang, K.; Jaimes, A. Unsupervised detection of sub-events in large scale disasters. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 354–361. [Google Scholar]
- Nurwidyantoro, A.; Winarko, E. Event detection in social media: A survey. In Proceedings of the International Conference on ICT for Smart Society, Jakarta, Indonesia, 13–14 June 2013; pp. 1–5. [Google Scholar]
- Saeed, Z.; Abbasi, R.A.; Maqbool, O.; Sadaf, A.; Razzak, I.; Daud, A.; Xu, G. What’s happening around the world? a survey and framework on event detection techniques on Twitter. J. Grid Comput. 2019, 17, 279–312. [Google Scholar] [CrossRef] [Green Version]
- Panagiotou, N.; Katakis, I.; Gunopulos, D. Detecting events in online social networks: Definitions, trends and challenges. In Solving Large Scale Learning Tasks Challenges and Algorithms; Springer: Cham, Switzerland, 2016; pp. 42–84. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. A survey on real-time event detection from the Twitter data stream. J. Inf. Sci. 2018, 44, 443–463. [Google Scholar] [CrossRef]
- Said, N.; Ahmad, K.; Riegler, M.; Pogorelov, K.; Hassan, L.; Ahmad, N.; Conci, N. Natural disasters detection in social media and satellite imagery: A survey. Multimed. Tools Appl. 2019, 78, 31267–31302. [Google Scholar] [CrossRef] [Green Version]
- Zarrinkalam, F.; Bagheri, E. Event identification in social networks. Encycl. Semant. Comput. Robot. Intell. 2017, 1, 1630002. [Google Scholar] [CrossRef] [Green Version]
- Cordeiro, M.; Gama, J. Online social networks event detection: A survey. In Solving Large Scale Learning Tasks Challenges and Algorithms; Springer: Cham, Switzerland, 2016; pp. 1–41. [Google Scholar]
- Alsaedi, N.; Burnap, P. Arabic event detection in social media. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 384–401. [Google Scholar]
- Hossny, A.H.; Mitchell, L. Event detection in Twitter: A keyword volume approach. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1200–1208. [Google Scholar]
- Kotzé, E.; Senekal, B.A.; Daelemans, W. Automatic classification of social media reports on violent incidents in South Africa using machine learning. S. Afr. J. Sci. 2020, 116, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Ristea, A.; Al Boni, M.; Resch, B.; Gerber, M.S.; Leitner, M. Spatial crime distribution and prediction for sporting events using social media. Int. J. Geogr. Inf. Sci. 2020, 34, 1708–1739. [Google Scholar] [CrossRef] [Green Version]
- Hatebase. Available online: Https://hatebase.org/ (accessed on 8 August 2018).
- Mohammad, S.; Turney, P. Emotions evoked by common words and phrases: Using mechanical turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 26–34. [Google Scholar]
- Mohammad, S.; Turney, P. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef] [Green Version]
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic event detection in smart cities using big data analytics. In Proceedings of the International Conference on Smart Cities, Infrastructure, Technologies and Applications, Jeddah, Saudi Arabia, 27–29 November 2017; pp. 111–122. [Google Scholar]
- Tableau. Available online: Https://www.tableau.com/trial/tableau-software (accessed on 10 April 2022).
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic detection and validation of smart city events using HPC and apache spark platforms. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 55–78. [Google Scholar]
- Apache Spark. Available online: Https://spark.apache.org/docs/2.2.0/mllib-feature-extraction.html#tf-idf (accessed on 10 April 2022).
- About Underbelly Festival. Available online: Http://www.underbellyfestival.com/about (accessed on 10 April 2022).
- The Luna Winter Cinema 2018. Available online: Https://www.thelunacinema.com/ (accessed on 10 April 2022).
- Google Maps Platform. Available online: Https://developers.google.com/maps/documenta-tion/geocoding/start (accessed on 10 April 2022).
- Alomari, E.; Katib, I.; Mehmood, R. Iktishaf: A big data road-traffic event detection tool using Twitter and spark machine learning. Mob. Netw. Appl. 2020, 1–16. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Hightower, J.; Borriello, G. Particle filters for location estimation in ubiquitous computing: A case study. In International Conference on Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 88–106. [Google Scholar]
- Pekar, V.; Binner, J.; Najafi, H.; Hale, C.; Schmidt, V. Early detection of heterogeneous disaster events using social media. J. Assoc. Inf. Sci. Technol. 2020, 71, 43–54. [Google Scholar] [CrossRef]
- Spruce, M.D.; Arthur, R.; Robbins, J.; Williams, H.T. Social sensing of high-impact rainfall events worldwide: A benchmark comparison against manually curated impact observations. Nat. Hazards Earth Syst. Sci. 2021, 21, 2407–2425. [Google Scholar] [CrossRef]
- Robbins, J.C.; Titley, H.A. Evaluating high-impact precipitation forecasts from the Met Office Global Hazard Map (GHM) using a global impact database. Meteorol. Appl. 2018, 25, 548–560. [Google Scholar] [CrossRef] [Green Version]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. Acm Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Joachims, T. Training linear SVMs in linear time. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 217–226. [Google Scholar]
- Guimarães, N.; Miranda, F.; Figueira, Á. Identifying journalistically relevant social media texts using human and automatic methodologies. Int. J. Grid Util. Comput. 2020, 11, 72–83. [Google Scholar] [CrossRef]
- Crowdflower: Make Your Data Useful. Available online: Https://www.crowdflower.com/ (accessed on 21 August 2016).
- Kolya, A.K.; Ekbal, A.B.; Yopadhyay, S. A simple approach for Monolingual Event Tracking system in Bengali. In Proceedings of the 2009 Eighth International Symposium on Natural Language Processing, Bangkok, Thailand, 20–22 October 2009; pp. 48–53. [Google Scholar]
- Nolasco, D.; Oliveira, J. Subevents detection through topic modeling in social media posts. Future Gener. Comput. Syst. 2019, 93, 290–303. [Google Scholar] [CrossRef]
- Feng, X.; Zhang, S.; Liang, W.; Liu, J. Efficient location-based event detection in social text streams. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Suzhou, China, 14–16 June 2015; pp. 213–222. [Google Scholar]
- Zhang, C.; Liu, L.; Lei, D.; Yuan, Q.; Zhuang, H.; Hanratty, T.; Han, J. Triovecevent: Embedding-based online local event detection in geo-tagged tweet streams. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 595–604. [Google Scholar]
- Jain, A.; Kasiviswanathan, G.; Huang, R. Towards accurate event detection in social media: A weakly supervised approach for learning implicit event indicators. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 8–15 December 2016; pp. 70–77. [Google Scholar]
- Bodnar, T.; Tucker, C.; Hopkinson, K.; Bilén, S.G. Increasing the veracity of event detection on social media networks through user trust modeling. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 636–643. [Google Scholar]
- Abebe, M.A.; Tekli, J.; Getahun, F.; Chbeir, R.; Tekli, G. Generic metadata representation framework for social-based event detection, description, and linkage. Knowl. Based Syst. 2020, 188, 104817. [Google Scholar] [CrossRef]
- Gu, Y.; Qian, Z.; Chen, F. From Twitter to detector: Real-time traffic incident detection using social media data. Transp. Res. Part C Emerg. Technol. 2016, 67, 321–342. [Google Scholar] [CrossRef]
- Nguyen, D.; Jung, J. Real-time event detection for online behavioral analysis of big social data. Future Gener. Comput. Syst. 2017, 66, 137–145. [Google Scholar] [CrossRef]
- Bide, P.; Dhage, S. Similar Event Detection and Event Topic Mining in Social Network Platform. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–11. [Google Scholar]
- Zhang, Z.; He, Q.; Gao, J.; Ni, M. A deep learning approach for detecting traffic accidents from social media data. Transp. Res. Part C Emerg. Technol. 2018, 86, 580–596. [Google Scholar] [CrossRef] [Green Version]
- Porter, M. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases VLDB, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Shi, K.; Gong, C.; Lu, H.; Zhu, Y.; Niu, Z. Wide-grained capsule network with sentence-level feature to detect meteorological event in social network. Future Gener. Comput. Syst. 2020, 102, 323–332. [Google Scholar] [CrossRef]
- Burel, G.; Alani, H. Crisis Event Extraction Service (Crees)-Automatic Detection and Classification of Crisis-Related Content on Social Media. In Proceedings of the 15th International Conference on Information Systems for Crisis Response and Management, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Abavisani, M.; Wu, L.; Hu, S.; Tetreault, J.; Jaimes, A. Multimodal categorization of crisis events in social media. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14679–14689. [Google Scholar]
- Fan, C.; Wu, F.; Mostafavi, A. A hybrid machine learning pipeline for automated mapping of events and locations from social media in disasters. IEEE Access 2020, 8, 10478–10490. [Google Scholar] [CrossRef]
- Huang, L.; Liu, G.; Chen, T.; Yuan, H.; Shi, P.; Miao, Y. Similarity-based emergency event detection in social media. J. Saf. Sci. Resil. 2021, 2, 11–19. [Google Scholar] [CrossRef]
- Shen, C.; Li, Z.; Chu, Y.; Zhao, Z. GAR: Graph adversarial representation for adverse drug event detection on Twitter. Appl. Soft Comput. 2021, 106, 107324. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, H.; Li, J.; Song, Y.; Li, X. Event detection and evolution in multilingual social streams. Front. Comput. Sci. 2020, 5, 1–15. [Google Scholar]
- Ahmad, Z.; Varshney, D.; Ekbal, A.; Bhattacharyya, P. Multilingual Event Identification in Disaster Domain; Indian Institute of Technology Patna: Bihta, India, 2019. [Google Scholar]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Sub-event detection from Twitter streams as a sequence labeling problem. arXiv 2019, arXiv:1903.05396. [Google Scholar]
- Chen, G.; Kong, Q.; Mao, W. Online event detection and tracking in social media based on neural similarity metric learning. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 182–184. [Google Scholar]
- Aldhaheri, A.; Lee, J. Event detection on large social media using temporal analysis. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–6. [Google Scholar]
- Qiu, X.; Zou, Q.; Richard Shi, C. Single-Pass On-Line Event Detection in Twitter Streams. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzhen, China, 26 February–1 March 2021; pp. 522–529. [Google Scholar]
- Ali, D.; Missen, M.M.S.; Husnain, M. Multiclass Event Classification from Text. Sci. Program. 2021, 2021, 6660651. [Google Scholar] [CrossRef]
- Alhalabi, W.; Jussila, J.; Jambi, K.; Visvizi, A.; Qureshi, H.; Lytras, M.; Malibari, A.; Adham, R. Social mining for terroristic behavior detection through Arabic tweets characterization. Future Gener. Comput. Syst. 2021, 116, 132–144. [Google Scholar] [CrossRef]
- Alkhammash, E.; Jussila, J.; Lytras, M.; Visvizi, A. Annotation of smart cities Twitter micro-contents for enhanced citizen’s engagement. IEEE Access 2019, 7, 116267–116276. [Google Scholar] [CrossRef]
- Li, Q.; Nourbakhsh, A.; Shah, S.; Liu, X. Real-time novel event detection from social media. In Proceedings of the 2017 IEEE 33Rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 1129–1139. [Google Scholar]
- Owoputi, O.; O’Connor, B.; Dyer, C.; Gimpel, K.; Schneider, N.; Smith, N. Improved part-of-speech tagging for online conversational text with word clusters. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 380–390. [Google Scholar]
- Di Girolamo, R.; Esposito, C.; Moscato, V.; Sperli, G. Evolutionary game theoretical on—Line event detection over tweet streams. Knowl. Based Syst. 2021, 211, 106563. [Google Scholar] [CrossRef]
- Warren, J.; Marz, N. Big Data: Principles and best Practices of Scalable Realtime Data Systems; Simon and Schuster: New York, NY, USA, 2015. [Google Scholar]
- Saeed, Z.; Abbasi, R.; Razzak, M.; Xu, G. Event detection in Twitter stream using weighted dynamic heartbeat graph approach [application notes]. IEEE Comput. Intell. Mag. 2019, 14, 29–38. [Google Scholar] [CrossRef]
- Ansah, J.; Liu, L.; Kang, W.; Liu, J.; Li, J. Leveraging burst in Twitter network communities for event detection. World Wide Web 2020, 23, 2851–2876. [Google Scholar] [CrossRef]
- Khandpur, R.; Ji, T.; Jan, S.; Wang, G.; Lu, C.; Ramakrishnan, N. Crowdsourcing cybersecurity: Cyber attack detection using social media. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; 2017; pp. 1049–1057. [Google Scholar]
- Ritter, A.; Wright, E.; Casey, W.; Mitchell, T. Weakly supervised extraction of computer security events from Twitter. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 896–905. [Google Scholar]
- Kleinberg, J. Bursty and hierarchical structure in streams. Data Min. Knowl. Discov. 2003, 7, 373–397. [Google Scholar] [CrossRef]
- Alomari, E.; Mehmood, R.; Katib, I. Sentiment analysis of Arabic tweets for road traffic congestion and event detection. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 37–54. [Google Scholar]
- Rossi, C.; Acerbo, F.; Ylinen, K.; Juga, I.; Nurmi, P.; Bosca, A.; Tarasconi, F.; Cristoforetti, M.; Alikadic, A. Early detection and information extraction for weather-induced floods using social media streams. Int. J. Disaster Risk Reduct. 2018, 30, 145–157. [Google Scholar] [CrossRef] [Green Version]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Tarasconi, F.; Di Tomaso, V. Geometric and statistical analysis of emotions and topics in corpora. Ital. J. Comput. Linguist. 2015, 1, 91–103. [Google Scholar] [CrossRef]
- PostgreSQL: The World’s Most Advanced Open Source Relational Database. Available online: Https://www.postgresql.org/ (accessed on 20 August 2017).
- De Rosa, M.; Fenza, G.; Gallo, A.; Gallo, M.; Loia, V. Pharmacovigilance in the era of social media: Discovering adverse drug events cross-relating Twitter and PubMed. Future Gener. Comput. Syst. 2021, 114, 394–402. [Google Scholar] [CrossRef]
- Anantharam, P.; Barnaghi, P.; Thirunarayan, K.; Sheth, A. Extracting city traffic events from social streams. Acm Trans. Intell. Syst. Technol. (TIST) 2015, 6, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Ramshaw, L.; Marcus, M. Text chunking using transformation-based learning. In Natural Language Processing Using Very Large Corpora; Springer: Berlin/Heidelberg, Germany, 1999; pp. 157–176. [Google Scholar]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Fedoryszak, M.; Frederick, B.; Rajaram, V.; Zhong, C. Real-time event detection on social data streams. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2774–2782. [Google Scholar]
- Choi, D.; Park, S.; Ham, D.; Lim, H.; Bok, K.; Yoo, J. Local Event Detection Scheme by Analyzing Relevant Documents in Social Networks. Appl. Sci. 2021, 11, 577. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Q.; Xie, H.; Wang, Q.; Liu, W. Learning representation from multiple media domains for enhanced event discovery. Pattern Recognit. 2021, 110, 107640. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Neural Information Processing Systems Foundation; Curran Associates, Inc.: New York, NY, USA, 2014. [Google Scholar]
- Comito, C.; Forestiero, A.; Pizzuti, C. Bursty event detection in Twitter streams. ACM Trans. Knowl. Discov. Data (TKDD) 2019, 13, 1–28. [Google Scholar] [CrossRef]
- Gao, Y.; Zhao, S.; Yang, Y.; Chua, T. Multimedia social event detection in microblog. In International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2015; pp. 269–281. [Google Scholar]
- Reuter, T.; Cimiano, P.; Drumond, L.; Buza, K.; Schmidt-Thieme, L. Scalable event-based clustering of social media via record linkage techniques. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Shi, L.; Liu, L.; Wu, Y.; Jiang, L.; Ayorinde, A. Event detection and multisource propagation for online social network management. J. Netw. Syst. Manag. 2020, 28, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Mavroeidis, D.; Calabrese, F.; Frossard, P. Multiscale event detection in social media. Data Min. Knowl. Discov. 2015, 29, 1374–1405. [Google Scholar] [CrossRef]
- Blondel, V.; Guillaume, J.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Hasan, M.; Orgun, M.; Schwitter, R. Real-time event detection from the Twitter data stream using the TwitterNews+ Framework. Inf. Process. Manag. 2019, 56, 1146–1165. [Google Scholar] [CrossRef]
- Valkanas, G.; Gunopulos, D. Event Detection from Social Media Data. IEEE Data Eng. Bull. 2013, 36, 51–58. [Google Scholar]
- Sun, X.; Wu, Y.; Liu, L.; Panneerselvam, J. Efficient event detection in social media data streams. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications, Dependable, Autonomic and Secure Computing, Pervasive Intelligence and Computing, Liverpool, UK, 26–28 October 2015; pp. 1711–1717. [Google Scholar]
- Sivaraman, N.; Tokala, J.; Rupesh, R.; Muthiah, S. Event Detection in Twitter using Social Synchrony and Average Number of Common Friends. In Proceedings of the 13th ACM Web Science Conference 2021, Virtual Event, 21–25 June 2021; pp. 115–119. [Google Scholar]
- Akbari, M.; Hu, X.; Liqiang, N.; Chua, T. From tweets to wellness: Wellness event detection from Twitter streams. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Zakharchenko, A.; Peráček, T.; Fedushko, S.; Syerov, Y.; Trach, O. When Fact-Checking and ‘BBC Standards’ Are Helpless: ‘Fake Newsworthy Event’ Manipulation and the Reaction of the ‘High-Quality Media’ on It. Sustainability 2021, 13, 573. [Google Scholar] [CrossRef]
- Pomytkina, L.; Podkopaieva, Y.; Hordiienko, K. Peculiarities of Manifestation of Student Youth’Roles and Positions in the Cyberbullying Process. Int. J. Mod. Educ. Comput. Sci. 2021, 13, 1–10. [Google Scholar] [CrossRef]
- Frome, A.; Corrado, G.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A Deep Visual-Semantic Embedding Model. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2013; Volume 26. [Google Scholar]
- Kiela, D.; Grave, E.; Joulin, A.; Mikolov, T. Efficient large-scale multimodal classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kiela, D.; Bhooshan, S.; Firooz, H.; Perez, E.; Testuggine, D. Supervised multimodal bitransformers for classifying images and text. arXiv arXiv:1909.02950, 2019.
- Alvaro, N.; Miyao, Y.; Collier, N. TwiMed: Twitter and PubMed comparable corpus of drugs, diseases, symptoms, and their relations. Jmir Public Health Surveill. 2017, 3, e6396. [Google Scholar] [CrossRef] [Green Version]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multicorpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Shamma, D.; Kennedy, L.; Churchill, E. Peaks and persistence: Modeling the shape of microblog conversations. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, Hangzhou, China, 19–23 March 2011; pp. 355–358. [Google Scholar]
- Aiello, L.; Petkos, G.; Martin, C.; Corney, D.; Papadopoulos, S.; Skraba, R.; Göker, A.; Kompatsiaris, I.; Jaimes, A. Sensing trending topics in Twitter. IEEE Trans. Multimed. 2013, 15, 1268–1282. [Google Scholar] [CrossRef]
- Guille, A.; Favre, C. Mention-anomaly-based event detection and tracking in Twitter. In Proceedings of the 2014 IEEE/ACM International Conference on Advances In Social Networks Analysis And Mining (ASONAM 2014), Beijing, China, 17–20 August 2014; pp. 375–382. [Google Scholar]
- Allan, J.; Lavrenko, V.; Jin, H. First story detection in TDT is hard. In Proceedings of the Ninth International Conference on Information And Knowledge Management, McLean, VA, USA, 6–11 November 2000; pp. 374–381. [Google Scholar]
- Allan, J.; Lavrenko, V.; Malin, D.; Swan, R. Detections, bounds, and timelines: Umass and tdt-3. In Topic Detection and Tracking Workshop; Citeseer: Princeton, NJ, USA, 2000; pp. 167–174. [Google Scholar]
- Petrović, S.; Osborne, M.; Lavrenko, V. Using paraphrases for improving first story detection in news and Twitter. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montréal, QC, Canada, 3–8 June 2012; pp. 338–346. [Google Scholar]
- Petrović, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to Twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 181–189. [Google Scholar]
- Saeed, Z.; Abbasi, R.; Razzak, I.; Maqbool, O.; Sadaf, A.; Xu, G. Enhanced heartbeat graph for emerging event detection on Twitter using time series networks. Expert Syst. Appl. 2019, 136, 115–132. [Google Scholar] [CrossRef]
- Olteanu, A.; Vieweg, S.; Castillo, C. What to expect when the unexpected happens: Social media communications across crises. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 994–1009. [Google Scholar]
- Reuter, T.; Cimiano, P. Event-based classification of social media streams. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012; pp. 1–8. [Google Scholar]
- Becker, H.; Naaman, M.; Gravano, L. Learning similarity metrics for event identification in social media. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 4–6 February 2010; pp. 291–300. [Google Scholar]
- Dey, N.; Rahman, M.; Mredula, M.; Hosen, A.; Ra, I. Using Machine Learning to Detect Events on the Basis of Bengali and Banglish Facebook Posts. Electronics 2021, 10, 2367. [Google Scholar] [CrossRef]




| Ref. | Selected Features | Used Language | Evaluation Matrices |
|---|---|---|---|
| [3] | Events specific words and phrases frequency, sentiment score | Bengali | Accuracy, receiver operating characteristics (ROC), area under curve (AUC) |
| [4] | Total followers, total users, personal description’s length, total tweets, average retweeting, average recommendations, average comments, average length of 165 tweets, time of tweet and average links in tweet | × | Accuracy |
| [5] | Word embeddings(in the statistical classification of health mention) | × | × |
| [7] | Bag of words, part-of-speech, emoticon, named entity recognition, sentiment, event, time, origin, hashtags, links and urls | × | × |
| [18] | Retweet ratio, hashtags, temporal, spatial and textual features(near duplicate ratio, mention ratio, retweet ration, hashtag ratio, url ratio, sentiment) | × | F measure |
| [19] | Word-pair frequency | English | Accuracy, ROC, recall, F |
| [20] | Unigram, Word2Vec | English, Africaans | Accuracy, macro-recall, macro-precision, macro-F1, micro-F1 |
| [32] | TF-IDF | Arabic | Precision, F1, recall, and accuracy |
| [33] | Keywords, number of words, context | English, Japanese | Precision, recall & F-score |
| [43] | Text statistics (number of words, post length, word embeddings), domain (several lexicons from Oxford Topic Dictionary), sentiment (positive, negative and neutral), and entities (person, locations, organizations, and dates) were considered features. Additionally, they also counted user agreement rate deviation, user’s correct words percentage, and user’s consistency regarding news relevance for human approach. For automatic approach, identifications of people, location, date, organizations, and keywords. | × | F1 |
| [45] | Context words, suffix and prefix of word, named entity information, first word (binary value), length of word (binary value), infrequent word (binary value), digit features, position of the word, POS information, Gazetteer list, common words—these are the features for named entity recognition | × | Recall, precision |
| [47] | Heuristis features such as PosTag, PosTagBefore, PosTagAfter, LabelAfter, and IsSymWord | × | Precision, recall, F1 value |
| [50] | Numerical features (no. of friends, tweets, favorites, followers, and favored), n-garms from the text data | × | ROC, accuracy |
| [51] | Temporal, spatial, and semantic | × | Normalized mutual information (NMI) and F-score measures |
| [52] | “*Road-name*”, “exit”, “accident”, “traffic”, “roadwork”, “lane”, “PA”, “mile”, “cleared”, and “post” | × | Confusion matrix |
| [53] | Occurrence score, diffusion degree, diffusion sensitivity | × | Precision, recall |
| Ref. | Selected Features | Used Languages | Evaluation Metrics |
|---|---|---|---|
| [6] | Unigrams | × | ROC curve |
| [9] | Word unigrams, bigrams, part-of-speech (POS) tags, binary features, and scalar features | × | Detection rate, hit ratio |
| [55] | Individual and paired tokens | English | Accuracy, precision |
| [65] | Multilingual word embedding, monolingual word embedding | Hindi, Bengali, and English | Precision, recall, F1, confusion matrix |
| [70] | Unigram and bigram tokens | Urdu | Accuracy, precision, recall, and F1 |
| Ref. | Size | Duration of Data Collection | Area | Collection Method |
|---|---|---|---|---|
| [4] 1 dataset created | 80 million | August–October 2014 | Beijing | Weibo API |
| [5] 3 datasets used | BreathMelbourne (2,672,578 tweets), CoughMelbourne (985,180 tweets), and OtherMelbourne (152,113 tweets) | 2014–2016 | Australia (Melbourne) | Twitter REST API |
| [19] 1 dataset created | 6 billion words pairs | Data collected for 540 days (4 million tweets per day) | × | |
| [20] 1 dataset created | 15 WhatsApp groups between. In total, 23,360 WhatsApp messages were retrieved in either English or Afrikaans | 30 May 2018 and 18 February 2019 | South Africa | × |
| [21] 1 dataset created | Crime incident data were downloaded from Chicago Police Department’s (Citizen Law Enforcement Analysis and Reporting) database (111,936 incidents). Twitter data (9,436,276 GPS-tagged tweets) also collected. | 31 October 2012 and 14 April 2014. Twitter—31 October 2012 and 14 April 2014 | Chicago | Twitter API |
| [27] 1 dataset created | 3 million tweets | Collected from 21 August–13 September 2017 | London | × |
| [32] 1 dataset created | 2.5 million tweets (2,511,000 tweets) | 23 September–7 October 2018 | Saudi Arabia (Riyadh, Makkah) | Twitter REST API |
| [33] 3 datasets created | 597 tweets for training, 621 for location & 2037 for trajectory detection | Japan | ||
| [37] 1 dataset created | Met Office data, 44.7 million tweets | Met—1 January 2017–30 June 2017, Twitter—1 January 2017–30 June 2017 | Across the world (USA, UK, Australia, Malaysia, Saudi Arabia, Angola, India, Haiti) | Met—manual Twitter—Twitter streaming API |
| [43] 2 datasets created | 4994 Facebook posts and comments, 4994 tweets (human approach). For the automatic approach, 7853 posts from Facebook and 3831 tweets were collected | 7–14 September 2016 | USA | × |
| [45] 1 dataset created | 108,305 news documents with 2,822,737 total sentences. | India | × | |
| [46] 2 datasets used | × | Political protest of Brazil (2013), Zika epidemic dataset (2015–2016) | Brazil | built in API |
| [50] 4 datasets used | Boston Marathon 2012, The Dark Knight Rises 2012, bombing of the White House in 2013, bomb threat at Harvard 2013 | × | USA | × |
| Ref. | Size | Duration of Data Collection | Area | Collection Method |
|---|---|---|---|---|
| [6] 1 dataset | Tweets of 44 games with a file size of over 6 GB | × | × | Streaming API of Twitter |
| [9] 2 datasets used | Joplin (206,764 tweets) and Sandy (140,000 tweets) | × | Missouri (USA), northeastern US | Twitter’s API |
| [55] 1 dataset created | Over 3 million tweets collected during. 584,000 geotagged tweets from Northern Virginia, 2,420,000 geotagged tweets from New York City | (January–December 2014) | Northern Virginia, New York | Twitter streaming API with geolocation filter |
| [58] 1 dataset created | 1,123,000 Weibo posts | × | China | Sina Weibo API |
| [59] 1 dataset created | CrisisLexT26 dataset (28,000 tweets with 26 different crises) | 2013 and 2012 | × | × |
| [60] 1 dataset used | CrisisMMD dataset | 2017 | × | |
| [61] 1 dataset used | About 21 million tweets | Hurricane Harvey of 2017 | Houston | Twitter PowerTrack API and filtering rules |
| [65] 1 dataset used | Total dataset 2191 documents (Hindi: 922, Bengali: 999, and English: 270 | × | × | Crawling |
| [66] 1 dataset used | 2M preprocessed tweets filtered from 6.1M collected ones | Tweets from 2010 (soccer matches) and 2014 (FIFA World Cup) | × | × |
| [67] 1 dataset created | 9,563,979 tweets for evaluation, 33,808 event-related and 33,808 non-event-related tweets for training, for similarity metric learning, 1,000,000 tweet pairs as positive, and another 1000,000 tweet pairs as negative | Evaluation tweets were collected between 10 November 2016 and 10 December 2016. | × | Twitter public API |
| [68] 1 dataset | 17 GB | Time period of three weeks from 17 September 2014 to 20 November 2014 | × | Twitter Streaming API |
| [70] 1 dataset created | 0.15 million (103,965) lab- eled sentences | × | × | PHP-based web crawler was used |
| Ref. | Size | Duration of Data Collection | Area | Collection Method |
|---|---|---|---|---|
| [10] 2 datasets used | Hurricane Harvey of 2017 (795,461 distinct unlabeled tweets), Nepal Earthquake of 2015 (635,150 distinct unlabeled tweets) | × | × | × |
| [78] 4 datasets used | 1. Free Port (FP)—200,800 tweets2. US–Ghana Military Base (USGH)—100,000 tweets3. Live exports—3,200,000 tweets4. Newcastle Harbour Blockade (NHB)—4,900,305 tweets | 1. January–April 20172. 19–30 March 20183. 3–30 June 20184. February–May 2016 | 1. Indonesia2. Ghana3. Australia4. Australia | DS 2,3,4 collected by Twitter public API. DS 1 was provided by Data to Decisions CRC (D2DCRC) |
| [79] 1 dataset used | 5,146,666,178 tweets | 27 months: from August 2014 to October 2016 | × | × |
| [82] 1 dataset created | × | 17 May–14 June 2018 | Jeddah, Makkah | REST search API for Twitter searching |
| [83] 1 dataset used | 260k tweets | × | Italy | × |
| [89] 1 dataset created | 20,000 tweets during 2009–2019. Four thousand papers from 1974–2019 | Tweets (2009–2019), papers (1974–2019) | × | Selenium WebDriver for Twitter data collection, used official API through Europe PMC services for PubMed data collection |
| [90] 1 dataset created | 8 million | 4 months | San Francisco Bay | × |
| [94] 1 dataset created | Total of 119,243 tweets and 137,942 relevant documents were considered | Data collected for the whole month of August 2020 | × | Twitter’s standard API |
| [97] FA cup, US election (2012), and 1 created dataset | × | December 2014 | Manhattan (created one) | × |
| [98] 1 dataset used | Brand-Social-Net dataset (3 million tweets with 1.3 million images) | June–July 2012 | × | × |
| [100] 1 dataset created | 1,500,000 posts and 36,845 users | × | × | Twitter API |
| [105] 1 dataset used | Data consisted of 49,918 posts and 4916 users | 14 April 2015 to 15 April 2015 | Nepal, China | By SinaAPI |
| [106] 2 datasets used | 3.3 M dataset (3.3 million tweets), ICWSM Dataset (1,280,000 tweets) | 3.3 M dataset (from 15 January 2018 to 4 March 2018), ICWSM Dataset (from 14 December 2011 to 11 January 2012) | × | Using Twitter API |
| Round 1 Question | Round 2 Question | Round 3 Question | Round 4 Question | ||
|---|---|---|---|---|---|
| Ref | Detected What? | Was the Model Real-Time? | Location or Time Detected? | Is the Model Language-Independent? | Comments |
| [3] | Protest, religious, celebrating | No | No | No | Real-time, location, and time detection with multilingual features would be better |
| [6] | Sports event | Yes | No | No | |
| [7] | Rumor | No | No | No | Incorporating time and location detection would be commendable |
| [9] | Disaster-related event | No | No | No | Introducing a multilingual model would show better performance |
| Including time and location detection would make the model more efficient | |||||
| [18] | Disruptive | Yes | No | No | Location and time detection with multilingual feature would be better |
| [19] | Protest | Yes | No | Used multiple languages | Incorporating multiple languages is praiseworthy; should be extended with more languages |
| [25] | Congestion | Yes | Location only | No | Time detection with multilingual feature would be better |
| [33] | Earthquake | Yes | Yes | No | Multilingual detection would be better in covering worldwide events |
| [45] | Monolingual event tracking from newspaper corpus | No | No | No | A robust model with real-time, place, and location with various languages would be better |
| [52] | Traffic detection | Yes | Yes | No | Introducing a multilingual model would be great |
| [61] | Disaster event | No | Location only | No | Detecting time of the disaster would be excellent |
| [64] | General events | Yes | No | Yes | Location and time detection would result in a better model |
| [65] | Disaster event | No | No | multilingual | Extracting time and location of disaster would be better |
| [70] | Multiclass event classification | No | No | No | Considering multiple languages with real-time feature would be better |
| [71] | Terroristic behavior | No | Location only | Multilingual | A real-time-based model would show much better performance |
| [73] | Novel events | Yes | Yes | No | Multilingual approach would make the model more robust |
| [77] | Trending events | No | No | No | Real-time event detection would be better |
| [79] | Cyber-attack | No | No | No | Making the model a real-time one would be great |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mredula, M.S.; Dey, N.; Rahman, M.S.; Mahmud, I.; Cho, Y.-Z. A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data. Sensors 2022, 22, 4531. https://doi.org/10.3390/s22124531
Mredula MS, Dey N, Rahman MS, Mahmud I, Cho Y-Z. A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data. Sensors. 2022; 22(12):4531. https://doi.org/10.3390/s22124531
Chicago/Turabian StyleMredula, Motahara Sabah, Noyon Dey, Md. Sazzadur Rahman, Imtiaz Mahmud, and You-Ze Cho. 2022. "A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data" Sensors 22, no. 12: 4531. https://doi.org/10.3390/s22124531
APA StyleMredula, M. S., Dey, N., Rahman, M. S., Mahmud, I., & Cho, Y.-Z. (2022). A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data. Sensors, 22(12), 4531. https://doi.org/10.3390/s22124531