
Towards Building a Visual Behaviour Analysis Pipeline for Suicide Detection and Prevention

Abstract
:1. Introduction
2. Background and Related Work
2.1. Intelligent Surveillance for Suicide Detection and Prevention
2.2. Pre-Suicidal Behaviour Recognition for Early Detection and Prevention
2.3. Skeleton-Based Action Recognition
2.3.1. Feature Extraction for Skeleton-Based Action Recognition
2.3.2. Deep Neural Network Architecture for Skeleton-Based Action Recognition
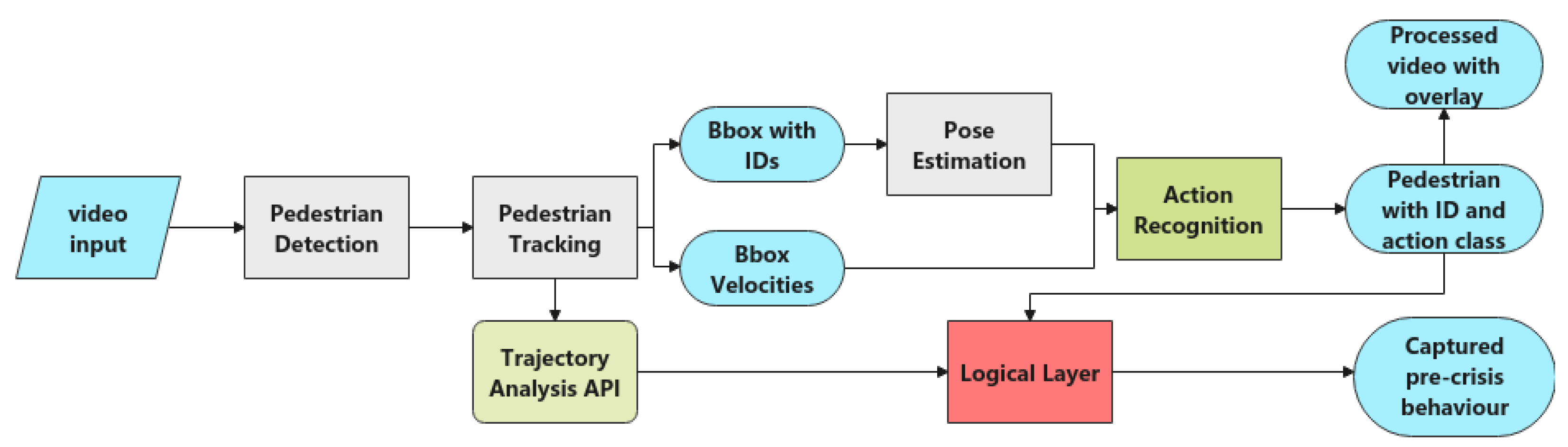
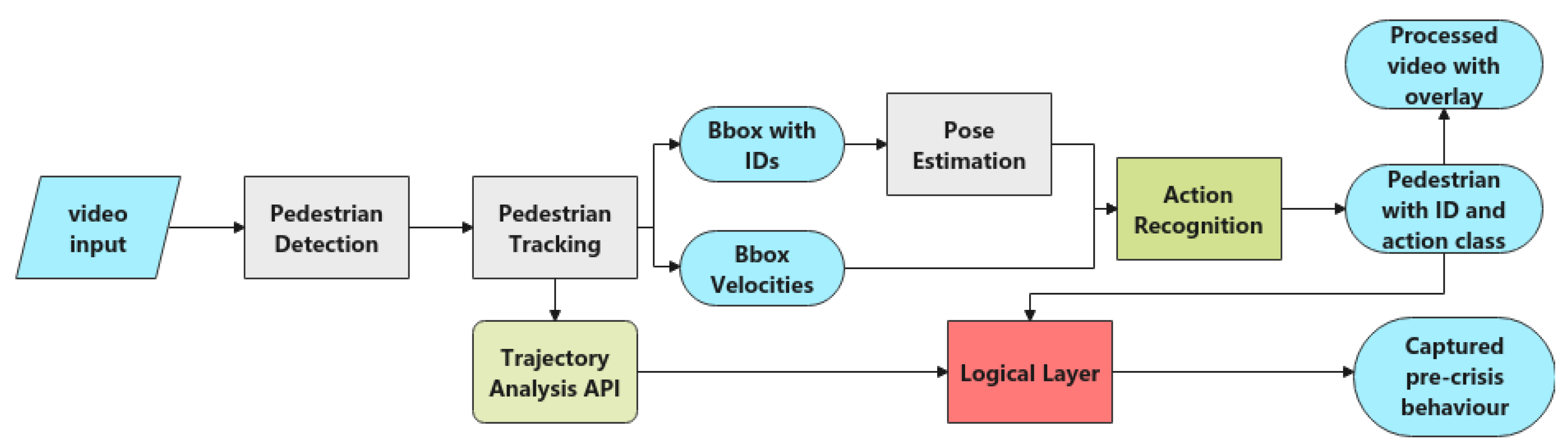
3. Methodology
3.1. Pedestrian Detection, Pedestrian Tracking and Pose Estimation
3.2. Action Recognition
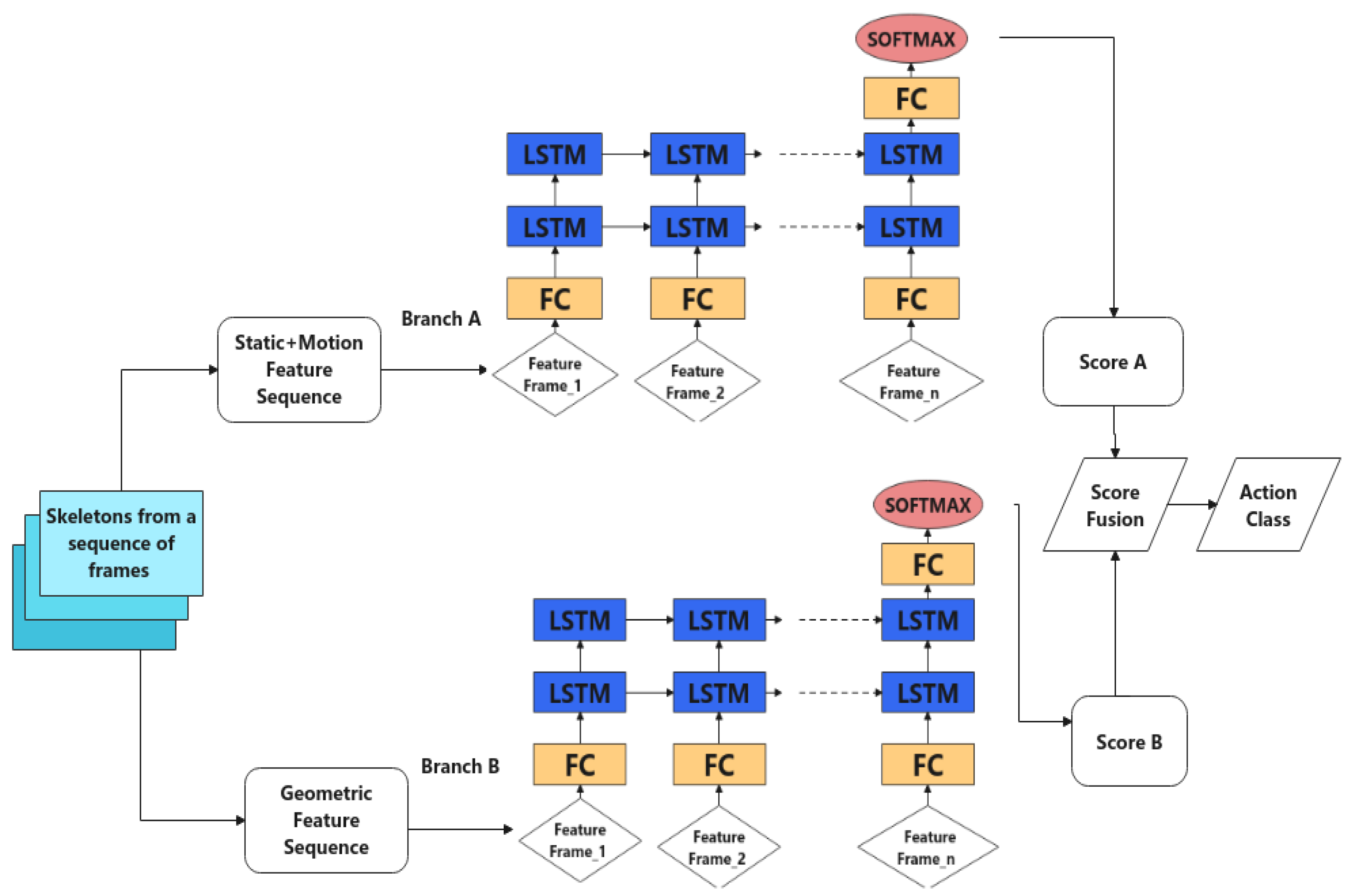
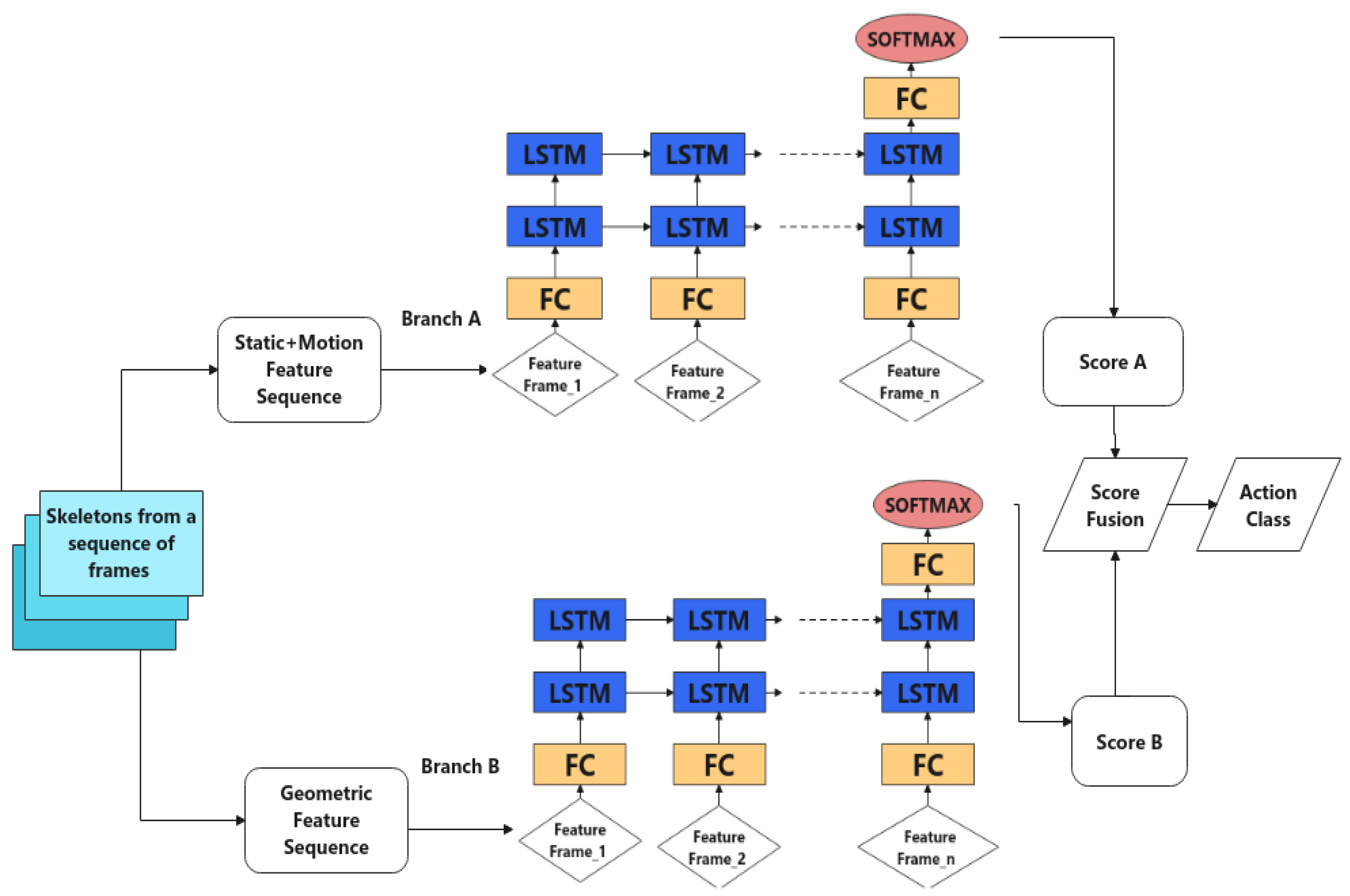
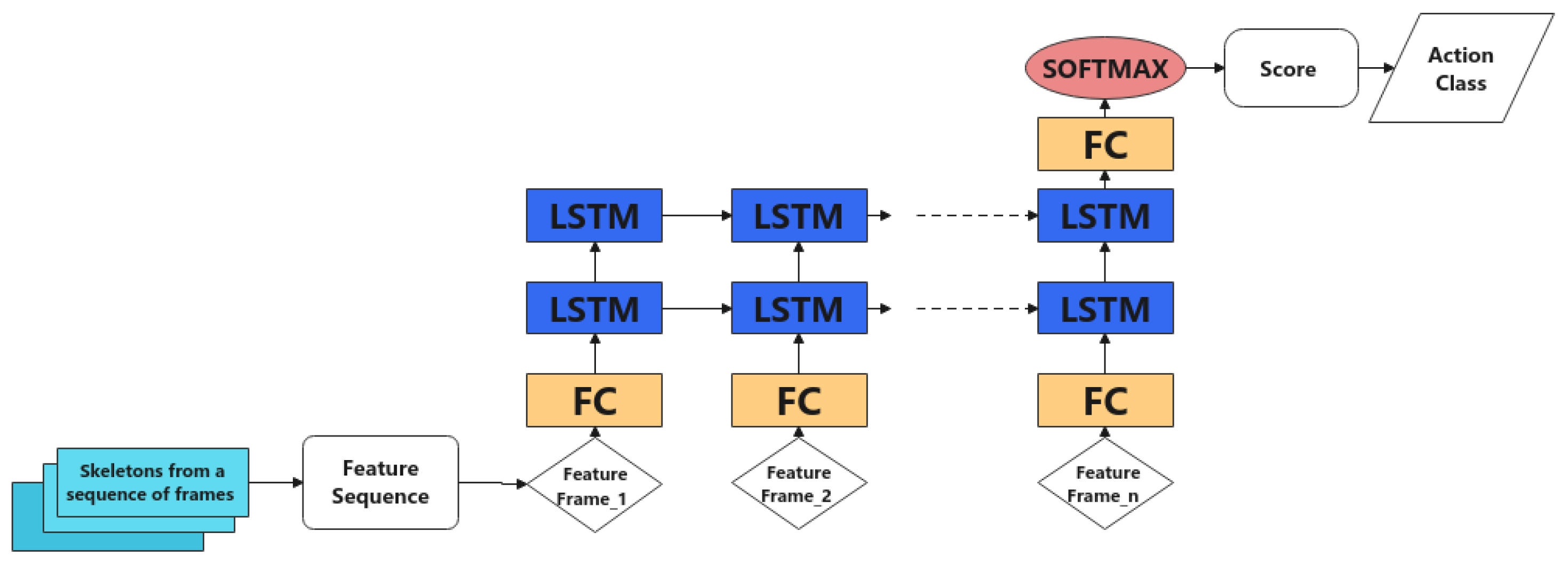
3.2.1. Feature Extraction from Skeleton Sequence
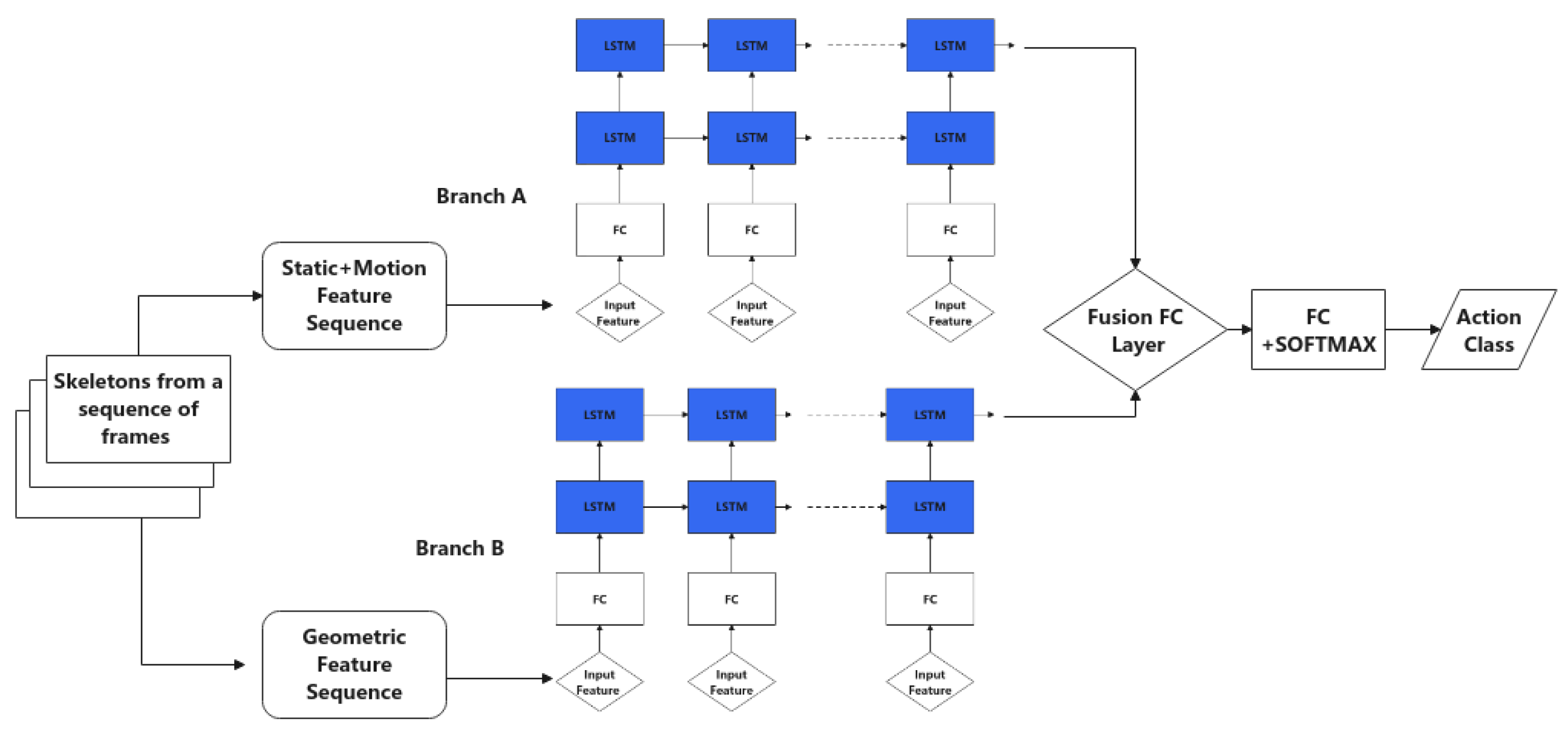
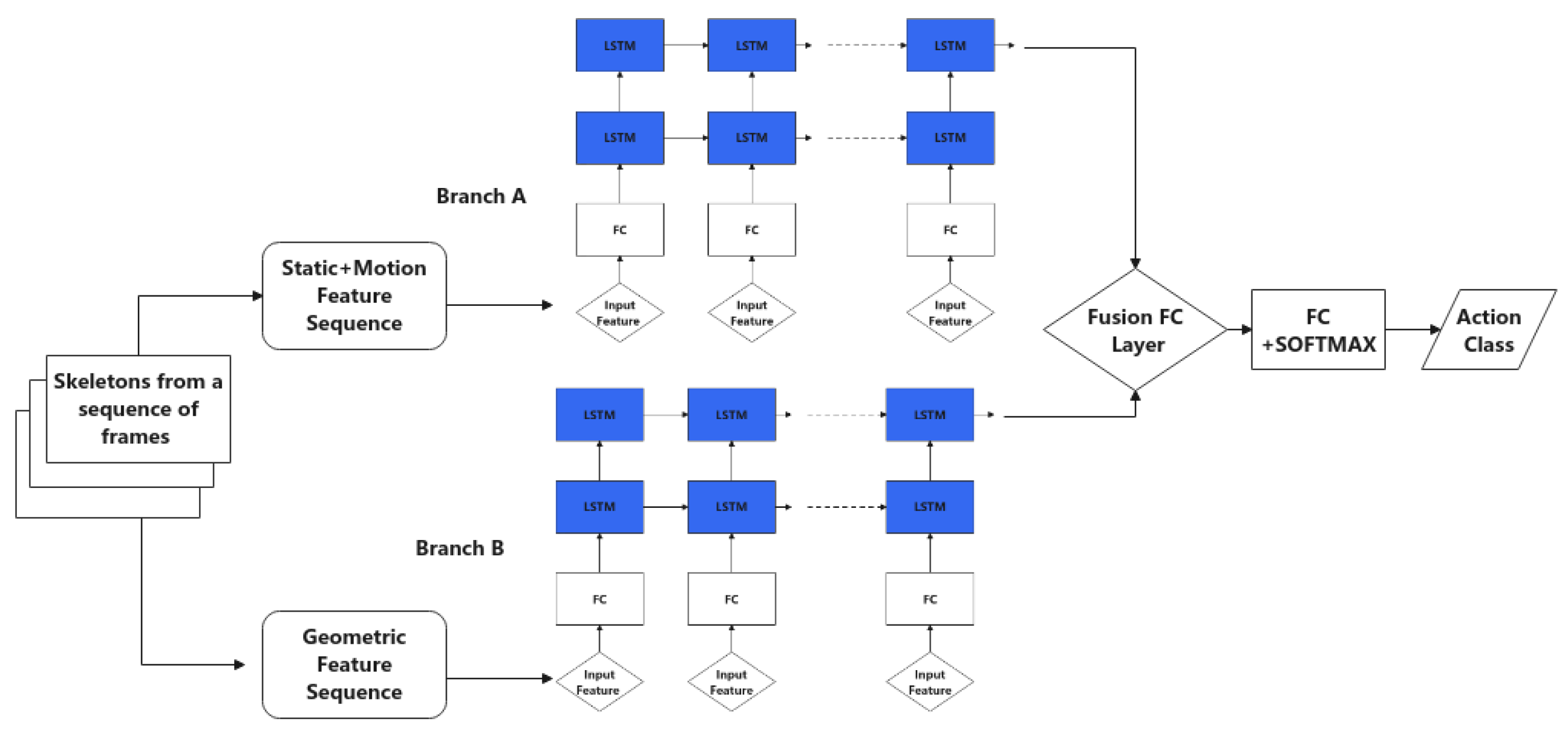
3.2.2. Neural Networks
3.2.3. Score Fusion
3.2.4. Application and Logical Layer
3.3. Implementation Details
4. Experiments
4.1. Experiment 1: Features and Network Structures
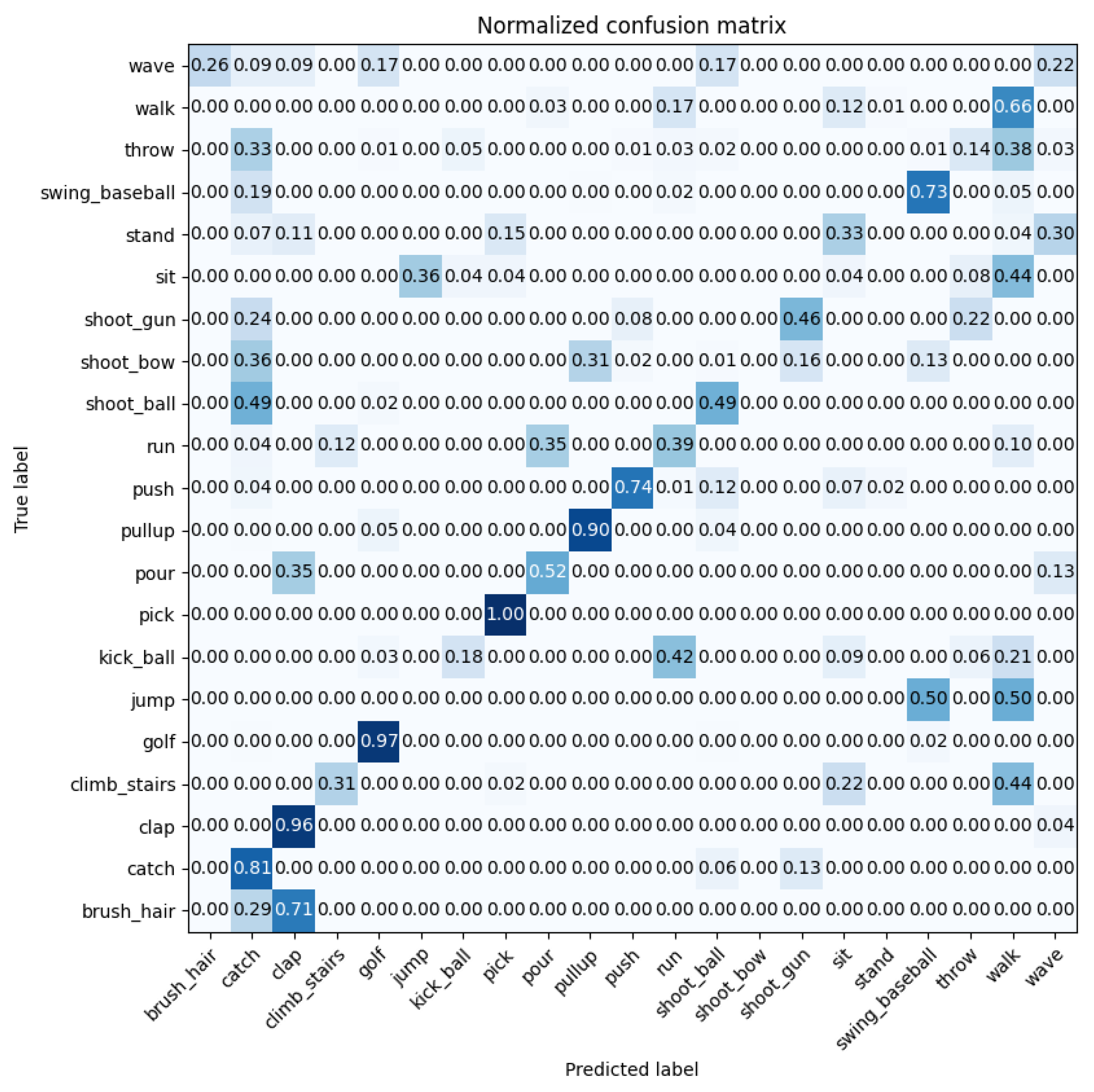
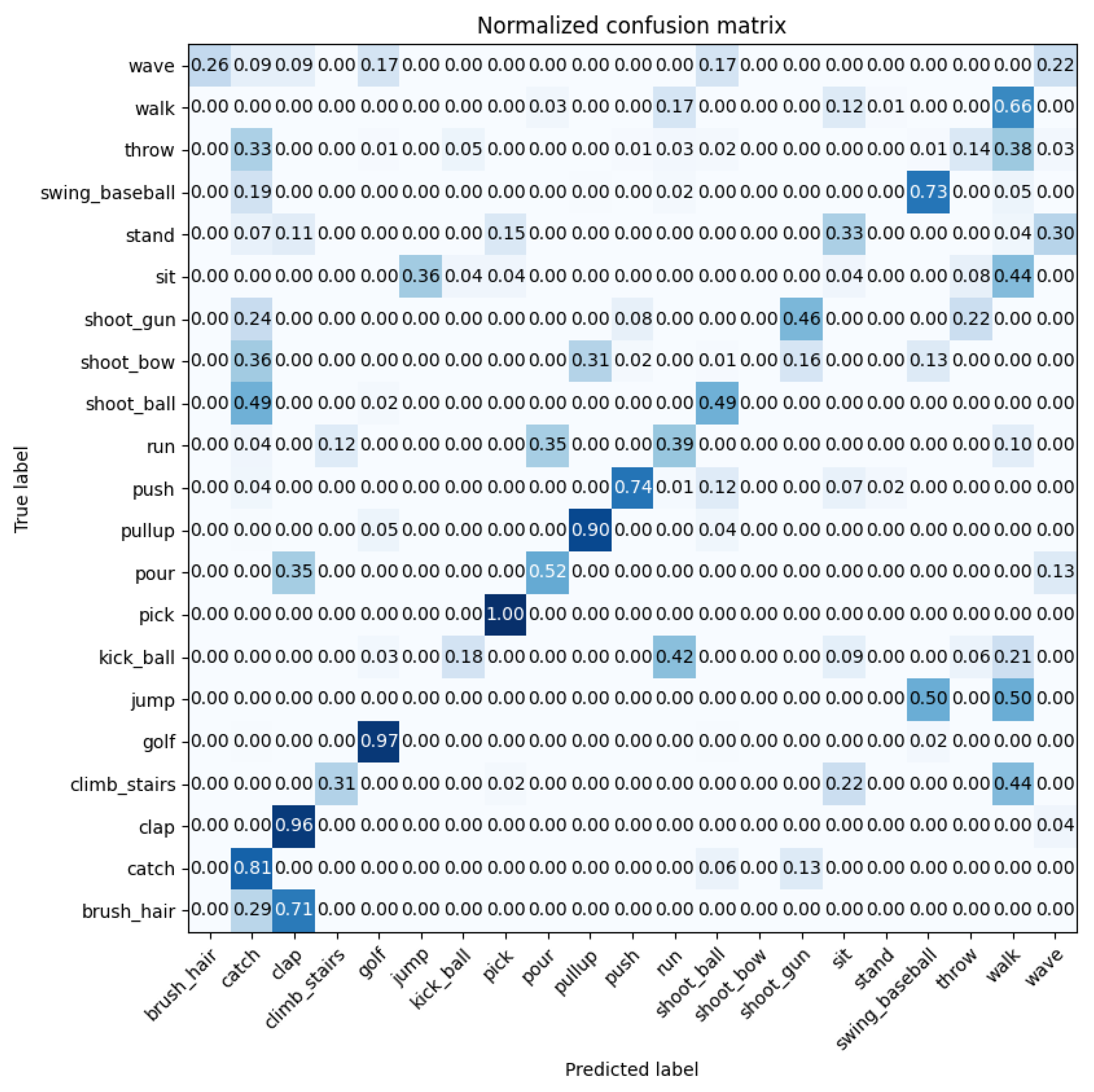
4.2. Experiment 2: JHMDB Evaluation
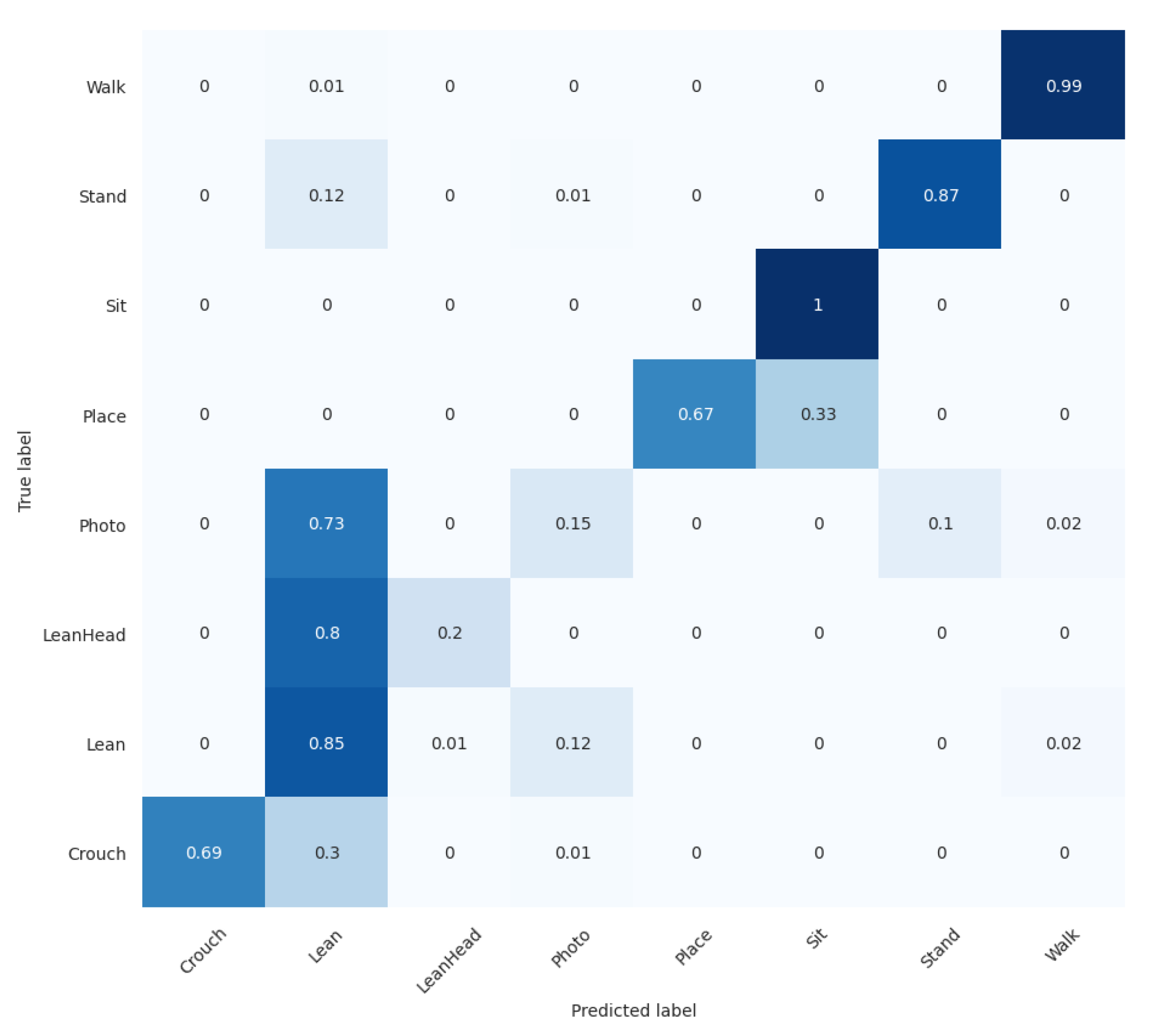
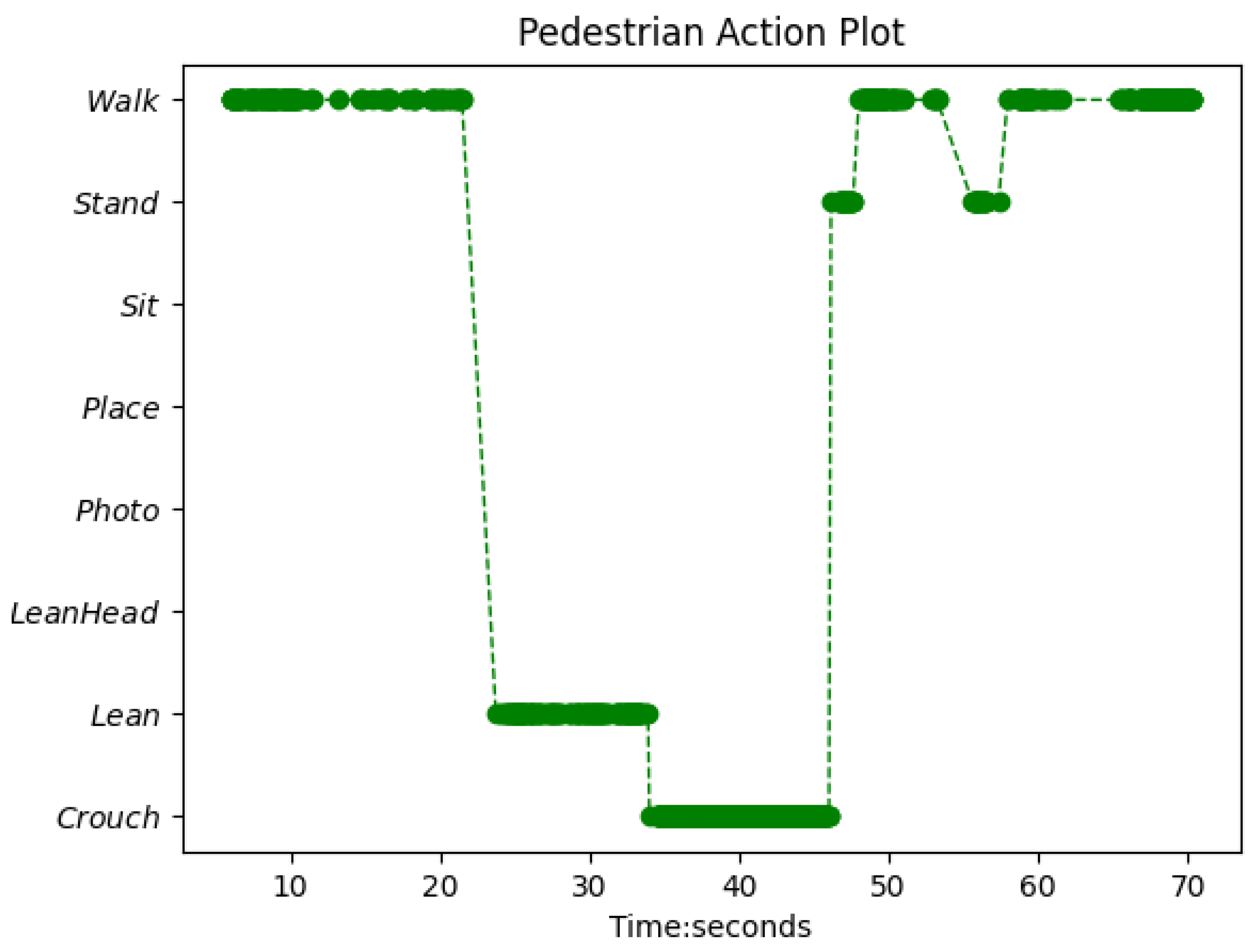
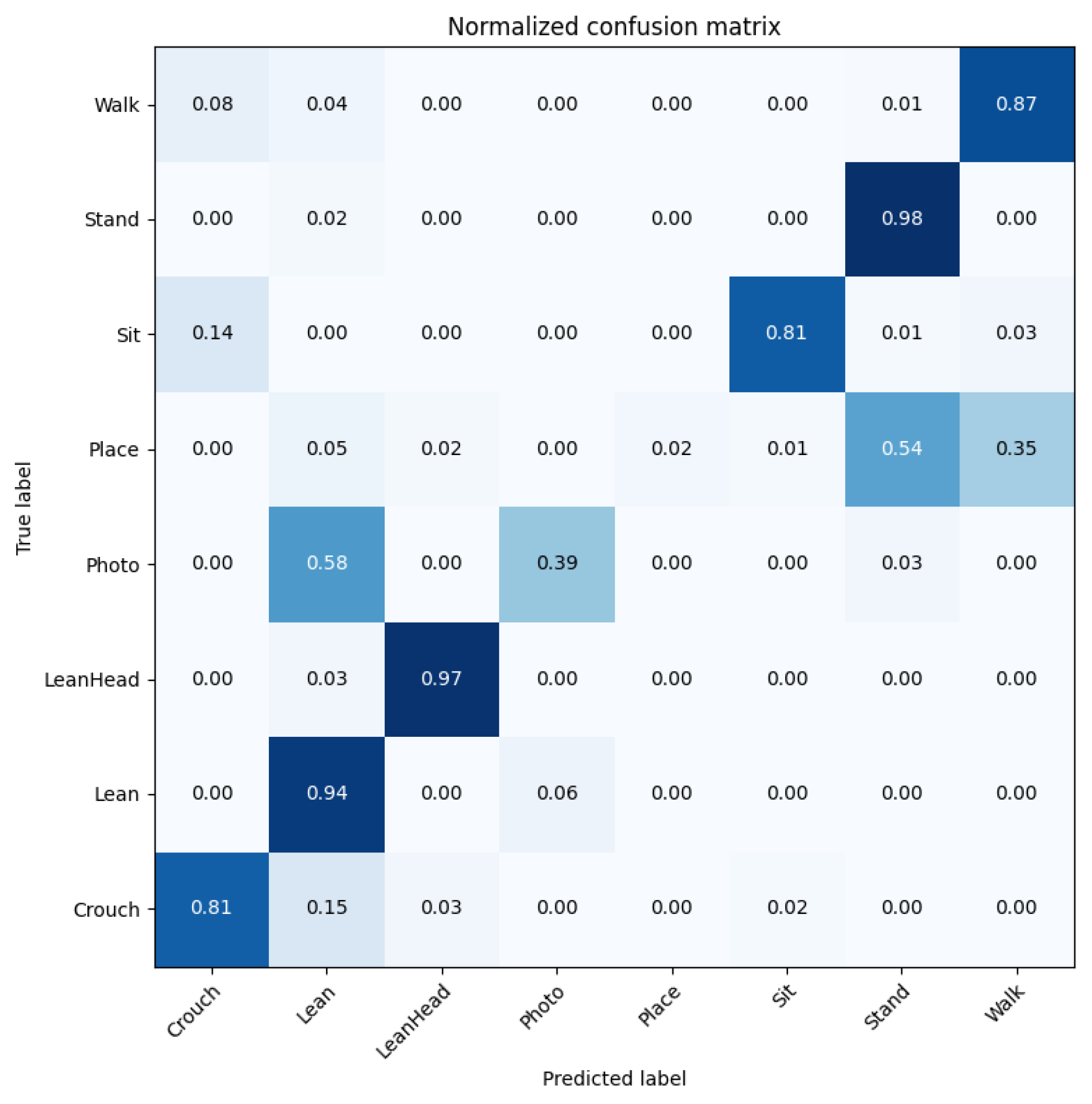
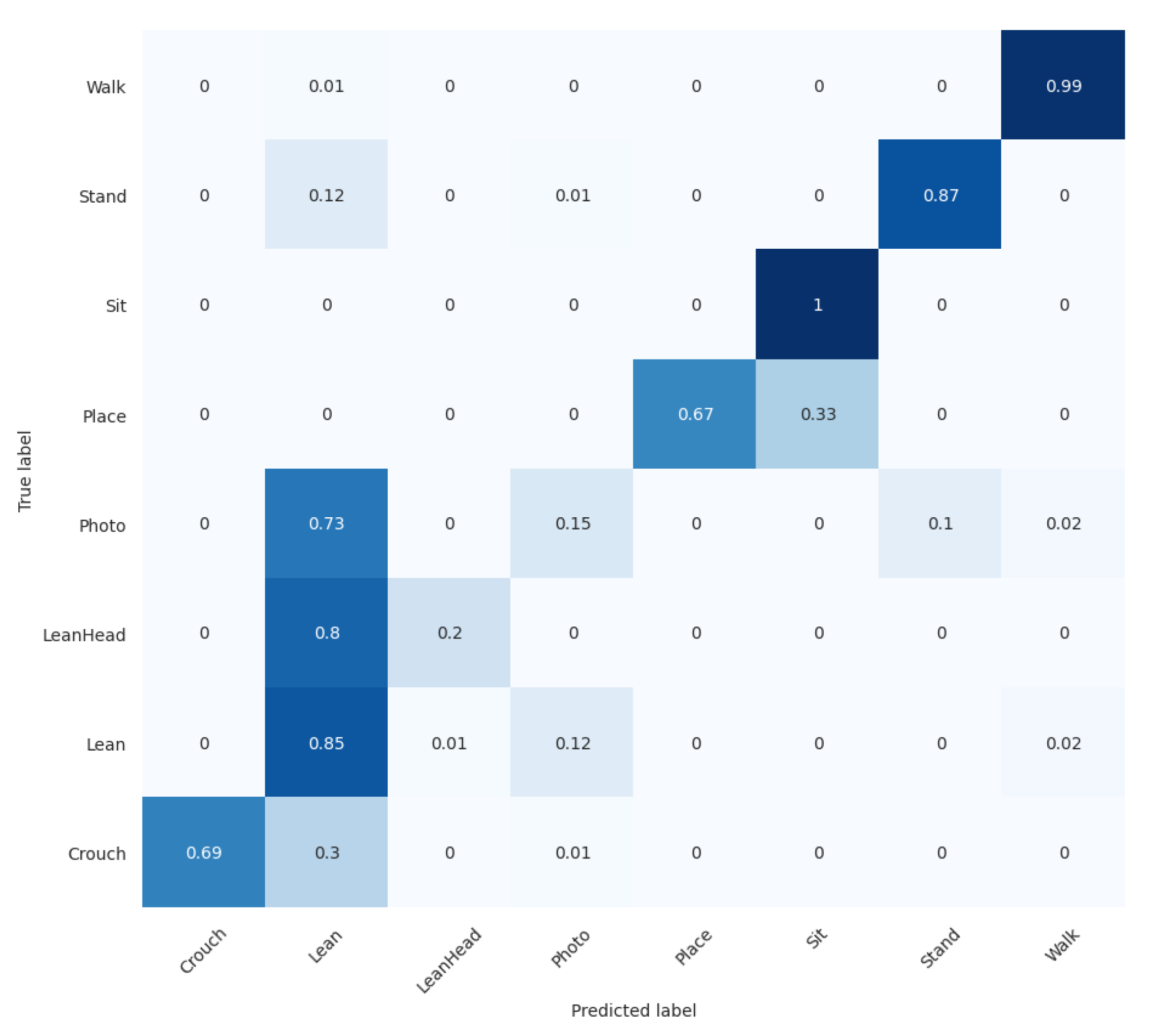
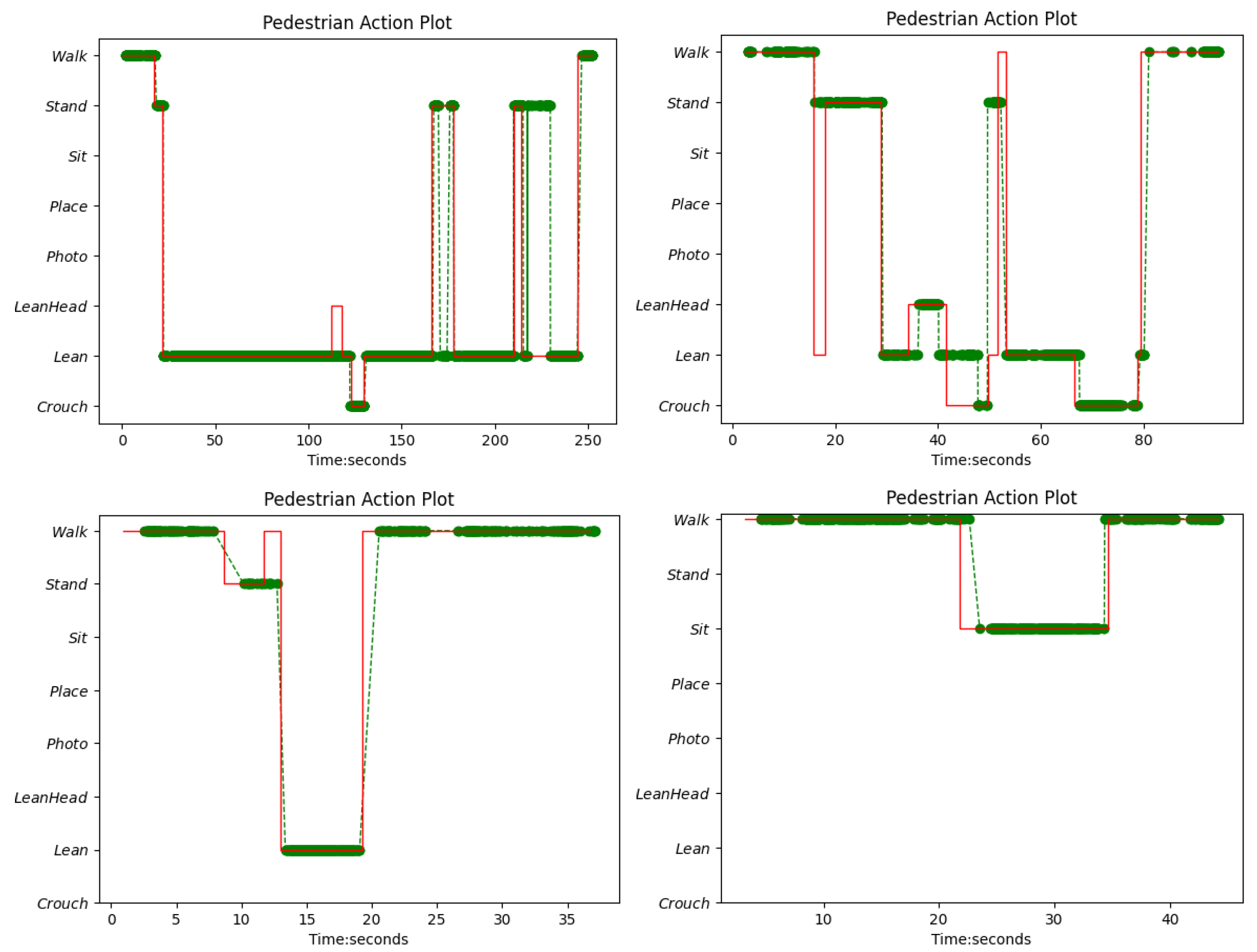
4.3. Experiment 3: Action Recognition Model for Suicide Prevention
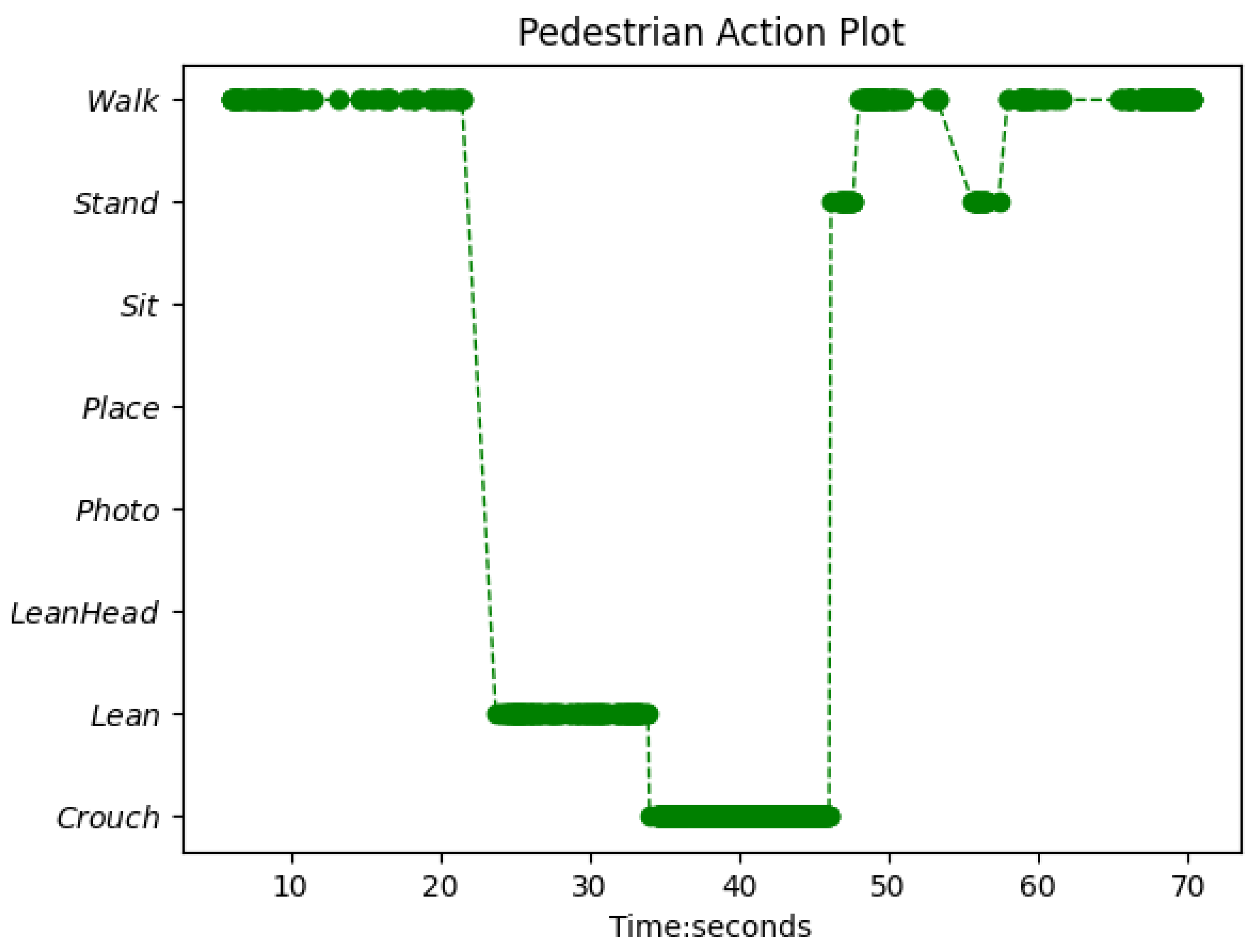
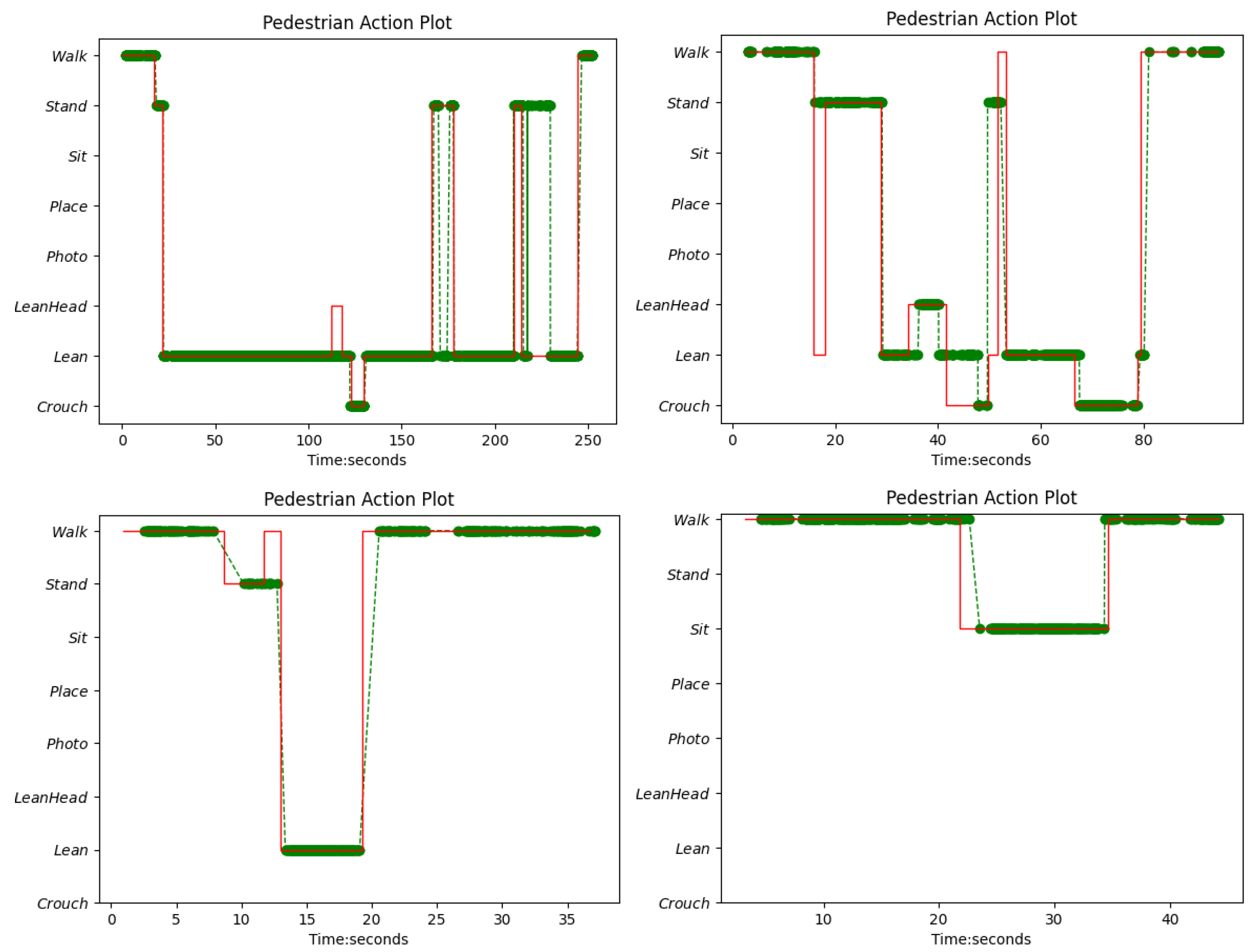
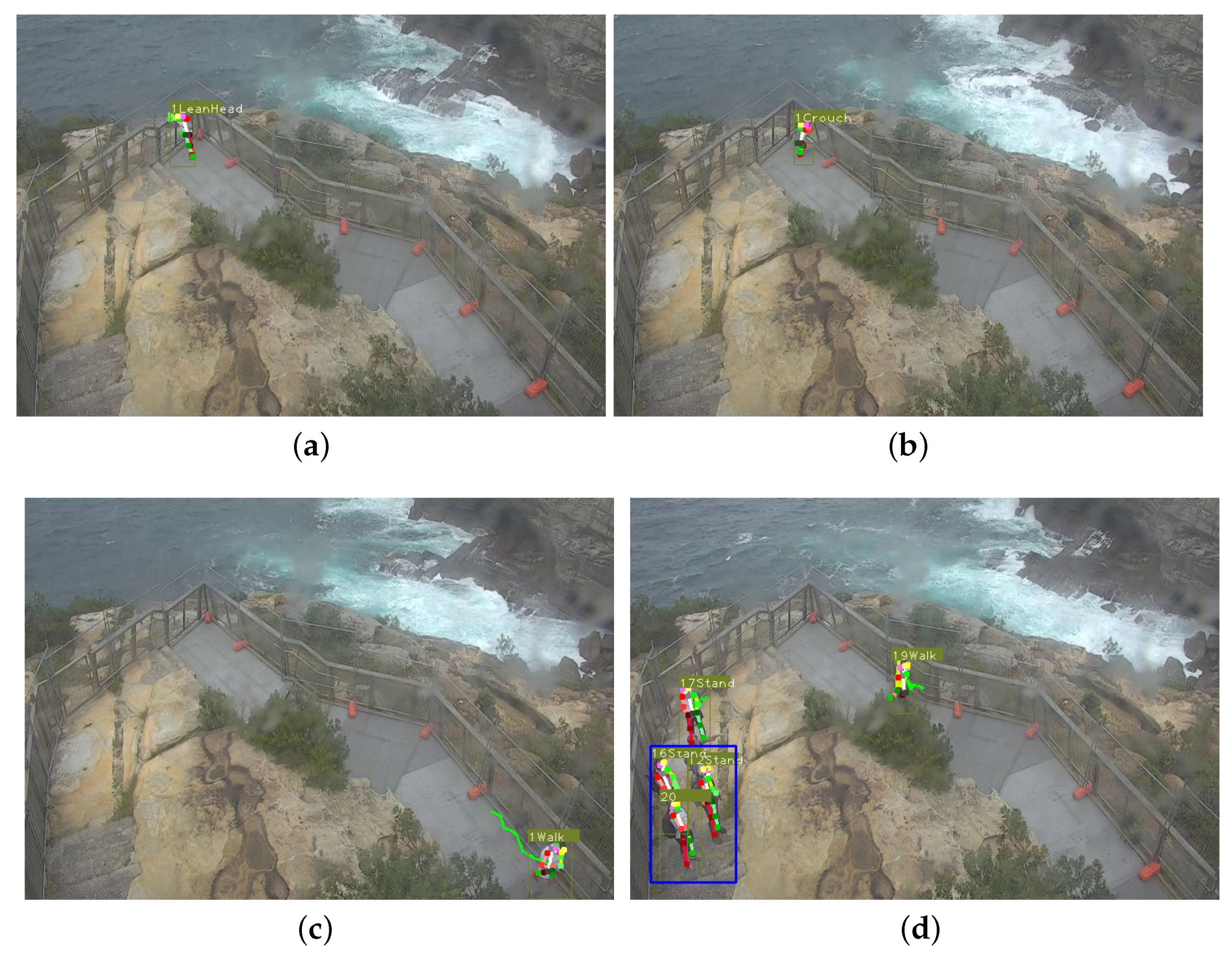
4.4. Experiment 4: Action Detection and Logical Analysis for Suicide Prevention
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Revathi, A.R.; Kumar, D. A Survey Of Activity Recognition Additionally, Understanding The Behavior In Video Survelliance. arXiv 2012, arXiv:cs.CV/1207.6774. [Google Scholar]
- Li, T.; Sun, Z.; Chen, X. Group-Skeleton-Based Human Action Recognition in Complex Events. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–15 October 2020. [Google Scholar] [CrossRef]
- Andersson, M. Deep learning for behaviour recognition in surveillance applications. In Counterterrorism, Crime Fighting, Forensics, and Surveillance Technologies III; Bouma, H., Prabhu, R., Stokes, R.J., Yitzhaky, Y., Eds.; International Society for Optics and Photonics SPIE: Washington, DC, USA, 2019; Volume 11166, pp. 251–257. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Larsen, M.E.; Cummins, N.; Boonstra, T.W.; O’Dea, B.; Tighe, J.; Nicholas, J.; Shand, F.; Epps, J.; Christensen, H. The use of technology in Suicide Prevention. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 7316–7319. [Google Scholar] [CrossRef]
- Benton, A.; Mitchell, M.; Hovy, D. Multi-Task Learning for Mental Health using Social Media Text. arXiv 2017, arXiv:cs.CL/1712.03538. [Google Scholar]
- Ji, S.; Yu, C.; Fung, S.F.; Pan, S.; Long, G. Supervised learning for suicidal ideation detection in online user content. Complexity 2018, 2018, 1076–2787. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, A.; Dutta, R.; Velupillai, S.; Sanyal, J.; Stewart, R.; Chandran, D. Identifying Suicide Ideation and Suicidal Attempts in a Psychiatric Clinical Research Database using Natural Language Processing. Sci. Rep. 2018, 8, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pirkis, J.; Too, L.S.; Spittal, M.J.; Krysinska, K.; Robinson, J.; Cheung, Y.T.D. Interventions to reduce suicides at suicide hotspots: A systematic review and meta-analysis. Lancet 2015, 2, 994–1001. [Google Scholar] [CrossRef]
- Mishara, B.L.; Bardon, C.; Dupont, S. Can CCTV identify people in public transit stations who are at risk of attempting suicide? An analysis of CCTV video recordings of attempters and a comparative investigation. BMC Public Health 2016, 16, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Reid, S.; Coleman, S.; Kerr, D.; Vance, P.; O’Neill, S. Feature Extraction with Computational Intelligence for Head Pose Estimation. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1269–1274. [Google Scholar] [CrossRef]
- Onie, S.; Li, X.; Liang, M.; Sowmya, A.; Larsen, M.E. The Use of Closed-Circuit Television and Video in Suicide Prevention: Narrative Review and Future Directions. JMIR Ment. Health 2021, 8, e27663. [Google Scholar] [CrossRef]
- Lin, W. A Survey on Behavior Analysis in Video Surveillance Applications. Video Surveill. IntechOpen 2011, 281–291. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Yun, K.; Park, J.; Choi, J.Y. Skeleton-based Action Recognition of People Handling Objects. arXiv 2019, arXiv:cs.CV/1901.06882. [Google Scholar]
- Lee, J.; Lee, C.M.; Park, N.K. Application of Sensor Network System to Prevent Suicide from the Bridge. Multimed. Tools Appl. 2016, 75, 14557–14568. [Google Scholar] [CrossRef]
- Bouachir, W.; Noumeir, R. Automated video surveillance for preventing suicide attempts. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention Automated Video Surveillance for Preventing Suicide Attempts, Madrid, Spain, 23–25 November 2016. [Google Scholar] [CrossRef]
- Lee, S.; Kim, H.; Lee, S.; Kim, Y.; Lee, D.; Ju, J.; Myung, H. Detection of a Suicide by Hanging Based on a 3-D Image Analysis. IEEE Sens. J. 2014, 14, 2934–2935. [Google Scholar] [CrossRef]
- Mackenzie, J.M.; Borrill, J.; Hawkins, E.; Fields, B.; Kruger, I.; Noonan, I.; Marzano, L. Behaviours preceding suicides at railway and underground locations: A multimethodological qualitative approach. BMJ Open 2018, 8, e021076. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos; NIPS’14; MIT Press: Cambridge, MA, USA, 2014; pp. 568–576. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal Relational Reasoning in Videos. In Proceedings of the European Conference on Computer Vision, Munich, Germnay, 8–14 September 2018. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Crasto, N.; Weinzaepfel, P.; Alahari, K.; Schmid, C. MARS: Motion-Augmented RGB Stream for Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. arXiv 2015, arXiv:cs.CV/1503.08909. [Google Scholar]
- Johansson, G. Visual perception of biological motion and a model for its analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Yao, A.; Gall, J.; Fanelli, G.; Gool, L.V. Does Human Action Recognition Benefit from Pose Estimation? In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2011; pp. 67.1–67.11. [Google Scholar] [CrossRef] [Green Version]
- Jhuang, H.; Gall, J.; Zuffi, S.; Schmid, C.; Black, M.J. Towards understanding action recognition. In Proceedings of the International Conf. on Computer Vision (ICCV), Sydeny, NSW, Australia, 1–8 December 2013; pp. 3192–3199. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Zhuang, Y.; Nie, F.; Yang, Y.; Wu, F.; Xiao, J. Learning a 3D Human Pose Distance Metric from Geometric Pose Descriptor. IEEE Trans. Vis. Comput. Graph. 2010, 17, 1676–1689. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Wu, Y.; Sakti, S.; Nakamura, S. Make Skeleton-based Action Recognition Model Smaller, Faster and Better. arXiv 2019, arXiv:1907.09658. [Google Scholar] [CrossRef] [Green Version]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.P.; Guerry, J.; Saux, B.L.; Filliat, D. 3D Hand Gesture Recognition Using a Depth and Skeletal Dataset: SHREC’17 Track. In Proceedings of the Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; 3Dor ’17. pp. 33–38. [Google Scholar] [CrossRef]
- Choutas, V.; Weinzaepfel, P.; Revaud, J.; Schmid, C. PoTion: Pose MoTion Representation for Action Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Duan, H.; Zhao, Y.; Chen, K.; Shao, D.; Lin, D.; Dai, B. Revisiting skeleton-based action recognition. arXiv 2021, arXiv:2104.13586. [Google Scholar]
- Ludl, D.; Gulde, T.; Curio, C. Simple yet Efficient Real-Time Pose-Based Action Recognition. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 30 June–15 July 2019; pp. 581–588. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar] [CrossRef] [Green Version]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-Occurrence Feature Learning for Skeleton Based Action Recognition Using Regularized Deep LSTM Networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Palo Alto, CA, USA, 2016. AAAI’16. pp. 3697–3703. [Google Scholar]
- Zhang, S.; Liu, X.; Xiao, J. On geometric features for skeleton-based action recognition using multilayer lstm networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 148–157. [Google Scholar]
- Ahmed, S.A.; Dogra, D.P.; Kar, S.; Roy, P. Surveillance scene representation and trajectory abnormality detection using aggregation of multiple concepts. Expert Syst. Appl. 2018, 101, 43–55. [Google Scholar] [CrossRef]
- Jocher, G. Ultralytics/yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 February 2021). [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, 13th European Conference, Part IV2014, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef] [Green Version]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 13–23 June 2018; pp. 7297–7306. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 12–14 July 2017; pp. 585–590. [Google Scholar]
- Zolfaghari, M.; Oliveira, G.; Sedaghat, N.; Brox, T. Chained Multi-stream Networks Exploiting Pose, Motion, and Appearance for Action Classification and Detection. arXiv 2017, arXiv:1704.00616. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. PYSKL: Towards Good Practices for Skeleton Action Recognition. arXiv 2022, arXiv:2205.09443. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geometric Feature List | Dimension | Description |
|---|---|---|
| Limb Orientation | 13 | Limb angle |
| Limb Length | 13 | Limb lengths |
| Inner Angles | 13 | For every 3 adjacent joints, calculate the inner angle between 2 limbs that share the same joint |
| Long Length | 13 | For every 3 adjacent joints, calculate the distance between 2 non-adjacent joints |
| End Length | 10 | For every end joint (defined as joint that has only one side connected to another joint, including nose, wrists and ankles), calculate the distance between every two end joints |
| Total | 62 |
| Feature Type | Sequence Length | Dimension | Accuracy (%) |
|---|---|---|---|
| Static | 30 | 28 | 52.53 |
| Motion | 30 | 68 | 38.79 |
| Geometric | 30 | 62 | 41.91 |
| Static + Motion concatenation | 30 | 96 | 62.81 |
| Static + Motion concatenation | 15 | 96 | 58.10 |
| Static + Motion concatenation | 45 | 96 | 61.39 |
| Model Structure | Feature Dimension | Accuracy (%) |
|---|---|---|
| Early Fusion | 158 | 45.28 |
| Mid Fusion | [96, 62] | 54.51 |
| Late Fusion: branch A | 96 | 62.81 |
| Late Fusion: branch B | 62 | 43.06 |
| * Late Fusion: score fusion | [96, 62] | 64.01 |
| Method | JHMDB-1 | JHMDB-1-GT | JHMDB |
|---|---|---|---|
| Zholfaghari et al. [50] | 45.5 | 56.8 | N/A |
| PoTion [33] | 59.1 | 67.9 | 57.0 |
| DD-Net [31] | N/A | 77.2 | N/A |
| EHPI [35] | 60.3 | 65.5 | 60.5 |
| Proposed method | 61.24 | 64.01 | 60.2 |
| Data Types | Crouch | Lean | Lean-Head | Photo | Place | Sit | Stand | Walk |
|---|---|---|---|---|---|---|---|---|
| Num of Clips | 10 | 14 | 10 | 10 | 10 | 15 | 14 | 12 |
| Num of Frames | 7163 | 9894 | 6534 | 1455 | 1045 | 14.451 | 11.944 | 3704 |
| Actions | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Crouch | 0.7385 | 0.8125 | 0.7737 | 2165 |
| Lean | 0.7593 | 0.9318 | 0.8367 | 2434 |
| LeanHead | 0.9621 | 0.9689 | 0.9655 | 1545 |
| Photo | 0.5016 | 0.3883 | 0.4378 | 394 |
| Place | 0.8571 | 0.0245 | 0.0476 | 245 |
| Sit | 0.9920 | 0.8208 | 0.8983 | 3912 |
| Stand | 0.9282 | 0.9844 | 0.9555 | 3021 |
| Average | 0.8198 | 0.7045 | 0.7022 | 1959 |
| Accuracy | Split1 | Split2 | Split3 | Average |
|---|---|---|---|---|
| Branch A | 84.21 | 78.01 | 82.95 | 81.72 |
| Branch B | 74.60 | 48.56 | 67.21 | 63.45 |
| Fused | 86.52 | 75.62 | 84.22 | 82.12 |
| PoseC3D | 89.71 | 81.25 | 82.21 | 84.39 |
| IoU | Crouch | Lean | Lean-Head | Photo | Place | Sit | Stand | Walk |
|---|---|---|---|---|---|---|---|---|
| 0.1 | 100 | 46.7 | 33.3 | 0 | 0 | 66.7 | 53.5 | 64.8 |
| 0.2 | 100 | 46.7 | 33.3 | 0 | 0 | 66.7 | 53.5 | 60.2 |
| 0.3 | 62.5 | 43.3 | 33.3 | 0 | 0 | 66.7 | 53.5 | 60.2 |
| 0.4 | 62.5 | 38.7 | 33.3 | 0 | 0 | 66.7 | 35.0 | 49.6 |
| 0.5 | 62.5 | 30.6 | 33.3 | 0 | 0 | 66.7 | 25.7 | 41.4 |
| 0.6 | 62.5 | 30.6 | 0 | 0 | 0 | 66.7 | 22.2 | 30.9 |
| 0.7 | 62.5 | 22.7 | 0 | 0 | 0 | 66.7 | 5.5 | 20.2 |
| 0.8 | 37.5 | 14.0 | 0 | 0 | 0 | 66.7 | 2.4 | 16.3 |
| 0.9 | 25.0 | 7.7 | 0 | 0 | 0 | 0 | 0 | 3 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Total Clips | TP | FP | TN | FN |
|---|---|---|---|---|
| 15 | 4 | 1 | 9 | 1 |
| Total Crisis Behaviours | Total Identification | Correct | False | Miss |
|---|---|---|---|---|
| 12 | 11 | 8 | 3 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Onie, S.; Liang, M.; Larsen, M.; Sowmya, A. Towards Building a Visual Behaviour Analysis Pipeline for Suicide Detection and Prevention. Sensors 2022, 22, 4488. https://doi.org/10.3390/s22124488
Li X, Onie S, Liang M, Larsen M, Sowmya A. Towards Building a Visual Behaviour Analysis Pipeline for Suicide Detection and Prevention. Sensors. 2022; 22(12):4488. https://doi.org/10.3390/s22124488
Chicago/Turabian StyleLi, Xun, Sandersan Onie, Morgan Liang, Mark Larsen, and Arcot Sowmya. 2022. "Towards Building a Visual Behaviour Analysis Pipeline for Suicide Detection and Prevention" Sensors 22, no. 12: 4488. https://doi.org/10.3390/s22124488
APA StyleLi, X., Onie, S., Liang, M., Larsen, M., & Sowmya, A. (2022). Towards Building a Visual Behaviour Analysis Pipeline for Suicide Detection and Prevention. Sensors, 22(12), 4488. https://doi.org/10.3390/s22124488