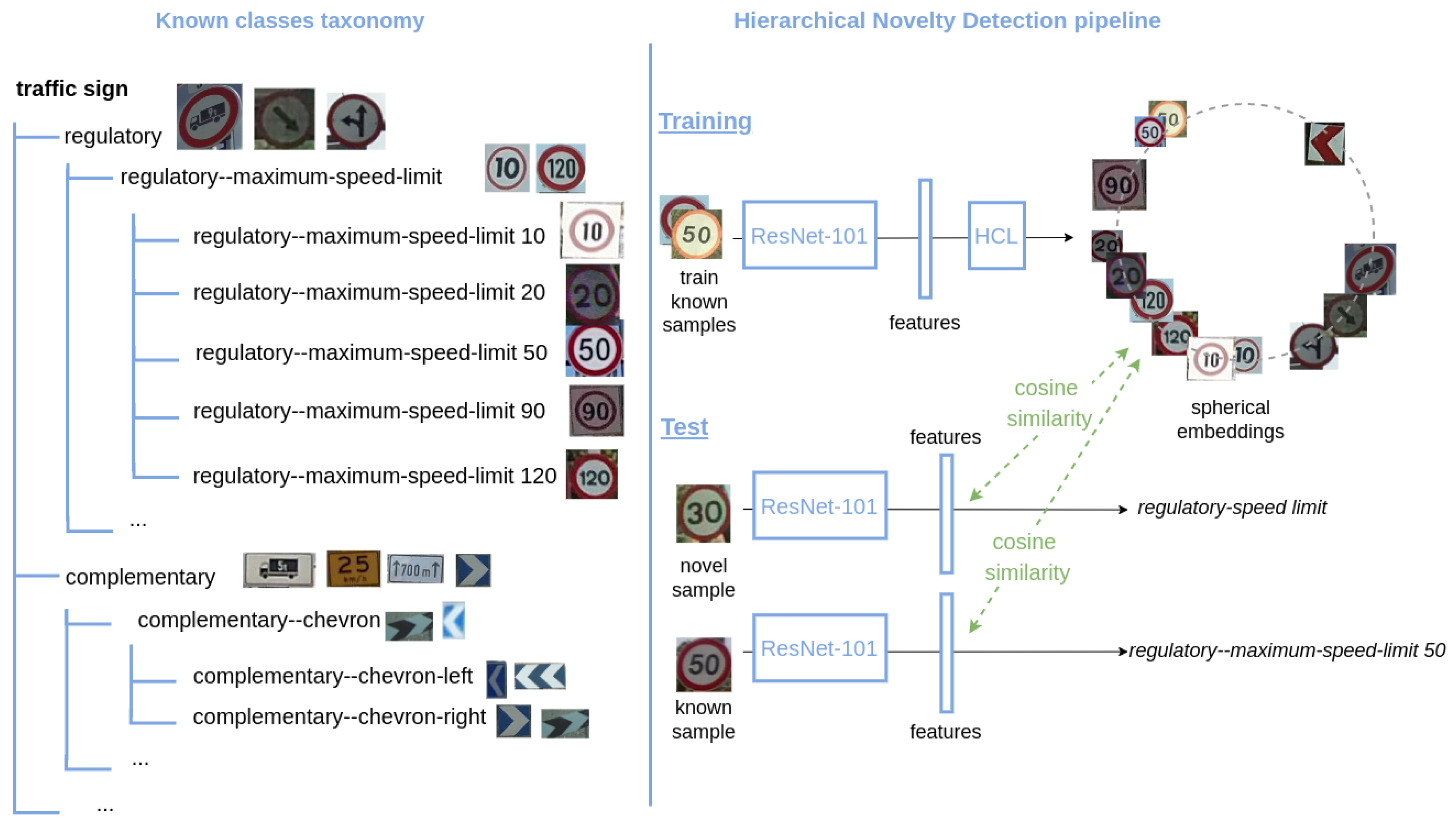
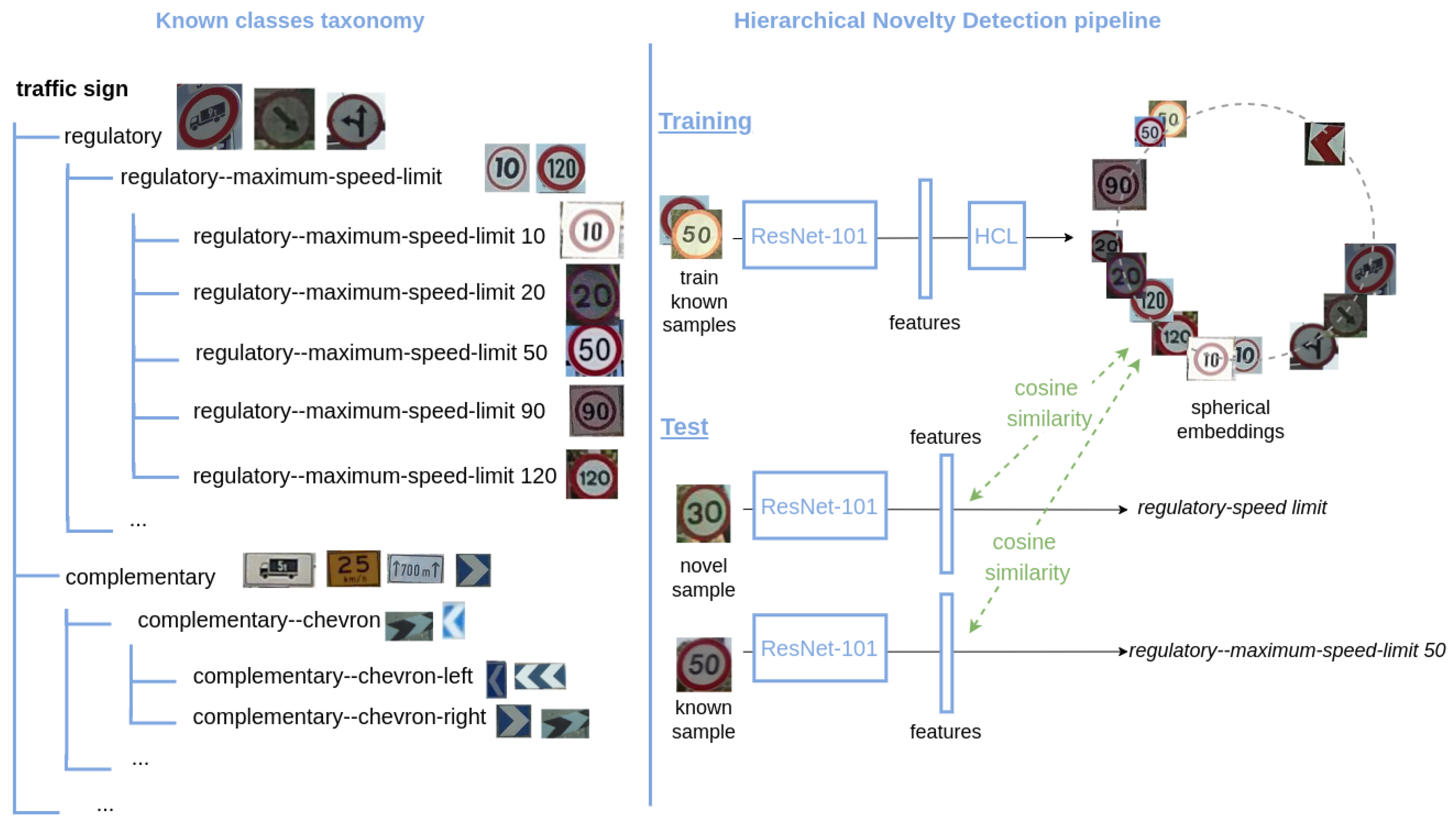
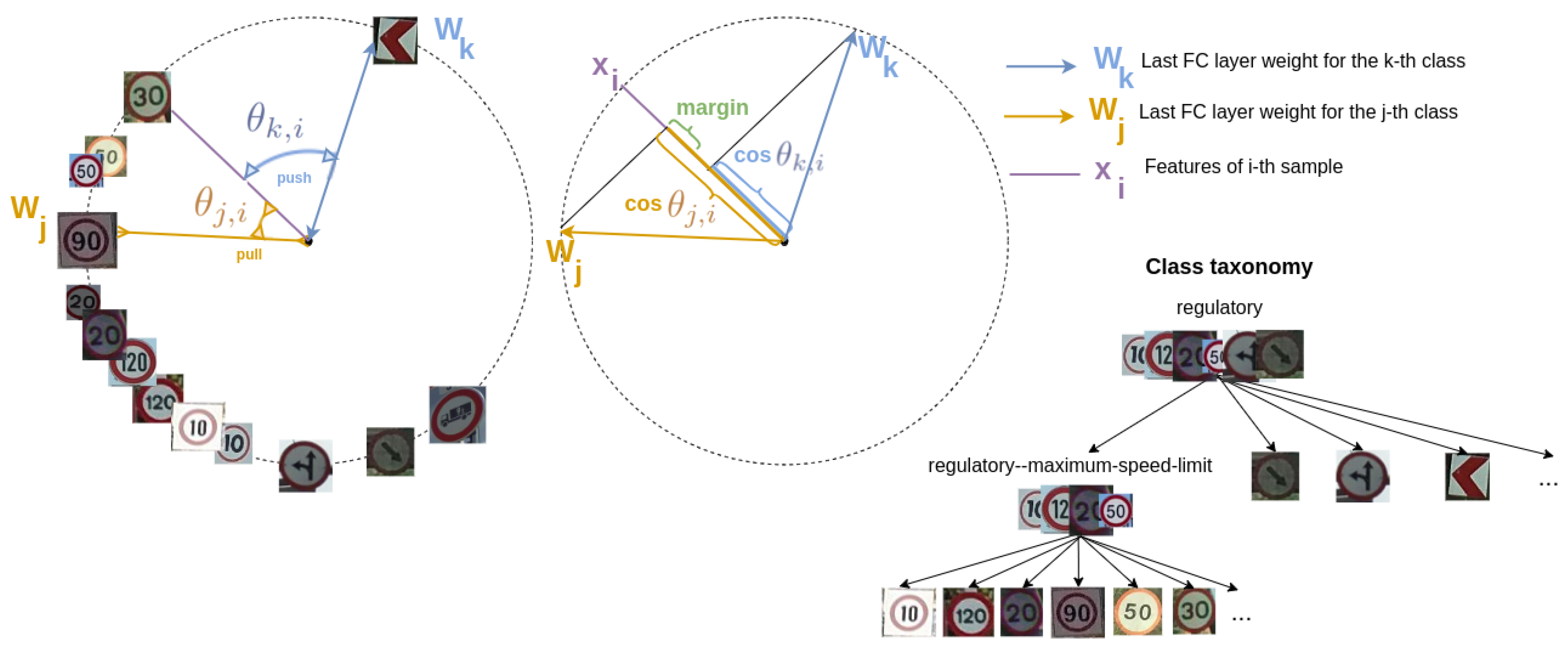
Our experiments are divided into three parts. To evaluate the performance of our approach, HCL, in
Section 6.1, we compare it to the state-of-the-art models in hierarchical novelty detection, i.e.,
TD+LOO [
5] and
Relabel [
5]. In
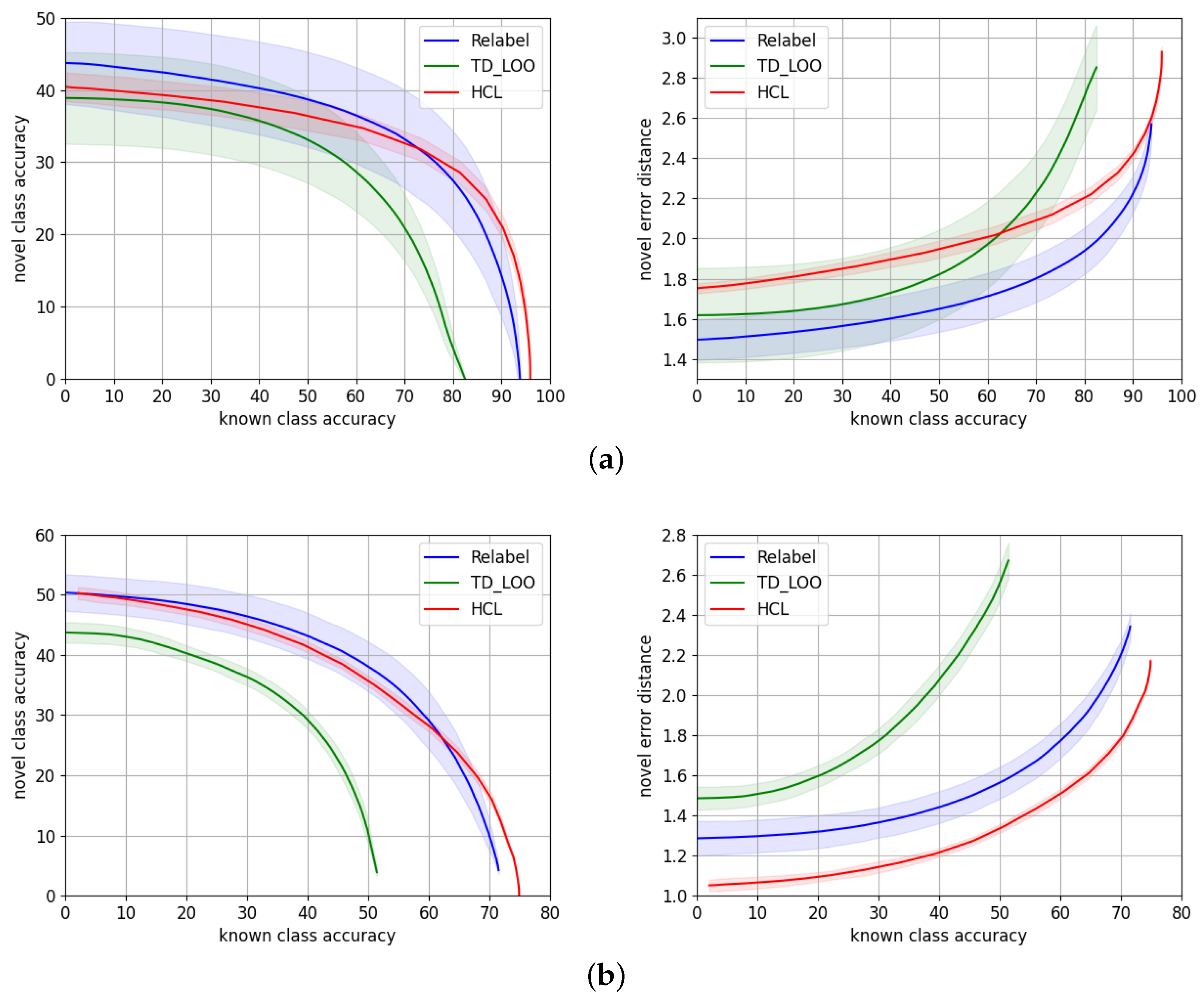
Section 6.1.1, we first consider the benchmarks where these models were originally evaluated, i.e., AWA2 and CUB. Then, in
Section 6.1.2, we perform the evaluation on the target traffic signs benchmarks TT100K and MTSD. In the next sections, we provide a more exhaustive evaluation of HCL on TT100K and MTSD. We compare the performance of different training strategies in
Section 6.2. Finally, in
Section 6.3, we analyze the individual contribution of each of the terms of HCL.
6.2. Training Strategies
We consider three different settings to train HCL. In particular, we train HCL on top of features that are extracted from ResNet-101 models that are previously trained, either on only ImageNet, or fine-tuned to the target dataset via the cross-entropy loss. The third setting we compare is when we train simultaneously HCL and the ResNet-101 backbone that is pretrained on ImageNet. We keep the fine-tuning procedure that is detailed in the previous
Section 6.1.2.
Using the hyperparameters from
Table A1, we repeat each new experiment for 10 times, as some training variants we compare in this section are time-consuming, and HCL was shown to be not so variable in previous results.
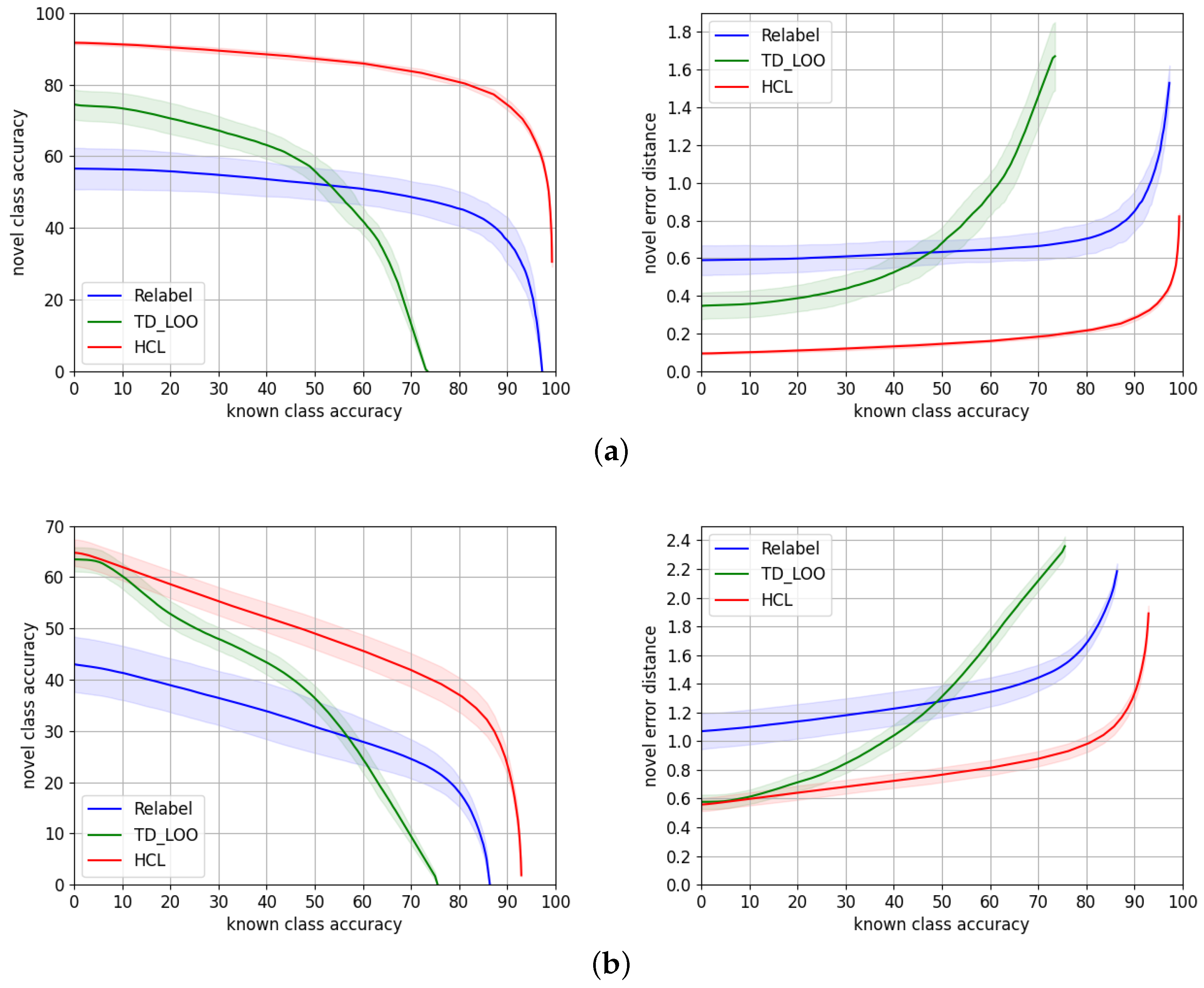
Table 4 reports the average metrics
for these three training strategies at 50%, 70%, and 80% known accuracy points, while the performance through the entire range is depicted in
Figure 6.
The gap of performance on both datasets between using features from a network only trained on Imagenet, and features fine-tuned to the target dataset, justifies the need of performing such fine-tuning, especially because, in a traffic sign recognition application, we aim to maximize the novel accuracy at the highest known accuracy range.
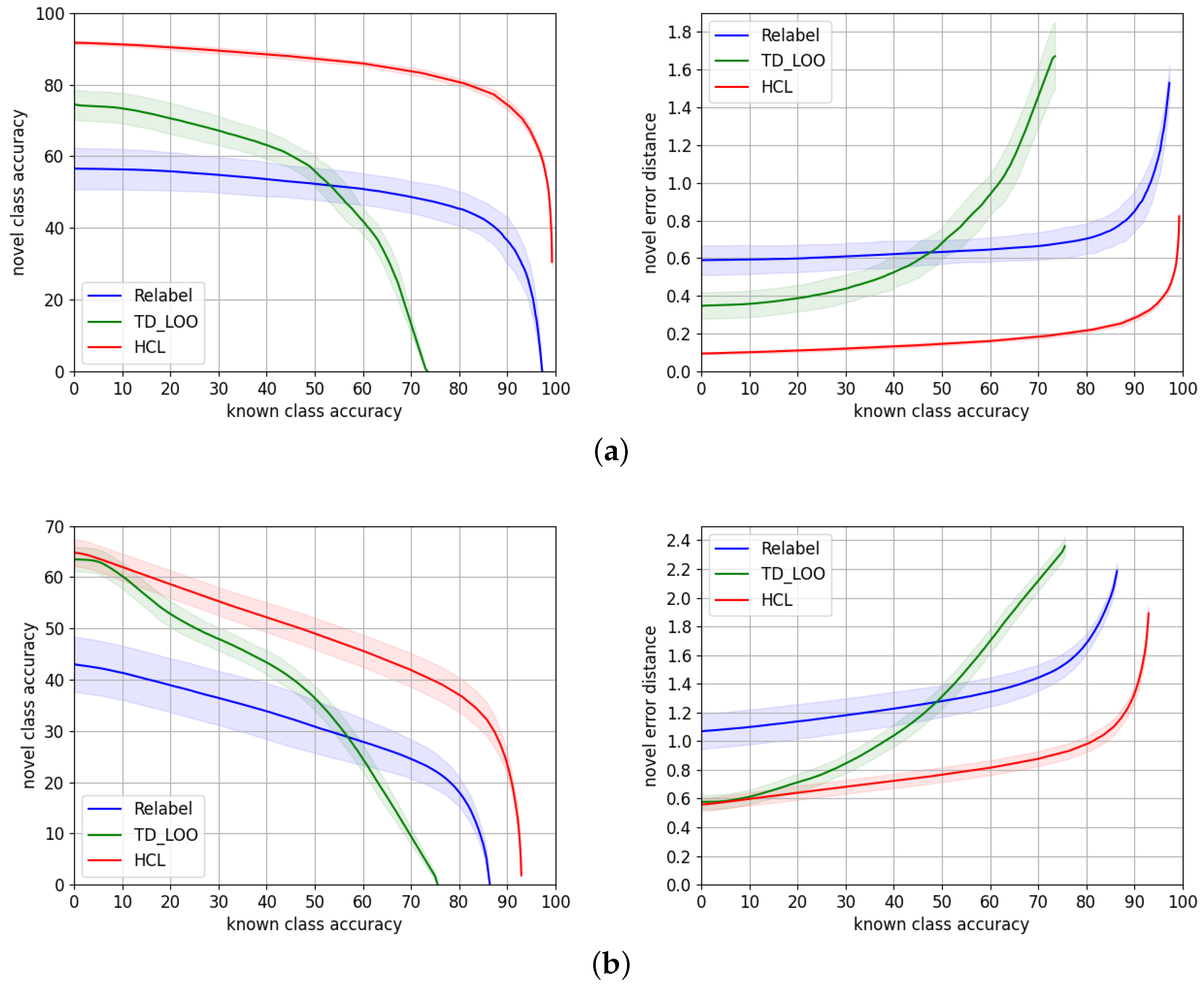
On TT100K, training HCL on top of fine-tuned features works significantly better than training jointly HCL and the ResNet-101 backbone. This is probably because fine-tuning on TT100K is overfitting the dataset, which has few samples of a very specific kind of data (traffic signs). Then, training HCL from high quality features as a starting point is much easier than jointly learning suitable features along with proper class prototypes that are consistent with the taxonomy.
However,
MTSD is a much larger dataset with a greater number of classes with higher inter and intra-class variability, as discussed in
Section 4.2. The gap of performance in this case is therefore smaller. The accuracy curve overlaps for almost the entire range, although the gap in error distance is consistent. This means for a very similar number of correct predictions, and the errors of the wrong predictions are smaller when we use fine-tuned features, presumably because these fine-tuned features allow for doing a more precise classification of novel samples. The reason might be learning two objectives, i.e., class
prototypes and suitable features, is a more challenging task than only learning the
prototypes with a fixed set of features. This involves a less noisy signal to learn from, since features are not being updated during training. This effect that also occurred on TT100K at a smaller scale is magnified with larger datasets with high intra-class variability, as in this case.
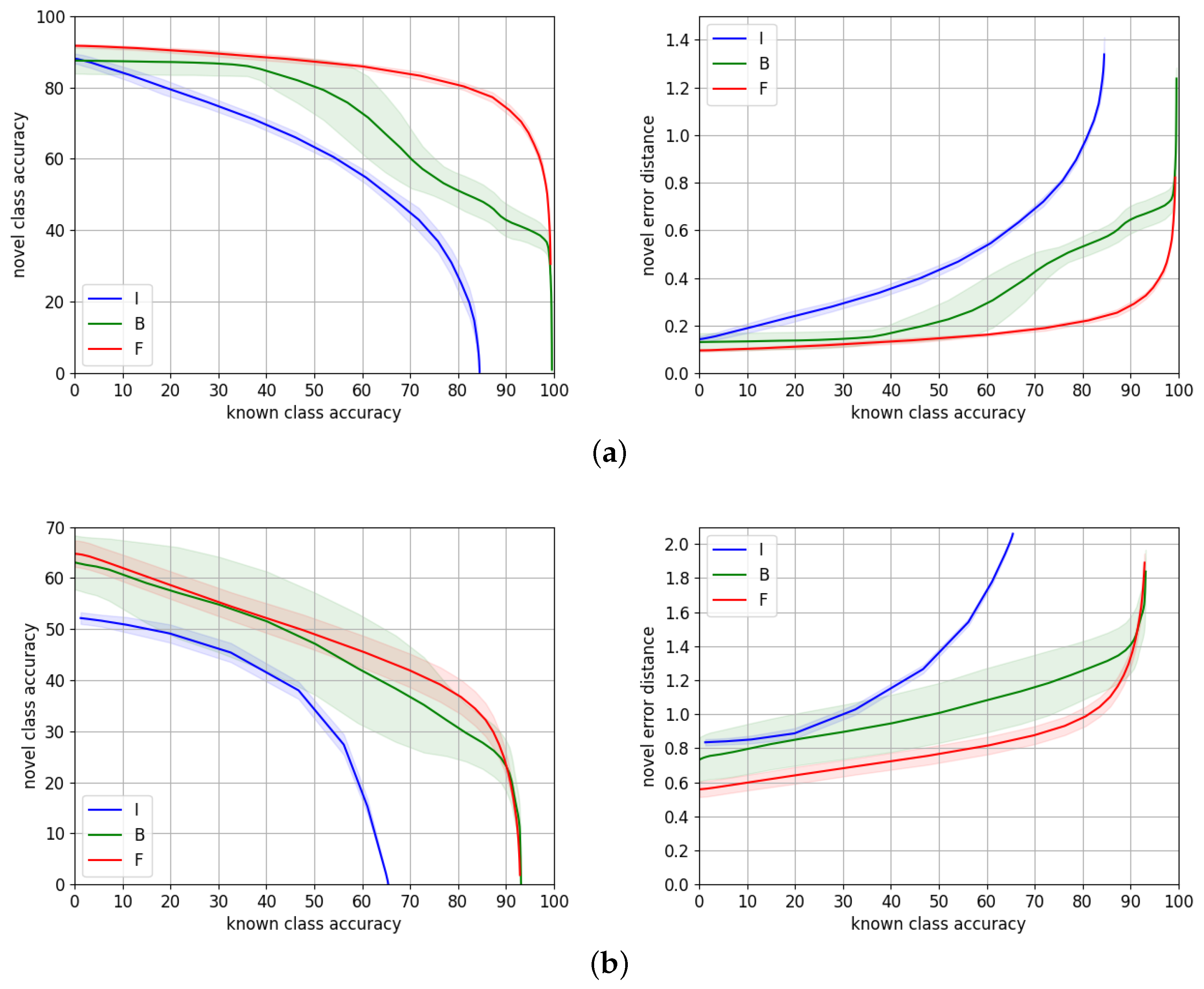
As expected, the variability of the experiments when we train the backbone is higher than when we only train HCL, for both datasets. This is due to the additional variability introduced by training ResNet-101.
To conclude, our proposed approach, HCL, reaches its highest performance when trained from features fine-tuned to the target dataset. It is able to predict correctly 75% and 24% of novel samples, for TT100K and MTSD, respectively, when we predict known samples with 90% accuracy. It also predicts novel samples with an accuracy of 81% and 36% at 80% known accuracy for TT100K and MTSD, respectively.
6.3. Ablation Study of Hierarchical Cosine Loss
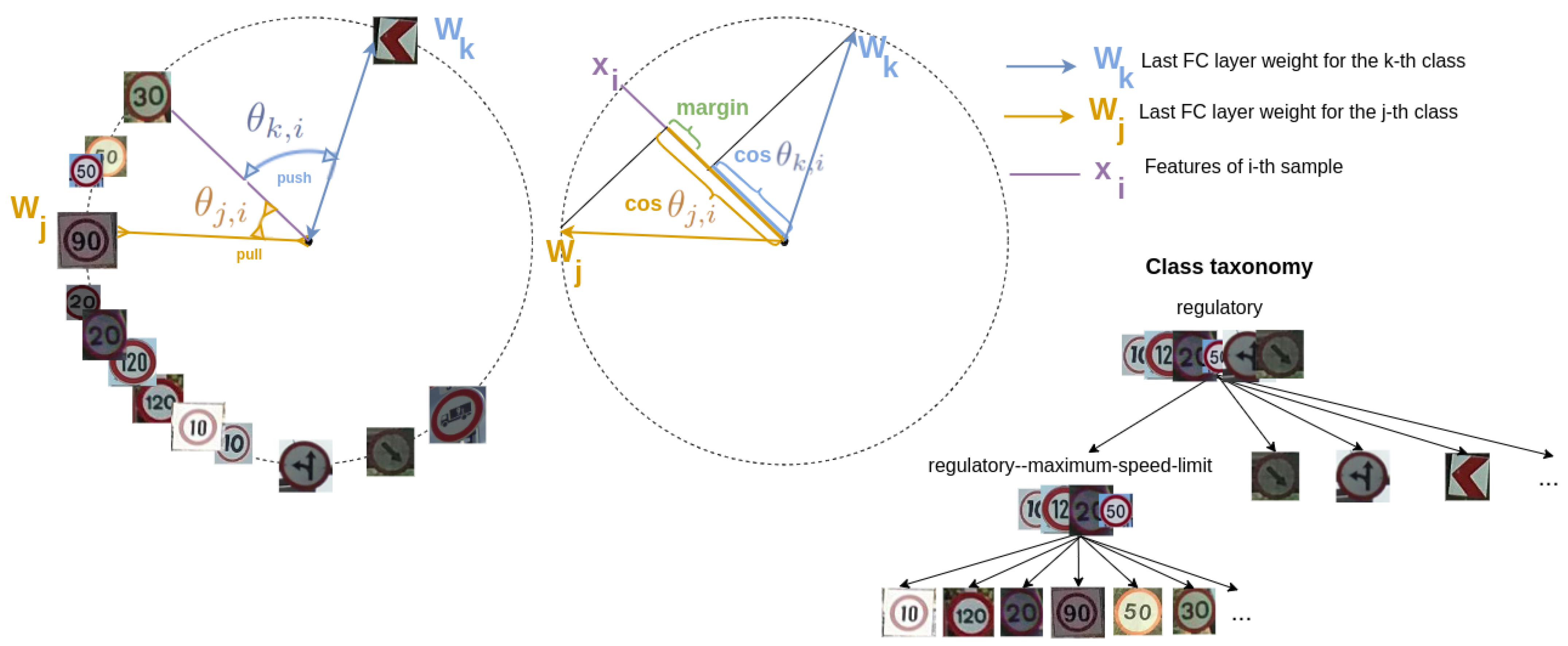
In order to analyze the individual contribution of the terms of HCL (Equation (
1)), we conduct the following ablation study. We take as a baseline the contribution of only the Normalized Softmax loss (NSL)
, then adding the contribution of the remaining terms that will be finally compared to an experiment in which all the terms contribute to the training. The latter is the best performing HCL experiment, according to the validation set. We train the terms of HCL over a set of constant features, fine-tuned to the target dataset. These fine-tuned features correspond to those used in the previous experiments. Note that this independent training of HCL allows for isolating the effect of the loss. Otherwise, training jointly the backbone and HCL would introduce a variability that would mask the actual variation of the individual loss terms.
In
Table 5, we assess the individual performance of the different terms of HCL, defined in
Section 3.2, on features fine-tuned to MTSD or TT100K. For each dataset, the first row shows, as a baseline, the metrics when we set the HCL regularization parameters to
, i.e., we train using only the NSL
. In the experiments of the next rows, we keep
and add the different terms on each experiment, e.g., the second row corresponds to
where only the NSL
and Hierarchical Centers term
are contributing to the training. Similarly, the third row corresponds to the experiments where we use only the
and
terms with regularization parameters
, and in the fourth row we train using
and
regularized by
. The last row, where
, reports the performance of the full version of HCL, including all the terms. Despite the NSL weight
always being set to 1, we made sure its contribution to the loss was not leading the training, i.e., the loss that is being analyzed individually at each case is not being neglected and actually contributes to the training. That is, we made sure that the weights applied to the individual terms were appropriate to show the individual effect of the loss terms. Each training variant has been repeated 10 times, and we report an error of
on
Table 5.
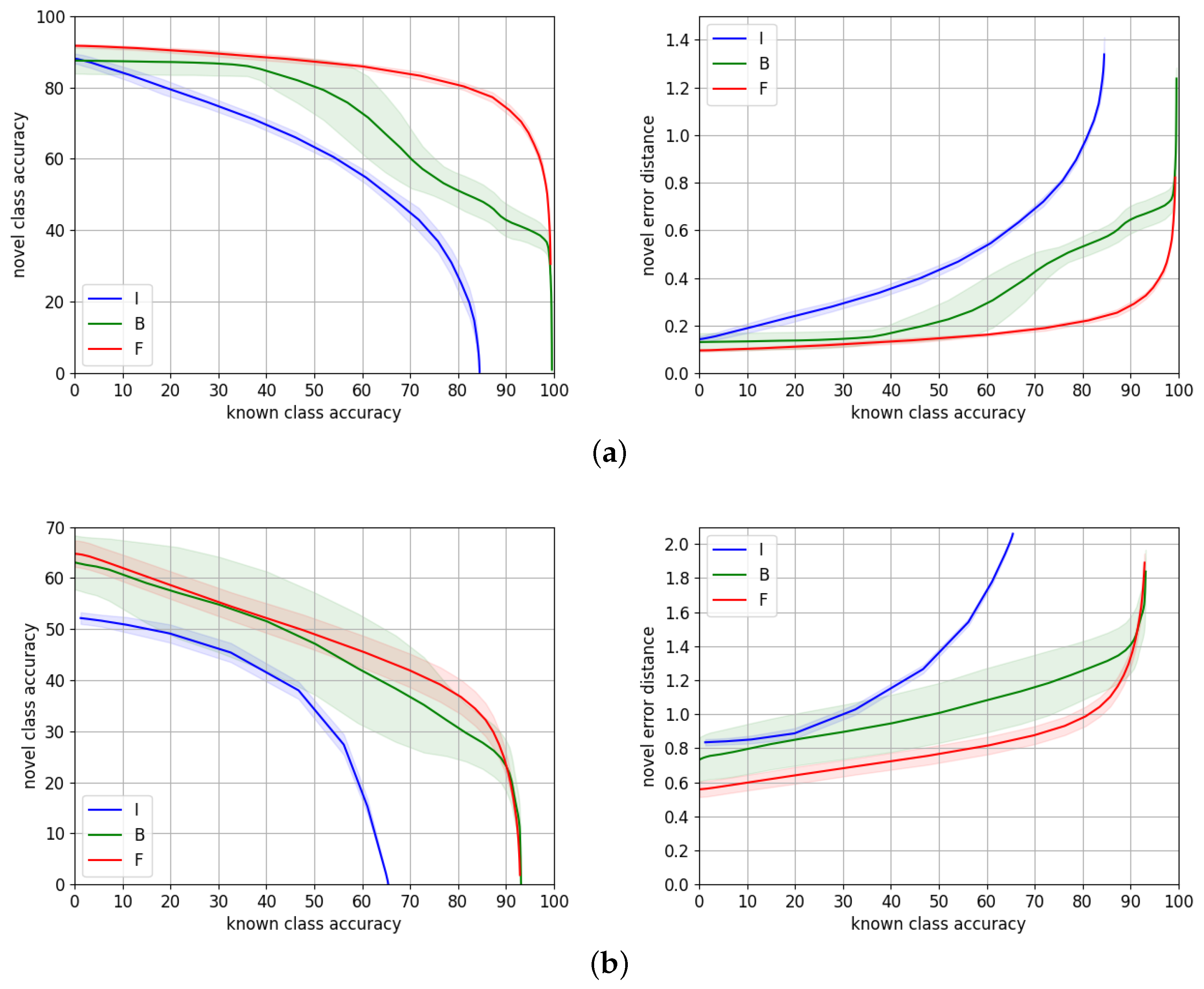
For TT100K, the first experiment, in which we only use the NSL , obtains the best average metrics among the compared variants. However, the difference of performance is very small. In fact, if we take into account the variability of the experiments, we could consider all the variants to perform similarly. The cause of this result might be that the performance on this dataset is so good that it reaches a limit that is hard to surpass. Making small modifications on the loss is not translated into a significant change in performance. In this scenario, making even very small improvements is not straightforward, and it would probably mean it is overfitting the dataset.
The results on MTSD are more enlightening; it is a more challenging dataset, closer to a real-life scenario. Using the different terms of HCL always improves the average novel accuracy at 70% and 80% known accuracies w.r.t. the NSL baseline. The variant that performs best on these metrics is the full version of HCL. The distance error is also decreased for all the variants except for that obtains equivalent performance. The best error distance is achieved by , but as before, if we consider the variability of the results, the differences w.r.t. the full version of HCL are not significant.
A remarkable outcome we can draw from these experiments is that the Hierarchical Triplets term
improves the average metrics at the cost of increasing the variability of the method. This is expected as this constraint introduces different information that depends on the training data. As discussed in
Section 3.2, we make triplets from the batch that is fed to the network. If batches are different, so will the triplets also be. In the case of MTSD, which is a much larger dataset than TT100K, it is possible to make a much larger number of triplets that introduce different information, consequently affecting the training result. This is also applied to the C-triplet term
for the same reason. There are more available pairs of different classes in a larger dataset, therefore affecting the training outcome.
It is also worth mentioning that the variability of is expected to be low due to the kind of experiments we carry. Its cost depends on the angle between class prototypes. Using fixed pre-computed features that are not changing through the training only requires finding the class prototypes. Training the ResNet-101 backbone would also be translated into a higher variability for this term.
In summary, this ablation study shows that the proposed HCL terms can help with improving the performance, as shown in MTSD results. On TT100K, they do not improve the performance of the NSL alone on average because it already reaches a very high value. Some of the HCL terms () have shown to increase the potential performance at the cost of increasing the variability of the results. Triplet mining strategies might help to mitigate this issue.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}