
Integration of Deep Learning Network and Robot Arm System for Rim Defect Inspection Application



Abstract
:1. Introduction
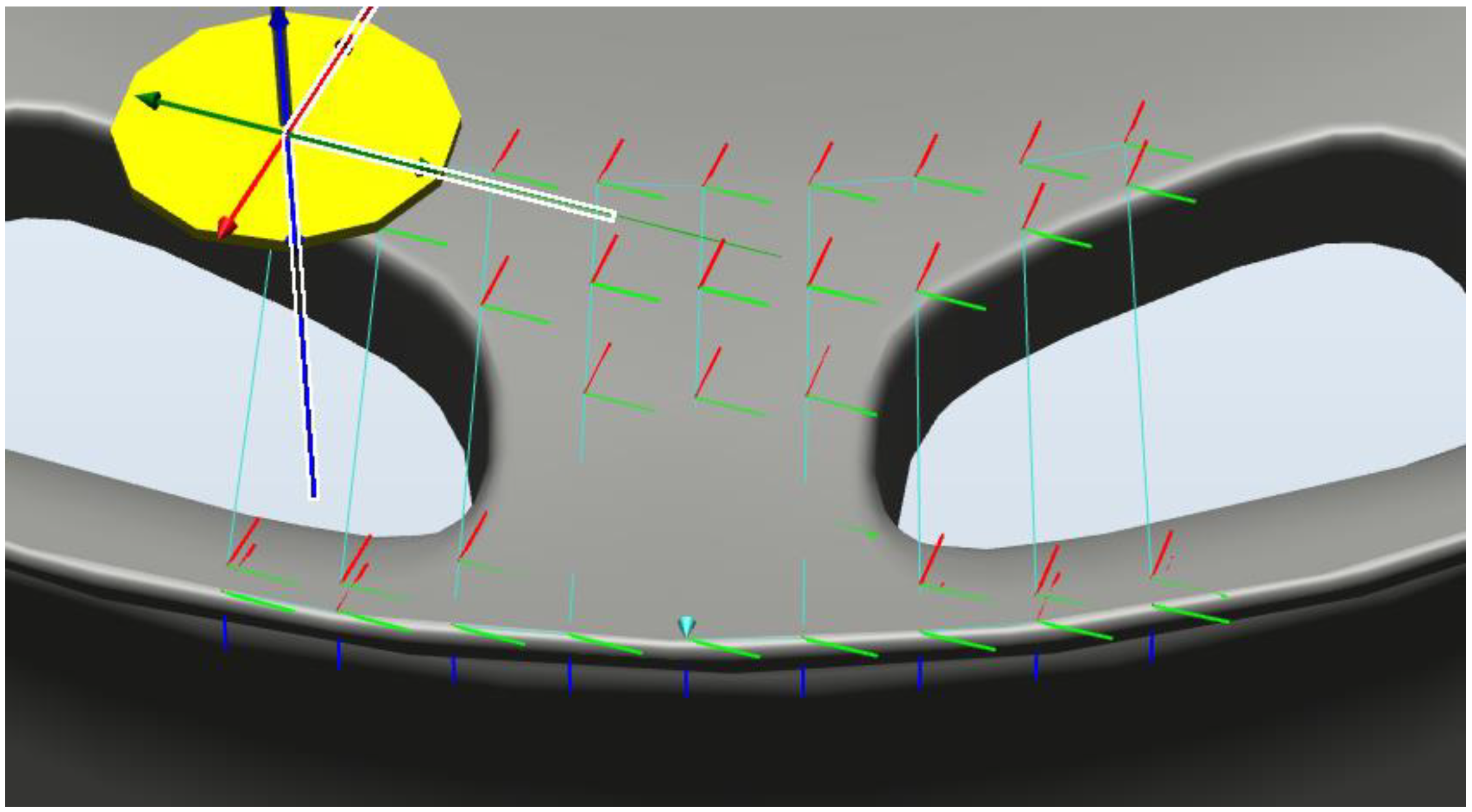
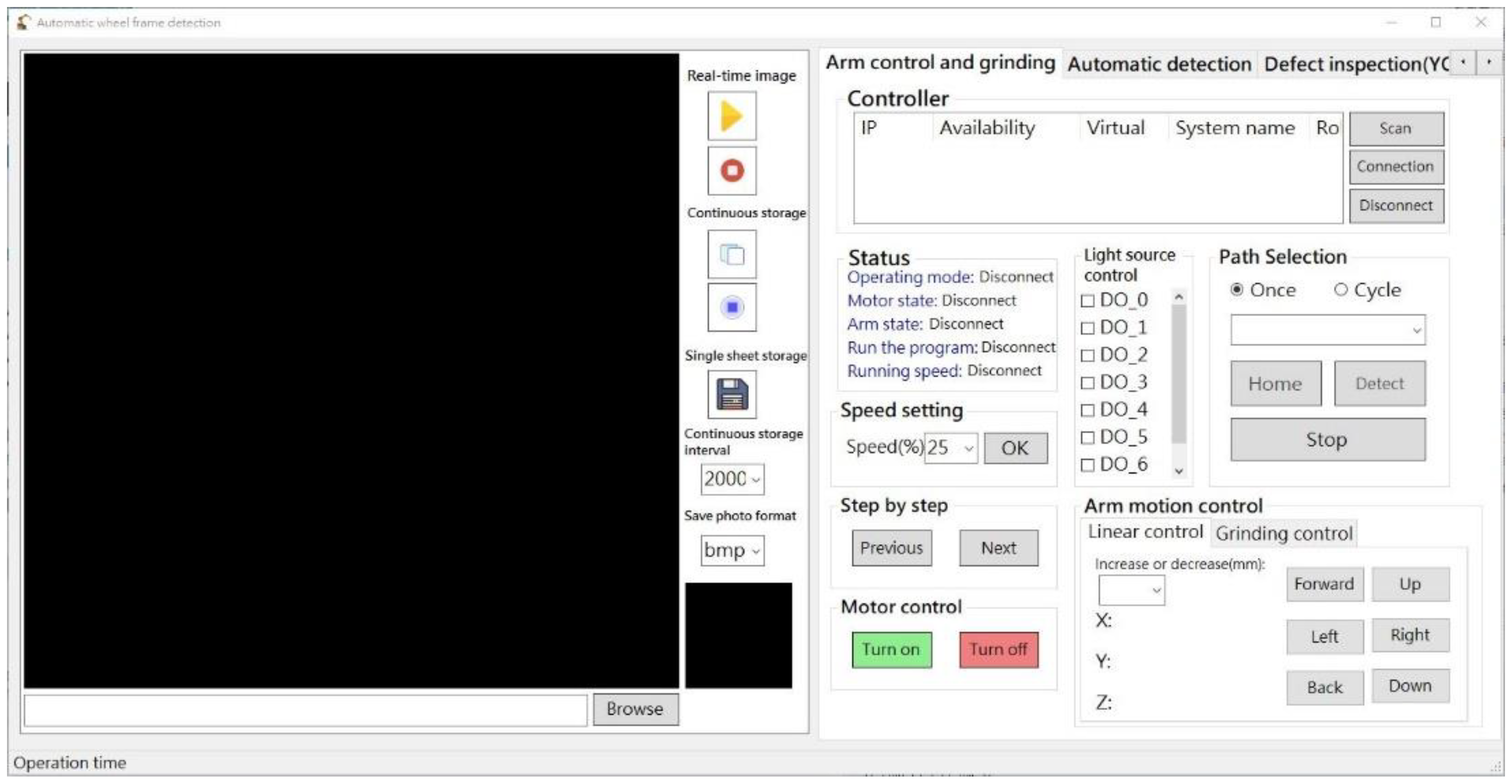
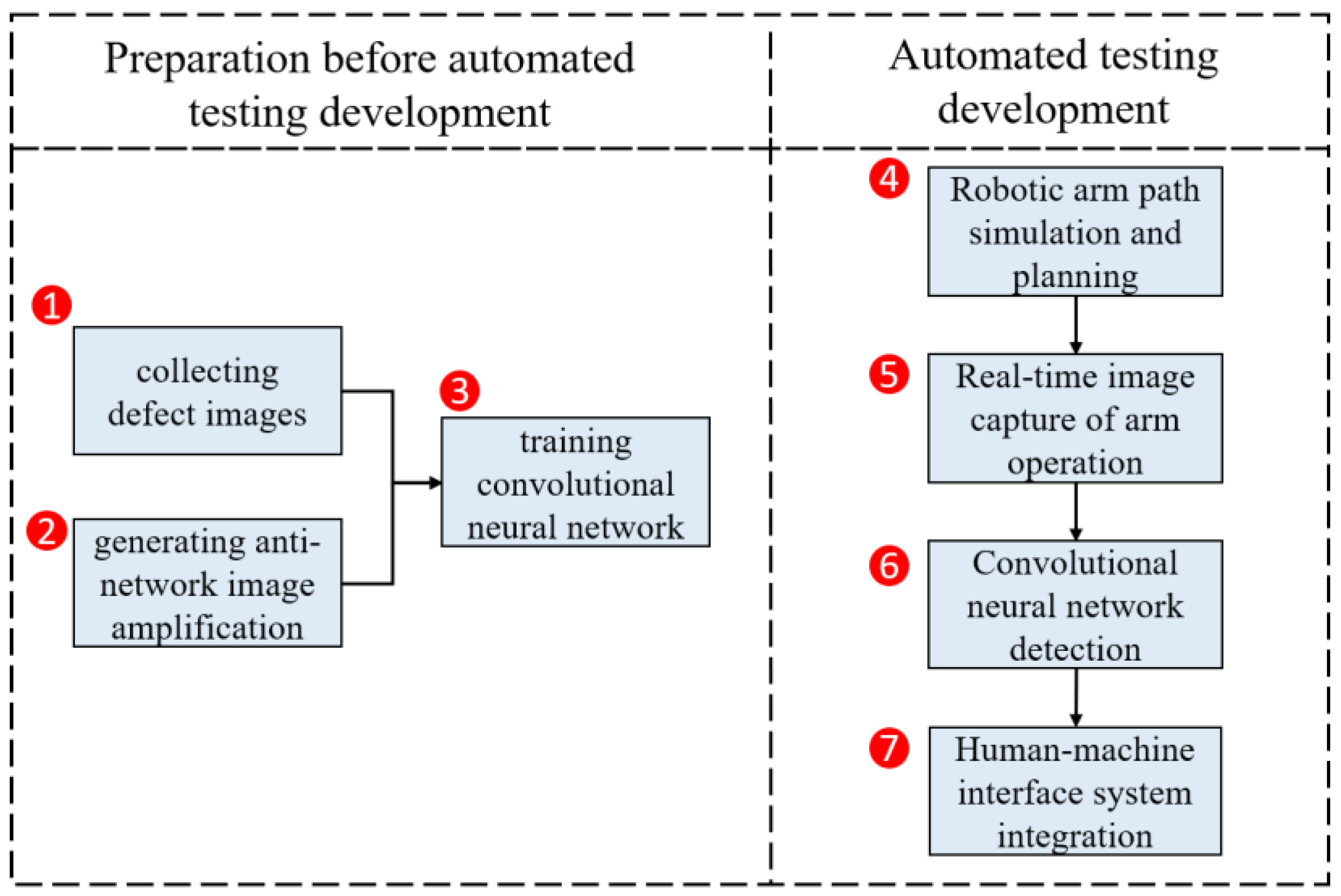
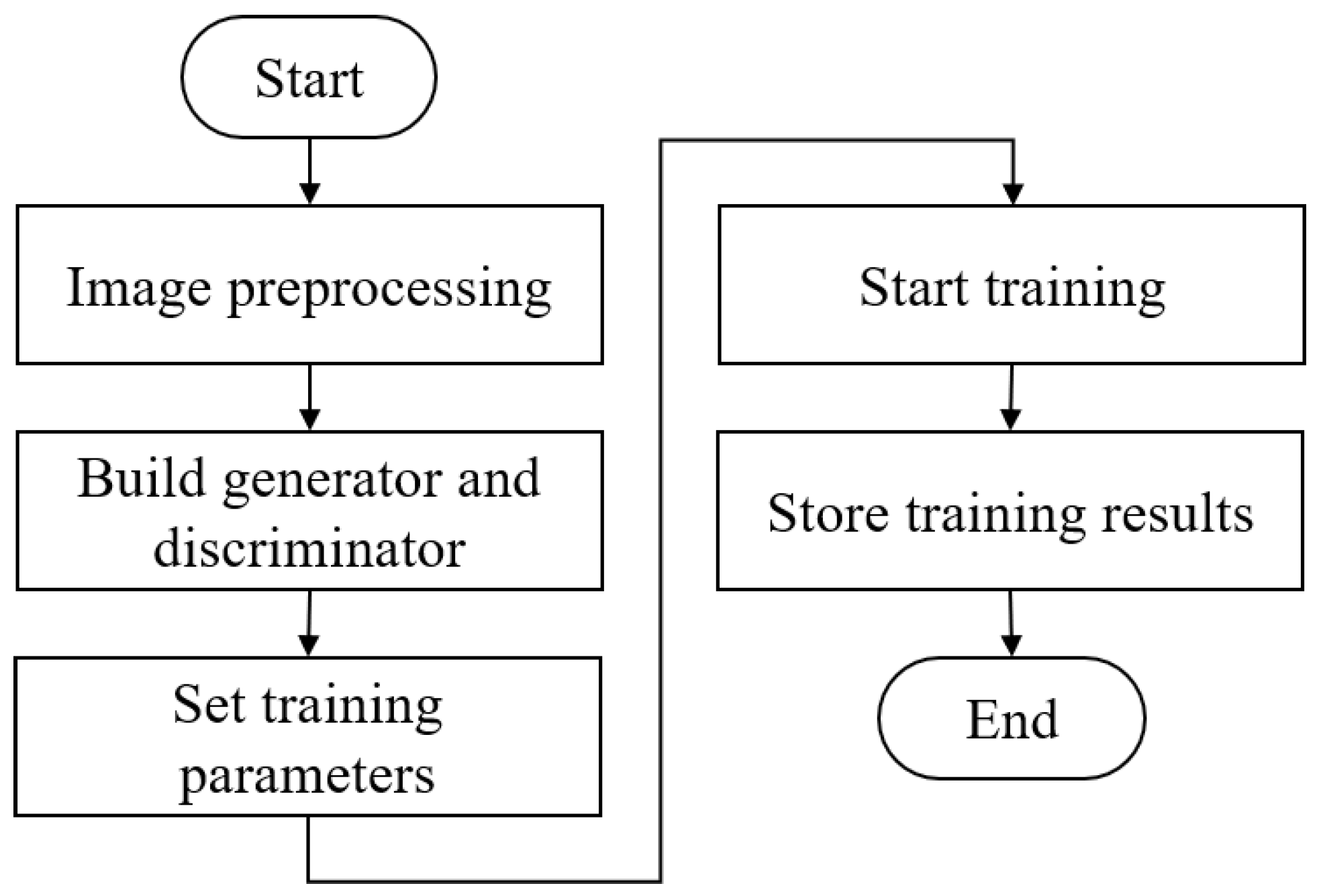
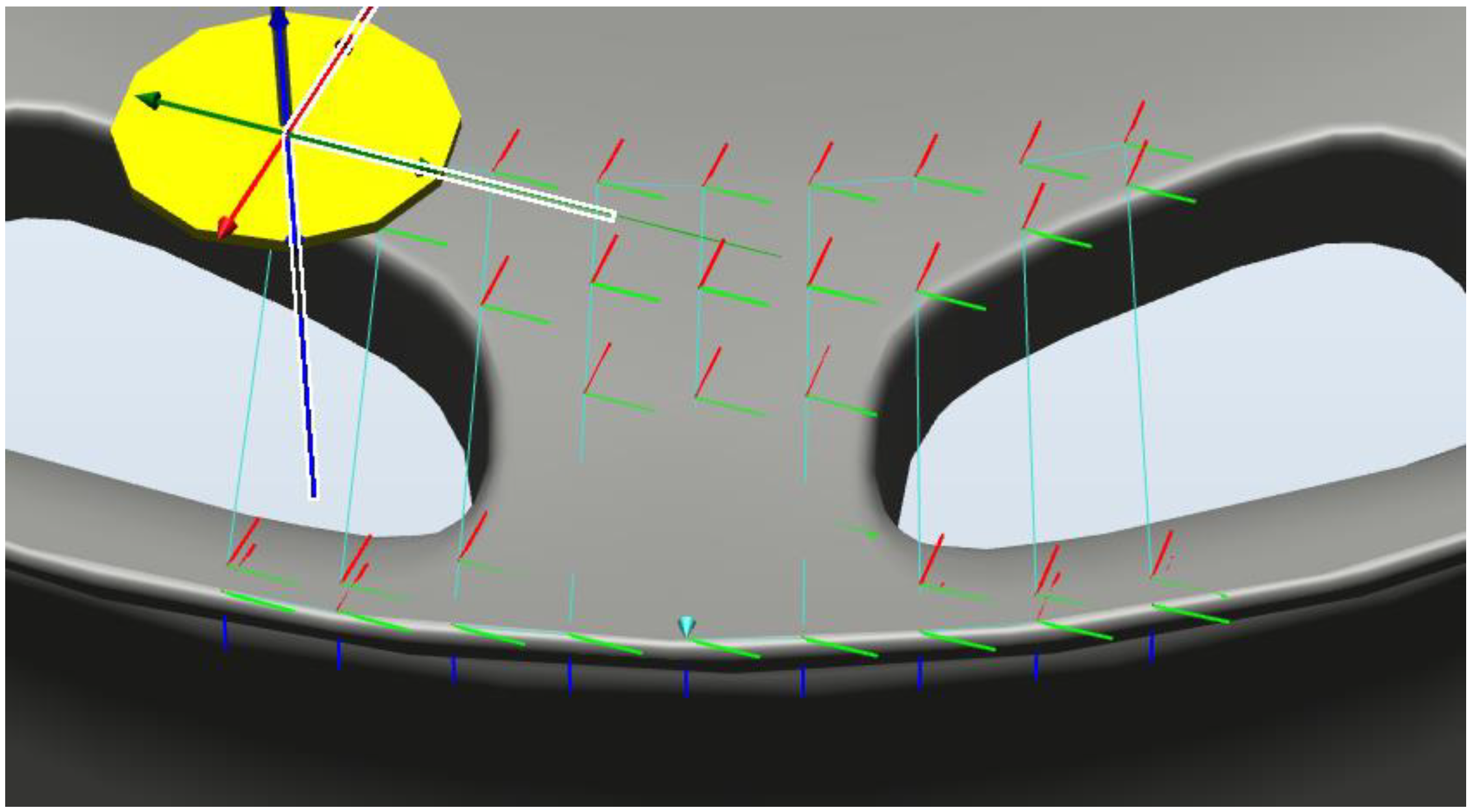
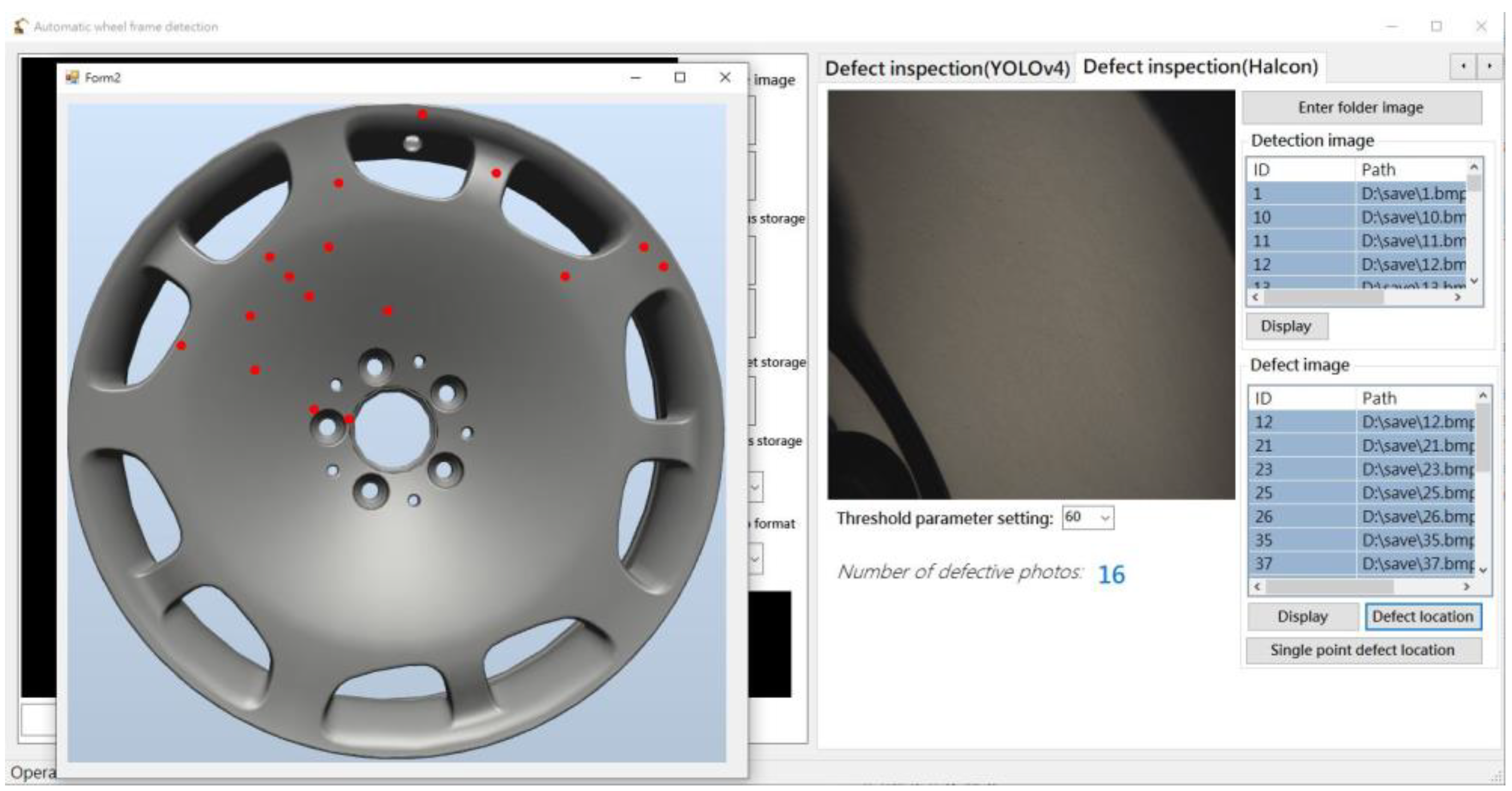
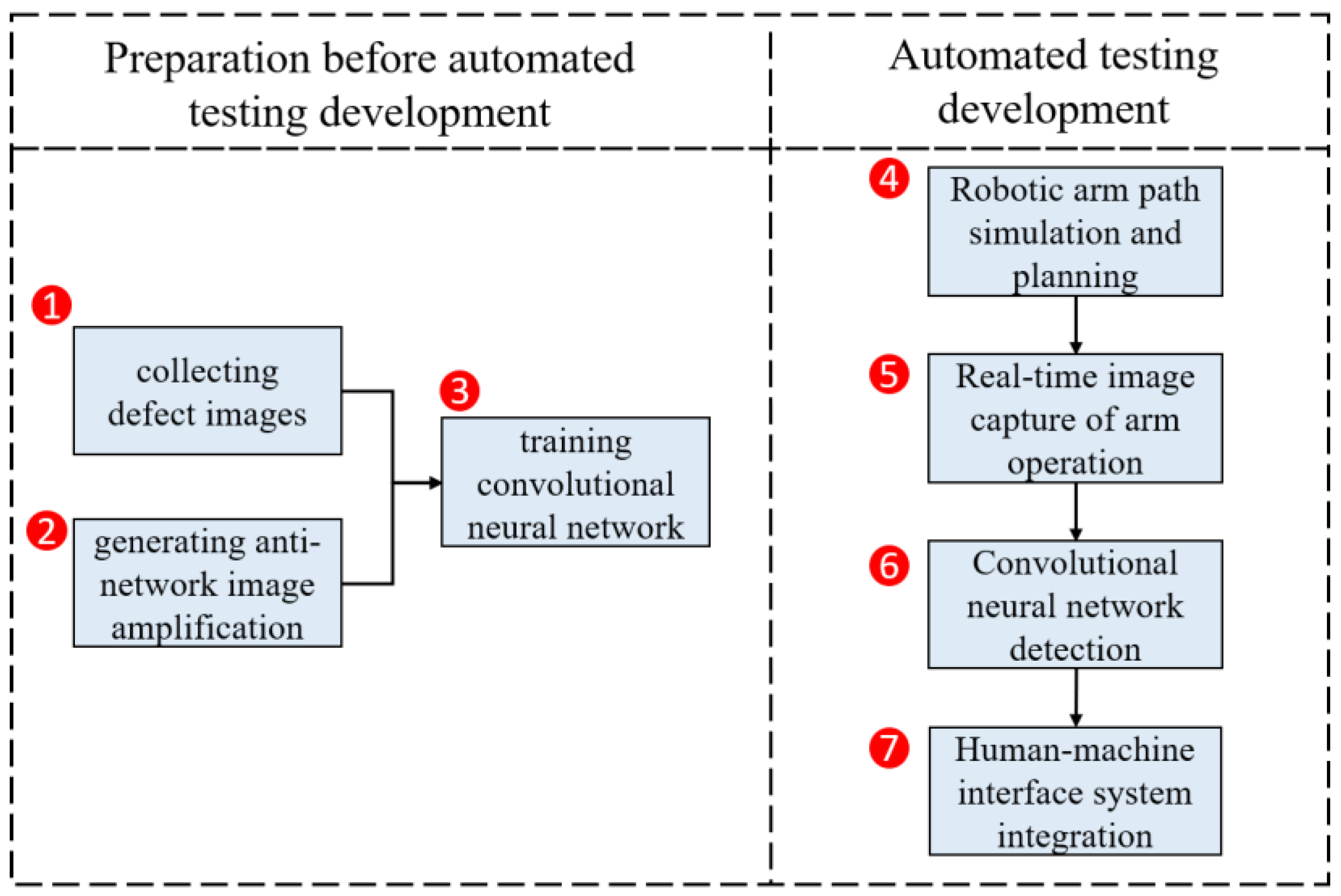
2. System Design
3. Related Works
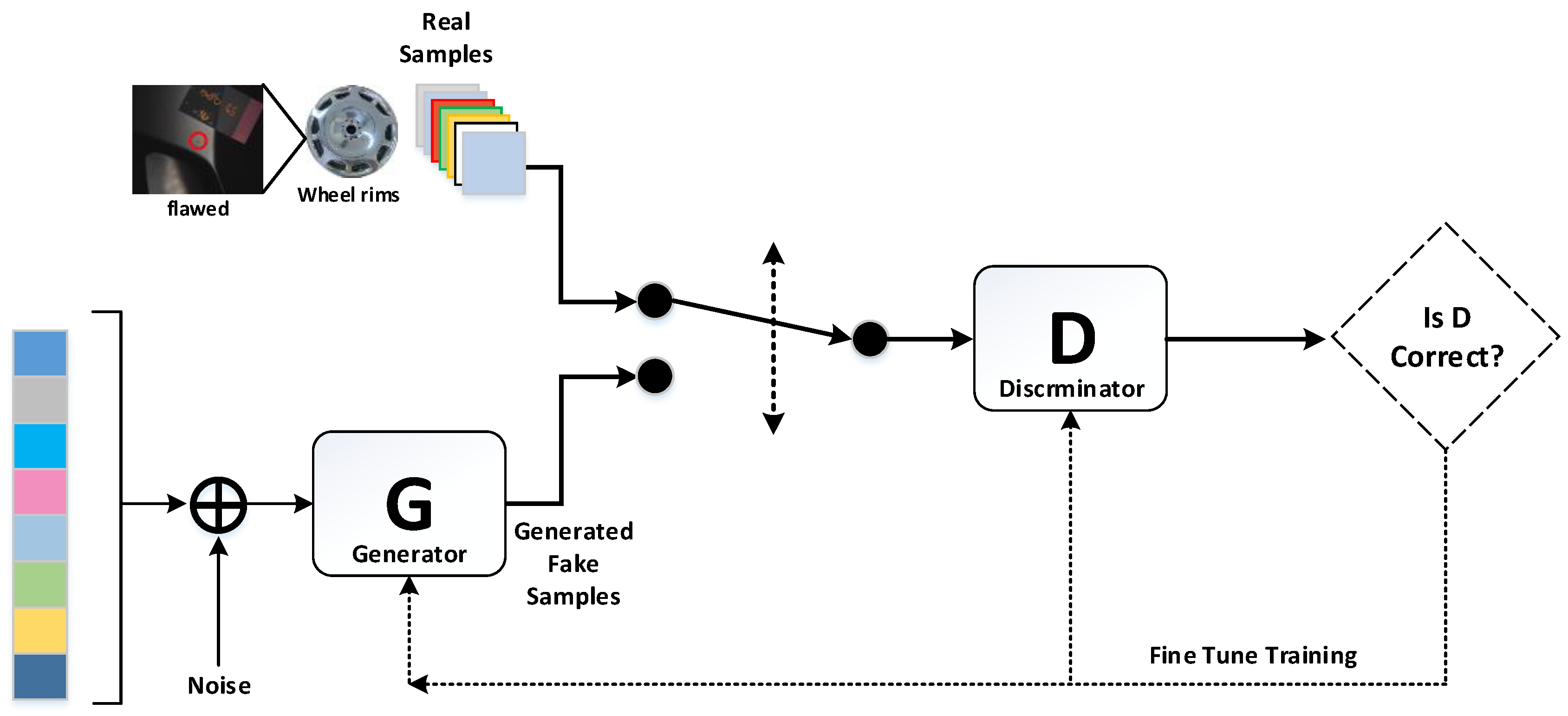
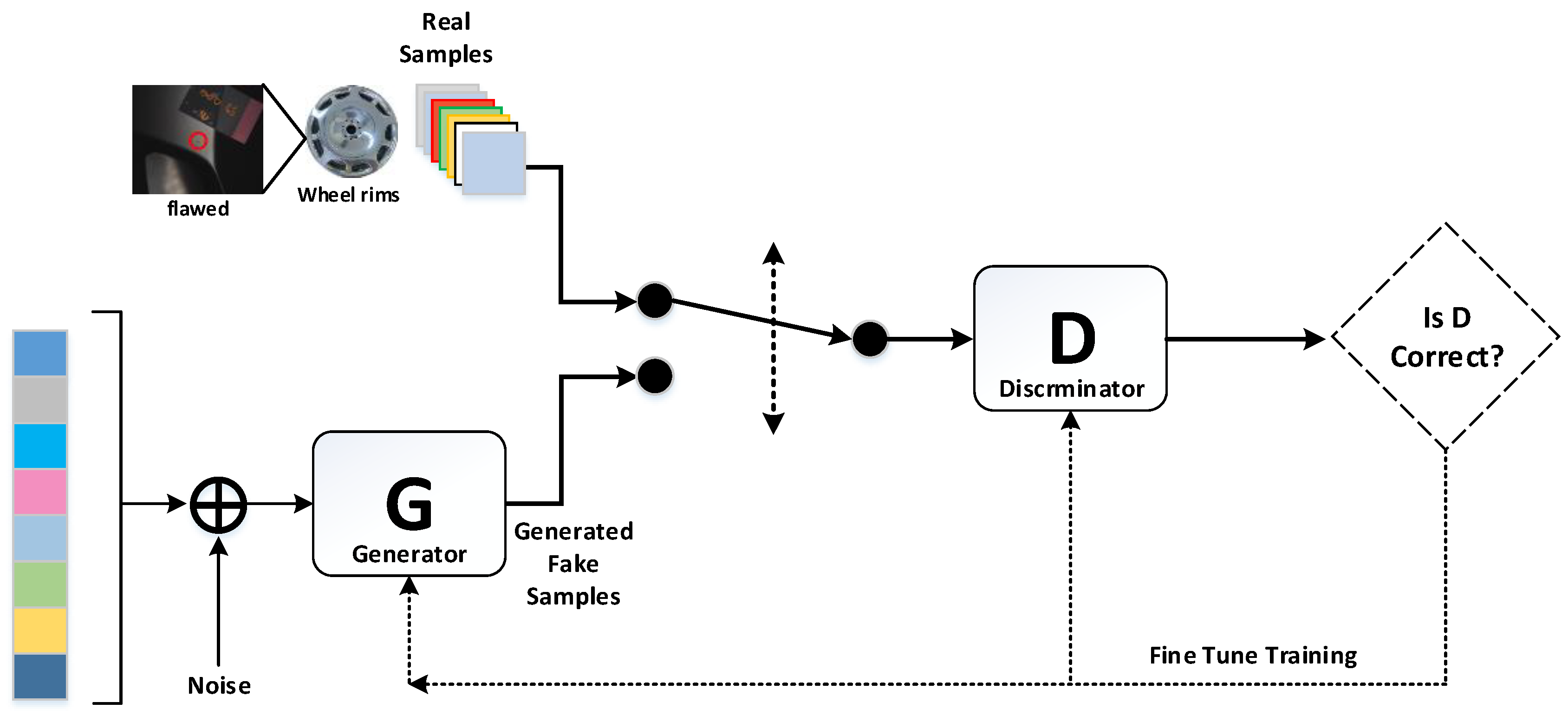
3.1. GAN and DCGAN
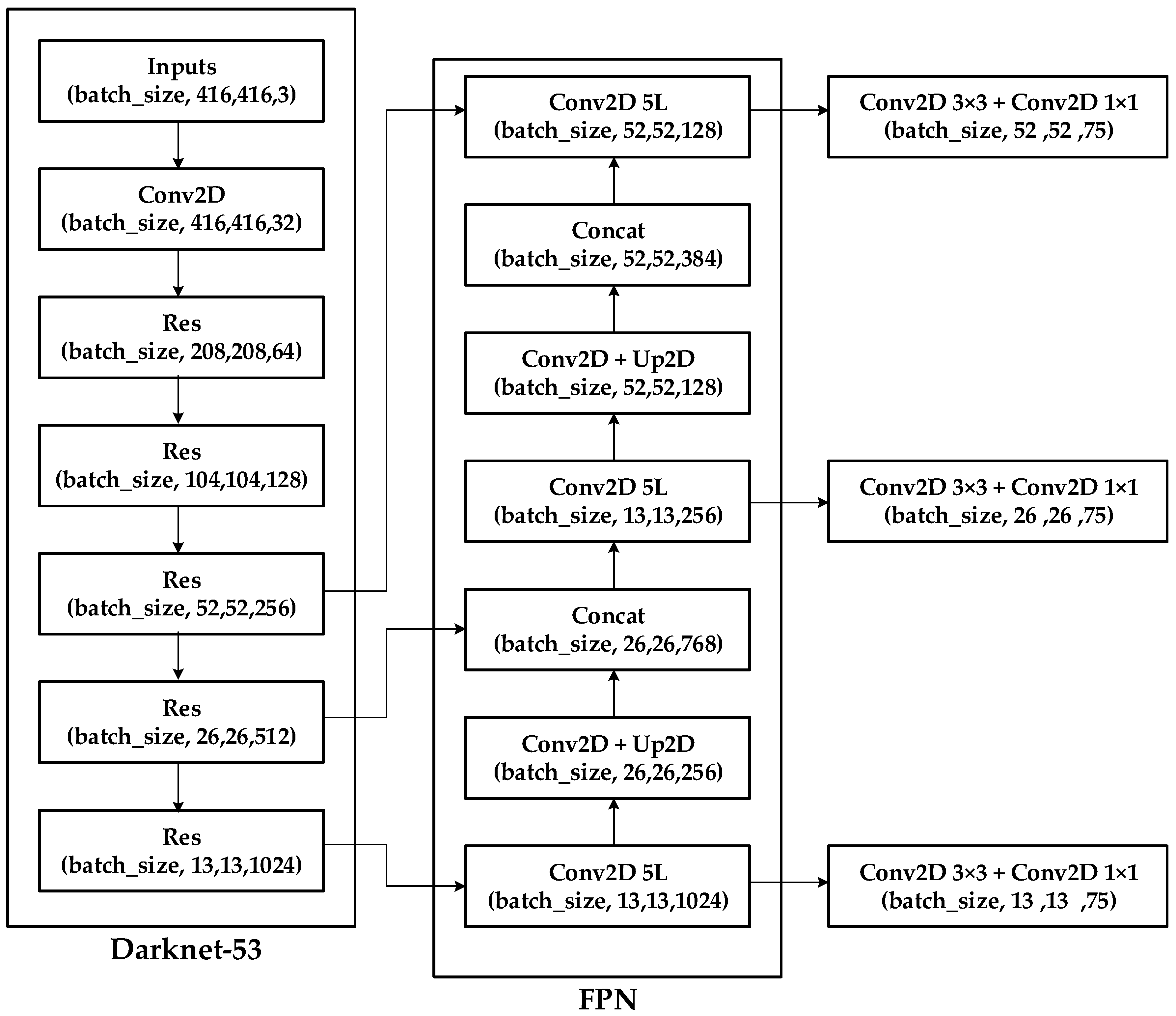
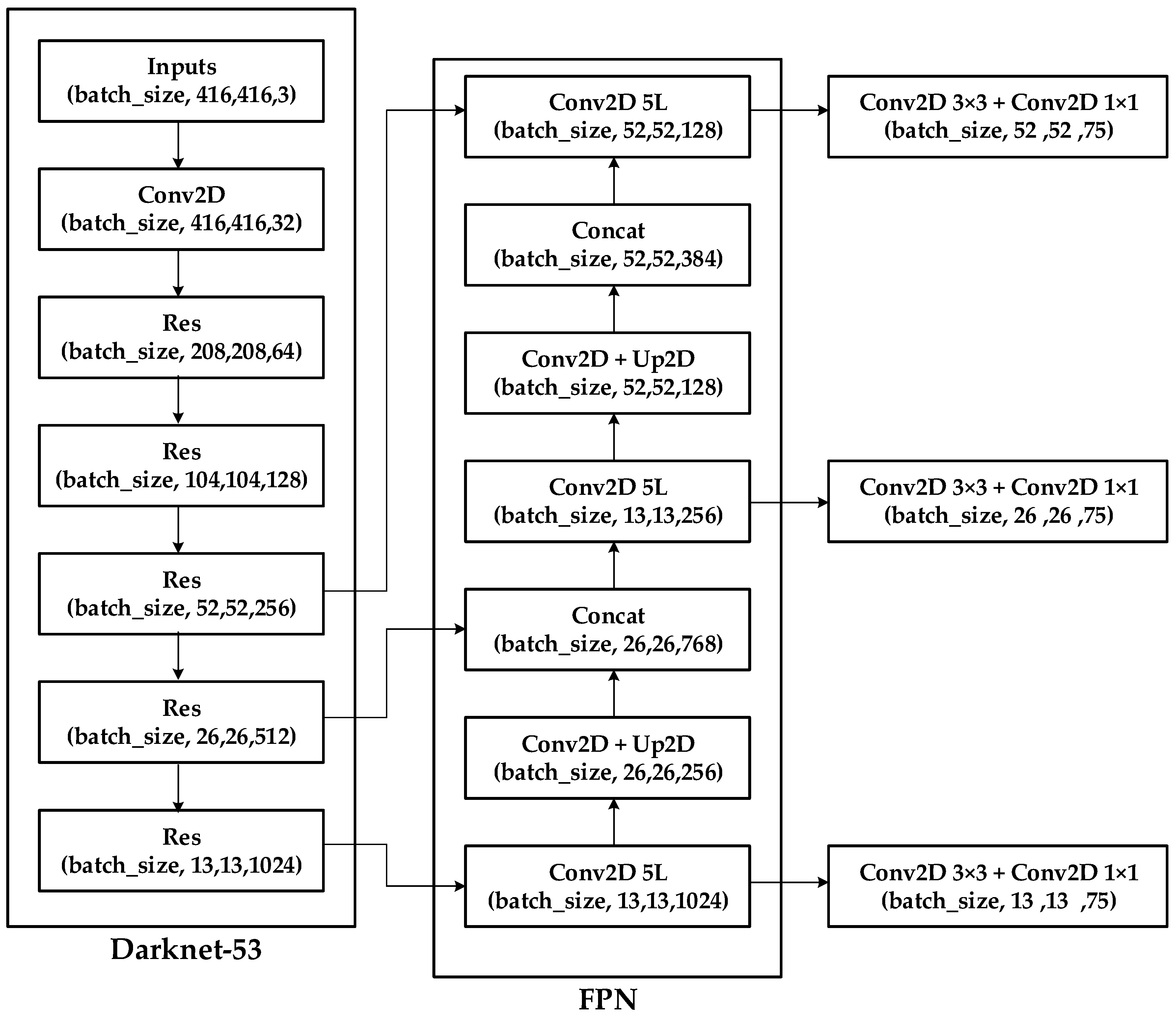
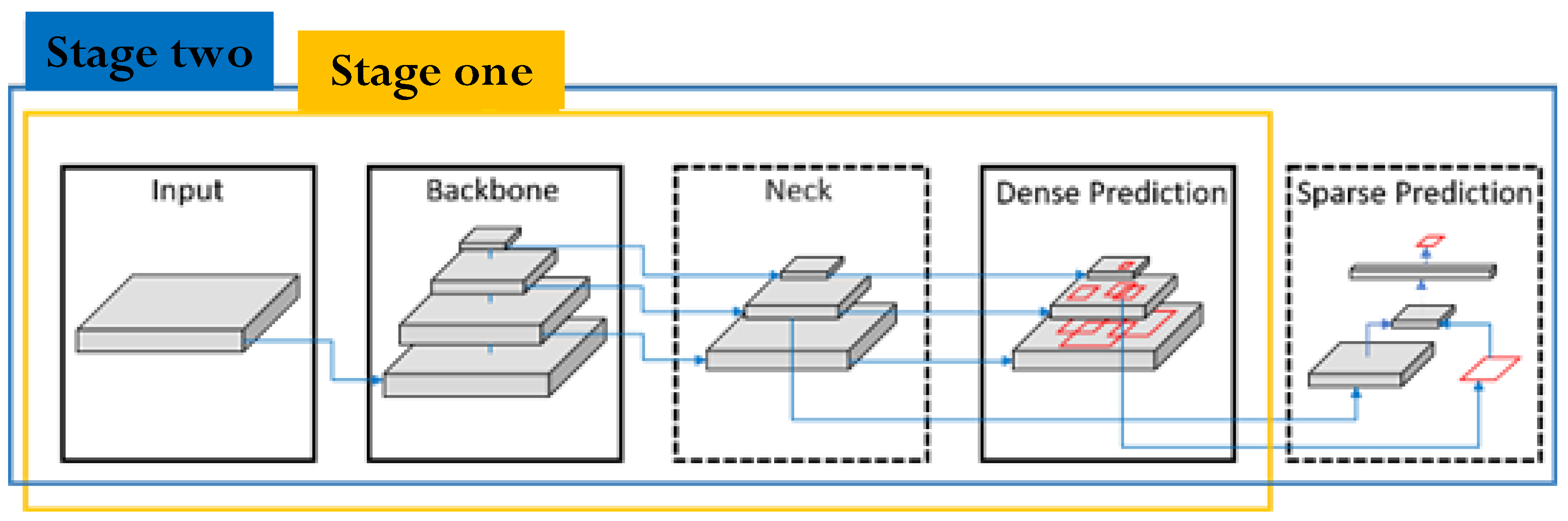
3.2. YOLO v3 and v4
3.2.1. Input
3.2.2. Backbone
3.2.3. Neck
3.2.4. Head
- (1)
- (2)
- BoF for detector: Complete intersection over union loss (CIOU loss) is used to improve convergence accuracy, while cross mini-batch normalization (CmBN) is used to reduce the computational burden, and self-adversarial training (SAT) is used for data enhancement [9], and DropBlock and Mosaic are used for data augmentation.
- (3)
- Bag of Specials (BoS) for backbone: CSPNet is used to improve accuracy and reduce memory usage and implement the Mish activation function and multi-input weighted residual connections (MiWRC).
- (4)
- BoS for detector: A spatial attention module (SAM-block) is used to improve training efficiency in implementing distance intersection over union (DIoU-NMS), the SPP-block, the PAN path-aggregation block, and the Mish activation function.
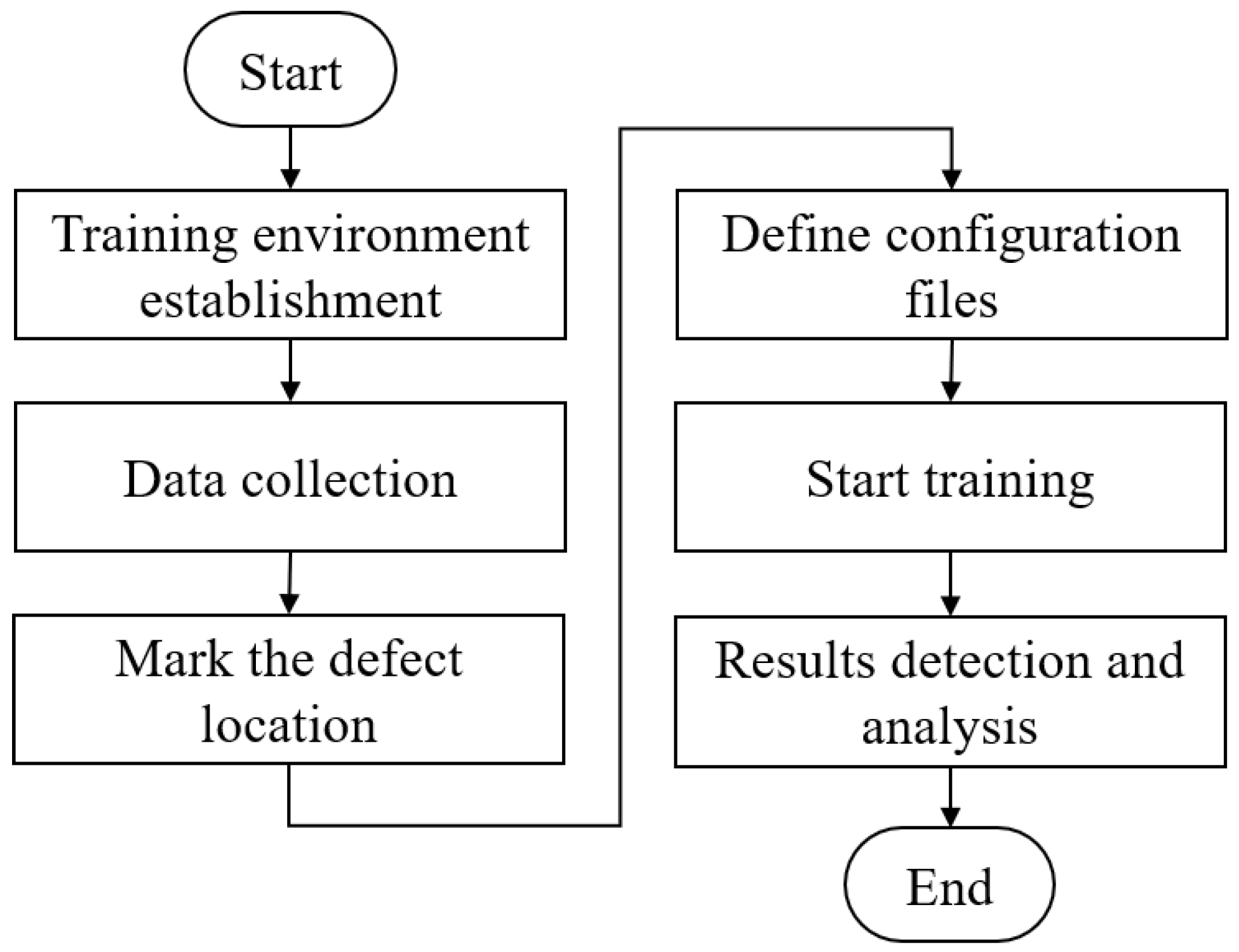
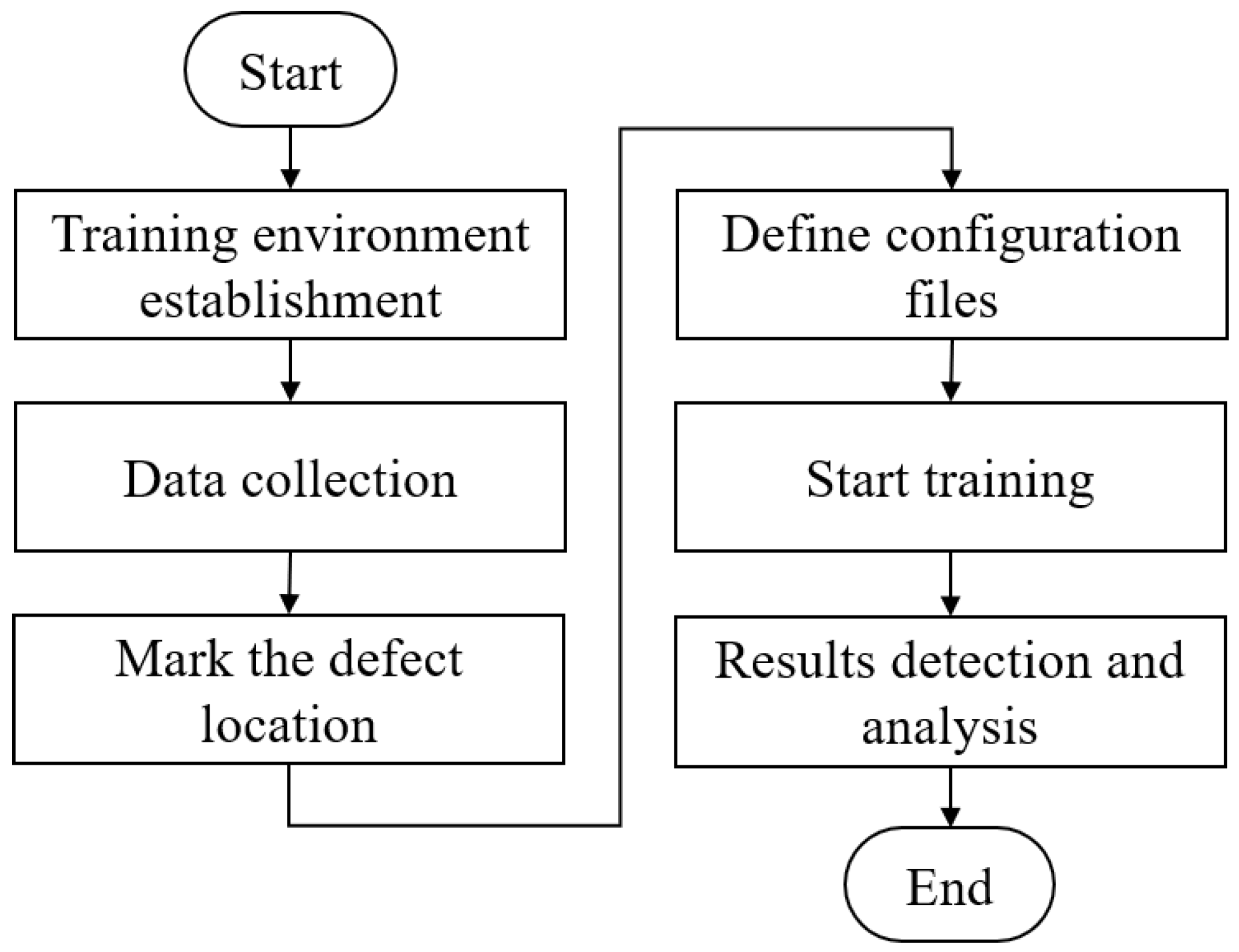
4. Experimental Results
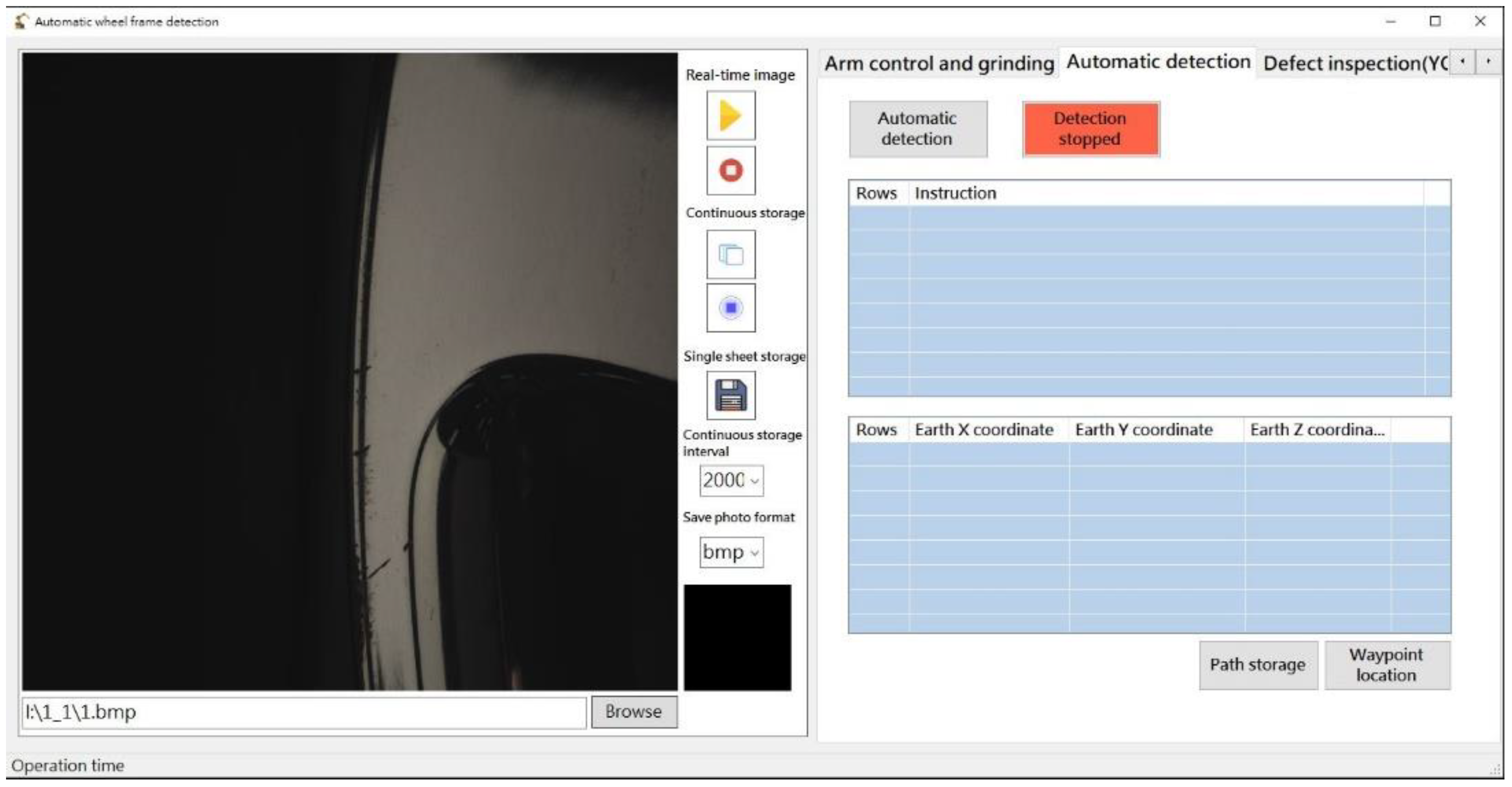
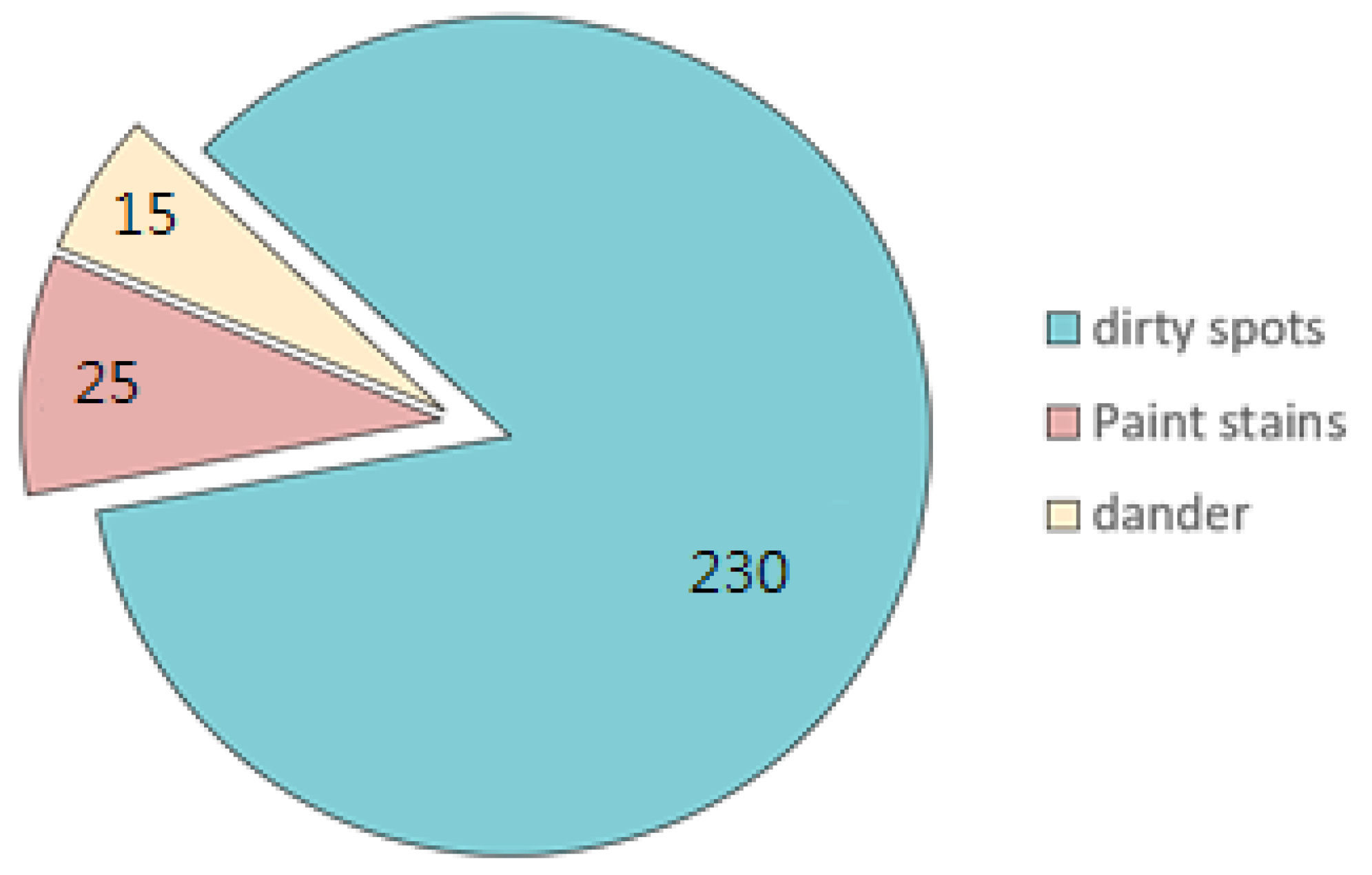
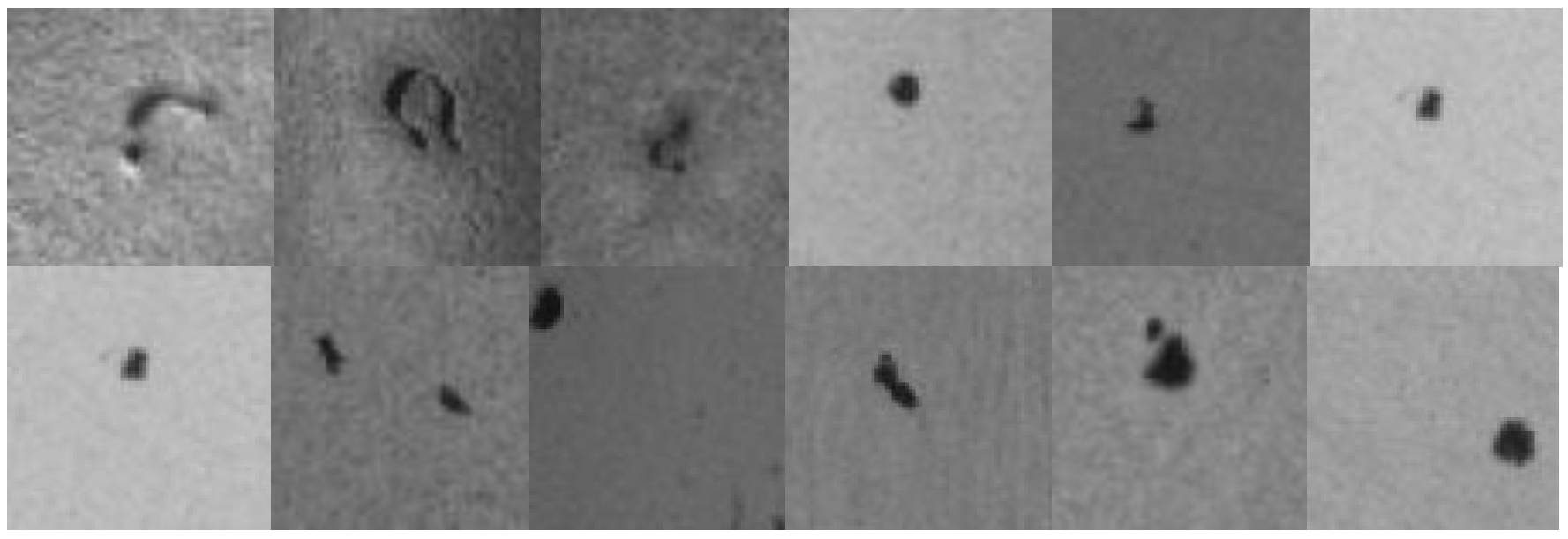
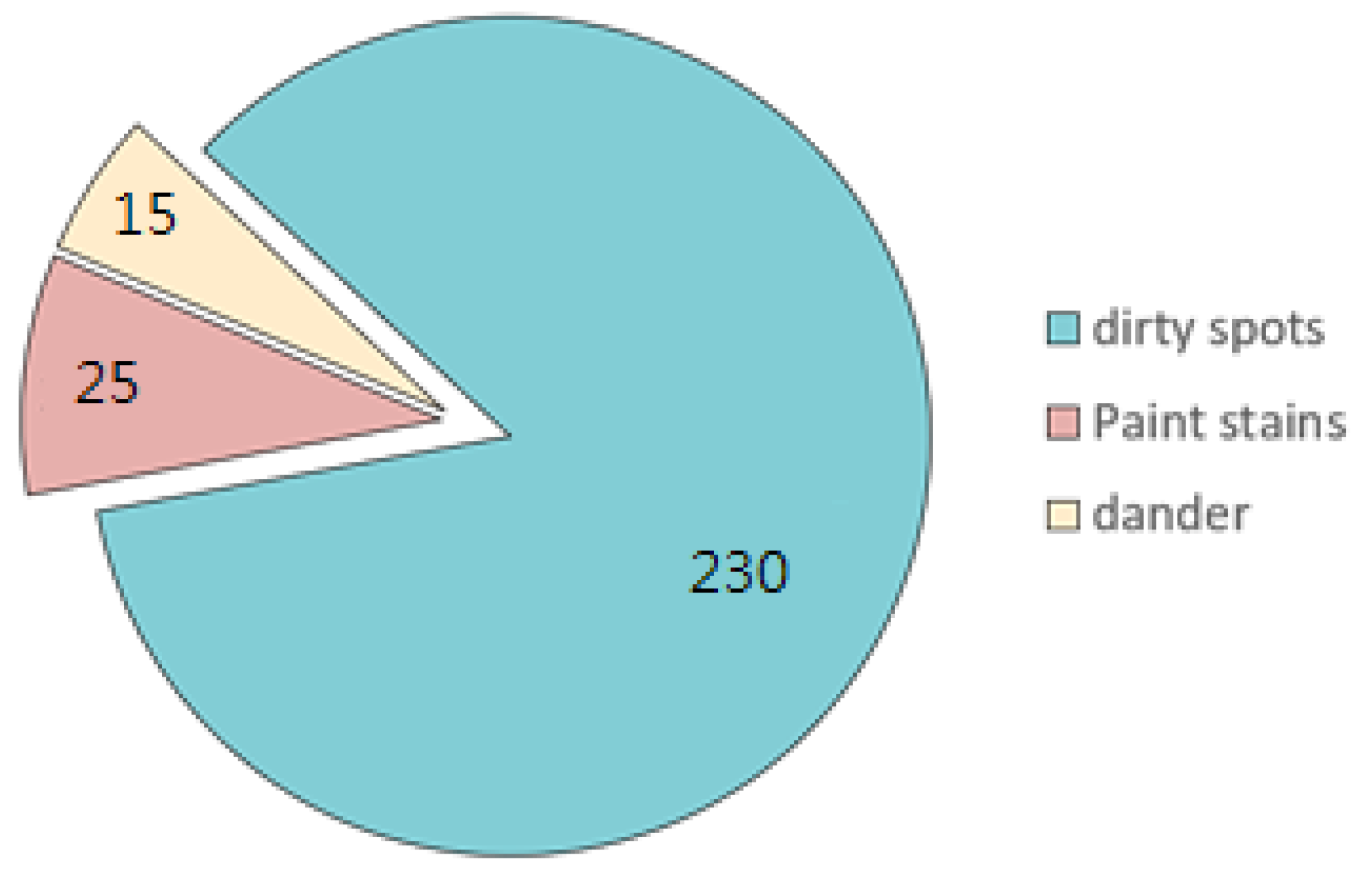
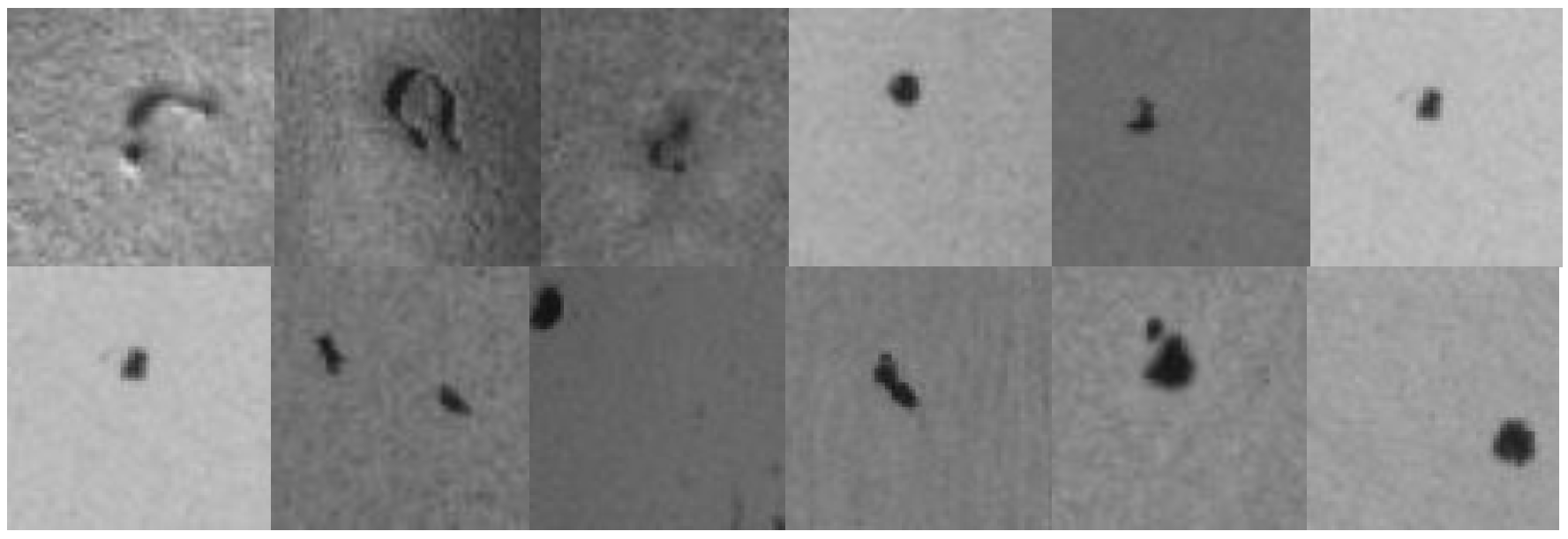
4.1. Collecting a Dataset of Images Showing Manufacturing Flaws
4.2. Image Dataset
4.3. Image Augmentation and Scaling
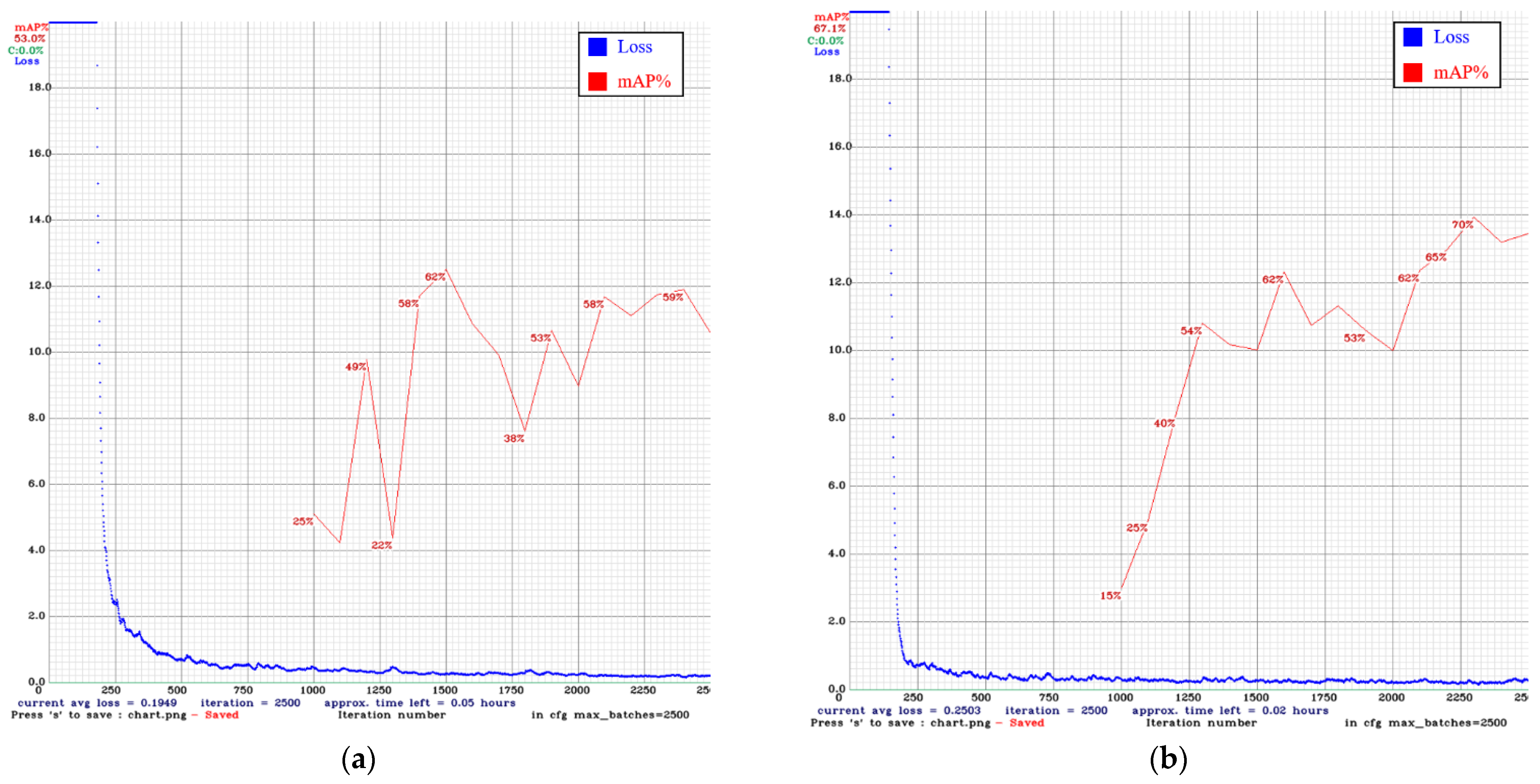
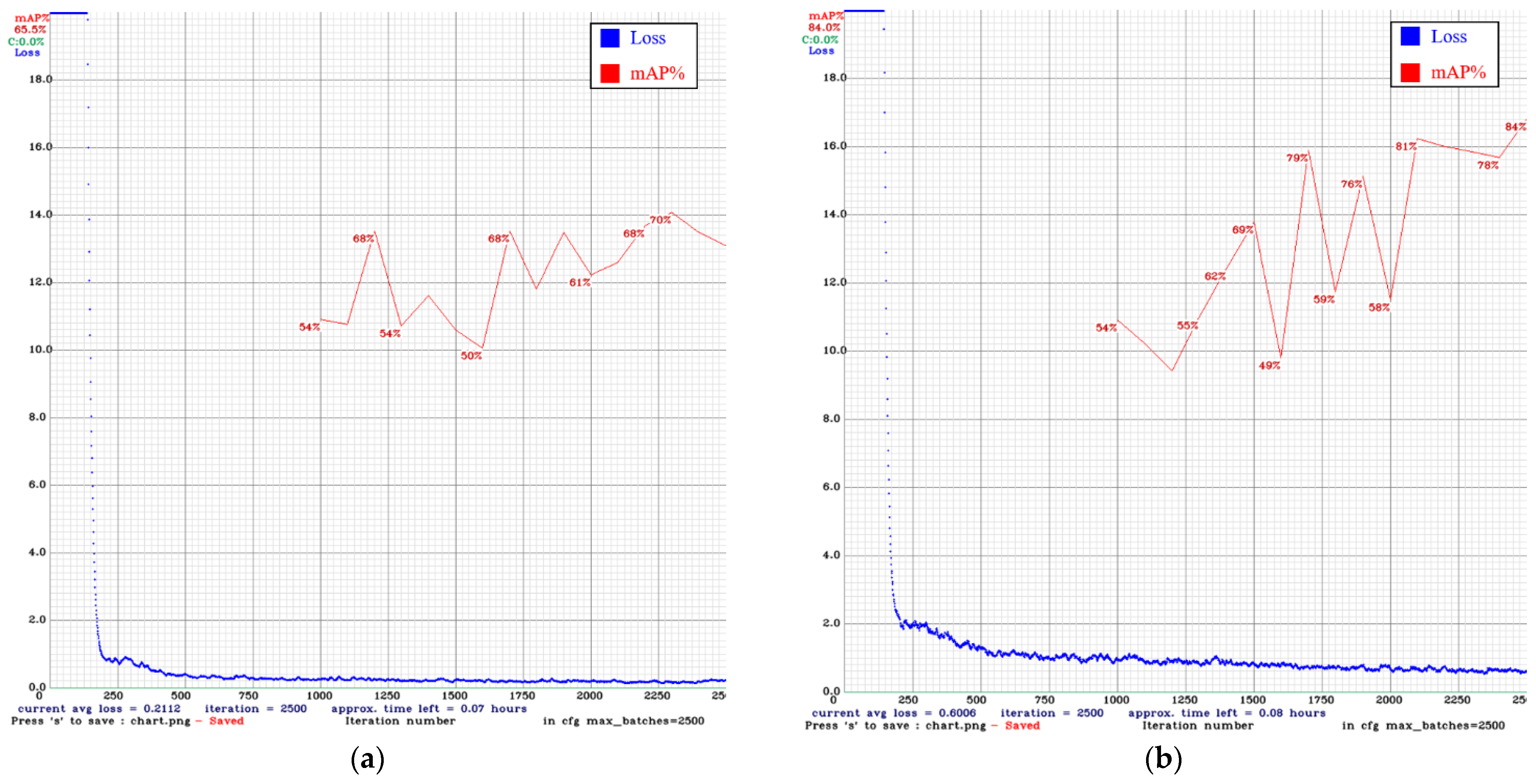
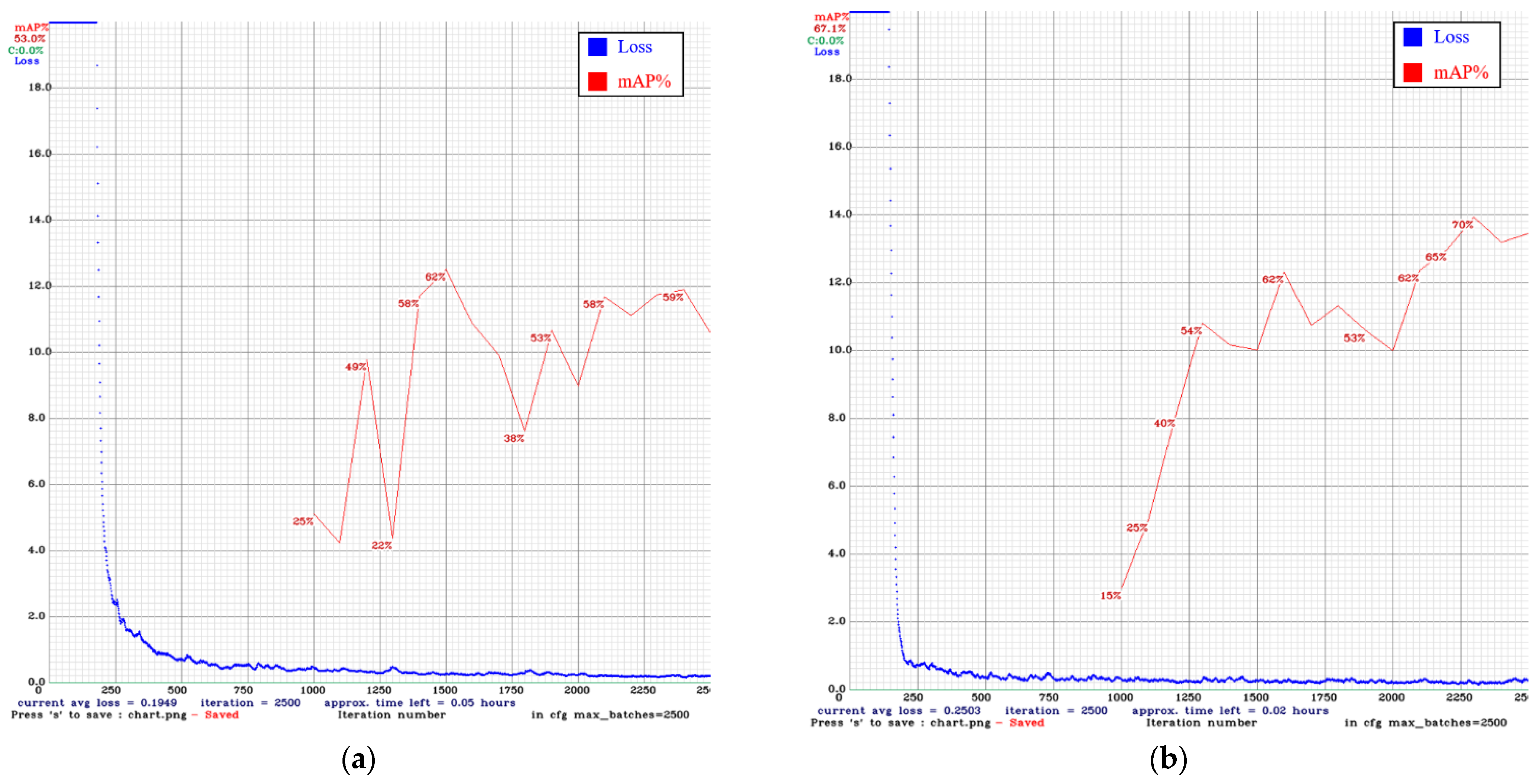
4.4. Training Results
4.5. Training the Convolutional Neural Network
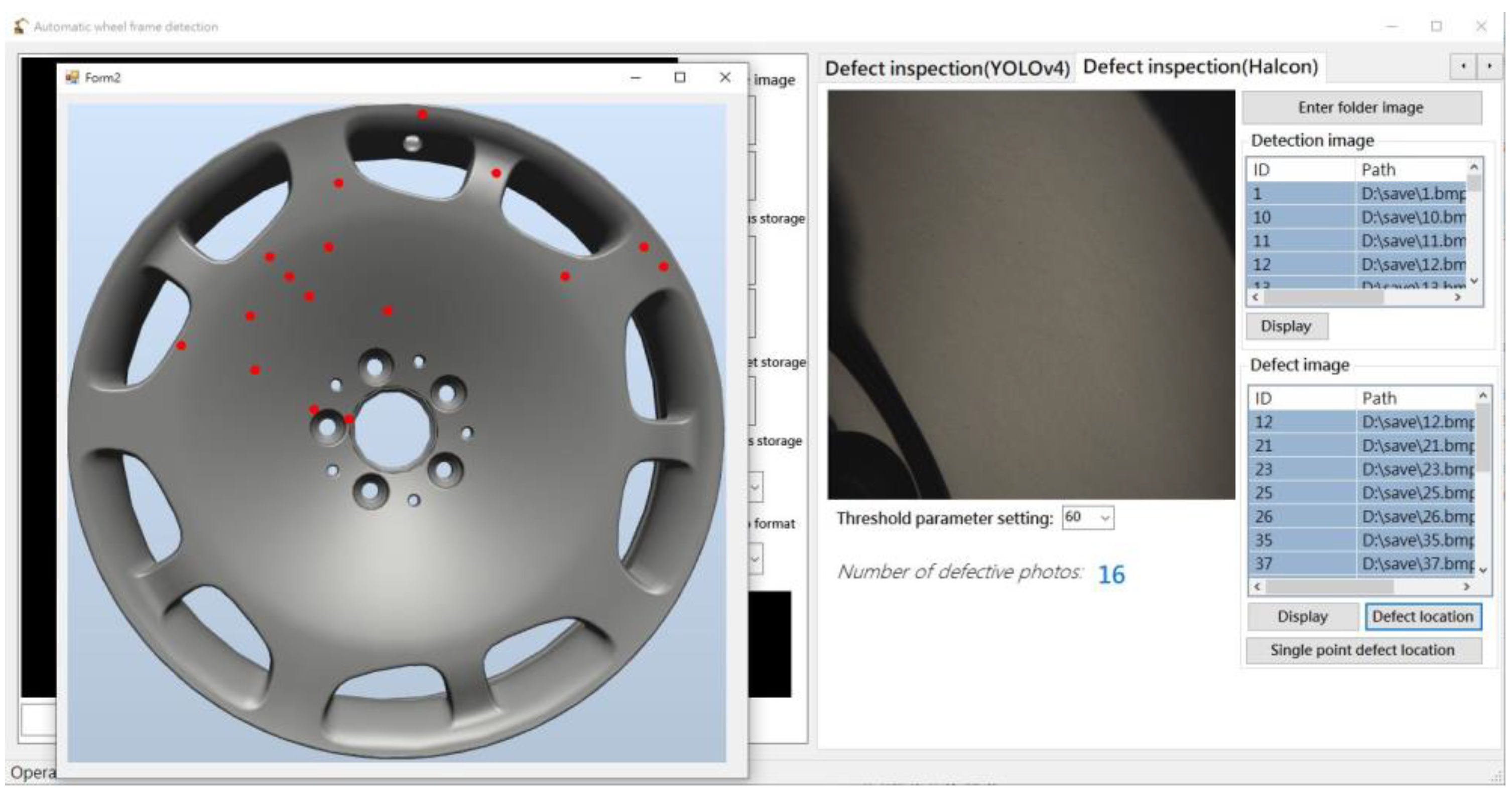
4.6. CNN Detection Results
- True Positive (TP): Correctly identified positive samples.
- True Negative (TN): Correctly identified negative samples.
- False Positive (FP): Incorrectly identified as positive samples (type-I error).
- False Negative (FN): Incorrectly identified as negative samples (type-II error).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mery, D.; Jaeger, T.; Filbert, D. A review of methods for automated recognition of casting defects. Insight-Wigston Northamp. 2002, 44, 428–436. [Google Scholar]
- Zhang, J.; Guo, Z.; Jiao, T.; Wang, M. Defect detection of aluminum alloy wheels in radiography images using adaptive threshold and morphological reconstruction. Appl. Sci. 2018, 12, 2365. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Hao, L.; Jiao, T.; Que, L.; Wang, M. Mathematical morphology approach to internal defect analysis of a356 aluminum alloy wheel hubs. Aims Math. 2020, 5, 3256–3273. [Google Scholar] [CrossRef]
- Lee, K.-H.; Kim, H.-S.; Lee, S.-J.; Choo, S.-W. High precision hand-eye self-calibration for industrial robots. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–2. [Google Scholar]
- Bae, S.-H.; Kim, E.-J.; Yang, S.-J.; Park, J.-K.; Kuc, T.-Y. A dynamic visual servoing of robot manipulator with eye-in-hand camera. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 24–27. [Google Scholar]
- Han, K.; Sun, M.; Zhou, X.; Zhang, G.; Dang, H.; Liu, Z. A new method in wheel hub surface defect detection: Object detection algorithm based on deep learning. In Proceedings of the 2017 International Conference on Advanced Mechatronic Systems (ICAMechS), Xiamen, China, 6–9 December 2017; pp. 335–338. [Google Scholar]
- Sun, X.; Gu, J.; Huang, R.; Zou, R.; Palomares, B.G. Surface defects recognition of wheel hub based on improved faster R-CNN. Electronics 2019, 8, 481. [Google Scholar] [CrossRef] [Green Version]
- Degadwala, S.; Vyas, D.; Chakraborty, U.; Dider, A.R.; Biswas, H. Yolo-v4 deep learning model for medical face mask detection. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 209–213. [Google Scholar]
- Chen, X.; An, Z.; Huang, L.; He, S.; Zhang, X.; Lin, S. Surface defect detection of electric power equipment in substation based on improved YOLO v4 algorithm. In Proceedings of the 2020 10th International Conference on Power and Energy Systems (ICPES), Chengdu, China, 25–27 December 2020; pp. 256–261. [Google Scholar]
- Jiang, S.; Zhu, M.; He, Y.; Zheng, Z.; Zhou, F.; Zhou, G. Ship detection with sar based on YOLO. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1647–1650. [Google Scholar]
- Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Jiang, X.; Hartomo, K.D. Yolo v4 for advanced traffic sign recognition with synthetic training data generated by various GAN. IEEE Access 2021, 9, 97228–97242. [Google Scholar] [CrossRef]
- Sabir, S.; Rosato, D.; Hartmann, S.; Gühmann, C. Signal generation using 1d deep convolutional generative adversarial networks for fault diagnosis of electrical machines. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3907–3914. [Google Scholar]
- Lorencin, L.; Šegota, S.B.; Anđelić, N.; Mrzljak, V.; Ćabov, T.; Španjol, J.; Car, Z. On urinary bladder cancer diagnosis: Utilization of deep convolutional generative adversarial networks for data augmentation. Biology 2021, 10, 175. [Google Scholar] [CrossRef]
- Venu, S.K.; Ravula, S. Evaluation of deep convolutional generative adversarial networks for data augmentation of chest X-ray images. Future Internet 2021, 13, 8. [Google Scholar] [CrossRef]
- Goodfellow, L.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial network. Machine Learning. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Bau, D.; Zhu, J.-Y.; Strobelt, H.; Zhou, B.; Tenenbaum, J.B.; Freeman, W.T.; Torralba, A. GAN dissection: Visuzlizing and understanding generative adversarial networks. Computer Vision and Pattern Recognition. arXiv 2018, arXiv:1811.10597. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. Machine Learning. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Computer Vision and Pattern Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. Computer Vision and Pattern Recognition. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. Computer Vision and Pattern Recognition. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Mark Liao, H.-Y.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. Computer Vision and Pattern Recognition. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Machine Learning. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Lin, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. Computer Vision and Pattern Recognition. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. Machine Learning. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization strategy to train strong classifiers with localizable features. Computer Vision and Pattern Recognition. arXiv 2019, arXiv:1905.04899. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.Y. DropBlock: A regularization method for convolutional networks. Computer Vision and Pattern Recognition. arXiv 2018, arXiv:1810.12890. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help. Machine Learning. arXiv 2019, arXiv:1906.02629. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Firmware | 2.25.3 | Gain Range | 0 dB~48 dB |
| Resolution | 2448 × 2048 | Exposure Range | 0.006 ms~32 s |
| Frame Rate | 75 FPS | Interface | USB3.1 |
| Chrome | Color | Dimensions/Mass | 44 mm × 29 mm × 58 mm/90 g |
| Sensor | Sony IMX250, CMOS,2/3” | Power Requirements | 5 V via USB3.1 or 8~24 V via GPIO |
| Readout Method | Global shutter | Lens Mount | C-mount |
| Experiment\Total Sample | Total Number of Samples (Photos) | Number of Training Samples (Photos) | Number of Testing Samples (Photos) |
|---|---|---|---|
| YOLO v3 Original images | 245 | 196 | 49 |
| YOLO v4 Original images | 245 | 196 | 49 |
| YOLO v3 Original images + DCGAN | 545 | 436 | 109 |
| YOLO v4 Original images + DCGAN | 545 | 436 | 109 |
| Analysis\Methods | YOLO v3 | YOLO v4 | YOLO v3 + DCGAN | YOLO v4 + DCGAN |
|---|---|---|---|---|
| TP | 217 | 98 | 176 | 213 |
| FP | 268 | 67 | 153 | 56 |
| FN | 89 | 209 | 130 | 93 |
| TN | 562 | 770 | 677 | 774 |
| Analysis\Methods | YOLO v3 | YOLO v4 | YOLO v3 + DCGAN | YOLO v4 + DCGAN |
|---|---|---|---|---|
| Total number of defects | 306 | 307 | 306 | 306 |
| detected | 217 | 98 | 176 | 213 |
| Accuracy | 68.5% | 75.8% | 75% | 86.8% |
| Recall | 70.9% | 31.9% | 57.5% | 69.6% |
| Precision | 44.7% | 59.3% | 53.4% | 79.1% |
| Methods\Analysis | Accuracy | Precision | Recall |
|---|---|---|---|
| YOLO v4 + DCGAN (5000) | 80.6% | 66.4% | 56.2% |
| YOLO v4 + DCGAN (4000) | 63.7% | 41.1% | 80.0% |
| YOLO v4 + DCGAN (3000) | 76.1% | 54.4% | 70.2% |
| YOLO v4 + DCGAN (2000) | 86.8% | 79.1% | 69.6% |
| Methods\Time | Robot | detect | Total |
|---|---|---|---|
| YOLO v3 | 2 min 39 s | 56.3 s | 3 min 35.3 s |
| YOLO v3 + DCGAN | 2 min 39 s | 56.2 s | 3 min 35.2 s |
| YOLO v4 | 2 min 39 s | 56.3 s | 3 min 35.3 s |
| YOLO v4 + DCGAN(5000) | 2 min 39 s | 56.1 s | 3 min 35.1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, W.-L.; Chiu, Y.-Y.; Lin, B.-H.; Wang, C.-C.; Wu, Y.-T.; You, C.-Y.; Chien, Y.-R. Integration of Deep Learning Network and Robot Arm System for Rim Defect Inspection Application. Sensors 2022, 22, 3927. https://doi.org/10.3390/s22103927
Mao W-L, Chiu Y-Y, Lin B-H, Wang C-C, Wu Y-T, You C-Y, Chien Y-R. Integration of Deep Learning Network and Robot Arm System for Rim Defect Inspection Application. Sensors. 2022; 22(10):3927. https://doi.org/10.3390/s22103927
Chicago/Turabian StyleMao, Wei-Lung, Yu-Ying Chiu, Bing-Hong Lin, Chun-Chi Wang, Yi-Ting Wu, Cheng-Yu You, and Ying-Ren Chien. 2022. "Integration of Deep Learning Network and Robot Arm System for Rim Defect Inspection Application" Sensors 22, no. 10: 3927. https://doi.org/10.3390/s22103927
APA StyleMao, W.-L., Chiu, Y.-Y., Lin, B.-H., Wang, C.-C., Wu, Y.-T., You, C.-Y., & Chien, Y.-R. (2022). Integration of Deep Learning Network and Robot Arm System for Rim Defect Inspection Application. Sensors, 22(10), 3927. https://doi.org/10.3390/s22103927