
LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images

Abstract
:1. Introduction
- A new Anchor Generation algorithm, LAG, was proposed. In the LAG, overfitting and mismatch problems of using the general Anchor Generation algorithm on the aerial image dataset were alleviated by dividing the objects into corresponding layers and generating anchors of each layer by analyzing objects which belong to the layer. Experiments with different input sizes and hyperparameters showed our algorithm achieves better results than the general algorithm.
- LA-YOLO method was proposed by introducing LAG into the YOLO model. The experiments under different anchor strategies have shown that the detection performance of the YOLO model was significantly improved by LAG without increasing the number of prediction boxes compared to the strategies of increasing anchors amount and adjusting the layers of anchors.
- The LAG can be used as a module with good generality for a variety of detectors. The experiments on object DetectIon in Optical Remote sensing images (DIOR) and Vision Meets Drone (VisDrone) datasets have shown that introducing LAG to other YOLO and non-YOLO detectors, such as You Only Learn One Representation (YOLOR) and Cascade Regions with CNN features (Cascade R-CNN), can significantly improve detection performance.
2. Related Work
2.1. General Object Detection
2.2. Yolo Detectors
2.3. Cascade R-CNN
2.4. Aerial Image Object Detection
2.5. Anchor Generation and Assignment
3. Method Introduction
3.1. Limitations of Anchor Generation Algorithm in YOLO
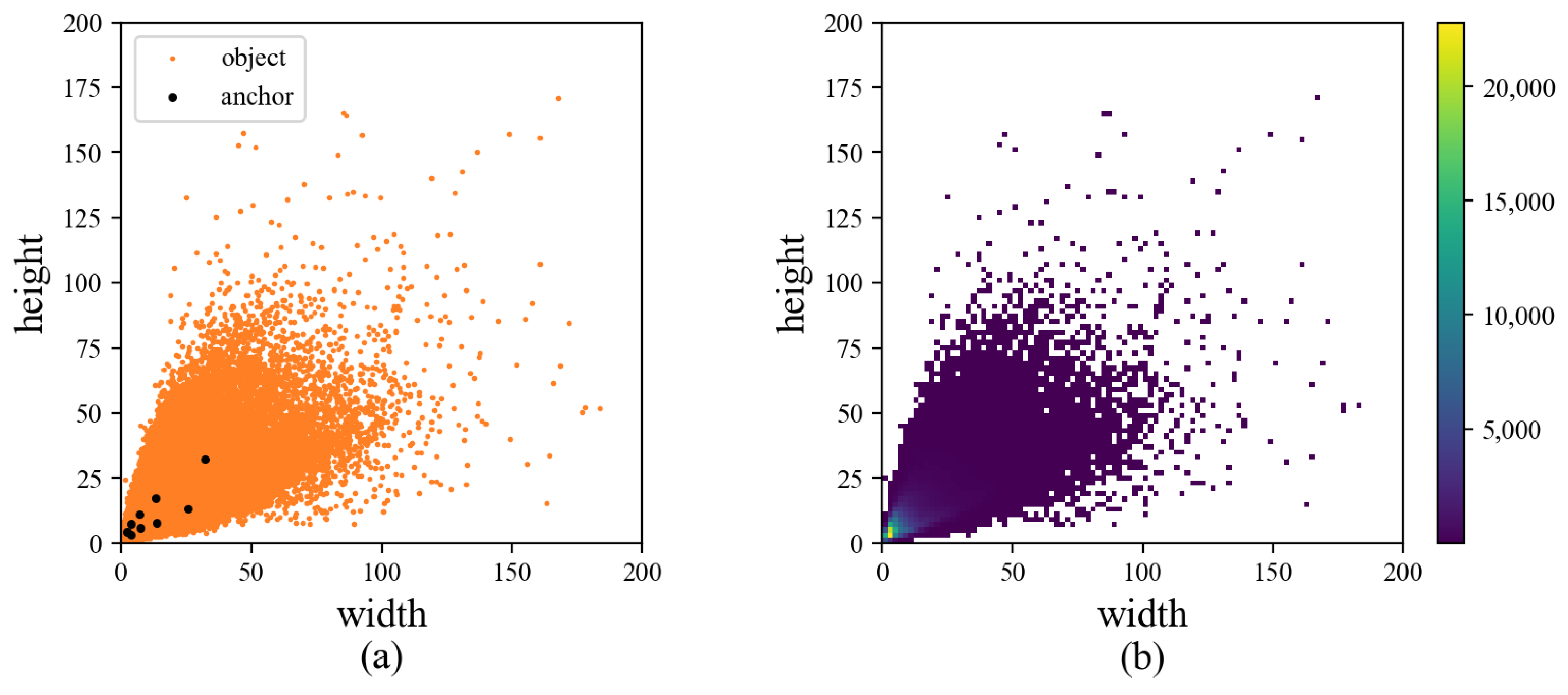
- Anchors will overfit partial objects when training on datasets with uneven distribution. Obtaining anchors by the whole training set are easy to overmatch a part of objects on the dataset with uneven distribution of scale and shape. For example, there will be more anchors to match the small objects the best when most objects in the dataset are small objects, thus weakening the matching of objects of other sizes. As shown in Figure 1, the large number of small targets makes anchors prefer to match the majority.
- The anchor generation and setting are inconsistent with the idea of layered multi-scale detection. For the dataset with only small and medium objects, the anchors obtained by the whole dataset are generally small. Even the largest anchors are unsuitable for the deep layer. But the strategy of equal assigning anchors will set them to the deep layer, which results in some small objects being matched to an inappropriate head. As shown in Figure 1a, nearly all anchors obtained by the general algorithm are small, but they will still be evenly assigned from the low layer to the deep layer according to the number of heads.
3.2. Layered Anchor Generation
| Algorithm 1 Layered Anchor Generation(LAG) |
|
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Criteria
4.3. Experiment Details
4.4. Ablation
4.4.1. Ablation of the Hyperparameter
4.4.2. Ablation of the Input Size
4.5. Experiments on Different Anchor Settings
4.6. Effects on Different Detectors
4.7. Compare with Other Sota Detectors
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| LAG | Layered Anchor Generation |
| YOLOv3 | You Only Look Once version 3 |
| YOLOv5 | You Only Look Once version 5 |
| YOLOR | You Only Learn One Representation |
| Cascade R-CNN | Cascade Regions with CNN features |
| VisDrone | Vision Meets Drone |
| DIOR | object DetectIon in Optical Remote sensing images |
| ResNet | Deep Residual Network |
| FPN | Feature Pyramid Networks |
| SPP | Spatial Pyramid Pooling |
| SENet | Squeeze-and-Excitation Networks |
| ECA | Efficient Channel Attention |
| DECA | Dilated Efficient Channel Attention |
| UAV | Unmanned Aerial Vehicles |
| RPN | Region Proposal Network |
| YOLOv2 | You Only Look Once version 2 |
| YOLOv4 | You Only Look Once version 4 |
| NMS | Non-Maximum Suppression |
| SCRDet | Rotation detector for Small, Cluttered and Rotated objects |
| Faster R-CNN | Faster Regions with CNN |
| R3Det | Refined Rotation RetinaNet |
| YOLT | You Only Look Twice |
| TPH-YOLOv5 | Transformer Prediction Heads-You Only Look Once version 5 |
| IoU | Intersection over Union |
| MS COCO | Microsoft Common Objects in Context |
| AP | Average Precision |
| NAS-FCOS | Neural Architecture Search-Fully Convolutional One-Stage object detector |
| PAA | Probabilistic Anchor Assignment |
| ATSS | Adaptive Training Sample Selection |
References
- Veganzones, M.A.; Tochon, G.; Dalla-Mura, M.; Plaza, A.J.; Chanussot, J. Hyperspectral image segmentation using a new spectral unmixing-based binary partition tree representation. IEEE Trans. Image Process. 2014, 23, 3574–3589. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Ren, F.; Pedrycz, W. Fuzzy C-means clustering through SSIM and patch for image segmentation. Appl. Soft Comput. 2020, 87, 105928. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wang, J.; Yu, J.; He, Z. DECA: A novel multi-scale efficient channel attention module for object detection in real-life fire images. Appl. Intell. 2021, 52, 1362–1375. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1804–2767. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012; Chaurasia, A.; Xie, T.; Liu, C.; Abhiram, V.; Laughing; tkianai; et al. ultralytics/yolov5: v5.0—YOLOv5-P6 1280 Models, AWS, Supervise.ly and YouTube Integrations, version 5.0; CERN Data Centre & Invenio.: Prévessin-Moëns, France, 2021. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; Volume 1, pp. 281–297. [Google Scholar]
- Zhang, H.; Hu, Z.; Hao, R. Joint information fusion and multi-scale network model for pedestrian detection. Vis. Comput. 2021, 37, 2433–2442. [Google Scholar] [CrossRef]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Hurtik, P.; Molek, V.; Hula, J.; Vajgl, M.; Vlasanek, P.; Nejezchleba, T. Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3. arXiv 2020, arXiv:2005.13243. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The Vision Meets Drone Object detection Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2847–2854. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Jocher, G.; Kwon, Y.; guigarfr; perry0418; Veitch-Michaelis, J.; Ttayu; Suess, D.; Baltacı, F.; Bianconi, G.; IlyaOvodov; et al. ultralytics/yolov3: v9.5.0—YOLOv5 v5.0 Release Compatibility Update for YOLOv3, version 9.5.0; CERN Data Centre & Invenio.: Prévessin-Moëns, France, 2021. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020, arXiv:2007.03496. [Google Scholar]
- Wang, N.; Gao, Y.; Chen, H.; Wang, P.; Tian, Z.; Shen, C.; Zhang, Y. NAS-FCOS: Fast Neural Architecture Search for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kim, K.; Lee, H.S. Probabilistic Anchor Assignment with IoU Prediction for Object Detection. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| YOLOv3 | (416,416) | 31.2 | 15.1 | 9.4 | 24.4 | 31.2 | 16.2 |
| +LAG(d = 0.025) | 32.1 | 16.7 | 9.3 | 26.7 | 38.7 | 17.5 | |
| +LAG(d = 0.05) | 33.7 | 17.8 | 9.8 | 28.5 | 42.1 | 18.7 | |
| +LAG(d = 0.1) | 33.0 | 17.1 | 9.1 | 27.7 | 42.9 | 18.1 | |
| +LAG(d = 0.125) | 32.9 | 16.6 | 9.1 | 27.1 | 43.0 | 17.8 | |
| +LAG(d = 0.15) | 32.2 | 16.5 | 8.7 | 26.3 | 44.8 | 17.5 | |
| +LAG(d = 0.2) | 32.6 | 16.2 | 8.9 | 26.1 | 43.7 | 17.4 |
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| YOLOv3 | (320,320) | 23.6 | 10.4 | 6.4 | 17.9 | 28.4 | 11.8 |
| +LAG | 26.2 | 13.0 | 6.3 | 21.9 | 36.6 | 14.0 | |
| YOLOv3 | (416,416) | 31.2 | 15.1 | 9.4 | 24.4 | 31.2 | 16.2 |
| +LAG | 33.7 | 17.8 | 9.8 | 28.5 | 42.1 | 18.7 | |
| YOLOv3 | (640,640) | 42.8 | 22.6 | 15.5 | 34.1 | 43.7 | 24.0 |
| +LAG | 45.0 | 25.5 | 16.2 | 37.9 | 50.1 | 26.0 | |
| YOLOv3 | (768,768) | 47.2 | 26.4 | 18.5 | 37.2 | 51.0 | 27.0 |
| +LAG | 48.4 | 28.2 | 18.8 | 39.8 | 53.1 | 28.2 |
| Method | Input Size | Settings 1 | Quantities 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | (416,416) | [3,3,3] | 79.9 | 63.0 | 8.6 | 36.3 | 71.9 | 58.6 | 10,647 |
| [9,0,0] | 77.8 | 60.8 | 8.8 | 35.9 | 70.1 | 56.0 | 24,336 | ||
| [7,1,1] | 79.0 | 62.7 | 8.0 | 34.4 | 71.6 | 58.1 | 19,773 | ||
| [0,9,0] | 77.7 | 61.2 | 7.5 | 36.9 | 70.9 | 56.7 | 6084 | ||
| [1,7,1] | 78.9 | 62.0 | 8.7 | 33.9 | 70.7 | 57.6 | 7605 | ||
| [0,0,9] | 74.6 | 58.2 | 4.2 | 31.9 | 69.8 | 54.3 | 1521 | ||
| [1,1,7] | 78.6 | 59.3 | 8.9 | 33.9 | 67.9 | 55.3 | 4563 | ||
| [4,2,3] | 80.2 | 63.7 | 8.4 | 37.8 | 72.3 | 59.3 | 12,675 | ||
| [4,4,4] | 79.7 | 63.1 | 10.2 | 37.6 | 71.9 | 58.7 | 14,196 |
| Method | Input Size | Settings | Quantities | ||||||
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | (416,416) | [3,3,3] | 79.9 | 63.0 | 8.6 | 36.3 | 71.9 | 58.6 | 10,647 |
| [4,2,3] | 80.2 | 63.7 | 8.4 | 37.8 | 72.3 | 59.3 | 12,675 | ||
| [6,1,2] | 80.0 | 63.7 | 8.8 | 36.2 | 72.5 | 59.2 | 17,238 | ||
| [4,4,4] | 79.7 | 63.1 | 10.2 | 37.6 | 71.9 | 58.7 | 14,196 | ||
| [5,5,5] | 80.0 | 63.4 | 9.3 | 37.2 | 72.3 | 59.2 | 17,745 | ||
| [6,6,6] | 80.4 | 64.1 | 10.7 | 37.4 | 72.4 | 59.6 | 21,294 | ||
| [7,7,7] | 80.0 | 63.5 | 8.6 | 37.7 | 72.4 | 59.2 | 24,843 | ||
| [8,8,8] | 80.3 | 63.9 | 8.9 | 37.0 | 72.6 | 59.5 | 28,392 | ||
| [9,9,9] | 80.2 | 63.6 | 9.2 | 37.0 | 72.6 | 59.4 | 31,941 | ||
| [3,3,3]+LAG | 80.8 | 64.2 | 9.0 | 36.9 | 73.1 | 59.8 | 10,647 |
| Category | [3,3,3] | [4,4,4] | [3,3,3]+LAG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| airplane | 6.5 | 47.0 | 88.3 | 80.6 | 11.8 | 49.1 | 88.1 | 80.9 | 10.1 | 48.6 | 88.6 | 81.1 |
| airport | None | 15.2 | 59.7 | 58.1 | None | 17.7 | 59.8 | 58.4 | None | 12.6 | 61.3 | 59.6 |
| baseballfield | 7.7 | 77.9 | 89.4 | 83.6 | 6.3 | 75.8 | 89.3 | 83.1 | 6.7 | 78.9 | 89.6 | 83.7 |
| basketballcourt | 0 | 52.4 | 86.8 | 75.2 | 0 | 54.3 | 87.2 | 75.9 | 0 | 52.9 | 86.9 | 75.0 |
| bridge | 4.7 | 19.2 | 59.4 | 32.6 | 5.4 | 16.3 | 59.3 | 32.1 | 5.0 | 19.3 | 61.5 | 34.3 |
| chimney | 0 | 2.6 | 86.9 | 81.1 | 0 | 5.7 | 87.1 | 81.2 | 0 | 6.7 | 87.5 | 82.0 |
| dam | 3.1 | 19.3 | 39.9 | 36.5 | 20.9 | 21.7 | 39.1 | 36.2 | 0.7 | 25.2 | 43.2 | 39.7 |
| Expressway-Service-area | 0 | 3.3 | 73.9 | 57.2 | 0 | 3.9 | 73.1 | 57.2 | 0 | 7.2 | 75.6 | 60.4 |
| Expressway-toll-station | 5.5 | 60.2 | 87.2 | 57.1 | 5.4 | 58.4 | 86.5 | 56.0 | 9.7 | 61.7 | 88.5 | 59.5 |
| golffield | None | 7.8 | 60.6 | 58.3 | None | 7.1 | 61.8 | 59.6 | None | 6.6 | 64.1 | 61.6 |
| groundtrackfield | 17.6 | 46.1 | 85.8 | 65.3 | 19.9 | 46.2 | 85.1 | 65.4 | 18.5 | 46.5 | 85.3 | 65.3 |
| harbor | 4.1 | 17.5 | 55.8 | 46.5 | 5.2 | 19.5 | 55.7 | 46.5 | 3.8 | 21.3 | 56.6 | 47.9 |
| overpass | 2.1 | 14.1 | 66.9 | 44.9 | 3.0 | 15.2 | 67.5 | 45.5 | 3.5 | 14.2 | 69.1 | 47.2 |
| ship | 39.6 | 62.6 | 73.3 | 49.5 | 39.4 | 62.8 | 72.8 | 49.7 | 39.5 | 62.3 | 72.8 | 49.3 |
| stadium | 0 | 2.5 | 75.2 | 73.4 | 0.2 | 21.5 | 74.8 | 73.0 | 0 | 2.6 | 78.5 | 76.7 |
| storagetank | 9.5 | 75.2 | 89.9 | 70.1 | 9.7 | 75.7 | 89.7 | 70.3 | 8.9 | 76.4 | 90.2 | 70.4 |
| tenniscourt | 6.4 | 62.4 | 96.1 | 83.6 | 6.4 | 62.5 | 96.3 | 83.9 | 8.0 | 62.7 | 96.5 | 84.2 |
| trainstation | 0 | 18.2 | 31.0 | 29.7 | 0 | 14.8 | 31.5 | 30.0 | 0 | 12.9 | 33.5 | 31.8 |
| vehicle | 32.6 | 69.3 | 62.4 | 47.8 | 32.5 | 69.4 | 63.7 | 47.8 | 31.6 | 68.4 | 63.1 | 46.5 |
| windmill | 16.3 | 52.7 | 68.6 | 40.7 | 17.3 | 53.7 | 70.5 | 41.8 | 15.3 | 51.7 | 70.0 | 39.9 |
| mean | 8.6 | 36.3 | 71.9 | 58.6 | 10.2 | 37.6 | 71.9 | 58.7 | 9.0 | 36.9 | 73.1 | 59.8 |
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| YOLOv3 | (416,416) | 79.9 | 63.0 | 8.6 | 36.3 | 71.9 | 58.6 |
| +LAG | 80.8 | 64.2 | 9.0 | 36.9 | 73.1 | 59.8 | |
| YOLOv5 | (640,640) | 79.8 | 62.5 | 9.1 | 38.4 | 69.5 | 57.5 |
| +LAG | 80.2 | 63.1 | 8.7 | 38.4 | 70.9 | 58.4 | |
| YOLOR | (1280,1280) | 80.6 | 66.5 | 14.1 | 40.3 | 75.0 | 62.4 |
| +LAG | 80.9 | 67.7 | 13.8 | 40.6 | 75.8 | 63.0 | |
| Cascade R-CNN | 74.9 | 60.2 | 7.2 | 32.5 | 66.9 | 54.4 | |
| +LAG | 75.6 | 60.9 | 7.7 | 33.1 | 68.0 | 55.3 |
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| YOLOv3 | (416,416) | 31.2 | 15.1 | 9.4 | 24.4 | 31.2 | 16.2 |
| +LAG | 33.7 | 17.8 | 9.8 | 28.5 | 42.1 | 18.7 | |
| YOLOv5 | (640,640) | 33.0 | 17.4 | 10.2 | 27.4 | 36.4 | 18.2 |
| +LAG | 34.7 | 19.6 | 10.7 | 30.5 | 42.9 | 19.9 | |
| YOLOR | (1280,1280) | 54.9 | 35.6 | 25.3 | 46.0 | 55.7 | 34.4 |
| +LAG | 57.0 | 37.8 | 26.6 | 49.3 | 59.3 | 36.2 | |
| Cascade R-CNN | 38.8 | 24.7 | 14.3 | 35.7 | 43.4 | 23.7 | |
| +LAG | 42.3 | 25.8 | 17.0 | 35.0 | 41.3 | 25.2 |
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| AutoAssign | 76.7 | 56.4 | 7.5 | 32.0 | 64.1 | 52.2 | |
| NAS-FCOS | 72.8 | 51.3 | 6.0 | 29.4 | 59.5 | 48.1 | |
| PAA | 74.8 | 57.0 | 6.0 | 31.1 | 65.9 | 52.9 | |
| VarifocalNet | 74.0 | 57.9 | 6.5 | 32.4 | 66.3 | 53.3 | |
| ATSS | 73.5 | 56.3 | 6.4 | 31.5 | 64.2 | 51.9 | |
| LA-YOLOv3 | (416,416) | 80.8 | 64.2 | 9.0 | 36.9 | 73.1 | 59.8 |
| LA-YOLOv5 | (640,640) | 80.2 | 63.1 | 8.7 | 38.4 | 70.9 | 58.4 |
| LA-YOLOR | (1280,1280) | 80.9 | 67.7 | 13.8 | 40.6 | 75.8 | 63.0 |
| LA-Cascade R-CNN | 75.6 | 60.9 | 7.7 | 33.1 | 68.0 | 55.3 |
| Method | Input Size | ||||||
|---|---|---|---|---|---|---|---|
| AutoAssign | 36.2 | 19.8 | 12.4 | 29.8 | 37.4 | 20.4 | |
| NAS-FCOS | 31.5 | 18.0 | 9.8 | 28.1 | 36.4 | 18.1 | |
| PAA | 36.0 | 21.3 | 11.4 | 32.8 | 44.4 | 21.1 | |
| VarifocalNet | 38.0 | 23.6 | 13.8 | 34.1 | 42.8 | 22.8 | |
| ATSS | 36.8 | 22.0 | 12.6 | 33.7 | 42.3 | 21.8 | |
| LA-YOLOv3 | (416,416) | 33.7 | 17.8 | 9.8 | 28.5 | 42.1 | 18.7 |
| LA-YOLOv5 | (640,640) | 34.7 | 19.6 | 10.7 | 30.5 | 42.9 | 19.9 |
| LA-YOLOR | (1280,1280) | 57.0 | 37.8 | 26.6 | 49.3 | 59.3 | 36.2 |
| LA-Cascade R-CNN | 42.3 | 25.8 | 17.0 | 35.0 | 41.3 | 25.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, X.; Yu, J.; Tan, H.; Wang, J. LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images. Sensors 2022, 22, 3891. https://doi.org/10.3390/s22103891
Wan X, Yu J, Tan H, Wang J. LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images. Sensors. 2022; 22(10):3891. https://doi.org/10.3390/s22103891
Chicago/Turabian StyleWan, Xueqiang, Jiong Yu, Haotian Tan, and Junjie Wang. 2022. "LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images" Sensors 22, no. 10: 3891. https://doi.org/10.3390/s22103891
APA StyleWan, X., Yu, J., Tan, H., & Wang, J. (2022). LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images. Sensors, 22(10), 3891. https://doi.org/10.3390/s22103891