
An ASIP for Neural Network Inference on Embedded Devices with 99% PE Utilization and 100% Memory Hidden under Low Silicon Cost

Abstract
:1. Introduction
- (1)
- DLP can flexibly accelerate most CNNs and even common mathematical operations by designing a dedicated ISA and hardware system based on SIMD architecture.
- (2)
- DLP can be easily expanded at the Soc-level to increase computing power for various embedded applications.
- (3)
- Based on the hardware system, a scheduling framework is proposed to reduce the latency of memory access, improve utilization and reduce data access, which can effectively optimize performance and energy consumption.
2. ISA Design Considerations
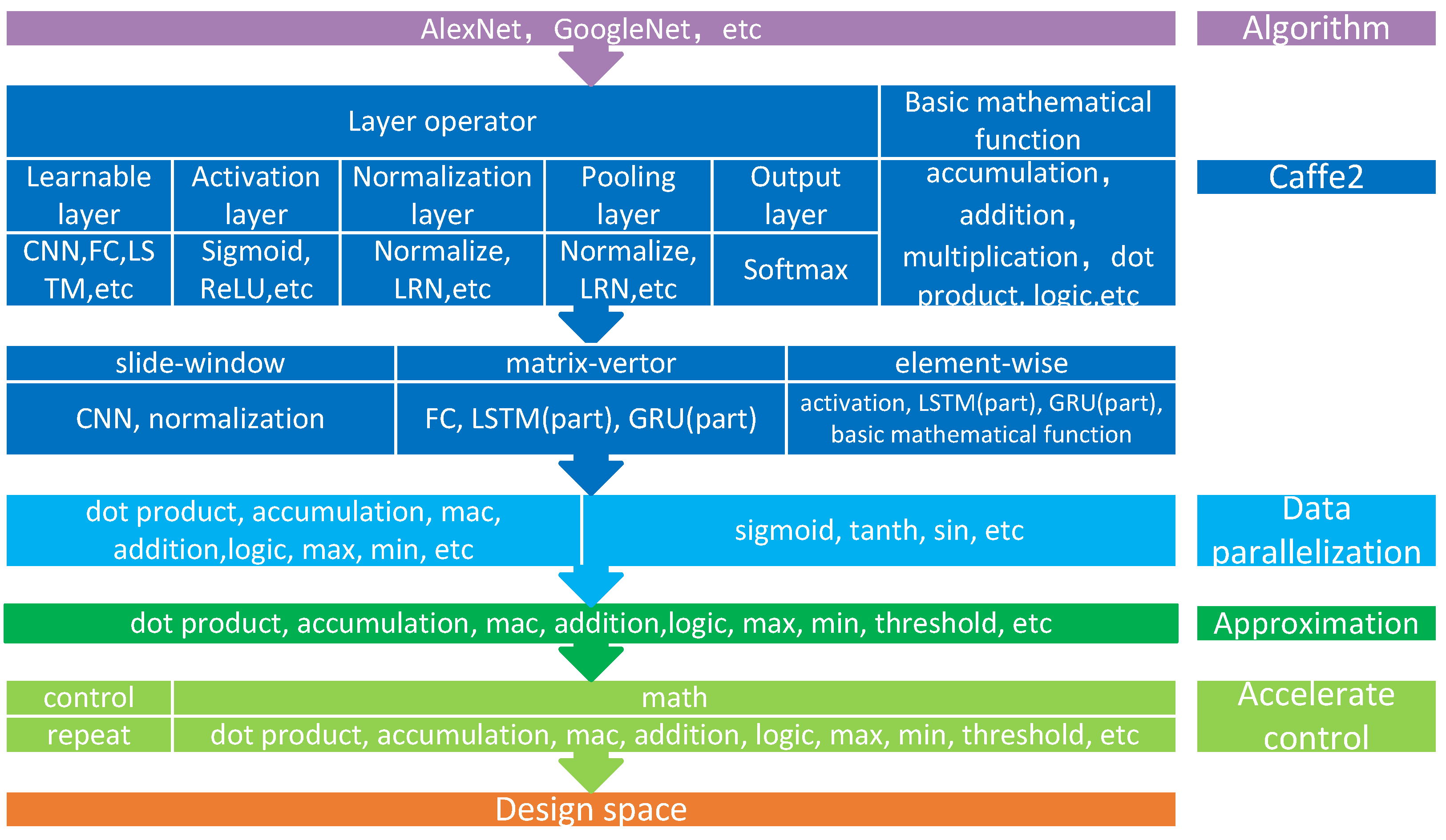
2.1. Design Space Exploration
2.2. Data Parallelization
2.3. Approximation
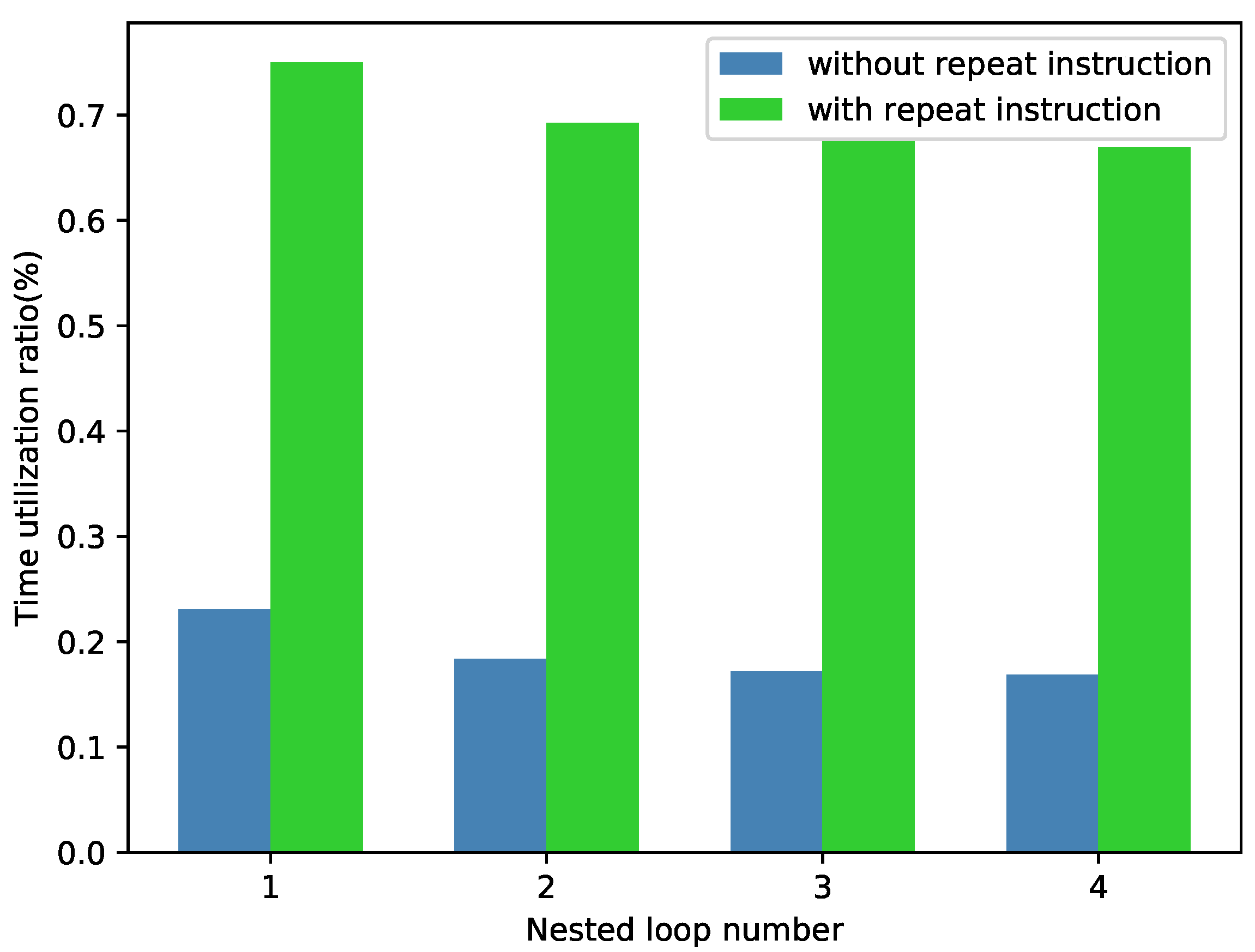
2.4. Control Acceleration
3. ISA Overview
3.1. Instruction Resume
3.2. Program Examples
| Algorithm 1: Program examples |
Convolution code ldi g0 1 ldi g1 2 ldi g2 32 ldi g3 3 ldi g4 3 ldi lacr2 0 loop5: ldi lacr1 0 loop4: ldi lacr0 0 loop3: car repeat 2 3 4 repeat 1 2 3 repeat 0 1 3 mac acr.vi [0].ii.d [0].v.h tacc<shl15> [0].v acr.ii.d add lacr0 lacr0.i.v g1.i.w sub g8 lacr0.i.v g2.i.w jmp.ne loop3 add lacr1 lacr1.i.v g0.i.w sub g8 lacr1.i.v g3.i.w jmp.ne loop4 add lacr2 lacr2.i.v g0.i.w sub g8 lacr2.i.v g4.i.w jmp.ne loop5 Maximum pooling code ldi g0 1 ldi g1 2 ldi g2 32 ldi g3 3 ldi lacr1 0 loop4: ldi lacr0 0 loop3: repeat 2 5 4 car repeat 1 2 3 repeat 0 1 3 max acr.vi [0].vi.w tacc<shl15> [0].v acr.vi.w add lacr0 lacr0.i.v g1.i.w sub g8 lacr0.i.v g2.i.w jmp.ne loop3 add lacr1 lacr1.i.v g0.i.w sub g8 lacr1.i.v g3.i.w jmp.ne loop4 full connect code repeat 1 3 3 car repeat 0 1 3 mac acr.vi [0].vi.v [0].vi.w tacc<shl15> [0].v acr.vi.w |
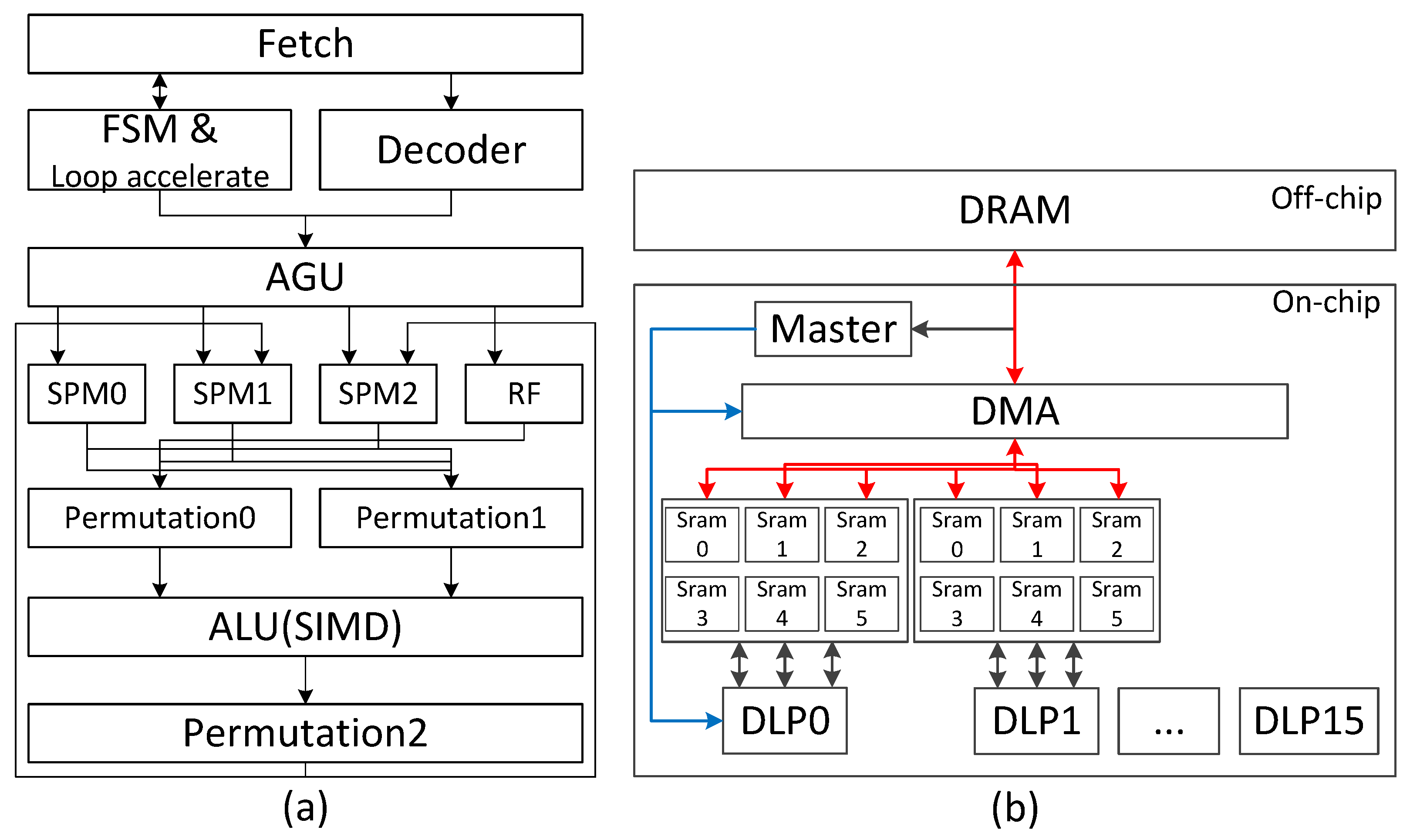
4. The Hardware Design
4.1. DLP Micro-Architecture Implementation
4.2. Extension of the DLP Compute Capability
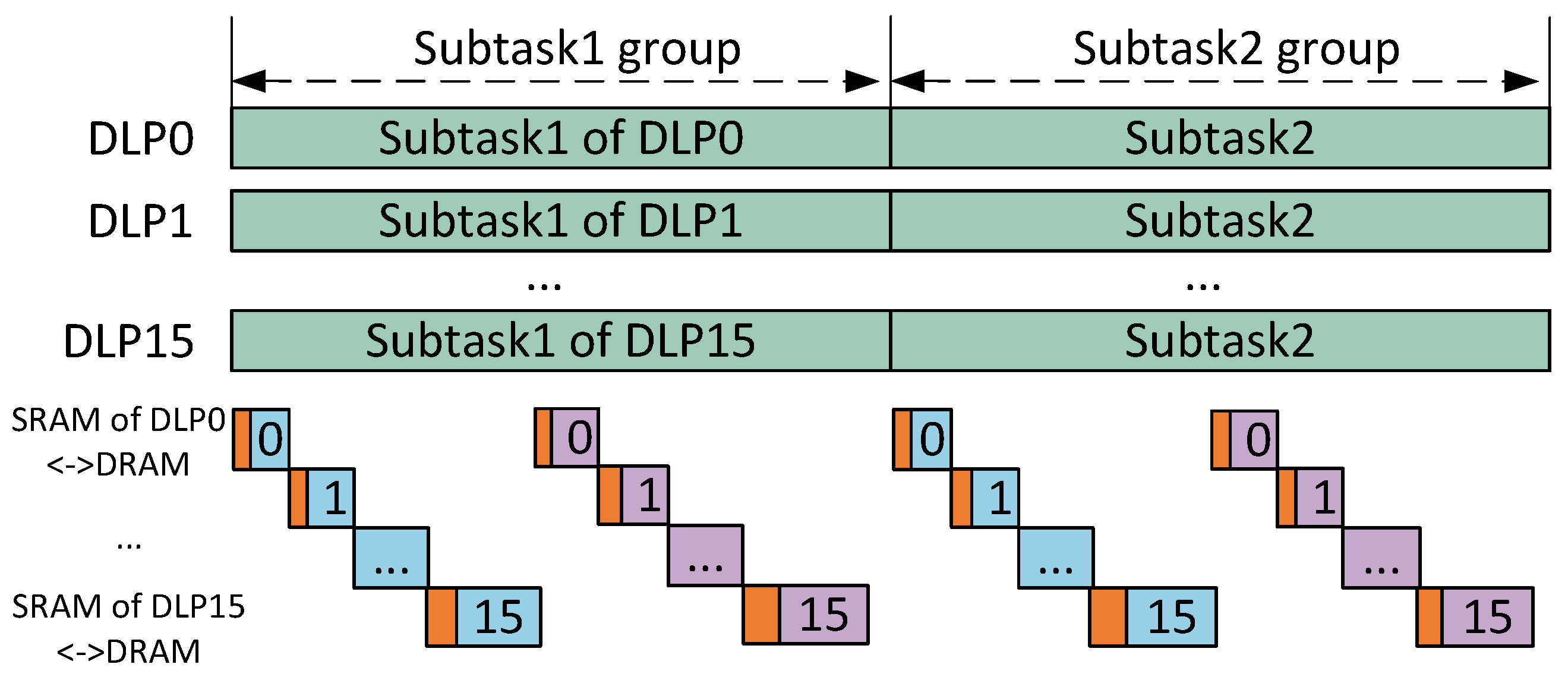
5. Scheduling Framework
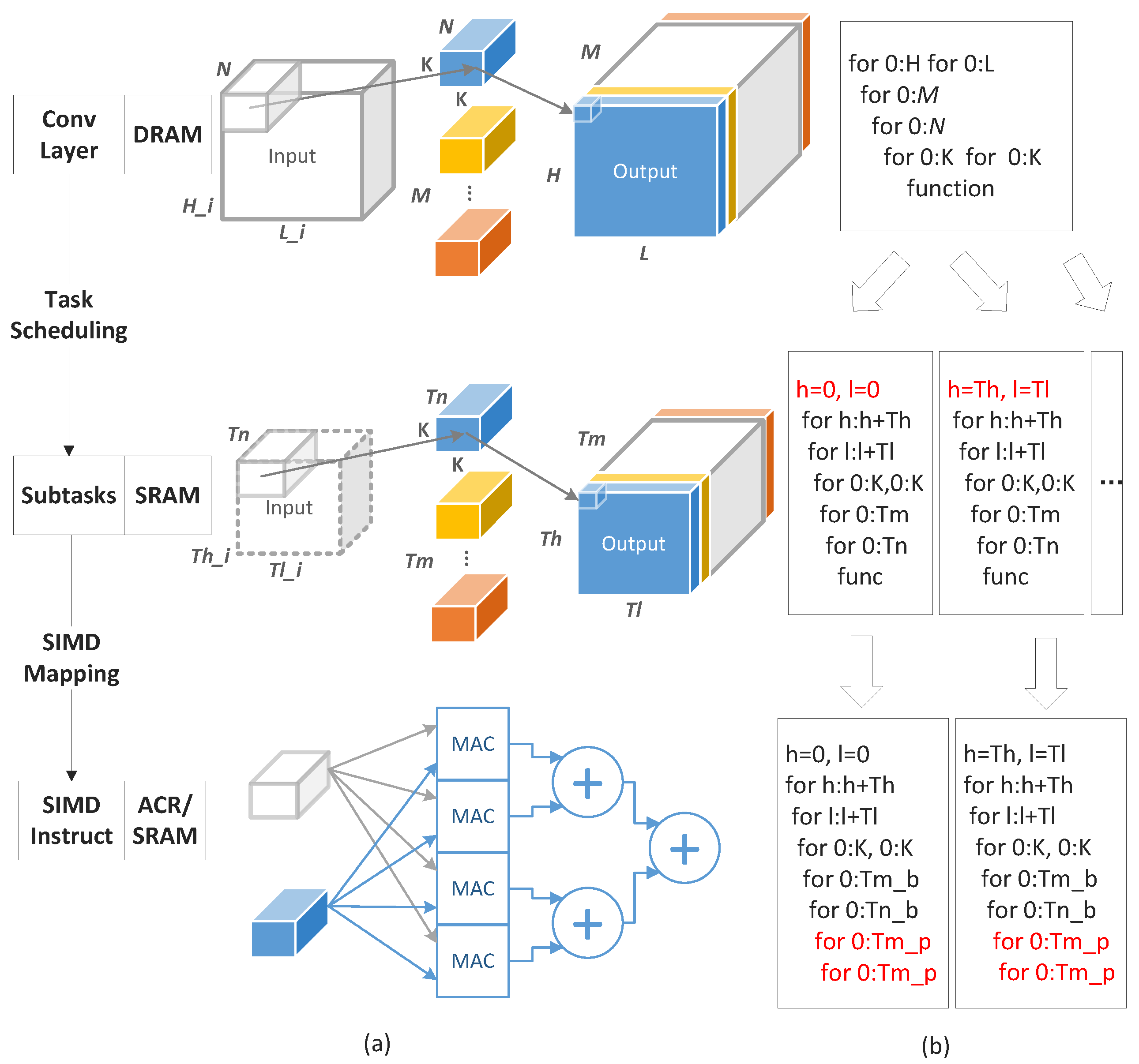
5.1. The Main Challenges of CNN Acceleration
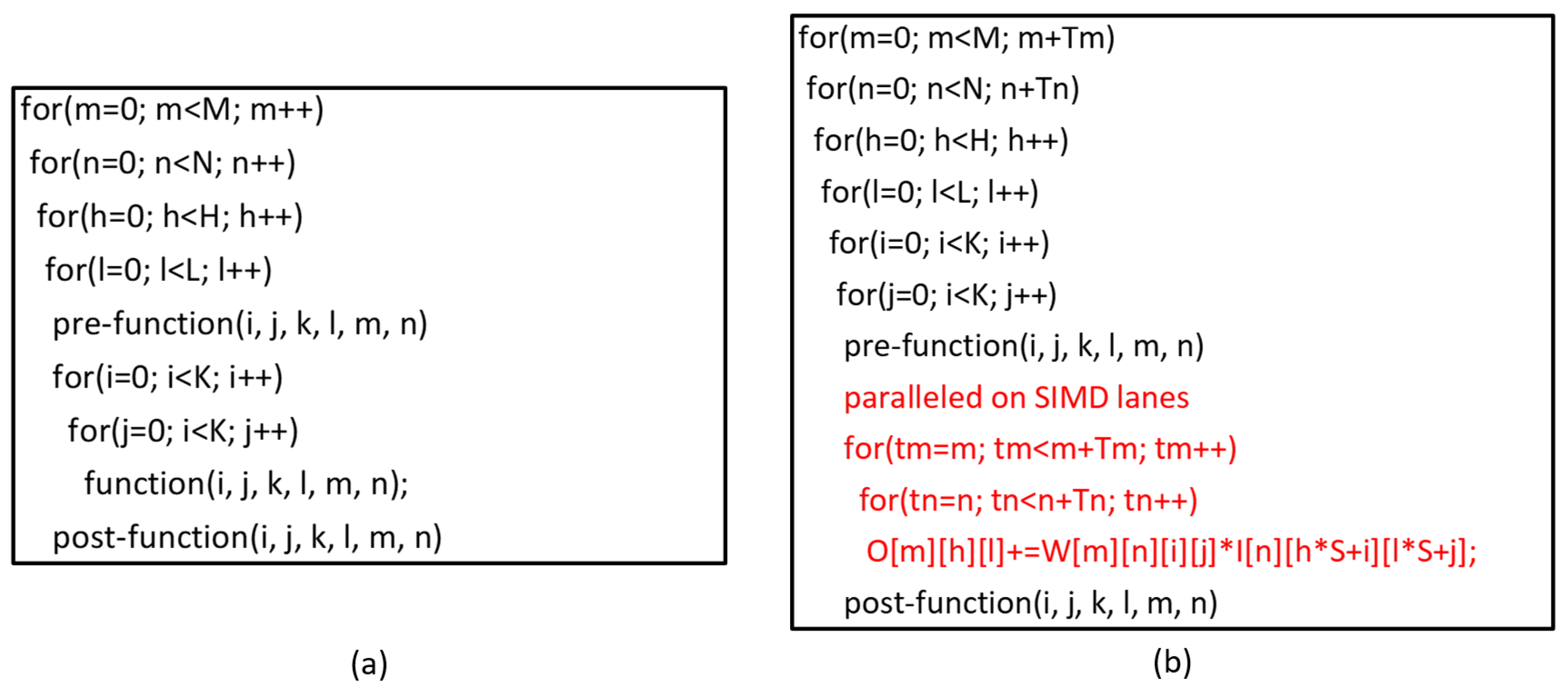
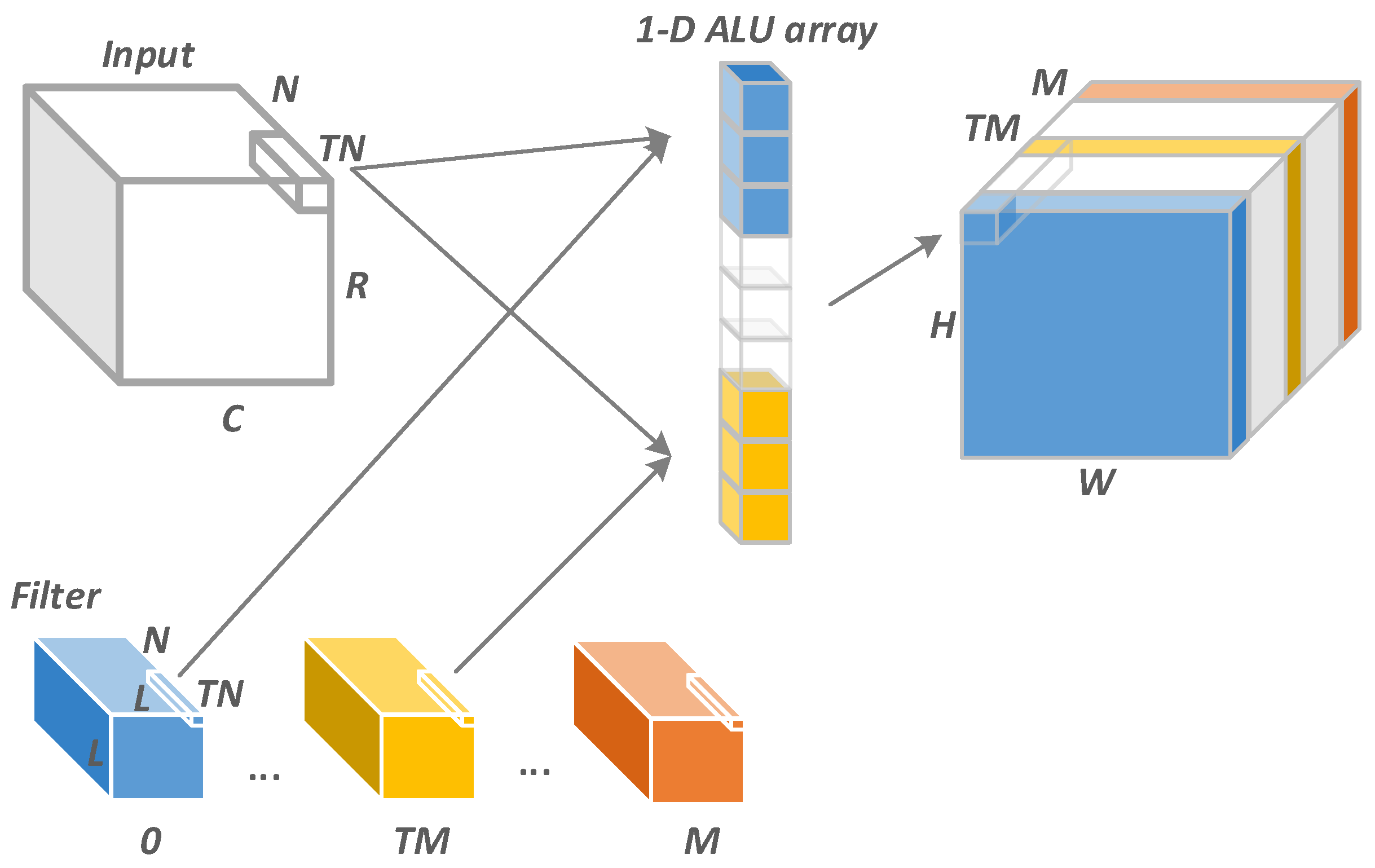
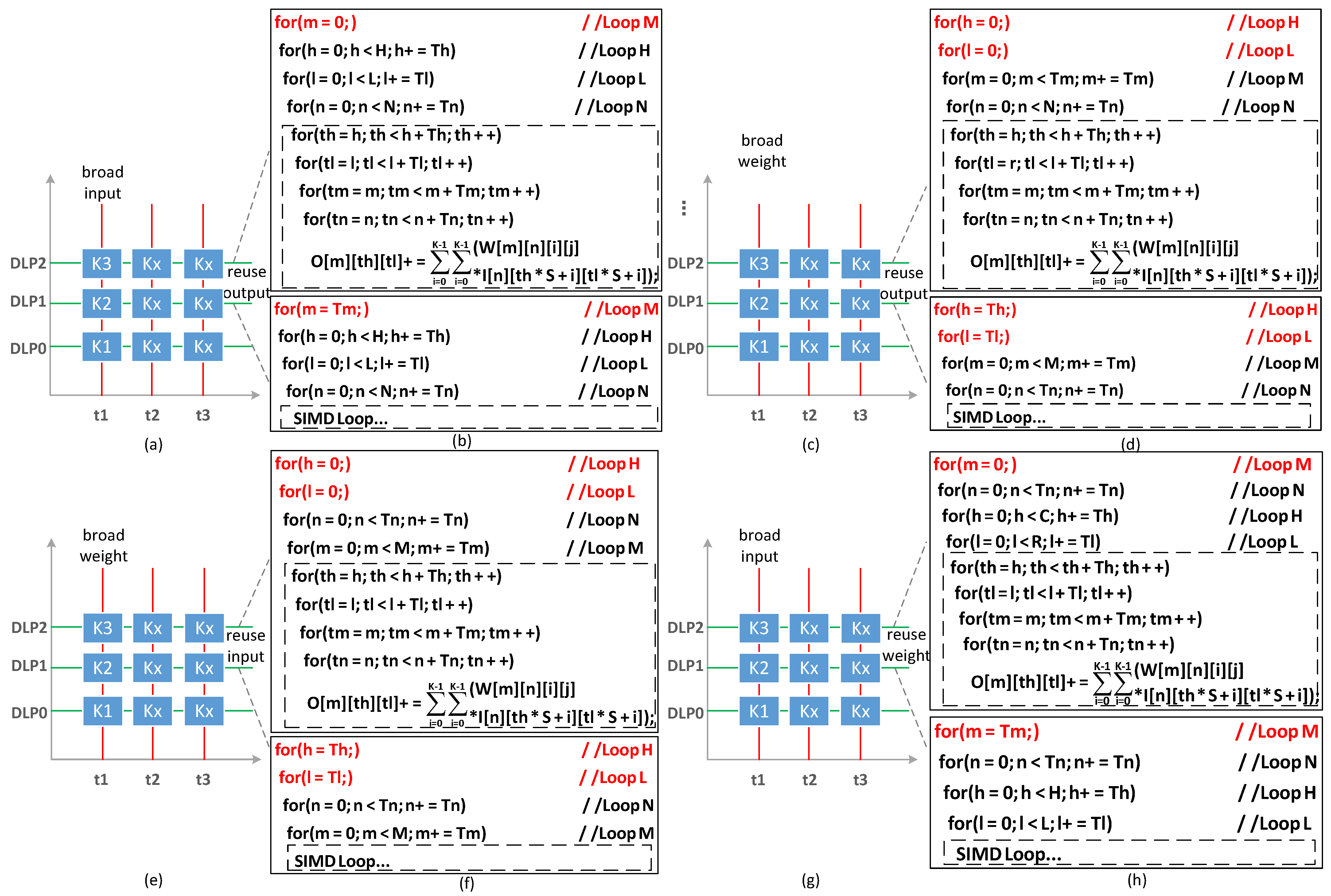
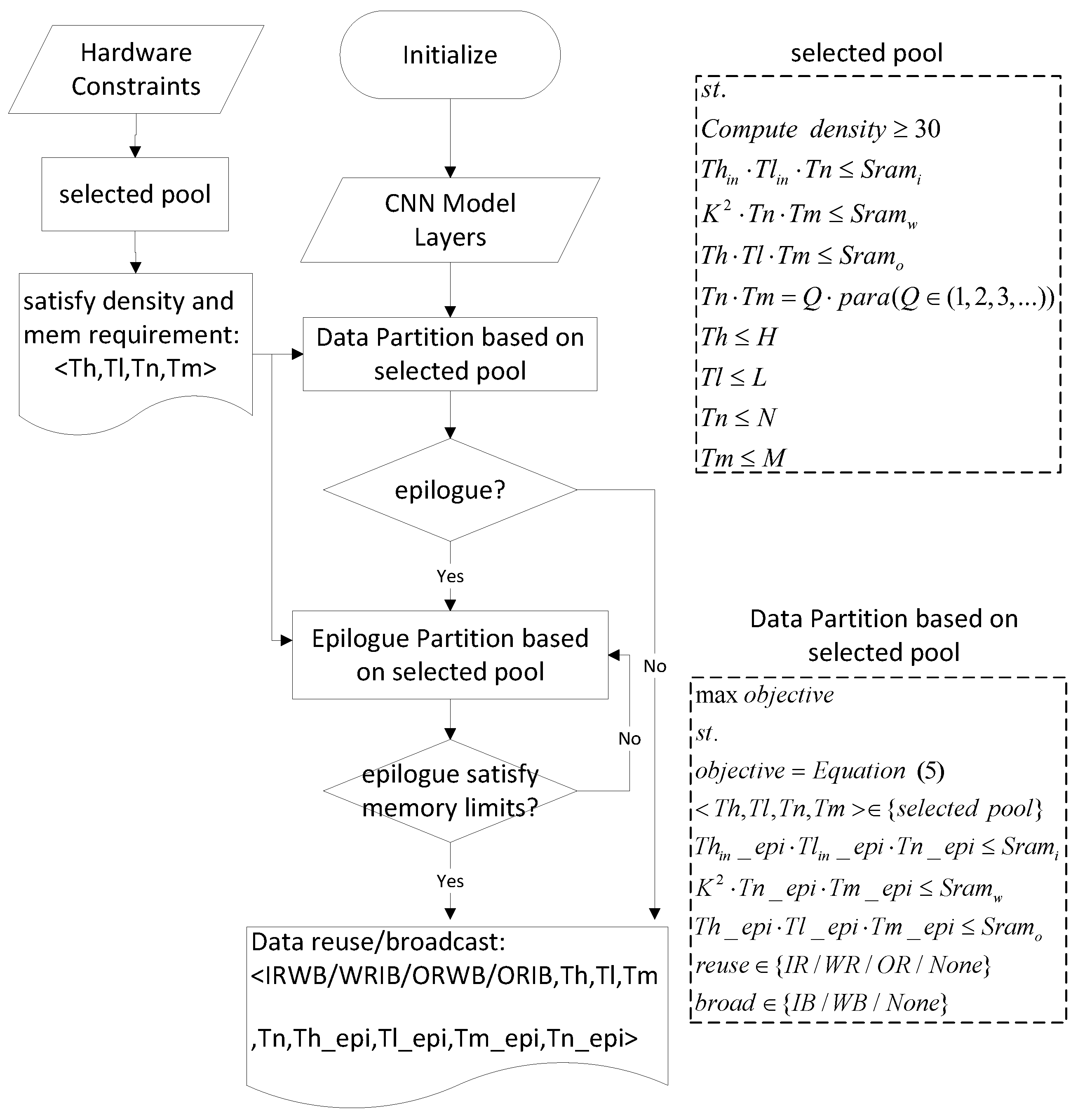
5.2. The Mapping of CNN
5.3. Reuse and Broadcast Pattern
5.4. Workflow
6. Experiment
6.1. Characteristics
6.2. Flexibility
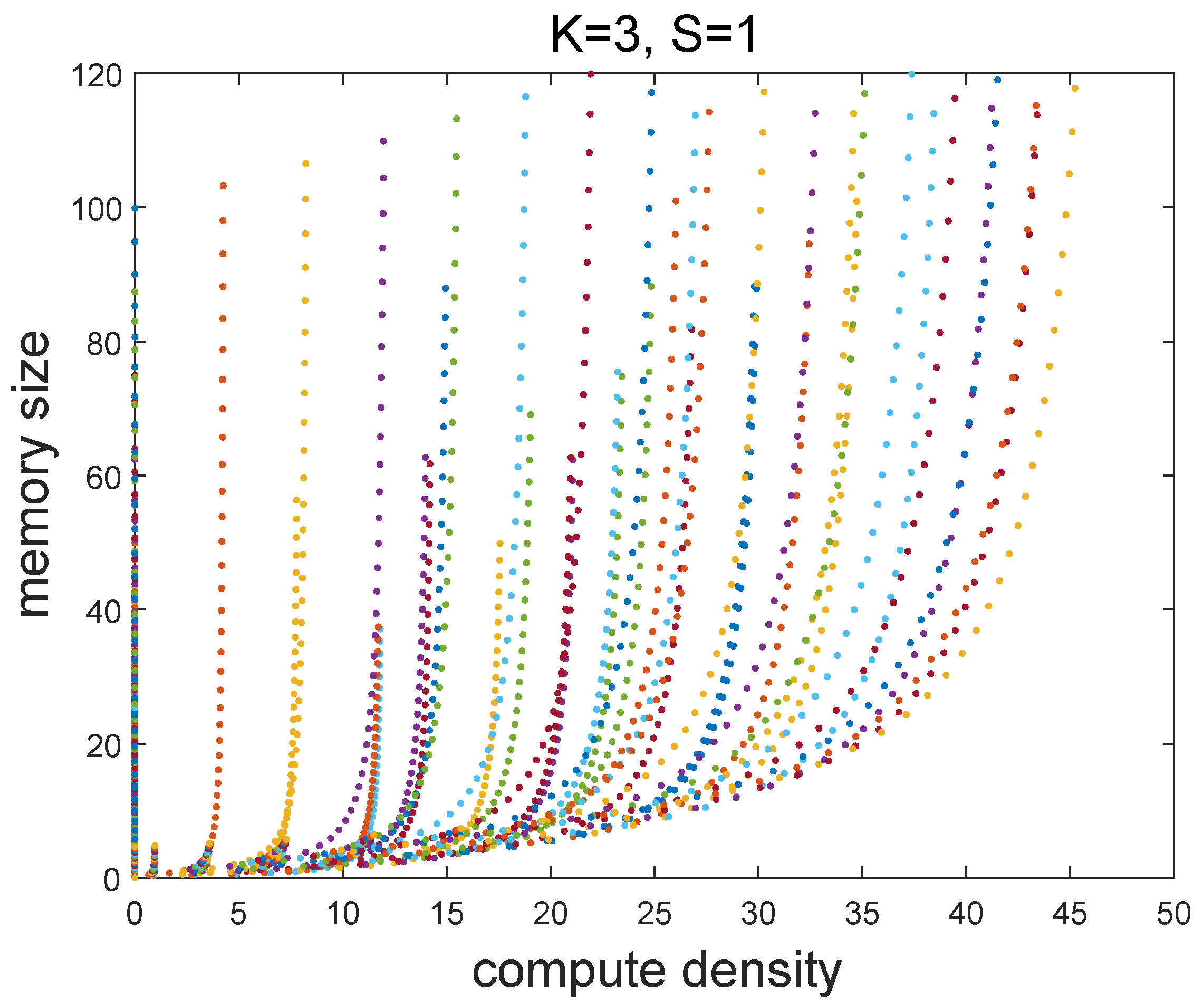
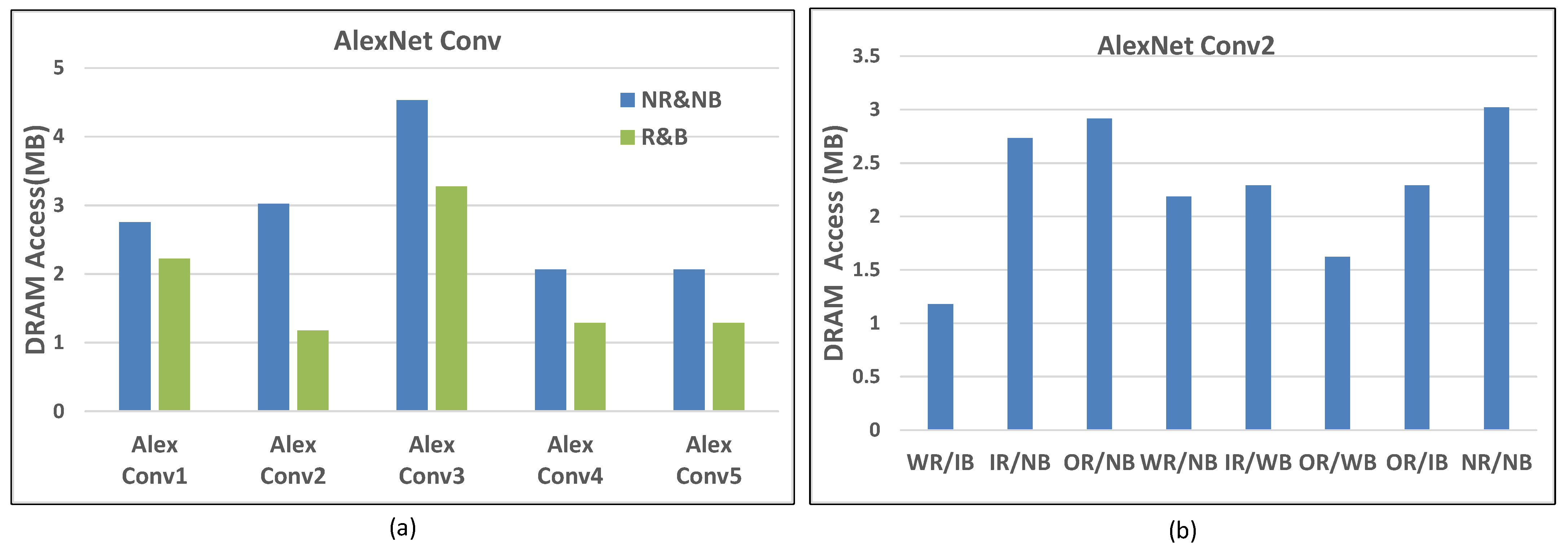
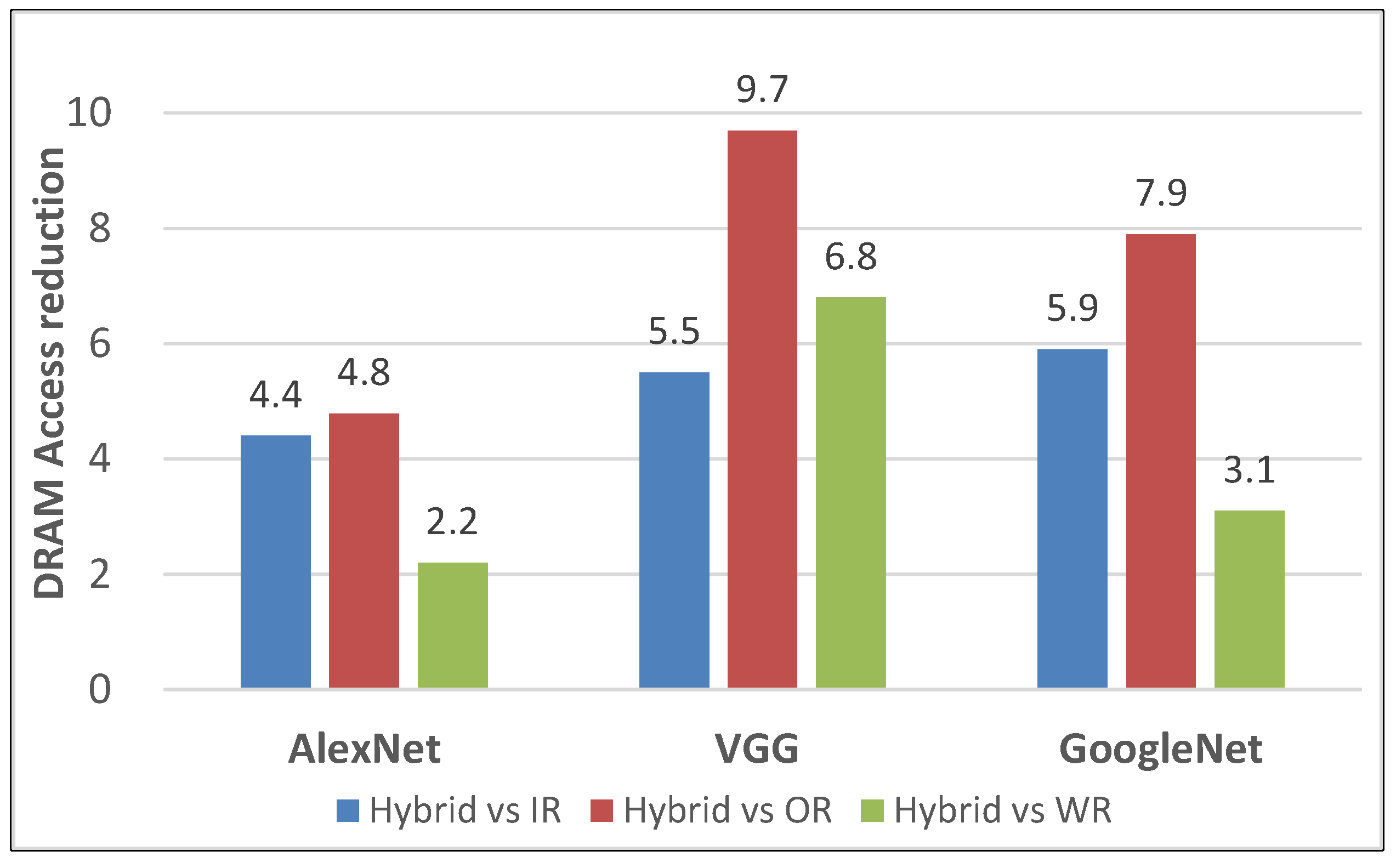
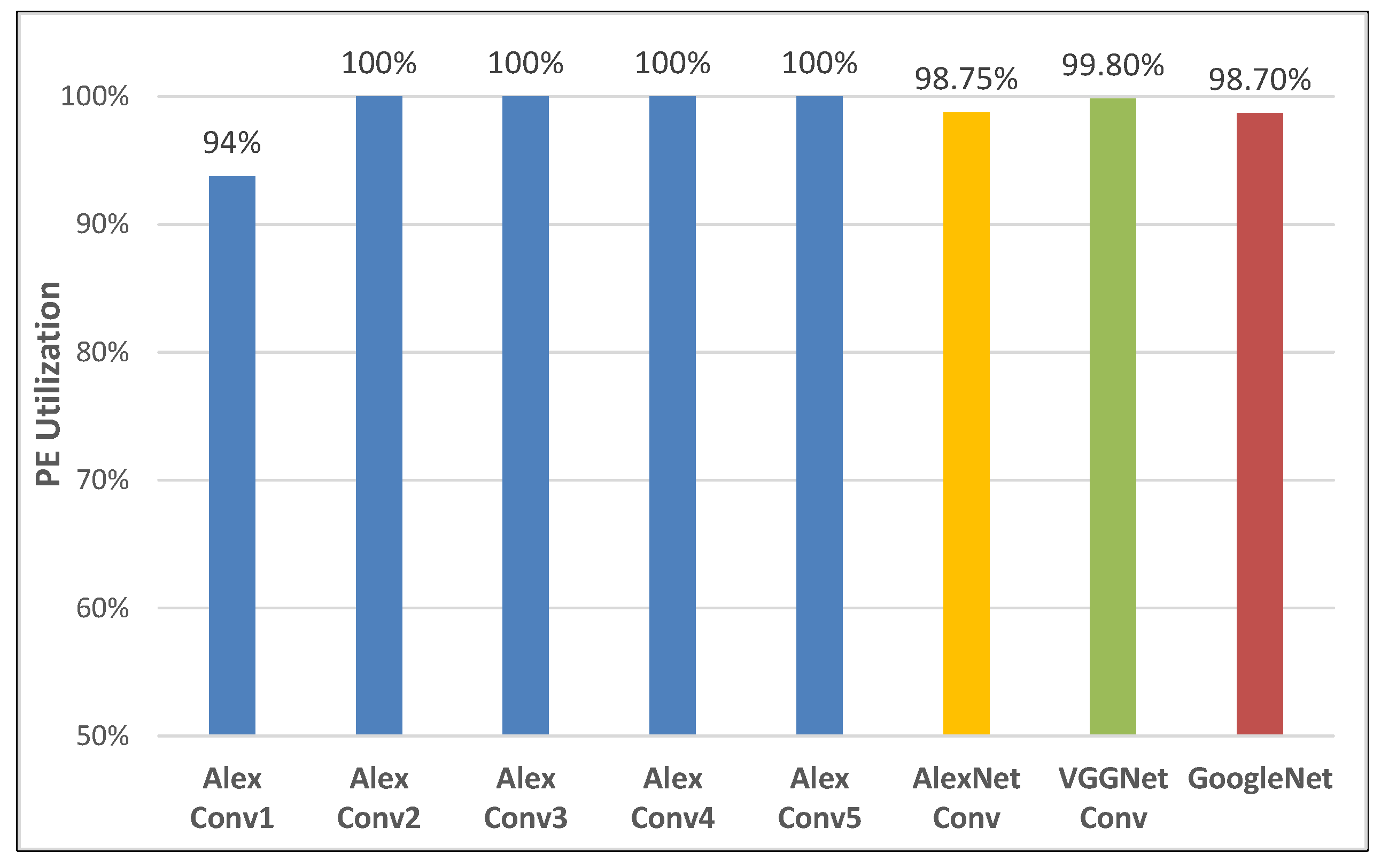
6.3. Results of Scheduling Framework
6.4. Energy Consumption and DRAM Access
6.5. Performance
6.6. Design Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chenarlogh, V.A.; Razzazi, F.; Mohammadyahya, N. A multi-view human action recognition system in limited data case using multi-stream CNN. In Proceedings of the 2019 5th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Shahrood, Iran, 18–19 December 2019; pp. 1–11. [Google Scholar]
- Roshani, M.; Sattari, M.A.; Ali, P.J.M.; Roshani, G.H.; Nazemi, B.; Corniani, E.; Nazemi, E. Application of GMDH neural network technique to improve measuring precision of a simplified photon attenuation based two-phase flowmeter. Flow Meas. Instrum. 2020, 75, 101804. [Google Scholar] [CrossRef]
- Jafari Gukeh, M.; Moitra, S.; Ibrahim, A.N.; Derrible, S.; Megaridis, C.M. Machine Learning Prediction of TiO2-Coating Wettability Tuned via UV Exposure. ACS Appl. Mater. Interfaces 2021, 13, 46171–46179. [Google Scholar] [CrossRef] [PubMed]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Parashar, A.; Rhu, M.; Mukkara, A.; Puglielli, A.; Dally, W.J. SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks. Int. Symp. 2017, 45, 27–40. [Google Scholar]
- Huang, B.; Huan, Y.; Chu, H.; Xu, J.; Liu, L.; Zheng, L.; Zou, Z. IECA: An In-Execution Configuration CNN Accelerator With 30.55 GOPS/mm2 Area Efficiency. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 4672–4685. [Google Scholar] [CrossRef]
- Tu, F.; Wu, W.; Wang, Y.; Chen, H.; Xiong, F.; Shi, M.; Li, N.; Deng, J.; Chen, T.; Liu, L.; et al. Evolver: A deep learning processor with on-device quantization–voltage–frequency tuning. IEEE J. Solid-State Circuits 2020, 56, 658–673. [Google Scholar] [CrossRef]
- Ghani, A.; Aina, A.; See, C.H.; Yu, H.; Keates, S. Accelerated Diagnosis of Novel Coronavirus (COVID-19)—Computer Vision with Convolutional Neural Networks (CNNs). Electronics 2022, 11, 1148. [Google Scholar] [CrossRef]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient speech recognition engine with sparse lstm on fpga. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 75–84. [Google Scholar]
- Ouyang, P.; Yin, S.; Wei, S. A fast and power efficient architecture to parallelize LSTM based RNN for cognitive intelligence applications. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Kadetotad, D.; Yin, S.; Berisha, V.; Chakrabarti, C.; Seo, J.s. An 8.93 TOPS/W LSTM recurrent neural network accelerator featuring hierarchical coarse-grain sparsity for on-device speech recognition. IEEE J. Solid-State Circuits 2020, 55, 1877–1887. [Google Scholar] [CrossRef]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM international conference on multimodal interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Azimirad, V.; Ramezanlou, M.T.; Sotubadi, S.V.; Janabi-Sharifi, F. A consecutive hybrid spiking-convolutional (CHSC) neural controller for sequential decision making in robots. Neurocomputing 2022, 490, 319–336. [Google Scholar] [CrossRef]
- Yin, S.; Ouyang, P.; Tang, S.; Tu, F.; Li, X.; Zheng, S.; Lu, T.; Gu, J.; Liu, L.; Wei, S. A high energy efficient reconfigurable hybrid neural network processor for deep learning applications. IEEE J. Solid-State Circuits 2017, 53, 968–982. [Google Scholar] [CrossRef]
- Liu, S.; Du, Z.; Tao, J.; Dong, H.; Tao, L.; Yuan, X.; Chen, Y.; Chen, T. Cambricon: An Instruction Set Architecture for Neural Networks. In Proceedings of the ACM/IEEE International Symposium on Computer Architecture, Seoul, Korea, 18–22 June 2016. [Google Scholar]
- Liu, D. Embedded DSP Processor Design: Application Specific Instruction Set Processors; Morgan Kaufmann: Burlington, MA, USA, 2008. [Google Scholar]
- Markham, A.; Jia, Y. Caffe2: Portable High-Performance Deep Learning Framework from Facebook; NVIDIA Corporation: Santa Clara, CA, USA, 2017. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the International Conference on Machine Learning, Hong Kong, China, 20-22 November 2015; pp. 1737–1746. [Google Scholar]
- Gysel, P. Ristretto: Hardware-oriented approximation of convolutional neural networks. arXiv 2016, arXiv:1605.06402. [Google Scholar]
- Amdahl, G.M. Validity of the single processor approach to achieving large scale computing capabilities, reprinted from the afips conference proceedings, vol. 30 (atlantic city, nj, apr. 18–20), afips press, reston, va., 1967, pp. 483–485, when dr. amdahl was at international business machines corporation, sunnyvale, california. IEEE Solid-State Circuits Soc. Newsl. 2007, 12, 19–20. [Google Scholar]
- Horowitz, M. Energy Table for 45 nm Process, Stanford VLSI Wiki. Available online: https://sites.google.com/site/seecproject (accessed on 27 February 2020).
- Cong, J.; Xiao, B. Minimizing computation in convolutional neural networks. In International Conference on Artificial Neural Networks; Springer: Heidelberg, Germany, 2014; pp. 281–290. [Google Scholar]
- Gao, M. Scalable Near-Data Processing Systems for Data-Intensive Applications; Stanford University: Stanford, CA, USA, 2018. [Google Scholar]
- Shukla, S.; Fleischer, B.; Ziegler, M.; Silberman, J.; Oh, J.; Srinivasan, V.; Choi, J.; Mueller, S.; Agrawal, A.; Babinsky, T.; et al. A scalable multi-TeraOPS core for AI training and inference. IEEE Solid-State Circuits Lett. 2018, 1, 217–220. [Google Scholar] [CrossRef]
- Ju, Y.; Gu, J. A 65nm Systolic Neural CPU Processor for Combined Deep Learning and General-Purpose Computing with 95% PE Utilization, High Data Locality and Enhanced End-to-End Performance. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65, pp. 1–3. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loop6 | Loop5 | Loop4 | Loop3 | Loop2 | Loop1 | Function1 | Function2 | |
|---|---|---|---|---|---|---|---|---|
| window-sweep | √ | √ | √ | √ | √ | √ | √ | √ |
| martix-vector mul | √ | √ | √ | √ | ||||
| element-wise | √ | √ | √ | √ | √ |
| Function | Approximation Method | Approximation Expression |
|---|---|---|
| sigmoid | segment | |
| tanh | segment | |
| sin | Taylor |
| Operation | Notation | Type | |
|---|---|---|---|
| compute | add | add | type1 |
| subtract | sub | type1 | |
| multiply | mul | type1 | |
| multiply and accumulate | mac | type1 | |
| maximum | max | type1 | |
| triangular accumulate | tacc | type2 | |
| logic | not | not | type2 |
| and | and | type1 | |
| or | or | type1 | |
| shift | shift right | shr | type1 |
| shift left | shl | type1 | |
| control | no operation | nop | type4 |
| clear accumulator register | car | type4 | |
| jump | jmp | type5 | |
| repeat | repeat | type6 | |
| data transfer | copy | copy | type2 |
| load immediate operand | ldi | type3 | |
| Type | Expression | |||||
|---|---|---|---|---|---|---|
| 8 bit | 4 bit | 7 bit | 13 bit | 16 bit | 16 bit | |
| type1 | opcode | cdt | opt | dst | src0 | src1 |
| type2 | opcode | - | - | dst | src0 | - |
| type3 | opcode | - | - | dst | - | - |
| type4 | opcode | - | - | - | - | - |
| Notation | ||
|---|---|---|
| option | shift | shiftr = 0–15/shiftl = 1–15 |
| round | rnd | |
| saturation | sat | |
| condition | equal | eq |
| not equal | neq |
| Operand | Segment | Notation | |||
|---|---|---|---|---|---|
| src0/src1 | dst | 10 bit | addr | reg | reg |
| LVM addr by reg | [reg] | ||||
| imm16 | imm16 | ||||
| accumulator register | acr | ||||
| 3 bit | length | i/ii/iii/iv/v/vi | |||
| - | 3 bit | pattern | w/d/f/e/h/v | ||
| DLP | Soc-Level Scheme | |
|---|---|---|
| Technology | TSMC 65 nm LP | None |
| SRAM | 32 KB | 512 KB |
| Frequency | 200 Mhz | 200 Mhz |
| MAC unit | 32 | 512 |
| Peak Performance | 12.8GOPS | 204.8GOPS |
| Average Performance | 12.25GOPS | 196GOPS |
| Average Power | 25.75 mW | 813 mW |
| Precision | 8-bit Fixed Point | 8-bit Fixed Point |
| AlexNet | <Th, Tl, Tn, Tm> | <Reuse, Broad> | Compute Density |
|---|---|---|---|
| Conv1 | <27, 79, 2, 16> | <IR, WB> | 37 |
| Conv2 | <7, 13, 48, 4> | <WR, IB> | 45 |
| Conv3 | <13, 13, 16, 12> | <OR, IB> | 39 |
| Conv4 | <13, 13, 16, 12> | <OR, IB> | 39 |
| Conv5 | <13, 13, 16, 12> | <OR, IB> | 39 |
| GTX 1080 Ti | ISSCC16 [5] | VLSI18 [25] | ISSCC22 [26] | This Work | |
|---|---|---|---|---|---|
| Process | 16 nm | 65 nm | 14 nm | 65 nm | 65 nm |
| Architecture | GPU | CNN | ASIP | CPU + CNN | ASIP |
| Benchmark | - | AlexNet | ResNet18ResNet50 | VGG16ResNet18 | VGG16AlexNet |
| Frequency | 1582 MHz | 250 MHz | 1500 MHz | 400 MHz | 200 MHz |
| MAC Number | 1582 Core | 168 | 500 | 100 | 512 |
| Bit Frequency | FP32 | INT16 | FP16/32 | INT8 | FXP8 |
| SRAM | 11 GB | 181 KB | 2048 KB | 150 KB | 512 KB |
| MAC/SRAM | - | 0.93 | 0.24 | 0.67 | 1 |
| PE Utilization | - | 68.70% | 92 98% | 95% | 99% |
| Efficiency (TOPS/W) | 0.041 | c: 0.166 s: 0.08 | - | c: 0.66(CNN) | c: 0.475 s: 0.241 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Chen, H.; Liu, D. An ASIP for Neural Network Inference on Embedded Devices with 99% PE Utilization and 100% Memory Hidden under Low Silicon Cost. Sensors 2022, 22, 3841. https://doi.org/10.3390/s22103841
Gao M, Chen H, Liu D. An ASIP for Neural Network Inference on Embedded Devices with 99% PE Utilization and 100% Memory Hidden under Low Silicon Cost. Sensors. 2022; 22(10):3841. https://doi.org/10.3390/s22103841
Chicago/Turabian StyleGao, Muxuan, He Chen, and Dake Liu. 2022. "An ASIP for Neural Network Inference on Embedded Devices with 99% PE Utilization and 100% Memory Hidden under Low Silicon Cost" Sensors 22, no. 10: 3841. https://doi.org/10.3390/s22103841
APA StyleGao, M., Chen, H., & Liu, D. (2022). An ASIP for Neural Network Inference on Embedded Devices with 99% PE Utilization and 100% Memory Hidden under Low Silicon Cost. Sensors, 22(10), 3841. https://doi.org/10.3390/s22103841