
Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network




Abstract
:1. Introduction
- We compared the existing SOTA networks of DL for real-time vehicle detection and classification.
- We minimized the effects of domain-shift that the DL networks suffer from with the help of transfer learning-based fine-tuning.
- We created and provide a vehicle classification dataset of seven vehicle classes.
- We propose a multi-vehicle tracking algorithm that obtains lane-based statistics such as count, speed, and average speed along with the vehicle classification.
2. Related Works and Background
2.1. Vehicle Detection and Classification
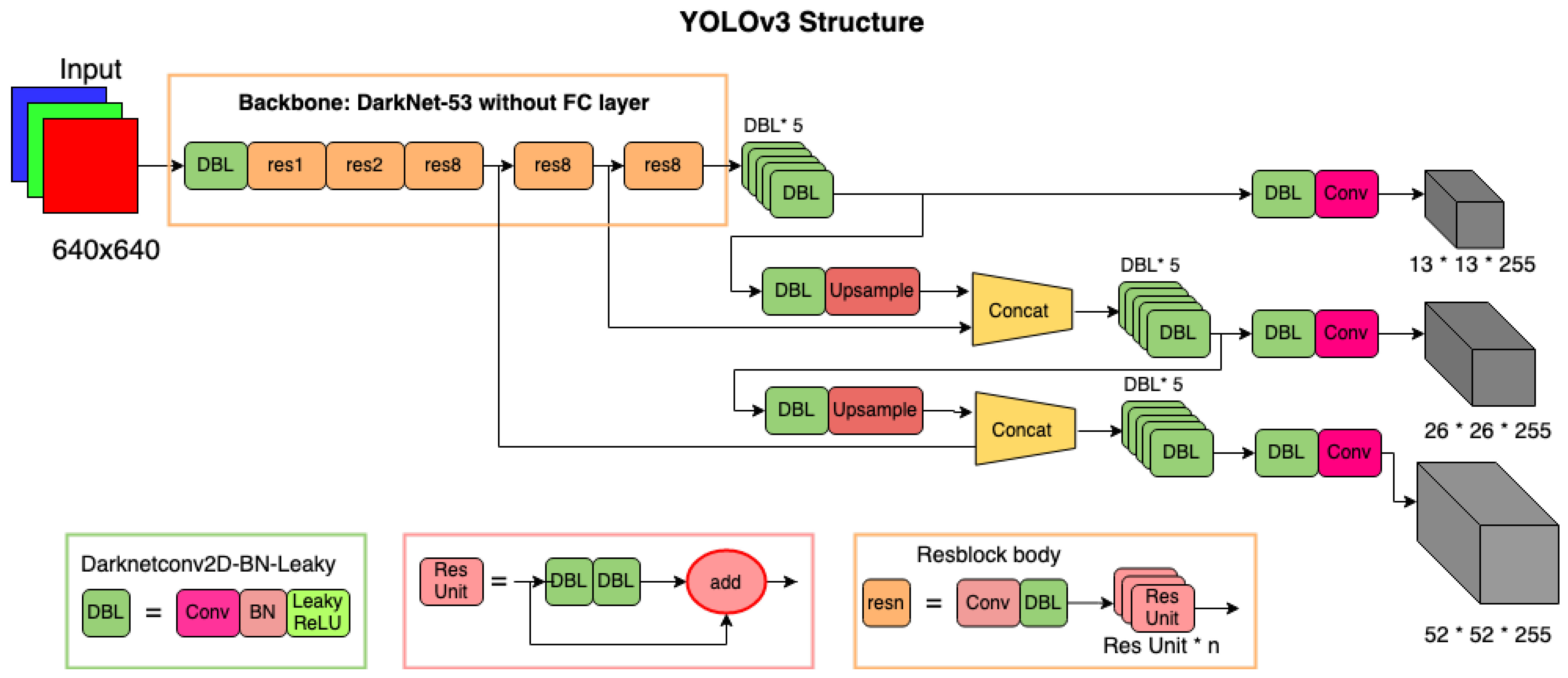
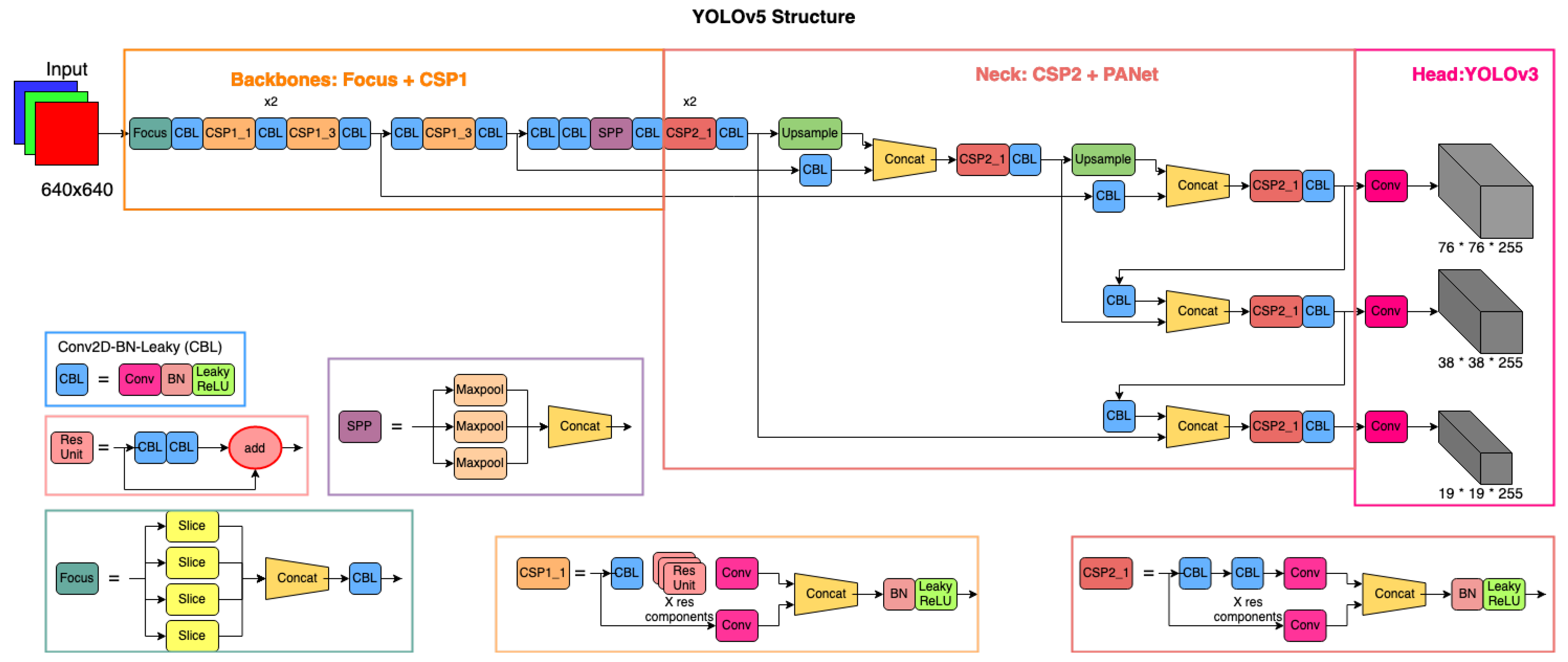
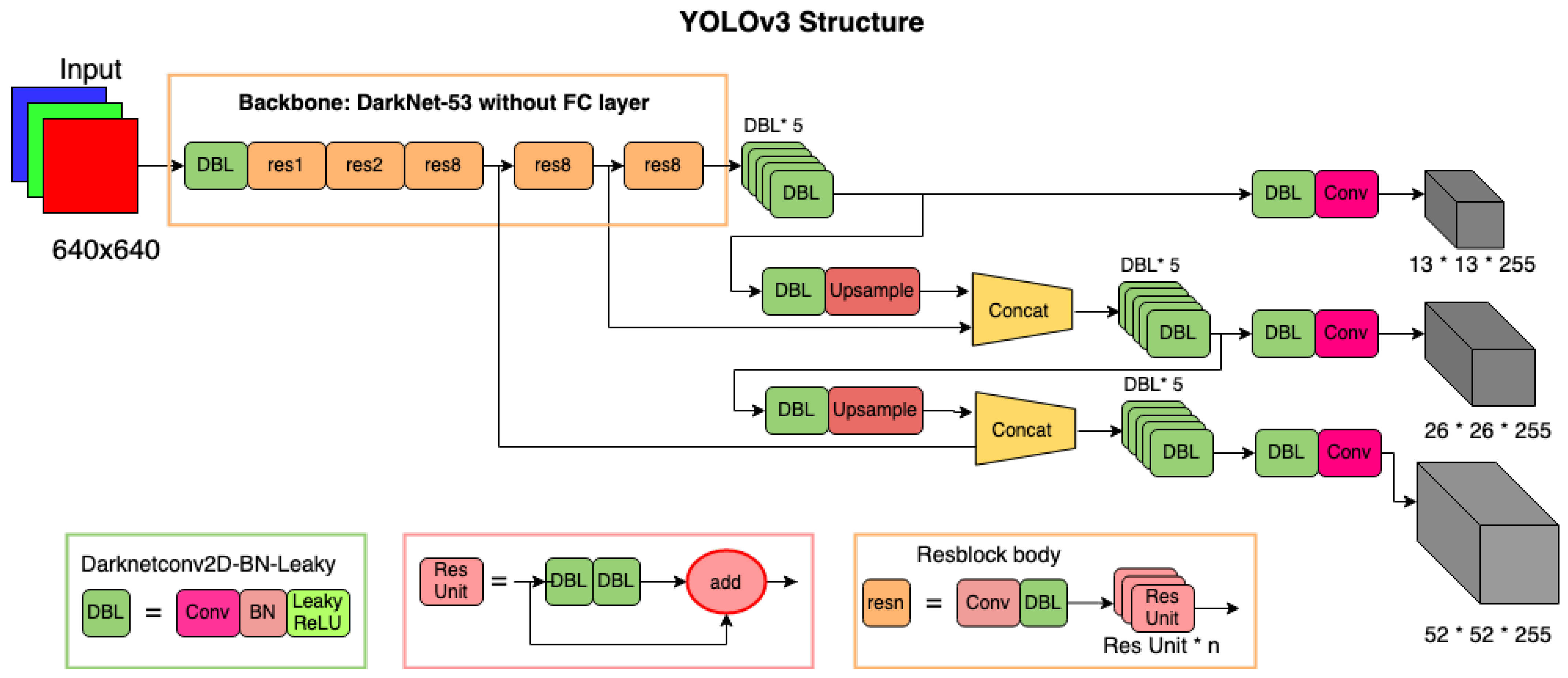
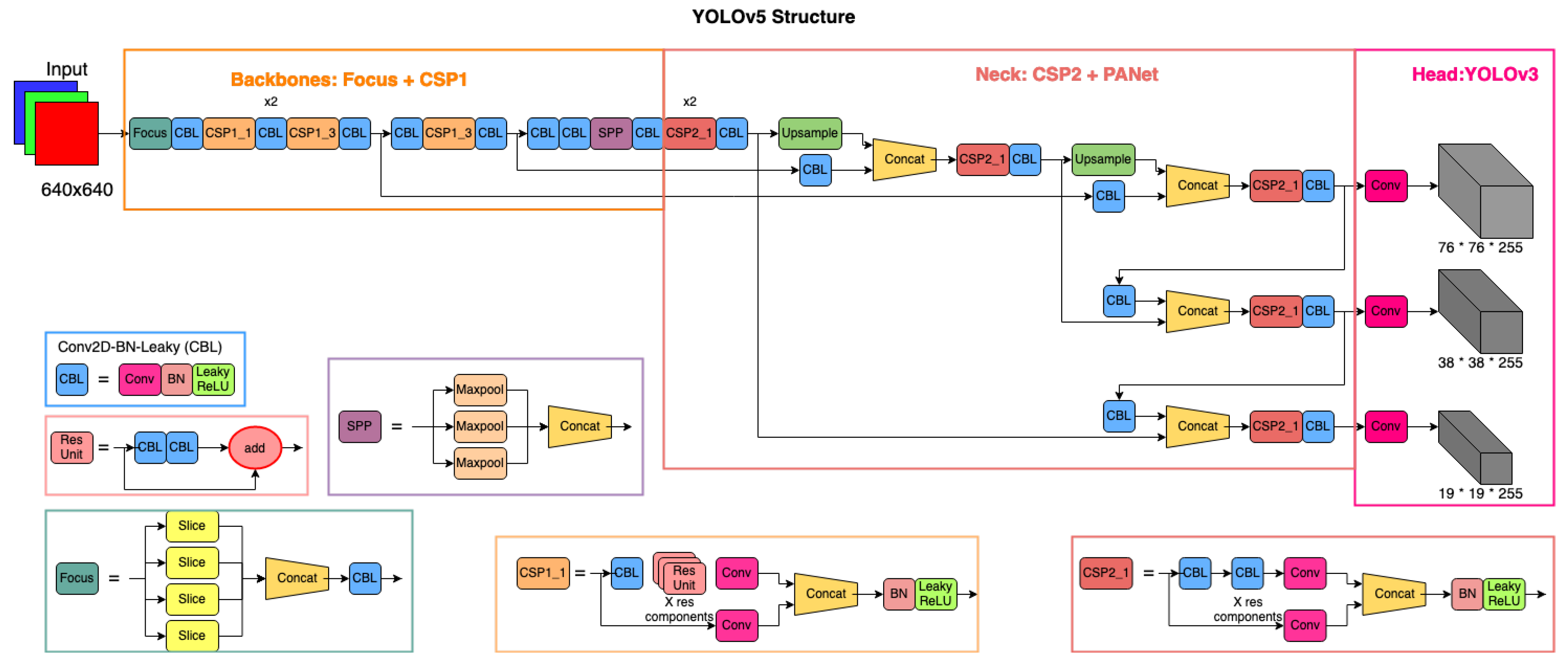
2.2. Vehicle Detection Using YOLO (You Only Look Once)
2.3. Vehicle Tracking
2.4. The Domain-Shift Problem and Transfer Learning
3. Method
3.1. Training Dataset
- TR1 consists of a large number of training samples collected from surveillance videos to train a base Model M1, which was trained for a high number of steps.
- TR2 consists of a small number of samples collected from the cameras used on the highway during the implementation of the overall system to train the fine-tuned Model M2 with the base knowledge transferred from M1.
3.2. YOLO-Based Detection and Classification
3.3. Transfer Learning-Based Fine-Tuning
3.4. Camera Registration and Road ROI Selection
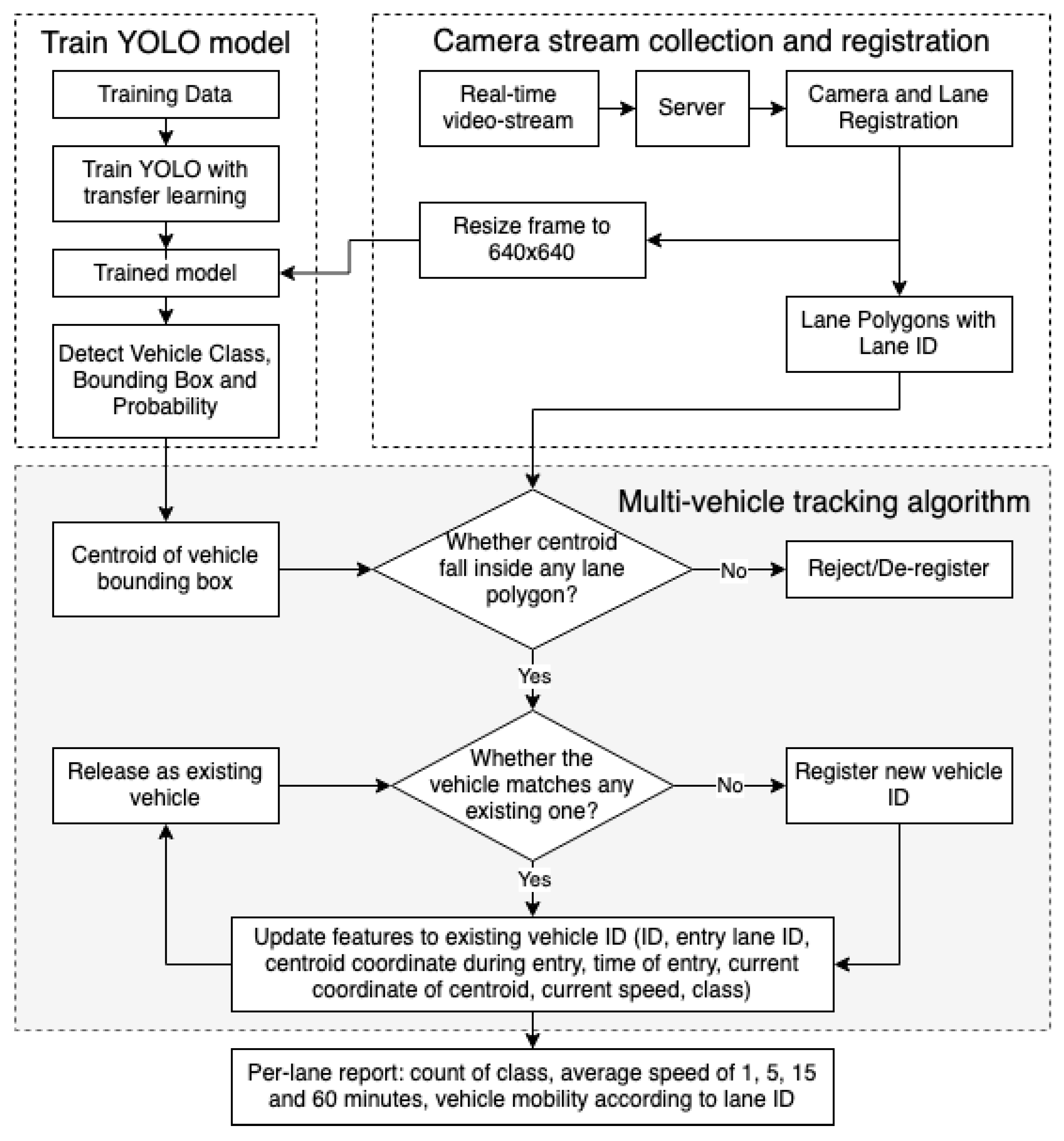
3.5. Multi-Vehicle Tracking with Speed Detection
- Calculate the centroid of the bounding box and check whether the centroid falls inside any registered lane polygons within the video stream.
- (a)
- If not, it is rejected/deregistered, meaning that the vehicle class and bounding box are stored, but do not pass through the tracking process.
- (b)
- If yes, the filtered vehicle is checked as to whether it matches any existing vehicle that was detected in previous image frames.
- If not (the vehicle is new), it is first registered with a new vehicle ID and passed to the step of updating features to the vehicle ID.
- If yes (vehicle exists), it is directly passed to the step of updating features to vehicle ID.
- Update the following features to vehicle ID: the ID of the vehicle, the lane the vehicle entered, the coordinates of the centroid of the vehicle on the image frame it first entered the lane polygon, the time of entry, the latest coordinates of the centroid of the vehicle, and the calculated speed of the vehicle. Calculate the following:
- (a)
- Distance: the difference between the coordinate of the latest and first centroid that entered the lane polygon. Convert distance to meters using the reference length provided earlier while registering the lane.
- (b)
- Time: the difference in time between when the vehicle was first recorded within the lane polygon and the current time recorded.
- (c)
- Speed := distance/time
- Release the vehicle ID as an existing vehicle to be matched with the upcoming vehicles.
- From the feature in Step 2, prepare a per-lane report including the count of class, the average speed in different ranges of time, and the vehicle mobility according to lane ID.
4. Results and Discussion
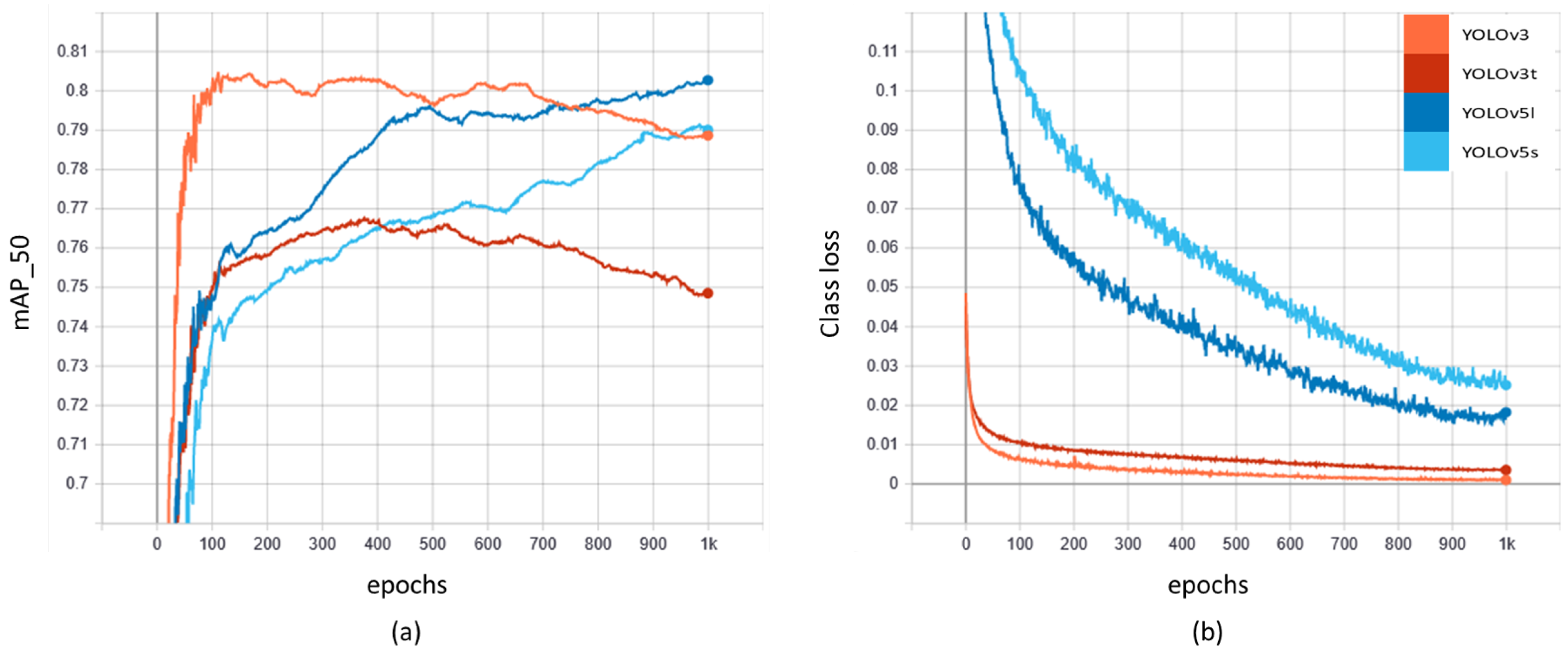
4.1. Training YOLO Models on TR1
4.2. The Domain-Shift Problem and Transfer Learning
4.3. Tracking, Counting, and Speed Detection from Fine-Tuned Networks
4.4. Count and Classification on Different Qualities of the Stream
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Radopoulou, S.C.; Brilakis, I. Improving road asset condition monitoring. Transp. Res. Procedia 2016, 14, 3004–3012. [Google Scholar] [CrossRef] [Green Version]
- United Nations General Assembly. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Kalake, L.; Wan, W.; Hou, L. Analysis Based on Recent Deep Learning Approaches Applied in Real-Time Multi-Object Tracking: A Review. IEEE Access 2021, 9, 32650–32671. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 Jun–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T.; Vilari no, R. Yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 June 2021).
- Chen, Z.; Pears, N.; Freeman, M.; Austin, J. Road vehicle classification using support vector machines. In Proceedings of the 2009 IEEE International Conference on Intelligent Computing and Intelligent Systems, Shanghai, China, 20–22 November 2009; IEEE: Piscataway, NJ, USA, 2009; Volume 4, pp. 214–218. [Google Scholar]
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2421–2424. [Google Scholar]
- Negri, P.; Clady, X.; Hanif, S.M.; Prevost, L. A cascade of boosted generative and discriminative classifiers for vehicle detection. EURASIP J. Adv. Signal Process. 2008, 2008, 782432. [Google Scholar] [CrossRef] [Green Version]
- Uke, N.; Thool, R. Moving vehicle detection for measuring traffic count using opencv. J. Autom. Control Eng. 2013, 1. [Google Scholar] [CrossRef]
- Ferryman, J.M.; Worrall, A.D.; Sullivan, G.D.; Baker, K.D. A Generic Deformable Model for Vehicle Recognition. In Proceedings of the British Machine Vision Conference, Birmingham, UK, 11–14 September 1995; BMVC Press: Guildford, UK, 1995; Volume 1, pp. 127–136. [Google Scholar]
- Jung, H.; Choi, M.K.; Jung, J.; Lee, J.H.; Kwon, S.; Young Jung, W. ResNet-based vehicle classification and localization in traffic surveillance systems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 61–67. [Google Scholar]
- Zhuo, L.; Jiang, L.; Zhu, Z.; Li, J.; Zhang, J.; Long, H. Vehicle classification for large-scale traffic surveillance videos using convolutional neural networks. Mach. Vis. Appl. 2017, 28, 793–802. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6569–6578. [Google Scholar]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef] [Green Version]
- Du, L.; Chen, W.; Fu, S.; Kong, H.; Li, C.; Pei, Z. Real-time detection of vehicle and traffic light for intelligent and connected vehicles based on YOLOv3 network. In Proceedings of the 5th International Conference on Transportation Information and Safety (ICTIS), Liverpool, UK, 14–17 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 388–392. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Yuan, Y.; Shi, C. Object tracking using SIFT features and mean shift. Comput. Vis. Image Underst. 2009, 113, 345–352. [Google Scholar] [CrossRef]
- Mahto, P.; Garg, P.; Seth, P.; Panda, J. Refining Yolov4 for Vehicle Detection. Int. J. Adv. Res. Eng. Technol. (IJARET) 2020, 11, 409–419. [Google Scholar]
- Wu, C.W.; Zhong, M.T.; Tsao, Y.; Yang, S.W.; Chen, Y.K.; Chien, S.Y. Track-clustering error evaluation for track-based multi-camera tracking system employing human re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–9. [Google Scholar]
- Meyer, D.; Denzler, J.; Niemann, H. Model based extraction of articulated objects in image sequences for gait analysis. In Proceedings of the International Conference on Image Processing, Santa Barbara, CA, USA, 26–29 October 1997; IEEE: Piscataway, NJ, USA, 1997; Volume 3, pp. 78–81. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cui, Z.; Xiao, S.; Feng, J.; Yan, S. Recurrently target-attending tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1449–1458. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Zhang, Y.; Wang, J.; Yang, X. Real-time vehicle detection and tracking in video based on faster R-CNN. J. Phys. Conf. Ser. 2017, 887, 012068. [Google Scholar] [CrossRef]
- Exner, D.; Bruns, E.; Kurz, D.; Grundhöfer, A.; Bimber, O. Fast and robust CAMShift tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 9–16. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; TR 95-041; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Wang, Y. A Novel Vehicle Tracking Algorithm Using Video Image Processing. In Proceedings of the 2018 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Hunan, China, 10–11 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5–8. [Google Scholar]
- Hou, X.; Wang, Y.; Chau, L.P. Vehicle tracking using deep sort with low confidence track filtering. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Liu, T.; Liu, Y. Deformable model-based vehicle tracking and recognition using 3-D constrained multiple-Kernels and Kalman filter. IEEE Access 2021, 9, 90346–90357. [Google Scholar] [CrossRef]
- Wende, F.; Cordes, F.; Steinke, T. On improving the performance of multi-threaded CUDA applications with concurrent kernel execution by kernel reordering. In Proceedings of the 2012 Symposium on Application Accelerators in High Performance Computing, Argonne, IL, USA, 10–11 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 74–83. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Neupane, B.; Horanont, T.; Aryal, J. Deep learning-based semantic segmentation of urban features in satellite images: A review and meta-analysis. Remote Sensing 2021, 13, 808. [Google Scholar] [CrossRef]
- Majid Roodposhti, S.; Aryal, J.; Lucieer, A.; Bryan, B. Uncertainty assessment of hyperspectral image classification: Deep learning vs. random forest. Entropy 2019, 21, 78. [Google Scholar] [CrossRef] [Green Version]
- Kouw, W.M.; Loog, M. An introduction to domain adaptation and transfer learning. arXiv 2018, arXiv:1812.11806. [Google Scholar]
- Taormina, V.; Cascio, D.; Abbene, L.; Raso, G. Performance of fine-tuning convolutional neural networks for HEP-2 image classification. Appl. Sci. 2020, 10, 6940. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, H.; Huang, Y.; Ding, X. Vehicle type recognition in surveillance images from labeled web-nature data using deep transfer learning. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2913–2922. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, L.; Chen, X. A vehicle recognition algorithm based on deep transfer learning with a multiple feature subspace distribution. Sensors 2018, 18, 4109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jo, S.Y.; Ahn, N.; Lee, Y.; Kang, S.J. Transfer learning-based vehicle classification. In Proceedings of the 2018 International SoC Design Conference (ISOCC), Daegu, Korea, 12–15 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 127–128. [Google Scholar]
- Nezafat, R.V.; Salahshour, B.; Cetin, M. Classification of truck body types using a deep transfer learning approach. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3144–3149. [Google Scholar]
- Zhang, G.; Zhang, D.; Lu, X.; Cao, Y. Smoky Vehicle Detection Algorithm Based On Improved Transfer Learning. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 155–159. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lv, N.; Xiao, J.; Qiao, Y. Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model. Processes 2022, 10, 701. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle Type | TR1 Samples | Labels for TR2 | TR2 Samples |
|---|---|---|---|
| Car | 10,478 | 2276 | 2585 |
| Bus | 540 + 4431 | 20 | 274 |
| Taxi | 1605 | 232 | 323 |
| Bike | 2572 | 508 | 562 |
| Pickup | 6056 | 1868 | 2042 |
| Truck | 2656 | 524 | 666 |
| Trailer | 1179 | 81 | 160 |
| Total | 29,474 | 5509 | 6612 |
| Classes | Average Precision (AP) | |||
|---|---|---|---|---|
| YOLOv3 | YOLOv3t | YOLOv5l | YOLOv5s | |
| car | 0.770 | 0.739 | 0.797 | 0.790 |
| bus | 0.933 | 0.906 | 0.926 | 0.913 |
| taxi | 0.765 | 0.788 | 0.846 | 0.849 |
| bike | 0.775 | 0.694 | 0.780 | 0.773 |
| pickup | 0.726 | 0.647 | 0.733 | 0.674 |
| truck | 0.849 | 0.819 | 0.828 | 0.841 |
| trailer | 0.703 | 0.648 | 0.708 | 0.690 |
| mAP_50 | 0.789 | 0.749 | 0.803 | 0.790 |
| Class Loss | 0.001 | 0.003 | 0.018 | 0.025 |
| Train time (hours) | 101.03 | 35.03 | 65.03 | 37.01 |
| Model Size (MB) | 120.56 | 17.02 | 91.58 | 14.07 |
| Classes | Average Precision (AP) | |||
|---|---|---|---|---|
| YOLOv3 | YOLOv3t | YOLOv5l | YOLOv5s | |
| car | 0.314 | 0.338 | 0.326 | 0.369 |
| bus | 0.22 | 0.172 | 0.158 | 0.16 |
| taxi | 0.538 | 0.468 | 0.536 | 0.503 |
| bike | 0.338 | 0.258 | 0.358 | 0.304 |
| pickup | 0.296 | 0.268 | 0.279 | 0.284 |
| truck | 0.255 | 0.178 | 0.199 | 0.071 |
| trailer | 0.129 | 0.105 | 0.041 | 0.023 |
| mAP_50 | 0.299 | 0.255 | 0.271 | 0.245 |
| Classes | Average Precision (AP) | |||
|---|---|---|---|---|
| YOLOv3 | YOLOv3t | YOLOv5l | YOLOv5s | |
| car | 0.764 | 0.755 | 0.722 | 0.745 |
| bus | 0.861 | 0.761 | 0.762 | 0.750 |
| taxi | 0.660 | 0.687 | 0.733 | 0.673 |
| bike | 0.792 | 0.724 | 0.817 | 0.784 |
| pickup | 0.757 | 0.719 | 0.686 | 0.711 |
| truck | 0.688 | 0.584 | 0.654 | 0.628 |
| trailer | 0.447 | 0.457 | 0.499 | 0.492 |
| mAP_50 | 0.710 | 0.670 | 0.695 | 0.683 |
| Class Loss | 0.015 | 0.028 | 0.033 | 0.036 |
| Train time (hours) | 7.83 | 2.83 | 7.98 | 2.55 |
| Model Size (MB) | 120.59 | 17.02 | 91.61 | 14.09 |
| Camera | No. of Frames | Vehicle Face | Class | GT | YOLOv3 | YOLOv3t | YOLOv5l | YOLOv5s | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | OA | P | R | OA | P | R | OA | P | R | OA | |||||
| Cam 1 | 7500 | Back | car | 217 | 0.99 | 0.95 | 0.97 | 0.96 | 0.91 | 0.93 | 0.99 | 0.97 | 0.98 | 0.98 | 0.91 | 0.95 |
| bus | 5 | 0.56 | 1.00 | 0.78 | 0.80 | 0.80 | 0.80 | 1.00 | 0.80 | 0.90 | 0.80 | 0.80 | 0.80 | |||
| taxi | 6 | 0.86 | 1.00 | 0.93 | 0.86 | 1.00 | 0.93 | 0.75 | 1.00 | 0.88 | 0.86 | 1.00 | 0.93 | |||
| bike | 20 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.95 | 1.00 | 0.98 | 1.00 | 0.90 | 0.95 | |||
| pickup | 99 | 0.98 | 0.86 | 0.92 | 0.92 | 0.86 | 0.89 | 0.98 | 0.96 | 0.97 | 0.88 | 0.84 | 0.86 | |||
| truck | 4 | 0.33 | 0.50 | 0.42 | 0.43 | 0.75 | 0.59 | 0.60 | 0.75 | 0.68 | 0.43 | 0.75 | 0.59 | |||
| trailer | 1 | 0.50 | 1.00 | 0.75 | 0.50 | 1.00 | 0.75 | 1.00 | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | |||
| Total | 352 | 0.74 | 0.90 | 0.82 | 0.78 | 0.90 | 0.84 | 0.90 | 0.93 | 0.91 | 0.71 | 0.74 | 0.72 | |||
| Cam 2 | 9060 | Side | car | 16 | 1.00 | 0.88 | 0.94 | 1.00 | 0.94 | 0.97 | 1.00 | 0.94 | 0.97 | 0.93 | 0.88 | 0.90 |
| bike | 1 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||
| pickup | 12 | 0.85 | 0.92 | 0.88 | 0.92 | 0.92 | 0.92 | 0.92 | 1.00 | 0.96 | 0.83 | 0.83 | 0.83 | |||
| truck | 3 | 0.75 | 1.00 | 0.88 | 0.75 | 1.00 | 0.88 | 1.00 | 1.00 | 1.00 | 0.43 | 1.00 | 0.71 | |||
| trailer | 4 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.25 | 0.63 | |||
| Total | 36 | 0.92 | 0.96 | 0.94 | 0.93 | 0.97 | 0.95 | 0.98 | 0.99 | 0.99 | 0.84 | 0.79 | 0.82 | |||
| Cam 3 | 8800 | Side | car | 87 | 0.96 | 0.93 | 0.95 | 0.99 | 0.86 | 0.92 | 0.98 | 0.94 | 0.96 | 0.99 | 0.83 | 0.91 |
| taxi | 6 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||
| bike | 12 | 1.00 | 0.83 | 0.92 | 1.00 | 0.83 | 0.92 | 1.00 | 0.83 | 0.92 | 1.00 | 0.83 | 0.92 | |||
| pickup | 91 | 0.93 | 0.93 | 0.93 | 0.87 | 0.97 | 0.92 | 0.96 | 0.98 | 0.97 | 0.86 | 1.00 | 0.93 | |||
| truck | 12 | 1.00 | 0.58 | 0.79 | 0.86 | 0.50 | 0.68 | 0.92 | 1.00 | 0.96 | 0.82 | 0.75 | 0.78 | |||
| trailer | 3 | 0.43 | 1.00 | 0.71 | 0.43 | 1.00 | 0.71 | 1.00 | 0.67 | 0.83 | 0.67 | 0.33 | 0.50 | |||
| Total | 211 | 0.89 | 0.88 | 0.88 | 0.86 | 0.86 | 0.86 | 0.98 | 0.90 | 0.94 | 0.89 | 0.79 | 0.84 | |||
| Cam 4 | 9575 | Front | car | 149 | 0.96 | 0.89 | 0.92 | 0.88 | 0.92 | 0.90 | 0.95 | 0.97 | 0.96 | 0.92 | 0.95 | 0.94 |
| taxi | 4 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||
| bike | 25 | 1.00 | 0.96 | 0.98 | 1.00 | 0.96 | 0.98 | 1.00 | 1.00 | 1.00 | 0.96 | 1.00 | 0.98 | |||
| pickup | 73 | 0.81 | 0.92 | 0.86 | 0.82 | 0.75 | 0.79 | 0.94 | 0.90 | 0.92 | 0.91 | 0.84 | 0.87 | |||
| truck | 5 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |||
| Total | 256 | 0.95 | 0.95 | 0.95 | 0.94 | 0.93 | 0.93 | 0.98 | 0.98 | 0.98 | 0.96 | 0.96 | 0.96 | |||
| Grand Total | 855 | 0.88 | 0.92 | 0.90 | 0.88 | 0.92 | 0.90 | 0.96 | 0.95 | 0.95 | 0.85 | 0.82 | 0.83 | |||
| Video | Frames | Manual Count | Method Count | OA |
|---|---|---|---|---|
| Vid 1 | 90,000 | 3617 | 3390 | 93.7 |
| Vid 2 | 7500 | 552 | 545 | 98.7 |
| Vid 3 | 7500 | 514 | 512 | 99.6 |
| Vid 4 | 7500 | 14 | 12 | 85.7 |
| Average Acc. | 94.4 | |||
| Video | Frames | Correct Classif. | False Classif. | R | P | OA |
|---|---|---|---|---|---|---|
| Vid 1 (Noisy) | 90,000 | 2851 | 766 | 78.8 | 84.1 | 81.4 |
| Vid 3 (Clear) | 15,000 | 470 | 30 | 94.0 | 94.0 | 94.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neupane, B.; Horanont, T.; Aryal, J. Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network. Sensors 2022, 22, 3813. https://doi.org/10.3390/s22103813
Neupane B, Horanont T, Aryal J. Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network. Sensors. 2022; 22(10):3813. https://doi.org/10.3390/s22103813
Chicago/Turabian StyleNeupane, Bipul, Teerayut Horanont, and Jagannath Aryal. 2022. "Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network" Sensors 22, no. 10: 3813. https://doi.org/10.3390/s22103813
APA StyleNeupane, B., Horanont, T., & Aryal, J. (2022). Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network. Sensors, 22(10), 3813. https://doi.org/10.3390/s22103813