
Performance Evaluation of a Voice-Based Depression Assessment System Considering the Number and Type of Input Utterances

 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Ethical Considerations
2.2. Subjects
2.3. Voice Recordings
2.4. Voice Analysis
3. Results
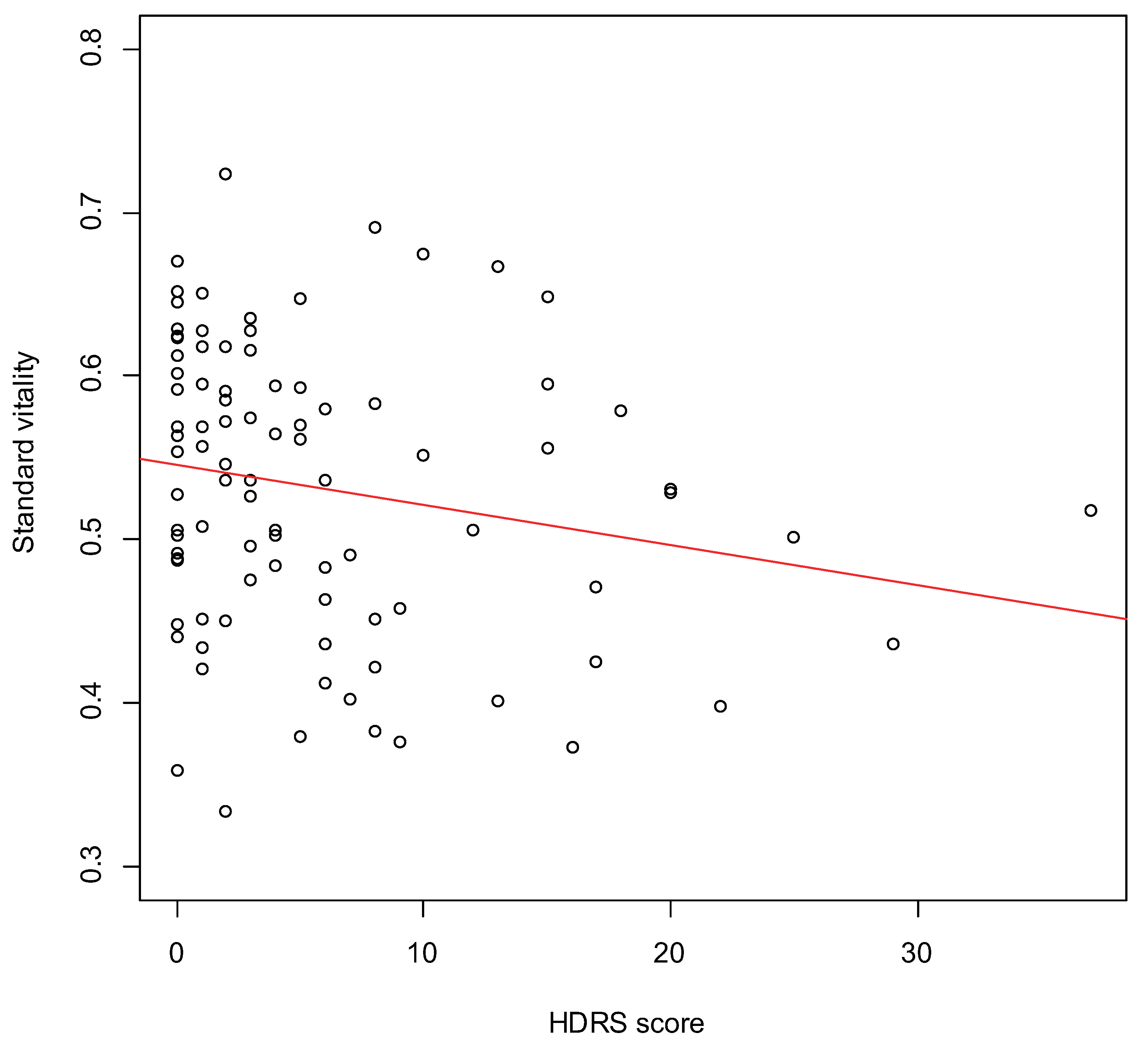
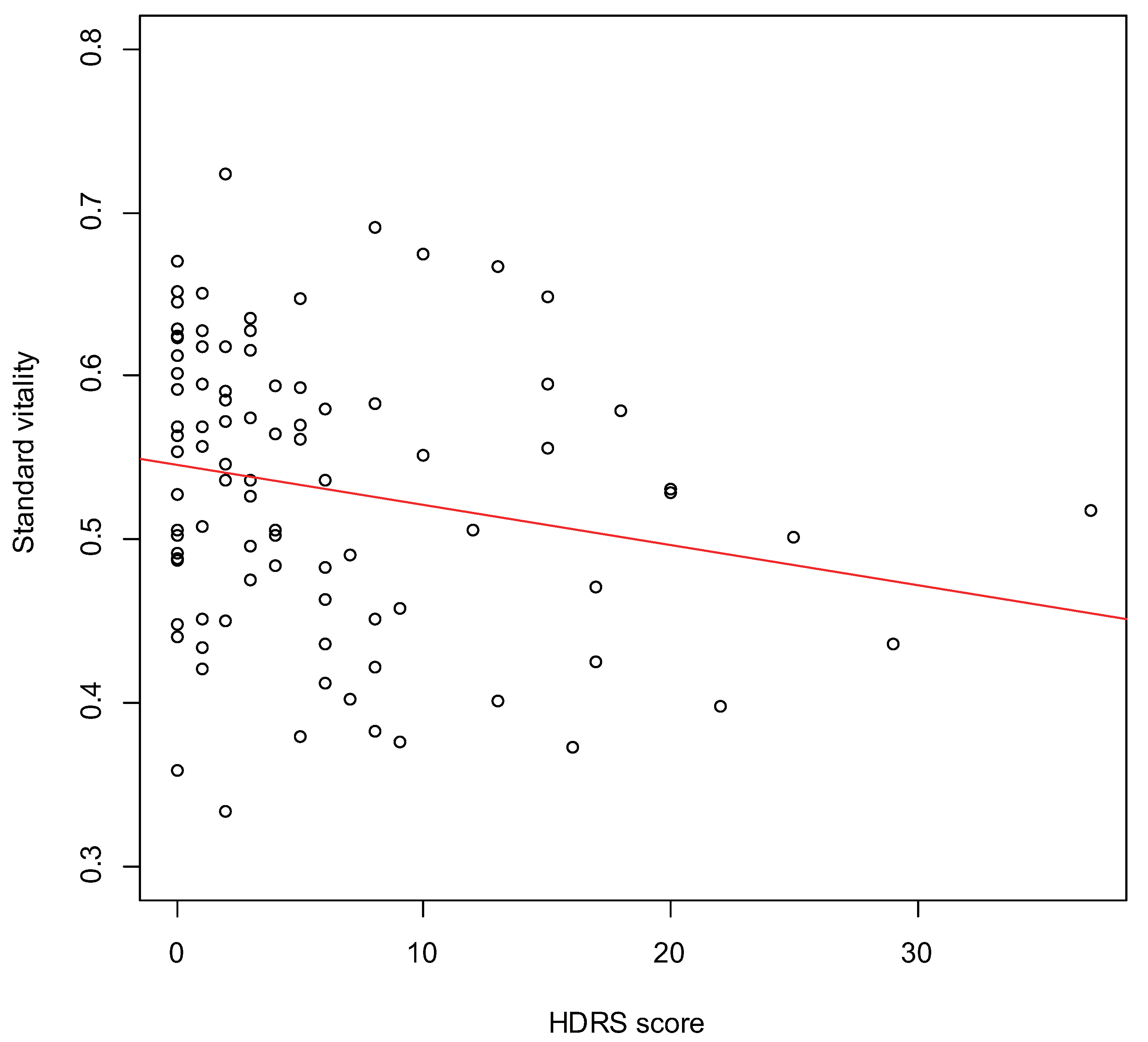
3.1. Validity of Vitality
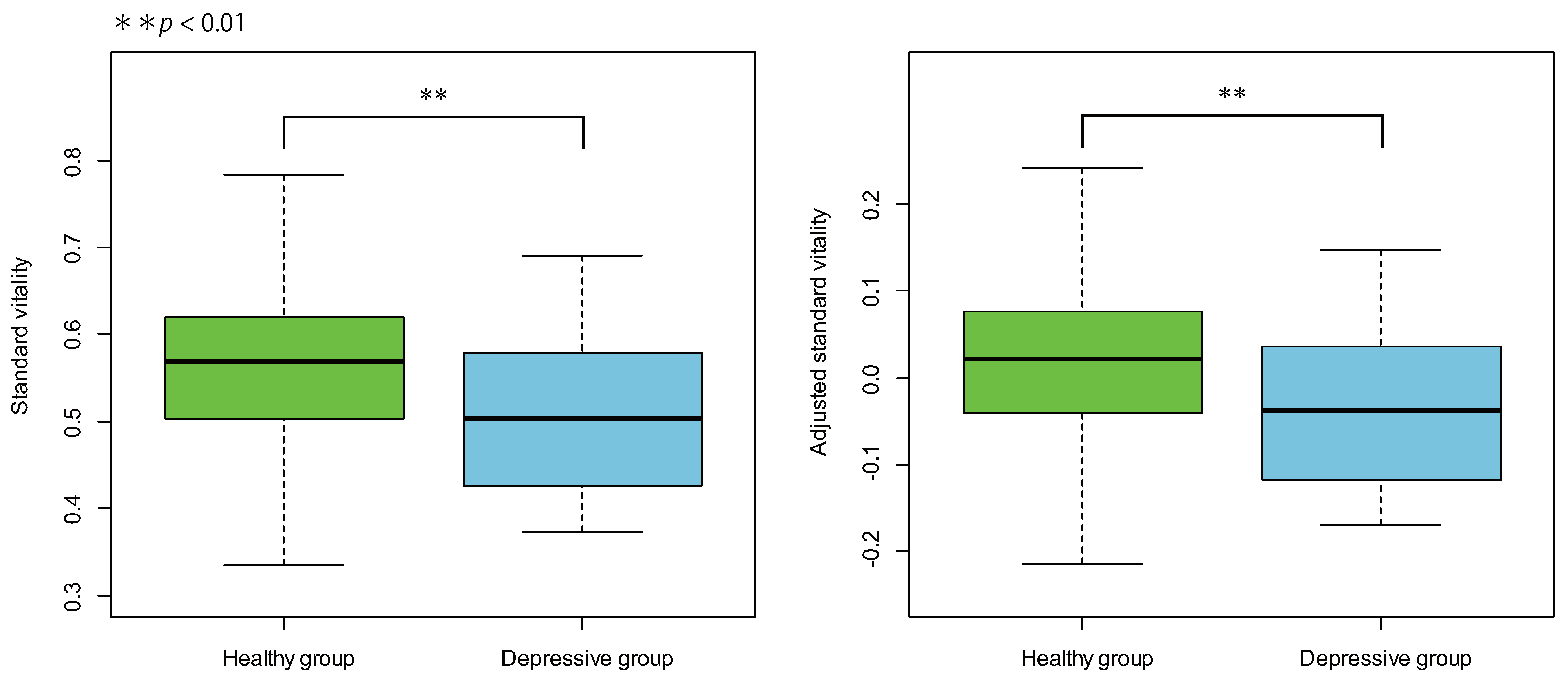
3.2. Differences Due to Recording Location
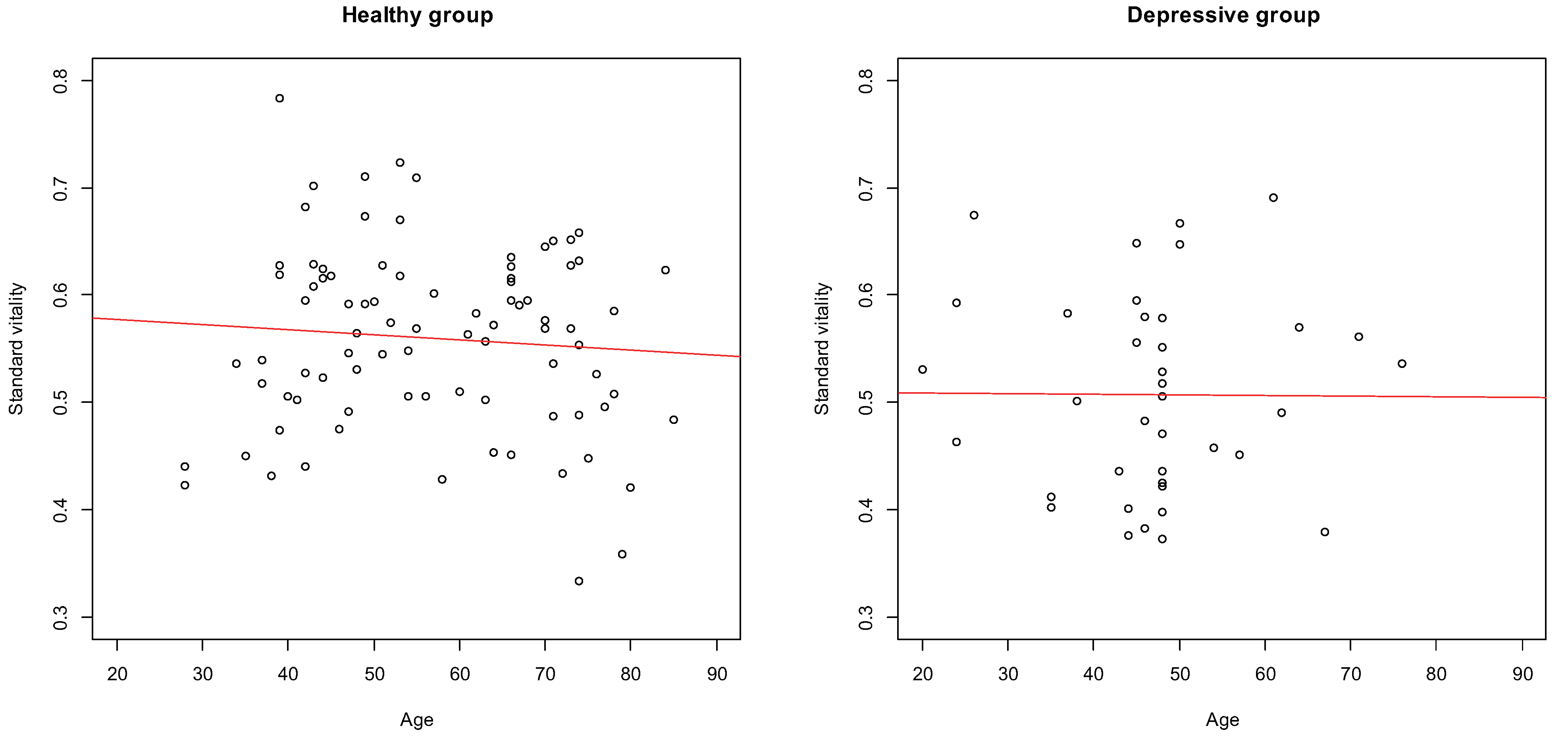
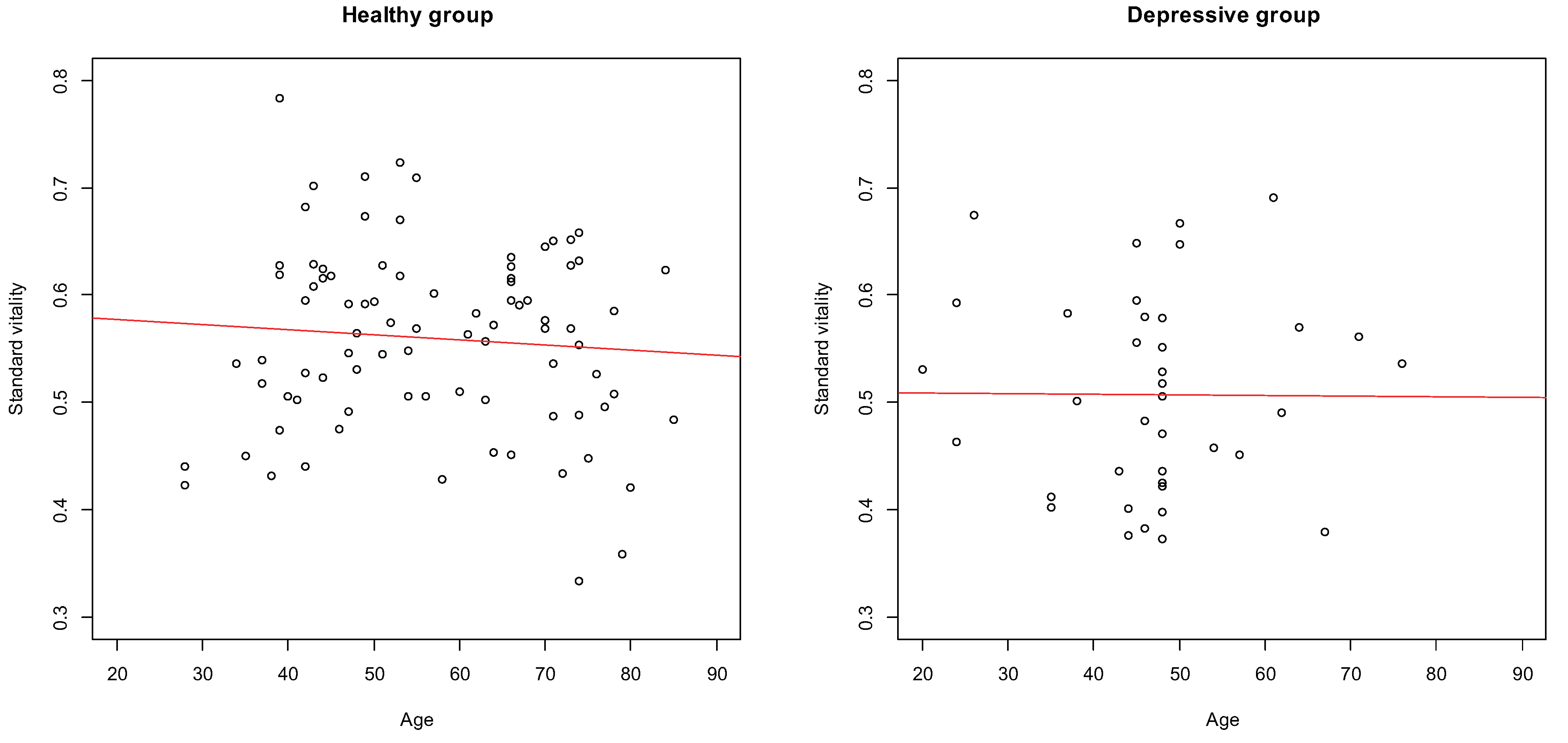
3.3. Differences Due Age
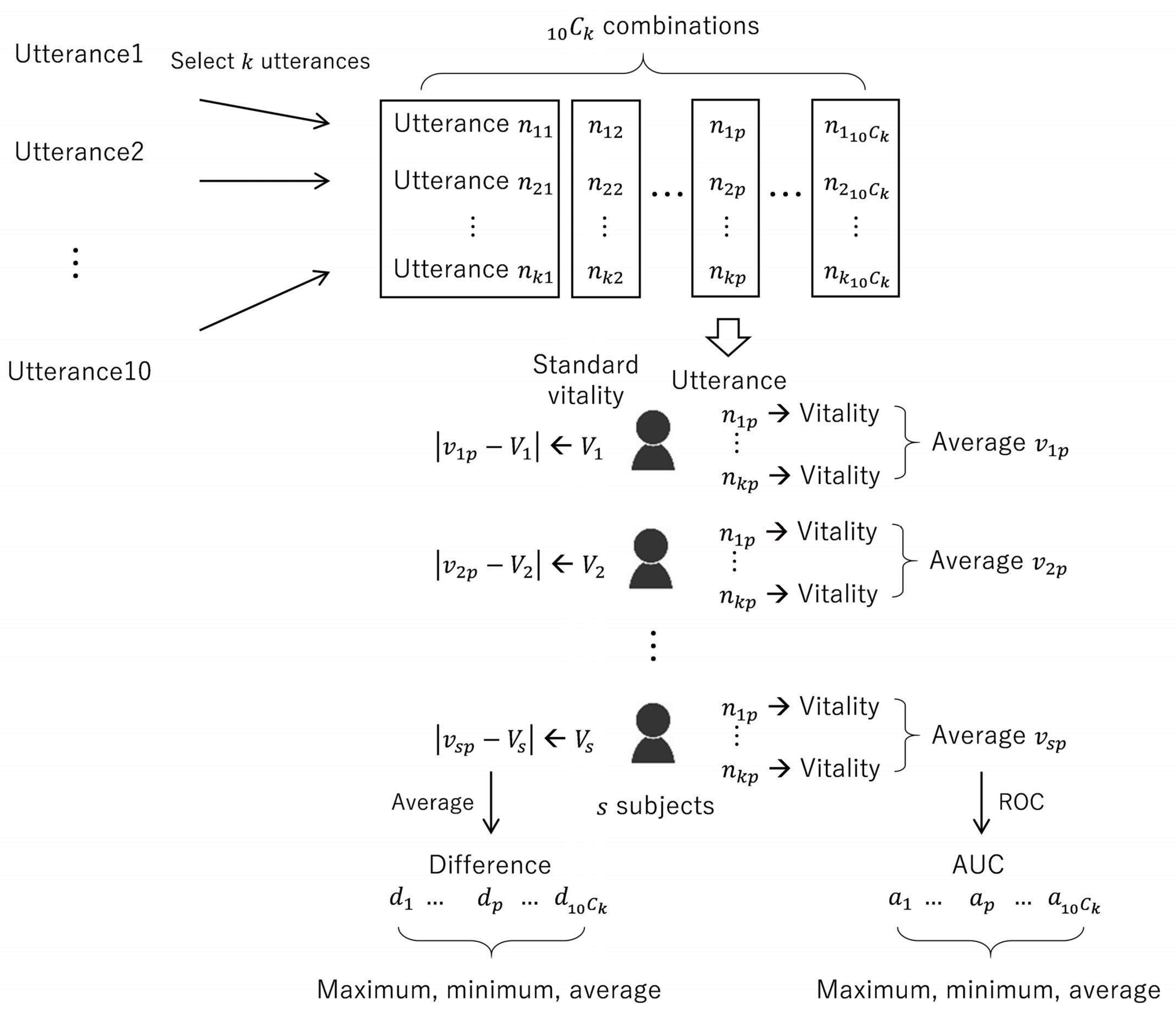
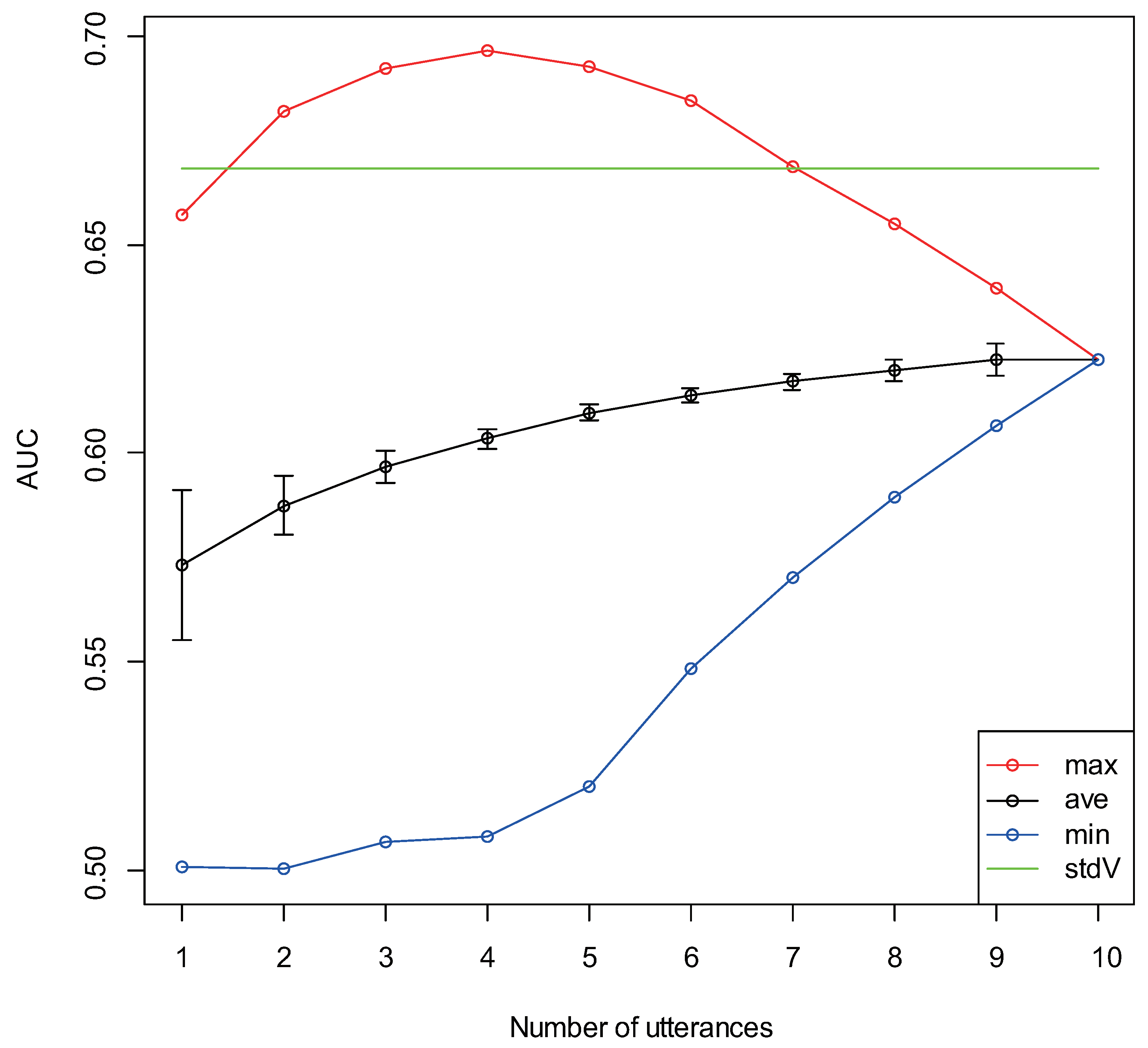
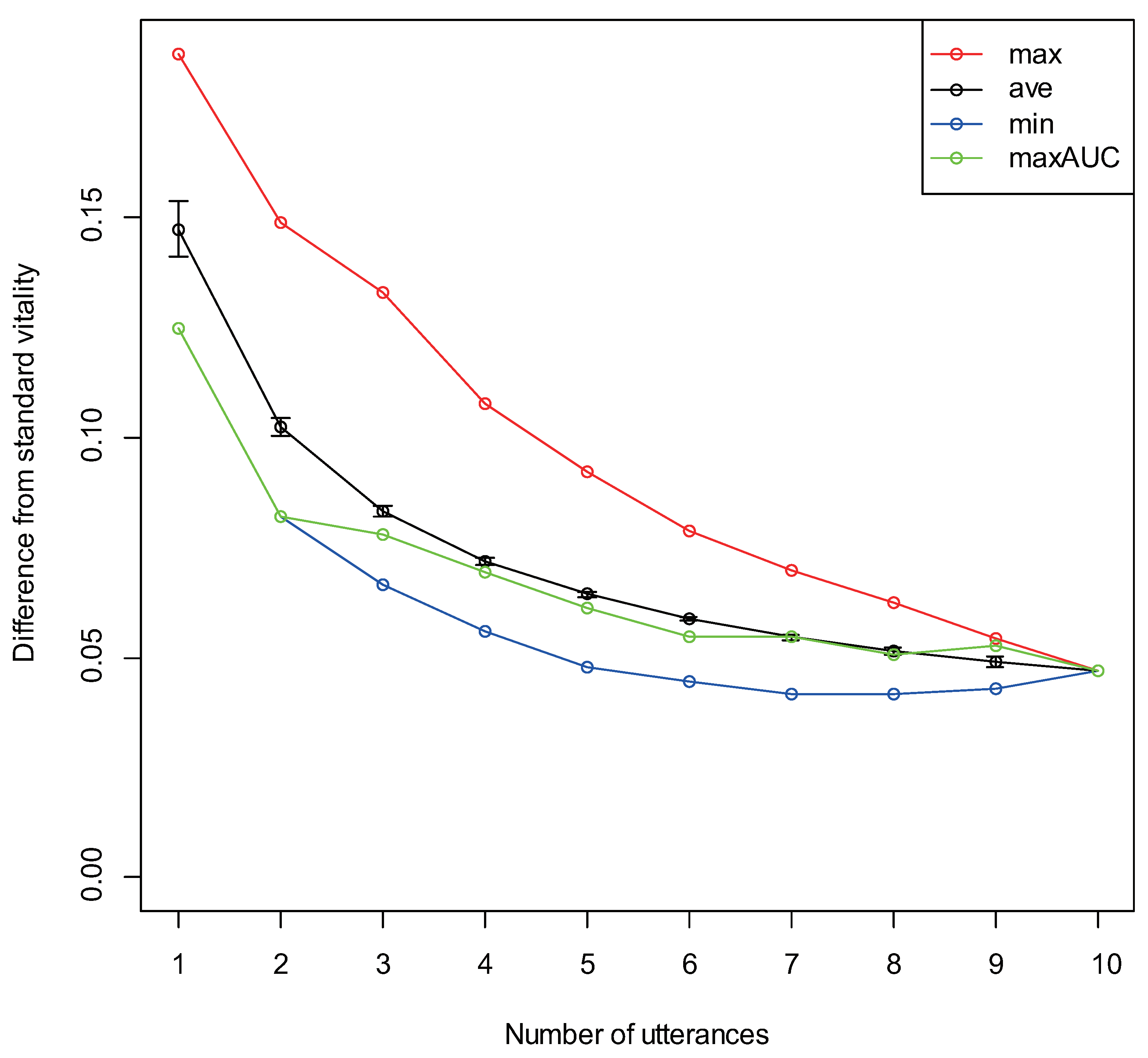
3.4. Differences Due to Number of Utterances
3.5. Differences Due to Type of Utterance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PHQ9 | Patient Health Questionnaire 9 |
| GHQ | General Health Questionnaire |
| BDI | Beck Depression Inventory |
| HDRS/HAM-D | Hamilton Depression Rating Scale |
| SDKs | Software Development Kits |
| MIMOSYS | Mind Monitoring System |
| ST | Sensibility Technology |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
References
- Cohen, S.; Kessler, R.C.; Gordon, L.U. Measuring Stress: A Guide for Health and Social Scientists; Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Perkins, A. Saving money by reducing stress. Harvard Bus. Rev. 1994, 72, 12. [Google Scholar]
- Okumura, Y.; Higuchi, T. Cost of depression among adults in Japan. Prim. Care Companion CNS Disord. 2011, 13, e1–e9. [Google Scholar] [CrossRef]
- Okuda, A.; Suzuki, T.; Kishi, T.; Yamanouchi, Y.; Umeda, K.; Haitoh, H.; Hashimoto, S.; Ozaki, N.; Iwata, N. Duration of untreated illness and antidepressant fluvoxamine response in major depressive disorder. Psychiatry Clin. Neurosci. 2010, 64, 268–273. [Google Scholar] [CrossRef] [PubMed]
- Izawa, S.; Sugaya, N.; Shirotsuki, K.; Yamada, K.C.; Ogawa, N.; Ouchi, Y.; Nagano, Y.; Suzuki, K.; Nomura, S. Salivary dehydroepiandrosterone secretion in response to acute psychosocial stress and its correlations with biological and psychological changes. Biol. Psychol. 2008, 79, 294–298. [Google Scholar] [CrossRef]
- Suzuki, G.; Tokuno, S.; Nibuya, M.; Ishida, T.; Yamamoto, T.; Mukai, Y.; Mitani, K.; Tsumatori, G.; Scott, D.; Shimizu, K. Decreased plasma brain-derived neurotrophic factor and vascular endothelial growth factor concentrations during military training. PLoS ONE 2014, 9, e89455. [Google Scholar] [CrossRef] [PubMed]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B. The PHQ-9: Validity of a brief depression severity measure. J. Gen. Intern. Med. 2001, 16, 606–613. [Google Scholar] [CrossRef] [PubMed]
- Goldberg, D.P. Manual of the General Health Questionnaire; NFER Publishing: Windsor, UK, 1978. [Google Scholar]
- Beck, A.T.; Ward, C.H.; Mendelson, M.; Mock, J.; Erbaugh, J. An inventory for measuring depression. Arch. Gen. Psychiatry 1961, 4, 561–571. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Delgado-Rodríguez, M.; Llorca, J. Bias. J. Epidemiol. Community Health 2004, 58, 635–641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamilton, M. A rating scale for depression. J. Neurol. Neurosurg. Psychiatry 1960, 23, 56–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ekman, P. Facial expressions of emotion: New findings, new questions. Psychol. Sci. 1992, 3, 34–38. [Google Scholar] [CrossRef]
- Kitahara, Y.; Tohkura, Y. Prosodic control to express emotions for man-machine speech interaction. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 1992, E75-A, 155–163. [Google Scholar]
- Jan, A.; Meng, H.; Gaus, Y.F.A.; Zhang, F.; Turabzadeh, S. Automatic depression scale prediction using facial expression dynamics and regression. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; pp. 73–80. [Google Scholar]
- Mitsuyoshi, S.; Nakamura, M.; Omiya, Y.; Shinohara, S.; Hagiwara, N.; Tokuno, S. Mental status assessment of disaster relief personnel by vocal affect display based on voice emotion recognition. Disaster Mil. Med. 2017, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, H.; Hu, B.; Liu, Z.; Yan, L.; Wang, T.; Liu, F.; Kang, H.; Li, X. Investigation of different speech types and emotions for detecting depression using different classifiers. Speech Commun. 2017, 90, 39–46. [Google Scholar] [CrossRef]
- Mundt, J.C.; Vogel, A.P.; Feltner, D.E.; Lenderking, W.R. Vocal acoustic biomarkers of depression severity and treatment response. Biol. Psychiatry 2012, 72, 580–587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shinohara, S.; Nakamura, M.; Omiya, Y.; Higuchi, H.; Hagiwara, N.; Mitsuyoshi, S.; Toda, H.; Saito, T.; Tanichi, M.; Yoshino, A.; et al. Depressive mood assessment method based on emotion level derived from voice: Comparison of voice features of individuals with major depressive disorders and healthy controls. Int. J. Environ. Res. Public Health 2021, 18, 5435. [Google Scholar] [CrossRef] [PubMed]
- Tokuno, S. Pathophysiological voice analysis for diagnosis and monitoring of depression. In Understanding Depression; Kim, Y.K., Ed.; Springer: Singapore, 2018; pp. 83–95. [Google Scholar]
- Fiedler, K. Affective influences on social information processing. In Handbook of Affect and Social Cognition; Forgas, J.P., Ed.; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 2001; pp. 163–185. [Google Scholar]
- Key Aspects of Treatment of Depression-10 [Translated from Japanese]. Available online: https://www.jcptd.jp/medical/point_10.pdf (accessed on 16 November 2021).
- Mitsuyoshi, S.; Ren, F.; Tanaka, Y.; Kuroiwa, S. Non-verbal voice emotion analysis system. Int. J. ICIC 2006, 2, 819–830. [Google Scholar]
- Higuchi, M.; Nakamura, M.; Shinohara, S.; Omiya, Y.; Takano, T.; Mitsuyoshi, S.; Tokuno, S. Effectiveness of a voice-based mental health evaluation system for mobile devices: Prospective study. JMIR Form Res. 2020, 4, e16455. [Google Scholar] [CrossRef] [PubMed]
- Hagiwara, N.; Omiya, Y.; Shinohara, S.; Nakamura, M.; Higuchi, M.; Mitsuyoshi, S.; Yasunaga, H.; Tokuno, S. Validity of Mind Monitoring System as a Mental Health Indicator using Voice. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 338–344. [Google Scholar] [CrossRef]
- Higuchi, M.; Nakamura, M.; Shinohara, S.; Omiya, Y.; Hagiwara, N.; Takano, T.; Toda, H.; Saito, T.; Yoshino, A.; Mitsuyoshi, S.; et al. Effectiveness of voice-based mental health evaluation indicator in estimating depression. In Proceedings of the Human Communication Group Symposium, Mie, Japan, 12–14 December 2018. (In Japanese). [Google Scholar]
- R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 16 November 2021).



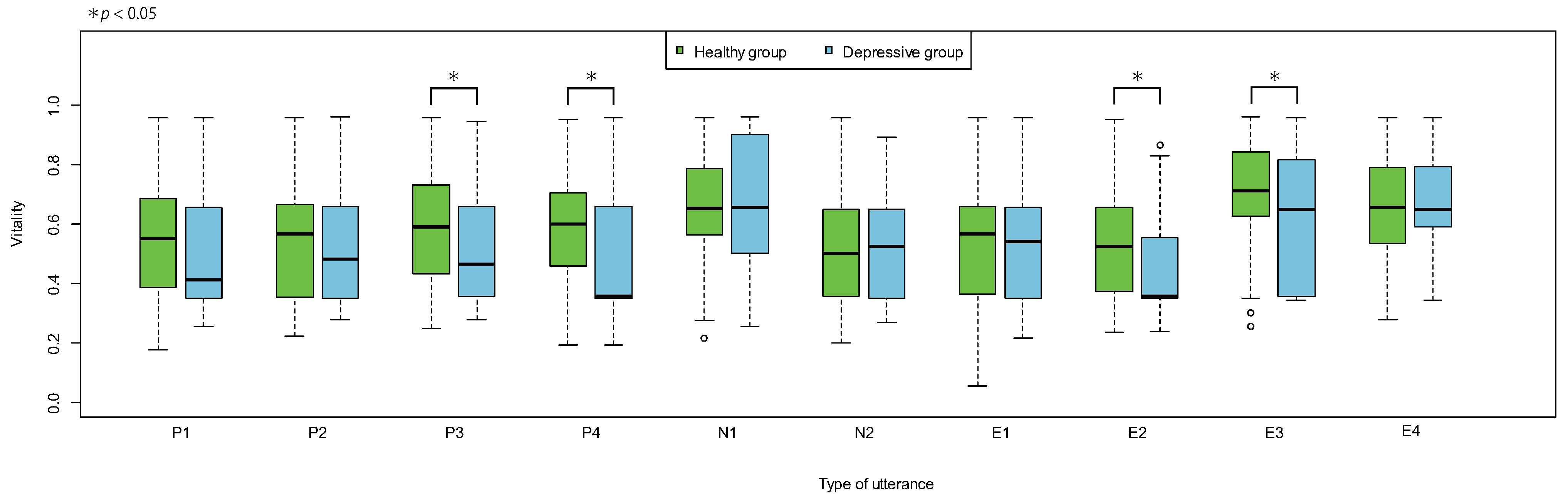

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
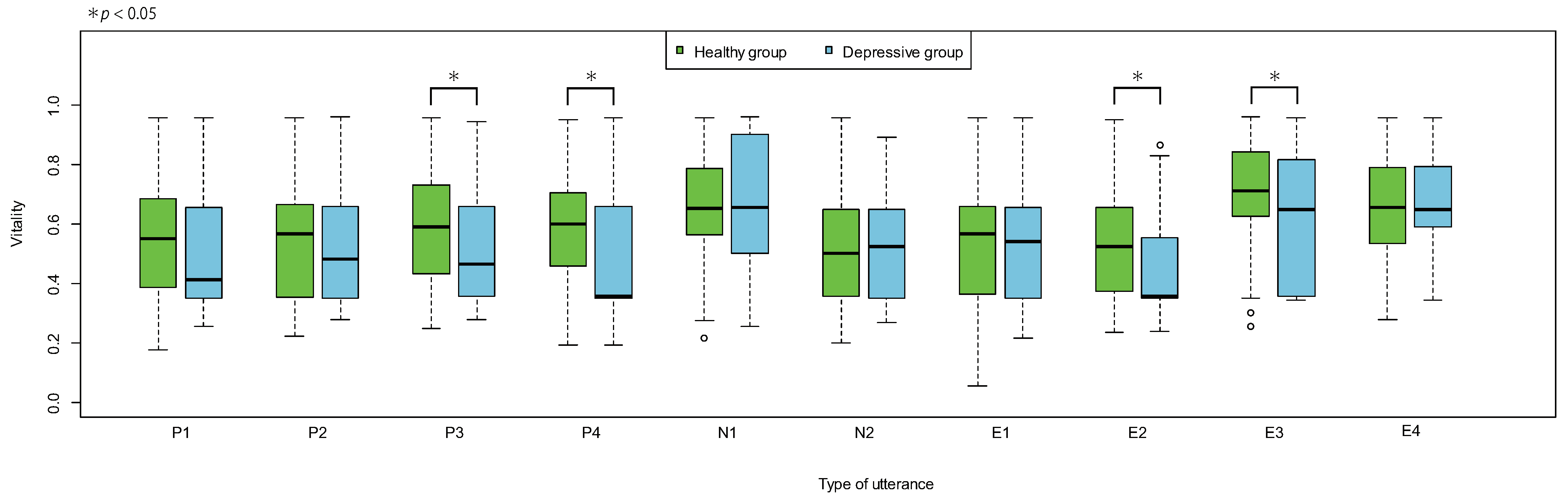{kind=link}
| Facility | Sex | Number of Healthy Subjects | Number of Depressed Patients | Age (Mean ± SD) | |
|---|---|---|---|---|---|
| HDRS < 5 | HDRS ≥ 5 | ||||
| H1 | Male | 10 | 21 | 27 | 48.3 ± 12.9 |
| Female | 4 | 34 | 11 | 60.7 ± 14.3 | |
| Total | 14 | 55 | 38 | 53.9 ± 14.8 | |
| H2 | Male | 12 | 0 | 0 | 47.6 ± 10.6 |
| Female | 11 | 0 | 0 | 59.8 ± 13.3 | |
| Total | 23 | 0 | 0 | 53.4 ± 13.2 | |
| Healthy group total 92 | Depressive group total 38 | ||||
| Type | Phrase |
|---|---|
| P1 | I’m feeling very well |
| P2 | I slept very well yesterday |
| P3 | I have an appetite |
| P4 | I feel calm |
| N1 | I am tired and drained |
| N2 | I am short-tempered |
| E1 | I-ro-ha-ni-ho-he-to (Similar to “a–b–c”) |
| E2 | It’s fine today (Mic test phrase commonly used in Japan) |
| E3 | Once upon a time |
| E4 | Galapagos Islands |
| Number of Utterances | Combination of Utterances That Gives Maximum AUC | Combination of Utterances That Gives Minimum AUC |
|---|---|---|
| 1 | E2 | N2 |
| 2 | P4, E2 | N1, E4 |
| 3 | P4, E2, E3 | N1, N2, E4 |
| 4 | P3, P4, E2, E3 | N1, N2, E1, E4 |
| 5 | P1, P3, P4, E2, E3 | P2, N1, N2, E1, E4 |
| 6 | P1, P2, P3, P4, E2, E3 | P2, P4, N1, N2, E1, E4 |
| Number of Utterances | Combination of Utterances That Gives Maximum Difference | Combination of Utterances That Gives Minimum Difference |
|---|---|---|
| 1 | E3 | E2 |
| 2 | N1, E3 | P4, E2 |
| 3 | N1, E3, E4 | N2, E2, E4 |
| 4 | P3, N1, E3, E4 | P4, N2, E2, E4 |
| 5 | P3, P4, N1, E3, E4 | P4, N1, N2, E1, E2 |
| 6 | P3, P4, N1, E1, E3, E4 | P3, P4, N1, N2, E1, E2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Higuchi, M.; Sonota, N.; Nakamura, M.; Miyazaki, K.; Shinohara, S.; Omiya, Y.; Takano, T.; Mitsuyoshi, S.; Tokuno, S. Performance Evaluation of a Voice-Based Depression Assessment System Considering the Number and Type of Input Utterances. Sensors 2022, 22, 67. https://doi.org/10.3390/s22010067
Higuchi M, Sonota N, Nakamura M, Miyazaki K, Shinohara S, Omiya Y, Takano T, Mitsuyoshi S, Tokuno S. Performance Evaluation of a Voice-Based Depression Assessment System Considering the Number and Type of Input Utterances. Sensors. 2022; 22(1):67. https://doi.org/10.3390/s22010067
Chicago/Turabian StyleHiguchi, Masakazu, Noriaki Sonota, Mitsuteru Nakamura, Kenji Miyazaki, Shuji Shinohara, Yasuhiro Omiya, Takeshi Takano, Shunji Mitsuyoshi, and Shinichi Tokuno. 2022. "Performance Evaluation of a Voice-Based Depression Assessment System Considering the Number and Type of Input Utterances" Sensors 22, no. 1: 67. https://doi.org/10.3390/s22010067
APA StyleHiguchi, M., Sonota, N., Nakamura, M., Miyazaki, K., Shinohara, S., Omiya, Y., Takano, T., Mitsuyoshi, S., & Tokuno, S. (2022). Performance Evaluation of a Voice-Based Depression Assessment System Considering the Number and Type of Input Utterances. Sensors, 22(1), 67. https://doi.org/10.3390/s22010067