1. Introduction
Unmanned Aerial Vehicles (UAVs) are aircrafts without a human pilot on board. UAVs are able to establish on-demand wireless connectivity faster than terrestrial communications and they can adjust their height and position to provide robust channels with short-range line-of-sight links [
1]. Therefore, UAV-aided wireless communication is a promising solution to provide temporary connections to devices without infrastructure coverage (e.g., due to severe shadowing in urban areas) or after telecommunication infrastructure has been damaged in natural disasters [
1].
UAVs are identified as an important component of future-generation (5G/B5G) wireless networks due to their salient attributes (dynamic deployment ability, strong line-of-sight connection links and additional design degrees of freedom with the controlled mobility) [
2].
In UAV-assisted wireless communications, UAVs are employed to provide wireless access for terrestrial users.
We distinguish between three use cases [
1]:
- (1)
UAV-aided ubiquitous coverage: UAVs act as aerial base stations to achieve seamless coverage for a given geographical area. Some related applications are a fast communication service recovery in disaster scenarios and temporary traffic offloading in cellular hotspots.
- (2)
UAV-aided relaying: UAVs are employed as aerial relays between far-apart terrestrial users or user groups. Some examples of applications include UAV-enabled cellular coverage extension and emergency response.
- (3)
UAV-aided information dissemination and data collection: UAVs are used as aerial access points (APs) to disseminate (or collect) information to (from) ground nodes. Some related applications are UAV-aided wireless sensor networks and IoT communications.
The use of UAVs as aerial nodes to provide wireless sensing support has several advantages compared to ground sensing [
3]. UAV-based sensing has a wider field of view due to the elevated height and reduced signal blockage of UAVs. In addition, UAV mobility enables to sense hard-to-reach poisonous or hazardous areas. Furthermore, the mobility of UAVs enables to perform sensing performance optimization by dynamically adjusting the trajectory of the UAVs.
UAV-based sensing has a wide range of potential applications, such as precision agriculture, smart logistics, 3D environment map construction, search and rescue, and military operations. There is a growing interest in the development of UAV-based sensing applications.
In Ref. [
4], a complete framework for the data acquisition from wireless sensor nodes using a swarm of UAVs is introduced. It covers all the steps from the sensor clustering to the collision-avoidance strategy. In addition, a hybrid UAV-WSN system that improves the acquisition of environmental data in large areas has been proposed [
5].
UAVs are a popular and cost-effective technology to capture high spatial and temporal resolution remote sensing (RS) images for a wide range of precision agriculture applications [
6]. UAVs equipped with dual-band crop-growth sensors can achieve high-throughput acquisition of crop-growth information. IoT and UAV can monitor the incidence of crop diseases and pests from the ground micro and air macro perspectives, respectively [
7]. In these applications, UAVs collect data from sensor nodes distributed over a large area. It is required to synchronize the UAV route with the activation period of each sensor node. The UAV path through all sensor nodes is optimized in Ref. [
8] to reduce the flight time of the UAV and maximize the sensor nodes’ lifetime. In addition, an aerial-based data collection system based on the integration of IoT, LoRaWAN, and UAVs has been developed [
9]. It consists of three main parts: (a) sensor nodes distributed throughout a farm; (b) a LoRaWAN-based communication network, which collects data from sensors and conveys them to the cloud; and (c) a path planning optimization technique for the UAV to collect data from all sensors.
In IoT communications [
10], UAVs have also been proposed to assist the localisation of terrestrial Internet of Things (IoT) sensors and provide relay services in 6G networks. A mobile IoT device [
11], located at a distant unknown location, has been traced using a group of UAVs equipped with received signal strength indicator (RSSI) sensors. In smart logistics, a UAV-based system aimed at automating inventory tasks has been designed and evaluated [
12]. It is able to keep the traceability of industrial items attached to Radio-Frequency IDentification (RFID) tags.
In search and rescue operations, a real-time human detection and gesture recognition system based on a UAV with a camera is proposed [
13]. The system is able to detect, track, and count people; it also recognizes human rescue gestures. Yolo3-tiny is used for human detection and a deep neural network is used for gesture recognition. UAV-assisted wireless networks can benefit from gigabit data transmissions by using 5G millimeter wave (mmWave) communications. The millimeter wave frequency band ranges from around 30 GHz to 300 GHz, corresponding to wavelengths from 10 to 1 mm. This key technology delivers higher data rates due to a higher bandwidth [
14].
UAV-enabled mmWave networks offer a lot of potential advantages. On the one hand, the large available spectrum resources of mmWave communication and flexible beamforming can meet the requirements of high data rate and flexible coverage for UAVs serving as base stations (UAV-BSs) in UAV-assisted cellular networks [
3]. These networks consist of a base station (BS) mounted on a flying UAV in the air, and mobile stations (MSs) distributed on the ground or at low altitude. High data rate communication links between the MSs and UAV BS are desirable in typical applications (e.g., to send control commands and large video monitoring traffic data from many camera sensors) [
15]. On the other hand, the existence of a line-of-sight (LOS) path in the link from a UAV to the ground favors that mmWave communication obtains a high beamforming gain. However, higher propagation loss and the use of a large number of antennas in mmWave networks give rise to high energy consumption and UAVs are constrained by their low-capacity onboard battery.
Energy harvesting (EH) is a viable solution to reduce the energy cost of UAV-enabled mmWave networks; green energy can be harvested from renewable energy sources (e.g., solar, wind, electromagnetic radiations) to power UAVs. Energy-harvesting powered UAVs can prolong longer their operational duration as well as the wireless connectivity services they offer [
16,
17,
18]. However, the random nature of renewable energy makes it challenging to maintain robust connectivity in UAV-assisted terrestrial cellular networks. Energy cooperation (also known as energy sharing or energy transfer) has been introduced in Ref. [
19] to alleviate the harvested energy imbalance problem, where a source assists a relay by transferring a portion of its remaining energy to the relay.
We consider a UAV-assisted mmWave cellular network. Some UAVs will have plenty of energy because their flight duration is shorter or because they have harvested abundant energy due to better environmental conditions (e.g., sunshine without clouds). Energy cooperation allows that these UAVs can send their excessive energy to other UAVs with reduced energy.
In the literature, several works have investigated energy cooperation in renewable energy harvesting-enabled cellular networks. In Ref. [
20], an adaptive traffic management and energy cooperation algorithm has been developed to jointly determine the amount of energy shared between BSs, the user association to BSs, and the sub-channel and power allocation in BSs. In Ref. [
21], an energy-aware power allocation algorithm was developed in energy cooperation-enabled mmWave cellular networks. It uses renewable energy harvesting to maximize the network utility while keeping the data and energy queue lengths at a low level. In Ref. [
22], a power allocation strategy is proposed that uses energy cooperation to maximize the throughput in ultra-dense Internet of Things (IoT) networks. However, these contributions do not analyze energy cooperation in UAV-assisted cellular networks.
Several authors proposed using energy transfer in UAV-enabled wireless communication systems. In Ref. [
23], the total energy consumption of a UAV is minimized while accomplishing the minimal data transmission requests of the users; in the downlink the UAV transfers wireless energy to charge the users, while in the uplink the users utilize the harvested energy to transmit data to the UAV. Similarly, in Ref. [
24], a downlink wireless power transfer and an uplink information transfer is proposed for mmWave UAV-to-ground networks. However, these contributions do not analyze energy cooperation between UAV-BSs.
In this paper, we propose a power allocation algorithm based on energy harvesting and energy cooperation to maximize the throughput of a UAV-assisted mmWave cellular network. This optimal power allocation and energy transfer problem can be regarded as a discrete-time Markov Decision Process (MDP) [
25] with continuous state and action space. As statistical or complete knowledge about the environment, the real channel state, and the energy harvesting arrival is not easily observable, traditional model-based methods cannot be leveraged to tackle with this MDP. Therefore, we adopt multi-agent deep reinforcement learning (DRL) [
26] to solve this problem and propose a multi-UAV power allocation and energy cooperation algorithm based on the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) [
27] method to optimize the policies for UAVs. To the best of our knowledge this is the first paper that analyses energy cooperation between UAV-BSs in UAV-assisted mmWave cellular networks and develops a DRL algorithm to maximize the network throughput. The proposed DRL algorithm can be applied in an emergency communication system for disaster scenarios. In these scenarios user devices that are out of the coverage range from UAVs cannot obtain wireless access. Therefore, it is important that UAVs increase their wireless coverage and reduce the channel access delay. Since UAVs are limited by their battery power, energy harvesting and energy cooperation are promising solutions to satisfy the requirements of an emergency communication system.
The contributions of this paper are summarized as follows:
We study optimal power allocation strategies for UAV-assisted mmWave cellular networks when there is channel-state uncertainty and the amount of harvested energy can be treated as a stochastic process.
We formulate the renewable energy resource allocation problem for throughput maximization using multi-agent DRL and propose an MADDPG-based multi-UAV power allocation algorithm based on energy cooperation to solve this problem.
Simulation results show that our proposed algorithm outperforms the Random Power (RP), Maximal Power (MP) and value-based Deep Q-Learning (DQL) algorithms and achieves a higher average network throughput.
The paper is structured as follows. In
Section 2, we analyze our system model. In
Section 3, we state the renewable energy resource allocation problem and formulate it as an MDP with the objective to maximize the throughput. In
Section 4, we introduce the MADDPG-based multi-UAV power allocation algorithm based on energy cooperation for solving the MDP. Simulation results are presented in
Section 5. Finally, the paper is concluded in
Section 6.
2. System Model
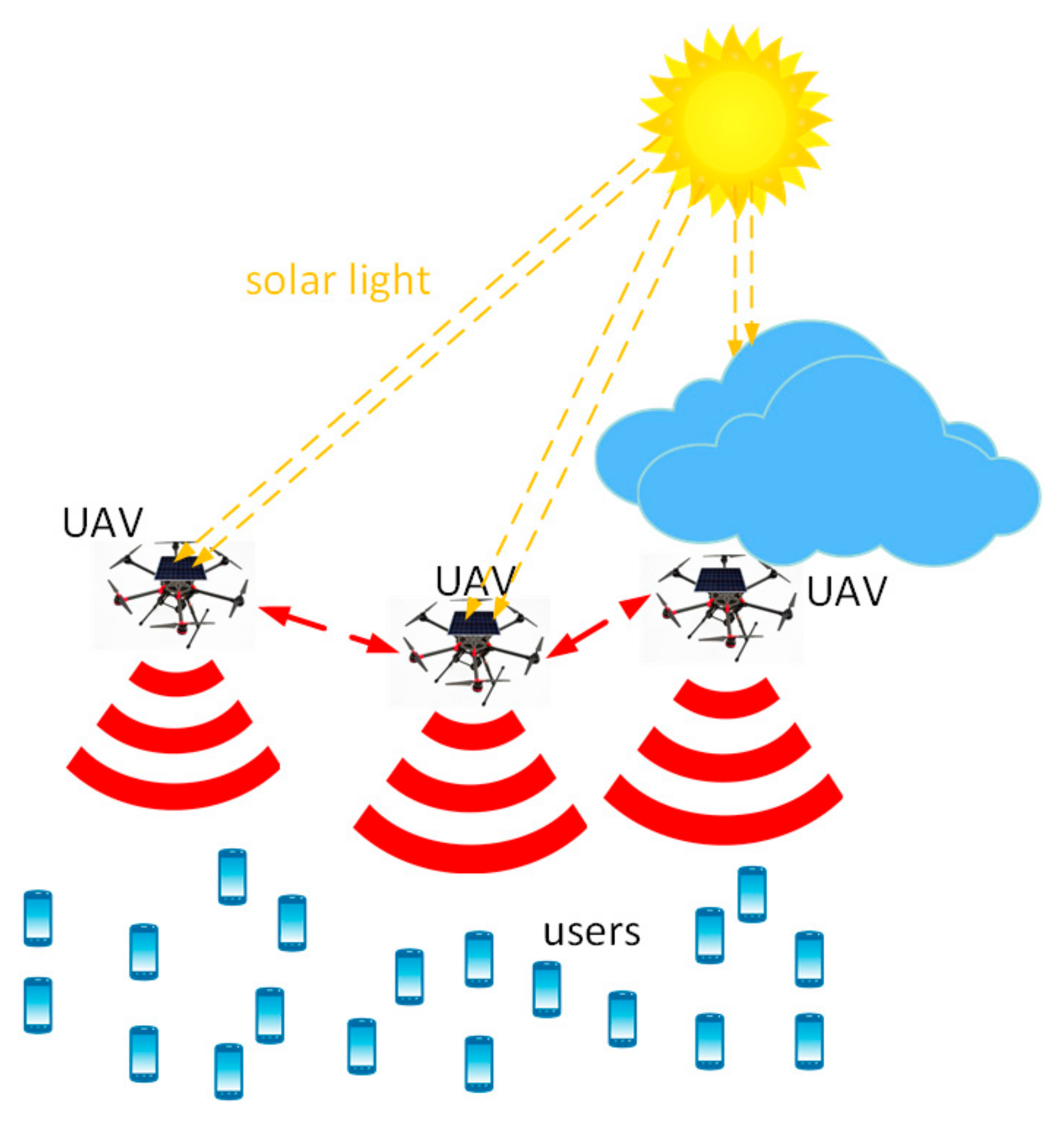
Our network architecture is shown in
Figure 1. For clarity, we summarize all the following notations and their definitions in
Table 1. We consider a multi-antenna mmWave UAV-enabled wireless communication system, where multiple UAV-mounted aerial base stations (BSs) fly over the region and serve a group of users on the ground. We consider that each UAV is dedicated to serve a cluster of users with the same requirements. The locations of the UAV-enabled BSs are modelled as a Poisson point process (PPP)
with density
. We consider that users are static. We assume that the location of users is modelled as a Poisson cluster process (PCP)
with density
[
28]. We also assume that all UAVs are elevated at the same altitude
.
UAVs are powered by hybrid energy sources. Onboard energy, along with a part of the harvested energy, is used to maintain the flight while the rest harvested energy is used to support the communication modules of the UAVs. The imbalance of energy harvesting between UAVs is compensated through energy cooperation.
The UAVs and user sets are denoted as and . The total number of users served by UAVj, , can be represented by Lj only associated with UAVj. For simplicity, the typical user set is associated with the closest UAV-BS; that is, the UAV that maximizes the average received SNR.
This paper focuses on the design of an optimal power allocation strategy to maximize the throughput for multi-UAV networks over N time slots. It is assumed that all UAVs communicate without the assistance of a central controller and have no global knowledge of wireless channel communication environments. This means that the channel state information (CSI) between a UAV and the mobile devices of the users is known locally.
2.1. Blockage Model
A major challenge in mmWave communications is the blockage effect [
14], namely, mmWave signals are blocked by physical obstacles in their propagation. We adopt the building blockage model introduced in Ref. [
29], which defines an urban area as a set of buildings in a square grid. The mean number of buildings per square kilometer is
. The fraction of area covered by buildings to the total area is
Each building has a height which is a Rayleigh-distributed random variable with scale parameter
. The probability of a UAV having a line-of-sight (LOS) connection to the user
when the horizontal transmission distance is
is given by
where
is the transmitter height,
is the receiver height,
and
is the floor function. Furthermore, the probability for a non-line-of-sight (NLOS) transmission is
2.2. UAV-to-Ground Channel Model
The path loss law in the UAV network is given by [
30]:
where
is a Bernoulli random variable with parameter
. The parameters
and
are the LOS and NLOS path loss exponents, and
and
are the intercepts of the LOS and NLOS links.
The amplitude of the received UAV-to-ground mmWave signal can be modelled as a Nakagami- fading distribution for both the LOS and NLOS propagation conditions at mmWave frequency bands. Let . be the small-scale fading term on the -th link. is a normalized Gamma random variable. for LOS and for NLOS, where and represent the Nakagami fading parameters for the LOS and NLOS links.
At time slot
, the LOS channel gain from the
-th UAV BS located at
to a
-th ground user located at
can be expressed as
where
is the directional antenna gain.
When the transmission has the maximum antenna gain, the channel gain is .
2.3. Directional Beamforming
Beamforming, also known as spatial filtering, concentrates the signal energy over a narrow beam by means of highly directional signal transmission or reception; this way, the spectral efficiency is improved [
14]. The narrow beams of the mmWave signals allow to achieve highly directional signals along the desired directions. We assume that
and
antenna arrays are deployed at both the UAV-BSs and the mobile user sets, respectively. It is required to use efficient alignment policies (beam tracking, beam training, hierarchical beam codebook design, accurate estimation of the channel, etc.) to align the beams between transmitter and receiver [
14].
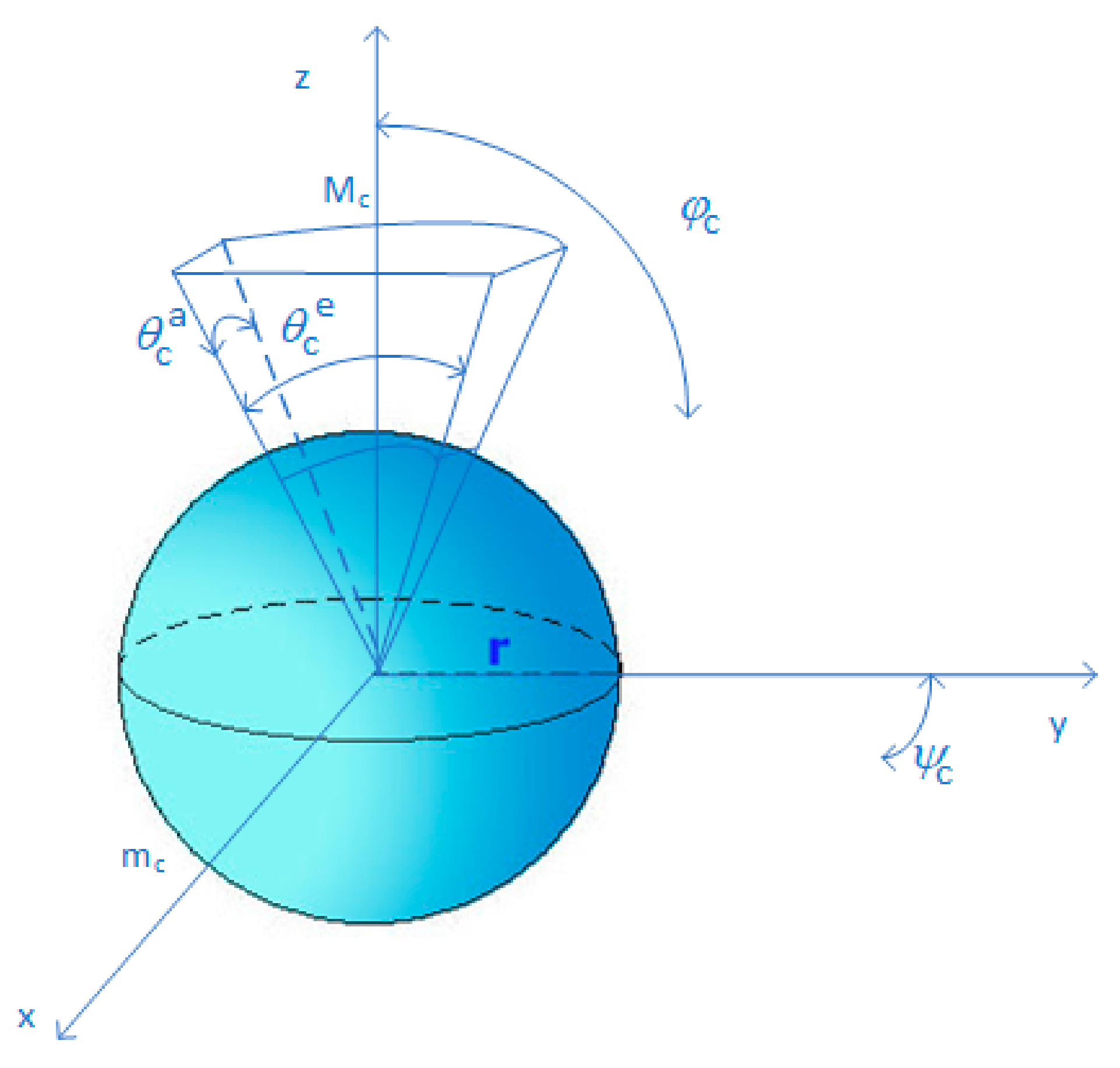
We consider that the UAV-BS and user set antennas adopt a sectorized model that is shown in
Figure 2. The antenna array pattern is characterized by four parameters: the half-power beamwidth in the azimuth plane
, the half-power beamwidth in the elevation plane
, the mean lobe gain
and the side lobe gain
, where
refers to the transmitter (UAV-BS) and the receiver (user set), respectively.
The directivity gain at one receiver located at
from the
-th UAV-BS can be expressed as follows:
where
,
denotes the directional antenna gain.
The transmitter and receiver should adjust their antenna directions towards each other to achieve the maximum beamforming gain .
2.4. Signal Model
The UAV-to-ground user pair communication is affected by the interference signals from the remaining UAVs. Therefore, the received signal-to-interference-plus-noise ratio (SINR) from UAV
located at
to user
at time slot
can be expressed as
where
denotes the channel gain between UAV
j and user
at time slot
,
is the transmit power selected by UAV
j at time slot
,
is the interference to UAV
j that satisfies
and
is the noise power level.
3. Problem Formulation
In this section, we investigate the optimal power allocation and energy transfer problem for throughput maximization in UAV-enabled mmWave networks, which can be regarded as MDP. Since the real channel state and energy harvesting arrival are not easily observable, traditional model-based methods are infeasible to tackle with this MDP. Therefore, we reformulate this problem using multi-agent DRL to make it solvable.
3.1. Throughput Maximization Problem
We introduce the following notation:
is one time slot of a finite horizon of N time slots.
is the time slot duration.
is the amount of harvested energy for UAVj at time slot .
is the battery capacity of each UAVj.
is the battery state for UAVj at time slot .
is the transmission power allocated by UAVj to serve all its users.
The theoretical downlink rate of user
connected to UAV
j at time slot
is given by
where
is the mm Wave transmission bandwidth.
The total throughput at timeslot
is
The current battery capacity of each UAVj stores mainly the renewable energy harvested during the current time slot, the energy transferred by other UAVs during the energy cooperation process, and the remaining energy from the last time slot.
The charging rate of the energy storage is usually less than the energy arrival rate, because of the limited energy conversion efficiency of the circuits. We consider that the charging rate and energy arrival rate are expressed as and respectively. Therefore, ≥ 0, where 0 is the imperfect conversion efficiency. In the rest of the paper, the energy arrival rate refers to the effective energy arrival rate that is assimilated by the system, i.e., the charging rate of the storage .
After is harvested at time slot , it is stored in the battery and is available for transmission in time slot . The rechargeable battery is assumed to be ideal, which means that no energy is lost with energy storing or retrieving. Once the battery is full, the additional harvested energy is removed.
The battery energy level of UAV
j at the time
is
where
denotes the energy transferred from UAV
j to UAV
j’,
denotes the energy transferred from UAV
j’ to UAV
j and
is the energy transfer efficiency between two UAVs.
The problem can be formulated as follows:
P1. Throughput optimization problem
Find:
The objective function of problem P1 aims at finding the best values of that maximizes the throughput. We observe that P1 is a non-linear optimization problem.
Constraint (10) limits the harvested energy. Constraint (11) determines that the total energy consumed by each UAV should not exceed its battery level. Constraint (12) refers to the total allocated power by UAV to serve all its users at time . Since the energy storage at each UAV is limited, Constraint (13) expresses that the total energy transferred from UAVj to other UAVs should not exceed the current battery energy level. The same applies to Constraint (14) for the total transferred energy transferred from UAVj’ to other UAVs.
The optimization problem may be solved only if the complete information about energy harvesting arrival and channel state information (CSI) is known. RL algorithms can achieve near-optimal performance even without prior knowledge about the CSI, the user arrival, the energy arrival, etc. [
31]. In what follows, we analyze this problem under the MDP framework and reformulate it by adopting multi-agent RL.
3.2. Multi-Agent RL Formulation
The proposed problem can be considered an MDP. Therefore, multi-agent RL can be adopted to solve this problem efficiently.
Each UAV can be regarded as an agent in the proposed system and all the network settings can be regarded as the environment. UAVs can be characterized by a tuple as follows:
denotes the state space including all possible states of UAVs in the system at each time slot. The state of the -th UAV, denoted by , is described by the current SINR of the users served by UAVj, the link’s corresponding downlink rate at the last time slot and the current harvested energy of UAVj, respectively.
, refers to the SINR of the current serving users of UAV. }, refers to the downlink rate of the current serving users of UAV.
denotes the action space consisting on all the available actions of -th UAV at each time slot. The action of the -th UAV, denoted by , is defined as . This means that each UAV selects the power allocated to serve its users. At state , the available action set of the -th UAV is expressed as .
is the state transition function, which maps the state spaces and the action spaces of all UAVs in the current time slot to their state spaces in the next time slot.
is the reward function of the -th UAV, which maps the state spaces and the action spaces of the UAV in the current time slot to its expected reward. The reward of the -th UAV, denoted by , is defined as .
Each UAV is motivated to maximize the throughput by making decisions on power allocation. In our system, the policy of a UAV is defined as a mapping from its state space to its action space, denoted by . At the beginning of each time slot the -th UAV observes the state of all UAVs, from state space , and takes an action based on its policy . Actually, a UAV cannot know the states of other UAVs by itself. However, before making decision in a cycle, the UAV can observe the states of other UAVs by sending a beacon. After making the decision, the UAV will keep its decision unchanged till the end of the current cycle. The policy of the -th UAV can be defined as , where is the state of all UAVs in the system and is the action of the -th UAV. After that, the UAV receives a reward and then observes the next state , namely, the states of all UAVs at the beginning of the next time slot. Therefore, the throughput maximization problem can be transformed into maximizing the total accumulated rewards of all UAVs in the system by optimizing their policies; that is,
P2. Maximization of the total accumulated rewards
4. Proposed Multi-Agent Reinforcement Learning Algorithm
Our target is to design an efficient algorithm for power allocation and energy transfer for UAVs that maximizes the throughput. Existing approaches such as dynamic programming is not suitable for such challenging tasks. Therefore, we adopt an RL algorithm to cope with the problem (P2). DRL has a better performance on tasks that have a sophisticated state space and time-varying environment than traditional reinforcement learning. There are different kinds of DRL that could deal with different situations, e.g., Deep Q-Learning (DQL) could work well with a limited action space and deep deterministic policy gradient (DDPG [
32]) has a remarkable performance with continued action space. There are two ways to apply the DDPG algorithm in our proposed scenario. The first solution would be to have a global DDPG agent that outputs all UAVs’ actions and there is only one reward function in this centralized fully observable case. However, if we consider one action (transmission power) with an infinite action space for each UAV, a global agent would have to cope with an exponential number of actions, which would become a problem. Another solution is to apply DDPG on each UAV; in this case, we would have multiple DDPG agents that output actions for each UAV. However, this solution is inefficient compared to MADDPG [
27] because at every time slot each UAV agent will be trying to learn to predict the actions of the other UAVs while also taking its own actions. On the other hand, MADDPG is the state-of-the art solution for multi-agent DRL. It employs a centralized critic and decentralized actors. Actors can use the estimated policies of other agents for learning. This way, agents are supplied with information about the other UAVs’ observations and potential actions, transforming an unpredictable environment into a predictable one. This additional information is used to simplify the training, as long as it is not used at the test time (centralized training with decentralized execution). In this paper, we propose a MADDPG-based multi-UAV design algorithm for power allocation and energy transfer to optimize multiple UAVs’ policies. Afterwards, we introduce the training process of the proposed algorithm.
4.1. Algorithm Design
MADDPG is an actor-critic algorithm [
33] designed for multi-agent environments. Actors are responsible for learning policies and critics evaluate the actors’ action choices.
MADDPG adopts a strategy based on centralized training and distributed execution. Each UAV works as an agent and has an actor network , which means that each agent takes continuous policies with regard to parameters . Each agent also has a critic network . The critics are fed with information about the global state and actions of all agents. They are aware of the actions of all agents and output a value that describes how good joint action is on state . Target networks serve as stable targets for learning. Each agent has an actor target network and a critic target network .
The loss function of the critic network is calculated by
where
is the replay buffer that stores historical experience.
is defined as
The gradient of the expected reward for agent
with deterministic policies
is given by
The MADDPG algorithm is shown as Algorithm 1.
| Algorithm 1: MADDPG-based multi-UAV power allocation algorithm based on energy cooperation
|
Input: The structures of the actor network, critic network, and their target networks; Number of episodes
Output: Policy
;
1: Initialize the replay memory
with size X.
2: Initialize critics
and actors with random weights
Initialize target networks with random weights
and
3: Receive initial state
;
4: for do
5: for do
6: Each agent selects an action
is the exploration of the action.
7: Receive reward
and observe next state
8: Store
in the replay memory
9: if is full do
10: Sample a batch of random samples
from .
11: Set with (17).
12: Update the actor of the estimated network
with (18).
13: Update the critic of the estimated network
with (16).
Update the target network parameters with
14: end for
15: end for
16: Return
.
17: Choose optimal action
at time . |
4.2. Complexity Analysis
The computation complexity and the space complexity for the proposed MADDPG algorithm can be estimated by the replay memory and the neural networks’ architecture. In MADDPG, the training network of each agent consists of two sets of actor networks and two sets of critic networks. The time complexity (computations) is given with regard to the floating-point operations per second (FLOPS). The neural networks are fully connected layer networks. For dot products of a vector and a matrix, the FLOPS is because for every column in matrix we need to multiply times and add times. It is also necessary to derive the computations of the activation layers. In this case addition, subtraction, multiplication, division, exponentiation, square root, etc., count as a single FLOP. Therefore, the computations are with inputs for ReLU layers, for sigmoid layers and for tanh layers.
We consider that is the unit number in the -th layer of the actor, and the number of neurons in the -th layer of the critic. The number of layers for the actor and critic networks are and , respectively.
Therefore, the time complexity of the training is:
where
means the unit number in the
-th layer and
means the corresponding parameters determined by the type of the activation layer.
Space is needed to store the learning transition. The memory replay in MADDPG occupies some space to store the state sets; therefore, the space complexity is
. For a fully connected layer in both the actor and the critic network, there is a
matrix and a
bias vector. The memory for a fully connected layer is
The space complexity of the neural networks is given by
5. Simulation Results
In this section, we present the simulation results of the multi-UAV power allocation and energy transfer algorithm. The simulation parameters are given in
Table 2. We assume that the mmWave network is operated at 28 GHz. We set each actor or critic network as a four-layer neural network with two hidden layers, in which the number of neurons in the two hidden layers are 64 and 128, respectively. The activation function for the hidden layers is rectified linear unit (ReLU)
. The Adam algorithm is adopted as the optimizer and the learning rate is set as exponentially decayed to improve the performance of the training.
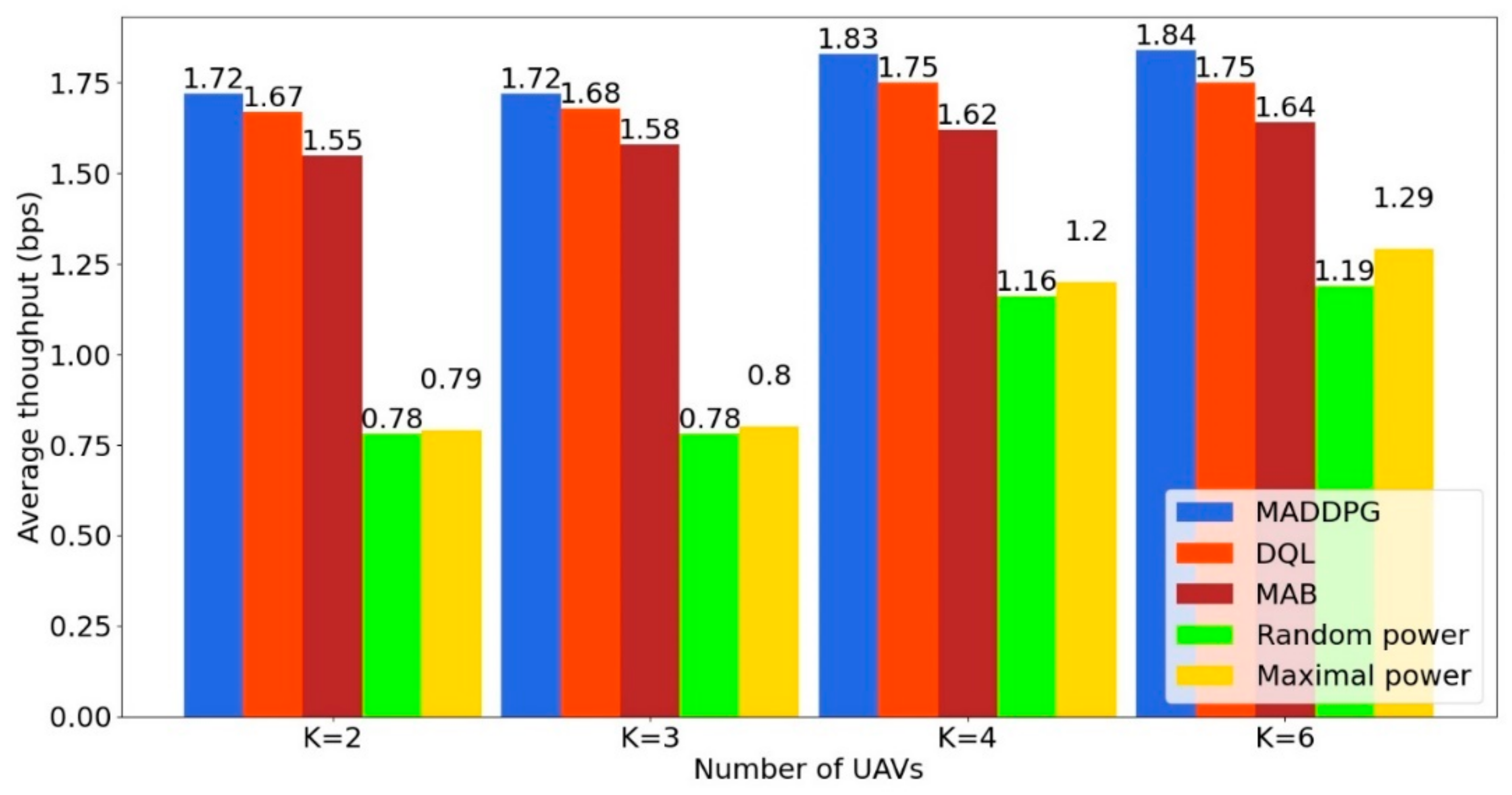
Next, we compare the proposed algorithm MADDPG with the Random Power (RP), Maximal Power (MP), Multi-Armed Bandit (MAB) and value-based Deep Q-Learning (DQL) algorithms. Upper confidence bound (UCB) is used to solve the MAB problem. RP and MP are two classical algorithms, whereas MADDPG, DQL and MAB are RL-based algorithms. Maximal Power (MP) consumes as much energy as possible in each time slot to improve its immediate throughput regardless of the future and the performance of the other UAVs. Random Power (RP) only consumes a part of the energy chosen randomly in each time slot. The average throughput for the five power allocation schemes is shown in
Figure 3 as a function of the number of UAVs. We observe that the average throughput is increased with the number of UAVs. MADDPG achieves the highest average throughput in all testing scenarios and outperforms the other algorithms. The gap between the RP/MP allocation schemes and the rest of the algorithms is decreased when the number of UAVs increases.
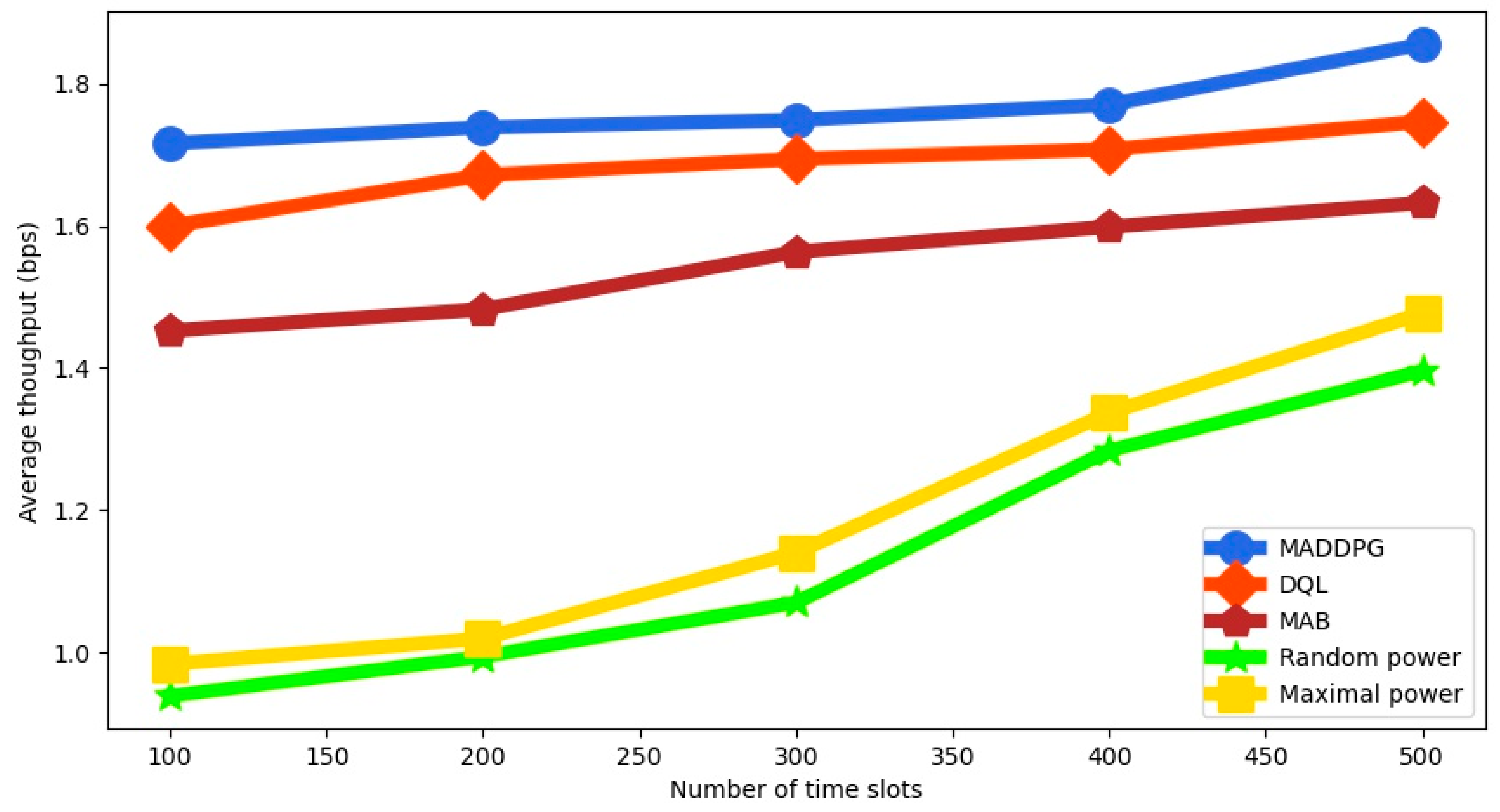
The average throughput for the different policies is shown in
Figure 4 as a function of the number of time slots. We can observe that MADDPG always outperforms the other algorithms. Since MADDPG does not divide the action space into discrete values like DQL, it can select a better action in each time slot without quantization errors. We notice that when the number of time slots increases, the average throughput is much larger for the RL-based algorithms, because they can adjust the transmission power in a smart way. MAB shows similar but worse behavior than DQL.
The average throughput as a function of the number of users is illustrated in
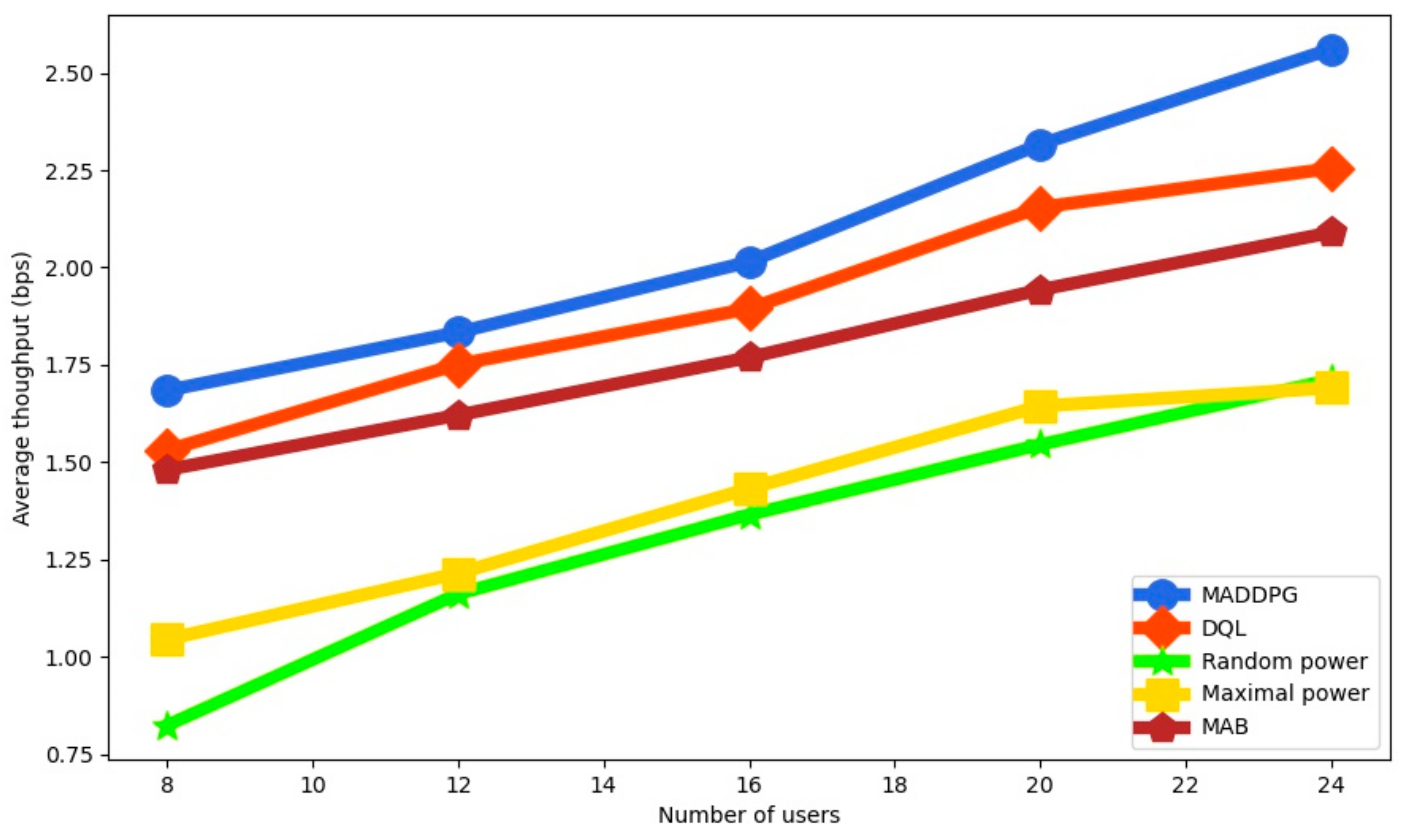
Figure 5 with four UAVs. We observe that the average throughput is increased because more users are served. MADDPG improves the average throughput compared to the other approaches. It is 13.6% higher than DQL, 22.53% higher than MAB, 46.24% higher than RP and 49.56% higher than RP for 24 users, which proves the effectiveness of the proposed approach.
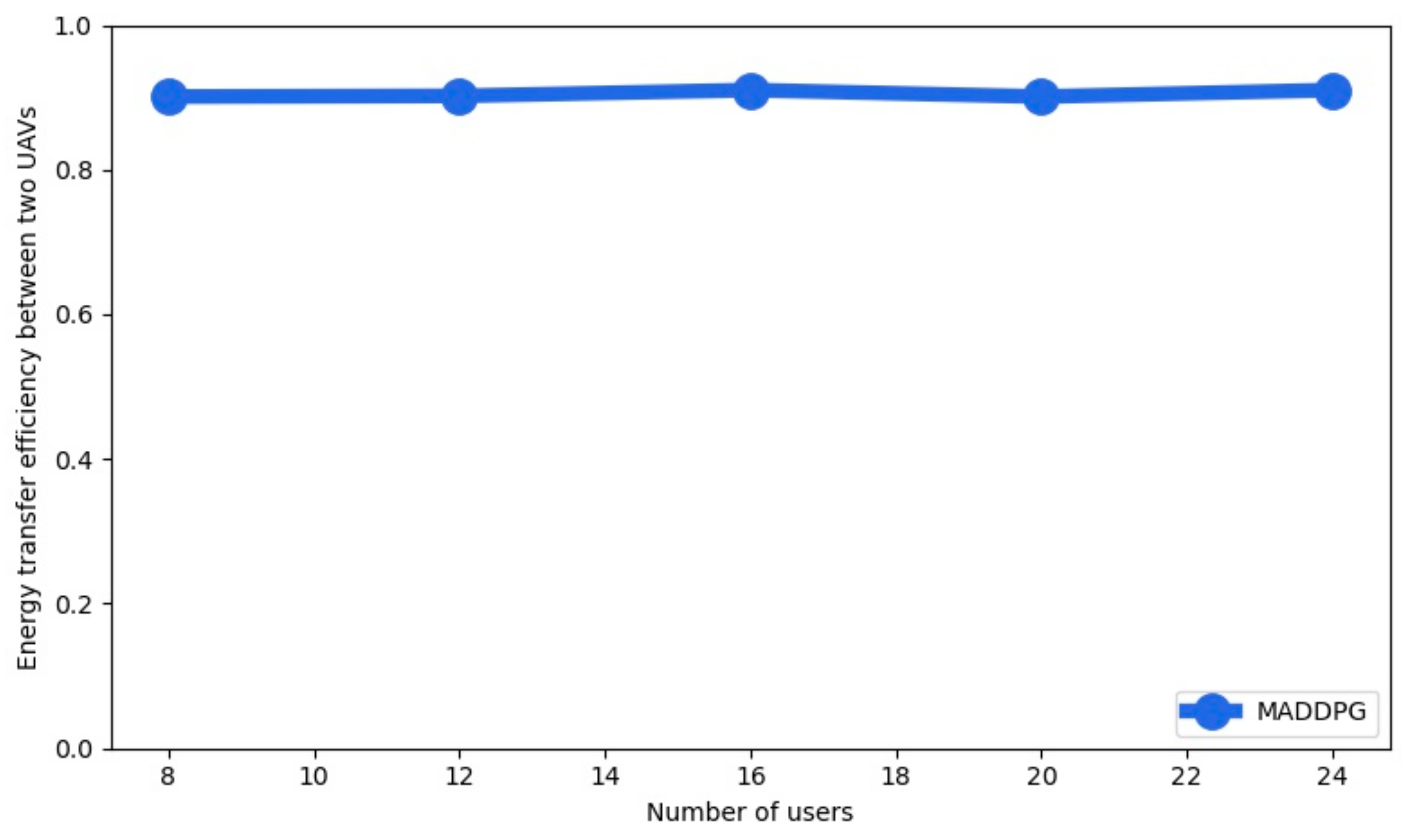
The energy transfer efficiency between two UAVs is shown in
Figure 6 as a function of the number of users with four UAVs for MADDPG. We observe that the energy transfer efficiency has a high value for a different number of users.
The average throughput for the RL-algorithms is shown in
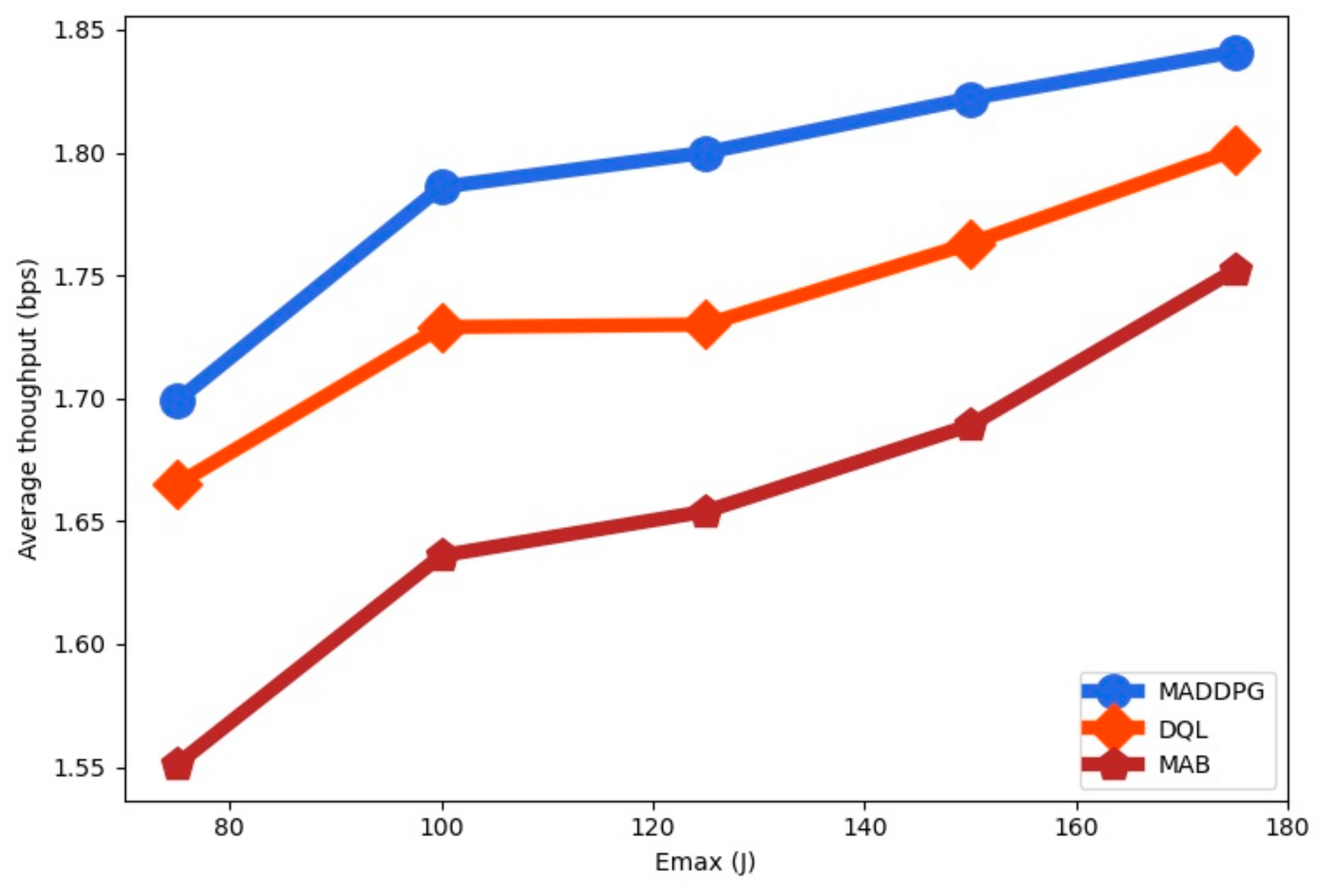
Figure 7 as a function of the energy arrival
. We observe that the average throughput is increased with the maximum energy harvested
. The average throughput for MADDPG is higher than for DQL and for MAB. Since the amount of collected energy is lower than the size of the battery capacity the throughput is increased for larger values of
.
The average throughput for the RL-algorithms is shown in
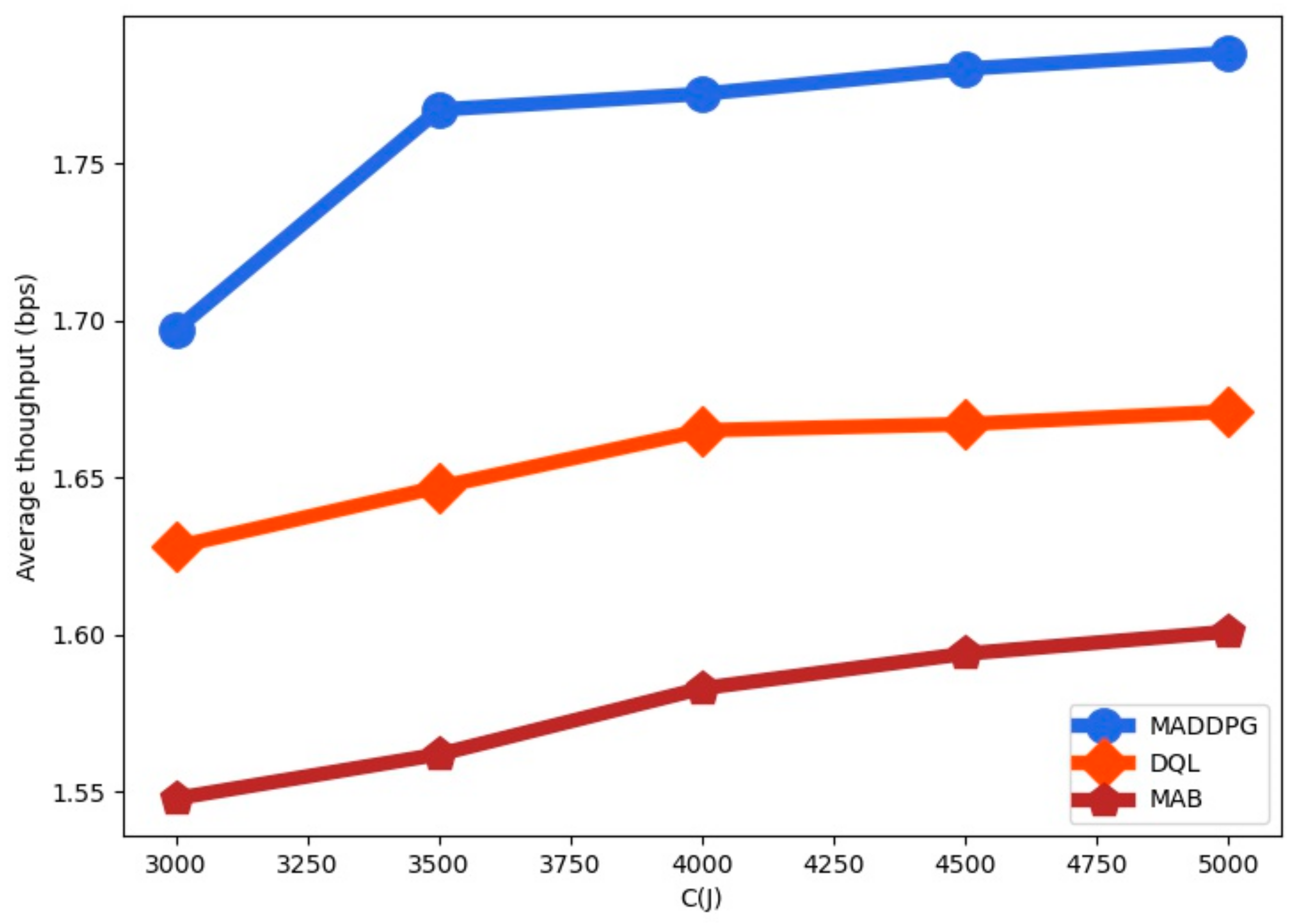
Figure 8 as a function of the battery capacity
. We observe that the average throughput is increased with the battery capacity. The average throughput is higher for MADDPG than for DQL and for MAB. We observe that when the battery capacity is increased the throughput values for the policies tend to stabilize since the value of
limits the system throughput increase.
The average throughput for the RL-algorithms is shown in
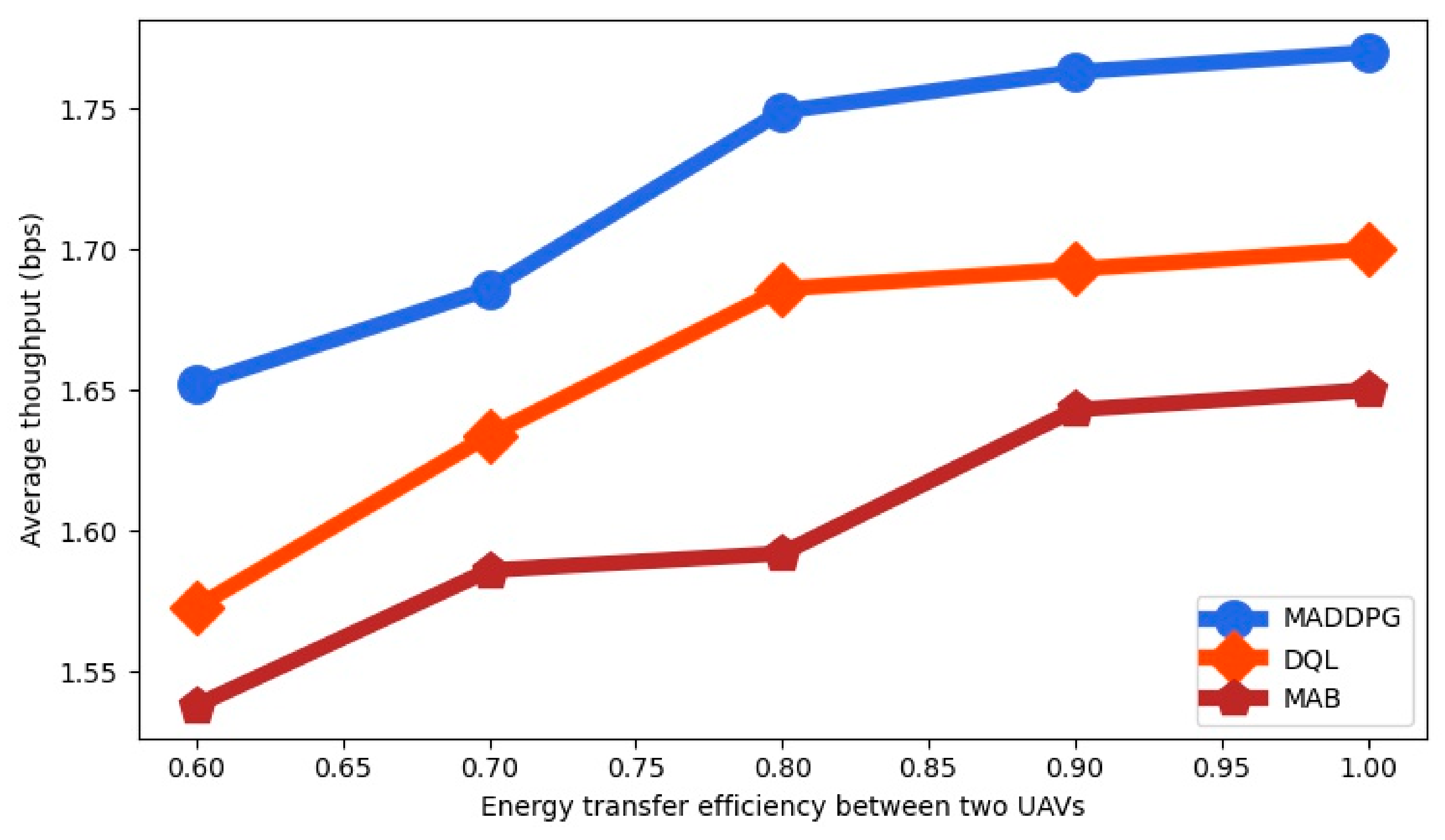
Figure 9 as a function of the energy transfer efficiency between two UAVs
. We observe that the average throughput is increased with the energy transfer efficiency. The average throughput is higher for MADDPG than for DQL and for MAB for all the values of
.
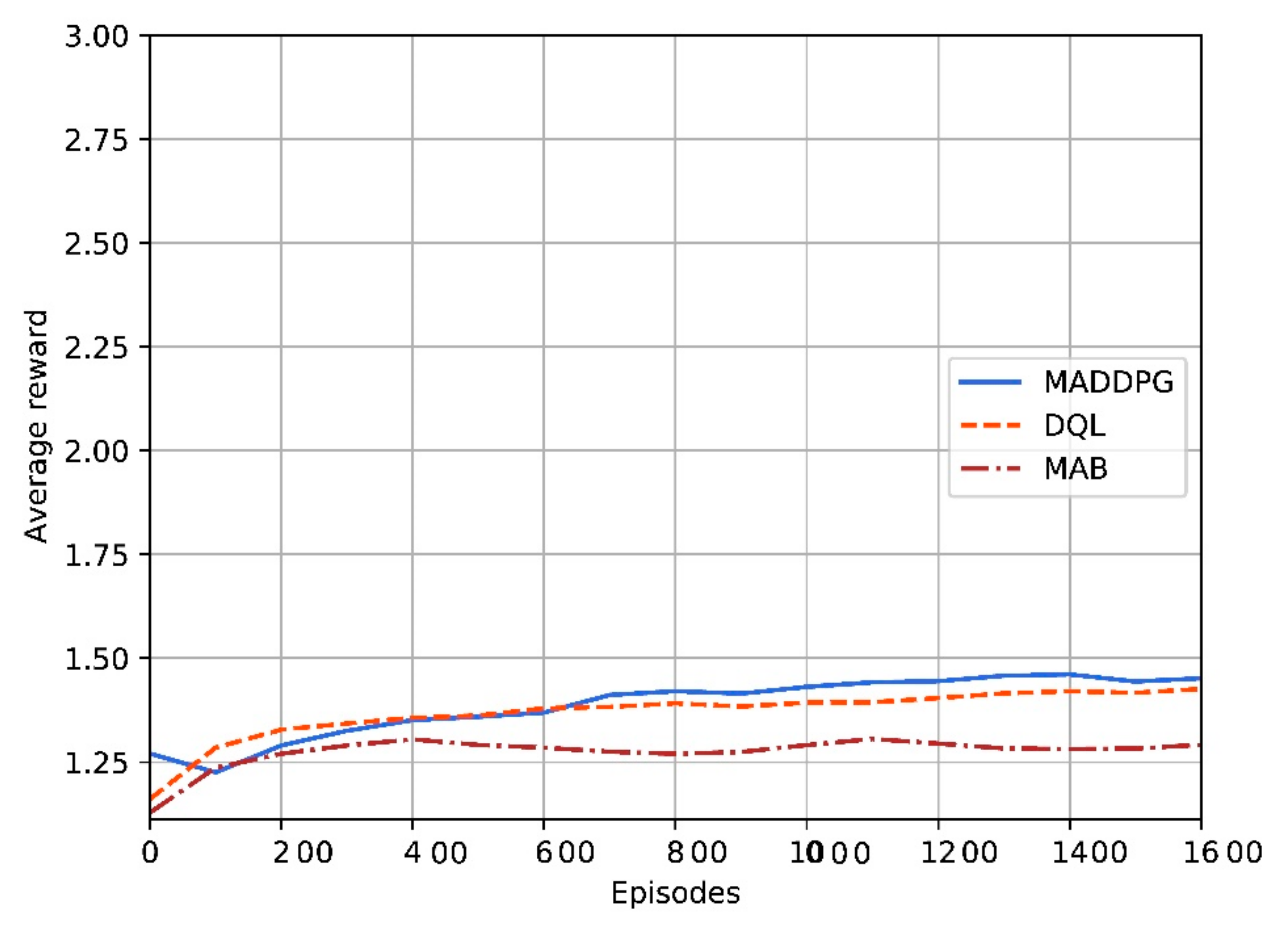
The convergence behavior of the reinforcement-based algorithms in terms of average reward is shown in
Figure 10 for a network of three UAVs and 14 users. The convergence behavior is around 1400 iterations for MADDPG. For DQL it is shorter (around 600 iterations). Finally, for MAB the convergence time is larger (around 1100 iterations).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}