4.3.1. Select The Next 1-hop and 2-hop Node
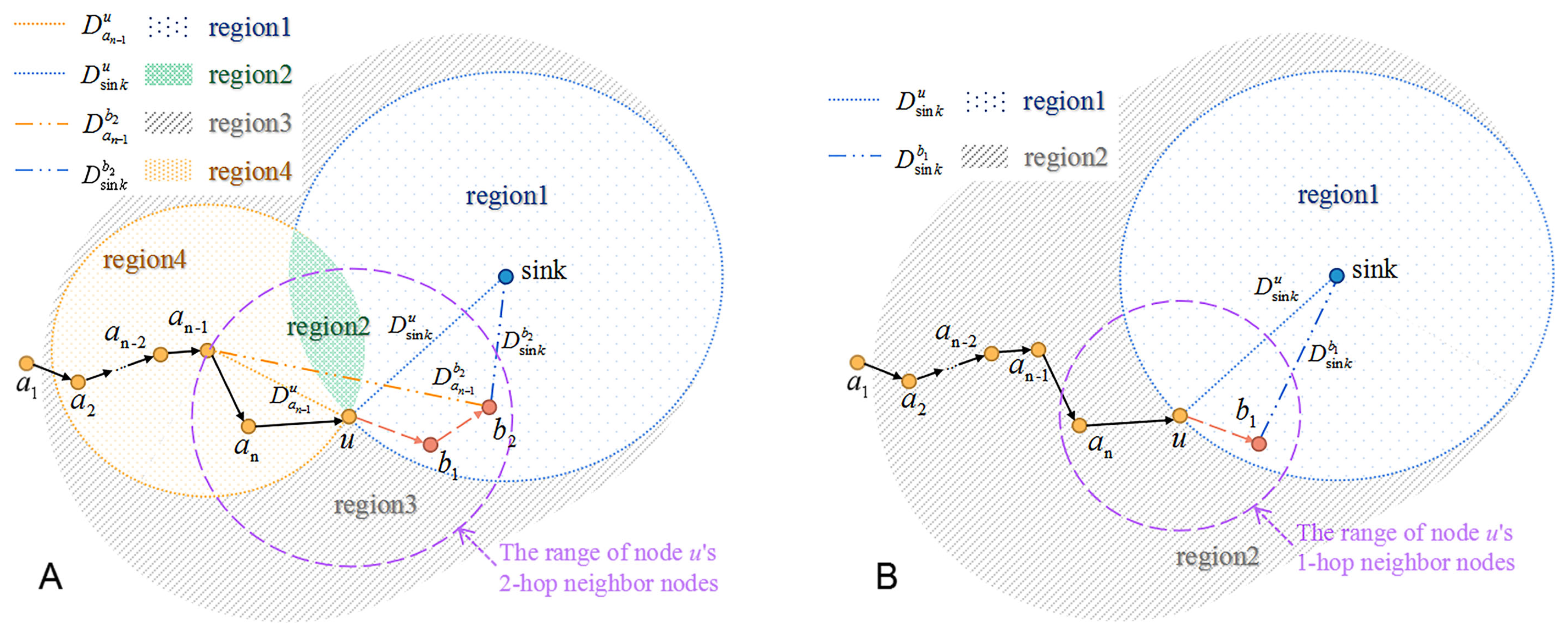
As shown in
Figure 6A, for the current forwarder
u, node
,
,
and
are represented as its last 2-hop, last 1-hop, next 2-hop and next 1-hop nodes, respectively.
,
,
and
denote the distance from node
to
u, the sink to
u,
to
and the sink to
, respectively. The nearby region around node
u is divided into four parts, and weight
is set for
ith region (
i = 1, 2, 3, 4). The division rule is shown as following:
The shorter distance from the chosen next-hop node to the sink is set as the prime target, and the long-distance from the chosen next-hop node to node is set as the secondary target. Intuitively, nodes in region1 are the best choice of next hop nodes because they are farther to node but nearer to the sink than node u. Nodes in region2 transmit data closer to upstream forwarders, and thus they are the second choice. Nodes of region3 or region4 would transmit data packets farther away from the sink node than node u, so these nodes are the worse choices than those of region1 or region2.
Through the above analysis, the weight factors of these four regions could be set as: , which indicates that a smaller weight represents a better choice of next-hop nodes.
In summary, the greedy forwarding mechanism is expressed in the form of probability, that is, each neighbor node is given a weight between 0 and 1 according to the distance, and the weight represents the probability that the node is selected as the next-hop node. The traditional greedy forwarding mechanism (the current forwarder chooses the neighbor node that is closer to the sink than itself) can also be converted into the following probability forms according to the above idea: The weight of the neighbor node that is closer to the sink than the current forwarder is set as 1, which means that neighbor node is the better choice. The following formula can express the above traditional greedy forwarding mechanism:
Therefore, as depicted in
Figure 6B, the nearby region around the current forwarder
u is divided into two parts. The neighbor node in region 1 is closer to the sink than the current forwarder, while the neighbor node in region 2 is farther to the sink than the current forwarder. Thus, the weight factor of region 1 and region 2 could be set as 1 and 0, respectively.
According to the number of discharges, nodes are graded into three discharge levels (
):
(the discharge number is relatively the smallest),
(the discharge number is relatively medium), and
(the discharge number is relatively the highest). The weights of them are:
,
,
, where
and
. Assume that
, where
and
represent the weight factor
of node
and
, respectively. It is critical to reduce the data forwarding traffic of nodes whose discharge numbers are relatively higher than those of other nodes because high voltage discharges have interference on communication [
5,
6]. Clearly, smaller
indicates less interference on communication.
Finally,
P is defined as the parameter to select the next 1-hop and 2-hop nodes:
where
is a weight factor between 0 and 1 that determines the relative significance placed on
and
E.
E denotes the energy consumption factor, which is calculated as:
where
,
and
represent the energy consumption of communication by
u,
and
, respectively.
,
and
denote the residual energy of
u,
and
, which is defined as:
where
denotes the initial energy.
and
represent the energy consumption of the lure lamp and discharges, respectively. As shown in the example of
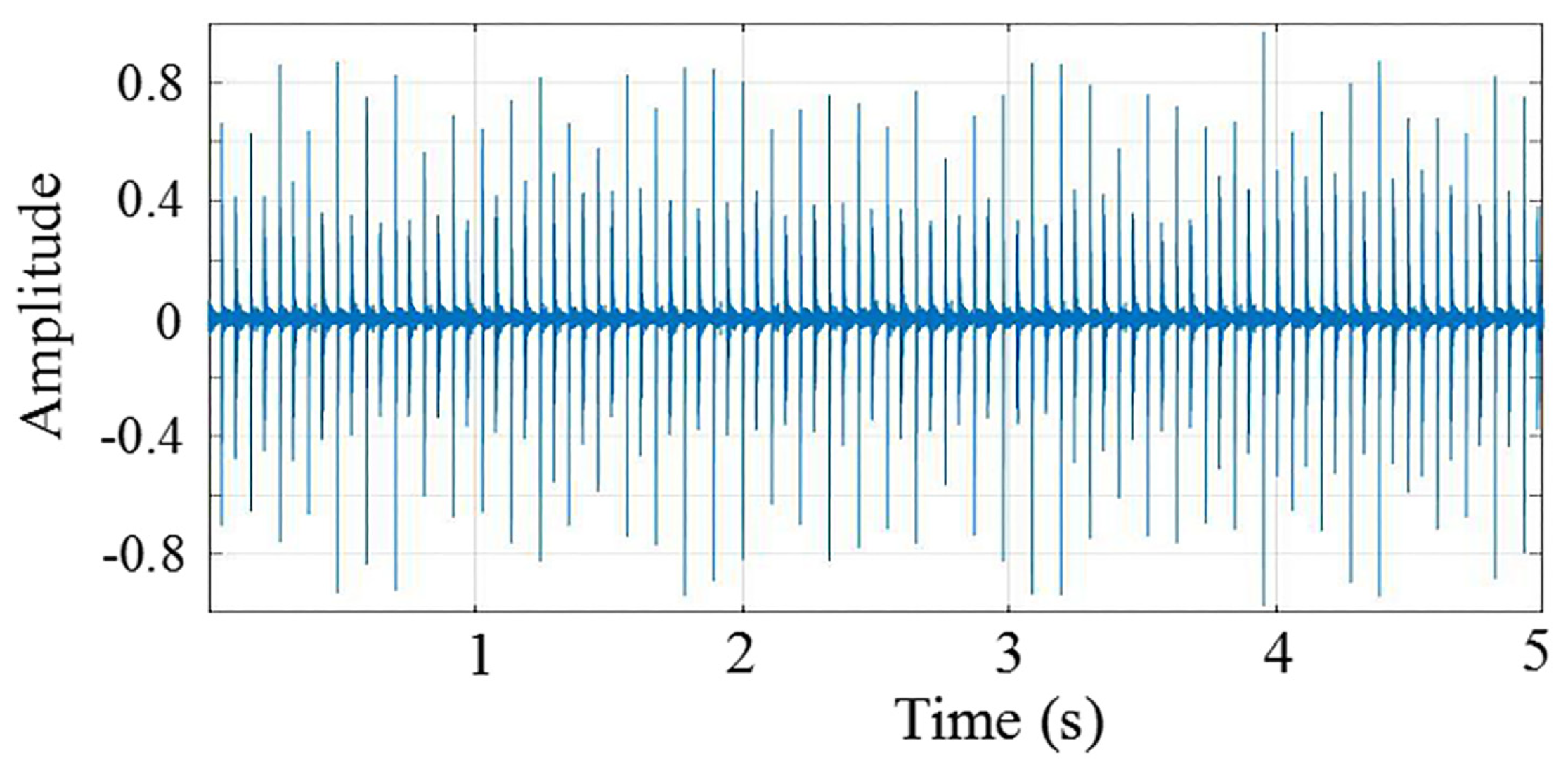
Figure 7, the energy consumption of node2 is less than that of node1, but accounts for about 80% of the whole energy of node2. However, node1 consumes about only 50% of its total energy. Obviously, node1 is the better choice. Therefore, we adopt the ratio of communication energy consumption (
,
and
) to residual energy (
,
and
) to evaluate the energy consumption of nodes.
In summary, the current forwarder u calculates P of all optional paths and selects the path with the smallest P, since the smallest , , and E indicate the best choice of the alternative paths. Especially, due to the different magnitude of and E, it is necessary to normalize them respectively.
Finally, the current forwarder u sends a burst packet to the next 1-hop and 2-hop nodes. These nodes add their IDs to this packet successively.
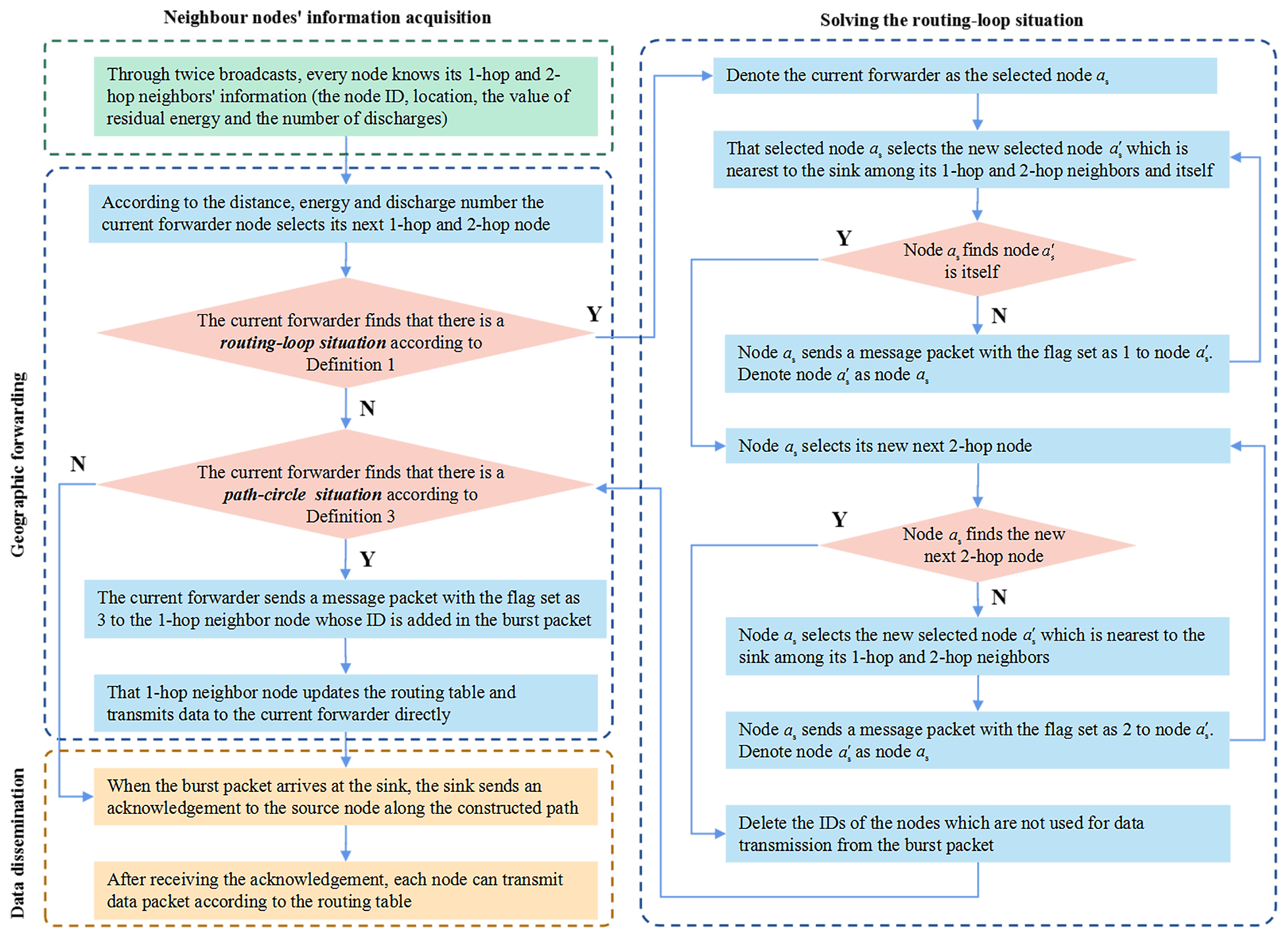
4.3.2. Solve Routing-Loop Situation
Definition 1 (Routing-Loop Situation).Let denote all the nodes on the found path from node to u, e.g., Figure 8A. If the next 1-hop or 2-hop node selected by the current forwarder u belongs to A, the data packet will be circularly transmitted among the previous forwarders , and this kind of situation is defined as arouting-loop situation
, as depicted in Figure 8A. Definition 2 (Block Circle and Block Line).In Definition 1, if has only three 1-hop neighbors (, , ), this situation is defined as a block circle
. As shown in Figure 8A, if the node at the end of the path has only one neighbor () and the other nodes have only two neighbors, we define this situation as a block line.
These cases also make the data transmitted among the previous forwarders because the next hop nodes can only be chosen from the previous forwarders. Therefore, the block circle
and block line
are the special cases of the routing-loop situation.
The routing-loop situation may also appear in our algorithm. The routing-loop situation may also appear in our algorithm. The following approach is proposed to solve this situation.
Step 1: If the current forwarder
u finds that the ID of its next 2-hop node has been stored in the burst packet which has the IDs of all nodes on the found path (mentioned in
Section 4.1), there occurs a
routing-loop situation according to Definition 1. Then,
u is denoted as the selected node
.
Step 2: That selected node
selects the new selected node
which is nearest to the sink among itself and its 1-hop and 2-hop neighbors in
A (e.g., in
Figure 8A,
u calculates the distances from
,
,
u,
, and
to the sink, respectively, and selects the node
with the smallest distance).
Step 3: If
finds that
is itself, that is, there are no neighbors on the found path
A nearer to the sink than itself, Step 4 will be executed. Otherwise, node
sends node
a message packet with the flag set as 1. Denote node
as node
, and then execute Step 2. The above Step 2 and Step 3 are repeated until
is the nearest node to the sink among the nodes on the loop. (e.g., In
Figure 8A, node
has the smallest distance to the sink than other nodes in
A and it is denoted as the final
).
Step 4: Node (e.g., ) selects its new next 2-hop node from the nodes .
Step 5: If
does not find a new path to break the loop, it selects the new selected node
(e.g.,
) which is nearest to the sink among its 1-hop and 2-hop neighbors in
A. Then,
sends a message packet with the flag set as 2 to node
. Finally, denote node
as node
, and then execute Step 4. Therefore, Step 4 and Step 5 are executed repeatedly until a new path is built to break the loop (e.g., in
Figure 8B, if we assume that
could not find that new path for some reason, node
selects the new next 2-hop node to build that path).
In summary, starting from node (e.g., ), the nodes on the found path A find their new next 2-hop nodes in a specified order until a new path is built to break the loop.
Step 6: If a new path without
routing-loop situation is built, delete the IDs of the nodes which are not used for data transmission from the burst packet (e.g.,
,
u,
in
Figure 8B).
Figure 7.
The energy consumption of node2 is less than that of node1. However, node1 consumes only 50% of its total energy while node2 consumes about 80% of the whole energy.
Figure 7.
The energy consumption of node2 is less than that of node1. However, node1 consumes only 50% of its total energy while node2 consumes about 80% of the whole energy.
Figure 8.
(A) The current forwarder u finds that if it chooses node as the next 2-hop node (as shown by the purple dotted line), there will be a routing loop . Then, u selects the node with the smallest distance to the sink from its neighbors , , u, , and . After that, as shown by the blue dotted line, u sends a message packet to to inform to select the node nearest to the sink from the neighbors. In this way, we can acquire the node which is nearest to the sink on the found path. (B) If could not find any new next 2-hop node to break the loop, will send the message packet with the flag set as 2 to (as shown by the blue dotted line). is nearest to the sink among the neighbors of . Then, selects the new next 2-hop node. The green dotted line denotes the new path explored by .
Figure 8.
(A) The current forwarder u finds that if it chooses node as the next 2-hop node (as shown by the purple dotted line), there will be a routing loop . Then, u selects the node with the smallest distance to the sink from its neighbors , , u, , and . After that, as shown by the blue dotted line, u sends a message packet to to inform to select the node nearest to the sink from the neighbors. In this way, we can acquire the node which is nearest to the sink on the found path. (B) If could not find any new next 2-hop node to break the loop, will send the message packet with the flag set as 2 to (as shown by the blue dotted line). is nearest to the sink among the neighbors of . Then, selects the new next 2-hop node. The green dotted line denotes the new path explored by .
Figure 9 shows two
routing-loop situations occurring in THECB during the simulation. The ID is labeled near the node. To solve this problem, the node (ID 23, ID 79) nearest the sink among all nodes on the found path explores the new path.
The Step Back and Mark method proposed by [
15] is designed to solve the
block line (in [
15], the
block line has only one node and is named as the
block node). In this method, if the current forwarder has no 1-hop neighbors except its previous forwarders, which means the next-hop node can only be chosen from the previous forwarders, it will step back to its last 1-hop node which will try to find a new available next-hop node. This step will be executed repeatedly until the new available next-hop node is found. Therefore, based on this mechanism, the Step Back and Mark (SBM) method can be extended to solve the
routing-loop situation which is more general than the
block line. The new mechanism is the following: If the next-hop node is chosen from the previous forwarders, the next-hop node will step back to its last 1-hop node which will try to find a new available next-hop node. This step will be executed repeatedly until the new available next-hop node is found. This method can be summarized as: In the order from the node that finds this situation to the source node, nodes on the built path attempt to find a newly available path (e.g., in
Figure 8B, nodes explore the new path in the following order:
).
In our method, the nodes explore the new path according to the sort of distances from these nodes to the sink. As shown in
Figure 8B, let
and
denote the new path found by
using the SBM method, and found by
based on our method, respectively. It is seen that
is longer than
because
is closer to the sink than
. In particular, the difference between the two paths would be larger in more sparse networks. Although sending message packets in our method when solving the
routing-loop situation costs some energy, due to (1) this process is only executed during building the routing table and may not consume energy frequently, and (2) the new path to break the loop established by our method may be shorter than that of the SBM method, especially in the sparse network such as SIL-IoTs, which indicates our method may save more energy consumption of communication and improve the transmission speed than the Step Back and Mark method in multiple data transmission after the routing table is established, it is still highly significant to design and adapt our method.



 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}