1. Introduction
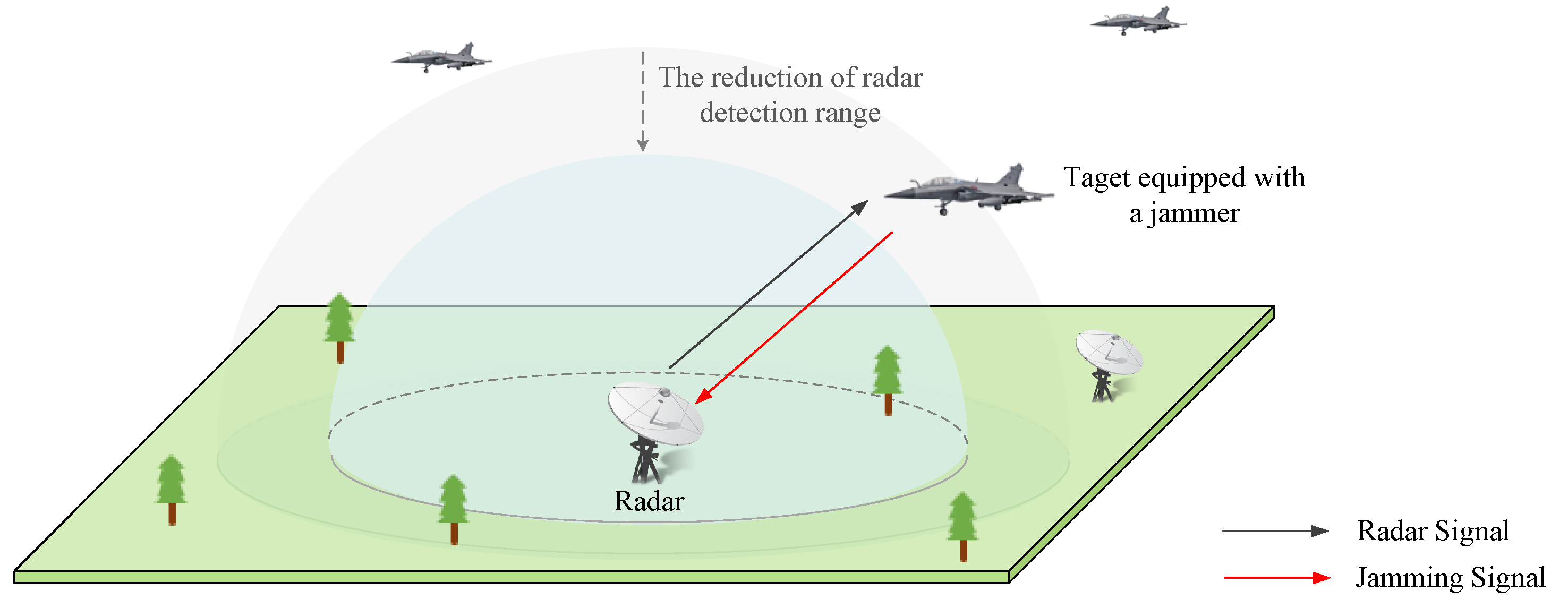
In radar jamming, accurate decision-making is an important prerequisite for effective jamming. For single-mode radar with only a few fixed parameter combinations, the jamming decision-making based on template matching can be efficient [
1]. Nowadays, with the improvement of electronic technology, modern radars tend to be adaptive. Adaptive radars can perform various tasks through automatic work mode switching, where work modes vary with different radars. Take a ground-based radar with search, tracking, and recognition modes as an example: The radar initially scans the entire airspace at the search mode, and switches to the tracking mode when a mission-related target is detected, then transitions to the recognition mode after the target is confirmed. If the echo signal quality drops or the target is lost due to the jamming, the radar will take anti-jamming measures autonomously or return to the search mode. For phased array radars with modes named “range while scan” (RWS), “track and search” (TAS), “Single Target Track” (STT), etc., the adaptive switching strategy is more complicated. Additionally, in each work mode, the pulse parameters can be changed in real time to improve radar’s performance or survivability based on environment detecting [
2,
3]. In such context, the effectiveness of conventional jamming decision-making methods is decreasing because of a large shortage of prior knowledge about the radars [
4]. Therefore, it is urgently necessary to develop radar jamming technology.
Inspired by the cognitive radio, the application of intelligent algorithms in radar confrontation became possible [
1,
5,
6,
7]. To solve the problem of the low rate of template matching under the incomplete jamming rule library condition, a jamming decision-making method based on clustering and resampling–support vector machine is proposed in [
1]. In [
5], a discrete dynamic Bayesian network is established to guide decision-making in self-defense electronic jamming. In [
6], an improved chaos genetic algorithm is applied to the allocation of interference strategy. In [
7], a particle swarm optimization algorithm is applied to solving optimal jamming power allocation strategy aiming at cognitive MIMO radar. However, these traditional machine learning methods often require large amounts of tagged radar data acquired in advance, which are difficult to be obtained in actual scenarios.
Up to now, there have been many works on the application of reinforcement learning (RL) in communication jamming and anti-jamming [
8,
9,
10,
11,
12], providing new ideas for radar confrontation. RL is a type of machine learning technology, where an agent learns from interacting with the environment and takes maximizing the feedback from the environment as its learning goal [
13]. In [
14], the framework of intelligent jamming based on RL is described, where the cognitive jammer and the radar are respectively regarded as the agent and the environment. In [
4], the conversion between different radar working states is modeled, where an RL model is trained to choose the jamming mode against each radar state. A frequency-agile radar is considered in [
15], and a jamming frequency selection algorithm based on Q-learning is proposed to solve the optimal frequency for each jamming pulse. In [
16,
17,
18,
19], other methods based on RL are used to optimize the strategy of combating jamming for radar. Compared with the traditional machine learning methods mentioned above, the agent in RL can learn with no tagged data needed, which makes it more adaptable to the unknown environment. The jamming system equipped with RL can obtain training samples during the jamming process, and update the jamming strategy dynamically based on the change of the radar signal.
However, in the existing work of jamming decision-making based on RL, two common measures of the adaptive radar including mode switching and parameter agility have not been jointly considered. For example, [
14] focuses on macro-level modeling of radar jamming, abstracting radar modes into the environment state in RL. What is not noticed is that the jamming effectiveness will be weakened due to the agile actions such as frequency agility [
16] and dynamic pulse repetition interval [
20] taken by radar in each mode. In [
15], the authors aim at the frequency hopping of the radar without considering multiple work modes. According to the authors of [
3], if only static behavior of radar is considered, such as a single work mode, it is easy to result in a subjective or local optimal jamming strategy. Moreover, when facing the adaptive radar with multi-modes and the ability of parameter agility, a large jamming action space is usually needed to ensure that the correct actions are included, which greatly increases the complexity of jamming parameters generating. As high complexity will lead to a long convergence time, the jammer can hardly find the optimal jamming strategy in a limited time, which can be fatal to the protected target.
To overcome the problems above, a two-level jamming decision-making framework is developed in this paper. On this basis, a dual Q-learning (DQL) model is proposed to obtain the optimal jamming strategy. Specifically, the jamming decision-making process is disassembled into two levels, where the jamming mode is decided in the first level with the outer Q-learning, and the pulse parameters for the decided jamming mode are selected in the second level with the inner Q-learning. This structure greatly reduces the dimension of the action space of the jammer. With smaller action space and fewer parameters to be learned, it can effectively avoid falling into the local optimum while shortening the convergence time.
Another issue needed to be considered is how to express the feedback from the environment of RL in the jamming decision-making scene. Different from the previous methods where the feedback is statically assigned through the experience matrix, in this paper, we evaluate the effectiveness of jamming as the feedback of the DQL model. On jamming effectiveness evaluation, currently most of the research is based on data collected from the radar side which is impractical due to the non-cooperative nature of the battlefield. However, there are only a few studies on the evaluation from the jamming side. In [
21], the accumulated amplitude extracted from signals is chosen as the characteristic statistic to evaluate the jamming effectiveness. In [
22], the authors advise using the change of the radar threat level as the basis for the evaluation. In [
23], an evaluation method based on feature space weighting in non-cooperative scenes is proposed, where the weight values of evaluation indicators are solved with offline simulated radar data. Considering the variability of the indicator’s contribution to the evaluation result, in this paper, the indicators’ weight values are calculated with their entropy and are updated constantly based on the real-time radar data. With the dynamic weights, the jamming effectiveness is evaluated through measuring the distance between the indicator vectors before and after jamming. The evaluation result is served as the feedback of the environment, based on which the DQL model updates dynamically.
The main contributions of this paper are summarized as follows:
An RL model named DQL is constructed to guide the jamming decision-making against adaptive radars, where the jamming mode and jamming parameters are hierarchically selected and jointly optimized. Because of the reduced dimensionality of action space, the globally optimal solution can easily be found with a shorter convergence time.
A new jamming effectiveness evaluation method based on indicator vector space is proposed to serve the feedback to the DQL model, which effectively overcomes the dependence on subjective experience when the model updates. Additionally, in view of the variable electromagnetic environment, the indicators’ weights are calculated dynamically with the real-time radar data, to make the evaluation result more credible.
The rest of this paper is organized as follows. The system model is introduced and the problem of jamming strategy optimization is formulated in
Section 2. The proposed DQL model and jamming effectiveness evaluation method are explained in
Section 3. The details of the simulations and the analysis of results are shown in
Section 4, followed by the conclusion presented in
Section 5.
3. Proposed Jamming Scheme Based on DQL Model
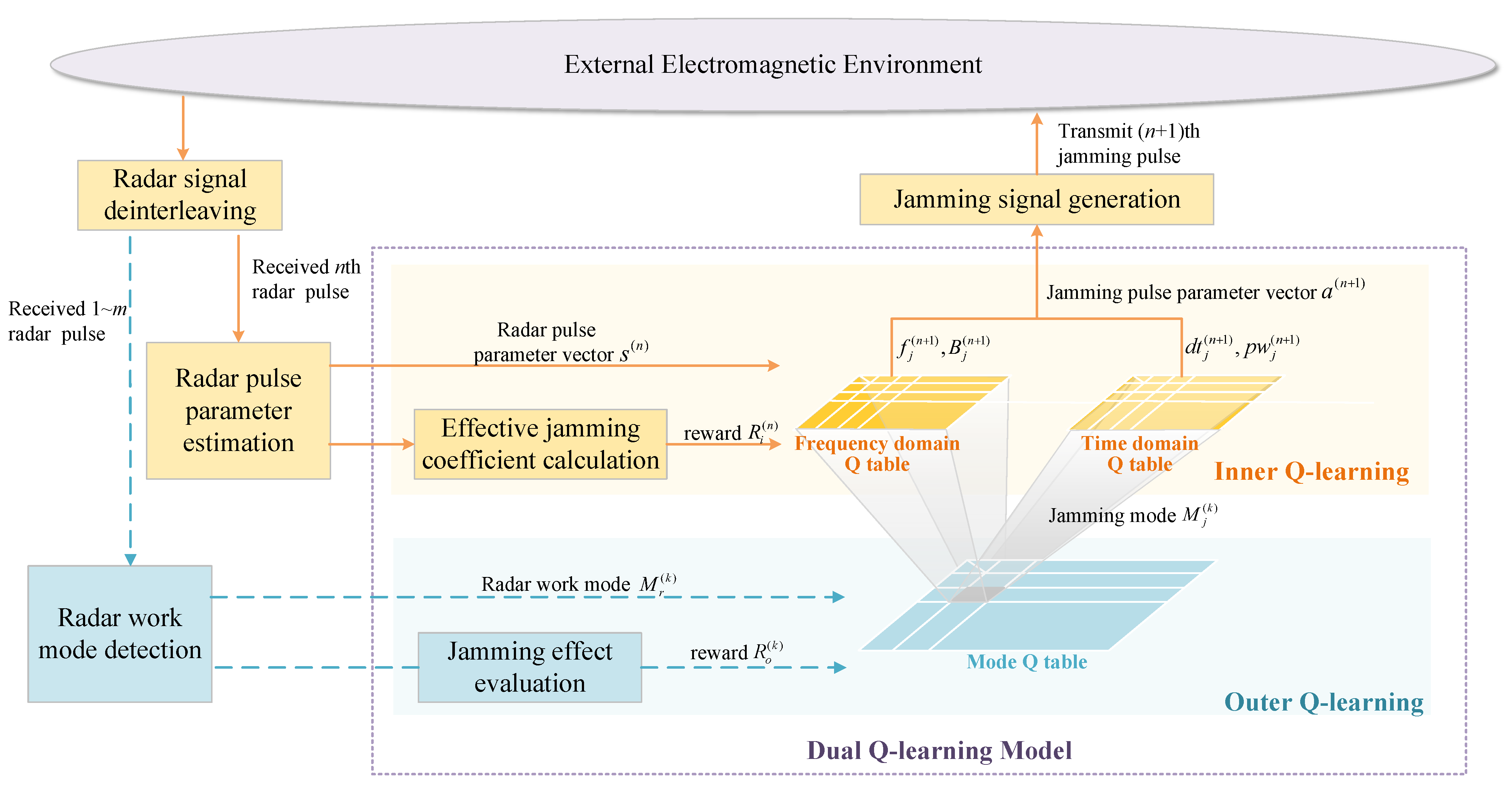
To interfere the adaptive radar with mode switching and parameter agility, we propose an RL model named dual Q-learning to optimize jamming strategy, as shown in
Figure 2. The jammer’s action space is disassembled into two subspaces containing jamming mode and pulse parameters respectively to reduce the dimensionality, based on which the jamming procedure can be divided into two levels. The jamming mode is determined in the first decision-making level, and specific parameters in frequency and time domain are selected in the second level according to the jamming mode. Two interactive Q-learning models are constructed to find the global optimal solution, and a dynamic method for jamming effectiveness evaluation is designed to obtain the feedback of the DQL model. The interaction between the two levels can be described as: the jamming mode determined in the first level has a guiding effect on the selection in the second level, and the pulse parameters selected in the second level directly determine the SJR at the radar receiver and affect the mode switching of the radar, thereby affecting the next input state of the first level.
3.1. Jamming Decision-Making through DQL Model
In the jamming procedure based on the DQL model mentioned above, the outer Q-learning and the inner Q-learning model are trained simultaneously to solve the optimal jamming strategy.
3.1.1. Outer Q-Learning
The outer Q-learning is modeled to acquire the jamming mode in the first decision-making level, where the radar work mode and the jamming mode are regarded as the environment state and the action of the agent, respectively. When obtaining radar work mode
at time
k, the jammer chooses jamming mode
as:
in the outer Q table is updated when the new radar mode
is obtained at time
according to the following rule:
where
is the learning rate of the outer Q-learning, which signifies the updating stride of Q value.
is the reward calculated at time
for the outer Q-learning, which depends on the evaluation result of jamming effectiveness according to radar mode switching. The evaluation method will be introduced in the next section.
3.1.2. Inner Q-Learning
The inner Q-learning is modeled to solve the optimal jamming parameters in the second decision-making level. The jamming mode selected in the first decision-making level maps to inner Q tables in frequency and time domains. When obtaining the
nth radar pulse parameter vector
, the jammer takes
and
as the input states of frequency and time domain Q tables respectively, and the jamming parameters will be chosen according to:
where
,
in the frequency domain Q table,
,
in the time domain Q table. The power of jamming signal
is calculated as
, where
varies with different jamming modes. Then the jamming parameter vector
can be constituted. After the receiving of
nth radar pulse, the transmission of next jamming pulse will start after a delay of
, aiming at the
th radar pulse. In summary, the jammer predicts the radar parameters one step in advance, in order to interfere the next radar pulse in time. When the
th radar pulse parameter vector
is obtained,
in the inner Q table is updated according to the following rule:
where
is the reward of the inner Q-learning calculated with
and
.
for the frequency domain Q table,
for the time domain Q table.
Both in the outer and inner Q-learning, -greedy policy is used to choose the jamming mode or parameters, which is an effective way to balance the exploration and exploitation. In this paper, we define which decreases as the count of iterations increases, where k represents the number of the iteration and the coefficient determines the decay rate. is set differently for two decision-making levels: for the outer Q-learning and for the inner Q-learning. Taking the outer Q-learning as an example, the jammer randomly chooses a jamming mode with probability , and chooses the optimal jamming mode according to Equation (10) with probability . According to the explanation above, a jamming algorithm based on the DQL model is proposed, and more details are shown in Algorithm 1.
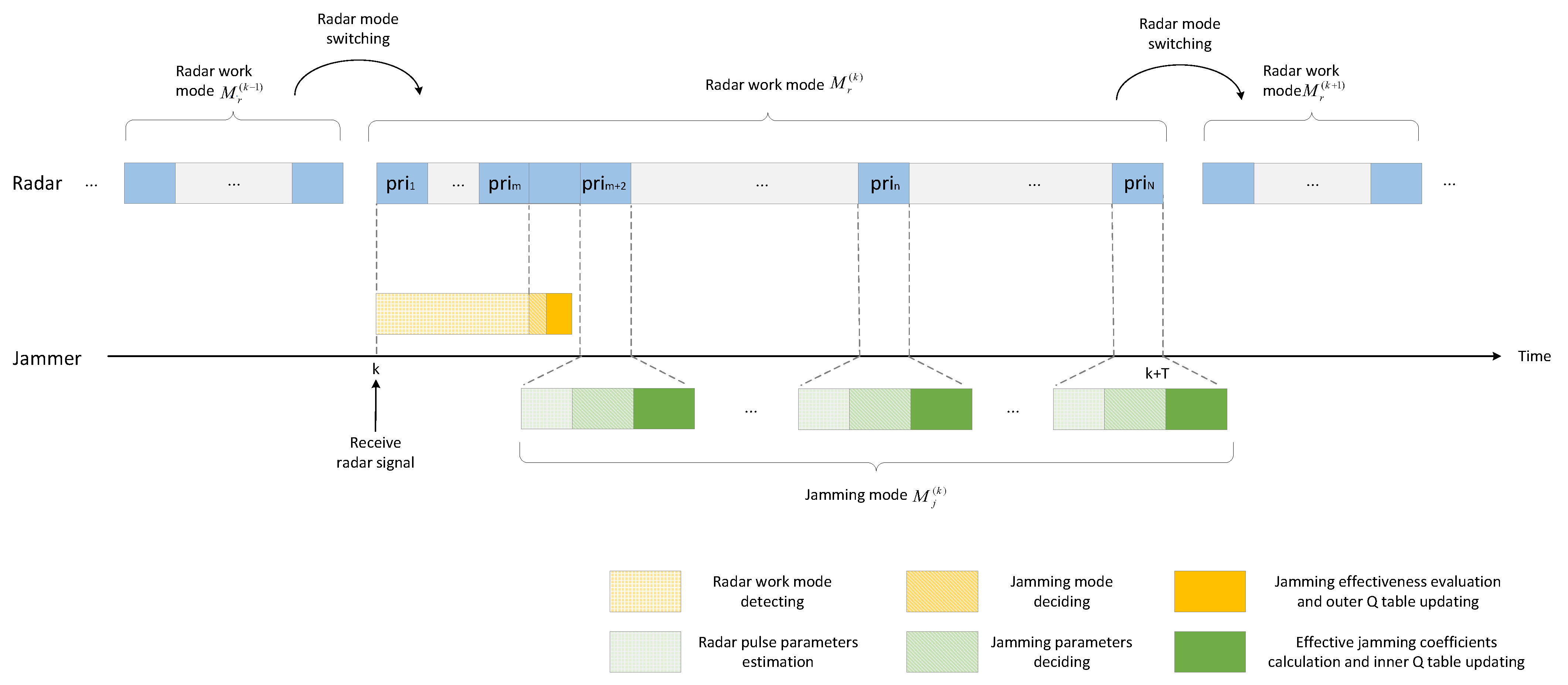
The time series of learning and jamming decision-making with the DQL model is shown in
Figure 3. During a jamming round, the outer Q-learning is performed only once at the beginning to obtain the jamming mode. Under the constraints of the jamming mode, the inner Q-learning is performed in each subsequent PRI to determine the jamming parameters.
| Algorithm 1: Jamming algorithm based on DQL model |
(K and denote the amount of jamming rounds in simulation and the total
number of pulses in the kth jamming round respectively. m represents the
number of pulses required for radar mode discerning.) |
| for do |
![Sensors 22 00145 i001]() |
| end |
3.2. Jamming Effectiveness Evaluation through Dynamic Measuring of Vector Distance
Jamming effectiveness evaluation is an important part of the jamming decision-making method based on the DQL model proposed in the previous section. The evaluation result provides the reward for the outer Q-learning. In the radar confrontation, the most intuitive impact of effective jamming on the radar is the reduction of detection probability, which is hard to be known from the jamming side. Therefore, the jamming effectiveness can only be estimated according to the parameters of the radar signal received by the jammer.
To evaluate the jamming effectiveness, we firstly construct an evaluation indicator set , where each indicator is a measurable parameter of the radar signal. When the radar is jammed, there are two possible ways for it to change its parameters. One is to switch its work mode. For example, the low SNR causes the radar to lose track of the target, so it shifts from the tracking mode to the search mode. The other possible way is that the radar takes anti-jamming measures in order to improve its performance. For instance, after receiving suppressive jamming, the radar increases the bandwidth to improve its range resolution. Usually, the indicators that can characterize the work mode switching of the radar include beam dwell time, PRI, etc, and the indicators that can characterize the anti-jamming measures taken by the radar include BW, PW, transmitting power, range and speed of frequency agility, etc. The indicators of these two aspects are considered to construct the evaluation indicator set .
Based on , a method of vector distance measuring is proposed to calculate jamming effectiveness, where the weight values of evaluation indicators are updated dynamically during the confrontation process. More details are explained as follows.
3.2.1. The Jamming Effectiveness Evaluation Method Based on Vector Distance Measuring
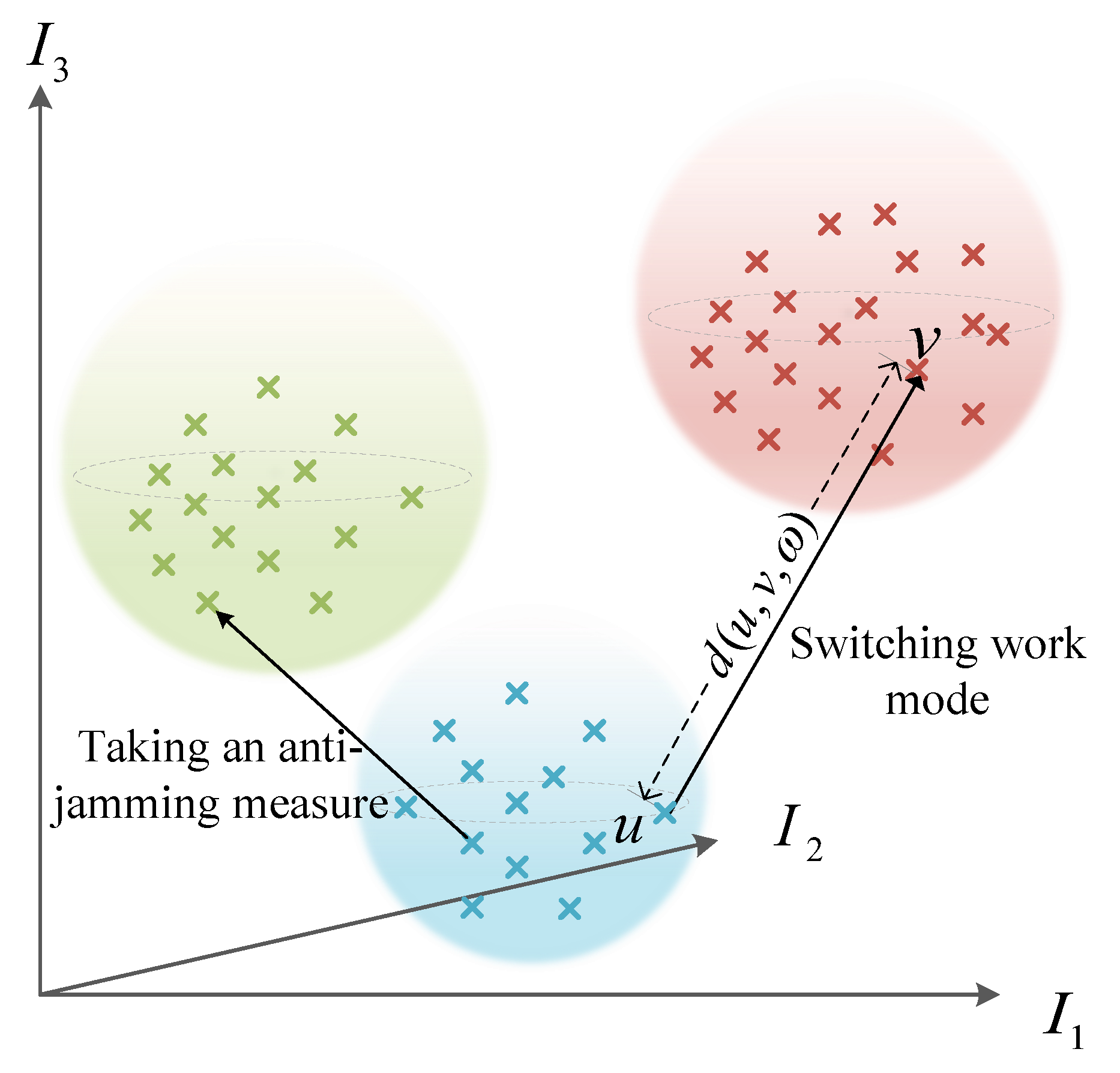
We construct a
l-dimensional vector space
based on
, where each dimension represents an evaluation indicator. To explain clearly,
Figure 4 shows a 3-dimensional vector space of three indicators. As shown, for the same radar state, the evaluation indicator vectors are often clustered together. When the radar switches its working mode or takes anti-jamming measures, the evaluation indicator vector will shift in space. The greater the offset along the increasing direction of the coordinate axes is, the more effective the jamming is. Therefore, the jamming efficiency can be evaluated by measuring the shift of the evaluation indicator vector before and after the jamming.
According to the above analysis, a jamming effect evaluation method based on vector distance measuring is proposed. As known, Euclidean distance can be used to calculate the absolute distance between vectors. We assign a weight for each evaluation indicator on the basis of Euclidean distance, where each weight reflects the contribution of the corresponding indicator to the evaluation result. The calculation formula of Euclidean distance with the indicator weight is expressed as:
where
,
are two indicator vectors in
.
is the weight vector for
l indicators,
.
is the value of
ith indicator in vector
.
identifies the symbol of the distance
, which indicates the direction in which the evaluation indicator vector shifts.
The feedback
of the DQL model at time
k based on jamming effectiveness evaluation is calculated as:
where
is the normalized evaluation indicator vector obtained at time
k.
is the weight vector calculated at time
k, and the calculation method for it is described below.
3.2.2. The Method of Dynamically Weighting for Evaluation Indicators
As the contribution of different indicators to the evaluation result will vary with the change of the radar status, is objectively modified through the method of dynamic entropy weight calculation. We horizontally compare the value of each indicator measured in different jamming rounds, and calculate their entropy values to obtain the weights. For each indicator, as a result of the difference between each measurement, its weight is not static, but changes with the received radar signal parameters. Thus, an online evaluation model is established.
For calculating the dynamic entropy weights of evaluation indicators, we define a matrix
, where
m evaluation indicator vectors can be stored. Once a new radar state is detected, the
l evaluation indicators of it are calculated and assigned to a column in
. If all the columns in
have been assigned values, the earliest assigned column will be overwritten by the new evaluation indicator vector.
in
denotes the value of the
ith indicator in the
jth vector. In order to nondimensionalize the calculation and eliminate the impact of different order of magnitudes, the original matrix needs to be normalized to a matrix
. The normalization formula is expressed as:
where
indicates that the vector distance
d is positively correlated to the
ith indicator in
, which means the lager the value of
is, the better the jamming effectiveness is. Then the proportion of the
jth vector for indicator
is calculated as
, and the entropy of indicator
can be calculated as:
Finally, the weight for each indicator is expressed as:
As shown in
Figure 2, when a new radar mode is detected at time
k, the jamming effectiveness of the last jamming round is evaluated, with which
is calculated and served as the feedback of the DQL model. The jamming effectiveness evaluation algorithm based on vector distance measuring with dynamic weight is shown in Algorithm 2.
| Algorithm 2: Jamming effectiveness evaluation algorithm |
| Input: Evaluation indicator vector |
| Output: Jamming effect evaluation result |
![Sensors 22 00145 i002]() |
Calculate the Euclidean distance between normalized and
the last indicator vector with the weight vector according to Equation (14) |
| Calculate the feedback of the DQL model through Equation (15). |
4. Numerical Results
To verify the proposed algorithms, a radar parameter template is firstly created, shown in
Table 1. Referring to [
25,
26], four kinds of radar work modes are considered in this paper, including search, acquisition, tracking, and guidance. For the target, the work mode of guidance has the highest threat level, followed by tracking, acquisition, and search. The beam dwell times when the radar is at these four work modes are 80 ms, 100 ms, 120 ms, and 140 ms respectively. For each work mode, two sub-modes are specified with different parameter agility patterns.
The mode switching rule of the radar can be described as: when SJR > −4 db, the radar will raises its threat level; when −7 db < SJR < −4 db, the radar will take anti-jamming measures while maintaining the current work mode, including , , and ; when SJR < −7 db, the radar will reduce its threat level.
For the jammer, the jamming mode can be switched between
and
, which denote frequency-spot jamming and blocking jamming respectively. The optional jamming parameters for each jamming mode are illustrated in
Table 2.
Other parameters in our simulation are given as:
30 dB,
= 5 dB,
= 10 dB,
= 5 dB,
R = 10 km,
. Considering that radar antennas are generally linearly polarized, while jammer antennas are circularly polarized or obliquely polarized,
is given as 0.5. The parameters in the proposed algorithms are set as:
,
,
, and
. The evaluation indicator set
is constructed of indicators
, which are shown in
Table 3. For each radar mode, the average PRI of all pulses in a period is calculated as indicator PRI, the difference between the maximum and minimum frequency is taken as the range of frequency agility, and the reciprocal of the number of continuous pulses with the same frequency is regarded as the speed of frequency agility.
Based on the above description, 200 jamming rounds are simulated.
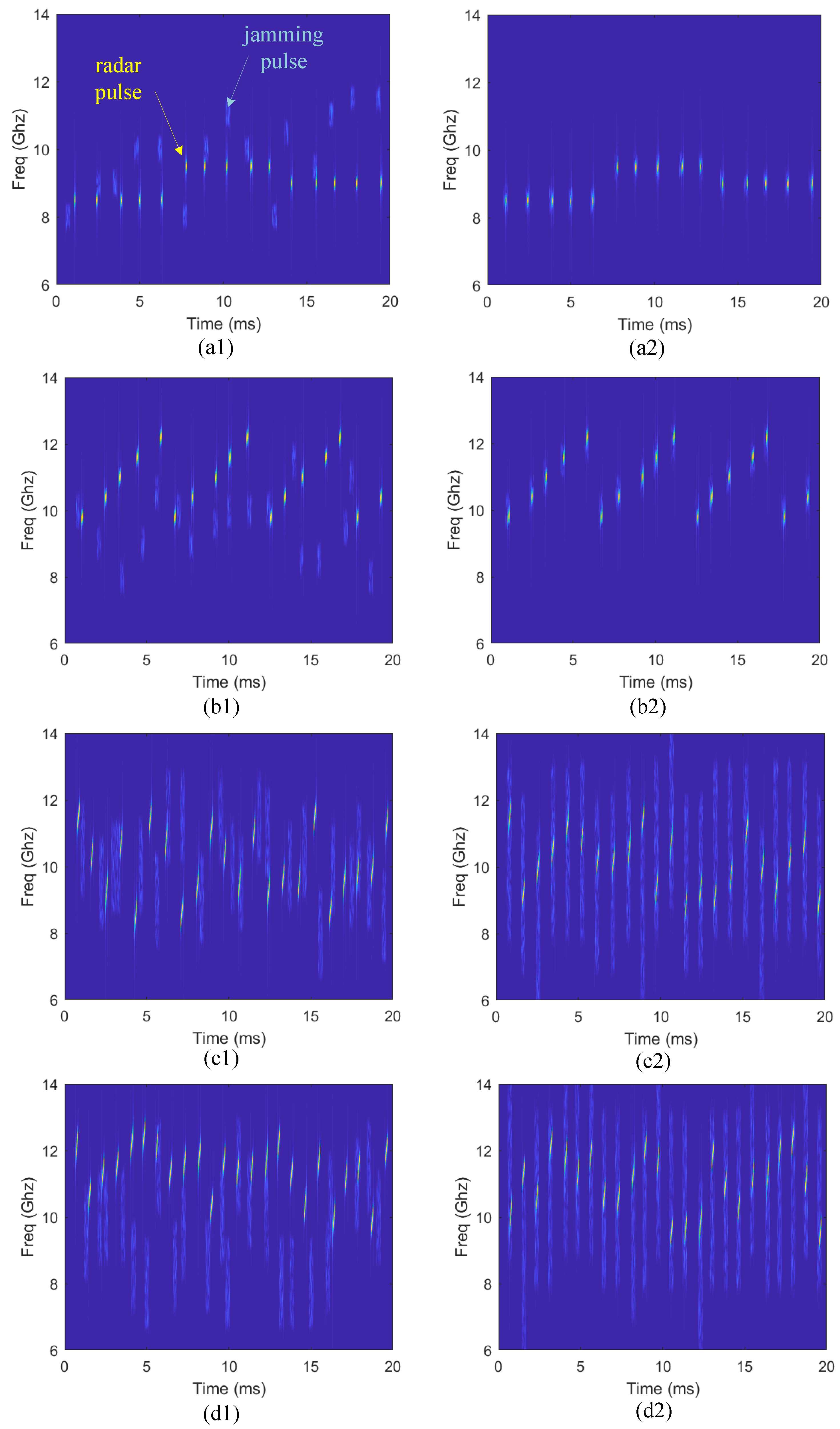
Figure 5 intuitively shows the time-frequency information under four different radar work modes at the initial and convergent stage of learning.
Figure 5a1, b1, c1,d1 show the radar and jamming signals at the initial stage, and four other figures show the convergent stage under the same radar work mode. Compared with the random selection of jamming parameters at the initial stage, the jamming pulses can accurately cover radar pulses in time and frequency domains to achieve effective jamming at the convergent stage. Besides, it can be found that if the radar is at modes where the CF changes regularly, the jammer chooses frequency-spot jamming mode
, otherwise, it chooses to block jamming mode
, which accords with the common perception.
We compared the performance of our algorithm with the improved chaos genetic algorithm [
6], the standard Q-learning [
15] and the random parameter selection method. The average JSR of each jamming round is calculated to reflect the jamming effect intuitively. The learning rate and discount rate are set with the same value both in the standard Q-learning and our algorithm. The following results are obtained through 500 independent simulations and their average values are taken to make the figures.
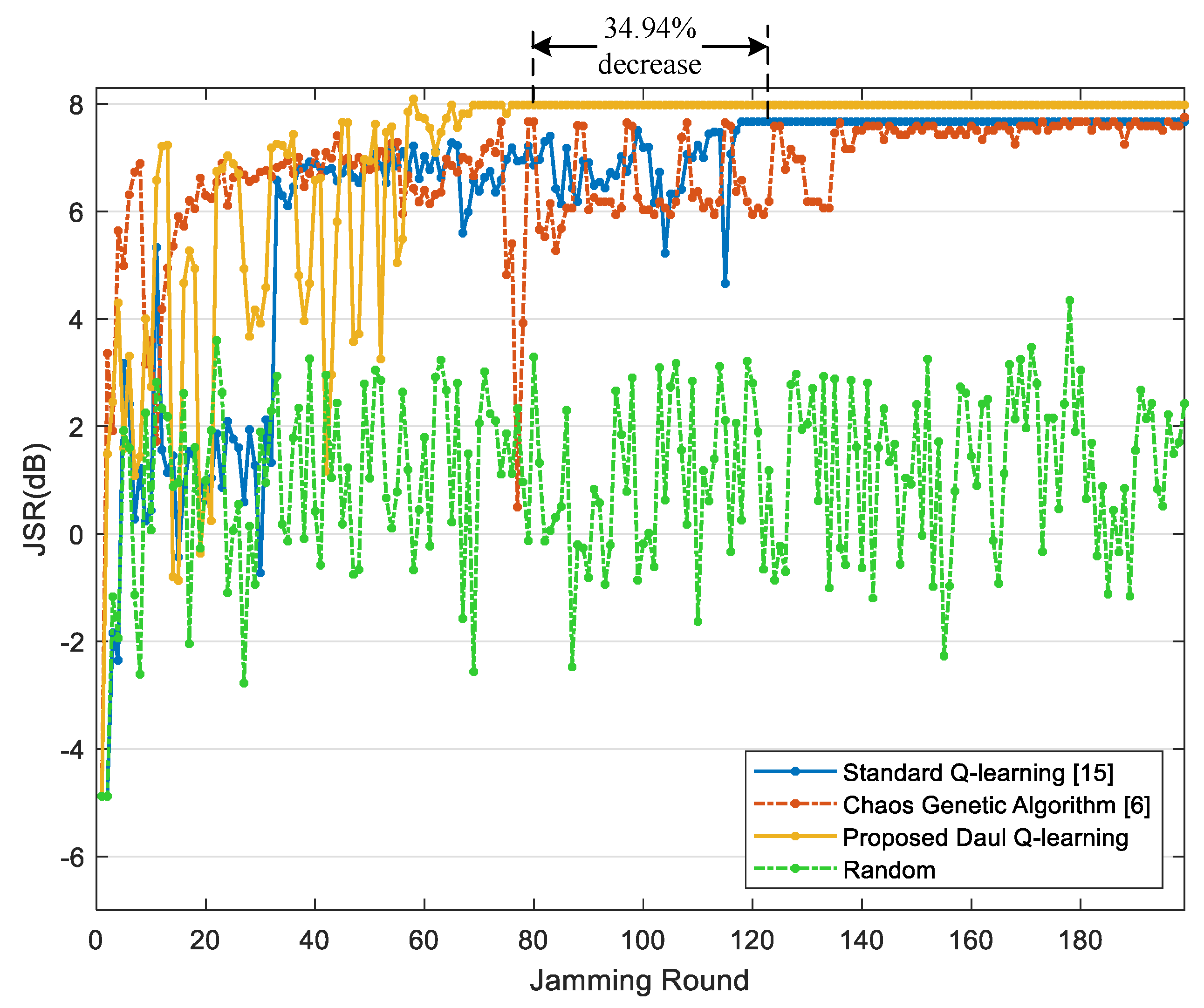
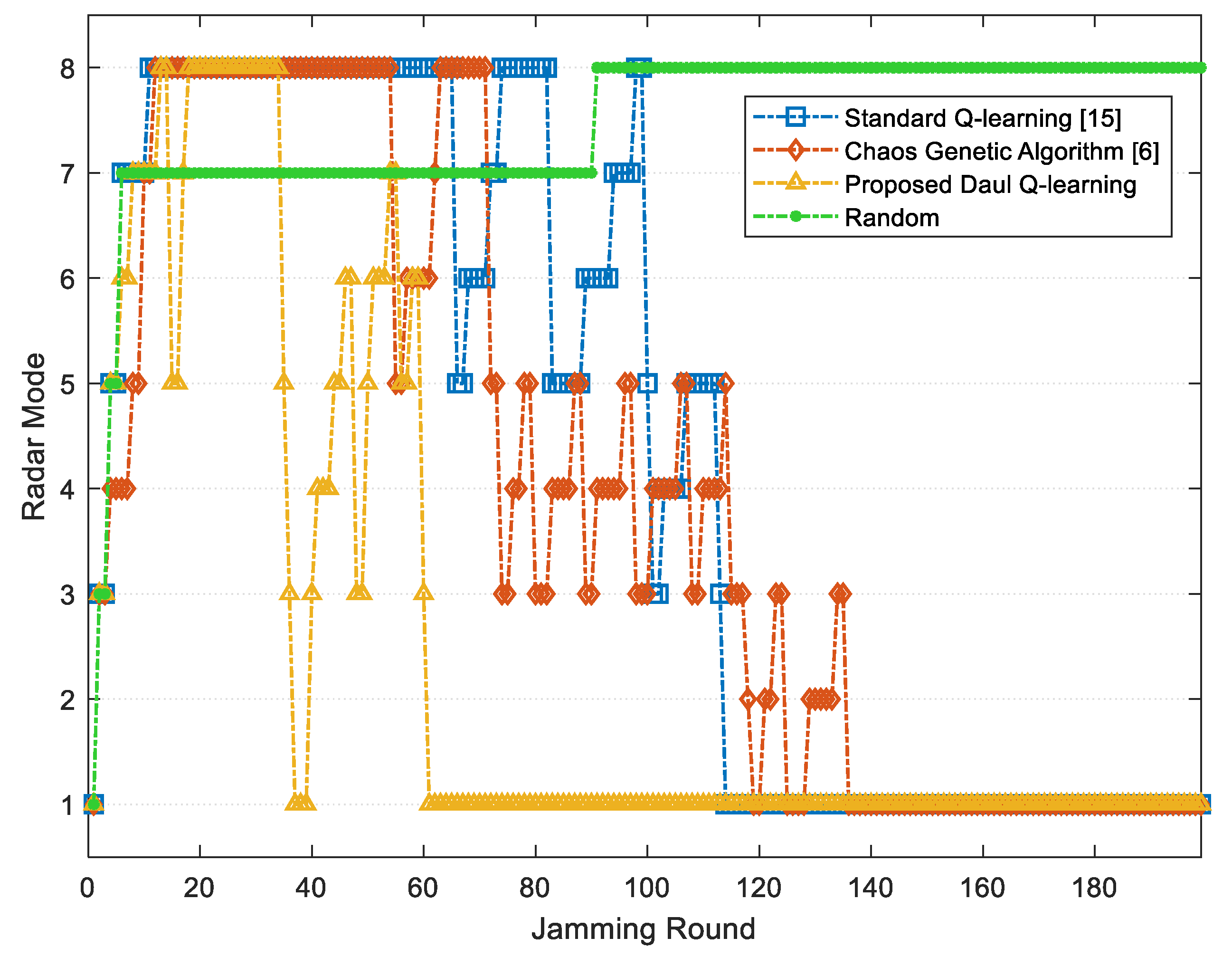
Figure 6 and
Figure 7 respectively show the average JSR and the radar threat level obtained through three methods during 200 jamming rounds. As shown, the improved chaos genetic algorithm [
6], the standard Q-learning [
15] and the proposed jamming algorithm based on the DQL model can all minimize the threat level of radar, and both the latter two methods can converge and stabilize the JSR within 200 jamming rounds. However, compared with the standard Q-learning, the proposed algorithm can reach the optimal average JSR 7.98 dB, which is 4.05% increased. Further, the convergence time of the proposed jamming algorithm declines by 34.94%, and the number of jamming rounds when the radar is at guidance modes including
and
reduces by 64.94%. As the high radar threat level is dangerous for the target, the proposed jamming algorithm based on the DQL model can improve the survivability of the target.
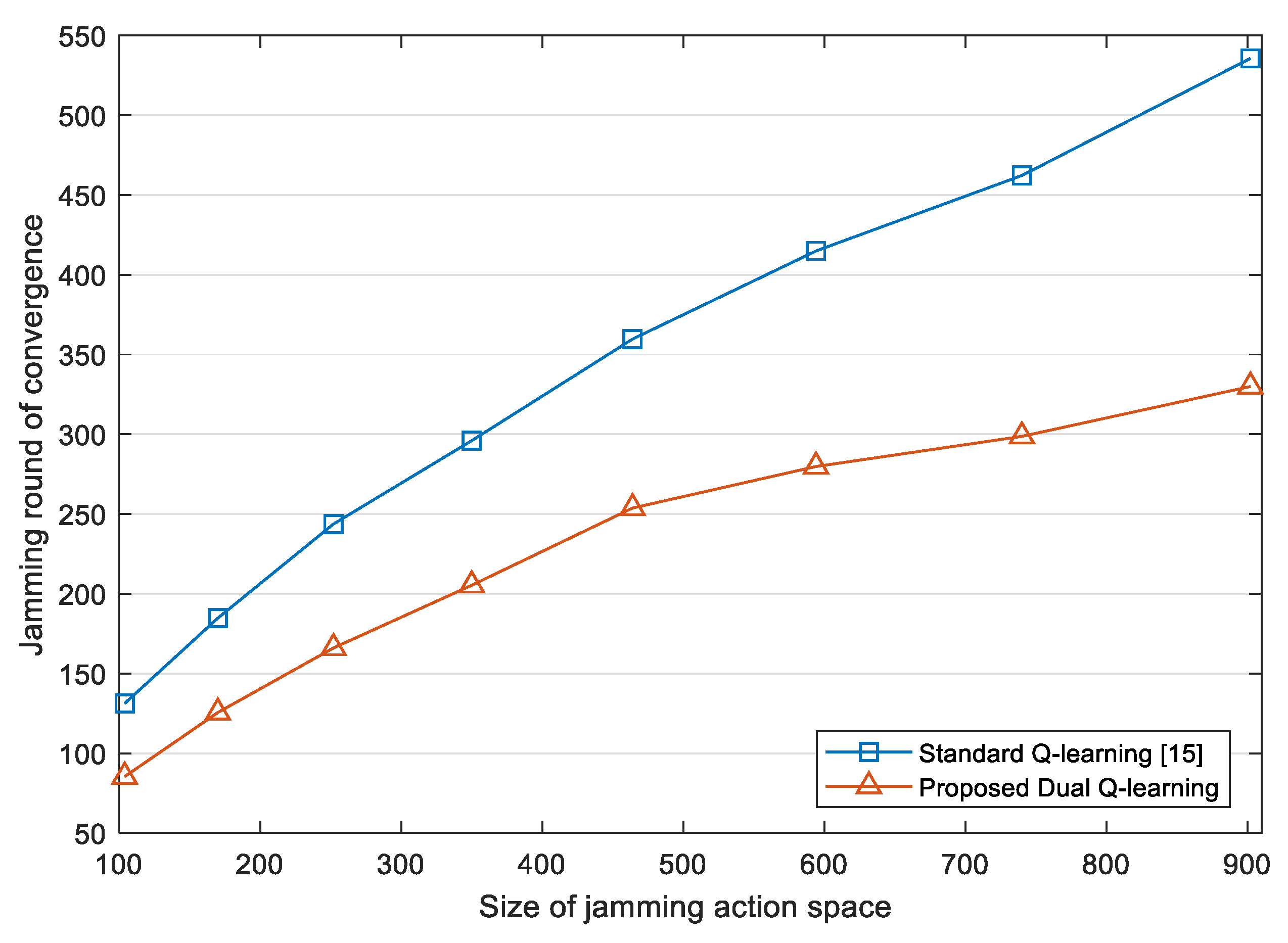
In order to further explore the convergence performance of the proposed jamming algorithm, we use the jamming round in which JSR is stable to indicate the convergence time. For jamming round
i, we calculate the variance of JSR from jamming round
to jamming round
. If the variance is less than 0.01, it is considered that JSR reaches a stable state in jamming round
i.
Figure 8 compares the convergence time of the jamming algorithm based on the standard Q-learning [
15] and the proposed DQL model. It is shown that the convergence time of the proposed jamming algorithm is generally lower than that of the standard Q-learning, and as the size of jamming action space increases, the gap between the two grows. Thus, our jamming algorithm based on the DQL model has better scalability, and is more adaptable when larger jamming action space is needed in face of adaptive even unknown radars.
5. Conclusions
In this paper, a two-level framework is developed for jamming decision-making against the adaptive radar, and a dual Q-learning model is proposed to optimize the jamming strategy. The jamming mode and pulse parameters are determined hierarchically, greatly reducing the dimensionality of the search space and improving the learning efficiency of the model. In addition, we proposed a new method to calculate the jamming effectiveness by measuring the distance of indicator vectors, where the indicators are dynamically weighted to adapt to the changing environment. The jamming effectiveness evaluation result is served as the feedback value to update the DQL model.
Simulation results show that with the proposed jamming method, the radar joint strategy of mode switching and pulse parameters can be learned within limited interactions, and the optimal jamming effectiveness is reached while the radar’s threat level is minimized. Furthermore, compared with the standard Q-learning, our method improves the average JSR by 4.05% and reduces the convergence time by 34.94%.
It should be emphasized that due to the complex electromagnetic environment, the estimation of radar work mode and pulse parameters is often inaccurate. When there are errors in the input state, the performance of the proposed DQL model will deteriorate. Therefore, in the near future, how to enhance the robustness of the model to deal with the uncertainty of the input is the focus of our investigation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}