
Application of Deep Learning on Millimeter-Wave Radar Signals: A Review


Abstract
1. Introduction
2. Overview of the Radar Signal Processing Chain
2.1. Range, Velocity, and Angle Estimation
2.2. Radar Signal Processing and Imaging
3. Overview of Deep Learning
3.1. Machine Learning
3.2. Deep Learning
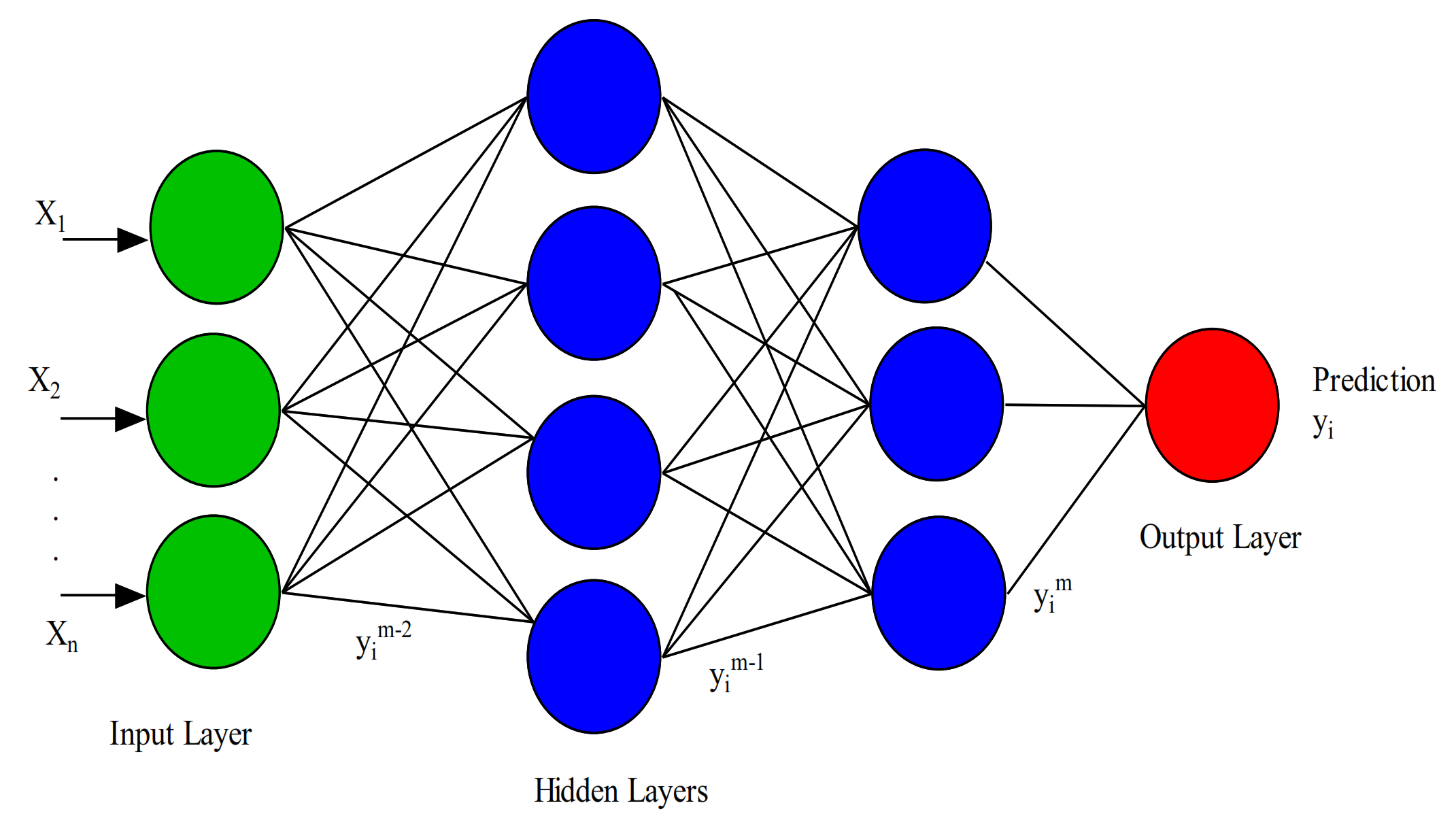
3.3. Training Deep Learning Models
3.4. Deep Neural Network Models
3.4.1. Deep Convolutional Neural Networks
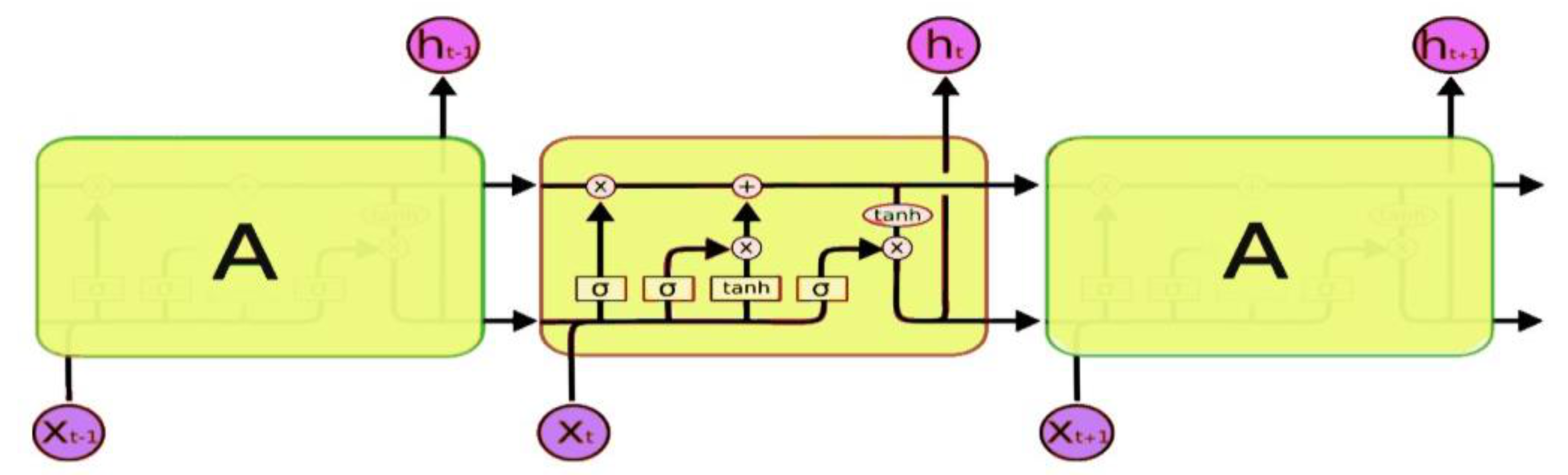
3.4.2. Recurrent Neural Networks (RNNs) and Long Short-term Memory (LSTM)
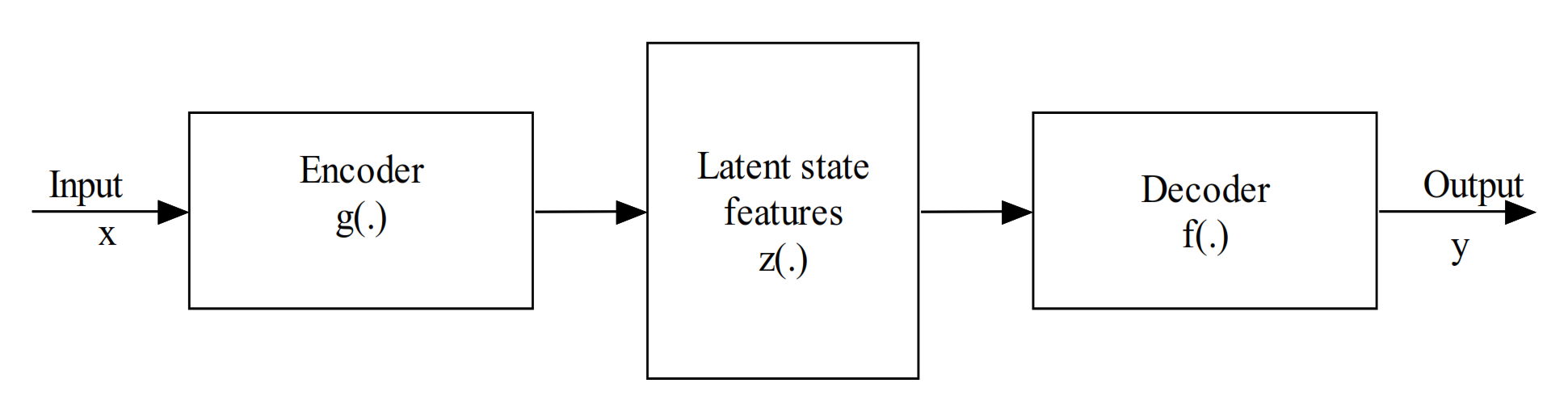
3.4.3. Encoder-Decoder
3.4.4. Generative Adversarial Networks (GANs)
3.4.5. Restricted Boltzmann Machine (RBM) and Deep Belief Networks (DBNs)
3.5. Object Detection Models
3.5.1. One-Stage Object Detectors
3.5.2. Two-Stage Object Detectors
4. Detection and Classification of Radar Signals Using Deep Learning Algorithms
4.1. Radar Occupancy Grid Maps
- After the radar grid map generation, some significant information from the raw radar data may be lost, and thus, they cannot contribute to the classification task.
- The technique may result in a huge map, with many pixels in the grid map being empty, therefore adding more burden to the system complexity.
4.2. Radar Range-Velocity-Azimuth Maps
4.3. Radar Micro-Doppler Signatures
4.4. Radar Point Clouds
4.5. Radar Signal Projection
4.6. Summary
5. Deep Learning-Based Multi-Sensor Fusion of Radar and Camera Data
5.1. Radar Signal Representations
5.1.1. Radar Signal Projection
5.1.2. Radar Point Clouds
5.1.3. Range-Doppler-Azimuth Tensor
5.2. Level of Data Fusion
5.2.1. Data Level Fusion
5.2.2. Feature Level Fusion
5.2.3. Decision-Level Fusion
5.3. Fusion Operations
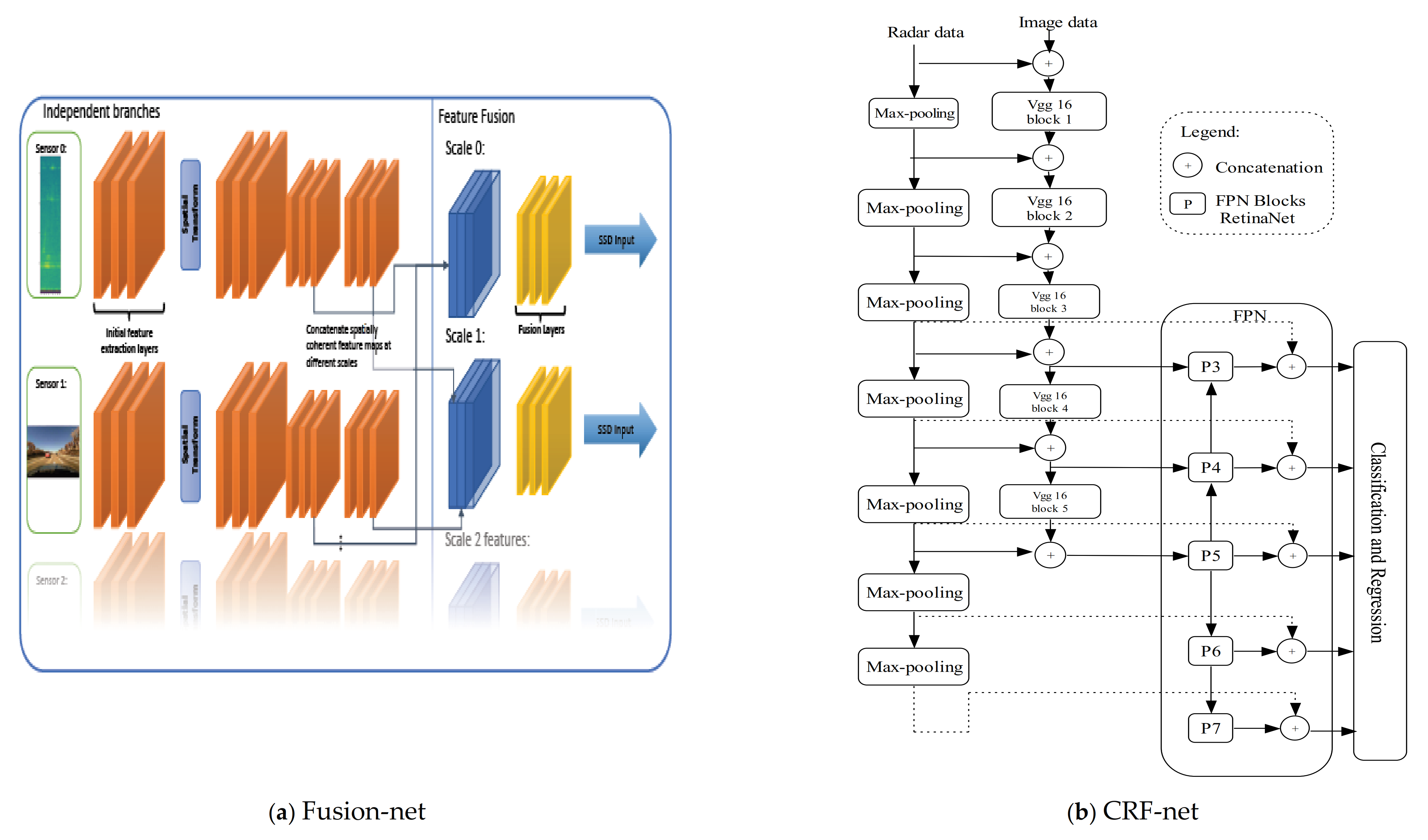
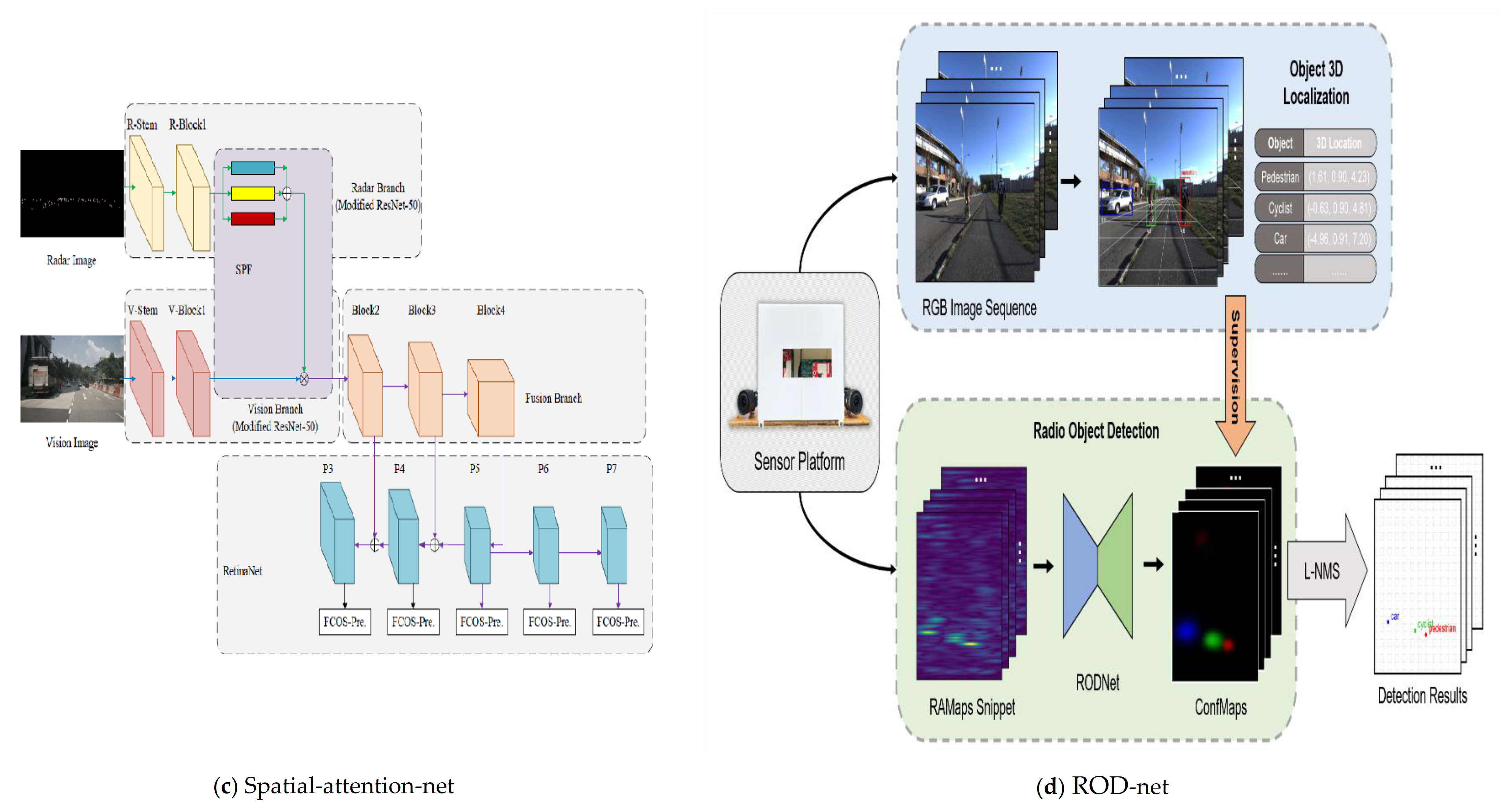
5.4. Fusion Network Architectures
6. Datasets
7. Conclusions, Discussion, and Future Research Prospects
Author Contributions
Funding
Conflicts of Interest
References
- Urmson, C.; Anhalt, J.; Bagnell, D.; Baker, C.; Bittner, R.; Clark, M.; Dolan, J.; Duggins, D.; Galatali, T.; Geyer, C. Autonomous driving in urban environments: Boss and the urban challenge. J. Field Robot. 2008, 25, 425–466. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part C Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Giacalone, J.-P.; Bourgeois, L.; Ancora, A. Challenges in aggregation of heterogeneous sensors for Autonomous Driving Systems. In Proceedings of the 2019 IEEE Sensors Applications Symposium (SAS), Sophia Antipolis, France, 11–13 March 2019; pp. 1–5. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 52, 436–444. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Ieee Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Song, S.; Chandraker, M. Joint SFM and detection cues for monocular 3D localization in road scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3734–3742. [Google Scholar]
- Song, S.; Chandraker, M. Robust scale estimation in real-time monocular SFM for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1566–1573. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5632–5640. [Google Scholar]
- Ansari, J.A.; Sharma, S.; Majumdar, A.; Murthy, J.K.; Krishna, K.M. The earth ain’t flat: Monocular reconstruction of vehicles on steep and graded roads from a moving camera. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 8404–8410. [Google Scholar]
- de Ponte Müller, F. Survey on ranging sensors and cooperative techniques for relative positioning of vehicles. Sensors 2017, 17, 271. [Google Scholar] [CrossRef] [PubMed]
- Yoneda, K.; Suganuma, N.; Yanase, R.; Aldibaja, M. Automated driving recognition technologies for adverse weather conditions. Iatss Res. 2019, 43, 253–262. [Google Scholar] [CrossRef]
- Schneider, M. Automotive radar-status and trends. In Proceedings of the German Microwave Conference, Ulm, Germany, 5–7 April 2005; pp. 144–147. [Google Scholar]
- Nabati, R.; Qi, H. CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1527–1536. [Google Scholar]
- Rashinkar, P.; Krushnasamy, V. An overview of data fusion techniques. In Proceedings of the 2017 International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 21–23 February 2017; pp. 694–697. [Google Scholar]
- Fung, M.L.; Chen, M.Z.; Chen, Y.H. Sensor fusion: A review of methods and applications. In Proceedings of the 2017 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 3853–3860. [Google Scholar]
- Fayyad, J.; Jaradat, M.A.; Gruyer, D.; Najjaran, H. Deep learning sensor fusion for autonomous vehicle perception and localization: A review. Sensors 2020, 20, 4220. [Google Scholar] [CrossRef] [PubMed]
- Bombini, L.; Cerri, P.; Medici, P.; Alessandretti, G. Radar-vision fusion for vehicle detection. In Proceedings of the International Workshop on Intelligent Transportation, Hamburg, Germany, 14–15 May 2006; pp. 65–70. [Google Scholar]
- Chavez-Garcia, R.O.; Burlet, J.; Vu, T.-D.; Aycard, O. Frontal object perception using radar and mono-vision. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 159–164. [Google Scholar]
- Zhong, Z.; Liu, S.; Mathew, M.; Dubey, A. Camera radar fusion for increased reliability in adas applications. Electron. Imaging 2018, 2018, 258-251–258-254. [Google Scholar] [CrossRef]
- Wang, T.; Zheng, N.; Xin, J.; Ma, Z. Integrating millimeter wave radar with a monocular vision sensor for on-road obstacle detection applications. Sensors 2011, 11, 8992–9008. [Google Scholar] [CrossRef] [PubMed]
- Alessandretti, G.; Broggi, A.; Cerri, P. Vehicle and guard rail detection using radar and vision data fusion. IEEE Trans. Intell. Transp. Syst. 2007, 8, 95–105. [Google Scholar] [CrossRef]
- Chavez-Garcia, R.O.; Aycard, O. Multiple sensor fusion and classification for moving object detection and tracking. IEEE Trans. Intell. Transp. Syst. 2015, 17, 525–534. [Google Scholar] [CrossRef]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-road vehicle detection and tracking using MMW radar and monovision fusion. Ieee Trans. Intell. Transp. Syst. 2016, 17, 2075–2084. [Google Scholar] [CrossRef]
- Kim, D.Y.; Jeon, M. Data fusion of radar and image measurements for multi-object tracking via Kalman filtering. Inf. Sci. 2014, 278, 641–652. [Google Scholar] [CrossRef]
- Long, N.; Wang, K.; Cheng, R.; Yang, K.; Bai, J. Fusion of millimeter wave radar and RGB-depth sensors for assisted navigation of the visually impaired. In Proceedings of the Millimetre Wave and Terahertz Sensors and Technology XI, Berlin, Germany, 10–11 September 2018; p. 1080006. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Du, X.; Ang, M.H.; Karaman, S.; Rus, D. A general pipeline for 3d detection of vehicles. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3194–3200. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland; Volume 11220, pp. 641–656. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Qi, C.; Liu, W.; Wu, C.; Su, H.; Guibas, L. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Heuel, S.; Rohling, H. Two-stage pedestrian classification in automotive radar systems. In Proceedings of the 12th International Radar Symposium (IRS), Leipzig, Germany, 7–9 September 2011; pp. 477–484. [Google Scholar]
- Cao, P.; Xia, W.; Ye, M.; Zhang, J.; Zhou, J. Radar-ID: Human identification based on radar micro-Doppler signatures using deep convolutional neural networks. Iet RadarSonar Navig. 2018, 12, 729–734. [Google Scholar] [CrossRef]
- Angelov, A.; Robertson, A.; Murray-Smith, R.; Fioranelli, F. Practical classification of different moving targets using automotive radar and deep neural networks. Iet RadarSonar Navig. 2018, 12, 1082–1089. [Google Scholar] [CrossRef]
- Kwon, J.; Kwak, N. Human detection by neural networks using a low-cost short-range Doppler radar sensor. In Proceedings of the 2017 IEEE Radar Conference (RadarConf), Seattle, WA, USA, 8–12 May 2017; pp. 755–760. [Google Scholar]
- Capobianco, S.; Facheris, L.; Cuccoli, F.; Marinai, S. Vehicle classification based on convolutional networks applied to fmcw radar signals. In Proceedings of the Italian Conference for the Traffic Police, Advances in Intelligent Systems and Computing, Rome, Italy, 22 March 2018; Springer: Cham, Switzerland; Volume 728, pp. 115–128. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Meyer, M.; Kuschk, G. Automotive radar dataset for deep learning based 3d object detection. In Proceedings of the 2019 16th European Radar Conference (EuRAD), Paris, France, 2–4 October 2019; pp. 129–132. [Google Scholar]
- Ouaknine, A.; Newson, A.; Rebut, J.; Tupin, F.; Pérez, P. CARRADA Dataset: Camera and Automotive Radar with Range-Angle-Doppler Annotations. arXiv 2020, arXiv:2005.01456. [Google Scholar]
- Danzer, A.; Griebel, T.; Bach, M.; Dietmayer, K. 2d car detection in radar data with pointnets. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 61–66. [Google Scholar]
- Wang, L.; Tang, J.; Liao, Q. A study on radar target detection based on deep neural networks. IEEE Sens. Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Nabati, R.; Qi, H. Rrpn: Radar region proposal network for object detection in autonomous vehicles. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3093–3097. [Google Scholar]
- John, V.; Nithilan, M.; Mita, S.; Tehrani, H.; Sudheesh, R.; Lalu, P. So-net: Joint semantic segmentation and obstacle detection using deep fusion of monocular camera and radar. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Image and Video Technology, PSIVT 2019, Sydney, Australia, 18–22 September 2019; Springer: Cham, Switzerland, 2020; Volume 11994, pp. 138–148. [Google Scholar]
- Feng, Z.; Zhang, S.; Kunert, M.; Wiesbeck, W. Point cloud segmentation with a high-resolution automotive radar. In Proceedings of the AmE 2019-Automotive meets Electronics, 10th GMM-Symposium, Dortmund, Germany, 12–13 March 2019; pp. 1–5. [Google Scholar]
- Schumann, O.; Lombacher, J.; Hahn, M.; Wöhler, C.; Dickmann, J. Scene understanding with automotive radar. Ieee Trans. Intell. Veh. 2019, 5, 188–203. [Google Scholar] [CrossRef]
- Schumann, O.; Hahn, M.; Dickmann, J.; Wöhler, C. Semantic segmentation on radar point clouds. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 2179–2186. [Google Scholar]
- Gao, X.; Xing, G.; Roy, S.; Liu, H. Experiments with mmwave automotive radar test-bed. In Proceedings of the 2019 53rd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2019; pp. 1–6. [Google Scholar]
- Lim, T.-Y.; Ansari, A.; Major, B.; Fontijne, D.; Hamilton, M.; Gowaikar, R.; Subramanian, S. Radar and camera early fusion for vehicle detection in advanced driver assistance systems. In Proceedings of the Machine Learning for Autonomous Driving Workshop at the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chadwick, S.; Maddern, W.; Newman, P. Distant vehicle detection using radar and vision. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8311–8317. [Google Scholar]
- Nobis, F.; Geisslinger, M.; Weber, M.; Betz, J.; Lienkamp, M. A deep learning-based radar and camera sensor fusion architecture for object detection. In Proceedings of the 2019 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 15–17 October 2019; pp. 1–7. [Google Scholar]
- Meyer, M.; Kuschk, G. Deep learning based 3d object detection for automotive radar and camera. In Proceedings of the 2019 16th European Radar Conference (EuRAD), Paris, France, 2–4 October 2019; pp. 133–136. [Google Scholar]
- John, V.; Mita, S. RVNet: Deep sensor fusion of monocular camera and radar for image-based obstacle detection in challenging environments. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 351–364. [Google Scholar]
- Chang, S.; Zhang, Y.; Zhang, F.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z. Spatial Attention fusion for obstacle detection using mmwave radar and vision sensor. Sensors 2020, 20, 956. [Google Scholar] [CrossRef] [PubMed]
- Bilik, I.; Longman, O.; Villeval, S.; Tabrikian, J. The rise of radar for autonomous vehicles: Signal processing solutions and future research directions. Ieee Signal Process. Mag. 2019, 36, 20–31. [Google Scholar] [CrossRef]
- Richards, M.A. Fundamentals of Radar Signal Processing. McGraw-Hill Education: Georgia Institute of Technology, Atlanta, GA, USA, 2014. [Google Scholar]
- Iovescu, C.; Rao, S. The Fundamentals of Millimeter Wave Sensors. Texas Instruments Inc.: Dallas, TX, USA, 2017; pp. 1–8. [Google Scholar]
- Ramasubramanian, K.; Ramaiah, K. Moving from legacy 24 ghz to state-of-the-art 77-ghz radar. Atzelektronik Worldw. 2018, 13, 46–49. [Google Scholar] [CrossRef]
- Pelletier, M.; Sivagnanam, S.; Lamontagne, P. Angle-of-arrival estimation for a rotating digital beamforming radar. In Proceedings of the 2013 IEEE Radar Conference (RadarCon13), Ottawa, ON, Canada, 29 April–3 May 2013; pp. 1–6. [Google Scholar]
- Stoica, P.; Wang, Z.; Li, J. Extended derivations of MUSIC in the presence of steering vector errors. IEEE Trans. Signal Process. 2005, 53, 1209–1211. [Google Scholar] [CrossRef]
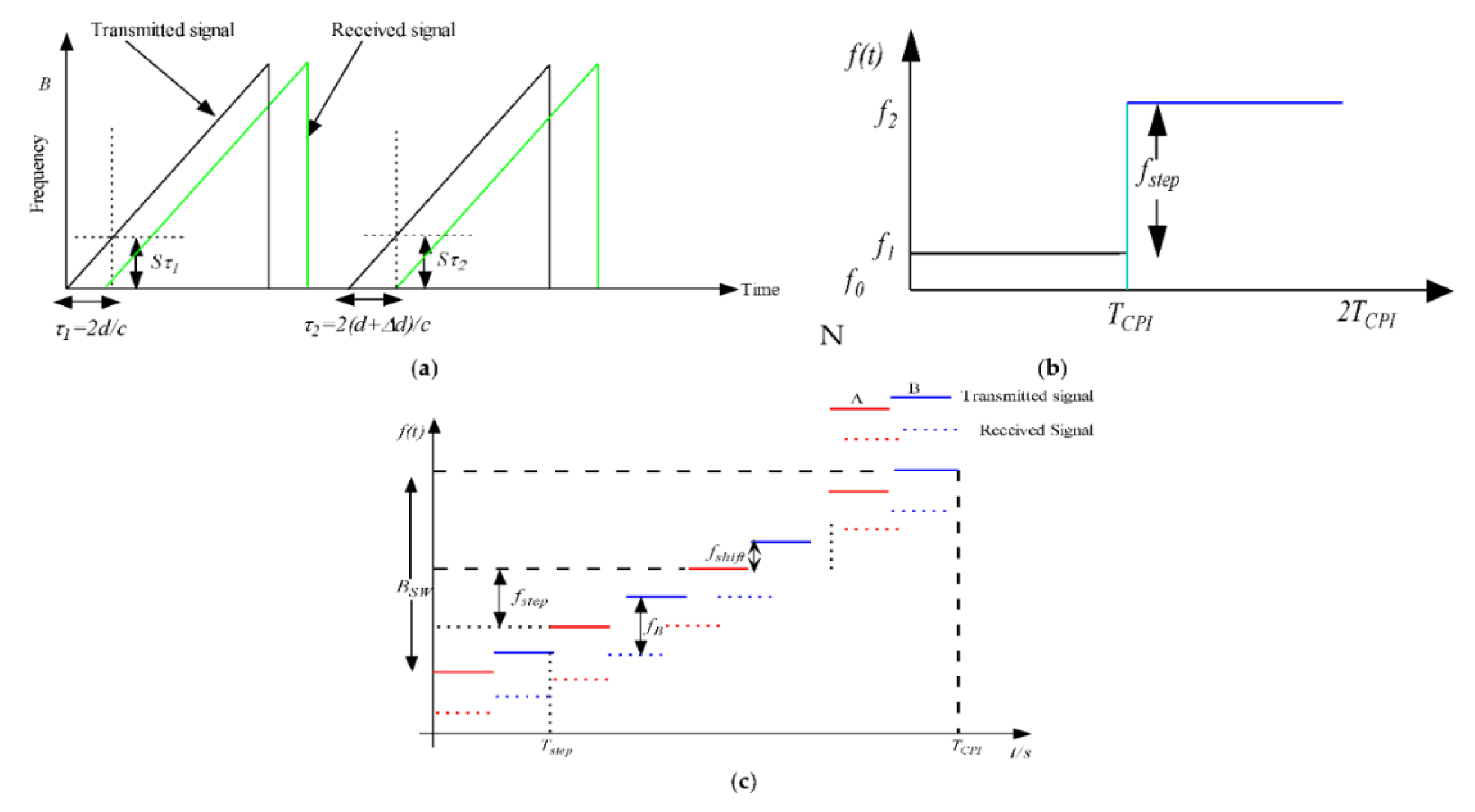
- Rohling, H.; Moller, C. Radar waveform for automotive radar systems and applications. In Proceedings of the 2008 IEEE Radar Conference, Rome, Italy, 26–30 May 2008; pp. 1–4. [Google Scholar]
- Kuroda, H.; Nakamura, M.; Takano, K.; Kondoh, H. Fully-MMIC 76 GHz radar for ACC. In Proceedings of the ITSC2000. 2000 IEEE Intelligent Transportation Systems. Proceedings (Cat. No. 00TH8493), Dearborn, MI, USA, 1–3 October 2000; pp. 299–304. [Google Scholar]
- Wang, W.; Du, J.; Gao, J. Multi-target detection method based on variable carrier frequency chirp sequence. Sensors 2018, 18, 3386. [Google Scholar] [CrossRef]
- Song, Y.K.; Liu, Y.J.; Song, Z.L. The design and implementation of automotive radar system based on MFSK waveform. In Proceedings of the E3S Web of Conferences, 2018 4th International Conference on Energy Materials and Environment Engineering (ICEMEE 2018), Zhuhai, China, 4 June 2018; Volume 38, p. 01049. [Google Scholar]
- Marc-Michael, M. Combination of LFCM and FSK modulation principles for automotive radar systems. In Proceedings of the German Radar Symposium, Berlin, Germany, 11–12 October 2000. [Google Scholar]
- Finn, H. Adaptive detection mode with threshold control as a function of spatially sampled clutter-level estimates. Rca Rev. 1968, 29, 414–465. [Google Scholar]
- Hezarkhani, A.; Kashaninia, A. Performance analysis of a CA-CFAR detector in the interfering target and homogeneous background. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 1568–1572. [Google Scholar]
- Messali, Z.; Soltani, F.; Sahmoudi, M. Robust radar detection of CA, GO and SO CFAR in Pearson measurements based on a non linear compression procedure for clutter reduction. SignalImage Video Process. 2008, 2, 169–176. [Google Scholar] [CrossRef]
- Sander, J.; Ester, M.; Kriegel, H.-P.; Xu, X. Density-based clustering in spatial databases: The algorithm gdbscan and its applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.-Y.; Sainath, T. Deep learning for audio signal processing. Ieee J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef]
- Buettner, R.; Bilo, M.; Bay, N.; Zubac, T. A Systematic Literature Review of Medical Image Analysis Using Deep Learning. In Proceedings of the 2020 IEEE Symposium on Industrial Electronics & Applications (ISIEA), TBD, Penang, Malaysia, 17–18 July 2020; pp. 1–4. [Google Scholar]
- Graves, A.; Mohamed, A.-r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE international conference on acoustics, speech and signal processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object detection and instance segmentation in remote sensing imagery based on precise mask R-CNN. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar]
- Rathi, A.; Deb, D.; Babu, N.S.; Mamgain, R. Two-level Classification of Radar Targets Using Machine Learning. In Smart Trends in Computing and Communications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 231–242. [Google Scholar]
- Abeynayake, C.; Son, V.; Shovon, M.H.I.; Yokohama, H. Machine learning based automatic target recognition algorithm applicable to ground penetrating radar data. In Proceedings of the Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XXIV, SPIE 11012, Baltimore, MA, USA, 10 May 2019; p. 1101202. [Google Scholar]
- Carrera, E.V.; Lara, F.; Ortiz, M.; Tinoco, A.; León, R. Target Detection using Radar Processors based on Machine Learning. In Proceedings of the 2020 IEEE ANDESCON, Quito, Ecuador, 13–16 October 2020; pp. 1–5. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Fukushima, K. A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K.J. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. SpeechSignal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA , 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh annual Conference of the International Speech Communication Association Makuhari, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. In Proceedings of the IET 9th International Conference on Artificial Neural Networks: ICANN ’99, Edinburgh, UK, 7–10 September 1999; pp. 850–855. [Google Scholar]
- Olah, C. Understanding Lstm Networks, 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs (accessed on 11 December 2020).
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Wang, Y.; Jiang, Z.; Gao, X.; Hwang, J.-N.; Xing, G.; Liu, H. RODNet: Object Detection under Severe Conditions Using Vision-Radio Cross-Modal Supervision. arXiv 2020, arXiv:2003.01816. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Lekic, V.; Babic, Z. Automotive radar and camera fusion using Generative Adversarial Networks. Comput. Vis. Image Underst. 2019, 184, 1–8. [Google Scholar] [CrossRef]
- Wang, H.; Raj, B. On the origin of deep learning. arXiv 2017, arXiv:1702.07800. [Google Scholar]
- Le Roux, N.; Bengio, Y. Representational power of restricted Boltzmann machines and deep belief networks. Neural Comput. 2008, 20, 1631–1649. [Google Scholar] [CrossRef] [PubMed]
- Salakhutdinov, R.; Hinton, G. Deep boltzmann machines. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Okinawa, Japan, 16–18 April 2019; 2009; pp. 448–455. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Werber, K.; Rapp, M.; Klappstein, J.; Hahn, M.; Dickmann, J.; Dietmayer, K.; Waldschmidt, C. Automotive radar gridmap representations. In Proceedings of the 2015 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Heidelberg, Germany, 27–29 April 2015; pp. 1–4. [Google Scholar]
- Elfes, A. Using occupancy grids for mobile robot perception and navigation. Computer 1989, 22, 46–57. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Dubé, R.; Hahn, M.; Schütz, M.; Dickmann, J.; Gingras, D. Detection of parked vehicles from a radar based occupancy grid. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 1415–1420. [Google Scholar]
- Lombacher, J.; Hahn, M.; Dickmann, J.; Wöhler, C. Potential of radar for static object classification using deep learning methods. In Proceedings of the 2016 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), San Diego, CA, USA, 19–20 May 2016; pp. 1–4. [Google Scholar]
- Lombacher, J.; Hahn, M.; Dickmann, J.; Wöhler, C. Object classification in radar using ensemble methods. In Proceedings of the 2017 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Nagoya, Japan, 19–21 March 2017; pp. 87–90. [Google Scholar]
- Bufler, T.D.; Narayanan, R.M. Radar classification of indoor targets using support vector machines. Iet RadarSonar Navig. 2016, 10, 1468–1476. [Google Scholar] [CrossRef]
- Lombacher, J.; Laudt, K.; Hahn, M.; Dickmann, J.; Wöhler, C. Semantic radar grids. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1170–1175. [Google Scholar]
- Sless, L.; El Shlomo, B.; Cohen, G.; Oron, S. Road scene understanding by occupancy grid learning from sparse radar clusters using semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 867–875. [Google Scholar]
- Bartsch, A.; Fitzek, F.; Rasshofer, R. Pedestrian recognition using automotive radar sensors. Adv. Radio Sci. 2012, 10, 45–55. [Google Scholar] [CrossRef]
- Heuel, S.; Rohling, H.; Thoma, R. Pedestrian recognition based on 24 GHz radar sensors. In Ultra-Wideband Radio Technologies for Communications, Localization and Sensor Applications; InTech: Rijeka, Croatia, 2013; Chapter 10; pp. 241–256. [Google Scholar]
- Schumann, O.; Wöhler, C.; Hahn, M.; Dickmann, J. Comparison of random forest and long short-term memory network performances in classification tasks using radar. In Proceedings of the 2017 Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 10–12 October 2017; pp. 1–6. [Google Scholar]
- Nabati, R.; Qi, H. Radar-Camera Sensor Fusion for Joint Object Detection and Distance Estimation in Autonomous Vehicles. arXiv 2020, arXiv:2009.08428. [Google Scholar]
- Lucaciu, F. Estimating Pose and Dimension of Parked Automobiles on Radar Grids. Master’s Thesis, Institute of Photogrammetry University of Stuttgart, Stuttgart, Germany, July 2017. [Google Scholar]
- Heuel, S.; Rohling, H. Pedestrian classification in automotive radar systems. In Proceedings of the 2012 13th International Radar Symposium, Warsaw, Poland, 23–25 May 2012; pp. 39–44. [Google Scholar]
- Heuel, S.; Rohling, H. Pedestrian recognition in automotive radar sensors. In Proceedings of the 2013 14th International Radar Symposium (IRS), Dresden, Germany, 19–21 June 2013; pp. 732–739. [Google Scholar]
- Sheeny, M.; Wallace, A.; Wang, S. 300 GHz radar object recognition based on deep neural networks and transfer learning. Iet RadarSonar Navig. 2020, 14, 1483–1493. [Google Scholar] [CrossRef]
- Patel, K.; Rambach, K.; Visentin, T.; Rusev, D.; Pfeiffer, M.; Yang, B. Deep learning-based object classification on automotive radar spectra. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar]
- Major, B.; Fontijne, D.; Ansari, A.; Teja Sukhavasi, R.; Gowaikar, R.; Hamilton, M.; Lee, S.; Grzechnik, S.; Subramanian, S. Vehicle detection with automotive radar using deep learning on range-azimuth-doppler tensors. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seol, Korea, 27–28 October 2019. [Google Scholar]
- Palffy, A.; Dong, J.; Kooij, J.F.; Gavrila, D.M. CNN based road user detection using the 3D radar cube. IEEE Robot. Autom. Lett. 2020, 5, 1263–1270. [Google Scholar] [CrossRef]
- Brodeski, D.; Bilik, I.; Giryes, R. Deep radar detector. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–6. [Google Scholar]
- Jokanović, B.; Amin, M. Fall detection using deep learning in range-Doppler radars. Ieee Trans. Aerosp. Electron. Syst. 2017, 54, 180–189. [Google Scholar] [CrossRef]
- Abdulatif, S.; Wei, Q.; Aziz, F.; Kleiner, B.; Schneider, U. Micro-doppler based human-robot classification using ensemble and deep learning approaches. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 1043–1048. [Google Scholar]
- Zhao, M.; Li, T.; Abu Alsheikh, M.; Tian, Y.; Zhao, H.; Torralba, A.; Katabi, D. Through-wall human pose estimation using radio signals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7356–7365. [Google Scholar]
- Zhao, M.; Tian, Y.; Zhao, H.; Alsheikh, M.A.; Li, T.; Hristov, R.; Kabelac, Z.; Katabi, D.; Torralba, A. RF-based 3D skeletons. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 267–281. [Google Scholar]
- Gill, T.P. The Doppler Effect: An Introduction to the Theory of the Effect; Academic Press: Cambridge, MA, USA, 1965. [Google Scholar]
- Chen, V.C. Analysis of radar micro-Doppler with time-frequency transform. In Proceedings of the Tenth IEEE Workshop on Statistical Signal and Array Processing (Cat. No. 00TH8496), Pocono Manor, PA, USA, 16 August 2000; pp. 463–466. [Google Scholar]
- Chen, V.C.; Li, F.; Ho, S.-S.; Wechsler, H. Micro-Doppler effect in radar: Phenomenon, model, and simulation study. Ieee Trans. Aerosp. Electron. Syst. 2006, 42, 2–21. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Q.; Qiu, C.-W.; Liang, X.-J.; Li, K.-M. Micro-Doppler effect analysis and feature extraction in ISAR imaging with stepped-frequency chirp signals. Ieee Trans. Geosci. Remote Sens. 2009, 48, 2087–2098. [Google Scholar]
- Zabalza, J.; Clemente, C.; Di Caterina, G.; Ren, J.; Soraghan, J.J.; Marshall, S. Robust PCA for micro-Doppler classification using SVM on embedded systems. Ieee Trans. Aerosp. Electron. Syst. 2014, 50, 2304–2310. [Google Scholar] [CrossRef]
- Nanzer, J.A.; Rogers, R.L. Bayesian classification of humans and vehicles using micro-Doppler signals from a scanning-beam radar. Ieee Microw. Wirel. Compon. Lett. 2009, 19, 338–340. [Google Scholar] [CrossRef]
- Du, L.; Ma, Y.; Wang, B.; Liu, H. Noise-robust classification of ground moving targets based on time-frequency feature from micro-Doppler signature. Ieee Sens. J. 2014, 14, 2672–2682. [Google Scholar] [CrossRef]
- Kim, Y.; Ling, H. Human activity classification based on micro-Doppler signatures using a support vector machine. Ieee Trans. Geosci. Remote Sens. 2009, 47, 1328–1337. [Google Scholar]
- Kim, Y.; Moon, T. Human detection and activity classification based on micro-Doppler signatures using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 8–12. [Google Scholar] [CrossRef]
- Li, Y.; Du, L.; Liu, H. Hierarchical classification of moving vehicles based on empirical mode decomposition of micro-Doppler signatures. Ieee Trans. Geosci. Remote Sens. 2012, 51, 3001–3013. [Google Scholar] [CrossRef]
- Molchanov, P.; Harmanny, R.I.; de Wit, J.J.; Egiazarian, K.; Astola, J. Classification of small UAVs and birds by micro-Doppler signatures. Int. J. Microw. Wirel. Technol. 2014, 6, 435–444. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A survey. Ieee Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar] [CrossRef]
- Singh, A.D.; Sandha, S.S.; Garcia, L.; Srivastava, M. Radhar: Human activity recognition from point clouds generated through a millimeter-wave radar. In Proceedings of the 3rd ACM Workshop on Millimeter-wave Networks and Sensing Systems, Los Cabos, Mexico, 25 October 2019; pp. 51–56. [Google Scholar]
- Lee, S. Deep Learning on Radar Centric 3D Object Detection. arXiv 2020, arXiv:2003.00851. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Brooks, D.A.; Schwander, O.; Barbaresco, F.; Schneider, J.-Y.; Cord, M. Temporal deep learning for drone micro-Doppler classification. In Proceedings of the 2018 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; pp. 1–10. [Google Scholar]
- Simony, M.; Milzy, S.; Amendey, K.; Gross, H.-M. Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Cao, C.; Gao, J.; Liu, Y.C. Research on Space Fusion Method of Millimeter Wave Radar and Vision Sensor. Procedia Comput. Sci. 2020, 166, 68–72. [Google Scholar] [CrossRef]
- Hsu, Y.-W.; Lai, Y.-H.; Zhong, K.-Q.; Yin, T.-K.; Perng, J.-W. Developing an On-Road Object Detection System Using Monovision and Radar Fusion. Energies 2020, 13, 116. [Google Scholar] [CrossRef]
- Jin, F.; Sengupta, A.; Cao, S.; Wu, Y.-J. MmWave Radar Point Cloud Segmentation using GMM in Multimodal Traffic Monitoring. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 28–30 April 2020; pp. 732–737. [Google Scholar]
- Zhang, X.; Zhou, M.; Qiu, P.; Huang, Y.; Li, J. Radar and vision fusion for the real-time obstacle detection and identification. Ind. Robot Int. J. Robot. Res. Appl. 2019. [Google Scholar] [CrossRef]
- Zhou, T.; Jiang, K.; Xiao, Z.; Yu, C.; Yang, D. Object Detection Using Multi-Sensor Fusion Based on Deep Learning. CICTP 2019, 2019, 5770–5782. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Bijelic, M.; Gruber, T.; Mannan, F.; Kraus, F.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11682–11692. [Google Scholar]
- de Jong, R.J.; Heiligers, M.J.; de Wit, J.J.; Uysal, F. Radar and Video Multimodal Learning for Human Activity Classification. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–6. [Google Scholar]
- Feng, D.; Haase-Schuetz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. Ieee Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Jha, H.; Lodhi, V.; Chakravarty, D. Object detection and identification using vision and radar data fusion system for ground-based navigation. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 590–593. [Google Scholar]
- Gaisser, F.; Jonker, P.P. Road user detection with convolutional neural networks: An application to the autonomous shuttle WEpod. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 101–104. [Google Scholar]
- Kang, D.; Kum, D. Camera and radar sensor fusion for robust vehicle localization via vehicle part localization. IEEE Access 2020, 8, 75223–75236. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Sengupta, A.; Jin, F.; Cao, S. A DNN-LSTM based Target Tracking Approach using mmWave Radar and Camera Sensor Fusion. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 688–693. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Hu, W.; Yang, K. Unifying obstacle detection, recognition, and fusion based on millimeter wave radar and RGB-depth sensors for the visually impaired. Rev. Sci. Instrum. 2019, 90, 044102. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. Ieee Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef]
- Barnes, D.; Gadd, M.; Murcutt, P.; Newman, P.; Posner, I. The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6433–6438. [Google Scholar]
- Nowruzi, F.E.; Kolhatkar, D.; Kapoor, P.; Al Hassanat, F.; Heravi, E.J.; Laganiere, R.; Rebut, J.; Malik, W. Deep Open Space Segmentation using Automotive Radar. In Proceedings of the 2020 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Linz, Austria, 23 November 2020; pp. 1–4. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Radar Signal Representation | Network Model | Task | Object Type | Dataset | Remarks/Limitation |
|---|---|---|---|---|---|---|
| A. Angelov et al., [38] | Micro-Doppler signatures | CNN and LSTM | Target classification | Car, people, and bicycle | Self-developed | Their dataset is small. Hence, a larger radar dataset is required to train the neural network. |
| A. Danzer et al., [45] | Radar pointclouds | PointNet [149] and Frustum PointNets [35] | Car detection | Cars | Self-developed | Their dataset is relatively small, with only one radar object per measurement cycle. Besides, it contains a few object classes. |
| O. Schumann et al., [50] | Radar pointclouds | CNN, RNN | Segmentation and classification of static objects | Car, building, curbstone, pole, vegetation, and other | Self-developed | Their approach needs to be evaluated using a large-scale radar dataset. |
| O. Schumann et al., [51] | Radar pointclouds. | PointNet++ [145] | Segmentation | Car, truck, pedestrian, pedestrian group, bike, and static object | Self-developed | They used the whole radar point clouds as input, and obtained probabilities for each radar reflection point, thus avoiding the clustering algorithm. No semantic instance segmentation was performed. |
| S. Chadwick et al., [54] | Radar image | CNN | Distant vehicle detection | Vehicles | Self-developed | They used a very trivial radar image generation that does not consider the sparsity of radar data. |
| O. Schumann et al., [117] | Radar target clusters | Random forest classifier and LSTM | Classification | Car, pedestrian, bike, truck, pedestrian group, and garbage | Self-developed | Only classes with many samples returned the highest accuracy. |
| M. Sheeny et al., [122] | Range profile | CNN | Object detection and recognition | Bike, trolley, mannequin, cone, traffic sign, stuffed dog | Self-developed | Their system captured only indoor objects, and they did not make use of the Doppler information. |
| K. Patel et al., [123] | Range-Azimuth | CNN, SVM, and KNN | Object classification | Construction barrier, motorbike, baby carriage, bicycle, garbage container, car, and stop sign | Self-developed | Their system works on the ROIs instead of the complete rang-azimuth maps. And also the first to the allowed classification of multiple objects with radar data in real scenes. |
| B. Major et al., [124] | Range-azimuth-Doppler tensor. | CNN | Object detection | Vehicles | Self-developed | They showed how to leveraged the radar signal velocity dimension to improve the detection results |
| A Palffy et al., [125] | Range-Azimuth and radar Point clouds | CNN | Road users detection | Pedestrians, cyclists, and cars | Self-developed | They are the first to utilized both low-level and target-level radar data to addressed moving road user detection. |
| D. Brodeski et al., [126] | Range-Doppler-Azimuth-Elevation | CNN | Target detection | 2-Classes object, and non-object | Self-built (in the anechoic chamber) | Real-world data was not included. |
| Y. Kim and T. Moon [139] | Micro-Doppler signatures | CNN | Human detection and activity classification | Human, dog, horse, and car | Self-developed | Their system could only detect humans presence or absence in the radar signal since there is no range and angle dimensions. |
| S. Lee [144] | Bird-eye- view | 3D object detection | Cars | Cars | Astyx HiRes [39] | Radar Doppler information was not incorporated into the network. |
| Reference | Sensors | Sensors Signal Representation | Network Architecture | Level of Fusion | Fusion Operation | Problem | Object Type | Dataset |
|---|---|---|---|---|---|---|---|---|
| R. Nabati and H. Qi [47] | Radar and visual camera | RGB image and radar signal projections | Fast-R-CNN (Two-stage) | Mid-level fusion | Region proposal | Object detection | 2D vehicle | Nuscenes [41] |
| V. John et al., [48] | Radar and camera | RGB image and radar signal projections | Yolo object detector (Tiny Yolov3), and, Encoder-decoder | Feature level | Feature concatenation | Vehicle Detection and Free space Segmentation | Vehicles and free space | Nuscenes [41] |
| L.Teck-Yian et al., [53] | Radar and camera | RGB image and Radar Range-Azimuth image | Modified SSD With two branches each for one sensor | Early level fusion | Feature concatenation | Detection and classification | 3D vehicles | Self-recorded |
| S. Chadwick et al., [54] | Radar and visual camera | RGB image and Radar range-velocity maps | One-stage detector | Middle | Feature concatenation and addition | Object detection | 2D vehicle | Self-recorded |
| F. Nobis et al. (CRF-Net), [55] | Radar and visual camera | RGB image and radar signal projections | RetinaNetwith a VGG backbone | Deeper layers | Feature concatenated | Object detection | 2D road vehicles | NuScenes [41] |
| Meyer and Kuschk [56] | Radar and visual camera | RGB image and radar point clouds | Faster RCNN (Two-stage) | Early and Middle | Average Mean | Object Detection | 3D vehicle | Astyx hiRes 2019 [43] |
| Vijay John and Seiichi Mita [57] | Radar and camera | RGB image and radar signal projections | Yolo object detector (Tiny Yolov3) | Feature level(late) | Feature concatenation | 2D image-based obstacle detection | vehicles, pedestrians, two-wheelers, and objects (movable objects and debris) | Nuscenes [41] |
| S. Chang et al., [58] | Radar and camera | RGB image and radar signal projections | Fully convolutional one-stage object detection framework (FCOS) | Feature level | spatial attention feature fusion (SAF) | Obstacle detection | Bicycle, car, motorcycle, bus, train, truck | Nuscenes [41] |
| W.Yizhou et al.(RODnet), [98] | Radar and Stereo videos | 2D image and Radar Range-Azimuth maps | 3D autoencoder, 3D stacked hourglass, and 3D stacked hourglass with temporal inception layers | Mid level | Cross-modal learning and supervision | Object detection | Pedestrians, cyclists, and cars. | CRUW [98] |
| V. Lekic and Z. Babic [100] | Radar and visual camera | RGB image and Radar grid maps | GANs (CMGGAN model) | Mid-level | Feature fusion and semantic fusion | Segmentation | Free space | Self-recorded |
| Mario Bijelic et al., [156] | Camera, lidar, radar, and gated NIR sensor | Gated image, RGB image, Lidar projection, and radar projection | Modified VGG [88] backbone, and SSD blocks | Early feature fusion (Adaptive fusion steered by entropy) | Feature concatenation | Object detection | Vehicles | A novel multimodal dataset in adverse weather dataset [156] |
| Richard J. de Jong [157] | Radar and camera | RGB image and Radar micro-Doppler spectrograms | CNN | Data, middle and feature level fusion | Feature concatenation | Human Activity Classification | Walking person | Self-recorded |
| Dataset | Sensing Modalities | Size | Scenes | Labels | Frame Rate | Radar Signal Representation | Type of Objects | Recording Condition | Recording Location | Published Year | Availability/LINK |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Nuscenes [41] | Visual Cameras (6), 3D Lidar, and Radars (5) | 1.4 frames (Cameras and Radars) and 390 K frames of Lidar | 1 K | 2D/3D bounding boxes (1.4M) | 1 HZ/10 HZ | 2D radar point clouds | 23 object classes | Nightime/rain and light weather | Boston, Singapore. | 2019 | Public, (https://www.nuscenes.org/download (accessed on 20 January 2021)) |
| Astyx HiRes [43] | Radar, visual cameras, and 3D Lidar | 500 frames | n.a | 3D bounding boxes | n.a. | 3D Radar point clouds | Car, bus, motorcycle, person, trailer, and truck | Daylight | n.a. | 2019 | Public, (http://www.astyx.netaccessed on 30 December 2020)) |
| CARRADA [44] | Radar and Visual camera | 12,726 total number of frames | n.a | Sparse point, bounding boxes, and dense masks. | n.a. | Range-angle and range-Doppler raw radar data | cars, pedestrians, and cyclist | n.a. | Canada | 2020 | To be released |
| [52] | Radar | n.a. | Parking lot, campus road, city road and, freeway | Metadata (Object location and class) | 30 fps | Raw radar I-Q samples | Pedestrian, cyclist, and cars | Under challenging light conditions | n.a. | 2019 | To be released via (https://github.com/yizhou-wang/UWCR (accessed on 5 December 2020) |
| CRUW [98] | Stereo cameras and 77GHz FMCW Radars (2) | More than 400 K frames | Campus road, city street, highway, parking lot, etc | Annotations (Object location and class) | 30 fps | Range-Azimuth maps (RAMaps) | About 260 K objects | Different autonomous driving scenarios, including dark, strong light, and blur | n.a | 2020 | Self-collected |
| [156] | Cameras(2), Lidars(2), radar, gated NIR, and FIR | 1.4 M frames | 10,000 km of driving | 2D/3D (each 100k) | 10 Hz | Radar signal projections | n.a | Clear, nighttime, dense fog, light fog, rain, and snow | Northern Europe (Germany, Sweden, Denmark, and Finland) | February and December 2019 | On request |
| Oxford Robot-Car [170] | Visual cameras (6), 2D & 3D Lidars (4), GNSS, Radar, and Inertial sensors | 240 k (Radar), 2.4 frames (Lidar) and 11,070,651 frames (Stereo camera | n.a. | No | n.a. | Range-Azimuth maps | Vehicles and pedestrians | Direct sunlight, heavy rain, night, and snow | Oxford | 2017, 2020 | Public, (https://ori.ox.ac.uk/oxford-radar-robotcar-dataset (accessed on 7 January 2021)) |
| SCORP [171] | Radar and Visual camera | 3913 frames | 11 Driving sequences | Bounding boxes. | n.a. | SCA, RDA, and DoA tensors | n.a. | n.a. | n.a. | 2020 | Public, (https://rebrand.ly/SCORP (accessed on 27 November 2020)) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdu, F.J.; Zhang, Y.; Fu, M.; Li, Y.; Deng, Z. Application of Deep Learning on Millimeter-Wave Radar Signals: A Review. Sensors 2021, 21, 1951. https://doi.org/10.3390/s21061951
Abdu FJ, Zhang Y, Fu M, Li Y, Deng Z. Application of Deep Learning on Millimeter-Wave Radar Signals: A Review. Sensors. 2021; 21(6):1951. https://doi.org/10.3390/s21061951
Chicago/Turabian StyleAbdu, Fahad Jibrin, Yixiong Zhang, Maozhong Fu, Yuhan Li, and Zhenmiao Deng. 2021. "Application of Deep Learning on Millimeter-Wave Radar Signals: A Review" Sensors 21, no. 6: 1951. https://doi.org/10.3390/s21061951
APA StyleAbdu, F. J., Zhang, Y., Fu, M., Li, Y., & Deng, Z. (2021). Application of Deep Learning on Millimeter-Wave Radar Signals: A Review. Sensors, 21(6), 1951. https://doi.org/10.3390/s21061951