
Real-Time Detection of Concealed Threats with Passive Millimeter Wave and Visible Images via Deep Neural Networks


Abstract
:1. Introduction
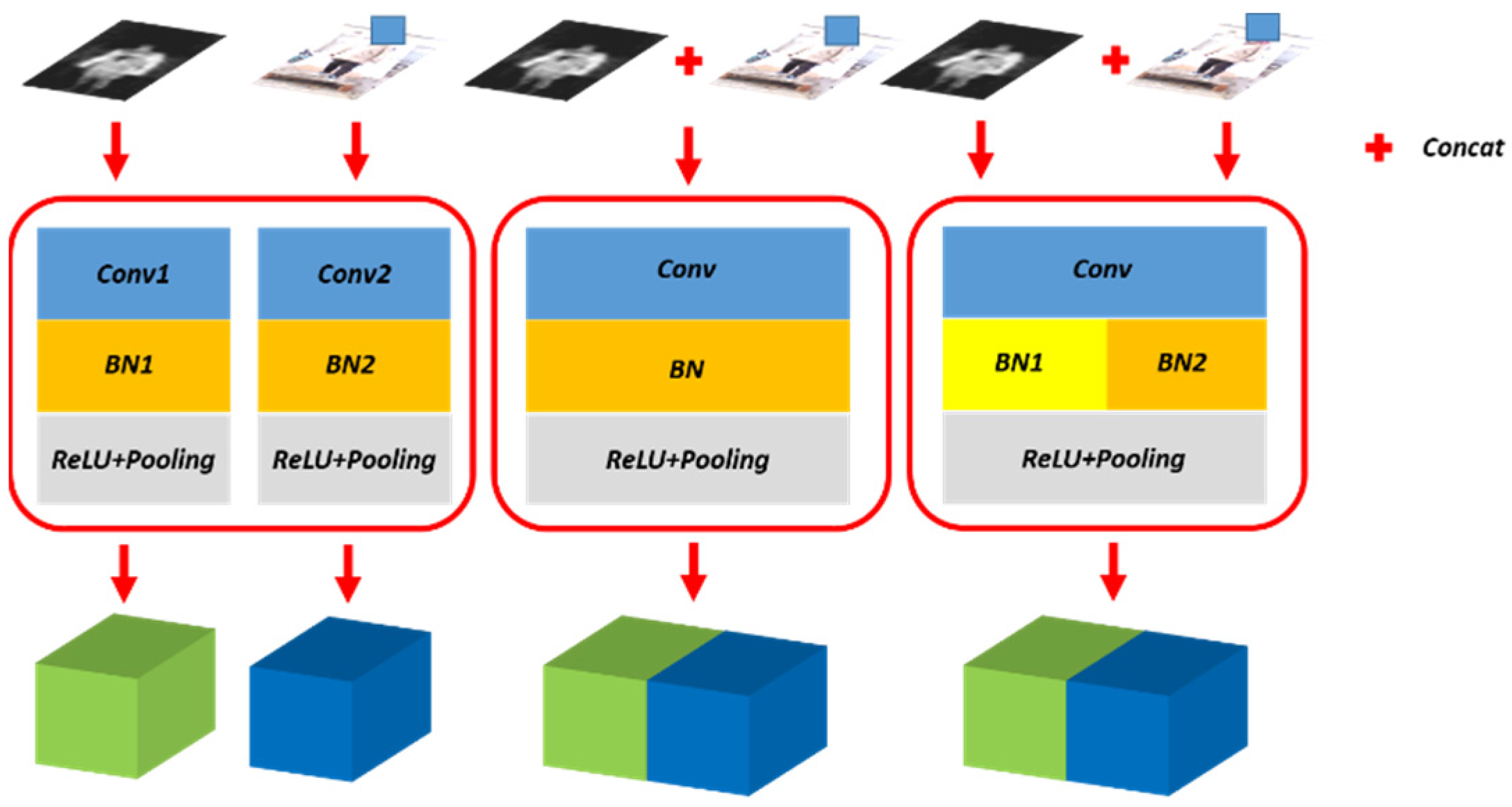
- The combination of VI and PMMWI. The combination of VI and PMMWI lies in two aspects. First, the weights of our segmentation network are shared between PMMWI and VI except for the batch normalization layer [21]. The combination of PMMWI and VI accelerates the training process of network and improve the segmentation effects. Second, the false alarm can be excluded by a detection method that combined the high penetrability of PMMWI and the high resolution of VI. The experimental results show that our method improves the accuracy and robustness of the detection.
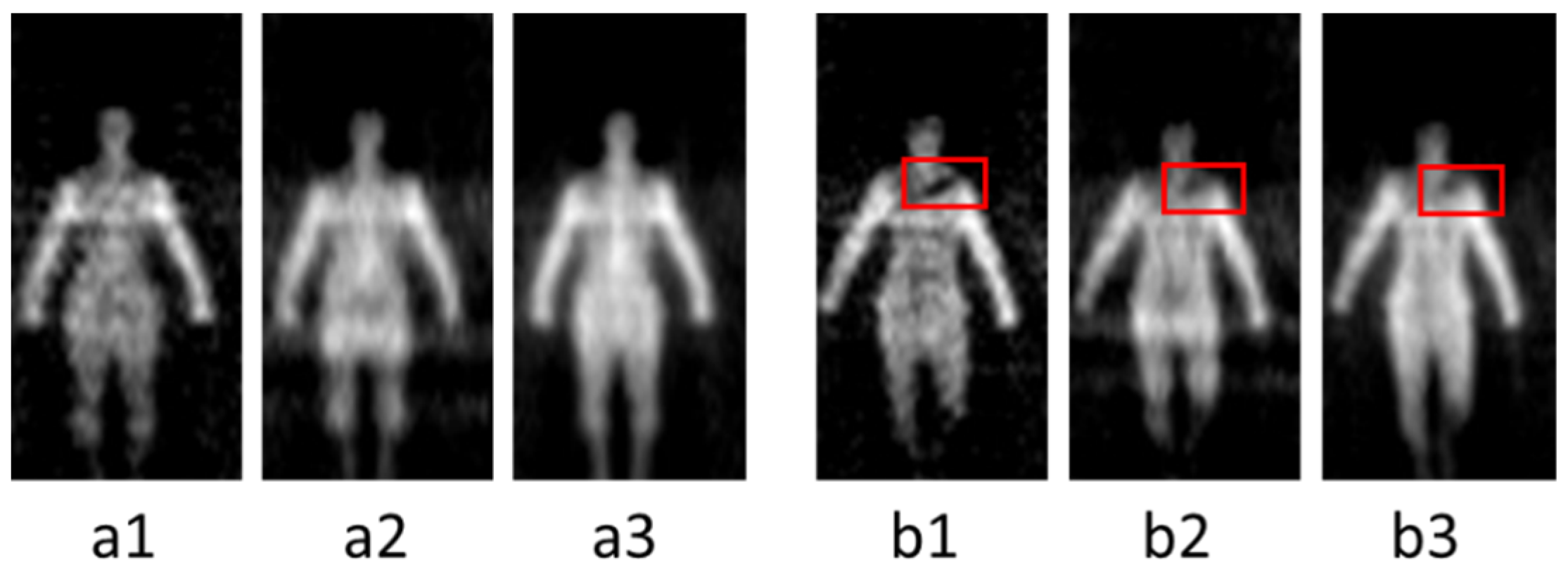
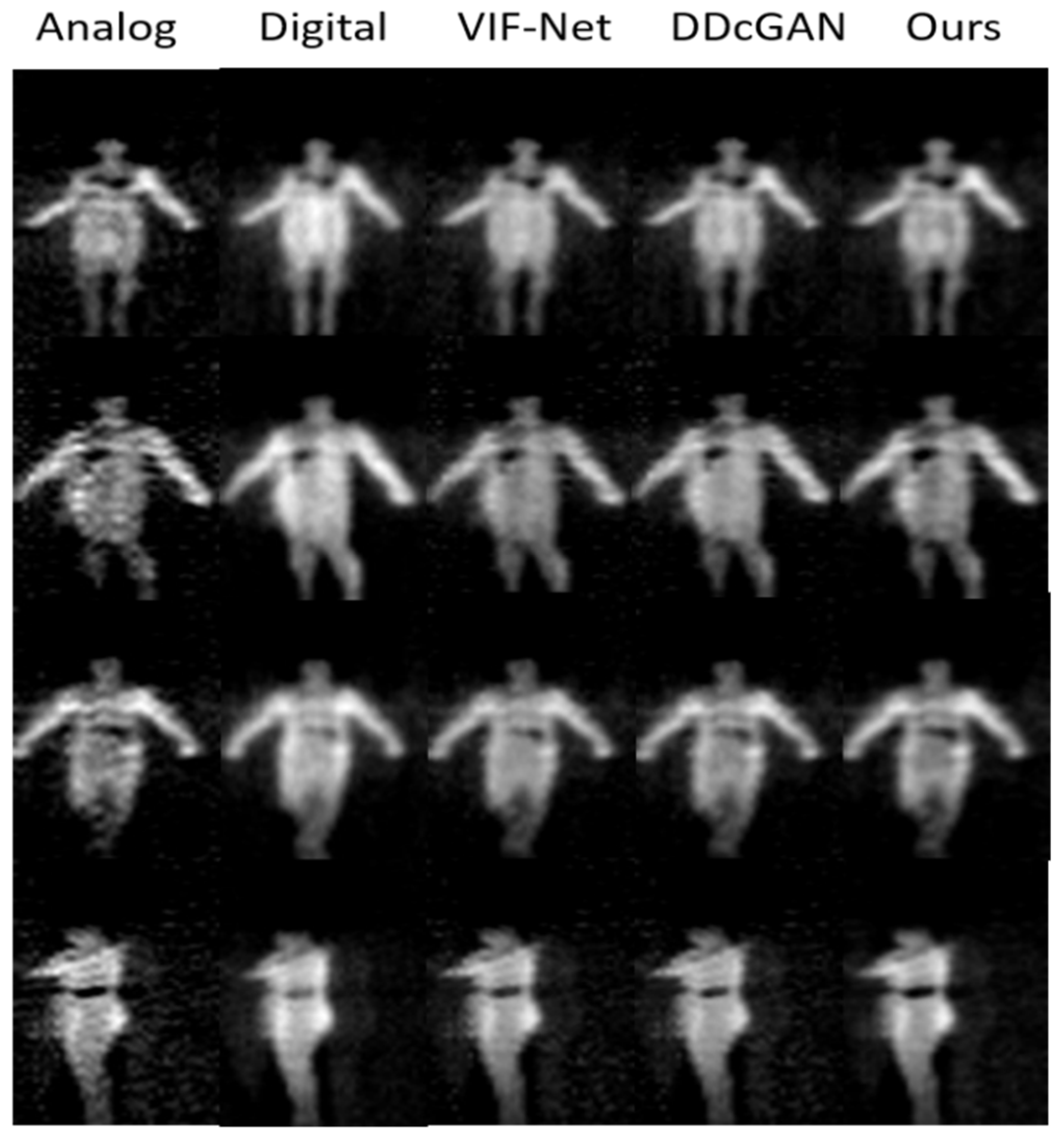
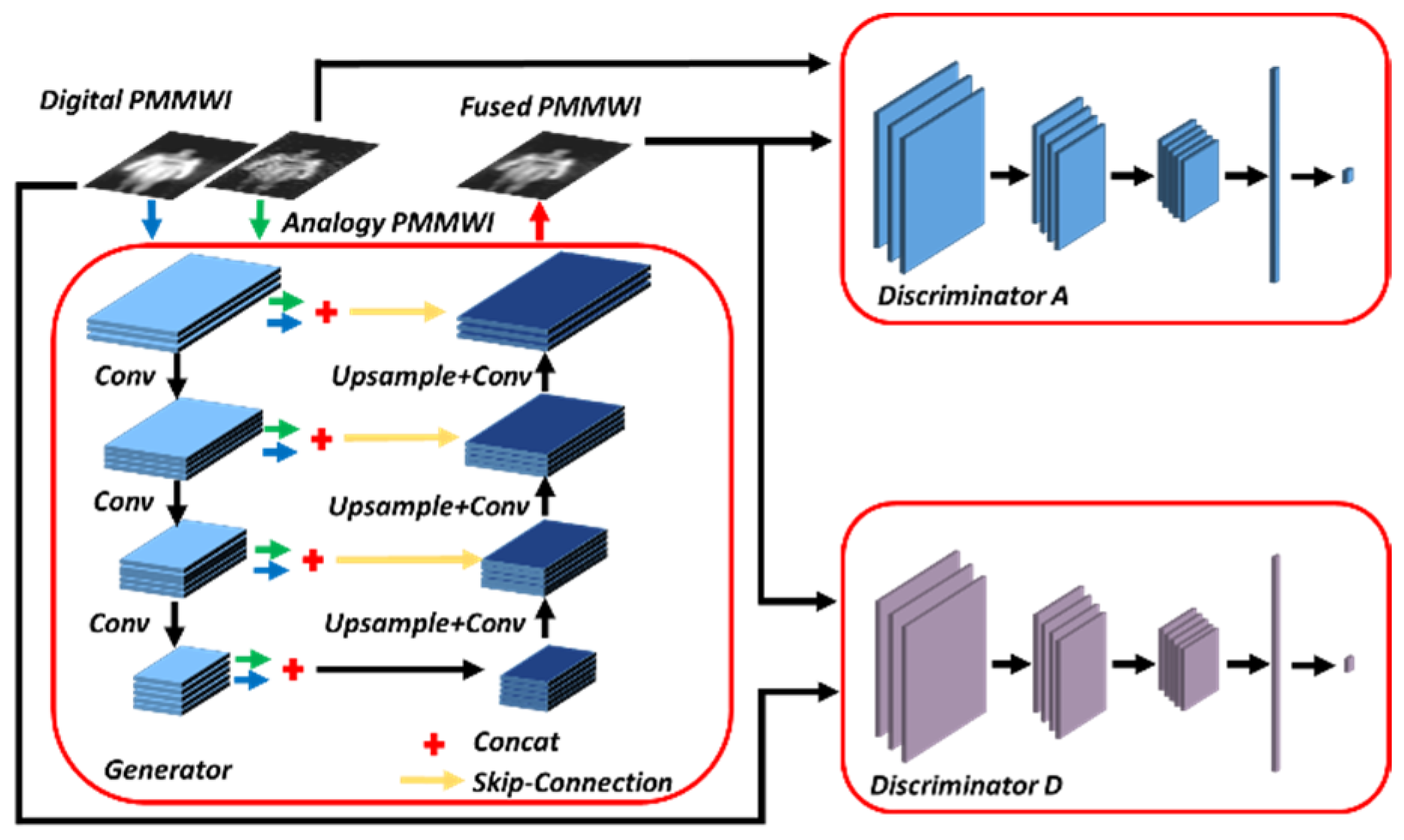
- The fusion of multi-source PMMWIs. A GAN-based network is developed to achieve the fusion of digital PMMWI and analog PMMWI, which can generate the images with higher contrast and SNR. Our method introduces multiple image information to overcome the defects of denoising techniques [22]. Meanwhile, the proposed network is lightweight and easy for training.
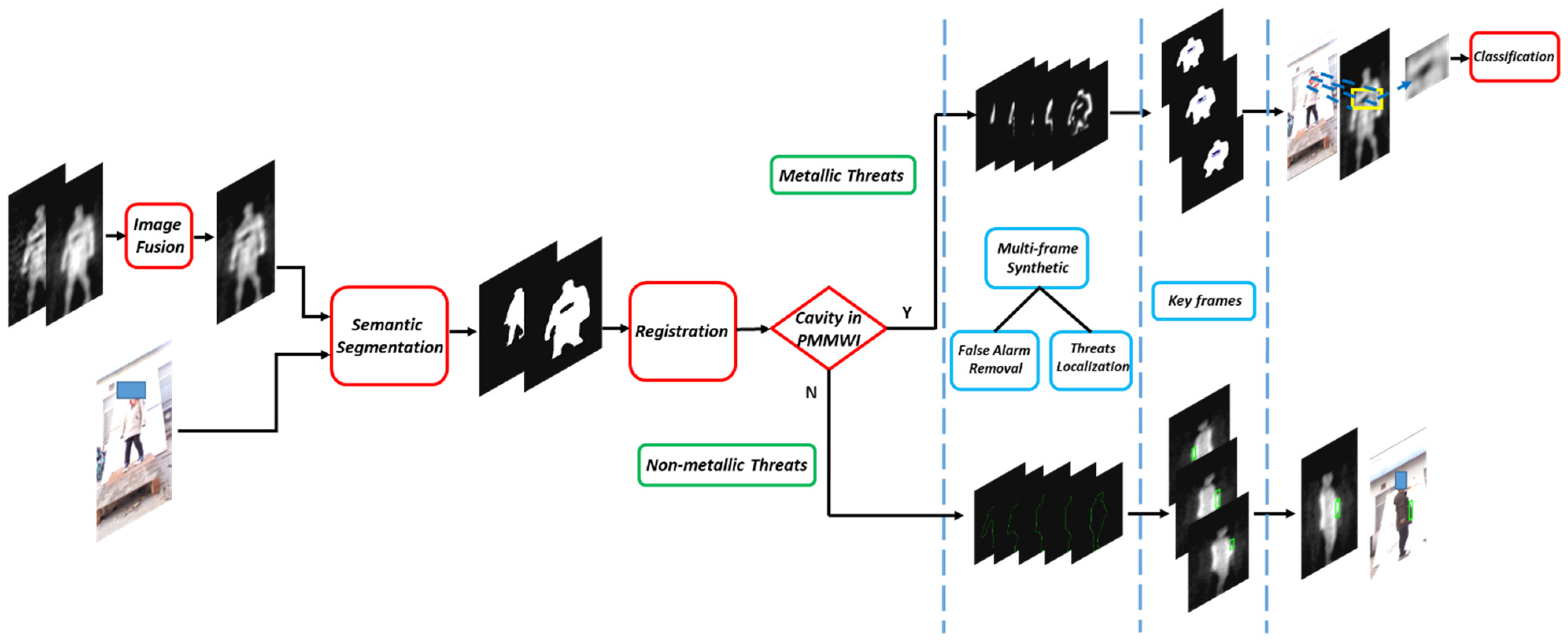
- A multi-stage detection pipeline is proposed. Through the fusion and segmentation stages, imaging quality and the accuracy of detection are improved. Moreover, the non-metallic threats can be also identified from human body by contour information, to which few researches have referred. Additionally, the efficiency of the detection is enhanced, for the method facilitated the detection of a non-stationary manner through inspection channels.
2. Related Works
3. The Proposed Method
3.1. Image Fusion Network
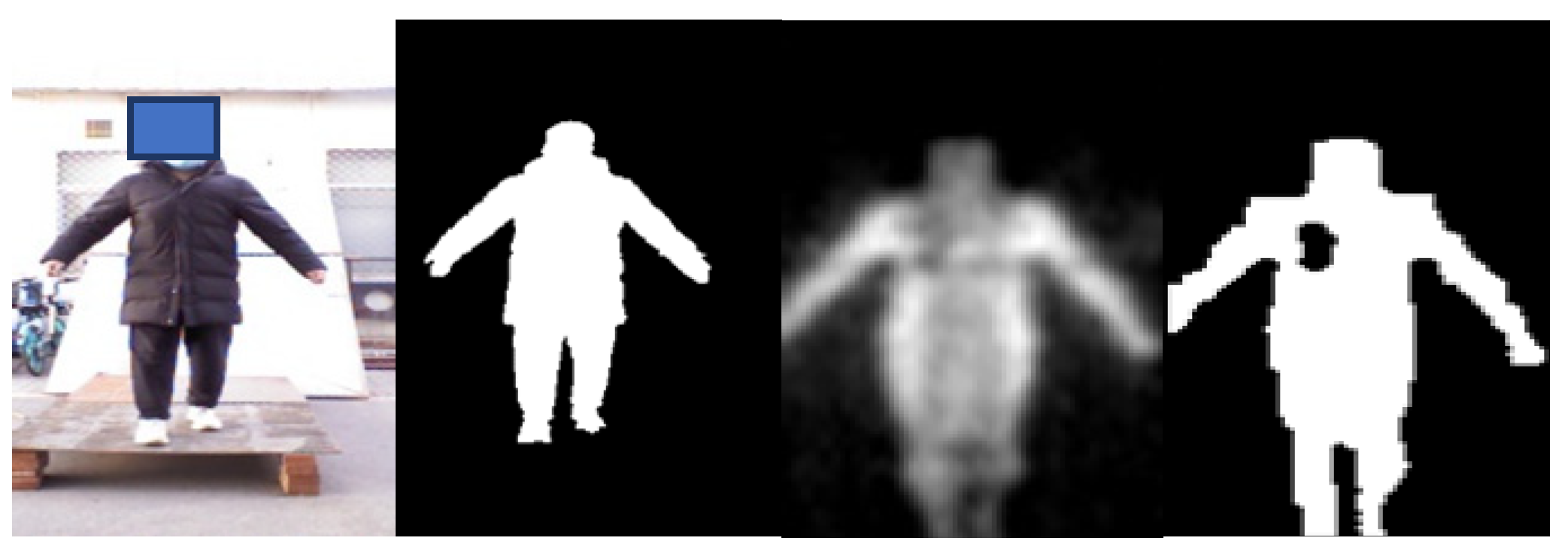
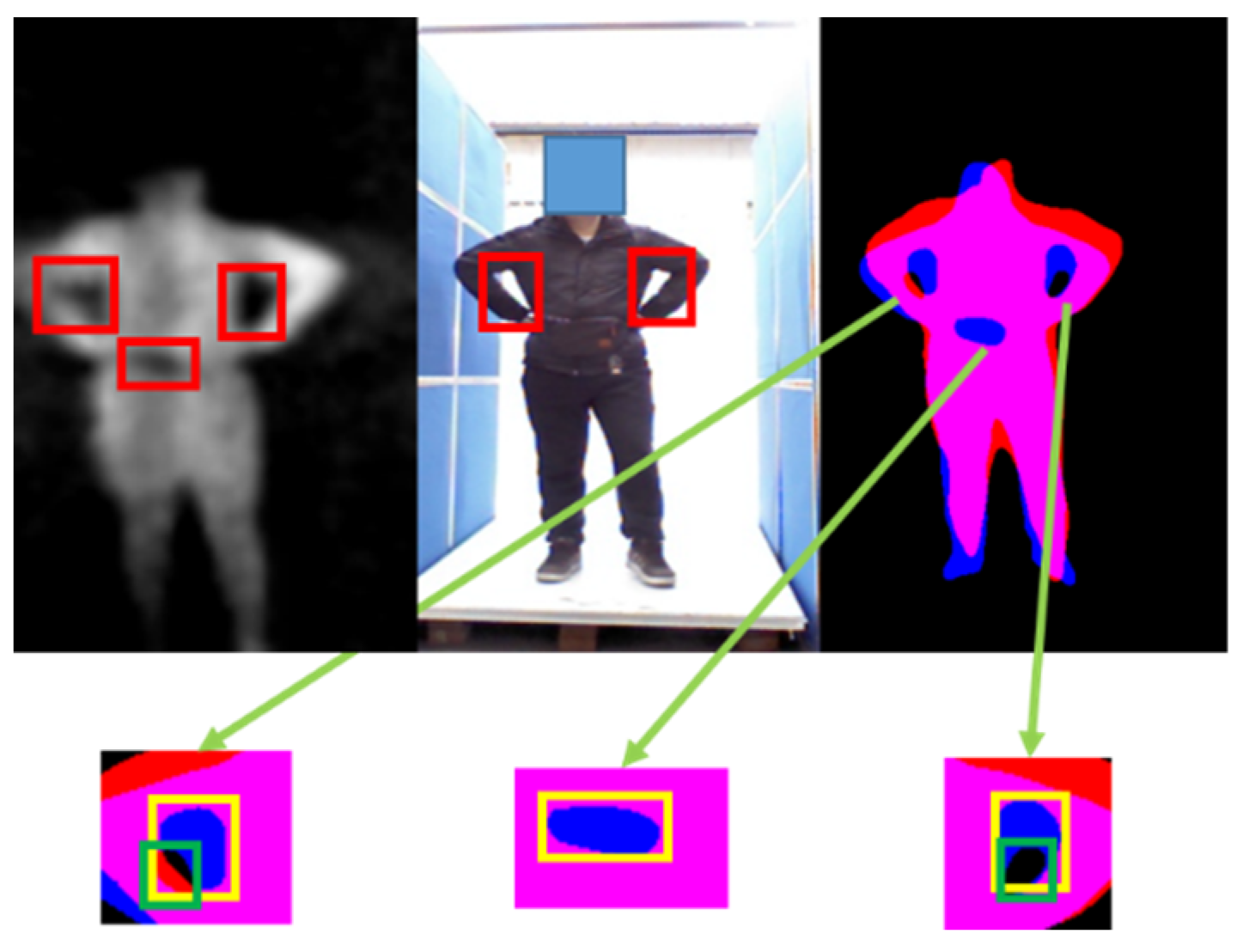
3.2. Semantic Segmentation Network
3.3. Image Registration Network
| Algorithm 1 Extraction of the similar sub-region |
| Input: original image with width and height , |
| transformation parameters |
| Output: sub-region |
| 1. Calculate the transformation parameters by (6) |
| - Coordinate of sub-region in normalized Coordinate System: |
| 2. Resize the sub-region: top-left: , bottom-right: |
| 3. Add offset: top-left: , bottom-right: |
| - Coordinate of sub-region in: |
| 4. Project to : top-left: , bottom-right: |
| 5. Extract the sub-region from |
3.4. Detection and Synthesis Strategy
3.4.1. Comprehensive Analyzer
3.4.2. Metallic Threats Classification Network
3.4.3. Anomaly Area Detection Network
4. Experimental Setup
4.1. Experiment Environment
4.2. The Collected Dataset
4.3. Experimental Results and Discussion
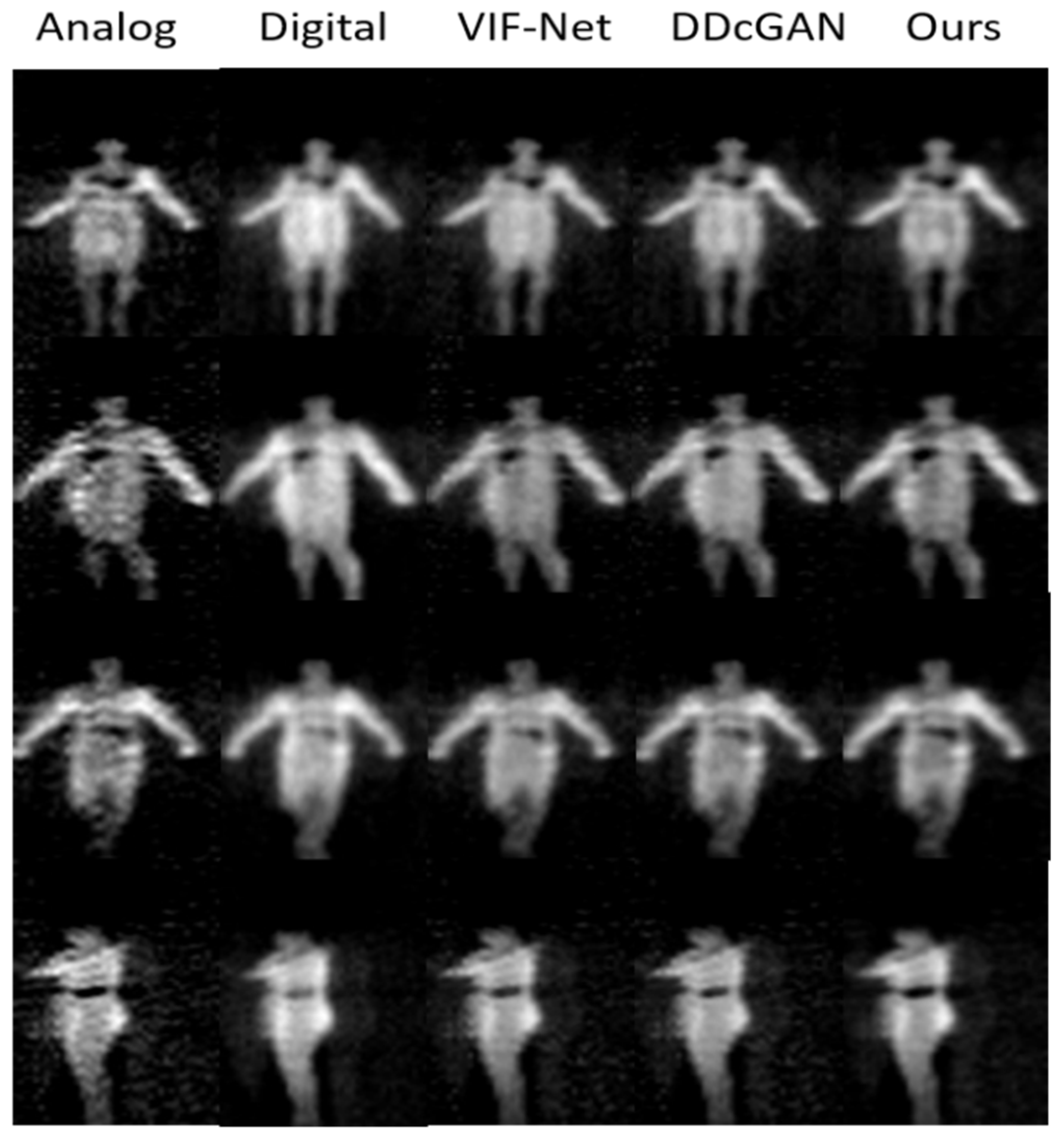
4.3.1. Image Fusion
4.3.2. Image Segmentation
4.3.3. Image Registration
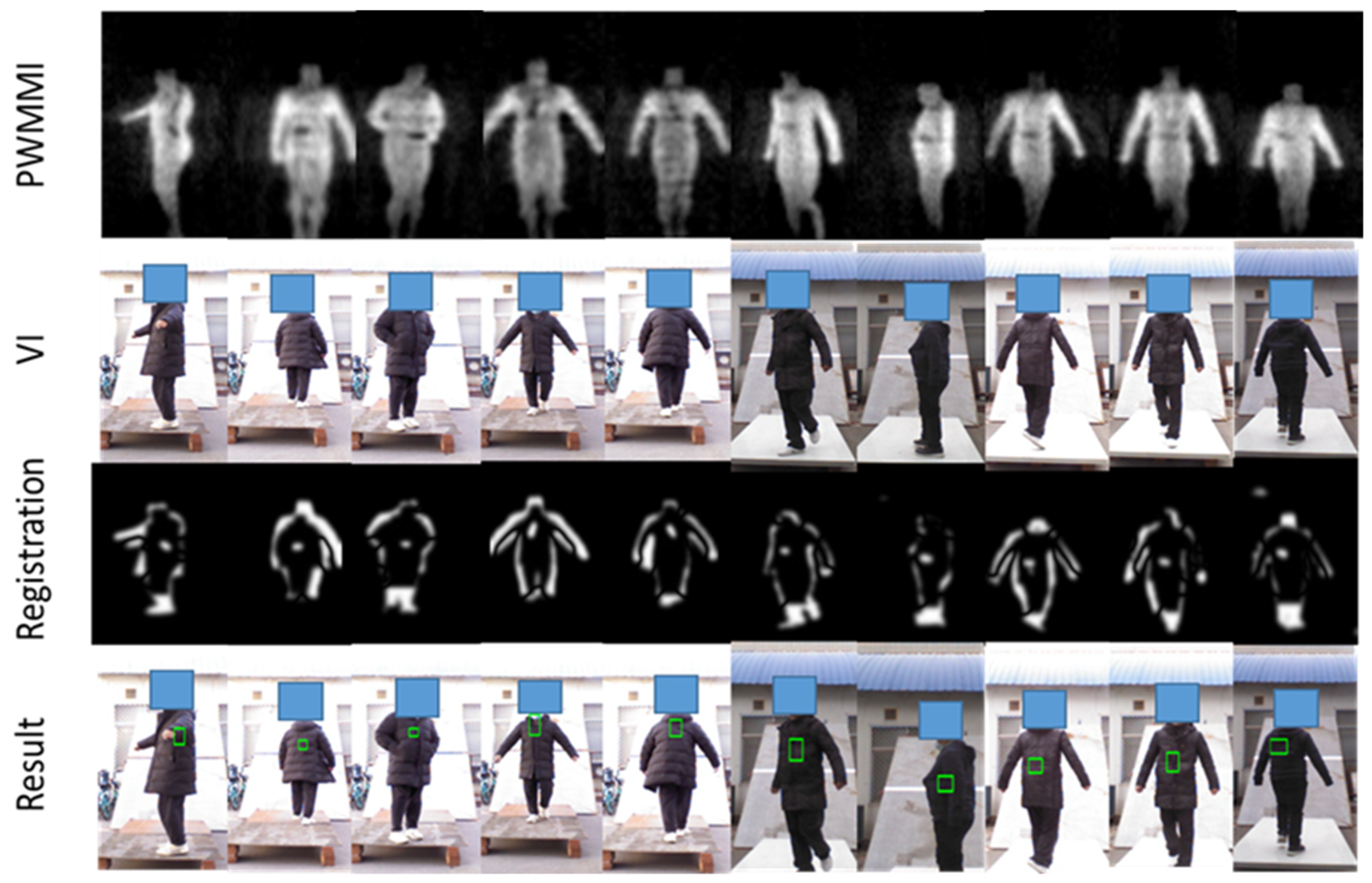
4.3.4. Mental Threats Detection
4.3.5. Non-Mental Threat Detection
4.3.6. Online Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Chang, T.; Cui, H.L. Review of Active Millimeter Wave Imaging Techniques for Personnel Security Screening. IEEE Access 2019, 7, 148336–148350. [Google Scholar] [CrossRef]
- Xing, W.; Zhang, J.; Liang, G. A Fast Detection Method Based on Deep Learning of Millimeter Wave Human Image. In Proceedings of the the 2018 International Conference, Houston, TX, USA, 10–15 June 2018. [Google Scholar]
- Singh, M.K.; Park, H.; Kim, S.H.; Tiwary, U.S.; Kim, Y.H. Linear and nonlinear methods for passive millimeter-wave image deblurring. In Proceedings of the IEEE International Geoscience & Remote Sensing Symposium, Seoul, Korea, 29 July 2005. [Google Scholar]
- Garcia-Rial, F.; Montesano, D.; Gomez, I.; Callejero, C.; Bazus, F.; Grajal, J. Combining Commercially Available Active and Passive Sensors Into a Millimeter-Wave Imager for Concealed Weapon Detection. IEEE Trans. Microw. Theory Tech. 2019, 67, 1167–1183. [Google Scholar] [CrossRef]
- Petkie, D.T.; Lucia, F.; Casto, C.; Helminger, P.; Franck, C. Active and passive millimeter and sub-millimeter-wave imaging. In Technologies for Optical Countermeasures II; Femtosecond Phenomena II; and Passive Millimetre-Wave and Terahertz Imaging II; International Society for Optics and Photonics: Bellingham, WA, USA, 2005; Volume 5989. [Google Scholar]
- Babacan, S.D.; Luessi, M.; Spinoulas, L.; Katsaggelos, A.K.; Raptis, A. Compressive passive millimeter-wave imaging. In Proceedings of the 18th IEEE International Conference on Image Processing, ICIP 2011, Brussels, Belgium, 11–14 September 2011. [Google Scholar]
- Kozacik, S.; Paolini, A.; Bonnett, J.; Harrity, C.; Prather, D.W. Real-time image processing for passive mmW imagery. In Passive and Active Millimeter-Wave Imaging XVIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9462. [Google Scholar]
- Martin, R.D.; Shi, S.; Zhang, Y.; Wright, A.; Prather, D.W. Video rate passive millimeter-wave imager utilizing optical upconversion with improved size, weight, and power. In Passive and Active Millimeter-Wave Imaging XVIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9462, pp. 3135–3152. [Google Scholar]
- Salmon, N.A.; Beale, J.; Hayward, S.; Hall, P.; Macpherson, R.; Metcalfe, R.; Harvey, A. Compact and light-weight digital beam-forming passive millimetre-wave imagers. In Millimetre Wave and Terahertz Sensors and Technology; International Society for Optics and Photonics: Bellingham, WA, USA, 2008. [Google Scholar]
- Zheng, C.; Yao, X.; Hu, A.; Miao, J. A passive millimeter-wave imager used for concealed weapon detection. Prog. Electromagn. Res. 2013, 46, 379–397. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Yao, X.; Hu, A.; Miao, J. Initial results of a passive millimeter-wave imager used for concealed weapon detection BHU-2D-U. Prog. Electromagn. Res. 2013, 43, 151–163. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Liu, K.; Hu, A.; Miao, J. Improved design of a passive millimeter-wave synthetic aperture interferometric imager for indoor applications. In Millimetre Wave and Terahertz Sensors and Technology VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; p. 965105. [Google Scholar]
- Chen, C.; Mehdi, G.; Wang, C.; Dilshad, U.; Hu, A.; Miao, J. A GaAs Power Detector Design for C-band Wideband Complex Cross-Correlation Measurement. IEEE Trans. Instrum. Meas. 2019, 69, 5673–5683. [Google Scholar] [CrossRef]
- Guo, X.; Asif, M.; Hu, A.; Li, Z.; Miao, J. A 1-GHz 64-Channel Cross-Correlation System for Real-Time Interferometric Aperture Synthesis Imaging. Sensors 2019, 19, 1739. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, X.; Mehdi, G.; Asif, M.; Hu, A.; Miao, J.J.I.A. 1-Bit/2-Level Analog-to-Digital Conversion Based on Comparator and FPGA for Aperture Synthesis Passive Millimeter-Wave Imager. IEEE Access 2019, 7, 51933–51939. [Google Scholar] [CrossRef]
- Guo, X.; Asif, M.; Hu, A.; Miao, J. Design of a low-cost cross-correlation system for aperture synthesis passive millimeter wave imager. In Millimetre Wave and Terahertz Sensors and Technology XI; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; p. 1080003. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2012; pp. 17–36. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? arXiv 2018, arXiv:1909.09139. [Google Scholar]
- Lopez-Tapia, S.; Molina, R.; de la Blanca, N.P. Deep CNNs for Object Detection Using Passive Millimeter Sensors. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2580–2589. [Google Scholar] [CrossRef]
- Işıker, H.; Özdemir, C. A multi-thresholding method based on Otsu’s algorithm for the detection of concealed threats in passive millimeter-wave images. Frequenz 2019, 73, 179–187. [Google Scholar] [CrossRef]
- Yu, W.; Chen, X.; Wu, L. Segmentation of concealed objects in passive millimeter-wave images based on the Gaussian mixture model. J. Infrared Millim. Terahertz Waves 2015, 36, 400–421. [Google Scholar] [CrossRef]
- Chen, Y.; Pang, L.; Liu, H.; Xu, X. Wavelet fusion for concealed object detection using passive millimeter wave sequence images. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Beijing, China, 7–10 May 2018; Volume 42, pp. 193–198. [Google Scholar]
- Zhu, S.; Li, Y. A multi-class classification system for passive millimeter-wave image. In Proceedings of the 2018 International Conference on Microwave and Millimeter Wave Technology (ICMMT), Chengdu, China, 6–9 May 2018; pp. 7–11. [Google Scholar]
- Mateos, J.; López, A.; Vega, M.; Molina, R.; Katsaggelos, A.K. Multiframe blind deconvolution of passive millimeter wave images using variational dirichlet blur kernel estimation. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AR, USA, 25–28 September 2016; pp. 2678–2682. [Google Scholar]
- Wang, X.; Gou, S.; Li, J.; Zhao, Y.; Mao, S. Self-paced feature attention fusion network for concealed object detection in millimeter-wave image. IEEE Trans. Circuits Syst. Video Technol. 2021. [Google Scholar] [CrossRef]
- Pang, L.; Liu, H.; Chen, Y.; Miao, J. Real-time concealed object detection from passive millimeter wave images based on the YOLOv3 algorithm. Sensors 2020, 20, 1678. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.; Xiong, J.; Liu, Y.; Zhang, Y.; Yang, J. Research on Fast Target Detection And Classification Algorithm for Passive Millimeter Wave Imaging. In Proceedings of the 2019 International Conference on Control, Automation and Information Sciences (ICCAIS), Chengdu, China, 23–26 October 2019; pp. 1–6. [Google Scholar]
- Li, Y.; Ye, W.; Chen, J.F.; Gong, M.; Zhang, Y.; Li, F. A visible and passive millimeter wave image fusion algorithm based on pulse-coupled neural network in Tetrolet domain for early risk warning. Math. Probl. Eng. 2018, 2018, 4205308. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Qin, S. High-performance detection of concealed forbidden objects on human body with deep neural networks based on passive millimeter wave and visible imagery. J. Infrared Millim. Terahertz Waves 2019, 40, 314–347. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A Dual-discriminator Conditional Generative Adversarial Network for Multi-resolution Image Fusion. IEEE Trans Image Process 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards diverse and natural image descriptions via a conditional gan. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2970–2979. [Google Scholar]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The importance of skip connections in biomedical image segmentation. In Deep Learning and Data Labeling for Medical Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 179–187. [Google Scholar]
- Wang, Z.; Li, J.; Enoh, M. Removing ring artifacts in CBCT images via generative adversarial networks with unidirectional relative total variation loss. Neural Comput. Appl. 2019, 31, 5147–5158. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef] [PubMed]
- Ayyachamy, S.; Alex, V.; Khened, M.; Krishnamurthi, G. Medical image retrieval using Resnet-18. In Medical Imaging 2019: Imaging Informatics for Healthcare, Research, and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; p. 1095410. [Google Scholar]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Wang, Y.; Li, J.; Lu, Y.; Fu, Y.; Jiang, Q. Image quality evaluation based on image weighted separating block peak signal to noise ratio. In Proceedings of the International Conference on Neural Networks & Signal Processing, Nanjing, China, 14–17 December 2003. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Height | 1.6 m |
|---|---|
| Width | 0.8 m |
| Frequency | 32–36 GHz |
| Number of channels | 1024 |
| Imaging Resolution | 4 cm@2 m |
| Temperature Resolution | 1–2 K |
| Imaging Frame Rate | 25 FPS |
| Observation Distance | 1–4 m |
| Number of Pixels * | 80 × 160 |
| Observation Range * | 1m × 2m |
| Network | EN | PSNR | SSIM |
|---|---|---|---|
| VIF-Net | 5.595 | 20.633 | 0.868 |
| DDcGAN | 6.203 | 20.547 | 0.867 |
| Ours | 6.158 | 22.350 | 0.901 |
| Network | IOU | Parameters |
|---|---|---|
| Network not shared | 0.9276 | 141.74 M |
| Network shared | 0.9230 | 70.87 M |
| Separate Batch Normalization | 0.9271 | 70.88 M |
| Ground Truth | Metallic Gun | Metallic Knife | Other | |
|---|---|---|---|---|
| Prediction | ||||
| Metallic Gun | 219 | 5 | 7 | |
| Metallic Knife | 29 | 114 | 4 | |
| Other | 2 | 10 | 372 | |
| Time | Network Size | |
|---|---|---|
| Image Fusion | 10.74 ms | 15.24 M |
| Image Segmentation | 13.77 ms | 70.88 M |
| Image Registration | 11.28 ms | 40.24 M |
| Detection (non-metallic) | 12.32 ms | 22.26 M |
| Detection (metallic) | 13.77 ms | 43.74 M |
| Position | Metallic (Recall) | Non-Metallic (Recall) | Average (Recall) | Metallic Precision) | Non-Metallic (Precision) | Average (Precision) |
|---|---|---|---|---|---|---|
| Front Chest | 95% | 83.33% | 89.17% | 91.34% | 90.91% | 91.13% |
| Back | 97% | 84.33% | 90.67% | 93.26% | 92.63% | 92.95% |
| Abdomen | 94% | 80.66% | 87.33% | 94% | 92.06% | 93.03% |
| Lower Back | 95% | 84.33% | 89.67% | 93.14% | 91.01% | 92.07% |
| Side Waist | 84% | 85.33% | 84.67% | 94.38% | 90.78% | 92.58% |
| Ground Truth | Metallic Gun | Metallic Knife | Other | |
|---|---|---|---|---|
| Prediction | ||||
| Metallic Gun | 210 | 3 | 0 | |
| Metallic Knife | 12 | 216 | 0 | |
| Other | 10 | 14 | 0 | |
| Algorithm | Recall | Precision | FPS |
|---|---|---|---|
| YOLOv3 | 89.34% | 89.03% | 34 |
| HBPSNs-4 | 87.37% | 90.57% | 18 |
| Ours | 90.30% | 92.35% | 24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Zhang, D.; Qin, S.; Cui, T.J.; Miao, J. Real-Time Detection of Concealed Threats with Passive Millimeter Wave and Visible Images via Deep Neural Networks. Sensors 2021, 21, 8456. https://doi.org/10.3390/s21248456
Yang H, Zhang D, Qin S, Cui TJ, Miao J. Real-Time Detection of Concealed Threats with Passive Millimeter Wave and Visible Images via Deep Neural Networks. Sensors. 2021; 21(24):8456. https://doi.org/10.3390/s21248456
Chicago/Turabian StyleYang, Hao, Dinghao Zhang, Shiyin Qin, Tie Jun Cui, and Jungang Miao. 2021. "Real-Time Detection of Concealed Threats with Passive Millimeter Wave and Visible Images via Deep Neural Networks" Sensors 21, no. 24: 8456. https://doi.org/10.3390/s21248456
APA StyleYang, H., Zhang, D., Qin, S., Cui, T. J., & Miao, J. (2021). Real-Time Detection of Concealed Threats with Passive Millimeter Wave and Visible Images via Deep Neural Networks. Sensors, 21(24), 8456. https://doi.org/10.3390/s21248456