
Smart Pothole Detection Using Deep Learning Based on Dilated Convolution


Abstract
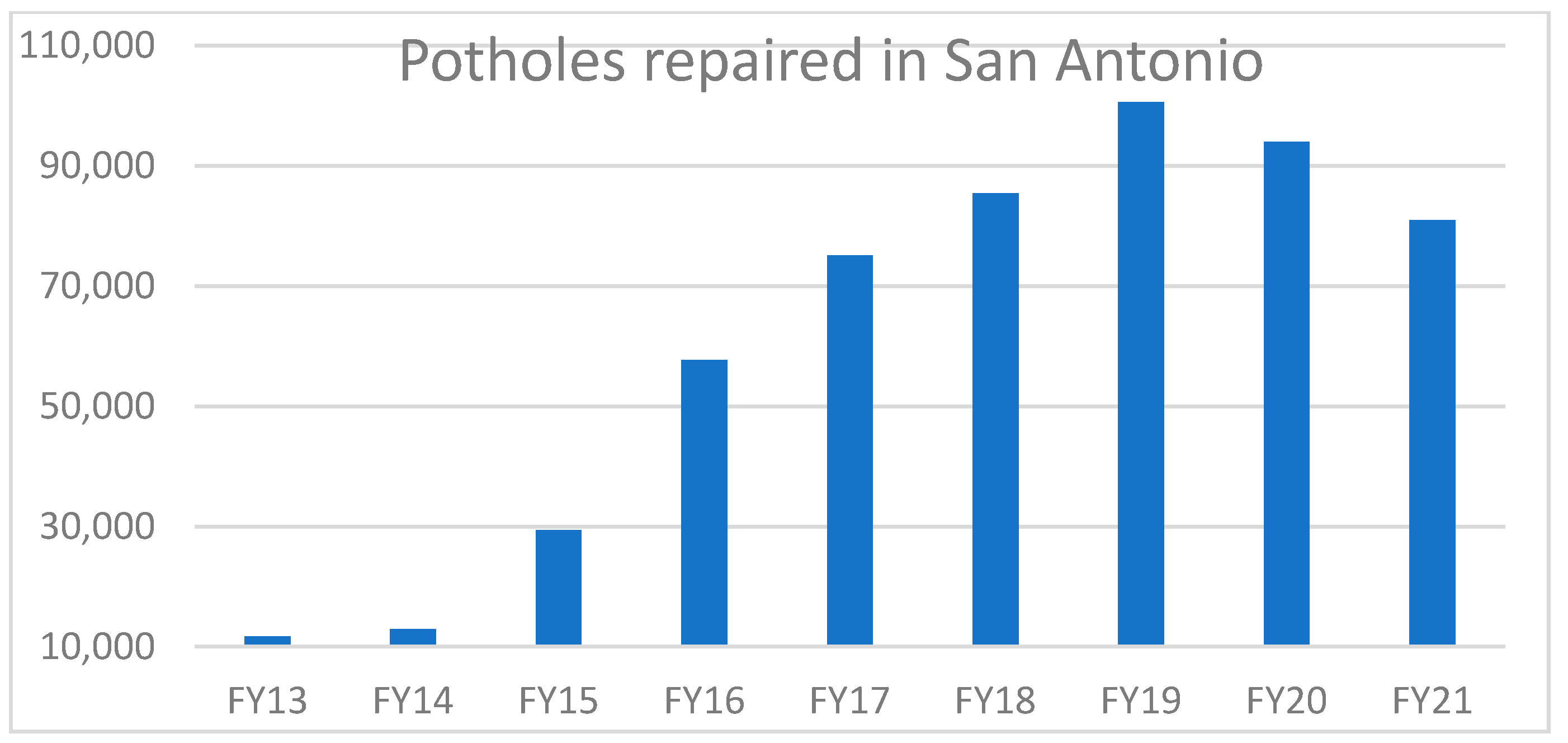
:1. Introduction
2. Related Work
2.1. Sensor-Based Pothole Detection Approaches
2.2. Three-Dimensional (3D) Reconstruction Pothole Detection Approaches
2.3. Image Processing Pothole Detection Techniques
2.4. Model-Based Approaches for Potholes Detection Techniques
3. Materials and Methods
3.1. Faster R-CNN
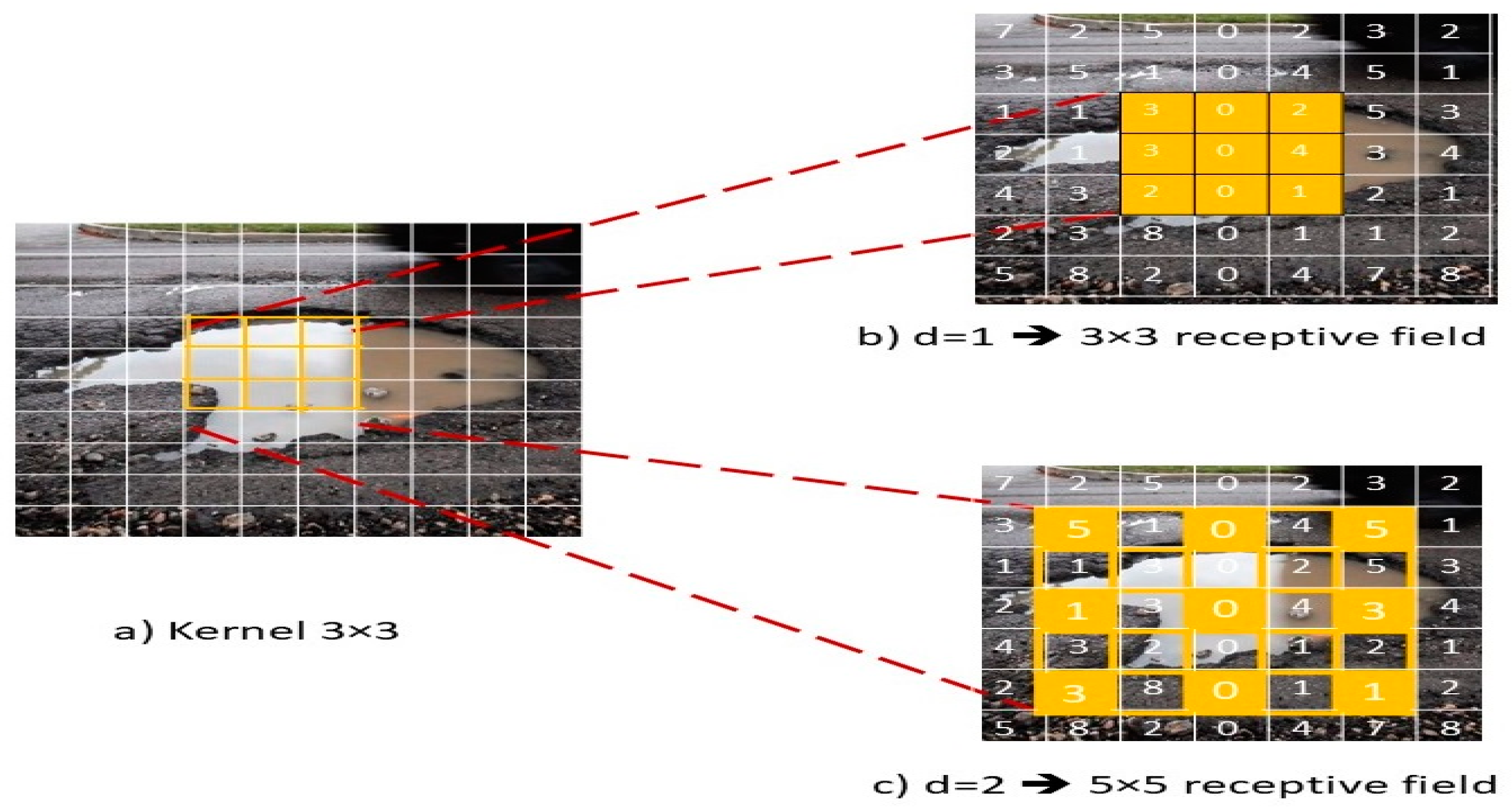
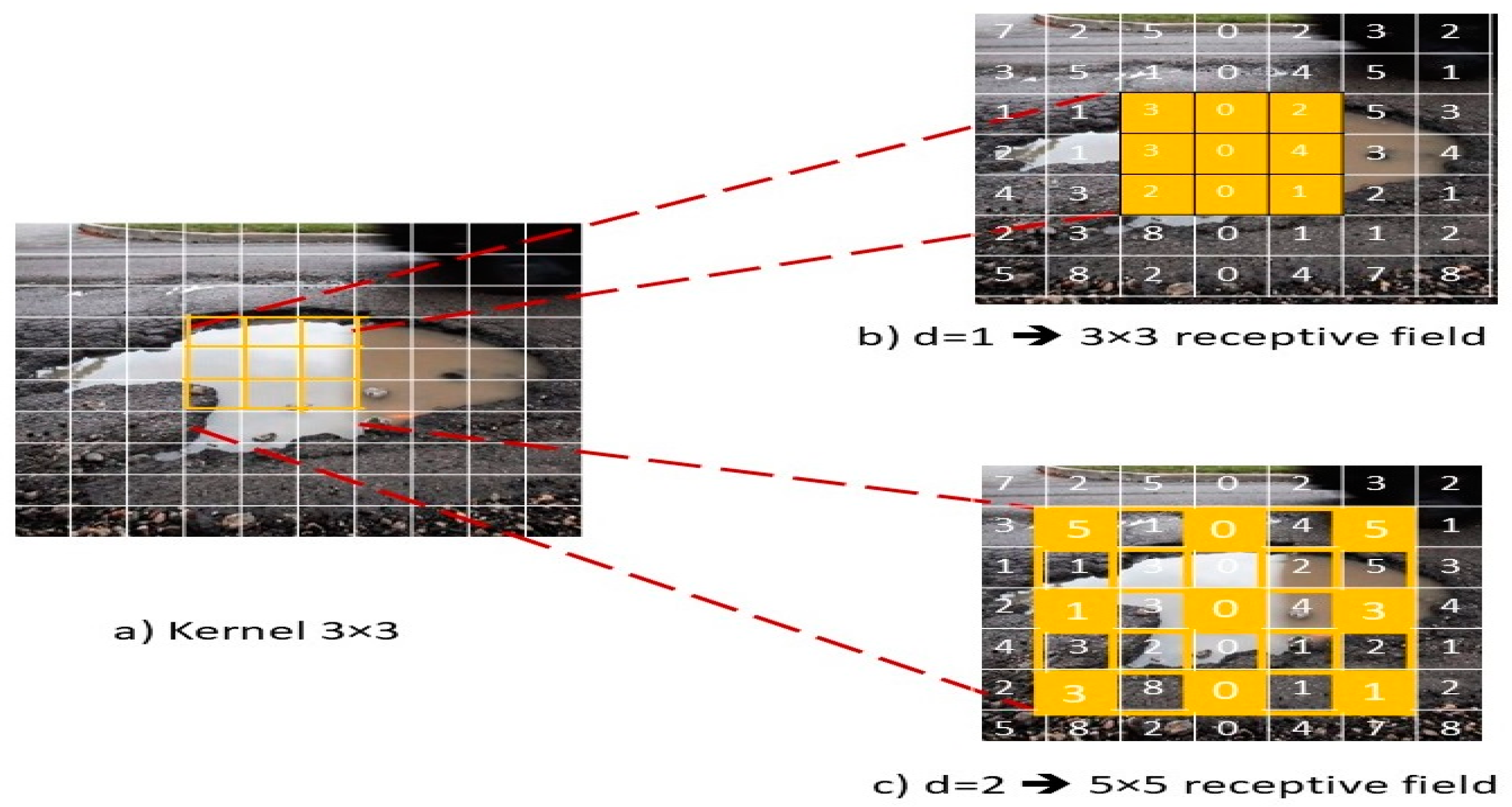
3.2. Proposed Dilated CNN
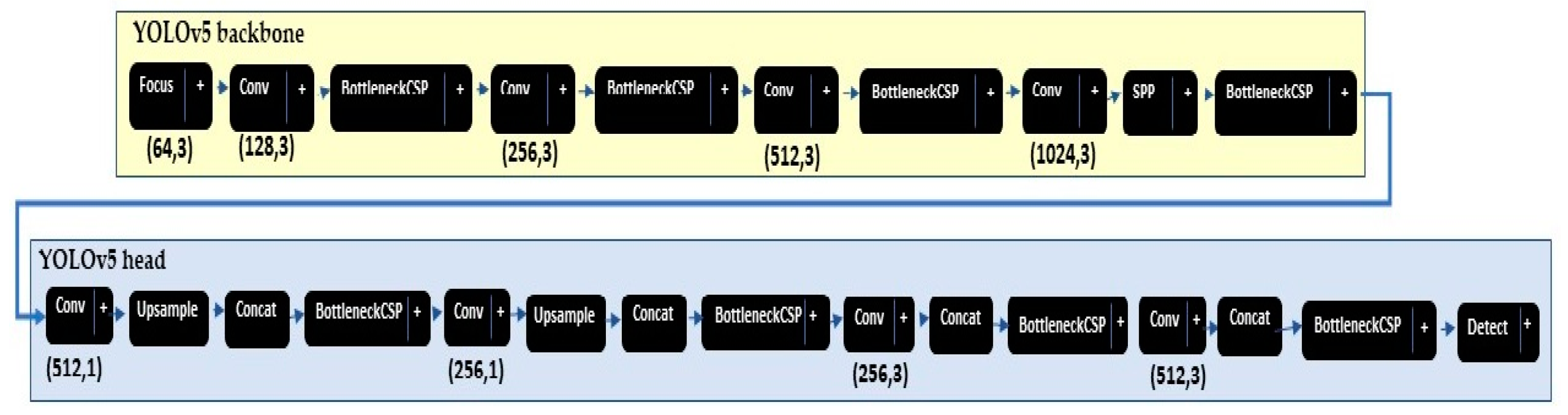
3.3. YOLOV5
4. Results
4.1. Setup
4.1.1. Dataset Preparation
4.1.2. Dataset Augmentation
4.2. Performance Evaluation Mertics
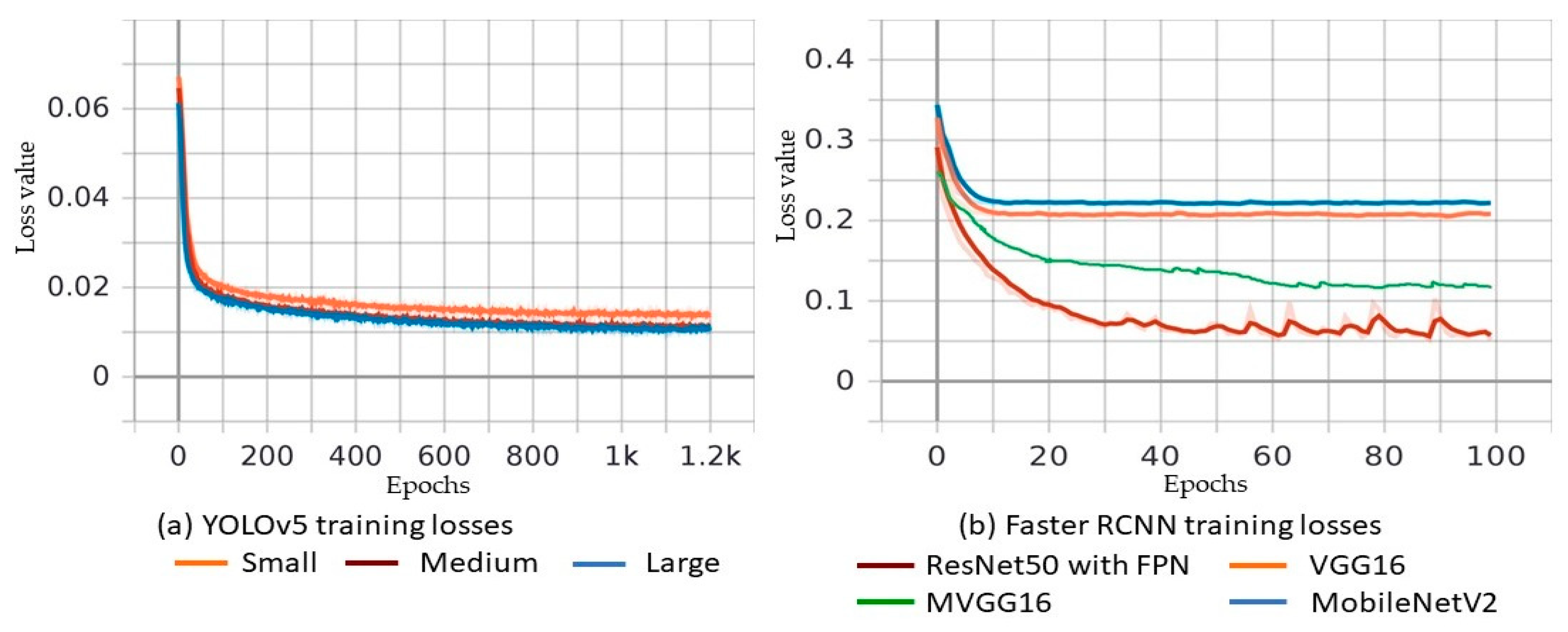
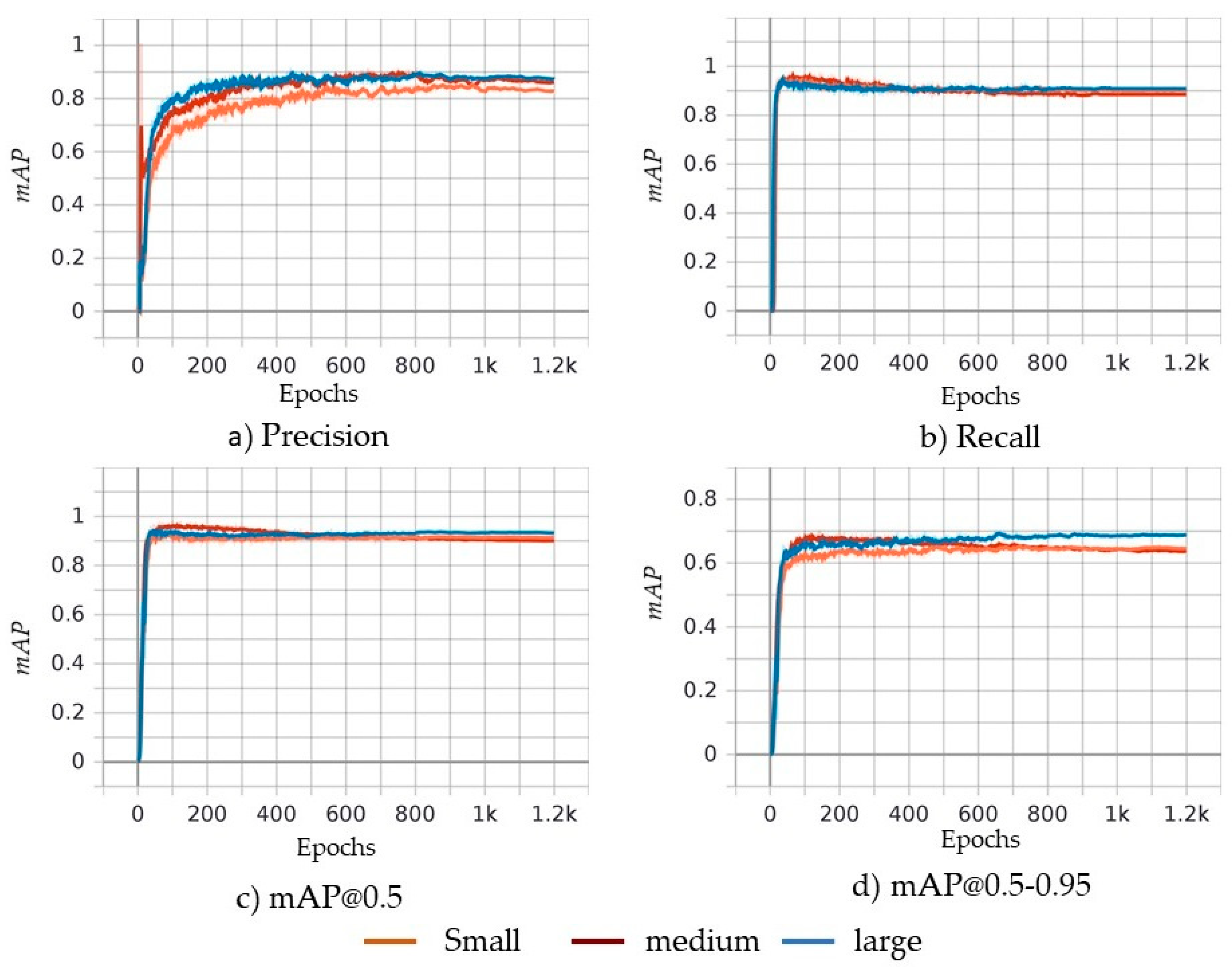
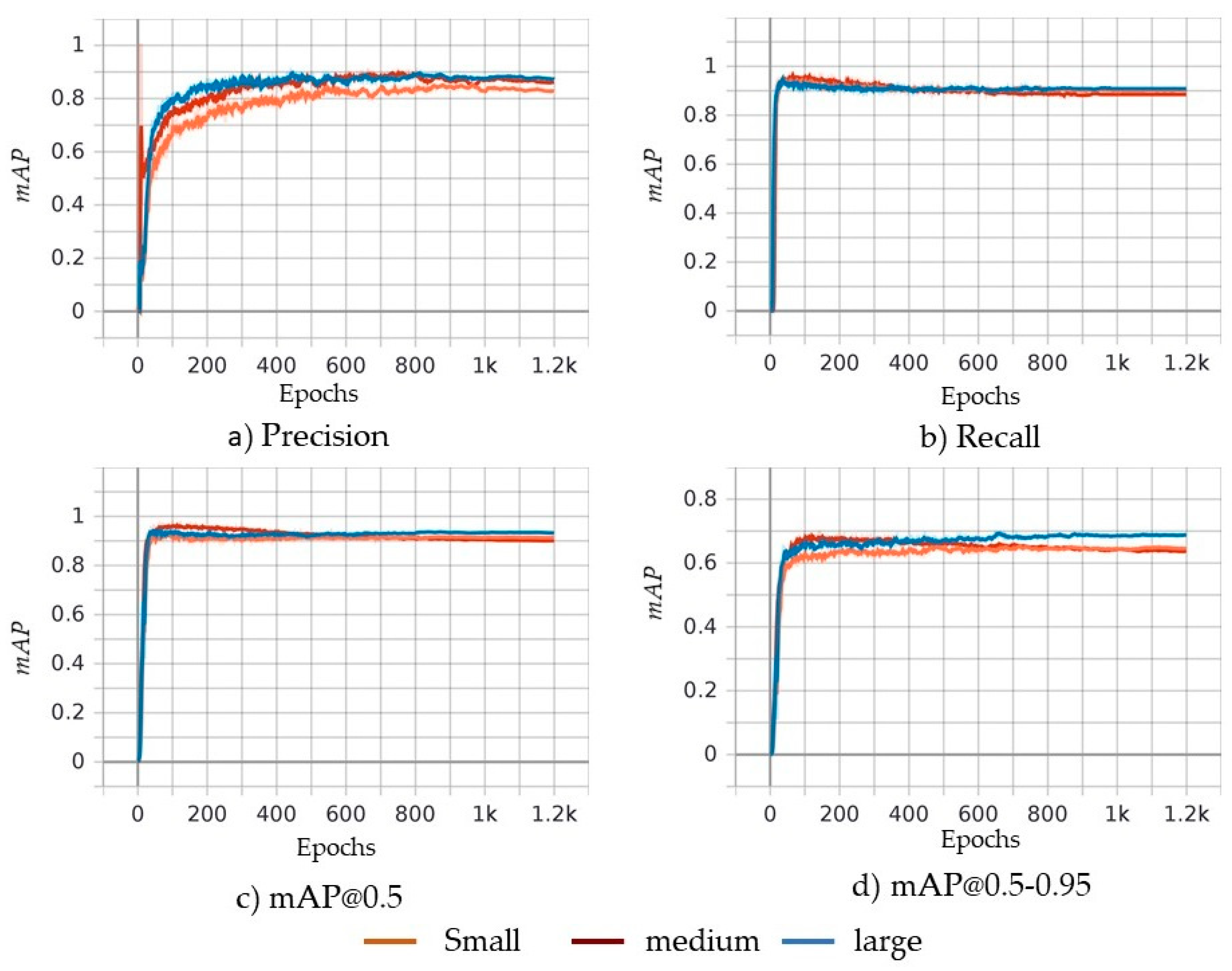
5. Object Detection Results and Discussion
Comparison of YOLOv5 and Faster R-CNN (MVGG16)
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Solanke, V.L.; Patil, D.D.; Patkar, A.S.; Tamrale, G.S.; Kale, P.A.G. Analysis of existing road surface on the basis of pothole characteristics. Glob. J. Res. Eng. 2019, 19, 1–5. [Google Scholar]
- T.A.A. Association. Pothole Damage Costs Drivers $3 Billion Annually Nationwide. Available online: http://news.aaa-calif.com/news/pothole-damage-costs-drivers-3-billion-annually-nationwide (accessed on 7 September 2020).
- The Economic Times. Supreme Court Takes Note of 3597 Deaths Due to Pothole-Related Accidents in 2017. Available online: https://economictimes.indiatimes.com/news/politics-and-nation/supreme-court-takes-note-of-3597-deaths-due-to-pothole-related-accidents-in-2017/articleshow/65858401.cms (accessed on 21 October 2021).
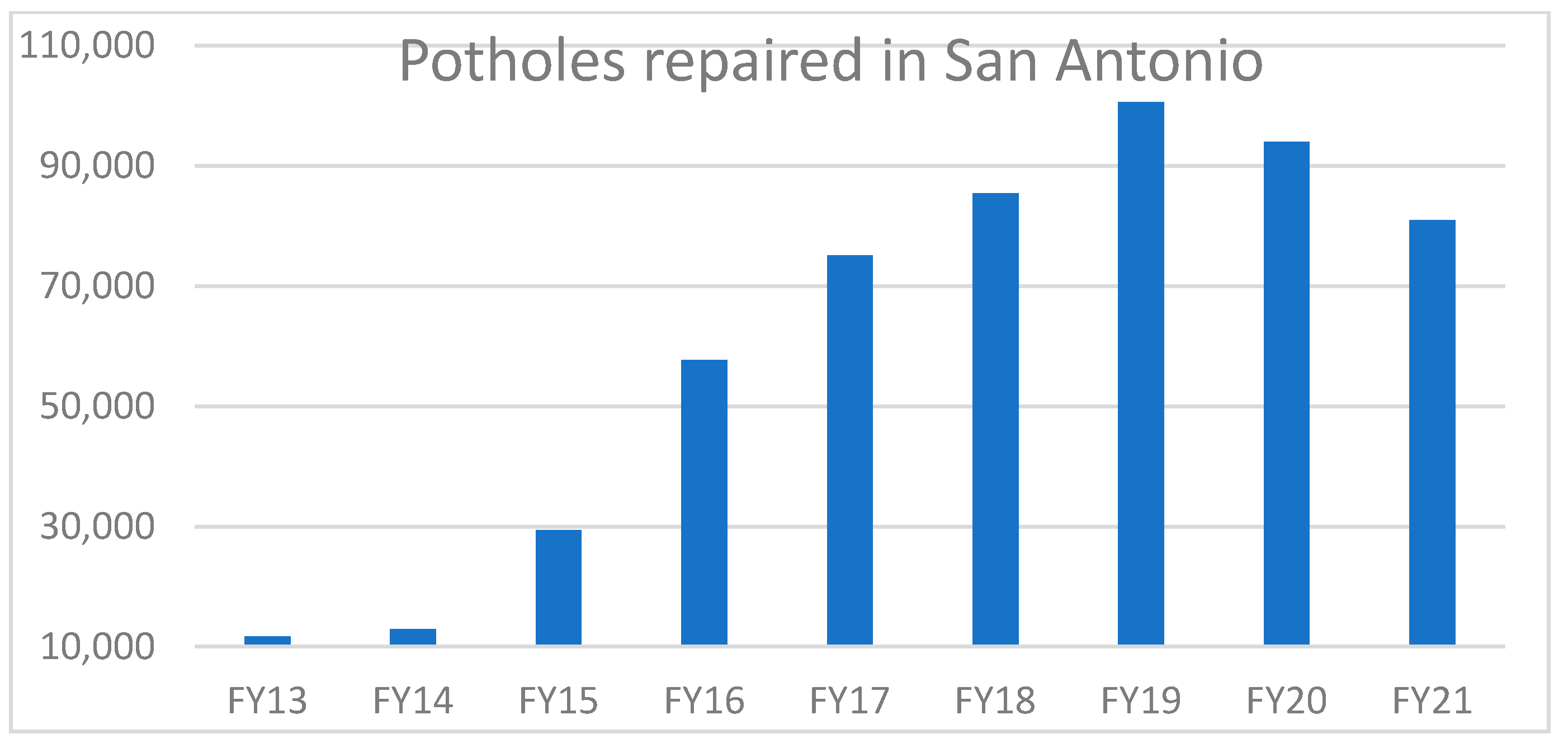
- S. Portal. City of San Antonio: Potholes. 2018. Available online: https://www.sanantonio.gov/PublicWorks/FAQs/Streets (accessed on 10 September 2020).
- San Antonio. “San Antonio Fiscal Year 2019 2nd Quarter Report: Providing Services/Measuring Results” San Antonio. 2019. Available online: https://www.sanantonio.gov/Portals/0/Files/budget/FY2019/FY2019-six-plus-six-Performance-Measures.pdf (accessed on 22 November 2021).
- Portal, C. City of Chicago Data Portal. 2021. Available online: https://data.cityofchicago.org/ (accessed on 27 July 2021).
- Bureau of Transportation Statistics. Road Condition. 2018. Available online: https://www.bts.gov/road-condition (accessed on 10 September 2020).
- Yu, B.X.; Yu, X. Vibration-based system for pavement condition evaluation. In Proceedings of the 9th International Conference on Applications of Advanced Technology in Transportation (AATT), Chicago, IL, USA, 13–16 August 2006. [Google Scholar]
- Zoysa, K.D.; Keppitiyagama, C.; Seneviratne, G.P.; Shihan, W. A public transport system based sensor network for road surface condition monitoring. In Proceedings of the Workshop on Networked Systems for Developing Regions, Kyoto, Japan, 27 August 2007. [Google Scholar]
- Eriksson, G. The pothole patrol: Using a mobile sensor network for road surface monitoring. In Proceedings of the Sixth Annual International conference on Mobile Systems, Applications and Service, Boston, MA, USA, 6–11 August 2008. [Google Scholar]
- Mednis, A.; Strazdins, G.; Zviedris, R.; Kanonirs, G.; Selavo, L. Real time pothole detection using android smartphones with accelerometers. In Proceedings of the 2011 International Conference on Distributed Computing in Sensor Systems and Workshops (DCOSS), Barcelona, Spain, 27–29 June 2011. [Google Scholar]
- Tai, Y.-C.; Chan, C.-W.; Hsu, J.Y.-J. Automatic road anomaly detection using smart mobile device. In Proceedings of the Conference on Technologies and Applications of Artificial Intelligence (TAAI2010), Hsinchu City, Taiwan, 18–20 November 2010. [Google Scholar]
- Chang, K.; Chang, J.R.; Liu, J.K. Detetction of pavement distress using 3D laser scanning. In Proceedings of the ASCE International Conference on Computing in Civil Engineering, Cancun, Mexico, 12–15 July 2005. [Google Scholar]
- Yu, X.; Salari, E. Pavement pothole detection and severity measurement using laser imaging. In Proceedings of the International Conference on Electro/Information Technology, Mankato, MN, USA, 15–17 May 2011. [Google Scholar]
- Moazzam, I.; Kamal, K.; Mathavan, S.; Usman, S.; Rahman, M. Metrology and visualization of potholes using the Microsoft Kinect sensor. In Proceedings of the 16th International IEEE Annual Conference on Intelligent Transportation Systems, The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Staniek, M. Stereo vision techniques in the road pavement evaluation. Balt. J. Road Bridge Eng. 2017, 12, 38–47. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, K.C.P. Challenges and feasibility for comprehensive automated survey of pavement conditions. In Proceedings of the 8th International Conference on Applications of Advanced Technologies in Transportation Engineering, Beijing, China, 26–28 May 2004. [Google Scholar]
- Hou, Z.; Wang, K.C.P.; Gong, W. Experimentation of 3D pavement imaging through stereovision. In Proceedings of the International Conference on Transportation Engineering, Chengdu, China, 22–24 July 2007. [Google Scholar]
- Zhang, Z.; Ai, X.; Chan, C.K.; Dahnoun, N. An efficient algorithm for pothole detection using stereo vision. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Nienaber, S.; Booysen, M.T.; Kroon, R. Detecting potholes using simple image processing techniques and real-world footage. In Proceedings of the 34th Southern African Transport Conference (SATC 2015), Pretoria, South Africa, 6–9 July 2015. [Google Scholar]
- Koch, C.; Jog, G.M.; Brilakis, I. Ptholes detection with image processing and spectral clustering. J. Comput. Civ. Eng. 2013, 27, 370–378. [Google Scholar] [CrossRef]
- Bhat, A.; Narkar, P.; Shetty, D.; Vyas, D. Detection of Potholes using Image Processing Techniques. IOSR J. Eng. 2018, 2, 52–56. [Google Scholar]
- Jog, G.M.; Koch, C.; Golparvar-Fard, M.; Brilakis, I. Pothole properties measurement through visual 2D recognition and 3D reconstruction. In Proceedings of the ASCE Interntional Conference on Computing in Civil Engineering, Clearwater Beach, FL, USA, 17–20 June 2012. [Google Scholar]
- Lokeshwor, H.; Das, L.K.; Sud, S.K. Method for automated assessment of potholes, cracks and patches from road surface video clips. Procedia Soc. Behav. Sci. 2013, 104, 312–321. [Google Scholar]
- Kim, T.; Ryu, S.-K. System and Method for Detecting Potholes based on Video Data. J. Emerg. Trends Comput. Inf. Sci. 2014, 5, 703–709. [Google Scholar]
- Muslim, M.; Sulistyaningrum, D.; Setiyono, B. Detection andcounting potholes using morphological method from road video. AIP Conf. Proc. 2020, 2242, 030011. [Google Scholar]
- Lin, J.; Liu, Y. Potholes detection based on svm in the pavement distress image. In Proceedings of the 2010 Ninth International Symposium on Distributed Computing and Applications to Business, Engineering and Science, Hong Kong, China, 10–121 August 2010. [Google Scholar]
- Yousaf, M.H.; Azhar, K.; Murtaza, F.; Hussain, F. Visual analysis of asphalt pavement for detection and localization of potholes. Adv. Eng. Inform. 2018, 38, 527–537. [Google Scholar] [CrossRef]
- Hoang, N.-D. An artificial intelligence method for asphalt pavement pothole detection using least squares support vector machine and neural network with steerable filter-based feature exteraction. Adv. Civ. Eng. 2018, 2018, 7419058. [Google Scholar] [CrossRef] [Green Version]
- Hoang, N.-D.; Huynh, T.-C.; Tran, V.-D. Computer Vision-Based Patched and Unpatched Pothole Classification Using Machine Learning Approach Optimized by Forensic-Based Investigation Metaheuristic. Complexity 2021, 2021, 3511375. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, a.H. Road Damage Detection Using Deep Neural Networks with Images Captured through a Smartphone. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Kotha, M.; Chadalavada, M.; Karuturi, S.H.; Venkataraman, H. PotSense: Pothole Detection on Indian Roads using Smartphone Sensors. In Proceedings of the 1st ACM Workshop on Autonomous and Intelligent Mobile Systems, Bangalore, India, 11 January 2020. [Google Scholar]
- Baek, K.; Byun, Y.; Song, H. Pothole detection using machine learning. Adv. Sci Technol. Lett. 2018, 150, 151–155. [Google Scholar]
- Dharneeshkar, J.; Aniruthan, S.; Karthika, R.; Parameswaran, L. Deep Learning based Detection of potholes in Indian roads using YOLO. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020. [Google Scholar]
- Shaghouri, A.A.; Alkhatib, R.; Berjaoui, S. Real-Time Pothole Detection Using Deep Learning. arXiv 2021, arXiv:2107.06356. [Google Scholar]
- Silvister, S.; Komandur, D.; Kokate, S.; Khochare, A.; More, U.; Musale, V.; Joshi, A. Deep learning approach to detect potholes in real-time using smartphone. In Proceedings of the 2019 IEEE Pune Section International Conference (PuneCon), Pune, India, 16–19 December 2019. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Joffe, S.; Shlens, J.; Wojan, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ping, P.; Yang, X.; Gao, Z. A Deep Learning Approach for Street Pothole Detection. In Proceedings of the IEEE Sixth International Conference on Big Data Computing Service and Applications, Oxford, UK, 3–6 August 2020. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Siddique, J.M.; Ahmed, K.R. Deep Learning Technologies to Mitigate Deer-Vehicle Collisions. In Deep Learning and Big Data for Intelligent Transportation; Springer Studies in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 945. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef] [Green Version]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-Target Recognition of Bananas and Automatic Positioning for the Inflorescence Axis Cutting Point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef]
- Cao, X.; Yan, H.; Huang, Z.; Ai, S.; Xu, Y.; Fu, R.; Zou, X. A Multi-Objective Particle Swarm Optimization for Trajectory Planning of Fruit Picking Manipulator. Agronomy 2021, 11, 2286. [Google Scholar] [CrossRef]
- Ahmed, K.R. Parallel Dilated CNN for Detecting and Classifying Defects in Surface Steel Strips in Real-Time. In IntelliSys2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Li, L.; He, Y. High-accuracy multi-camera reconstruction enhanced by adaptive point cloud correction algorithm. Opt. Lasers Eng. 2019, 122, 170–183. [Google Scholar] [CrossRef]
- Hautakangas, H.; Nieminen, J. Data Mining for Pothole Detection Pro Gradu Seminar. Available online: https://slidetodoc.com/data-mining-for-pothole-detection-pro-gradu-seminar/ (accessed on 22 November 2021).
- Liao, P.S.; Chen, T.S.; Chung, P.C. A fast algorithm for multilevel thresholding. J. Inf. Sci. Eng. 2001, 17, 713–727. [Google Scholar]
- Matt, G.; Golub, H.; Von Matt, U. Quadratically constrained least squares and quadratic problems. Numer. Math. 1991, 59, 561–580. [Google Scholar]
- Ai, X.; Gao, Y.; Rarity, J.G.; Dahnoun, N. Obstacle detection using u-disparity on quadratic road surfaces. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Umbaugh, S.E. Digital Image Processing and Analysis: Human and Computer Vision Applications with CVIP Tools, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Ouma, Y.O.; Hahn, M. Pothole detection on asphalt pavements from 2D-colour pothole images using fuzzy c-means clustering and morphological reconstruction. Autom. Constr. 2017, 83, 196–211. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.; Ryu, S.-K. Intelligent compaction terminal system for asphalt pavement in Korea. J. Emerg. Trends Comput. Inform. Sci. 2015, 6, 154–158. [Google Scholar]
- Ryu, S.-K.; Kim, T.; Kim, Y.-R. Image-based pothole detection system for its service and road management system. Math. Probl. Eng. 2015, 2015, 968361. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Srivastava, S.; Divekar, A.V.; Anilkumar, C.; Naik, I.; Kulkarni, V.; Pattabiraman, V. Comparative analysis of deep learning image detection algorithms. J. Big Data 2021, 8, 66. [Google Scholar] [CrossRef]
- Nguyen, N.-D.; Do, T.; Ngo, T.D.; Le, D.-D. An Evaluation of Deep Learning Methods for Small Object Detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Deng, S.L.W. Very deep convolutional neural network-based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of theComputer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G. “Yolov5” LIC, Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 12 January 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lin, T.; Dollár, P.; Girshic, R.; Hariharan, K.H.B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206v1. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Roeder, L. Netron App Github. 2021. Available online: https://github.com/lutzroeder/netron (accessed on 27 November 2021).
- Bradski, G. The OpenCV Library. Dr. Dobbs J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Ketkar, N. Introduction to PyTorch. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 195–208. [Google Scholar]
- Kirk, D. Nvidia cuda software and gpu parallel computing architecture. In Proceedings of the 6th International Symposium on Memory Management—ISMM ’07, Montreal, QC, Canada, 21–22 October 2007. [Google Scholar]
- Oliphant, T.E. A Guide to NumPy, 2nd ed.; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2015. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- MakeML. MakeML: Potholes Dataset. Available online: https://makeml.app/datasets/potholes (accessed on 15 October 2021).
- Chitholian, A.R. Roboflow: Potholes Dataset. Available online: https://public.roboflow.com/object-detection/pothole (accessed on 15 October 2021).
- Lin, T. Labelimg. 2021. Available online: https://github.com/tzutalin/labelImg (accessed on 1 May 2021).
- Chen, X.-W.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Limitations |
|---|---|
| Sensor-based [8,9,10,11,12] |
|
| 3D reconstruction Laser [13,14,15], Stereo vision [16,17,18,19] |
|
| Image processing Images [21,22,23,24] Videos [21,25,26,27,28] |
|
| Model-based [29,30,31,32,33,34,35,36,37] Machine learning |
|
| Deep learning |
|
| Parameters | YOLOv5 | Faster R-CNN | ||
|---|---|---|---|---|
| ResNet50 (FPN) | VGG16, MVGG16 | MobileNetv2, InceptionV3 | ||
| Batch Size | YL = 8, Ym, Ys = 16 | 2 | 2 | 2 |
| Epochs | 1200 | 100 | 100 | 100 |
| Learning Rate | 0.0032 | 0.005 | 0.0001 | 0.0001 |
| Optimizer | SGD | SGD | Adam | Adam |
| Anchor Sizes | Dynamic | 32, 64, 128, 256, 512 | 8, 16, 32, 64, 128, 256, 512 | 8, 16, 32, 64, 128, 256, 512 |
| Metrics | YOLOv5 | Faster R-CNN [43] | ||||||
|---|---|---|---|---|---|---|---|---|
| Yl | Ym | YS | ResNet50 (FPN) | VGG16 | MVGG16 | Mobile-Net V2 | Inception V3 | |
| Precision (P) | 86.43% | 86.96% | 76.73% | 91.9% | 69.8% | 81.4% | 63.1% | 72.3% |
| Training Loss | 0.015 | 0.017 | 0.020 | 0.065 | 0.226 | 0.136 | 0.209 | 0.194 |
| Mean Average Precision (mAP@0.5–0.95) | 63.43% | 61.54% | 58.9% | 64.12% | 35.3% | 45.4% | 30.5% | 32.3% |
| Inference speed: Image resolution (1774 × 2365) | 0.014 s | 0.012 s | 0.009 s | 0.098 s | 0.114 s | 0.047 s | 0.036 s | 0.052 s |
| Inference speed: Image resolution (204 × 170) | 0.018 s | 0.013 s | 0.009 s | 0.065 s | 0.119 s | 0.052 s | 0.032 s | 0.056 s |
| Training time/epoch | 26 s | 16 s | 12 s | 124 s | 173 s | 105 s | 80 s | 95 s |
| Total training time | 31,200 s | 19,200 s | 14,400 s | 12,400 s | 17,300 s | 10,500 s | 8000 s | 9500 s |
| Model Size (MB) | 95.3 | 43.3 | 14.8 | 165.7 | 175.5 | 134.5 | 329.8 | 417.2 |
| YOLOv5 (Ys) | Faster R-CNN with MVGG16 | YOLOR- P6 | YOLOR- W6 | |
|---|---|---|---|---|
| Training (batch size, epochs, learning rate) | (16, 1200, 0.0032) | (2, 100, 0.0001) | (8, 1200, 0.01) | (8, 1200, 0.01) |
| Training Loss | 0.020 | 0.136 | 0.0170 | 0.015 |
| mAP@0.5-0.95 | 58.9% | 45.4% | 43.2% | 44.6% |
| Inference speed: Image resolution (1774 × 2365) | 0.009 s | 0.047 s | 0.03 s | 0.032 s |
| Inference speed: Image resolution (204 × 170) | 0.009 s | 0.052 s | 0.03 s | 0.032 s |
| Model Size (MB) | 14.8 | 134.5 | 291.8 | 624.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, K.R. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors 2021, 21, 8406. https://doi.org/10.3390/s21248406
Ahmed KR. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors. 2021; 21(24):8406. https://doi.org/10.3390/s21248406
Chicago/Turabian StyleAhmed, Khaled R. 2021. "Smart Pothole Detection Using Deep Learning Based on Dilated Convolution" Sensors 21, no. 24: 8406. https://doi.org/10.3390/s21248406
APA StyleAhmed, K. R. (2021). Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors, 21(24), 8406. https://doi.org/10.3390/s21248406