
Human Segmentation and Tracking Survey on Masks for MADS Dataset



Abstract
:1. Introduction
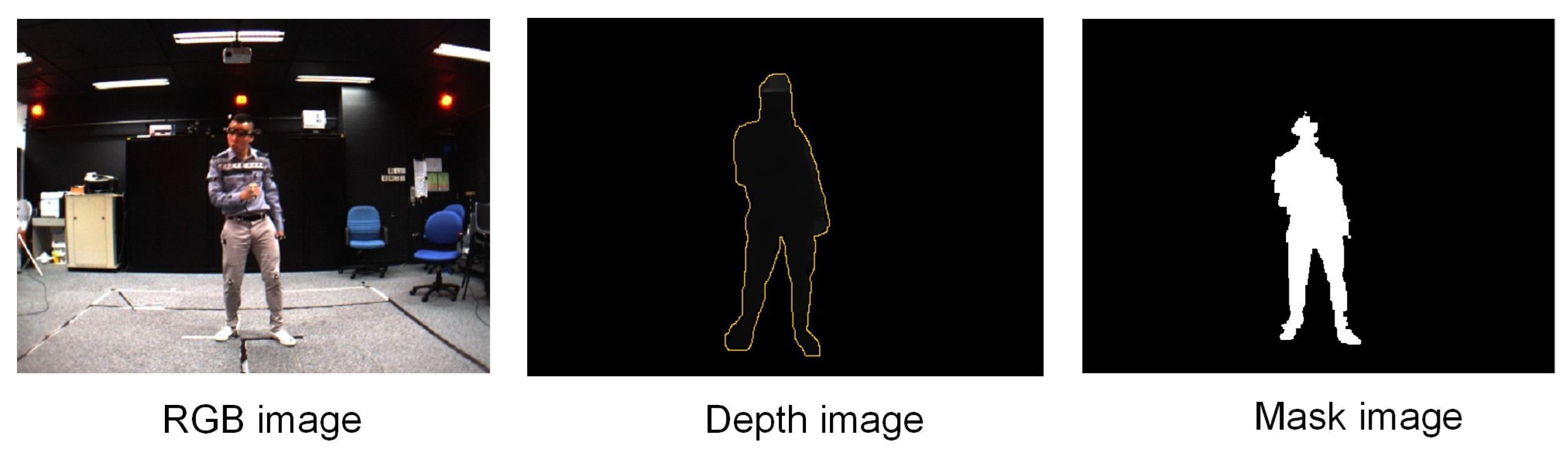
- We manually prepared human masks for nearly 28 k images captured from a single-view. The marking process was performed using the interactive-segmentation tool (http://web.archive.org/web/20110827170646/, http://kspace.cdvp.dcu.ie/public/interactive-segmentation/index.html (accessed on 18 April 2021)).
- We summarised significant studies on human segmentation and human tracking in RGB images, in which we focus on survey studies that use CNNs for human segmentation and tracking in video. Our survey process is based on methods, datasets, evaluations, and metrics for human segmentation and human tracking. We ultimately analyze the challenges during the process. We also refer to the implementation or the source code path of each study. In particular, we investigate the challenges and results in human segmentation and human tracking in images and video.
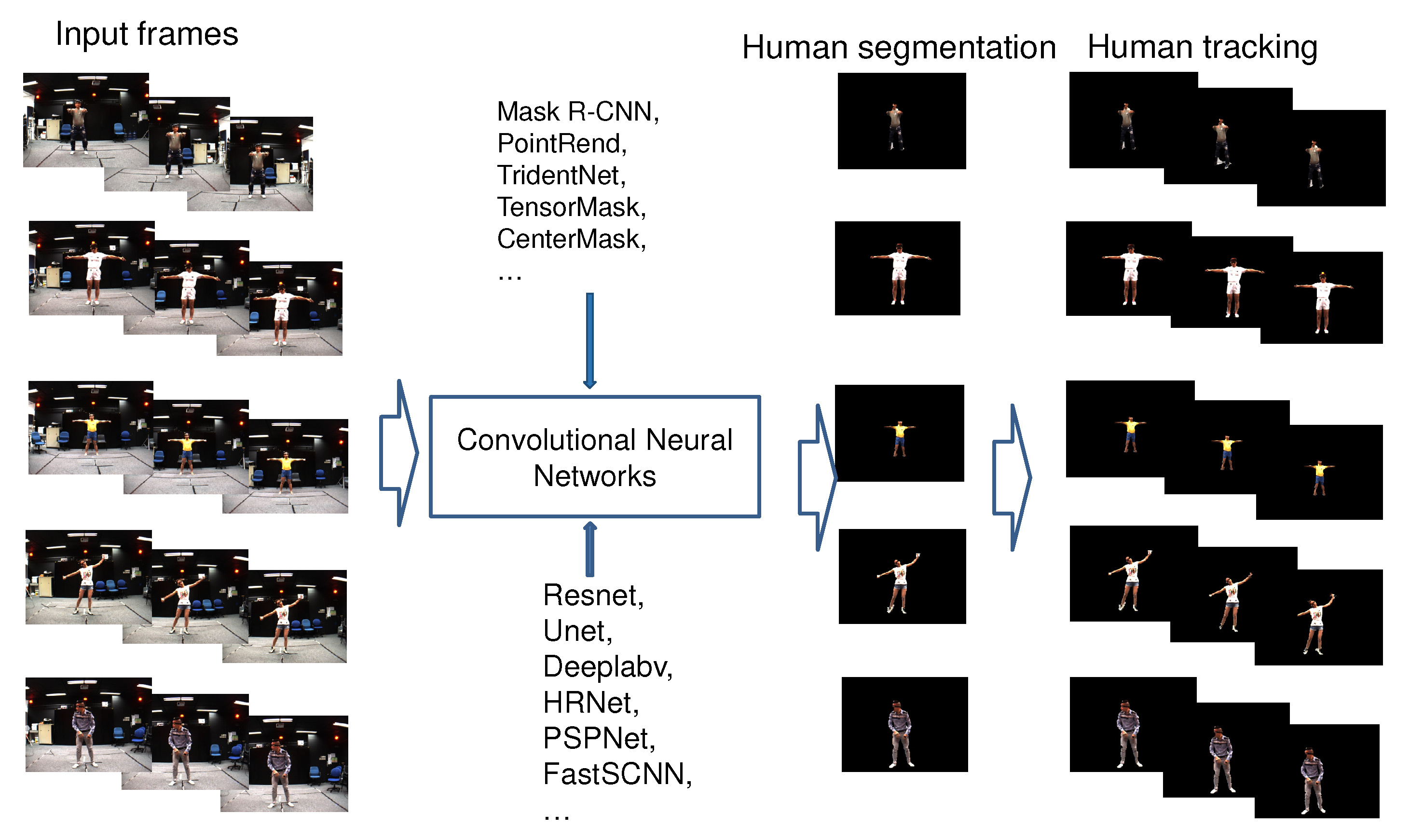
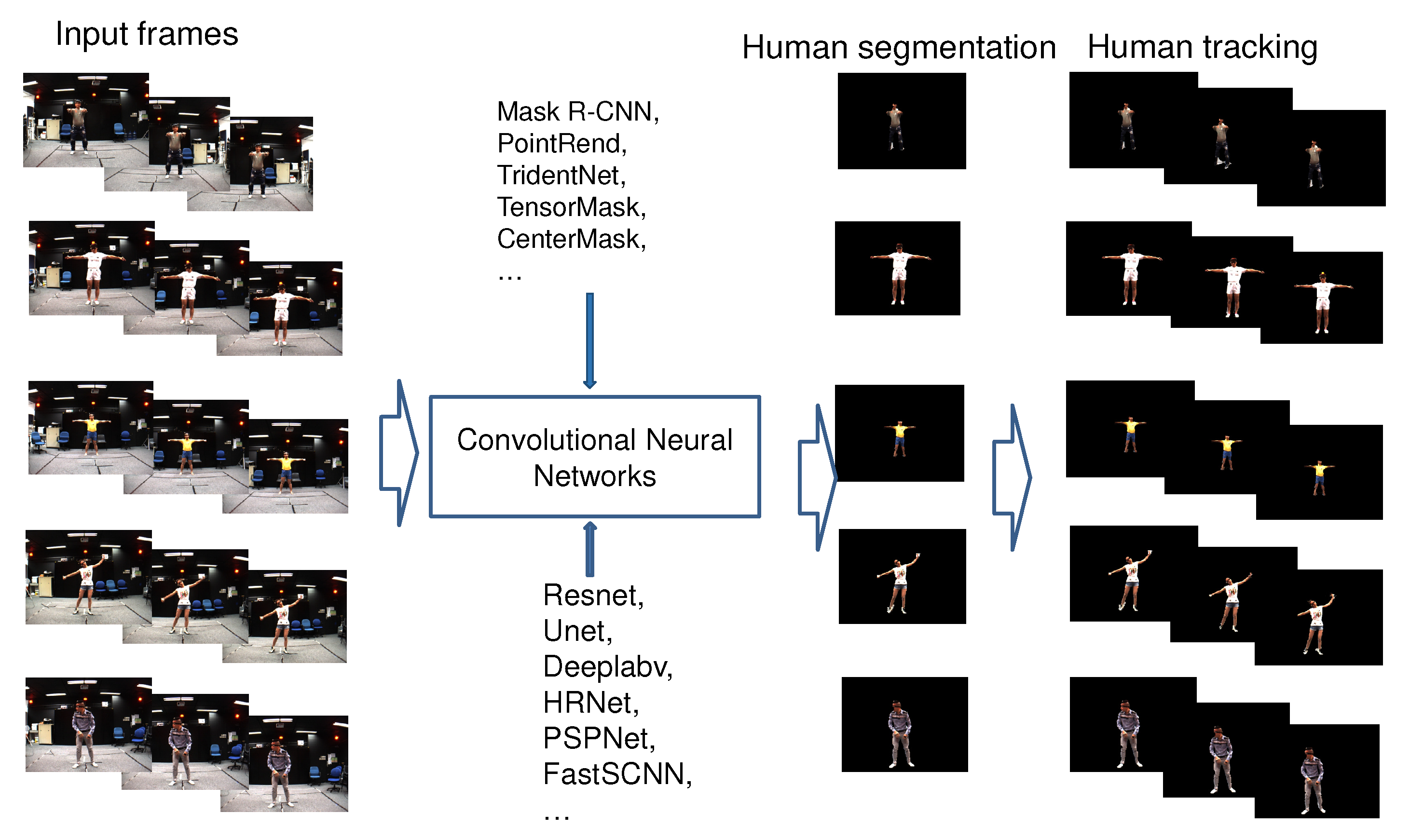
- We fine-tuned a set of parameters of the recently published CNNs (Mask R-CNN, PointRend, TridentNet, TensorMask, CenterMask, etc.) to retrain the model for human segmentation and tracking on the video that was captured from single-views of the MADS dataset, as illustred in Figure 1. The data of the MADS dataset was divided into different ratios for training and evaluation.
- We evaluated the results of human segmentation in images based on the retrained CNN models (Mask R-CNN, PointRend, TridentNet, TensorMask, CenterMask) according to the data rates of the MADS dataset. We used the most significant CNNs in recent years for object segmentation.
2. Related Works
3. Human Segmentation and Tracking by CNNs—Survey
3.1. CNN-Based Human Segmentation
3.1.1. Methods
3.1.2. Datasets, Metrics and Results
3.1.3. Discussions
3.2. CNN-Based Human Tracking
3.2.1. Methods
3.2.2. Datasets, Metrics and Results
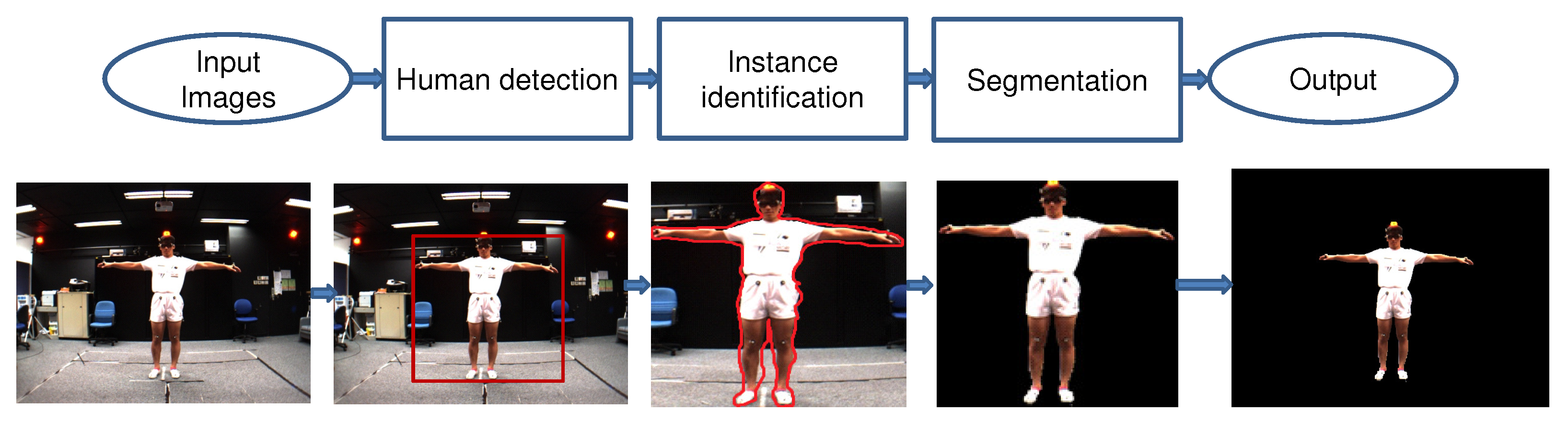
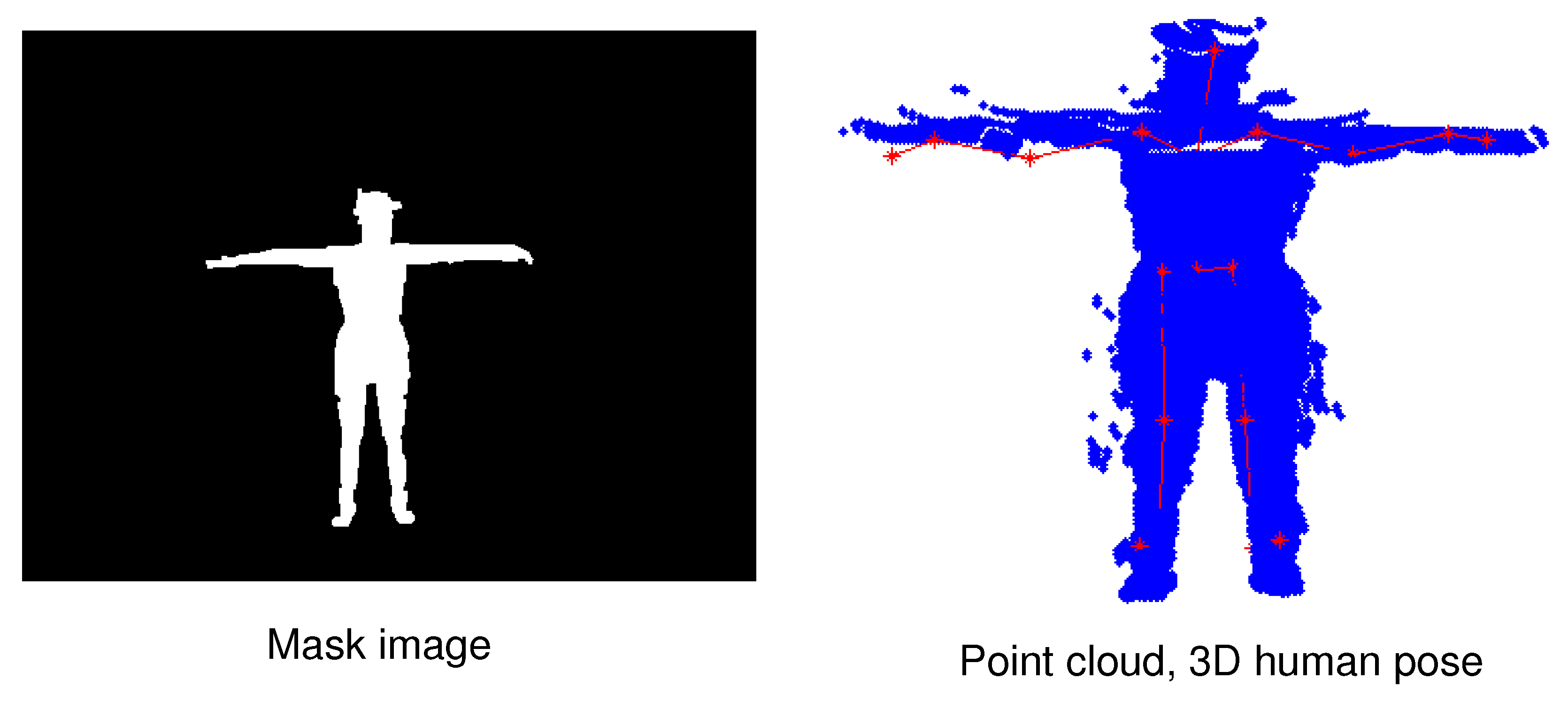
4. Human Mask of MADS Dataset
5. Human Segmentation and Tracking of MADS Dataset
5.1. Methods
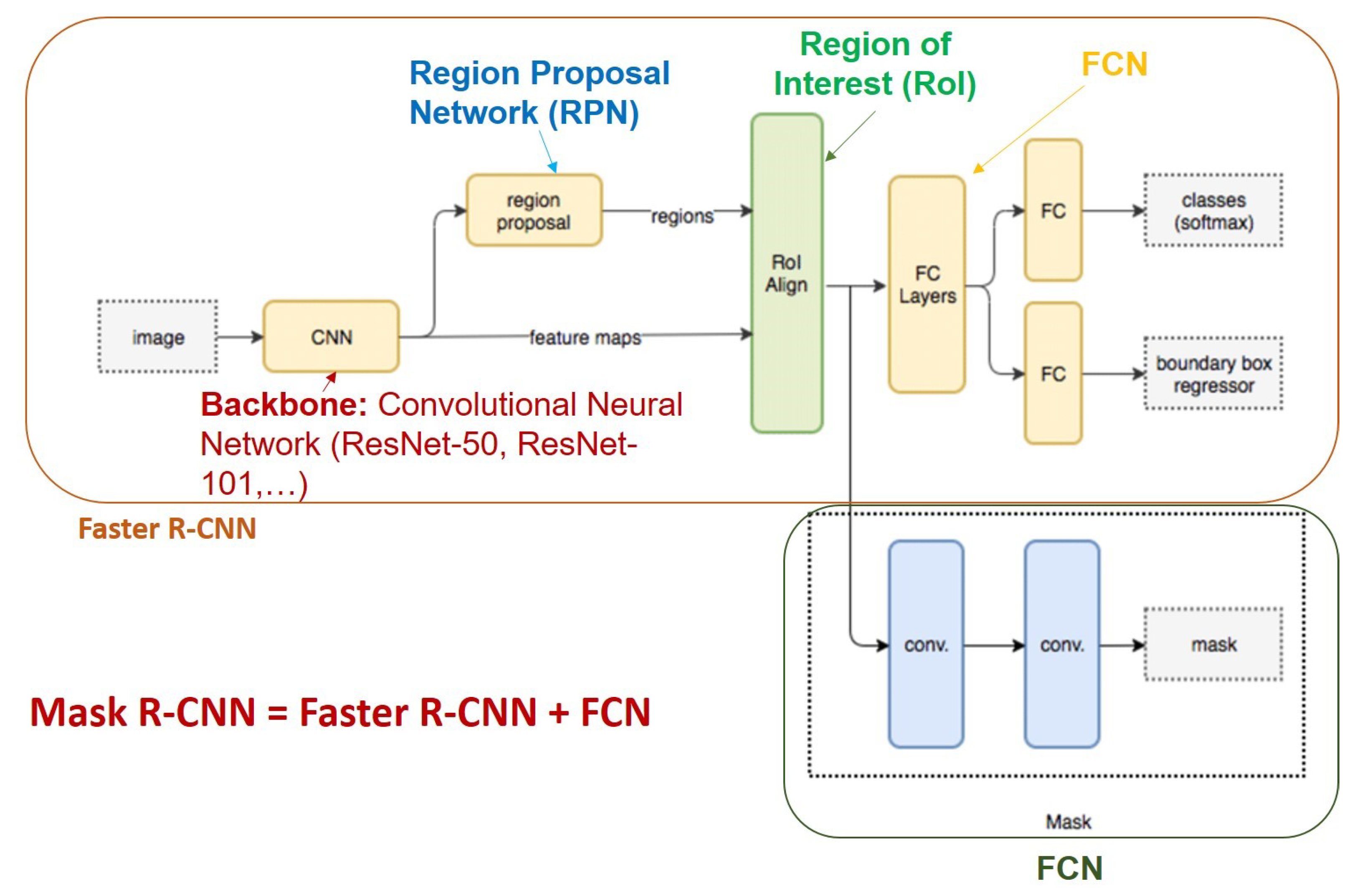
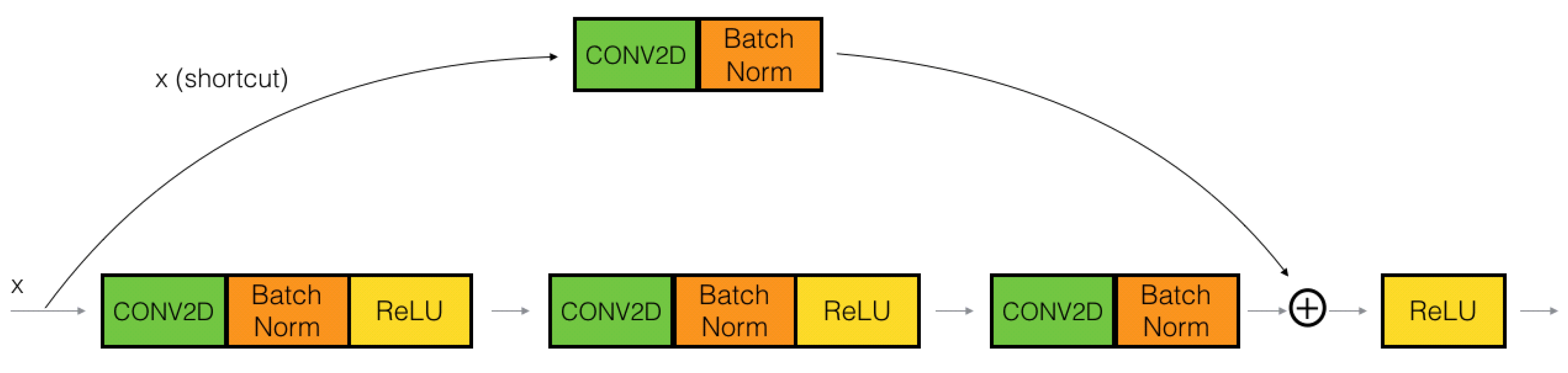
- Mask R-CNN [40] is an improvement of Faster R-CNN [2] for image segmentation at the pixel level. The operation of Mask R-CNN for human instance segmentation does the following several steps.Backbone Model: Using ConvNet like Resnet to extract human features from the input image.Region Proposal Network (RPN): The model uses the extracted feature applied to the RPN network to predict whether the object is in that area or not. After this step, bounding boxes at the possible areas of objects from the prediction model will be obtained.Region of Interest (RoI): The bounding boxes from the human detection areas will have different sizes, so through this step, all those bounding boxes will be merged to a certain size at 1 person. These regions are then passed through a fully connected layer to predict the layer labels and bounding boxes. The gradual elimination of bounding boxes through the calculation of the IOU. If the IOU is greater than or equal to 0.5 then be taken into account else be discarded.Segmentation Mask: Mask R-CNN adds the third branch to predict the person’s mask parallel to the current branches. Mask detection is a Fully-Connected Network (FCN) applied to each RoI. The architecture of the Mask-RCNN is illustrated in Figure 6.In this paper, we use Mask-RCNN’s code developed in [41]. The backbone model used is ResNet-50 and the pre-trained weights is“COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml”.It is trained with ResNet-50-FPN on COCO trainval35k takes 32 h in our synchronized 8-GPU implementation (0.72 s per 16-image mini-batch) [40]. The code that we used for training, validation, testing is shared under the link (https://github.com/duonglong289/detectron2 (accessed on 10 June 2021)).
- PointRend [49]: PointRend is an enhancement of the Mask R-CNN for human instance and human semantic segmentation. This network only differs from Mask R-CNN in the prediction step on bounding-boxes (FCN), Mask R-CNN [40] performs the coarse prediction on a low-resolution () grid for instance segmentation, the grid is not irrespective of object size. However, it is not suitable for large objects, it generates undesirable “blobby” output that over smooths the fine-level details of large objects. PointRend predicts on the high-resolution output grid (), to avoid computations over the entire high-resolution grid. PointRend suggests 3 strategies: choose a small number of real-value points to make predictions, extract features of selected points, a small neural network trained to predict a label from this point-wise feature representation of a point head. In this paper, the pre-trained weights that we use is“InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml”.That means the backbone we use is the ResNet-50. It is trained on the COCO [61] dataset with train2017 (∼118 k images). The code that we used for training, validation, testing is shared in the link (https://github.com/duonglong289/detectron2/tree/master/projects/PointRend (accessed on 15 June 2021)).
- TridentNet [51]: TridentNet is proposed for human detection by bounding-box on images that are based on the start-of-the-art Faster R-CNN. TridentNet can improve the limitations of two groups of networks for object detection (one-stage methods: YOLO, SSD, and two-stage methods: Faster R-CNN, R-FCN). TridentNet generates scale-specific feature maps with a uniform representational power for training with multiple branches; trident blocks share the same parameters with different dilation rates. TridentNet training with ResNet-50 backbone on 8 GPUs, the pre-trained weights initialized in file “tridentnet_fast_R_50_C4_1x.yaml”. The code that we used for training, validation, testing is shared at the link (https://github.com/duonglong289/detectron2/tree/master/projects/TridentNet (accessed on 16 June 2021)).
- TensorMask [50]: TensorMask is an improvement of Mask R-CNN to use structured 4D tensors ((V, U) represent relative mask position; (H, W) represent the object position) to represent mask image content in a set of densely sliding windows. The dense mask predictor of TensorMask extends the original dense bounding box predictor of Mask R-CNN. TensorMask performs multiclass classification in parallel to mask prediction. The code we use has the pre-trained weights initialized in the file “tensormask_R_50_FPN_1x.yaml” and the ResNet-50 backbone on 8 GPUs are used. The code that we used for training, validation, testing is shared in the link (https://github.com/duonglong289/detectron2/tree/master/projects/TensorMask (accessed on 16 June 2021)).
- CenterMask [52]: CenterMask is an improvement of Mask R-CNN. During the implementation of Mask R-CNN, Centermask added a novel spatial attention-guided mask (SAG-Mask) branch to anchor-free one stage object detector (FCOS), the SAG-Mask branch predicts a segmentation mask on each box with the spatial attention the map that helps to focus on informative pixels and suppress noise. Although, in the present paper [52] used the backbone network VoVNetV2 based on VoVNet [55] to ease optimization and boosts the performance, that shows better performance and faster speed than ResNet [74] and DenseNet [75]. In this paper, we still use the pre-trained weights initialized in file “centermask_R_50_FPN_1x.yaml” The code that we used for training, validation, testing is shared in the link (https://github.com/duonglong289/centermask2 (accessed on 16 June 2021)).
5.2. Experiments
5.3. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Liu, Z.; Zhou, L.; Leung, H.; Chan, A.B. Martial Arts, Dancing and Sports dataset: A Challenging Stereo and Multi-View Dataset for 3D Human Pose Estimation. Image Vis. Comput. 2017, 61, 22–39. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Xu, Y.; Zhou, X.; Chen, S.; Li, F. Deep learning for multiple object tracking: A survey. IET Comput. Vis. 2019, 13, 411–419. [Google Scholar] [CrossRef]
- Tsai, J.-K.; Hsu, C.-C.; Wang, W.-Y.; Huang, S.-K. Deep Learning-Based Real-Time Multiple-Person Action Recognition System. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef]
- Yao, R.; Lin, G.; Xia, S.; Zhao, J.; Zhou, Y. Video object segmentation and tracking: A survey. arXiv 2019, arXiv:1904.09172. [Google Scholar] [CrossRef]
- Xu, J.; Wang, R.; Rakheja, V. Literature Review: Human Segmentation with Static Camera. arXiv 2019, arXiv:1910.12945v1. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 1440–1448. [Google Scholar] [CrossRef]
- Wang, H. Detection of Humans in Video Streams Using Convolutional Neural Networks. In Degree Project Computer Science and Engineering; KTH, School of Computer Science and Communication (CSC): Stockholm, Sweden, 2017. [Google Scholar]
- Jonathan, L.; Evan, S.; Trevor, D. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Handbook of approximation algorithms and metaheuristics. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Red HooK, NY, USA, 3–6 December 2012; pp. 1–1432. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Ciaparrone, G.; Luque Sánchez, F.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef] [Green Version]
- Renuka, J. Accuracy, Precision, Recall and F1 Score: Interpretation of Performance Measures. 2016. Available online: https://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/ (accessed on 4 January 2021).
- Zhang, W.; Shang, L.; Chan, A.B. A robust likelihood function for 3D human pose tracking. IEEE Trans. Image Process. 2014, 23, 5374–5389. [Google Scholar] [CrossRef]
- Liefeng, B.; Cristian, S. Twin Gaussian Processes for Structured Prediction. Int. J. Comput. Vis. 2010, 87, 28–52. [Google Scholar]
- Helten, T.; Baak, A.; Bharaj, G.; Muller, M.; Seidel, H.P.; Theobalt, C. Personalization and evaluation of a real-time depth-based full body tracker. In Proceedings of the 2013 International Conference on 3D Vision, Seattle, WA, USA, 1–29 July 2013; pp. 279–286. [Google Scholar] [CrossRef]
- Ye, M.; Shen, Y.; Du, C.; Pan, Z.; Yang, R. Real-time simultaneous pose and shape estimation for articulated objects using a single depth camera. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1517–1532. [Google Scholar] [CrossRef] [PubMed]
- Nicolas, B. Calibrating the Depth and Color Camera. 2018. Available online: http://nicolas.burrus.name/index.php/Research/KinectCalibration (accessed on 10 January 2018).
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand PointNet: 3D Hand Pose Estimation Using Point Sets. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8417–8426. [Google Scholar] [CrossRef]
- Moon, G.; Chang, J.; Lee, K.M. V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-Point Regression PointNet for 3D Hand Pose Estimation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Haque, A.; Peng, B.; Luo, Z.; Alahi, A.; Yeung, S.; Li, F.-F. Towards viewpoint invariant 3D human pose estimation. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Amsterdam, The Netherlands, 2016; Volume 9905, pp. 160–177. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Hu, L.; Deng, X.; Xia, S. Weakly Supervised Adversarial Learning for 3D Human Pose Estimation from Point Clouds. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1851–1859. [Google Scholar] [CrossRef] [PubMed]
- D’Eusanio, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. RefiNet: 3D Human Pose Refinement with Depth Maps. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2020. [Google Scholar]
- Zhang, Z.; Hu, L.; Deng, X.; Xia, S. A Survey on 3D Hand Skeleton and Pose Estimation by Convolutional Neural Network. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 144–159. [Google Scholar]
- Harshall, L. Understanding Semantic Segmentation with UNET. 2019. Available online: https://towardsdatascience.com/understanding-semantic-segmentation-with/-unet-6be4f42d4b47 (accessed on 4 January 2021).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zou, J.; He, K.; Sun, J. Accelerating Very Deep Convolutional Networks for Classification and Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1943–1955. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haque, M.F.; Lim, H.; Kang, D.S. Object Detection Based on VGG with ResNet Network. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; pp. 1–3. [Google Scholar]
- Hung, G.L.; Sahimi, M.S.B.; Samma, H.; Almohamad, T.A.; Lahasan, B. Faster R-CNN Deep Learning Model for Pedestrian Detection from Drone Images. In SN Computer Science; Springer: Singapore, 2020; Volume 1, pp. 1–9. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3305. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 379–387. [Google Scholar]
- Singh, M.; Basu, A.; Mandal, M.K. Human activity recognition based on silhouette directionality. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1280–1292. [Google Scholar] [CrossRef]
- Singh, M.; Mandai, M.; Basu, A. Pose recognition using the radon transform. Midwest Symp. Circuits Syst. 2005, 2005, 1091–1094. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870v3. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 14 June 2021).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Neverova, N.; Novotny, D.; Vedaldi, A. Correlated Uncertainty for Learning Dense Correspondences from Noisy Labels. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Guler, R.A.; Natalia Neverova, I.K. DensePose: Dense Human Pose Estimation In The Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-DeepLab. arXiv 2019, arXiv:1910.04751. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollár, P. Tensormask: A Foundation for Dense Object Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. PersonLab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, S.H.; Li, R.; Dong, X.; Rosin, P.; Cai, Z.; Han, X.; Yang, D.; Huang, H.; Hu, S.M. Pose2Seg: Detection free human instance segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 889–898. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 14 June 2021).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2010 (VOC2010) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2010/workshop/index.html (accessed on 15 June 2021).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 16 June 2021).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Zurich, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sanchez, S.; Romero, H.; Morales, A. A review: Comparison of performance metrics of pretrained models for object detection using the TensorFlow framework. In Proceedings of the IOP Conference Series Materials Science and Engineering, Chennai, India, 30–31 October 2020. [Google Scholar]
- Watada, J.; Musa, Z.; Jain, L.C.; Fulcher, J. Human tracking: A state-of-art survey. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; Volume 6277, pp. 454–463. [Google Scholar] [CrossRef]
- Chahyati, D.; Fanany, M.I.; Arymurthy, A.M. Tracking People by Detection Using CNN Features. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2017; Volume 124, pp. 167–172. [Google Scholar] [CrossRef]
- Laplaza Galindo, J. Tracking and Approaching People Using Deep Learning Techniques. Master’s Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2018. [Google Scholar]
- Khan, G.; Tariq, Z.; Usman Ghani Khan, M. Multi-Person Tracking Based on Faster R-CNN and Deep Appearance Features. In Visual Object Tracking with Deep Neural Networks; IntechOpen: London, UK, 2019; pp. 1–23. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A. Deep Cosine Metric Learning for Person Re-identification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 748–756. [Google Scholar] [CrossRef] [Green Version]
- Haq, E.U.; Huang, J.; Li, K.; Haq, H.U. Human detection and tracking with deep convolutional neural networks under the constrained of noise and occluded scenes. Multimed. Tools Appl. 2020, 79, 30685–30708. [Google Scholar] [CrossRef]
- Leal-Taixe, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
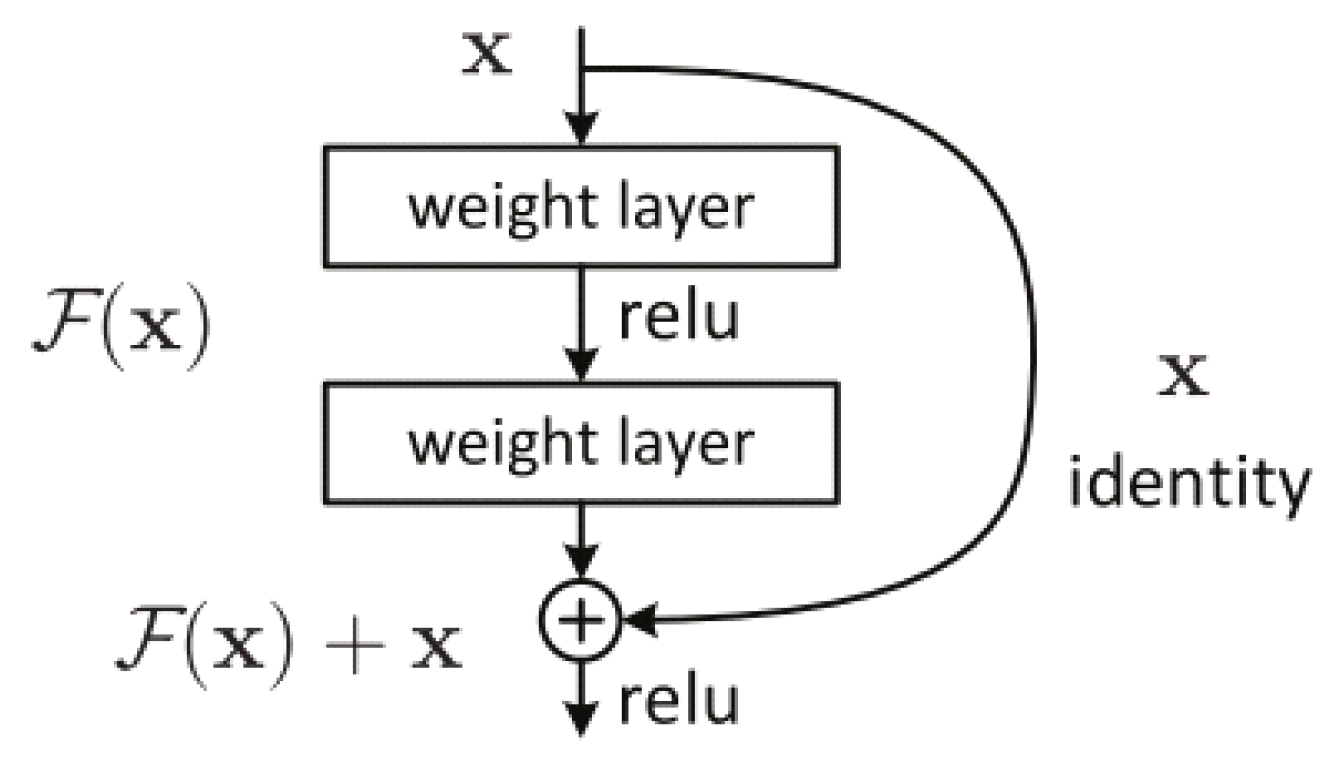
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Amsterdam, The Netherlands, 2016; Volume 9908, pp. 630–645. [Google Scholar] [CrossRef] [Green Version]
- Hieu, N.V.; Hien, N.L.H. Recognition of Plant Species using Deep Convolutional Feature Extraction. Int. J. Emerg. Technol. 2020, 11, 904–910. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement/ Dataset/Methods | mAP (Mean Average Precision) (%) | ||||||
|---|---|---|---|---|---|---|---|
| PV 2007 | PV 2010 | PV 2012 | COCO (Year) | IC 2013 | IC 2014 | IC 2015 | |
| R-CNN [31] | 58.7 | 58.1 | - | - | 31.4 | - | - |
| SPPnet [32] | 58.9 | - | - | - | - | 35.11 | - |
| VGG vs. Fast R-CNN [15] | 66.1 | - | - | - | - | - | - |
| VGG vs. ResNet [34] | - | - | 93.7 | - | - | - | - |
| VGG 16 [15] | 89.3 | - | 89 | - | - | - | - |
| Fast R-CNN [11] | 69.9 | 72.7 | 72.0 | 35.9 (2015) | - | - | 42.9 |
| Faster R-CNN [2] | 78.8 | - | 75.9 | 42.7 (2015) | - | - | 32.6 |
| YOLO v1 [63] | 63.4 | - | 63.5 | - | - | - | - |
| YOLO v2 [4] | 78.6 | - | 81.3 | 21.6 (2015) | |||
| YOLO v3 [5] | - | - | - | 60.6 (2015) | - | - | - |
| YOLO v4 [6] | - | - | - | 65.7 (2017) | - | - | - |
| SSD300 [3] | 74.3 | - | 79.4 | 23.2 (2015) | - | - | - |
| SSD500 [3] | 76.8 | 83.3 | 26.8 (2015) | - | - | - | |
| Measurement/ Dataset/Methods | Procesing Time (fps) |
|---|---|
| PV 2007 | |
| R-CNN [31] | 0.076 |
| SPPnet [32] | 0.142 |
| VGG vs. Fast R-CNN [15] | 7 |
| VGG vs. ResNet [34] | 5 |
| Fast R-CNN [11] | 0.5 |
| Faster R-CNN [2] | 7 |
| YOLO v1 [63] | 45 |
| YOLO v2 [4] | 40 |
| YOLO v3 [5] | 45 |
| YOLO v4 [6] | 54 |
| SSD300 [3] | 46 |
| SSD500 [3] | 19 |
| Measurement/ Method/ | Backbone | ||
|---|---|---|---|
| Mask R-CNN [40] | Resnet50-fpn | 43.3 | 64.8 |
| PersonLab [56] | Resnet101 | 47.6 | 59.2 |
| PersonLab [56] | Resnet101(ms scale) | 49.2 | 62.1 |
| PersonLab [56] | Resnet152 | 48.3 | 59.5 |
| PersonLab [56] | Resnet152(ms scale) | 49.7 | 62.1 |
| Pose2Seg [57] | Resnet50-fpn | 49.8 | 67.0 |
| Pose2Seg(GTKpt) [57] | Resnet50-fpn | 53.9 | 67.9 |
| Measurement/ CNNs | Backbone Network | IS | SS | |||||
|---|---|---|---|---|---|---|---|---|
| CenterMask | VoVNetV2-99 | 38.3 | 43.5 | 25.8 | 47.8 | 57.3 | √ | - |
| TridentNet | ResNet-101 | - | 42.0 | 24.9 | 47.0 | 56.9 | - | √ |
| TensorMask | ResNet-101-FPN | - | 37.1 | 17.4 | 39.1 | 51.6 | √ | - |
| PointRend (IS) | X101-FPN | 40.9 | - | - | - | - | √ | √ |
| Panoptic-DeepLab | Xception-71 | 39.0 | - | - | - | - | √ | √ |
| Measurement/Model | MOTA (MOT Accuracy) [%] | MOTP (MOT Precision) [%] |
|---|---|---|
| SORT [73] | 59.8 | 79.6 |
| Deep SORT [69] | 61.4 | 79.1 |
| Faster RCNN + DAF [68] | 75.2 | 81.3 |
| Faster RCNN [66] (Ecdist) | 61.26 | - |
| Faster RCNN [66] (SNN) | 47.38 | - |
| Measurement/Model | Processing Time [ms] |
|---|---|
| ResNet-34 | 52.09 |
| ResNet-50 | 104.13 |
| ResNet-101 | 158.35 |
| ResNet-152 | 219.06 |
| ResNet-30 | 48.93 |
| Dataset | Model | Accuracy [%] |
|---|---|---|
| INRIA dataset | VGG-16 | 96.4 |
| CNNs + DA [34] | 98.8 | |
| PPSS dataset | VGG-16 | 94.3 |
| CNNs + DA [34] | 98.3 |
| Ratios (%) | The Number of Frames for Training | The Number of Frames for Testing |
|---|---|---|
| rate_50_50 | 14,414 | 14,414 |
| rate_60_40 | 17,047 | 11,492 |
| rate_70_30 | 19,141 | 8616 |
| rate_80_20 | 21,473 | 5742 |
| CNN Model | Training/Testing Ratios (%) | (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| Mask R-CNN [40] | rate_50_50 | 59.25 | 71.45 | 65.82 | 7.22 | 86.85 | 86.80 |
| rate_60_40 | 59.12 | 72.02 | 65.29 | 7.18 | 86.45 | 86.22 | |
| rate_70_30 | 59.44 | 71.85 | 65.84 | 6.72 | 87.50 | 86.55 | |
| rate_80_20 | 59.96 | 71.98 | 66.35 | 7.16 | 88.04 | 86.58 | |
| PointRend [49] | rate_50_50 | 63.25 | 78.98 | 72.19 | 8.03 | 67.89 | 84.71 |
| rate_60_40 | 64.58 | 79.81 | 72.87 | 9.64 | 68.84 | 85.78 | |
| rate_70_30 | 67.90 | 81.40 | 74.30 | 13.82 | 72.11 | 88.69 | |
| rate_80_20 | 66.67 | 80.91 | 73.53 | 11.29 | 71.74 | 87.52 | |
| TridentNet [51] | rate_50_50 | 61.17 | 70.84 | 65.89 | 6.42 | 91.39 | 88.77 |
| rate_60_40 | 55.50 | 71.80 | 66.25 | 0.75 | 50.81 | 79.66 | |
| rate_70_30 | 61.28 | 70.87 | 65.85 | 5.71 | 91.53 | 88.86 | |
| rate_80_20 | 61.50 | 70.96 | 66.67 | 6.18 | 92.01 | 88.23 | |
| TensorMask [50] | rate_50_50 | 67.11 | 80.95 | 74.15 | 11.78 | 69.58 | 88.49 |
| rate_60_40 | 67.41 | 81.71 | 74.01 | 12.36 | 73.79 | 87.67 | |
| rate_70_30 | 64.37 | 79.81 | 72.38 | 7.93 | 67.09 | 85.74 | |
| rate_80_20 | 64.78 | 80.20 | 73.13 | 8.95 | 69.69 | 85.63 | |
| CenterMask [52] | rate_50_50 | 65.94 | 79.78 | 73.09 | 8.39 | 71.59 | 87.75 |
| rate_60_40 | 64.75 | 79.89 | 72.08 | 9.21 | 68.03 | 86.24 | |
| rate_70_30 | 65.40 | 79.36 | 71.57 | 6.77 | 68.72 | 87.95 | |
| rate_80_20 | 69.47 | 81.63 | 75.04 | 12.95 | 74.44 | 91.10 |
| CNN Model | Training/Testing Ratios (%) | (%) | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|---|---|
| PointRend [49] | rate_50_50 | 58.73 | 78.86 | 69.17 | 9.35 | 59.70 | 80.63 |
| rate_60_40 | 59.39 | 79.26 | 68.48 | 10.81 | 55.64 | 81.07 | |
| rate_70_30 | 62.66 | 81.23 | 70.70 | 14.11 | 60.39 | 83.55 | |
| rate_80_20 | 61.93 | 80.58 | 70.48 | 11.48 | 63.29 | 83.17 | |
| TensorMask [50] | rate_50_50 | 54.10 | 79.38 | 65.71 | 8.48 | 52.30 | 74.35 |
| rate_60_40 | 57.08 | 80.01 | 67.97 | 10.23 | 55.36 | 77.26 | |
| rate_70_30 | 47.71 | 77.97 | 55.07 | 5.88 | 38.55 | 69.53 | |
| rate_80_20 | 50.87 | 78.39 | 60.42 | 6.70 | 44.74 | 72.12 | |
| CenterMask [52] | rate_50_50 | 53.43 | 79.18 | 65.85 | 8.47 | 56.48 | 71.71 |
| rate_60_40 | 52.24 | 78.69 | 64.28 | 8.80 | 53.35 | 70.93 | |
| rate_70_30 | 52.67 | 78.96 | 64.60 | 7.19 | 54.36 | 71.27 | |
| rate_80_20 | 61.28 | 81.19 | 72.10 | 13.61 | 66.89 | 79.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, V.-H.; Scherer, R. Human Segmentation and Tracking Survey on Masks for MADS Dataset. Sensors 2021, 21, 8397. https://doi.org/10.3390/s21248397
Le V-H, Scherer R. Human Segmentation and Tracking Survey on Masks for MADS Dataset. Sensors. 2021; 21(24):8397. https://doi.org/10.3390/s21248397
Chicago/Turabian StyleLe, Van-Hung, and Rafal Scherer. 2021. "Human Segmentation and Tracking Survey on Masks for MADS Dataset" Sensors 21, no. 24: 8397. https://doi.org/10.3390/s21248397
APA StyleLe, V.-H., & Scherer, R. (2021). Human Segmentation and Tracking Survey on Masks for MADS Dataset. Sensors, 21(24), 8397. https://doi.org/10.3390/s21248397