Abstract
Detecting saliency in videos is a fundamental step in many computer vision systems. Saliency is the significant target(s) in the video. The object of interest is further analyzed for high-level applications. The segregation of saliency and the background can be made if they exhibit different visual cues. Therefore, saliency detection is often formulated as background subtraction. However, saliency detection is challenging. For instance, dynamic background can result in false positive errors. In another scenario, camouflage will result in false negative errors. With moving cameras, the captured scenes are even more complicated to handle. We propose a new framework, called saliency detection via background model completion (SD-BMC), that comprises a background modeler and a deep learning background/foreground segmentation network. The background modeler generates an initial clean background image from a short image sequence. Based on the idea of video completion, a good background frame can be synthesized with the co-existence of changing background and moving objects. We adopt the background/foreground segmenter, which was pre-trained with a specific video dataset. It can also detect saliency in unseen videos. The background modeler can adjust the background image dynamically when the background/foreground segmenter output deteriorates during processing a long video. To the best of our knowledge, our framework is the first one to adopt video completion for background modeling and saliency detection in videos captured by moving cameras. The F-measure results, obtained from the pan-tilt-zoom (PTZ) videos, show that our proposed framework outperforms some deep learning-based background subtraction models by 11% or more. With more challenging videos, our framework also outperforms many high-ranking background subtraction methods by more than 3%.
1. Introduction
High-level applications such as human motion analysis [1] and intelligent transportation system [2] demand the localization of targets in the video. For instance, in video surveillance, humans are detected for motion recognition. Vehicles are located in an intelligent transportation system. This foremost task can be achieved via saliency detection. Assuming that the background scene possesses invariant characteristics, a target is detected due to its deviated visual cues. One approach is to formulate the task as background/foreground segmentation. With the estimated background scene model, the foreground (i.e., saliency) is segmented by a pixelwise background subtraction algorithm. The foreground is defined as a region of interest that is not a part of the background. While it is usually a moving object, it may also stop suddenly. Therefore, the region outside the foreground such as the shadow is considered as the background. The background may have moving elements, but their motions are not of interest.
However, the two assumptions—invariant background and deviation of foreground—may be violated in some circumstances. For instances, background motion and illumination change can result in false detection (false positive). With the pre-generated background model, background pixels may be predicted as foreground pixels. This is a false positive (FP) error that is due to image feature(s) of the background pixel different from the background model. On the other hand, camouflage and intermittent object motion will result in missing detection. This false negative (FN) error is due to the fact that some foreground pixels may be erroneously identified as the background pixels if they have similar image feature(s) to the background model.
The saliency detection task becomes more challenging with the use of moving camera. The assumption of a static background is violated. Videos can be captured by a pan-tilt-zoom (PTZ) camera or free-moving (e.g., hand-held) camera. The pan and tilt camera motions can capture a broader vision field. Zooming can focus the region of interest with a higher resolution. While these camera motions are constrained, free-moving camera can perform any kind of motion without constraint. Systems that can handle such type of video are of interest. They demand sophisticated techniques for generating and maintaining the background model, as well as foreground segmentation.
Researchers have proposed various background subtraction algorithms. Many background subtraction methods are deterministic, i.e., background/foreground segmentation is achieved based on hand-crafted features. One earliest approach is to adopt statistical models [3,4]. Elgammal et al. [5] utilized kernel estimator to characterize the probability density function (pdf) of the background pixels. Some researchers have presented the survey on the background subtraction techniques [6,7]. Sobral and Vacavant [8] evaluated 29 background subtraction methods. In general, background subtraction comprises three main parts—background modeler, background/foreground classifier, and background updating.
Another approach is to use neural networks for saliency detection. Its cognitive power is made possible with the structure simulating complex connectivity of neurons. Maddalena and Petrosino [9] proposed Self Organizing Background Subtraction (SOBS). The background scene is modeled with the weights of the neurons. The network compares the current image frame with the background model and outputs pixelwise background/foreground classification. Recently, a popular approach is to develop deep learning models, such as convolutional neural network (CNN). The layered structure can accommodate multi-scale representation, with which image data are transformed and abstract features are extracted. Wang et al. [10] proposed a basic CNN model, with which multi-resolution CNN and cascaded CNN architectures were designed for object segmentation. Lim and Keles [11] proposed an encoder–decoder network for object segmentation. The encoder part is a triple CNN for multi-scale feature extraction. The concatenated feature map is fed to a transposed convolutional network in the decoder part. They [12] further proposed another model that uses feature pooling module on top of the encoder part.
In this paper, we propose a new framework, called saliency detection via background model completion (SD-BMC), that comprises a background modeler and a deep learning background/foreground segmentation network. Our framework can detect saliency in videos captured by moving camera. The results, obtained from the benchmark datasets, show that our proposed framework outperforms many high-ranking background subtraction models. Our contributions can be summarized as follows:
- Inspired by the filling of missing pixels via the inpainting technique, we adopt a video completion module for modeling the background scene. In order to generate a clean background frame, foreground objects will be substituted by the estimated background colors. Guided by the optical flow, the video completion module can generate good background model for video captured by moving camera, which is not possible for other existing methods.
- We adopt the BSUV-Net 2.0 [13] for background/foreground segmentation. Although the model is pre-trained with the CDNet [14] video dataset, it can also segment the foreground in unseen videos. However, most of the videos in CDNet are captured by static camera. Although BSUV-Net 2.0 is enhanced with more training videos of moving camera, we find that the model still produces many FP and FN errors. Therefore, we replace the background frame generation method of BSUV-Net 2.0 with our video completion-based background modeler.
- We propose a framework that comprises video completion-based background modeler and the enhanced BSUV-Net 2.0 foreground segmentation network. To thoroughly evaluate the new framework, we create our own video dataset with videos captured by PTZ camera and free-moving camera. The results show that our framework outperforms many high-ranking background subtraction models.
The paper is organized as follows. The related research studies on background subtraction, particularly with videos captured by moving camera, are reviewed in the following section. Section 3 elaborates our saliency detection framework. We compare our framework with other high-ranking background subtraction algorithms. Quantitative and visual results are presented in Section 4. Discussion is also made on the performance of all these methods. Finally, we draw the conclusion in Section 5.
2. Related Work
Many methods have been proposed for segmenting foreground in videos captured by stationary cameras. In this section, we review sophisticated methods that are proposed to handle videos captured by moving cameras. Moving cameras can be categorized into two types: constrained moving camera and freely moving camera. For instance, PTZ camera belongs to the first category. In the second category, examples are hand-held camera, smartphone or camera mounted on drones. Methods developed for constrained camera may not perform well with freely moving camera.
Hishinuma et al. [15] considered the camera small pan/tilt motion as translational. The translation amount is computed from the correlation of the FFT phase terms of stationary background blocks. The synthesized still background model is then used for foreground segmentation. In [16], camera motion is compensated by calculating the homography transformation between two image frames. Scene model, which is a panoramic background, is then generated from the motion compensated video. Foreground objects are detected by comparing the panoramic background with individual image frames of the video. Szolgay et al. [4] proposed a method for detecting moving objects in video taken by a wearable camera. Global camera motion is estimated first by a hierarchical block matching algorithm and then refined by a robust motion estimator. The foreground is identified as the difference between motion-compensated image frames. Tao and Ling [17] proposed a neural network for segmenting foreground in videos captured by PTZ cameras. Deep learning features are extracted by a pre-trained network. Homography matrix is estimated from previous image frames and current image frame with a semantic attention based deep homography estimator. The warped previous frames, current frames, and their features are fed into the fusion network for foreground mask prediction. Komagal and Yogameena [18] reviewed the methods and the datasets for foreground segmentation research with PTZ camera.
With the use of a freely moving camera, both background and foreground are changing. The assumption of background modeling may be violated. For instance, when background and foreground motions are similar, the background model is contaminated with foreground colors. In another scenario, inaccurate camera motion estimation will give rise to false positive errors. Yun et al. [19] proposed an adaptive scheme that can update the background model in accordance with the changes of background. The scheme compensates three types of change—background motion produced by moving camera, foreground motion, and illumination change. Knowing that an explicit camera motion model is not reliable, Sajid et al. [20] proposed an online framework such that both background and foreground models are continuously updated. Background motion is estimated with a low-rank approximation. Motion and appearance models are combined to produce the background/foreground classification. Zhu and Elgammal [21] proposed a multi-layered framework for background subtraction. In each layer, both motion and appearance model are estimated and used for foreground detection. A probability map is inferred by kernel density estimator [5]. Finally, a segmented foreground is generated from the multi-layered outputs by multi-label graph-cut. Chapel and Bouwmans [22] reviewed moving object detection methods with moving camera. They grouped methods into two categories in accordance with scene representation—single-plane and multi-plane. Methods in the first group may generate a panoramic background by image mosaics. Some methods detect moving objects via motion segmentation. Multi-plane approach estimates several planes (may be real or not) as scene representation. Matched feature points are located and eventually used for background/foreground classification.
We adopt the background-centric approach for saliency detection. Instead of modeling the background based on camera motion compensation, which may be inaccurate, we generate and update the background dynamically via video completion and continuous monitoring of foreground segmentation result. Our background modeler, based on the optical flow information, can generate a much better background frame for video captured by a moving camera than other methods. As demonstrated in our results, our framework with the cascade of background modeler and deep-learning foreground segmenter outperforms many high-ranking background subtraction models in saliency detection.
Various video datasets were created for background subtraction research. The CDNet 2014 dataset [14] contains videos grouped under 11 categories. Each video record provides the original image sequence and the corresponding ground truths. Many of the videos were captured in different challenging scenes. For instance, the “PTZ” category contains four videos captured by PTZ camera. The Hopkins 155 dataset [23] contains indoor and outdoor panning videos. Perazzi et al. [24] proposed three versions of the Densely Annotated Video Segmentation (DAVIS) dataset. Some videos were captured by shaking camera. The SegTrack v2 dataset [25] contains videos captured by a moving camera with ground truth of the moving object. The Labeled and Annotated Sequences for Integral Evaluation of SegmenTation Algorithms (LASIESTA) [26] database contains real indoor and outdoor videos with pan, tilt, or shaking cameras. In our experimentations, we create our own dataset comprising videos captured by PTZ camera and moving camera extracted from various publicly available video datasets.
3. Saliency Detection Framework
The saliency detection framework SD-BMC is shown in Figure 1. It performs two main tasks—generation of initial background model and continuous saliency detection with updating of background model. First, in part (a), we initialize the system with the first 100 frames. We use the background image generated by the foreground segmenter (BSUV-Net 2.0 [13]) with median filter to create masks in this step. These masks, together with the initial image sequence, will be placed into the video completion-based background modeler (FGVC [27]). From the sequence of completed frames, the most recent one is selected as the background frame (see the dotted arrow). In the stream of saliency detection in part (b), the initial background frame and the current image sequence will be input to the foreground segmenter. The foreground segmenter is pre-trained with CDNet video dataset. As shown in our results, it also performs well with unseen videos. Therefore, we do not retrain the foreground segmenter. The background model will be updated based on the new input masks that are the current foreground segmentation results. The stream of saliency detection with feedback will continue until all video frames are processed.
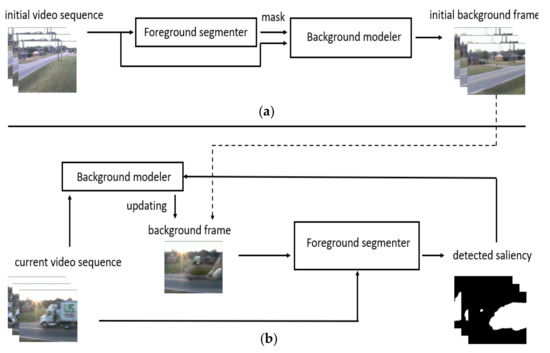
Figure 1.
Overview of the saliency detection framework: (a) background model initialization; (b) continuous saliency detection.
3.1. Evaluation Metrics
In order to evaluate the performance of our framework, we compute eight quantitative measures: Recall, Specificity, False Positive Rate (FPR), False Negative Rate (FNR), Percentage of Wrong Classifications (PWC), F-Measure, Precision, and Matthew’s Correlation Coefficient (MCC) (where TP is true positive, FP is false positive, FN is false negative, and TN is true negative). F-Measure, calculated based on Recall and Precision, is often used as a single numeric measure for ranking different methods.
3.2. Background Modeler
Many background modeling algorithms can estimate a clean background frame and even the image sequence contains moving objects. However, if the foreground objects exist too long, there will be phenomena such as ghosts in the background image. The problem becomes more complicated with video captured by a moving camera. Deep learning-based methods have been proposed for background modeling. For instance, Farnoosh et al. [28] proposed a variational autoencoder (VAE) framework for background estimation from videos recorded by fixed camera. In our experimentation on videos of moving camera, there are always blur pixels existing in the final background images.
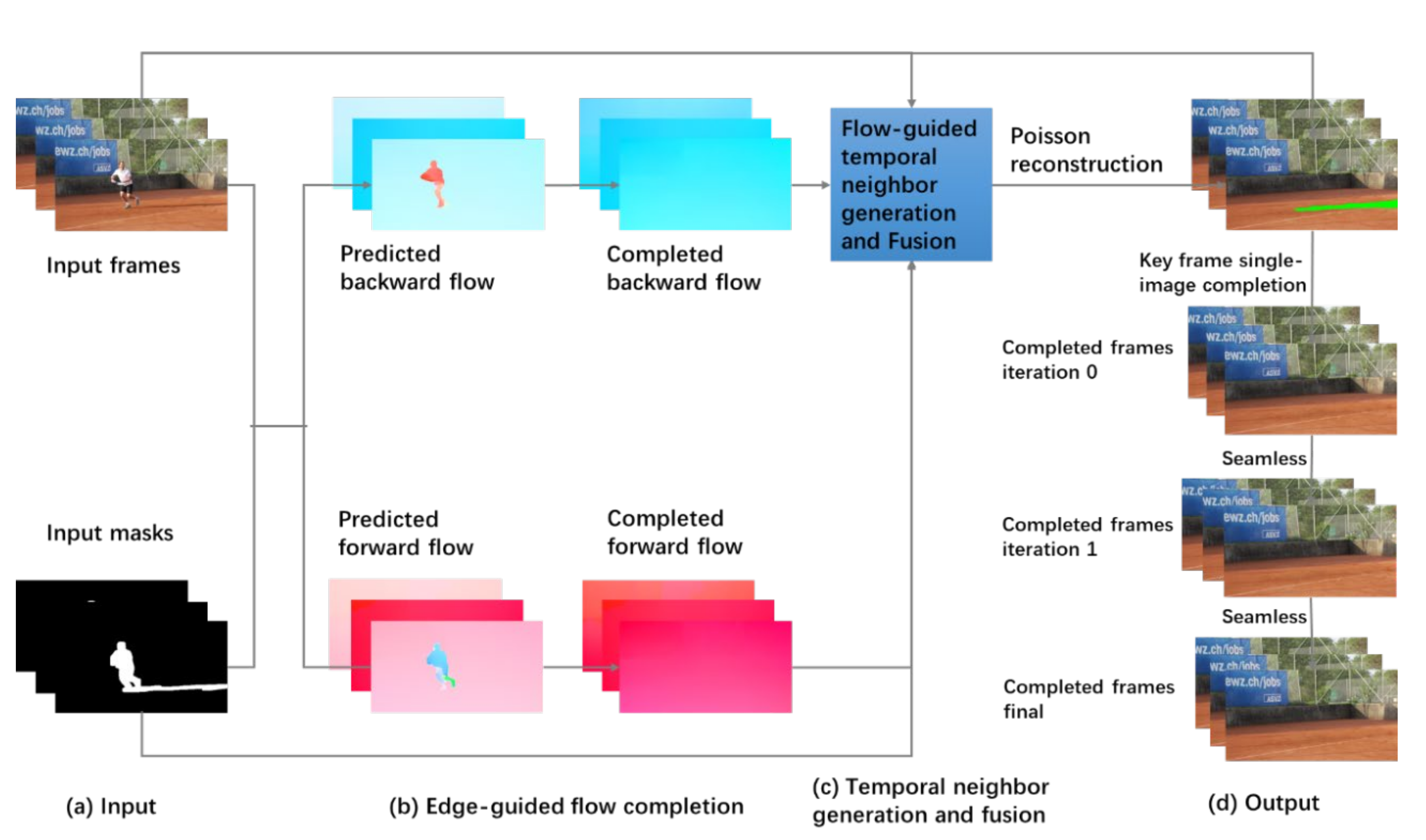
We adopt and modify the video completion method FGVC [27] for background modeling. The algorithm can generate a clean background image with more attention to the masks corresponding to the foreground objects and also the changing scene between adjacent image frames. Figure 2 shows our video completion-based background modeler. In part (a), the color video sequence and the corresponding binary masks are input to the background modeler. The masks are the foreground regions that need to be completed. They are the results of foreground segmenter, as shown in Figure 1b. Next, in part (b), optical flow F between adjacent frames is computed with FlowNet2 [29]. The forward flow is computed from Ii to Ii+1.
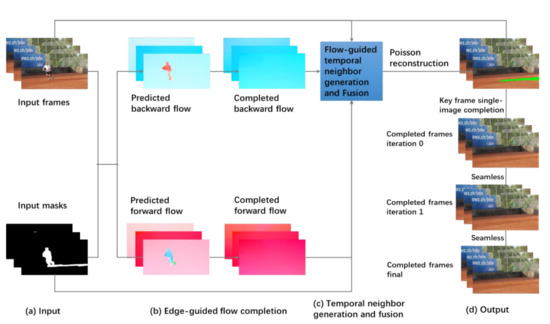
Figure 2.
Video completion-based background modeler.
The backward flow is computed from Ii+1 to Ii.
Moreover, flow between some non-adjacent frames is also computed. This can help to estimate missing background colors when camera motion is large. The backward flow and forward flow are predicted from the color video sequence and the corresponding masks. In each flow field, flow edges are extracted. Guided by the flow edge map, a completed optical flow field is generated. In part (c), a set of candidate pixels are computed for each missing pixel. Most of the missing pixels can be filled with inpainting via fusion of the candidate pixels. After that, the network will use Poisson reconstruction [30] to generate the initial completed background frame:
where is the weighted average image, and is the weighted average gradient. Finally, in the last part (d), the modeler will fix the remaining missing pixels with a number of inpainting iterations until there is no missing pixel.
Experimentation is performed to determine the length of the video sequence for background generation. If it is too short, there may not be a sufficient number of candidate pixels for background color synthesis. If it is too long, the time for background generation will be long, and the actual saliency detection will be delayed. First, we choose 30 frames for background generation. Figure 3 shows background modeling on two videos. It can be observed that ghosts exist in the background frame. Then, we lengthen the initialization sequence to 100 frames. Most of the foreground pixels can be substituted with background colors. Table 1 compares the F-measure of saliency detection on the PTZ category of CDNet 2014 dataset. Finally, we fix the length to 100 frames.

Figure 3.
Visual results of background modeling: (a) original frame; (b) 30 initialization frames; and (c) 100 initialization frames.

Table 1.
F-measure of saliency detection with two settings for background modeling.
3.3. Foreground Segmentation
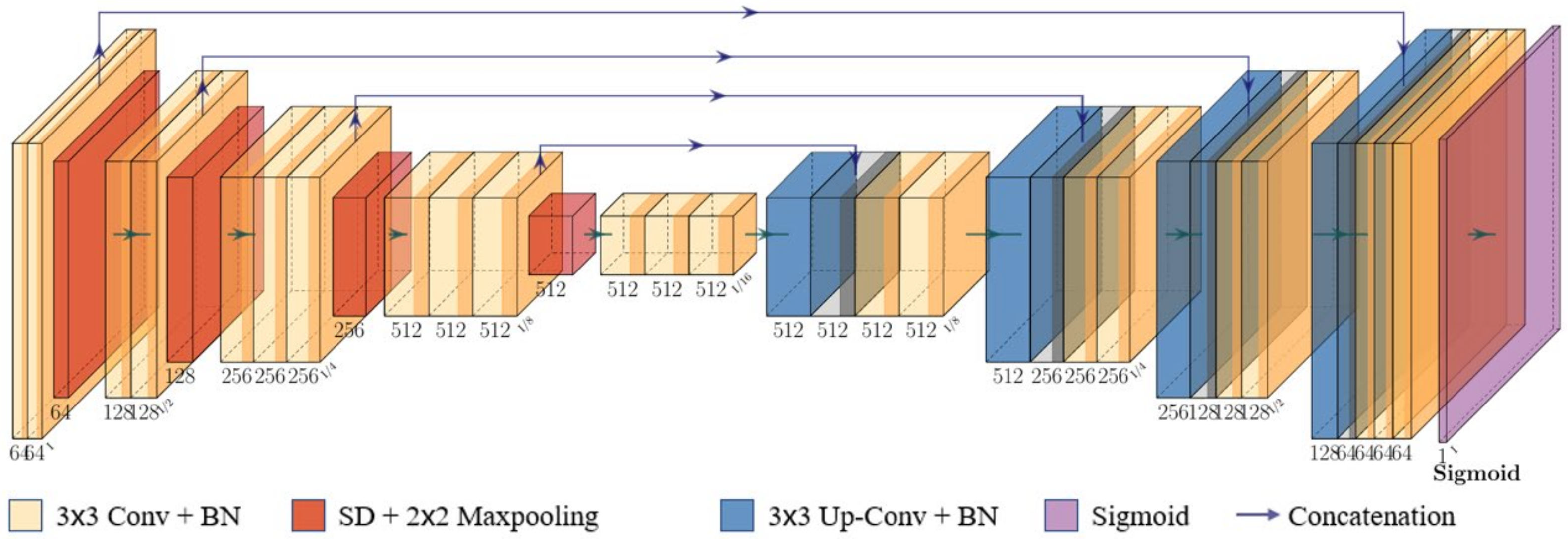
We adopt BSUV-Net 2.0 [13] as foreground segmenter. As shown in Figure 4, it has a U-Net [31] like structure. Based on BSUV-Net [32], BSUV-Net 2.0 further improves background subtraction performance on complicated videos with more spatio-temporal data augmentations. The encoder–decoder structure contains five convolutional blocks in the downsampling path, four convolutional blocks in the upsampling path, and their links via concatenation. The detail of the configuration is shown in Table 2.
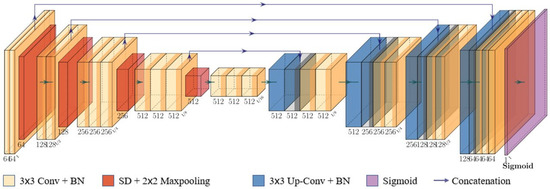
Figure 4.
Structure of foreground segmenter.
Table 2.
Layer Configuration of Foreground Segmenter (SD: spatial dropout layer; BN: batch normalization).
An empty background frame, a recent background frame, the current frame and corresponding foreground probability maps (FPM) are needed for background/foreground separation. The input has a total of 12 channels. In order to avoid overfitting problems and to increase the generalization of the network, it uses a batch normalization layer for each convolution layer in the encoder part and a convolution transpose layer in the decoder part. Spatial dropout layers are also used before max-pooling to make the network more generative. Finally, the network uses the sigmoid function to obtain the prediction value S(x) of the pixels in output binary saliency detection:
where x is the output of a neuron in the last layer.
Tezcan et al. [13] simulated some changes, e.g., changes that look similar to videos captured by PTZ camera, for data augmentation in training the model. However, as shown in our experimental results, BSUV-Net 2.0 is still not good enough in saliency detection with videos captured by PTZ camera and freely moving cameras. It is because the background modeling method cannot generate a fairly good background frame for complicated videos. Therefore, in our saliency detection stream, we disable the default background modeling method. Instead, we use video completion-based background modeler that can generate a better background frame.
4. Result and Discussion
4.1. Datasets
We test our saliency detection framework on CDNet 2014 dataset [14] and our customized dataset. As shown in Table 3, CDNet 2014 comprises 11 categories, each of which contains four to six videos. Each video record provides the original image sequence and the corresponding ground truths. Some videos, e.g., the PTZ category, were captured in challenging scenes.
Table 3.
CDNet 2014 Dataset Categories and Video Scene.
Our customized dataset comprises 22 videos from the FBMS dataset [33] and eight videos from the LASIESTA dataset [26]. The videos were captured by handheld cameras and PTZ cameras. For videos selected from the FBMS dataset, we used manually defined ground truths for 20 continuous frames randomly chosen after the 100th frame in each video. For videos from the LASIESTA dataset, each record provides a number of ground truth images. Table 4 shows the details of our customized dataset.
Table 4.
Customized Dataset Categories and Video Scene.
4.2. Performance Evaluation
We implement SD-BMC with the Python-based Pytorch. The computing platform comprised Intel Xeon Silver 4108 CPU 1.8 G 16 Cores and a HPC Cluster with NVIDIA RTX 2080 Ti 11 GB × 8 GPU nodes. The background frame, either in the initialization or in the updating process, is generated from a sequence of 100 image frames. Therefore, each video is partitioned into sections of 100 frames. If the last section contains less than 100 frames, we input all remaining frames into our framework. We resized the original image sequence and ground truth images with a resolution of 320 × 240.
We compare SD-BMC with six background subtraction algorithms—BSUV-Net [32], BSUV-Net 2.0 [13], Fast BSUV-Net 2.0 [13], PAWCS [34], SuBSENSE [35], and ViBe [36]. Tezcan et al. [32] first proposed the BSUV-Net. Background frames were estimated from the video. The current frame of the video and the background frames are input into the fully convolutional neural network for background subtraction. They proposed the second version of the model [13] by training with data simulating spatiotemporal changes. Moreover, they developed the Fast BSUV-Net 2.0 [13] which is a real-time version of the model. St-Charles et al. proposed SuBSENSE [35] and PAWCS [34] for change detection. The background model is a codebook that is generated based on the persistence of pixel features. They are among the high-ranking methods in CDNet 2014. Barnich et al. [36] adopted the bag-of-words approach and proposed an efficient background subtraction method ViBe. At each pixel location, some samples are randomly selected from the image sequence and stored as background colors. The background model is also updated with a random process.
4.3. Quantitative and Visual Results
Table 5 shows the numerical results of SD-BMC on CDNet 2014 dataset. Table 6 shows the average results of BSUV-Net, BSUV-Net 2.0, Fast BSUV-Net 2.0, and SD-BMC. The best results are highlighted in red. The second best results are highlighted in blue. Table 7 compares the results of BSUV-Net, BSUV-Net 2.0, Fast BSUV-Net 2.0, and SD-BMC on the PTZ category of CDNet 2014. Figure 5 shows some visual results of BSUV-Net 2.0 and SD-BMC.
Table 5.
Evaluation Metrics of SD-BMC on CDNet 2014.
Table 6.
Average evaluation metrics of BSUV-Net, BSUV-Net 2.0, Fast BSUV-Net 2.0, and SD-BMC on CDNet 2014.
Table 7.
Evaluation metrics of BSUV-Net, BSUV-Net 2.0, Fast BSUV-Net 2.0, and SD-BMC on PTZ category of CDNet 2014.


Figure 5.
Visual results of BSUV-Net 2.0 and SD-BMC on CDNet 2014.
Our saliency detection framework achieves the best average Recall, FPR, PWC, and Precision on CDNet 2014 dataset. As shown in the visual results, SD-BMC can achieve comparable performance as BSUV-Net 2.0 in many video categories. The superiority of SD-BMC over BSUV-Net 2.0 can be observed in the PTZ category. Due to the poor background frame, BSUV-Net 2.0 produces a large amount of FP errors. The quantitative results shown in Table 7 clearly indicate that SD-BMC outperforms the other three models in all evaluation metrics on PTZ videos. When a single numeric result, F-measure, is chosen for ranking, SD-BMC outperforms all other methods by more than 11%.
Table 8 shows the average results of BSUV-Net, BSUV-Net 2.0, PAWCS, SuBSENSE, ViBe, and SD-BMC on customized dataset. Table 9 compares the F-measure on individual videos. Table 10 compares the MCC on individual videos. Figure 6 shows some visual results of BSUV-Net, BSUV-Net 2.0, PAWCS, SuBSENSE, ViBe, and SD-BMC.
Table 8.
Average evaluation metrics of BSUV-Net, BSUV-Net 2.0, PAWCS, SuBSENSE, ViBe, and SD-BMC on customized dataset.
Table 9.
F-measure of BSUV-Net, BSUV-Net 2.0, PAWCS, SuBSENSE, ViBe, and SD-BMC on Individual Videos of the Customized Dataset.
Table 10.
MCC of BSUV-Net, BSUV-Net 2.0, PAWCS, SuBSENSE, ViBe, and SD-BMC on Individual Videos of the Customized Dataset.

Figure 6.
Visual results on customized dataset.
The videos in the customized dataset are more challenging. We classify the videos, in accordance to their contents, into three groups: animals, people, and things. SD-BMC achieves the best average Recall, FNR, PWC, MCC, and F-Measure. We select a single numeric result, F-measure, for assessing the performance of all methods on individual videos. As shown in Table 9, SD-BMC achieves the best F-measure in many videos. The average F-measure in “animals” and “things” groups are higher than all other methods, while in “people” group, the average F-measure is slightly lower than BSUV-Net 2.0. Similarly, as shown in Table 10, SD-BMC achieves the best average MCC in “animals” and “things” groups, while in “people” group the average MCC is second best. Moreover, all MCC results of SD-BMC are positive, while other methods have some negative MCC due to large FP and FN errors. As shown in Figure 6, SD-BMC can detect saliency very close to the ground truth. BSUV-Net, PAWCS, SuBSENSE, and ViBe produce many FP errors. The second best method, BSUV-Net 2.0, produces more FP and FN errors than SD-BMC. As shown in video marple3, BSUV-Net 2.0 produces FN errors due to camouflage. SD-BMC can segment the human with fewer FN errors. Overall, SD-BMC outperforms BSUV-Net 2.0 in F-Measure result by more than 3%.
4.4. Comparative Analysis
According to the results on the CDNet 2014 dataset, we found that SD-BMC outperforms other methods in the PTZ category. For other video categories, SD-BMC achieves comparable results with other methods. The reason is that our video completion-based background modeler, together with the feedback scheme, can generate clear and updated background images. FGVC is a non-scene-specific method, which could be generalized to unseen videos. As FGVC can capture temporal and spatial information, this modeler can generate much better background images. On contrary, the empty background images used in BSUV-Net 2.0 are very blur, which could significantly affect the final saliency detection result. PAWCS and SuBSENSE, which are designed for fixed camera, produce even worse background frame. Figure 7 shows the comparison of background images.

Figure 7.
Comparison of background frames used in BSUV-Net 2.0, PAWCS, SuBSENSE, and SD-BMC on PTZ video.
In Table 9, the F-Measure values of BSUV-Net and PAWCS on “cats06” video are left blank. It is because these two methods have zero Recall value. Therefore, their F-Measures cannot be calculated. It is clear that methods that are designed for fixed camera, e.g., PAWCS, SuBSENSE, and ViBe, cannot achieve accurate background subtraction on videos captured by moving camera. The deep learning model BSUV-Net, which can tackle unseen videos, also fails to detect the foreground in many videos of the customized dataset. The enhanced model BSUV-Net 2.0, which is trained with PTZ such as augmented data, performs much better than the first version. SD-BMC, as compared with BSUV-Net 2.0, can detect more accurate saliency with fewer FP and FN errors.
5. Conclusions
We propose a new framework, SD-BMC, for the detection of salient regions in each video frames. The framework contains two major modules: video completion-based background modeler and the deep learning-based foreground segmenter network. In order to enable our framework for long-term saliency detection, the background modeler can adjust the background image dynamically via a feedback mechanism. SD-BMC can best segment foregrounds in videos captured by moving camera. In order to demonstrate this capability, we create our customized dataset with challenging videos captured by PTZ camera and handheld camera. The results, obtained from the PTZ videos, show that our proposed framework outperforms some deep learning-based background subtraction models by 11% or more in the F-Measure result. With more challenging videos, our framework also outperforms many high-ranking background subtraction methods by more than 3%.
Although the results show that SD-BMC is superior to other deterministic as well as deep learning-based background subtraction methods, there are still more method that can further improve it. In this study, we focus on designing a saliency detection framework for moving camera videos. In the future, we will work on new models for other challenging scenarios. The background modeling process can be made faster in order to tackle abrupt changes. Moreover, the foreground segmenter can adopt a teacher–student structure. While the complex teacher model is used in the training process, the testing process will be performed by a simpler student model. The lite model can be used for real-time saliency detection.
Author Contributions
Y.-P.Z.: Methodology, Investigation, Software, Writing—Original draft preparation; K.-L.C.: Conceptualization, Methodology, Supervision, Writing—Original draft preparation, Writing—Reviewing and Editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This work is supported by Hong Kong Innovation and Technology Commission (InnoHK Project CIMDA).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hsieh, J.-W.; Hsu, Y.-T.; Liao, H.-Y.M.; Chen, C.-C. Video-based human movement analysis and its application to surveillance systems. IEEE Trans. Multimed. 2008, 10, 372–384. [Google Scholar] [CrossRef] [Green Version]
- Akilan, T.; Wu, Q.J.; Safaei, A.; Huo, J.; Yang, Y. A 3D CNN-LSTM-based image-to-image foreground segmentation. IEEE Trans. Intell. Transp. Syst. 2020, 21, 959–971. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef] [Green Version]
- Szolgay, D.; Benois-Pineau, J.; Megret, R.; Gaestel, Y.; Dartigues, J.-F. Detection of moving foreground objects in videos with strong camera motion. Pattern Anal. Appl. 2011, 14, 311–328. [Google Scholar] [CrossRef] [Green Version]
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 2002, 90, 1151–1163. [Google Scholar] [CrossRef] [Green Version]
- Elhabian, S.Y.; El-Sayed, K.M.; Ahmed, S.H. Moving object detection in spatial domain using background removal techniques—State-of-art. Recent Pat. Comput. Sci. 2008, 1, 32–54. [Google Scholar] [CrossRef]
- Bouwmans, T. Recent advanced statistical background modeling for foreground detection—A systematic survey. Recent Pat. Comput. Sci. 2011, 4, 147–176. [Google Scholar]
- Sobral, A.; Vacavant, A. A comprehensive review of background subtraction algorithms evaluated with synthetic and real videos. Comput. Vis. Image Underst. 2014, 122, 4–21. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. A self organizing approach to background subtraction for visual surveillance applications. IEEE Trans. Image Process. 2008, 17, 1168–1177. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Luo, Z.; Jodoin, P.-M. Interactive deep learning method for segmenting moving objects. Pattern Recognit. Lett. 2017, 96, 66–75. [Google Scholar] [CrossRef]
- Lim, L.A.; Keles, H.Y. Foreground segmentation using a triplet convolutional neural network for multiscale feature encoding. arXiv 2018, arXiv:1801.02225. [Google Scholar]
- Lim, L.A.; Keles, H.Y. Foreground segmentation using convolution neural networks for multiscale feature encoding. Pattern Recognit. Lett. 2018, 112, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Tezcan, M.O.; Ishwar, P.; Konrad, J. BSUV-Net 2.0: Spatio-temporal data augmentations for video-agnostic supervised background subtraction. IEEE Access 2021, 9, 53849–53860. [Google Scholar] [CrossRef]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. A novel video dataset for change detection benchmarking. IEEE Trans. Image Process. 2014, 23, 4663–4679. [Google Scholar] [CrossRef]
- Hishinuma, Y.; Suzuki, T.; Nakagami, K.; Nishitani, T. Transformed domain GMM foreground segmentation for mobile video camera. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2217–2220. [Google Scholar]
- Amri, S.; Barhoumi, W.; Zagrouba, E. A robust framework for joint background/foreground segmentation of complex video scenes filmed with freely moving camera. Multimed. Tools Appl. 2010, 46, 175–205. [Google Scholar] [CrossRef]
- Tao, Y.; Ling, Z. Deep features homography transformation fusion network—A universal foreground segmentation algorithm for PTZ cameras and a comparative study. Sensors 2020, 20, 3420. [Google Scholar] [CrossRef] [PubMed]
- Komagal, E.; Yogameena, B. Foreground segmentation with PTZ camera: A survey. Multimed. Tools Appl. 2018, 77, 22489–22542. [Google Scholar] [CrossRef]
- Yun, K.; Lim, J.; Choi, J.Y. Scene conditional background update for moving object detection in a moving camera. Pattern Recognit. Lett. 2017, 88, 57–63. [Google Scholar] [CrossRef]
- Sajid, H.; Cheung, S.-C.S.; Jacobs, N. Motion and appearance based background subtraction for freely moving cameras. Signal Process. Image Commun. 2019, 75, 11–21. [Google Scholar] [CrossRef]
- Zhu, Y.; Elgammal, A. A multilayer-based framework for online background subtraction with freely moving cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5132–5141. [Google Scholar]
- Chapel, M.-N.; Bouwmans, T. Moving objects detection with a moving camera: A comprehensive review. Comput. Sci. Rev. 2020, 38, 100310. [Google Scholar] [CrossRef]
- Tron, R.; Vidal, R. A benchmark for the comparison of 3d motion segmentation algorithms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Li, F.; Kim, T.; Humayun, A.; Tsai, D.; Rehg, J.M. Video segmentation by tracking many figure-ground segments. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2192–2199. [Google Scholar]
- Cuevas, C.; Yanez, E.M.; Garcia, N. Labeled dataset for integral evaluation of moving object detection algorithms: LASIESTA. Comput. Vis. Image Underst. 2016, 152, 103–117. [Google Scholar] [CrossRef]
- Gao, C.; Saraf, A.; Huang, J.-B.; Kopf, J. Flow-edge guided video completion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Farnoosh, A.; Rezaei, B.; Ostadabbas, S. DEEPPBM: Deep probabilistic background model estimation from video sequences. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 13–18 September 2020. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Berger, M.; Tagliassacchi, A.; Seversky, L.; Alliez, P.; Guennebaud, G.; Levine, J.; Sharf, A.; Silva, C. A survey of surface reconstruction from point clouds. Proc. Comput. Graph. Forum 2016, 36, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Tezcan, M.O.; Ishwar, P.; Konrad, J. BSUV-Net: A fully-convolutional neural network for background subtraction of unseen videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2763–2772. [Google Scholar]
- Ochs, P.; Malik, J.; Brox, T. Segmentation of moving objects by long term video analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1187–1200. [Google Scholar] [CrossRef] [Green Version]
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. A self-adjusting approach to change detection based on background word consensus. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 990–997. [Google Scholar]
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. SuBSENSE: A universal change detection method with local adaptive sensitivity. IEEE Trans. Image Process. 2015, 24, 359–373. [Google Scholar] [CrossRef] [PubMed]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A powerful random technique to estimate the background in video sequences. In Proceedings of the International Conference Acoustics, Speech and Signal Processing, Washington, DC, USA, 19–24 April 2009; pp. 945–948. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).