1. Introduction
When any fault occurs in a rotating machinery part, the vibration data carry the fault information in a series of periodic impulses. Due to the presence of various signals and noise in the environment, the fault information in raw vibration data may be easily submerged in the noise. Thus, the separation of faulty information might get complicated. Generally, signal-processing methods are applied to extract the tiniest information possible. Typically, the baseline condition has smaller impulses, and fault conditions have relatively higher impulses, making them easier to differentiate. However, in the practical field, the search for the fault occurrence in the whole signal is unfeasible by human convention. Thus, the use of artificial intelligence for finding the fault pattern in the signal is a popular method [
1]. Artificial intelligence or machine learning methods offer automated fault diagnosis by learning from the fault features from the previous data.
Typically, signal processing requires skilled human interaction to select tunable parameters during preprocessing. The time-frequency adaptive decomposition methods can automatically decompose a signal without skilled human intervention. A robust time-frequency analysis, empirical mode decomposition (EMD), was first presented in 1998. Since its arrival, EMD has been applied to stationery and non-stationary signals in numerous fault diagnosis research [
2,
3]. In EMD, the time scale is divided into a set of orthogonal components known as intrinsic mode function (IMF). In papers [
4,
5], the authors used EMD and EEMD for bearings and gears fault diagnosis. Nguyen et al. [
6] proposed a novel fault diagnosis technique for rolling bearing. A combination of EMD, NB classifier, and noise components threshold was suggested for their approach. However, the major drawback is the mode mixing of the IMFs.
To solve the mode-mixing problem, Huang and Wu [
7] proposed the EEMD, which can overcome the limitations of EMD. Wu et al. [
8] added an autoregressive model with EEMD to detect looseness faults of rotor systems. EEMD-based methods were proposed by Lei et al. [
9] to identify initial rub-impact faults of rotors and compared EEMD with EMD to show superiority. Nonetheless, white noise can still be highly present in the IMFs of EEMD after even performing a bunch of ensembles. To significantly decrease the white noise, many ensembles are required that enhance the computational cost. Yeh et al. [
10] proposed CEEMD to reduce the limitations of EEMD. CEEMD adds white noise in positive and negative pairs that can reduce the residual noise in the reconstructed signal with fewer ensembles. Yang [
11] combined CEEMD and wavelet threshold for noise reduction of rolling bearing vibration signals. IMFs were obtained using CEEMD and selected based on kurtosis index and correlation coefficients. The fault impulses were obtained using the envelope spectrum. CEEMD can significantly decrease white noise, but it does not eliminate the limitations and needs further attention. To address this problem, Faysal et al. [
12] proposed noise eliminated EEMD, which reduces the white noise in the IMFs while maintaining the same number of ensembles. In this method, the ensemble white noise is also decomposed and subtracted from the original ensemble IMFs. Therefore, more white noise can be eliminated from the resulting IMFs.
Lately, deep learning has become the most attractive research trend in the area of AI. With the ability to learn features from raw data by deep architectures with many layers of non-linear data processing units, the deep neural network (DNN) model is a promising tool for intelligent fault diagnosis. In supervised learning algorithms, the convolution layer model is the most influential architecture for computer vision and pattern recognition [
13]. Generally, the CNN architecture is a handy tool for image processing and learning features from the input images. The wavelet representation of images can be an ideal input because it can extract the most information from 1D time-domain signals and represent them with both time and frequency information. The wavelet images can be presented as spectrogram or scalogram plots [
14]. Kumar et al. applied grayscale spectrogram images from analytical WT as the input of CNN for centrifugal pump defects identification [
15]. Analysis showed that the proposed improved CNN significantly improved identification accuracy by about 3.2% over traditional CNN. Nevertheless, compared to the spectrogram representations, which produce a constant resolution, a scalogram approach is more suitable for the chore of fault classification due to its detailed depiction of the signal. Wavelet scalogram representations have been proven effective and gaining more popularity over spectrogram representation [
16]. Scalogram is defined as the time-frequency representation that depicts the obtained energy density using CWT [
17]. Verstraete et al. applied CNN on two public bearing datasets for fault diagnosis [
18]. Three different types of input images were produced, namely, STFT spectrogram, wavelet scalogram, and HHT image. Comparing the output accuracy from all the image types, the wavelet scalogram appeared to be the best fit. The previous research shows that the wavelet scalograms have a much higher advantage than the other image representations.
As the years went by, the CNN architecture has also increased in its size and layers to obtain better performance [
19,
20,
21]. Although these models perform with good accuracy, their training time is very high, which is a high price for a small improvement. Moreover, CNN can be computationally cumbersome and not all the processing units can afford that. The embedded system can only process up to a certain limit; on the other hand, a quick processing system is anticipated in the practical fields. For this reason, researchers have been more focused on a lightweight CNN model without much compromise of accuracy. A lightweight CNN consists of only a few convolution layers and fully connected layers. Therefore, it uses less random-access memory and processing units. Fang et al. used two CNN models, where the first one was a 1D CNN to extract the multichannel features from the original signal [
22]. Later, a lightweight CNN was applied where the weights were adjusted via a spatial attention mechanism to classify the features. The experimental results demonstrate that the proposed method has excellent anti-noise ability and domain adaptability. Thus, it is a widespread practice in fault diagnosis research to choose a lightweight CNN model over a very deep CNN for faster model training.
Although CNN is very handy in image processing, a downside is that this classifier requires massive training data to generalize well. Several data augmentation techniques are available to introduce more data during the training phase. The most common ones are (1) geometrical transformation and (2) the addition of white noise. In geometrical transformation, the image is rotated, flipped, adjusted brightness, transitioned, and cropped to augment new samples [
23]. However, this approach would not work well with the wavelet scalograms because scalograms are a graphical representation, unlike images of objects. A transformed representation of a graph would have a new meaning and may result in reduced accuracy. In the second approach of white noise addition, some degree of noise is added with the original signal to introduce some abnormality in the training data. This technique works well because the test data might be noisy in the practical field and differ considerably from the training data. However, white noise addition is not the best approach for the ensemble algorithms, such as EEMD, CEEMD, and NEEEMD, because these algorithms already use ensemble noise to reduce the white noise.
One of the most impressive and arising techniques in deep learning, generative adversarial networks (GANs), has been getting much attention ever since its arrival [
24]. GANs is an unsupervised learning algorithm used for image generation where it takes some real images and produces similar outputs from complete white noise. Thus, GANs can be used for data augmentation, where the augmented data never existed before, and it saves the classifier from repeated training samples. Arjovsky proposed Wasserstein GAN, which is a big step towards the improvement of GANs to produce realistic images [
25]. However, WGAN works best for medical images, and the performance of images generated from signals is unknown. Wang proposed a fault diagnosis method for planetary gearbox by combining GANs and autoencoder [
26]. However, as it uses the vanilla GANs, the output is comparatively noisy, and the use of autoencoders can lose necessary data, which needs additional research. Radford proposed DCGAN, which uses convolution instead of dense layers and produces high-resolution hyper-realistic images [
27]. Since its arrival, DCGAN has been a popular tool for data augmentation in medical imaging and fault diagnosis fields. A method called FaultFace was proposed for ball-bearing joint failure detection, which uses a 2D representation of time-frequency signals from an unbalanced dataset [
28]. DCGAN was applied to generate more 2D samples for employing a balanced dataset. The obtained output proves that the FaultFace strategy can achieve good performance for an unbalanced dataset. Liang used wavelet image samples of different bearing and gearbox load conditions as the input of CNN classifier [
29]. After using the augmented image samples from DCGAN, the classifier performed more accurately for various load conditions and obtained higher robustness. Therefore, DCGAN appears to be an ideal fit for GAN-based data augmentation using vibration signals.
4. Classification Models
In this study, mainly two different classification models are developed using bearing and the blade dataset. The bearing dataset has only one classification model, and the blade dataset contains three classification models. A detailed description of those models is provided in the following subsection.
4.1. Bearing Fault Classification
Collected vibration signals include the following operating conditions: (1) normal condition, (2) inner race fault, (3) ball fault, and (4) outer race fault. Each fault condition includes three different fault sizes, 0.007, 0.014, and 0.021 inches in diameter. In total, 10 different conditions (1 normal, 9 fault conditions) were considered for the fault diagnosis, and the fault categories are presented in
Table 1.
In this work, 600 data points are taken in each bearing sample. The bearing dataset has 10 different classes and 200 samples in each class. For each class, the data are partitioned into train, validation and test set in such a way that the train, validation and test set have 50%, 25%, 25% data, respectively. The training set has 100 samples to train the classifier model, and the validation set has 50 samples to observe and maintain the performance of the training set. Later, 50 testing samples are used to measure the performance of the classifier. For 10 classes in total, the classifier consists of 2000 samples, where 1000, 500, and 500 are for train, validation, and test, respectively.
4.2. Blade Fault Classification
In the blade fault test rig, three different blade faults were induced in different rotor rows. A total of 21 different blade fault conditions based on the fault type and rotor location were examined in this study. The blade data are divided into two different categories for classification: (1) Fault diagnosis: 3-class classification, (2) fault localization: 7-class classification. A detailed description of each category is provided in
Table 2 and
Table 3. Here, R(number) represents the row location of fault occurrence for the particular dataset.
The 3-class fault diagnosis classification has 7 sets of fault data in each class and 21 total sets of data for the whole classifier. The total train, validation, and test data for this model are 5250, 1575, and 1575. Each class contains 1750, 525, and 525 train, validation and test samples.
The 7-class fault localize classification has 3 sets of fault data in each class and 21 total datasets for the whole classifier. The total train, validation, and test data for this model are 5250, 1575, and 1575. Therefore, each class contains 750, 225, and 225 train, validation, and test samples.
5. NEEEMD
The NEEMD takes a different approach than CEEMD to eliminate the white noise in the final stage. Instead of adding a negative white noise at the primary stage, it subtracts the IMFs of the same white noise from the final IMFs. The steps of NEEEMD are followings:
- 1.
Add ensemble white noise (whose length is the same as the original signal with a mean of 0 and the standard deviation of 1 to the original signal and obtain .
- 2.
Decompose
using EMD (see
Appendix A) [
32] and obtain the ensemble means of the IMFs,
.
- 3.
Take the input ensemble white noise
and apply EMD on each one of it.
where
, N is the number of IMFs and
is the IMFs of noise (
).
denotes the residue of the
trail.
- 4.
Compute the ensemble means of the IMFs for the noise.
Subtract the IMFs of noise from the IMFs obtained from EEMD for the reduction of white noise.
- 5.
The original signal can be obtained such that,
where
is the residue of the white noise.
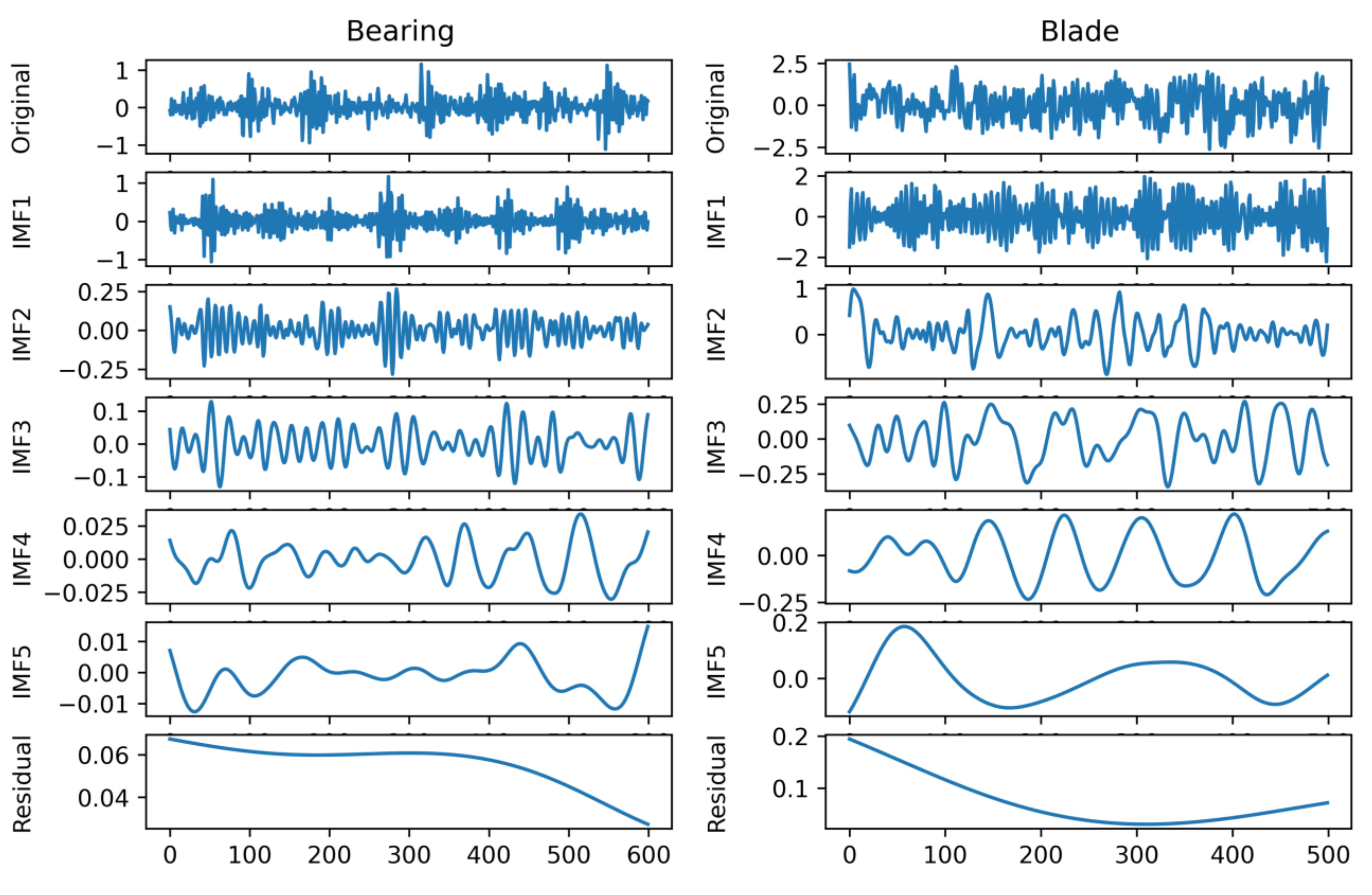
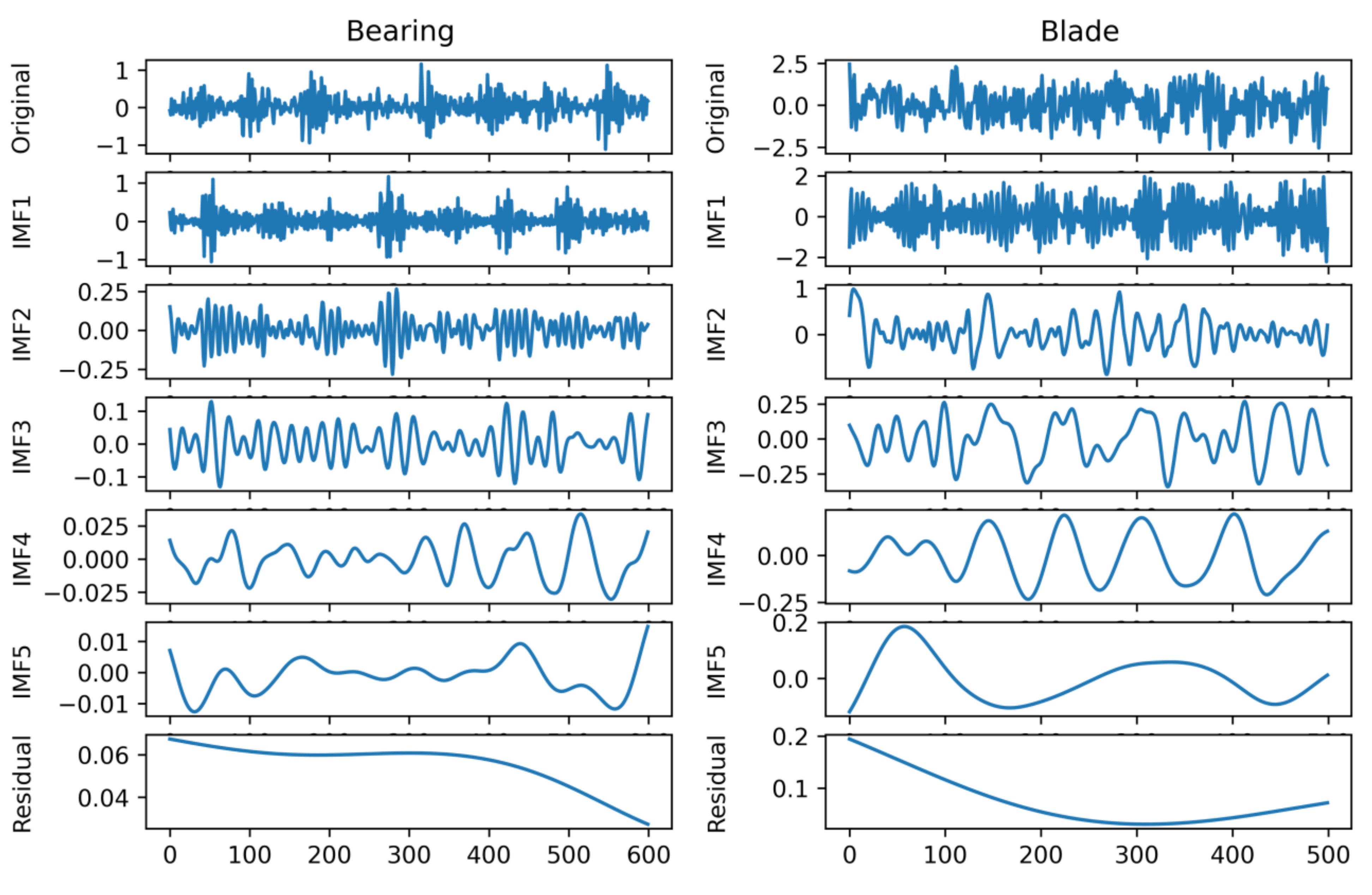
Decomposing the signal provides several IMFs and a residual signal, which is a monotonous signal. For visualization, one random sample from the bearing and blade signal is decomposed using NEEEMD.
Figure 6 represents the outputs of NEEEMD for both bearing and blade samples. Here, no mode mixing phenomena were observed in the IMFs. Moreover, the residuals were monotonous, containing virtually no necessary information.
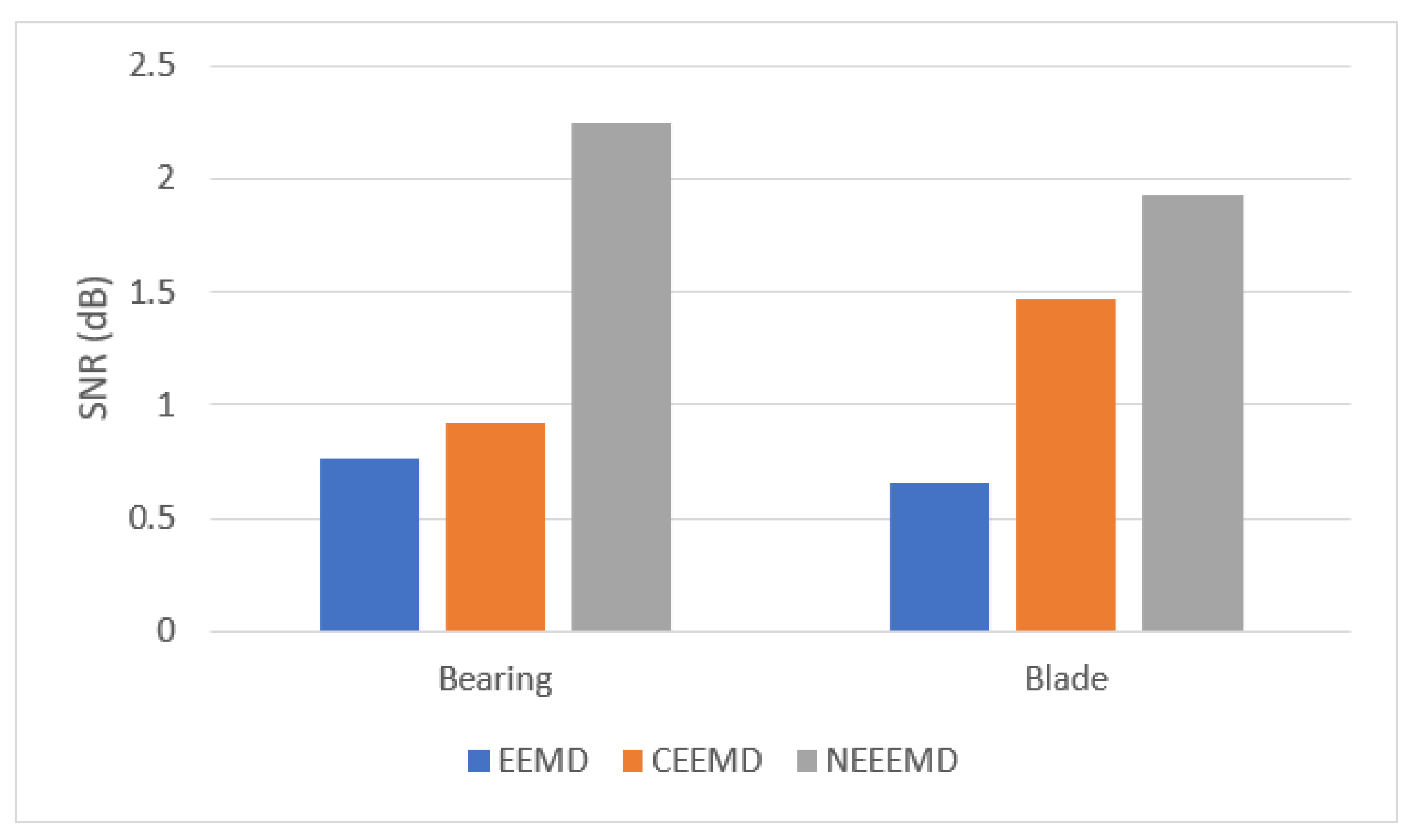
It is necessary to prove the superiority of NEEEMD over EEMD and CEEMD statistically. All the statistical analyses of the bearing and blade datasets show a similar trend for EEMD, CEEMD, and NEEEMD. However, only one random sample from the bearing and blade datasets is presented in this study due to space constraints. The final IMFs of NEEEMD are supposed to have less white noise presence than EEMD and CEEMD. To illustrate the effect of reduced white noise, signal-to-noise ratio (SNR) is considered. SNR is computed using the original and reconstructed signals, where the reconstructed signal is the sum of the resulting IMFs. The formula for computing SNR is provided in Equation (6). It is the ratio of the power of the original signal to the power of the reconstructed signal. The SNR of NEEEMD from one random bearing and blade fault sample is compared with EEMD and CEEMD. The outputs are presented in
Figure 7. It is seen that in both bearing and blade samples, EEMD obtained the lowest SNR value. CEEMD obtained higher SNR than EEMD, whereas NEEEMD obtained the highest SNR. Therefore, the reconstructed signal from NEEEMD has less noise in it than EEMD and CEEMD.
A frequently used statistical evaluation parameter, RRMSE, is implemented to calculate the restoration error to further emphasize the proposed method’s effect. The ratio between the root-mean-square of the original and reference signal to the root-mean-square of the reference signal is defined as RRMSE [
33]. The equation for RRMSE is presented as follows:
Here, is the original signal, and is the reconstructed signal.
Figure 8 represents the RRMSE values from a random bearing and sample. EEMD obtained higher RRMSE values, 0.0705 for bearing, and 0.0361 for blade sample. CEEMD had a lower reconstructed error than EEMD, 0.0695 and 0.0339 for bearing and blade, respectively. NEEEMD achieved the lowest RRMSE, which are 0.0629 and 0.0304 for bearing and blade. Therefore, NEEEMD has a much lower reconstruction error than EEMD and CEEMD, and proves to be more effective than those previous two improvements.
Next, the signal strength is considered to evaluate the degree of information the reconstructed signal carries. The kurtosis value is an excellent parameter for measuring the signal strength. Wang et al. [
34] used the multiplication of the kurtosis in the time and the envelope spectrum domain, which can be applied to determine the strength of the signal. The method is called TESK and is defined as:
where,
where,
as the IMF to be analyzed,
as the standard deviation of
,
as the mean of
,
as the envelope power spectrum of
,
as the mean of
,
as the standard deviation of
and
as the expectation operator.
The higher the
value, the more information the signal contains. Thus, the total value of
from different signals can be compared to determine the performance of the algorithms.
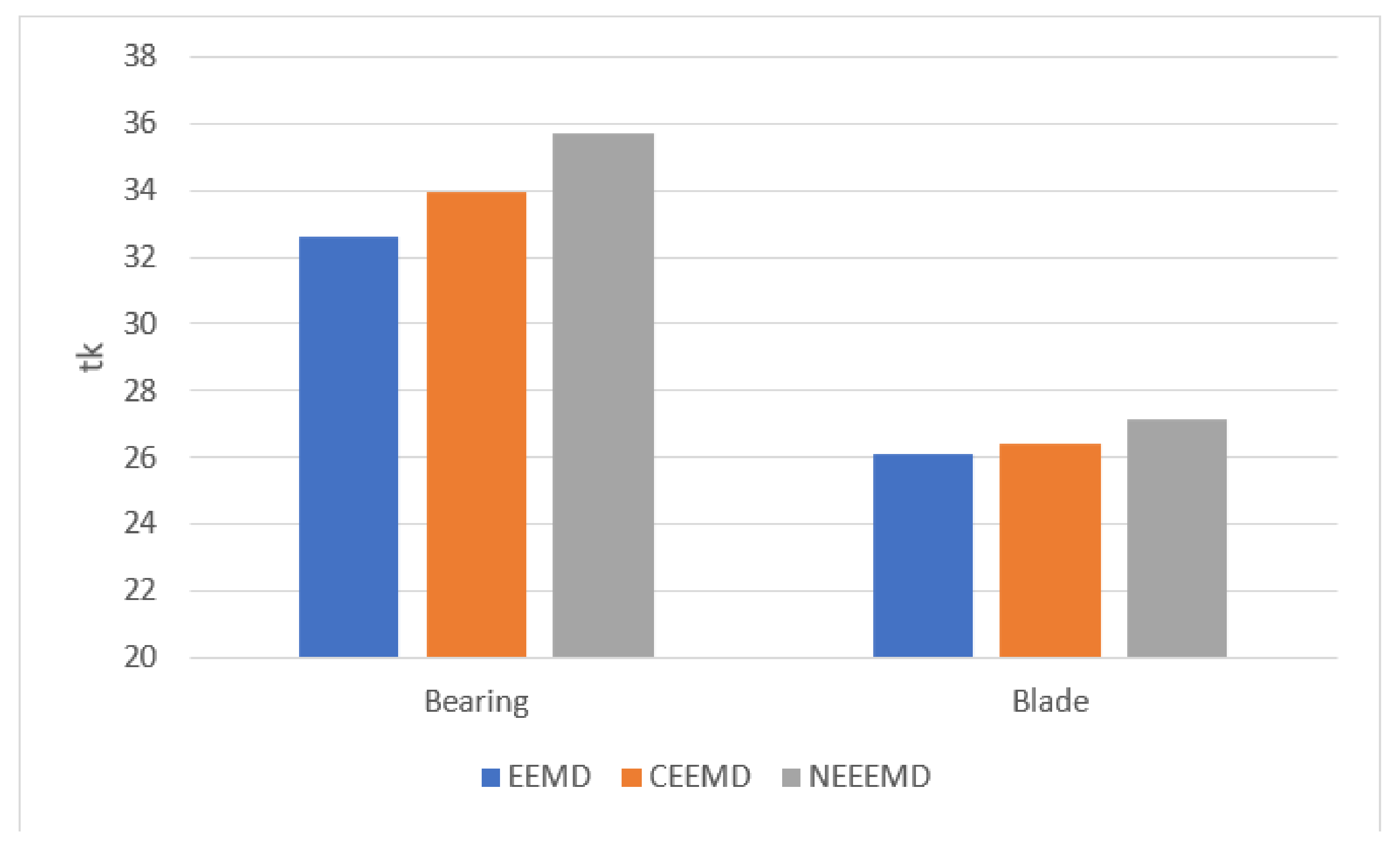
Figure 9 shows the
values from both bearing and blade samples. For the bearing sample, EEMD has the lowest signal strength, as the
value is 32.64. The second highest is CEEMD with
value of 33.97. NEEEMD has the highest signal strength as it obtained the highest
value, 35.71. The
values of the blade sample were relatively closer since the sample length is smaller than the bearing sample. Nevertheless, NEEEMD obtained the highest
value as well. The
values are 26.08, 26.38, and 27.14 for EEMD, CEEMD, and NEEEMD, respectively. Therefore, in both bearing and blade samples, the NEEEMD signal contains the highest signal strength.
6. Features for Deep Learning
The deep learning classifiers in this study work with two types of input samples, namely, grayscale images and scalogram images. The 2D grayscale vibration images are produced from the 1D raw vibration data [
35]. The produced image dimension is
pixels. However, each bearing data sample has 600 data points. Therefore, the samples are converted from a
vector to a
matrix and produced the 2D grayscale images. Still, the generated images have a size of
pixels, so the images are upsampled to produce images of size
. The blade sample length is 500. Therefore, images are upsampled from a
matrix in this case. Since the images are 2D grayscale, the number of the input channel for CNN, in this case, is 1.
Scalograms are one type of time-frequency representation that uses CWT analysis to obtain the energy density of the signal. A sliding window is used in wavelet representation, which has different resolutions in different regions. CWT decomposes the raw signal into a time scale, which is represented by scaling and translating operations. Morlet wavelet is applied with the time-bandwidth product and symmetry parameter set to 60 and 3, respectively. According to the range of energy of the wavelet in frequency and time, the minimum and maximum scales are automatically determined using 10 voices per octave [
36]. Points out of the cone of influence have been handled by the approximation used in MathWorks MATLAB [
37].
Typically, when a signal is decomposed using the adaptive methods, it produces several IMFs. In the previous studies, the authors considered all the individual IMFs as individual samples and applied multichannel CNN for classification [
38,
39,
40]. However, that approach requires
n-channel CNN for
n-IMFs, enhancing the preprocessing and classification duration
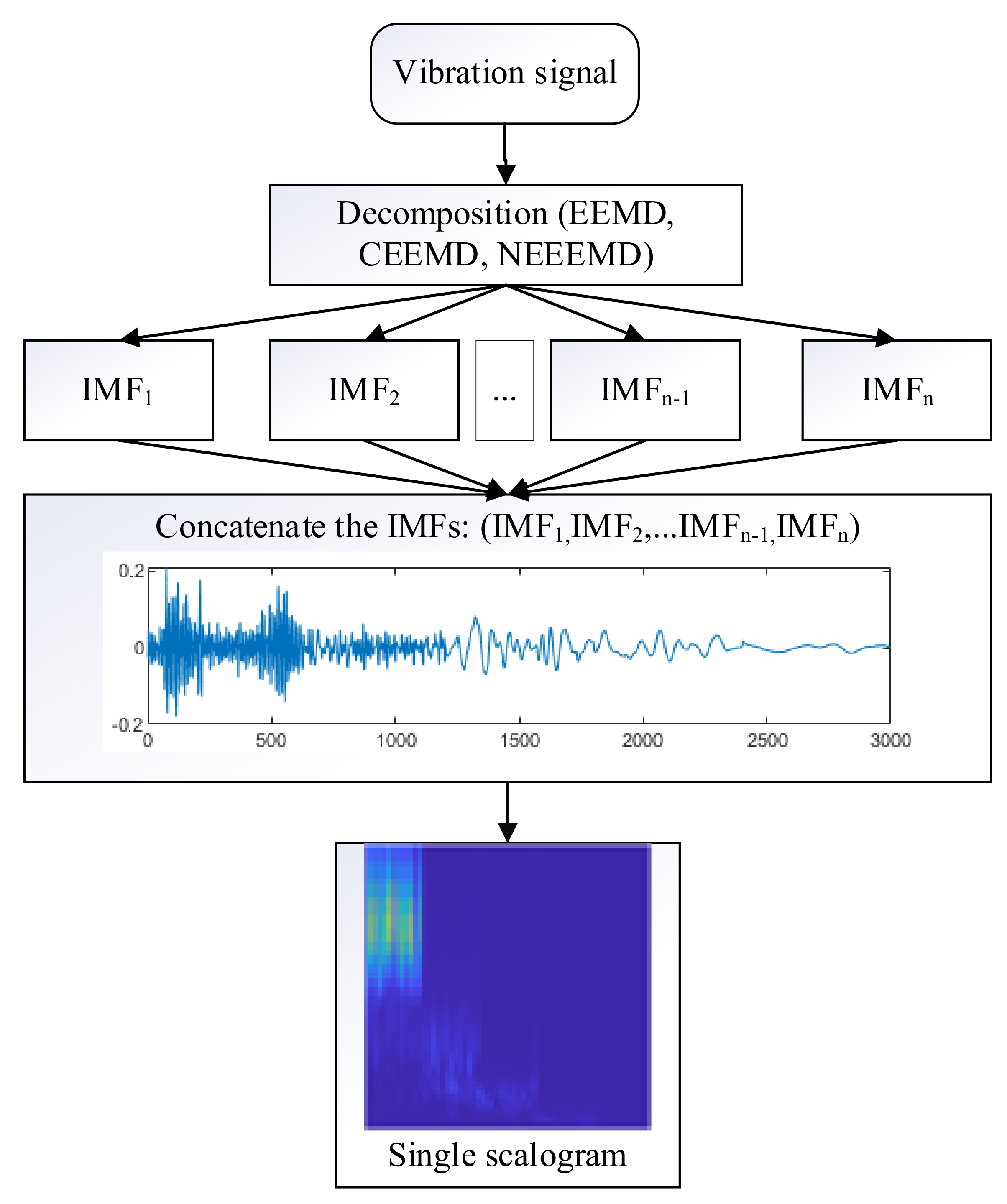
n times. For practical application, it is burdensome to do all the computation for the desired outcome. Thus, in this study, all the IMFs have been concatenated and flattened into a single signal. From the single signal, one scalogram image is produced. Thus, the computation time for
n IMFs was reduced to 1/
n times.
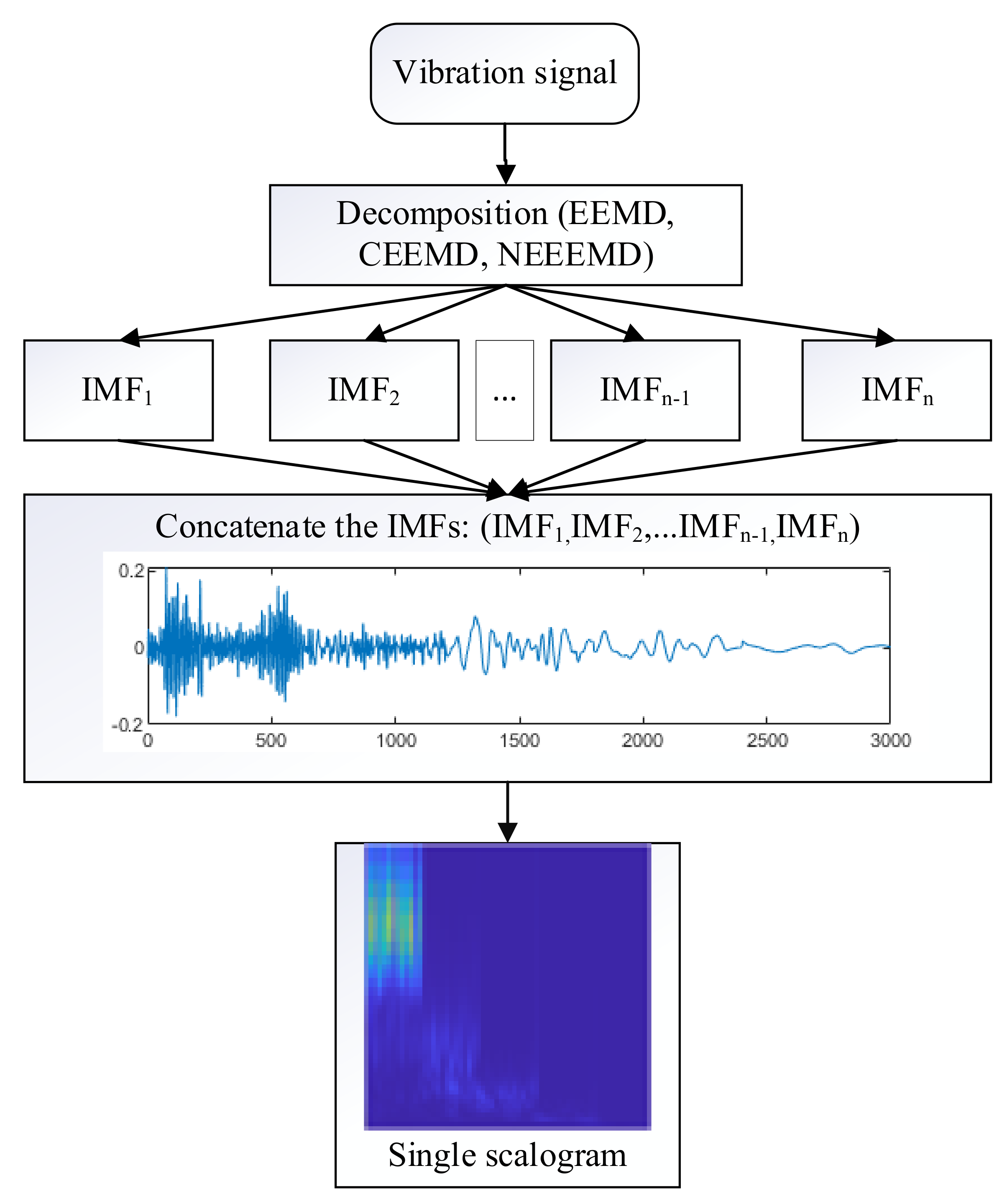
Figure 10 represents the proposed approach for scalogram images input into the classifier model. Here, five IMFs were generated using all the decomposition methods of this study. Concatenating these five IMFs produces a single sample with a length of five times the original sample. Thus, the length of the bearing sample would be 3000, and the blade sample would be 2500. Next, one single scalogram is generated from that sample.
The colors in the scalogram plot show the relative values of the CWT coefficients. The light areas mean higher values of the CWT coefficients, and therefore, the signal is very similar to the wavelet. On the other hand, dark area means lower values of the CWT coefficients, and it shows that the corresponding time and scale versions of the wavelet are dissimilar to the signal. An RGB (three channels) representation of the time-frequency image is better than a grayscale (one channel) image because more channels contain higher information. Therefore, only RGB scalograms of
pixels are produced in this study. The scalograms are generated from EEMD, CEEMD, and NEEEMD. Moreover, the scalograms are also obtained from the vibration signals, which are purely CWT scalograms.
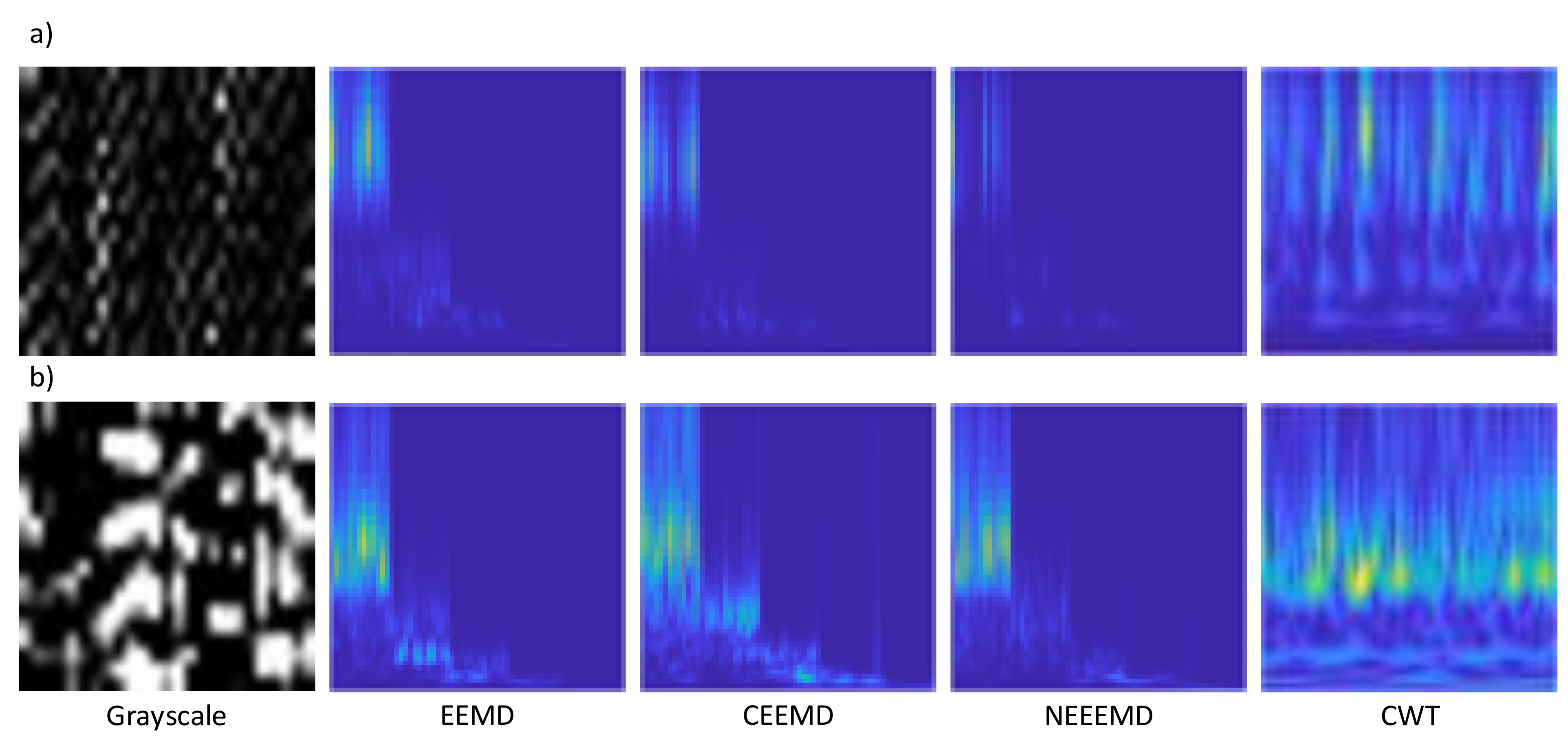
Figure 11 represents one random sample from each different image type for the bearing and blade dataset. Here, the grayscale samples contain no color values as it has only black and white pixels. Scalograms from the decomposition have five concatenated IMFs, which are clearly visible in their scalogram images. Finally, the CWT scalograms are the pure scalogram samples that are generated from the original sample.
7. Deep Learning Classifier
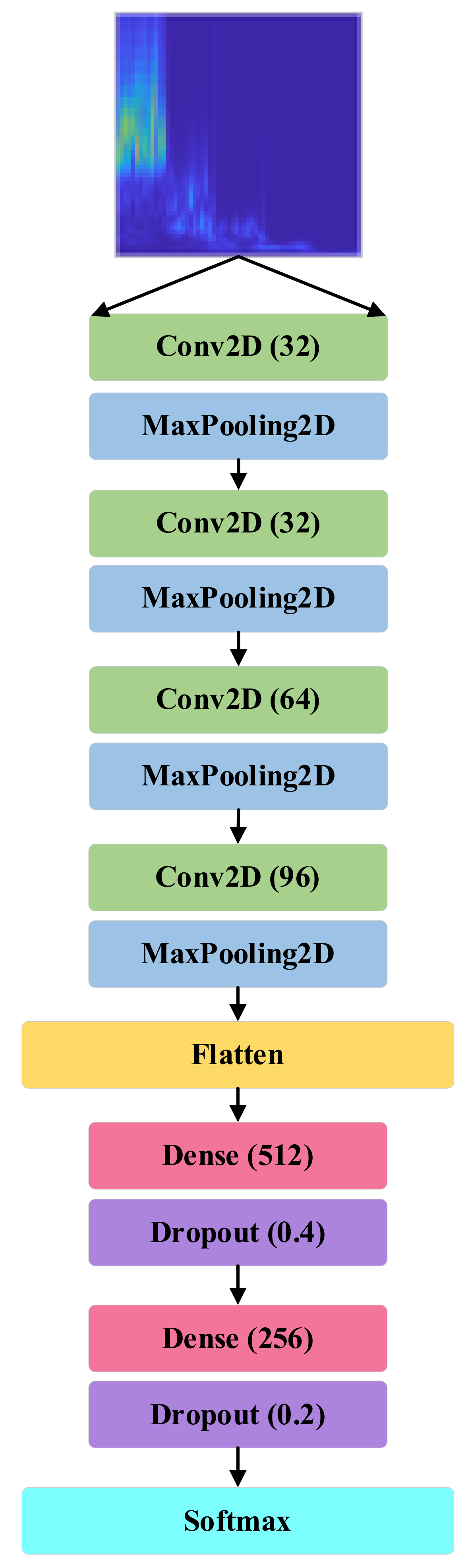
The proposed classifier architecture (
Figure 12) consists of only four convolution layers and two dense layers. The input layer of the CNN model consists of three channels that take
size RGB images. The first convolution layer has 64 output filters with a kernel size of
. The first convolution layer is followed by three other convolution layers where the output filter size is 32, 64, and 96, respectively, and a
kernel is used in all of them. ‘Same’ padding is used in all these convolution layers. A max-pooling layer of
pixels is applied after every convolution layer. The output from these three convolution layers is flattened and connected to two dense layers and their respective dropout layers. The first dense layer has 512 neurons with a dropout factor of 0.4 and the second one has 256 neurons with a dropout value of 0.2. ReLU activation function is applied in all of the layers. A softmax activation function is used in the output layer where the layer size is the same as the number of data classes. In the case of binary class, a sigmoid activation function is applied as per convention with only one hidden unit [
41]. The bearing model architecture with the number of parameters is presented in
Table 4. All models were generated in Python using the Keras library. The total number of parameters and total trainable parameters for this model is 1,006,410.
Hyperparameters Tuning
Training the CNN model corresponds to a bunch of optimizable parameters. Among the tunable parameters, the most prominent are learning rate, optimizer, loss function, and batch size. An ideal set of these parameter selections for an individual architecture leads to better classification performance. The grid search method was applied in hyperparameter tuning, and the optimum parameters were selected [
42].
The deep neural network algorithms use stochastic gradient descent to minimize the error. The learning rate indicates how the model estimates the error each time the weights are updated. Choosing the learning rate is important because a slow learning rate may take a long time to converge, whereas a high learning rate may miss convergence at all. On the other hand, the loss function is used to differentiate the performance of the model between the prediction score and the ground truth. Among many types of loss functions, the cross-entropy loss function is used extraneously and employed in this study.
It is crucial to obtain a low loss using the loss function. To minimize the loss function, implementing an appropriate optimizer is important. An appropriate optimizer sets a bridge between the learning rate and loss function during the gradient descent. The Adam optimizer is an adaptive learning rate optimization algorithm designed especially for DNN. Adam uses momentum in order to accelerate the learning rate when the learning rate becomes slow after a few iterations. The use of Adam can help to prevent being stuck in the local minima of the loss. Adam optimizer is applied to optimize the loss function where the learning rate is set at 0.0001.
The other few important factors of hyperparameters are epoch, early stopping. Epoch refers to how many iterations of forward and backward propagation are conducted before the algorithm is stopped. Another handy trick while training the algorithm is that it is divided into mini-batches instead of taking all the input train samples. This strategy requires less memory usage and trains faster. The early stopping method observes the validation loss or accuracy to monitor if the model is being overfitted. When the model starts to get overfit, the training process is terminated even before the highest number of epochs is reached. In this study, the training data are divided into batches of 16, and the epoch is set at 100. The early stopping criterion is utilized to avoid overfitting the model. As a result, the increase of validation loss is observed for 15 instances, and the best model is saved based on the lowest validation loss. Thus, the overfitting problem is avoided, and the model converges to the minimum loss at an epoch lower than 100 in most cases.
9. Outputs from the Classifiers
This section compares outputs from NEEEMD scalograms classification using CNN with related scalograms and grayscale images. The train, validation, and test accuracies are obtained for comparison. Moreover, the individual class performance from the test results is used to obtain the sensitivity values for comparison. The sensitivity values are considered because this study emphasizes mainly the correct identification of fault types.
Table 5 represents the output accuracy from the bearing fault classifiers, and
Table 6 represents its class sensitivity. The order of validation and test accuracies for the CNN classifiers are grayscale, CWT, EEMD, CEEMD, and NEEEMD scalograms. Here, the lowest validation and test accuracies are 95.60% and 94.40%, obtained by the grayscale images. The highest validation and test accuracy obtained by NEEEMD scalograms are 98.20% and 98%. The sensitivity values show that NEEEMD scalograms obtained the highest sensitivity for each individual class. In other methods, some classes obtained the highest sensitivity but not for all classes. Therefore, all the classes had the most correctly identified fault occurrence using the NEEEMD scalogram samples for the bearing classifier.
The output accuracy and sensitivity for the blade fault diagnosis classifier are presented in
Table 7 and
Table 8. The order of the validation and test accuracy is similar to the order of bearing fault classifier output. All the output accuracies of the scalograms had small differences among train, validation, and test accuracy, indicating a well-trained classifier. However, the validation and test accuracies had comparatively lower accuracy than the training accuracy in grayscale samples. Therefore, the classifier trained on grayscale samples was more overfit than the others. EEMD obtained slightly higher accuracy than CWT scalograms, and the same goes for CEEMD when compared with EEMD. NEEEMD scalograms obtained the highest validation and test accuracies, which were 97.84% and 96.31%. All the output accuracies are reflected in the sensitivity of classes. In grayscale samples, a large proportion of class 0 was misclassified. On the other hand, the NEEEMD scalogram classifier had the highest individual class sensitivity.
Table 9 and
Table 10 list the output accuracy and sensitivity from blade fault localize classifiers. The NEEEMD scalograms obtained the highest validation and test accuracy for CNN as well. However, the grayscale and CWT samples obtained a highly overfit model. The validation and test accuracies deviate much from the training accuracy. The grayscale samples had a train, validation, and test accuracy of 98.38%, 71.75%, and 59.81%. For the CWT scalograms, the train, validation, and test accuracies are 95.98%, 75.17%, and 68.44%. These outputs indicate the poor performance of grayscale and CWT scalograms for a higher-class classification. On the other hand, the scalogram samples from EEMD, CEEMD, and NEEEMD obtained much less overfit classifier as the validation and test accuracies were very close to the training accuracy. NEEEMD obtained the highest validation and test accuracies, 93.27%, and 92.25%, respectively. In terms of sensitivity, a few classes from grayscale and CWT samples are below 0.50, meaning more samples were misclassified and correctly classified. On the other hand, NEEEMD had the highest sensitivity for all individual classes. Therefore, the NEEEMD scalogram can still obtain very high accuracy and sensitivity for a higher-class classification.
This section shows that the combination of NEEEMD scalograms and the CNN model performed the best. The grayscale samples and CNN. In most of the scalograms and CNN models, the output performance was very close to each other. Thus, more analysis is needed for additional justification of the best model for different situations. Therefore, all of the scalogram classification models will be undertaken for further evaluation using model robustness for noisy test samples.
9.1. Robustness Evaluation
When predicting new data, the data can be quite deviated from the original signal, or they may contain high noise in the real application. Therefore, it is essential to ensure that the model can still hold good robustness when classifying new data. Gaussian white noise is added with the test samples and it is predicted using the trained model to verify the robustness of all the models. The white noise is added directly to the scalogram images (as salt-pepper noise) and incremented at a step of 0.05 standard deviation (SD). The outputs from the scalogram samples of NEEEMD, CEEMD, EEMD, and CWT are compared. The grayscale vibration image classification using CNN and the machine learning classifiers are not considered as they already performed with considerably low accuracy in the earlier stage. The outputs from all the datasets and classifiers are obtained in the following figures.
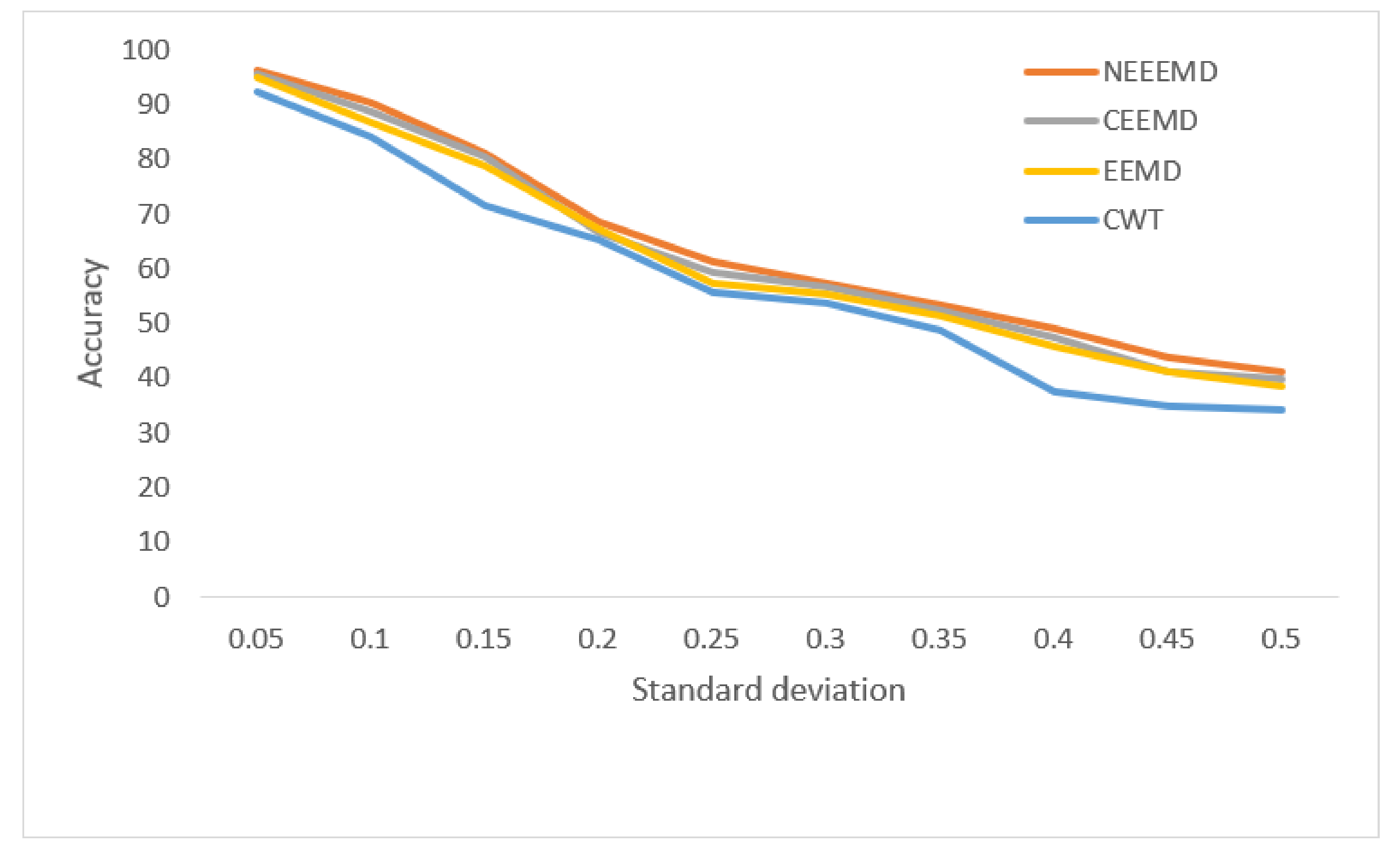
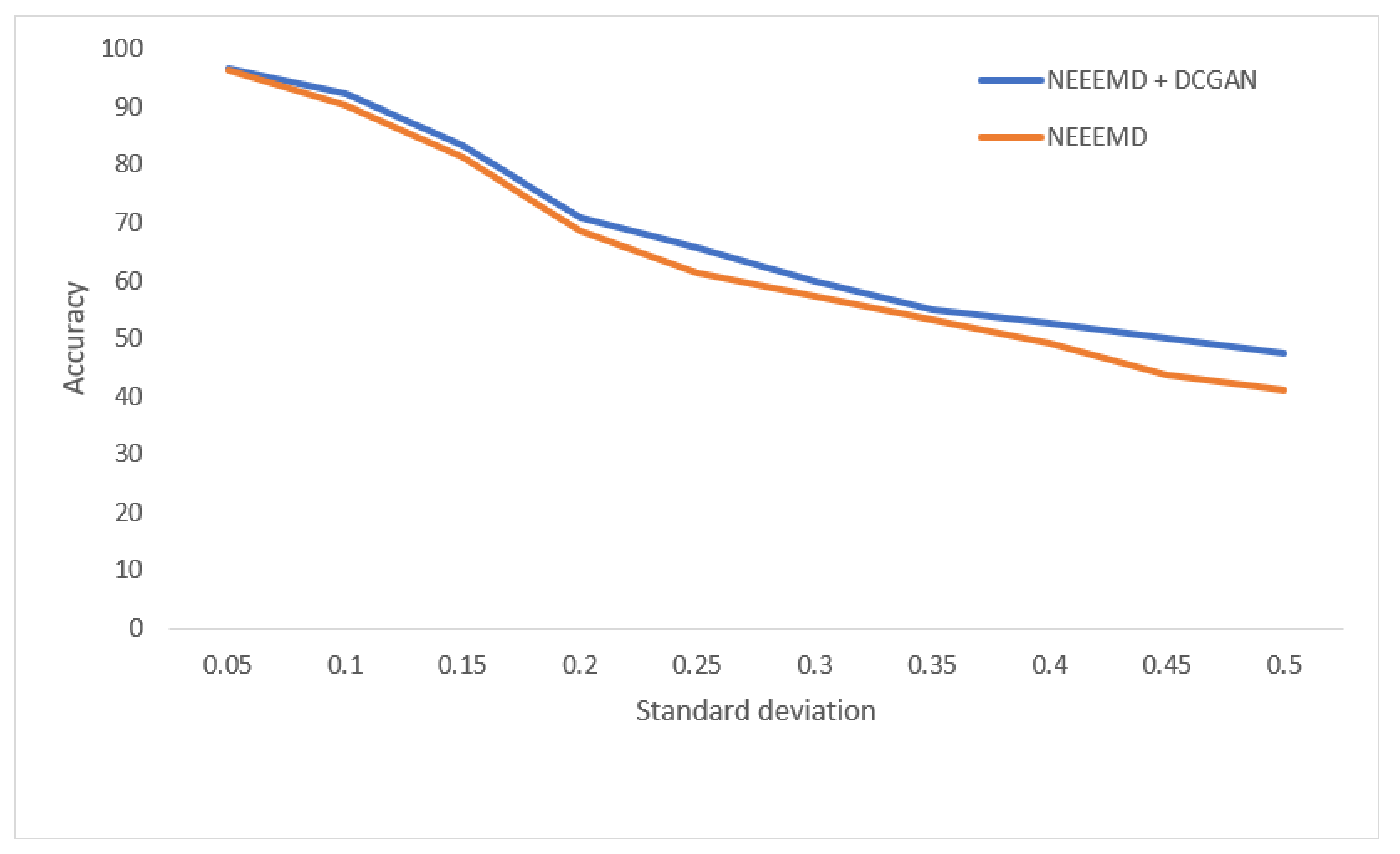
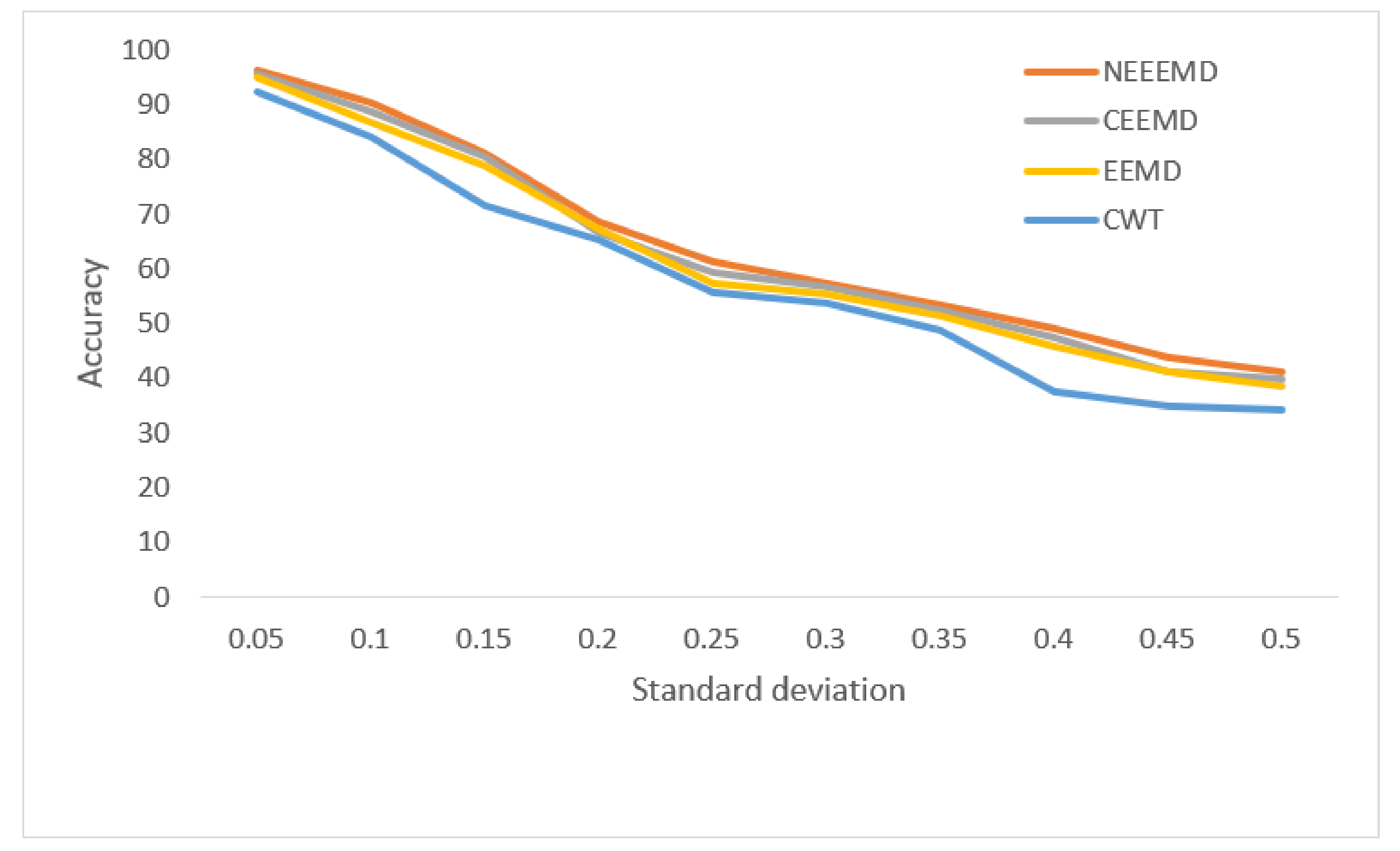
In
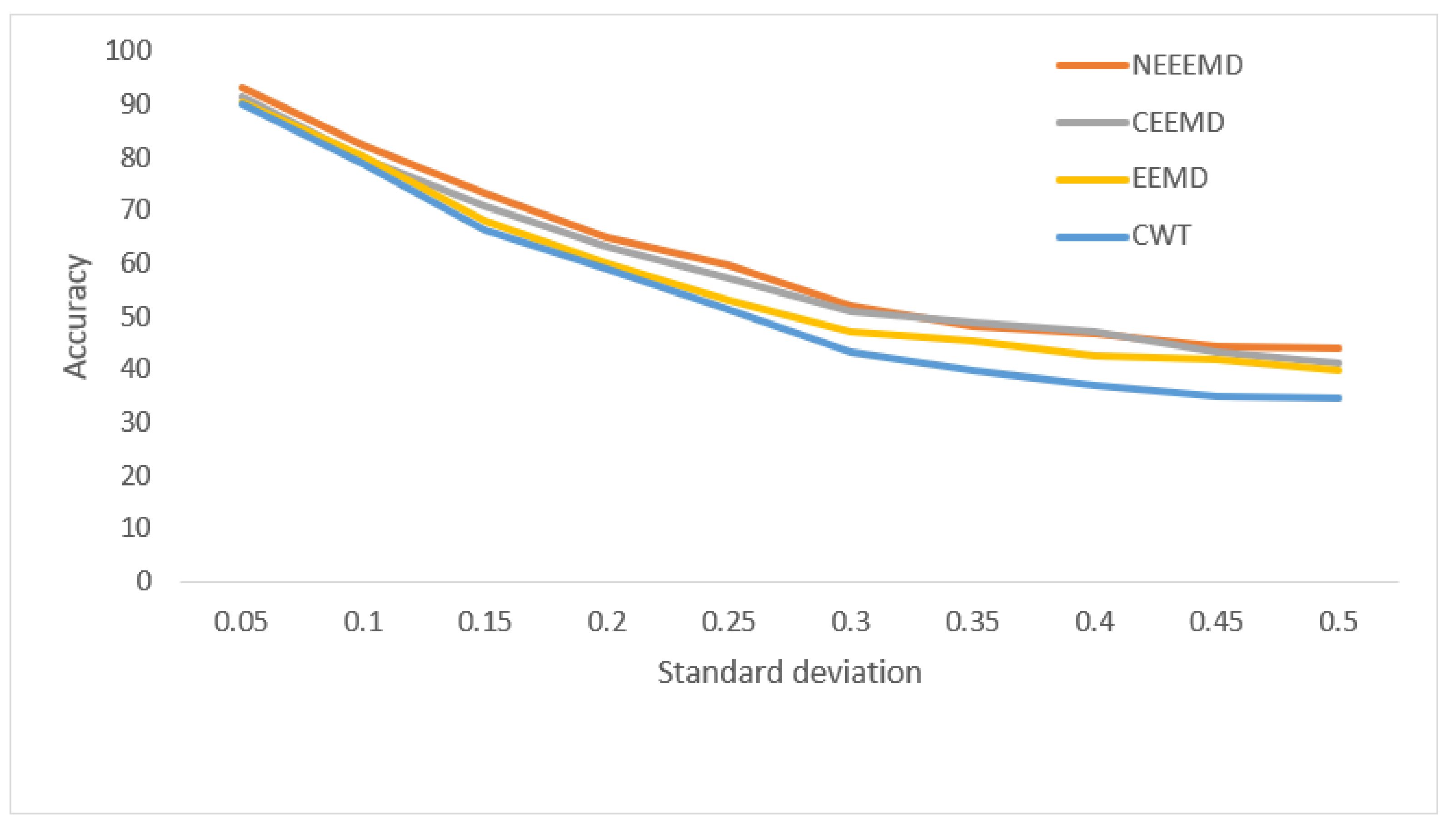
Figure 13, the bearing test dataset with different noise levels shows accuracies in the descending order of NEEEMD, CEEMD, EEMD, and CWT. The CWT samples model’s robustness keeps falling most for a higher order of noise. The NEEEMD, CEEMD, and EEMD models’ robustness are close, but the NEEEMD model could maintain the highest robustness all the way. In
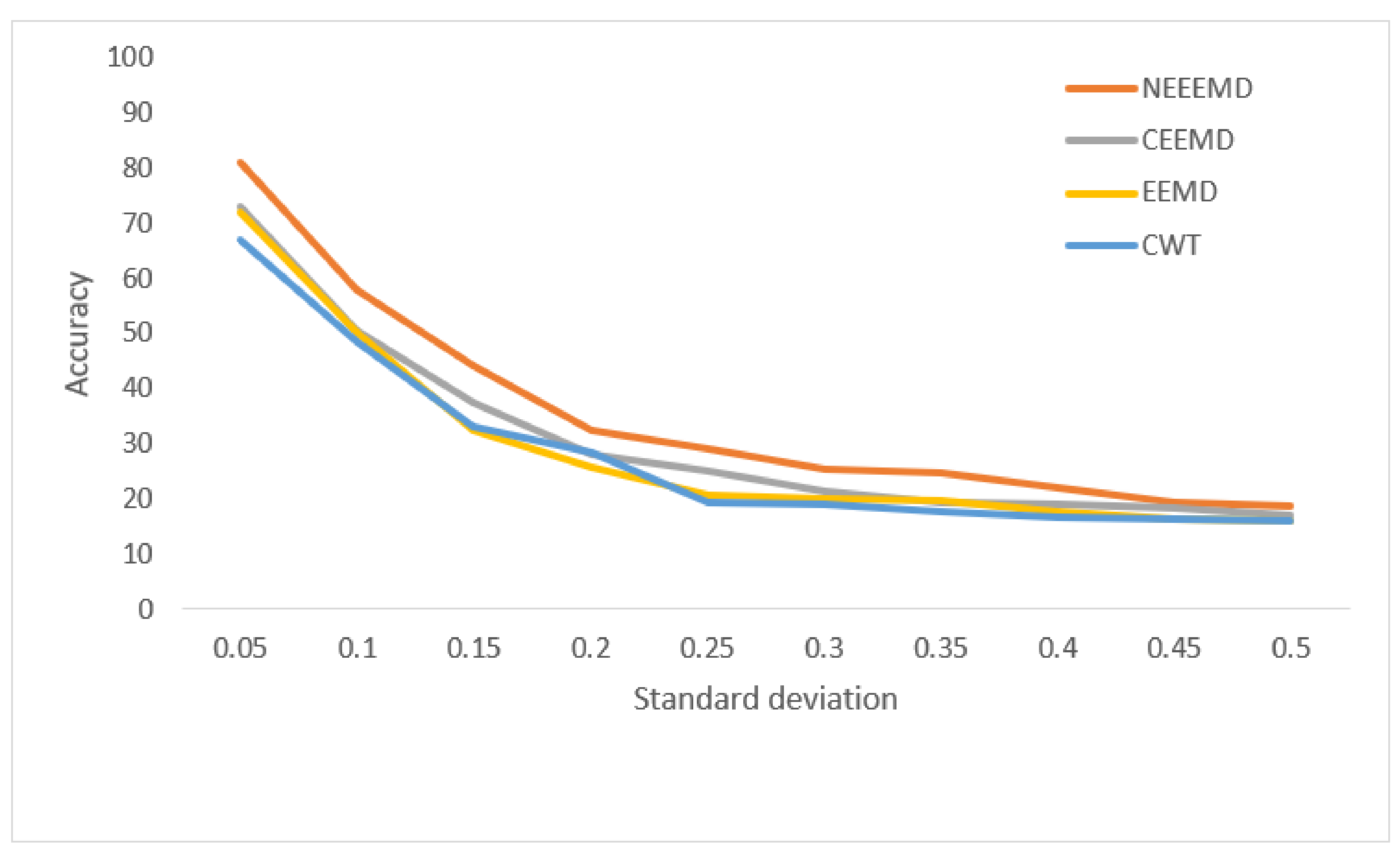
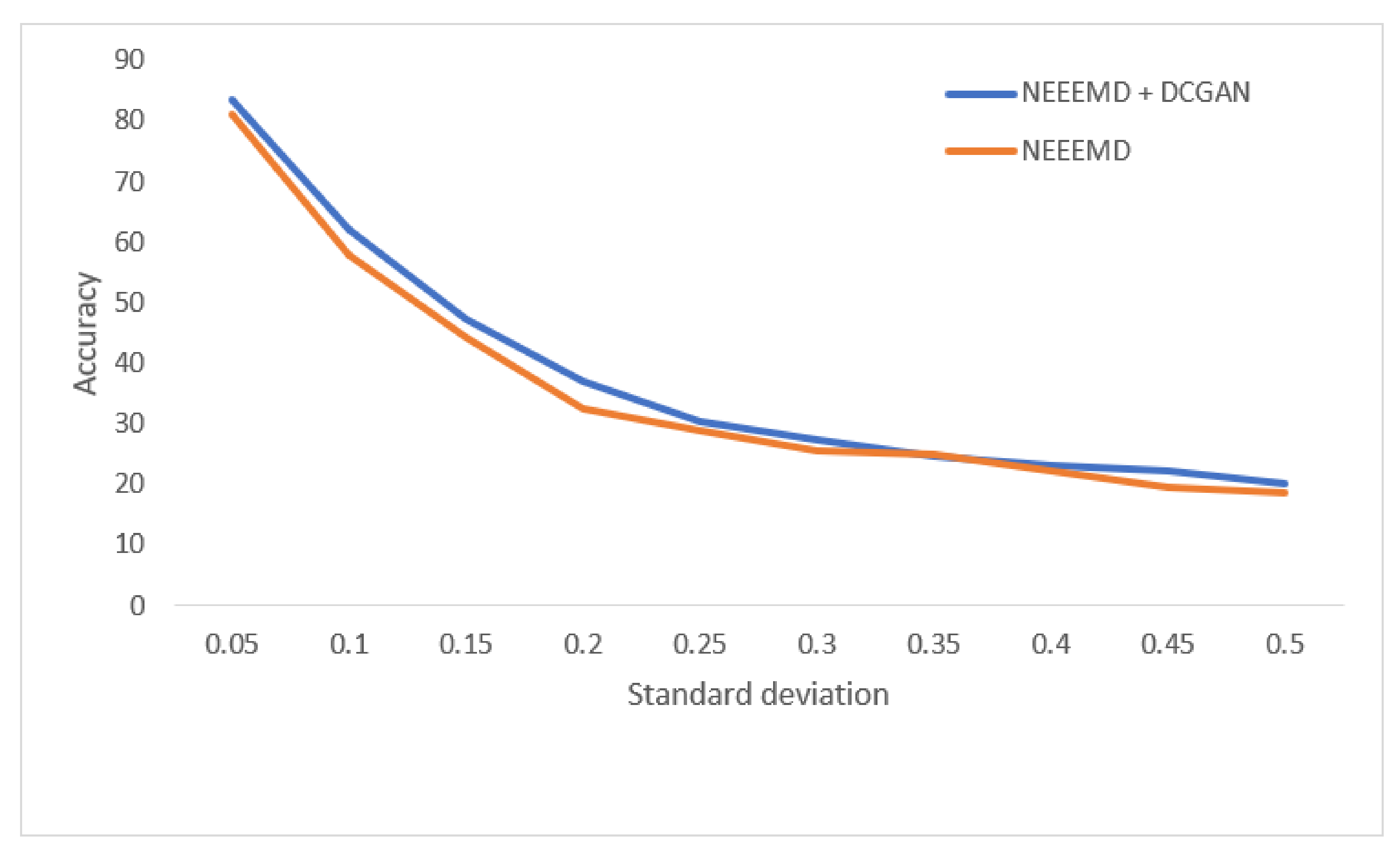
Figure 14, the models’ robustness for the fault diagnosis classifier is obtained. The robustness of CWT was the lowest for all the SD, followed by EEMD. The robustness of NEEEMD and CEEMD are very close. The robustness of NEEEMD is higher than CEEMD for all the SDs except for only 0.35 SD, where it lags by a tiny portion. Apart from that, the NEEEMD samples for the fault diagnosis model performed with the highest robustness. In
Figure 15, the differences in robustness for the fault localize classifiers were much higher in the earlier stages of noise SDs. The robustness of NEEEMD is much higher than all the other comparable methods. However, at the highest level of noise SD, these performance differences shrink. Nevertheless, for different noise SD levels, the accuracy curve of CEEMD, EEMD, CWT overlap at some point. Meaning, these three models’ order of robustness varies at different noise SDs. On the other hand, the accuracies of the NEEEMD model are comparatively higher than the other scalogram samples. These outputs indicate that the proposed NEEEMD scalograms with CNN classifier can provide the highest robustness than the other methods considered in this study.
9.2. Performance with Augmented Samples
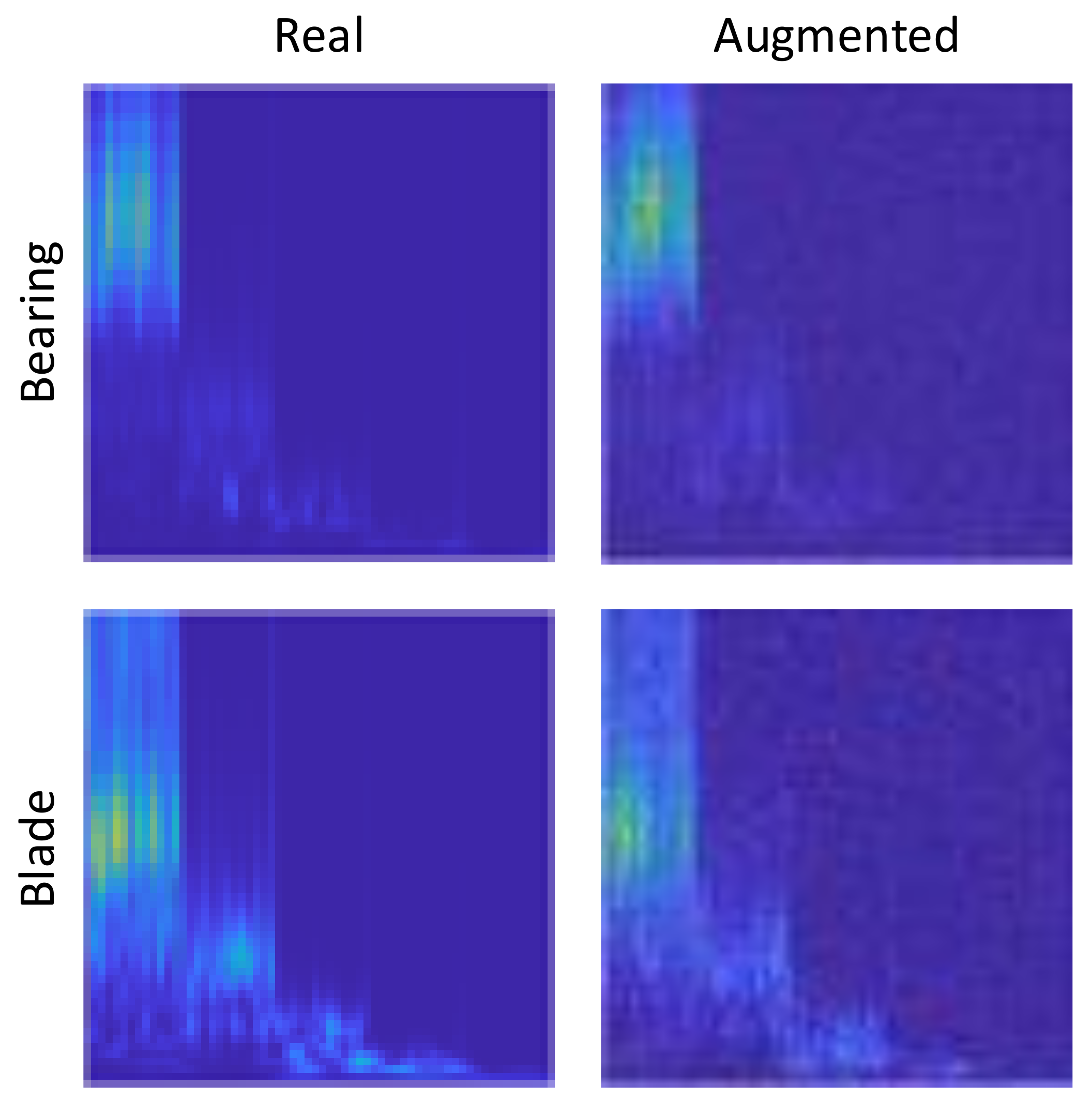
Now that it is established that the proposed NEEEMD scalograms + CNN models performed better than all the other methods, additional improvement in performance is conducted. The goal is to increase the number of training samples with the augmented data to investigate how the classifier performance changes. The fake samples from DCGAN output show that the fake samples could significantly mimic the original samples of the respective classes. However, DCGAN takes in a complete white noise to perform augmentation, and the presence of some noise can still be seen in the output samples. How to further improve this output and reduce noise is another research problem. For the classifier models, it can be predicted that adding the augmented samples in proportion with the original training samples should somewhat improve the accuracy. Nevertheless, populating the classifier with too many fake samples might have a reverse effect because the classifier would learn most from the fake data. DCGAN is applied to the samples from every single class of bearing and blade data. The desired amount of augmented samples are generated during the process. One random output of bearing and blade data using DCGAN are presented in
Figure 16 for visualization. The augmented samples have some degree of white noise presented in them as it is completely generated from random white noise. However, the augmented scalograms still successfully very much mimic the real scalograms.
In [
43], the authors attempted to find the relation between classifier accuracy and the train size. They considered three different CNN classifier models from different literature and gradually increased the training accuracy. It is observed that as the training size is increased, the accuracy also improves. However, after a turning point, the accuracy and model robustness are decreased. Moreover, it is established that for DNN, there is no definite right number of samples as the right number depends on the types of data and model architecture. It shows how the accuracy is the highest at the turning point, and the number of samples is the right number of samples for the model.
The bearing dataset has only 100 training samples. To observe how the model reacts to the increased training samples, the augmented samples are increased at a step of 50 for each class. Thus, for each increment, 500 new fake samples are added. The accuracy obtained using fake samples from DCGAN is listed in
Table 11. As the number of training samples is increased, the validation and test accuracy also increase. The highest validation and test accuracy are obtained at fake samples of 150 per class, i.e., a total of 2500 training samples. This is the turning point of our classifier model for the increased samples, and beyond this point, the accuracy keeps falling gradually. Therefore, the validation and test accuracy are enhanced from 98.2% to 99.6% and 98% to 99.6%, respectively, whereas it falls to 97.4% and 97.2%, respectively.
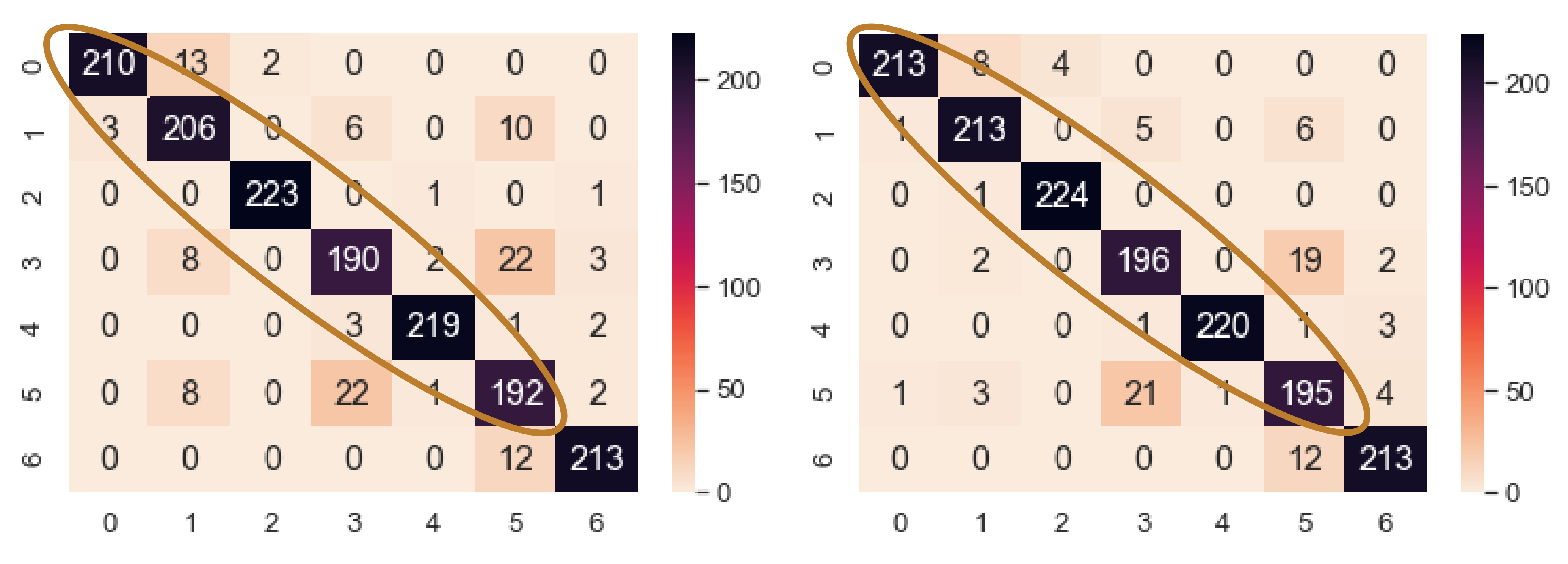
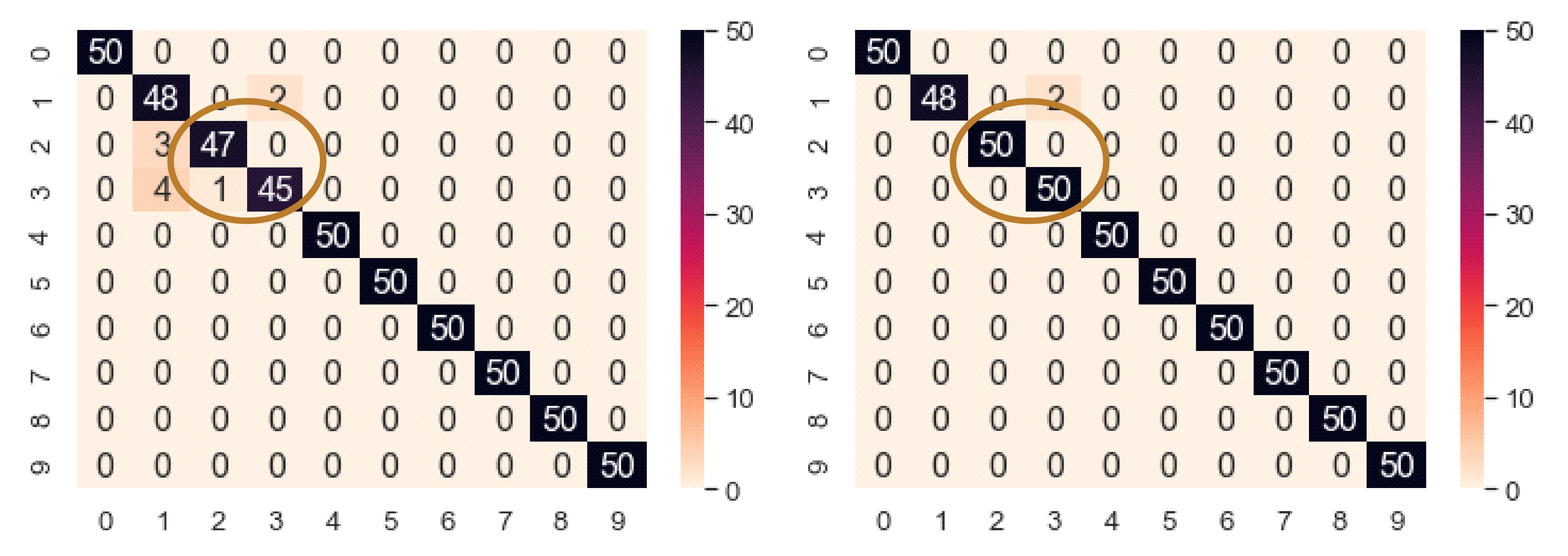
Figure 17 shows the performance improvement of NEEEMD + DCGAN from NEEEMD only. In only NEEEMD scalograms output, all the inner race fault classes had several misclassified samples. On the other hand, in NEEEMD + DCGAN output, only class 1 and class 2 contain misclassified samples. The higher fault severity of inner race, i.e., class 2 and class 3 had all correctly classified samples. Therefore, apart from class 1, all the other classes of NEEEMD + DCGAN were correctly classified. Thus, it can be concluded that, DCGAN improved the classifier robustness and produced more correctly classified samples.
The fault diagnosis model has 3 fault classes, each containing 1750 samples. The fake samples are added in a batch of 100 for each class. It means that for 3 classes, 300 samples are added with the training data in each step. At around 300 fake samples for each class, i.e., 900 more added samples and 5250 original samples (6150 total samples), the classifier reaches its turning point and achieves the highest accuracy, as shown in
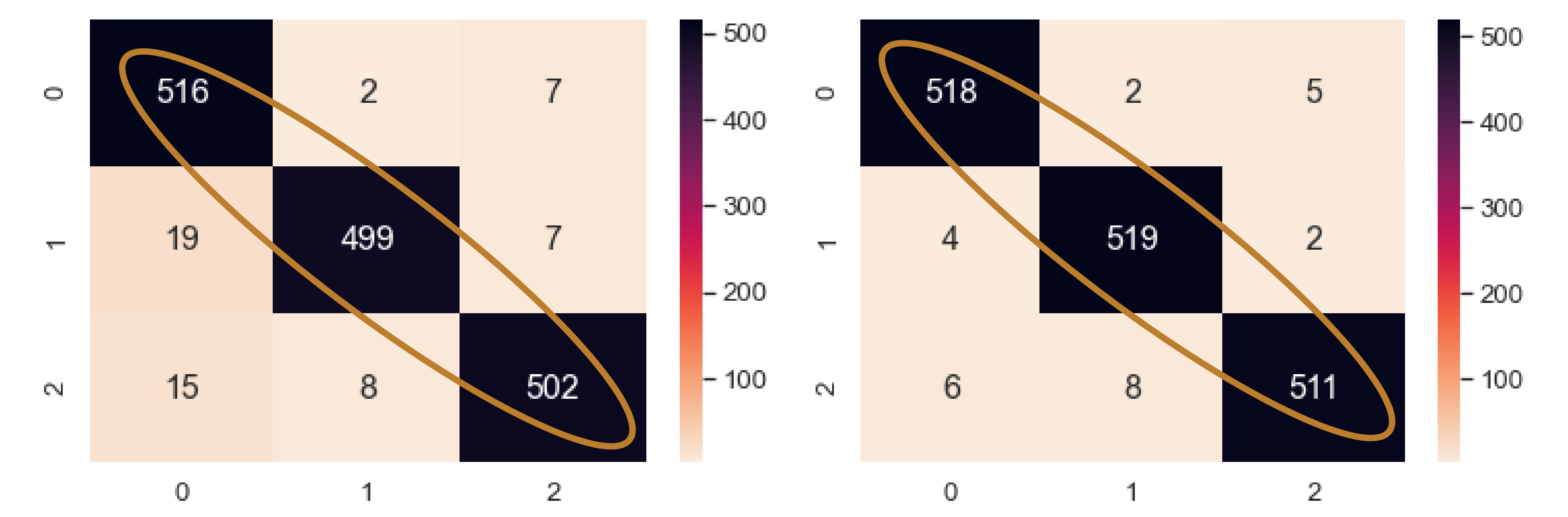
Table 12. The validation and test accuracy rose to 98.60% and 98.29% from 97.84% and 96.31%, respectively, and again fell to 96.76% and 95.24%. The confusion matrix for the 3-class classifier is shown in
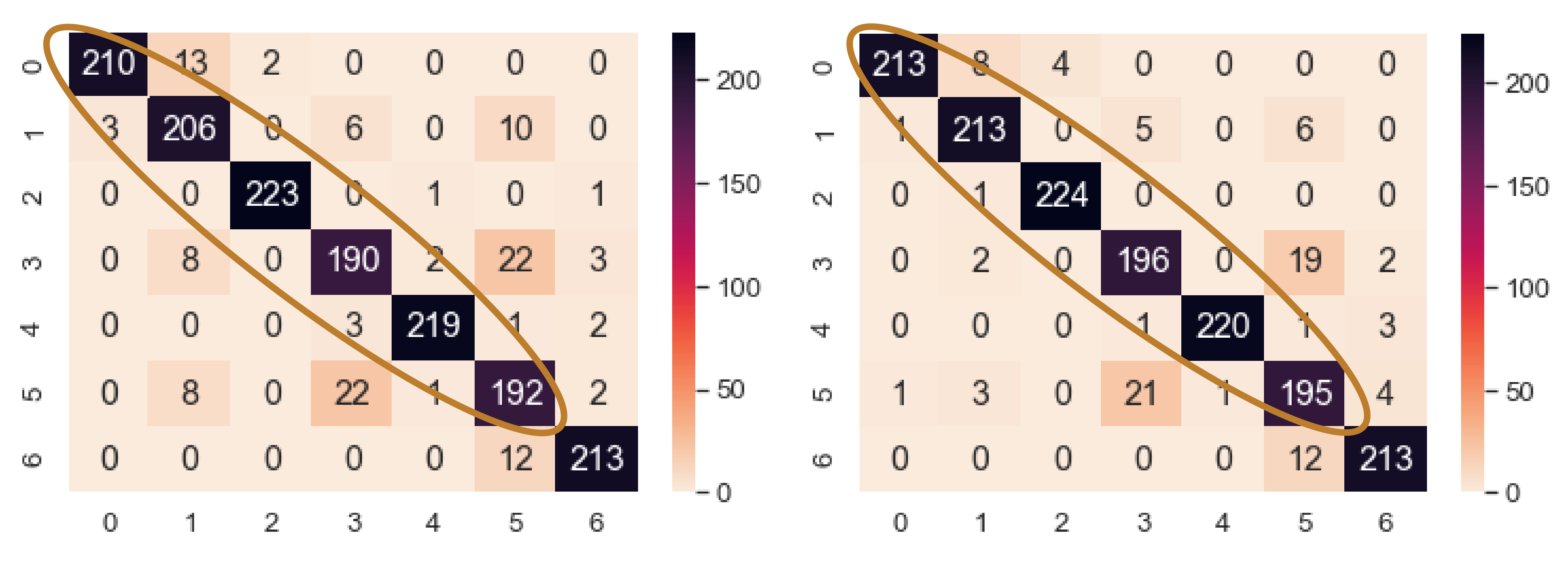
Figure 18. Here, all the classes had more correctly classified samples than the previous model with no augmentation. Class 0, 1, and 2 had 2, 20, and 9 more correctly classified samples, respectively, than the previous best model. As a result, the sensitivity for each class of the NEEEMD + DCGAN improved.
The fault localize model has 7 fault classes, each containing 750 samples. The fake samples are added in a batch of 100 for each class. This means that for 7 classes, 700 samples are added with the training data in each step. From
Table 13, around 400 fake samples for each class, i.e., 2800 more added samples and 5250 original samples (total 8050 training samples), the classifier reaches its turning point and achieves the highest accuracy. The validation and test accuracy raise to highest 94.67% and 93.59% from 93.27% and 92.25%, respectively, and again falls to 91.68% and 89.84%. The confusion matrix is shown in
Figure 19. Here, only class 6 had the same number of correctly classified samples in both cases. All the other classes in NEEEMD + DCGAN contain higher classified samples than NEEEMD only. The number of increased correctly classified samples are 3, 7, 1, 6, 1, and 3, in the order of the classes, respectively.
The improved performance using NEEEMD and DCGAN samples at the turning point is compared with the NEEEMD scalograms + CNN output and presented in
Table 14. The train, validation, test accuracies, and sensitivity values are considered to compare the bearing fault classification and three blade fault classifications. All four models show impressive improvements in validation and test accuracies. The sensitivity values for the classes are also obtained. All of the classes from NEEEMD + DCGAN show higher sensitivity values than the NEEEMD samples. Therefore, the fake samples generated from the DCGAN help to increase the CNN performance.
9.3. Improvement in Robustness
For all cases, the model accuracy increases up to a point with the increment of training samples. It can be concluded that the right amount of training samples will make the classifier more accurate. However, in order to develop a more robust model, some researchers tried to add some degree of white noise to the training data during the training phase. This technique also helps to reduce the overfitting problem. It first showed the effect of added white noise during backpropagation for a more generalized model [
44]. It is found that the input noise is effective for a more generalized classification and regression model. Kosko et al. showed that noise could generalize the classifier as well as speed up backpropagation learning [
45]. The augmented samples using DCGAN has some presence of noise in all of them. Since these noisy augmented samples are incorporated with the other training samples, a more robust classifier is expected. Gaussian white noise is added with the test samples and predicted using the trained model to verify our hypothesis. The outputs from the scalogram samples of NEEEMD + DCGAN are compared with NEEEMD to observe the performance improvement. The outputs from all the datasets and classifiers are obtained in the following figures.
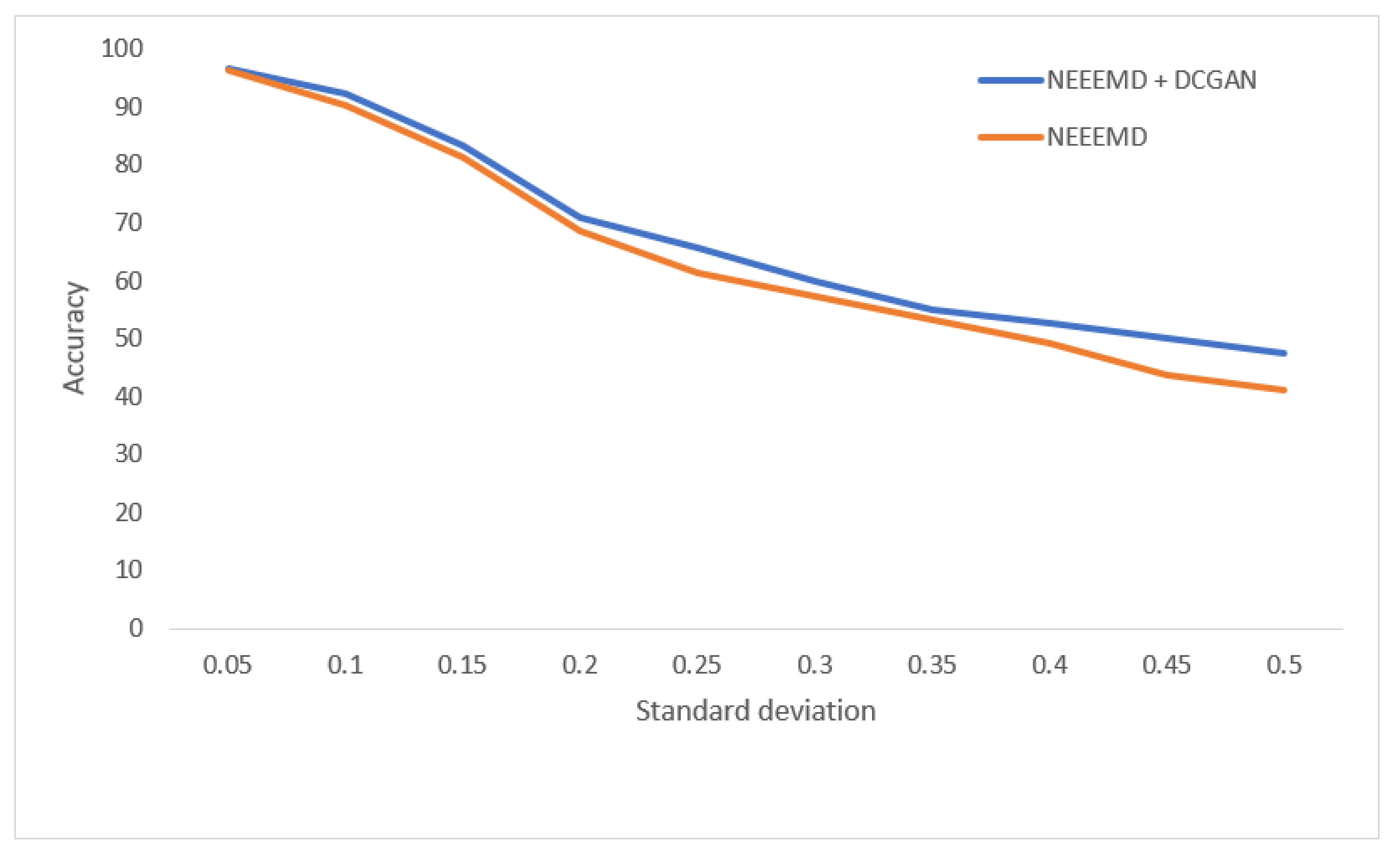
In
Figure 20, for the bearing fault classifier, as the noise SD levels rise, the NEEEMD + DCGAN model performed with significantly higher robustness than the NEEEMD scalograms model. In
Figure 21, for the blade fault diagnosis model, the NEEEMD + DCGAN model maintains relatively constant higher robustness than the NEEEMD model. In
Figure 22, the fault localization model for NEEEMD + DCGAN has higher robustness at all the noise SDs except 0.35 SD. At 0.35 SD, the robustness is the same for both NEEEMD + DCGAN and NEEEMD samples only. Apart from this only exception, the NEEEMD + DCGAN model performed with considerably higher robustness in all the classifier models. This proves that the augmented samples from DCGAN not only improved our classification accuracy, but also enhanced the models’ robustness.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}