3.2. Answer to RQ2
The second research question concerned the neuroimaging biomarkers and parameters used for the classification and prediction of the progression of AD. For AD detection, non-invasive biomarkers, such as MRI and PET, have been used commonly. During the feature selection process, the most commonly chosen features from these biomarkers are the mean sub cortical volumes, gray matter densities, cortical thickness, brain glucose metabolism, and cerebral amyloid-β accumulation in regions of interest. The neuroimaging data acquired from these technologies have been used for providing a computer-aided system to help physicians to improve healthcare systems. MRI is well-known and uses biomarkers and has demonstrated excellent performance in the implementations of AD vs. NC classifications. MRI provides the ability to study pathological brain alterations accompanying AD. It uses a magnetic field and radiofrequency pulses to generate a 3D representation of soft tissues, bones. Different types of MRI images have been used in the included studies. The sMRI was used in [
62,
63,
64,
68]. sMRI facilitates the tracing of brain atrophy and aids in finding out the possible cause of AD; it has additional advantages related to its high spatial resolution and its availability. Functional MRI (fMRI) also reflects the changes associated with blood flow. Resting-state fMRI (rs-fMRI) captures the fluctuations in blood oxygenation levels of subjects in the rest state. As a result, the brain regions affected by neuron-degeneration demonstrate diverse patterns of blood oxygenation levels. The fMRI has been used in one included study [
58]. Several of the authors have used the T1-weighted sequence(T1w) of sMRI scans. T1w sequences are part of the MRI protocols and are thought of as the most anatomical of images. These sequences approximate the closest appearance of tissues such as white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF) [
87]. These measurements are one of the most significant biomarkers to detect AD progression [
68]. T1w images were used in [
59,
60,
61,
69,
70]. The T1w sequences used are of different types, for example, 3T or 1.5 T baseline. Here, 3T/1.5T implies a 3Tesla/1.5 Tesla MRI, which is produced by a magnetic field of 3 Tesla or 1.5 Tesla and results in a cleaner and more complete image [
88]. The authors of [
89] used T1w MP-RAGE sequences of MRI and obtained excellent results. Magnetization-prepared rapid gradient echo (MP-RAGE) is a sequence of sMRI which captures high tissue contrast and offers high spatial resolution with whole-brain coverage in a short time period. PET is nuclear medicine functional imaging technology used to observe the metabolic process for AD detection. It has been used for many years for research and clinical purposes. Meanwhile, 18F-FDG-PET is the most widely used type of PET image. It provides a measure of cellular glucose metabolism. It can be used to assist the neurocognitive disorder due to AD [
90]. It is mainly beneficial for the early detection of AD, as it can demonstrate the distinctive patterns of AD earlier them MRI for MCI subjects [
91]. Another type of PET is amyloid-PET, which is used to assess brain amyloid deposition, one of the main neuropathological milestones of AD, with an elevated sensitivity and specificity in patients with established Alzheimer’s disease who underwent an autopsy within one year of PET imaging [
91]. Several studies used different combinations of biomarkers to improve the accuracy of AD detection [
92,
93].PET images were used in [
65,
66,
67]. In [
65], the authors used18F-FDG-PET with sMRI, and in [
66], the combination of 18F-FDG-PET with AV-45 PET obtained comparatively good accuracy for detecting the progression of AD. Another type of future PET is tau-PET imaging [
94]. Abnormal deposition of tau is a key contributing factor to neurodegenerative diseases such as AD. The advances in neuroimaging technologies have steered the advancement of tau-specific tracers for PET such as THK5351 and THK5357 [
95]. These images are specifically helpful in monitoring the progression of the disease. We did not find any article where the authors used tau-PET for predicting the AD progression by using DL and TL methods. Additionally, a few additional factors that are pertinent to AD detection are gender, age, the pattern of speech, EEG, tau protein, Aβ protein, retinal abnormalities, postural kinematics analysis, MMSE and CDR score, logical memory test, and some genes believed to be responsible for AD [
23]. A detailed explanation of the discussed neuroimaging modalities for AD detection was given in [
91].
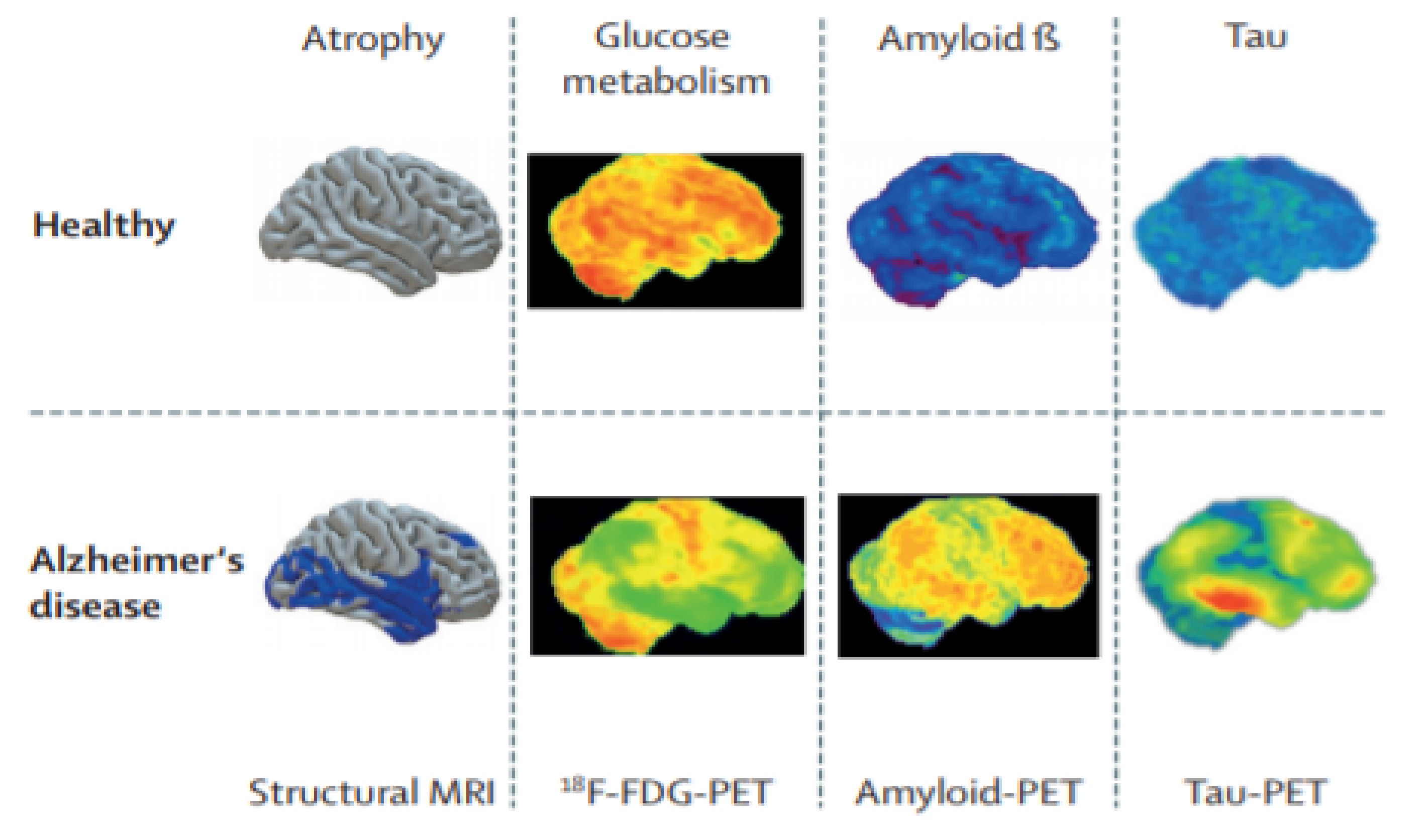
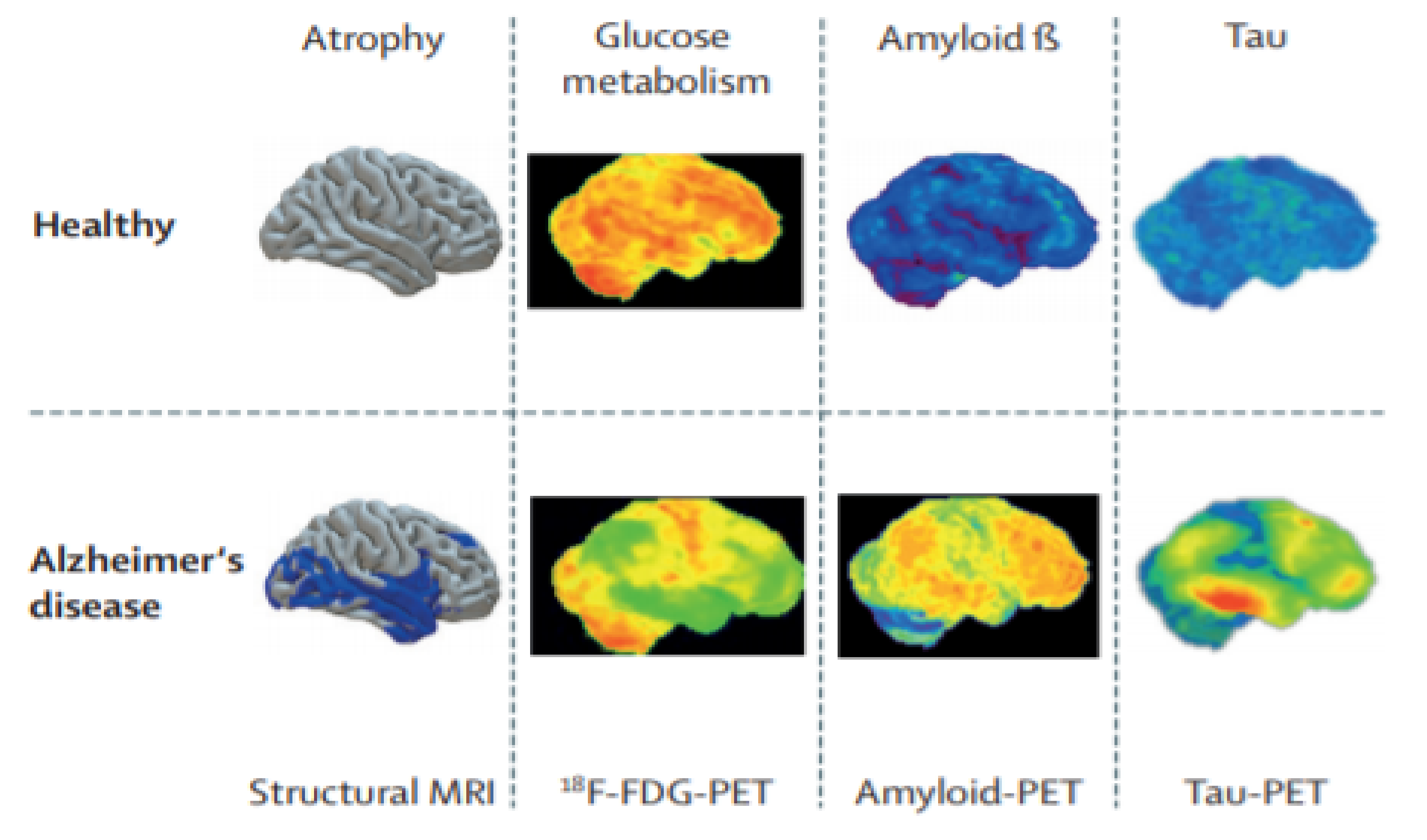
Figure 5 presents healthy and AD images. Their clinical acceptability decreases from left to right. In the sMRI, grey matter volume is displayed in blue, in the 18F-FDG PET images, reduced metabolism is displayed in green, in the amyloid-PET images, the small quantity of deposited amyloid is displayed in green or blue, and in the tau-PET images of AD patients, low tau-tracer retention is displayed in green or blue. Two other types of future PET images are TSPO-PET [
95] and SV2A-PET [
96], which can be integrated into future research with DL techniques for the detection of AD progression.
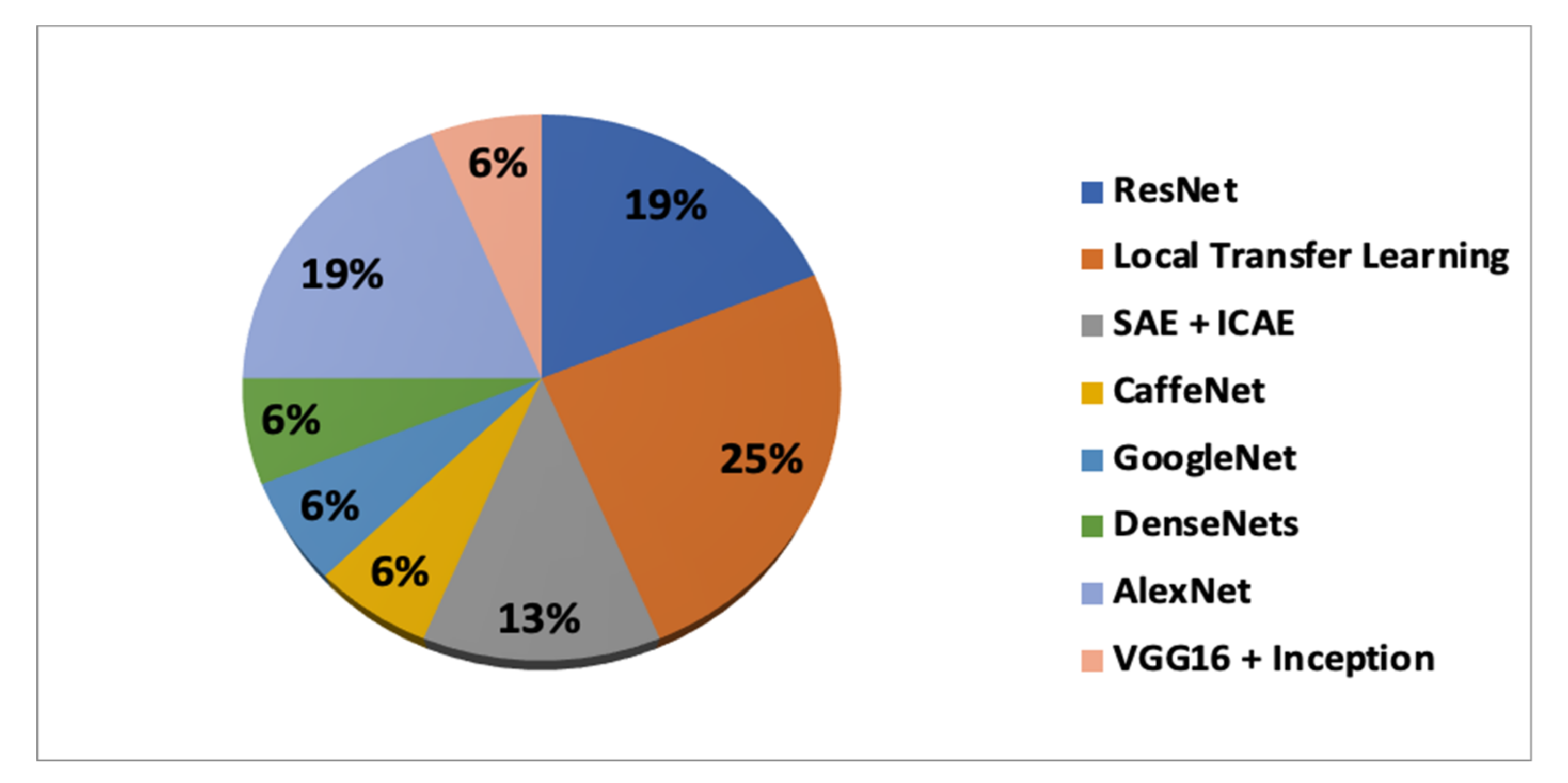
The distribution of neuroimaging modalities used in the included studies is given in
Table 2.
In
Table 3, the accuracies achieved by the type of neuroimaging biomarkers in the included studies are given.
3.3. Answer to RQ3
The third research question focuses on the used pre-processing techniques and the input management of neuroimaging modalities for the classification and prediction of the progression of AD. Pre-processing is one of the main contributing factors to determine the success of any AI-based system. It removes artifacts and noise from the data to enhance the quality of the image and improves feature extraction. Pre-processing steps are not needed in some DL architectures [
98,
99]. Nevertheless, most of the included studies used some of the following pre-processing methods on the raw neuroimaging data.
1. Intensity Normalization: The use of different scanners and parameters for examining subjects at different times may cause large variations in the intensities. It can cause performance degradation in subsequent processing, such as registration, segmentation, and tissue volume measurement [
99]. Normalization relates to plotting the intensities of all the voxels against a reference scale so that alike structures have identical intensities. The most common method is to use the non-parametric, non-uniform intensity, normalization (N3) algorithm. This is used for correcting the intensity’s non-uniformity, by sharpening histogram peaks [
100]. It has been applied in the included articles [
58,
63,
69]. In [
60], the authors normalized the intensities of the MRI scan to [0, 1]. In [
66], the brainstem region was utilized for internal normalization, as it is expected not to be affected by AD, hence the mean intensity in the brainstem region is calculated and used to distribute the average intensities respectively for each subject.
2. Spatial Smoothing: An FWHM Gaussian filter between 5 and 8 mm reduces noise level and preserves the signals present in the image [
101]. It was applied in three of the included studies [
58,
62,
64].
3. Registration (Spatial Normalization): Registration is the process of mapping a subject’s neuroimaging image to a reference brain space. It allows comparison among subjects of varying anatomy [
102]. It standardizes neuroimaging images regarding a common template such as MNI [
103]. The authors registered the neuroimaging images into the MNI template by using different methods. In [
58], linear transformation with 12 DOF (such as translation, scaling, shear, and rotation) was used. The Diffeomorphic Anatomical Registration Exponentiated Lie Algebra (DARTEL) registration [
104] was used in several studies [
59,
60,
64]. In [
62], linear (affine) registration was performed using the SyN algorithm [
105]. In [
61], the authors used non-linear registration by using the unified segmentation approach [
106]. In [
62], the images were spatially normalized to the 152 average T1 MNI template. In [
65], the authors performed image registration via a highly dimensional, highly accurate non-rigid registration method (LDDMM) [
107], widely thought of as being the prominent registration tool. Another registration process found in the literature is co-registering multiple modalities. Anterior commissure (AC) and posterior commissure (PC) are two main landmarks in the brain. AC-PC line [
108] has been embraced as a standard by the neuroimaging community, and in many examples, the reference plane for axial imaging to achieve the comparison between different subjects. In [
66], the authors registered PET images such that the forward-facing and the rearmost axis of the subjects were parallel to the AC–PC line. In [
69], the authors implemented the affine registration method [
109] to linearly align the MR images to a template. In [
70], the authors conducted rigid registration to the MNI152 space to ensure consistency of orientation and position. The authors of [
64,
67,
70] applied interpolation methods [
110] to transfer data into the same voxel sizes and dimensions.
4. Gradwrap: Correct geometry distortion due to gradient non-linearity. It was used in one included study [
63].
5. Tissue segmentation: Tissue segmentation aims at partitioning a neuroimaging modality into segments corresponding to different tissues (grey matter (GM), white matter (WM), and cerebrospinal fluid (CSF)), probability maps and metabolic intensities of the brain region in the case of PET images. Probability maps are used as the input of the classification model. Probability maps contribute the quantitative measurement of the spatial distribution of these tissues in the brain. Neurodegeneration causes changes in the volume of GM at its initial stages, specifically in the temporal lobe area [
111]. This process was conducted in [
59,
62,
64,
65,
67] using different software tools.
6. Bias-field correction: This is a low-frequency, smooth signal that degrades neuroimaging images, particularly those formed by old MRI machines [
112]. A pre-processing step is needed for correcting bias-field inhomogeneities. This process was applied in three of the included studies [
60,
61,
63] by using the N41TK [
113] algorithm.
7. BrainExtraction (Skull Stripping): For eliminating non-brain tissues, such as neck and skull tissues. It was used in three of the included studies [
58,
61,
69]. In [
61], the authors applied a mask-based approach for skull-striping.
8. Motion Correction: Used to eliminate and make the impact of head motions more precise during the data acquisition process. It was used in one included study [
58].
9. High-pass filtering: Used to eliminate the low-frequency noise signal, which is generated because of psychological artifacts. It was used in one of the included studies [
58].
In [
68], the authors used the entropy-based sorting mechanism to choose the most informative images from the axial plane of each 3D MRI scan, and they did not use any other pre-processing methods.
In
Table 4, the dissemination of each pre-processing method from the included studies is given; as we can see, almost 50% of studies performed intensity normalization and registration.
Based on the extracted features from the neuroimaging modalities, the management of input data can be allocated to the following four categories.
1. Voxel-based input management: In this approach, voxel intensity values of the complete neuroimaging modalities or tissue components are used. The registration method is necessary for this approach to map all the images into a standard 3D space. In [
59], the authors performed tissue segmentation and registration on T1-weighted MRI to generate the GM, WM, and CSF tissue probability maps in MNI space. Several research studies [
60,
61,
70] performed a full brain image analysis of T1W sMRI. In [
66], the authors performed the full brain analysis in multimodality mode (18 FDG-PET and AV-45 PET) and co-registration by using the AC–PC line. The advantage of full brain analysis is that the spatial information is fully integrated, and we can obtain 3D information from neuroimaging scans. The drawback of this approach is the high dimensionality and computational load. In [
64], the authors segmented the sMRI images into GM, WM, and CSF by using the DARTEL method and used PCA and SFS for the precise selection of the best features.
2. Slice-based input management: In this approach, 2D slices are extracted from 3D brain scans either by using the researcher’s logic or standard projections such as the horizontal plane, frontal plane, and median plane. Full brain analysis is not possible, as all the information of 3D brain scans cannot be converted into a 2D slice. For tissue segmentation, generally, slice-based methods take tissues from the central part of the brain. In [
58], the authors performed many pre-processing steps, as given in
Table S4, to convert 3D rs-fMRI scans to 2D images, along with the image height and time axis, and they obtained 6160 2D images for each fMRI scan and saved them in PNG format. In [
63], the authors used Matlab and NifTi to convert 3DMRI scans of each subject into 160 2D image slices. In [
67], the authors converted the NifTi images (created from the gray matter density maps of each subject) averaged from the Z-axis into 65 PNG images. In [
68], the authors performed the entropy-based sorting mechanism to select the 32 most informative images from the axial plane view of each 3D scan. The advantage of this approach is to decrease the number of parameters to thousands from millions during the training and testing phase of the model. Because of using 2D representations of 3D scans, the adjacent 2D images lose spatial dependency.
3. ROI-based input management: Studies based on the region of interest focused on the areas that are identified to be informative. In this context, the informative parts that are affected in the early stage of AD have to be recognized. The hippocampus, amygdala, and entorhinal cortex, grey matter in the entire brain, and the temporal and parietal lobe must be treated with greater precedence for AD or MCI classification, whereas the amygdala and hippocampus can be used for predicting the conversion of MCI to AD [
114]. Meanwhile, the occipital lobe, thalamus, globus pallidus, and putamen ought to be low priority choices for the early diagnosis of AD. This approach also requires the previous knowledge of the brain atlas, such as automated anatomical labeling (AAL) [
115] or Kabbani reference work [
116]. In [
62], the authors identified the utmost discriminative brain regions for classifying the pMCI vs. sMCI by approximating occlusion sensitivity utilizing the network occlusion approach [
117]. They occluded brain networks in reference to the AAL brain atlas one at a time, and the significance of each brain region was assessed. The most relevant weights were perceived in the “hippocampus, temporal superior, par hippocampal gyrus, middle and inferior gyrus, occipital superior, fusiform gyrus, middle and inferior gyrus including cuneus and calcarine, lingual gyrus, frontal middle, and inferior gyrus regions, precuneus, and cerebellum 6, crux 1 and 2 regions” [
62]. They concluded that the hippocampus and amygdala subcortical regions in the medial temporal lobe are the most informative regions in the early AD. In [
65], the authors segmented the sMRI into GM and WM and divided the GM into 85 cortical and subcortical anatomical ROIs. In [
69], the authors performed the segmentation of the hippocampus from other regions and create a binary mask for the individual hippocampus. After that, the centroid of each hippocampus was calculated, and patches were extracted from the centroid for further implementation. The ROI-based approach has the advantage of low feature dimension and easy interpretation, but it ignores all the details of abnormalities. Still, research is ongoing to identify the most informative or affected part of the brain due to AD [
33,
118].
4. Patch-Based Input Management: A patch is a 3D cube; in this approach, disease-related patterns are identified by mining the features from patches. The core issue is to select the most discriminative patches for expressing both patch-level and image-level features [
32]. In [
65], the segmented ROI is additionally sectioned into smaller regions of variable dimensions, termed as patches, for implementing the multiscale method. This method states that the signal extracted at multiple scales from the fine-scale to the coarse-scale can be applied concurrently to detect deviations due to AD. The sizes of the patches were decided based on the consideration to retain sufficient comprehensive information as well as to avoid large feature dimensions. The subdivision of ROI into patches is performed by the k-means clustering algorithm [
119], where ROI can be clustered by using spatial coordinates. In [
69], a binary mask was created by means of the segmentation of each hippocampus, and 3D patches were created by cropping at the centroid of each mask. Three-dimensional patches decomposed further into two patches, for the internal and external hippocampus. The benefit of this approach is that it is sensitive to small changes, but selecting the most informative patch is still a challenge. The input management method-wise analysis of different pre-processing techniques for neuroimaging biomarkers has been summarized in
Table S4.
We conclude that input management is also a critical issue. A 2D-slice input has the advantage of fewer training parameters and a less complex network, but also has the drawback of losing spatial dependency between nearby slices. Voxel-based input management considers all the brain information but treats all regions equally, without any consideration of the anatomical structure, and has the drawback of high feature dimensionality and load on the processors. An ROI-based input is easily interpretable and has been used in clinical diagnosis, but in this method, the entire brain is represented by fewer features, and it provides knowledge about only a particular part of the brain, such as the hippocampus. Research is still ongoing to recognize the uses of other brain regions in detecting AD. Sometimes the ignorance of small abnormalities in the ROI may be the cause of damage to discriminative information and restrict the true command of extracted features. Nevertheless, patch-based input management can competently handle large feature dimensions and are responsive to small changes [
120]. In
Table 5, the distribution of input management approaches in the included studies is given.
3.4. Answer to RQ4
Out of 13, two studies performed multiclass classification and 11 studies performed binary classification. The accuracy performance metric was used consistently in all the included studies. In [
58], the authors performed multiclass (AD, NC, sMCI, pMCI, SMC, MCI, respectively) classification by using the softmax classifier and rs-fMRI, and achieved an average accuracy of 97.92% and 97.98% for the off the shelf and fine-tuned models, respectively. In [
63], the authors performed three-way discrimination among the NC, sMCI, and pMCI, respectively, by using the GoogleNet/softmax and CaffeNet/softmax, and obtained an overall accuracy score of 83.23% and 87.78%, respectively. In [
59,
60], the authors implemented all possible binary classifications for distinguishing NC, sMCI, and pMCI (AD vs. NC, NC vs. sMCI, pMCI vs. sMCI, NC vs. pMCI, and AD vs. sMCI, AD vs. pMCI) by usingT1wMRI. In [
61], the authors performed binary classification for AD vs. NC and sMCI vs. pMCI by using three input management approaches (ROI-based, patch-based, subject-level); for implementing all these methods, three different datasets and T1wMRI were used. Datasets are discussed in detail in
Section 3.5.In [
62], the authors performed binary classifications tasks (AD vs. NC, sMCI vs. pMCI, NC vs. pMCI, AD vs. sMCI) by using ResNet, SVM classifier and sMRI. In [
64], the authors performed only one binary classification task (sMCI vs.pMCI) by using CaffeNet and sMRI biomarkers. They combined PCA and SFS for feature selection and finally adopted SVM for the prediction. In [
65], the authors used multimodality (FDG-PET metabolism imaging and sMRI) and an ensemble of classifiers, multiple networks were trained, and then they chose the final classification result (PCA followed by SVM) to identify subjects classes (AD vs. NC, sMCI vs. pMCI). In [
66], the authors performed the binary classification for AD vs. NC and sMCI vs. pMCI by using multimodality(FDG and AV-45 PET) and softmax classifier. In [
67], the authors performed the binary classification sMCI vs. pMCI by using FDG-PET images, AlexNet, and SFS feature selection followed by an SVM classifier. In [
68], the authors used three different models (VGG16-from scratch, VGG16-TL, InceptionV4-TL), softmax classifier, and sMRI biomarkers for the binary classification of AD vs. NC. In [
69], the authors conducted the multi-class classification (AD vs. NC, sMCI vs. pMCI, and sMCI vs. NC) by constructing DenseNets on the decomposed patches of the internal and external hippocampus of T1wMRI images, cascaded by RNN to learn the features from both hippocampi and the softmax classifier. The authors also compared the proposed method by implementing other commonly used hippocampus analysis methods such as disease detection by shape and volume analysis of the hippocampus. In [
70], the authors performed a binary classification task (sMCI vs. pMCI) by extending feature-based transfer learning with knowledge transfer. They introduced a surrogate age marker that was captured through pre-training, and then they applied fine-tuning for the final prediction by combining the output of 3D CNN and surrogate age marker. They used T1wMRI and a fully connected layer obtained through flattening for predicting the value of surrogate age marker.
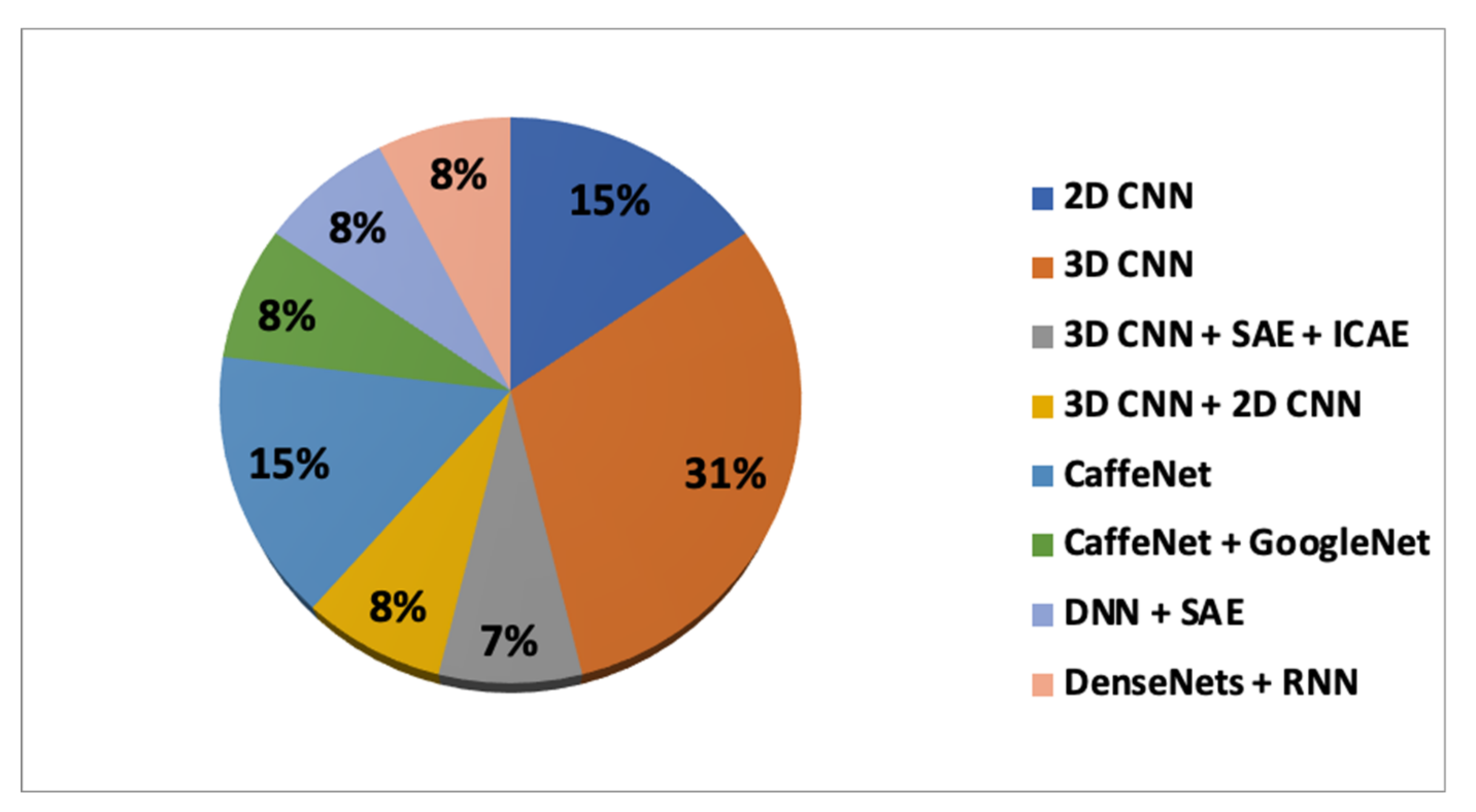
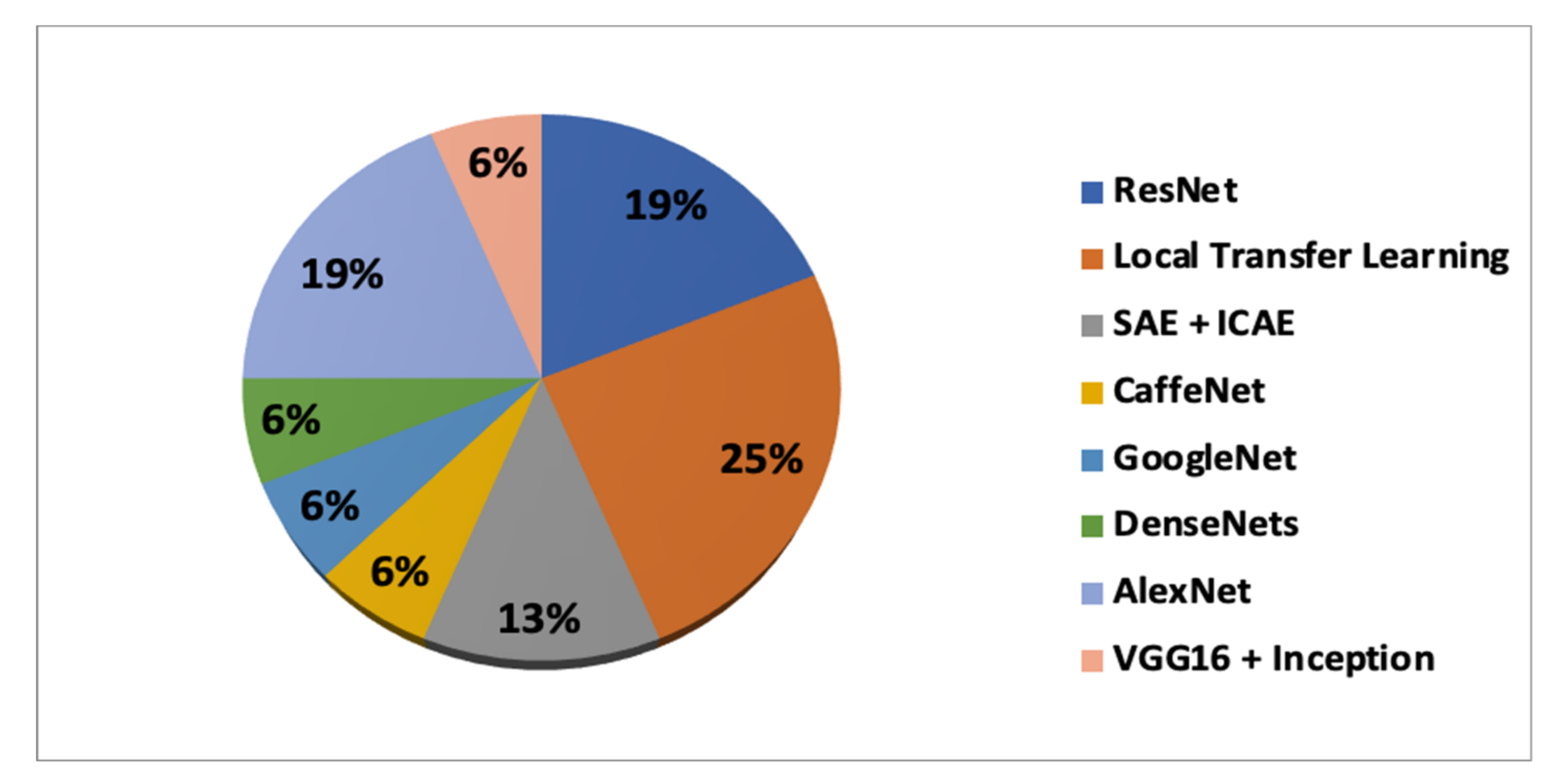
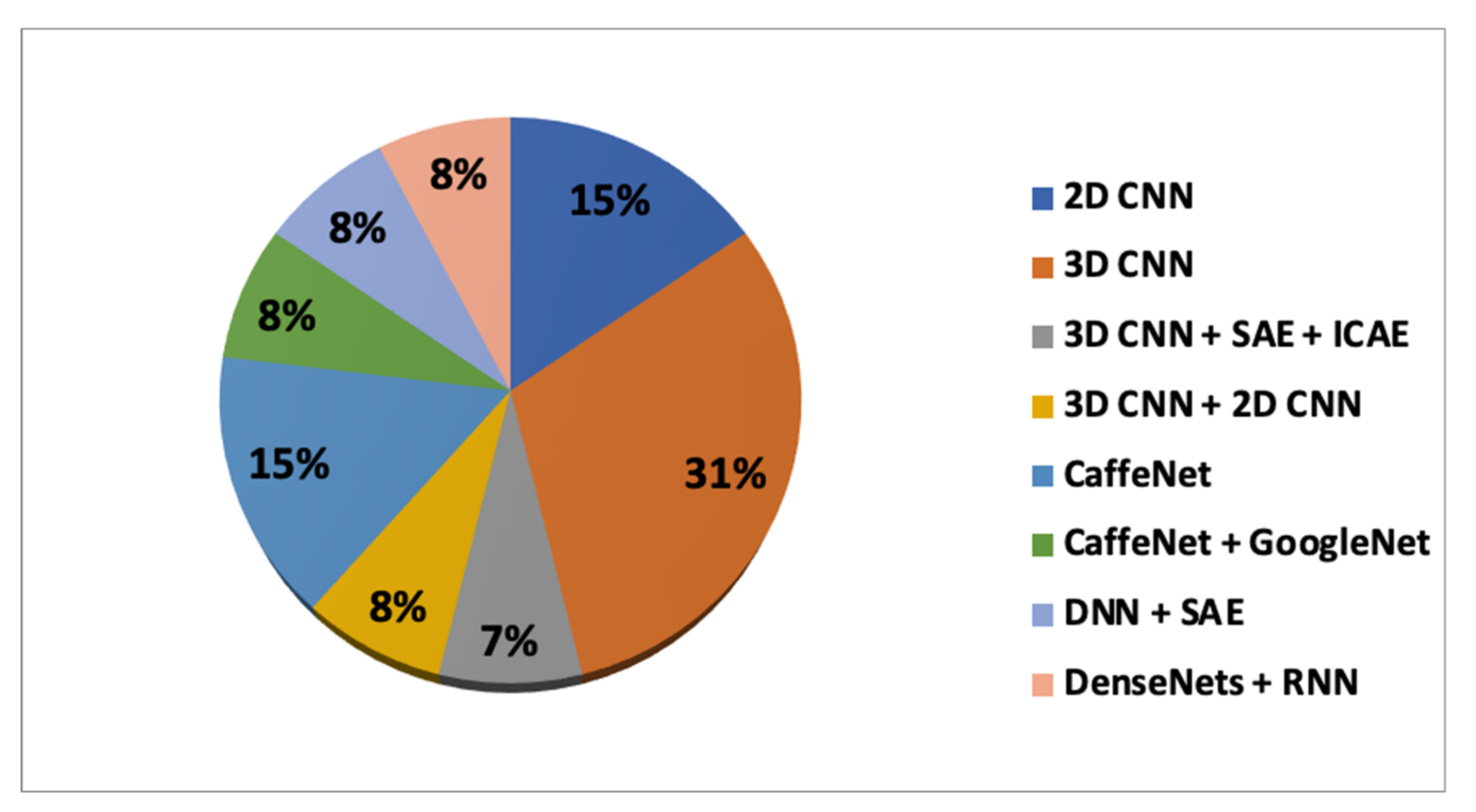
In
Table 6, the accuracy achieved according to the DL and TL combinations is presented. It can be seen that the maximum accuracy achieved for classifying the sMCI vs.pMCI is 87.78%, obtained through the combination of CaffeNet (training) and ImageNet(transfer learning).
In
Table 7, the accuracy achieved according to the input management and neuroimaging biomarkers is presented. It can be seen that the maximum accuracy achieved for classifying the sMCI vs. pMCI is 87.78%, obtained through the combination of slice-based and sMRI.
3.5. Answer to RQ5
Numerous online datasets of neuroimaging biomarkers are available that have been developed with the motive of providing the free availability of neuroimaging data to the community of scientists to assist in forthcoming discoveries in the neurosciences. Datasets such as ADNI [
121], OASIS [
122], AIBL [
123], IXI [
124], and MIRIAD [
125] are freely available online.
ADNI: ADNI was developed by longitudinal multicenter studies. It was released in 2004 by the National Institute of Aging (NIA), the National Institute of Biomedical Imaging and Bioengineering (NIBIB), and some other national institutes as a USD 60 million, 5-year partnership project, based in North America. The acquisition of all the data was achieved through the ADNI protocol. To date, they have four variants: ADNI-1 (400 MCI,200 sMCI, and 200 NC contribute to the research and were followed for 2–3 years, with MRI and FDG-PET biomarkers only), ADNI-Grand Opportunities (the existing ADNI-1 cohort + 200 EMCI subjects), ADNI-2 (ADNI-1, ADNI-GO cohort + 150 NC,100 EMCI,150 LMCI, and 150 mild AD subjects,107 SMC subjects and also amyloid PET images have been added), and ADNI-3(which began in 2016 and will remain up to 2022, and tau-PET has already been added as a key indicator for AD, while further research is ongoing for the discovery, optimization, standardization, and validation of clinical trial measures for AD detection). In this work, this is the most used dataset, being used in 92% of studies by itself or in combination with other datasets.
OASIS: OASIS-3 is the latest release in the OASIS series. The formerly released OASIS-Cross-sectional and OASIS-Longitudinal datasets have been utilized for AD research, OASIS-3 is the longitudinal, cognitive biomarker dataset for normal aging and AD. It contains the neuroimaging data generated from 2168 MRI sessions and 1608 PET sessions by using 1098 subjects (609 NC and 489 people at different stages of cognitive debility) in the age range of 43-95 years. It was used in 16% of the studies in our review.
AIBL: This is known as Australian ADNI, and adds scientific value to the ADNI cohort. It contains 250 MR/flutemetamol, 200 MR/florbetapir, and 50 MR/PIB images. It was used in 8% of the studies in our review.
IXI: This contains 600 images from normal, healthy subjects. Researchers can download T1wMRI, T2wMRI, and DTI images directly in NIFTI format. It was utilized in 8% of the studies in our review.
MIRIAD: This is a database consisting of MRI scans of 46 AD and 23 NC subjects, and scans were collected at interims from 2 weeks to 2 years. This study has the objective to examine the viability of using MRI for clinical trials of AD.
Meanwhile, several studies preferred to use their own datasets. In [
59], the authors designed a self-regulating dataset “MILAN” of 3D T1 weighted images, acquired from 229 subjects (124 AD,50 MCI,55 NC), recruited at the Neurology Department, Scientific Institute, and University Vita-Salute San Raffaele, Milan. The distribution of the discussed datasets in the included studies is given in
Table 8.
Only some studies used the combination of different types of datasets. For developing a clinically acceptable system, researchers should use data of different homogeneities [
126]. The size of the datasets must be balanced either by taking the same number of images for training and testing or by redefining the loss function. Other points such as patient overlapping, set sampling or ground truth should also be considered for the uniform distribution of data and avoiding data leakage during training and testing. Techniques for avoiding data leakage and overfitting are discussed in
Section 3.7. Furthermore, all the other details, such as sample size and the combination of different datasets from all included articles, has been summarized in
Table S3.
3.6. Answer to RQ 6
Different software packages are available to assist researchers in perfoming the pre-processing of neuroimaging data and the implementation of DL and TL methods. The following brain image analysis packages were used for the pre-processing of neuroimaging biomarkers in the included articles. The pre-processing pipeline implemented by these packages is given in
Table S4.
FSL [
127]: This is the all-inclusive library of tools for analyzing sMRI, fMRI, and DTI neuroimaging data. Most of the tools can be run either by command line or GUI interface. It was used in [
58,
59].
SPM12 [
128]: Thus is intended for the analysis of neuroimaging data sequences; the sequences can be a succession of images from diverse allies. The current release, updated on 13 January 2020, is specifically intended for the analysis of fMRI and PET images. It was used in [
59,
60,
62,
64].
Nipype [
129]: This is an open-source Python project developed by the Nipy community [
130], provides an even interface to the currently available brain imaging software, and facilitates communication amongst these packages (for example, AFNI [
131], ANTS [
132], Camino [
133], FreeSurfer [
134], FSL, MNE [
135], Slicer [
136], SPM [
137]) within a single flow. It eases the learning curve required to use diverse packages. One of the most important advantages is that it makes one’s research reproducible and shares one’s processing workflows with the research community. It was used in [
61].
MATLAB [
138]: The image processing toolbox permits one’s to mechanize common image processing workflows. The researcher can section image data, perform batch processing for large datasets, perform the registration of images, create histograms, and manipulate ROIs. MATLAB was used in [
63,
68].
NifTi_2014 toolkit [
139]: This is a tool for analyzing and processing neuroimaging images that can be loaded by MRIcro software [
140] and MATLAB2015b [
141]. It was used in [
67].
FreeSurfer [
134]: This is an open-source collection for analyzing and processing MRI images, developed by the Laboratory for Computational Neuroimaging (LCN), USA. It is a set of automated tools for the renewal of the brain cortical surface from sMRI and the overlap of fMRI onto the recreated surfaces. It was used in [
65].
MRIcron [
140]: This allows users to view medical images in various formats, and creates format headers for exporting neuroimaging biomarkers to other platforms. It is a stand-alone program but includes tools to analyze MRI, fMRI, and PET images. It can be used for the efficient viewing and exporting of neuroimaging data and to identify ROIs. It was used in [
70].
Moreover, in [
66], the authors did not perform any pre-processing of FDG and AV-45 PET images. Pre-processed images were downloaded from the ADNI at the most progressive pre-processing stage, and were used for deep CNN training and testing. The dissemination of pre-processing software in the included articles is given in
Table 9.
Software packages such as CAFFE [
85], Keras [
142], Tensorflow [
143], Theano [
144], Pytorch [
145], MatConvNet [
146], and the Deep Learning toolbox [
147] have been used for implementing DL and TL algorithms. In
Table 10, details of the packages used in the included articles are given. The distribution of software packages in the included articles is given in
Table 11.
3.7. Answer to RQ7
Dataset size has a notable impact on the performance of classifiers on an unseen test dataset [
44]. The available datasets of AD and MCI subjects are of a relatively small size, with only a few hundred samples. DL algorithms tend to be easily over-fitted when trained on a lower number of samples due to a large number of training parameters. In this section, we discuss the techniques used in the included articles for reducing overfitting.
Data Augmentation: This is a way of increasing the heterogeneity of training datasets without collecting new data. It generates new data samples from the existing data. It can be categorized into two methods. The first category is transformation methods, which cover a mixture of simple transformations such as random translation, rotation, reflection, distortion, blurring and flipping, cropping, noise injection, gamma correction, scaling, and intensity variations by arbitrarily adjusting brightness, contrast, saturation, and hue on the training data. Transformation methods were used in [
59,
60] to improve the classifier performance. The second type of method is neuroimaging data synthesis [
148], intended to generate a new dataset that shares features with the source dataset [
68]. It can be implemented by using autoencoders (AE) [
149] and generative adversarial networks (GAN) [
150,
151] for neuroimaging biomarkers. Nevertheless, this area needs to be explored and the effectiveness of the synthesis images for predicting AD still must be proved. In [
58], the authors obtained 6120 2D images from each fMRI scan by using pre-processing techniques. In [
63], the authors employed a novel strategy for data augmentation, based on the image integration method Shin [
152], to create sample image patches from MRI. It uses the information from training data adequately to implement the constraint of the three-channel input of CNN. In [
66], the authors performed the augmentation of PET images by flicking them in the left–right direction. In [
69], the hippocampus centroid is shifted by ±2 voxels in the x and z directions to extract more patches. Technical insights of the augmentation approaches from included articles are given in
Table S3. Nevertheless, some studies did not perform augmentation at all [
62,
64,
65,
67,
68,
70], and relied only on TL methods to reduce overfitting.
Transfer Learning: This is the idea of utilizing a model trained on a certain chore (for example, the ImageNet classification task or unsupervised learning task), conducive to achieving the task of AD classification or predicting the progression of MCI to AD. TL methods may reduce the overfitting by providing a better weight initialization of DL models. It also reduces the time needed for training the DL models and provides better performance compared to training from scrap [
153].
Regularization: This can be performed by using different approaches, such as dropout, weight decay, and L1/L2 regularization. Dropout relies on the idea of arbitrarily and independently dropping neurons, setting their output value equal to zero, which makes the network less intricate and less vulnerable to overfitting. It improves the generalization capability of the DL model. The number of nodes chosen varied from 25% to 50% from one study to another. Weight decay also increases the generalizability of the model by regularizing the updated weights, multiplying them by a factor slightly smaller than one; it also reduces the complexity of the model. Dropout and weight were employed in several of the included studies [
61,
62,
65,
69,
70].
Batch Normalization: This is a technique for training DL models, which standardizes the input to a layer for each mini-batch. It speeds up the training process and increases the performance and generalizability of the models.
Early stopping: This involves stopping the training process at a former point. It helps in determining the number of iterations needed for training the model, before being critically overfitted. It was used in several of the included studies [
62,
65]. In [
65], the validation set was only used to define the early stopping time-point.
Cross-Validation: In this technique, the database is divided into training and testing sets many times by keeping the same proportion but rotating the instances every time. It is a statistical method for testing the performance of classifiers. The most-used cross-validation method is k-fold. In our review, the value of k ranges between 5 and 10. It was used in 85% of included articles
Another major issue that was taken care of by the researchers is data leakage, which also leads to the overfitting and biased evaluation of classification algorithms. It occurs because of using test data in the training process [
10].The following four main causes of data leakage were noticed.
Wrong data split: This implies that images of similar subjects are used at several points in time (training, validation, and testing) [
154]. For unbiased evaluation or to reduce overfitting, the researchers have to split the data at the subject level, not at the image level.
Late Split: Perform data augmentation after splitting the datasets for an unbiased evaluation. If augmentation is conducted before the split, the same images may be found at multiple points in time.
Prejudice Transfer Learning: When the source and destination targets overlap, when a model is trained during the task of AD vs. NC classification and used for initializing the weights of another task MCI vs. AD, in this case, AD subjects used in the training set of the source task can be in the testing or validation set of the target task. Researchers have to use different datasets for the source and destination, as the authors did in [
59,
60,
65,
66].
Absence of an independent validation set: An unrelated validation set (from the test set) should be used for hyper parameter optimization.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}