
Deep Cooperative Spectrum Sensing Based on Residual Neural Network Using Feature Extraction and Random Forest Classifier


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- When generating the signals, severe noise conditions were taken into account, such as the wide range of distances between users and the high noise level itself. In addition, a large amount of instances was generated.
- The spectral and transformation features were extracted to represent the signal received by each UU in a vector, reducing needs for a complex classification model.
- The proposed ResNet and some deep learning approaches such as CNN and RNN were trained and tested, as well as classical machine learning algorithms such as RF and support vector machine (SVM). The corresponding accuracy of these networks is analyzed and compared.
- A high level of accuracy in the correct identification of LUs was achieved by taking into account the high level of and the cooperation of few UUs. Therefore, the experimental results validate the effectiveness of the proposed scheme.
2. Related Works
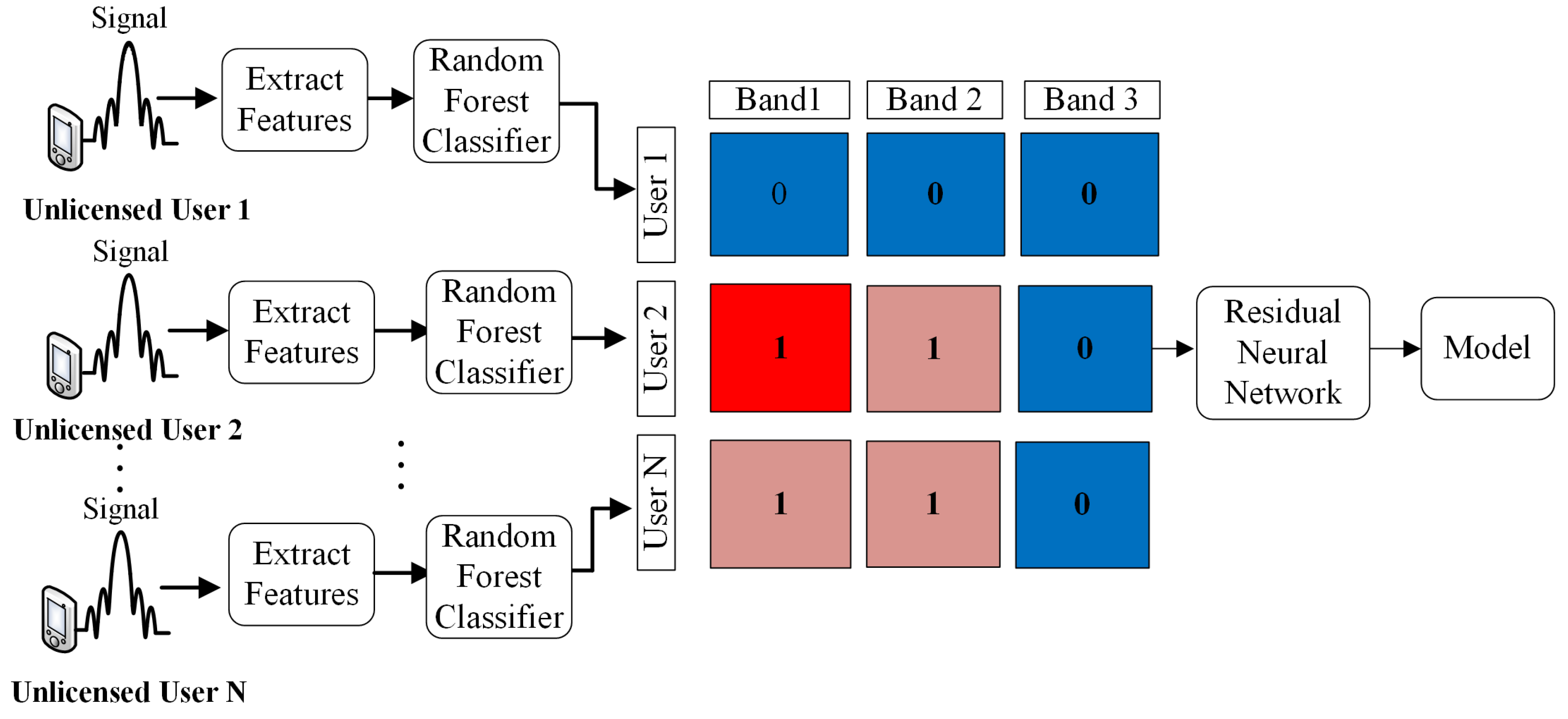
3. Proposed Deep Cooperative Spectrum Sensing Using Random Forest and Residual Neural Network
3.1. Setup
3.2. System Model
3.3. Dataset
3.3.1. Signal Generation
3.3.2. Feature Extraction
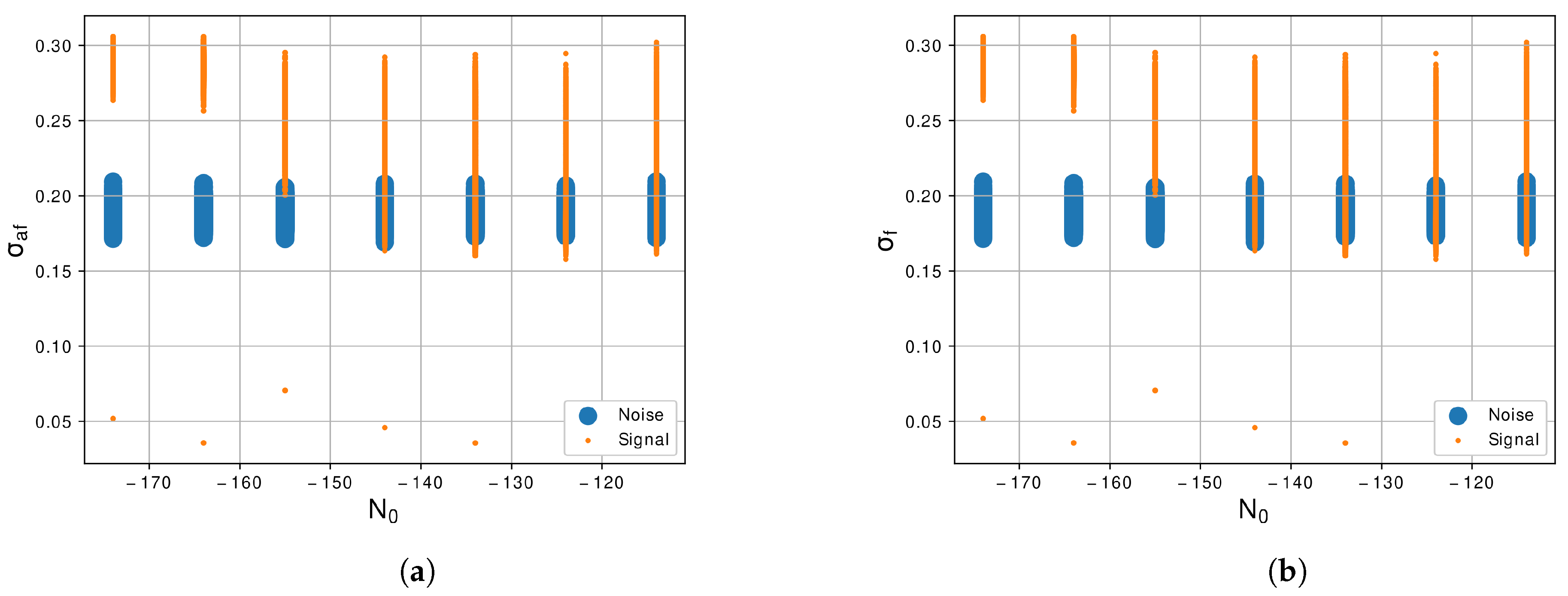
- Maximum value of the power spectrum density (PSD) of the normalized and centralized instantaneous amplitude ():where the number of samples by segment and is the normalized and centralized instantaneous amplitude, . Being the Hilbert transform, the received signal sampled at and is given by .
- Standard deviation of the normalized and centralized instantaneous amplitude ():where is the average of the normalized and centralized instantaneous amplitude.
- Standard deviation of the centralized nonlinear absolute instantaneous phase () is evaluated over non-weak ranges of the signal segment. The weak segments refer to values of the amplitude, , that are susceptible to phase distortions due to the insertion of Gaussian noise, then the region where as non-weak segments was defined. The is expressed below:where and C is the total of samples in the non-weak segment of the signal. The variable is the nonlinear phase described by angulation between the real and imaginary components of the Hilbert transform of the received signal . Furthermore, is the value of the nonlinear component of the instantaneous phase in instants of time .
- Standard deviation of the centralized direct nonlinear phase ():
- Standard deviation of normalized and centralized instantaneous frequency () is evaluated over non-weak ranges of a signal segment, is obtained according to the following expression:being , where is the digital sequence symbol rate, and is the instantaneous frequency given by the derivative relative to the time of divided by , .
- Standard deviation of the absolute value of the normalized and centralized instantaneous frequency ():
- Maximum PSD value of normalized and centralized instantaneous frequency () is given by the equation:
- Maximum value of the discrete cosine transform ():The maximum value resulting from the use of the discrete cosine transform over the complex wrap of the signal, given by the , represents the feature.
- Maximum value of the Walsh–Hadamard Transform ():being the matrix of two points and ⨂ the Kronecker product. The feature is obtained by calculating the maximum value of the coefficients of the Walsh–Hadamard transform of the complex wrap of the signal.
- Standard deviation of the discrete Wavelet transform ():where is the discrete Wavelet transform.
3.3.3. Random Forest Classifier
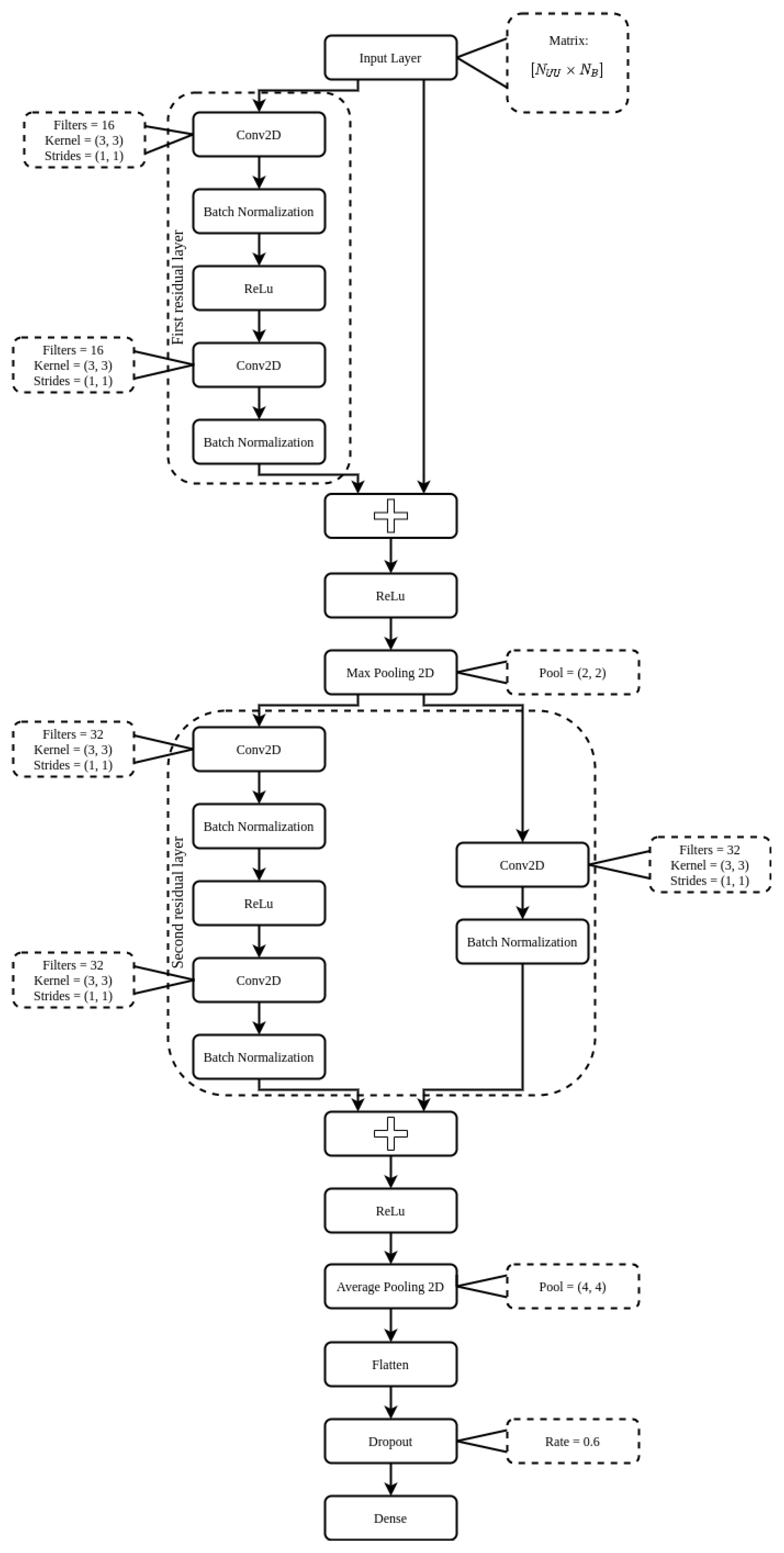
3.4. Residual Convolutional Neural Network
3.5. Metrics
- Accuracy:where is true positive, is true negative, is false positive and is false negative.
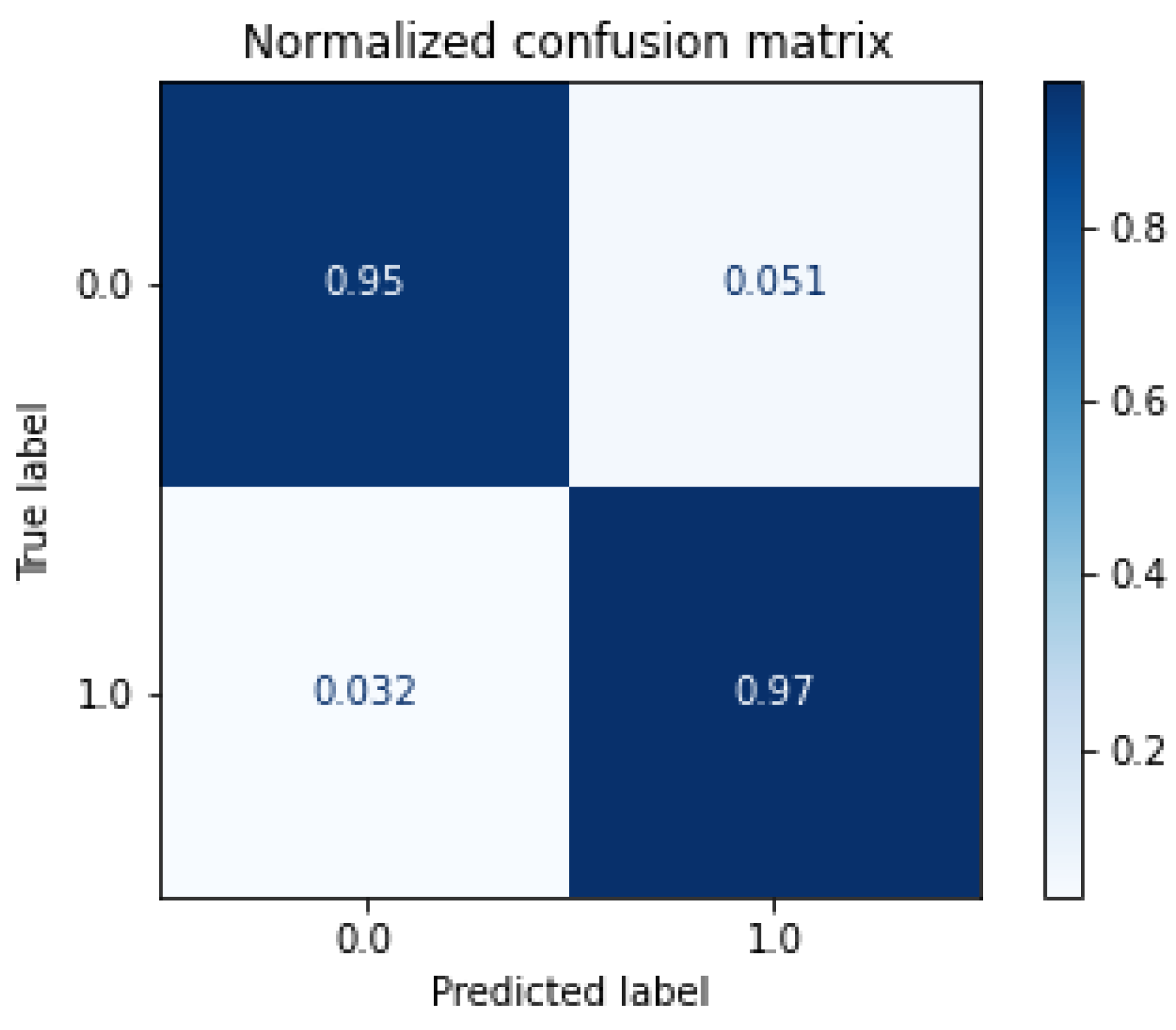
- Confusion matrix, Figure 3:
4. Experiments and Results
4.1. Dataset Generation
4.2. Css Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akyildiz, I.F.; Lee, W.-Y.; Vuran, M.C.; Mohanty, S. A survey on spectrum management in cognitive radio networks. IEEE Commun. Mag. 2008, 46, 40–48. [Google Scholar] [CrossRef] [Green Version]
- Akyildiz, I.F.; Lo, B.F.; Balakrishnan, R. Cooperative spectrum sensing in cognitive radio networks: A survey. Phys. Commun. 2011, 4, 40–62. [Google Scholar] [CrossRef]
- Subhedar, M.; Birajdar, G. Spectrum Sensing Techniques in Cognitive Radio Networks: A Survey. Int. J. Next-Gener. Netw. 2011, 3, 37–51. [Google Scholar] [CrossRef]
- Singh, J.; Shukla, A. Spectrum Sensing in MIMO Cognitive Radio Networks Using Likelihood Ratio Tests with Unknown CSI. In Intelligent Communication, Control and Devices; Springer: Singapore, 2020; pp. 185–193. [Google Scholar]
- Shellhammer, S.J. Spectrum sensing in IEEE 802.22. Iapr Wksp. Cogn. Info. Process. 2008, 9–10. [Google Scholar]
- Zeng, Y.; Liang, Y.-C.; Hoang, A.T.; Zhang, R. A Review on Spectrum Sensing for Cognitive Radio: Challenges and Solutions. EURASIP J. Adv. Signal Process. 2010, 2010, 381465. [Google Scholar] [CrossRef] [Green Version]
- Jin, M.; Guo, Q.; Xi, J.; Li, Y.; Yu, Y.; Huang, D. Spectrum Sensing Using Weighted Covariance Matrix in Rayleigh Fading Channels. IEEE Trans. Veh. Technol. 2015, 64, 5137–5148. [Google Scholar] [CrossRef]
- Arjoune, Y.; Kaabouch, N. A Comprehensive Survey on Spectrum Sensing in Cognitive Radio Networks: Recent Advances, New Challenges, and Future Research Directions. Sensors 2019, 19, 126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, M.S.; Kumar, K. Progression on spectrum sensing for cognitive radio networks: A survey, classification, challenges and future research issues. J. Netw. Comput. Appl. 2019, 143, 47–76. [Google Scholar] [CrossRef]
- Jain, P.P.; Pawar, P.R.; Patil, P.; Pradhan, D. Narrowband Spectrum Sensing in Cognitive Radio Detection Methodologies. Int. J. Comput. Sci. Eng. 2019, 7, 105–113. [Google Scholar] [CrossRef]
- Arjoune, Y.; El Mrabet, Z.; El Ghazi, H.; Tamtaoui, A. Spectrum sensing: Enhanced energy detection technique based on noise measurement. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018. [Google Scholar]
- Liu, X.; Sun, C.; Zhou, M.; Wu, C.; Peng, B.; Li, P. Reinforcement learning-based multislot double-threshold spectrum sensing with Bayesian fusion for industrial big spectrum data. IEEE Trans. Ind. Inform. 2020, 17, 3391–3400. [Google Scholar] [CrossRef]
- Ilyas, I.; Paul, S.; Rahman, A.; Kundu, R.K. Comparative evaluation of cyclostationary detection based cognitive spectrum sensing. In Proceedings of the 2016 IEEE 7th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 20–22 October 2016; pp. 1–7. [Google Scholar]
- Kabeel, A.A.; Hussein, A.H.; Khalaf, A.A.; Hamed, H.F. A utilization of multiple antenna elements for matched filter based spectrum sensing performance enhancement in cognitive radio system. AEU Int. J. Electron. Commun. 2019, 107, 98–109. [Google Scholar] [CrossRef]
- Dannana, S.; Chapa, B.P.; Rao, G.S. Spectrum Sensing Using Matched Filter Detection. In Intelligent Engineering Informatics; Springer: Singapore, 2018; pp. 497–503. [Google Scholar]
- Chen, A.-Z.; Shi, Z.-P. A Real-Valued Weighted Covariance-Based Detection Method for Cognitive Radio Networks With Correlated Multiple Antennas. IEEE Commun. Lett. 2018, 22, 2290–2293. [Google Scholar] [CrossRef]
- Sun, H.; Nallanathan, A.; Wang, C.-X.; Chen, Y. Wideband spectrum sensing for cognitive radio networks: A survey. IEEE Wirel. Commun. 2013, 20, 74–81. [Google Scholar] [CrossRef] [Green Version]
- Quan, Z.; Cui, S.; Sayed, A.H.; Poor, H.V. Optimal Multiband Joint Detection for Spectrum Sensing in Cognitive Radio Networks. IEEE Trans. Signal Process. 2008, 57, 1128–1140. [Google Scholar] [CrossRef] [Green Version]
- Sharma, K.; Sharma, A. Design of Cosine Modulated Filter Banks exploiting spline function for spectrum sensing in Cognitive Radio applications. In Proceedings of the 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; pp. 1–5. [Google Scholar]
- Hoyos, E.A.; Parra, O.J.S.; Muñoz, W.Y.C.; Sanabria, L.F.M. Centralized sub-Nyquist wideband spectrum sensing for cognitive radio networks over fading channels. Comput. Commun. 2020, 153, 561–568. [Google Scholar] [CrossRef]
- Vasavada, Y.; Prakash, C. Sub-Nyquist Spectrum Sensing of Sparse Wideband Signals Using Low-Density Measurement Matrices. IEEE Trans. Signal Process. 2020, 68, 3723–3737. [Google Scholar] [CrossRef]
- Solanki, S.; Dehalwar, V.; Choudhary, J. Deep Learning for Spectrum Sensing in Cognitive Radio. Symmetry 2021, 13, 147. [Google Scholar] [CrossRef]
- Varun, M.; Annadurai, C. PALM-CSS: A high accuracy and intelligent machine learning based cooperative spectrum sensing methodology in cognitive health care networks. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4631–4642. [Google Scholar] [CrossRef]
- Shachi, P.; Sudhindra, K.R.; Suma, M.N. Convolutional neural network for cooperative spectrum sensing with spatio-temporal dataset. In Proceedings of the 2020 International Conference on Artificial Intelligence and Signal Processing (AISP), Amaravati, India, 10–12 January 2020; pp. 1–5. [Google Scholar]
- Ghasemi, A.; Sousa, E.S. Spectrum sensing in cognitive radio networks: The cooperation-processing tradeoff. Wirel. Commun. Mob. Comput. 2007, 7, 1049–1060. [Google Scholar] [CrossRef]
- Zhang, W.; Mallik, R.K.; Letaief, K.B. Cooperative spectrum sensing optimization in cognitive radio networks. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008. [Google Scholar]
- Nasser, A.; Chaitou, M.; Mansour, A.; Yao, K.C.; Charara, H. A Deep Neural Network Model for Hybrid Spectrum Sensing in Cognitive Radio. Wirel. Pers. Commun. 2021, 118, 281–299. [Google Scholar] [CrossRef]
- Lee, W.; Kim, M.; Cho, D.-H. Deep Cooperative Sensing: Cooperative Spectrum Sensing Based on Convolutional Neural Networks. IEEE Trans. Veh. Technol. 2019, 68, 3005–3009. [Google Scholar] [CrossRef]
- Shawel, B.S.; Woledegebre, D.H.; Pollin, S. Deep-learning based cooperative spectrum prediction for cognitive networks. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018; pp. 133–137. [Google Scholar]
- Furtado, R.S.; Torres, Y.P.; Silva, M.O.; Colares, G.S.; Pereira, A.M.C.; Amoedo, D.A.; Valadao, M.D.M.; Carvalho, C.B.; da Costa, A.L.A.; Junior, W.S.S. Automatic Modulation Classification in Real Tx/Rx Environment using Machine Learning and SDR. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Online, 10–12 January 2021. [Google Scholar]
- Mishra, A.; Dehalwar, V.; Jobanputra, J.H.; Kolhe, M.L. Spectrum hole detection for cognitive radio through energy detection using random forest. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020. [Google Scholar]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 2–14 February 2013. [Google Scholar]
- Couronné, R.; Probst, P.; Boulesteix, A.-L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.; Park, D.; Lee, H.-N. Compressive Sensing Spectroscopy Using a Residual Convolutional Neural Network. Sensors 2020, 20, 594. [Google Scholar] [CrossRef] [Green Version]
- Shi, Z.; Gao, W.; Zhang, S.; Liu, J.; Kato, N. Machine Learning-Enabled Cooperative Spectrum Sensing for Non-Orthogonal Multiple Access. IEEE Trans. Wirel. Commun. 2020, 19, 5692–5702. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valadão, M.D.M.; Amoedo, D.; Costa, A.; Carvalho, C.; Sabino, W. Deep Cooperative Spectrum Sensing Based on Residual Neural Network Using Feature Extraction and Random Forest Classifier. Sensors 2021, 21, 7146. https://doi.org/10.3390/s21217146
Valadão MDM, Amoedo D, Costa A, Carvalho C, Sabino W. Deep Cooperative Spectrum Sensing Based on Residual Neural Network Using Feature Extraction and Random Forest Classifier. Sensors. 2021; 21(21):7146. https://doi.org/10.3390/s21217146
Chicago/Turabian StyleValadão, Myke D. M., Diego Amoedo, André Costa, Celso Carvalho, and Waldir Sabino. 2021. "Deep Cooperative Spectrum Sensing Based on Residual Neural Network Using Feature Extraction and Random Forest Classifier" Sensors 21, no. 21: 7146. https://doi.org/10.3390/s21217146
APA StyleValadão, M. D. M., Amoedo, D., Costa, A., Carvalho, C., & Sabino, W. (2021). Deep Cooperative Spectrum Sensing Based on Residual Neural Network Using Feature Extraction and Random Forest Classifier. Sensors, 21(21), 7146. https://doi.org/10.3390/s21217146