Abstract
Peak-to-peak intervals in Photoplethysmography (PPG) can be used for heart rate variability (HRV) estimation if the PPG is collected from a healthy person at rest. Many factors, such as a person’s movements or hardware issues, can affect the signal quality and make some parts of the PPG signal unsuitable for reliable peak detection. Therefore, a robust HRV estimation algorithm should not only detect peaks, but also identify corrupted signal parts. We introduce such an algorithm in this paper. It uses continuous wavelet transform (CWT) for peak detection and a combination of features derived from CWT and metrics based on PPG signals’ self-similarity to identify corrupted parts. We tested the algorithm on three different datasets: a newly introduced Welltory-PPG-dataset containing PPG signals collected with smartphones using the Welltory app, and two publicly available PPG datasets: TROIKAand PPG-DaLiA. The algorithm demonstrated good accuracy in peak-to-peak intervals detection and HRV metric estimation.
1. Introduction
Heart rate variability (HRV) is the physiological phenomenon of variation in the time interval between heartbeats [1]. Typically, HRV is estimated using electrocardiography (ECG). R peaks, the upward deflections in ventricular depolarization complexes in ECG [2] are detected, and the distances between consecutive R peaks, called RR intervals, are analyzed. There is a substantial body of research that detects R peaks in ECG using various signal processing methods [3], as well as time series classification tools such as interval feature transformation [4].
Photoplethysmography (PPG) is a non-invasive and low-cost optical measurement technique that provides important information about the cardiovascular system [5,6]. PPG tracks blood volume changes in peripheral blood vessels by illuminating the skin and measuring changes in light absorption. In practice, PPG signals are often collected using wrist-worn devices with optical sensors, such as smartwatches [7,8], or using a smartphone camera attached to a user’s finger [9,10] (we will refer to such signals as smartphone PPG). PPG signals are used to estimate heart rate [7,8,10,11], as well as blood oxygen saturation, blood pressure [6,10], etc.
Research [12,13,14,15] shows that, if a PPG signal is collected from a healthy subject at rest, then the intervals between consecutive major peaks in PPG can serve as a substitute for RR intervals in ECG for various heart rate variability metrics. At the same time, PPG signals collected during or right after exercise or from a patient with cardiovascular disease can have peak-to-peak intervals that differ significantly from RR intervals in ECG and cannot be used for HRV estimation [12,15].
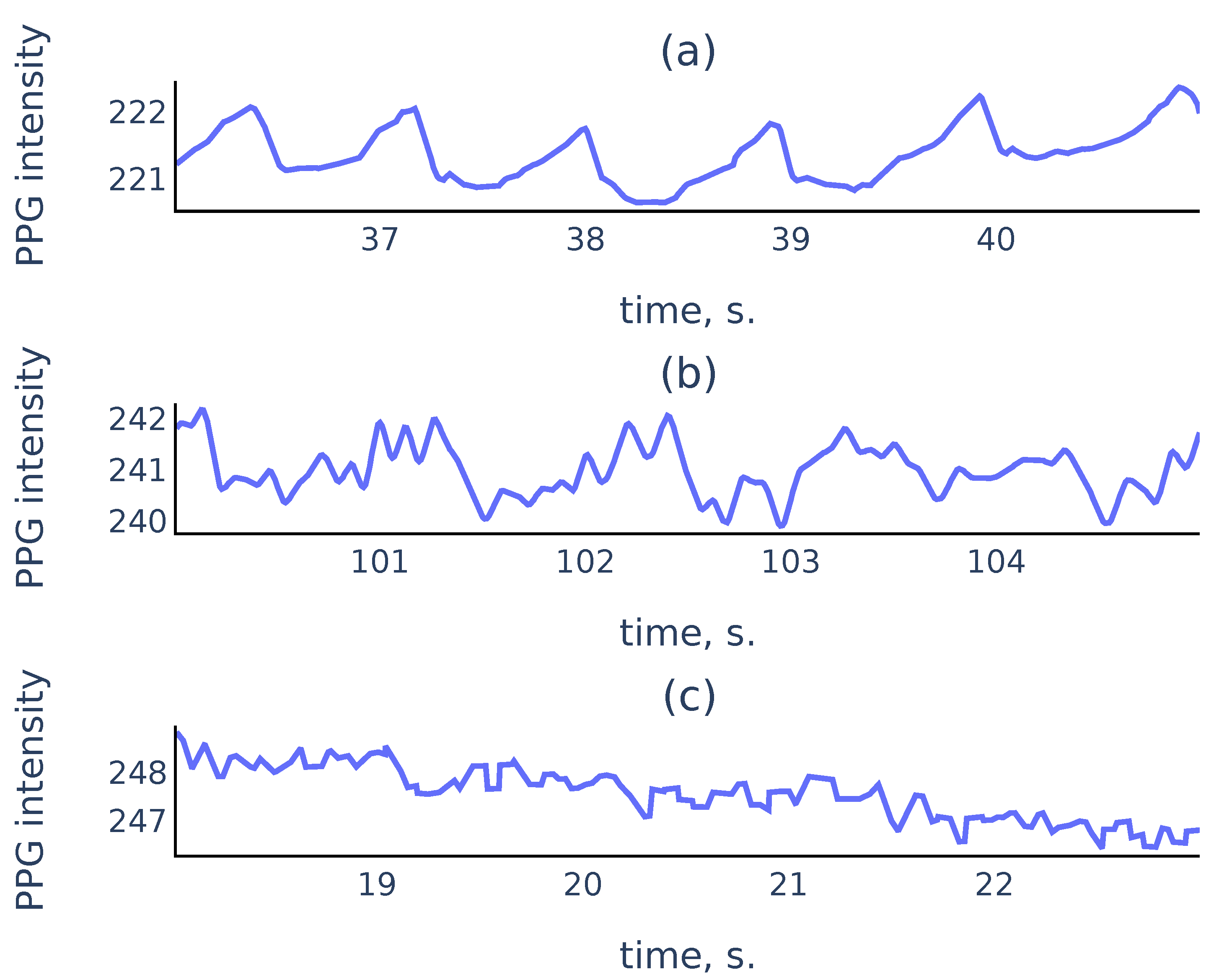
In practice, PPG signals collected in an uncontrolled environment often suffer from measurement artifacts that can corrupt sufficiently long parts of the signals and make these parts unsuitable for reliable peak detection. Figure 1 shows three common types of smartphone PPG signals that we encounter in practice:
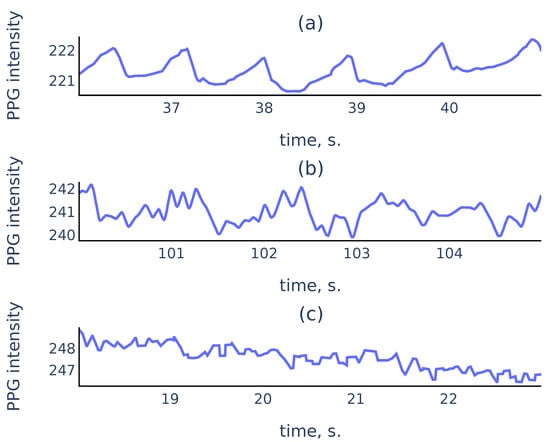
Figure 1.
Examples of PPG signals: (a) a clean signal with clearly visible peaks; (b) a noisy signal where peaks associated to cardiac cycles still can be recognized; (c) a corrupted signal where no accurate peak detection is possible.
While it is easy to perform well on signals like Figure 1a, a reliable algorithm must also distinguish corrupted parts like Figure 1c to exclude them from the analysis. For the signal parts such as Figure 1b, a reliable algorithm should choose peaks corresponding to cardiac cycles rather than the noise in the signal.
Several algorithms were developed for peak-to-peak interval detection in PPG using slope analysis [16,17], automatic multiscale peak detection [18,19], neural networks [20], adaptive threshold peak detection [21,22]. Existing algorithms filter out erroneous intervals using outlier detection based solely on the lengths of detected intervals. In our algorithm, we propose to analyze the signal during the detected intervals to estimate their reliability. A real-time algorithm for peak detection and signal quality estimation in smartphone PPG was proposed in [9]. As a real-time algorithm, it was restricted in computational complexity and the variety of methods that can be used. Therefore we propose a new offline algorithm that uses continuous wavelet transform (CWT).
CWT is a tool that provides a representation of a signal in the time-scale domain. It is used for time-frequency localization [23] and pattern matching [24]. CWT was successfully used for the analysis of ECG signals [25], electroencephalogram (EEG), and other time series data [26]. Peak detection using continuous or discrete wavelet transform was performed in various contexts in [24,27,28,29,30,31,32].
The main features of CWT that we use in the proposed algorithm are the ridge lines, i.e., curves consisting of points of local maxima at fixed scales in the time-scale domain. Using the correspondence between peaks in the signal and the ridge lines in CWT with the Mexican hat mother wavelet (see Section 2.3), our algorithm uses the ridge lines lengths to detect the peaks in PPG that correspond to the heartbeats. The algorithm also uses the shape of the ridge lines and signal self-similarity characteristics as features to identify corrupted parts in PPG signals. We describe the proposed algorithm in detail in Section 3.
We evaluate the accuracy of the proposed algorithm on three different publicly available datasets: Welltory-PPG-dataset, TROIKA [7] and PPG-DaLiA [8]. Note that, since PPG signals during exercise cannot be used for HRV estimation according to [12,15], for validation using TROIKA [7] and PPG-DaLiA [8] we only used parts of the signals that were collected before any labeled physical activity. Welltory-PPG-dataset is a new publicly available dataset that we introduce in this paper. It consists of smartphone PPG measurements with simultaneously collected ground truth RR intervals from the Polar H10 chest strap device. We introduce this dataset, since most publicly available PPG datasets (such as TROIKA [7] and PPG-DaLiA [8]) are collected using wrist-worn devices and are aimed at heart rate detection during physical activity, and the existing smartphone PPG dataset [33] consists of 10-second signals which are too short for a reliable HRV assessment. We describe the dataset structure and data collection process in Section 2.1.1.
While CWT is used for various signal types, including ECG, EEG, etc., it has not been used before for peak detection in PPG. In contrast with existing PPG analysis algorithms, our algorithm filters out unreliable peak-to-peak intervals by detecting corrupted parts in the signal. Our algorithm demonstrated good accuracy in basic HRV metrics on three publicly available datasets containing PPG from different sources. Thus, we conclude that the algorithm should generalize well to various PPG signals of different origins, be robust to signal corruption, and can be able to be used for reliable HRV estimation from PPG signals collected in an uncontrolled environment.
The paper is organized as follows. The datasets used for algorithm validation are described in Section 2.1. HRV metrics used for accuracy estimation are described in Section 2.2. Section 2.3 contains a discussion about CWT and the ridge lines. A detailed description of the proposed algorithm is given in Section 3. Section 4 contains tables with HRV metrics estimation errors on the used validation datasets. Section 5 provides additional discussion. It contains a justification of the methods used in the proposed algorithm, its limitations, and its comparison with previously developed algorithms. Moreover, it contains a justification of the choice of the ground truth labels in Welltory-PPG-dataset. Section 6 contains concluding remarks.
2. Materials and Methods
2.1. Datasets
2.1.1. Welltory-PPG-Dataset
This is a newly introduced dataset. It is publicly available at https://github.com/Welltory/welltory-ppg-dataset (accessed on 1 July 2021). The dataset consists of 21 records containing three time series: red, green, and blue channel PPG signals, and simultaneously collected RR intervals. RR intervals were collected using a Polar H10 chest strap and manually examined by an expert to ensure their accuracy. PPG data were obtained via a smartphone camera using the Welltory app. Signal lengths vary from 68 to 112 s.
Data Collection
Each participant put their index finger over a smartphone camera, which recorded a video. For each frame in the video stream, we record its capture time and three numbers: r, g, b, which are the average values of red, green, and blue components of the frame pixel colors. Each participant was simultaneously wearing the Polar H10 chest strap. After each measurement was complete, the RR intervals detected by the Polar device during the measurement were collected. Each dataset record consists of the following arrays:
- Time: moments of camera frame capture times in milliseconds elapsed from the measurement start;
- R, G, B: arrays of numbers r, g, b for all captured frames;
- RR: sequence of RR intervals collected from the Polar device during the measurement.
Participants
Thirteen healthy volunteers between the ages of 25 and 35 participated in the data collection. Each participant made one or two measurements using their Android smartphone. All participants provided written informed consent for publication.
2.1.2. Previously Published PPG Datasets
In addition to Welltory-PPG-dataset, we used two publicly available datasets: TROIKA [7] and PPG-DaLiA [8] for algorithm validation. These datasets were introduced for heart rate estimation and contain simultaneous PPG and ECG signals and accelerometer readings collected during exercise and other labeled physical activity. Since PPG signals collected during exercise are unsuitable for HRV estimation [12,15], we used signal parts not labeled with physical activity. In TROIKA these parts are the initial 30-second chunks of the signals. In PPG-DaLiA these are the intervals that are labeled as “sitting”.
2.2. HRV Metrics
We use two basic metrics of heart rate variability: SDNN, and RMSSD. For a sequence of normal RR intervals , its SDNN is defined as the standard deviation:
RMSSD, the root mean square of the successive differences of RR intervals, is defined as
The latter metric has a geometric interpretation in terms of the Poincaré plot of the sequence : for the distribution of pairs of consecutive RR intervals, RMSSD is proportional to the standard deviation of the distance from the points to the main diagonal
2.3. Continuous Wavelet Transform
For a mother wavelet function let denote its scaled and translated version:
Here is the scale parameter, and is the translation parameter. Then for a function its continuous wavelet transform (CWT) is defined as [23] ([2.4]):
The coefficients show matching between the signal and the mother wavelet dilated with scale a and centered at position b. In our algorithm we chose to be the Mexican hat wavelet function. It is proportional to the second derivative of the Gaussian function and is defined as:
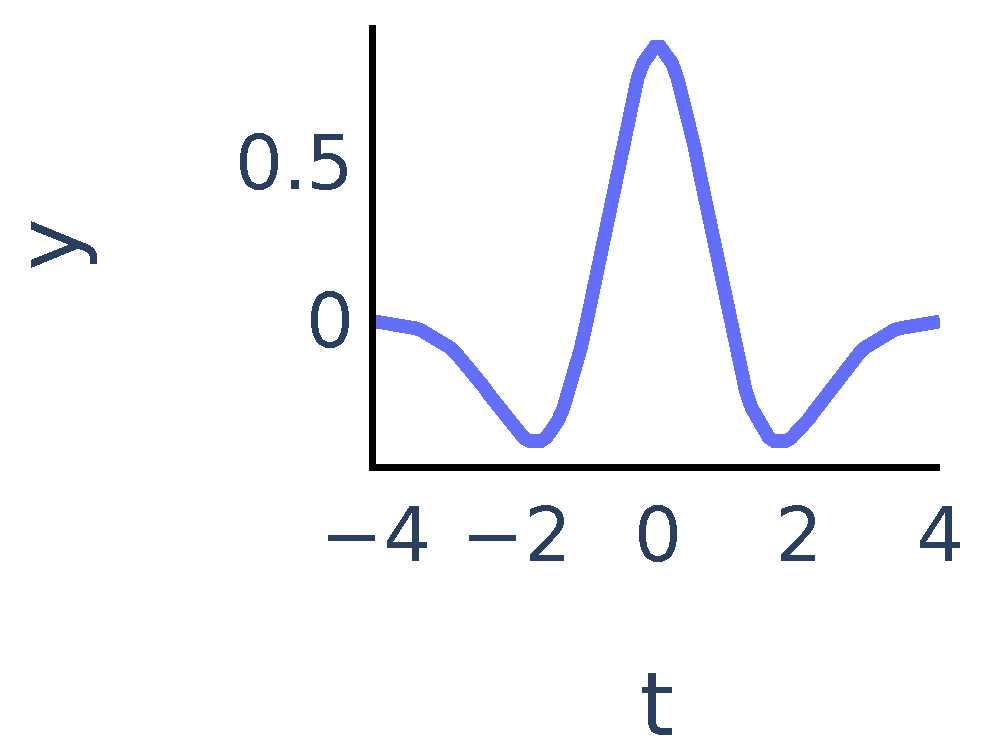
It exhibits typical features of a single peak (Figure 2):
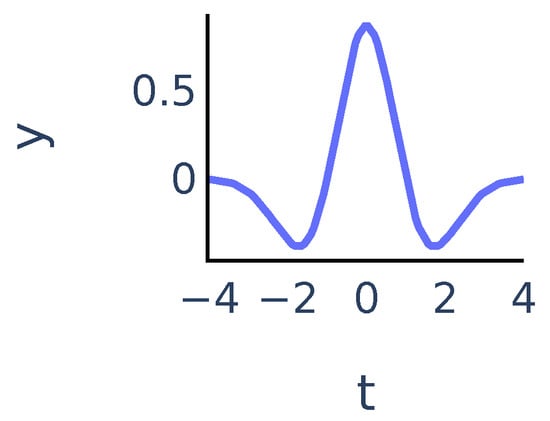
Figure 2.
Mexican hat wavelet function .
We will say that is a ridge point if the function has a local maximum at point . For a fixed a the ridge points at scale a show the time instants where the signal most resembles the peak at scale a. We will consider continuous curves in the -plane that consist of ridge points. Following [24], we will call such curves ridge lines. So ridge lines indicate the position of peaks in the signal at different scales. We discuss this in more detail in Section 3.3.1.
3. Proposed Algorithm
In this section, we describe the proposed algorithm. In the rest of the paper, we will refer to peaks in PPG that correspond to heartbeats as R peaks for brevity. Peak-to-peak intervals will be referred to as RR intervals. We will use the CWT of the PPG signal with the Mexican hat function as the mother wavelet as the main tool.
In the first step of the algorithm, we perform signal preprocessing that addresses the two most common problems: abrupt shifts, or steps in signals and signals becoming almost constant due to hardware issues. A detailed description of preprocessing steps is given in Section 3.1. Then we perform R peak detection. To detect R peaks in the signal, we will identify their corresponding ridge lines in the CWT. Our algorithm for R peak detection is based on two principles that must hold for non-corrupted PPG signals collected from healthy subjects at rest:
- the R peaks correspond to longer ridge lines, i.e., lines that are present on a larger scale range (see Section 3.3 for more details).
- PPG signals are almost periodic, so normal R peaks arise approximately at a frequency determined by the heart rate that varies gradually over time.
Therefore, we use a 2-step process for R peak detection. First, we estimate the heart rate from the PPG signal using the short-time Fourier transform spectrogram of the signal. Then, the algorithm uses the estimated heart rate as additional information to choose ridge lines corresponding to R peaks. Informally speaking, the algorithm chooses the most persistent ridge lines that arise in the CWT at a frequency corresponding to the estimated heart rate. Finally, the locations of R peaks are predicted as positions of the chosen ridge lines at the smallest scale. A detailed description of the R peak detection algorithm is given in Section 3.3.
After the R peaks are detected, we consider the corresponding RR intervals. We evaluate the quality of detected RR intervals to identify and discard RR intervals found in corrupted parts of the signal. Since a non-corrupted PPG signal is almost periodic, the quality estimation is based on two considerations:
- A signal must have similar shapes inside detected RR intervals;
- The ridge lines in CWT that define the edges of a RR interval must have similar shapes. In particular, the distances between them should be approximately the same on different scale levels.
We assign to each RR interval its quality score based on the principles above and then discard the RR intervals with quality scores below an automatically determined threshold. We give a detailed description of the quality score calculation and the choice of the quality threshold in Section 3.4.
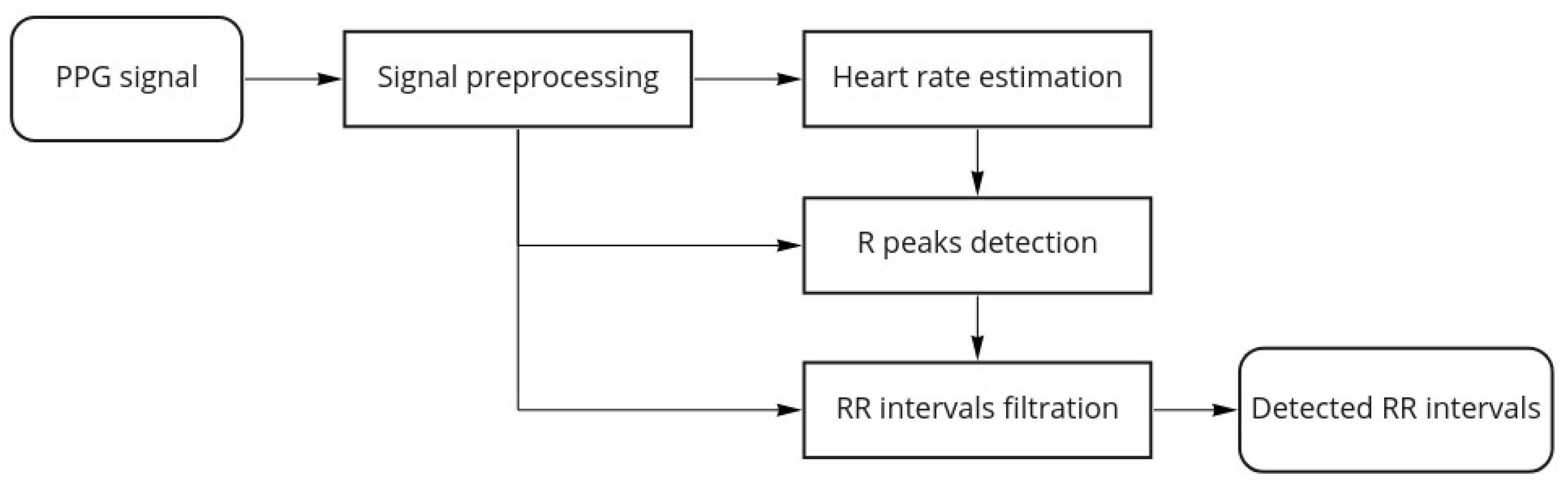
Figure 3 shows the proposed algorithm workflow for a single channel PPG:
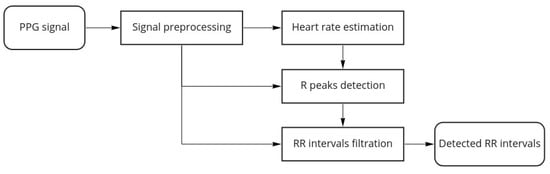
Figure 3.
Algorithm workflow.
Once the algorithm finishes, we estimate the overall quality of the signal as the following ratio:
where is the total number of RR intervals detected by the R peaks detection part of the algorithm and is the number of detected RR intervals that were discarded by the filtration part of the algorithm.
In some cases, valleys in the PPG signals can be easier to locate than peaks. Thus, as a final step, we apply our algorithm to both the PPG signal and the negative of the PPG signal and obtain two sets of detected RR intervals. Then we choose the result that has the smallest discarded ratio as the algorithm output.
For a multi-channel PPG signal (e.g., smartphone PPG containing values in the red, green, and blue channels of the video frames captured by a smartphone camera), we choose the best channel as the one that has the smallest discarded ratio. Note that research [34] suggests that channels with shorter wavelength should have the best signal to motion ratio. We do not make an a priori choice of the channel to avoid issues with device-specific color representations.
3.1. Signal Preprocessing
Most smartphone cameras provide frames at a rate of 30 frames per second. To increase accuracy, we interpolate the signal to a uniformly sampled sequence with a sampling frequency Hz, as the upsampling is necessary for accurate HRV estimation [17]. Most cameras produce red, green, and blue channel values in the standard range (0, 255). If the PPG signal is given in another range, we rescale it to the standard range. Signal preprocessing aims to identify the following common issues with the signal:
- Step detection. In smartphone PPG signals, removing from or reapplying the finger to the camera results in abrupt steps in the signal. To detect such steps, we compute the running amplitude with a window length of 1 s. If the running amplitude exceeds 4 times the median of the running amplitude, a step in the signal is detected. The threshold value 4 was chosen empirically by examining a number of examples.
- Constant signal detection. Sometimes the signal becomes constant if there are issues with color rendering in the frame or there is no finger over the camera at all. Analysis of examples shows that is a reliable threshold value for running signal amplitude to detect a constant signal.
Parts of the signal labeled as having signal steps or constant signal are set to zero. Then, we split the signal into continuous chunks between the labeled parts and set the chunks shorter than 2 s to zero. For every remaining chunk, we remove the trend by subtracting the running average in 2 s windows and apply a low-pass filter with a 10 Hz threshold to avoid aliasing and remove high-frequency noise.
3.2. Heart Rate Estimation
In this subsection, we describe the algorithm for heart rate estimation from a PPG signal. Our approach is similar to the TROIKA [7] in that we are estimating heart rate by constructing a continuous curve consisting of peaks in the spectrogram columns. Our context is different from one in [7] in two aspects: firstly, we are interested in PPG collected at rest, so we expect motion artifacts associated with occasional movement, rather than intensive physical exercise considered in [7]. Secondly, we do not collect accelerometer data to estimate the subject’s movements. Therefore we use the following approach:
- First we filter the spectrogram using a convolution with a 2d filter that highlights curves with a bounded rate of change;
- We consider local maxima in the columns of the filtered spectrogram;
- We find a rough estimate of heart rate frequency and construct a continuous curve consisting of local maxima that are closest to the estimate.
We describe our approach in detail below. Suppose that is a discrete signal obtained by a uniform sampling with frequency f from a function with a discrete step :
3.2.1. Sliding Window Spectrogram
As a feature, we use the signal spectrogram computed with a sliding Dirichlet window of 5 s in length. The spectrogram is computed as the squared magnitude of the short time Fourier transform (STFT) for frequencies , uniformly sampled between and Hz, with stride = s:
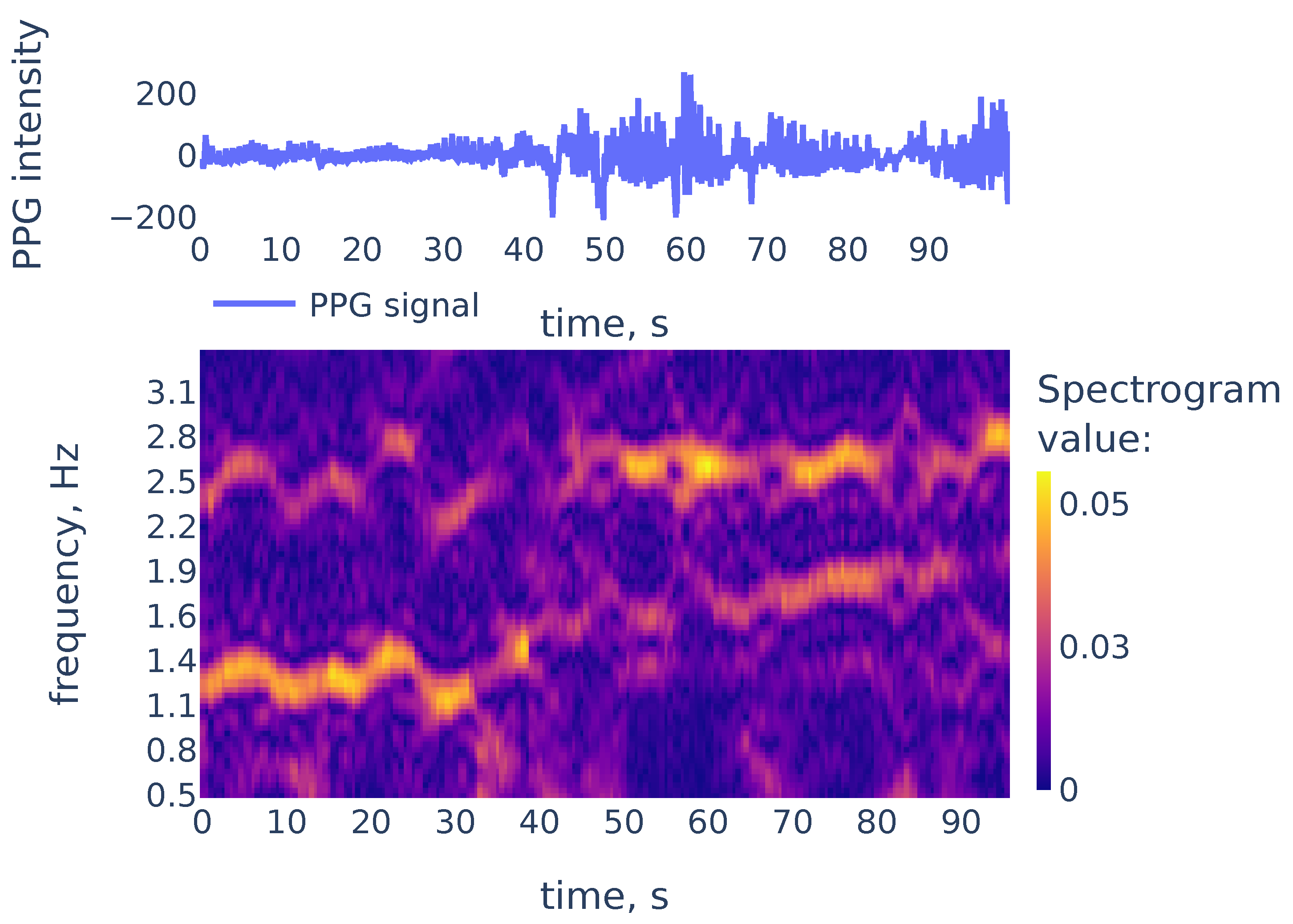
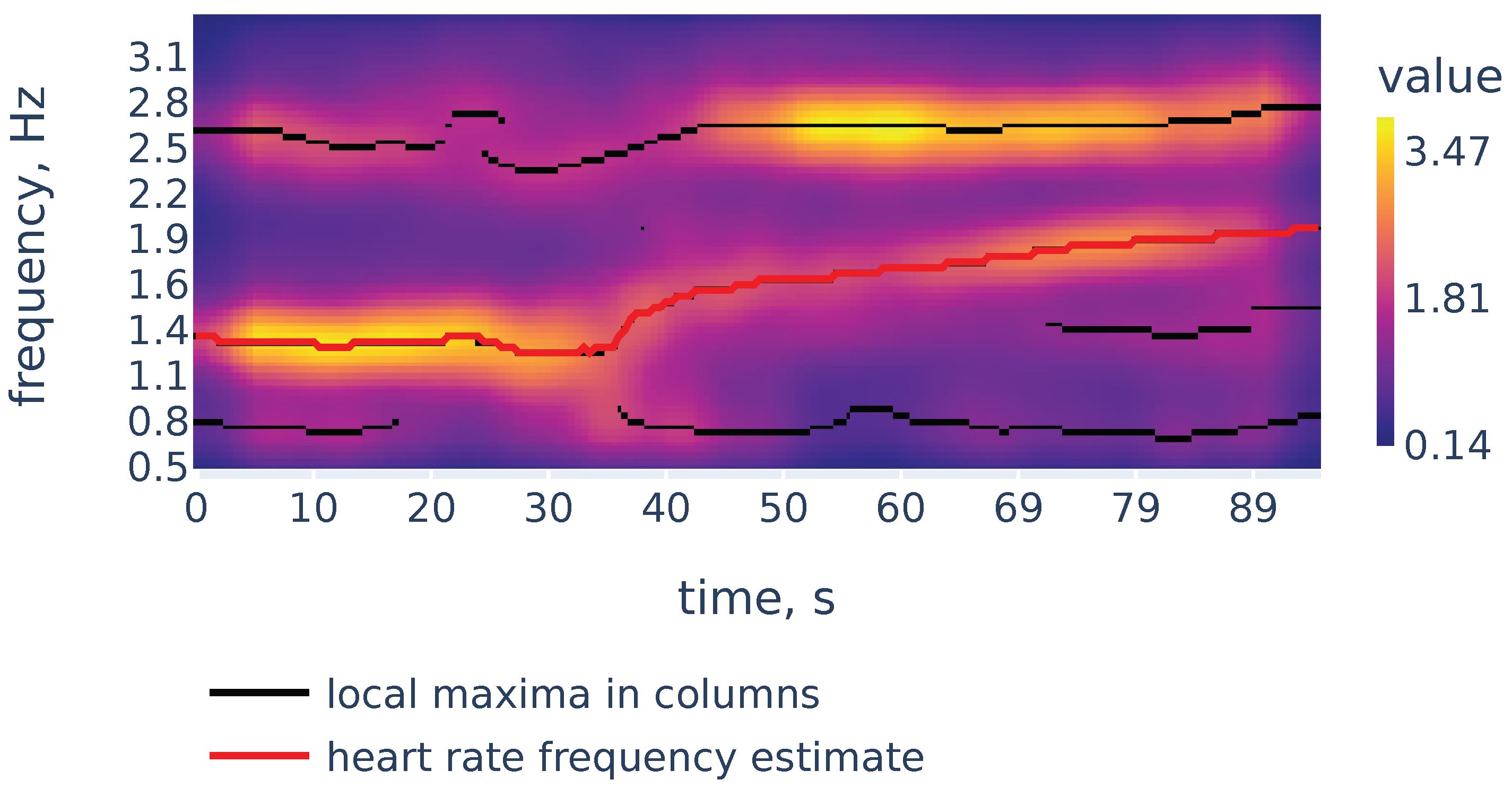
While peaks in a spectrum of a single window may be associated with measurement artifacts, the heart rate corresponds to a continuous curve in the spectrogram. An example of the spectrogram is given in Figure 4.
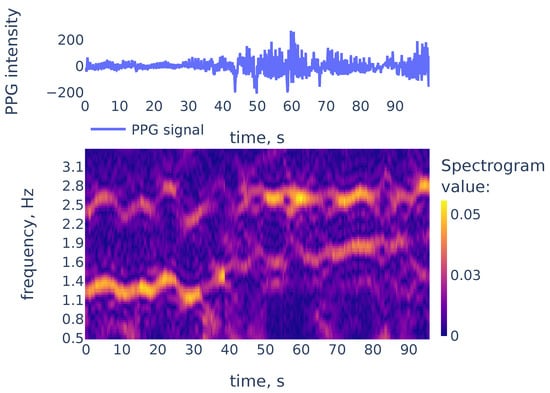
Figure 4.
The PPG signal (top) and its corresponding STFT spectrogram (bottom), part of the PPG signal of subject 01 in the TROIKA dataset. Heart rate frequency is growing from Hz to Hz.
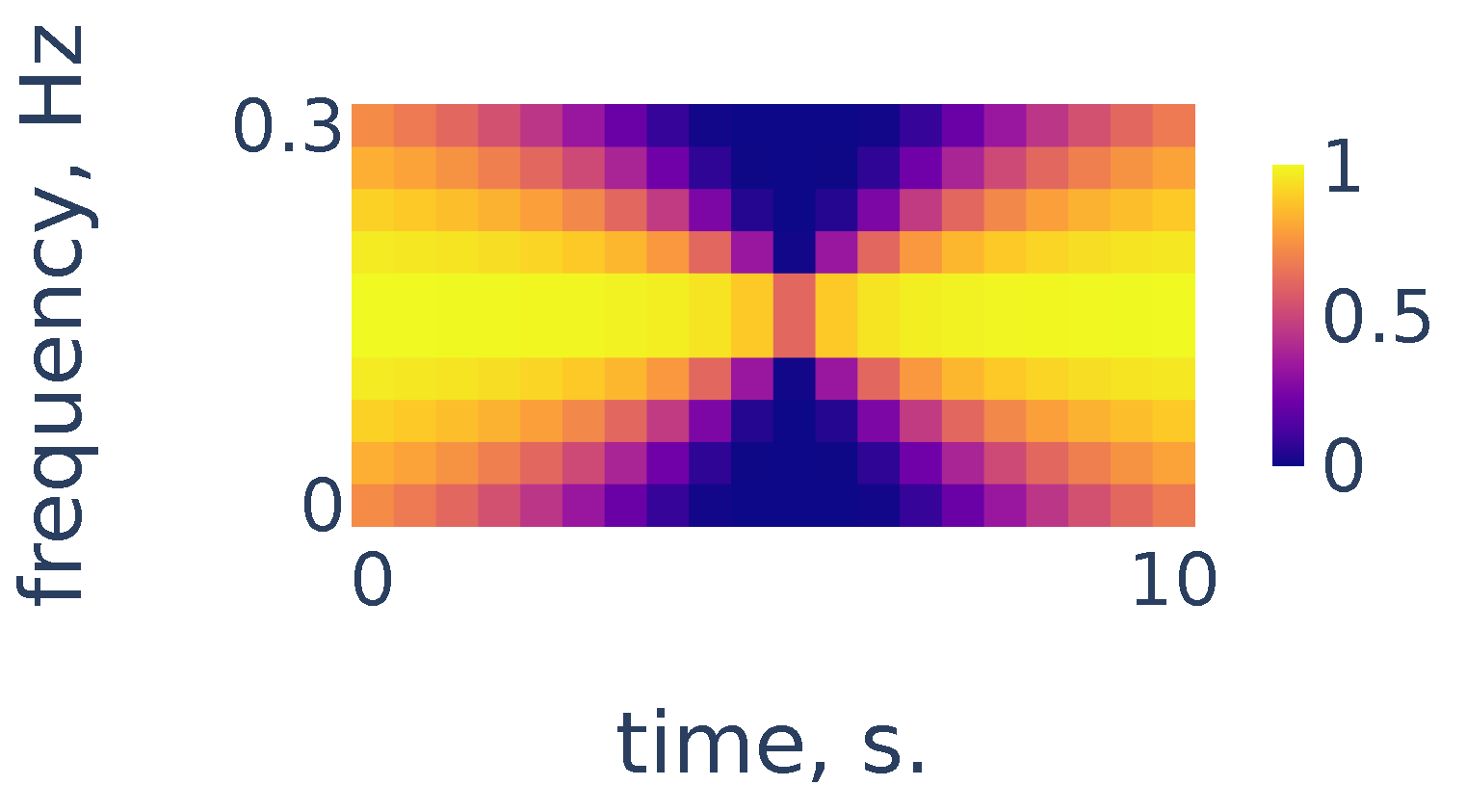
As we can see in Figure 4, the heart rate frequency in that example gradually grows from Hz at the beginning to Hz at the end. The curve is clearly seen for the first 30 s and, after that, it becomes smudged between 30 and 50. To simplify the curve detection we convolve the spectrogram with a 2d filter shown in Figure 5, which highlights continuously evolving curves on the spectrogram:
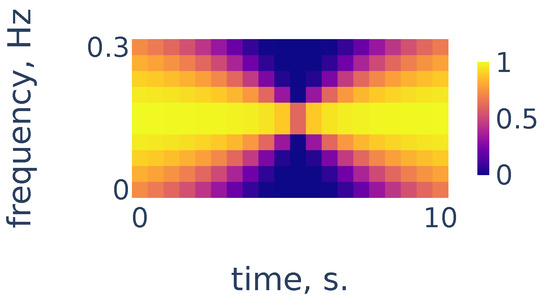
Figure 5.
Continuity filter highlighting curves with bounded rates of change; the horizontal length is adjusted to correspond to 10 s of time and the vertical length corresponds to a change in frequency of Hz.
3.2.2. Local Maxima in the Spectrogram Columns
After the filtration, let us consider the points of local maxima in the columns of the spectrogram. We will construct the curve associated with heart rate frequency by following these points of local maxima in a continuous manner. To find the initial point on the curve, we need to choose between the local maxima in the first column of the spectrogram. In some cases, the point of the highest local maximum does not necessarily correspond to the actual heart rate. Therefore, we find a rough estimate of the heart rate and then choose the peak that is closest to this estimate. To find a rough estimate, we consider a bandpass filtration of the PPG signal with a narrow bandwidth and count the number of peaks and the number of zero crossings in the filtration. For more in detail, we use Algorithm 1. It takes i, an index of the spectrogram column as an input, and returns the frequency of a peak in the i-th spectrogram column, such that this frequency is the closest to the rough heart rate estimate.
| Algorithm 1 Rough estimate of heart rate frequency in the i-th spectrogram column |
|
Now we construct a curve in the spectrogram plane showing heart rate frequency during the measurement. First, we choose the initial frequency using Algorithm 1 for the 0-th column of the spectrogram. Then we construct the continuous curve following along local maxima in columns of the spectrogram. If at some step we cannot proceed continuously, then we perform Algorithm 1 again to find the point of local maximum in the spectrogram column that is closest to the rough estimate. Along the way, we apply exponential smoothing to the obtained curve for a more robust estimate. In more detail, we use the Algorithm 2:
| Algorithm 2 Construction of the heart rate frequency curve |
|
Now let us demonstrate the work of Algorithm 2. Figure 6 shows the filtered version of the spectrogram of Figure 4, the curves consisting of local maxima in the columns, and the heart rate frequency curve constructed by Algorithm 2. It correctly identifies the heart rate frequency change during the measurement.
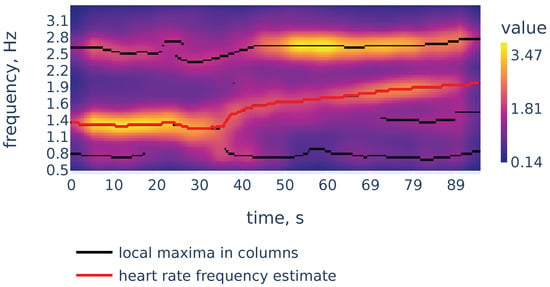
Figure 6.
Filtered spectrogram. Black lines show the curves consisting of local maxima in the spectrogram columns.
3.3. R Peak Detection
3.3.1. Signal Scalogram and Ridge Lines
Recall our notation for the signal that is uniformly sampled from function with frequency f:
where variable t represents time measured in seconds. Let denote the Mexican hat wavelet function given from Equation (5). Consider scales evenly spaced on a logarithmic scale:
Define the scalogram of the signal as the finite sum approximation to the integral that defines CWT of the function in Equation (4):
The chosen scales range from to This range was chosen empirically to accurately reflect the position of R peaks on the smallest scale and provide enough smoothing to remove noisy peaks on the large scale.
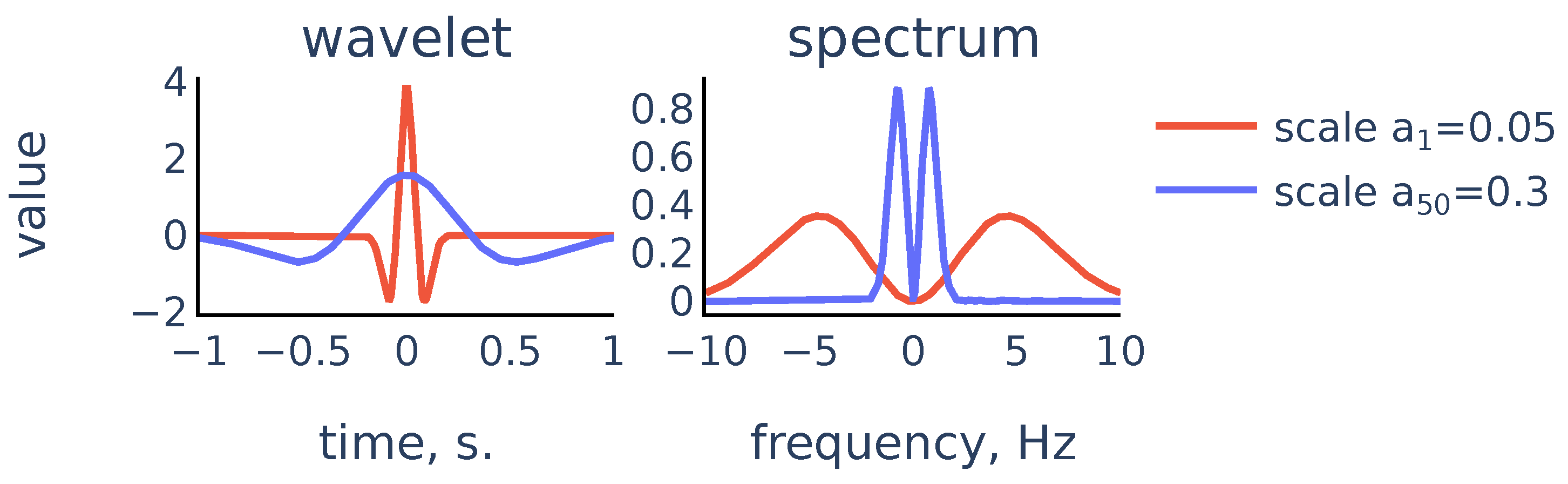
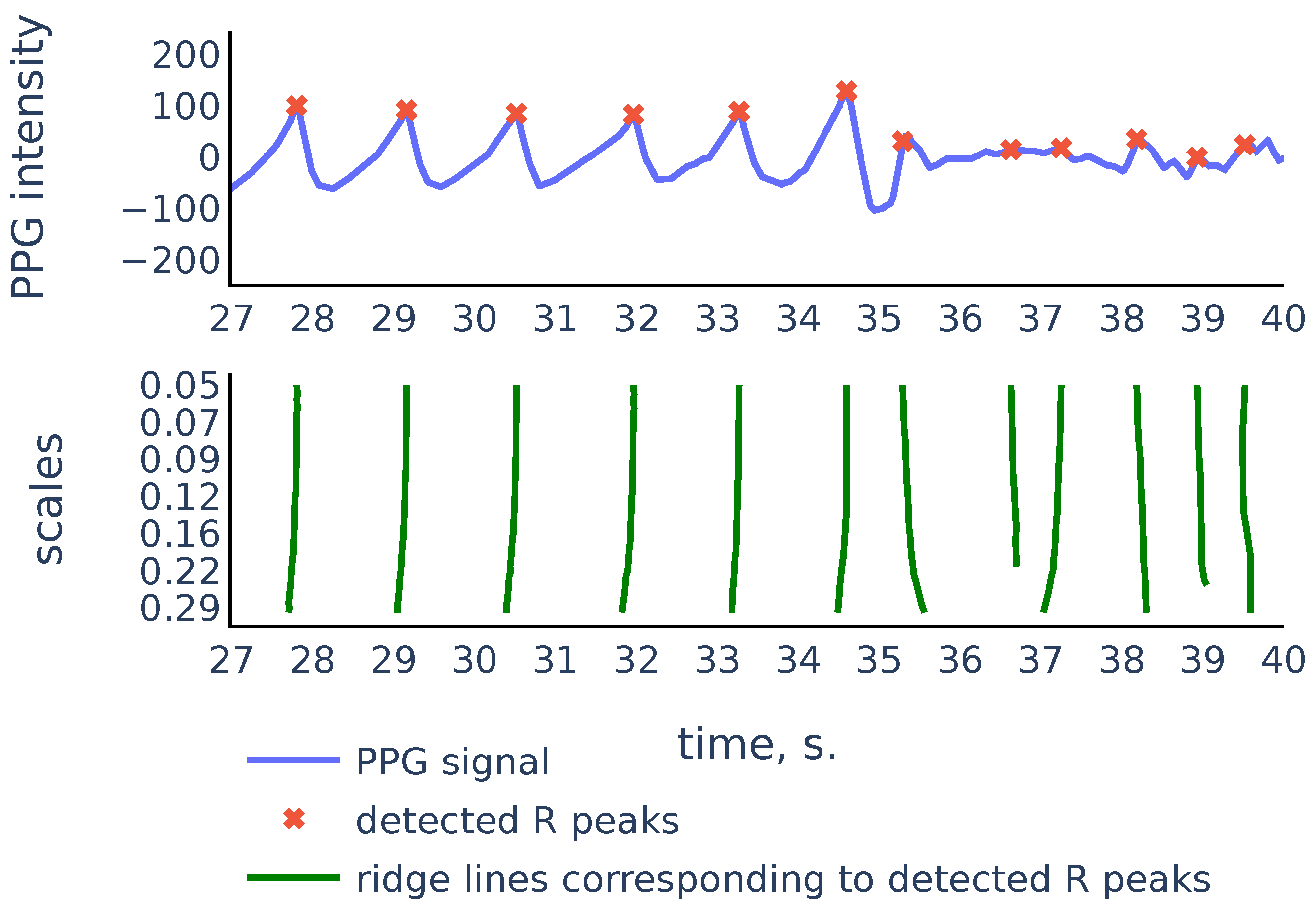
So the scalogram is a discretization of the CWT, thus the rows of the scalogram represent similarities of the signal with a typical peak shape on the corresponding scales. The ridge lines in CWT will correspond to ridge lines in the plane consisting of points of local maxima in the scalogram rows Note that convolution with the scaled wavelet performs bandpass filtration, with wider bandwidth for smaller scales and narrower bandwidth for larger scales, as we can see in Figure 7. Thus, we can consider rows of the scalogram as filtration, or smoothing of the initial signal, and the ridge lines indicate locations of peaks in the signal at different levels of smoothing. The R peaks in the signal are the more persistent peaks, which exist at different levels of smoothing, and therefore R peaks are tips of longer ridge lines that are present on a larger scale range. Figure 8 shows a typical example that illustrates this idea:
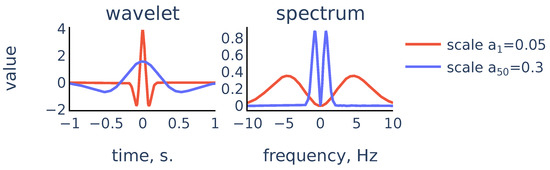
Figure 7.
Scaled Mexican hat wavelet and its frequency spectrum for the smallest scale and the largest scale in the chosen scale range.
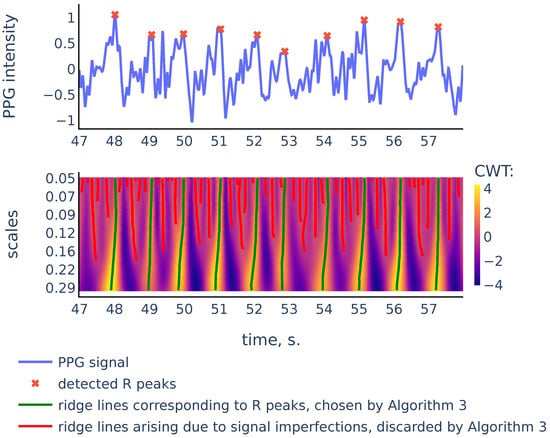
Figure 8.
PPG signal, the corresponding scalogram computed with the Mexican hat wavelet for the scale range , and the ridge lines in the scalogram. This signal is a part of the red channel PPG from subject 01 in the Welltory-PPG-dataset. The R peaks in the signal are detected as top points of the ridge lines chosen by the filtration Algorithm 3.
As we can see in Figure 8, there are more ridge lines in the upper part of the scalogram, corresponding to noisy peaks in the signal, but we are able to distinguish ridge lines that correspond to R-peaks by choosing the longer lines and using our previous estimates of heart rate as a heuristic that suggests how often the actual ridge lines are expected to appear on the scalogram plane. In the next section we will discuss in detail the Algorithm 3 that chooses the ridge lines that correspond to R peaks.
3.3.2. Choosing Ridge Lines Associated to R-Peaks
Recall that we defined scalogram in Equation (10) as a matrix of shape For a ridge line and a scale denote by the time coordinate of the point on with scale level (if such a point exists):
For a given set of ridge lines sorted according to their top points define their RR intervals as the distances between the top points:
We will use these RR intervals to determine which curves to choose. First, we choose all the ridge lines that stretch from the bottom to the top of the scalogram. These are the curves corresponding to the most persistent peaks in the signal that are likely to be R-peaks. Some of the remaining curves are added to the set of chosen curves based on the likelihood of observing the corresponding set of RR intervals given the previously estimated heart rate frequency.
We estimate the likelihood of a set of potential RR intervals as follows. According to [35], the length of RR intervals can be modeled as Inverse Gaussian distribution. In practice, the Inverse Gaussian distribution can be approximated by log-normal distribution [36], thus we may assume that logarithms of RR intervals are normally distributed, so the average log-likelihood of a set of RR intervals given the heart rate frequency is proportional to
where and the expected heart rate frequency during interval , and is the expected length of RR interval. We use this estimate of likelihood to finally choose the ridge lines associated to R-peaks, as described in Algorithm 3:
| Algorithm 3 Choosing ridge lines in the scalogram |
|
3.4. RR Intervals Filtration
PPG signals often contain corrupted parts where no accurate R-peak detection is possible, so these parts must be discarded to ensure robust HRV estimation. To identify such parts we use the following method. After we have detected RR intervals, we assign to each detected interval a number between 0 and 1 (its quality) that reflects the likelihood that the found interval is accurate and reliable. Then a quality threshold is determined and the RR intervals with the quality below the threshold are discarded.
To develop a quality estimate, we use the following principles:
- Parts of the signal inside the neighbor intervals must have similar shapes and amplitudes;
- The distance between ridge lines defining the neighbor R-peaks must be approximately the same on different resolution levels.
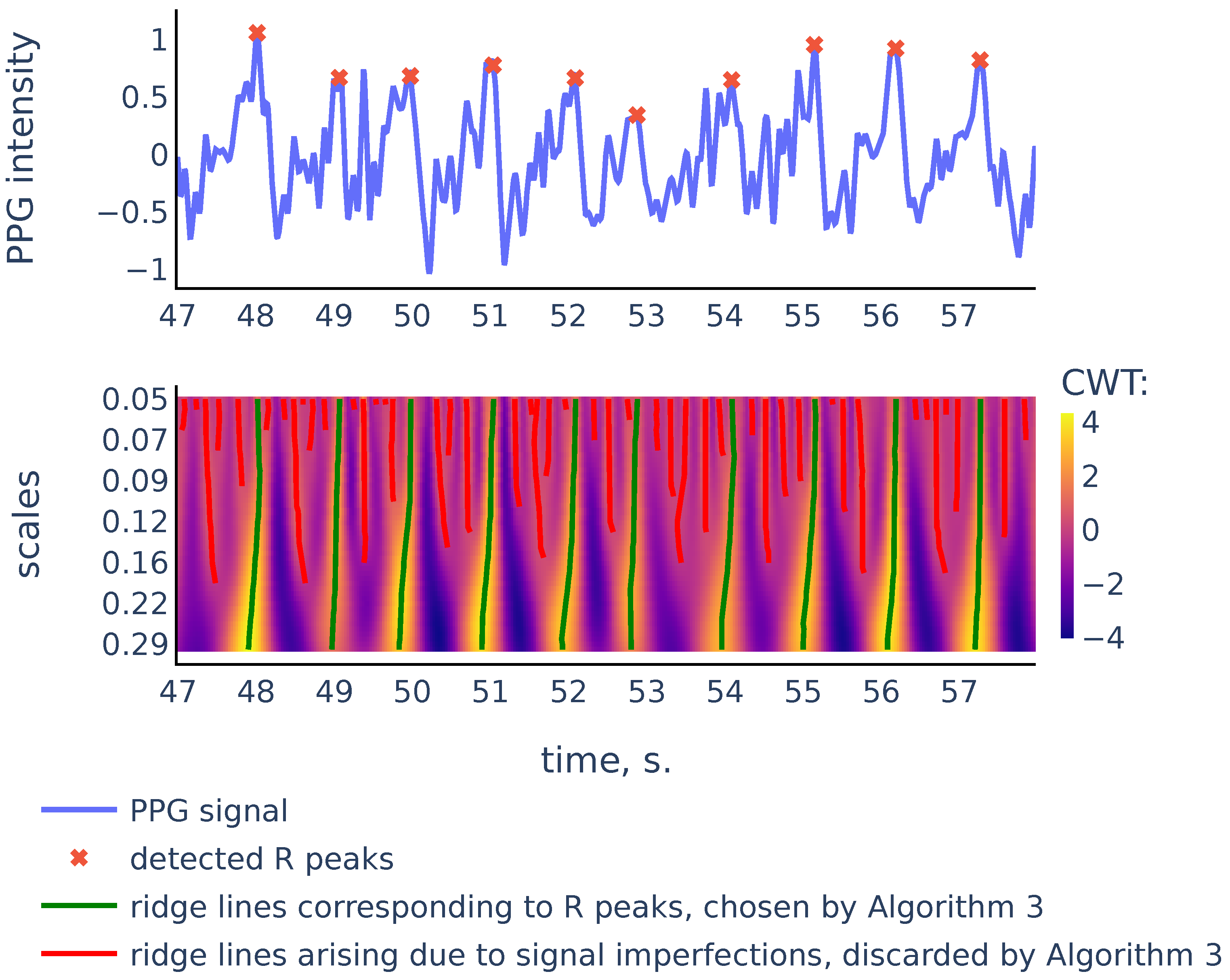
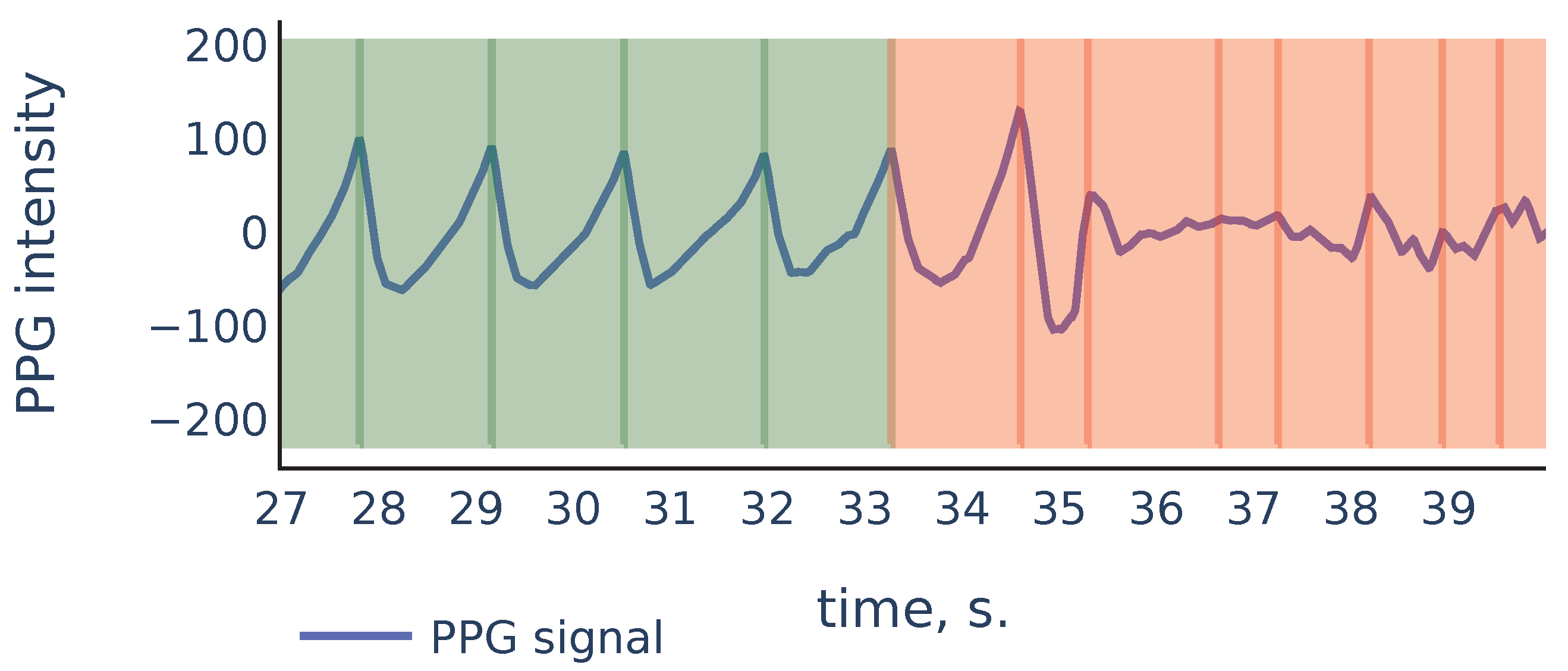
Let us consider the example shown in Figure 9 to illustrate the principles above:
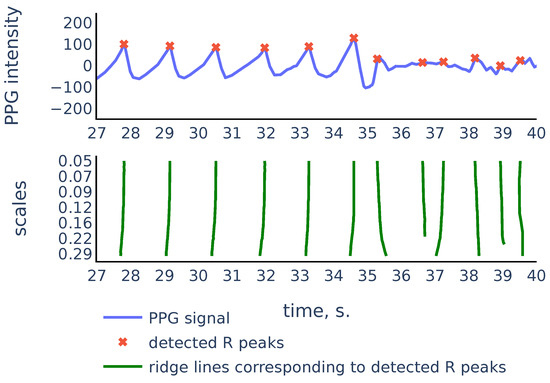
Figure 9.
Part of the S3 signal of the PPG-DaLiA dataset.
As we can see, in the corrupted part of the signal starting from 35 s, the signal parts inside RR intervals often can be weakly correlated, their amplitudes can be significantly different, and also the corresponding ridge lines do not repeat the same shape, and they bend in different ways, so the distance between varies on different scale levels more than it does for ridge lines in non-corrupted part of the signal. In the following discussion, we will describe our algorithm that filters out the RR intervals in the corrupted parts of the signal. For the signal shown in Figure 9 it produces the result shown in Figure 10:
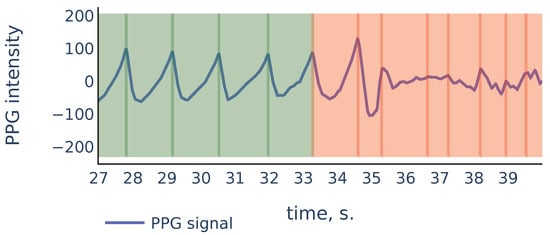
Figure 10.
Filtration of the RR intervals of Figure 9. Green intervals are kept by the algorithm and red intervals are discarded.
To define the quality of the RR intervals, we introduce two auxiliary quality measures: similarity-based quality and CWT-based quality. In the following discussion, we denote by the sigmoid function.
3.4.1. Similarity-Based Quality
Let and be two signal chunks. Let and denote x and y resampled to vectors of size 50. Define the correlation similarity between x and y as the correlation coefficient between and , limited by 0 from below:
Let and denote the amplitudes of signals x and y. Suppose that is greater than and denote their quotient by . Define the amplitude similarity as
The formula (14) is chosen empirically to assign low values to pairs of signals where amplitudes are different by 4 times and more. Finally, define the similarity score between x and y as the geometric mean of its correlation similarity and amplitude similarity:
Now, if is a sequence of detected RR intervals with R-peaks located at indices , then the similarity quality of the i-th RR interval is defined as the geometric mean of its similarities with the neighbor RR intervals (using a single neighbor for or ):
3.4.2. CWT-Based Quality
Suppose that and are two ridge lines. Consider a sequence for all where both and are defined. Let
be the standard deviation of distances between points on and measured in milliseconds. Now suppose that ends of some intervals were detected using curves and in the scalogram. Then we define the CWT-based quality of the interval as
3.4.3. Filtration
Suppose is the sequence of detected RR intervals. Define the quality of each of the RR intervals as the product of similarity- and CWT-based quality:
Now we filter intervals by quality using an automatically determined threshold as follows:
- Select all intervals with quality greater than
- Sort the qualities of the selected intervals in descending order. Denote the resulting sequence by
- Set the quality threshold as where the index maximizes the product
The initial rigid threshold of is chosen empirically based on a number of signals examined. The final choice of the threshold value allows us to cut off the intervals that have substantially smaller quality than the rest of the intervals while trying to maximize the number of remaining intervals.
3.4.4. Outlier Detection
In addition to quality-based filtration, we apply outlier detection in the sequence of RR intervals based on their lengths. We use the following algorithm similar to one introduced in [37]. Suppose that is the sequence of detected RR intervals lengths. We then mark certain RR intervals as outliers and discard them from the final answer using Algorithm 4:
| Algorithm 4 Algorithm to check if the i-th interval in is an outlier |
|
4. Results
We tested our algorithm’s accuracy on three datasets: Welltory-PPG-dataset, TROIKA, and PPG-DaLiA, using two HRV metrics: SDNN defined by Equation (1) and RMSSD defined by Equation (2). For each PPG signal and a sequence of reference RR intervals, we compute the following quantities:
- Discarded ratio: ratio of the number of RR intervals that were discarded by the filtration part of the algorithm to the total number of RR intervals detected by the algorithm peak detection part, cf. Equation (6).
- SDNN ae (RMSSD ae): the absolute error of estimation of SDNN (RMSSD), i.e., the difference between SDNN (RMSSD) derived from the sequence of intervals detected by the algorithm in PPG, and SDNN (RMSSD) derived from the sequence of reference RR intervals.
- RR mae: the mean absolute error in RR interval detection, i.e., the mean absolute difference between an interval detected by the algorithm and the corresponding reference RR interval.
The values of SDNN ae, RMSSD ae, RR mae are given in milliseconds. Table 1 shows the error values for samples in Welltory-PPG-dataset:

Table 1.
Algorithm performance on the Welltory-PPG-dataset.
Recall that the TROIKA dataset contains PPG from subjects during treadmill exercises with simultaneous ECG. To verify the accuracy of our algorithm, we chose parts of the PPG data collected in the first 30 s of each PPG signal when the subjects were at rest according to the dataset description. Reference RR intervals were derived from ECG signals using a simple algorithm detecting local maxima of a given minimum height and manually verified for accuracy. Table 2 shows the error values for samples in the TROIKA dataset:
Table 2.
Algorithm performance on the TROIKA dataset.
The PPG-DaLiA dataset contains simultaneous PPG and ECG signals during annotated physical activity. For our analysis, we used parts of the signals with activity marked as “sitting”. This gives a signal of approximately 10 minutes for each subject. As in the previous dataset, reference RR intervals were derived from ECG signals using a simple algorithm detecting local maxima of given minimal height and manually verified for accuracy. For each subject, we cut the signal into non-overlapping 100-second segments. For each segment, we applied our algorithm and calculated the discarded ratio, SDNN ae, RMSSD ae, and RR mae metrics. The mean values of the calculated errors per subject are presented in Table 3. Note that the ECG readings for subjects 8 and 12 contain ectopic beats. Those beats were excluded from calculations of reference SDNN and RMSSD values.
Table 3.
Algorithm performance on the PPG-DaLiA dataset.
5. Discussion
5.1. Justification of the Ground Truth RR Intervals Source in Welltory-PPG-Dataset
The Polar H10 device was chosen as a source of ground truth labels since it uses ECG for RR interval detection and has demonstrated good accuracy in several studies [38,39,40,41]. In particular, the study [38] reports that the difference between ECG RR intervals and Polar H10 RR intervals has a mean of ms and limits of agreement of ms at rest, and therefore recommends it as the “gold standard for RR interval assessments”. Chest strap devices were also used as a source of ground truth RR intervals in a number of research papers [42,43]. Additionally, the collected RR intervals in the Welltory-PPG-dataset were manually examined by an expert to ensure their accuracy.
5.2. Justification of the Chosen Methods
5.2.1. Signal Preprocessing
We chose the simple preprocessing procedure of Section 3.1 to avoid most basic signal issues such as vanished signal and abrupt shift. Since CWT with Mexican hat wavelet does not require baseline removal [24], this simple preprocessing is sufficient and also allows us to avoid signal distortion with more extensive preprocessing.
5.2.2. Heart Rate Estimation
Non-stationarities in the PPG signals are relatively moderate, as the heart rate changes gradually for healthy individuals at rest. Therefore STFT provides an adequate estimate of the time-frequency presentation of the signal and allows us to estimate the moving average heart rate.
5.2.3. Wavelet Based Peak Detection
We chose the Mexican hat function as the mother wavelet due to its good time–space resolution [44]. Other commonly used wavelets such as Morlet can provide a better resolution in the frequency-space, however, they show a less accurate localization in the time-domain and therefore reduce accuracy in peak detection. Note that the Mexican hat wavelet is broad in frequency, which can create difficulties when CWT is used for time–frequency localization, however, for the task of peak detection, it is more important to provide good localization in the time domain.
The scale range for the CWT from to is chosen empirically. The smallest scale provides enough small-scale details of the initial signal, and decreasing the smallest scale does not give any accuracy improvements of R-peak detection.
5.3. Relation to Previous Work
In the heart rate detection part, we estimated heart rate by constructing a continuous curve consisting of peaks in the spectrogram. This approach is similar to one used in [7]. The difference is that in our context we do not expect heavy motion artifacts, as the data are collected at rest, and we do not have access to accelerometer data to filter out the motion impact. However, as we expect our PPG signals to be collected in an uncontrolled environment, we also do not have an initialization period as in [7], where we can safely choose the location of the highest peak in the periodogram as the heart rate estimate. Instead, we use a rough estimate using counting of peaks and zero crossings in a sufficiently smooth approximation to the signal as a prior estimate and then choose peaks in the periodogram that are closest to the prior estimate.
Ridge lines in the CWT with the Mexican hat mother wavelet were also used for peak detection in [24]. The novelty in our approach is that we use the length of the ridge lines as a feature to choose the right peaks, rather than the signal-to-noise ratio used in [24]. Another difference is that in our context we can use almost-periodicity of PPG signals as a heuristic when choosing the ridge lines. Moreover, in our approach we use the similarity in the ridge lines shapes to estimate the PPG signal quality.
5.4. Accuracy Comparison with Other Algorithms
Among the variety of algorithms proposed for automatic heart rate variability estimation from PPG [13,14,17,19,20,22] only [20] was tested on publicly available data. The algorithm of [20] was tested on the TROIKA dataset, reporting sufficiently large errors in HRV metric estimations (with SDNN error on average and standard deviation of ms). However, the test was run on entire signals, including treadmill exercise, where inter-beat intervals derived from PPG (even if detected correctly) cannot be used as substitutes of RR intervals for HRV estimation as shown in [12,15]. Therefore it is not possible to directly compare the results of our algorithm with the results reported in [20].
5.5. Limitations
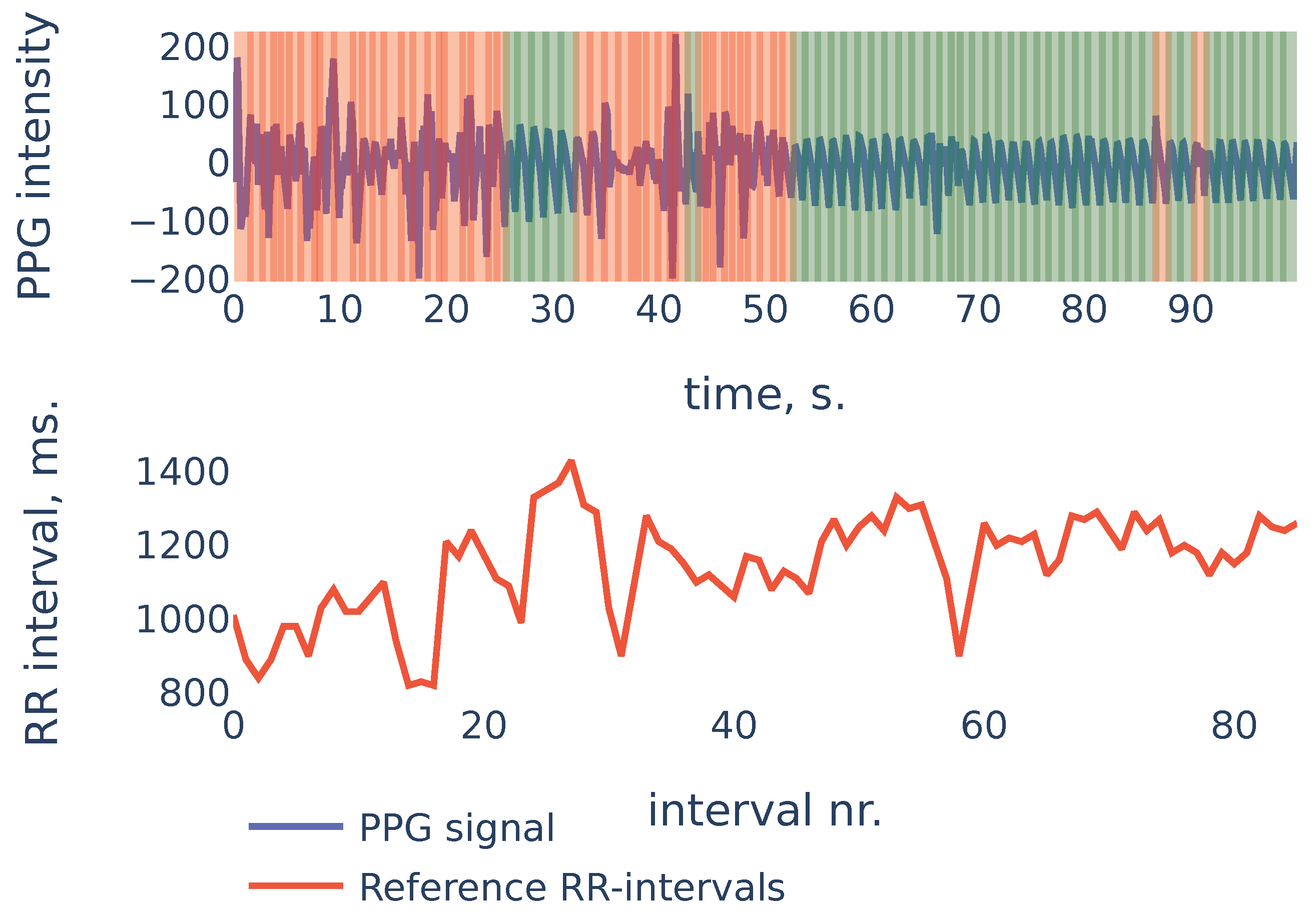
To give more insight into algorithm accuracy, let us consider a typical example where SDNN of the algorithm-detected RR intervals is slightly different from reference intervals’ SDNN. The signal shown in Figure 11 is the first 100 s segment from subject in the PPG-DaLiAdataset:
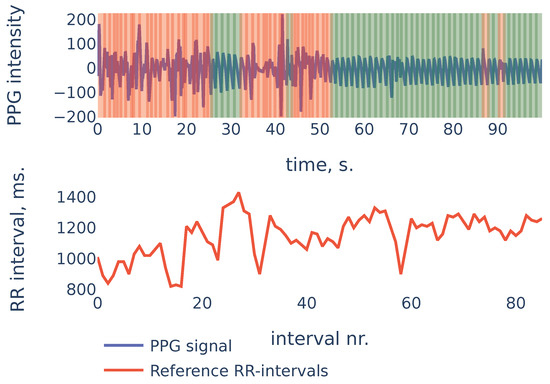
Figure 11.
PPG-DaLiA, Subject S3, interval 0 to 100 s.
In the example of Figure 11 the heart rate was decreasing during the first 20 seconds. At the same time, the first 20 seconds of PPG contained a lot of noise and were discarded by the algorithm (the red region on the plot). As a result, the PPG-derived SDNN of shows the estimate of the SDNN during the last 80 seconds of the measurement, rather than the whole signal. The reference RR intervals SDNN during the last 80 seconds are , and due to the non-stationarity of the signal, it is slightly smaller than the whole signal reference SDNN of .
This example demonstrates one limitation of our algorithm: as the algorithm detects RR intervals in non-corrupted parts of the PPG signal, in the case when the characteristics change slightly over time (as heart rate in the previous example), the HRV estimation produced by the algorithm will be accurate for the non-corrupted interval but may slightly differ from the overall HRV estimates.
5.6. Directions for Future Research
The Empirical Wavelet Transform [45] (EWT) is an adaptive method that was successfully applied for EEG signals [46]. As a direction for future research, it would be interesting to see if EWT can be used instead of CWT to improve algorithm accuracy or execution speed.
6. Conclusions
We propose an algorithm that can accurately detect peak-to-peak intervals in PPG signals and identify corrupted parts in the signal where such detection is not possible. These requirements are necessary for the algorithm to be suitable for automatic analysis of PPG signals collected in an uncontrolled environment. The algorithm was tested on three publicly available datasets with PPG signals from different sources. The algorithm is able to recognize corrupted parts of PPG signals and the detected intervals provide accurate estimates for the most common HRV metrics: for SDNN, the mean absolute error is 4.07 ms on the Welltory-PPG-dataset, 6.86 ms on the TROIKA dataset and 7.85 ms on the PPG-DaLiAdataset; for RMSSD, it is 6.32 ms on the Welltory-PPG-dataset, 12.3 ms on the TROIKA dataset and on 6.09 ms on the PPG-DaLiAdataset. Therefore, we conclude that the algorithm performs well on various PPG signals; it can be used to automatically analyze PPG signals obtained in an uncontrolled environment; for PPG collected from healthy subjects at rest, the detected intervals can be used for accurate and reliable estimates of basic HRV metrics. The algorithm cannot be used for HRV estimation from PPG signals collected during or right after exercise since, in that case, the PPG signal does not contain sufficient information [12,15].
Author Contributions
Conceptualization, A.N., K.T., E.S., P.P.; methodology, A.N., K.T.; software, A.N., K.T.; validation, A.N., K.T.; formal analysis, A.N., K.T.; investigation, A.N., K.T.; resources, E.S., P.P.; data curation, K.T.; writing—original draft preparation, A.N., K.T.; writing—review and editing, A.N., K.T.; visualization, A.N., K.T.; supervision, E.S., P.P.; project administration, E.S., P.P. funding acquisition, E.S., P.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Welltory Inc.
Informed Consent Statement
Written informed consent for publication was obtained from all volunteers participated in data collection for Welltory-PPG-dataset.
Data Availability Statement
The newly introduced Welltory-PPG-dataset is publicly available at https://github.com/Welltory/welltory-ppg-dataset (accessed on 1 July 2021). Other datasets used in this paper are PPG-DaLiA [8] available at https://archive.ics.uci.edu/ml/datasets/PPG-DaLiA (accessed on 1 July 2021) and TROIKA [7] available at https://sites.google.com/site/researchbyzhang/ieeespcup2015 (accessed on 1 July 2021).
Acknowledgments
Authors would like to thank all the participants for taking part in data collection for the Welltory-PPG-dataset. We would especially like to thank Elizaveta Morozova for her help with the organization of the study. We would also like to thank Marina Kovaleva for valuable discussions and Asya Paloni and Julia Harryson for helping with manuscript preparation.
Conflicts of Interest
The authors of this study have paid consulting agreements with Welltory Inc. The company that provided the data for this study is an interested party when it comes to the results of this research. Special official confirmation was obtained from the company, which confirms that the data provided fully match the description of the data and were not specially selected in any way other than in accordance with the selection criteria described in this publication.
Abbreviations
The following abbreviations are used in this manuscript:
| PPG | Photoplethysmography |
| ECG | Electrocardiography |
| EEG | Electroencephalography |
| RR intervals | Intervals between consecutive R peaks |
| STFT | Short-time Fourier transform |
| CWT | Continuous wavelet transform |
| HRV | Heart rate variability |
| SDNN | Standard deviation of RR intervals, cf. Equation (1) |
| RMSSD | Root mean square of the successive differences of RR intervals, cf. Equation (2) |
| MAE | Mean absolute error |
References
- Londhe, A.; Atulkar, M. Heart Rate Variability: A Methodological Survey. In Proceedings of the 2019 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 21–22 February 2019; pp. 57–63. [Google Scholar] [CrossRef]
- Wasilewski, J.; Poloński, L. An Introduction to ECG Interpretation. In ECG Signal Processing, Classification and Interpretation; Gacek, A., Pedrycz, W., Eds.; Springer: London, UK, 2012; pp. 1–20. [Google Scholar] [CrossRef]
- Yadav, A.; Grover, N. A Review of R Peak Detection Techniques of Electrocardiogram (ECG). J. Eng. Technol. 2017, 8. Available online: https://journal.utem.edu.my/index.php/jet/article/view/1946 (accessed on 5 October 2021).
- Yan, L.; Liu, Y.; Liu, Y. Interval Feature Transformation for Time Series Classification Using Perceptually Important Points. Appl. Sci. 2020, 10, 5428. [Google Scholar] [CrossRef]
- Kamal, A.A.; Harness, J.B.; Irving, G.; Mearns, A.J. Skin photoplethysmography–A review. Comput. Methods Programs Biomed. 1989, 4, 257–269. [Google Scholar] [CrossRef]
- Allen, J. Photoplethysmography and its application in clinical physiological measurement. Physiol. Meas. 2007, 28, R1–R39. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Pi, Z.; Liu, B. TROIKA: A General Framework for Heart Rate Monitoring Using Wrist-Type Photoplethysmographic Signals During Intensive Physical Exercise. IEEE Trans. Biomed. Eng. 2015, 62, 522–531. [Google Scholar] [CrossRef] [Green Version]
- Reiss, A.; Indlekofer, I.; Schmidt, P.; Van Laerhoven, K. Deep PPG: Large-Scale Heart Rate Estimation with Convolutional Neural Networks. Sensors 2019, 19, 3079. [Google Scholar] [CrossRef] [Green Version]
- Tyapochkin, K.; Smorodnikova, E.; Pravdin, P. Smartphone PPG: Signal Processing, Quality Assessment, and Impact on HRV Parameters. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4237–4240. [Google Scholar] [CrossRef]
- Němcová, A.; Jordanova, I.; Varecka, M.; Smisek, R.; Maršánová, L.; Smital, L.; Vitek, M. Monitoring of heart rate, blood oxygen saturation, and blood pressure using a smartphone. Biomed. Signal Process. Control 2020, 59, 101928. [Google Scholar] [CrossRef]
- Koenig, N.; Seeck, A.; Eckstein, J.; Mainka, A.; Huebner, T.; Voss, A.; Weber, S. Validation of a New Heart Rate Measurement Algorithm for Fingertip Recording of Video Signals with Smartphones. Telemed. e-Health 2016, 22, 631–636. [Google Scholar] [CrossRef]
- Kageyama, T.; KABUTO, M.; Kaneko, T.; Nishikido, N. Accuracy of Pulse Rate Variability Parameters Obtained from Finger Plethysmogram: A Comparison with Heart Rate Variability Parameters Obtained from ECG. J. Occup. Health 1997, 39, 154–155. [Google Scholar] [CrossRef]
- Giardino, N.; Edelberg, R. Comparison of Finger Plethysmograph to ECG in the Measurement of Heart Rate Variability. Psychophysiology 2002, 39, 246–253. [Google Scholar] [CrossRef]
- Lin, W.H.; Wu, D.; Li, Y.; Zhang, H. Comparison of Heart Rate Variability from PPG with That from ECG. In The International Conference on Health Informatics. IFMBE Proceedings; Zhang, Y.T., Ed.; Springer: Cham, Switzerland, 2014; Volume 42. [Google Scholar] [CrossRef]
- Pinheiro, N.; Couceiro, R.; Henriques, J.; Muehlsteff, J.; Quintal, I.; Gonçalves, L.; de Carvalho, P. Can PPG Be Used for HRV Analysis? In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 2945–2949. [Google Scholar] [CrossRef]
- Altini, M.; Amft, O. HRV4Training: Large-scale longitudinal training load analysis in unconstrained free-living settings using a smartphone application. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 2610–2613. [Google Scholar] [CrossRef]
- Plews, D.; Scott, B.; Altini, M.; Wood, M.; Kilding, A.; Laursen, P. Comparison of Heart Rate Variability Recording With Smart Phone Photoplethysmographic, Polar H7 Chest Strap and Electrocardiogram Methods. Int. J. Sport. Physiol. Perform. 2017, 12, 1324–1328. [Google Scholar] [CrossRef]
- Scholkmann, F.; Boss, J.; Wolf, M. An Efficient Algorithm for Automatic Peak Detection in Noisy Periodic and Quasi-Periodic Signals. Algorithms 2012, 5, 588–603. [Google Scholar] [CrossRef] [Green Version]
- Alwosheel, A.; Alasaad, A.; Alqaraawi, A. Heart rate variability estimation in Photoplethysmography signals using Bayesian learning approach. Healthc. Technol. Lett. 2016, 3, 136–142. [Google Scholar] [CrossRef] [Green Version]
- Wittenberg, T.; Koch, R.; Pfeiffer, N.; Lang, N.; Struck, M.; Amft, O.; Eskofier, B. Evaluation of HRV estimation algorithms from PPG data using neural networks. Curr. Dir. Biomed. Eng. 2020, 6, 505–509. [Google Scholar] [CrossRef]
- Guede-Fernandez, F.; Ferrer-Mileo, V.; Ramos-Castro, J.; Fernández-Chimeno, M.; García-González, M. Real Time Heart Rate Variability Assessment from Android Smartphone Camera Photoplethysmography: Postural and Device Influences. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; Volume 2015, pp. 7332–7335. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Ferrer-Mileo, V.; Mateu-Mateus, M.; Ramos-Castro, J.; García-González, M.; Fernández-Chimeno, M. A photoplethysmography smartphone-based method for heart rate variability assessment: Device model and breathing influences. Biomed. Signal Process. Control 2020, 57, 101717. [Google Scholar] [CrossRef]
- Daubechies, I. Ten Lectures on Wavelets; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992. [Google Scholar]
- Du, P.; Kibbe, W.; Lin, S. Improved peak detection in mass spectrum by incorporating continuous wavelet transform-based pattern matching. Bioinformatics 2006, 22, 2059–2065. [Google Scholar] [CrossRef] [Green Version]
- Addison, P. Wavelet transforms and the ECG: A review. Physiol. Meas. 2005, 26, R155–R199. [Google Scholar] [CrossRef] [Green Version]
- Ghaderpour, E.; Pagiatakis, S.; Hassan, Q. A Survey on Change Detection and Time Series Analysis with Applications. Appl. Sci. 2021, 11, 6141. [Google Scholar] [CrossRef]
- Li, C.; Zheng, C.; Tai, C. Detection of ECG characteristic points using wavelet transform. IEEE Trans. Biomed. Eng. 1995, 42, 21–28. [Google Scholar] [CrossRef]
- Kadambe, S.; Murray, R.; Boudreaux-Bartels, G. Wavelet transform-based QRS complex detector. IEEE Trans. Biomed. Eng. 1999, 46, 838–848. [Google Scholar] [CrossRef]
- Coombes, K.; Tsavachidis, S.; Morris, J.; Baggerly, K.; Hung, M.C.; Kuerer, H. Data Acquired from Surface-Enhanced Laser Desorption and Ionization by Denoising Spectra with the Undecimated Discrete Wavelet Transform. Proteomics 2005, 5, 4107–4117. [Google Scholar] [CrossRef]
- Nenadic, Z.; Burdick, J. Spike Detection Using the Continuous Wavelet Transform. IEEE Trans. Biomed. Eng. 2005, 52, 74–87. [Google Scholar] [CrossRef] [Green Version]
- Wee, A.; Grayden, D.; Zhu, Y.; Petkovic, K.; Smith, D. A continuous wavelet transform algorithm for peak detection. Electrophoresis 2008, 29, 4215–4225. [Google Scholar] [CrossRef]
- Gregoire, J.; Dale, D.; van Dover, R. A wavelet transform algorithm for peak detection and application to powder X-ray diffraction data. Rev. Sci. Instrum. 2011, 82, 015105. [Google Scholar] [CrossRef] [Green Version]
- Nemcova, A.; Smisek, R.; Vargova, E.; Maršánová, L.; Vitek, M.; Smital, L. Brno University of Technology Smartphone PPG Database (BUT PPG) (version 1.0.0). PhysioNet 2021. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, S.; Vullings, R.; Biswas, D.; Simoes-Capela, N.; Helleputte, N.; Van Hoof, C.; Groenendaal, W. Motion Artifact Reduction for Wrist-Worn Photoplethysmograph Sensors Based on Different Wavelengths. Sensors 2019, 19, 673. [Google Scholar] [CrossRef] [Green Version]
- Barbieri, R.; Matten, E.; Alabi, A.; Brown, E. A point-process model of human heartbeat intervals: New definitions of heart rate and heart rate variability. Am. J. Physiol. Heart Circ. Physiol. 2005, 288, H424–H435. [Google Scholar] [CrossRef] [Green Version]
- Takagi, K.; Kumagai, S.; Matsunaga, c.; Kusaka, Y. Application of inverse Gaussian distribution to occupational exposure data. Ann. Occup. Hyg. 1997, 41, 505–514. [Google Scholar] [CrossRef]
- Vila, X.; Palacios Ortega, F.; Presedo, J.; Fernandez-Delgado, M.; Félix, P.; Barro, S. Time-frequency analysis of heart-rate variability. IEEE Eng. Med. Biol. Mag. 1997, 16, 119–126. [Google Scholar] [CrossRef]
- Gilgen-Ammann, R.; Schweizer, T.; Wyss, T. RR interval signal quality of a heart rate monitor and an ECG Holter at rest and during exercise. Eur. J. Appl. Physiol. 2019, 119, 1525–1532. [Google Scholar] [CrossRef]
- Hinde, K.; White, G.; Armstrong, N. Wearable Devices Suitable for Monitoring Twenty Four Hour Heart Rate Variability in Military Populations. Sensors 2021, 21, 1061. [Google Scholar] [CrossRef]
- Pereira, R.D.A.; Alves, J.L.D.B.; Silva, J.H.D.C.; Costa, M.D.S.; Silva, A.S. Validity of a Smartphone Application and Chest Strap for Recording RR Intervals at Rest in Athletes. Int. J. Sports Physiol. Perform. 2020, 15, 896–899. [Google Scholar] [CrossRef]
- Speer, K.; Semple, S.; Naumovski, N.; McKune, A. Measuring Heart Rate Variability Using Commercially Available Devices in Healthy Children: A Validity and Reliability Study. Eur. J. Investig. Health Psychol. Educ. 2020, 10, 390–404. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernando, D.; Roca, S.; Sancho, J.; Alesanco, A.; Bailón, R. Validation of the Apple Watch for Heart Rate Variability Measurements during Relax and Mental Stress in Healthy Subjects. Sensors 2018, 18, 2619. [Google Scholar] [CrossRef] [Green Version]
- Greve, M.; Kviesis-Kipge, E.; Rubenis, O.; Rubins, U.; Mevcnika, V.; Grabovskis, A.; Marcinkevivcs, Z. Comparison of Pulse Rate Variability Derived from Digital Photoplethysmography over the Temporal Artery with the Heart Rate Variability Derived from a Polar Heart Rate Monitor. In Proceedings of the 7th conference of European Study Group on Cardiovascular Oscillations (2012), Kazimierz Dolny, Poland, 22–25 April 2012; pp. 1–3. [Google Scholar]
- Torrence, C.; Compo, G. A Practical Guide to Wavelet Analysis. Bull. Am. Meteorol. Soc. 1998, 79, 61–78. [Google Scholar] [CrossRef] [Green Version]
- Gilles, J. Empirical Wavelet Transform. IEEE Trans. Signal Process. 2013, 61, 3999–4010. [Google Scholar] [CrossRef]
- Bhattacharyya, A.; Sharma, M.; Pachori, R.; Sircar, P.; Acharya, U.R. A novel approach for automated detection of focal EEG signals using empirical wavelet transform. Neural Comput. Appl. 2018, 29, 47–57. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).